KarhunenLoeveSVDAlgorithm¶
(Source code, png)
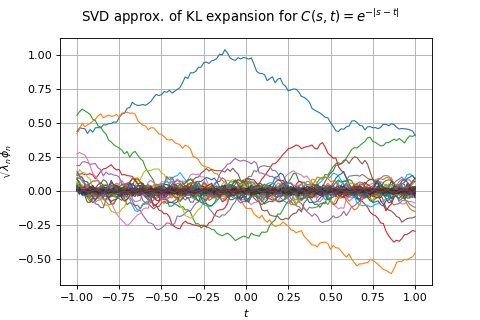
- class KarhunenLoeveSVDAlgorithm(*args)¶
Computation of Karhunen-Loeve decomposition using SVD approximation.
- Available constructors:
KarhunenLoeveSVDAlgorithm(sample, threshold, centeredSample)
KarhunenLoeveSVDAlgorithm(sample, verticesWeights, threshold, centeredSample)
KarhunenLoeveSVDAlgorithm(sample, verticesWeights, sampleWeights, threshold, centeredSample)
- Parameters:
- sample
ProcessSample The sample containing the observations.
- verticesWeightssequence of float
The weights associated to the vertices of the mesh defining the sample.
- sampleWeightssequence of float
The weights associated to the fields of the sample.
- thresholdpositive float, default=0.0
The threshold used to select the most significant eigenmodes, defined in
KarhunenLoeveAlgorithm.- centeredSamplebool, default=False
Flag to tell if the sample is drawn according to a centered process or if it has to be centered using the empirical mean.
- sample
Notes
The Karhunen-Loeve SVD algorithm solves the Fredholm problem associated to the covariance function
 : see
: see KarhunenLoeveAlgorithmto get the notations. If the mesh is regular, then this decomposition is equivalent to the principal component analysis (PCA) (see [pearson1907], [hotelling1933], [jackson1991], [jolliffe2002]). In other fields such as computational fluid dynamics for example, this is called proper orthogonal decomposition (POD) (see [luo2018]).The SVD approach is a particular case of the quadrature approach (see
KarhunenLoeveQuadratureAlgorithm) where we consider the functional basis of
of
 defined on
defined on  by:
by:![\vect{\theta}_p^j(\vect{s})= \left[\mat{C}(\vect{s}, \vect{s}_p) \right]_{:, j}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScxMDAuNTY2NDk0cHQnIGhlaWdodD0nMTUuODA3MTc4cHQnIHZpZXdCb3g9JzE0My43MzkxNjEgLTE1LjgwNzE3OCAxMDAuNTY2NDk0IDE1LjgwNzE3OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzMtNTgnIGQ9J00xLjYxNzkzMy0yLjk4ODc5MkMxLjYxNzkzMy0zLjI1OTc3NiAxLjQwMjc0LTMuNDM1MTE4IDEuMTc5NTc3LTMuNDM1MTE4Qy45MDg1OTMtMy40MzUxMTggLjczMzI1LTMuMjE5OTI1IC43MzMyNS0yLjk5Njc2MkMuNzMzMjUtMi43MjU3NzggLjk0ODQ0My0yLjU1MDQzNiAxLjE3MTYwNi0yLjU1MDQzNkMxLjQ0MjU5LTIuNTUwNDM2IDEuNjE3OTMzLTIuNzY1NjI5IDEuNjE3OTMzLTIuOTg4NzkyWk0xLjYxNzkzMy0uNDM4MzU2QzEuNjE3OTMzLS43MDkzNCAxLjQwMjc0LS44ODQ2ODIgMS4xNzk1NzctLjg4NDY4MkMuOTA4NTkzLS44ODQ2ODIgLjczMzI1LS42Njk0ODkgLjczMzI1LS40NDYzMjZDLjczMzI1LS4xNzUzNDIgLjk0ODQ0MyAwIDEuMTcxNjA2IDBDMS40NDI1OSAwIDEuNjE3OTMzLS4yMTUxOTMgMS42MTc5MzMtLjQzODM1NlonLz4KPHBhdGggaWQ9J2cyLTU5JyBkPSdNMi4zMzEyNTggLjA0NzgyMUMyLjMzMTI1OC0uNjQ1NTc5IDIuMTA0MTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yMzEzODItMS4xNTk2NTEgMS4wNDAxLS44NDg4MTcgMS4wNDAxLS41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNy0uMDQ3ODIxIDIuMDIwNDIzLS4xNTU0MTdDMi4wNDQzMzQtLjE3OTMyOCAyLjA1NjI4OS0uMTc5MzI4IDIuMDY4MjQ0LS4xNzkzMjhDMi4wOTIxNTQtLjE3OTMyOCAyLjA5MjE1NC0uMDExOTU1IDIuMDkyMTU0IC4wNDc4MjFDMi4wOTIxNTQgLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IC4wNDc4MjFaJy8+CjxwYXRoIGlkPSdnNC00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzQtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c0LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnNC05MScgZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicvPgo8cGF0aCBpZD0nZzQtOTMnIGQ9J00xLjg1MzA1MS04Ljk2NjM3NkguMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicvPgo8cGF0aCBpZD0nZzEtNTknIGQ9J00xLjQ5MDQxMS0uMTE5NTUyQzEuNDkwNDExIC4zOTg1MDYgMS4zNzg4MjkgLjg1MjgwMiAuODg0NjgyIDEuMzQ2OTQ5Qy44NTI4MDIgMS4zNzA4NTkgLjgzNjg2MiAxLjM4NjggLjgzNjg2MiAxLjQyNjY1Qy44MzY4NjIgMS40OTA0MTEgLjkwMDYyMyAxLjUzODIzMiAuOTU2NDEzIDEuNTM4MjMyQzEuMDUyMDU1IDEuNTM4MjMyIDEuNzEzNTc0IC45MDg1OTMgMS43MTM1NzQtLjAyMzkxQzEuNzEzNTc0LS41MzM5OTggMS41MjIyOTEtLjg4NDY4MiAxLjE3MTYwNi0uODg0NjgyQy44OTI2NTMtLjg4NDY4MiAuNzMzMjUtLjY2MTUxOSAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjIyMzE2MyAuODg0NjgyIDAgMS4xNzk1NzcgMEMxLjM3MDg1OSAwIDEuNDkwNDExLS4xMTE1ODIgMS40OTA0MTEtLjExOTU1MlonLz4KPHBhdGggaWQ9J2cxLTEwNicgZD0nTTMuMjkxNjU2LTQuOTczMzVDMy4yOTE2NTYtNS4xMjQ3ODIgMy4xNzIxMDUtNS4yNzYyMTQgMi45ODA4MjItNS4yNzYyMTRDMi43NDE3MTktNS4yNzYyMTQgMi41MzQ0OTYtNS4wNTMwNTEgMi41MzQ0OTYtNC44NDU4MjhDMi41MzQ0OTYtNC42OTQzOTYgMi42NTQwNDctNC41NDI5NjQgMi44NDUzMy00LjU0Mjk2NEMzLjA4NDQzMy00LjU0Mjk2NCAzLjI5MTY1Ni00Ljc2NjEyNyAzLjI5MTY1Ni00Ljk3MzM1Wk0xLjYyNTkwMyAuMzk4NTA2QzEuNTA2MzUxIC44ODQ2ODIgMS4xMTU4MTYgMS40MDI3NCAuNjI5NjM5IDEuNDAyNzRDLjUwMjExNyAxLjQwMjc0IC4zODI1NjUgMS4zNzA4NTkgLjM2NjYyNSAxLjM2Mjg4OUMuNjEzNjk5IDEuMjQzMzM3IC42NDU1NzkgMS4wMjgxNDQgLjY0NTU3OSAuOTU2NDEzQy42NDU1NzkgLjc2NTEzMSAuNTAyMTE3IC42NjE1MTkgLjMzNDc0NSAuNjYxNTE5Qy4xMDM2MTEgLjY2MTUxOS0uMTExNTgyIC44NjA3NzItLjExMTU4MiAxLjEyMzc4NkMtLjExMTU4MiAxLjQyNjY1IC4xODMzMTMgMS42MjU5MDMgLjYzNzYwOSAxLjYyNTkwM0MxLjEyMzc4NiAxLjYyNTkwMyAyLjAwMDQ5OCAxLjMyMzAzOSAyLjIzOTYwMSAuMzY2NjI1TDIuOTU2OTEyLTIuNDg2Njc1QzIuOTgwODIyLTIuNTgyMzE2IDIuOTk2NzYyLTIuNjQ2MDc3IDIuOTk2NzYyLTIuNzY1NjI5QzIuOTk2NzYyLTMuMjAzOTg1IDIuNjQ2MDc3LTMuNTE0ODE5IDIuMTgzODExLTMuNTE0ODE5QzEuMzM4OTc5LTMuNTE0ODE5IC44NDQ4MzItMi4zOTkwMDQgLjg0NDgzMi0yLjI5NTM5MkMuODQ0ODMyLTIuMjIzNjYxIC45MDA2MjMtMi4xOTE3ODEgLjk2NDM4NC0yLjE5MTc4MUMxLjA1MjA1NS0yLjE5MTc4MSAxLjA2MDAyNS0yLjIxNTY5MSAxLjExNTgxNi0yLjMzNTI0M0MxLjM1NDkxOS0yLjg4NTE4MSAxLjc2MTM5NS0zLjI5MTY1NiAyLjE1OTktMy4yOTE2NTZDMi4zMjcyNzMtMy4yOTE2NTYgMi40MjI5MTQtMy4xODAwNzUgMi40MjI5MTQtMi45MTcwNjFDMi40MjI5MTQtMi44MDU0NzkgMi4zOTkwMDQtMi42OTM4OTggMi4zNzUwOTMtMi41ODIzMTZMMS42MjU5MDMgLjM5ODUwNlonLz4KPHBhdGggaWQ9J2cxLTExMicgZD0nTS40MTQ0NDYgLjk2NDM4NEMuMzUwNjg1IDEuMjE5NDI3IC4zMzQ3NDUgMS4yODMxODggLjAxNTk0IDEuMjgzMTg4Qy0uMDk1NjQxIDEuMjgzMTg4LS4xOTEyODMgMS4yODMxODgtLjE5MTI4MyAxLjQzNDYyQy0uMTkxMjgzIDEuNTA2MzUxLS4xMTk1NTIgMS41NDYyMDItLjA3OTcwMSAxLjU0NjIwMkMwIDEuNTQ2MjAyIC4wMzE4OCAxLjUyMjI5MSAuNjIxNjY5IDEuNTIyMjkxQzEuMTk1NTE3IDEuNTIyMjkxIDEuMzYyODg5IDEuNTQ2MjAyIDEuNDE4NjggMS41NDYyMDJDMS40NTA1NiAxLjU0NjIwMiAxLjU3MDExMiAxLjU0NjIwMiAxLjU3MDExMiAxLjM5NDc3QzEuNTcwMTEyIDEuMjgzMTg4IDEuNDU4NTMxIDEuMjgzMTg4IDEuMzYyODg5IDEuMjgzMTg4Qy45ODAzMjQgMS4yODMxODggLjk4MDMyNCAxLjIzNTM2NyAuOTgwMzI0IDEuMTYzNjM2Qy45ODAzMjQgMS4xMDc4NDYgMS4xMjM3ODYgLjU0MTk2OCAxLjM2Mjg4OS0uMzkwNTM1QzEuNDY2NTAxLS4yMDcyMjMgMS43MTM1NzQgLjA3OTcwMSAyLjE0Mzk2IC4wNzk3MDFDMy4xMjQyODQgLjA3OTcwMSA0LjE0NDQ1OC0xLjA1MjA1NSA0LjE0NDQ1OC0yLjIwNzcyMUM0LjE0NDQ1OC0yLjk5Njc2MiAzLjYzNDM3MS0zLjUxNDgxOSAyLjk5Njc2Mi0zLjUxNDgxOUMyLjUxODU1NS0zLjUxNDgxOSAyLjEzNTk5LTMuMTg4MDQ1IDEuOTA0ODU3LTIuOTQ4OTQxQzEuNzM3NDg0LTMuNTE0ODE5IDEuMjAzNDg3LTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMjY3NzUtMi43MjU3NzggLjIzOTEwMy0yLjMxOTMwMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42Mjk2MzktMi44MzczNiAuNzczMTAxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMjk5MTI4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMTA4MzQ0IDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuODM3MzYgMS4zMjMwMzktMi42NDYwNzcgMS4zMDcwOTgtMi41ODIzMTZMLjQxNDQ0NiAuOTY0Mzg0Wk0xLjg4MDk0Ni0yLjQ1NDc5NUMxLjkyMDc5Ny0yLjU5MDI4NiAxLjkyMDc5Ny0yLjYwNjIyNyAyLjA0MDM0OS0yLjc0OTY4OUMyLjM0MzIxMy0zLjEwODM0NCAyLjY4NTkyOC0zLjI5MTY1NiAyLjk3Mjg1Mi0zLjI5MTY1NkMzLjM3MTM1Ny0zLjI5MTY1NiAzLjUyMjc5LTIuOTAxMTIxIDMuNTIyNzktMi41NDI0NjZDMy41MjI3OS0yLjI0NzU3MiAzLjM0NzQ0Ny0xLjM5NDc3IDMuMTA4MzQ0LS45MjQ1MzNDMi45MDExMjEtLjQ5NDE0NyAyLjUxODU1NS0uMTQzNDYyIDIuMTQzOTYtLjE0MzQ2MkMxLjYwMTk5My0uMTQzNDYyIDEuNDc0NDcxLS43NjUxMzEgMS40NzQ0NzEtLjgyMDkyMkMxLjQ3NDQ3MS0uODM2ODYyIDEuNDkwNDExLS45MjQ1MzMgMS40OTgzODEtLjk0ODQ0M0wxLjg4MDk0Ni0yLjQ1NDc5NVonLz4KPHBhdGggaWQ9J2cwLTE4JyBkPSdNNi41Mzk0NzctNS44NTgwMzJDNi41Mzk0NzctNy45NjIxNDIgNS4yOTYxMzktOC4zOTI1MjggNC41NjY4NzQtOC4zOTI1MjhDMy42MjI0MTYtOC4zOTI1MjggMi40MjY4OTktNy43NzA4NTkgMS41MzAyNjItNi4xNDQ5NTZDLjkyMDU0OC01LjAyMTE3MSAuNTQ5OTM4LTMuMzk1MjY4IC41NDk5MzgtMi40MjY4OTlDLjU0OTkzOC0uNjkzNCAxLjQ1ODUzMSAuMDk1NjQxIDIuNTM0NDk2IC4wOTU2NDFDMy4zMzU0OTIgLjA5NTY0MSA0LjM4NzU0Ny0uMzcwNjEgNS4yMTI0NTMtMS41OTAwMzdDNi4yMTY2ODctMy4wNjA1MjMgNi41Mzk0NzctNC45NjEzOTUgNi41Mzk0NzctNS44NTgwMzJaTTIuMzY3MTIzLTQuNDM1MzY3QzIuNTM0NDk2LTUuMTI4NzY3IDIuODQ1MzMtNi4yMTY2ODcgMy4yMDM5ODUtNi44MzgzNTZDMy40Nzg5NTQtNy4zMjg1MTggMy45NjkxMTYtNy45NjIxNDIgNC41NDI5NjQtNy45NjIxNDJDNS4wNDUwODEtNy45NjIxNDIgNS4yNjAyNzQtNy40MzYxMTUgNS4yNjAyNzQtNi43MzA3NkM1LjI2MDI3NC01Ljk3NzU4NCA0Ljk5NzI2LTQuOTM3NDg0IDQuODY1NzUzLTQuNDM1MzY3SDIuMzY3MTIzWk00LjcyMjI5MS0zLjg2MTUxOUMzLjk4MTA3MS0uNjU3NTM0IDIuOTc2ODM3LS4zMzQ3NDUgMi41NTg0MDYtLjMzNDc0NUMyLjM5MTAzNC0uMzM0NzQ1IDIuMTM5OTc1LS4zODI1NjUgMS45NzI2MDMtLjc1MzE3NkMxLjgyOTE0MS0xLjA3NTk2NSAxLjgyOTE0MS0xLjU0MjIxNyAxLjgyOTE0MS0xLjU1NDE3MkMxLjgyOTE0MS0yLjIzNTYxNiAyLjA5MjE1NC0zLjM0NzQ0NyAyLjIyMzY2MS0zLjg2MTUxOUg0LjcyMjI5MVonLz4KPHBhdGggaWQ9J2cwLTY3JyBkPSdNMTAuMTg1ODAzLTguMDQ1ODI4QzEwLjE5Nzc1OC04LjEwNTYwNCAxMC4yMjE2NjktOC4xNjUzOCAxMC4yMjE2NjktOC4yMzcxMTFDMTAuMjIxNjY5LTguNDA0NDgzIDEwLjA1NDI5Ni04LjQwNDQ4MyA5LjkyMjc5LTguNDA0NDgzTDguODEwOTU5LTcuNTQzNzExQzguMjYxMDIxLTguMTUzNDI1IDcuNDQ4MDctOC40MDQ0ODMgNi42MjMxNjMtOC40MDQ0ODNDMi43NzM1OTktOC40MDQ0ODMgLjY1NzUzNC01LjQ3NTQ2NyAuNjU3NTM0LTMuMDI0NjU4Qy42NTc1MzQtLjc2NTEzMSAyLjQ2Mjc2NSAuMjAzMjM4IDQuNTU0OTE5IC4yMDMyMzhDNS41NTkxNTMgLjIwMzIzOCA2LjU3NTM0Mi0uMTA3NTk3IDcuNDgzOTM1LS43NzcwODZDOC42NDM1ODctMS42Mzc4NTggOC44NTg3OC0yLjczNzczMyA4Ljg1ODc4LTIuNzk3NTA5QzguODU4NzgtMi45NjQ4ODIgOC42OTE0MDctMi45NjQ4ODIgOC41ODM4MTEtMi45NjQ4ODJDOC4zNTY2NjMtMi45NjQ4ODIgOC4zNDQ3MDctMi45NDA5NzEgOC4yODQ5MzItMi43Mzc3MzNDNy43OTQ3Ny0xLjIxOTQyNyA2LjI0MDU5OC0uMzU4NjU1IDQuODc3NzA5LS4zNTg2NTVDNC4xNDg0NDMtLjM1ODY1NSAzLjUwMjg2NC0uNTI2MDI3IDMuMDEyNzAyLS45MDg1OTNDMi4zNjcxMjMtMS4zOTg3NTUgMi4zMTkzMDMtMi4yMTE3MDYgMi4zMTkzMDMtMi41MzQ0OTZDMi4zMTkzMDMtMi44ODExOTYgMi41MTA1ODUtNS4xMTY4MTIgMy42OTQxNDctNi41MDM2MTFDNC4zMzk3MjYtNy4yNjg3NDIgNS40OTkzNzctNy44NDI1OSA2LjgxNDQ0Ni03Ljg0MjU5QzguMjcyOTc2LTcuODQyNTkgOC44ODI2OS02Ljc0MjcxNSA4Ljg4MjY5LTUuNjkwNjZDOC44ODI2OS01LjU1OTE1MyA4Ljg0NjgyNC01LjM5MTc4MSA4Ljg0NjgyNC01LjI3MjIyOUM4Ljg0NjgyNC01LjA5MjkwMiA5LjAwMjI0Mi01LjA5MjkwMiA5LjE2OTYxNC01LjA5MjkwMkM5LjQzMjYyOC01LjA5MjkwMiA5LjQ0NDU4My01LjEwNDg1NyA5LjUwNDM1OS01LjM1NTkxNUwxMC4xODU4MDMtOC4wNDU4MjhaJy8+CjxwYXRoIGlkPSdnMC0xMTUnIGQ9J000Ljk0OTQ0LTQuNzEwMzM2QzQuNTU0OTE5LTQuNTU0OTE5IDQuNDQ3MzIzLTQuMTk2MjY0IDQuNDQ3MzIzLTQuMDI4ODkyQzQuNDQ3MzIzLTMuNzE4MDU3IDQuNjk4MzgxLTMuNTM4NzMgNC45NjEzOTUtMy41Mzg3M0M1LjI0ODMxOS0zLjUzODczIDUuNjkwNjYtMy43Nzc4MzMgNS42OTA2Ni00LjM1MTY4MUM1LjY5MDY2LTQuOTg1MzA1IDUuMDU3MDM2LTUuNDAzNzM2IDMuOTgxMDcxLTUuNDAzNzM2QzMuNjM0MzcxLTUuNDAzNzM2IDIuOTY0ODgyLTUuMzc5ODI2IDIuNDE0OTQ0LTQuOTYxMzk1QzEuODc2OTYxLTQuNTU0OTE5IDEuNjg1Njc5LTMuODYxNTE5IDEuNjg1Njc5LTMuNTYyNjRDMS42ODU2NzktMy4yMDM5ODUgMS44NTMwNTEtMi44NjkyNCAyLjExNjA2NS0yLjY1NDA0N0MyLjQ1MDgwOS0yLjM5MTAzNCAyLjY1NDA0Ny0yLjM1NTE2OCAzLjQ2Njk5OS0yLjE5OTc1MUMzLjgyNTY1NC0yLjEzOTk3NSA0LjU0Mjk2NC0yLjAwODQ2OCA0LjU0Mjk2NC0xLjQ3MDQ4NkM0LjU0Mjk2NC0xLjQyMjY2NSA0LjU0Mjk2NC0uMzM0NzQ1IDIuNzYxNjQ0LS4zMzQ3NDVDMi4xNzU4NDEtLjMzNDc0NSAxLjczMzQ5OS0uNDU0Mjk2IDEuNDcwNDg2LS42NDU1NzlDMS44NzY5NjEtLjc2NTEzMSAyLjEyODAyLTEuMTExODMxIDIuMTI4MDItMS40NzA0ODZDMi4xMjgwMi0xLjkwMDg3MiAxLjc4MTMyLTIuMDIwNDIzIDEuNTQyMjE3LTIuMDIwNDIzQzEuMTM1NzQxLTIuMDIwNDIzIC42ODE0NDUtMS42ODU2NzkgLjY4MTQ0NS0xLjA4NzkyQy42ODE0NDUtLjMxMDgzNCAxLjUxODMwNiAuMDk1NjQxIDIuNzM3NzMzIC4wOTU2NDFDNS40NjM1MTIgLjA5NTY0MSA1LjQ2MzUxMi0xLjk0ODY5MiA1LjQ2MzUxMi0xLjk2MDY0OEM1LjQ2MzUxMi0yLjM2NzEyMyA1LjI2MDI3NC0yLjY4OTkxMyA0Ljk4NTMwNS0yLjkyOTAxNkM0LjYxNDY5NS0zLjI1MTgwNiA0LjE2MDM5OS0zLjMzNTQ5MiAzLjc0MTk2OC0zLjQwNzIyM0MzLjA4NDQzMy0zLjUyNjc3NSAyLjYxODE4Mi0zLjYxMDQ2MSAyLjYxODE4Mi00LjA1MjgwMkMyLjYxODE4Mi00LjA3NjcxMiAyLjYxODE4Mi00Ljk3MzM1IDMuOTU3MTYxLTQuOTczMzVDNC4xOTYyNjQtNC45NzMzNSA0LjYyNjY1LTQuOTQ5NDQgNC45NDk0NC00LjcxMDMzNlonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzE0My43MzkxNjEnIHk9Jy01LjM5MDg4NicgeGxpbms6aHJlZj0nI2cwLTE4Jy8+Cjx1c2UgeD0nMTUwLjgzNzQ5NycgeT0nLTEwLjUzODI0JyB4bGluazpocmVmPScjZzEtMTA2Jy8+Cjx1c2UgeD0nMTUwLjgzNzQ5NycgeT0nLTIuNDM1MzcxJyB4bGluazpocmVmPScjZzEtMTEyJy8+Cjx1c2UgeD0nMTU1LjU5ODQwNicgeT0nLTUuMzkwODg2JyB4bGluazpocmVmPScjZzQtNDAnLz4KPHVzZSB4PScxNjAuMTUwNzMyJyB5PSctNS4zOTA4ODYnIHhsaW5rOmhyZWY9JyNnMC0xMTUnLz4KPHVzZSB4PScxNjYuNTAxOTE1JyB5PSctNS4zOTA4ODYnIHhsaW5rOmhyZWY9JyNnNC00MScvPgo8dXNlIHg9JzE3NC4zNzUwNycgeT0nLTUuMzkwODg2JyB4bGluazpocmVmPScjZzQtNjEnLz4KPHVzZSB4PScxODYuODAwNTUxJyB5PSctNS4zOTA4ODYnIHhsaW5rOmhyZWY9JyNnNC05MScvPgo8dXNlIHg9JzE5MC4wNTIyMTInIHk9Jy01LjM5MDg4NicgeGxpbms6aHJlZj0nI2cwLTY3Jy8+Cjx1c2UgeD0nMjAwLjY1MzIzNicgeT0nLTUuMzkwODg2JyB4bGluazpocmVmPScjZzQtNDAnLz4KPHVzZSB4PScyMDUuMjA1NTYyJyB5PSctNS4zOTA4ODYnIHhsaW5rOmhyZWY9JyNnMC0xMTUnLz4KPHVzZSB4PScyMTEuNTU2NzQ1JyB5PSctNS4zOTA4ODYnIHhsaW5rOmhyZWY9JyNnMi01OScvPgo8dXNlIHg9JzIxNi44MDA5MDMnIHk9Jy01LjM5MDg4NicgeGxpbms6aHJlZj0nI2cwLTExNScvPgo8dXNlIHg9JzIyMy4xNTIwODcnIHk9Jy0zLjU5NzYyMycgeGxpbms6aHJlZj0nI2cxLTExMicvPgo8dXNlIHg9JzIyNy45MTI5OTYnIHk9Jy01LjM5MDg4NicgeGxpbms6aHJlZj0nI2c0LTQxJy8+Cjx1c2UgeD0nMjMyLjQ2NTMyMicgeT0nLTUuMzkwODg2JyB4bGluazpocmVmPScjZzQtOTMnLz4KPHVzZSB4PScyMzUuNzE2OTgzJyB5PSctMS41NDk3NDYnIHhsaW5rOmhyZWY9JyNnMy01OCcvPgo8dXNlIHg9JzIzOC4wNjkzMDcnIHk9Jy0xLjU0OTc0NicgeGxpbms6aHJlZj0nI2cxLTU5Jy8+Cjx1c2UgeD0nMjQwLjQyMTYzMScgeT0nLTEuNTQ5NzQ2JyB4bGluazpocmVmPScjZzEtMTA2Jy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
