Conditional distributions¶
The library offers some modelisation capacities on conditional distributions:
Case 1: Create a joint distribution using conditioning,
Case 2: Condition a joint distribution by some values of its marginals,
Case 3: Create a distribution whose parameters are random,
Case 4: Create a Bayesian posterior distribution.
Case 1: Create a joint distribution using conditioning¶
The objective is to create the joint distribution of the random vector  where
where  follows the distribution
follows the distribution  and
and  follows the distribution
follows the distribution  where
where  with
with  a link function of input dimension
the dimension of and output dimension the dimension of
a link function of input dimension
the dimension of and output dimension the dimension of  .
.
This distribution is limited to the continuous case, ie when both the conditioning and the conditioned distributions are continuous. Its probability density function is defined as:

with  the PDF of the distribution of
where has been replaced by
the PDF of the distribution of
where has been replaced by  ,
,
 the PDF of .
the PDF of .
See the class JointByConditioningDistribution.
Case 2: Condition a joint distribution to some values of its marginals¶
Let  be a random vector of dimension
be a random vector of dimension  . Let
. Let  be a set of indices of components of ,
be a set of indices of components of ,  its complementary in
its complementary in
 and
and  a real vector of dimension equal to the cardinal of
a real vector of dimension equal to the cardinal of  .
The objective is to create the distribution of:
.
The objective is to create the distribution of:

See the class PointConditionalDistribution.
This class requires the following features:
each component
 is continuous or discrete: e.g., it can not be a
is continuous or discrete: e.g., it can not be a Mixtureof discrete and continuous distributions,the copula of
is continuous: e.g., it can not be the MinCopula,the random vector
 is continuous or discrete: all its components must be discrete
or all its components must be continuous,
is continuous or discrete: all its components must be discrete
or all its components must be continuous,the random vector
 may have some discrete components and some continuous components.
may have some discrete components and some continuous components.
Then, the pdf (probability density function if is continuous or probability distribution function if
is discrete) of  is defined by (in the following
expression, we assumed a particular order of the conditioned components among the whole set of components for easy reading):
is defined by (in the following
expression, we assumed a particular order of the conditioned components among the whole set of components for easy reading):
(1)¶
where:

with:
 is the probability density copula of ,
is the probability density copula of ,if
is a continuous component,  is its probability density function,
is its probability density function,if
is a discrete component,  where
where
 is its support and
is its support and  the Dirac distribution centered on
the Dirac distribution centered on
 .
.
Then, if is continuous, we have:

and if is discrete with its support denoted by
 , we have:
, we have:

Simplification mechanisms to compute (1) are implemented for some distributions. We detail some cases where a simplification has been implemented.
Elliptical distributions: This is the case for normal and Student distributions. If follows a normal or a Student distribution,
then respectively follows a normal or a Student distribution with modified parameters.
See Conditional Normal and
Conditional Student for the formulas of the conditional distributions.
Mixture distributions Let be a random vector of dimension which distribution is defined by a
Mixture of  discrete or continuous atoms. Let denote by
discrete or continuous atoms. Let denote by  the PDF (Probability Density
Function for continuous atoms and Probability Distribution Function for discrete one) of each atom, with respective weights
the PDF (Probability Density
Function for continuous atoms and Probability Distribution Function for discrete one) of each atom, with respective weights  .
Then we get:
.
Then we get:

We denote by  the PDF of the
the PDF of the  -th atom conditioned by . Then, if
-th atom conditioned by . Then, if
 , we get:
, we get:

which finally leads to:
(2)¶
where  with
with  .
The constant normalizes the weights so that
.
The constant normalizes the weights so that  .
.
Noting that  is the PDF of the -th atom
conditioned by , we show that the random vector
is the PDF of the -th atom
conditioned by , we show that the random vector  is the Mixture built from the
-conditioned atoms with weights
is the Mixture built from the
-conditioned atoms with weights  .
.
Conclusion: The conditional distribution of a Mixture is a Mixture of conditional distributions.
Kernel Mixture distributions: The Kernel Mixture distribution is a particular Mixture: all the weights are identical and
all the kernels of the combination are of the same
discrete or continuous family. The kernels are centered on the sample points. The multivariate kernel
is a tensorized product of the same univariate kernel.
Let be a random vector of dimension defined by a Kernel Mixture distribution based on the sample
 and the kernel
and the kernel  . In the continuous case, is the kernel PDF and we have:
. In the continuous case, is the kernel PDF and we have:

where  is the kernel normalized by the bandwidth
is the kernel normalized by the bandwidth  :
:

Following the Mixture case, we still have the relation (2). As the multivariate kernel is the tensorized product of the univariate kernel, we get:

Conclusion: The conditional distribution of a Kernel Mixture is a Mixture which atoms are the tensorized product of the kernel on the remaining components
and which weights  are proportional to:
are proportional to:

as we have  in (2).
in (2).
Truncated distributions: Let be a random vector of dimension which PDF is  . Let
. Let  be a domain of
be a domain of  and let
and let  be the random vector
truncated to the domain . It has the following PDF:
be the random vector
truncated to the domain . It has the following PDF:

where  . Let be in the support of the margin of
. Let be in the support of the margin of
 , denoted by
, denoted by  . We denote by
. We denote by  the conditional random vector:
the conditional random vector:

The random vector is defined on the domain:

The domain  as
as  .
Then, for all
.
Then, for all  , we have:
, we have:

which is:
(3)¶
Now, we denote by the conditional random vector:

Then, we have:

Let  the truncated random vector defined by:
the truncated random vector defined by:

Then, we have:

where  . Noting that:
. Noting that:

we get:

