Note
Go to the end to download the full example code.
Bandwidth sensitivity in kernel smoothing¶
Introduction¶
When we have a sample, we may estimate the probability density function of the underlying distribution using kernel smoothing. One of the parameters of this method is the bandwidth, which can be either set by the user, or estimated from the data. This is especially true when the density is multimodal. In this example, we consider a bimodal distribution and see how the bandwidth can change the estimated probability density function.
We consider the distribution:

for any  where
where  is the density of the Normal distribution
is the density of the Normal distribution
 ,
,  is the density of the Normal distribution
is the density of the Normal distribution
 and the weights are
and the weights are  and
and  .
.
This is a mixture of two Normal distributions: 1/4th of the observations have the
distribution and 3/4th of the observations have the distribution.
This example is considered in (Wand, Jones, 1994), page 14, Figure 2.3.
We consider a sample generated from independent realizations of  and
want to approximate the distribution from kernel smoothing.
More precisely, we want to observe the sensitivity of the resulting density to the
bandwidth.
and
want to approximate the distribution from kernel smoothing.
More precisely, we want to observe the sensitivity of the resulting density to the
bandwidth.
References¶
“Kernel Smoothing”, M.P.Wand, M.C.Jones. Chapman and Hall / CRC (1994).
Generate the mixture by merging two samples¶
In this section, we show that a mixture of two Normal distributions is
nothing more than the merged sample of two independent Normal distributions.
In order to generate a sample with size  , we sample
, we sample
 points from the first Normal distribution
and
points from the first Normal distribution
and  points from the second Normal
distribution . Then we merge the two samples.
points from the second Normal
distribution . Then we merge the two samples.
import openturns as ot
import openturns.viewer as otv
We choose a rather large sample size:  .
.
n = 1000
Then we define the two Normal distributions and their parameters.
w1 = 0.75
w2 = 1.0 - w1
distribution1 = ot.Normal(0.0, 1.0)
distribution2 = ot.Normal(1.5, 1.0 / 3.0)
We generate two independent sub-samples from the two Normal distributions.
sample1 = distribution1.getSample(int(w1 * n))
sample2 = distribution2.getSample(int(w2 * n))
Then we merge the sub-samples into a larger one with the add method of the Sample class.
sample = ot.Sample(sample1)
sample.add(sample2)
sample.getSize()
1000
In order to see the result, we build a kernel smoothing approximation on the sample. In order to keep it simple, let us use the default bandwidth selection rule.
factory = ot.KernelSmoothing()
fit = factory.build(sample)
graph = fit.drawPDF()
view = otv.View(graph)
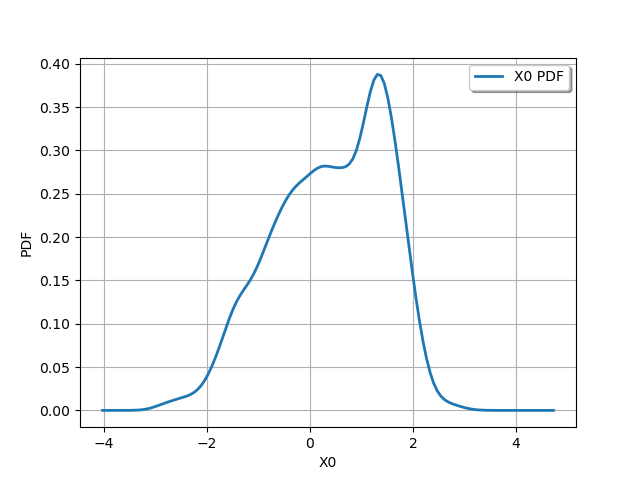
We see that the distribution of the merged sample has two modes. However, these modes are not clearly distinct. To distinguish them, we could increase the sample size. However, it might be interesting to see if the bandwidth selection rule can be better chosen: this is the purpose of the next section.
