Note
Go to the end to download the full example code
Posterior sampling using a PythonDistribution¶
In this example we are going to show how to do Bayesian inference using the RandomWalkMetropolisHastings algorithm in a statistical model defined through a PythonDistribution.
This method is illustrated on a simple lifetime study test-case, which involves censored data, as described hereafter.
In the following, we assume that the lifetime  of an industrial component follows the Weibull distribution
of an industrial component follows the Weibull distribution  , with CDF given by
, with CDF given by  .
.
Our goal is to estimate the model parameters  based on
a dataset of recorded failures
based on
a dataset of recorded failures  some of which
correspond to actual failures, and the remaining are right-censored.
Let
some of which
correspond to actual failures, and the remaining are right-censored.
Let  represent the nature of each
datum,
represent the nature of each
datum,  if
if  corresponds to an actual failure,
corresponds to an actual failure,
 if it is right-censored.
if it is right-censored.
Note that the likelihood of each recorded failure is given by the Weibull density:

On the other hand, the likelihood of each right-censored observation is given by:

Furthermore, assume that the prior information available on is represented by independent prior laws, whose respective densities are denoted by  and
and 
The posterior distribution of  represents the update of the prior information on given the dataset.
Its PDF is known up to a multiplicative constant:
represents the update of the prior information on given the dataset.
Its PDF is known up to a multiplicative constant:
![\pi(\alpha, \beta | (t_1, f_1), \ldots, (t_n, f_n) ) \propto \pi(\alpha)\pi(\beta) \left(\frac{\alpha}{\beta}\right)^{\sum_i f_i} \left(\prod_{f_i = 