Note
Go to the end to download the full example code.
Linear Regression with interval-censored observations¶
1. Model formulation¶
We consider the following linear model:

where the observation vector  is modeled as
the sum of:
is modeled as
the sum of:
a linear part, with an
 design matrix
design matrix  and unknown regression coefficients
and unknown regression coefficients  ,
,a Gaussian error term
 ,
,
where  represents a known precision (inverse variance) matrix
for measurement errors,
and
represents a known precision (inverse variance) matrix
for measurement errors,
and  an unknown precision parameter
quantifying the variability of the observed phenomenon.
an unknown precision parameter
quantifying the variability of the observed phenomenon.
1.1. Likelihood of the linear regression model¶
The above linear regression model can thus be written:

We then have the following likelihood:

where  is the Mahalanobis distance between
and
is the Mahalanobis distance between
and  with covariance matrice
with covariance matrice  :
:

1.2. Interval Censorship¶
We now assume that, instead of observing directly the
 as described above, we only have access to
discretized values
as described above, we only have access to
discretized values  , where
, where
 is a grid length and
is a grid length and  means that
means that
 .
.
1.3. Remarks¶
The presence of a composite matrix
 makes
estimation more complex than with a spherical one
makes
estimation more complex than with a spherical one
 since we would then have explicit (closed-form)
maximum likelihood estimators, and also conjugate priors leading to
explicit full joint posterior distributions.
since we would then have explicit (closed-form)
maximum likelihood estimators, and also conjugate priors leading to
explicit full joint posterior distributions.Another difficulty is the presence of censored data, since the likelihood is no more available in closed-form. As we will see, this can be overcome thanks to Bayesian inference.
Heteroscedastic linear modeling under interval censorship as formulated above was originally motivated by an industrial case-study in seismology, wherein the
 correspond to the observed
intensity of an earthquake in a distant site, and explanatory
variables
correspond to the observed
intensity of an earthquake in a distant site, and explanatory
variables  are derived from the epicentral distance to the
earthquake’s source as well as its characteristics (magnitude,
depth). But it can also arise in many different contexts, as soon as
observations are available with known statistical precisions (hence
the heteroscedasticity) and limited numerical accuracy (hence the
censorship).
are derived from the epicentral distance to the
earthquake’s source as well as its characteristics (magnitude,
depth). But it can also arise in many different contexts, as soon as
observations are available with known statistical precisions (hence
the heteroscedasticity) and limited numerical accuracy (hence the
censorship).
1.4 Simulate the dataset¶
import openturns as ot
from openturns.viewer import View
import numpy as np
ot.Log.Show(ot.Log.NONE)
ot.RandomGenerator.SetSeed(1)
n = 10
delta = 0.5
Build the design matrix
X = ot.Sample([[1.0]] * n)
X.stack(ot.Normal(0.0, 10.0).getSample(n))
Make the precision matrix a diagonal matrix and sample
its diagonal coefficients from an Exponential distribution.
Q = np.ones((n, 1)) + ot.Exponential().getSample(n)
Choose values for the parameters  and .
and .
theta_true = np.array([[0.0], [1.0]])
p = len(theta_true)
tau_true = 0.1
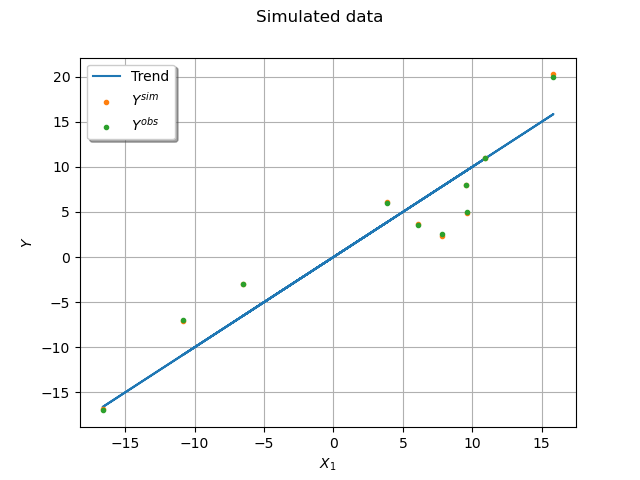
First sample uncensored, and then censored observation data.
mean_true = np.dot(X, theta_true).ravel()
std_true = np.sqrt(1.0 / tau_true + 1.0 / Q).ravel()
Y_sim = mean_true + [x[0] for x in ot.Normal().getSample(n)] * std_true
Yobs_sim = np.round(Y_sim / delta) * delta
Plot the simulated dataset.
graph = ot.Graph("Simulated data", "$X_1$", "$Y$", True, "upper left", 16)
cloud_obs = ot.Cloud(X[:, 1].asPoint(), Yobs_sim)
cloud_obs.setPointStyle("bullet")
cloud_sim = ot.Cloud(X[:, 1].asPoint(), Y_sim)
cloud_sim.setPointStyle("bullet")
curve = ot.Curve(X[:, 1].asPoint(), mean_true)
curve.setLineWidth(1.5)
graph.add(curve)
graph.add(cloud_sim)
graph.add(cloud_obs)
graph.setLegends(["Trend", "$Y^{sim}$", "$Y^{obs}$"])
_ = View(graph)
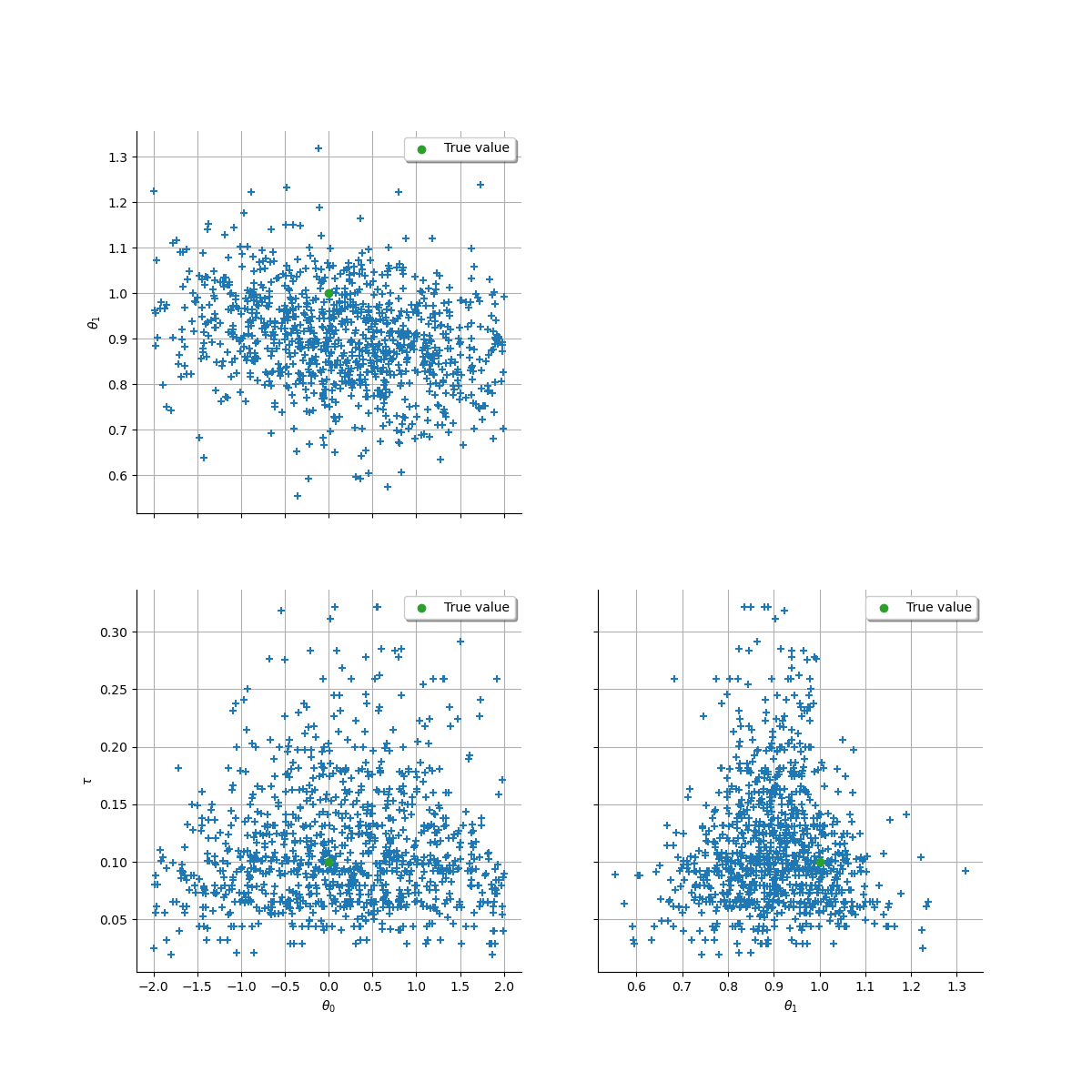
2. Bayesian Inference¶
2.1. Choice of a prior law¶
We use the standard Normal-Gamma prior for and
:

where all parameters are assumed a priori independent if not stated otherwise.
Furthermore, a default choice for the hyperparameters consists in having all prior variances go to infinity, equivalent to the degenerate case:

But the resulting prior is improper. Hence, posterior propriety needs to be proven first.
A simpler solution is to ensure prior (hence posterior) propriety by
imposing bounds  on all parameters following:
on all parameters following:

where inequalites are taken componentwise. When all hyperparameters go to
 as described above, the prior converges to a product of
uniform distributions.
as described above, the prior converges to a product of
uniform distributions.
We will use this product of univariate uniforms as a prior in the following. As discussed above, there is no simple way to obtain the posterior distribution, justifying the use of Monte-Carlo Markov chain techniques, as described hereafter.
lower = (Yobs_sim.ravel() - delta).tolist()
upper = (Yobs_sim.ravel() + delta).tolist()
# Global support of the joint distribution: theta, tau, outputs
support = ot.Interval([-2.0] * p + [1e-4] + lower, [2.0] * p + [1e1] + upper)
prior = ot.JointDistribution(
[ot.Uniform(-2.0, 2.0), ot.Uniform(-2.0, 2.0), ot.Uniform(1e-4, 1e1)]
)
# Initialize to true value
initial_state = theta_true[:, 0].tolist() + [tau_true] + Y_sim.ravel().tolist()
initial_state = ot.Point(initial_state)
2.2. Posterior sampling¶
The solution we advocate consists in sampling from the joint posterior
distribution of all uncertain parameters, including the vector of
continuous intensities  seen here as a latent variable.
Indeed, adding to the vector of sampled variables yields a
posterior density which is available in closed form, up to an unknown
multiplicative factor
seen here as a latent variable.
Indeed, adding to the vector of sampled variables yields a
posterior density which is available in closed form, up to an unknown
multiplicative factor

This allows one to perform the following Metropolis within Gibbs sampling
scheme, wherein the pre-defined blocks of variables
 are updated in turn, according to their
conditional posterior density, or to a Markov kernel targeting it, as
described in the following.
are updated in turn, according to their
conditional posterior density, or to a Markov kernel targeting it, as
described in the following.
2.2.1. Updating ¶

hence the latent variables are updated by simply simulating
independent univariate truncated normals.
Step 1 : Create associated RandomVector
marginals_trunc = [
ot.TruncatedNormal(Yobs_sim[i], 1.0, lower[i], upper[i]) for i in range(len(X))
]
trunc_cond_Y = ot.JointDistribution(marginals_trunc)
RV_Y = ot.RandomVector(trunc_cond_Y)
Step 2 : Link function, giving the parameters of the univariate truncated normals in function of the chain’s current state
gen_params = np.array(trunc_cond_Y.getParameter())
def py_link_function_y(x):
"""
link function for Y conditional density
Input
x: vector with length (p + 1 + n), containing the current state of (theta, tau, Y)
Output
params: vector with length 4*n, corresponding to mean, std, a and b, for each component of Y
Notes
a and b represent the upper and lower bounds for the truncated normals
"""
theta = [x[i] for i in range(p)]
tau = x[p]
# compute conditional mean and standard deviates
mean = np.dot(X, theta)
std = np.sqrt(1.0 / tau + 1.0 / Q)
# inject values in blueprint
params = gen_params.copy()
params[::4] = mean
params[1::4] = std.ravel()
return params
2.2.2. Updating ¶
 Due to the
partial conjugacy of the conditional prior
Due to the
partial conjugacy of the conditional prior  this is explicit, and given by the following box-constrained
multivariate normal:
this is explicit, and given by the following box-constrained
multivariate normal:

with

or equivalently, thanks to the matrix Woodsbury identity:

By having all hyperparameters go to  we obtain the following
simplified form:
we obtain the following
simplified form:

Explicit simulation from a box-constrained multivariate normal can be done with a simple rejection sampling scheme:
Step 1 : Create associated RandomVector
class BoxConstrainedNormal(ot.PythonRandomVector):
"""
Multivariate normal distribution
under box constraints
"""
def __init__(
self, d=2, mu=np.zeros(2), Sigma=np.eye(2), r=np.zeros(2), s=np.ones(2)
):
for x in mu, Sigma, r, s:
if len(x) != d:
print("expectation or bound does not have size %s" % d)
raise ValueError
if Sigma.shape != (d, d):
print("covariance matrix not have dimensions (%s,%s)" % (d, d))
raise ValueError
super(BoxConstrainedNormal, self).__init__(d)
self.mu = mu
self.Sigma = Sigma
self.r = r
self.s = s
self.interval = ot.Interval(r, s)
def setParameter(self, parameter):
d = self.getDimension()
self.mu = np.array(parameter[:d])
self.Sigma = np.array(parameter[d: d + d * d]).reshape(d, d)
self.r = np.array(parameter[-2 * d: -d])
self.s = np.array(parameter[-d:])
self.interval = ot.Interval(self.r, self.s)
def getParameter(self):
return np.concatenate(
[self.mu.ravel(), self.Sigma.ravel(), self.r.ravel(), self.s.ravel()]
)
def getRealization(self):
accept = False
proposaldist = ot.Normal(self.mu, ot.CovarianceMatrix(self.Sigma))
while not accept:
proposal = proposaldist.getRealization()
accept = self.interval.contains(proposal)
return proposal
RV_theta = ot.RandomVector(BoxConstrainedNormal())
Step 2 : Link function, giving the parameters of the box-constrained normal in function of and values
def py_link_function_theta(x):
tau = x[p]
Y = [x[i] for i in range(p + 1, len(x))]
# conditional mean and variance
# for diagonal Q
Itilde_inv = 1.0 / (1.0 + tau / Q)
Xtilde = Itilde_inv * X
Sigma_n = np.linalg.inv(np.dot(Xtilde.T, X)) / tau
mu_n = np.dot(Xtilde.T, Y)
mu_n = tau * np.dot(Sigma_n, mu_n)
# extract parameters in correct order (coherent with getParameter() method of RV_theta)
return np.concatenate(
[
mu_n.ravel(),
Sigma_n.ravel(),
support.getLowerBound()[:p],
support.getUpperBound()[:p],
]
)
2.2.3. Updating ¶
 is proportional to:
is proportional to:

Hence, can be updated using the Random-walk
Metropolis-Hastings algorithm.
Step 1 : compute tau’s conditional posterior density, up to a multiplicative factor
def marginals_Y(theta, tau):
mu = np.dot(X, theta).ravel()
sigma = np.sqrt(1.0 / tau + 1.0 / Q).ravel()
return [ot.Normal(mu[i], sigma[i]) for i in range(len(X))]
def py_log_density(x):
theta = [x[i] for i in range(p)]
tau = x[p]
Y = [x[p + 1 + i] for i in range(len(X))]
ld = ot.JointDistribution(marginals_Y(theta, tau)).computeLogPDF(Y)
return [ld]
Step 2 : define the proposal distribution
proposal_tau = ot.Normal(0.0, 1e-1)
2.3. Initialization¶
To avoid all numerical problems, it is better to provide the algorithm
with a starting point not too far from the posterior mode. To this end,
we propose to set  for simplicity, then solve the
following optimization problem
for simplicity, then solve the
following optimization problem
![\widehat\theta,\widehat\tau = \arg\max_{\vect{\theta},\tau} \pi(\vect{\theta},\tau|\vect{Y}^{obs},\vect{Y}=\vect{Y}^{obs})
= \arg\max_{\theta\in[\vect{\theta}_{\min};\vect{\theta}_{\max}]
\tau\in[\tau_{\min};\tau_{\max}]} \mathcal N(\vect{Y}^{obs}|\vect{\theta} \mat{X}; \tau^{-1} \mat{I}_n + \mat{Q}^{-1}).](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc0NzQuOTkzOTQ2cHQnIGhlaWdodD0nMjEuNzUxNzY3cHQnIHZpZXdCb3g9JzAgLTIyLjk0NzI4MSA0NzQuOTkzOTQ2IDIxLjc1MTc2Nyc+CjxkZWZzPgo8cGF0aCBpZD0nZzgtNDknIGQ9J00yLjUwMjYxNS01LjA3Njk2MUMyLjUwMjYxNS01LjI5MjE1NCAyLjQ4NjY3NS01LjMwMDEyNSAyLjI3MTQ4Mi01LjMwMDEyNUMxLjk0NDcwNy00Ljk4MTMyIDEuNTIyMjkxLTQuNzkwMDM3IC43NjUxMzEtNC43OTAwMzdWLTQuNTI3MDI0Qy45ODAzMjQtNC41MjcwMjQgMS40MTA3MS00LjUyNzAyNCAxLjg3Mjk3Ni00Ljc0MjIxN1YtLjY1MzU0OUMxLjg3Mjk3Ni0uMzU4NjU1IDEuODQ5MDY2LS4yNjMwMTQgMS4wOTE5MDUtLjI2MzAxNEguODEyOTUxVjBDMS4xMzk3MjYtLjAyMzkxIDEuODI1MTU2LS4wMjM5MSAyLjE4MzgxMS0uMDIzOTFTMy4yMzU4NjYtLjAyMzkxIDMuNTYyNjQgMFYtLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNi0uMjYzMDE0IDIuNTAyNjE1LS4zNTg2NTUgMi41MDI2MTUtLjY1MzU0OVYtNS4wNzY5NjFaJy8+CjxwYXRoIGlkPSdnOC01OScgZD0nTTEuNjE3OTMzLTIuOTg4NzkyQzEuNjE3OTMzLTMuMjU5Nzc2IDEuNDAyNzQtMy40MzUxMTggMS4xNzk1NzctMy40MzUxMThDLjkwODU5My0zLjQzNTExOCAuNzMzMjUtMy4yMTk5MjUgLjczMzI1LTIuOTk2NzYyQy43MzMyNS0yLjcyNTc3OCAuOTQ4NDQzLTIuNTUwNDM2IDEuMTcxNjA2LTIuNTUwNDM2QzEuNDQyNTktMi41NTA0MzYgMS42MTc5MzMtMi43NjU2MjkgMS42MTc5MzMtMi45ODg3OTJaTTEuNDE4NjgtLjA2Mzc2MUMxLjQxODY4IC40NTQyOTYgMS4yNTEzMDggLjkxNjU2MyAuOTAwNjIzIDEuMzE1MDY4Qy44NTI4MDIgMS4zNzg4MjkgLjgzNjg2MiAxLjM4NjggLjgzNjg2MiAxLjQyNjY1Qy44MzY4NjIgMS40OTgzODEgLjkwODU5MyAxLjU0NjIwMiAuOTQ4NDQzIDEuNTQ2MjAyQzEuMDUyMDU1IDEuNTQ2MjAyIDEuNjQxODQzIC45MDA2MjMgMS42NDE4NDMtLjA0NzgyMUMxLjY0MTg0My0uMzEwODM0IDEuNjA5OTYzLS44ODQ2ODIgMS4xNzE2MDYtLjg4NDY4MkMuOTA4NTkzLS44ODQ2ODIgLjczMzI1LS42Nzc0NiAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjIwNzIyMyAuOTAwNjIzIDAgMS4xNzk1NzcgMEMxLjMxNTA2OCAwIDEuMzYyODg5LS4wMjM5MSAxLjQxODY4LS4wNjM3NjFaJy8+CjxwYXRoIGlkPSdnOC05MScgZD0nTTIuMTU5OSAxLjk5MjUyOFYxLjYyNTkwM0gxLjM1NDkxOVYtNS42MTA5NTlIMi4xNTk5Vi01Ljk3NzU4NEguOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonLz4KPHBhdGggaWQ9J2c4LTkzJyBkPSdNMS4zNTQ5MTktNS45Nzc1ODRILjE4MzMxM1YtNS42MTA5NTlILjk4ODI5NFYxLjYyNTkwM0guMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonLz4KPHBhdGggaWQ9J2czLTAnIGQ9J001LjU3MTEwOC0xLjgwOTIxNUM1LjY5ODYzLTEuODA5MjE1IDUuODczOTczLTEuODA5MjE1IDUuODczOTczLTEuOTkyNTI4UzUuNjk4NjMtMi4xNzU4NDEgNS41NzExMDgtMi4xNzU4NDFIMS4wMDQyMzRDLjg3NjcxMi0yLjE3NTg0MSAuNzAxMzctMi4xNzU4NDEgLjcwMTM3LTEuOTkyNTI4Uy44NzY3MTItMS44MDkyMTUgMS4wMDQyMzQtMS44MDkyMTVINS41NzExMDhaJy8+CjxwYXRoIGlkPSdnMy01MCcgZD0nTTQuNjMwNjM1LTEuODA5MjE1QzQuNzU4MTU3LTEuODA5MjE1IDQuOTMzNDk5LTEuODA5MjE1IDQuOTMzNDk5LTEuOTkyNTI4UzQuNzU4MTU3LTIuMTc1ODQxIDQuNjMwNjM1LTIuMTc1ODQxSDEuMDc1OTY1QzEuMTc5NTc3LTMuMjgzNjg2IDIuMTA0MTEtNC4xMjg1MTggMy4zMTU1NjctNC4xMjg1MThINC42MzA2MzVDNC43NTgxNTctNC4xMjg1MTggNC45MzM0OTktNC4xMjg1MTggNC45MzM0OTktNC4zMTE4MzFTNC43NTgxNTctNC40OTUxNDMgNC42MzA2MzUtNC40OTUxNDNIMy4yOTE2NTZDMS44NTcwMzYtNC40OTUxNDMgLjcwMTM3LTMuMzc5MzI4IC43MDEzNy0xLjk5MjUyOEMuNzAxMzctLjU5Nzc1OCAxLjg2NTAwNiAuNTEwMDg3IDMuMjkxNjU2IC41MTAwODdINC42MzA2MzVDNC43NTgxNTcgLjUxMDA4NyA0LjkzMzQ5OSAuNTEwMDg3IDQuOTMzNDk5IC4zMjY3NzVTNC43NTgxNTcgLjE0MzQ2MiA0LjYzMDYzNSAuMTQzNDYySDMuMzE1NTY3QzIuMTA0MTEgLjE0MzQ2MiAxLjE3OTU3Ny0uNzAxMzcgMS4wNzU5NjUtMS44MDkyMTVINC42MzA2MzVaJy8+CjxwYXRoIGlkPSdnNy05NycgZD0nTTIuODM5MzUyLTEuNzgxMzJDMi44MzkzNTItMi4zMzcyMzUgMi4yNzE0ODItMi42NjYwMDIgMS42MDE5OTMtMi42NjYwMDJDMS4zMTUwNjgtMi42NjYwMDIgLjYwOTcxNC0yLjYzNjExNSAuNjA5NzE0LTIuMTMzOTk4Qy42MDk3MTQtMS45NzI2MDMgLjcxNzMxLTEuODQxMDk2IC45MDI2MTUtMS44NDEwOTZDMS4wNzU5NjUtMS44NDEwOTYgMS4xODk1MzktMS45NzI2MDMgMS4xODk1MzktMi4xMjgwMkMxLjE4OTUzOS0yLjIzNTYxNiAxLjE0MTcxOS0yLjMzNzIzNSAxLjAzNDEyMi0yLjM4NTA1NkMxLjIzMTM4Mi0yLjQ3NDcyIDEuNTMwMjYyLTIuNDc0NzIgMS41OTAwMzctMi40NzQ3MkMyLjAxNDQ0Ni0yLjQ3NDcyIDIuMzQzMjEzLTIuMjIzNjYxIDIuMzQzMjEzLTEuNzY5MzY1Vi0xLjYxMzk0OEMyLjA2ODI0NC0xLjYwMTk5MyAxLjU5MDAzNy0xLjU5MDAzNyAxLjE1MzY3NC0xLjQzNDYyQy43NTkxNTMtMS4yOTcxMzYgLjM4MjU2NS0xLjAyODE0NCAuMzgyNTY1LS42Mjc2NDZDLjM4MjU2NS0uMDk1NjQxIDEuMDE2MTg5IC4wNTk3NzYgMS40ODI0NDEgLjA1OTc3NkMxLjk4NDU1OCAuMDU5Nzc2IDIuMjgzNDM3LS4xOTEyODMgMi40MTQ5NDQtLjQxODQzMUMyLjQ1Njc4Ny0uMTA3NTk3IDIuNjU0MDQ3IC4wMjk4ODggMi44NjMyNjMgLjAyOTg4OEMyLjg4NzE3MyAuMDI5ODg4IDMuNTI2Nzc1IC4wMjk4ODggMy41MjY3NzUtLjUzNzk4M1YtLjg2Njc1SDMuMzA1NjA0Vi0uNTQ5OTM4QzMuMzA1NjA0LS40OTAxNjIgMy4zMDU2MDQtLjIyMTE3MSAzLjA3MjQ3OC0uMjIxMTcxUzIuODM5MzUyLS40OTAxNjIgMi44MzkzNTItLjU0OTkzOFYtMS43ODEzMlpNMi4zNDMyMTMtLjg0ODgxN0MyLjM0MzIxMy0uMjI3MTQ4IDEuNzI3NTIyLS4xMzE1MDcgMS41MzYyMzktLjEzMTUwN0MxLjIxMzQ1LS4xMzE1MDcgLjkwODU5My0uMzI4NzY3IC45MDg1OTMtLjYyNzY0NkMuOTA4NTkzLS45NjIzOTEgMS4yMzEzODItMS4zOTg3NTUgMi4zNDMyMTMtMS40MzQ2MlYtLjg0ODgxN1onLz4KPHBhdGggaWQ9J2c3LTEwNScgZD0nTTEuMzU2OTEyLTMuNjgyMTkyQzEuMzU2OTEyLTMuODYxNTE5IDEuMjA3NDcyLTQuMDQwODQ3IC45OTgyNTctNC4wNDA4NDdDLjgxMjk1MS00LjA0MDg0NyAuNjM5NjAxLTMuODk3Mzg1IC42Mzk2MDEtMy42ODIxOTJTLjgxMjk1MS0zLjMyMzUzNyAuOTk4MjU3LTMuMzIzNTM3QzEuMjA3NDcyLTMuMzIzNTM3IDEuMzU2OTEyLTMuNTAyODY0IDEuMzU2OTEyLTMuNjgyMTkyWk0uNDA2NDc2LTIuNTcwMzYxVi0yLjMzNzIzNUMuODAwOTk2LTIuMzM3MjM1IC44NTQ3OTUtMi4yOTUzOTIgLjg1NDc5NS0yLjAwMjQ5MVYtLjQ5MDE2MkMuODU0Nzk1LS4yMzMxMjYgLjc5NTAxOS0uMjMzMTI2IC4zODI1NjUtLjIzMzEyNlYwQy41NTU5MTUtLjAxMTk1NSAxLjAyMjE2Ny0uMDIzOTEgMS4wODE5NDMtLjAyMzkxUzEuNTk2MDE1LS4wMTE5NTUgMS43NTE0MzIgMFYtLjIzMzEyNkMxLjM4MDgyMi0uMjMzMTI2IDEuMzI3MDI0LS4yMzMxMjYgMS4zMjcwMjQtLjQ4NDE4NFYtMi42MzYxMTVMLjQwNjQ3Ni0yLjU3MDM2MVonLz4KPHBhdGggaWQ9J2c3LTEwOScgZD0nTTUuMjA2NDc2LTEuODA1MjNDNS4yMDY0NzYtMi40MTQ5NDQgNC44NDc4MjEtMi42MzYxMTUgNC4yNjIwMTctMi42MzYxMTVDMy43MDYxMDItMi42MzYxMTUgMy4zNzczMzUtMi4zMTkzMDMgMy4yNDU4MjgtMi4wOTIxNTRDMy4xMDgzNDQtMi42MzYxMTUgMi40OTg2My0yLjYzNjExNSAyLjMzMTI1OC0yLjYzNjExNUMxLjc4NzI5OC0yLjYzNjExNSAxLjQ1MjU1My0yLjMzNzIzNSAxLjMwOTA5MS0yLjA4NjE3N0gxLjMwMzExM1YtMi42MzYxMTVMLjM3NjU4OC0yLjU3MDM2MVYtMi4zMzcyMzVDLjc5NTAxOS0yLjMzNzIzNSAuODQ4ODE3LTIuMjk1MzkyIC44NDg4MTctMi4wMDI0OTFWLS40OTAxNjJDLjg0ODgxNy0uMjMzMTI2IC43ODkwNDEtLjIzMzEyNiAuMzc2NTg4LS4yMzMxMjZWMEMuNDE4NDMxLS4wMDU5NzggLjgyNDkwNy0uMDIzOTEgMS4wOTM4OTgtLjAyMzkxUzEuNzU3NDEtLjAwNTk3OCAxLjgxNzE4NiAwVi0uMjMzMTI2QzEuNDA0NzMyLS4yMzMxMjYgMS4zNDQ5NTYtLjIzMzEyNiAxLjM0NDk1Ni0uNDkwMTYyVi0xLjU0MjIxN0MxLjM0NDk1Ni0yLjE5OTc1MSAxLjkxMjgyNy0yLjQ0NDgzMiAyLjI3NzQ2LTIuNDQ0ODMyQzIuNjg5OTEzLTIuNDQ0ODMyIDIuNzc5NTc3LTIuMTg3Nzk2IDIuNzc5NTc3LTEuODE3MTg2Vi0uNDkwMTYyQzIuNzc5NTc3LS4yMzMxMjYgMi43MTk4MDEtLjIzMzEyNiAyLjMwNzM0Ny0uMjMzMTI2VjBDMi4zNDkxOTEtLjAwNTk3OCAyLjc1NTY2Ni0uMDIzOTEgMy4wMjQ2NTgtLjAyMzkxUzMuNjg4MTY5LS4wMDU5NzggMy43NDc5NDUgMFYtLjIzMzEyNkMzLjMzNTQ5Mi0uMjMzMTI2IDMuMjc1NzE2LS4yMzMxMjYgMy4yNzU3MTYtLjQ5MDE2MlYtMS41NDIyMTdDMy4yNzU3MTYtMi4xOTk3NTEgMy44NDM1ODctMi40NDQ4MzIgNC4yMDgyMTktMi40NDQ4MzJDNC42MjA2NzItMi40NDQ4MzIgNC43MTAzMzYtMi4xODc3OTYgNC43MTAzMzYtMS44MTcxODZWLS40OTAxNjJDNC43MTAzMzYtLjIzMzEyNiA0LjY1MDU2LS4yMzMxMjYgNC4yMzgxMDctLjIzMzEyNlYwQzQuMjc5OTUtLjAwNTk3OCA0LjY4NjQyNi0uMDIzOTEgNC45NTU0MTctLjAyMzkxUzUuNjE4OTI5LS4wMDU5NzggNS42Nzg3MDUgMFYtLjIzMzEyNkM1LjI2NjI1Mi0uMjMzMTI2IDUuMjA2NDc2LS4yMzMxMjYgNS4yMDY0NzYtLjQ5MDE2MlYtMS44MDUyM1onLz4KPHBhdGggaWQ9J2c3LTExMCcgZD0nTTMuMjY5NzM4LTEuODA1MjNDMy4yNjk3MzgtMi4zOTEwMzQgMi45MzQ5OTQtMi42MzYxMTUgMi4zMzEyNTgtMi42MzYxMTVDMS44MDUyMy0yLjYzNjExNSAxLjQ3NjQ2My0yLjM2MTE0NiAxLjMwMzExMy0yLjA3NDIyMlYtMi42MzYxMTVMLjM3NjU4OC0yLjU3MDM2MVYtMi4zMzcyMzVDLjc5NTAxOS0yLjMzNzIzNSAuODQ4ODE3LTIuMjk1MzkyIC44NDg4MTctMi4wMDI0OTFWLS40OTAxNjJDLjg0ODgxNy0uMjMzMTI2IC43ODkwNDEtLjIzMzEyNiAuMzc2NTg4LS4yMzMxMjZWMEMuNDE4NDMxLS4wMDU5NzggLjgyNDkwNy0uMDIzOTEgMS4wOTM4OTgtLjAyMzkxUzEuNzU3NDEtLjAwNTk3OCAxLjgxNzE4NiAwVi0uMjMzMTI2QzEuNDA0NzMyLS4yMzMxMjYgMS4zNDQ5NTYtLjIzMzEyNiAxLjM0NDk1Ni0uNDkwMTYyVi0xLjU0MjIxN0MxLjM0NDk1Ni0yLjE5OTc1MSAxLjkwNjg0OS0yLjQ0NDgzMiAyLjI3NzQ2LTIuNDQ0ODMyQzIuNjc3OTU4LTIuNDQ0ODMyIDIuNzczNTk5LTIuMTkzNzczIDIuNzczNTk5LTEuODIzMTYzVi0uNDkwMTYyQzIuNzczNTk5LS4yMzMxMjYgMi43MTM4MjMtLjIzMzEyNiAyLjMwMTM3LS4yMzMxMjZWMEMyLjM0MzIxMy0uMDA1OTc4IDIuNzQ5Njg5LS4wMjM5MSAzLjAxODY4LS4wMjM5MVMzLjY4MjE5Mi0uMDA1OTc4IDMuNzQxOTY4IDBWLS4yMzMxMjZDMy4zMjk1MTQtLjIzMzEyNiAzLjI2OTczOC0uMjMzMTI2IDMuMjY5NzM4LS40OTAxNjJWLTEuODA1MjNaJy8+CjxwYXRoIGlkPSdnNy0xMjAnIGQ9J00yLjEyMjA0Mi0xLjM5ODc1NUwyLjcxMzgyMy0yLjAyMDQyM0MzLjAyNDY1OC0yLjMxOTMwMyAzLjM1MzQyNS0yLjM0MzIxMyAzLjUxNDgxOS0yLjM0MzIxM1YtMi41NzYzMzlDMy40MzcxMTEtMi41NzAzNjEgMy4xNzQwOTctMi41NTI0MjggMi45ODI4MTQtMi41NTI0MjhDMi43Njc2MjEtMi41NTI0MjggMi40MDI5ODktMi41NzAzNjEgMi4zNjcxMjMtMi41NzYzMzlWLTIuMzQzMjEzQzIuNDM4ODU0LTIuMzMxMjU4IDIuNDg2Njc1LTIuMjgzNDM3IDIuNDg2Njc1LTIuMjExNzA2QzIuNDg2Njc1LTIuMTEwMDg3IDIuNDM4ODU0LTIuMDYyMjY3IDIuMjY1NTA0LTEuODY1MDA2TDEuOTcyNjAzLTEuNTYwMTQ5TDEuNDU4NTMxLTIuMTE2MDY1QzEuMzk4NzU1LTIuMTc1ODQxIDEuMzkyNzc3LTIuMTg3Nzk2IDEuMzkyNzc3LTIuMjIzNjYxQzEuMzkyNzc3LTIuMzEzMzI1IDEuNDg4NDE4LTIuMzQzMjEzIDEuNTU0MTcyLTIuMzQzMjEzVi0yLjU3NjMzOUMxLjQxMDcxLTIuNTY0Mzg0IC45OTgyNTctMi41NTI0MjggLjg1NDc5NS0yLjU1MjQyOEMuNzQxMjItMi41NTI0MjggLjM3NjU4OC0yLjU2NDM4NCAuMjQ1MDgxLTIuNTc2MzM5Vi0yLjM0MzIxM0MuNTg1ODAzLTIuMzQzMjEzIC42OTkzNzctMi4zMzEyNTggLjg0ODgxNy0yLjE2OTg2M0wxLjYzMTg4LTEuMzIxMDQ2QzEuNjczNzI0LTEuMjc5MjAzIDEuNjc5NzAxLTEuMjczMjI1IDEuNjc5NzAxLTEuMjYxMjdDMS42Nzk3MDEtMS4yNDMzMzcgMS4xNDE3MTktLjY5MzQgMS4wNzU5NjUtLjYyNzY0NkMuOTIwNTQ4LS40NjYyNTIgLjY5OTM3Ny0uMjM5MTAzIC4yMDkyMTUtLjIzMzEyNlYwQy4yODY5MjQtLjAwNTk3OCAuNTQ5OTM4LS4wMjM5MSAuNzQxMjItLjAyMzkxQy44MjQ5MDctLjAyMzkxIDEuMjMxMzgyLS4wMTE5NTUgMS4zNjI4ODkgMFYtLjIzMzEyNkMxLjI4NTE4MS0uMjM5MTAzIDEuMjQzMzM3LS4yODY5MjQgMS4yNDMzMzctLjM2NDYzM0MxLjI0MzMzNy0uNDY2MjUyIDEuMzE1MDY4LS41NDM5NiAxLjM0NDk1Ni0uNTc5ODI2QzEuNTAwMzc0LS43NTkxNTMgMS42Njc3NDYtLjkzMjUwMyAxLjgzNTExOC0xLjA5OTg3NUwyLjM2NzEyMy0uNTI2MDI3QzIuNDg2Njc1LS4zOTQ1MjEgMi40ODY2NzUtLjM4MjU2NSAyLjQ4NjY3NS0uMzUyNjc3QzIuNDg2Njc1LS4yOTI5MDIgMi40MzI4NzctLjIzMzEyNiAyLjMyNTI4LS4yMzMxMjZWMEMyLjUyMjU0LS4wMTE5NTUgMi45NzY4MzctLjAyMzkxIDMuMDI0NjU4LS4wMjM5MUMzLjI0NTgyOC0uMDIzOTEgMy41NTY2NjMtLjAwNTk3OCAzLjYzNDM3MSAwVi0uMjMzMTI2QzMuMzM1NDkyLS4yMzMxMjYgMy4xODYwNTItLjIzMzEyNiAzLjAyNDY1OC0uNDEyNDUzTDIuMTIyMDQyLTEuMzk4NzU1WicvPgo8cGF0aCBpZD0nZzQtNzgnIGQ9J00zLjY1ODI4MS02Ljg2MjI2N0MzLjg3MzQ3NC02LjI0MDU5OCA0LjEzNjQ4OC01LjM0Mzk2IDQuNjc0NDcxLTMuODczNDc0QzUuNDI3NjQ2LTEuODQxMDk2IDUuNzYyMzkxLTEuMDk5ODc1IDYuNDkxNjU2IC4wMzU4NjZDNi42NTkwMjkgLjI4NjkyNCA2LjY3MDk4NCAuMjk4ODc5IDYuNzc4NTggLjI5ODg3OUM2Ljk0NTk1MyAuMjk4ODc5IDcuMTk3MDExIC4xNTU0MTcgNy4zMjg1MTggLjA1OTc3NkM3LjQ5NTg5LS4wOTU2NDEgNy41MDc4NDYtLjEwNzU5NyA3LjYzOTM1Mi0uNjkzNEM4LjM1NjY2My0zLjgzNzYwOSA5LjI2NTI1NS03LjExMzMyNSA5LjUwNDM1OS03LjY2MzI2M0M5LjUxNjMxNC03LjY4NzE3MyA5Ljc1NTQxNy04LjE0MTQ2OSAxMS4yMjU5MDMtOC4xNjUzOEMxMS40NjUwMDYtOC4xNzczMzUgMTEuNjkyMTU0LTguODEwOTU5IDExLjY5MjE1NC05LjA3Mzk3M0MxMS42OTIxNTQtOS4yNjUyNTUgMTEuNjIwNDIzLTkuMjY1MjU1IDExLjQ1MzA1MS05LjI2NTI1NUMxMC4yNTc1MzQtOS4yNjUyNTUgOS43MTk1NTItOC43NjMxMzggOS41NzYwOS04LjYwNzcyMUM5LjI0MTM0NS04LjE3NzMzNSA4Ljk1NDQyMS03LjMwNDYwOCA4LjQwNDQ4My01LjMwODA5NUM3Ljk4NjA1Mi0zLjc3NzgzMyA3LjYwMzQ4Ny0yLjIyMzY2MSA3LjIzMjg3Ny0uNjgxNDQ1QzYuNTc1MzQyLTEuNjczNzI0IDYuMjA0NzMyLTIuNjE4MTgyIDUuNjMwODg0LTQuMTYwMzk5QzQuOTk3MjYtNS44NTgwMzIgNC42MTQ2OTUtNy4xMDEzNyA0LjI5MTkwNS04LjE3NzMzNUM0LjIyMDE3NC04LjQxNjQzOCA0LjIwODIxOS04LjQyODM5NCA0LjEwMDYyMy04LjQyODM5NEM0LjA3NjcxMi04LjQyODM5NCAzLjgzNzYwOS04LjQyODM5NCAzLjQ5MDkwOS04LjE0MTQ2OUMzLjM3MTM1Ny04LjAzMzg3MyAzLjM1OTQwMi03LjkyNjI3NiAzLjM0NzQ0Ny03Ljc5NDc3QzMuMDEyNzAyLTQuNjE0Njk1IDEuODg4OTE3LTEuNDcwNDg2IDEuNTY2MTI3LS44OTY2MzhDMS40NzA0ODYtLjcxNzMxIDEuMzI3MDI0LS41MDIxMTcgMS4wODc5Mi0uNTAyMTE3Qy45NjgzNjktLjUwMjExNyAuNTAyMTE3LS41NjE4OTMgLjE5MTI4My0uODQ4ODE3Qy4xMzE1MDctLjg5NjYzOCAuMTA3NTk3LS44OTY2MzggLjA5NTY0MS0uODk2NjM4Qy0uMDk1NjQxLS44OTY2MzgtLjM0NjctLjI5ODg3OS0uMzQ2Ny0uMDExOTU1Qy0uMzQ2NyAuMzU4NjU1IC4zODI1NjUgLjU5Nzc1OCAuNzE3MzEgLjU5Nzc1OEMxLjQ4MjQ0MSAuNTk3NzU4IDIuMDkyMTU0LTEuMDg3OTIgMi4yODM0MzctMS42Mzc4NThDMy4wNjA1MjMtMy44MDE3NDMgMy40MzExMzMtNS41ODMwNjQgMy42NTgyODEtNi44NjIyNjdaJy8+CjxwYXRoIGlkPSdnNC0xMDYnIGQ9J00xLjkwMDg3Mi04LjUzNTk5QzEuOTAwODcyLTguNzUxMTgzIDEuOTAwODcyLTguOTY2Mzc2IDEuNjYxNzY4LTguOTY2Mzc2UzEuNDIyNjY1LTguNzUxMTgzIDEuNDIyNjY1LTguNTM1OTlWMi41NTg0MDZDMS40MjI2NjUgMi43NzM1OTkgMS40MjI2NjUgMi45ODg3OTIgMS42NjE3NjggMi45ODg3OTJTMS45MDA4NzIgMi43NzM1OTkgMS45MDA4NzIgMi41NTg0MDZWLTguNTM1OTlaJy8+CjxwYXRoIGlkPSdnMS0xOCcgZD0nTTYuNTM5NDc3LTUuODU4MDMyQzYuNTM5NDc3LTcuOTYyMTQyIDUuMjk2MTM5LTguMzkyNTI4IDQuNTY2ODc0LTguMzkyNTI4QzMuNjIyNDE2LTguMzkyNTI4IDIuNDI2ODk5LTcuNzcwODU5IDEuNTMwMjYyLTYuMTQ0OTU2Qy45MjA1NDgtNS4wMjExNzEgLjU0OTkzOC0zLjM5NTI2OCAuNTQ5OTM4LTIuNDI2ODk5Qy41NDk5MzgtLjY5MzQgMS40NTg1MzEgLjA5NTY0MSAyLjUzNDQ5NiAuMDk1NjQxQzMuMzM1NDkyIC4wOTU2NDEgNC4zODc1NDctLjM3MDYxIDUuMjEyNDUzLTEuNTkwMDM3QzYuMjE2Njg3LTMuMDYwNTIzIDYuNTM5NDc3LTQuOTYxMzk1IDYuNTM5NDc3LTUuODU4MDMyWk0yLjM2NzEyMy00LjQzNTM2N0MyLjUzNDQ5Ni01LjEyODc2NyAyLjg0NTMzLTYuMjE2Njg3IDMuMjAzOTg1LTYuODM4MzU2QzMuNDc4OTU0LTcuMzI4NTE4IDMuOTY5MTE2LTcuOTYyMTQyIDQuNTQyOTY0LTcuOTYyMTQyQzUuMDQ1MDgxLTcuOTYyMTQyIDUuMjYwMjc0LTcuNDM2MTE1IDUuMjYwMjc0LTYuNzMwNzZDNS4yNjAyNzQtNS45Nzc1ODQgNC45OTcyNi00LjkzNzQ4NCA0Ljg2NTc1My00LjQzNTM2N0gyLjM2NzEyM1pNNC43MjIyOTEtMy44NjE1MTlDMy45ODEwNzEtLjY1NzUzNCAyLjk3NjgzNy0uMzM0NzQ1IDIuNTU4NDA2LS4zMzQ3NDVDMi4zOTEwMzQtLjMzNDc0NSAyLjEzOTk3NS0uMzgyNTY1IDEuOTcyNjAzLS43NTMxNzZDMS44MjkxNDEtMS4wNzU5NjUgMS44MjkxNDEtMS41NDIyMTcgMS44MjkxNDEtMS41NTQxNzJDMS44MjkxNDEtMi4yMzU2MTYgMi4wOTIxNTQtMy4zNDc0NDcgMi4yMjM2NjEtMy44NjE1MTlINC43MjIyOTFaJy8+CjxwYXRoIGlkPSdnMS03MycgZD0nTTUuMjcyMjI5LTcuMzg4Mjk0QzUuMzIwMDUtNy41OTE1MzIgNS4zMzIwMDUtNy42MDM0ODcgNS41NzExMDgtNy42MjczOTdDNS43NTA0MzYtNy42MzkzNTIgNS45MDU4NTMtNy42MzkzNTIgNi4wODUxODEtNy42MzkzNTJINi4zMzYyMzlDNi41ODcyOTgtNy42MzkzNTIgNi41OTkyNTMtNy42NTEzMDggNi42NTkwMjktNy42OTkxMjhDNi43MzA3Ni03Ljc0Njk0OSA2Ljc2NjYyNS03LjkxNDMyMSA2Ljc2NjYyNS03Ljk4NjA1MkM2Ljc2NjYyNS04LjEyOTUxNCA2LjY0NzA3My04LjIwMTI0NSA2LjUwMzYxMS04LjIwMTI0NUM2LjIwNDczMi04LjIwMTI0NSA1Ljg5Mzg5OC04LjE3NzMzNSA1LjU5NTAxOS04LjE3NzMzNUM1LjI4NDE4NC04LjE3NzMzNSA0Ljk2MTM5NS04LjE2NTM4IDQuNjM4NjA1LTguMTY1MzhDNC4zMDM4NjEtOC4xNjUzOCAzLjk2OTExNi04LjE3NzMzNSAzLjY0NjMyNi04LjE3NzMzNUMzLjMzNTQ5Mi04LjE3NzMzNSAzLjAxMjcwMi04LjIwMTI0NSAyLjcxMzgyMy04LjIwMTI0NUMyLjU4MjMxNi04LjIwMTI0NSAyLjM2NzEyMy04LjIwMTI0NSAyLjM2NzEyMy03Ljg1NDU0NUMyLjM2NzEyMy03LjYzOTM1MiAyLjU1ODQwNi03LjYzOTM1MiAyLjc3MzU5OS03LjYzOTM1MkgzLjAyNDY1OEMzLjEzMjI1NC03LjYzOTM1MiAzLjQxOTE3OC03LjYyNzM5NyAzLjY1ODI4MS03LjYxNTQ0MkwxLjk0ODY5Mi0uODAwOTk2QzEuOTAwODcyLS42MDk3MTQgMS44ODg5MTctLjU5Nzc1OCAxLjY2MTc2OC0uNTg1ODAzQzEuNTE4MzA2LS41NjE4OTMgMS4zMDMxMTMtLjU2MTg5MyAxLjE0NzY5Ni0uNTYxODkzSC44OTY2MzhDLjY1NzUzNC0uNTYxODkzIC40NTQyOTYtLjU2MTg5MyAuNDU0Mjk2LS4yMTUxOTNDLjQ1NDI5Ni0uMDU5Nzc2IC41ODU4MDMgMCAuNzE3MzEgMEMxLjAxNjE4OSAwIDEuMzI3MDI0LS4wMjM5MSAxLjYyNTkwMy0uMDIzOTFDMS45NDg2OTItLjAyMzkxIDIuMjcxNDgyLS4wMzU4NjYgMi41OTQyNzEtLjAzNTg2NkMyLjkyOTAxNi0uMDM1ODY2IDMuMjUxODA2LS4wMjM5MSAzLjU4NjU1LS4wMjM5MUMzLjg5NzM4NS0uMDIzOTEgNC4yMDgyMTkgMCA0LjUwNzA5OCAwQzQuNjI2NjUgMCA0Ljg2NTc1MyAwIDQuODY1NzUzLS4zNDY3QzQuODY1NzUzLS41NjE4OTMgNC42NjI1MTYtLjU2MTg5MyA0LjQ1OTI3OC0uNTYxODkzSDQuMjA4MjE5QzQuMTI0NTMzLS41NjE4OTMgMy43MzAwMTItLjU3Mzg0OCAzLjU3NDU5NS0uNTg1ODAzTDUuMjcyMjI5LTcuMzg4Mjk0WicvPgo8cGF0aCBpZD0nZzEtODEnIGQ9J001LjMwODA5NSAuNjgxNDQ1QzUuMzA4MDk1IDEuMjkxMTU4IDUuMzkxNzgxIDIuMzE5MzAzIDYuNDY3NzQ2IDIuMzE