Note
Click here to download the full example code
Perfom stepwise regression¶
In this example we perform the selection of the most suitable function basis for a linear regression model with the help of the stepwise algorithm.
We consider te so-called Linthurst data set, which contains measures of aerial biomass (BIO) as well as 5 five physicochemical properties of the soil: salinity (SAL), pH, K, Na, and Zn.
The data set is taken from the book ‘Applied Regression Analysis, A Research Tool’ by John O. Rawlings, Sastry G. Pantula and David A. Dickey and is provided below:
import openturns as ot
from openturns.viewer import View
import numpy as np
import matplotlib.pyplot as plt
description = ["BIO", "SAL", "pH", "K", "Na", "Zn"]
data = [[676, 33, 5, 1441.67, 35185.5, 16.4524],
[516, 35, 4.75, 1299.19, 28170.4, 13.9852],
[1052, 32, 4.2, 1154.27, 26455, 15.3276],
[868, 30, 4.4, 1045.15, 25072.9, 17.3128],
[1008, 33, 5.55, 521.62, 31664.2, 22.3312],
[436, 33, 5.05, 1273.02, 25491.7, 12.2778],
[544, 36, 4.25, 1346.35, 20877.3, 17.8225],
[680, 30, 4.45, 1253.88, 25621.3, 14.3516],
[640, 38, 4.75, 1242.65, 27587.3, 13.6826],
[492, 30, 4.6, 1281.95, 26511.7, 11.7566],
[984, 30, 4.1, 553.69, 7886.5, 9.882],
[1400, 37, 3.45, 494.74, 14596, 16.6752],
[1276, 33, 3.45, 525.97, 9826.8, 12.373],
[1736, 36, 4.1, 571.14, 11978.4, 9.4058],
[1004, 30, 3.5, 408.64, 10368.6, 14.9302],
[396, 30, 3.25, 646.65, 17307.4, 31.2865],
[352, 27, 3.35, 514.03, 12822, 30.1652],
[328, 29, 3.2, 350.73, 8582.6, 28.5901],
[392, 34, 3.35, 496.29, 12369.5, 19.8795],
[236, 36, 3.3, 580.92, 14731.9, 18.5056],
[392, 30, 3.25, 535.82, 15060.6, 22.1344],
[268, 28, 3.25, 490.34, 11056.3, 28.6101],
[252, 31, 3.2, 552.39, 8118.9, 23.1908],
[236, 31, 3.2, 661.32, 13009.5, 24.6917],
[340, 35, 3.35, 672.15, 15003.7, 22.6758],
[2436, 29, 7.1, 528.65, 10225, 0.3729],
[2216, 35, 7.35, 563.13, 8024.2, 0.2703],
[2096, 35, 7.45, 497.96, 10393, 0.3205],
[1660, 30, 7.45, 458.38, 8711.6, 0.2648],
[2272, 30, 7.4, 498.25, 10239.6, 0.2105],
[824, 26, 4.85, 936.26, 20436, 18.9875],
[1196, 29, 4.6, 894.79, 12519.9, 20.9687],
[1960, 25, 5.2, 941.36, 18979, 23.9841],
[2080, 26, 4.75, 1038.79, 22986.1, 19.9727],
[1764, 26, 5.2, 898.05, 11704.5, 21.3864],
[412, 25, 4.55, 989.87, 17721, 23.7063],
[416, 26, 3.95, 951.28, 16485.2, 30.5589],
[504, 26, 3.7, 939.83, 17101.3, 26.8415],
[492, 27, 3.75, 925.42, 17849, 27.7292],
[636, 27, 4.15, 954.11, 16949.6, 21.5699],
[1756, 24, 5.6, 720.72, 11344.6, 19.6531],
[1232, 27, 5.35, 782.09, 14752.4, 20.3295],
[1400, 26, 5.5, 773.3, 13649.8, 19.588],
[1620, 28, 5.5, 829.26, 14533, 20.1328],
[1560, 28, 5.4, 856.96, 16892.2, 19.242]]
input_description = ["SAL", "pH", "K", "Na", "Zn"]
output_description = ["BIO"]
sample = ot.Sample(np.array(data))
dimension = sample.getDimension()-1
n = sample.getSize()
Complete linear model¶
We consider a linear model with the purpose of predicting the aerial biomass as a function of the soil physicochemical properties, and we wish to identify the predictive variables which result in the most simple and precise linear regression model.
We start by creating a linear model which takes into account all of the physicochemical variables present within the Linthrust data set.
Let us consider the following linear model  . If all of the predictive variables
are considered, the regression can be performed with the help of the LinearModelAlgorithm class.
. If all of the predictive variables
are considered, the regression can be performed with the help of the LinearModelAlgorithm class.
input_sample = sample[:, 1:dimension+1]
output_sample = sample[:, 0]
algo_full = ot.LinearModelAlgorithm(input_sample, output_sample)
algo_full.run()
result_full = ot.LinearModelResult(algo_full.getResult())
print('R-squared = ', result_full.getRSquared())
print('Adjusted R-squared = ', result_full.getAdjustedRSquared())
Out:
R-squared = 0.677310820565376
Adjusted R-squared = 0.6359404129455524
Forward stepwise regression¶
We now wish to perform the selection of the most important predictive variables through a stepwise algorithm.
It is first necessary to define a suitable function basis for the regression. Each variable is associated to a univariate basis
and an additional basis is used in order to represent the constant term  .
.
functions = []
functions.append(ot.SymbolicFunction(input_description, ['1.0']))
for i in range(dimension):
functions.append(ot.SymbolicFunction(
input_description, [input_description[i]]))
basis = ot.Basis(functions)
Plese note that this example uses a linear basis with respect to the various predictors for the sake of clarity. However, this is not a necessity, and more complex and non linear relations between predictors may be considered (e.g., polynomial bases).
We now perform a forward stepwise regression. We suppose having no information regarding the given data set, and therefore the set of minimal indices only contains the constant term (indexed by 0).
The first regression is performed by relying on the Akaike Information Criterion (AIC), which translates into a penalty term equal to 2. In practice, the algorithm selects the functional basis subset that minimizes the AIC by iteratively adding the single function which provides the largest improvement until convergence is reached.
minimalIndices = [0]
direction = ot.LinearModelStepwiseAlgorithm.FORWARD
penalty = 2.0
algo_forward = ot.LinearModelStepwiseAlgorithm(
input_sample, basis, output_sample, minimalIndices, direction)
algo_forward.setPenalty(penalty)
algo_forward.run()
result_forward = algo_forward.getResult()
print('Selected basis: ', result_forward.getCoefficientsNames())
print('R-squared = ', result_forward.getRSquared())
print('Adjusted R-squared = ', result_forward.getAdjustedRSquared())
Out:
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[Na]]
R-squared = 0.658432822226285
Adjusted R-squared = 0.6421677185227748
With this first forward stepwise regression, the results show that the selected optimal basis contains a constant term, plus two linear terms depending respectively on the pH value (pH) and on the sodium concentration (Na).
As can be expected, the R-squared value diminishes if compared to the regression on the entire basis, as the stepwise regression results in a lower number of predictive variables. However, it can also be seen that the adjusted R-squared, which is a metric that also takes into account the ratio between the amount of training data and the number of explanatory variables, is improved if compared to the complete model.
Backward stepwise regression¶
We now perform a backward stepwise regression, meaning that rather than iteratively adding predictive variables, we will be removing them,
starting from the complete model.
This regression is performed by relying on the Bayesian Information Criterion (BIC), which translates into a penalty term equal to  .
.
minimalIndices = [0]
direction = ot.LinearModelStepwiseAlgorithm.BACKWARD
penalty = np.log(n)
algo_backward = ot.LinearModelStepwiseAlgorithm(
input_sample, basis, output_sample, minimalIndices, direction)
algo_backward.setPenalty(penalty)
algo_backward.run()
result_backward = algo_backward.getResult()
print('Selected basis: ', result_backward.getCoefficientsNames())
print('R-squared = ', result_backward.getRSquared())
print('Adjusted R-squared = ', result_backward.getAdjustedRSquared())
Out:
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[K]]
R-squared = 0.6475759074104157
Adjusted R-squared = 0.6307938077632926
It is interesting to point out that although both approaches converge towards a model characterized by 2 predictive variables, the selected variables do not coincide.