The SVD approach is used when the covariance function is not explicitly known but only through
 fields
fields  respectively
associated to the weights
respectively
associated to the weights  . The weights are not necessarily all equal
when, for example, the fields have been generated from an importance sampling technique.
. The weights are not necessarily all equal
when, for example, the fields have been generated from an importance sampling technique.The SVD approach consists in approximating
 by its empirical estimator computed from the fields
which have been centered and in taking the
by its empirical estimator computed from the fields
which have been centered and in taking the  vertices of the mesh of
vertices of the mesh of  as
the quadrature points to compute the integrals of the Fredholm problem.
as
the quadrature points to compute the integrals of the Fredholm problem.We denote by
 the centered fields. If the mean process is not known,
it is approximated by
the centered fields. If the mean process is not known,
it is approximated by  .
.The empirical estimator of
is then defined by:
where
 if the
if the  are already centered or
if the mean process is known, and
are already centered or
if the mean process is known, and  if the mean
process has been estimated from the fields.
if the mean
process has been estimated from the fields.We suppose now that
 , and we note
, and we note  and
and
 (see
(see
KarhunenLoeveQuadratureAlgorithm).As the matrix
 is nonsingular, the Galerkin and collocation
approaches are equivalent and both lead to the following singular value problem for
is nonsingular, the Galerkin and collocation
approaches are equivalent and both lead to the following singular value problem for  :
:(1)¶

The SVD decomposition of
 is:
is:
where the matrices
 ,
,
 ,
,
 are such that :
are such that : ,
, ,
, .
.
Then the columns of
 are the eigenvectors of
are the eigenvectors of  associated to the eigenvalues
associated to the eigenvalues  .