5MzAzQzcuOTUwMTg3IDIuMzE5MzAzIDguNjMxNjMxIC4yNTEwNTkgOC42MzE2MzEgMEM4LjYzMTYzMS0uMTE5NTUyIDguNTM1OTktLjIxNTE5MyA4LjQxNjQzOC0uMjE1MTkzQzguMjcyOTc2LS4yMTUxOTMgOC4yMjUxNTYtLjA5NTY0MSA4LjIwMTI0NS0uMDM1ODY2QzcuOTc0MDk3IC41NjE4OTMgNy4wODk0MTUgLjU2MTg5MyA2Ljk2OTg2MyAuNTYxODkzQzYuNzA2ODQ5IC41NjE4OTMgNi4zOTYwMTUgLjU2MTg5MyA2LjA5NzEzNi0uMTMxNTA3QzguOTkwMjg2LTEuMTk1NTE3IDkuNzQzNDYyLTMuOTU3MTYxIDkuNzQzNDYyLTUuMzIwMDVDOS43NDM0NjItNy4zNTI0MjggOC4zMzI3NTItOC40MDQ0ODMgNi4yNjQ1MDgtOC40MDQ0ODNDMi41NzAzNjEtOC40MDQ0ODMgLjYzMzYyNC01LjIzNjM2NCAuNjMzNjI0LTIuODQ1MzNDLjYzMzYyNC0uNzUzMTc2IDIuMTI4MDIgLjIwMzIzOCA0LjEyNDUzMyAuMjAzMjM4QzQuMjY3OTk1IC4yMDMyMzggNC43MTAzMzYgLjIwMzIzOCA1LjMwODA5NSAuMDgzNjg2Vi42ODE0NDVaTTMuMjAzOTg1LS41MTQwNzJDMi40NjI3NjUtLjg3MjcyNyAyLjIyMzY2MS0xLjYwMTk5MyAyLjIyMzY2MS0yLjQwMjk4OUMyLjIyMzY2MS0zLjA4NDQzMyAyLjU1ODQwNi01LjI2MDI3NCAzLjU4NjU1LTYuNTk5MjUzQzQuMzUxNjgxLTcuNTc5NTc3IDUuMzY3ODctNy45MjYyNzYgNi4xNDQ5NTYtNy45MjYyNzZDNy4xNzMxMDEtNy45MjYyNzYgOC4xNTM0MjUtNy4zNTI0MjggOC4xNTM0MjUtNS43NzQzNDZDOC4xNTM0MjUtNS42OTA2NiA3Ljk5ODAwNy0yLjAzMjM3OSA1Ljg1ODAzMi0uNzUzMTc2QzUuNjE4OTI5LTEuMzM4OTc5IDUuMjk2MTM5LTEuODUzMDUxIDQuNTY2ODc0LTEuODUzMDUxQzMuOTA5MzQtMS44NTMwNTEgMy4xOTIwMy0xLjMzODk3OSAzLjE5MjAzLS42Njk0ODlDMy4xOTIwMy0uNTczODQ4IDMuMTkyMDMtLjU2MTg5MyAzLjIwMzk4NS0uNTE0MDcyWk01LjI5NjEzOS0uNDY2MjUyQzUuMjEyNDUzLS40MzAzODYgNC43MzQyNDctLjI3NDk2OSA0LjI0NDA4NS0uMjc0OTY5QzQuMDI4ODkyLS4yNzQ5NjkgMy42MjI0MTYtLjI3NDk2OSAzLjYyMjQxNi0uNjY5NDg5QzMuNjIyNDE2LTEuMDUyMDU1IDQuMDg4NjY3LTEuNDIyNjY1IDQuNTc4ODI5LTEuNDIyNjY1QzQuODg5NjY0LTEuNDIyNjY1IDUuMjcyMjI5LTEuMzM4OTc5IDUuMjk2MTM5LS40NjYyNTJaJy8+CjxwYXRoIGlkPSdnMS04OCcgZD0nTTYuOTU3OTA4LTQuNzIyMjkxTDguNTM1OTktNi4yNzY0NjNMOS4yNzcyMS03LjAyOTYzOUM5Ljc1NTQxNy03LjQ4MzkzNSA5Ljg5ODg3OS03LjYyNzM5NyAxMS4xNDIyMTctNy42MzkzNTJDMTEuMzY5MzY1LTcuNjM5MzUyIDExLjM5MzI3NS03Ljk1MDE4NyAxMS4zOTMyNzUtNy45ODYwNTJDMTEuMzkzMjc1LTguMDU3NzgzIDExLjM0NTQ1NS04LjIwMTI0NSAxMS4xNTQxNzItOC4yMDEyNDVDMTAuNzM1NzQxLTguMjAxMjQ1IDEwLjI4MTQ0NS04LjE2NTM4IDkuODUxMDU5LTguMTY1MzhDOS41MDQzNTktOC4xNjUzOCA4LjY0MzU4Ny04LjIwMTI0NSA4LjI5Njg4Ny04LjIwMTI0NUM4LjIwMTI0NS04LjIwMTI0NSA3Ljk2MjE0Mi04LjIwMTI0NSA3Ljk2MjE0Mi03Ljg2NjUwMUM3Ljk2MjE0Mi03LjY1MTMwOCA4LjE1MzQyNS03LjYzOTM1MiA4LjI2MTAyMS03LjYzOTM1MkM4LjYxOTY3Ni03LjYyNzM5NyA4LjkzMDUxMS03LjUzMTc1NiA4Ljk3ODMzMS03LjUxOTgwMUw2LjY5NDg5NC01LjI2MDI3NEw1LjU5NTAxOS03LjU2NzYyMUM1LjcxNDU3LTcuNTkxNTMyIDYuMDg1MTgxLTcuNjM5MzUyIDYuMjg4NDE4LTcuNjM5MzUyQzYuNDE5OTI1LTcuNjM5MzUyIDYuNjM1MTE4LTcuNjM5MzUyIDYuNjM1MTE4LTcuOTc0MDk3QzYuNjM1MTE4LTguMTQxNDY5IDYuNTI3NTIyLTguMjAxMjQ1IDYuMzcyMTA1LTguMjAxMjQ1QzUuOTY1NjI5LTguMjAxMjQ1IDQuOTYxMzk1LTguMTY1MzggNC41NTQ5MTktOC4xNjUzOEM0LjI3OTk1LTguMTY1MzggNC4wMDQ5ODEtOC4xNzczMzUgMy43MzAwMTItOC4xNzczMzVTMy4xNjgxMi04LjIwMTI0NSAyLjg5MzE1MS04LjIwMTI0NUMyLjc4NTU1NC04LjIwMTI0NSAyLjU1ODQwNi04LjIwMTI0NSAyLjU1ODQwNi03Ljg2NjUwMUMyLjU1ODQwNi03LjYzOTM1MiAyLjcxMzgyMy03LjYzOTM1MiAzLjA0ODU2OC03LjYzOTM1MkMzLjIxNTk0LTcuNjM5MzUyIDMuMzQ3NDQ3LTcuNjM5MzUyIDMuNTE0ODE5LTcuNjI3Mzk3QzMuNjgyMTkyLTcuNjAzNDg3IDMuNjk0MTQ3LTcuNTkxNTMyIDMuNzY1ODc4LTcuNDQ4MDdMNS40MTU2OTEtMy45OTMwMjZMMi40MTQ5NDQtMS4wMjgxNDRDMi4xOTk3NTEtLjgyNDkwNyAxLjk0ODY5Mi0uNTczODQ4IC44ODQ2ODItLjU2MTg5M0MuNjY5NDg5LS41NjE4OTMgLjQ2NjI1Mi0uNTYxODkzIC40NjYyNTItLjIxNTE5M0MuNDY2MjUyLS4xMzE1MDcgLjUyNjAyNyAwIC43MDUzNTUgMEMuOTkyMjc5IDAgMS43MjE1NDQtLjAzNTg2NiAyLjAwODQ2OC0uMDM1ODY2QzIuMzU1MTY4LS4wMzU4NjYgMy4yMTU5NCAwIDMuNTYyNjQgMEMzLjY1ODI4MSAwIDMuODk3Mzg1IDAgMy44OTczODUtLjM0NjdDMy44OTczODUtLjU2MTg5MyAzLjY4MjE5Mi0uNTYxODkzIDMuNTg2NTUtLjU2MTg5M0MzLjM0NzQ0Ny0uNTYxODkzIDMuMTA4MzQ0LS41OTc3NTggMi44ODExOTYtLjY4MTQ0NUw1LjY2Njc1LTMuNDU1MDQ0TDcuMDE3Njg0LS42MzM2MjRDNy4wMDU3MjktLjYzMzYyNCA2LjYxMTIwOC0uNTYxODkzIDYuMzI0Mjg0LS41NjE4OTNDNi4yMDQ3MzItLjU2MTg5MyA1Ljk3NzU4NC0uNTYxODkzIDUuOTc3NTg0LS4yMTUxOTNDNS45Nzc1ODQtLjE3OTMyOCA1Ljk4OTUzOSAwIDYuMjQwNTk4IDBDNi42NDcwNzMgMCA3LjY2MzI2My0uMDM1ODY2IDguMDY5NzM4LS4wMzU4NjZDOC4zNDQ3MDctLjAzNTg2NiA4LjYxOTY3Ni0uMDIzOTEgOC44OTQ2NDUtLjAyMzkxUzkuNDU2NTM4IDAgOS43MzE1MDcgMEM5LjgyNzE0OCAwIDEwLjA2NjI1MiAwIDEwLjA2NjI1Mi0uMzQ2N0MxMC4wNjYyNTItLjU2MTg5MyA5Ljg3NDk2OS0uNTYxODkzIDkuNTg4MDQ1LS41NjE4OTNDOS40MjA2NzItLjU2MTg5MyA5LjMwMTEyMS0uNTYxODkzIDkuMTIxNzkzLS41NzM4NDhDOC45NDI0NjYtLjU5Nzc1OCA4LjkzMDUxMS0uNjA5NzE0IDguODQ2ODI0LS43NjUxMzFMNi45NTc5MDgtNC43MjIyOTFaJy8+CjxwYXRoIGlkPSdnMS04OScgZD0nTTguNzc1MDkzLTcuMTczMTAxQzkuMDM4MTA3LTcuNDQ4MDcgOS4zMTMwNzYtNy42MjczOTcgMTAuMTE0MDcyLTcuNjM5MzUyQzEwLjI0NTU3OS03LjYzOTM1MiAxMC40NjA3NzItNy42MzkzNTIgMTAuNDYwNzcyLTcuOTg2MDUyQzEwLjQ2MDc3Mi04LjA1Nzc4MyAxMC40MDA5OTYtOC4yMDEyNDUgMTAuMjQ1NTc5LTguMjAxMjQ1QzkuODk4ODc5LTguMjAxMjQ1IDkuNTA0MzU5LTguMTY1MzggOS4xNDU3MDQtOC4xNjUzOEM4LjcwMzM2Mi04LjE2NTM4IDguMjQ5MDY2LTguMjAxMjQ1IDcuODE4NjgtOC4yMDEyNDVDNy43MzQ5OTQtOC4yMDEyNDUgNy40OTU4OS04LjIwMTI0NSA3LjQ5NTg5LTcuODU0NTQ1QzcuNDk1ODktNy42MzkzNTIgNy42OTkxMjgtNy42MzkzNTIgNy44MTg2OC03LjYzOTM1MlM4LjE3NzMzNS03LjYxNTQ0MiA4LjM1NjY2My03LjU1NTY2Nkw1LjExNjgxMi00LjA4ODY2N0wzLjU4NjU1LTcuNTkxNTMyQzMuOTIxMjk1LTcuNjM5MzUyIDMuOTMzMjUtNy42MzkzNTIgNC4yNTYwNC03LjYzOTM1MkM0LjQ1OTI3OC03LjYzOTM1MiA0LjY2MjUxNi03LjY1MTMwOCA0LjY2MjUxNi03Ljk4NjA1MkM0LjY2MjUxNi04LjE0MTQ2OSA0LjUzMTAwOS04LjIwMTI0NSA0LjM5OTUwMi04LjIwMTI0NUMzLjk5MzAyNi04LjIwMTI0NSAyLjk1MjkyNy04LjE2NTM4IDIuNTQ2NDUxLTguMTY1MzhDMi4yNzE0ODItOC4xNjUzOCAxLjk4NDU1OC04LjE3NzMzNSAxLjcyMTU0NC04LjE3NzMzNUMxLjQzNDYyLTguMTc3MzM1IDEuMTM1NzQxLTguMjAxMjQ1IC44NjA3NzItOC4yMDEyNDVDLjc0MTIyLTguMjAxMjQ1IC41MjYwMjctOC4yMDEyNDUgLjUyNjAyNy03Ljg1NDU0NUMuNTI2MDI3LTcuNjM5MzUyIC42OTM0LTcuNjM5MzUyIDEuMDE2MTg5LTcuNjM5MzUyQzEuMTcxNjA2LTcuNjM5MzUyIDEuMzE1MDY4LTcuNjM5MzUyIDEuNDgyNDQxLTcuNjI3Mzk3QzEuNjI1OTAzLTcuNjAzNDg3IDEuNjQ5ODEzLTcuNjAzNDg3IDEuNzIxNTQ0LTcuNDQ4MDdMMy41Mzg3My0zLjI3NTcxNkwyLjkxNzA2MS0uODEyOTUxQzIuODY5MjQtLjYwOTcxNCAyLjg1NzI4NS0uNTk3NzU4IDIuNjQyMDkyLS41ODU4MDNDMi40Mzg4NTQtLjU2MTg5MyAyLjIzNTYxNi0uNTYxODkzIDIuMDIwNDIzLS41NjE4OTNDMS42NjE3NjgtLjU2MTg5MyAxLjYzNzg1OC0uNTYxODkzIDEuNTkwMDM3LS41MTQwNzJDMS41MTgzMDYtLjQ1NDI5NiAxLjQ3MDQ4Ni0uMjk4ODc5IDEuNDcwNDg2LS4yMTUxOTNDMS40NzA0ODYtLjE5MTI4MyAxLjQ4MjQ0MSAwIDEuNzMzNDk5IDBDMi4wMzIzNzkgMCAyLjM0MzIxMy0uMDIzOTEgMi42NDIwOTItLjAyMzkxQzIuOTI5MDE2LS4wMjM5MSAzLjIyNzg5NS0uMDM1ODY2IDMuNTE0ODE5LS4wMzU4NjZDMy45MjEyOTUtLjAzNTg2NiA0LjkzNzQ4NCAwIDUuMzQzOTYgMEM1LjQ1MTU1NyAwIDUuNjkwNjYgMCA1LjY5MDY2LS4zNDY3QzUuNjkwNjYtLjU2MTg5MyA1LjUyMzI4OC0uNTYxODkzIDUuMTg4NTQzLS41NjE4OTNDNC45Mzc0ODQtLjU2MTg5MyA0LjcxMDMzNi0uNTczODQ4IDQuNDU5Mjc4LS41ODU4MDNMNS4xMjg3NjctMy4yNzU3MTZMOC43NzUwOTMtNy4xNzMxMDFaJy8+CjxwYXRoIGlkPSdnNS0xOCcgZD0nTTMuODE3Njg0LTMuOTEzMzI1QzMuODE3Njg0LTQuOTA5NTg5IDMuNDM1MTE4LTUuNjEwOTU5IDIuNzczNTk5LTUuNjEwOTU5QzEuNTg2MDUyLTUuNjEwOTU5IC4zNTA2ODUtMy4zOTUyNjggLjM1MDY4NS0xLjYxNzkzM0MuMzUwNjg1LS44NTI4MDIgLjYxMzY5OSAuMDc5NzAxIDEuNDAyNzQgLjA3OTcwMUMyLjU2NjM3NiAuMDc5NzAxIDMuODE3Njg0LTIuMDgwMTk5IDMuODE3Njg0LTMuOTEzMzI1Wk0xLjI0MzMzNy0yLjkwMTEyMUMxLjYxNzkzMy00LjUxMTA4MyAyLjI3MTQ4Mi01LjM4Nzc5NiAyLjc2NTYyOS01LjM4Nzc5NkMzLjI0MzgzNi01LjM4Nzc5NiAzLjI0MzgzNi00LjUzNDk5NCAzLjI0MzgzNi00LjM4MzU2MkMzLjI0MzgzNi0zLjkzNzIzNSAzLjEwMDM3NC0zLjI5MTY1NiAzLjAwNDczMi0yLjkwMTEyMUgxLjI0MzMzN1pNMi45MzMwMDEtMi42MzAxMzdDMi41NTg0MDYtMS4wMjgxNDQgMS45MDQ4NTctLjE0MzQ2MiAxLjQxMDcxLS4xNDM0NjJDLjk4MDMyNC0uMTQzNDYyIC45MzI1MDMtLjc4MTA3MSAuOTMyNTAzLTEuMTQ3Njk2Qy45MzI1MDMtMS42NDk4MTMgMS4wODM5MzUtMi4yOTUzOTIgMS4xNzE2MDYtMi42MzAxMzdIMi45MzMwMDFaJy8+CjxwYXRoIGlkPSdnNS0yOCcgZD0nTTIuNTAyNjE1LTIuOTA5MDkxSDMuOTI5MjY1QzQuMDU2Nzg3LTIuOTA5MDkxIDQuMTQ0NDU4LTIuOTA5MDkxIDQuMjI0MTU5LTIuOTcyODUyQzQuMzE5ODAxLTMuMDYwNTIzIDQuMzQzNzExLTMuMTY0MTM0IDQuMzQzNzExLTMuMjExOTU1QzQuMzQzNzExLTMuNDM1MTE4IDQuMTQ0NDU4LTMuNDM1MTE4IDQuMDA4OTY2LTMuNDM1MTE4SDEuNjAxOTkzQzEuNDM0NjItMy40MzUxMTggMS4xMzE3NTYtMy40MzUxMTggLjc0MTIyLTMuMDUyNTUzQy40NTQyOTYtMi43NjU2MjkgLjIzMTEzMy0yLjM5OTAwNCAuMjMxMTMzLTIuMzQzMjEzQy4yMzExMzMtMi4yNzE0ODIgLjI4NjkyNC0yLjI0NzU3MiAuMzUwNjg1LTIuMjQ3NTcyQy40MzAzODYtMi4yNDc1NzIgLjQ0NjMyNi0yLjI3MTQ4MiAuNDk0MTQ3LTIuMzM1MjQzQy44ODQ2ODItMi45MDkwOTEgMS4zNTQ5MTktMi45MDkwOTEgMS41MzgyMzItMi45MDkwOTFIMi4yMjM2NjFMMS41MzgyMzItLjcwMTM3QzEuNDgyNDQxLS41MTgwNTcgMS4zNzg4MjktLjE5MTI4MyAxLjM3ODgyOS0uMTUxNDMyQzEuMzc4ODI5IC4wMzE4OCAxLjU0NjIwMiAuMDk1NjQxIDEuNjQxODQzIC4wOTU2NDFDMS45MzY3MzcgLjA5NTY0MSAxLjk4NDU1OC0uMTgzMzEzIDIuMDA4NDY4LS4zMDI4NjRMMi41MDI2MTUtMi45MDkwOTFaJy8+CjxwYXRoIGlkPSdnNS01OScgZD0nTTEuNDkwNDExLS4xMTk1NTJDMS40OTA0MTEgLjM5ODUwNiAxLjM3ODgyOSAuODUyODAyIC44ODQ2ODIgMS4zNDY5NDlDLjg1MjgwMiAxLjM3MDg1OSAuODM2ODYyIDEuMzg2OCAuODM2ODYyIDEuNDI2NjVDLjgzNjg2MiAxLjQ5MDQxMSAuOTAwNjIzIDEuNTM4MjMyIC45NTY0MTMgMS41MzgyMzJDMS4wNTIwNTUgMS41MzgyMzIgMS43MTM1NzQgLjkwODU5MyAxLjcxMzU3NC0uMDIzOTFDMS43MTM1NzQtLjUzMzk5OCAxLjUyMjI5MS0uODg0NjgyIDEuMTcxNjA2LS44ODQ2ODJDLjg5MjY1My0uODg0NjgyIC43MzMyNS0uNjYxNTE5IC43MzMyNS0uNDQ2MzI2Qy43MzMyNS0uMjIzMTYzIC44ODQ2ODIgMCAxLjE3OTU3NyAwQzEuMzcwODU5IDAgMS40OTA0MTEtLjExMTU4MiAxLjQ5MDQxMS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzUtOTgnIGQ9J00xLjk0NDcwNy01LjI5MjE1NEMxLjk1MjY3Ny01LjMwODA5NSAxLjk3NjU4OC01LjQxMTcwNiAxLjk3NjU4OC01LjQxOTY3NkMxLjk3NjU4OC01LjQ1OTUyNyAxLjk0NDcwNy01LjUzMTI1OCAxLjg0OTA2Ni01LjUzMTI1OEMxLjgxNzE4Ni01LjUzMTI1OCAxLjU3MDExMi01LjUwNzM0NyAxLjM4NjgtNS40OTE0MDdMLjk0MDQ3My01LjQ1OTUyN0MuNzY1MTMxLTUuNDQzNTg3IC42ODU0My01LjQzNTYxNiAuNjg1NDMtNS4yOTIxNTRDLjY4NTQzLTUuMTgwNTczIC43OTcwMTEtNS4xODA1NzMgLjg5MjY1My01LjE4MDU3M0MxLjI3NTIxOC01LjE4MDU3MyAxLjI3NTIxOC01LjEzMjc1MiAxLjI3NTIxOC01LjA2MTAyMUMxLjI3NTIxOC01LjAxMzIgMS4xOTU1MTctNC42OTQzOTYgMS4xNDc2OTYtNC41MTEwODNMLjQ1NDI5Ni0xLjczNzQ4NEMuMzkwNTM1LTEuNDY2NTAxIC4zOTA1MzUtMS4zNDY5NDkgLjM5MDUzNS0xLjIxMTQ1N0MuMzkwNTM1LS4zOTA1MzUgLjg5MjY1MyAuMDc5NzAxIDEuNTA2MzUxIC4wNzk3MDFDMi40ODY2NzUgLjA3OTcwMSAzLjUwNjg0OS0xLjA1MjA1NSAzLjUwNjg0OS0yLjIwNzcyMUMzLjUwNjg0OS0yLjk5Njc2MiAyLjk5Njc2Mi0zLjUxNDgxOSAyLjM1OTE1My0zLjUxNDgxOUMxLjkxMjgyNy0zLjUxNDgxOSAxLjU3MDExMi0zLjIyNzg5NSAxLjM5NDc3LTMuMDc2NDYzTDEuOTQ0NzA3LTUuMjkyMTU0Wk0xLjUwNjM1MS0uMTQzNDYyQzEuMjE5NDI3LS4xNDM0NjIgLjkzMjUwMy0uMzY2NjI1IC45MzI1MDMtLjk0ODQ0M0MuOTMyNTAzLTEuMTYzNjM2IC45NjQzODQtMS4zNjI4ODkgMS4wNjAwMjUtMS43NDU0NTVDMS4xMTU4MTYtMS45NzY1ODggMS4xNzE2MDYtMi4xOTk3NTEgMS4yMzUzNjctMi40MzA4ODRDMS4yNzUyMTgtMi41NzQzNDYgMS4yNzUyMTgtMi41OTAyODYgMS4zNzA4NTktMi43MDk4MzhDMS42NDE4NDMtMy4wNDQ1ODMgMi4wMDA0OTgtMy4yOTE2NTYgMi4zMzUyNDMtMy4yOTE2NTZDMi43MzM3NDgtMy4yOTE2NTYgMi44ODUxODEtMi45MDExMjEgMi44ODUxODEtMi41NDI0NjZDMi44ODUxODEtMi4yNDc1NzIgMi43MDk4MzgtMS4zOTQ3NyAyLjQ3MDczNS0uOTI0NTMzQzIuMjYzNTEyLS40OTQxNDcgMS44ODA5NDYtLjE0MzQ2MiAxLjUwNjM1MS0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzUtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c1LTExMScgZD0nTTMuOTY5MTE2LTIuMTM1OTlDMy45NjkxMTYtMi45MTcwNjEgMy40MTEyMDgtMy41MTQ4MTkgMi41ODIzMTYtMy41MTQ4MTlDMS40NTA1Ni0zLjUxNDgxOSAuMzUwNjg1LTIuNDE0OTQ0IC4zNTA2ODUtMS4yOTkxMjhDLjM1MDY4NS0uNDg2MTc3IC45MjQ1MzMgLjA3OTcwMSAxLjczNzQ4NCAuMDc5NzAxQzIuODc3MjEgLjA3OTcwMSAzLjk2OTExNi0xLjAzNjExNSAzLjk2OTExNi0yLjEzNTk5Wk0xLjc0NTQ1NS0uMTQzNDYyQzEuNDY2NTAxLS4xNDM0NjIgLjk5NjI2NC0uMjg2OTI0IC45OTYyNjQtMS4wMjAxNzRDLjk5NjI2NC0xLjM0Njk0OSAxLjE0NzY5Ni0yLjIwNzcyMSAxLjUzMDI2Mi0yLjcwMTg2OEMxLjkyMDc5Ny0zLjIwMzk4NSAyLjM1OTE1My0zLjI5MTY1NiAyLjU3NDM0Ni0zLjI5MTY1NkMyLjkwMTEyMS0zLjI5MTY1NiAzLjMyMzUzNy0zLjA5MjQwMyAzLjMyMzUzNy0yLjQyMjkxNEMzLjMyMzUzNy0yLjEwNDExIDMuMTgwMDc1LTEuMzQ2OTQ5IDIuODc3MjEtLjg2ODc0MkMyLjU4MjMxNi0uNDE0NDQ2IDIuMTQzOTYtLjE0MzQ2MiAxLjc0NTQ1NS0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzUtMTE1JyBkPSdNMy4yMTE5NTUtMi45OTY3NjJDMy4wMjg2NDMtMi45NjQ4ODIgMi44NjEyNy0yLjgyMTQyIDIuODYxMjctMi42MjIxNjdDMi44NjEyNy0yLjQ3ODcwNSAyLjk1NjkxMi0yLjM3NTA5MyAzLjEzMjI1NC0yLjM3NTA5M0MzLjI1MTgwNi0yLjM3NTA5MyAzLjQ5ODg3OS0yLjQ2Mjc2NSAzLjQ5ODg3OS0yLjgyMTQyQzMuNDk4ODc5LTMuMzE1NTY3IDIuOTgwODIyLTMuNTE0ODE5IDIuNDg2Njc1LTMuNTE0ODE5QzEuNDE4NjgtMy41MTQ4MTkgMS4wODM5MzUtMi43NTc2NTkgMS4wODM5MzUtMi4zNTExODNDMS4wODM5MzUtMi4yNzE0ODIgMS4wODM5MzUtMS45ODQ1NTggMS4zNzg4MjktMS43NjEzOTVDMS41NjIxNDItMS42MTc5MzMgMS42OTc2MzQtMS41OTQwMjIgMi4xMTIwOC0xLjUxNDMyMUMyLjM5MTAzNC0xLjQ1ODUzMSAyLjg0NTMzLTEuMzc4ODI5IDIuODQ1MzMtLjk2NDM4NEMyLjg0NTMzLS43NTcxNjEgMi42OTM4OTgtLjQ5NDE0NyAyLjQ3MDczNS0uMzQyNzE1QzIuMTc1ODQxLS4xNTE0MzIgMS43ODUzMDUtLjE0MzQ2MiAxLjY1Nzc4My0uMTQzNDYyQzEuNDY2NTAxLS4xNDM0NjIgLjkyNDUzMy0uMTc1MzQyIC43MjUyOC0uNDk0MTQ3QzEuMTMxNzU2LS41MTAwODcgMS4xODc1NDctLjgzNjg2MiAxLjE4NzU0Ny0uOTMyNTAzQzEuMTg3NTQ3LTEuMTcxNjA2IC45NzIzNTQtMS4yMjczOTcgLjg3NjcxMi0xLjIyNzM5N0MuNzQ5MTkxLTEuMjI3Mzk3IC40MjI0MTYtMS4xMzE3NTYgLjQyMjQxNi0uNjkzNEMuNDIyNDE2LS4yMjMxNjMgLjkxNjU2MyAuMDc5NzAxIDEuNjU3NzgzIC4wNzk3MDFDMy4wNDQ1ODMgLjA3OTcwMSAzLjMzOTQ3Ny0uOTAwNjIzIDMuMzM5NDc3LTEuMjM1MzY3QzMuMzM5NDc3LTEuOTUyNjc3IDIuNTU4NDA2LTIuMTA0MTEgMi4yNjM1MTItMi4xNTk5QzEuODgwOTQ2LTIuMjMxNjMxIDEuNTcwMTEyLTIuMjg3NDIyIDEuNTcwMTEyLTIuNjIyMTY3QzEuNTcwMTEyLTIuNzY1NjI5IDEuNzA1NjA0LTMuMjkxNjU2IDIuNDc4NzA1LTMuMjkxNjU2QzIuNzgxNTY5LTMuMjkxNjU2IDMuMDkyNDAzLTMuMjAzOTg1IDMuMjExOTU1LTIuOTk2NzYyWicvPgo8cGF0aCBpZD0nZzAtMTgnIGQ9J000LjU5MDc4NS0zLjg1NzUzNEM0LjU5MDc4NS01LjIyMDQyMyAzLjc4NTgwMy01LjYwMjk4OSAzLjE2NDEzNC01LjYwMjk4OUMyLjU5ODI1Ny01LjYwMjk4OSAxLjgzMzEyNi01LjI4NDE4NCAxLjIzNTM2Ny00LjM5OTUwMkMuNTQ5OTM4LTMuMzc5MzI4IC4zOTA1MzUtMi4xMjAwNSAuMzkwNTM1LTEuNjY1NzUzQy4zOTA1MzUtLjQ4NjE3NyAxLjAzNjExNSAuMDcxNzMxIDEuODI1MTU2IC4wNzE3MzFDMi4zMzUyNDMgLjA3MTczMSAzLjA0NDU4My0uMTgzMzEzIDMuNjQyMzQxLS45ODAzMjRDNC4zNTk2NTEtMS45Mjg3NjcgNC41OTA3ODUtMy4yMzU4NjYgNC41OTA3ODUtMy44NTc1MzRaTTEuNjU3NzgzLTIuOTcyODUyQzEuODE3MTg2LTMuNjE4NDMxIDEuOTc2NTg4LTQuMTQ0NDU4IDIuMjYzNTEyLTQuNjA2NzI1QzIuNDU0Nzk1LTQuOTE3NTU5IDIuNzk3NTA5LTUuMjY4MjQ0IDMuMTQ4MTk0LTUuMjY4MjQ0QzMuNTYyNjQtNS4yNjgyNDQgMy42NzQyMjItNC43OTgwMDcgMy42NzQyMjItNC40MTU0NDJDMy42NzQyMjItMy45OTMwMjYgMy41NTQ2Ny0zLjQ4MjkzOSAzLjQzNTExOC0yLjk3Mjg1MkgxLjY1Nzc4M1pNMy4zMzE1MDctMi41NTg0MDZDMy4yMDM5ODUtMi4wNzIyMjkgMy4wNDQ1ODMtMS40NzQ0NzEgMi43ODk1MzktMS4wNDQwODVDMi40NzA3MzUtLjQ5NDE0NyAyLjEyMDA1LS4yNjMwMTQgMS44MzMxMjYtLjI2MzAxNEMxLjU3MDExMi0uMjYzMDE0IDEuMzE1MDY4LS40NjIyNjcgMS4zMTUwNjgtMS4xMjM3ODZDMS4zMTUwNjgtMS41NzgwODIgMS40MjY2NS0yLjA0MDM0OSAxLjU1NDE3Mi0yLjU1ODQwNkgzLjMzMTUwN1onLz4KPHBhdGggaWQ9J2c5LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOS00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzktNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzktNTknIGQ9J00yLjE5OTc1MS00LjU3ODgyOUMyLjE5OTc1MS00LjkwMTYxOSAxLjkyNDc4Mi01LjE1MjY3NyAxLjYyNTkwMy01LjE1MjY3N0MxLjI3OTIwMy01LjE1MjY3NyAxLjA0MDEtNC44Nzc3MDkgMS4wNDAxLTQuNTc4ODI5QzEuMDQwMS00LjIyMDE3NCAxLjMzODk3OS0zLjk5MzAyNiAxLjYxMzk0OC0zLjk5MzAyNkMxLjkzNjczNy0zLjk5MzAyNiAyLjE5OTc1MS00LjI0NDA4NSAyLjE5OTc1MS00LjU3ODgyOVpNMS45OTY1MTMtLjExOTU1MkMxLjk5NjUxMyAuMjk4ODc5IDEuOTk2NTEzIDEuMTQ3Njk2IDEuMjY3MjQ4IDIuMDQ0MzM0QzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuMzk4NzU1IDIuMzA3MzQ3IDIuMjM1NjE2IDEuNDIyNjY1IDIuMjM1NjE2IC4wMjM5MUMyLjIzNTYxNi0uNDE4NDMxIDIuMTk5NzUxLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjY3MjQ4LTEuMTU5NjUxIDEuMDQwMS0uODk2NjM4IDEuMDQwMS0uNTg1ODAzQzEuMDQwMS0uMjYzMDE0IDEuMjY3MjQ4IDAgMS42MjU5MDMgMEMxLjg1MzA1MSAwIDEuOTM2NzM3LS4wNzE3MzEgMS45OTY1MTMtLjExOTU1MlonLz4KPHBhdGggaWQ9J2c5LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnOS05NycgZD0nTTQuNjE0Njk1LTMuMTkyMDNDNC42MTQ2OTUtMy44Mzc2MDkgNC42MTQ2OTUtNC4zMTU4MTYgNC4wODg2NjctNC43ODIwNjdDMy42NzAyMzctNS4xNjQ2MzMgMy4xMzIyNTQtNS4zMzIwMDUgMi42MDYyMjctNS4zMzIwMDVDMS42MjU5MDMtNS4zMzIwMDUgLjg3MjcyNy00LjY4NjQyNiAuODcyNzI3LTMuOTA5MzRDLjg3MjcyNy0zLjU2MjY0IDEuMDk5ODc1LTMuMzk1MjY4IDEuMzc0ODQ0LTMuMzk1MjY4QzEuNjYxNzY4LTMuMzk1MjY4IDEuODY1MDA2LTMuNTk4NTA2IDEuODY1MDA2LTMuODg1NDNDMS44NjUwMDYtNC4zNzU1OTIgMS40MzQ2Mi00LjM3NTU5MiAxLjI1NTI5My00LjM3NTU5MkMxLjUzMDI2Mi00Ljg3NzcwOSAyLjEwNDExLTUuMDkyOTAyIDIuNTgyMzE2LTUuMDkyOTAyQzMuMTMyMjU0LTUuMDkyOTAyIDMuODM3NjA5LTQuNjM4NjA1IDMuODM3NjA5LTMuNTYyNjRWLTMuMDg0NDMzQzEuNDM0NjItMy4wNDg1NjggLjUyNjAyNy0yLjA0NDMzNCAuNTI2MDI3LTEuMTIzNzg2Qy41MjYwMjctLjE3OTMyOCAxLjYyNTkwMyAuMTE5NTUyIDIuMzU1MTY4IC4xMTk1NTJDMy4xNDQyMDkgLjExOTU1MiAzLjY4MjE5Mi0uMzU4NjU1IDMuOTA5MzQtLjkzMjUwM0MzLjk1NzE2MS0uMzcwNjEgNC4zMjc3NzEgLjA1OTc3NiA0Ljg0MTg0MyAuMDU5Nzc2QzUuMDkyOTAyIC4wNTk3NzYgNS43ODYzMDEtLjEwNzU5NyA1Ljc4NjMwMS0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OC0uMzgyNTY1IDUuMjM2MzY0LS4yODY5MjQgNS4wNjg5OTEtLjI4NjkyNEM0LjYxNDY5NS0uMjg2OTI0IDQuNjE0Njk1LS45MjA1NDggNC42MTQ2OTUtMS4wOTk4NzVWLTMuMTkyMDNaTTMuODM3NjA5LTEuNjg1Njc5QzMuODM3NjA5LS41MTQwNzIgMi45NjQ4ODItLjExOTU1MiAyLjQ1MDgwOS0uMTE5NTUyQzEuODY1MDA2LS4xMTk1NTIgMS4zNzQ4NDQtLjU0OTkzOCAxLjM3NDg0NC0xLjEyMzc4NkMxLjM3NDg0NC0yLjcwMTg2OCAzLjQwNzIyMy0yLjg0NTMzIDMuODM3NjA5LTIuODY5MjRWLTEuNjg1Njc5WicvPgo8cGF0aCBpZD0nZzktMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzktMTA5JyBkPSdNOC41NzE4NTYtMi45MDUxMDZDOC41NzE4NTYtNC4wMTY5MzYgOC41NzE4NTYtNC4zNTE2ODEgOC4yOTY4ODctNC43MzQyNDdDNy45NTAxODctNS4yMDA0OTggNy4zODgyOTQtNS4yNzIyMjkgNi45ODE4MTgtNS4yNzIyMjlDNS45ODk1MzktNS4yNzIyMjkgNS40ODc0MjItNC41NTQ5MTkgNS4yOTYxMzktNC4wODg2NjdDNS4xMjg3NjctNS4wMDkyMTUgNC40ODMxODgtNS4yNzIyMjkgMy43MzAwMTItNS4yNzIyMjlDMi41NzAzNjEtNS4yNzIyMjkgMi4xMTYwNjUtNC4yNzk5NSAyLjAyMDQyMy00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMLjM4MjU2NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTctNC43OTQwMjIgMS4yOTExNTgtNC43MTAzMzYgMS4yOTExNTgtNC4xMjQ1MzNWLS44ODQ2ODJDMS4yOTExNTgtLjM0NjcgMS4xNTk2NTEtLjM0NjcgLjM4MjU2NS0uMzQ2N1YwQy42OTM0LS4wMjM5MSAxLjMzODk3OS0uMDIzOTEgMS42NzM3MjQtLjAyMzkxQzIuMDIwNDIzLS4wMjM5MSAyLjY2NjAwMi0uMDIzOTEgMi45NzY4MzcgMFYtLjM0NjdDMi4yMTE3MDYtLjM0NjcgMi4wNjgyNDQtLjM0NjcgMi4wNjgyNDQtLjg4NDY4MlYtMy4xMDgzNDRDMi4wNjgyNDQtNC4zNjM2MzYgMi44OTMxNTEtNS4wMzMxMjYgMy42MzQzNzEtNS4wMzMxMjZTNC41NDI5NjQtNC40MjM0MTIgNC41NDI5NjQtMy42OTQxNDdWLS44ODQ2ODJDNC41NDI5NjQtLjM0NjcgNC40MTE0NTctLjM0NjcgMy42MzQzNzEtLjM0NjdWMEMzLjk0NTIwNS0uMDIzOTEgNC41OTA3ODUtLjAyMzkxIDQuOTI1NTI5LS4wMjM5MUM1LjI3MjIyOS0uMDIzOTEgNS45MTc4MDgtLjAyMzkxIDYuMjI4NjQzIDBWLS4zNDY3QzUuNDYzNTEyLS4zNDY3IDUuMzIwMDUtLjM0NjcgNS4zMjAwNS0uODg0NjgyVi0zLjEwODM0NEM1LjMyMDA1LTQuMzYzNjM2IDYuMTQ0OTU2LTUuMDMzMTI2IDYuODg2MTc3LTUuMDMzMTI2UzcuNzk0NzctNC40MjM0MTIgNy43OTQ3Ny0zLjY5NDE0N1YtLjg4NDY4MkM3Ljc5NDc3LS4zNDY3IDcuNjYzMjYzLS4zNDY3IDYuODg2MTc3LS4zNDY3VjBDNy4xOTcwMTEtLjAyMzkxIDcuODQyNTktLjAyMzkxIDguMTc3MzM1LS4wMjM5MUM4LjUyNDAzNS0uMDIzOTEgOS4xNjk2MTQtLjAyMzkxIDkuNDgwNDQ4IDBWLS4zNDY3QzguODgyNjktLjM0NjcgOC41ODM4MTEtLjM0NjcgOC41NzE4NTYtLjcwNTM1NVYtMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOS0xMTQnIGQ9J00xLjk5NjUxMy0yLjc4NTU1NEMxLjk5NjUxMy0zLjk0NTIwNSAyLjQ3NDcyLTUuMDMzMTI2IDMuMzk1MjY4LTUuMDMzMTI2QzMuNDkwOTA5LTUuMDMzMTI2IDMuNTE0ODE5LTUuMDMzMTI2IDMuNTYyNjQtNS4wMjExNzFDMy40NjY5OTktNC45NzMzNSAzLjI3NTcxNi00LjkwMTYxOSAzLjI3NTcxNi00LjU3ODgyOUMzLjI3NTcxNi00LjIzMjEzIDMuNTUwNjg1LTQuMTAwNjIzIDMuNzQxOTY4LTQuMTAwNjIzQzMuOTgxMDcxLTQuMTAwNjIzIDQuMjIwMTc0LTQuMjU2MDQgNC4yMjAxNzQtNC41Nzg4MjlDNC4yMjAxNzQtNC45Mzc0ODQgMy44OTczODUtNS4yNzIyMjkgMy4zODMzMTMtNS4yNzIyMjlDMi4zNjcxMjMtNS4yNzIyMjkgMi4wMjA0MjMtNC4xNzIzNTQgMS45NDg2OTItMy45NDUyMDVIMS45MzY3MzdWLTUuMjcyMjI5TC4zMzQ3NDUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTQ3Njk2LTQuNzk0MDIyIDEuMjQzMzM3LTQuNzEwMzM2IDEuMjQzMzM3LTQuMTI0NTMzVi0uODg0NjgyQzEuMjQzMzM3LS4zNDY3IDEuMTExODMxLS4zNDY3IC4zMzQ3NDUtLjM0NjdWMEMuNjY5NDg5LS4wMjM5MSAxLjMyNzAyNC0uMDIzOTEgMS42ODU2NzktLjAyMzkxQzIuMDA4NDY4LS4wMjM5MSAyLjg1NzI4NS0uMDIzOTEgMy4xMzIyNTQgMFYtLjM0NjdIMi44OTMxNTFDMi4wMjA0MjMtLjM0NjcgMS45OTY1MTMtLjQ3ODIwNyAxLjk5NjUxMy0uOTA4NTkzVi0yLjc4NTU1NFonLz4KPHBhdGggaWQ9J2c5LTEyMCcgZD0nTTMuMzQ3NDQ3LTIuODIxNDJDMy42OTQxNDctMy4yNzU3MTYgNC4xOTYyNjQtMy45MjEyOTUgNC40MjM0MTItNC4xNzIzNTRDNC45MTM1NzQtNC43MjIyOTEgNS40NzU0NjctNC44MDU5NzggNS44NTgwMzItNC44MDU5NzhWLTUuMTUyNjc3QzUuMzQzOTYtNS4xMjg3NjcgNS4zMjAwNS01LjEyODc2NyA0Ljg1Mzc5OC01LjEyODc2N0M0LjM5OTUwMi01LjEyODc2NyA0LjM3NTU5Mi01LjEyODc2NyAzLjc3NzgzMy01LjE1MjY3N1YtNC44MDU5NzhDMy45MzMyNS00Ljc4MjA2NyA0LjEyNDUzMy00LjcxMDMzNiA0LjEyNDUzMy00LjQzNTM2N0M0LjEyNDUzMy00LjIzMjEzIDQuMDE2OTM2LTQuMTAwNjIzIDMuOTQ1MjA1LTQuMDA0OTgxTDMuMTgwMDc1LTMuMDM2NjEzTDIuMjQ3NTcyLTQuMjY3OTk1QzIuMjExNzA2LTQuMzE1ODE2IDIuMTM5OTc1LTQuNDIzNDEyIDIuMTM5OTc1LTQuNTA3MDk4QzIuMTM5OTc1LTQuNTc4ODI5IDIuMTk5NzUxLTQuNzk0MDIyIDIuNTU4NDA2LTQuODA1OTc4Vi01LjE1MjY3N0MyLjI1OTUyNy01LjEyODc2NyAxLjY0OTgxMy01LjEyODc2NyAxLjMyNzAyNC01LjEyODc2N0MuOTMyNTAzLTUuMTI4NzY3IC45MDg1OTMtNS4xMjg3NjcgLjE3OTMyOC01LjE1MjY3N1YtNC44MDU5NzhDLjc4OTA0MS00LjgwNTk3OCAxLjAxNjE4OS00Ljc4MjA2NyAxLjI2NzI0OC00LjQ1OTI3OEwyLjY2NjAwMi0yLjYzMDEzN0MyLjY4OTkxMy0yLjYwNjIyNyAyLjczNzczMy0yLjUzNDQ5NiAyLjczNzczMy0yLjQ5ODYzUzEuODA1MjMtMS4yOTExNTggMS42ODU2NzktMS4xMzU3NDFDMS4xNTk2NTEtLjQ5MDE2MiAuNjMzNjI0LS4zNTg2NTUgLjExOTU1Mi0uMzQ2N1YwQy41NzM4NDgtLjAyMzkxIC41OTc3NTgtLjAyMzkxIDEuMTExODMxLS4wMjM5MUMxLjU2NjEyNy0uMDIzOTEgMS41OTAwMzctLjAyMzkxIDIuMTg3Nzk2IDBWLS4zNDY3QzEuOTAwODcyLS4zODI1NjUgMS44NTMwNTEtLjU2MTg5MyAxLjg1MzA1MS0uNzI5MjY1QzEuODUzMDUxLS45MjA1NDggMS45MzY3MzctMS4wMTYxODkgMi4wNTYyODktMS4xNzE2MDZDMi4yMzU2MTYtMS40MjI2NjUgMi42MzAxMzctMS45MTI4MjcgMi45MTcwNjEtMi4yODM0MzdMMy44OTczODUtMS4wMDQyMzRDNC4xMDA2MjMtLjc0MTIyIDQuMTAwNjIzLS43MTczMSA0LjEwMDYyMy0uNjQ1NTc5QzQuMTAwNjIzLS41NDk5MzggNC4wMDQ5ODEtLjM1ODY1NSAzLjY4MjE5Mi0uMzQ2N1YwQzMuOTkzMDI2LS4wMjM5MSA0LjU3ODgyOS0uMDIzOTEgNC45MTM1NzQtLjAyMzkxQzUuMzA4MDk1LS4wMjM5MSA1LjMzMjAwNS0uMDIzOTEgNi4wNDkzMTUgMFYtLjM0NjdDNS40MTU2OTEtLjM0NjcgNS4yMDA0OTgtLjM3MDYxIDQuOTEzNTc0LS43NTMxNzZMMy4zNDc0NDctMi44MjE0MlonLz4KPHBhdGggaWQ9J2c2LTE4JyBkPSdNNS4yOTYxMzktNi4wMTM0NUM1LjI5NjEzOS03LjIzMjg3NyA0LjkxMzU3NC04LjQxNjQzOCAzLjkzMzI1LTguNDE2NDM4QzIuMjU5NTI3LTguNDE2NDM4IC40NzgyMDctNC45MTM1NzQgLjQ3ODIwNy0yLjI4MzQzN0MuNDc4MjA3LTEuNzMzNDk5IC41OTc3NTggLjExOTU1MiAxLjg1MzA1MSAuMTE5NTUyQzMuNDc4OTU0IC4xMTk1NTIgNS4yOTYxMzktMy4yOTk2MjYgNS4yOTYxMzktNi4wMTM0NVpNMS42NzM3MjQtNC4zMjc3NzFDMS44NTMwNTEtNS4wMzMxMjYgMi4xMDQxMS02LjAzNzM2IDIuNTgyMzE2LTYuODg2MTc3QzIuOTc2ODM3LTcuNjAzNDg3IDMuMzk1MjY4LTguMTc3MzM1IDMuOTIxMjk1LTguMTc3MzM1QzQuMzE1ODE2LTguMTc3MzM1IDQuNTc4ODI5LTcuODQyNTkgNC41Nzg4MjktNi42OTQ4OTRDNC41Nzg4MjktNi4yNjQ1MDggNC41NDI5NjQtNS42NjY3NSA0LjE5NjI2NC00LjMyNzc3MUgxLjY3MzcyNFpNNC4xMTI1NzgtMy45NjkxMTZDMy44MTM2OTktMi43OTc1MDkgMy41NjI2NC0yLjA0NDMzNCAzLjEzMjI1NC0xLjI5MTE1OEMyLjc4NTU1NC0uNjgxNDQ1IDIuMzY3MTIzLS4xMTk1NTIgMS44NjUwMDYtLjExOTU1MkMxLjQ5NDM5Ni0uMTE5NTUyIDEuMTk1NTE3LS40MDY0NzYgMS4xOTU1MTctMS41OTAwMzdDMS4xOTU1MTctMi4zNjcxMjMgMS4zODY4LTMuMTgwMDc1IDEuNTc4MDgyLTMuOTY5MTE2SDQuMTEyNTc4WicvPgo8cGF0aCBpZD0nZzYtMjUnIGQ9J00zLjA5NjM4OS00LjUwNzA5OEg0LjQ0NzMyM0M0LjEyNDUzMy0zLjE2ODEyIDMuOTIxMjk1LTIuMjk1MzkyIDMuOTIxMjk1LTEuMzM4OTc5QzMuOTIxMjk1LTEuMTcxNjA2IDMuOTIxMjk1IC4xMTk1NTIgNC40MTE0NTcgLjExOTU1MkM0LjY2MjUxNiAuMTE5NTUyIDQuODc3NzA5LS4xMDc1OTcgNC44Nzc3MDktLjMxMDgzNEM0Ljg3NzcwOS0uMzcwNjEgNC44Nzc3MDktLjM5NDUyMSA0Ljc5NDAyMi0uNTczODQ4QzQuNDcxMjMzLTEuMzk4NzU1IDQuNDcxMjMzLTIuNDI2ODk5IDQuNDcxMjMzLTIuNTEwNTg1QzQuNDcxMjMzLTIuNTgyMzE2IDQuNDcxMjMzLTMuNDMxMTMzIDQuNzIyMjkxLTQuNTA3MDk4SDYuMDYxMjdDNi4yMTY2ODctNC41MDcwOTggNi42MTEyMDgtNC41MDcwOTggNi42MTEyMDgtNC44ODk2NjRDNi42MTEyMDgtNS4xNTI2NzcgNi4zODQwNi01LjE1MjY3NyA2LjE2ODg2Ny01LjE1MjY3N0gyLjIzNTYxNkMxLjk2MDY0OC01LjE1MjY3NyAxLjU1NDE3Mi01LjE1MjY3NyAxLjAwNDIzNC00LjU2Njg3NEMuNjkzNC00LjIyMDE3NCAuMzEwODM0LTMuNTg2NTUgLjMxMDgzNC0zLjUxNDgxOVMuMzcwNjEtMy40MTkxNzggLjQ0MjM0MS0zLjQxOTE3OEMuNTI2MDI3LTMuNDE5MTc4IC41Mzc5ODMtMy40NTUwNDQgLjU5Nzc1OC0zLjUyNjc3NUMxLjIxOTQyNy00LjUwNzA5OCAxLjg0MTA5Ni00LjUwNzA5OCAyLjEzOTk3NS00LjUwNzA5OEgyLjgyMTQyQzIuNTU4NDA2LTMuNjEwNDYxIDIuMjU5NTI3LTIuNTcwMzYxIDEuMjc5MjAzLS40NzgyMDdDMS4xODM1NjItLjI4NjkyNCAxLjE4MzU2Mi0uMjYzMDE0IDEuMTgzNTYyLS4xOTEyODNDMS4xODM1NjIgLjA1OTc3NiAxLjM5ODc1NSAuMTE5NTUyIDEuNTA2MzUxIC4xMTk1NTJDMS44NTMwNTEgLjExOTU1MiAxLjk0ODY5Mi0uMTkxMjgzIDIuMDkyMTU0LS42OTM0QzIuMjgzNDM3LTEuMzAzMTEzIDIuMjgzNDM3LTEuMzI3MDI0IDIuNDAyOTg5LTEuODA1MjNMMy4wOTYzODktNC41MDcwOThaJy8+CjxwYXRoIGlkPSdnNi0yOCcgZD0nTTMuNDMxMTMzLTQuNTA3MDk4SDUuNDE1NjkxQzUuNTcxMTA4LTQuNTA3MDk4IDUuOTY1NjI5LTQuNTA3MDk4IDUuOTY1NjI5LTQuODg5NjY0QzUuOTY1NjI5LTUuMTUyNjc3IDUuNzM4NDgxLTUuMTUyNjc3IDUuNTIzMjg4LTUuMTUyNjc3SDIuMjM1NjE2QzEuOTYwNjQ4LTUuMTUyNjc3IDEuNTU0MTcyLTUuMTUyNjc3IDEuMDA0MjM0LTQuNTY2ODc0Qy42OTM0LTQuMjIwMTc0IC4zMTA4MzQtMy41ODY1NSAuMzEwODM0LTMuNTE0ODE5Uy4zNzA2MS0zLjQxOTE3OCAuNDQyMzQxLTMuNDE5MTc4Qy41MjYwMjctMy40MTkxNzggLjUzNzk4My0zLjQ1NTA0NCAuNTk3NzU4LTMuNTI2Nzc1QzEuMjE5NDI3LTQuNTA3MDk4IDEuODQxMDk2LTQuNTA3MDk4IDIuMTM5OTc1LTQuNTA3MDk4SDMuMTMyMjU0TDEuODg4OTE3LS40MDY0NzZDMS44MjkxNDEtLjIyNzE0OCAxLjgyOTE0MS0uMjAzMjM4IDEuODI5MTQxLS4xNjczNzJDMS44MjkxNDEtLjAzNTg2NiAxLjkxMjgyNyAuMTMxNTA3IDIuMTUxOTMgLjEzMTUwN0MyLjUyMjU0IC4xMzE1MDcgMi41ODIzMTYtLjE5MTI4MyAyLjYxODE4Mi0uMzcwNjFMMy40MzExMzMtNC41MDcwOThaJy8+CjxwYXRoIGlkPSdnNi01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnNi01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzItOTgnIGQ9J00zLjMxMTU4Mi04LjE4OTI5TDYuNTYzMzg3LTYuNzE4ODA0TDYuNzA2ODQ5LTYuOTgxODE4TDMuMzIzNTM3LTguODk0NjQ1TC0uMDU5Nzc2LTYuOTgxODE4TC4wNzE3MzEtNi43MTg4MDRMMy4zMTE1ODItOC4xODkyOVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9Jy41NDQ3ODYnIHk9Jy0xNC4zMTI5OCcgeGxpbms6aHJlZj0nI2cyLTk4Jy8+Cjx1c2UgeD0nMCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTE4Jy8+Cjx1c2UgeD0nNS43ODAzNDEnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9JzExLjIzODI1MicgeT0nLTExLjE1ODE2OScgeGxpbms6aHJlZj0nI2cyLTk4Jy8+Cjx1c2UgeD0nMTEuMDI0NScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTI4Jy8+Cjx1c2UgeD0nMjAuNzY0MjY3JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktNjEnLz4KPHVzZSB4PSczMy4xODk3NDcnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS05NycvPgo8dXNlIHg9JzM5LjA0MjczOCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTExNCcvPgo8dXNlIHg9JzQzLjU5NTA2MycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTEwMycvPgo8dXNlIHg9JzUxLjYwMzEzNCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTEwOScvPgo8dXNlIHg9JzYxLjM1ODExOCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTk3Jy8+Cjx1c2UgeD0nNjcuMjExMTA4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTIwJy8+Cjx1c2UgeD0nNTYuNDgzMjcxJyB5PSctMy42MzA4MjQnIHhsaW5rOmhyZWY9JyNnMC0xOCcvPgo8dXNlIHg9JzYxLjQ3ODQ1NScgeT0nLTMuNjMwODI0JyB4bGluazpocmVmPScjZzUtNTknLz4KPHVzZSB4PSc2My44MzA3NzknIHk9Jy0zLjYzMDgyNCcgeGxpbms6aHJlZj0nI2c1LTI4Jy8+Cjx1c2UgeD0nNzUuMzgxNzYyJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzYtMjUnLz4KPHVzZSB4PSc4Mi40NTEwMzInIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9Jzg3LjAwMzM1OCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nOTQuMTAxNjkzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzYtNTknLz4KPHVzZSB4PSc5OS4zNDU4NTInIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNi0yOCcvPgo8dXNlIHg9JzEwNS43NjQ3OTMnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNC0xMDYnLz4KPHVzZSB4PScxMDkuMDg1NjgzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzEtODknLz4KPHVzZSB4PScxMjAuMjA1NTc0JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtMTExJy8+Cjx1c2UgeD0nMTI0LjI5ODYyNCcgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c1LTk4Jy8+Cjx1c2UgeD0nMTI3LjkyMTIwOScgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c1LTExNScvPgo8dXNlIHg9JzEzMi4zMzUyNTknIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9JzEzNy41Nzk0MTgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS04OScvPgo8dXNlIHg9JzE1Mi4wMjAxMzgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS02MScvPgo8dXNlIHg9JzE2NC40NDU2MTknIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS04OScvPgo8dXNlIHg9JzE3NS41NjU1MScgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c1LTExMScvPgo8dXNlIHg9JzE3OS42NTg1NicgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c1LTk4Jy8+Cjx1c2UgeD0nMTgzLjI4MTE0NCcgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c1LTExNScvPgo8dXNlIHg9JzE4Ny42OTUxOTUnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzE5NS41NjgzNScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTYxJy8+Cjx1c2UgeD0nMjA3Ljk5MzgzMScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTk3Jy8+Cjx1c2UgeD0nMjEzLjg0NjgyMScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTExNCcvPgo8dXNlIHg9JzIxOC4zOTkxNDcnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS0xMDMnLz4KPHVzZSB4PScyNjcuOTk2NTEyJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTA5Jy8+Cjx1c2UgeD0nMjc3Ljc1MTQ5NicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTk3Jy8+Cjx1c2UgeD0nMjgzLjYwNDQ4NicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTEyMCcvPgo8dXNlIHg9JzIyNi40MDcyMTgnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c1LTE4Jy8+Cjx1c2UgeD0nMjMwLjU5Mjk1MicgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzMtNTAnLz4KPHVzZSB4PScyMzYuMjM4NTI5JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnOC05MScvPgo8dXNlIHg9JzIzOC41OTA4NTMnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2cwLTE4Jy8+Cjx1c2UgeD0nMjQzLjU4NjAzNycgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzctMTA5Jy8+Cjx1c2UgeD0nMjQ5LjU2MzU1OScgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzctMTA1Jy8+Cjx1c2UgeD0nMjUxLjY2Njc1OCcgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzctMTEwJy8+Cjx1c2UgeD0nMjU2LjIwNTIzNScgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzgtNTknLz4KPHVzZSB4PScyNTguNTU3NTU4JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnMC0xOCcvPgo8dXNlIHg9JzI2My41NTI3NDInIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c3LTEwOScvPgo8dXNlIHg9JzI2OS41MzAyNjQnIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c3LTk3Jy8+Cjx1c2UgeD0nMjczLjE4MzE4OScgeT0nLTIuMTkxNzc4JyB4bGluazpocmVmPScjZzctMTIwJy8+Cjx1c2UgeD0nMjc3LjUyNzkzOScgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzgtOTMnLz4KPHVzZSB4PScyNzkuODgwMjYyJyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNS0yOCcvPgo8dXNlIHg9JzI4NC41NTg2MTEnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2czLTUwJy8+Cjx1c2UgeD0nMjkwLjIwNDE4OCcgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzgtOTEnLz4KPHVzZSB4PScyOTIuNTU2NTEyJyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNS0yOCcvPgo8dXNlIHg9JzI5Ni4zMTQ2OTcnIHk9Jy0xLjg5Njg0OCcgeGxpbms6aHJlZj0nI2c3LTEwOScvPgo8dXNlIHg9JzMwMi4yOTIyMTgnIHk9Jy0xLjg5Njg0OCcgeGxpbms6aHJlZj0nI2c3LTEwNScvPgo8dXNlIHg9JzMwNC4zOTU0MTcnIHk9Jy0xLjg5Njg0OCcgeGxpbms6aHJlZj0nI2c3LTExMCcvPgo8dXNlIHg9JzMwOC45MzM4OTQnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c4LTU5Jy8+Cjx1c2UgeD0nMzExLjI4NjIxNycgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzUtMjgnLz4KPHVzZSB4PSczMTUuMDQ0NDAyJyB5PSctMi4xOTE3NzgnIHhsaW5rOmhyZWY9JyNnNy0xMDknLz4KPHVzZSB4PSczMjEuMDIxOTIzJyB5PSctMi4xOTE3NzgnIHhsaW5rOmhyZWY9JyNnNy05NycvPgo8dXNlIHg9JzMyNC42NzQ4NDknIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c3LTEyMCcvPgo8dXNlIHg9JzMyOS4wMTk1OTgnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c4LTkzJy8+Cjx1c2UgeD0nMzMzLjM2NDQyJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzQtNzgnLz4KPHVzZSB4PSczNDQuOTM1MjMnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzM0OS40ODc1NTYnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS04OScvPgo8dXNlIHg9JzM2MC42MDc0NDcnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNS0xMTEnLz4KPHVzZSB4PSczNjQuNzAwNDk2JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtOTgnLz4KPHVzZSB4PSczNjguMzIzMDgxJyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtMTE1Jy8+Cjx1c2UgeD0nMzcyLjczNzEzMScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c0LTEwNicvPgo8dXNlIHg9JzM3Ni4wNTgwMjEnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS0xOCcvPgo8dXNlIHg9JzM4My4xNTYzNTcnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzM5NS40MTAzMzEnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS01OScvPgo8dXNlIHg9JzQwMC42NTQ0OScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTI4Jy8+Cjx1c2UgeD0nNDA3LjA3MzQzMScgeT0nLTE2LjA5NDM0JyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzQxMy42NTk5MzgnIHk9Jy0xNi4wOTQzNCcgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nNDE4LjM5MjI1MycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTczJy8+Cjx1c2UgeD0nNDI1LjQzMjQ4NycgeT0nLTkuMzY0ODkxJyB4bGluazpocmVmPScjZzUtMTEwJy8+Cjx1c2UgeD0nNDMzLjcyNTQ4NScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nNDQ1LjQ4NjgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS04MScvPgo8dXNlIHg9JzQ1NS44NzExMzcnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nNDYyLjQ1NzY0NCcgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nNDY3LjE4OTk1OScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nNDcxLjc0MjI4NScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTU4Jy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
Note that the unconstrained optimization over for fixed
is explicit, since:

But we have shown that the conditional posterior density of
is Gaussian. Hence the unconstrained conditional
posterior mode (and mean) is given by:

If this point does not respect the constraints, then we simply project each component unto the constrained space.
Hence the following 1D problem remains to be solved:
![\widehat\tau = \arg\max_{\tau\in[\tau_{\min};\tau_{\max}]} \mathcal N(\vect{Y}^{obs}|\vect{\mu}_n(\tau) \mat{X}; \tau^{-1} \mat{I}_n + \mat{Q}^{-1}).](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyNTguMjE2NTlwdCcgaGVpZ2h0PScyMC41NDUxNzhwdCcgdmlld0JveD0nNjUuMTYzMTg1IC0yMS43NDA2OTIgMjU4LjIxNjU5IDIwLjU0NTE3OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtMjInIGQ9J00zLjI4NzY3MS0zLjk2OTExNkMzLjM1OTQwMi00LjI3OTk1IDMuNDkwOTA5LTQuNzk0MDIyIDMuNDkwOTA5LTQuODc3NzA5QzMuNDkwOTA5LTUuMTI4NzY3IDMuMjk5NjI2LTUuNDAzNzM2IDIuOTI5MDE2LTUuNDAzNzM2QzIuMzA3MzQ3LTUuNDAzNzM2IDIuMTUxOTMtNC44MDU5NzggMi4xMTYwNjUtNC42NjI1MTZMLjUyNjAyNyAxLjY4NTY3OUMuNDc4MjA3IDEuODc2OTYxIC40NzgyMDcgMS45NDg2OTIgLjQ3ODIwNyAxLjk5NjUxM0MuNDc4MjA3IDIuMzc5MDc4IC43ODkwNDEgMi41MjI1NCAxLjA0MDEgMi41MjI1NEMxLjI2NzI0OCAyLjUyMjU0IDEuNTkwMDM3IDIuMzkxMDM0IDEuNzU3NDEgMi4wNTYyODlDMS44MjkxNDEgMS45MTI4MjcgMi4yMjM2NjEgLjI3NDk2OSAyLjMwNzM0Ny0uMDk1NjQxQzIuNzk3NTA5IC4wOTU2NDEgMy4zMzU0OTIgLjA5NTY0MSAzLjQ5MDkwOSAuMDk1NjQxQzMuODk3Mzg1IC4wOTU2NDEgNC40NDczMjMgLjAyMzkxIDUuMTY0NjMzLS42MjE2NjlDNS40NTE1NTctLjA3MTczMSA2LjEyMTA0NiAuMDk1NjQxIDYuNTYzMzg3IC4wOTU2NDFTNy4zNTI0MjgtLjE1NTQxNyA3LjYwMzQ4Ny0uNTg1ODAzQzcuOTAyMzY2LTEuMDY0MDEgOC4wNTc3ODMtMS43MDk1ODkgOC4wNTc3ODMtMS43NjkzNjVDOC4wNTc3ODMtMS45MzY3MzcgNy44Nzg0NTYtMS45MzY3MzcgNy43NzA4NTktMS45MzY3MzdDNy42MzkzNTItMS45MzY3MzcgNy41OTE1MzItMS45MzY3MzcgNy41MzE3NTYtMS44NzY5NjFDNy41MDc4NDYtMS44NTMwNTEgNy41MDc4NDYtMS44MjkxNDEgNy40MzYxMTUtMS41MzAyNjJDNy4xOTcwMTEtLjU3Mzg0OCA2LjkyMjA0Mi0uMzM0NzQ1IDYuNjIzMTYzLS4zMzQ3NDVDNi40OTE2NTYtLjMzNDc0NSA2LjM0ODE5NC0uMzgyNTY1IDYuMzQ4MTk0LS43NzcwODZDNi4zNDgxOTQtLjk4MDMyNCA2LjM5NjAxNS0xLjE3MTYwNiA2LjUxNTU2Ny0xLjY0OTgxM0w2LjgyNjQwMS0yLjg2OTI0QzYuODg2MTc3LTMuMTMyMjU0IDcuMDA1NzI5LTMuNjIyNDE2IDcuMDg5NDE1LTMuOTQ1MjA1QzcuMTYxMTQ2LTQuMjIwMTc0IDcuMjgwNjk3LTQuNjk4MzgxIDcuMjgwNjk3LTQuNzgyMDY3QzcuMjgwNjk3LTUuMDMzMTI2IDcuMDg5NDE1LTUuMzA4MDk1IDYuNzE4ODA0LTUuMzA4MDk1QzYuNDc5NzAxLTUuMzA4MDk1IDYuMDYxMjctNS4xNjQ2MzMgNS45Mjk3NjMtNC42NzQ0NzFMNS4xMDQ4NTctMS4zNjI4ODlDNS4wNTcwMzYtMS4xNDc2OTYgNC44NTM3OTgtLjk0NDQ1OCA0LjYzODYwNS0uNzY1MTMxQzQuMjU2MDQtLjQ0MjM0MSAzLjg5NzM4NS0uMzM0NzQ1IDMuNTc0NTk1LS4zMzQ3NDVDMi43NjE2NDQtLjMzNDc0NSAyLjY4OTkxMy0uOTIwNTQ4IDIuNjg5OTEzLTEuMjc5MjAzQzIuNjg5OTEzLTEuNjAxOTkzIDIuNzYxNjQ0LTEuODg4OTE3IDIuODA5NDY1LTIuMTA0MTFMMy4yODc2NzEtMy45NjkxMTZaJy8+CjxwYXRoIGlkPSdnMC03MycgZD0nTTUuMjcyMjI5LTcuMzg4Mjk0QzUuMzIwMDUtNy41OTE1MzIgNS4zMzIwMDUtNy42MDM0ODcgNS41NzExMDgtNy42MjczOTdDNS43NTA0MzYtNy42MzkzNTIgNS45MDU4NTMtNy42MzkzNTIgNi4wODUxODEtNy42MzkzNTJINi4zMzYyMzlDNi41ODcyOTgtNy42MzkzNTIgNi41OTkyNTMtNy42NTEzMDggNi42NTkwMjktNy42OTkxMjhDNi43MzA3Ni03Ljc0Njk0OSA2Ljc2NjYyNS03LjkxNDMyMSA2Ljc2NjYyNS03Ljk4NjA1MkM2Ljc2NjYyNS04LjEyOTUxNCA2LjY0NzA3My04LjIwMTI0NSA2LjUwMzYxMS04LjIwMTI0NUM2LjIwNDczMi04LjIwMTI0NSA1Ljg5Mzg5OC04LjE3NzMzNSA1LjU5NTAxOS04LjE3NzMzNUM1LjI4NDE4NC04LjE3NzMzNSA0Ljk2MTM5NS04LjE2NTM4IDQuNjM4NjA1LTguMTY1MzhDNC4zMDM4NjEtOC4xNjUzOCAzLjk2OTExNi04LjE3NzMzNSAzLjY0NjMyNi04LjE3NzMzNUMzLjMzNTQ5Mi04LjE3NzMzNSAzLjAxMjcwMi04LjIwMTI0NSAyLjcxMzgyMy04LjIwMTI0NUMyLjU4MjMxNi04LjIwMTI0NSAyLjM2NzEyMy04LjIwMTI0NSAyLjM2NzEyMy03Ljg1NDU0NUMyLjM2NzEyMy03LjYzOTM1MiAyLjU1ODQwNi03LjYzOTM1MiAyLjc3MzU5OS03LjYzOTM1MkgzLjAyNDY1OEMzLjEzMjI1NC03LjYzOTM1MiAzLjQxOTE3OC03LjYyNzM5NyAzLjY1ODI4MS03LjYxNTQ0MkwxLjk0ODY5Mi0uODAwOTk2QzEuOTAwODcyLS42MDk3MTQgMS44ODg5MTctLjU5Nzc1OCAxLjY2MTc2OC0uNTg1ODAzQzEuNTE4MzA2LS41NjE4OTMgMS4zMDMxMTMtLjU2MTg5MyAxLjE0NzY5Ni0uNTYxODkzSC44OTY2MzhDLjY1NzUzNC0uNTYxODkzIC40NTQyOTYtLjU2MTg5MyAuNDU0Mjk2LS4yMTUxOTNDLjQ1NDI5Ni0uMDU5Nzc2IC41ODU4MDMgMCAuNzE3MzEgMEMxLjAxNjE4OSAwIDEuMzI3MDI0LS4wMjM5MSAxLjYyNTkwMy0uMDIzOTFDMS45NDg2OTItLjAyMzkxIDIuMjcxNDgyLS4wMzU4NjYgMi41OTQyNzEtLjAzNTg2NkMyLjkyOTAxNi0uMDM1ODY2IDMuMjUxODA2LS4wMjM5MSAzLjU4NjU1LS4wMjM5MUMzLjg5NzM4NS0uMDIzOTEgNC4yMDgyMTkgMCA0LjUwNzA5OCAwQzQuNjI2NjUgMCA0Ljg2NTc1MyAwIDQuODY1NzUzLS4zNDY3QzQuODY1NzUzLS41NjE4OTMgNC42NjI1MTYtLjU2MTg5MyA0LjQ1OTI3OC0uNTYxODkzSDQuMjA4MjE5QzQuMTI0NTMzLS41NjE4OTMgMy43MzAwMTItLjU3Mzg0OCAzLjU3NDU5NS0uNTg1ODAzTDUuMjcyMjI5LTcuMzg4Mjk0WicvPgo8cGF0aCBpZD0nZzAtODEnIGQ9J001LjMwODA5NSAuNjgxNDQ1QzUuMzA4MDk1IDEuMjkxMTU4IDUuMzkxNzgxIDIuMzE5MzAzIDYuNDY3NzQ2IDIuMzE5MzAzQzcuOTUwMTg3IDIuMzE5MzAzIDguNjMxNjMxIC4yNTEwNTkgOC42MzE2MzEgMEM4LjYzMTYzMS0uMTE5NTUyIDguNTM1OTktLjIxNTE5MyA4LjQxNjQzOC0uMjE1MTkzQzguMjcyOTc2LS4yMTUxOTMgOC4yMjUxNTYtLjA5NTY0MSA4LjIwMTI0NS0uMDM1ODY2QzcuOTc0MDk3IC41NjE4OTMgNy4wODk0MTUgLjU2MTg5MyA2Ljk2OTg2MyAuNTYxODkzQzYuNzA2ODQ5IC41NjE4OTMgNi4zOTYwMTUgLjU2MTg5MyA2LjA5NzEzNi0uMTMxNTA3QzguOTkwMjg2LTEuMTk1NTE3IDkuNzQzNDYyLTMuOTU3MTYxIDkuNzQzNDYyLTUuMzIwMDVDOS43NDM0NjItNy4zNTI0MjggOC4zMzI3NTItOC40MDQ0ODMgNi4yNjQ1MDgtOC40MDQ0ODNDMi41NzAzNjEtOC40MDQ0ODMgLjYzMzYyNC01LjIzNjM2NCAuNjMzNjI0LTIuODQ1MzNDLjYzMzYyNC0uNzUzMTc2IDIuMTI4MDIgLjIwMzIzOCA0LjEyNDUzMyAuMjAzMjM4QzQuMjY3OTk1IC4yMDMyMzggNC43MTAzMzYgLjIwMzIzOCA1LjMwODA5NSAuMDgzNjg2Vi42ODE0NDVaTTMuMjAzOTg1LS41MTQwNzJDMi40NjI3NjUtLjg3MjcyNyAyLjIyMzY2MS0xLjYwMTk5MyAyLjIyMzY2MS0yLjQwMjk4OUMyLjIyMzY2MS0zLjA4NDQzMyAyLjU1ODQwNi01LjI2MDI3NCAzLjU4NjU1LTYuNTk5MjUzQzQuMzUxNjgxLTcuNTc5NTc3IDUuMzY3ODctNy45MjYyNzYgNi4xNDQ5NTYtNy45MjYyNzZDNy4xNzMxMDEtNy45MjYyNzYgOC4xNTM0MjUtNy4zNTI0MjggOC4xNTM0MjUtNS43NzQzNDZDOC4xNTM0MjUtNS42OTA2NiA3Ljk5ODAwNy0yLjAzMjM3OSA1Ljg1ODAzMi0uNzUzMTc2QzUuNjE4OTI5LTEuMzM4OTc5IDUuMjk2MTM5LTEuODUzMDUxIDQuNTY2ODc0LTEuODUzMDUxQzMuOTA5MzQtMS44NTMwNTEgMy4xOTIwMy0xLjMzODk3OSAzLjE5MjAzLS42Njk0ODlDMy4xOTIwMy0uNTczODQ4IDMuMTkyMDMtLjU2MTg5MyAzLjIwMzk4NS0uNTE0MDcyWk01LjI5NjEzOS0uNDY2MjUyQzUuMjEyNDUzLS40MzAzODYgNC43MzQyNDctLjI3NDk2OSA0LjI0NDA4NS0uMjc0OTY5QzQuMDI4ODkyLS4yNzQ5NjkgMy42MjI0MTYtLjI3NDk2OSAzLjYyMjQxNi0uNjY5NDg5QzMuNjIyNDE2LTEuMDUyMDU1IDQuMDg4NjY3LTEuNDIyNjY1IDQuNTc4ODI5LTEuNDIyNjY1QzQuODg5NjY0LTEuNDIyNjY1IDUuMjcyMjI5LTEuMzM4OTc5IDUuMjk2MTM5LS40NjYyNTJaJy8+CjxwYXRoIGlkPSdnMC04OCcgZD0nTTYuOTU3OTA4LTQuNzIyMjkxTDguNTM1OTktNi4yNzY0NjNMOS4yNzcyMS03LjAyOTYzOUM5Ljc1NTQxNy03LjQ4MzkzNSA5Ljg5ODg3OS03LjYyNzM5NyAxMS4xNDIyMTctNy42MzkzNTJDMTEuMzY5MzY1LTcuNjM5MzUyIDExLjM5MzI3NS03Ljk1MDE4NyAxMS4zOTMyNzUtNy45ODYwNTJDMTEuMzkzMjc1LTguMDU3NzgzIDExLjM0NTQ1NS04LjIwMTI0NSAxMS4xNTQxNzItOC4yMDEyNDVDMTAuNzM1NzQxLTguMjAxMjQ1IDEwLjI4MTQ0NS04LjE2NTM4IDkuODUxMDU5LTguMTY1MzhDOS41MDQzNTktOC4xNjUzOCA4LjY0MzU4Ny04LjIwMTI0NSA4LjI5Njg4Ny04LjIwMTI0NUM4LjIwMTI0NS04LjIwMTI0NSA3Ljk2MjE0Mi04LjIwMTI0NSA3Ljk2MjE0Mi03Ljg2NjUwMUM3Ljk2MjE0Mi03LjY1MTMwOCA4LjE1MzQyNS03LjYzOTM1MiA4LjI2MTAyMS03LjYzOTM1MkM4LjYxOTY3Ni03LjYyNzM5NyA4LjkzMDUxMS03LjUzMTc1NiA4Ljk3ODMzMS03LjUxOTgwMUw2LjY5NDg5NC01LjI2MDI3NEw1LjU5NTAxOS03LjU2NzYyMUM1LjcxNDU3LTcuNTkxNTMyIDYuMDg1MTgxLTcuNjM5MzUyIDYuMjg4NDE4LTcuNjM5MzUyQzYuNDE5OTI1LTcuNjM5MzUyIDYuNjM1MTE4LTcuNjM5MzUyIDYuNjM1MTE4LTcuOTc0MDk3QzYuNjM1MTE4LTguMTQxNDY5IDYuNTI3NTIyLTguMjAxMjQ1IDYuMzcyMTA1LTguMjAxMjQ1QzUuOTY1NjI5LTguMjAxMjQ1IDQuOTYxMzk1LTguMTY1MzggNC41NTQ5MTktOC4xNjUzOEM0LjI3OTk1LTguMTY1MzggNC4wMDQ5ODEtOC4xNzczMzUgMy43MzAwMTItOC4xNzczMzVTMy4xNjgxMi04LjIwMTI0NSAyLjg5MzE1MS04LjIwMTI0NUMyLjc4NTU1NC04LjIwMTI0NSAyLjU1ODQwNi04LjIwMTI0NSAyLjU1ODQwNi03Ljg2NjUwMUMyLjU1ODQwNi03LjYzOTM1MiAyLjcxMzgyMy03LjYzOTM1MiAzLjA0ODU2OC03LjYzOTM1MkMzLjIxNTk0LTcuNjM5MzUyIDMuMzQ3NDQ3LTcuNjM5MzUyIDMuNTE0ODE5LTcuNjI3Mzk3QzMuNjgyMTkyLTcuNjAzNDg3IDMuNjk0MTQ3LTcuNTkxNTMyIDMuNzY1ODc4LTcuNDQ4MDdMNS40MTU2OTEtMy45OTMwMjZMMi40MTQ5NDQtMS4wMjgxNDRDMi4xOTk3NTEtLjgyNDkwNyAxLjk0ODY5Mi0uNTczODQ4IC44ODQ2ODItLjU2MTg5M0MuNjY5NDg5LS41NjE4OTMgLjQ2NjI1Mi0uNTYxODkzIC40NjYyNTItLjIxNTE5M0MuNDY2MjUyLS4xMzE1MDcgLjUyNjAyNyAwIC43MDUzNTUgMEMuOTkyMjc5IDAgMS43MjE1NDQtLjAzNTg2NiAyLjAwODQ2OC0uMDM1ODY2QzIuMzU1MTY4LS4wMzU4NjYgMy4yMTU5NCAwIDMuNTYyNjQgMEMzLjY1ODI4MSAwIDMuODk3Mzg1IDAgMy44OTczODUtLjM0NjdDMy44OTczODUtLjU2MTg5MyAzLjY4MjE5Mi0uNTYxODkzIDMuNTg2NTUtLjU2MTg5M0MzLjM0NzQ0Ny0uNTYxODkzIDMuMTA4MzQ0LS41OTc3NTggMi44ODExOTYtLjY4MTQ0NUw1LjY2Njc1LTMuNDU1MDQ0TDcuMDE3Njg0LS42MzM2MjRDNy4wMDU3MjktLjYzMzYyNCA2LjYxMTIwOC0uNTYxODkzIDYuMzI0Mjg0LS41NjE4OTNDNi4yMDQ3MzItLjU2MTg5MyA1Ljk3NzU4NC0uNTYxODkzIDUuOTc3NTg0LS4yMTUxOTNDNS45Nzc1ODQtLjE3OTMyOCA1Ljk4OTUzOSAwIDYuMjQwNTk4IDBDNi42NDcwNzMgMCA3LjY2MzI2My0uMDM1ODY2IDguMDY5NzM4LS4wMzU4NjZDOC4zNDQ3MDctLjAzNTg2NiA4LjYxOTY3Ni0uMDIzOTEgOC44OTQ2NDUtLjAyMzkxUzkuNDU2NTM4IDAgOS43MzE1MDcgMEM5LjgyNzE0OCAwIDEwLjA2NjI1MiAwIDEwLjA2NjI1Mi0uMzQ2N0MxMC4wNjYyNTItLjU2MTg5MyA5Ljg3NDk2OS0uNTYxODkzIDkuNTg4MDQ1LS41NjE4OTNDOS40MjA2NzItLjU2MTg5MyA5LjMwMTEyMS0uNTYxODkzIDkuMTIxNzkzLS41NzM4NDhDOC45NDI0NjYtLjU5Nzc1OCA4LjkzMDUxMS0uNjA5NzE0IDguODQ2ODI0LS43NjUxMzFMNi45NTc5MDgtNC43MjIyOTFaJy8+CjxwYXRoIGlkPSdnMC04OScgZD0nTTguNzc1MDkzLTcuMTczMTAxQzkuMDM4MTA3LTcuNDQ4MDcgOS4zMTMwNzYtNy42MjczOTcgMTAuMTE0MDcyLTcuNjM5MzUyQzEwLjI0NTU3OS03LjYzOTM1MiAxMC40NjA3NzItNy42MzkzNTIgMTAuNDYwNzcyLTcuOTg2MDUyQzEwLjQ2MDc3Mi04LjA1Nzc4MyAxMC40MDA5OTYtOC4yMDEyNDUgMTAuMjQ1NTc5LTguMjAxMjQ1QzkuODk4ODc5LTguMjAxMjQ1IDkuNTA0MzU5LTguMTY1MzggOS4xNDU3MDQtOC4xNjUzOEM4LjcwMzM2Mi04LjE2NTM4IDguMjQ5MDY2LTguMjAxMjQ1IDcuODE4NjgtOC4yMDEyNDVDNy43MzQ5OTQtOC4yMDEyNDUgNy40OTU4OS04LjIwMTI0NSA3LjQ5NTg5LTcuODU0NTQ1QzcuNDk1ODktNy42MzkzNTIgNy42OTkxMjgtNy42MzkzNTIgNy44MTg2OC03LjYzOTM1MlM4LjE3NzMzNS03LjYxNTQ0MiA4LjM1NjY2My03LjU1NTY2Nkw1LjExNjgxMi00LjA4ODY2N0wzLjU4NjU1LTcuNTkxNTMyQzMuOTIxMjk1LTcuNjM5MzUyIDMuOTMzMjUtNy42MzkzNTIgNC4yNTYwNC03LjYzOTM1MkM0LjQ1OTI3OC03LjYzOTM1MiA0LjY2MjUxNi03LjY1MTMwOCA0LjY2MjUxNi03Ljk4NjA1MkM0LjY2MjUxNi04LjE0MTQ2OSA0LjUzMTAwOS04LjIwMTI0NSA0LjM5OTUwMi04LjIwMTI0NUMzLjk5MzAyNi04LjIwMTI0NSAyLjk1MjkyNy04LjE2NTM4IDIuNTQ2NDUxLTguMTY1MzhDMi4yNzE0ODItOC4xNjUzOCAxLjk4NDU1OC04LjE3NzMzNSAxLjcyMTU0NC04LjE3NzMzNUMxLjQzNDYyLTguMTc3MzM1IDEuMTM1NzQxLTguMjAxMjQ1IC44NjA3NzItOC4yMDEyNDVDLjc0MTIyLTguMjAxMjQ1IC41MjYwMjctOC4yMDEyNDUgLjUyNjAyNy03Ljg1NDU0NUMuNTI2MDI3LTcuNjM5MzUyIC42OTM0LTcuNjM5MzUyIDEuMDE2MTg5LTcuNjM5MzUyQzEuMTcxNjA2LTcuNjM5MzUyIDEuMzE1MDY4LTcuNjM5MzUyIDEuNDgyNDQxLTcuNjI3Mzk3QzEuNjI1OTAzLTcuNjAzNDg3IDEuNjQ5ODEzLTcuNjAzNDg3IDEuNzIxNTQ0LTcuNDQ4MDdMMy41Mzg3My0zLjI3NTcxNkwyLjkxNzA2MS0uODEyOTUxQzIuODY5MjQtLjYwOTcxNCAyLjg1NzI4NS0uNTk3NzU4IDIuNjQyMDkyLS41ODU4MDNDMi40Mzg4NTQtLjU2MTg5MyAyLjIzNTYxNi0uNTYxODkzIDIuMDIwNDIzLS41NjE4OTNDMS42NjE3NjgtLjU2MTg5MyAxLjYzNzg1OC0uNTYxODkzIDEuNTkwMDM3LS41MTQwNzJDMS41MTgzMDYtLjQ1NDI5NiAxLjQ3MDQ4Ni0uMjk4ODc5IDEuNDcwNDg2LS4yMTUxOTNDMS40NzA0ODYtLjE5MTI4MyAxLjQ4MjQ0MSAwIDEuNzMzNDk5IDBDMi4wMzIzNzkgMCAyLjM0MzIxMy0uMDIzOTEgMi42NDIwOTItLjAyMzkxQzIuOTI5MDE2LS4wMjM5MSAzLjIyNzg5NS0uMDM1ODY2IDMuNTE0ODE5LS4wMzU4NjZDMy45MjEyOTUtLjAzNTg2NiA0LjkzNzQ4NCAwIDUuMzQzOTYgMEM1LjQ1MTU1NyAwIDUuNjkwNjYgMCA1LjY5MDY2LS4zNDY3QzUuNjkwNjYtLjU2MTg5MyA1LjUyMzI4OC0uNTYxODkzIDUuMTg4NTQzLS41NjE4OTNDNC45Mzc0ODQtLjU2MTg5MyA0LjcxMDMzNi0uNTczODQ4IDQuNDU5Mjc4LS41ODU4MDNMNS4xMjg3NjctMy4yNzU3MTZMOC43NzUwOTMtNy4xNzMxMDFaJy8+CjxwYXRoIGlkPSdnMy03OCcgZD0nTTMuNjU4MjgxLTYuODYyMjY3QzMuODczNDc0LTYuMjQwNTk4IDQuMTM2NDg4LTUuMzQzOTYgNC42NzQ0NzEtMy44NzM0NzRDNS40Mjc2NDYtMS44NDEwOTYgNS43NjIzOTEtMS4wOTk4NzUgNi40OTE2NTYgLjAzNTg2NkM2LjY1OTAyOSAuMjg2OTI0IDYuNjcwOTg0IC4yOTg4NzkgNi43Nzg1OCAuMjk4ODc5QzYuOTQ1OTUzIC4yOTg4NzkgNy4xOTcwMTEgLjE1NTQxNyA3LjMyODUxOCAuMDU5Nzc2QzcuNDk1ODktLjA5NTY0MSA3LjUwNzg0Ni0uMTA3NTk3IDcuNjM5MzUyLS42OTM0QzguMzU2NjYzLTMuODM3NjA5IDkuMjY1MjU1LTcuMTEzMzI1IDkuNTA0MzU5LTcuNjYzMjYzQzkuNTE2MzE0LTcuNjg3MTczIDkuNzU1NDE3LTguMTQxNDY5IDExLjIyNTkwMy04LjE2NTM4QzExLjQ2NTAwNi04LjE3NzMzNSAxMS42OTIxNTQtOC44MTA5NTkgMTEuNjkyMTU0LTkuMDczOTczQzExLjY5MjE1NC05LjI2NTI1NSAxMS42MjA0MjMtOS4yNjUyNTUgMTEuNDUzMDUxLTkuMjY1MjU1QzEwLjI1NzUzNC05LjI2NTI1NSA5LjcxOTU1Mi04Ljc2MzEzOCA5LjU3NjA5LTguNjA3NzIxQzkuMjQxMzQ1LTguMTc3MzM1IDguOTU0NDIxLTcuMzA0NjA4IDguNDA0NDgzLTUuMzA4MDk1QzcuOTg2MDUyLTMuNzc3ODMzIDcuNjAzNDg3LTIuMjIzNjYxIDcuMjMyODc3LS42ODE0NDVDNi41NzUzNDItMS42NzM3MjQgNi4yMDQ3MzItMi42MTgxODIgNS42MzA4ODQtNC4xNjAzOTlDNC45OTcyNi01Ljg1ODAzMiA0LjYxNDY5NS03LjEwMTM3IDQuMjkxOTA1LTguMTc3MzM1QzQuMjIwMTc0LTguNDE2NDM4IDQuMjA4MjE5LTguNDI4Mzk0IDQuMTAwNjIzLTguNDI4Mzk0QzQuMDc2NzEyLTguNDI4Mzk0IDMuODM3NjA5LTguNDI4Mzk0IDMuNDkwOTA5LTguMTQxNDY5QzMuMzcxMzU3LTguMDMzODczIDMuMzU5NDAyLTcuOTI2Mjc2IDMuMzQ3NDQ3LTcuNzk0NzdDMy4wMTI3MDItNC42MTQ2OTUgMS44ODg5MTctMS40NzA0ODYgMS41NjYxMjctLjg5NjYzOEMxLjQ3MDQ4Ni0uNzE3MzEgMS4zMjcwMjQtLjUwMjExNyAxLjA4NzkyLS41MDIxMTdDLjk2ODM2OS0uNTAyMTE3IC41MDIxMTctLjU2MTg5MyAuMTkxMjgzLS44NDg4MTdDLjEzMTUwNy0uODk2NjM4IC4xMDc1OTctLjg5NjYzOCAuMDk1NjQxLS44OTY2MzhDLS4wOTU2NDEtLjg5NjYzOC0uMzQ2Ny0uMjk4ODc5LS4zNDY3LS4wMTE5NTVDLS4zNDY3IC4zNTg2NTUgLjM4MjU2NSAuNTk3NzU4IC43MTczMSAuNTk3NzU4QzEuNDgyNDQxIC41OTc3NTggMi4wOTIxNTQtMS4wODc5MiAyLjI4MzQzNy0xLjYzNzg1OEMzLjA2MDUyMy0zLjgwMTc0MyAzLjQzMTEzMy01LjU4MzA2NCAzLjY1ODI4MS02Ljg2MjI2N1onLz4KPHBhdGggaWQ9J2czLTEwNicgZD0nTTEuOTAwODcyLTguNTM1OTlDMS45MDA4NzItOC43NTExODMgMS45MDA4NzItOC45NjYzNzYgMS42NjE3NjgtOC45NjYzNzZTMS40MjI2NjUtOC43NTExODMgMS40MjI2NjUtOC41MzU5OVYyLjU1ODQwNkMxLjQyMjY2NSAyLjc3MzU5OSAxLjQyMjY2NSAyLjk4ODc5MiAxLjY2MTc2OCAyLjk4ODc5MlMxLjkwMDg3MiAyLjc3MzU5OSAxLjkwMDg3MiAyLjU1ODQwNlYtOC41MzU5OVonLz4KPHBhdGggaWQ9J2c2LTk3JyBkPSdNMi44MzkzNTItMS43ODEzMkMyLjgzOTM1Mi0yLjMzNzIzNSAyLjI3MTQ4Mi0yLjY2NjAwMiAxLjYwMTk5My0yLjY2NjAwMkMxLjMxNTA2OC0yLjY2NjAwMiAuNjA5NzE0LTIuNjM2MTE1IC42MDk3MTQtMi4xMzM5OThDLjYwOTcxNC0xLjk3MjYwMyAuNzE3MzEtMS44NDEwOTYgLjkwMjYxNS0xLjg0MTA5NkMxLjA3NTk2NS0xLjg0MTA5NiAxLjE4OTUzOS0xLjk3MjYwMyAxLjE4OTUzOS0yLjEyODAyQzEuMTg5NTM5LTIuMjM1NjE2IDEuMTQxNzE5LTIuMzM3MjM1IDEuMDM0MTIyLTIuMzg1MDU2QzEuMjMxMzgyLTIuNDc0NzIgMS41MzAyNjItMi40NzQ3MiAxLjU5MDAzNy0yLjQ3NDcyQzIuMDE0NDQ2LTIuNDc0NzIgMi4zNDMyMTMtMi4yMjM2NjEgMi4zNDMyMTMtMS43NjkzNjVWLTEuNjEzOTQ4QzIuMDY4MjQ0LTEuNjAxOTkzIDEuNTkwMDM3LTEuNTkwMDM3IDEuMTUzNjc0LTEuNDM0NjJDLjc1OTE1My0xLjI5NzEzNiAuMzgyNTY1LTEuMDI4MTQ0IC4zODI1NjUtLjYyNzY0NkMuMzgyNTY1LS4wOTU2NDEgMS4wMTYxODkgLjA1OTc3NiAxLjQ4MjQ0MSAuMDU5Nzc2QzEuOTg0NTU4IC4wNTk3NzYgMi4yODM0MzctLjE5MTI4MyAyLjQxNDk0NC0uNDE4NDMxQzIuNDU2Nzg3LS4xMDc1OTcgMi42NTQwNDcgLjAyOTg4OCAyLjg2MzI2MyAuMDI5ODg4QzIuODg3MTczIC4wMjk4ODggMy41MjY3NzUgLjAyOTg4OCAzLjUyNjc3NS0uNTM3OTgzVi0uODY2NzVIMy4zMDU2MDRWLS41NDk5MzhDMy4zMDU2MDQtLjQ5MDE2MiAzLjMwNTYwNC0uMjIxMTcxIDMuMDcyNDc4LS4yMjExNzFTMi44MzkzNTItLjQ5MDE2MiAyLjgzOTM1Mi0uNTQ5OTM4Vi0xLjc4MTMyWk0yLjM0MzIxMy0uODQ4ODE3QzIuMzQzMjEzLS4yMjcxNDggMS43Mjc1MjItLjEzMTUwNyAxLjUzNjIzOS0uMTMxNTA3QzEuMjEzNDUtLjEzMTUwNyAuOTA4NTkzLS4zMjg3NjcgLjkwODU5