Both directions stepwise regression¶
A third available option consists in performing a stepwise regression in both directions, meaning that at each iteration the predictive variables can be either added or removed. In this case, a set of starting indices must be provided to the algorithm.
minimalIndices = [0]
startIndices = [0, 2, 3]
penalty = np.log(n)
direction = ot.LinearModelStepwiseAlgorithm.BOTH
algo_both = ot.LinearModelStepwiseAlgorithm(
input_sample, basis, output_sample, minimalIndices, direction, startIndices)
algo_both.setPenalty(penalty)
algo_both.run()
result_both = algo_both.getResult()
print('Selected basis: ', result_both.getCoefficientsNames())
print('R-squared = ', result_both.getRSquared())
print('Adjusted R-squared = ', result_both.getAdjustedRSquared())
Out:
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[K]]
R-squared = 0.6475759074104157
Adjusted R-squared = 0.6307938077632926
It is interesting to note that the basis varies depending on the selected set of starting indices, as is shown below. An informed initialization might therefore improve the model selection and the resulting regression
minimalIndices = [0]
startIndices = [0, 1]
penalty = np.log(n)
direction = ot.LinearModelStepwiseAlgorithm.BOTH
algo_both = ot.LinearModelStepwiseAlgorithm(
input_sample, basis, output_sample, minimalIndices, direction, startIndices)
algo_both.setPenalty(penalty)
algo_both.run()
result_both = algo_both.getResult()
print('Selected basis: ', result_both.getCoefficientsNames())
print('R-squared = ', result_both.getRSquared())
print('Adjusted R-squared = ', result_both.getAdjustedRSquared())
Out:
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[Na]]
R-squared = 0.658432822226285
Adjusted R-squared = 0.6421677185227748
Graphical analyses¶
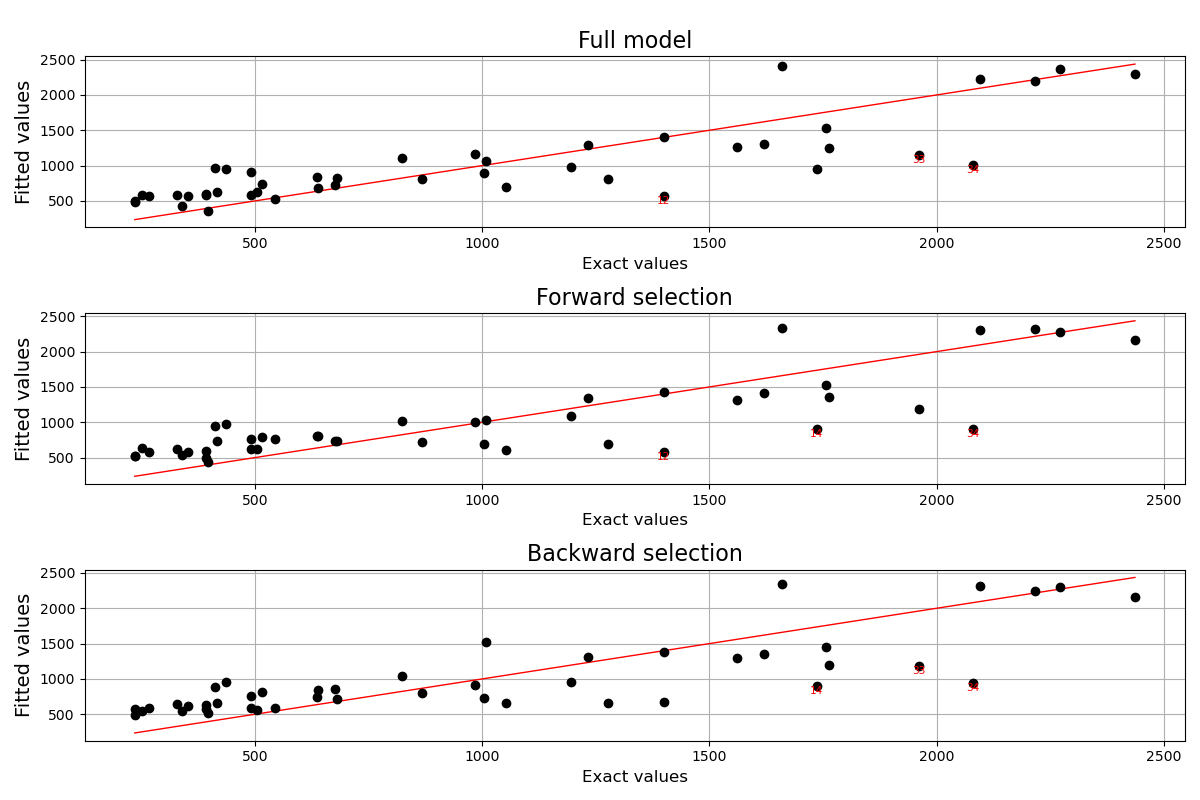
Finally, we can rely on the LinearModelAnalysis class in order to analyse the predictive differences between the obtained models.
analysis_full = ot.LinearModelAnalysis(result_full)
analysis_full.setName('Full model')
analysis_forward = ot.LinearModelAnalysis(result_forward)
analysis_forward.setName('Forward selection')
analysis_backward = ot.LinearModelAnalysis(result_backward)
analysis_backward.setName('Backward selection')
fig = plt.figure(figsize=(12, 8))
for k, analysis in enumerate([analysis_full, analysis_forward, analysis_backward]):
graph = analysis.drawModelVsFitted()
ax = fig.add_subplot(3, 1, k + 1)
ax.set_title(analysis.getName(), fontdict={'fontsize': 16})
graph.setXTitle('Exact values')
ax.xaxis.label.set_size(12)
ax.yaxis.label.set_size(14)
graph.setTitle('')
v = View(graph, figure=fig, axes=[ax])
plt.tight_layout()
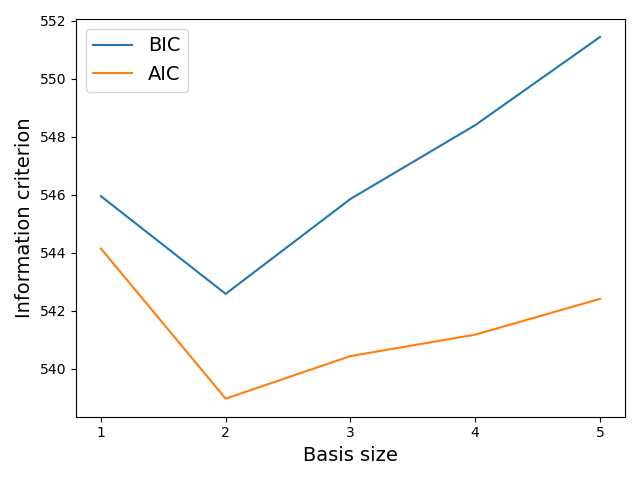
For illustrative purposes, we show the Bayesian Information Criterion (BIC) and Akaike Information Criterion (AIC) values which are computed during the iterations of the forward step-wise regression. Please note that in order to do so, we set the penalty parameter to a negligible value (meaning that the basis selection only takes into account the model likelihood, and not the number of parameters characterizing the linear model).
minimalIndices = [0]
penalty = 1e-10
direction = ot.LinearModelStepwiseAlgorithm.FORWARD
BIC = []
AIC = []
for iterations in range(1, 6):
algo_forward = ot.LinearModelStepwiseAlgorithm(
input_sample, basis, output_sample, minimalIndices, direction)
algo_forward.setPenalty(penalty)
algo_forward.setMaximumIterationNumber(iterations)
algo_forward.run()
result_forward = algo_forward.getResult()
RSS = np.sum(np.array(result_forward.getSampleResiduals())
** 2) # Residual sum of squares
LL = n*np.log(RSS/n) # Log-likelihood
BIC.append(LL + iterations*np.log(n)) # Bayesian Information Criterion
AIC.append(LL + iterations*2) # Akaike Information Criterion
print('Selected basis: ', result_forward.getCoefficientsNames())
plt.figure()
plt.plot(np.arange(1, 6), BIC, label='BIC')
plt.plot(np.arange(1, 6), AIC, label='AIC')
plt.xticks(np.arange(1, 6))
plt.xlabel('Basis size', fontsize=14)
plt.ylabel('Information criterion', fontsize=14)
plt.legend(fontsize=14)
plt.tight_layout()
Out:
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH]]
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[Na]]
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[Na],[SAL,pH,K,Na,Zn]->[Zn]]
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[Na],[SAL,pH,K,Na,Zn]->[Zn],[SAL,pH,K,Na,Zn]->[SAL]]
Selected basis: [[SAL,pH,K,Na,Zn]->[1.0],[SAL,pH,K,Na,Zn]->[pH],[SAL,pH,K,Na,Zn]->[Na],[SAL,pH,K,Na,Zn]->[Zn],[SAL,pH,K,Na,Zn]->[SAL],[SAL,pH,K,Na,Zn]->[K]]
The graphic above shows that the optimal linear model in terms of compromise between prediction likelihood and model complexity should take into account the influence of 2 regession variables as well as the constant term. This is coherent with the results previously obtained
Total running time of the script: ( 0 minutes 0.411 seconds)