Maximum Likelihood Principle¶
This method deals with the parametric modeling of a probability
distribution for a random vector
 . The appropriate
probability distribution is found by using a sample of data
. The appropriate
probability distribution is found by using a sample of data
 . Such an approach
can be described in two steps as follows:
. Such an approach
can be described in two steps as follows:
Choose a probability distribution (e.g. the Normal distribution, or any other distribution available),
Find the parameter values
 that characterize the
probability distribution (e.g. the mean and standard deviation for
the Normal distribution) which best describes the sample
.
that characterize the
probability distribution (e.g. the mean and standard deviation for
the Normal distribution) which best describes the sample
.
The maximum likelihood method is used for the second step.
This method is restricted to the
case where  and continuous probability distributions.
Please note therefore that
and continuous probability distributions.
Please note therefore that  in the following
text. The maximum likelihood estimate (MLE) of is
defined as the value of which maximizes the
likelihood function
in the following
text. The maximum likelihood estimate (MLE) of is
defined as the value of which maximizes the
likelihood function  :
:

Given that  is a sample of
independent identically distributed (i.i.d) observations,
is a sample of
independent identically distributed (i.i.d) observations,
 represents the
probability of observing such a sample assuming that they are taken from
a probability distribution with parameters . In
concrete terms, the likelihood
is calculated as
follows:
represents the
probability of observing such a sample assuming that they are taken from
a probability distribution with parameters . In
concrete terms, the likelihood
is calculated as
follows:

if the distribution is continuous, with density
 .
.
For example, if we suppose that  is a Gaussian distribution
with parameters
is a Gaussian distribution
with parameters  (i.e. the mean
and standard deviation),
(i.e. the mean
and standard deviation),
![\begin{aligned}
L\left(x_1,\ldots, x_N, \vect{\theta}\right) &=& \prod_{j=1}^{N} \frac{1}{\sigma \sqrt{2\pi}} \exp \left[ -\frac{1}{2} \left( \frac{x_j-\mu}{\sigma} \right)^2 \right] \\
&=& \frac{1}{\sigma^N (2\pi)^{N/2}} \exp \left[ -\frac{1}{2\sigma^2} \sum_{j=1}^N \left( x_j-\mu \right)^2 \right]
\end{aligned}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyOTQuNDcxNjA2cHQnIGhlaWdodD0nNzguNDYxMzMycHQnIHZpZXdCb3g9JzQ3LjAzNTY4MyAtNzkuNjU2ODQ2IDI5NC40NzE2MDYgNzguNDYxMzMyJz4KPGRlZnM+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cyLTExMicgZD0nTTQuNjUwNTYgMTAuMjIxNjY5TDIuNTQ2NDUxIDUuNTcxMTA4QzIuNDYyNzY1IDUuMzc5ODI2IDIuNDAyOTg5IDUuMzc5ODI2IDIuMzY3MTIzIDUuMzc5ODI2QzIuMzU1MTY4IDUuMzc5ODI2IDIuMjk1MzkyIDUuMzc5ODI2IDIuMTYzODg1IDUuNDc1NDY3TDEuMDI4MTQ0IDYuMzM2MjM5Qy44NzI3MjcgNi40NTU3OTEgLjg3MjcyNyA2LjQ5MTY1NiAuODcyNzI3IDYuNTI3NTIyQy44NzI3MjcgNi41ODcyOTggLjkwODU5MyA2LjY1OTAyOSAuOTkyMjc5IDYuNjU5MDI5QzEuMDY0MDEgNi42NTkwMjkgMS4yNjcyNDggNi40OTE2NTYgMS4zOTg3NTUgNi4zOTYwMTVDMS40NzA0ODYgNi4zMzYyMzkgMS42NDk4MTMgNi4yMDQ3MzIgMS43ODEzMiA2LjEwOTA5MUw0LjEzNjQ4OCAxMS4yODU2NzlDNC4yMjAxNzQgMTEuNDc2OTYxIDQuMjc5OTUgMTEuNDc2OTYxIDQuMzg3NTQ3IDExLjQ3Njk2MUM0LjU2Njg3NCAxMS40NzY5NjEgNC42MDI3NCAxMS40MDUyMyA0LjY4NjQyNiAxMS4yMzc4NThMMTAuMTE0MDcyIDBDMTAuMTk3NzU4LS4xNjczNzIgMTAuMTk3NzU4LS4yMTUxOTMgMTAuMTk3NzU4LS4yMzkxMDNDMTAuMTk3NzU4LS4zNTg2NTUgMTAuMTAyMTE3LS40NzgyMDcgOS45NTg2NTUtLjQ3ODIwN0M5Ljg2MzAxNC0uNDc4MjA3IDkuNzc5MzI4LS40MTg0MzEgOS42ODM2ODYtLjIyNzE0OEw0LjY1MDU2IDEwLjIyMTY2OVonLz4KPHBhdGggaWQ9J2cxLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cxLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzEtMzQnIGQ9J00zLjI4NzY3MSAzNS4zNzUzNDJINi44MjY0MDFWMzQuNjM0MTIySDQuMDI4ODkyVi4yNjMwMTRINi44MjY0MDFWLS40NzgyMDdIMy4yODc2NzFWMzUuMzc1MzQyWicvPgo8cGF0aCBpZD0nZzEtMzUnIGQ9J00yLjkyOTAxNiAzNC42MzQxMjJILjEzMTUwN1YzNS4zNzUzNDJIMy42NzAyMzdWLS40NzgyMDdILjEzMTUwN1YuMjYzMDE0SDIuOTI5MDE2VjM0LjYzNDEyMlonLz4KPHBhdGggaWQ9J2cxLTg4JyBkPSdNMTUuMTM1MjQzIDE2LjczNzIzNUwxNi41ODE4MTggMTIuOTExNTgySDE2LjI4MjkzOUMxNS44MTY2ODcgMTQuMTU0OTE5IDE0LjU0OTQ0IDE0Ljk2Nzg3IDEzLjE3NDU5NSAxNS4zMjY1MjZDMTIuOTIzNTM3IDE1LjM4NjMwMSAxMS43NTE5MyAxNS42OTcxMzYgOS40NTY1MzggMTUuNjk3MTM2SDIuMjQ3NTcyTDguMzMyNzUyIDguNTU5OUM4LjQxNjQzOCA4LjQ2NDI1OSA4LjQ0MDM0OSA4LjQyODM5NCA4LjQ0MDM0OSA4LjM2ODYxOEM4LjQ0MDM0OSA4LjM0NDcwNyA4LjQ0MDM0OSA4LjMwODg0MiA4LjM1NjY2MyA4LjE4OTI5TDIuNzg1NTU0IC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IC41NzM4NDggMTIuMDI2ODk5IC43NDEyMiAxMi4xMzQ0OTYgLjc2NTEzMUMxMi43ODAwNzUgLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0Qy43MjkyNjUgMCAuNzE3MzEgLjAxMTk1NSAuNjgxNDQ1IC4wODM2ODZDLjY2OTQ4OSAuMTE5NTUyIC42Njk0ODkgLjM0NjcgLjY2OTQ4OSAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TC44MDA5OTYgMTYuMzkwNTM1Qy42ODE0NDUgMTYuNTMzOTk4IC42ODE0NDUgMTYuNTkzNzczIC42ODE0NDUgMTYuNjA1NzI5Qy42ODE0NDUgMTYuNzM3MjM1IC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJy8+CjxwYXRoIGlkPSdnMS04OScgZD0nTTE0LjU5NzI2IDE2LjczNzIzNVYxNi4wOTE2NTZDMTMuMDA3MjIzIDE2LjA5MTY1NiAxMi42MzY2MTMgMTUuNTQxNzE5IDEyLjYzNjYxMyAxNC43NzY1ODhWMS45NjA2NDhDMTIuNjM2NjEzIDEuMTgzNTYyIDEzLjAxOTE3OCAuNjQ1NTc5IDE0LjU5NzI2IC42NDU1NzlWMEguNjY5NDg5Vi42NDU1NzlDMi4yNTk1MjcgLjY0NTU3OSAyLjYzMDEzNyAxLjE5NTUxNyAyLjYzMDEzNyAxLjk2MDY0OFYxNC43NzY1ODhDMi42MzAxMzcgMTUuNTUzNjc0IDIuMjQ3NTcyIDE2LjA5MTY1NiAuNjY5NDg5IDE2LjA5MTY1NlYxNi43MzcyMzVINi40MTk5MjVWMTYuMDkxNjU2QzQuODI5ODg4IDE2LjA5MTY1NiA0LjQ1OTI3OCAxNS41NDE3MTkgNC40NTkyNzggMTQuNzc2NTg4Vi42NDU1NzlIMTAuODA3NDcyVjE0Ljc3NjU4OEMxMC44MDc0NzIgMTUuNTUzNjc0IDEwLjQyNDkwNyAxNi4wOTE2NTYgOC44NDY4MjQgMTYuMDkxNjU2VjE2LjczNzIzNUgxNC41OTcyNlonLz4KPHBhdGggaWQ9J2czLTYxJyBkPSdNMy43MDYxMDItNS42NDI4MzlDMy43NTM5MjMtNS43NTQ0MjEgMy43NTM5MjMtNS43NzAzNjEgMy43NTM5MjMtNS43OTQyNzFDMy43NTM5MjMtNS44OTc4ODMgMy42NzQyMjItNS45Nzc1ODQgMy41NzA2MS01Ljk3NzU4NEMzLjQ0MzA4OC01Ljk3NzU4NCAzLjQxMTIwOC01Ljg4MTk0MyAzLjM3OTMyOC01LjgwMjI0MkwuNTE4MDU3IDEuNjU3NzgzQy40NzAyMzcgMS43NjkzNjUgLjQ3MDIzNyAxLjc4NTMwNSAuNDcwMjM3IDEuODA5MjE1Qy40NzAyMzcgMS45MTI4MjcgLjU0OTkzOCAxLjk5MjUyOCAuNjUzNTQ5IDEuOTkyNTI4Qy43ODEwNzEgMS45OTI1MjggLjgxMjk1MSAxLjg5Njg4NyAuODQ0ODMyIDEuODE3MTg2TDMuNzA2MTAyLTUuNjQyODM5WicvPgo8cGF0aCBpZD0nZzMtNzgnIGQ9J002LjMxMjMyOS00LjU3NDg0NEM2LjQwNzk3LTQuOTY1MzggNi41ODMzMTMtNS4xNTY2NjMgNy4xNTcxNjEtNS4xODA1NzNDNy4yMzY4NjItNS4xODA1NzMgNy4zMDA2MjMtNS4yMjgzOTQgNy4zMDA2MjMtNS4zMzIwMDVDNy4zMDA2MjMtNS4zNzk4MjYgNy4yNjA3NzItNS40NDM1ODcgNy4xODEwNzEtNS40NDM1ODdDNy4xMjUyOC01LjQ0MzU4NyA2Ljk3Mzg0OC01LjQxOTY3NiA2LjM4NDA2LTUuNDE5Njc2QzUuNzQ2NDUxLTUuNDE5Njc2IDUuNjQyODM5LTUuNDQzNTg3IDUuNTcxMTA4LTUuNDQzNTg3QzUuNDQzNTg3LTUuNDQzNTg3IDUuNDE5Njc2LTUuMzU1OTE1IDUuNDE5Njc2LTUuMjkyMTU0QzUuNDE5Njc2LTUuMTg4NTQzIDUuNTIzMjg4LTUuMTgwNTczIDUuNTk1MDE5LTUuMTgwNTczQzYuMDgxMTk2LTUuMTY0NjMzIDYuMDgxMTk2LTQuOTQ5NDQgNi4wODExOTYtNC44Mzc4NThDNi4wODExOTYtNC43OTgwMDcgNi4wODExOTYtNC43NTgxNTcgNi4wNDkzMTUtNC42MzA2MzVMNS4xNzI2MDMtMS4xMzk3MjZMMy4yNTE4MDYtNS4zMDAxMjVDMy4xODgwNDUtNS40NDM1ODcgMy4xNzIxMDUtNS40NDM1ODcgMi45ODA4MjItNS40NDM1ODdIMS45NDQ3MDdDMS44MDEyNDUtNS40NDM1ODcgMS42OTc2MzQtNS40NDM1ODcgMS42OTc2MzQtNS4yOTIxNTRDMS42OTc2MzQtNS4xODA1NzMgMS43OTMyNzUtNS4xODA1NzMgMS45NjA2NDgtNS4xODA1NzNDMi4wMjQ0MDgtNS4xODA1NzMgMi4yNjM1MTItNS4xODA1NzMgMi40NDY4MjQtNS4xMzI3NTJMMS4zNzg4MjktLjg1MjgwMkMxLjI4MzE4OC0uNDU0Mjk2IDEuMDc1OTY1LS4yNzg5NTQgLjU0MTk2OC0uMjYzMDE0Qy40OTQxNDctLjI2MzAxNCAuMzk4NTA2LS4yNTUwNDQgLjM5ODUwNi0uMTExNTgyQy4zOTg1MDYtLjA2Mzc2MSAuNDM4MzU2IDAgLjUxODA1NyAwQy41NDk5MzggMCAuNzMzMjUtLjAyMzkxIDEuMzA3MDk4LS4wMjM5MUMxLjkzNjczNy0uMDIzOTEgMi4wNTYyODkgMCAyLjEyODAyIDBDMi4xNTk5IDAgMi4yNzk0NTIgMCAyLjI3OTQ1Mi0uMTUxNDMyQzIuMjc5NDUyLS4yNDcwNzMgMi4xOTE3ODEtLjI2MzAxNCAyLjEzNTk5LS4yNjMwMTRDMS44NDkwNjYtLjI3MDk4NCAxLjYwOTk2My0uMzE4ODA0IDEuNjA5OTYzLS41OTc3NThDMS42MDk5NjMtLjYzNzYwOSAxLjYzMzg3My0uNzQ5MTkxIDEuNjMzODczLS43NTcxNjFMMi42Nzc5NTgtNC45MTc1NTlIMi42ODU5MjhMNC45MDE2MTktLjE0MzQ2MkM0Ljk1NzQxLS4wMTU5NCA0Ljk2NTM4IDAgNS4wNTMwNTEgMEM1LjE2NDYzMyAwIDUuMTcyNjAzLS4wMzE4OCA1LjIwNDQ4My0uMTY3MzcyTDYuMzEyMzI5LTQuNTc0ODQ0WicvPgo8cGF0aCBpZD0nZzMtMTA2JyBkPSdNMy4yOTE2NTYtNC45NzMzNUMzLjI5MTY1Ni01LjEyNDc4MiAzLjE3MjEwNS01LjI3NjIxNCAyLjk4MDgyMi01LjI3NjIxNEMyLjc0MTcxOS01LjI3NjIxNCAyLjUzNDQ5Ni01LjA1MzA1MSAyLjUzNDQ5Ni00Ljg0NTgyOEMyLjUzNDQ5Ni00LjY5NDM5NiAyLjY1NDA0Ny00LjU0Mjk2NCAyLjg0NTMzLTQuNTQyOTY0QzMuMDg0NDMzLTQuNTQyOTY0IDMuMjkxNjU2LTQuNzY2MTI3IDMuMjkxNjU2LTQuOTczMzVaTTEuNjI1OTAzIC4zOTg1MDZDMS41MDYzNTEgLjg4NDY4MiAxLjExNTgxNiAxLjQwMjc0IC42Mjk2MzkgMS40MDI3NEMuNTAyMTE3IDEuNDAyNzQgLjM4MjU2NSAxLjM3MDg1OSAuMzY2NjI1IDEuMzYyODg5Qy42MTM2OTkgMS4yNDMzMzcgLjY0NTU3OSAxLjAyODE0NCAuNjQ1NTc5IC45NTY0MTNDLjY0NTU3OSAuNzY1MTMxIC41MDIxMTcgLjY2MTUxOSAuMzM0NzQ1IC42NjE1MTlDLjEwMzYxMSAuNjYxNTE5LS4xMTE1ODIgLjg2MDc3Mi0uMTExNTgyIDEuMTIzNzg2Qy0uMTExNTgyIDEuNDI2NjUgLjE4MzMxMyAxLjYyNTkwMyAuNjM3NjA5IDEuNjI1OTAzQzEuMTIzNzg2IDEuNjI1OTAzIDIuMDAwNDk4IDEuMzIzMDM5IDIuMjM5NjAxIC4zNjY2MjVMMi45NTY5MTItMi40ODY2NzVDMi45ODA4MjItMi41ODIzMTYgMi45OTY3NjItMi42NDYwNzcgMi45OTY3NjItMi43NjU2MjlDMi45OTY3NjItMy4yMDM5ODUgMi42NDYwNzctMy41MTQ4MTkgMi4xODM4MTEtMy41MTQ4MTlDMS4zMzg5NzktMy41MTQ4MTkgLjg0NDgzMi0yLjM5OTAwNCAuODQ0ODMyLTIuMjk1MzkyQy44NDQ4MzItMi4yMjM2NjEgLjkwMDYyMy0yLjE5MTc4MSAuOTY0Mzg0LTIuMTkxNzgxQzEuMDUyMDU1LTIuMTkxNzgxIDEuMDYwMDI1LTIuMjE1NjkxIDEuMTE1ODE2LTIuMzM1MjQzQzEuMzU0OTE5LTIuODg1MTgxIDEuNzYxMzk1LTMuMjkxNjU2IDIuMTU5OS0zLjI5MTY1NkMyLjMyNzI3My0zLjI5MTY1NiAyLjQyMjkxNC0zLjE4MDA3NSAyLjQyMjkxNC0yLjkxNzA2MUMyLjQyMjkxNC0yLjgwNTQ3OSAyLjM5OTAwNC0yLjY5Mzg5OCAyLjM3NTA5My0yLjU4MjMxNkwxLjYyNTkwMyAuMzk4NTA2WicvPgo8cGF0aCBpZD0nZzAtMTgnIGQ9J002LjUzOTQ3Ny01Ljg1ODAzMkM2LjUzOTQ3Ny03Ljk2MjE0MiA1LjI5NjEzOS04LjM5MjUyOCA0LjU2Njg3NC04LjM5MjUyOEMzLjYyMjQxNi04LjM5MjUyOCAyLjQyNjg5OS03Ljc3MDg1OSAxLjUzMDI2Mi02LjE0NDk1NkMuOTIwNTQ4LTUuMDIxMTcxIC41NDk5MzgtMy4zOTUyNjggLjU0OTkzOC0yLjQyNjg5OUMuNTQ5OTM4LS42OTM0IDEuNDU4NTMxIC4wOTU2NDEgMi41MzQ0OTYgLjA5NTY0MUMzLjMzNTQ5MiAuMDk1NjQxIDQuMzg3NTQ3LS4zNzA2MSA1LjIxMjQ1My0xLjU5MDAzN0M2LjIxNjY4Ny0zLjA2MDUyMyA2LjUzOTQ3Ny00Ljk2MTM5NSA2LjUzOTQ3Ny01Ljg1ODAzMlpNMi4zNjcxMjMtNC40MzUzNjdDMi41MzQ0OTYtNS4xMjg3NjcgMi44NDUzMy02LjIxNjY4NyAzLjIwMzk4NS02LjgzODM1NkMzLjQ3ODk1NC03LjMyODUxOCAzLjk2OTExNi03Ljk2MjE0MiA0LjU0Mjk2NC03Ljk2MjE0MkM1LjA0NTA4MS03Ljk2MjE0MiA1LjI2MDI3NC03LjQzNjExNSA1LjI2MDI3NC02LjczMDc2QzUuMjYwMjc0LTUuOTc3NTg0IDQuOTk3MjYtNC45Mzc0ODQgNC44NjU3NTMtNC40MzUzNjdIMi4zNjcxMjNaTTQuNzIyMjkxLTMuODYxNTE5QzMuOTgxMDcxLS42NTc1MzQgMi45NzY4MzctLjMzNDc0NSAyLjU1ODQwNi0uMzM0NzQ1QzIuMzkxMDM0LS4zMzQ3NDUgMi4xMzk5NzUtLjM4MjU2NSAxLjk3MjYwMy0uNzUzMTc2QzEuODI5MTQxLTEuMDc1OTY1IDEuODI5MTQxLTEuNTQyMjE3IDEuODI5MTQxLTEuNTU0MTcyQzEuODI5MTQxLTIuMjM1NjE2IDIuMDkyMTU0LTMuMzQ3NDQ3IDIuMjIzNjYxLTMuODYxNTE5SDQuNzIyMjkxWicvPgo8cGF0aCBpZD0nZzUtNDknIGQ9J00yLjUwMjYxNS01LjA3Njk2MUMyLjUwMjYxNS01LjI5MjE1NCAyLjQ4NjY3NS01LjMwMDEyNSAyLjI3MTQ4Mi01LjMwMDEyNUMxLjk0NDcwNy00Ljk4MTMyIDEuNTIyMjkxLTQuNzkwMDM3IC43NjUxMzEtNC43OTAwMzdWLTQuNTI3MDI0Qy45ODAzMjQtNC41MjcwMjQgMS40MTA3MS00LjUyNzAyNCAxLjg3Mjk3Ni00Ljc0MjIxN1YtLjY1MzU0OUMxLjg3Mjk3Ni0uMzU4NjU1IDEuODQ5MDY2LS4yNjMwMTQgMS4wOTE5MDUtLjI2MzAxNEguODEyOTUxVjBDMS4xMzk3MjYtLjAyMzkxIDEuODI1MTU2LS4wMjM5MSAyLjE4MzgxMS0uMDIzOTFTMy4yMzU4NjYtLjAyMzkxIDMuNTYyNjQgMFYtLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNi0uMjYzMDE0IDIuNTAyNjE1LS4zNTg2NTUgMi41MDI2MTUtLjY1MzU0OVYtNS4wNzY5NjFaJy8+CjxwYXRoIGlkPSdnNS01MCcgZD0nTTIuMjQ3NTcyLTEuNjI1OTAzQzIuMzc1MDkzLTEuNzQ1NDU1IDIuNzA5ODM4LTIuMDA4NDY4IDIuODM3MzYtMi4xMjAwNUMzLjMzMTUwNy0yLjU3NDM0NiAzLjgwMTc0My0zLjAxMjcwMiAzLjgwMTc0My0zLjczNzk4M0MzLjgwMTc0My00LjY4NjQyNiAzLjAwNDczMi01LjMwMDEyNSAyLjAwODQ2OC01LjMwMDEyNUMxLjA1MjA1NS01LjMwMDEyNSAuNDIyNDE2LTQuNTc0ODQ0IC40MjI0MTYtMy44NjU1MDRDLjQyMjQxNi0zLjQ3NDk2OSAuNzMzMjUtMy40MTkxNzggLjg0NDgzMi0zLjQxOTE3OEMxLjAxMjIwNC0zLjQxOTE3OCAxLjI1OTI3OC0zLjUzODczIDEuMjU5Mjc4LTMuODQxNTk0QzEuMjU5Mjc4LTQuMjU2MDQgLjg2MDc3Mi00LjI1NjA0IC43NjUxMzEtNC4yNTYwNEMuOTk2MjY0LTQuODM3ODU4IDEuNTMwMjYyLTUuMDM3MTExIDEuOTIwNzk3LTUuMDM3MTExQzIuNjYyMDE3LTUuMDM3MTExIDMuMDQ0NTgzLTQuNDA3NDcyIDMuMDQ0NTgzLTMuNzM3OTgzQzMuMDQ0NTgzLTIuOTA5MDkxIDIuNDYyNzY1LTIuMzAzMzYyIDEuNTIyMjkxLTEuMzM4OTc5TC41MTgwNTctLjMwMjg2NEMuNDIyNDE2LS4yMTUxOTMgLjQyMjQxNi0uMTk5MjUzIC40MjI0MTYgMEgzLjU3MDYxTDMuODAxNzQzLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2LTEuMjY3MjQ4IDMuNDY2OTk5LS44Njg3NDIgMy4zNzEzNTctLjcxNzMxQzMuMzIzNTM3LS42NTM1NDkgMi43MTc4MDgtLjY1MzU0OSAyLjU5MDI4Ni0uNjUzNTQ5SDEuMTcxNjA2TDIuMjQ3NTcyLTEuNjI1OTAzWicvPgo8cGF0aCBpZD0nZzUtNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2c2LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnNi00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzYtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnNi01MCcgZD0nTTUuMjYwMjc0LTIuMDA4NDY4SDQuOTk3MjZDNC45NjEzOTUtMS44MDUyMyA0Ljg2NTc1My0xLjE0NzY5NiA0Ljc0NjIwMi0uOTU2NDEzQzQuNjYyNTE2LS44NDg4MTcgMy45ODEwNzEtLjg0ODgxNyAzLjYyMjQxNi0uODQ4ODE3SDEuNDEwNzFDMS43MzM0OTktMS4xMjM3ODYgMi40NjI3NjUtMS44ODg5MTcgMi43NzM1OTktMi4xNzU4NDFDNC41OTA3ODUtMy44NDk1NjQgNS4yNjAyNzQtNC40NzEyMzMgNS4yNjAyNzQtNS42NTQ3OTVDNS4yNjAyNzQtNy4wMjk2MzkgNC4xNzIzNTQtNy45NTAxODcgMi43ODU1NTQtNy45NTAxODdTLjU4NTgwMy02Ljc2NjYyNSAuNTg1ODAzLTUuNzM4NDgxQy41ODU4MDMtNS4xMjg3NjcgMS4xMTE4MzEtNS4xMjg3NjcgMS4xNDc2OTYtNS4xMjg3NjdDMS4zOTg3NTUtNS4xMjg3NjcgMS43MDk1ODktNS4zMDgwOTUgMS43MDk1ODktNS42OTA2NkMxLjcwOTU4OS02LjAyNTQwNSAxLjQ4MjQ0MS02LjI1MjU1MyAxLjE0NzY5Ni02LjI1MjU1M0MxLjA0MDEtNi4yNTI1NTMgMS4wMTYxODktNi4yNTI1NTMgLjk4MDMyNC02LjI0MDU5OEMxLjIwNzQ3Mi03LjA1MzU0OSAxLjg1MzA1MS03LjYwMzQ4NyAyLjYzMDEzNy03LjYwMzQ4N0MzLjY0NjMyNi03LjYwMzQ4NyA0LjI2Nzk5NS02Ljc1NDY3IDQuMjY3OTk1LTUuNjU0Nzk1QzQuMjY3OTk1LTQuNjM4NjA1IDMuNjgyMTkyLTMuNzUzOTIzIDMuMDAwNzQ3LTIuOTg4NzkyTC41ODU4MDMtLjI4NjkyNFYwSDQuOTQ5NDRMNS4yNjAyNzQtMi4wMDg0NjhaJy8+CjxwYXRoIGlkPSdnNi02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzYtMTAxJyBkPSdNNC41Nzg4MjktMi43NzM1OTlDNC44NDE4NDMtMi43NzM1OTkgNC44NjU3NTMtMi43NzM1OTkgNC44NjU3NTMtMy4wMDA3NDdDNC44NjU3NTMtNC4yMDgyMTkgNC4yMjAxNzQtNS4zMzIwMDUgMi43NzM1OTktNS4zMzIwMDVDMS40MTA3MS01LjMzMjAwNSAuMzU4NjU1LTQuMTAwNjIzIC4zNTg2NTUtMi42MTgxODJDLjM1ODY1NS0xLjA0MDEgMS41NzgwODIgLjExOTU1MiAyLjkwNTEwNiAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNC44NjU3NTMtMS4xNzE2MDYgNC44NjU3NTMtMS40MjI2NjVDNC44NjU3NTMtMS40OTQzOTYgNC44MDU5NzgtMS41NDIyMTcgNC43MzQyNDctMS41NDIyMTdDNC42Mzg2MDUtMS41NDIyMTcgNC42MTQ2OTUtMS40ODI0NDEgNC41OTA3ODUtMS40MjI2NjVDNC4yNzk5NS0uNDE4NDMxIDMuNDc4OTU0LS4xNDM0NjIgMi45NzY4MzctLjE0MzQ2MlMxLjI2NzI0OC0uNDc4MjA3IDEuMjY3MjQ4LTIuNTQ2NDUxVi0yLjc3MzU5OUg0LjU3ODgyOVpNMS4yNzkyMDMtMy4wMDA3NDdDMS4zNzQ4NDQtNC44Nzc3MDkgMi40MjY4OTktNS4wOTI5MDIgMi43NjE2NDQtNS4wOTI5MDJDNC4wNDA4NDctNS4wOTI5MDIgNC4xMTI1NzgtMy40MDcyMjMgNC4xMjQ1MzMtMy4wMDA3NDdIMS4yNzkyMDNaJy8+CjxwYXRoIGlkPSdnNi0xMTInIGQ9J00yLjkyOTAxNiAxLjk3MjYwM0MyLjE2Mzg4NSAxLjk3MjYwMyAyLjAyMDQyMyAxLjk3MjYwMyAyLjAyMDQyMyAxLjQzNDYyVi0uNjQ1NTc5QzIuMjM1NjE2LS4zNDY3IDIuNzI1Nzc4IC4xMTk1NTIgMy40OTA5MDkgLjExOTU1MkM0Ljg2NTc1MyAuMTE5NTUyIDYuMDczMjI1LTEuMDQwMSA2LjA3MzIyNS0yLjU4MjMxNkM2LjA3MzIyNS00LjEwMDYyMyA0Ljk0OTQ0LTUuMjcyMjI5IDMuNjQ2MzI2LTUuMjcyMjI5QzIuNTk0MjcxLTUuMjcyMjI5IDIuMDMyMzc5LTQuNTE5MDU0IDEuOTk2NTEzLTQuNDcxMjMzVi01LjI3MjIyOUwuMzM0NzQ1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE3MTYwNi00Ljc5NDAyMiAxLjI0MzMzNy00LjcxMDMzNiAxLjI0MzMzNy00LjE4NDMwOVYxLjQzNDYyQzEuMjQzMzM3IDEuOTcyNjAzIDEuMTExODMxIDEuOTcyNjAzIC4zMzQ3NDUgMS45NzI2MDNWMi4zMTkzMDNDLjY0NTU3OSAyLjI5NTM5MiAxLjI5MTE1OCAyLjI5NTM5MiAxLjYyNTkwMyAyLjI5NTM5MkMxLjk3MjYwMyAyLjI5NTM5MiAyLjYxODE4MiAyLjI5NTM5MiAyLjkyOTAxNiAyLjMxOTMwM1YxLjk3MjYwM1pNMi4wMjA0MjMtMy44MTM2OTlDMi4wMjA0MjMtNC4wNDA4NDcgMi4wMjA0MjMtNC4wNTI4MDIgMi4xNTE5My00LjI0NDA4NUMyLjUxMDU4NS00Ljc4MjA2NyAzLjA5NjM4OS01LjAwOTIxNSAzLjU1MDY4NS01LjAwOTIxNUM0LjQ0NzMyMy01LjAwOTIxNSA1LjE2NDYzMy0zLjkyMTI5NSA1LjE2NDYzMy0yLjU4MjMxNkM1LjE2NDYzMy0xLjE1OTY1MSA0LjM1MTY4MS0uMTE5NTUyIDMuNDMxMTMzLS4xMTk1NTJDMy4wNjA1MjMtLjExOTU1MiAyLjcxMzgyMy0uMjc0OTY5IDIuNDc0NzItLjUwMjExN0MyLjE5OTc1MS0uNzc3MDg2IDIuMDIwNDIzLTEuMDE2MTg5IDIuMDIwNDIzLTEuMzUwOTM0Vi0zLjgxMzY5OVonLz4KPHBhdGggaWQ9J2c2LTEyMCcgZD0nTTMuMzQ3NDQ3LTIuODIxNDJDMy42OTQxNDctMy4yNzU3MTYgNC4xOTYyNjQtMy45MjEyOTUgNC40MjM0MTItNC4xNzIzNTRDNC45MTM1NzQtNC43MjIyOTEgNS40NzU0NjctNC44MDU5NzggNS44NTgwMzItNC44MDU5NzhWLTUuMTUyNjc3QzUuMzQzOTYtNS4xMjg3NjcgNS4zMjAwNS01LjEyODc2NyA0Ljg1Mzc5OC01LjEyODc2N0M0LjM5OTUwMi01LjEyODc2NyA0LjM3NTU5Mi01LjEyODc2NyAzLjc3NzgzMy01LjE1MjY3N1YtNC44MDU5NzhDMy45MzMyNS00Ljc4MjA2NyA0LjEyNDUzMy00LjcxMDMzNiA0LjEyNDUzMy00LjQzNTM2N0M0LjEyNDUzMy00LjIzMjEzIDQuMDE2OTM2LTQuMTAwNjIzIDMuOTQ1MjA1LTQuMDA0OTgxTDMuMTgwMDc1LTMuMDM2NjEzTDIuMjQ3NTcyLTQuMjY3OTk1QzIuMjExNzA2LTQuMzE1ODE2IDIuMTM5OTc1LTQuNDIzNDEyIDIuMTM5OTc1LTQuNTA3MDk4QzIuMTM5OTc1LTQuNTc4ODI5IDIuMTk5NzUxLTQuNzk0MDIyIDIuNTU4NDA2LTQuODA1OTc4Vi01LjE1MjY3N0MyLjI1OTUyNy01LjEyODc2NyAxLjY0OTgxMy01LjEyODc2NyAxLjMyNzAyNC01LjEyODc2N0MuOTMyNTAzLTUuMTI4NzY3IC45MDg1OTMtNS4xMjg3NjcgLjE3OTMyOC01LjE1MjY3N1YtNC44MDU5NzhDLjc4OTA0MS00LjgwNTk3OCAxLjAxNjE4OS00Ljc4MjA2NyAxLjI2NzI0OC00LjQ1OTI3OEwyLjY2NjAwMi0yLjYzMDEzN0MyLjY4OTkxMy0yLjYwNjIyNyAyLjczNzczMy0yLjUzNDQ5NiAyLjczNzczMy0yLjQ5ODYzUzEuODA1MjMtMS4yOTExNTggMS42ODU2NzktMS4xMzU3NDFDMS4xNTk2NTEtLjQ5MDE2MiAuNjMzNjI0LS4zNTg2NTUgLjExOTU1Mi0uMzQ2N1YwQy41NzM4NDgtLjAyMzkxIC41OTc3NTgtLjAyMzkxIDEuMTExODMxLS4wMjM5MUMxLjU2NjEyNy0uMDIzOTEgMS41OTAwMzctLjAyMzkxIDIuMTg3Nzk2IDBWLS4zNDY3QzEuOTAwODcyLS4zODI1NjUgMS44NTMwNTEtLjU2MTg5MyAxLjg1MzA1MS0uNzI5MjY1QzEuODUzMDUxLS45MjA1NDggMS45MzY3MzctMS4wMTYxODkgMi4wNTYyODktMS4xNzE2MDZDMi4yMzU2MTYtMS40MjI2NjUgMi42MzAxMzctMS45MTI4MjcgMi45MTcwNjEtMi4yODM0MzdMMy44OTczODUtMS4wMDQyMzRDNC4xMDA2MjMtLjc0MTIyIDQuMTAwNjIzLS43MTczMSA0LjEwMDYyMy0uNjQ1NTc5QzQuMTAwNjIzLS41NDk5MzggNC4wMDQ5ODEtLjM1ODY1NSAzLjY4MjE5Mi0uMzQ2N1YwQzMuOTkzMDI2LS4wMjM5MSA0LjU3ODgyOS0uMDIzOTEgNC45MTM1NzQtLjAyMzkxQzUuMzA4MDk1LS4wMjM5MSA1LjMzMjAwNS0uMDIzOTEgNi4wNDkzMTUgMFYtLjM0NjdDNS40MTU2OTEtLjM0NjcgNS4yMDA0OTgtLjM3MDYxIDQuOTEzNTc0LS43NTMxNzZMMy4zNDc0NDctMi44MjE0MlonLz4KPHBhdGggaWQ9J2c0LTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnNC0yNScgZD0nTTMuMDk2Mzg5LTQuNTA3MDk4SDQuNDQ3MzIzQzQuMTI0NTMzLTMuMTY4MTIgMy45MjEyOTUtMi4yOTUzOTIgMy45MjEyOTUtMS4zMzg5NzlDMy45MjEyOTUtMS4xNzE2MDYgMy45MjEyOTUgLjExOTU1MiA0LjQxMTQ1NyAuMTE5NTUyQzQuNjYyNTE2IC4xMTk1NTIgNC44Nzc3MDktLjEwNzU5NyA0Ljg3NzcwOS0uMzEwODM0QzQuODc3NzA5LS4zNzA2MSA0Ljg3NzcwOS0uMzk0NTIxIDQuNzk0MDIyLS41NzM4NDhDNC40NzEyMzMtMS4zOTg3NTUgNC40NzEyMzMtMi40MjY4OTkgNC40NzEyMzMtMi41MTA1ODVDNC40NzEyMzMtMi41ODIzMTYgNC40NzEyMzMtMy40MzExMzMgNC43MjIyOTEtNC41MDcwOThINi4wNjEyN0M2LjIxNjY4Ny00LjUwNzA5OCA2LjYxMTIwOC00LjUwNzA5OCA2LjYxMTIwOC00Ljg4OTY2NEM2LjYxMTIwOC01LjE1MjY3NyA2LjM4NDA2LTUuMTUyNjc3IDYuMTY4ODY3LTUuMTUyNjc3SDIuMjM1NjE2QzEuOTYwNjQ4LTUuMTUyNjc3IDEuNTU0MTcyLTUuMTUyNjc3IDEuMDA0MjM0LTQuNTY2ODc0Qy42OTM0LTQuMjIwMTc0IC4zMTA4MzQtMy41ODY1NSAuMzEwODM0LTMuNTE0ODE5Uy4zNzA2MS0zLjQxOTE3OCAuNDQyMzQxLTMuNDE5MTc4Qy41MjYwMjctMy40MTkxNzggLjUzNzk4My0zLjQ1NTA0NCAuNTk3NzU4LTMuNTI2Nzc1QzEuMjE5NDI3LTQuNTA3MDk4IDEuODQxMDk2LTQuNTA3MDk4IDIuMTM5OTc1LTQuNTA3MDk4SDIuODIxNDJDMi41NTg0MDYtMy42MTA0NjEgMi4yNTk1MjctMi41NzAzNjEgMS4yNzkyMDMtLjQ3ODIwN0MxLjE4MzU2Mi0uMjg2OTI0IDEuMTgzNTYyLS4yNjMwMTQgMS4xODM1NjItLjE5MTI4M0MxLjE4MzU2MiAuMDU5Nzc2IDEuMzk4NzU1IC4xMTk1NTIgMS41MDYzNTEgLjExOTU1MkMxLjg1MzA1MSAuMTE5NTUyIDEuOTQ4NjkyLS4xOTEyODMgMi4wOTIxNTQtLjY5MzRDMi4yODM0MzctMS4zMDMxMTMgMi4yODM0MzctMS4zMjcwMjQgMi40MDI5ODktMS44MDUyM0wzLjA5NjM4OS00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c0LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNC01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnNC01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzQtNzYnIGQ9J000LjM4NzU0Ny03LjI0NDgzMkM0LjQ5NTE0My03LjY5OTEyOCA0LjUzMTAwOS03LjgxODY4IDUuNTgzMDY0LTcuODE4NjhDNS45MDU4NTMtNy44MTg2OCA1Ljk4OTUzOS03LjgxODY4IDUuOTg5NTM5LTguMDQ1ODI4QzUuOTg5NTM5LTguMTY1MzggNS44NTgwMzItOC4xNjUzOCA1LjgxMDIxMi04LjE2NTM4QzUuNTcxMTA4LTguMTY1MzggNS4yOTYxMzktOC4xNDE0NjkgNS4wNTcwMzYtOC4xNDE0NjlIMy40NTUwNDRDMy4yMjc4OTUtOC4xNDE0NjkgMi45NjQ4ODItOC4xNjUzOCAyLjczNzczMy04LjE2NTM4QzIuNjQyMDkyLTguMTY1MzggMi41MTA1ODUtOC4xNjUzOCAyLjUxMDU4NS03LjkzODIzMkMyLjUxMDU4NS03LjgxODY4IDIuNjE4MTgyLTcuODE4NjggMi43OTc1MDktNy44MTg2OEMzLjUyNjc3NS03LjgxODY4IDMuNTI2Nzc1LTcuNzIzMDM5IDMuNTI2Nzc1LTcuNTkxNTMyQzMuNTI2Nzc1LTcuNTY3NjIxIDMuNTI2Nzc1LTcuNDk1ODkgMy40Nzg5NTQtNy4zMTY1NjNMMS44NjUwMDYtLjg4NDY4MkMxLjc1NzQxLS40NjYyNTIgMS43MzM0OTktLjM0NjcgLjg5NjYzOC0uMzQ2N0MuNjY5NDg5LS4zNDY3IC41NDk5MzgtLjM0NjcgLjU0OTkzOC0uMTMxNTA3Qy41NDk5MzggMCAuNjIxNjY5IDAgLjg2MDc3MiAwSDYuMjE2Njg3QzYuNDc5NzAxIDAgNi40OTE2NTYtLjAxMTk1NSA2LjU3NTM0Mi0uMjI3MTQ4TDcuNDk1ODktMi43NzM1OTlDNy41MTk4MDEtMi44MzMzNzUgNy41NDM3MTEtMi45MDUxMDYgNy41NDM3MTEtMi45NDA5NzFDNy41NDM3MTEtMy4wMTI3MDIgNy40ODM5MzUtMy4wNjA1MjMgNy40MjQxNTktMy4wNjA1MjNDNy40MTIyMDQtMy4wNjA1MjMgNy4zNTI0MjgtMy4wNjA1MjMgNy4zMjg1MTgtMy4wMTI3MDJDNy4zMDQ2MDgtMy4wMDA3NDcgNy4zMDQ2MDgtMi45NzY4MzcgNy4yMDg5NjYtMi43NDk2ODlDNi44MjY0MDEtMS42OTc2MzQgNi4yODg0MTgtLjM0NjcgNC4yNjc5OTUtLjM0NjdIMy4xMjAyOTlDMi45NTI5MjctLjM0NjcgMi45MjkwMTYtLjM0NjcgMi44NTcyODUtLjM1ODY1NUMyLjcyNTc3OC0uMzcwNjEgMi43MTM4MjMtLjM5NDUyMSAyLjcxMzgyMy0uNDkwMTYyQzIuNzEzODIzLS41NzM4NDggMi43Mzc3MzMtLjY0NTU3OSAyLjc2MTY0NC0uNzUzMTc2TDQuMzg3NTQ3LTcuMjQ0ODMyWicvPgo8cGF0aCBpZD0nZzQtMTIwJyBkPSdNNS42NjY3NS00Ljg3NzcwOUM1LjI4NDE4NC00LjgwNTk3OCA1LjE0MDcyMi00LjUxOTA1NCA1LjE0MDcyMi00LjI5MTkwNUM1LjE0MDcyMi00LjAwNDk4MSA1LjM2Nzg3LTMuOTA5MzQgNS41MzUyNDMtMy45MDkzNEM1Ljg5Mzg5OC0zLjkwOTM0IDYuMTQ0OTU2LTQuMjIwMTc0IDYuMTQ0OTU2LTQuNTQyOTY0QzYuMTQ0OTU2LTUuMDQ1MDgxIDUuNTcxMTA4LTUuMjcyMjI5IDUuMDY4OTkxLTUuMjcyMjI5QzQuMzM5NzI2LTUuMjcyMjI5IDMuOTMzMjUtNC41NTQ5MTkgMy44MjU2NTQtNC4zMjc3NzFDMy41NTA2ODUtNS4yMjQ0MDggMi44MDk0NjUtNS4yNzIyMjkgMi41OTQyNzEtNS4yNzIyMjlDMS4zNzQ4NDQtNS4yNzIyMjkgLjcyOTI2NS0zLjcwNjEwMiAuNzI5MjY1LTMuNDQzMDg4Qy43MjkyNjUtMy4zOTUyNjggLjc3NzA4Ni0zLjMzNTQ5MiAuODYwNzcyLTMuMzM1NDkyQy45NTY0MTMtMy4zMzU0OTIgLjk4MDMyNC0zLjQwNzIyMyAxLjAwNDIzNC0zLjQ1NTA0NEMxLjQxMDcxLTQuNzgyMDY3IDIuMjExNzA2LTUuMDMzMTI2IDIuNTU4NDA2LTUuMDMzMTI2QzMuMDk2Mzg5LTUuMDMzMTI2IDMuMjAzOTg1LTQuNTMxMDA5IDMuMjAzOTg1LTQuMjQ0MDg1QzMuMjAzOTg1LTMuOTgxMDcxIDMuMTMyMjU0LTMuNzA2MTAyIDIuOTg4NzkyLTMuMTMyMjU0TDIuNTgyMzE2LTEuNDk0Mzk2QzIuNDAyOTg5LS43NzcwODYgMi4wNTYyODktLjExOTU1MiAxLjQyMjY2NS0uMTE5NTUyQzEuMzYyODg5LS4xMTk1NTIgMS4wNjQwMS0uMTE5NTUyIC44MTI5NTEtLjI3NDk2OUMxLjI0MzMzNy0uMzU4NjU1IDEuMzM4OTc5LS43MTczMSAxLjMzODk3OS0uODYwNzcyQzEuMzM4OTc5LTEuMDk5ODc1IDEuMTU5NjUxLTEuMjQzMzM3IC45MzI1MDMtMS4yNDMzMzdDLjY0NTU3OS0xLjI0MzMzNyAuMzM0NzQ1LS45OTIyNzkgLjMzNDc0NS0uNjA5NzE0Qy4zMzQ3NDUtLjEwNzU5NyAuODk2NjM4IC4xMTk1NTIgMS40MTA3MSAuMTE5NTUyQzEuOTg0NTU4IC4xMTk1NTIgMi4zOTEwMzQtLjMzNDc0NSAyLjY0MjA5Mi0uODI0OTA3QzIuODMzMzc1LS4xMTk1NTIgMy40MzExMzMgLjExOTU1MiAzLjg3MzQ3NCAuMTE5NTUyQzUuMDkyOTAyIC4xMTk1NTIgNS43Mzg0ODEtMS40NDY1NzUgNS43Mzg0ODEtMS43MDk1ODlDNS43Mzg0ODEtMS43NjkzNjUgNS42OTA2Ni0xLjgxNzE4NiA1LjYxODkyOS0xLjgxNzE4NkM1LjUxMTMzMy0xLjgxNzE4NiA1LjQ5OTM3Ny0xLjc1NzQxIDUuNDYzNTEyLTEuNjYxNzY4QzUuMTQwNzIyLS42MDk3MTQgNC40NDczMjMtLjExOTU1MiAzLjkwOTM0LS4xMTk1NTJDMy40OTA5MDktLjExOTU1MiAzLjI2Mzc2MS0uNDMwMzg2IDMuMjYzNzYxLS45MjA1NDhDMy4yNjM3NjEtMS4xODM1NjIgMy4zMTE1ODItMS4zNzQ4NDQgMy41MDI4NjQtMi4xNjM4ODVMMy45MjEyOTUtMy43ODk3ODhDNC4xMDA2MjMtNC41MDcwOTggNC41MDcwOTgtNS4wMzMxMjYgNS4wNTcwMzYtNS4wMzMxMjZDNS4wODA5NDYtNS4wMzMxMjYgNS40MTU2OTEtNS4wMzMxMjYgNS42NjY3NS00Ljg3NzcwOVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzQ3LjAzNTY4MycgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c0LTc2Jy8+Cjx1c2UgeD0nNTYuOTkyNjg3JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtNDAnLz4KPHVzZSB4PSc2MS41NDUwMTMnIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC0xMjAnLz4KPHVzZSB4PSc2OC4xOTcxJyB5PSctNTYuOTQxODY0JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PSc3Mi45Mjk0MTUnIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC01OScvPgo8dXNlIHg9Jzc4LjE3MzU3MycgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c0LTU4Jy8+Cjx1c2UgeD0nODMuNDE3NzMyJyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzQtNTgnLz4KPHVzZSB4PSc4OC42NjE4OTEnIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC01OCcvPgo8dXNlIHg9JzkzLjkwNjA1JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzQtNTknLz4KPHVzZSB4PSc5OS4xNTAyMDknIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC0xMjAnLz4KPHVzZSB4PScxMDUuODAyMjk2JyB5PSctNTYuOTQxODY0JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxMTMuODcwNzMzJyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzQtNTknLz4KPHVzZSB4PScxMTkuMTE0ODkyJyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzAtMTgnLz4KPHVzZSB4PScxMjYuMjEzMjI4JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtNDEnLz4KPHVzZSB4PScxMzQuMDg2Mzc5JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScxODIuOTY4MjEyJyB5PSctNzMuNjc5MTQ4JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxNzkuMTE1MzInIHk9Jy03MC4wOTI1OTEnIHhsaW5rOmhyZWY9JyNnMS04OScvPgo8dXNlIHg9JzE3OS40MDEwMDcnIHk9Jy00NC44OTgyMzYnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PScxODMuMjg1MDMyJyB5PSctNDQuODk4MjM2JyB4bGluazpocmVmPScjZzUtNjEnLz4KPHVzZSB4PScxODkuODcxNTM5JyB5PSctNDQuODk4MjM2JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScyMDkuNjM2NTkyJyB5PSctNjYuODIyODg1JyB4bGluazpocmVmPScjZzYtNDknLz4KPHJlY3QgeD0nMTk3LjU3OTQyJyB5PSctNjEuOTYzMDEyJyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPScyOS45NjczMzQnLz4KPHVzZSB4PScxOTcuNTc5NDInIHk9Jy00OS4yMDQzMjQnIHhsaW5rOmhyZWY9JyNnNC0yNycvPgo8dXNlIHg9JzIwNC42NjE4MjQnIHk9Jy01OS4wOTM4ODknIHhsaW5rOmhyZWY9JyNnMi0xMTInLz4KPHJlY3QgeD0nMjE0LjYyNDQ5NScgeT0nLTU5LjU3MjA3NicgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMTIuOTIyMjYnLz4KPHVzZSB4PScyMTQuNjI0NDk1JyB5PSctNDkuMjA0MzI0JyB4bGluazpocmVmPScjZzYtNTAnLz4KPHVzZSB4PScyMjAuNDc3NDg1JyB5PSctNDkuMjA0MzI0JyB4bGluazpocmVmPScjZzQtMjUnLz4KPHVzZSB4PScyMzAuNzM0NzY2JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtMTAxJy8+Cjx1c2UgeD0nMjM1LjkzNzQyNCcgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c2LTEyMCcvPgo8dXNlIHg9JzI0Mi4xMTU1OCcgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c2LTExMicvPgo8dXNlIHg9JzI1MC42MTE0JyB5PSctNzkuMTc4NjUxJyB4bGluazpocmVmPScjZzEtMzQnLz4KPHVzZSB4PScyNTcuNTg1Mjc5JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzI2OC4wNzkyOScgeT0nLTY2LjgyMjg4NScgeGxpbms6aHJlZj0nI2c2LTQ5Jy8+CjxyZWN0IHg9JzI2OC4wNzkyOScgeT0nLTYxLjk2MzAxMicgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNS44NTI5OScvPgo8dXNlIHg9JzI2OC4wNzkyOScgeT0nLTUwLjUzNDQ2NCcgeGxpbms6aHJlZj0nI2c2LTUwJy8+Cjx1c2UgeD0nMjc3LjEyMDI5MScgeT0nLTc1LjU5MjA2NCcgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nMjg3LjExNjE3OCcgeT0nLTY2LjgyMjg4NScgeGxpbms6aHJlZj0nI2c0LTEyMCcvPgo8dXNlIHg9JzI5My43NjgyNjUnIHk9Jy02NS4wMjk2MjInIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PSczMDAuODA3MDg1JyB5PSctNjYuODIyODg1JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzMxMi43NjIyNDYnIHk9Jy02Ni44MjI4ODUnIHhsaW5rOmhyZWY9JyNnNC0yMicvPgo8cmVjdCB4PScyODcuMTE2MTc4JyB5PSctNjEuOTYzMDEyJyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSczMi42ODkwMzEnLz4KPHVzZSB4PScyOTkuOTE5NDk5JyB5PSctNTAuNTM0NDY0JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PSczMjEuMDAwNzIzJyB5PSctNzUuNTkyMDY0JyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PSczMjkuODAxMDk1JyB5PSctNzIuOTE1NDEnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzMzNC41MzM0MScgeT0nLTc5LjE3ODY1MScgeGxpbms6aHJlZj0nI2cxLTM1Jy8+Cjx1c2UgeD0nMTM0LjA4NjM3OScgeT0nLTE2LjU4MjE1JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScxNzcuOTI3MTE4JyB5PSctMjQuNjY5OTA4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHJlY3QgeD0nMTU0LjM0OTE4NCcgeT0nLTE5LjgxMDAzNScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNTMuMDA4ODU4Jy8+Cjx1c2UgeD0nMTU0LjM0OTE4NCcgeT0nLTguMzgxNDg4JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PScxNjEuNDMxNTg4JyB5PSctMTEuODM1MTk2JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxNjkuNTAwMDI2JyB5PSctOC4zODE0ODgnIHhsaW5rOmhyZWY9JyNnNi00MCcvPgo8dXNlIHg9JzE3NC4wNTIzNTEnIHk9Jy04LjM4MTQ4OCcgeGxpbms6aHJlZj0nI2c2LTUwJy8+Cjx1c2UgeD0nMTc5LjkwNTM0MicgeT0nLTguMzgxNDg4JyB4bGluazpocmVmPScjZzQtMjUnLz4KPHVzZSB4PScxODYuOTc0NjExJyB5PSctOC4zODE0ODgnIHhsaW5rOmhyZWY9JyNnNi00MScvPgo8dXNlIHg9JzE5MS41MjY5MzcnIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnMy03OCcvPgo8dXNlIHg9JzE5OC4zOTE1NDUnIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnMy02MScvPgo8dXNlIHg9JzIwMi42MjU3MjgnIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzIxMC41NDYwNTQnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c2LTEwMScvPgo8dXNlIHg9JzIxNS43NDg3MTInIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c2LTEyMCcvPgo8dXNlIHg9JzIyMS45MjY4NjgnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c2LTExMicvPgo8dXNlIHg9JzIzMC40MjI2ODknIHk9Jy0zNy4wMjU2NzQnIHhsaW5rOmhyZWY9JyNnMS0zNCcvPgo8dXNlIHg9JzIzNy4zOTY1NjcnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScyNTMuNzk3OTQ1JyB5PSctMjQuNjY5OTA4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHJlY3QgeD0nMjQ3Ljg5MDU3OCcgeT0nLTE5LjgxMDAzNScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMTcuNjY3NzA5Jy8+Cjx1c2UgeD0nMjQ3Ljg5MDU3OCcgeT0nLTguMzgxNDg4JyB4bGluazpocmVmPScjZzYtNTAnLz4KPHVzZSB4PScyNTMuNzQzNTY4JyB5PSctOC4zODE0ODgnIHhsaW5rOmhyZWY9JyNnNC0yNycvPgo8dXNlIHg9JzI2MC44MjU5NzInIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzI3My41OTU0NTQnIHk9Jy0zMS41MjYxNzEnIHhsaW5rOmhyZWY9JyNnMy03OCcvPgo8dXNlIHg9JzI2OC43NDYyOTgnIHk9Jy0yNy45Mzk2MTQnIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzI3MC4wMjgyNDknIHk9Jy0yLjc0NTI1OScgeGxpbms6aHJlZj0nI2czLTEwNicvPgo8dXNlIHg9JzI3My45MTIyNzQnIHk9Jy0yLjc0NTI1OScgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMjgwLjQ5ODc4MScgeT0nLTIuNzQ1MjU5JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScyODguMDA3NDEzJyB5PSctMTYuNTgyMTUnIHhsaW5rOmhyZWY9JyNnNi00MCcvPgo8dXNlIHg9JzI5Mi41NTk3MzgnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c0LTEyMCcvPgo8dXNlIHg9JzI5OS4yMTE4MjYnIHk9Jy0xNC43ODg4ODcnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PSczMDYuMjUwNjQ2JyB5PSctMTYuNTgyMTUnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMzE4LjIwNTgwNycgeT0nLTE2LjU4MjE1JyB4bGluazpocmVmPScjZzQtMjInLz4KPHVzZSB4PSczMjUuMjQ4Nzc3JyB5PSctMTYuNTgyMTUnIHhsaW5rOmhyZWY9JyNnNi00MScvPgo8dXNlIHg9JzMyOS44MDEwOTUnIHk9Jy0yMi4zOTM2ODUnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzMzNC41MzM0MScgeT0nLTM3LjAyNTY3NCcgeGxpbms6aHJlZj0nI2cxLTM1Jy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
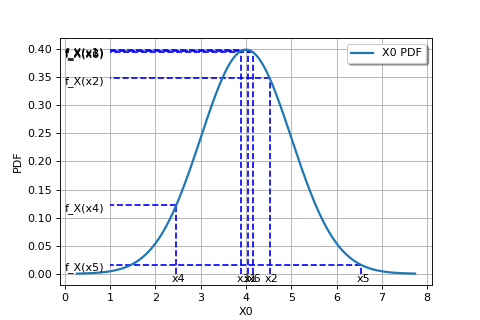
The following figure graphically illustrates the maximum likelihood method, in the particular case of a Gaussian probability distribution.
(Source code, png)
{kind=link}
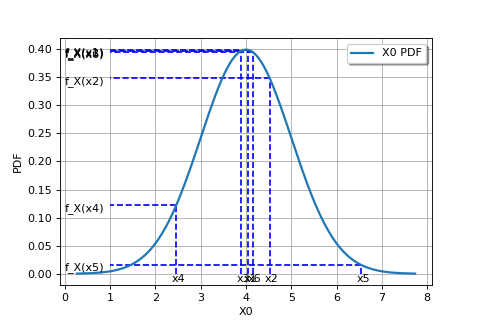
In general, in order to maximize the likelihood function classical optimization algorithms (e.g. gradient type) can be used. The Gaussian distribution case is an exception to this, as the maximum likelihood estimators are obtained analytically:
