Kriging the cantilever beam model using HMAT¶
In this example, we create a kriging metamodel of the cantilever beam. We use a squared exponential covariance model for the kriging. In order to estimate the hyper-parameters, we use a design of experiments which size is 100.
We consider a cantilever beam defined by its Young’s modulus  , its length
, its length  and its section modulus
and its section modulus  . One end is built in a wall and we apply a concentrated bending load
. One end is built in a wall and we apply a concentrated bending load  at the other end of the beam, resulting in a vertical deviation
at the other end of the beam, resulting in a vertical deviation  .
.
Inputs
- : Young modulus (Pa), Beta(
 ,
,  , a =
, a =  ,
,  )
) - : Loading (N), Lognormal(
 ,
,  , shift=
, shift= )
) - : Length of beam (cm), Uniform(min=250.0, max= 260.0)
- : Moment of inertia (cm^4), Beta(
 ,
,  , a = 310, b = 450).
, a = 310, b = 450).
In the previous table  and
and  are the mean and the standard deviation of .
are the mean and the standard deviation of .
We assume that the random variables E, F, L and I are dependent and associated with a gaussian copula which correlation matrix is :

In other words, we consider that the variables L and I are negatively correlated : when the length L increases, the moment of intertia I decreases.
Output
The vertical displacement at free end of the cantilever beam is:

Definition of the model¶
[1]:
import openturns as ot
We define the symbolic function which evaluates the output Y depending on the inputs E, F, L and I.
[2]:
model = ot.SymbolicFunction(["E", "F", "L", "I"], ["F*L^3/(3*E*I)"])
Then we define the distribution of the input random vector.
[3]:
# Young's modulus E
E = ot.Beta(0.9, 2.27, 2.5e7, 5.0e7) # in N/m^2
E.setDescription("E")
# Load F
F = ot.LogNormal() # in N
F.setParameter(ot.LogNormalMuSigma()([30.e3, 9e3, 15.e3]))
F.setDescription("F")
# Length L
L = ot.Uniform(250., 260.) # in cm
L.setDescription("L")
# Moment of inertia I
I = ot.Beta(2.5, 1.5, 310, 450) # in cm^4
I.setDescription("I")
Finally, we define the dependency using a NormalCopula.
[4]:
dimension = 4 # number of inputs
R = ot.CorrelationMatrix(dimension)
R[2, 3] = -0.2
myCopula = ot.NormalCopula(ot.NormalCopula.GetCorrelationFromSpearmanCorrelation(R))
myDistribution = ot.ComposedDistribution([E, F, L, I], myCopula)
Create the design of experiments¶
We consider a simple Monte-Carlo sampling as a design of experiments. This is why we generate an input sample using the getSample method of the distribution. Then we evaluate the output using the model function.
[5]:
sampleSize_train = 100
X_train = myDistribution.getSample(sampleSize_train)
Y_train = model(X_train)
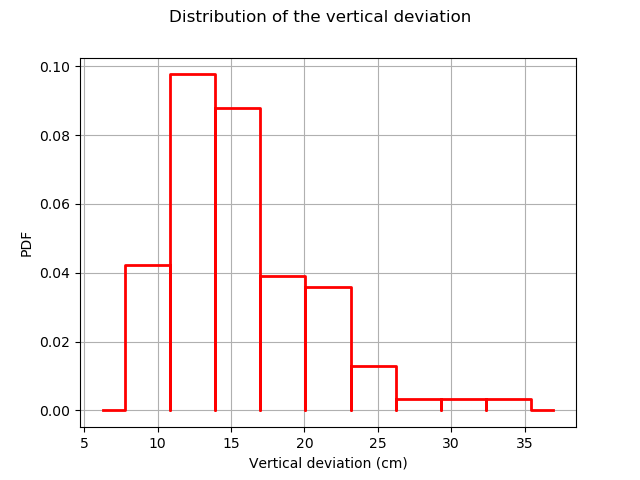
The following figure presents the distribution of the vertical deviations Y on the training sample. We observe that the large deviations occur less often.
[6]:
histo = ot.HistogramFactory().build(Y_train).drawPDF()
histo.setXTitle("Vertical deviation (cm)")
histo.setTitle("Distribution of the vertical deviation")
histo.setLegends([""])
histo
[6]:
Create the metamodel¶
In order to create the kriging metamodel, we first select a constant trend with the ConstantBasisFactory class. Then we use a squared exponential covariance model.
[7]:
basis = ot.ConstantBasisFactory(dimension).build()
covarianceModel = ot.SquaredExponential([1.]*dimension, [1.0])
We rely on H-Matrix approximation for accelerating the evaluation. We change default parameters (compression, recompression) to higher values. The model is less accurate but very fast to build & evaluate.