which is:
(4)¶
The equivalence of the relations (3) and (4) proves the conclusion.
Conclusion: The conditional distribution of a truncated distribution is the truncated distribution of the conditional distribution. Care: the truncation domains are not exactly the same.
The following figure illustrates the case where  with
with  .
We plot:
.
We plot:
the PDF of
![\inputRV|\inputRV\in [-0.5, 1.0]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNSAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc5My40MDE4OThwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgOTMuNDAxODk4IDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtODgnIGQ9J002Ljk1NzkwOC00LjcyMjI5MUw4LjUzNTk5LTYuMjc2NDYzTDkuMjc3MjEtNy4wMjk2MzlDOS43NTU0MTctNy40ODM5MzUgOS44OTg4NzktNy42MjczOTcgMTEuMTQyMjE3LTcuNjM5MzUyQzExLjM2OTM2NS03LjYzOTM1MiAxMS4zOTMyNzUtNy45NTAxODcgMTEuMzkzMjc1LTcuOTg2MDUyQzExLjM5MzI3NS04LjA1Nzc4MyAxMS4zNDU0NTUtOC4yMDEyNDUgMTEuMTU0MTcyLTguMjAxMjQ1QzEwLjczNTc0MS04LjIwMTI0NSAxMC4yODE0NDUtOC4xNjUzOCA5Ljg1MTA1OS04LjE2NTM4QzkuNTA0MzU5LTguMTY1MzggOC42NDM1ODctOC4yMDEyNDUgOC4yOTY4ODctOC4yMDEyNDVDOC4yMDEyNDUtOC4yMDEyNDUgNy45NjIxNDItOC4yMDEyNDUgNy45NjIxNDItNy44NjY1MDFDNy45NjIxNDItNy42NTEzMDggOC4xNTM0MjUtNy42MzkzNTIgOC4yNjEwMjEtNy42MzkzNTJDOC42MTk2NzYtNy42MjczOTcgOC45MzA1MTEtNy41MzE3NTYgOC45NzgzMzEtNy41MTk4MDFMNi42OTQ4OTQtNS4yNjAyNzRMNS41OTUwMTktNy41Njc2MjFDNS43MTQ1Ny03LjU5MTUzMiA2LjA4NTE4MS03LjYzOTM1MiA2LjI4ODQxOC03LjYzOTM1MkM2LjQxOTkyNS03LjYzOTM1MiA2LjYzNTExOC03LjYzOTM1MiA2LjYzNTExOC03Ljk3NDA5N0M2LjYzNTExOC04LjE0MTQ2OSA2LjUyNzUyMi04LjIwMTI0NSA2LjM3MjEwNS04LjIwMTI0NUM1Ljk2NTYyOS04LjIwMTI0NSA0Ljk2MTM5NS04LjE2NTM4IDQuNTU0OTE5LTguMTY1MzhDNC4yNzk5NS04LjE2NTM4IDQuMDA0OTgxLTguMTc3MzM1IDMuNzMwMDEyLTguMTc3MzM1UzMuMTY4MTItOC4yMDEyNDUgMi44OTMxNTEtOC4yMDEyNDVDMi43ODU1NTQtOC4yMDEyNDUgMi41NTg0MDYtOC4yMDEyNDUgMi41NTg0MDYtNy44NjY1MDFDMi41NTg0MDYtNy42MzkzNTIgMi43MTM4MjMtNy42MzkzNTIgMy4wNDg1NjgtNy42MzkzNTJDMy4yMTU5NC03LjYzOTM1MiAzLjM0NzQ0Ny03LjYzOTM1MiAzLjUxNDgxOS03LjYyNzM5N0MzLjY4MjE5Mi03LjYwMzQ4NyAzLjY5NDE0Ny03LjU5MTUzMiAzLjc2NTg3OC03LjQ0ODA3TDUuNDE1NjkxLTMuOTkzMDI2TDIuNDE0OTQ0LTEuMDI4MTQ0QzIuMTk5NzUxLS44MjQ5MDcgMS45NDg2OTItLjU3Mzg0OCAuODg0NjgyLS41NjE4OTNDLjY2OTQ4OS0uNTYxODkzIC40NjYyNTItLjU2MTg5MyAuNDY2MjUyLS4yMTUxOTNDLjQ2NjI1Mi0uMTMxNTA3IC41MjYwMjcgMCAuNzA1MzU1IDBDLjk5MjI3OSAwIDEuNzIxNTQ0LS4wMzU4NjYgMi4wMDg0NjgtLjAzNTg2NkMyLjM1NTE2OC0uMDM1ODY2IDMuMjE1OTQgMCAzLjU2MjY0IDBDMy42NTgyODEgMCAzLjg5NzM4NSAwIDMuODk3Mzg1LS4zNDY3QzMuODk3Mzg1LS41NjE4OTMgMy42ODIxOTItLjU2MTg5MyAzLjU4NjU1LS41NjE4OTNDMy4zNDc0NDctLjU2MTg5MyAzLjEwODM0NC0uNTk3NzU4IDIuODgxMTk2LS42ODE0NDVMNS42NjY3NS0zLjQ1NTA0NEw3LjAxNzY4NC0uNjMzNjI0QzcuMDA1NzI5LS42MzM2MjQgNi42MTEyMDgtLjU2MTg5MyA2LjMyNDI4NC0uNTYxODkzQzYuMjA0NzMyLS41NjE4OTMgNS45Nzc1ODQtLjU2MTg5MyA1Ljk3NzU4NC0uMjE1MTkzQzUuOTc3NTg0LS4xNzkzMjggNS45ODk1MzkgMCA2LjI0MDU5OCAwQzYuNjQ3MDczIDAgNy42NjMyNjMtLjAzNTg2NiA4LjA2OTczOC0uMDM1ODY2QzguMzQ0NzA3LS4wMzU4NjYgOC42MTk2NzYtLjAyMzkxIDguODk0NjQ1LS4wMjM5MVM5LjQ1NjUzOCAwIDkuNzMxNTA3IDBDOS44MjcxNDggMCAxMC4wNjYyNTIgMCAxMC4wNjYyNTItLjM0NjdDMTAuMDY2MjUyLS41NjE4OTMgOS44NzQ5NjktLjU2MTg5MyA5LjU4ODA0NS0uNTYxODkzQzkuNDIwNjcyLS41NjE4OTMgOS4zMDExMjEtLjU2MTg5MyA5LjEyMTc5My0uNTczODQ4QzguOTQyNDY2LS41OTc3NTggOC45MzA1MTEtLjYwOTcxNCA4Ljg0NjgyNC0uNzY1MTMxTDYuOTU3OTA4LTQuNzIyMjkxWicvPgo8cGF0aCBpZD0nZzEtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMS01MCcgZD0nTTYuNTUxNDMyLTIuNzQ5Njg5QzYuNzU0NjctMi43NDk2ODkgNi45Njk4NjMtMi43NDk2ODkgNi45Njk4NjMtMi45ODg3OTJTNi43NTQ2Ny0zLjIyNzg5NSA2LjU1MTQzMi0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMy00LjgyOTg4OCAzLjAwMDc0Ny01Ljk3NzU4NCA0LjY4NjQyNi01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3LTUuOTc3NTg0IDYuOTY5ODYzLTUuOTc3NTg0IDYuOTY5ODYzLTYuMjE2Njg3UzYuNzU0NjctNi40NTU3OTEgNi41NTE0MzItNi40NTU3OTFINC42NjI1MTZDMi42MTgxODItNi40NTU3OTEgLjk5MjI3OS00LjkwMTYxOSAuOTkyMjc5LTIuOTg4NzkyUzIuNjE4MTgyIC40NzgyMDcgNC42NjI1MTYgLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IC40NzgyMDcgNi45Njk4NjMgLjQ3ODIwNyA2Ljk2OTg2MyAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMtMS4xNDc2OTYgMS40ODI0NDEtMi43NDk2ODlINi41NTE0MzJaJy8+CjxwYXRoIGlkPSdnMS0xMDYnIGQ9J00xLjkwMDg3Mi04LjUzNTk5QzEuOTAwODcyLTguNzUxMTgzIDEuOTAwODcyLTguOTY2Mzc2IDEuNjYxNzY4LTguOTY2Mzc2UzEuNDIyNjY1LTguNzUxMTgzIDEuNDIyNjY1LTguNTM1OTlWMi41NTg0MDZDMS40MjI2NjUgMi43NzM1OTkgMS40MjI2NjUgMi45ODg3OTIgMS42NjE3NjggMi45ODg3OTJTMS45MDA4NzIgMi43NzM1OTkgMS45MDA4NzIgMi41NTg0MDZWLTguNTM1OTlaJy8+CjxwYXRoIGlkPSdnMi01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnMi01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzMtNDgnIGQ9J001LjM1NTkxNS0zLjgyNTY1NEM1LjM1NTkxNS00LjgxNzkzMyA1LjI5NjEzOS01Ljc4NjMwMSA0Ljg2NTc1My02LjY5NDg5NEM0LjM3NTU5Mi03LjY4NzE3MyAzLjUxNDgxOS03Ljk1MDE4NyAyLjkyOTAxNi03Ljk1MDE4N0MyLjIzNTYxNi03Ljk1MDE4NyAxLjM4NjgtNy42MDM0ODcgLjk0NDQ1OC02LjYxMTIwOEMuNjA5NzE0LTUuODU4MDMyIC40OTAxNjItNS4xMTY4MTIgLjQ5MDE2Mi0zLjgyNTY1NEMuNDkwMTYyLTIuNjY2MDAyIC41NzM4NDgtMS43OTMyNzUgMS4wMDQyMzQtLjk0NDQ1OEMxLjQ3MDQ4Ni0uMDM1ODY2IDIuMjk1MzkyIC4yNTEwNTkgMi45MTcwNjEgLjI1MTA1OUMzLjk1NzE2MSAuMjUxMDU5IDQuNTU0OTE5LS4zNzA2MSA0LjkwMTYxOS0xLjA2NDAxQzUuMzMyMDA1LTEuOTYwNjQ4IDUuMzU1OTE1LTMuMTMyMjU0IDUuMzU1OTE1LTMuODI1NjU0Wk0yLjkxNzA2MSAuMDExOTU1QzIuNTM0NDk2IC4wMTE5NTUgMS43NTc0MS0uMjAzMjM4IDEuNTMwMjYyLTEuNTA2MzUxQzEuMzk4NzU1LTIuMjIzNjYxIDEuMzk4NzU1LTMuMTMyMjU0IDEuMzk4NzU1LTMuOTY5MTE2QzEuMzk4NzU1LTQuOTQ5NDQgMS4zOTg3NTUtNS44MzQxMjIgMS41OTAwMzctNi41Mzk0NzdDMS43OTMyNzUtNy4zNDA0NzMgMi40MDI5ODktNy43MTEwODMgMi45MTcwNjEtNy43MTEwODNDMy4zNzEzNTctNy43MTEwODMgNC4wNjQ3NTctNy40MzYxMTUgNC4yOTE5MDUtNi40MDc5N0M0LjQ0NzMyMy01LjcyNjUyNiA0LjQ0NzMyMy00Ljc4MjA2NyA0LjQ0NzMyMy0zLjk2OTExNkM0LjQ0NzMyMy0zLjE2ODEyIDQuNDQ3MzIzLTIuMjU5NTI3IDQuMzE1ODE2LTEuNTMwMjYyQzQuMDg4NjY3LS4yMTUxOTMgMy4zMzU0OTIgLjAxMTk1NSAyLjkxNzA2MSAuMDExOTU1WicvPgo8cGF0aCBpZD0nZzMtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnMy01MycgZD0nTTEuNTMwMjYyLTYuODUwMzExQzIuMDQ0MzM0LTYuNjgyOTM5IDIuNDYyNzY1LTYuNjcwOTg0IDIuNTk0MjcxLTYuNjcwOTg0QzMuOTQ1MjA1LTYuNjcwOTg0IDQuODA1OTc4LTcuNjYzMjYzIDQuODA1OTc4LTcuODMwNjM1QzQuODA1OTc4LTcuODc4NDU2IDQuNzgyMDY3LTcuOTM4MjMyIDQuNzEwMzM2LTcuOTM4MjMyQzQuNjg2NDI2LTcuOTM4MjMyIDQuNjYyNTE2LTcuOTM4MjMyIDQuNTU0OTE5LTcuODkwNDExQzMuODg1NDMtNy42MDM0ODcgMy4zMTE1ODItNy41Njc2MjEgMy4wMDA3NDctNy41Njc2MjFDMi4yMTE3MDYtNy41Njc2MjEgMS42NDk4MTMtNy44MDY3MjUgMS40MjI2NjUtNy45MDIzNjZDMS4zMzg5NzktNy45MzgyMzIgMS4zMTUwNjgtNy45MzgyMzIgMS4zMDMxMTMtNy45MzgyMzJDMS4yMDc0NzItNy45MzgyMzIgMS4yMDc0NzItNy44NjY1MDEgMS4yMDc0NzItNy42NzUyMThWLTQuMTI0NTMzQzEuMjA3NDcyLTMuOTA5MzQgMS4yMDc0NzItMy44Mzc2MDkgMS4zNTA5MzQtMy44Mzc2MDlDMS40MTA3MS0zLjgzNzYwOSAxLjQyMjY2NS0zLjg0OTU2NCAxLjU0MjIxNy0zLjk5MzAyNkMxLjg3Njk2MS00LjQ4MzE4OCAyLjQzODg1NC00Ljc3MDExMiAzLjAzNjYxMy00Ljc3MDExMkMzLjY3MDIzNy00Ljc3MDExMiAzLjk4MTA3MS00LjE4NDMwOSA0LjA3NjcxMi0zLjk4MTA3MUM0LjI3OTk1LTMuNTE0ODE5IDQuMjkxOTA1LTIuOTI5MDE2IDQuMjkxOTA1LTIuNDc0NzJTNC4yOTE5MDUtMS4zMzg5NzkgMy45NTcxNjEtLjgwMDk5NkMzLjY5NDE0Ny0uMzcwNjEgMy4yMjc4OTUtLjA3MTczMSAyLjcwMTg2OC0uMDcxNzMxQzEuOTEyODI3LS4wNzE3MzEgMS4xMzU3NDEtLjYwOTcxNCAuOTIwNTQ4LTEuNDgyNDQxQy45ODAzMjQtMS40NTg1MzEgMS4wNTIwNTUtMS40NDY1NzUgMS4xMTE4MzEtMS40NDY1NzVDMS4zMTUwNjgtMS40NDY1NzUgMS42Mzc4NTgtMS41NjYxMjcgMS42Mzc4NTgtMS45NzI2MDNDMS42Mzc4NTgtMi4zMDczNDcgMS40MTA3MS0yLjQ5ODYzIDEuMTExODMxLTIuNDk4NjNDLjg5NjYzOC0yLjQ5ODYzIC41ODU4MDMtMi4zOTEwMzQgLjU4NTgwMy0xLjkyNDc4MkMuNTg1ODAzLS45MDg1OTMgMS4zOTg3NTUgLjI1MTA1OSAyLjcyNTc3OCAuMjUxMDU5QzQuMDc2NzEyIC4yNTEwNTkgNS4yNjAyNzQtLjg4NDY4MiA1LjI2MDI3NC0yLjQwMjk4OUM1LjI2MDI3NC0zLjgyNTY1NCA0LjMwMzg2MS01LjAwOTIxNSAzLjA0ODU2OC01LjAwOTIxNUMyLjM2NzEyMy01LjAwOTIxNSAxLjg0MTA5Ni00LjcxMDMzNiAxLjUzMDI2Mi00LjM3NTU5MlYtNi44NTAzMTFaJy8+CjxwYXRoIGlkPSdnMy05MScgZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicvPgo8cGF0aCBpZD0nZzMtOTMnIGQ9J00xLjg1MzA1MS04Ljk2NjM3NkguMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nMCcgeGxpbms6aHJlZj0nI2cwLTg4Jy8+Cjx1c2UgeD0nMTIuMjUzOTc0JyB5PScwJyB4bGluazpocmVmPScjZzEtMTA2Jy8+Cjx1c2UgeD0nMTUuNTc0ODY1JyB5PScwJyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PSczMS4xNDk2NjgnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS01MCcvPgo8dXNlIHg9JzQyLjQ0MDYzNicgeT0nMCcgeGxpbms6aHJlZj0nI2czLTkxJy8+Cjx1c2UgeD0nNDUuNjkyMjk4JyB5PScwJyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzU0Ljk5MDc5NScgeT0nMCcgeGxpbms6aHJlZj0nI2czLTQ4Jy8+Cjx1c2UgeD0nNjAuODQzNzg1JyB5PScwJyB4bGluazpocmVmPScjZzItNTgnLz4KPHVzZSB4PSc2NC4wOTU0NDYnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMy01MycvPgo8dXNlIHg9JzY5Ljk0ODQzNicgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTU5Jy8+Cjx1c2UgeD0nNzUuMTkyNTk1JyB5PScwJyB4bGluazpocmVmPScjZzMtNDknLz4KPHVzZSB4PSc4MS4wNDU1ODUnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi01OCcvPgo8dXNlIHg9Jzg0LjI5NzI0NycgeT0nMCcgeGxpbms6aHJlZj0nI2czLTQ4Jy8+Cjx1c2UgeD0nOTAuMTUwMjM3JyB5PScwJyB4bGluazpocmVmPScjZzMtOTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) conditioned by
conditioned by  (Cond dist of truncated),
(Cond dist of truncated),the PDF of the truncation to
![[-0.5, 1.0]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNSAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc1MC45NjEyNjJwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgNTAuOTYxMjYyIDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMS01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnMS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzItNDgnIGQ9J001LjM1NTkxNS0zLjgyNTY1NEM1LjM1NTkxNS00LjgxNzkzMyA1LjI5NjEzOS01Ljc4NjMwMSA0Ljg2NTc1My02LjY5NDg5NEM0LjM3NTU5Mi03LjY4NzE3MyAzLjUxNDgxOS03Ljk1MDE4NyAyLjkyOTAxNi03Ljk1MDE4N0MyLjIzNTYxNi03Ljk1MDE4NyAxLjM4NjgtNy42MDM0ODcgLjk0NDQ1OC02LjYxMTIwOEMuNjA5NzE0LTUuODU4MDMyIC40OTAxNjItNS4xMTY4MTIgLjQ5MDE2Mi0zLjgyNTY1NEMuNDkwMTYyLTIuNjY2MDAyIC41NzM4NDgtMS43OTMyNzUgMS4wMDQyMzQtLjk0NDQ1OEMxLjQ3MDQ4Ni0uMDM1ODY2IDIuMjk1MzkyIC4yNTEwNTkgMi45MTcwNjEgLjI1MTA1OUMzLjk1NzE2MSAuMjUxMDU5IDQuNTU0OTE5LS4zNzA2MSA0LjkwMTYxOS0xLjA2NDAxQzUuMzMyMDA1LTEuOTYwNjQ4IDUuMzU1OTE1LTMuMTMyMjU0IDUuMzU1OTE1LTMuODI1NjU0Wk0yLjkxNzA2MSAuMDExOTU1QzIuNTM0NDk2IC4wMTE5NTUgMS43NTc0MS0uMjAzMjM4IDEuNTMwMjYyLTEuNTA2MzUxQzEuMzk4NzU1LTIuMjIzNjYxIDEuMzk4NzU1LTMuMTMyMjU0IDEuMzk4NzU1LTMuOTY5MTE2QzEuMzk4NzU1LTQuOTQ5NDQgMS4zOTg3NTUtNS44MzQxMjIgMS41OTAwMzctNi41Mzk0NzdDMS43OTMyNzUtNy4zNDA0NzMgMi40MDI5ODktNy43MTEwODMgMi45MTcwNjEtNy43MTEwODNDMy4zNzEzNTctNy43MTEwODMgNC4wNjQ3NTctNy40MzYxMTUgNC4yOTE5MDUtNi40MDc5N0M0LjQ0NzMyMy01LjcyNjUyNiA0LjQ0NzMyMy00Ljc4MjA2NyA0LjQ0NzMyMy0zLjk2OTExNkM0LjQ0NzMyMy0zLjE2ODEyIDQuNDQ3MzIzLTIuMjU5NTI3IDQuMzE1ODE2LTEuNTMwMjYyQzQuMDg4NjY3LS4yMTUxOTMgMy4zMzU0OTIgLjAxMTk1NSAyLjkxNzA2MSAuMDExOTU1WicvPgo8cGF0aCBpZD0nZzItNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnMi01MycgZD0nTTEuNTMwMjYyLTYuODUwMzExQzIuMDQ0MzM0LTYuNjgyOTM5IDIuNDYyNzY1LTYuNjcwOTg0IDIuNTk0MjcxLTYuNjcwOTg0QzMuOTQ1MjA1LTYuNjcwOTg0IDQuODA1OTc4LTcuNjYzMjYzIDQuODA1OTc4LTcuODMwNjM1QzQuODA1OTc4LTcuODc4NDU2IDQuNzgyMDY3LTcuOTM4MjMyIDQuNzEwMzM2LTcuOTM4MjMyQzQuNjg2NDI2LTcuOTM4MjMyIDQuNjYyNTE2LTcuOTM4MjMyIDQuNTU0OTE5LTcuODkwNDExQzMuODg1NDMtNy42MDM0ODcgMy4zMTE1ODItNy41Njc2MjEgMy4wMDA3NDctNy41Njc2MjFDMi4yMTE3MDYtNy41Njc2MjEgMS42NDk4MTMtNy44MDY3MjUgMS40MjI2NjUtNy45MDIzNjZDMS4zMzg5NzktNy45MzgyMzIgMS4zMTUwNjgtNy45MzgyMzIgMS4zMDMxMTMtNy45MzgyMzJDMS4yMDc0NzItNy45MzgyMzIgMS4yMDc0NzItNy44NjY1MDEgMS4yMDc0NzItNy42NzUyMThWLTQuMTI0NTMzQzEuMjA3NDcyLTMuOTA5MzQgMS4yMDc0NzItMy44Mzc2MDkgMS4zNTA5MzQtMy44Mzc2MDlDMS40MTA3MS0zLjgzNzYwOSAxLjQyMjY2NS0zLjg0OTU2NCAxLjU0MjIxNy0zLjk5MzAyNkMxLjg3Njk2MS00LjQ4MzE4OCAyLjQzODg1NC00Ljc3MDExMiAzLjAzNjYxMy00Ljc3MDExMkMzLjY3MDIzNy00Ljc3MDExMiAzLjk4MTA3MS00LjE4NDMwOSA0LjA3NjcxMi0zLjk4MTA3MUM0LjI3OTk1LTMuNTE0ODE5IDQuMjkxOTA1LTIuOTI5MDE2IDQuMjkxOTA1LTIuNDc0NzJTNC4yOTE5MDUtMS4zMzg5NzkgMy45NTcxNjEtLjgwMDk5NkMzLjY5NDE0Ny0uMzcwNjEgMy4yMjc4OTUtLjA3MTczMSAyLjcwMTg2OC0uMDcxNzMxQzEuOTEyODI3LS4wNzE3MzEgMS4xMzU3NDEtLjYwOTcxNCAuOTIwNTQ4LTEuNDgyNDQxQy45ODAzMjQtMS40NTg1MzEgMS4wNTIwNTUtMS40NDY1NzUgMS4xMTE4MzEtMS40NDY1NzVDMS4zMTUwNjgtMS40NDY1NzUgMS42Mzc4NTgtMS41NjYxMjcgMS42Mzc4NTgtMS45NzI2MDNDMS42Mzc4NTgtMi4zMDczNDcgMS40MTA3MS0yLjQ5ODYzIDEuMTExODMxLTIuNDk4NjNDLjg5NjYzOC0yLjQ5ODYzIC41ODU4MDMtMi4zOTEwMzQgLjU4NTgwMy0xLjkyNDc4MkMuNTg1ODAzLS45MDg1OTMgMS4zOTg3NTUgLjI1MTA1OSAyLjcyNTc3OCAuMjUxMDU5QzQuMDc2NzEyIC4yNTEwNTkgNS4yNjAyNzQtLjg4NDY4MiA1LjI2MDI3NC0yLjQwMjk4OUM1LjI2MDI3NC0zLjgyNTY1NCA0LjMwMzg2MS01LjAwOTIxNSAzLjA0ODU2OC01LjAwOTIxNUMyLjM2NzEyMy01LjAwOTIxNSAxLjg0MTA5Ni00LjcxMDMzNiAxLjUzMDI2Mi00LjM3NTU5MlYtNi44NTAzMTFaJy8+CjxwYXRoIGlkPSdnMi05MScgZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicvPgo8cGF0aCBpZD0nZzItOTMnIGQ9J00xLjg1MzA1MS04Ljk2NjM3NkguMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTkxJy8+Cjx1c2UgeD0nMy4yNTE2NjEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMC0wJy8+Cjx1c2UgeD0nMTIuNTUwMTU4JyB5PScwJyB4bGluazpocmVmPScjZzItNDgnLz4KPHVzZSB4PScxOC40MDMxNDknIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS01OCcvPgo8dXNlIHg9JzIxLjY1NDgxJyB5PScwJyB4bGluazpocmVmPScjZzItNTMnLz4KPHVzZSB4PScyNy41MDc4JyB5PScwJyB4bGluazpocmVmPScjZzEtNTknLz4KPHVzZSB4PSczMi43NTE5NTknIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OScvPgo8dXNlIHg9JzM4LjYwNDk0OScgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTU4Jy8+Cjx1c2UgeD0nNDEuODU2NjEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OCcvPgo8dXNlIHg9JzQ3LjcwOTYwMScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTkzJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9NCAtLT4=) of
of  : (Truncation of cond dist).
: (Truncation of cond dist).
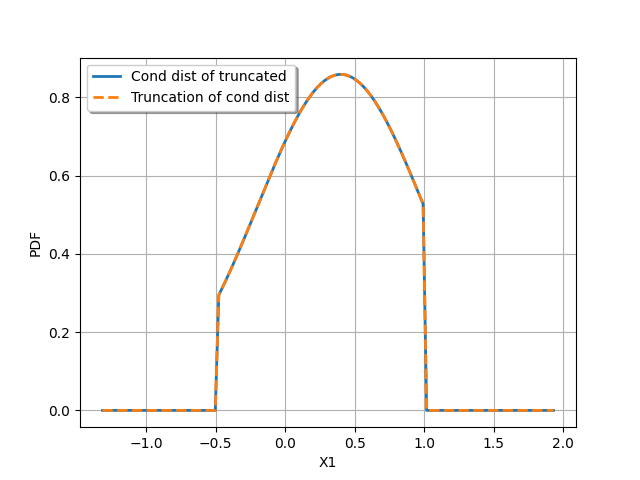
Note that the numerical range of the conditional distribution might be different from the range of the numerical range of the non conditioned
distribution. For example, consider a bivariate distribution  following a normal distribution with zero mean, unit variance and a
correlation
following a normal distribution with zero mean, unit variance and a
correlation  . Then consider
. Then consider  . The numerical range of
. The numerical range of  is
is ![[-3.01, 11.0]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNSAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc2Mi42NjcyNDJwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgNjIuNjY3MjQyIDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMS01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnMS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzItNDgnIGQ9J001LjM1NTkxNS0zLjgyNTY1NEM1LjM1NTkxNS00LjgxNzkzMyA1LjI5NjEzOS01Ljc4NjMwMSA0Ljg2NTc1My02LjY5NDg5NEM0LjM3NTU5Mi03LjY4NzE3MyAzLjUxNDgxOS03Ljk1MDE4NyAyLjkyOTAxNi03Ljk1MDE4N0MyLjIzNTYxNi03Ljk1MDE4NyAxLjM4NjgtNy42MDM0ODcgLjk0NDQ1OC02LjYxMTIwOEMuNjA5NzE0LTUuODU4MDMyIC40OTAxNjItNS4xMTY4MTIgLjQ5MDE2Mi0zLjgyNTY1NEMuNDkwMTYyLTIuNjY2MDAyIC41NzM4NDgtMS43OTMyNzUgMS4wMDQyMzQtLjk0NDQ1OEMxLjQ3MDQ4Ni0uMDM1ODY2IDIuMjk1MzkyIC4yNTEwNTkgMi45MTcwNjEgLjI1MTA1OUMzLjk1NzE2MSAuMjUxMDU5IDQuNTU0OTE5LS4zNzA2MSA0LjkwMTYxOS0xLjA2NDAxQzUuMzMyMDA1LTEuOTYwNjQ4IDUuMzU1OTE1LTMuMTMyMjU0IDUuMzU1OTE1LTMuODI1NjU0Wk0yLjkxNzA2MSAuMDExOTU1QzIuNTM0NDk2IC4wMTE5NTUgMS43NTc0MS0uMjAzMjM4IDEuNTMwMjYyLTEuNTA2MzUxQzEuMzk4NzU1LTIuMjIzNjYxIDEuMzk4NzU1LTMuMTMyMjU0IDEuMzk4NzU1LTMuOTY5MTE2QzEuMzk4NzU1LTQuOTQ5NDQgMS4zOTg3NTUtNS44MzQxMjIgMS41OTAwMzctNi41Mzk0NzdDMS43OTMyNzUtNy4zNDA0NzMgMi40MDI5ODktNy43MTEwODMgMi45MTcwNjEtNy43MTEwODNDMy4zNzEzNTctNy43MTEwODMgNC4wNjQ3NTctNy40MzYxMTUgNC4yOTE5MDUtNi40MDc5N0M0LjQ0NzMyMy01LjcyNjUyNiA0LjQ0NzMyMy00Ljc4MjA2NyA0LjQ0NzMyMy0zLjk2OTExNkM0LjQ0NzMyMy0zLjE2ODEyIDQuNDQ3MzIzLTIuMjU5NTI3IDQuMzE1ODE2LTEuNTMwMjYyQzQuMDg4NjY3LS4yMTUxOTMgMy4zMzU0OTIgLjAxMTk1NSAyLjkxNzA2MSAuMDExOTU1WicvPgo8cGF0aCBpZD0nZzItNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnMi01MScgZD0nTTIuMTk5NzUxLTQuMjkxOTA1QzEuOTk2NTEzLTQuMjc5OTUgMS45NDg2OTItNC4yNjc5OTUgMS45NDg2OTItNC4xNjAzOTlDMS45NDg2OTItNC4wNDA4NDcgMi4wMDg0NjgtNC4wNDA4NDcgMi4yMjM2NjEtNC4wNDA4NDdIMi43NzM1OTlDMy43ODk3ODgtNC4wNDA4NDcgNC4yNDQwODUtMy4yMDM5ODUgNC4yNDQwODUtMi4wNTYyODlDNC4yNDQwODUtLjQ5MDE2MiAzLjQzMTEzMy0uMDcxNzMxIDIuODQ1MzMtLjA3MTczMUMyLjI3MTQ4Mi0uMDcxNzMxIDEuMjkxMTU4LS4zNDY3IC45NDQ0NTgtMS4xMzU3NDFDMS4zMjcwMjQtMS4wNzU5NjUgMS42NzM3MjQtMS4yOTExNTggMS42NzM3MjQtMS43MjE1NDRDMS42NzM3MjQtMi4wNjgyNDQgMS40MjI2NjUtMi4zMDczNDcgMS4wODc5Mi0yLjMwNzM0N0MuODAwOTk2LTIuMzA3MzQ3IC40OTAxNjItMi4xMzk5NzUgLjQ5MDE2Mi0xLjY4NTY3OUMuNDkwMTYyLS42MjE2NjkgMS41NTQxNzIgLjI1MTA1OSAyLjg4MTE5NiAuMjUxMDU5QzQuMzAzODYxIC4yNTEwNTkgNS4zNTU5MTUtLjgzNjg2MiA1LjM1NTkxNS0yLjA0NDMzNEM1LjM1NTkxNS0zLjE0NDIwOSA0LjQ3MTIzMy00LjAwNDk4MSAzLjMyMzUzNy00LjIwODIxOUM0LjM2MzYzNi00LjUwNzA5OCA1LjAzMzEyNi01LjM3OTgyNiA1LjAzMzEyNi02LjMxMjMyOUM1LjAzMzEyNi03LjI1Njc4NyA0LjA1MjgwMi03Ljk1MDE4NyAyLjg5MzE1MS03Ljk1MDE4N0MxLjY5NzYzNC03Ljk1MDE4NyAuODEyOTUxLTcuMjIwOTIyIC44MTI5NTEtNi4zNDgxOTRDLjgxMjk1MS01Ljg2OTk4OCAxLjE4MzU2Mi01Ljc3NDM0NiAxLjM2Mjg4OS01Ljc3NDM0NkMxLjYxMzk0OC01Ljc3NDM0NiAxLjkwMDg3Mi01Ljk1MzY3NCAxLjkwMDg3Mi02LjMxMjMyOUMxLjkwMDg3Mi02LjY5NDg5NCAxLjYxMzk0OC02Ljg2MjI2NyAxLjM1MDkzNC02Ljg2MjI2N0MxLjI3OTIwMy02Ljg2MjI2NyAxLjI1NTI5My02Ljg2MjI2NyAxLjIxOTQyNy02Ljg1MDMxMUMxLjY3MzcyNC03LjY2MzI2MyAyLjc5NzUwOS03LjY2MzI2MyAyLjg1NzI4NS03LjY2MzI2M0MzLjI1MTgwNi03LjY2MzI2MyA0LjAyODg5Mi03LjQ4MzkzNSA0LjAyODg5Mi02LjMxMjMyOUM0LjAyODg5Mi02LjA4NTE4MSAzLjk5MzAyNi01LjQxNTY5MSAzLjY0NjMyNi00LjkwMTYxOUMzLjI4NzY3MS00LjM3NTU5MiAyLjg4MTE5Ni00LjMzOTcyNiAyLjU1ODQwNi00LjMyNzc3MUwyLjE5OTc1MS00LjI5MTkwNVonLz4KPHBhdGggaWQ9J2cyLTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnMi05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PScwJyB4bGluazpocmVmPScjZzItOTEnLz4KPHVzZSB4PSczLjI1MTY2MScgeT0nMCcgeGxpbms6aHJlZj0nI2cwLTAnLz4KPHVzZSB4PScxMi41NTAxNTgnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi01MScvPgo8dXNlIHg9JzE4LjQwMzE0OScgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTU4Jy8+Cjx1c2UgeD0nMjEuNjU0ODEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OCcvPgo8dXNlIHg9JzI3LjUwNzgnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OScvPgo8dXNlIHg9JzMzLjM2MDc5JyB5PScwJyB4bGluazpocmVmPScjZzEtNTknLz4KPHVzZSB4PSczOC42MDQ5NDknIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OScvPgo8dXNlIHg9JzQ0LjQ1NzkzOScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTQ5Jy8+Cjx1c2UgeD0nNTAuMzEwOTMnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS01OCcvPgo8dXNlIHg9JzUzLjU2MjU5MScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTQ4Jy8+Cjx1c2UgeD0nNTkuNDE1NTgxJyB5PScwJyB4bGluazpocmVmPScjZzItOTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) where as the
numerical range of
where as the
numerical range of  is
is ![[-7.65, 7.65]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNSAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc2Mi42NjcyNDJwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgNjIuNjY3MjQyIDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMS01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnMS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzItNTMnIGQ9J00xLjUzMDI2Mi02Ljg1MDMxMUMyLjA0NDMzNC02LjY4MjkzOSAyLjQ2Mjc2NS02LjY3MDk4NCAyLjU5NDI3MS02LjY3MDk4NEMzLjk0NTIwNS02LjY3MDk4NCA0LjgwNTk3OC03LjY2MzI2MyA0LjgwNTk3OC03LjgzMDYzNUM0LjgwNTk3OC03Ljg3ODQ1NiA0Ljc4MjA2Ny03LjkzODIzMiA0LjcxMDMzNi03LjkzODIzMkM0LjY4NjQyNi03LjkzODIzMiA0LjY2MjUxNi03LjkzODIzMiA0LjU1NDkxOS03Ljg5MDQxMUMzLjg4NTQzLTcuNjAzNDg3IDMuMzExNTgyLTcuNTY3NjIxIDMuMDAwNzQ3LTcuNTY3NjIxQzIuMjExNzA2LTcuNTY3NjIxIDEuNjQ5ODEzLTcuODA2NzI1IDEuNDIyNjY1LTcuOTAyMzY2QzEuMzM4OTc5LTcuOTM4MjMyIDEuMzE1MDY4LTcuOTM4MjMyIDEuMzAzMTEzLTcuOTM4MjMyQzEuMjA3NDcyLTcuOTM4MjMyIDEuMjA3NDcyLTcuODY2NTAxIDEuMjA3NDcyLTcuNjc1MjE4Vi00LjEyNDUzM0MxLjIwNzQ3Mi0zLjkwOTM0IDEuMjA3NDcyLTMuODM3NjA5IDEuMzUwOTM0LTMuODM3NjA5QzEuNDEwNzEtMy44Mzc2MDkgMS40MjI2NjUtMy44NDk1NjQgMS41NDIyMTctMy45OTMwMjZDMS44NzY5NjEtNC40ODMxODggMi40Mzg4NTQtNC43NzAxMTIgMy4wMzY2MTMtNC43NzAxMTJDMy42NzAyMzctNC43NzAxMTIgMy45ODEwNzEtNC4xODQzMDkgNC4wNzY3MTItMy45ODEwNzFDNC4yNzk5NS0zLjUxNDgxOSA0LjI5MTkwNS0yLjkyOTAxNiA0LjI5MTkwNS0yLjQ3NDcyUzQuMjkxOTA1LTEuMzM4OTc5IDMuOTU3MTYxLS44MDA5OTZDMy42OTQxNDctLjM3MDYxIDMuMjI3ODk1LS4wNzE3MzEgMi43MDE4NjgtLjA3MTczMUMxLjkxMjgyNy0uMDcxNzMxIDEuMTM1NzQxLS42MDk3MTQgLjkyMDU0OC0xLjQ4MjQ0MUMuOTgwMzI0LTEuNDU4NTMxIDEuMDUyMDU1LTEuNDQ2NTc1IDEuMTExODMxLTEuNDQ2NTc1QzEuMzE1MDY4LTEuNDQ2NTc1IDEuNjM3ODU4LTEuNTY2MTI3IDEuNjM3ODU4LTEuOTcyNjAzQzEuNjM3ODU4LTIuMzA3MzQ3IDEuNDEwNzEtMi40OTg2MyAxLjExMTgzMS0yLjQ5ODYzQy44OTY2MzgtMi40OTg2MyAuNTg1ODAzLTIuMzkxMDM0IC41ODU4MDMtMS45MjQ3ODJDLjU4NTgwMy0uOTA4NTkzIDEuMzk4NzU1IC4yNTEwNTkgMi43MjU3NzggLjI1MTA1OUM0LjA3NjcxMiAuMjUxMDU5IDUuMjYwMjc0LS44ODQ2ODIgNS4yNjAyNzQtMi40MDI5ODlDNS4yNjAyNzQtMy44MjU2NTQgNC4zMDM4NjEtNS4wMDkyMTUgMy4wNDg1NjgtNS4wMDkyMTVDMi4zNjcxMjMtNS4wMDkyMTUgMS44NDEwOTYtNC43MTAzMzYgMS41MzAyNjItNC4zNzU1OTJWLTYuODUwMzExWicvPgo8cGF0aCBpZD0nZzItNTQnIGQ9J00xLjQ3MDQ4Ni00LjE2MDM5OUMxLjQ3MDQ4Ni03LjE4NTA1NiAyLjk0MDk3MS03LjY2MzI2MyAzLjU4NjU1LTcuNjYzMjYzQzQuMDE2OTM2LTcuNjYzMjYzIDQuNDQ3MzIzLTcuNTMxNzU2IDQuNjc0NDcxLTcuMTczMTAxQzQuNTMxMDA5LTcuMTczMTAxIDQuMDc2NzEyLTcuMTczMTAxIDQuMDc2NzEyLTYuNjgyOTM5QzQuMDc2NzEyLTYuNDE5OTI1IDQuMjU2MDQtNi4xOTI3NzcgNC41NjY4NzQtNi4xOTI3NzdDNC44NjU3NTMtNi4xOTI3NzcgNS4wNjg5OTEtNi4zNzIxMDUgNS4wNjg5OTEtNi43MTg4MDRDNS4wNjg5OTEtNy4zNDA0NzMgNC42MTQ2OTUtNy45NTAxODcgMy41NzQ1OTUtNy45NTAxODdDMi4wNjgyNDQtNy45NTAxODcgLjQ5MDE2Mi02LjQwNzk3IC40OTAxNjItMy43Nzc4MzNDLjQ5MDE2Mi0uNDkwMTYyIDEuOTI0NzgyIC4yNTEwNTkgMi45NDA5NzEgLjI1MTA1OUM0LjI0NDA4NSAuMjUxMDU5IDUuMzU1OTE1LS44ODQ2ODIgNS4zNTU5MTUtMi40Mzg4NTRDNS4zNTU5MTUtNC4wMjg4OTIgNC4yNDQwODUtNS4wOTI5MDIgMy4wNDg1NjgtNS4wOTI5MDJDMS45ODQ1NTgtNS4wOTI5MDIgMS41OTAwMzctNC4xNzIzNTQgMS40NzA0ODYtMy44Mzc2MDlWLTQuMTYwMzk5Wk0yLjk0MDk3MS0uMDcxNzMxQzIuMTg3Nzk2LS4wNzE3MzEgMS44MjkxNDEtLjc0MTIyIDEuNzIxNTQ0LS45OTIyNzlDMS42MTM5NDgtMS4zMDMxMTMgMS40OTQzOTYtMS44ODg5MTcgMS40OTQzOTYtMi43MjU3NzhDMS40OTQzOTYtMy42NzAyMzcgMS45MjQ3ODItNC44NTM3OTggMy4wMDA3NDctNC44NTM3OThDMy42NTgyODEtNC44NTM3OTggNC4wMDQ5ODEtNC40MTE0NTcgNC4xODQzMDktNC4wMDQ5ODFDNC4zNzU1OTItMy41NjI2NCA0LjM3NTU5Mi0yLjk2NDg4MiA0LjM3NTU5Mi0yLjQ1MDgwOUM0LjM3NTU5Mi0xLjg0MTA5NiA0LjM3NTU5Mi0xLjMwMzExMyA0LjE0ODQ0My0uODQ4ODE3QzMuODQ5NTY0LS4yNzQ5NjkgMy40MTkxNzgtLjA3MTczMSAyLjk0MDk3MS0uMDcxNzMxWicvPgo8cGF0aCBpZD0nZzItNTUnIGQ9J001LjY3ODcwNS03LjQyNDE1OVYtNy42OTkxMjhIMi43OTc1MDlDMS4zNTA5MzQtNy42OTkxMjggMS4zMjcwMjQtNy44NTQ1NDUgMS4yNzkyMDMtOC4wODE2OTRIMS4wMTYxODlMLjY0NTU3OS01LjY5MDY2SC45MDg1OTNDLjk0NDQ1OC01LjkwNTg1MyAxLjA1MjA1NS02LjY0NzA3MyAxLjIwNzQ3Mi02Ljc3ODU4QzEuMzAzMTEzLTYuODUwMzExIDIuMTk5NzUxLTYuODUwMzExIDIuMzY3MTIzLTYuODUwMzExSDQuOTAxNjE5TDMuNjM0MzcxLTUuMDMzMTI2QzMuMzExNTgyLTQuNTY2ODc0IDIuMTA0MTEtMi42MDYyMjcgMi4xMDQxMS0uMzU4NjU1QzIuMTA0MTEtLjIyNzE0OCAyLjEwNDExIC4yNTEwNTkgMi41OTQyNzEgLjI1MTA1OUMzLjA5NjM4OSAuMjUxMDU5IDMuMDk2Mzg5LS4yMTUxOTMgMy4wOTYzODktLjM3MDYxVi0uOTY4MzY5QzMuMDk2Mzg5LTIuNzQ5Njg5IDMuMzgzMzEzLTQuMTM2NDg4IDMuOTQ1MjA1LTQuOTM3NDg0TDUuNjc4NzA1LTcuNDI0MTU5WicvPgo8cGF0aCBpZD0nZzItOTEnIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonLz4KPHBhdGggaWQ9J2cyLTkzJyBkPSdNMS44NTMwNTEtOC45NjYzNzZILjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUguMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi05MScvPgo8dXNlIHg9JzMuMjUxNjYxJyB5PScwJyB4bGluazpocmVmPScjZzAtMCcvPgo8dXNlIHg9JzEyLjU1MDE1OCcgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTU1Jy8+Cjx1c2UgeD0nMTguNDAzMTQ5JyB5PScwJyB4bGluazpocmVmPScjZzEtNTgnLz4KPHVzZSB4PScyMS42NTQ4MScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTU0Jy8+Cjx1c2UgeD0nMjcuNTA3OCcgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTUzJy8+Cjx1c2UgeD0nMzMuMzYwNzknIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS01OScvPgo8dXNlIHg9JzM4LjYwNDk0OScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTU1Jy8+Cjx1c2UgeD0nNDQuNDU3OTM5JyB5PScwJyB4bGluazpocmVmPScjZzEtNTgnLz4KPHVzZSB4PSc0Ny43MDk2MDEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi01NCcvPgo8dXNlIHg9JzUzLjU2MjU5MScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTUzJy8+Cjx1c2UgeD0nNTkuNDE1NTgxJyB5PScwJyB4bGluazpocmVmPScjZzItOTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) . See Create a Point Conditional Distribution to get
some more examples.
. See Create a Point Conditional Distribution to get
some more examples.
The computation of the numerical range is important to make possible the integration of the PDF on some domains. The library implements 3 strategies to compute it. We detail these strategies.
Strategy None: The numerical range of is the same as the
numerical range of . This range is exact for all distributions with bounded support. For distributions with unbounded
support,
it is potentially false when the conditional values are very close to the bounds of the initial numerical support.
Strategy Normal: Let be the Gaussian vector of dimension , which mean vector
is defined by  and covariance matrix is defined by
and covariance matrix is defined by  .
Then, we build the conditioned Gaussian vector:
.
Then, we build the conditioned Gaussian vector:

The numerical range  of
of
 is known exactly thanks to the simplification mechanism
implemented for Gaussian vectors. We assign to the
range :
is known exactly thanks to the simplification mechanism
implemented for Gaussian vectors. We assign to the
range :

Strategy NormalCopula: Let be the Gaussian vector of dimension , with zero mean,
unit variance and which correlation matrix  is defined from the Spearman correlation matrix of :
is defined from the Spearman correlation matrix of :
 . Thus, is the standard representant
of the normal copula having the same correlation as .
. Thus, is the standard representant
of the normal copula having the same correlation as .
For each conditioning value  , we define the quantile
, we define the quantile  of the normal distribution with zero mean and unit
variance associated to the same order as , for
of the normal distribution with zero mean and unit
variance associated to the same order as , for  :
:

where  is the CDF of the normal distribution with zero mean and unit variance. Then, we build the conditioned
Gaussian vector:
is the CDF of the normal distribution with zero mean and unit variance. Then, we build the conditioned
Gaussian vector:

which numerical range  can be exactly computed.
Let it be:
can be exactly computed.
Let it be:
![\cD\left(\vect{Y}_{\overline{\cI}}|\vect{Y}_\cI = \vect{q}_\cI \right) = \prod_{i\in \overline{\cI}}
\left[ y_i^{min}, y_i^{max}\right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNSAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScxNzkuNzYxOTc3cHQnIGhlaWdodD0nMjguODYzNTgycHQnIHZpZXdCb3g9JzEwNC4zOTA1MDMgLTMwLjA1OTA5NiAxNzkuNzYxOTc3IDI4Ljg2MzU4Mic+CjxkZWZzPgo8cGF0aCBpZD0nZzAtODknIGQ9J004Ljc3NTA5My03LjE3MzEwMUM5LjAzODEwNy03LjQ0ODA3IDkuMzEzMDc2LTcuNjI3Mzk3IDEwLjExNDA3Mi03LjYzOTM1MkMxMC4yNDU1NzktNy42MzkzNTIgMTAuNDYwNzcyLTcuNjM5MzUyIDEwLjQ2MDc3Mi03Ljk4NjA1MkMxMC40NjA3NzItOC4wNTc3ODMgMTAuNDAwOTk2LTguMjAxMjQ1IDEwLjI0NTU3OS04LjIwMTI0NUM5Ljg5ODg3OS04LjIwMTI0NSA5LjUwNDM1OS04LjE2NTM4IDkuMTQ1NzA0LTguMTY1MzhDOC43MDMzNjItOC4xNjUzOCA4LjI0OTA2Ni04LjIwMTI0NSA3LjgxODY4LTguMjAxMjQ1QzcuNzM0OTk0LTguMjAxMjQ1IDcuNDk1ODktOC4yMDEyNDUgNy40OTU4OS03Ljg1NDU0NUM3LjQ5NTg5LTcuNjM5MzUyIDcuNjk5MTI4LTcuNjM5MzUyIDcuODE4NjgtNy42MzkzNTJTOC4xNzczMzUtNy42MTU0NDIgOC4zNTY2NjMtNy41NTU2NjZMNS4xMTY4MTItNC4wODg2NjdMMy41ODY1NS03LjU5MTUzMkMzLjkyMTI5NS03LjYzOTM1MiAzLjkzMzI1LTcuNjM5MzUyIDQuMjU2MDQtNy42MzkzNTJDNC40NTkyNzgtNy42MzkzNTIgNC42NjI1MTYtNy42NTEzMDggNC42NjI1MTYtNy45ODYwNTJDNC42NjI1MTYtOC4xNDE0NjkgNC41MzEwMDktOC4yMDEyNDUgNC4zOTk1MDItOC4yMDEyNDVDMy45OTMwMjYtOC4yMDEyNDUgMi45NTI5MjctOC4xNjUzOCAyLjU0NjQ1MS04LjE2NTM4QzIuMjcxNDgyLTguMTY1MzggMS45ODQ1NTgtOC4xNzczMzUgMS43MjE1NDQtOC4xNzczMzVDMS40MzQ2Mi04LjE3NzMzNSAxLjEzNTc0MS04LjIwMTI0NSAuODYwNzcyLTguMjAxMjQ1Qy43NDEyMi04LjIwMTI0NSAuNTI2MDI3LTguMjAxMjQ1IC41MjYwMjctNy44NTQ1NDVDLjUyNjAyNy03LjYzOTM1MiAuNjkzNC03LjYzOTM1MiAxLjAxNjE4OS03LjYzOTM1MkMxLjE3MTYwNi03LjYzOTM1MiAxLjMxNTA2OC03LjYzOTM1MiAxLjQ4MjQ0MS03LjYyNzM5N0MxLjYyNTkwMy03LjYwMzQ4NyAxLjY0OTgxMy03LjYwMzQ4NyAxLjcyMTU0NC03LjQ0ODA3TDMuNTM4NzMtMy4yNzU3MTZMMi45MTcwNjEtLjgxMjk1MUMyLjg2OTI0LS42MDk3MTQgMi44NTcyODUtLjU5Nzc1OCAyLjY0MjA5Mi0uNTg1ODAzQzIuNDM4ODU0LS41NjE4OTMgMi4yMzU2MTYtLjU2MTg5MyAyLjAyMDQyMy0uNTYxODkzQzEuNjYxNzY4LS41NjE4OTMgMS42Mzc4NTgtLjU2MTg5MyAxLjU5MDAzNy0uNTE0MDcyQzEuNTE4MzA2LS40NTQyOTYgMS40NzA0ODYtLjI5ODg3OSAxLjQ3MDQ4Ni0uMjE1MTkzQzEuNDcwNDg2LS4xOTEyODMgMS40ODI0NDEgMCAxLjczMzQ5OSAwQzIuMDMyMzc5IDAgMi4zNDMyMTMtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MUMyLjkyOTAxNi0uMDIzOTEgMy4yMjc4OTUtLjAzNTg2NiAzLjUxNDgxOS0uMDM1ODY2QzMuOTIxMjk1LS4wMzU4NjYgNC45Mzc0ODQgMCA1LjM0Mzk2IDBDNS40NTE1NTcgMCA1LjY5MDY2IDAgNS42OTA2Ni0uMzQ2N0M1LjY5MDY2LS41NjE4OTMgNS41MjMyODgtLjU2MTg5MyA1LjE4ODU0My0uNTYxODkzQzQuOTM3NDg0LS41NjE4OTMgNC43MTAzMzYtLjU3Mzg0OCA0LjQ1OTI3OC0uNTg1ODAzTDUuMTI4NzY3LTMuMjc1NzE2TDguNzc1MDkzLTcuMTczMTAxWicvPgo8cGF0aCBpZD0nZzAtMTEzJyBkPSdNNi40OTE2NTYtNS4xODg1NDNDNi40OTE2NTYtNS4yNDgzMTkgNi40NDM4MzYtNS40MDM3MzYgNi4yNzY0NjMtNS40MDM3MzZDNi4yNjQ1MDgtNS40MDM3MzYgNS41NTkxNTMtNS4yMzYzNjQgNS4xODg1NDMtNC44ODk2NjRDNS4wMjExNzEtNS4wODA5NDYgNC42MTQ2OTUtNS40MDM3MzYgMy45MDkzNC01LjQwMzczNkMxLjgyOTE0MS01LjQwMzczNiAuNTM3OTgzLTMuNTE0ODE5IC41Mzc5ODMtMS44NzY5NjFDLjUzNzk4My0uNDA2NDc2IDEuNjM3ODU4IC4wOTU2NDEgMi42MzAxMzcgLjA5NTY0MUMzLjIwMzk4NSAuMDk1NjQxIDMuNjgyMTkyLS4xMzE1MDcgMy45MzMyNS0uMjg2OTI0TDMuNDc4OTU0IDEuNTMwMjYyQzMuNDMxMTMzIDEuNzA5NTg5IDMuNDE5MTc4IDEuNzIxNTQ0IDMuMzM1NDkyIDEuNzMzNDk5QzMuMjAzOTg1IDEuNzU3NDEgMy4wMTI3MDIgMS43NTc0MSAyLjg4MTE5NiAxLjc1NzQxQzIuNjc3OTU4IDEuNzU3NDEgMi42MDYyMjcgMS43NTc0MSAyLjU0NjQ1MSAxLjgyOTE0MVMyLjQ1MDgwOSAyLjA5MjE1NCAyLjQ1MDgwOSAyLjEwNDExQzIuNDUwODA5IDIuMTc1ODQxIDIuNDk4NjMgMi4zMTkzMDMgMi42ODk5MTMgMi4zMTkzMDNDMy4wOTYzODkgMi4zMTkzMDMgMy41Mzg3MyAyLjI4MzQzNyAzLjk1NzE2MSAyLjI4MzQzN0M0LjM5OTUwMiAyLjI4MzQzNyA0Ljg1Mzc5OCAyLjMxOTMwMyA1LjI4NDE4NCAyLjMxOTMwM0M1LjM2Nzg3IDIuMzE5MzAzIDUuNTk1MDE5IDIuMzE5MzAzIDUuNTk1MDE5IDEuOTcyNjAzQzUuNTk1MDE5IDEuNzY5MzY1IDUuMzkxNzgxIDEuNzU3NDEgNS4yODQxODQgMS43NTc0MUM1LjExNjgxMiAxLjc1NzQxIDQuOTI1NTI5IDEuNzU3NDEgNC43NzAxMTIgMS43NDU0NTVMNi40OTE2NTYtNS4xODg1NDNaTTQuMTg0MzA5LTEuMjc5MjAzQzQuMTI0NTMzLTEuMDc1OTY1IDQuMTI0NTMzLTEuMDUyMDU1IDMuOTkzMDI2LS45MzI1MDNDMy42MTA0NjEtLjU0OTkzOCAzLjEwODM0NC0uMzM0NzQ1IDIuNjg5OTEzLS4zMzQ3NDVDMS45NDg2OTItLjMzNDc0NSAxLjg4ODkxNy0uOTgwMzI0IDEuODg4OTE3LTEuMjQzMzM3QzEuODg4OTE3LTEuODY1MDA2IDIuMjk1MzkyLTMuMzM1NDkyIDIuNDg2Njc1LTMuODAxNzQzQzIuODU3Mjg1LTQuNjc0NDcxIDMuNDQzMDg4LTQuOTczMzUgMy45MzMyNS00Ljk3MzM1QzQuNjM4NjA1LTQuOTczMzUgNC45MjU1MjktNC40MTE0NTcgNC45MjU1MjktNC4yNzk5NUM0LjkyNTUyOS00LjIzMjEzIDQuOTEzNTc0LTQuMTQ4NDQzIDQuOTAxNjE5LTQuMTEyNTc4TDQuMTg0MzA5LTEuMjc5MjAzWicvPgo8cGF0aCBpZD0nZzEtMicgZD0nTTIuNDE0OTQ0IDEzLjg1NjA0SDQuNzEwMzM2VjEzLjM3NzgzM0gyLjg5MzE1MVYwSDQuNzEwMzM2Vi0uNDc4MjA3SDIuNDE0OTQ0VjEzLjg1NjA0WicvPgo8cGF0aCBpZD0nZzEtMycgZD0nTTIuNTU4NDA2IDEzLjg1NjA0Vi0uNDc4MjA3SC4yNjMwMTRWMEgyLjA4MDE5OVYxMy4zNzc4MzNILjI2MzAxNFYxMy44NTYwNEgyLjU1ODQwNlonLz4KPHBhdGggaWQ9J2cxLTg5JyBkPSdNMTQuNTk3MjYgMTYuNzM3MjM1VjE2LjA5MTY1NkMxMy4wMDcyMjMgMTYuMDkxNjU2IDEyLjYzNjYxMyAxNS41NDE3MTkgMTIuNjM2NjEzIDE0Ljc3NjU4OFYxLjk2MDY0OEMxMi42MzY2MTMgMS4xODM1NjIgMTMuMDE5MTc4IC42NDU1NzkgMTQuNTk3MjYgLjY0NTU3OVYwSC42Njk0ODlWLjY0NTU3OUMyLjI1OTUyNyAuNjQ1NTc5IDIuNjMwMTM3IDEuMTk1NTE3IDIuNjMwMTM3IDEuOTYwNjQ4VjE0Ljc3NjU4OEMyLjYzMDEzNyAxNS41NTM2NzQgMi4yNDc1NzIgMTYuMDkxNjU2IC42Njk0ODkgMTYuMDkxNjU2VjE2LjczNzIzNUg2LjQxOTkyNVYxNi4wOTE2NTZDNC44Mjk4ODggMTYuMDkxNjU2IDQuNDU5Mjc4IDE1LjU0MTcxOSA0LjQ1OTI3OCAxNC43NzY1ODhWLjY0NTU3OUgxMC44MDc0NzJWMTQuNzc2NTg4QzEwLjgwNzQ3MiAxNS41NTM2NzQgMTAuNDI0OTA3IDE2LjA5MTY1NiA4Ljg0NjgyNCAxNi4wOTE2NTZWMTYuNzM3MjM1SDE0LjU5NzI2WicvPgo8cGF0aCBpZD0nZzItNTAnIGQ9J000LjYzMDYzNS0xLjgwOTIxNUM0Ljc1ODE1Ny0xLjgwOTIxNSA0LjkzMzQ5OS0xLjgwOTIxNSA0LjkzMzQ5OS0xLjk5MjUyOFM0Ljc1ODE1Ny0yLjE3NTg0MSA0LjYzMDYzNS0yLjE3NTg0MUgxLjA3NTk2NUMxLjE3OTU3Ny0zLjI4MzY4NiAyLjEwNDExLTQuMTI4NTE4IDMuMzE1NTY3LTQuMTI4NTE4SDQuNjMwNjM1QzQuNzU4MTU3LTQuMTI4NTE4IDQuOTMzNDk5LTQuMTI4NTE4IDQuOTMzNDk5LTQuMzExODMxUzQuNzU4MTU3LTQuNDk1MTQzIDQuNjMwNjM1LTQuNDk1MTQzSDMuMjkxNjU2QzEuODU3MDM2LTQuNDk1MTQzIC43MDEzNy0zLjM3OTMyOCAuNzAxMzctMS45OTI1MjhDLjcwMTM3LS41OTc3NTggMS44NjUwMDYgLjUxMDA4NyAzLjI5MTY1NiAuNTEwMDg3SDQuNjMwNjM1QzQuNzU4MTU3IC41MTAwODcgNC45MzM0OTkgLjUxMDA4NyA0LjkzMzQ5OSAuMzI2Nzc1UzQuNzU4MTU3IC4xNDM0NjIgNC42MzA2MzUgLjE0MzQ2MkgzLjMxNTU2N0MyLjEwNDExIC4xNDM0NjIgMS4xNzk1NzctLjcwMTM3IDEuMDc1OTY1LTEuODA5MjE1SDQuNjMwNjM1WicvPgo8cGF0aCBpZD0nZzItNzMnIGQ9J000LjYzODYwNS00Ljk4MTMyQzQuNzgyMDY3LTQuOTgxMzIgNC44Nzc3MDktNC45ODEzMiA1LjA3Njk2MS01LjEwMDg3MkM1LjI5MjE1NC01LjIyMDQyMyA1LjM2Mzg4NS01LjMzMjAwNSA1LjM2Mzg4NS01LjM3OTgyNkM1LjM2Mzg4NS01LjQzNTYxNiA1LjM1NTkxNS01LjQ0MzU4NyA1LjE3MjYwMy01LjQ0MzU4N0gyLjg5MzE1MUMyLjM0MzIxMy01LjQ0MzU4NyAxLjc3NzMzNS01LjQwMzczNiAxLjI2NzI0OC01LjE5NjUxM0MuMzUwNjg1LTQuODEzOTQ4IC4yMzkxMDMtNC4yMzIxMyAuMjM5MTAzLTQuMTkyMjc5Qy4yMzkxMDMtNC4xNDQ0NTggLjI3MDk4NC00LjEyMDU0OCAuMzE4ODA0LTQuMTIwNTQ4Qy40NzAyMzctNC4xMjA1NDggLjg3NjcxMi00LjMxMTgzMSAuOTQ4NDQzLTQuNTI3MDI0QzEuMDQ0MDg1LTQuODEzOTQ4IDEuMDY3OTk1LTQuODYxNzY4IDEuNTIyMjkxLTQuOTI1NTI5QzEuODAxMjQ1LTQuOTY1MzggMi4wODgxNjktNC45ODEzMiAyLjM3NTA5My00Ljk4MTMySDMuMjU5Nzc2QzIuNzI1Nzc4LTQuNDg3MTczIDIuNDc4NzA1LTMuNDkwOTA5IDIuMjE1NjkxLTIuNDQ2ODI0QzIuMDcyMjI5LTEuODQxMDk2IDEuODQxMDk2LS45NDA0NzMgMS40NTg1MzEtLjUyNjAyN0MxLjQwMjc0LS40NzAyMzcgMS4zOTQ3Ny0uNDYyMjY3IDEuMTcxNjA2LS40NjIyNjdILjYwNTcyOUMuNDM4MzU2LS40NjIyNjcgLjM3NDU5NS0uNDYyMjY3IC4xNTk0MDItLjM1MDY4NUMuMDM5ODUxLS4yNzg5NTQtLjEyNzUyMi0uMTQzNDYyLS4xMjc1MjItLjA1NTc5MUMtLjEyNzUyMiAwLS4wNjM3NjEgMCAuMDcxNzMxIDBIMi45NjQ4ODJDNC4wMDA5OTYgMCA0LjY3ODQ1Ni0uNzAxMzcgNC42Nzg0NTYtLjk4MDMyNEM0LjY3ODQ1Ni0xLjAzNjExNSA0LjYzODYwNS0xLjA0NDA4NSA0LjU4MjgxNC0xLjA0NDA4NUM0LjQxNTQ0Mi0xLjA0NDA4NSA0LjEwNDYwOC0uODYwNzcyIDQuMDAwOTk2LS43MTczMUwzLjkxMzMyNS0uNTEwMDg3QzMuNzM3OTgzLS40NjIyNjcgMy41NTQ2Ny0uNDYyMjY3IDMuNDgyOTM5LS40NjIyNjdIMS44NTcwMzZDMi40NTQ3OTUtLjk3MjM1NCAyLjY3Nzk1OC0xLjc3NzMzNSAyLjkzMzAwMS0yLjgxMzQ1QzMuMTU2MTY0LTMuNzA2MTAyIDMuMzYzMzg3LTQuNTAzMTEzIDMuNzIyMDQyLTQuOTgxMzJINC42Mzg2MDVaJy8+CjxwYXRoIGlkPSdnMy02OCcgZD0nTTIuNDM4ODU0IDBDNS4yMjQ0MDggMCA5LjE1NzY1OS0yLjEyODAyIDkuMTU3NjU5LTUuMzkxNzgxQzkuMTU3NjU5LTYuNDU1NzkxIDguNjU1NTQyLTcuMTI1MjggOC4wNjk3MzgtNy40OTU4OUM3LjA0MTU5NC04LjE2NTM4IDUuOTQxNzE5LTguMTY1MzggNC44MDU5NzgtOC4xNjUzOEMzLjc3NzgzMy04LjE2NTM4IDMuMDcyNDc4LTguMTY1MzggMi4wNjgyNDQtNy43MzQ5OTRDLjQ3ODIwNy03LjAyOTYzOSAuMjUxMDU5LTYuMDM3MzYgLjI1MTA1OS01Ljk0MTcxOUMuMjUxMDU5LTUuODY5OTg4IC4yOTg4NzktNS44NDYwNzcgLjM3MDYxLTUuODQ2MDc3Qy41NjE4OTMtNS44NDYwNzcgLjgzNjg2Mi02LjAxMzQ1IC45MzI1MDMtNi4wNzMyMjVDMS4xODM1NjItNi4yNDA1OTggMS4yMTk0MjctNi4zMTIzMjkgMS4yOTExNTgtNi41Mzk0NzdDMS40NTg1MzEtNy4wMTc2ODQgMS43OTMyNzUtNy40MzYxMTUgMy4yOTk2MjYtNy41MDc4NDZDMy4xMDgzNDQtNS4wMDkyMTUgMi40OTg2My0yLjcyNTc3OCAxLjY2MTc2OC0uNjMzNjI0QzEuMjE5NDI3LS40NzgyMDcgLjkzMjUwMy0uMjAzMjM4IC45MzI1MDMtLjA4MzY4NkMuOTMyNTAzLS4wMTE5NTUgLjk0NDQ1OCAwIDEuMjA3NDcyIDBIMi40Mzg4NTRaTTIuNDk4NjMtLjY1NzUzNEMzLjg2MTUxOS0zLjk5MzAyNiA0LjExMjU3OC02LjA3MzIyNSA0LjI3OTk1LTcuNTA3ODQ2QzUuMDgwOTQ2LTcuNTA3ODQ2IDguMTQxNDY5LTcuNTA3ODQ2IDguMTQxNDY5LTQuODc3NzA5QzguMTQxNDY5LTIuNTM0NDk2IDYuMDM3MzYtLjY1NzUzNCAzLjE0NDIwOS0uNjU3NTM0SDIuNDk4NjNaJy8+CjxwYXRoIGlkPSdnMy0xMDYnIGQ9J00xLjkwMDg3Mi04LjUzNTk5QzEuOTAwODcyLTguNzUxMTgzIDEuOTAwODcyLTguOTY2Mzc2IDEuNjYxNzY4LTguOTY2Mzc2UzEuNDIyNjY1LTguNzUxMTgzIDEuNDIyNjY1LTguNTM1OTlWMi41NTg0MDZDMS40MjI2NjUgMi43NzM1OTkgMS40MjI2NjUgMi45ODg3OTIgMS42NjE3NjggMi45ODg3OTJTMS45MDA4NzIgMi43NzM1OTkgMS45MDA4NzIgMi41NTg0MDZWLTguNTM1OTlaJy8+CjxwYXRoIGlkPSdnNC05NycgZD0nTTMuMTI0Mjg0LTMuMDM2NjEzQzMuMDUyNTUzLTMuMTcyMTA1IDIuODIxNDItMy41MTQ4MTkgMi4zMzUyNDMtMy41MTQ4MTlDMS4zODY4LTMuNTE0ODE5IC4zNDI3MTUtMi40MDY5NzQgLjM0MjcxNS0xLjIyNzM5N0MuMzQyNzE1LS4zOTg1MDYgLjg3NjcxMiAuMDc5NzAxIDEuNDkwNDExIC4wNzk3MDFDMi4wMDA0OTggLjA3OTcwMSAyLjQzODg1NC0uMzI2Nzc1IDIuNTgyMzE2LS40ODYxNzdDMi43MjU3NzggLjA2Mzc2MSAzLjI2Nzc0NiAuMDc5NzAxIDMuMzYzMzg3IC4wNzk3MDFDMy43MzAwMTIgLjA3OTcwMSAzLjkxMzMyNS0uMjIzMTYzIDMuOTc3MDg2LS4zNTg2NTVDNC4xMzY0ODgtLjY0NTU3OSA0LjI0ODA3LTEuMTA3ODQ2IDQuMjQ4MDctMS4xMzk3MjZDNC4yNDgwNy0xLjE4NzU0NyA0LjIxNjE4OS0xLjI0MzMzNyA0LjEyMDU0OC0xLjI0MzMzN1M0LjAwODk2Ni0xLjE5NTUxNyAzLjk2MTE0Ni0uOTk2MjY0QzMuODQ5NTY0LS41NTc5MDggMy42OTgxMzItLjE0MzQ2MiAzLjM4NzI5OC0uMTQzNDYyQzMuMjAzOTg1LS4xNDM0NjIgMy4xMzIyNTQtLjI5NDg5NCAzLjEzMjI1NC0uNTE4MDU3QzMuMTMyMjU0LS42NTM1NDkgMy4yMDM5ODUtLjkyNDUzMyAzLjI1MTgwNi0xLjEyMzc4NlMzLjQxOTE3OC0xLjgwMTI0NSAzLjQ1MTA1OS0xLjk0NDcwN0wzLjYxMDQ2MS0yLjU1MDQzNkMzLjY1MDMxMS0yLjc0MTcxOSAzLjczNzk4My0zLjA3NjQ2MyAzLjczNzk4My0zLjExNjMxNEMzLjczNzk4My0zLjI5OTYyNiAzLjU4NjU1LTMuMzYzMzg3IDMuNDgyOTM5LTMuMzYzMzg3QzMuMzYzMzg3LTMuMzYzMzg3IDMuMTY0MTM0LTMuMjgzNjg2IDMuMTI0Mjg0LTMuMDM2NjEzWk0yLjU4MjMxNi0uODYwNzcyQzIuMTgzODExLS4zMTA4MzQgMS43NjkzNjUtLjE0MzQ2MiAxLjUxNDMyMS0uMTQzNDYyQzEuMTQ3Njk2LS4xNDM0NjIgLjk2NDM4NC0uNDc4MjA3IC45NjQzODQtLjg5MjY1M0MuOTY0Mzg0LTEuMjY3MjQ4IDEuMTc5NTc3LTIuMTIwMDUgMS4zNTQ5MTktMi40NzA3MzVDMS41ODYwNTItMi45NTY5MTIgMS45NzY1ODgtMy4yOTE2NTYgMi4zNDMyMTMtMy4yOTE2NTZDMi44NjEyNy0zLjI5MTY1NiAzLjAxMjcwMi0yLjcwOTgzOCAzLjAxMjcwMi0yLjYxNDE5N0MzLjAxMjcwMi0yLjU4MjMxNiAyLjgxMzQ1LTEuODAxMjQ1IDIuNzY1NjI5LTEuNTk0MDIyQzIuNjYyMDE3LTEuMjE5NDI3IDIuNjYyMDE3LTEuMjAzNDg3IDIuNTgyMzE2LS44NjA3NzJaJy8+CjxwYXRoIGlkPSdnNC0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzQtMTA5JyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjc0NTQ1NS0xLjkyODc2NyAxLjc5MzI3NS0yLjEyMDA1IDEuODA5MjE1LTIuMTk5NzUxQzEuODI1MTU2LTIuMjM5NjAxIDIuMDg4MTY5LTIuNzU3NjU5IDIuNDM4ODU0LTMuMDIwNjcyQzIuNzA5ODM4LTMuMjI3ODk1IDIuOTcyODUyLTMuMjkxNjU2IDMuMTk2MDE1LTMuMjkxNjU2QzMuNDkwOTA5LTMuMjkxNjU2IDMuNjUwMzExLTMuMTE2MzE0IDMuNjUwMzExLTIuNzQ5Njg5QzMuNjUwMzExLTIuNTU4NDA2IDMuNjAyNDkxLTIuMzc1MDkzIDMuNTE0ODE5LTIuMDE2NDM4QzMuNDU5MDI5LTEuODA5MjE1IDMuMzIzNTM3LTEuMjc1MjE4IDMuMjc1NzE2LTEuMDYwMDI1TDMuMTU2MTY0LS41ODE4MThDMy4xMTYzMTQtLjQ0NjMyNiAzLjA2MDUyMy0uMjA3MjIzIDMuMDYwNTIzLS4xNjczNzJDMy4wNjA1MjMgLjAxNTk0IDMuMjExOTU1IC4wNzk3MDEgMy4zMTU1NjcgLjA3OTcwMUMzLjQ1OTAyOSAuMDc5NzAxIDMuNTc4NTgtLjAxNTk0IDMuNjM0MzcxLS4xMTE1ODJDMy42NTgyODEtLjE1OTQwMiAzLjcyMjA0Mi0uNDMwMzg2IDMuNzYxODkzLS41OTc3NThMMy45NDUyMDUtMS4zMDcwOThDMy45NjkxMTYtMS40MjY2NSA0LjA0ODgxNy0xLjcyOTUxNCA0LjA3MjcyNy0xLjg0OTA2NkM0LjE4NDMwOS0yLjI3OTQ1MiA0LjE4NDMwOS0yLjI4NzQyMiA0LjM2NzYyMS0yLjU1MDQzNkM0LjYzMDYzNS0yLjk0MDk3MSA1LjAwNTIzLTMuMjkxNjU2IDUuNTM5MjI4LTMuMjkxNjU2QzUuODI2MTUyLTMuMjkxNjU2IDUuOTkzNTI0LTMuMTI0Mjg0IDUuOTkzNTI0LTIuNzQ5Njg5QzUuOTkzNTI0LTIuMzExMzMzIDUuNjU4NzgtMS4zOTQ3NyA1LjUwNzM0Ny0xLjAxMjIwNEM1LjQyNzY0Ni0uODA0OTgxIDUuNDAzNzM2LS43NDkxOTEgNS40MDM3MzYtLjU5Nzc1OEM1LjQwMzczNi0uMTQzNDYyIDUuNzc4MzMxIC4wNzk3MDEgNi4xMjEwNDYgLjA3OTcwMUM2LjkwMjExNyAuMDc5NzAxIDcuMjI4ODkyLTEuMDM2MTE1IDcuMjI4ODkyLTEuMTM5NzI2QzcuMjI4ODkyLTEuMjE5NDI3IDcuMTY1MTMxLTEuMjQzMzM3IDcuMTA5MzQtMS4yNDMzMzdDNy4wMTM2OTktMS4yNDMzMzcgNi45OTc3NTgtMS4xODc1NDcgNi45NzM4NDgtMS4xMDc4NDZDNi43ODI1NjUtLjQ0NjMyNiA2LjQ0NzgyMS0uMTQzNDYyIDYuMTQ0OTU2LS4xNDM0NjJDNi4wMTc0MzUtLjE0MzQ2MiA1Ljk1MzY3NC0uMjIzMTYzIDUuOTUzNjc0LS40MDY0NzZTNi4wMTc0MzUtLjc2NTEzMSA2LjA5NzEzNi0uOTY0Mzg0QzYuMjE2Njg3LTEuMjY3MjQ4IDYuNTY3MzcyLTIuMTgzODExIDYuNTY3MzcyLTIuNjMwMTM3QzYuNTY3MzcyLTMuMjI3ODk1IDYuMTUyOTI3LTMuNTE0ODE5IDUuNTc5MDc4LTMuNTE0ODE5QzUuMDI5MTQxLTMuNTE0ODE5IDQuNTc0ODQ0LTMuMjI3ODk1IDQuMjE2MTg5LTIuNzMzNzQ4QzQuMTUyNDI4LTMuMzcxMzU3IDMuNjQyMzQxLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuODYxMjctMy41MTQ4MTkgMi4zNzUwOTMtMy4zODcyOTggMS45MzY3MzctMi44MTM0NUMxLjg4MDk0Ni0zLjI5MTY1NiAxLjQ5ODM4MS0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODQ0ODMyLTMuNTE0ODE5IC42NDU1NzktMy4zNDc0NDcgLjUxMDA4Ny0zLjA3NjQ2M0MuMzE4ODA0LTIuNzAxODY4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnNC0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzQtMTIwJyBkPSdNMy45OTMwMjYtMy4xODAwNzVDMy42NDIzNDEtMy4wOTI0MDMgMy42MjY0MDEtMi43ODE1NjkgMy42MjY0MDEtMi43NDk2ODlDMy42MjY0MDEtMi41NzQzNDYgMy43NjE4OTMtMi40NTQ3OTUgMy45MzcyMzUtMi40NTQ3OTVTNC4zODM1NjItMi41OTAyODYgNC4zODM1NjItMi45MzMwMDFDNC4zODM1NjItMy4zODcyOTggMy44ODE0NDUtMy41MTQ4MTkgMy41ODY1NS0zLjUxNDgxOUMzLjIxMTk1NS0zLjUxNDgxOSAyLjkwOTA5MS0zLjI1MTgwNiAyLjcyNTc3OC0yLjk0MDk3MUMyLjU1MDQzNi0zLjM2MzM4NyAyLjEzNTk5LTMuNTE0ODE5IDEuODA5MjE1LTMuNTE0ODE5Qy45NDA0NzMtMy41MTQ4MTkgLjQ1NDI5Ni0yLjUxODU1NSAuNDU0Mjk2LTIuMjk1MzkyQy40NTQyOTYtMi4yMjM2NjEgLjUxMDA4Ny0yLjE5MTc4MSAuNTczODQ4LTIuMTkxNzgxQy42Njk0ODktMi4xOTE3ODEgLjY4NTQzLTIuMjMxNjMxIC43MDkzNC0yLjMyNzI3M0MuODkyNjUzLTIuOTA5MDkxIDEuMzcwODU5LTMuMjkxNjU2IDEuNzg1MzA1LTMuMjkxNjU2QzIuMDk2MTM5LTMuMjkxNjU2IDIuMjQ3NTcyLTMuMDY4NDkzIDIuMjQ3NTcyLTIuNzgxNTY5QzIuMjQ3NTcyLTIuNjIyMTY3IDIuMTUxOTMtMi4yNTU1NDIgMi4wODgxNjktMi4wMDA0OThDMi4wMzIzNzktMS43NjkzNjUgMS44NTcwMzYtMS4wNjAwMjUgMS44MTcxODYtLjkwODU5M0MxLjcwNTYwNC0uNDc4MjA3IDEuNDE4NjgtLjE0MzQ2MiAxLjA2MDAyNS0uMTQzNDYyQzEuMDI4MTQ0LS4xNDM0NjIgLjgyMDkyMi0uMTQzNDYyIC42NTM1NDktLjI1NTA0NEMxLjAyMDE3NC0uMzQyNzE1IDEuMDIwMTc0LS42Nzc0NiAxLjAyMDE3NC0uNjg1NDNDMS4wMjAxNzQtLjg2ODc0MiAuODc2NzEyLS45ODAzMjQgLjcwMTM3LS45ODAzMjRDLjQ4NjE3Ny0uOTgwMzI0IC4yNTUwNDQtLjc5NzAxMSAuMjU1MDQ0LS40OTQxNDdDLjI1NTA0NC0uMTI3NTIyIC42NDU1NzkgLjA3OTcwMSAxLjA1MjA1NSAuMDc5NzAxQzEuNDc0NDcxIC4wNzk3MDEgMS43NjkzNjUtLjIzOTEwMyAxLjkxMjgyNy0uNDk0MTQ3QzIuMDg4MTY5LS4xMDM2MTEgMi40NTQ3OTUgLjA3OTcwMSAyLjgzNzM2IC4wNzk3MDFDMy43MDYxMDIgLjA3OTcwMSA0LjE4NDMwOS0uOTE2NTYzIDQuMTg0MzA5LTEuMTM5NzI2QzQuMTg0MzA5LTEuMjE5NDI3IDQuMTIwNTQ4LTEuMjQzMzM3IDQuMDY0NzU3LTEuMjQzMzM3QzMuOTY5MTE2LTEuMjQzMzM3IDMuOTUzMTc2LTEuMTg3NTQ3IDMuOTI5MjY1LTEuMTA3ODQ2QzMuNzY5ODYzLS41NzM4NDggMy4zMTU1NjctLjE0MzQ2MiAyLjg1MzMtLjE0MzQ2MkMyLjU5MDI4Ni0uMTQzNDYyIDIuMzk5MDA0LS4zMTg4MDQgMi4zOTkwMDQtLjY1MzU0OUMyLjM5OTAwNC0uODEyOTUxIDIuNDQ2ODI0LS45OTYyNjQgMi41NTg0MDYtMS40NDI1OUMyLjYxNDE5Ny0xLjY4MTY5NCAyLjc4OTUzOS0yLjM4MzA2NCAyLjgyOTM5LTIuNTM0NDk2QzIuOTQwOTcxLTIuOTQ4OTQxIDMuMjE5OTI1LTMuMjkxNjU2IDMuNTc4NTgtMy4yOTE2NTZDMy42MTg0MzEtMy4yOTE2NTYgMy44MjU2NTQtMy4yOTE2NTYgMy45OTMwMjYtMy4xODAwNzVaJy8+CjxwYXRoIGlkPSdnNS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzUtMTIxJyBkPSdNMy4xNDQyMDkgMS4zMzg5NzlDMi44MjE0MiAxLjc5MzI3NSAyLjM1NTE2OCAyLjE5OTc1MSAxLjc2OTM2NSAyLjE5OTc1MUMxLjYyNTkwMyAyLjE5OTc1MSAxLjA1MjA1NSAyLjE3NTg0MSAuODcyNzI3IDEuNjI1OTAzQy45MDg1OTMgMS42Mzc4NTggLjk2ODM2OSAxLjYzNzg1OCAuOTkyMjc5IDEuNjM3ODU4QzEuMzUwOTM0IDEuNjM3ODU4IDEuNTkwMDM3IDEuMzI3MDI0IDEuNTkwMDM3IDEuMDUyMDU1UzEuMzYyODg5IC42ODE0NDUgMS4xODM1NjIgLjY4MTQ0NUMuOTkyMjc5IC42ODE0NDUgLjU3Mzg0OCAuODI0OTA3IC41NzM4NDggMS40MTA3MUMuNTczODQ4IDIuMDIwNDIzIDEuMDg3OTIgMi40Mzg4NTQgMS43NjkzNjUgMi40Mzg4NTRDMi45NjQ4ODIgMi40Mzg4NTQgNC4xNzIzNTQgMS4zMzg5NzkgNC41MDcwOTggLjAxMTk1NUw1LjY3ODcwNS00LjY1MDU2QzUuNjkwNjYtNC43MTAzMzYgNS43MTQ1Ny00Ljc4MjA2NyA1LjcxNDU3LTQuODUzNzk4QzUuNzE0NTctNS4wMzMxMjYgNS41NzExMDgtNS4xNTI2NzcgNS4zOTE3ODEtNS4xNTI2NzdDNS4yODQxODQtNS4xNTI2NzcgNS4wMzMxMjYtNS4xMDQ4NTcgNC45Mzc0ODQtNC43NDYyMDJMNC4wNTI4MDItMS4yMzEzODJDMy45OTMwMjYtMS4wMTYxODkgMy45OTMwMjYtLjk5MjI3OSAzLjg5NzM4NS0uODYwNzcyQzMuNjU4MjgxLS41MjYwMjcgMy4yNjM3NjEtLjExOTU1MiAyLjY4OTkxMy0uMTE5NTUyQzIuMDIwNDIzLS4xMTk1NTIgMS45NjA2NDgtLjc3NzA4NiAxLjk2MDY0OC0xLjA5OTg3NUMxLjk2MDY0OC0xLjc4MTMyIDIuMjgzNDM3LTIuNzAxODY4IDIuNjA2MjI3LTMuNTYyNjRDMi43Mzc3MzMtMy45MDkzNCAyLjgwOTQ2NS00LjA3NjcxMiAyLjgwOTQ2NS00LjMxNTgxNkMyLjgwOTQ2NS00LjgxNzkzMyAyLjQ1MDgwOS01LjI3MjIyOSAxLjg2NTAwNi01LjI3MjIyOUMuNzY1MTMxLTUuMjcyMjI5IC4zMjI3OS0zLjUzODczIC4zMjI3OS0zLjQ0MzA4OEMuMzIyNzktMy4zOTUyNjggLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU2MTg5My0zLjMzNTQ5MiAuNTczODQ4LTMuMzgzMzEzIC42MjE2NjktMy41NTA2ODVDLjkwODU5My00LjU1NDkxOSAxLjM2Mjg4OS01LjAzMzEyNiAxLjgyOTE0MS01LjAzMzEyNkMxLjkzNjczNy01LjAzMzEyNiAyLjEzOTk3NS01LjAzMzEyNiAyLjEzOTk3NS00LjYzODYwNUMyLjEzOTk3NS00LjMyNzc3MSAyLjAwODQ2OC0zLjk4MTA3MSAxLjgyOTE0MS0zLjUyNjc3NUMxLjI0MzMzNy0xLjk2MDY0OCAxLjI0MzMzNy0xLjU2NjEyNyAxLjI0MzMzNy0xLjI3OTIwM0MxLjI0MzMzNy0uMTQzNDYyIDIuMDU2Mjg5IC4xMTk1NTIgMi42NTQwNDcgLjExOTU1MkMzLjAwMDc0NyAuMTE5NTUyIDMuNDMxMTMzIC4wMTE5NTUgMy44NDk1NjQtLjQzMDM4NkwzLjg2MTUxOS0uNDE4NDMxQzMuNjgyMTkyIC4yODY5MjQgMy41NjI2NCAuNzUzMTc2IDMuMTQ0MjA5IDEuMzM4OTc5WicvPgo8cGF0aCBpZD0nZzYtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c2LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnNi02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMTA0LjM5MDUwMycgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2czLTY4Jy8+Cjx1c2UgeD0nMTE1LjkzNzIyOScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c2LTQwJy8+Cjx1c2UgeD0nMTIwLjQ4OTU1NScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2cwLTg5Jy8+CjxyZWN0IHg9JzEzMS42MDk0NDYnIHk9Jy0yMS4yNjUzMTcnIGhlaWdodD0nLjM1ODY1Nicgd2lkdGg9JzUuNzA3MDA4Jy8+Cjx1c2UgeD0nMTMxLjYwOTQ0NicgeT0nLTE0LjM4NDQ1OScgeGxpbms6aHJlZj0nI2cyLTczJy8+Cjx1c2UgeD0nMTM3LjMxNjQ1NCcgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2czLTEwNicvPgo8dXNlIHg9JzE0MC42MzczNDQnIHk9Jy0xNy41MDYwOTknIHhsaW5rOmhyZWY9JyNnMC04OScvPgo8dXNlIHg9JzE1MS43NTcyMzUnIHk9Jy0xNS43MTI4MzYnIHhsaW5rOmhyZWY9JyNnMi03MycvPgo8dXNlIHg9JzE2MC43ODUwNzInIHk9Jy0xNy41MDYwOTknIHhsaW5rOmhyZWY9JyNnNi02MScvPgo8dXNlIHg9JzE3My4yMTA1NTMnIHk9Jy0xNy41MDYwOTknIHhsaW5rOmhyZWY9JyNnMC0xMTMnLz4KPHVzZSB4PScxODAuMTM0NTM5JyB5PSctMTQuNjgzMzU2JyB4bGluazpocmVmPScjZzItNzMnLz4KPHVzZSB4PScxODUuODQxNTQ2JyB5PSctMTcuNTA2MDk5JyB4bGluazpocmVmPScjZzYtNDEnLz4KPHVzZSB4PScxOTMuNzE0NzAxJyB5PSctMTcuNTA2MDk5JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScyMDYuMTQwMTgyJyB5PSctMjguODYzNTYzJyB4bGluazpocmVmPScjZzEtODknLz4KPHVzZSB4PScyMDYuOTA5NDM4JyB5PSctMS42OTg2MzInIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyMDkuNzkyNTc4JyB5PSctMS42OTg2MzInIHhsaW5rOmhyZWY9JyNnMi01MCcvPgo8cmVjdCB4PScyMTUuNDM4MTU1JyB5PSctOC41Nzk0OTEnIGhlaWdodD0nLjM1ODY1Nicgd2lkdGg9JzUuMjA4ODc2Jy8+Cjx1c2UgeD0nMjE1LjQzODE1NScgeT0nLTEuNjk4NjMyJyB4bGluazpocmVmPScjZzItNzMnLz4KPHVzZSB4PScyMjMuNDA4NzY5JyB5PSctMjcuMTg5ODYyJyB4bGluazpocmVmPScjZzEtMicvPgo8dXNlIHg9JzIyOC4zOTAxMDQnIHk9Jy0xNy41MDYwOTknIHhsaW5rOmhyZWY9JyNnNS0xMjEnLz4KPHVzZSB4PScyMzQuNTI2NzU2JyB5PSctMjIuNDQyMjg1JyB4bGluazpocmVmPScjZzQtMTA5Jy8+Cjx1c2UgeD0nMjQyLjAxNzI4MicgeT0nLTIyLjQ0MjI4NScgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzI0NC45MDA0MjEnIHk9Jy0yMi40NDIyODUnIHhsaW5rOmhyZWY9JyNnNC0xMTAnLz4KPHVzZSB4PScyMzQuMDk3ODA3JyB5PSctMTQuNTUwNTg0JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjUwLjUzNjc1NicgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c1LTU5Jy8+Cjx1c2UgeD0nMjU1Ljc4MDkxNScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c1LTEyMScvPgo8dXNlIHg9JzI2MS45MTc1NjcnIHk9Jy0yMi40NDIyODUnIHhsaW5rOmhyZWY9JyNnNC0xMDknLz4KPHVzZSB4PScyNjkuNDA4MDkzJyB5PSctMjIuNDQyMjg1JyB4bGluazpocmVmPScjZzQtOTcnLz4KPHVzZSB4PScyNzMuOTA2MTAzJyB5PSctMjIuNDQyMjg1JyB4bGluazpocmVmPScjZzQtMTIwJy8+Cjx1c2UgeD0nMjYxLjQ4ODYxOCcgeT0nLTE0LjU1MDU4NCcgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzI3OS4xNzExMzMnIHk9Jy0yNy4xODk4NjInIHhsaW5rOmhyZWY9JyNnMS0zJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
Then, inversely, we compute the quantiles of each  for which have the same order as the bounds
for which have the same order as the bounds
 and
and  with respect :
with respect :

We assign to the numerical range defined by:
![\cD \left(\vect{X}_{\overline{\cI}}|\vect{X}_\cI = \vect{x}_\cI \right) = \prod_{i\in \overline{\cI}} \left[ x_i^{min},
x_i^{max}\right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNSAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScxODQuMDE1ODA4cHQnIGhlaWdodD0nMjguODYzNTgycHQnIHZpZXdCb3g9JzEwMi4yNjM1NzYgLTMwLjA1OTA5NiAxODQuMDE1ODA4IDI4Ljg2MzU4Mic+CjxkZWZzPgo8cGF0aCBpZD0nZzAtODgnIGQ9J002Ljk1NzkwOC00LjcyMjI5MUw4LjUzNTk5LTYuMjc2NDYzTDkuMjc3MjEtNy4wMjk2MzlDOS43NTU0MTctNy40ODM5MzUgOS44OTg4NzktNy42MjczOTcgMTEuMTQyMjE3LTcuNjM5MzUyQzExLjM2OTM2NS03LjYzOTM1MiAxMS4zOTMyNzUtNy45NTAxODcgMTEuMzkzMjc1LTcuOTg2MDUyQzExLjM5MzI3NS04LjA1Nzc4MyAxMS4zNDU0NTUtOC4yMDEyNDUgMTEuMTU0MTcyLTguMjAxMjQ1QzEwLjczNTc0MS04LjIwMTI0NSAxMC4yODE0NDUtOC4xNjUzOCA5Ljg1MTA1OS04LjE2NTM4QzkuNTA0MzU5LTguMTY1MzggOC42NDM1ODctOC4yMDEyNDUgOC4yOTY4ODctOC4yMDEyNDVDOC4yMDEyNDUtOC4yMDEyNDUgNy45NjIxNDItOC4yMDEyNDUgNy45NjIxNDItNy44NjY1MDFDNy45NjIxNDItNy42NTEzMDggOC4xNTM0MjUtNy42MzkzNTIgOC4yNjEwMjEtNy42MzkzNTJDOC42MTk2NzYtNy42MjczOTcgOC45MzA1MTEtNy41MzE3NTYgOC45NzgzMzEtNy41MTk4MDFMNi42OTQ4OTQtNS4yNjAyNzRMNS41OTUwMTktNy41Njc2MjFDNS43MTQ1Ny03LjU5MTUzMiA2LjA4NTE4MS03LjYzOTM1MiA2LjI4ODQxOC03LjYzOTM1MkM2LjQxOTkyNS03LjYzOTM1MiA2LjYzNTExOC03LjYzOTM1MiA2LjYzNTExOC03Ljk3NDA5N0M2LjYzNTExOC04LjE0MTQ2OSA2LjUyNzUyMi04LjIwMTI0NSA2LjM3MjEwNS04LjIwMTI0NUM1Ljk2NTYyOS04LjIwMTI0NSA0Ljk2MTM5NS04LjE2NTM4IDQuNTU0OTE5LTguMTY1MzhDNC4yNzk5NS04LjE2NTM4IDQuMDA0OTgxLTguMTc3MzM1IDMuNzMwMDEyLTguMTc3MzM1UzMuMTY4MTItOC4yMDEyNDUgMi44OTMxNTEtOC4yMDEyNDVDMi43ODU1NTQtOC4yMDEyNDUgMi41NTg0MDYtOC4yMDEyNDUgMi41NTg0MDYtNy44NjY1MDFDMi41NTg0MDYtNy42MzkzNTIgMi43MTM4MjMtNy42MzkzNTIgMy4wNDg1NjgtNy42MzkzNTJDMy4yMTU5NC03LjYzOTM1MiAzLjM0NzQ0Ny03LjYzOTM1MiAzLjUxNDgxOS03LjYyNzM5N0MzLjY4MjE5Mi03LjYwMzQ4NyAzLjY5NDE0Ny03LjU5MTUzMiAzLjc2NTg3OC03LjQ0ODA3TDUuNDE1NjkxLTMuOTkzMDI2TDIuNDE0OTQ0LTEuMDI4MTQ0QzIuMTk5NzUxLS44MjQ5MDcgMS45NDg2OTItLjU3Mzg0OCAuODg0NjgyLS41NjE4OTNDLjY2OTQ4OS0uNTYxODkzIC40NjYyNTItLjU2MTg5MyAuNDY2MjUyLS4yMTUxOTNDLjQ2NjI1Mi0uMTMxNTA3IC41MjYwMjcgMCAuNzA1MzU1IDBDLjk5MjI3OSAwIDEuNzIxNTQ0LS4wMzU4NjYgMi4wMDg0NjgtLjAzNTg2NkMyLjM1NTE2OC0uMDM1ODY2IDMuMjE1OTQgMCAzLjU2MjY0IDBDMy42NTgyODEgMCAzLjg5NzM4NSAwIDMuODk3Mzg1LS4zNDY3QzMuODk3Mzg1LS41NjE4OTMgMy42ODIxOTItLjU2MTg5MyAzLjU4NjU1LS41NjE4OTNDMy4zNDc0NDctLjU2MTg5MyAzLjEwODM0NC0uNTk3NzU4IDIuODgxMTk2LS42ODE0NDVMNS42NjY3NS0zLjQ1NTA0NEw3LjAxNzY4NC0uNjMzNjI0QzcuMDA1NzI5LS42MzM2MjQgNi42MTEyMDgtLjU2MTg5MyA2LjMyNDI4NC0uNTYxODkzQzYuMjA0NzMyLS41NjE4OTMgNS45Nzc1ODQtLjU2MTg5MyA1Ljk3NzU4NC0uMjE1MTkzQzUuOTc3NTg0LS4xNzkzMjggNS45ODk1MzkgMCA2LjI0MDU5OCAwQzYuNjQ3MDczIDAgNy42NjMyNjMtLjAzNTg2NiA4LjA2OTczOC0uMDM1ODY2QzguMzQ0NzA3LS4wMzU4NjYgOC42MTk2NzYtLjAyMzkxIDguODk0NjQ1LS4wMjM5MVM5LjQ1NjUzOCAwIDkuNzMxNTA3IDBDOS44MjcxNDggMCAxMC4wNjYyNTIgMCAxMC4wNjYyNTItLjM0NjdDMTAuMDY2MjUyLS41NjE4OTMgOS44NzQ5NjktLjU2MTg5MyA5LjU4ODA0NS0uNTYxODkzQzkuNDIwNjcyLS41NjE4OTMgOS4zMDExMjEtLjU2MTg5MyA5LjEyMTc5My0uNTczODQ4QzguOTQyNDY2LS41OTc3NTggOC45MzA1MTEtLjYwOTcxNCA4Ljg0NjgyNC0uNzY1MTMxTDYuOTU3OTA4LTQuNzIyMjkxWicvPgo8cGF0aCBpZD0nZzAtMTIwJyBkPSdNNi40MDc5Ny00Ljc5NDAyMkM1Ljk3NzU4NC00LjY3NDQ3MSA1Ljc2MjM5MS00LjI2Nzk5NSA1Ljc2MjM5MS0zLjk2OTExNkM1Ljc2MjM5MS0zLjcwNjEwMiA1Ljk2NTYyOS0zLjQxOTE3OCA2LjM2MDE0OS0zLjQxOTE3OEM2Ljc3ODU4LTMuNDE5MTc4IDcuMjIwOTIyLTMuNzY1ODc4IDcuMjIwOTIyLTQuMzUxNjgxQzcuMjIwOTIyLTQuOTg1MzA1IDYuNTg3Mjk4LTUuNDAzNzM2IDUuODU4MDMyLTUuNDAzNzM2QzUuMTc2NTg4LTUuNDAzNzM2IDQuNzM0MjQ3LTQuODg5NjY0IDQuNTc4ODI5LTQuNjc0NDcxQzQuMjc5OTUtNS4xNzY1ODggMy42MTA0NjEtNS40MDM3MzYgMi45MjkwMTYtNS40MDM3MzZDMS40MjI2NjUtNS40MDM3MzYgLjYwOTcxNC0zLjkzMzI1IC42MDk3MTQtMy41Mzg3M0MuNjA5NzE0LTMuMzcxMzU3IC43ODkwNDEtMy4zNzEzNTcgLjg5NjYzOC0zLjM3MTM1N0MxLjA0MDEtMy4zNzEzNTcgMS4xMjM3ODYtMy4zNzEzNTcgMS4xNzE2MDYtMy41MjY3NzVDMS41MTgzMDYtNC42MTQ2OTUgMi4zNzkwNzgtNC45NzMzNSAyLjg2OTI0LTQuOTczMzVDMy4zMjM1MzctNC45NzMzNSAzLjUzODczLTQuNzU4MTU3IDMuNTM4NzMtNC4zNzU1OTJDMy41Mzg3My00LjE0ODQ0MyAzLjM3MTM1Ny0zLjQ5MDkwOSAzLjI2Mzc2MS0zLjA2MDUyM0wyLjg1NzI4NS0xLjQyMjY2NUMyLjY3Nzk1OC0uNjkzNCAyLjI0NzU3Mi0uMzM0NzQ1IDEuODQxMDk2LS4zMzQ3NDVDMS43ODEzMi0uMzM0NzQ1IDEuNTA2MzUxLS4zMzQ3NDUgMS4yNjcyNDgtLjUxNDA3MkMxLjY5NzYzNC0uNjMzNjI0IDEuOTEyODI3LTEuMDQwMSAxLjkxMjgyNy0xLjMzODk3OUMxLjkxMjgyNy0xLjYwMTk5MyAxLjcwOTU4OS0xLjg4ODkxNyAxLjMxNTA2OC0xLjg4ODkxN0MuODk2NjM4LTEuODg4OTE3IC40NTQyOTYtMS41NDIyMTcgLjQ1NDI5Ni0uOTU2NDEzQy40NTQyOTYtLjMyMjc5IDEuMDg3OTIgLjA5NTY0MSAxLjgxNzE4NiAuMDk1NjQxQzIuNDk4NjMgLjA5NTY0MSAyLjk0MDk3MS0uNDE4NDMxIDMuMDk2Mzg5LS42MzM2MjRDMy4zOTUyNjgtLjEzMTUwNyA0LjA2NDc1NyAuMDk1NjQxIDQuNzQ2MjAyIC4wOTU2NDFDNi4yNTI1NTMgLjA5NTY0MSA3LjA2NTUwNC0xLjM3NDg0NCA3LjA2NTUwNC0xLjc2OTM2NUM3LjA2NTUwNC0xLjkzNjczNyA2Ljg4NjE3Ny0xLjkzNjczNyA2Ljc3ODU4LTEuOTM2NzM3QzYuNjM1MTE4LTEuOTM2NzM3IDYuNTUxNDMyLTEuOTM2NzM3IDYuNTAzNjExLTEuNzgxMzJDNi4xNTY5MTItLjY5MzQgNS4yOTYxMzktLjMzNDc0NSA0LjgwNTk3OC0uMzM0NzQ1QzQuMzUxNjgxLS4zMzQ3NDUgNC4xMzY0ODgtLjU0OTkzOCA0LjEzNjQ4OC0uOTMyNTAzQzQuMTM2NDg4LTEuMTgzNTYyIDQuMjkxOTA1LTEuODE3MTg2IDQuMzk5NTAyLTIuMjU5NTI3QzQuNDgzMTg4LTIuNTcwMzYxIDQuNzU4MTU3LTMuNjk0MTQ3IDQuODE3OTMzLTMuODg1NDNDNC45OTcyNi00LjYwMjc0IDUuNDE1NjkxLTQuOTczMzUgNS44MzQxMjItNC45NzMzNUM1Ljg5Mzg5OC00Ljk3MzM1IDYuMTY4ODY3LTQuOTczMzUgNi40MDc5Ny00Ljc5NDAyMlonLz4KPHBhdGggaWQ9J2cxLTInIGQ9J00yLjQxNDk0NCAxMy44NTYwNEg0LjcxMDMzNlYxMy4zNzc4MzNIMi44OTMxNTFWMEg0LjcxMDMzNlYtLjQ3ODIwN0gyLjQxNDk0NFYxMy44NTYwNFonLz4KPHBhdGggaWQ9J2cxLTMnIGQ9J00yLjU1ODQwNiAxMy44NTYwNFYtLjQ3ODIwN0guMjYzMDE0VjBIMi4wODAxOTlWMTMuMzc3ODMzSC4yNjMwMTRWMTMuODU2MDRIMi41NTg0MDZaJy8+CjxwYXRoIGlkPSdnMS04OScgZD0nTTE0LjU5NzI2IDE2LjczNzIzNVYxNi4wOTE2NTZDMTMuMDA3MjIzIDE2LjA5MTY1NiAxMi42MzY2MTMgMTUuNTQxNzE5IDEyLjYzNjYxMyAxNC43NzY1ODhWMS45NjA2NDhDMTIuNjM2NjEzIDEuMTgzNTYyIDEzLjAxOTE3OCAuNjQ1NTc5IDE0LjU5NzI2IC42NDU1NzlWMEguNjY5NDg5Vi42NDU1NzlDMi4yNTk1MjcgLjY0NTU3OSAyLjYzMDEzNyAxLjE5NTUxNyAyLjYzMDEzNyAxLjk2MDY0OFYxNC43NzY1ODhDMi42MzAxMzcgMTUuNTUzNjc0IDIuMjQ3NTcyIDE2LjA5MTY1NiAuNjY5NDg5IDE2LjA5MTY1NlYxNi43MzcyMzVINi40MTk5MjVWMTYuMDkxNjU2QzQuODI5ODg4IDE2LjA5MTY1NiA0LjQ1OTI3OCAxNS41NDE3MTkgNC40NTkyNzggMTQuNzc2NTg4Vi42NDU1NzlIMTAuODA3NDcyVjE0Ljc3NjU4OEMxMC44MDc0NzIgMTUuNTUzNjc0IDEwLjQyNDkwNyAxNi4wOTE2NTYgOC44NDY4MjQgMTYuMDkxNjU2VjE2LjczNzIzNUgxNC41OTcyNlonLz4KPHBhdGggaWQ9J2cyLTUwJyBkPSdNNC42MzA2MzUtMS44MDkyMTVDNC43NTgxNTctMS44MDkyMTUgNC45MzM0OTktMS44MDkyMTUgNC45MzM0OTktMS45OTI1MjhTNC43NTgxNTctMi4xNzU4NDEgNC42MzA2MzUtMi4xNzU4NDFIMS4wNzU5NjVDMS4xNzk1NzctMy4yODM2ODYgMi4xMDQxMS00LjEyODUxOCAzLjMxNTU2Ny00LjEyODUxOEg0LjYzMDYzNUM0Ljc1ODE1Ny00LjEyODUxOCA0LjkzMzQ5OS00LjEyODUxOCA0LjkzMzQ5OS00LjMxMTgzMVM0Ljc1ODE1Ny00LjQ5NTE0MyA0LjYzMDYzNS00LjQ5NTE0M0gzLjI5MTY1NkMxLjg1NzAzNi00LjQ5NTE0MyAuNzAxMzctMy4zNzkzMjggLjcwMTM3LTEuOTkyNTI4Qy43MDEzNy0uNTk3NzU4IDEuODY1MDA2IC41MTAwODcgMy4yOTE2NTYgLjUxMDA4N0g0LjYzMDYzNUM0Ljc1ODE1NyAuNTEwMDg3IDQuOTMzNDk5IC41MTAwODcgNC45MzM0OTkgLjMyNjc3NVM0Ljc1ODE1NyAuMTQzNDYyIDQuNjMwNjM1IC4xNDM0NjJIMy4zMTU1NjdDMi4xMDQxMSAuMTQzNDYyIDEuMTc5NTc3LS43MDEzNyAxLjA3NTk2NS0xLjgwOTIxNUg0LjYzMDYzNVonLz4KPHBhdGggaWQ9J2cyLTczJyBkPSdNNC42Mzg2MDUtNC45ODEzMkM0Ljc4MjA2Ny00Ljk4MTMyIDQuODc3NzA5LTQuOTgxMzIgNS4wNzY5NjEtNS4xMDA4NzJDNS4yOTIxNTQtNS4yMjA0MjMgNS4zNjM4ODUtNS4zMzIwMDUgNS4zNjM4ODUtNS4zNzk4MjZDNS4zNjM4ODUtNS40MzU2MTYgNS4zNTU5MTUtNS40NDM1ODcgNS4xNzI2MDMtNS40NDM1ODdIMi44OTMxNTFDMi4zNDMyMTMtNS40NDM1ODcgMS43NzczMzUtNS40MDM3MzYgMS4yNjcyNDgtNS4xOTY1MTNDLjM1MDY4NS00LjgxMzk0OCAuMjM5MTAzLTQuMjMyMTMgLjIzOTEwMy00LjE5MjI3OUMuMjM5MTAzLTQuMTQ0NDU4IC4yNzA5ODQtNC4xMjA1NDggLjMxODgwNC00LjEyMDU0OEMuNDcwMjM3LTQuMTIwNTQ4IC44NzY3MTItNC4zMTE4MzEgLjk0ODQ0My00LjUyNzAyNEMxLjA0NDA4NS00LjgxMzk0OCAxLjA2Nzk5NS00Ljg2MTc2OCAxLjUyMjI5MS00LjkyNTUyOUMxLjgwMTI0NS00Ljk2NTM4IDIuMDg4MTY5LTQuOTgxMzIgMi4zNzUwOTMtNC45ODEzMkgzLjI1OTc3NkMyLjcyNTc3OC00LjQ4NzE3MyAyLjQ3ODcwNS0zLjQ5MDkwOSAyLjIxNTY5MS0yLjQ0NjgyNEMyLjA3MjIyOS0xLjg0MTA5NiAxLjg0MTA5Ni0uOTQwNDczIDEuNDU4NTMxLS41MjYwMjdDMS40MDI3NC0uNDcwMjM3IDEuMzk0NzctLjQ2MjI2NyAxLjE3MTYwNi0uNDYyMjY3SC42MDU3MjlDLjQzODM1Ni0uNDYyMjY3IC4zNzQ1OTUtLjQ2MjI2NyAuMTU5NDAyLS4zNTA2ODVDLjAzOTg1MS0uMjc4OTU0LS4xMjc1MjItLjE0MzQ2Mi0uMTI3NTIyLS4wNTU3OTFDLS4xMjc1MjIgMC0uMDYzNzYxIDAgLjA3MTczMSAwSDIuOTY0ODgyQzQuMDAwOTk2IDAgNC42Nzg0NTYtLjcwMTM3IDQuNjc4NDU2LS45ODAzMjRDNC42Nzg0NTYtMS4wMzYxMTUgNC42Mzg2MDUtMS4wNDQwODUgNC41ODI4MTQtMS4wNDQwODVDNC40MTU0NDItMS4wNDQwODUgNC4xMDQ2MDgtLjg2MDc3MiA0LjAwMDk5Ni0uNzE3MzFMMy45MTMzMjUtLjUxMDA4N0MzLjczNzk4My0uNDYyMjY3IDMuNTU0NjctLjQ2MjI2NyAzLjQ4MjkzOS0uNDYyMjY3SDEuODU3MDM2QzIuNDU0Nzk1LS45NzIzNTQgMi42Nzc5NTgtMS43NzczMzUgMi45MzMwMDEtMi44MTM0NUMzLjE1NjE2NC0zLjcwNjEwMiAzLjM2MzM4Ny00LjUwMzExMyAzLjcyMjA0Mi00Ljk4MTMySDQuNjM4NjA1WicvPgo8cGF0aCBpZD0nZzMtNjgnIGQ9J00yLjQzODg1NCAwQzUuMjI0NDA4IDAgOS4xNTc2NTktMi4xMjgwMiA5LjE1NzY1OS01LjM5MTc4MUM5LjE1NzY1OS02LjQ1NTc5MSA4LjY1NTU0Mi03LjEyNTI4IDguMDY5NzM4LTcuNDk1ODlDNy4wNDE1OTQtOC4xNjUzOCA1Ljk0MTcxOS04LjE2NTM4IDQuODA1OTc4LTguMTY1MzhDMy43Nzc4MzMtOC4xNjUzOCAzLjA3MjQ3OC04LjE2NTM4IDIuMDY4MjQ0LTcuNzM0OTk0Qy40NzgyMDctNy4wMjk2MzkgLjI1MTA1OS02LjAzNzM2IC4yNTEwNTktNS45NDE3MTlDLjI1MTA1OS01Ljg2OTk4OCAuMjk4ODc5LTUuODQ2MDc3IC4zNzA2MS01Ljg0NjA3N0MuNTYxODkzLTUuODQ2MDc3IC44MzY4NjItNi4wMTM0NSAuOTMyNTAzLTYuMDczMjI1QzEuMTgzNTYyLTYuMjQwNTk4IDEuMjE5NDI3LTYuMzEyMzI5IDEuMjkxMTU4LTYuNTM5NDc3QzEuNDU4NTMxLTcuMDE3Njg0IDEuNzkzMjc1LTcuNDM2MTE1IDMuMjk5NjI2LTcuNTA3ODQ2QzMuMTA4MzQ0LTUuMDA5MjE1IDIuNDk4NjMtMi43MjU3NzggMS42NjE3NjgtLjYzMzYyNEMxLjIxOTQyNy0uNDc4MjA3IC45MzI1MDMtLjIwMzIzOCAuOTMyNTAzLS4wODM2ODZDLjkzMjUwMy0uMDExOTU1IC45NDQ0NTggMCAxLjIwNzQ3MiAwSDIuNDM4ODU0Wk0yLjQ5ODYzLS42NTc1MzRDMy44NjE1MTktMy45OTMwMjYgNC4xMTI1NzgtNi4wNzMyMjUgNC4yNzk5NS03LjUwNzg0NkM1LjA4MDk0Ni03LjUwNzg0NiA4LjE0MTQ2OS03LjUwNzg0NiA4LjE0MTQ2OS00Ljg3NzcwOUM4LjE0MTQ2OS0yLjUzNDQ5NiA2LjAzNzM2LS42NTc1MzQgMy4xNDQyMDktLjY1NzUzNEgyLjQ5ODYzWicvPgo8cGF0aCBpZD0nZzMtMTA2JyBkPSdNMS45MDA4NzItOC41MzU5OUMxLjkwMDg3Mi04Ljc1MTE4MyAxLjkwMDg3Mi04Ljk2NjM3NiAxLjY2MTc2OC04Ljk2NjM3NlMxLjQyMjY2NS04Ljc1MTE4MyAxLjQyMjY2NS04LjUzNTk5VjIuNTU4NDA2QzEuNDIyNjY1IDIuNzczNTk5IDEuNDIyNjY1IDIuOTg4NzkyIDEuNjYxNzY4IDIuOTg4NzkyUzEuOTAwODcyIDIuNzczNTk5IDEuOTAwODcyIDIuNTU4NDA2Vi04LjUzNTk5WicvPgo8cGF0aCBpZD0nZzQtOTcnIGQ9J00zLjEyNDI4NC0zLjAzNjYxM0MzLjA1MjU1My0zLjE3MjEwNSAyLjgyMTQyLTMuNTE0ODE5IDIuMzM1MjQzLTMuNTE0ODE5QzEuMzg2OC0zLjUxNDgxOSAuMzQyNzE1LTIuNDA2OTc0IC4zNDI3MTUtMS4yMjczOTdDLjM0MjcxNS0uMzk4NTA2IC44NzY3MTIgLjA3OTcwMSAxLjQ5MDQxMSAuMDc5NzAxQzIuMDAwNDk4IC4wNzk3MDEgMi40Mzg4NTQtLjMyNjc3NSAyLjU4MjMxNi0uNDg2MTc3QzIuNzI1Nzc4IC4wNjM3NjEgMy4yNjc3NDYgLjA3OTcwMSAzLjM2MzM4NyAuMDc5NzAxQzMuNzMwMDEyIC4wNzk3MDEgMy45MTMzMjUtLjIyMzE2MyAzLjk3NzA4Ni0uMzU4NjU1QzQuMTM2NDg4LS42NDU1NzkgNC4yNDgwNy0xLjEwNzg0NiA0LjI0ODA3LTEuMTM5NzI2QzQuMjQ4MDctMS4xODc1NDcgNC4yMTYxODktMS4yNDMzMzcgNC4xMjA1NDgtMS4yNDMzMzdTNC4wMDg5NjYtMS4xOTU1MTcgMy45NjExNDYtLjk5NjI2NEMzLjg0OTU2NC0uNTU3OTA4IDMuNjk4MTMyLS4xNDM0NjIgMy4zODcyOTgtLjE0MzQ2MkMzLjIwMzk4NS0uMTQzNDYyIDMuMTMyMjU0LS4yOTQ4OTQgMy4xMzIyNTQtLjUxODA1N0MzLjEzMjI1NC0uNjUzNTQ5IDMuMjAzOTg1LS45MjQ1MzMgMy4yNTE4MDYtMS4xMjM3ODZTMy40MTkxNzgtMS44MDEyNDUgMy40NTEwNTktMS45NDQ3MDdMMy42MTA0NjEtMi41NTA0MzZDMy42NTAzMTEtMi43NDE3MTkgMy43Mzc5ODMtMy4wNzY0NjMgMy43Mzc5ODMtMy4xMTYzMTRDMy43Mzc5ODMtMy4yOTk2MjYgMy41ODY1NS0zLjM2MzM4NyAzLjQ4MjkzOS0zLjM2MzM4N0MzLjM2MzM4Ny0zLjM2MzM4NyAzLjE2NDEzNC0zLjI4MzY4NiAzLjEyNDI4NC0zLjAzNjYxM1pNMi41ODIzMTYtLjg2MDc3MkMyLjE4MzgxMS0uMzEwODM0IDEuNzY5MzY1LS4xNDM0NjIgMS41MTQzMjEtLjE0MzQ2MkMxLjE0NzY5Ni0uMTQzNDYyIC45NjQzODQtLjQ3ODIwNyAuOTY0Mzg0LS44OTI2NTNDLjk2NDM4NC0xLjI2NzI0OCAxLjE3OTU3Ny0yLjEyMDA1IDEuMzU0OTE5LTIuNDcwNzM1QzEuNTg2MDUyLTIuOTU2OTEyIDEuOTc2NTg4LTMuMjkxNjU2IDIuMzQzMjEzLTMuMjkxNjU2QzIuODYxMjctMy4yOTE2NTYgMy4wMTI3MDItMi43MDk4MzggMy4wMTI3MDItMi42MTQxOTdDMy4wMTI3MDItMi41ODIzMTYgMi44MTM0NS0xLjgwMTI0NSAyLjc2NTYyOS0xLjU5NDAyMkMyLjY2MjAxNy0xLjIxOTQyNyAyLjY2MjAxNy0xLjIwMzQ4NyAyLjU4MjMxNi0uODYwNzcyWicvPgo8cGF0aCBpZD0nZzQtMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2c0LTEwOScgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS43NDU0NTUtMS45Mjg3NjcgMS43OTMyNzUtMi4xMjAwNSAxLjgwOTIxNS0yLjE5OTc1MUMxLjgyNTE1Ni0yLjIzOTYwMSAyLjA4ODE2OS0yLjc1NzY1OSAyLjQzODg1NC0zLjAyMDY3MkMyLjcwOTgzOC0zLjIyNzg5NSAyLjk3Mjg1Mi0zLjI5MTY1NiAzLjE5NjAxNS0zLjI5MTY1NkMzLjQ5MDkwOS0zLjI5MTY1NiAzLjY1MDMxMS0zLjExNjMxNCAzLjY1MDMxMS0yLjc0OTY4OUMzLjY1MDMxMS0yLjU1ODQwNiAzLjYwMjQ5MS0yLjM3NTA5MyAzLjUxNDgxOS0yLjAxNjQzOEMzLjQ1OTAyOS0xLjgwOTIxNSAzLjMyMzUzNy0xLjI3NTIxOCAzLjI3NTcxNi0xLjA2MDAyNUwzLjE1NjE2NC0uNTgxODE4QzMuMTE2MzE0LS40NDYzMjYgMy4wNjA1MjMtLjIwNzIyMyAzLjA2MDUyMy0uMTY3MzcyQzMuMDYwNTIzIC4wMTU5NCAzLjIxMTk1NSAuMDc5NzAxIDMuMzE1NTY3IC4wNzk3MDFDMy40NTkwMjkgLjA3OTcwMSAzLjU3ODU4LS4wMTU5NCAzLjYzNDM3MS0uMTExNTgyQzMuNjU4MjgxLS4xNTk0MDIgMy43MjIwNDItLjQzMDM4NiAzLjc2MTg5My0uNTk3NzU4TDMuOTQ1MjA1LTEuMzA3MDk4QzMuOTY5MTE2LTEuNDI2NjUgNC4wNDg4MTctMS43Mjk1MTQgNC4wNzI3MjctMS44NDkwNjZDNC4xODQzMDktMi4yNzk0NTIgNC4xODQzMDktMi4yODc0MjIgNC4zNjc2MjEtMi41NTA0MzZDNC42MzA2MzUtMi45NDA5NzEgNS4wMDUyMy0zLjI5MTY1NiA1LjUzOTIyOC0zLjI5MTY1NkM1LjgyNjE1Mi0zLjI5MTY1NiA1Ljk5MzUyNC0zLjEyNDI4NCA1Ljk5MzUyNC0yLjc0OTY4OUM1Ljk5MzUyNC0yLjMxMTMzMyA1LjY1ODc4LTEuMzk0NzcgNS41MDczNDctMS4wMTIyMDRDNS40Mjc2NDYtLjgwNDk4MSA1LjQwMzczNi0uNzQ5MTkxIDUuNDAzNzM2LS41OTc3NThDNS40MDM3MzYtLjE0MzQ2MiA1Ljc3ODMzMSAuMDc5NzAxIDYuMTIxMDQ2IC4wNzk3MDFDNi45MDIxMTcgLjA3OTcwMSA3LjIyODg5Mi0xLjAzNjExNSA3LjIyODg5Mi0xLjEzOTcyNkM3LjIyODg5Mi0xLjIxOTQyNyA3LjE2NTEzMS0xLjI0MzMzNyA3LjEwOTM0LTEuMjQzMzM3QzcuMDEzNjk5LTEuMjQzMzM3IDYuOTk3NzU4LTEuMTg3NTQ3IDYuOTczODQ4LTEuMTA3ODQ2QzYuNzgyNTY1LS40NDYzMjYgNi40NDc4MjEtLjE0MzQ2MiA2LjE0NDk1Ni0uMTQzNDYyQzYuMDE3NDM1LS4xNDM0NjIgNS45NTM2NzQtLjIyMzE2MyA1Ljk1MzY3NC0uNDA2NDc2UzYuMDE3NDM1LS43NjUxMzEgNi4wOTcxMzYtLjk2NDM4NEM2LjIxNjY4Ny0xLjI2NzI0OCA2LjU2NzM3Mi0yLjE4MzgxMSA2LjU2NzM3Mi0yLjYzMDEzN0M2LjU2NzM3Mi0zLjIyNzg5NSA2LjE1MjkyNy0zLjUxNDgxOSA1LjU3OTA3OC0zLjUxNDgxOUM1LjAyOTE0MS0zLjUxNDgxOSA0LjU3NDg0NC0zLjIyNzg5NSA0LjIxNjE4OS0yLjczMzc0OEM0LjE1MjQyOC0zLjM3MTM1NyAzLjY0MjM0MS0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjg2MTI3LTMuNTE0ODE5IDIuMzc1MDkzLTMuMzg3Mjk4IDEuOTM2NzM3LTIuODEzNDVDMS44ODA5NDYtMy4yOTE2NTYgMS40OTgzODEtMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjg0NDgzMi0zLjUxNDgxOSAuNjQ1NTc5LTMuMzQ3NDQ3IC41MTAwODctMy4wNzY0NjNDLjMxODgwNC0yLjcwMTg2OCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzQtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c0LTEyMCcgZD0nTTMuOTkzMDI2LTMuMTgwMDc1QzMuNjQyMzQxLTMuMDkyNDAzIDMuNjI2NDAxLTIuNzgxNTY5IDMuNjI2NDAxLTIuNzQ5Njg5QzMuNjI2NDAxLTIuNTc0MzQ2IDMuNzYxODkzLTIuNDU0Nzk1IDMuOTM3MjM1LTIuNDU0Nzk1UzQuMzgzNTYyLTIuNTkwMjg2IDQuMzgzNTYyLTIuOTMzMDAxQzQuMzgzNTYyLTMuMzg3Mjk4IDMuODgxNDQ1LTMuNTE0ODE5IDMuNTg2NTUtMy41MTQ4MTlDMy4yMTE5NTUtMy41MTQ4MTkgMi45MDkwOTEtMy4yNTE4MDYgMi43MjU3NzgtMi45NDA5NzFDMi41NTA0MzYtMy4zNjMzODcgMi4xMzU5OS0zLjUxNDgxOSAxLjgwOTIxNS0zLjUxNDgxOUMuOTQwNDczLTMuNTE0ODE5IC40NTQyOTYtMi41MTg1NTUgLjQ1NDI5Ni0yLjI5NTM5MkMuNDU0Mjk2LTIuMjIzNjYxIC41MTAwODctMi4xOTE3ODEgLjU3Mzg0OC0yLjE5MTc4MUMuNjY5NDg5LTIuMTkxNzgxIC42ODU0My0yLjIzMTYzMSAuNzA5MzQtMi4zMjcyNzNDLjg5MjY1My0yLjkwOTA5MSAxLjM3MDg1OS0zLjI5MTY1NiAxLjc4NTMwNS0zLjI5MTY1NkMyLjA5NjEzOS0zLjI5MTY1NiAyLjI0NzU3Mi0zLjA2ODQ5MyAyLjI0NzU3Mi0yLjc4MTU2OUMyLjI0NzU3Mi0yLjYyMjE2NyAyLjE1MTkzLTIuMjU1NTQyIDIuMDg4MTY5LTIuMDAwNDk4QzIuMDMyMzc5LTEuNzY5MzY1IDEuODU3MDM2LTEuMDYwMDI1IDEuODE3MTg2LS45MDg1OTNDMS43MDU2MDQtLjQ3ODIwNyAxLjQxODY4LS4xNDM0NjIgMS4wNjAwMjUtLjE0MzQ2MkMxLjAyODE0NC0uMTQzNDYyIC44MjA5MjItLjE0MzQ2MiAuNjUzNTQ5LS4yNTUwNDRDMS4wMjAxNzQtLjM0MjcxNSAxLjAyMDE3NC0uNjc3NDYgMS4wMjAxNzQtLjY4NTQzQzEuMDIwMTc0LS44Njg3NDIgLjg3NjcxMi0uOTgwMzI0IC43MDEzNy0uOTgwMzI0Qy40ODYxNzctLjk4MDMyNCAuMjU1MDQ0LS43OTcwMTEgLjI1NTA0NC0uNDk0MTQ3Qy4yNTUwNDQtLjEyNzUyMiAuNjQ1NTc5IC4wNzk3MDEgMS4wNTIwNTUgLjA3OTcwMUMxLjQ3NDQ3MSAuMDc5NzAxIDEuNzY5MzY1LS4yMzkxMDMgMS45MTI4MjctLjQ5NDE0N0MyLjA4ODE2OS0uMTAzNjExIDIuNDU0Nzk1IC4wNzk3MDEgMi44MzczNiAuMDc5NzAxQzMuNzA2MTAyIC4wNzk3MDEgNC4xODQzMDktLjkxNjU2MyA0LjE4NDMwOS0xLjEzOTcyNkM0LjE4NDMwOS0xLjIxOTQyNyA0LjEyMDU0OC0xLjI0MzMzNyA0LjA2NDc1Ny0xLjI0MzMzN0MzLjk2OTExNi0xLjI0MzMzNyAzLjk1MzE3Ni0xLjE4NzU0NyAzLjkyOTI2NS0xLjEwNzg0NkMzLjc2OTg2My0uNTczODQ4IDMuMzE1NTY3LS4xNDM0NjIgMi44NTMzLS4xNDM0NjJDMi41OTAyODYtLjE0MzQ2MiAyLjM5OTAwNC0uMzE4ODA0IDIuMzk5MDA0LS42NTM1NDlDMi4zOTkwMDQtLjgxMjk1MSAyLjQ0NjgyNC0uOTk2MjY0IDIuNTU4NDA2LTEuNDQyNTlDMi42MTQxOTctMS42ODE2OTQgMi43ODk1MzktMi4zODMwNjQgMi44MjkzOS0yLjUzNDQ5NkMyLjk0MDk3MS0yLjk0ODk0MSAzLjIxOTkyNS0zLjI5MTY1NiAzLjU3ODU4LTMuMjkxNjU2QzMuNjE4NDMxLTMuMjkxNjU2IDMuODI1NjU0LTMuMjkxNjU2IDMuOTkzMDI2LTMuMTgwMDc1WicvPgo8cGF0aCBpZD0nZzUtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2c1LTEyMCcgZD0nTTUuNjY2NzUtNC44Nzc3MDlDNS4yODQxODQtNC44MDU5NzggNS4xNDA3MjItNC41MTkwNTQgNS4xNDA3MjItNC4yOTE5MDVDNS4xNDA3MjItNC4wMDQ5ODEgNS4zNjc4Ny0zLjkwOTM0IDUuNTM1MjQzLTMuOTA5MzRDNS44OTM4OTgtMy45MDkzNCA2LjE0NDk1Ni00LjIyMDE3NCA2LjE0NDk1Ni00LjU0Mjk2NEM2LjE0NDk1Ni01LjA0NTA4MSA1LjU3MTEwOC01LjI3MjIyOSA1LjA2ODk5MS01LjI3MjIyOUM0LjMzOTcyNi01LjI3MjIyOSAzLjkzMzI1LTQuNTU0OTE5IDMuODI1NjU0LTQuMzI3NzcxQzMuNTUwNjg1LTUuMjI0NDA4IDIuODA5NDY1LTUuMjcyMjI5IDIuNTk0MjcxLTUuMjcyMjI5QzEuMzc0ODQ0LTUuMjcyMjI5IC43MjkyNjUtMy43MDYxMDIgLjcyOTI2NS0zLjQ0MzA4OEMuNzI5MjY1LTMuMzk1MjY4IC43NzcwODYtMy4zMzU0OTIgLjg2MDc3Mi0zLjMzNTQ5MkMuOTU2NDEzLTMuMzM1NDkyIC45ODAzMjQtMy40MDcyMjMgMS4wMDQyMzQtMy40NTUwNDRDMS40MTA3MS00Ljc4MjA2NyAyLjIxMTcwNi01LjAzMzEyNiAyLjU1ODQwNi01LjAzMzEyNkMzLjA5NjM4OS01LjAzMzEyNiAzLjIwMzk4NS00LjUzMTAwOSAzLjIwMzk4NS00LjI0NDA4NUMzLjIwMzk4NS0zLjk4MTA3MSAzLjEzMjI1NC0zLjcwNjEwMiAyLjk4ODc5Mi0zLjEzMjI1NEwyLjU4MjMxNi0xLjQ5NDM5NkMyLjQwMjk4OS0uNzc3MDg2IDIuMDU2Mjg5LS4xMTk1NTIgMS40MjI2NjUtLjExOTU1MkMxLjM2Mjg4OS0uMTE5NTUyIDEuMDY0MDEtLjExOTU1MiAuODEyOTUxLS4yNzQ5NjlDMS4yNDMzMzctLjM1ODY1NSAxLjMzODk3OS0uNzE3MzEgMS4zMzg5NzktLjg2MDc3MkMxLjMzODk3OS0xLjA5OTg3NSAxLjE1OTY1MS0xLjI0MzMzNyAuOTMyNTAzLTEuMjQzMzM3Qy42NDU1NzktMS4yNDMzMzcgLjMzNDc0NS0uOTkyMjc5IC4zMzQ3NDUtLjYwOTcxNEMuMzM0NzQ1LS4xMDc1OTcgLjg5NjYzOCAuMTE5NTUyIDEuNDEwNzEgLjExOTU1MkMxLjk4NDU1OCAuMTE5NTUyIDIuMzkxMDM0LS4zMzQ3NDUgMi42NDIwOTItLjgyNDkwN0MyLjgzMzM3NS0uMTE5NTUyIDMuNDMxMTMzIC4xMTk1NTIgMy44NzM0NzQgLjExOTU1MkM1LjA5MjkwMiAuMTE5NTUyIDUuNzM4NDgxLTEuNDQ2NTc1IDUuNzM4NDgxLTEuNzA5NTg5QzUuNzM4NDgxLTEuNzY5MzY1IDUuNjkwNjYtMS44MTcxODYgNS42MTg5MjktMS44MTcxODZDNS41MTEzMzMtMS44MTcxODYgNS40OTkzNzctMS43NTc0MSA1LjQ2MzUxMi0xLjY2MTc2OEM1LjE0MDcyMi0uNjA5NzE0IDQuNDQ3MzIzLS4xMTk1NTIgMy45MDkzNC0uMTE5NTUyQzMuNDkwOTA5LS4xMTk1NTIgMy4yNjM3NjEtLjQzMDM4NiAzLjI2Mzc2MS0uOTIwNTQ4QzMuMjYzNzYxLTEuMTgzNTYyIDMuMzExNTgyLTEuMzc0ODQ0IDMuNTAyODY0LTIuMTYzODg1TDMuOTIxMjk1LTMuNzg5Nzg4QzQuMTAwNjIzLTQuNTA3MDk4IDQuNTA3MDk4LTUuMDMzMTI2IDUuMDU3MDM2LTUuMDMzMTI2QzUuMDgwOTQ2LTUuMDMzMTI2IDUuNDE1NjkxLTUuMDMzMTI2IDUuNjY2NzUtNC44Nzc3MDlaJy8+CjxwYXRoIGlkPSdnNi00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzYtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c2LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScxMDIuMjYzNTc2JyB5PSctMTcuNTA2MDk5JyB4bGluazpocmVmPScjZzMtNjgnLz4KPHVzZSB4PScxMTMuODEwMzAyJyB5PSctMTcuNTA2MDk5JyB4bGluazpocmVmPScjZzYtNDAnLz4KPHVzZSB4PScxMTguMzYyNjI4JyB5PSctMTcuNTA2MDk5JyB4bGluazpocmVmPScjZzAtODgnLz4KPHJlY3QgeD0nMTMwLjYxNjYwMycgeT0nLTIxLjI2NTMxNycgaGVpZ2h0PScuMzU4NjU2JyB3aWR0aD0nNS43MDcwMDgnLz4KPHVzZSB4PScxMzAuNjE2NjAzJyB5PSctMTQuMzg0NDU5JyB4bGluazpocmVmPScjZzItNzMnLz4KPHVzZSB4PScxMzYuMzIzNjEnIHk9Jy0xNy41MDYwOTknIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PScxMzkuNjQ0NScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2cwLTg4Jy8+Cjx1c2UgeD0nMTUxLjg5ODQ3NScgeT0nLTE1LjcxMjgzNicgeGxpbms6aHJlZj0nI2cyLTczJy8+Cjx1c2UgeD0nMTYwLjkyNjMxMScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c2LTYxJy8+Cjx1c2UgeD0nMTczLjM1MTc5MicgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2cwLTEyMCcvPgo8dXNlIHg9JzE4MS4yMzA1NzInIHk9Jy0xNS43MTI4MzYnIHhsaW5rOmhyZWY9JyNnMi03MycvPgo8dXNlIHg9JzE4Ni45Mzc1OCcgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c2LTQxJy8+Cjx1c2UgeD0nMTk0LjgxMDczNScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c2LTYxJy8+Cjx1c2UgeD0nMjA3LjIzNjIxNicgeT0nLTI4Ljg2MzU2MycgeGxpbms6aHJlZj0nI2cxLTg5Jy8+Cjx1c2UgeD0nMjA4LjAwNTQ3MScgeT0nLTEuNjk4NjMyJyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjEwLjg4ODYxMScgeT0nLTEuNjk4NjMyJyB4bGluazpocmVmPScjZzItNTAnLz4KPHJlY3QgeD0nMjE2LjUzNDE4OCcgeT0nLTguNTc5NDkxJyBoZWlnaHQ9Jy4zNTg2NTYnIHdpZHRoPSc1LjIwODg3NicvPgo8dXNlIHg9JzIxNi41MzQxODgnIHk9Jy0xLjY5ODYzMicgeGxpbms6aHJlZj0nI2cyLTczJy8+Cjx1c2UgeD0nMjI0LjUwNDgwMicgeT0nLTI3LjE4OTg2MicgeGxpbms6aHJlZj0nI2cxLTInLz4KPHVzZSB4PScyMjkuNDg2MTM3JyB5PSctMTcuNTA2MDk5JyB4bGluazpocmVmPScjZzUtMTIwJy8+Cjx1c2UgeD0nMjM2LjEzODIyNCcgeT0nLTIyLjQ0MjI4NScgeGxpbms6aHJlZj0nI2c0LTEwOScvPgo8dXNlIHg9JzI0My42Mjg3NTEnIHk9Jy0yMi40NDIyODUnIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyNDYuNTExODknIHk9Jy0yMi40NDIyODUnIHhsaW5rOmhyZWY9JyNnNC0xMTAnLz4KPHVzZSB4PScyMzYuMTM4MjI0JyB5PSctMTQuNTUwNTg0JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjUyLjE0ODIyNScgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c1LTU5Jy8+Cjx1c2UgeD0nMjU3LjM5MjM4NCcgeT0nLTE3LjUwNjA5OScgeGxpbms6aHJlZj0nI2c1LTEyMCcvPgo8dXNlIHg9JzI2NC4wNDQ0NzEnIHk9Jy0yMi40NDIyODUnIHhsaW5rOmhyZWY9JyNnNC0xMDknLz4KPHVzZSB4PScyNzEuNTM0OTk3JyB5PSctMjIuNDQyMjg1JyB4bGluazpocmVmPScjZzQtOTcnLz4KPHVzZSB4PScyNzYuMDMzMDA3JyB5PSctMjIuNDQyMjg1JyB4bGluazpocmVmPScjZzQtMTIwJy8+Cjx1c2UgeD0nMjY0LjA0NDQ3MScgeT0nLTE0LjU1MDU4NCcgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzI4MS4yOTgwMzgnIHk9Jy0yNy4xODk4NjInIHhsaW5rOmhyZWY9JyNnMS0zJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
Case 3: Create a distribution whose parameters are random¶
The objective is to create the marginal distribution of in Case 1.
See the class DeconditionedDistribution.
This class requires the following features:
the
may be continuous, discrete or neither: e.g., it can be a
Mixtureof discrete and continuous distributions. In that case, its parameters set is the union of the parameters set of each of its atoms (the weights of the mixture are not considered as parameters).each component
 is continuous or discrete: e.g., it can not be a
is continuous or discrete: e.g., it can not be a Mixtureof discrete and continuous distributions, (so that the random vector may have some discrete components and some continuous components),the copula of
is continuous: e.g., it can not be the MinCopula,if
has both discrete components and continuous components, its copula must be the independent copula. The general case has
not been implemented yet.
We define:

where:
- is the probability density copula of ,
if
is a continuous component, is its probability density function,if
is a discrete component,  where
where
 is its support and
is its support and  the Dirac distribution centered on
the Dirac distribution centered on
 .
.
Then, the PDF of is defined by:

with the same convention as for .
Note that this is always possible to create the random vector whatever the distribution of :
see the class DeconditionedRandomVector. But remember that a DeconditionedRandomVector
(and more generally a RandomVector) can only be sampled.
Case 4: Create a Bayesian posterior distribution¶
Consider the random vector
where follows the distribution ,
with and following the prior distribution . The function
is a link function which input dimension
is the dimension of and which output dimension the dimension of .
The objective is to create the posterior distribution of given that we have a sample  of
.
of
.
See the class PosteriorDistribution.
This class requires the following features:
the
may be continuous, discrete or neither: e.g., it can be a
Mixtureof discrete and continuous distributions. In that case, its parameters set is the union of the parameters set of each of its atoms (the weights of the mixture are not considered as parameters).each component
is continuous or discrete: e.g., it can not be a Mixtureof discrete and continuous distributions, (the random vector may have some discrete components and some continuous components),the copula of
is continuous: e.g., it can not be the MinCopula.
If and are continuous random vector, then the posterior PDF of is
defined by:
(5)¶
with the PDF of the distribution of
where has been replaced by and the PDF of the prior distribution
of .
Note that the denominator of (5) is the PDF of the deconditioned distribution of  with respect to the
prior distribution of .
with respect to the
prior distribution of .
In the other cases, the PDF is the probability distribution function for the discrete components and the  are replaced by some
are replaced by some  .
.