.We deduce the modes and eigenvalues of the Fredholm problem for
 :
:
For
, we have:
The most computationally intensive part of the algorithm is the computation of the SVD decomposition. By default, it is done using LAPACK dgesdd routine. While being very accurate and reasonably fast for small to medium sized problems, it becomes prohibitively slow for large cases. The user can choose to use a stochastic algorithm instead, with the constraint that the number of singular values to be computed has to be fixed a priori. The following keys of
ResourceMapallow one to select and tune these algorithms:‘KarhunenLoeveSVDAlgorithm-UseRandomSVD’ which triggers the use of a random algorithm. By default, it is set to False and LAPACK is used.
‘KarhunenLoeveSVDAlgorithm-RandomSVDMaximumRank’ which fixes the number of singular values to compute. By default it is set to 1000.
‘KarhunenLoeveSVDAlgorithm-RandomSVDVariant’ which can be equal to either ‘Halko2010’ for [halko2010] (the default) or ‘Halko2011’ for [halko2011]. These two algorithms have very similar structures, the first one being based on a random compression of both the rows and columns of
, the
second one being based on an iterative compressed sampling of the columns of
.‘KarhunenLoeveSVDAlgorithm-halko2011Margin’ and ‘KarhunenLoeveSVDAlgorithm-halko2011Iterations’ to fix the parameters of the ‘halko2011’ variant. See [halko2011] for the details.
Examples
Create a Karhunen-Loeve SVD algorithm:
>>> import openturns as ot >>> mesh = ot.IntervalMesher([10]*2).build(ot.Interval([-1.0]*2, [1.0]*2)) >>> s = 0.01 >>> model = ot.AbsoluteExponential([1.0]*2) >>> sample = ot.GaussianProcess(model, mesh).getSample(8) >>> algorithm = ot.KarhunenLoeveSVDAlgorithm(sample, s)
Run it!
>>> algorithm.run() >>> result = algorithm.getResult()
Methods
Accessor to the object's name.
Accessor to the covariance model.
getName()Accessor to the object's name.
Accessor to number of modes to compute.
Get the result structure.
Accessor to the process sample.
Accessor to the weights of the sample.
Accessor to the threshold used to select the most significant eigenmodes.
Accessor to the weights of the vertices.
hasName()Test if the object is named.
run()Computation of the eigenvalues and eigenfunctions values at nodes.
setCovarianceModel(covariance)Accessor to the covariance model.
setName(name)Accessor to the object's name.
setNbModes(nbModes)Accessor to the maximum number of modes to compute.
setThreshold(threshold)Accessor to the limit ratio on eigenvalues.
- __init__(*args)¶
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getCovarianceModel()¶
Accessor to the covariance model.
- Returns:
- covModel
CovarianceModel The covariance model.
- covModel
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- getNbModes()¶
Accessor to number of modes to compute.
- Returns:
- nint
The maximum number of modes to compute. The actual number of modes also depends on the threshold criterion.
- getResult()¶
Get the result structure.
- Returns:
- resKL
KarhunenLoeveResult The structure containing all the results of the Fredholm problem.
- resKL
Notes
The structure contains all the results of the Fredholm problem.
- getSample()¶
Accessor to the process sample.
- Returns:
- sample
ProcessSample The process sample containing the observations of the process.
- sample
- getSampleWeights()¶
Accessor to the weights of the sample.
- Returns:
- weights
Point The weights associated to the fields of the sample.
- weights
Notes
The fields might not have the same weight, for example if they come from importance sampling.
- getThreshold()¶
Accessor to the threshold used to select the most significant eigenmodes.
- Returns:
- sfloat, positive
The threshold
 .
.
Notes
OpenTURNS truncates the sequence
 at the index defined in (3).
at the index defined in (3).
- getVerticesWeights()¶
Accessor to the weights of the vertices.
- Returns:
- weights
Point The weights associated to the vertices of the mesh defining the sample field.
- weights
Notes
The vertices might not have the same weight, for example if the mesh is not regular.
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- run()¶
Computation of the eigenvalues and eigenfunctions values at nodes.
Notes
Runs the algorithm and creates the result structure
KarhunenLoeveResult.
- setCovarianceModel(covariance)¶
Accessor to the covariance model.
- Parameters:
- covModel
CovarianceModel The covariance model.
- covModel
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
- setNbModes(nbModes)¶
Accessor to the maximum number of modes to compute.
- Parameters:
- nint
The maximum number of modes to compute. The actual number of modes also depends on the threshold criterion.

{kind=link}