[8]:
ot.ResourceMap.SetAsString("KrigingAlgorithm-LinearAlgebra", "HMAT")
ot.ResourceMap.SetAsScalar("HMatrix-AssemblyEpsilon", 1e-3)
ot.ResourceMap.SetAsScalar( "HMatrix-RecompressionEpsilon", 1e-4)
Finally, we use the KrigingAlgorithm class to create the kriging metamodel, taking the training sample, the covariance model and the trend basis as input arguments.
[9]:
algo = ot.KrigingAlgorithm(X_train, Y_train, covarianceModel, basis)
algo.run()
result = algo.getResult()
krigingMetamodel = result.getMetaModel()
The run method has optimized the hyperparameters of the metamodel.
We can then print the constant trend of the metamodel, which have been estimated using the least squares method.
[10]:
result.getTrendCoefficients()
[10]:
[class=Point name=Unnamed dimension=1 values=[17.5685]]
We can also print the hyperparameters of the covariance model, which have been estimated by maximizing the likelihood.
[11]:
result.getCovarianceModel()
[11]:
SquaredExponential(scale=[1.39955,1.4925,6.18574,3.56027], amplitude=[2.30964])
Validate the metamodel¶
We finally want to validate the kriging metamodel. This is why we generate a validation sample which size is equal to 100 and we evaluate the output of the model on this sample.
[12]:
sampleSize_test = 100
X_test = myDistribution.getSample(sampleSize_test)
Y_test = model(X_test)
The MetaModelValidation classe makes the validation easy. To create it, we use the validation samples and the metamodel.
[13]:
val = ot.MetaModelValidation(X_test, Y_test, krigingMetamodel)
The computePredictivityFactor computes the Q2 factor.
[14]:
Q2 = val.computePredictivityFactor()
Q2
[14]:
0.9870858569377771
Since the Q2 is larger than 95%, we can say that the quality is acceptable.
The residuals are the difference between the model and the metamodel.
[15]:
r = val.getResidualSample()
ot.HistogramFactory().build(r).drawPDF()
[15]:
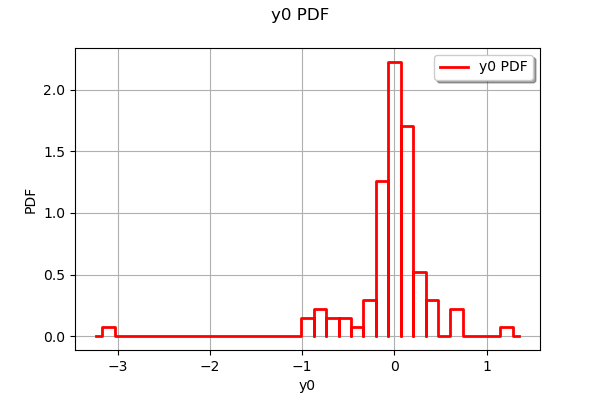
We observe that the negative residuals occur with nearly the same frequency of the positive residuals: this is a first sign of good quality. Furthermore, the residuals are most of the times contained in the [-1,1] interval, which is a sign of quality given the amplitude of the output (approximately from 5 to 25 cm).
The drawValidation method allows to compare the observed outputs and the metamodel outputs.
[16]:
graph = val.drawValidation()
graph.setLegends([""])
graph.setTitle("Q2 = %.2f%%" % (100*Q2))
graph
[16]:
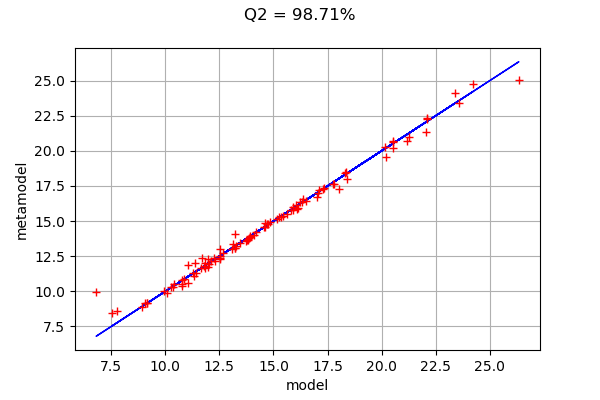
We observe that the metamodel predictions are close to the model outputs, since most red points are close to the diagonal. However, when we consider extreme deviations (i.e. less than 10 or larger than 20), then the quality is less obvious.
Given that the kriging metamodel quality is sensitive to the design of experiments, it might be interesting to consider a Latin Hypercube Sampling (LHS) design to further improve the predictions quality.