My0uNjI3NjQ2Qy45MDg1OTMtLjk2MjM5MSAxLjIzMTM4Mi0xLjM5ODc1NSAyLjM0MzIxMy0xLjQzNDYyVi0uODQ4ODE3WicvPgo8cGF0aCBpZD0nZzYtMTA1JyBkPSdNMS4zNTY5MTItMy42ODIxOTJDMS4zNTY5MTItMy44NjE1MTkgMS4yMDc0NzItNC4wNDA4NDcgLjk5ODI1Ny00LjA0MDg0N0MuODEyOTUxLTQuMDQwODQ3IC42Mzk2MDEtMy44OTczODUgLjYzOTYwMS0zLjY4MjE5MlMuODEyOTUxLTMuMzIzNTM3IC45OTgyNTctMy4zMjM1MzdDMS4yMDc0NzItMy4zMjM1MzcgMS4zNTY5MTItMy41MDI4NjQgMS4zNTY5MTItMy42ODIxOTJaTS40MDY0NzYtMi41NzAzNjFWLTIuMzM3MjM1Qy44MDA5OTYtMi4zMzcyMzUgLjg1NDc5NS0yLjI5NTM5MiAuODU0Nzk1LTIuMDAyNDkxVi0uNDkwMTYyQy44NTQ3OTUtLjIzMzEyNiAuNzk1MDE5LS4yMzMxMjYgLjM4MjU2NS0uMjMzMTI2VjBDLjU1NTkxNS0uMDExOTU1IDEuMDIyMTY3LS4wMjM5MSAxLjA4MTk0My0uMDIzOTFTMS41OTYwMTUtLjAxMTk1NSAxLjc1MTQzMiAwVi0uMjMzMTI2QzEuMzgwODIyLS4yMzMxMjYgMS4zMjcwMjQtLjIzMzEyNiAxLjMyNzAyNC0uNDg0MTg0Vi0yLjYzNjExNUwuNDA2NDc2LTIuNTcwMzYxWicvPgo8cGF0aCBpZD0nZzYtMTA5JyBkPSdNNS4yMDY0NzYtMS44MDUyM0M1LjIwNjQ3Ni0yLjQxNDk0NCA0Ljg0NzgyMS0yLjYzNjExNSA0LjI2MjAxNy0yLjYzNjExNUMzLjcwNjEwMi0yLjYzNjExNSAzLjM3NzMzNS0yLjMxOTMwMyAzLjI0NTgyOC0yLjA5MjE1NEMzLjEwODM0NC0yLjYzNjExNSAyLjQ5ODYzLTIuNjM2MTE1IDIuMzMxMjU4LTIuNjM2MTE1QzEuNzg3Mjk4LTIuNjM2MTE1IDEuNDUyNTUzLTIuMzM3MjM1IDEuMzA5MDkxLTIuMDg2MTc3SDEuMzAzMTEzVi0yLjYzNjExNUwuMzc2NTg4LTIuNTcwMzYxVi0yLjMzNzIzNUMuNzk1MDE5LTIuMzM3MjM1IC44NDg4MTctMi4yOTUzOTIgLjg0ODgxNy0yLjAwMjQ5MVYtLjQ5MDE2MkMuODQ4ODE3LS4yMzMxMjYgLjc4OTA0MS0uMjMzMTI2IC4zNzY1ODgtLjIzMzEyNlYwQy40MTg0MzEtLjAwNTk3OCAuODI0OTA3LS4wMjM5MSAxLjA5Mzg5OC0uMDIzOTFTMS43NTc0MS0uMDA1OTc4IDEuODE3MTg2IDBWLS4yMzMxMjZDMS40MDQ3MzItLjIzMzEyNiAxLjM0NDk1Ni0uMjMzMTI2IDEuMzQ0OTU2LS40OTAxNjJWLTEuNTQyMjE3QzEuMzQ0OTU2LTIuMTk5NzUxIDEuOTEyODI3LTIuNDQ0ODMyIDIuMjc3NDYtMi40NDQ4MzJDMi42ODk5MTMtMi40NDQ4MzIgMi43Nzk1NzctMi4xODc3OTYgMi43Nzk1NzctMS44MTcxODZWLS40OTAxNjJDMi43Nzk1NzctLjIzMzEyNiAyLjcxOTgwMS0uMjMzMTI2IDIuMzA3MzQ3LS4yMzMxMjZWMEMyLjM0OTE5MS0uMDA1OTc4IDIuNzU1NjY2LS4wMjM5MSAzLjAyNDY1OC0uMDIzOTFTMy42ODgxNjktLjAwNTk3OCAzLjc0Nzk0NSAwVi0uMjMzMTI2QzMuMzM1NDkyLS4yMzMxMjYgMy4yNzU3MTYtLjIzMzEyNiAzLjI3NTcxNi0uNDkwMTYyVi0xLjU0MjIxN0MzLjI3NTcxNi0yLjE5OTc1MSAzLjg0MzU4Ny0yLjQ0NDgzMiA0LjIwODIxOS0yLjQ0NDgzMkM0LjYyMDY3Mi0yLjQ0NDgzMiA0LjcxMDMzNi0yLjE4Nzc5NiA0LjcxMDMzNi0xLjgxNzE4NlYtLjQ5MDE2MkM0LjcxMDMzNi0uMjMzMTI2IDQuNjUwNTYtLjIzMzEyNiA0LjIzODEwNy0uMjMzMTI2VjBDNC4yNzk5NS0uMDA1OTc4IDQuNjg2NDI2LS4wMjM5MSA0Ljk1NTQxNy0uMDIzOTFTNS42MTg5MjktLjAwNTk3OCA1LjY3ODcwNSAwVi0uMjMzMTI2QzUuMjY2MjUyLS4yMzMxMjYgNS4yMDY0NzYtLjIzMzEyNiA1LjIwNjQ3Ni0uNDkwMTYyVi0xLjgwNTIzWicvPgo8cGF0aCBpZD0nZzYtMTEwJyBkPSdNMy4yNjk3MzgtMS44MDUyM0MzLjI2OTczOC0yLjM5MTAzNCAyLjkzNDk5NC0yLjYzNjExNSAyLjMzMTI1OC0yLjYzNjExNUMxLjgwNTIzLTIuNjM2MTE1IDEuNDc2NDYzLTIuMzYxMTQ2IDEuMzAzMTEzLTIuMDc0MjIyVi0yLjYzNjExNUwuMzc2NTg4LTIuNTcwMzYxVi0yLjMzNzIzNUMuNzk1MDE5LTIuMzM3MjM1IC44NDg4MTctMi4yOTUzOTIgLjg0ODgxNy0yLjAwMjQ5MVYtLjQ5MDE2MkMuODQ4ODE3LS4yMzMxMjYgLjc4OTA0MS0uMjMzMTI2IC4zNzY1ODgtLjIzMzEyNlYwQy40MTg0MzEtLjAwNTk3OCAuODI0OTA3LS4wMjM5MSAxLjA5Mzg5OC0uMDIzOTFTMS43NTc0MS0uMDA1OTc4IDEuODE3MTg2IDBWLS4yMzMxMjZDMS40MDQ3MzItLjIzMzEyNiAxLjM0NDk1Ni0uMjMzMTI2IDEuMzQ0OTU2LS40OTAxNjJWLTEuNTQyMjE3QzEuMzQ0OTU2LTIuMTk5NzUxIDEuOTA2ODQ5LTIuNDQ0ODMyIDIuMjc3NDYtMi40NDQ4MzJDMi42Nzc5NTgtMi40NDQ4MzIgMi43NzM1OTktMi4xOTM3NzMgMi43NzM1OTktMS44MjMxNjNWLS40OTAxNjJDMi43NzM1OTktLjIzMzEyNiAyLjcxMzgyMy0uMjMzMTI2IDIuMzAxMzctLjIzMzEyNlYwQzIuMzQzMjEzLS4wMDU5NzggMi43NDk2ODktLjAyMzkxIDMuMDE4NjgtLjAyMzkxUzMuNjgyMTkyLS4wMDU5NzggMy43NDE5NjggMFYtLjIzMzEyNkMzLjMyOTUxNC0uMjMzMTI2IDMuMjY5NzM4LS4yMzMxMjYgMy4yNjk3MzgtLjQ5MDE2MlYtMS44MDUyM1onLz4KPHBhdGggaWQ9J2c2LTEyMCcgZD0nTTIuMTIyMDQyLTEuMzk4NzU1TDIuNzEzODIzLTIuMDIwNDIzQzMuMDI0NjU4LTIuMzE5MzAzIDMuMzUzNDI1LTIuMzQzMjEzIDMuNTE0ODE5LTIuMzQzMjEzVi0yLjU3NjMzOUMzLjQzNzExMS0yLjU3MDM2MSAzLjE3NDA5Ny0yLjU1MjQyOCAyLjk4MjgxNC0yLjU1MjQyOEMyLjc2NzYyMS0yLjU1MjQyOCAyLjQwMjk4OS0yLjU3MDM2MSAyLjM2NzEyMy0yLjU3NjMzOVYtMi4zNDMyMTNDMi40Mzg4NTQtMi4zMzEyNTggMi40ODY2NzUtMi4yODM0MzcgMi40ODY2NzUtMi4yMTE3MDZDMi40ODY2NzUtMi4xMTAwODcgMi40Mzg4NTQtMi4wNjIyNjcgMi4yNjU1MDQtMS44NjUwMDZMMS45NzI2MDMtMS41NjAxNDlMMS40NTg1MzEtMi4xMTYwNjVDMS4zOTg3NTUtMi4xNzU4NDEgMS4zOTI3NzctMi4xODc3OTYgMS4zOTI3NzctMi4yMjM2NjFDMS4zOTI3NzctMi4zMTMzMjUgMS40ODg0MTgtMi4zNDMyMTMgMS41NTQxNzItMi4zNDMyMTNWLTIuNTc2MzM5QzEuNDEwNzEtMi41NjQzODQgLjk5ODI1Ny0yLjU1MjQyOCAuODU0Nzk1LTIuNTUyNDI4Qy43NDEyMi0yLjU1MjQyOCAuMzc2NTg4LTIuNTY0Mzg0IC4yNDUwODEtMi41NzYzMzlWLTIuMzQzMjEzQy41ODU4MDMtMi4zNDMyMTMgLjY5OTM3Ny0yLjMzMTI1OCAuODQ4ODE3LTIuMTY5ODYzTDEuNjMxODgtMS4zMjEwNDZDMS42NzM3MjQtMS4yNzkyMDMgMS42Nzk3MDEtMS4yNzMyMjUgMS42Nzk3MDEtMS4yNjEyN0MxLjY3OTcwMS0xLjI0MzMzNyAxLjE0MTcxOS0uNjkzNCAxLjA3NTk2NS0uNjI3NjQ2Qy45MjA1NDgtLjQ2NjI1MiAuNjk5Mzc3LS4yMzkxMDMgLjIwOTIxNS0uMjMzMTI2VjBDLjI4NjkyNC0uMDA1OTc4IC41NDk5MzgtLjAyMzkxIC43NDEyMi0uMDIzOTFDLjgyNDkwNy0uMDIzOTEgMS4yMzEzODItLjAxMTk1NSAxLjM2Mjg4OSAwVi0uMjMzMTI2QzEuMjg1MTgxLS4yMzkxMDMgMS4yNDMzMzctLjI4NjkyNCAxLjI0MzMzNy0uMzY0NjMzQzEuMjQzMzM3LS40NjYyNTIgMS4zMTUwNjgtLjU0Mzk2IDEuMzQ0OTU2LS41Nzk4MjZDMS41MDAzNzQtLjc1OTE1MyAxLjY2Nzc0Ni0uOTMyNTAzIDEuODM1MTE4LTEuMDk5ODc1TDIuMzY3MTIzLS41MjYwMjdDMi40ODY2NzUtLjM5NDUyMSAyLjQ4NjY3NS0uMzgyNTY1IDIuNDg2Njc1LS4zNTI2NzdDMi40ODY2NzUtLjI5MjkwMiAyLjQzMjg3Ny0uMjMzMTI2IDIuMzI1MjgtLjIzMzEyNlYwQzIuNTIyNTQtLjAxMTk1NSAyLjk3NjgzNy0uMDIzOTEgMy4wMjQ2NTgtLjAyMzkxQzMuMjQ1ODI4LS4wMjM5MSAzLjU1NjY2My0uMDA1OTc4IDMuNjM0MzcxIDBWLS4yMzMxMjZDMy4zMzU0OTItLjIzMzEyNiAzLjE4NjA1Mi0uMjMzMTI2IDMuMDI0NjU4LS40MTI0NTNMMi4xMjIwNDItMS4zOTg3NTVaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzItNTAnIGQ9J000LjYzMDYzNS0xLjgwOTIxNUM0Ljc1ODE1Ny0xLjgwOTIxNSA0LjkzMzQ5OS0xLjgwOTIxNSA0LjkzMzQ5OS0xLjk5MjUyOFM0Ljc1ODE1Ny0yLjE3NTg0MSA0LjYzMDYzNS0yLjE3NTg0MUgxLjA3NTk2NUMxLjE3OTU3Ny0zLjI4MzY4NiAyLjEwNDExLTQuMTI4NTE4IDMuMzE1NTY3LTQuMTI4NTE4SDQuNjMwNjM1QzQuNzU4MTU3LTQuMTI4NTE4IDQuOTMzNDk5LTQuMTI4NTE4IDQuOTMzNDk5LTQuMzExODMxUzQuNzU4MTU3LTQuNDk1MTQzIDQuNjMwNjM1LTQuNDk1MTQzSDMuMjkxNjU2QzEuODU3MDM2LTQuNDk1MTQzIC43MDEzNy0zLjM3OTMyOCAuNzAxMzctMS45OTI1MjhDLjcwMTM3LS41OTc3NTggMS44NjUwMDYgLjUxMDA4NyAzLjI5MTY1NiAuNTEwMDg3SDQuNjMwNjM1QzQuNzU4MTU3IC41MTAwODcgNC45MzM0OTkgLjUxMDA4NyA0LjkzMzQ5OSAuMzI2Nzc1UzQuNzU4MTU3IC4xNDM0NjIgNC42MzA2MzUgLjE0MzQ2MkgzLjMxNTU2N0MyLjEwNDExIC4xNDM0NjIgMS4xNzk1NzctLjcwMTM3IDEuMDc1OTY1LTEuODA5MjE1SDQuNjMwNjM1WicvPgo8cGF0aCBpZD0nZzQtMjgnIGQ9J00yLjUwMjYxNS0yLjkwOTA5MUgzLjkyOTI2NUM0LjA1Njc4Ny0yLjkwOTA5MSA0LjE0NDQ1OC0yLjkwOTA5MSA0LjIyNDE1OS0yLjk3Mjg1MkM0LjMxOTgwMS0zLjA2MDUyMyA0LjM0MzcxMS0zLjE2NDEzNCA0LjM0MzcxMS0zLjIxMTk1NUM0LjM0MzcxMS0zLjQzNTExOCA0LjE0NDQ1OC0zLjQzNTExOCA0LjAwODk2Ni0zLjQzNTExOEgxLjYwMTk5M0MxLjQzNDYyLTMuNDM1MTE4IDEuMTMxNzU2LTMuNDM1MTE4IC43NDEyMi0zLjA1MjU1M0MuNDU0Mjk2LTIuNzY1NjI5IC4yMzExMzMtMi4zOTkwMDQgLjIzMTEzMy0yLjM0MzIxM0MuMjMxMTMzLTIuMjcxNDgyIC4yODY5MjQtMi4yNDc1NzIgLjM1MDY4NS0yLjI0NzU3MkMuNDMwMzg2LTIuMjQ3NTcyIC40NDYzMjYtMi4yNzE0ODIgLjQ5NDE0Ny0yLjMzNTI0M0MuODg0NjgyLTIuOTA5MDkxIDEuMzU0OTE5LTIuOTA5MDkxIDEuNTM4MjMyLTIuOTA5MDkxSDIuMjIzNjYxTDEuNTM4MjMyLS43MDEzN0MxLjQ4MjQ0MS0uNTE4MDU3IDEuMzc4ODI5LS4xOTEyODMgMS4zNzg4MjktLjE1MTQzMkMxLjM3ODgyOSAuMDMxODggMS41NDYyMDIgLjA5NTY0MSAxLjY0MTg0MyAuMDk1NjQxQzEuOTM2NzM3IC4wOTU2NDEgMS45ODQ1NTgtLjE4MzMxMyAyLjAwODQ2OC0uMzAyODY0TDIuNTAyNjE1LTIuOTA5MDkxWicvPgo8cGF0aCBpZD0nZzQtOTgnIGQ9J00xLjk0NDcwNy01LjI5MjE1NEMxLjk1MjY3Ny01LjMwODA5NSAxLjk3NjU4OC01LjQxMTcwNiAxLjk3NjU4OC01LjQxOTY3NkMxLjk3NjU4OC01LjQ1OTUyNyAxLjk0NDcwNy01LjUzMTI1OCAxLjg0OTA2Ni01LjUzMTI1OEMxLjgxNzE4Ni01LjUzMTI1OCAxLjU3MDExMi01LjUwNzM0NyAxLjM4NjgtNS40OTE0MDdMLjk0MDQ3My01LjQ1OTUyN0MuNzY1MTMxLTUuNDQzNTg3IC42ODU0My01LjQzNTYxNiAuNjg1NDMtNS4yOTIxNTRDLjY4NTQzLTUuMTgwNTczIC43OTcwMTEtNS4xODA1NzMgLjg5MjY1My01LjE4MDU3M0MxLjI3NTIxOC01LjE4MDU3MyAxLjI3NTIxOC01LjEzMjc1MiAxLjI3NTIxOC01LjA2MTAyMUMxLjI3NTIxOC01LjAxMzIgMS4xOTU1MTctNC42OTQzOTYgMS4xNDc2OTYtNC41MTEwODNMLjQ1NDI5Ni0xLjczNzQ4NEMuMzkwNTM1LTEuNDY2NTAxIC4zOTA1MzUtMS4zNDY5NDkgLjM5MDUzNS0xLjIxMTQ1N0MuMzkwNTM1LS4zOTA1MzUgLjg5MjY1MyAuMDc5NzAxIDEuNTA2MzUxIC4wNzk3MDFDMi40ODY2NzUgLjA3OTcwMSAzLjUwNjg0OS0xLjA1MjA1NSAzLjUwNjg0OS0yLjIwNzcyMUMzLjUwNjg0OS0yLjk5Njc2MiAyLjk5Njc2Mi0zLjUxNDgxOSAyLjM1OTE1My0zLjUxNDgxOUMxLjkxMjgyNy0zLjUxNDgxOSAxLjU3MDExMi0zLjIyNzg5NSAxLjM5NDc3LTMuMDc2NDYzTDEuOTQ0NzA3LTUuMjkyMTU0Wk0xLjUwNjM1MS0uMTQzNDYyQzEuMjE5NDI3LS4xNDM0NjIgLjkzMjUwMy0uMzY2NjI1IC45MzI1MDMtLjk0ODQ0M0MuOTMyNTAzLTEuMTYzNjM2IC45NjQzODQtMS4zNjI4ODkgMS4wNjAwMjUtMS43NDU0NTVDMS4xMTU4MTYtMS45NzY1ODggMS4xNzE2MDYtMi4xOTk3NTEgMS4yMzUzNjctMi40MzA4ODRDMS4yNzUyMTgtMi41NzQzNDYgMS4yNzUyMTgtMi41OTAyODYgMS4zNzA4NTktMi43MDk4MzhDMS42NDE4NDMtMy4wNDQ1ODMgMi4wMDA0OTgtMy4yOTE2NTYgMi4zMzUyNDMtMy4yOTE2NTZDMi43MzM3NDgtMy4yOTE2NTYgMi44ODUxODEtMi45MDExMjEgMi44ODUxODEtMi41NDI0NjZDMi44ODUxODEtMi4yNDc1NzIgMi43MDk4MzgtMS4zOTQ3NyAyLjQ3MDczNS0uOTI0NTMzQzIuMjYzNTEyLS40OTQxNDcgMS44ODA5NDYtLjE0MzQ2MiAxLjUwNjM1MS0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzQtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c0LTExMScgZD0nTTMuOTY5MTE2LTIuMTM1OTlDMy45NjkxMTYtMi45MTcwNjEgMy40MTEyMDgtMy41MTQ4MTkgMi41ODIzMTYtMy41MTQ4MTlDMS40NTA1Ni0zLjUxNDgxOSAuMzUwNjg1LTIuNDE0OTQ0IC4zNTA2ODUtMS4yOTkxMjhDLjM1MDY4NS0uNDg2MTc3IC45MjQ1MzMgLjA3OTcwMSAxLjczNzQ4NCAuMDc5NzAxQzIuODc3MjEgLjA3OTcwMSAzLjk2OTExNi0xLjAzNjExNSAzLjk2OTExNi0yLjEzNTk5Wk0xLjc0NTQ1NS0uMTQzNDYyQzEuNDY2NTAxLS4xNDM0NjIgLjk5NjI2NC0uMjg2OTI0IC45OTYyNjQtMS4wMjAxNzRDLjk5NjI2NC0xLjM0Njk0OSAxLjE0NzY5Ni0yLjIwNzcyMSAxLjUzMDI2Mi0yLjcwMTg2OEMxLjkyMDc5Ny0zLjIwMzk4NSAyLjM1OTE1My0zLjI5MTY1NiAyLjU3NDM0Ni0zLjI5MTY1NkMyLjkwMTEyMS0zLjI5MTY1NiAzLjMyMzUzNy0zLjA5MjQwMyAzLjMyMzUzNy0yLjQyMjkxNEMzLjMyMzUzNy0yLjEwNDExIDMuMTgwMDc1LTEuMzQ2OTQ5IDIuODc3MjEtLjg2ODc0MkMyLjU4MjMxNi0uNDE0NDQ2IDIuMTQzOTYtLjE0MzQ2MiAxLjc0NTQ1NS0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzQtMTE1JyBkPSdNMy4yMTE5NTUtMi45OTY3NjJDMy4wMjg2NDMtMi45NjQ4ODIgMi44NjEyNy0yLjgyMTQyIDIuODYxMjctMi42MjIxNjdDMi44NjEyNy0yLjQ3ODcwNSAyLjk1NjkxMi0yLjM3NTA5MyAzLjEzMjI1NC0yLjM3NTA5M0MzLjI1MTgwNi0yLjM3NTA5MyAzLjQ5ODg3OS0yLjQ2Mjc2NSAzLjQ5ODg3OS0yLjgyMTQyQzMuNDk4ODc5LTMuMzE1NTY3IDIuOTgwODIyLTMuNTE0ODE5IDIuNDg2Njc1LTMuNTE0ODE5QzEuNDE4NjgtMy41MTQ4MTkgMS4wODM5MzUtMi43NTc2NTkgMS4wODM5MzUtMi4zNTExODNDMS4wODM5MzUtMi4yNzE0ODIgMS4wODM5MzUtMS45ODQ1NTggMS4zNzg4MjktMS43NjEzOTVDMS41NjIxNDItMS42MTc5MzMgMS42OTc2MzQtMS41OTQwMjIgMi4xMTIwOC0xLjUxNDMyMUMyLjM5MTAzNC0xLjQ1ODUzMSAyLjg0NTMzLTEuMzc4ODI5IDIuODQ1MzMtLjk2NDM4NEMyLjg0NTMzLS43NTcxNjEgMi42OTM4OTgtLjQ5NDE0NyAyLjQ3MDczNS0uMzQyNzE1QzIuMTc1ODQxLS4xNTE0MzIgMS43ODUzMDUtLjE0MzQ2MiAxLjY1Nzc4My0uMTQzNDYyQzEuNDY2NTAxLS4xNDM0NjIgLjkyNDUzMy0uMTc1MzQyIC43MjUyOC0uNDk0MTQ3QzEuMTMxNzU2LS41MTAwODcgMS4xODc1NDctLjgzNjg2MiAxLjE4NzU0Ny0uOTMyNTAzQzEuMTg3NTQ3LTEuMTcxNjA2IC45NzIzNTQtMS4yMjczOTcgLjg3NjcxMi0xLjIyNzM5N0MuNzQ5MTkxLTEuMjI3Mzk3IC40MjI0MTYtMS4xMzE3NTYgLjQyMjQxNi0uNjkzNEMuNDIyNDE2LS4yMjMxNjMgLjkxNjU2MyAuMDc5NzAxIDEuNjU3NzgzIC4wNzk3MDFDMy4wNDQ1ODMgLjA3OTcwMSAzLjMzOTQ3Ny0uOTAwNjIzIDMuMzM5NDc3LTEuMjM1MzY3QzMuMzM5NDc3LTEuOTUyNjc3IDIuNTU4NDA2LTIuMTA0MTEgMi4yNjM1MTItMi4xNTk5QzEuODgwOTQ2LTIuMjMxNjMxIDEuNTcwMTEyLTIuMjg3NDIyIDEuNTcwMTEyLTIuNjIyMTY3QzEuNTcwMTEyLTIuNzY1NjI5IDEuNzA1NjA0LTMuMjkxNjU2IDIuNDc4NzA1LTMuMjkxNjU2QzIuNzgxNTY5LTMuMjkxNjU2IDMuMDkyNDAzLTMuMjAzOTg1IDMuMjExOTU1LTIuOTk2NzYyWicvPgo8cGF0aCBpZD0nZzgtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c4LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnOC00MycgZD0nTTQuNzcwMTEyLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExLTIuNzYxNjQ0IDguNDUyMzA0LTIuNzYxNjQ0IDguNDUyMzA0LTIuOTc2ODM3QzguNDUyMzA0LTMuMjAzOTg1IDguMjQ5MDY2LTMuMjAzOTg1IDguMDY5NzM4LTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMi02LjY3MDk4NCA0Ljc3MDExMi02Ljg4NjE3NyA0LjU1NDkxOS02Ljg4NjE3N0M0LjMyNzc3MS02Ljg4NjE3NyA0LjMyNzc3MS02LjY4MjkzOSA0LjMyNzc3MS02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDLjg2MDc3Mi0zLjIwMzk4NSAuNjQ1NTc5LTMuMjAzOTg1IC42NDU1NzktMi45ODg3OTJDLjY0NTU3OS0yLjc2MTY0NCAuODQ4ODE3LTIuNzYxNjQ0IDEuMDI4MTQ0LTIuNzYxNjQ0SDQuMzI3NzcxVi41Mzc5ODNDNC4zMjc3NzEgLjcwNTM1NSA0LjMyNzc3MSAuOTIwNTQ4IDQuNTQyOTY0IC45MjA1NDhDNC43NzAxMTIgLjkyMDU0OCA0Ljc3MDExMiAuNzE3MzEgNC43NzAxMTIgLjUzNzk4M1YtMi43NjE2NDRaJy8+CjxwYXRoIGlkPSdnOC01OScgZD0nTTIuMTk5NzUxLTQuNTc4ODI5QzIuMTk5NzUxLTQuOTAxNjE5IDEuOTI0NzgyLTUuMTUyNjc3IDEuNjI1OTAzLTUuMTUyNjc3QzEuMjc5MjAzLTUuMTUyNjc3IDEuMDQwMS00Ljg3NzcwOSAxLjA0MDEtNC41Nzg4MjlDMS4wNDAxLTQuMjIwMTc0IDEuMzM4OTc5LTMuOTkzMDI2IDEuNjEzOTQ4LTMuOTkzMDI2QzEuOTM2NzM3LTMuOTkzMDI2IDIuMTk5NzUxLTQuMjQ0MDg1IDIuMTk5NzUxLTQuNTc4ODI5Wk0xLjk5NjUxMy0uMTE5NTUyQzEuOTk2NTEzIC4yOTg4NzkgMS45OTY1MTMgMS4xNDc2OTYgMS4yNjcyNDggMi4wNDQzMzRDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS4zOTg3NTUgMi4zMDczNDcgMi4yMzU2MTYgMS40MjI2NjUgMi4yMzU2MTYgLjAyMzkxQzIuMjM1NjE2LS40MTg0MzEgMi4xOTk3NTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yNjcyNDgtMS4xNTk2NTEgMS4wNDAxLS44OTY2MzggMS4wNDAxLS41ODU4MDNDMS4wNDAxLS4yNjMwMTQgMS4yNjcyNDggMCAxLjYyNTkwMyAwQzEuODUzMDUxIDAgMS45MzY3MzctLjA3MTczMSAxLjk5NjUxMy0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzgtNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2c4LTk3JyBkPSdNNC42MTQ2OTUtMy4xOTIwM0M0LjYxNDY5NS0zLjgzNzYwOSA0LjYxNDY5NS00LjMxNTgxNiA0LjA4ODY2Ny00Ljc4MjA2N0MzLjY3MDIzNy01LjE2NDYzMyAzLjEzMjI1NC01LjMzMjAwNSAyLjYwNjIyNy01LjMzMjAwNUMxLjYyNTkwMy01LjMzMjAwNSAuODcyNzI3LTQuNjg2NDI2IC44NzI3MjctMy45MDkzNEMuODcyNzI3LTMuNTYyNjQgMS4wOTk4NzUtMy4zOTUyNjggMS4zNzQ4NDQtMy4zOTUyNjhDMS42NjE3NjgtMy4zOTUyNjggMS44NjUwMDYtMy41OTg1MDYgMS44NjUwMDYtMy44ODU0M0MxLjg2NTAwNi00LjM3NTU5MiAxLjQzNDYyLTQuMzc1NTkyIDEuMjU1MjkzLTQuMzc1NTkyQzEuNTMwMjYyLTQuODc3NzA5IDIuMTA0MTEtNS4wOTI5MDIgMi41ODIzMTYtNS4wOTI5MDJDMy4xMzIyNTQtNS4wOTI5MDIgMy44Mzc2MDktNC42Mzg2MDUgMy44Mzc2MDktMy41NjI2NFYtMy4wODQ0MzNDMS40MzQ2Mi0zLjA0ODU2OCAuNTI2MDI3LTIuMDQ0MzM0IC41MjYwMjctMS4xMjM3ODZDLjUyNjAyNy0uMTc5MzI4IDEuNjI1OTAzIC4xMTk1NTIgMi4zNTUxNjggLjExOTU1MkMzLjE0NDIwOSAuMTE5NTUyIDMuNjgyMTkyLS4zNTg2NTUgMy45MDkzNC0uOTMyNTAzQzMuOTU3MTYxLS4zNzA2MSA0LjMyNzc3MSAuMDU5Nzc2IDQuODQxODQzIC4wNTk3NzZDNS4wOTI5MDIgLjA1OTc3NiA1Ljc4NjMwMS0uMTA3NTk3IDUuNzg2MzAxLTEuMDY0MDFWLTEuNzMzNDk5SDUuNTIzMjg4Vi0xLjA2NDAxQzUuNTIzMjg4LS4zODI1NjUgNS4yMzYzNjQtLjI4NjkyNCA1LjA2ODk5MS0uMjg2OTI0QzQuNjE0Njk1LS4yODY5MjQgNC42MTQ2OTUtLjkyMDU0OCA0LjYxNDY5NS0xLjA5OTg3NVYtMy4xOTIwM1pNMy44Mzc2MDktMS42ODU2NzlDMy44Mzc2MDktLjUxNDA3MiAyLjk2NDg4Mi0uMTE5NTUyIDIuNDUwODA5LS4xMTk1NTJDMS44NjUwMDYtLjExOTU1MiAxLjM3NDg0NC0uNTQ5OTM4IDEuMzc0ODQ0LTEuMTIzNzg2QzEuMzc0ODQ0LTIuNzAxODY4IDMuNDA3MjIzLTIuODQ1MzMgMy44Mzc2MDktMi44NjkyNFYtMS42ODU2NzlaJy8+CjxwYXRoIGlkPSdnOC0xMDMnIGQ9J00xLjQyMjY2NS0yLjE2Mzg4NUMxLjk4NDU1OC0xLjc5MzI3NSAyLjQ2Mjc2NS0xLjc5MzI3NSAyLjU5NDI3MS0xLjc5MzI3NUMzLjY3MDIzNy0xLjc5MzI3NSA0LjQ3MTIzMy0yLjYwNjIyNyA0LjQ3MTIzMy0zLjUyNjc3NUM0LjQ3MTIzMy0zLjg0OTU2NCA0LjM3NTU5Mi00LjMwMzg2MSAzLjk5MzAyNi00LjY4NjQyNkM0LjQ1OTI3OC01LjE2NDYzMyA1LjAyMTE3MS01LjE2NDYzMyA1LjA4MDk0Ni01LjE2NDYzM0M1LjEyODc2Ny01LjE2NDYzMyA1LjE4ODU0My01LjE2NDYzMyA1LjIzNjM2NC01LjE0MDcyMkM1LjExNjgxMi01LjA5MjkwMiA1LjA1NzAzNi00Ljk3MzM1IDUuMDU3MDM2LTQuODQxODQzQzUuMDU3MDM2LTQuNjc0NDcxIDUuMTc2NTg4LTQuNTMxMDA5IDUuMzY3ODctNC41MzEwMDlDNS40NjM1MTItNC41MzEwMDkgNS42Nzg3MDUtNC41OTA3ODUgNS42Nzg3MDUtNC44NTM3OThDNS42Nzg3MDUtNS4wNjg5OTEgNS41MTEzMzMtNS40MDM3MzYgNS4wOTI5MDItNS40MDM3MzZDNC40NzEyMzMtNS40MDM3MzYgNC4wMDQ5ODEtNS4wMjExNzEgMy44Mzc2MDktNC44NDE4NDNDMy40Nzg5NTQtNS4xMTY4MTIgMy4wNjA1MjMtNS4yNzIyMjkgMi42MDYyMjctNS4yNzIyMjlDMS41MzAyNjItNS4yNzIyMjkgLjcyOTI2NS00LjQ1OTI3OCAuNzI5MjY1LTMuNTM4NzNDLjcyOTI2NS0yLjg1NzI4NSAxLjE0NzY5Ni0yLjQxNDk0NCAxLjI2NzI0OC0yLjMwNzM0N0MxLjEyMzc4Ni0yLjEyODAyIC45MDg1OTMtMS43ODEzMiAuOTA4NTkzLTEuMzE1MDY4Qy45MDg1OTMtLjYyMTY2OSAxLjMyNzAyNC0uMzIyNzkgMS40MjI2NjUtLjI2MzAxNEMuODcyNzI3LS4xMDc1OTcgLjMyMjc5IC4zMjI3OSAuMzIyNzkgLjk0NDQ1OEMuMzIyNzkgMS43NjkzNjUgMS40NDY1NzUgMi40NTA4MDkgMi45MTcwNjEgMi40NTA4MDlDNC4zMzk3MjYgMi40NTA4MDkgNS41MjMyODggMS44MTcxODYgNS41MjMyODggLjkyMDU0OEM1LjUyMzI4OCAuNjIxNjY5IDUuNDM5NjAxLS4wODM2ODYgNC43MjIyOTEtLjQ1NDI5NkM0LjExMjU3OC0uNzY1MTMxIDMuNTE0ODE5LS43NjUxMzEgMi40ODY2NzUtLjc2NTEzMUMxLjc1NzQxLS43NjUxMzEgMS42NzM3MjQtLjc2NTEzMSAxLjQ1ODUzMS0uOTkyMjc5QzEuMzM4OTc5LTEuMTExODMxIDEuMjMxMzgyLTEuMzM4OTc5IDEuMjMxMzgyLTEuNTkwMDM3QzEuMjMxMzgyLTEuNzkzMjc1IDEuMzAzMTEzLTEuOTk2NTEzIDEuNDIyNjY1LTIuMTYzODg1Wk0yLjYwNjIyNy0yLjA0NDMzNEMxLjU1NDE3Mi0yLjA0NDMzNCAxLjU1NDE3Mi0zLjI1MTgwNiAxLjU1NDE3Mi0zLjUyNjc3NUMxLjU1NDE3Mi0zLjc0MTk2OCAxLjU1NDE3Mi00LjIzMjEzIDEuNzU3NDEtNC41NTQ5MTlDMS45ODQ1NTgtNC45MDE2MTkgMi4zNDMyMTMtNS4wMjExNzEgMi41OTQyNzEtNS4wMjExNzFDMy42NDYzMjYtNS4wMjExNzEgMy42NDYzMjYtMy44MTM2OTkgMy42NDYzMjYtMy41Mzg3M0MzLjY0NjMyNi0zLjMyMzUzNyAzLjY0NjMyNi0yLjgzMzM3NSAzLjQ0MzA4OC0yLjUxMDU4NUMzLjIxNTk0LTIuMTYzODg1IDIuODU3Mjg1LTIuMDQ0MzM0IDIuNjA2MjI3LTIuMDQ0MzM0Wk0yLjkyOTAxNiAyLjE5OTc1MUMxLjc4MTMyIDIuMTk5NzUxIC45MDg1OTMgMS42MTM5NDggLjkwODU5MyAuOTMyNTAzQy45MDg1OTMgLjgzNjg2MiAuOTMyNTAzIC4zNzA2MSAxLjM4NjggLjA1OTc3NkMxLjY0OTgxMy0uMTA3NTk3IDEuNzU3NDEtLjEwNzU5NyAyLjU5NDI3MS0uMTA3NTk3QzMuNTg2NTUtLjEwNzU5NyA0LjkzNzQ4NC0uMTA3NTk3IDQuOTM3NDg0IC45MzI1MDNDNC45Mzc0ODQgMS42Mzc4NTggNC4wMjg4OTIgMi4xOTk3NTEgMi45MjkwMTYgMi4xOTk3NTFaJy8+CjxwYXRoIGlkPSdnOC0xMDknIGQ9J004LjU3MTg1Ni0yLjkwNTEwNkM4LjU3MTg1Ni00LjAxNjkzNiA4LjU3MTg1Ni00LjM1MTY4MSA4LjI5Njg4Ny00LjczNDI0N0M3Ljk1MDE4Ny01LjIwMDQ5OCA3LjM4ODI5NC01LjI3MjIyOSA2Ljk4MTgxOC01LjI3MjIyOUM1Ljk4OTUzOS01LjI3MjIyOSA1LjQ4NzQyMi00LjU1NDkxOSA1LjI5NjEzOS00LjA4ODY2N0M1LjEyODc2Ny01LjAwOTIxNSA0LjQ4MzE4OC01LjI3MjIyOSAzLjczMDAxMi01LjI3MjIyOUMyLjU3MDM2MS01LjI3MjIyOSAyLjExNjA2NS00LjI3OTk1IDIuMDIwNDIzLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwuMzgyNTY1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNy00Ljc5NDAyMiAxLjI5MTE1OC00LjcxMDMzNiAxLjI5MTE1OC00LjEyNDUzM1YtLjg4NDY4MkMxLjI5MTE1OC0uMzQ2NyAxLjE1OTY1MS0uMzQ2NyAuMzgyNTY1LS4zNDY3VjBDLjY5MzQtLjAyMzkxIDEuMzM4OTc5LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFDMi4wMjA0MjMtLjAyMzkxIDIuNjY2MDAyLS4wMjM5MSAyLjk3NjgzNyAwVi0uMzQ2N0MyLjIxMTcwNi0uMzQ2NyAyLjA2ODI0NC0uMzQ2NyAyLjA2ODI0NC0uODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NC00LjM2MzYzNiAyLjg5MzE1MS01LjAzMzEyNiAzLjYzNDM3MS01LjAzMzEyNlM0LjU0Mjk2NC00LjQyMzQxMiA0LjU0Mjk2NC0zLjY5NDE0N1YtLjg4NDY4MkM0LjU0Mjk2NC0uMzQ2NyA0LjQxMTQ1Ny0uMzQ2NyAzLjYzNDM3MS0uMzQ2N1YwQzMuOTQ1MjA1LS4wMjM5MSA0LjU5MDc4NS0uMDIzOTEgNC45MjU1MjktLjAyMzkxQzUuMjcyMjI5LS4wMjM5MSA1LjkxNzgwOC0uMDIzOTEgNi4yMjg2NDMgMFYtLjM0NjdDNS40NjM1MTItLjM0NjcgNS4zMjAwNS0uMzQ2NyA1LjMyMDA1LS44ODQ2ODJWLTMuMTA4MzQ0QzUuMzIwMDUtNC4zNjM2MzYgNi4xNDQ5NTYtNS4wMzMxMjYgNi44ODYxNzctNS4wMzMxMjZTNy43OTQ3Ny00LjQyMzQxMiA3Ljc5NDc3LTMuNjk0MTQ3Vi0uODg0NjgyQzcuNzk0NzctLjM0NjcgNy42NjMyNjMtLjM0NjcgNi44ODYxNzctLjM0NjdWMEM3LjE5NzAxMS0uMDIzOTEgNy44NDI1OS0uMDIzOTEgOC4xNzczMzUtLjAyMzkxQzguNTI0MDM1LS4wMjM5MSA5LjE2OTYxNC0uMDIzOTEgOS40ODA0NDggMFYtLjM0NjdDOC44ODI2OS0uMzQ2NyA4LjU4MzgxMS0uMzQ2NyA4LjU3MTg1Ni0uNzA1MzU1Vi0yLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c4LTExNCcgZD0nTTEuOTk2NTEzLTIuNzg1NTU0QzEuOTk2NTEzLTMuOTQ1MjA1IDIuNDc0NzItNS4wMzMxMjYgMy4zOTUyNjgtNS4wMzMxMjZDMy40OTA5MDktNS4wMzMxMjYgMy41MTQ4MTktNS4wMzMxMjYgMy41NjI2NC01LjAyMTE3MUMzLjQ2Njk5OS00Ljk3MzM1IDMuMjc1NzE2LTQuOTAxNjE5IDMuMjc1NzE2LTQuNTc4ODI5QzMuMjc1NzE2LTQuMjMyMTMgMy41NTA2ODUtNC4xMDA2MjMgMy43NDE5NjgtNC4xMDA2MjNDMy45ODEwNzEtNC4xMDA2MjMgNC4yMjAxNzQtNC4yNTYwNCA0LjIyMDE3NC00LjU3ODgyOUM0LjIyMDE3NC00LjkzNzQ4NCAzLjg5NzM4NS01LjI3MjIyOSAzLjM4MzMxMy01LjI3MjIyOUMyLjM2NzEyMy01LjI3MjIyOSAyLjAyMDQyMy00LjE3MjM1NCAxLjk0ODY5Mi0zLjk0NTIwNUgxLjkzNjczN1YtNS4yNzIyMjlMLjMzNDc0NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xNDc2OTYtNC43OTQwMjIgMS4yNDMzMzctNC43MTAzMzYgMS4yNDMzMzctNC4xMjQ1MzNWLS44ODQ2ODJDMS4yNDMzMzctLjM0NjcgMS4xMTE4MzEtLjM0NjcgLjMzNDc0NS0uMzQ2N1YwQy42Njk0ODktLjAyMzkxIDEuMzI3MDI0LS4wMjM5MSAxLjY4NTY3OS0uMDIzOTFDMi4wMDg0NjgtLjAyMzkxIDIuODU3Mjg1LS4wMjM5MSAzLjEzMjI1NCAwVi0uMzQ2N0gyLjg5MzE1MUMyLjAyMDQyMy0uMzQ2NyAxLjk5NjUxMy0uNDc4MjA3IDEuOTk2NTEzLS45MDg1OTNWLTIuNzg1NTU0WicvPgo8cGF0aCBpZD0nZzgtMTIwJyBkPSdNMy4zNDc0NDctMi44MjE0MkMzLjY5NDE0Ny0zLjI3NTcxNiA0LjE5NjI2NC0zLjkyMTI5NSA0LjQyMzQxMi00LjE3MjM1NEM0LjkxMzU3NC00LjcyMjI5MSA1LjQ3NTQ2Ny00LjgwNTk3OCA1Ljg1ODAzMi00LjgwNTk3OFYtNS4xNTI2NzdDNS4zNDM5Ni01LjEyODc2NyA1LjMyMDA1LTUuMTI4NzY3IDQuODUzNzk4LTUuMTI4NzY3QzQuMzk5NTAyLTUuMTI4NzY3IDQuMzc1NTkyLTUuMTI4NzY3IDMuNzc3ODMzLTUuMTUyNjc3Vi00LjgwNTk3OEMzLjkzMzI1LTQuNzgyMDY3IDQuMTI0NTMzLTQuNzEwMzM2IDQuMTI0NTMzLTQuNDM1MzY3QzQuMTI0NTMzLTQuMjMyMTMgNC4wMTY5MzYtNC4xMDA2MjMgMy45NDUyMDUtNC4wMDQ5ODFMMy4xODAwNzUtMy4wMzY2MTNMMi4yNDc1NzItNC4yNjc5OTVDMi4yMTE3MDYtNC4zMTU4MTYgMi4xMzk5NzUtNC40MjM0MTIgMi4xMzk5NzUtNC41MDcwOThDMi4xMzk5NzUtNC41Nzg4MjkgMi4xOTk3NTEtNC43OTQwMjIgMi41NTg0MDYtNC44MDU5NzhWLTUuMTUyNjc3QzIuMjU5NTI3LTUuMTI4NzY3IDEuNjQ5ODEzLTUuMTI4NzY3IDEuMzI3MDI0LTUuMTI4NzY3Qy45MzI1MDMtNS4xMjg3NjcgLjkwODU5My01LjEyODc2NyAuMTc5MzI4LTUuMTUyNjc3Vi00LjgwNTk3OEMuNzg5MDQxLTQuODA1OTc4IDEuMDE2MTg5LTQuNzgyMDY3IDEuMjY3MjQ4LTQuNDU5Mjc4TDIuNjY2MDAyLTIuNjMwMTM3QzIuNjg5OTEzLTIuNjA2MjI3IDIuNzM3NzMzLTIuNTM0NDk2IDIuNzM3NzMzLTIuNDk4NjNTMS44MDUyMy0xLjI5MTE1OCAxLjY4NTY3OS0xLjEzNTc0MUMxLjE1OTY1MS0uNDkwMTYyIC42MzM2MjQtLjM1ODY1NSAuMTE5NTUyLS4zNDY3VjBDLjU3Mzg0OC0uMDIzOTEgLjU5Nzc1OC0uMDIzOTEgMS4xMTE4MzEtLjAyMzkxQzEuNTY2MTI3LS4wMjM5MSAxLjU5MDAzNy0uMDIzOTEgMi4xODc3OTYgMFYtLjM0NjdDMS45MDA4NzItLjM4MjU2NSAxLjg1MzA1MS0uNTYxODkzIDEuODUzMDUxLS43MjkyNjVDMS44NTMwNTEtLjkyMDU0OCAxLjkzNjczNy0xLjAxNjE4OSAyLjA1NjI4OS0xLjE3MTYwNkMyLjIzNTYxNi0xLjQyMjY2NSAyLjYzMDEzNy0xLjkxMjgyNyAyLjkxNzA2MS0yLjI4MzQzN0wzLjg5NzM4NS0xLjAwNDIzNEM0LjEwMDYyMy0uNzQxMjIgNC4xMDA2MjMtLjcxNzMxIDQuMTAwNjIzLS42NDU1NzlDNC4xMDA2MjMtLjU0OTkzOCA0LjAwNDk4MS0uMzU4NjU1IDMuNjgyMTkyLS4zNDY3VjBDMy45OTMwMjYtLjAyMzkxIDQuNTc4ODI5LS4wMjM5MSA0LjkxMzU3NC0uMDIzOTFDNS4zMDgwOTUtLjAyMzkxIDUuMzMyMDA1LS4wMjM5MSA2LjA0OTMxNSAwVi0uMzQ2N0M1LjQxNTY5MS0uMzQ2NyA1LjIwMDQ5OC0uMzcwNjEgNC45MTM1NzQtLjc1MzE3NkwzLjM0NzQ0Ny0yLjgyMTQyWicvPgo8cGF0aCBpZD0nZzctNDknIGQ9J00yLjUwMjYxNS01LjA3Njk2MUMyLjUwMjYxNS01LjI5MjE1NCAyLjQ4NjY3NS01LjMwMDEyNSAyLjI3MTQ4Mi01LjMwMDEyNUMxLjk0NDcwNy00Ljk4MTMyIDEuNTIyMjkxLTQuNzkwMDM3IC43NjUxMzEtNC43OTAwMzdWLTQuNTI3MDI0Qy45ODAzMjQtNC41MjcwMjQgMS40MTA3MS00LjUyNzAyNCAxLjg3Mjk3Ni00Ljc0MjIxN1YtLjY1MzU0OUMxLjg3Mjk3Ni0uMzU4NjU1IDEuODQ5MDY2LS4yNjMwMTQgMS4wOTE5MDUtLjI2MzAxNEguODEyOTUxVjBDMS4xMzk3MjYtLjAyMzkxIDEuODI1MTU2LS4wMjM5MSAyLjE4MzgxMS0uMDIzOTFTMy4yMzU4NjYtLjAyMzkxIDMuNTYyNjQgMFYtLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNi0uMjYzMDE0IDIuNTAyNjE1LS4zNTg2NTUgMi41MDI2MTUtLjY1MzU0OVYtNS4wNzY5NjFaJy8+CjxwYXRoIGlkPSdnNy01OScgZD0nTTEuNjE3OTMzLTIuOTg4NzkyQzEuNjE3OTMzLTMuMjU5Nzc2IDEuNDAyNzQtMy40MzUxMTggMS4xNzk1NzctMy40MzUxMThDLjkwODU5My0zLjQzNTExOCAuNzMzMjUtMy4yMTk5MjUgLjczMzI1LTIuOTk2NzYyQy43MzMyNS0yLjcyNTc3OCAuOTQ4NDQzLTIuNTUwNDM2IDEuMTcxNjA2LTIuNTUwNDM2QzEuNDQyNTktMi41NTA0MzYgMS42MTc5MzMtMi43NjU2MjkgMS42MTc5MzMtMi45ODg3OTJaTTEuNDE4NjgtLjA2Mzc2MUMxLjQxODY4IC40NTQyOTYgMS4yNTEzMDggLjkxNjU2MyAuOTAwNjIzIDEuMzE1MDY4Qy44NTI4MDIgMS4zNzg4MjkgLjgzNjg2MiAxLjM4NjggLjgzNjg2MiAxLjQyNjY1Qy44MzY4NjIgMS40OTgzODEgLjkwODU5MyAxLjU0NjIwMiAuOTQ4NDQzIDEuNTQ2MjAyQzEuMDUyMDU1IDEuNTQ2MjAyIDEuNjQxODQzIC45MDA2MjMgMS42NDE4NDMtLjA0NzgyMUMxLjY0MTg0My0uMzEwODM0IDEuNjA5OTYzLS44ODQ2ODIgMS4xNzE2MDYtLjg4NDY4MkMuOTA4NTkzLS44ODQ2ODIgLjczMzI1LS42Nzc0NiAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjIwNzIyMyAuOTAwNjIzIDAgMS4xNzk1NzcgMEMxLjMxNTA2OCAwIDEuMzYyODg5LS4wMjM5MSAxLjQxODY4LS4wNjM3NjFaJy8+CjxwYXRoIGlkPSdnNy05MScgZD0nTTIuMTU5OSAxLjk5MjUyOFYxLjYyNTkwM0gxLjM1NDkxOVYtNS42MTA5NTlIMi4xNTk5Vi01Ljk3NzU4NEguOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonLz4KPHBhdGggaWQ9J2c3LTkzJyBkPSdNMS4zNTQ5MTktNS45Nzc1ODRILjE4MzMxM1YtNS42MTA5NTlILjk4ODI5NFYxLjYyNTkwM0guMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonLz4KPHBhdGggaWQ9J2c1LTI4JyBkPSdNMy40MzExMzMtNC41MDcwOThINS40MTU2OTFDNS41NzExMDgtNC41MDcwOTggNS45NjU2MjktNC41MDcwOTggNS45NjU2MjktNC44ODk2NjRDNS45NjU2MjktNS4xNTI2NzcgNS43Mzg0ODEtNS4xNTI2NzcgNS41MjMyODgtNS4xNTI2NzdIMi4yMzU2MTZDMS45NjA2NDgtNS4xNTI2NzcgMS41NTQxNzItNS4xNTI2NzcgMS4wMDQyMzQtNC41NjY4NzRDLjY5MzQtNC4yMjAxNzQgLjMxMDgzNC0zLjU4NjU1IC4zMTA4MzQtMy41MTQ4MTlTLjM3MDYxLTMuNDE5MTc4IC40NDIzNDEtMy40MTkxNzhDLjUyNjAyNy0zLjQxOTE3OCAuNTM3OTgzLTMuNDU1MDQ0IC41OTc3NTgtMy41MjY3NzVDMS4yMTk0MjctNC41MDcwOTggMS44NDEwOTYtNC41MDcwOTggMi4xMzk5NzUtNC41MDcwOThIMy4xMzIyNTRMMS44ODg5MTctLjQwNjQ3NkMxLjgyOTE0MS0uMjI3MTQ4IDEuODI5MTQxLS4yMDMyMzggMS44MjkxNDEtLjE2NzM3MkMxLjgyOTE0MS0uMDM1ODY2IDEuOTEyODI3IC4xMzE1MDcgMi4xNTE5MyAuMTMxNTA3QzIuNTIyNTQgLjEzMTUwNyAyLjU4MjMxNi0uMTkxMjgzIDIuNjE4MTgyLS4zNzA2MUwzLjQzMTEzMy00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c1LTU4JyBkPSdNMi4xOTk3NTEtLjU3Mzg0OEMyLjE5OTc1MS0uOTIwNTQ4IDEuOTEyODI3LTEuMTU5NjUxIDEuNjI1OTAzLTEuMTU5NjUxQzEuMjc5MjAzLTEuMTU5NjUxIDEuMDQwMS0uODcyNzI3IDEuMDQwMS0uNTg1ODAzQzEuMDQwMS0uMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxLS4yODY5MjQgMi4xOTk3NTEtLjU3Mzg0OFonLz4KPHBhdGggaWQ9J2cxLTk4JyBkPSdNMy4zMTE1ODItOC4xODkyOUw2LjU2MzM4Ny02LjcxODgwNEw2LjcwNjg0OS02Ljk4MTgxOEwzLjMyMzUzNy04Ljg5NDY0NUwtLjA1OTc3Ni02Ljk4MTgxOEwuMDcxNzMxLTYuNzE4ODA0TDMuMzExNTgyLTguMTg5MjlaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc2NS4zNzY5MzcnIHk9Jy0xMS4xNTgxNjknIHhsaW5rOmhyZWY9JyNnMS05OCcvPgo8dXNlIHg9JzY1LjE2MzE4NScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c1LTI4Jy8+Cjx1c2UgeD0nNzQuOTAyOTUyJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtNjEnLz4KPHVzZSB4PSc4Ny4zMjg0MzMnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC05NycvPgo8dXNlIHg9JzkzLjE4MTQyMycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTExNCcvPgo8dXNlIHg9Jzk3LjczMzc0OScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTEwMycvPgo8dXNlIHg9JzEyMC41OTQ1ODQnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC0xMDknLz4KPHVzZSB4PScxMzAuMzQ5NTY4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtOTcnLz4KPHVzZSB4PScxMzYuMjAyNTU4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtMTIwJy8+Cjx1c2UgeD0nMTA1Ljc0MTgyJyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNC0yOCcvPgo8dXNlIHg9JzExMC40MjAxNjgnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2cyLTUwJy8+Cjx1c2UgeD0nMTE2LjA2NTc0NScgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzctOTEnLz4KPHVzZSB4PScxMTguNDE4MDY5JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNC0yOCcvPgo8dXNlIHg9JzEyMi4xNzYyNTQnIHk9Jy0xLjg5Njg0OCcgeGxpbms6aHJlZj0nI2c2LTEwOScvPgo8dXNlIHg9JzEyOC4xNTM3NzUnIHk9Jy0xLjg5Njg0OCcgeGxpbms6aHJlZj0nI2c2LTEwNScvPgo8dXNlIHg9JzEzMC4yNTY5NzQnIHk9Jy0xLjg5Njg0OCcgeGxpbms6aHJlZj0nI2c2LTExMCcvPgo8dXNlIHg9JzEzNC43OTU0NTEnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c3LTU5Jy8+Cjx1c2UgeD0nMTM3LjE0Nzc3NScgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzQtMjgnLz4KPHVzZSB4PScxNDAuOTA1OTU5JyB5PSctMi4xOTE3NzgnIHhsaW5rOmhyZWY9JyNnNi0xMDknLz4KPHVzZSB4PScxNDYuODgzNDgxJyB5PSctMi4xOTE3NzgnIHhsaW5rOmhyZWY9JyNnNi05NycvPgo8dXNlIHg9JzE1MC41MzY0MDYnIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c2LTEyMCcvPgo8dXNlIHg9JzE1NC44ODExNTYnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c3LTkzJy8+Cjx1c2UgeD0nMTU5LjIyNTk3NycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2czLTc4Jy8+Cjx1c2UgeD0nMTcwLjc5Njc4NycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTc1LjM0OTExMycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cwLTg5Jy8+Cjx1c2UgeD0nMTg2LjQ2OTAwNCcgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c0LTExMScvPgo8dXNlIHg9JzE5MC41NjIwNTMnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNC05OCcvPgo8dXNlIHg9JzE5NC4xODQ2MzgnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNC0xMTUnLz4KPHVzZSB4PScxOTguNTk4Njg4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzMtMTA2Jy8+Cjx1c2UgeD0nMjAxLjkxOTU3OCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cwLTIyJy8+Cjx1c2UgeD0nMjEwLjM4MjI1OScgeT0nLTguMzM1NDExJyB4bGluazpocmVmPScjZzQtMTEwJy8+Cjx1c2UgeD0nMjE2LjAxODU5MycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMjIwLjU3MDkxOScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c1LTI4Jy8+Cjx1c2UgeD0nMjI2Ljk4OTg2JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScyMzEuNTQyMTg2JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PScyNDMuNzk2MTYnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC01OScvPgo8dXNlIHg9JzI0OS4wNDAzMTknIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNS0yOCcvPgo8dXNlIHg9JzI1NS40NTkyNicgeT0nLTE2LjA5NDM0JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzI2Mi4wNDU3NjcnIHk9Jy0xNi4wOTQzNCcgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nMjY2Ljc3ODA4MicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cwLTczJy8+Cjx1c2UgeD0nMjczLjgxODMxNicgeT0nLTkuMzY0ODkxJyB4bGluazpocmVmPScjZzQtMTEwJy8+Cjx1c2UgeD0nMjgyLjExMTMxNCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMjkzLjg3MjYyOScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cwLTgxJy8+Cjx1c2UgeD0nMzA0LjI1Njk2NycgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PSczMTAuODQzNDczJyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PSczMTUuNTc1Nzg4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSczMjAuMTI4MTE0JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzUtNTgnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
The optimal value of is then given by:

def mu_n(tau):
x = ot.Point(initial_state)
x[p] = tau
# trick: posterior conditional mean is computed by the link function
return py_link_function_theta(x)[:p]
# optimization criterion
def log_cond_tau_post(tau):
x = ot.Point(initial_state)
x[p] = tau
# replace theta by its conditional posterior mean
x[:p] = py_link_function_theta(x)[:p]
# compute log conditional posterior of tau
ll = py_log_density(x)[0]
return ll
1D optimization
def func(X):
return [-log_cond_tau_post(X[0])]
problem = ot.OptimizationProblem(ot.PythonFunction(1, 1, func))
problem.setBounds(ot.Interval([1e-4], [1e4]))
solver = ot.TNC(problem)
solver.setStartingPoint([1.0])
solver.run()
tauhat = solver.getResult().getOptimalPoint()[0]
print("tauhat =", tauhat)
# inject result in initialState vector
x = ot.Point(initial_state)
x[:p] = mu_n(tauhat)
x[p] = tauhat
tauhat = 0.10077295009614318
Final step : create a MetropolisHastings object for each block
initialState = x
mi_Y = [i for i in range(p + 1, p + 1 + n)]
link_function_y = ot.PythonFunction(len(x), 4 * n, py_link_function_y)
rvmh_Y = ot.RandomVectorMetropolisHastings(RV_Y, initialState, mi_Y, link_function_y)
mi_theta = [i for i in range(p)]
link_function_theta = ot.PythonFunction(len(x), p + (p + 2) * p, py_link_function_theta)
rvmh_theta = ot.RandomVectorMetropolisHastings(
RV_theta, initialState, mi_theta, link_function_theta
)
log_pdf_tau = ot.PythonFunction(len(x), 1, py_log_density)
rwmh_tau = ot.RandomWalkMetropolisHastings(
log_pdf_tau, support, initialState, proposal_tau, [p]
)
# Now, assemble the blocks to create a Gibbs algorithm:
gibbs = ot.Gibbs([rvmh_Y, rvmh_theta, rwmh_tau])
Launch Algorithm
sampleSize = 1000
# Joint posterior density sample
sample = gibbs.getSample(sampleSize)
# compute acceptance rate
tau_post = np.array(sample[:, p]).ravel()
acc_rate = (tau_post[1:] != tau_post[:-1]).mean()
print("Acceptance rate: %s" % acc_rate)
Acceptance rate: 0.32732732732732733
Plot posterior distribution marginals
# extract interest parameters
post_sample = sample.getMarginal([i for i in range(p + 1)])
post_sample.setDescription(["$\\theta_0$", "$\\theta_1$", "$\\tau$"])
posterior = ot.KernelSmoothing().build(post_sample)
posterior = ot.TruncatedDistribution(posterior, prior.getRange())
grid = ot.GridLayout(1, 3)
grid.setTitle("Bayesian inference")
xlabs = [r"$\theta_0$", r"$\theta_1$", r"$\tau$"]
p_true = [theta_true[0][0], theta_true[1][0], tau_true]
for parameter_index in range(3):
graph = posterior.getMarginal(parameter_index).drawPDF()
bbox = graph.getBoundingBox()
bound = bbox.getUpperBound()[1]
prior_pdf = prior.getMarginal(parameter_index).drawPDF()
graph.add(prior_pdf)
curve_true = ot.Curve([p_true[parameter_index]] * 2, [0.0, bound])
graph.add(curve_true)
graph.setColors(ot.Drawable.BuildDefaultPalette(3))
graph.setLegends(["Posterior", "Prior", "True value"])
graph.setXTitle(xlabs[parameter_index])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
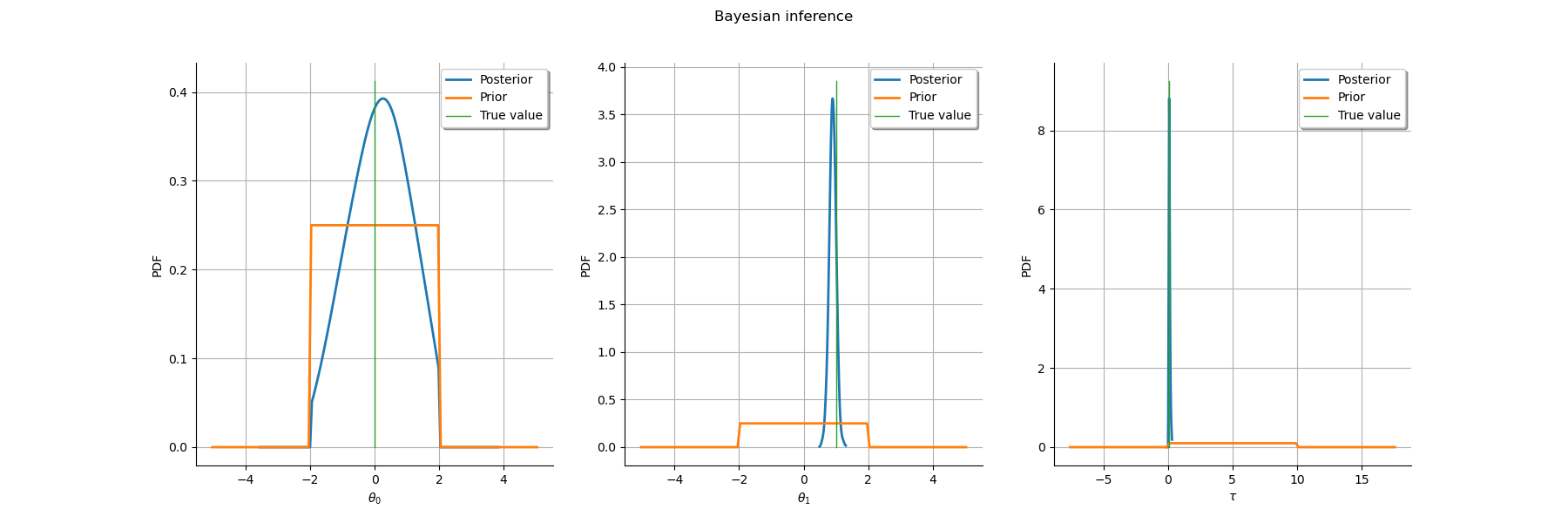
Draw pairplots of the posterior sample.
# sphinx_gallery_thumbnail_number = 3
grid = ot.VisualTest.DrawPairs(post_sample)
graph = grid.getGraph(0, 0)
pt = ot.Cloud(theta_true.T, "#2ca02c", "circle", "True value")
graph.add(pt)
grid.setGraph(0, 0, graph)
graph = grid.getGraph(1, 0)
pt = ot.Cloud([[theta_true[0, 0], tau_true]], "#2ca02c", "circle", "True value")
graph.add(pt)
grid.setGraph(1, 0, graph)
graph = grid.getGraph(1, 1)
pt = ot.Cloud([[theta_true[1, 0], tau_true]], "#2ca02c", "circle", "True value")
graph.add(pt)
grid.setGraph(1, 1, graph)
_ = View(grid)
View.ShowAll()