Empirical cumulative distribution function¶
The empirical cumulative distribution function provides a graphical representation of the probability distribution of a random vector without implying any prior assumption concerning the form of this distribution. It concerns a non-parametric approach which enables the description of complex behavior not necessarily detected with parametric approaches.
Therefore, using general notation, this means that we are looking for an
estimator  for the cumulative distribution function
for the cumulative distribution function
 of the random variable
of the random variable
 :
:

Let us first consider the uni-dimensional case, and let us denote
 . The empirical probability distribution is
the distribution created from a sample of observed values
. The empirical probability distribution is
the distribution created from a sample of observed values
 . It corresponds to a
discrete uniform distribution on
: where
. It corresponds to a
discrete uniform distribution on
: where  follows
this distribution,
follows
this distribution,

The empirical cumulative distribution function
with this distribution is constructed as follows:

The empirical cumulative distribution function  is defined
as the proportion of observations that are less than (or equal to)
is defined
as the proportion of observations that are less than (or equal to)
 and is thus an approximation of the cumulative distribution
function
and is thus an approximation of the cumulative distribution
function  which is the probability that an observation is
less than (or equal to) .
which is the probability that an observation is
less than (or equal to) .

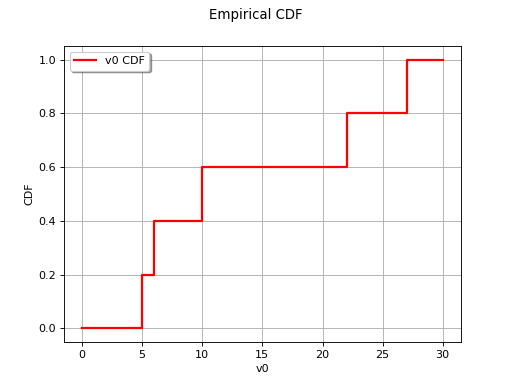
The diagram below provides an illustration of an ordered sample
 .
.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
The method is similar for the case  . The empirical
probability distribution is a distribution created from a sample
. The empirical
probability distribution is a distribution created from a sample
 . It
corresponds to a discrete uniform distribution on
: where
. It
corresponds to a discrete uniform distribution on
: where
 follows this distribution,
follows this distribution,

Thus we have:

in comparison with the theoretical probability density function  :
:

This method is also referred to in the literature as the empirical distribution function.
API:
See
UserDefinedfor the empirical distribution
Examples:
References: