Architecture¶
The project is an open source project. It aims at developing a computational platform designed to carry out industrial studies on uncertainty processing and risk analysis.
This platform is intended to be released as an open source contribution to a wide audience whose technical skills are very diverse. Another goal of the project is to make the community of users ultimately responsible for the platform and its evolution by contributing to its maintenance and developing new functions.
This architecture specifications document therefore serves two purposes:
to provide the design principles that govern the platform, in order to guide the development teams in their development process;
to inform external users about the platform’s architecture and its design, in order to facilitate their first steps with the platform.
To address these questions, the platform needs to be:
portable: the ability to build, execute and validate the application in different environments (operating system, hardware platform as well as software environment) based on a single set of source code files.
extensible: the possibility to add new functions to the application with a minimal impact on the existing code.
upgradable: the ability to control the impact of a replacement or a change on the technical architecture, following an upgrade of the technical infrastructure (such as the replacement of one tool by another or the use of a new storage format).
durable: the technical choices must have a lifespan comparable to the application’s while relying on standard and/or open source solutions.
Overview¶
This chapter will describe the general design of and a few design models that are widely used within the platform.
The core of the platform is a C++ library made of about 800 classes of various size.
The main user interface is a python module, automatically generated from the C++ library using the wrapping software SWIG. It allows for a usage through python scripts of any level of complexity.
The library relies on few mandatory dependencies (LAPACK), the other being optional.
Several GUIs have already been built on top of the C++ library or the Python module.
A service of modules is provided in order to extend the capabilities of the platform from the outside.
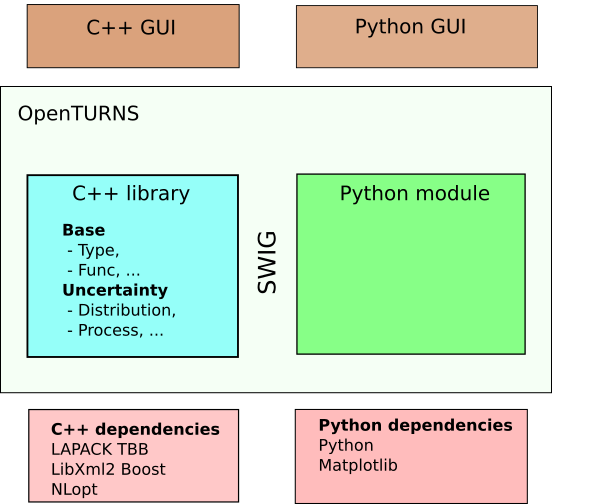
Software architecture overview¶
The C++ library¶
A multi-layered library¶
The library has a multi-layered architecture materialized by the source tree. The two main layers in the C++ library are the Base layer and the Uncertainty layer.
Base layer: it contains all the classes not related to the probabilistic concepts. It covers the elementary data types (vectors as Point, samples as Samples), the concept of models (Function), the linear algebra (Matrix, Tensor) and the general interest classes (memory management, resource management);
Uncertainty layer: it contains all the classes that deal with probabilistic concepts. It covers the probabilistic modelling (Distribution, RandomVector), the stochastic algorithms (MonteCarlo, FORM), the statistical estimation (DistributionFactory), the statistical testing (FittingTest)
A class in the Uncertainty layer can use any class in the Base or the Uncertainty layer. A class in the Base layer can ONLY USE classes in the Base layer.
Resource management¶
OpenTURNS uses extensively dynamic memory allocation. In order to tie to the Resource Acquisition Is Initialization (RAII) paradigm, all the memory management is delegated to smart pointers (the Pointer class). The benefits of this approach are:
An easy to implement copy on write mechanism, that permit a significant reduction of the memory footprint by allowing for a large data sharing between objects;
No C-like pointers in members of classes, which permits an automatic generation of the copy constructor, the assignment operator and the destructor of almost all the classes: there is no problem of deep copy versus reference copy;
The resource is released automatically when the objects are outside of the current scope and there is no more reference on the allocated memory;
There is a unique point where to prevent concurrent access in a parallel context, which is a key property for parallelism.
The Python module¶
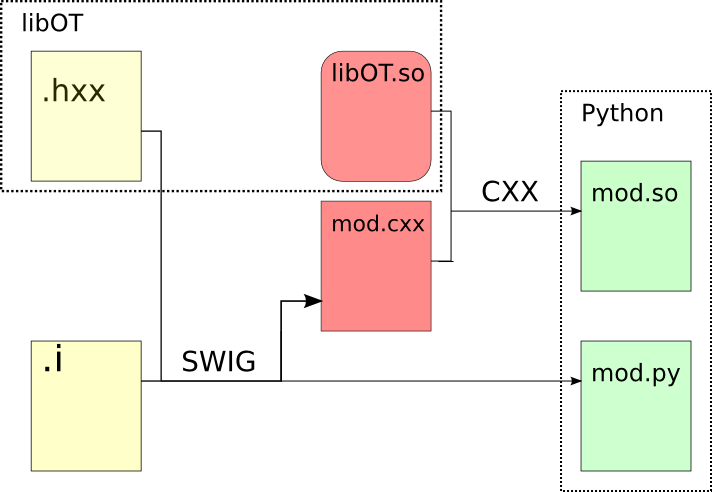
Python module generation process¶
Software environment¶
This section details the technical elements required by the OpenTURNS platform, namely the system requirements, the tools and the development environment of the project.
Target platforms¶
The platform is meant to carry out uncertainty treatment studies in a scientific environment. Most of the scientific codes being available on Unix platforms, the library is naturally designed to run on this family of systems. Unix being a standard with multiple implementations, available on different architectures, this gives a wide choice of target platforms.
The primary development platform is Linux, and the software is known to work on various distributions (Debian, Fedora, …).
The code also supports other platforms such as Windows and MacOS.
External dependencies¶
The tools chosen for the development of the platform are:
Category |
Name |
Version |
|---|---|---|
Configuration |
3.13 |
|
C/C++ compiler (C99/C++17) |
8 |
|
Linear algebra |
3.0 |
|
Linear algebra |
3.0 |
|
Linear algebra (optional, GPL) |
1.7 |
|
Linear algebra (optional) |
1.0.0 |
|
Legacy analytical parser (optional) |
2.2.3 |
|
Prime numbers (optional) |
7.5 |
|
Special functions (optional) |
1.46 |
|
Special functions (optional) |
4.0.0 |
|
Special functions (optional) |
1.1.0 |
|
Optimization (optional) |
2.6 |
|
Optimization (optional) |
1.3 |
|
Optimization (optional) |
1.11 |
|
Optimization (optional) |
19.8 |
|
Optimization (optional) |
1.8.7 |
|
Optimization (optional) |
3.11.9 |
|
Optimization (optional) |
2.12.0 |
|
Integration (optional) |
4.2.2 |
|
CSV parser (optional) |
2.5.33 |
|
CSV parser (optional) |
2.4 |
|
XML support (optional) |
2.6.27 |
|
HDF5 support (optional) |
1.10 |
|
Multithreading (optional) |
2017 |
|
Nearest neighbor search (optional) |
nanoflann <https://github.com/jlblancoc/nanoflann>_ |
1.3.2 |
Python support |
3.6 |
|
Plotting library (optional) |
3.0 |
|
C++/Python wrapper |
3.0.11 |
|
Version control |
2.5 |
|
ReSt to HTML (optional for doc) |
1.8 |
|
Sphinx extension (optional for doc) |
0.9.0 |
|
Sphinx extension (optional for doc) |
0.7 |
|
Sphinx extension (optional for doc) |
0.5 |
|
Sphinx extension (optional for doc) |
4.1 |
|
dill (optional for serialization) |
0.3.5 |
|
psutil (optional for coupling) |
N/A |
The versions given here are only meant as indications of minimum version and newer ones may be used.
Internal dependencies¶
We would like to acknowledge the following codes that are included into the library:
Optimization |
|
Mersenne twister RNG |
|
Differenciation |
|
Symbolic parser |
|
Faddeeva function |
|
Kendall Tau |
|
FFT |
|
KS distribution |
|
Optimization |
|
Quadrature |
Compilation infrastructure¶
The compilation infrastructure uses CMake, it covers:
The detection and configuration aspects of the platform;
The dependency management of the sources;
The generation of parallel makefiles;
The regression tests.
Version control¶
The project uses Git version-control system. The code repositories are hosted on GitHub (https://github.com/openturns/).
Continuous integration¶
The git code repository is monitored for changes by automated builds, allowing developers to detect problems early.
Each pull-request on the GitHub code repository triggers continuous integration jobs for the different target platforms to be run on several free continuous integration services:
CircleCI (https://circleci.com/) for Linux/MinGW
Github Actions (https://github.com/actions) for macOS/Windows
Each of these jobs checks that the library can be successfully compiled and that all unit tests pass. All jobs passing is one of the necessary conditions for the code to be integrated.
Packaging¶
The team officially provides binaries for the Debian operating system, and Windows. Note that is officially supported in Debian: it can be installed easily from the debian software repositories. Packages are also available for some RPM-based distributions such as Fedora, CentOS and openSUSE.
Design patterns¶
Introduction¶
Software design shows the recurrence of some patterns, whether within the same piece of software or in several applications (which can differ in many ways). These patterns have been catalogued, described and implemented in numerous situations that prove their universality and their ability to solve recurring problems that the software architect is faced with.
The following sections give an overview intended as much for the reader’s understanding of the document as to establish a common vocabulary for software architect. The latter ones will find here standard design diagrams applied to the specific case of , which can help them better apprehend the tool’s specificities and the design and implementation choices that were made.
Bridge pattern¶
This pattern is one of the most widely used in . Some examples are:
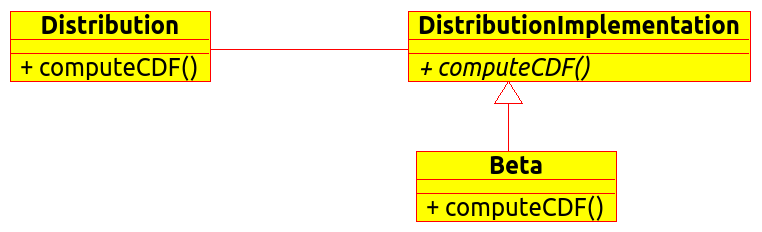
Drawable, that separate the generic high level interface of a drawable from the specific low level interface of the several drawable specializations;
Distribution, see [fig:bridge], that exposes a high level interface of the concept of probability distribution whereas the DistributionImplementation class exposes the low level interface of the same concept.
Singleton pattern¶
The Singleton is a pattern used to ensure that at any given time, there is only one instance of a class (A); it provides an access point for this unique instance.
This is implemented by creating a class (Singleton) with a static private attribute (uniqueInstance) initialized with an instance of class A and whose reference (or pointer) is returned by a static method (instance). Figure [fig:singleton] illustrates the Singleton pattern.
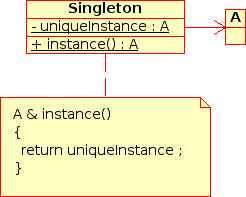
It is a very common pattern that allows one to find and share an object (which must remain unique) in different portions of code. Examples of such objects include shared hardware resources (standard output, error, log, etc.), but also internal functions that cannot or must not be duplicated (e.g. a random number generator). For example, the classes ResourceMap and IdFactory follow this pattern.
Factory pattern¶
This pattern allows one to define a unique interface for the creation of objects belonging to a class hierarchy without knowing in advance their exact type. Figure [fig:factory] illustrates this pattern. The creation of the concrete object (ClassA or ClassB) is delegated to a sub-class (ClassAFactory or ClassBFactory) which chooses the type of object to be created and the strategy to be used to create it.
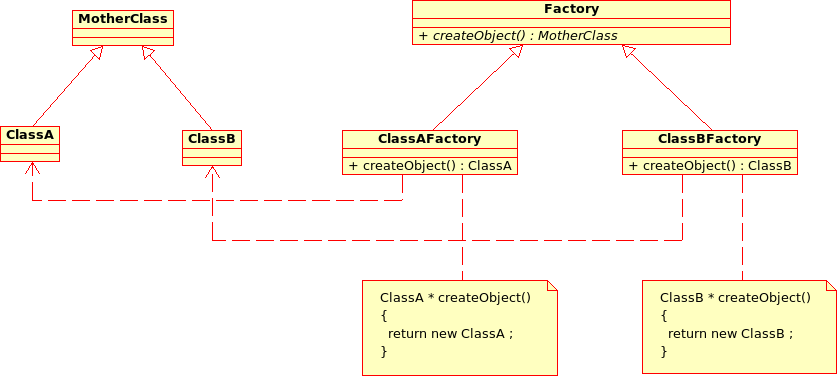
This pattern is often used to dynamically create objects belonging to related types (e.g. to instantiate objects within a GUI according to the user’s behavior). It can also be used to back up and read again a document written in a file by automatically re-instantiating objects. It is a pattern that makes code maintenance easier by clearly separating the objects and their instantiation in distinct and parallel class hierarchies. For example, the classes DistributionFactory, ApproximationAlgorithmImplementationFactory, BasisSequenceFactory follow this pattern.
Strategy pattern¶
The Strategy pattern defines a family of algorithm and makes them interchangeable as far as the client is concerned. Access to these algorithms is provided by a unique interface which encapsulates the algorithms’ implementation. Therefore, the implementation can change without the client being aware of it.
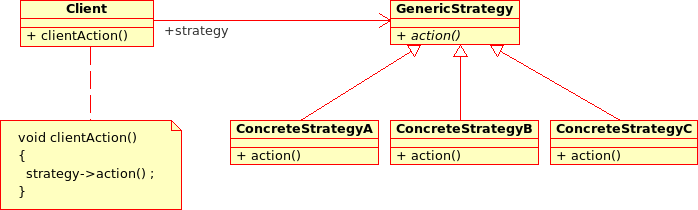
This pattern is very useful to provide a client with different implementations of an algorithm which are equivalent from a functional point of view. It can be noted that the Factory pattern described earlier makes use of the Strategy pattern. For example, the classes ComparisonOperator, HistoryStrategy follow this pattern.
Composite pattern¶
The Composite pattern is used to organize objects into a tree structure that represents the hierarchies between component and composite objects. It hides the complex structure of the object from the client handling the object.
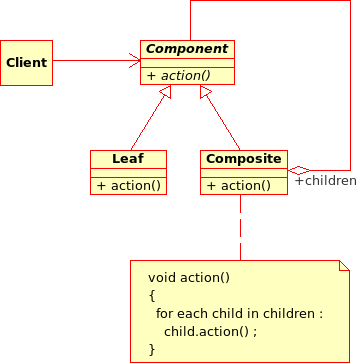
The Composite pattern is an essential element of the design model for the platform. It can be found in several modeling bricks, such as function composition (ComposedFunction) random vector composition (CompositeRandomVector), joint distributions (JointDistribution), etc.