Simulation based on a mixture¶
Since the distribution that we approximate is a mixture, it will be more convenient to create it from the Mixture class. It takes as input argument a list of distributions and a list of weights.
distribution = ot.Mixture([distribution1, distribution2], [w1, w2])
Then we generate a sample from it.
sample = distribution.getSample(n)
factory = ot.KernelSmoothing()
fit = factory.build(sample)
factory.getBandwidth()
We see that the default bandwidth is close to 0.17.
graph = distribution.drawPDF()
curve = fit.drawPDF()
graph.add(curve)
graph.setColors(["dodgerblue3", "darkorange1"])
graph.setLegends(["Mixture", "Kernel smoothing"])
graph.setLegendPosition("upper left")
view = otv.View(graph)
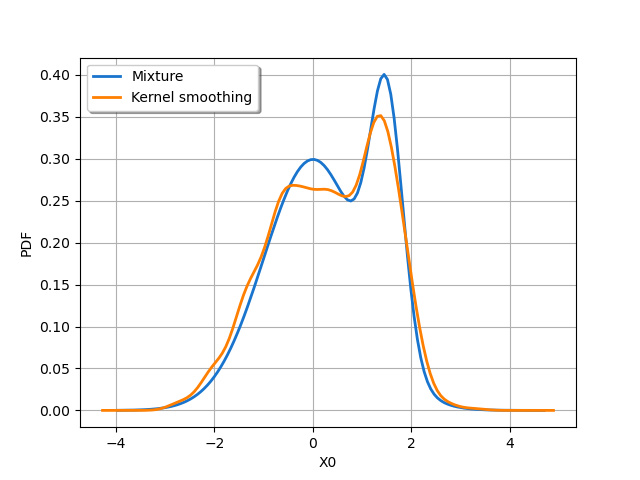
We see that the result of the kernel smoothing approximation of the mixture is similar to the previous one and could be improved.
Sensitivity to the bandwidth¶
In this section, we observe the sensitivity of the kernel smoothing to the bandwidth. We consider the three following bandwidths: the small bandwidth 0.05, the large bandwidth 0.54 and 0.18 which is in-between. For each bandwidth, we use the second optional argument of the build method in order to select a specific bandwidth value.
hArray = [0.05, 0.54, 0.18]
nLen = len(hArray)
grid = ot.GridLayout(1, len(hArray))
index = 0
for i in range(nLen):
fit = factory.build(sample, [hArray[i]])
graph = fit.drawPDF()
exact = distribution.drawPDF()
curve = exact.getDrawable(0)
curve.setLegend("Mixture")
curve.setLineStyle("dashed")
graph.add(curve)
graph.setXTitle("X")
graph.setTitle("h=%.4f" % (hArray[i]))
graph.setLegends([""])
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
bounding_box = graph.getBoundingBox()
upper_bound = bounding_box.getUpperBound()
upper_bound[1] = 0.5 # Common y-range
graph.setBoundingBox(bounding_box)
grid.setGraph(0, index, graph)
index += 1
view = otv.View(grid, figure_kw={"figsize": (10.0, 4.0)})
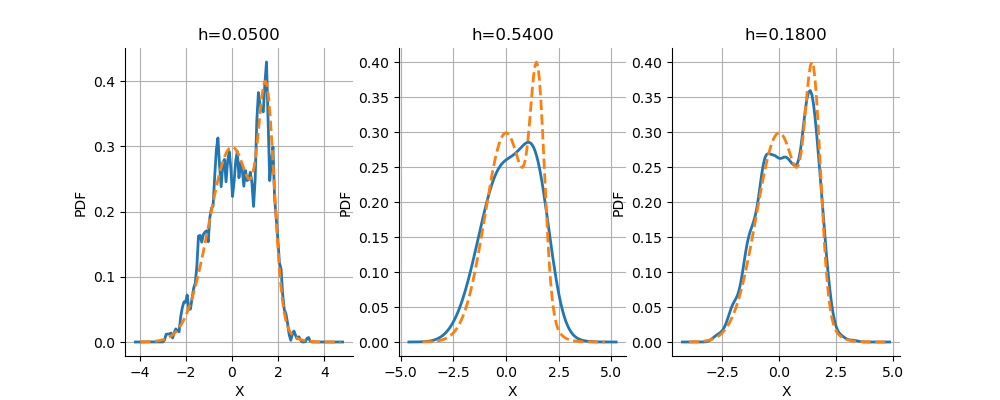
We see that when the bandwidth is too small, the resulting kernel smoothing has many more modes than the distribution it is supposed to approximate. When the bandwidth is too large, the approximated distribution is too smooth and has only one mode instead of the expected two modes which are in the mixture distribution. When the bandwidth is equal to 0.18, the two modes are correctly represented.
Sensitivity to the bandwidth rule¶
The library provides three different rules to compute the bandwidth. In this section, we compare the results that we can get with them.
h1 = factory.computeSilvermanBandwidth(sample)[0]
h1
0.3445636453391276
h2 = factory.computePluginBandwidth(sample)[0]
h2
0.2021709523195656
h3 = factory.computeMixedBandwidth(sample)[0]
h3
0.20851397168332242
factory.getBandwidth()[0]
0.18
We see that the default rule is the “Mixed” rule. This is because the sample is in dimension 1 and the sample size is quite large. For a small sample in 1 dimension, the “Plugin” rule would have been used.
The following script compares the results produced by the three rules.
hArray = [h1, h2, h3]
legends = ["Silverman", "Plugin", "Mixed"]
nLen = len(hArray)
grid = ot.GridLayout(1, len(hArray))
index = 0
for i in range(nLen):
fit = factory.build(sample, [hArray[i]])
graph = fit.drawPDF()
exact = distribution.drawPDF()
curve = exact.getDrawable(0)
curve.setLegend("Mixture")
curve.setLineStyle("dashed")
graph.add(curve)
graph.setLegends([""])
graph.setTitle("h=%.4f, %s" % (hArray[i], legends[i]))
graph.setXTitle("X")
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
if i > 0:
graph.setYTitle("")
bounding_box = graph.getBoundingBox()
upper_bound = bounding_box.getUpperBound()
upper_bound[1] = 0.5 # Common y-range
graph.setBoundingBox(bounding_box)
grid.setGraph(0, index, graph)
index += 1
view = otv.View(grid, figure_kw={"figsize": (10.0, 4.0)})
otv.View.ShowAll()
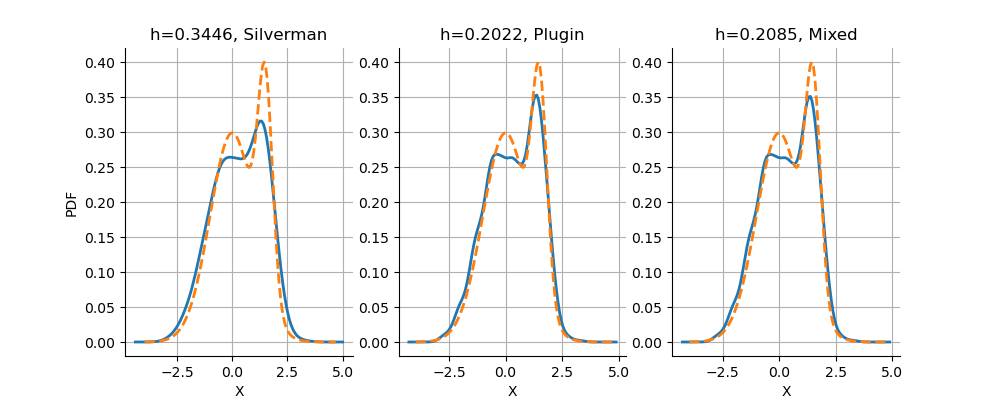
We see that the bandwidth produced by Silverman’s rule is too large, leading to an oversmoothed distribution. The results produced by the Plugin and Mixed rules are comparable in this case.