1} \frac{t_i}{\beta}\right)^{\alpha-1} \exp\left[-\sum_{i=1}^n\left(\frac{t_i}{\beta}\right)^\alpha\right].](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc0MjEuODgxMjMzcHQnIGhlaWdodD0nMzguNTU1NjczcHQnIHZpZXdCb3g9JzAgLTM5Ljc1MTE4NiA0MjEuODgxMjMzIDM4LjU1NTY3Myc+CjxkZWZzPgo8cGF0aCBpZD0nZzItMCcgZD0nTTUuNTcxMTA4LTEuODA5MjE1QzUuNjk4NjMtMS44MDkyMTUgNS44NzM5NzMtMS44MDkyMTUgNS44NzM5NzMtMS45OTI1MjhTNS42OTg2My0yLjE3NTg0MSA1LjU3MTEwOC0yLjE3NTg0MUgxLjAwNDIzNEMuODc2NzEyLTIuMTc1ODQxIC43MDEzNy0yLjE3NTg0MSAuNzAxMzctMS45OTI1MjhTLjg3NjcxMi0xLjgwOTIxNSAxLjAwNDIzNC0xLjgwOTIxNUg1LjU3MTEwOFonLz4KPHBhdGggaWQ9J2c0LTEwNScgZD0nTTIuMDgwMTk5LTMuNzMwMDEyQzIuMDgwMTk5LTMuODczNDc0IDEuOTcyNjAzLTMuOTY5MTE2IDEuODM1MTE4LTMuOTY5MTE2QzEuNjczNzI0LTMuOTY5MTE2IDEuNTAwMzc0LTMuODEzNjk5IDEuNTAwMzc0LTMuNjQwMzQ5QzEuNTAwMzc0LTMuNDkwOTA5IDEuNjA3OTctMy40MDEyNDUgMS43Mzk0NzctMy40MDEyNDVDMS45MzA3Ni0zLjQwMTI0NSAyLjA4MDE5OS0zLjU4MDU3MyAyLjA4MDE5OS0zLjczMDAxMlpNMS43MjE1NDQtMS42NDM4MzZDMS43NDU0NTUtMS43MDM2MTEgMS43OTkyNTMtMS44NDcwNzMgMS44MjMxNjMtMS45MDA4NzJDMS44NDEwOTYtMS45NTQ2NyAxLjg2NTAwNi0yLjAxNDQ0NiAxLjg2NTAwNi0yLjExNjA2NUMxLjg2NTAwNi0yLjQ1MDgwOSAxLjU2NjEyNy0yLjYzNjExNSAxLjI2NzI0OC0yLjYzNjExNUMuNjU3NTM0LTIuNjM2MTE1IC4zNjQ2MzMtMS44NDcwNzMgLjM2NDYzMy0xLjcxNTU2N0MuMzY0NjMzLTEuNjg1Njc5IC4zODg1NDMtMS42MzE4OCAuNDcyMjI5LTEuNjMxODhTLjU3Mzg0OC0xLjY2Nzc0NiAuNTkxNzgxLTEuNzIxNTQ0Qy43NTkxNTMtMi4zMDEzNyAxLjA3NTk2NS0yLjQzODg1NCAxLjI0MzMzNy0yLjQzODg1NEMxLjM2Mjg4OS0yLjQzODg1NCAxLjQwNDczMi0yLjM2MTE0NiAxLjQwNDczMi0yLjIyMzY2MUMxLjQwNDczMi0yLjEwNDExIDEuMzY4ODY3LTIuMDE0NDQ2IDEuMzU2OTEyLTEuOTcyNjAzTDEuMDQ2MDc3LTEuMjA3NDcyQy45NzQzNDYtMS4wMzQxMjIgLjk3NDM0Ni0xLjAyMjE2NyAuODk2NjM4LS44MTg5MjlDLjgxODkyOS0uNjM5NjAxIC43ODkwNDEtLjU2MTg5MyAuNzg5MDQxLS40NjAyNzRDLjc4OTA0MS0uMTU1NDE3IDEuMDY0MDEgLjA1OTc3NiAxLjM5Mjc3NyAuMDU5Nzc2QzEuOTk2NTEzIC4wNTk3NzYgMi4yOTUzOTItLjcyOTI2NSAyLjI5NTM5Mi0uODYwNzcyQzIuMjk1MzkyLS44NzI3MjcgMi4yODk0MTUtLjk0NDQ1OCAyLjE4MTgxOC0uOTQ0NDU4QzIuMDk4MTMyLS45NDQ0NTggMi4wOTIxNTQtLjkxNDU3IDIuMDU2Mjg5LS44MDA5OTZDMS45NjA2NDgtLjQ5NjEzOSAxLjcxNTU2Ny0uMTM3NDg0IDEuNDEwNzEtLjEzNzQ4NEMxLjMwMzExMy0uMTM3NDg0IDEuMjQ5MzE1LS4yMDkyMTUgMS4yNDkzMTUtLjM1MjY3N0MxLjI0OTMxNS0uNDcyMjI5IDEuMjg1MTgxLS41NjE4OTMgMS4zNjI4ODktLjc0NzE5OEwxLjcyMTU0NC0xLjY0MzgzNlonLz4KPHBhdGggaWQ9J2cwLTgwJyBkPSdNNC4xMjA1NDggNC4xMjg1MThDNC4yMTYxODkgNC4wMjQ5MDcgNC4yMTYxODkgNC4wMDg5NjYgNC4yMTYxODkgMy45ODUwNTZDNC4yMTYxODkgMy45NzcwODYgNC4yMTYxODkgMy45MzcyMzUgNC4xNTI0MjggMy44NTc1MzRMMS40MjY2NSAuMzY2NjI1SDQuNzQyMjE3QzUuNzU0NDIxIC4zNjY2MjUgNi4zNjgxMiAuNDg2MTc3IDYuNzM0NzQ1IC42MDU3MjlDNy4zODAzMjQgLjgyMDkyMiA3Ljk4NjA1MiAxLjI5MTE1OCA4LjIxNzE4NiAxLjkxMjgyN0g4LjQ2NDI1OUw3LjczODk3OSAwSC43MTczMUMuNDc4MjA3IDAgLjQ3MDIzNyAuMDA3OTcgLjQ3MDIzNyAuMjg2OTI0TDMuNTQ2NyA0LjI0MDFMLjU0OTkzOCA3LjczMTAwOUMuNDc4MjA3IDcuODE4NjggLjQ3MDIzNyA3LjgxODY4IC40NzAyMzcgNy44NTg1MzFDLjQ3MDIzNyA3Ljk3MDExMiAuNTczODQ4IDcuOTcwMTEyIC43MTczMSA3Ljk3MDExMkg3LjczODk3OUw4LjQ2NDI1OSA1LjkzNzczM0g4LjIxNzE4NkM4LjAyNTkwMyA2LjQ4NzY3MSA3LjQ4MzkzNSA3LjA2OTQ4OSA2LjUxOTU1MiA3LjMxNjU2M0M1Ljk1MzY3NCA3LjQ2MDAyNSA1LjM3OTgyNiA3LjQ4MzkzNSA0Ljc5ODAwNyA3LjQ4MzkzNUgxLjI0MzMzN0w0LjEyMDU0OCA0LjEyODUxOFonLz4KPHBhdGggaWQ9J2c3LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzctNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2czLTAnIGQ9J003Ljg3ODQ1Ni0yLjc0OTY4OUM4LjA4MTY5NC0yLjc0OTY4OSA4LjI5Njg4Ny0yLjc0OTY4OSA4LjI5Njg4Ny0yLjk4ODc5MlM4LjA4MTY5NC0zLjIyNzg5NSA3Ljg3ODQ1Ni0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyLTMuMjI3ODk1IC45OTIyNzktMy4yMjc4OTUgLjk5MjI3OS0yLjk4ODc5MlMxLjIwNzQ3Mi0yLjc0OTY4OSAxLjQxMDcxLTIuNzQ5Njg5SDcuODc4NDU2WicvPgo8cGF0aCBpZD0nZzMtNDcnIGQ9J004LjYzMTYzMS0uMzgyNTY1QzguNTgzODExLS4zODI1NjUgOC4zOTI1MjgtLjM1ODY1NSA4LjM1NjY2My0uMzU4NjU1QzcuNDEyMjA0LS4zNTg2NTUgNi43Nzg1OC0xLjI5MTE1OCA2LjM3MjEwNS0xLjkxMjgyN0M2LjI1MjU1My0yLjExNjA2NSA1LjkyOTc2My0yLjYwNjIyNyA1Ljc5ODI1Ny0yLjgwOTQ2NUM2LjA4NTE4MS0zLjQ1NTA0NCA2Ljg4NjE3Ny00LjkzNzQ4NCA4LjMwODg0Mi00LjkzNzQ4NEM4LjM5MjUyOC00LjkzNzQ4NCA4LjUwMDEyNS00LjkzNzQ4NCA4LjYzMTYzMS00LjkwMTYxOUM4LjYzMTYzMS01LjIxMjQ1MyA4LjYxOTY3Ni01LjIyNDQwOCA4LjU5NTc2Ni01LjI0ODMxOUM4LjUxMjA4LTUuMjcyMjI5IDguMzMyNzUyLTUuMjg0MTg0IDguMjI1MTU2LTUuMjg0MTg0QzYuNzA2ODQ5LTUuMjg0MTg0IDUuODIyMTY3LTMuODI1NjU0IDUuNTM1MjQzLTMuMjI3ODk1QzUuMDU3MDM2LTMuOTU3MTYxIDQuODg5NjY0LTQuMjIwMTc0IDQuNDQ3MzIzLTQuNTkwNzg1QzMuNzE4MDU3LTUuMjI0NDA4IDMuMDYwNTIzLTUuMjg0MTg0IDIuNzYxNjQ0LTUuMjg0MTg0QzEuNDM0NjItNS4yODQxODQgLjY2OTQ4OS0zLjk0NTIwNSAuNjY5NDg5LTIuNTcwMzYxQy42Njk0ODktMS4yMzEzODIgMS40MTA3MSAuMTMxNTA3IDIuNzI1Nzc4IC4xMzE1MDdDNC4yNDQwODUgLjEzMTUwNyA1LjEyODc2Ny0xLjMyNzAyNCA1LjQxNTY5MS0xLjkyNDc4MkM1Ljg5Mzg5OC0xLjE5NTUxNyA2LjA2MTI3LS45MzI1MDMgNi41MDM2MTEtLjU2MTg5M0M3LjIzMjg3NyAuMDcxNzMxIDcuODkwNDExIC4xMzE1MDcgOC4xODkyOSAuMTMxNTA3QzguMzMyNzUyIC4xMzE1MDcgOC41MjQwMzUgLjEwNzU5NyA4LjYzMTYzMSAuMDgzNjg2Vi0uMzgyNTY1Wk01LjE1MjY3Ny0yLjM0MzIxM0M0Ljg2NTc1My0xLjY5NzYzNCA0LjA2NDc1Ny0uMjE1MTkzIDIuNjQyMDkyLS4yMTUxOTNDMS40ODI0NDEtLjIxNTE5MyAuOTMyNTAzLTEuNDgyNDQxIC45MzI1MDMtMi41NzAzNjFDLjkzMjUwMy0zLjc1MzkyMyAxLjYwMTk5My00Ljc5NDAyMiAyLjU5NDI3MS00Ljc5NDAyMkMzLjUzODczLTQuNzk0MDIyIDQuMTcyMzU0LTMuODYxNTE5IDQuNTc4ODI5LTMuMjM5ODUxQzQuNjk4MzgxLTMuMDM2NjEzIDUuMDIxMTcxLTIuNTQ2NDUxIDUuMTUyNjc3LTIuMzQzMjEzWicvPgo8cGF0aCBpZD0nZzMtMTA2JyBkPSdNMS45MDA4NzItOC41MzU5OUMxLjkwMDg3Mi04Ljc1MTE4MyAxLjkwMDg3Mi04Ljk2NjM3NiAxLjY2MTc2OC04Ljk2NjM3NlMxLjQyMjY2NS04Ljc1MTE4MyAxLjQyMjY2NS04LjUzNTk5VjIuNTU4NDA2QzEuNDIyNjY1IDIuNzczNTk5IDEuNDIyNjY1IDIuOTg4NzkyIDEuNjYxNzY4IDIuOTg4NzkyUzEuOTAwODcyIDIuNzczNTk5IDEuOTAwODcyIDIuNTU4NDA2Vi04LjUzNTk5WicvPgo8cGF0aCBpZD0nZzUtMTEnIGQ9J000LjA2NDc1Ny0xLjExNTgxNkM0LjgwNTk3OC0xLjkyODc2NyA1LjA2ODk5MS0yLjk2NDg4MiA1LjA2ODk5MS0zLjAyODY0M0M1LjA2ODk5MS0zLjEwMDM3NCA1LjAyMTE3MS0zLjEzMjI1NCA0Ljk0OTQ0LTMuMTMyMjU0QzQuODQ1ODI4LTMuMTMyMjU0IDQuODM3ODU4LTMuMTAwMzc0IDQuNzkwMDM3LTIuOTMzMDAxQzQuNTY2ODc0LTIuMTIwMDUgNC4wODg2NjctMS40OTgzODEgNC4wNjQ3NTctMS40OTgzODFDNC4wNDg4MTctMS40OTgzODEgNC4wNDg4MTctMS42OTc2MzQgNC4wNDg4MTctMS44MjUxNTZDNC4wMzI4NzctMy4yMjc4OTUgMy4xMjQyODQtMy41MTQ4MTkgMi41ODIzMTYtMy41MTQ4MTlDMS40NTg1MzEtMy41MTQ4MTkgLjM1MDY4NS0yLjQyMjkxNCAuMzUwNjg1LTEuMjk5MTI4Qy4zNTA2ODUtLjUxMDA4NyAuOTAwNjIzIC4wNzk3MDEgMS43NDU0NTUgLjA3OTcwMUMyLjMwMzM2MiAuMDc5NzAxIDIuODkzMTUxLS4xMTk1NTIgMy41MjI3OS0uNTg5Nzg4QzMuNjk4MTMyIC4wMzk4NTEgNC4xNjAzOTkgLjA3OTcwMSA0LjMwMzg2MSAuMDc5NzAxQzQuNzU4MTU3IC4wNzk3MDEgNS4wMjExNzEtLjMyNjc3NSA1LjAyMTE3MS0uNDc4MjA3QzUuMDIxMTcxLS41NzM4NDggNC45MjU1MjktLjU3Mzg0OCA0LjkwMTYxOS0uNTczODQ4QzQuODEzOTQ4LS41NzM4NDggNC43OTgwMDctLjU0OTkzOCA0Ljc3NDA5Ny0uNDk0MTQ3QzQuNjQ2NTc1LS4xNTk0MDIgNC4zNzU1OTItLjE0MzQ2MiA0LjMzNTc0MS0uMTQzNDYyQzQuMjI0MTU5LS4xNDM0NjIgNC4wOTY2MzgtLjE0MzQ2MiA0LjA2NDc1Ny0xLjExNTgxNlpNMy40NjY5OTktLjg1MjgwMkMyLjkwMTEyMS0uMzQyNzE1IDIuMjMxNjMxLS4xNDM0NjIgMS43NjkzNjUtLjE0MzQ2MkMxLjM1NDkxOS0uMTQzNDYyIC45OTYyNjQtLjM4MjU2NSAuOTk2MjY0LTEuMDIwMTc0Qy45OTYyNjQtMS4yOTkxMjggMS4xMjM3ODYtMi4xMjAwNSAxLjQ5ODM4MS0yLjY1NDA0N0MxLjgxNzE4Ni0zLjEwMDM3NCAyLjI0NzU3Mi0zLjI5MTY1NiAyLjU3NDM0Ni0zLjI5MTY1NkMzLjAxMjcwMi0zLjI5MTY1NiAzLjI1OTc3Ni0yLjk4MDgyMiAzLjM2MzM4Ny0yLjQ5NDY0NUMzLjQ4MjkzOS0xLjk1MjY3NyAzLjQxOTE3OC0xLjMxNTA2OCAzLjQ2Njk5OS0uODUyODAyWicvPgo8cGF0aCBpZD0nZzUtMTAyJyBkPSdNMy4wNTI1NTMtMy4xNzIxMDVIMy43OTM3NzNDMy45NTMxNzYtMy4xNzIxMDUgNC4wNDg4MTctMy4xNzIxMDUgNC4wNDg4MTctMy4zMjM1MzdDNC4wNDg4MTctMy40MzUxMTggMy45NDUyMDUtMy40MzUxMTggMy44MDk3MTQtMy40MzUxMThIMy4xMDAzNzRDMy4yMjc4OTUtNC4xNTI0MjggMy4zMDc1OTctNC42MDY3MjUgMy4zODcyOTgtNC45NjUzOEMzLjQxOTE3OC01LjEwMDg3MiAzLjQ0MzA4OC01LjE4ODU0MyAzLjU2MjY0LTUuMjg0MTg0QzMuNjY2MjUyLTUuMzcxODU2IDMuNzMwMDEyLTUuMzg3Nzk2IDMuODE3Njg0LTUuMzg3Nzk2QzMuOTM3MjM1LTUuMzg3Nzk2IDQuMDY0NzU3LTUuMzYzODg1IDQuMTY4MzY5LTUuMzAwMTI1QzQuMTI4NTE4LTUuMjg0MTg0IDQuMDgwNjk3LTUuMjYwMjc0IDQuMDQwODQ3LTUuMjM2MzY0QzMuOTA1MzU1LTUuMTY0NjMzIDMuODA5NzE0LTUuMDIxMTcxIDMuODA5NzE0LTQuODYxNzY4QzMuODA5NzE0LTQuNjc4NDU2IDMuOTUzMTc2LTQuNTY2ODc0IDQuMTI4NTE4LTQuNTY2ODc0QzQuMzU5NjUxLTQuNTY2ODc0IDQuNTc0ODQ0LTQuNzY2MTI3IDQuNTc0ODQ0LTUuMDQ1MDgxQzQuNTc0ODQ0LTUuNDE5Njc2IDQuMTkyMjc5LTUuNjEwOTU5IDMuODA5NzE0LTUuNjEwOTU5QzMuNTM4NzMtNS42MTA5NTkgMy4wMzY2MTMtNS40ODM0MzcgMi43ODE1NjktNC43NTAxODdDMi43MDk4MzgtNC41NjY4NzQgMi43MDk4MzgtNC41NTA5MzQgMi40OTQ2NDUtMy40MzUxMThIMS44OTY4ODdDMS43Mzc0ODQtMy40MzUxMTggMS42NDE4NDMtMy40MzUxMTggMS42NDE4NDMtMy4yODM2ODZDMS42NDE4NDMtMy4xNzIxMDUgMS43NDU0NTUtMy4xNzIxMDUgMS44ODA5NDYtMy4xNzIxMDVIMi40NDY4MjRMMS44NzI5NzYtLjA3OTcwMUMxLjcyMTU0NCAuNzI1MjggMS42MDE5OTMgMS40MDI3NCAxLjE3OTU3NyAxLjQwMjc0QzEuMTU1NjY2IDEuNDAyNzQgLjk4ODI5NCAxLjQwMjc0IC44MzY4NjIgMS4zMDcwOThDMS4yMDM0ODcgMS4yMTk0MjcgMS4yMDM0ODcgLjg4NDY4MiAxLjIwMzQ4NyAuODc2NzEyQzEuMjAzNDg3IC42OTM0IDEuMDYwMDI1IC41ODE4MTggLjg4NDY4MiAuNTgxODE4Qy42Njk0ODkgLjU4MTgxOCAuNDM4MzU2IC43NjUxMzEgLjQzODM1NiAxLjA2Nzk5NUMuNDM4MzU2IDEuNDAyNzQgLjc4MTA3MSAxLjYyNTkwMyAxLjE3OTU3NyAxLjYyNTkwM0MxLjY2NTc1MyAxLjYyNTkwMyAyLjAwMDQ5OCAxLjExNTgxNiAyLjEwNDExIC45MTY1NjNDMi4zOTEwMzQgLjM5MDUzNSAyLjU3NDM0Ni0uNjA1NzI5IDIuNTkwMjg2LS42ODU0M0wzLjA1MjU1My0zLjE3MjEwNVonLz4KPHBhdGggaWQ9J2c1LTEwNScgZD0nTTIuMzc1MDkzLTQuOTczMzVDMi4zNzUwOTMtNS4xNDg2OTIgMi4yNDc1NzItNS4yNzYyMTQgMi4wNjQyNTktNS4yNzYyMTRDMS44NTcwMzYtNS4yNzYyMTQgMS42MjU5MDMtNS4wODQ5MzIgMS42MjU5MDMtNC44NDU4MjhDMS42MjU5MDMtNC42NzA0ODYgMS43NTM0MjUtNC41NDI5NjQgMS45MzY3MzctNC41NDI5NjRDMi4xNDM5Ni00LjU0Mjk2NCAyLjM3NTA5My00LjczNDI0NyAyLjM3NTA5My00Ljk3MzM1Wk0xLjIxMTQ1Ny0yLjA0ODMxOUwuNzgxMDcxLS45NDg0NDNDLjc0MTIyLS44Mjg4OTIgLjcwMTM3LS43MzMyNSAuNzAxMzctLjU5Nzc1OEMuNzAxMzctLjIwNzIyMyAxLjAwNDIzNCAuMDc5NzAxIDEuNDI2NjUgLjA3OTcwMUMyLjE5OTc1MSAuMDc5NzAxIDIuNTI2NTI2LTEuMDM2MTE1IDIuNTI2NTI2LTEuMTM5NzI2QzIuNTI2NTI2LTEuMjE5NDI3IDIuNDYyNzY1LTEuMjQzMzM3IDIuNDA2OTc0LTEuMjQzMzM3QzIuMzExMzMzLTEuMjQzMzM3IDIuMjk1MzkyLTEuMTg3NTQ3IDIuMjcxNDgyLTEuMTA3ODQ2QzIuMDg4MTY5LS40NzAyMzcgMS43NjEzOTUtLjE0MzQ2MiAxLjQ0MjU5LS4xNDM0NjJDMS4zNDY5NDktLjE0MzQ2MiAxLjI1MTMwOC0uMTgzMzEzIDEuMjUxMzA4LS4zOTg1MDZDMS4yNTEzMDgtLjU4OTc4OCAxLjMwNzA5OC0uNzMzMjUgMS40MTA3MS0uOTgwMzI0QzEuNDkwNDExLTEuMTk1NTE3IDEuNTcwMTEyLTEuNDEwNzEgMS42NTc3ODMtMS42MjU5MDNMMS45MDQ4NTctMi4yNzE0ODJDMS45NzY1ODgtMi40NTQ3OTUgMi4wNzIyMjktMi43MDE4NjggMi4wNzIyMjktMi44MzczNkMyLjA3MjIyOS0zLjIzNTg2NiAxLjc1MzQyNS0zLjUxNDgxOSAxLjM0Njk0OS0zLjUxNDgxOUMuNTczODQ4LTMuNTE0ODE5IC4yMzkxMDMtMi4zOTkwMDQgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMzk2MDEgLjQ5NDE0Ny0yLjMxOTMwM0MuNzE3MzEtMy4wNzY0NjMgMS4wODM5MzUtMy4yOTE2NTYgMS4zMjMwMzktMy4yOTE2NTZDMS40MzQ2Mi0zLjI5MTY1NiAxLjUxNDMyMS0zLjI1MTgwNiAxLjUxNDMyMS0zLjAyODY0M0MxLjUxNDMyMS0yLjk0ODk0MSAxLjUwNjM1MS0yLjgzNzM2IDEuNDI2NjUtMi41OTgyNTdMMS4yMTE0NTctMi4wNDgzMTlaJy8+CjxwYXRoIGlkPSdnNS0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzgtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c4LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnOC0xMDEnIGQ9J000LjU3ODgyOS0yLjc3MzU5OUM0Ljg0MTg0My0yLjc3MzU5OSA0Ljg2NTc1My0yLjc3MzU5OSA0Ljg2NTc1My0zLjAwMDc0N0M0Ljg2NTc1My00LjIwODIxOSA0LjIyMDE3NC01LjMzMjAwNSAyLjc3MzU5OS01LjMzMjAwNUMxLjQxMDcxLTUuMzMyMDA1IC4zNTg2NTUtNC4xMDA2MjMgLjM1ODY1NS0yLjYxODE4MkMuMzU4NjU1LTEuMDQwMSAxLjU3ODA4MiAuMTE5NTUyIDIuOTA1MTA2IC4xMTk1NTJDNC4zMjc3NzEgLjExOTU1MiA0Ljg2NTc1My0xLjE3MTYwNiA0Ljg2NTc1My0xLjQyMjY2NUM0Ljg2NTc1My0xLjQ5NDM5NiA0LjgwNTk3OC0xLjU0MjIxNyA0LjczNDI0Ny0xLjU0MjIxN0M0LjYzODYwNS0xLjU0MjIxNyA0LjYxNDY5NS0xLjQ4MjQ0MSA0LjU5MDc4NS0xLjQyMjY2NUM0LjI3OTk1LS40MTg0MzEgMy40Nzg5NTQtLjE0MzQ2MiAyLjk3NjgzNy0uMTQzNDYyUzEuMjY3MjQ4LS40NzgyMDcgMS4yNjcyNDgtMi41NDY0NTFWLTIuNzczNTk5SDQuNTc4ODI5Wk0xLjI3OTIwMy0zLjAwMDc0N0MxLjM3NDg0NC00Ljg3NzcwOSAyLjQyNjg5OS01LjA5MjkwMiAyLjc2MTY0NC01LjA5MjkwMkM0LjA0MDg0Ny01LjA5MjkwMiA0LjExMjU3OC0zLjQwNzIyMyA0LjEyNDUzMy0zLjAwMDc0N0gxLjI3OTIwM1onLz4KPHBhdGggaWQ9J2c4LTExMicgZD0nTTIuOTI5MDE2IDEuOTcyNjAzQzIuMTYzODg1IDEuOTcyNjAzIDIuMDIwNDIzIDEuOTcyNjAzIDIuMDIwNDIzIDEuNDM0NjJWLS42NDU1NzlDMi4yMzU2MTYtLjM0NjcgMi43MjU3NzggLjExOTU1MiAzLjQ5MDkwOSAuMTE5NTUyQzQuODY1NzUzIC4xMTk1NTIgNi4wNzMyMjUtMS4wNDAxIDYuMDczMjI1LTIuNTgyMzE2QzYuMDczMjI1LTQuMTAwNjIzIDQuOTQ5NDQtNS4yNzIyMjkgMy42NDYzMjYtNS4yNzIyMjlDMi41OTQyNzEtNS4yNzIyMjkgMi4wMzIzNzktNC41MTkwNTQgMS45OTY1MTMtNC40NzEyMzNWLTUuMjcyMjI5TC4zMzQ3NDUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTcxNjA2LTQuNzk0MDIyIDEuMjQzMzM3LTQuNzEwMzM2IDEuMjQzMzM3LTQuMTg0MzA5VjEuNDM0NjJDMS4yNDMzMzcgMS45NzI2MDMgMS4xMTE4MzEgMS45NzI2MDMgLjMzNDc0NSAxLjk3MjYwM1YyLjMxOTMwM0MuNjQ1NTc5IDIuMjk1MzkyIDEuMjkxMTU4IDIuMjk1MzkyIDEuNjI1OTAzIDIuMjk1MzkyQzEuOTcyNjAzIDIuMjk1MzkyIDIuNjE4MTgyIDIuMjk1MzkyIDIuOTI5MDE2IDIuMzE5MzAzVjEuOTcyNjAzWk0yLjAyMDQyMy0zLjgxMzY5OUMyLjAyMDQyMy00LjA0MDg0NyAyLjAyMDQyMy00LjA1MjgwMiAyLjE1MTkzLTQuMjQ0MDg1QzIuNTEwNTg1LTQuNzgyMDY3IDMuMDk2Mzg5LTUuMDA5MjE1IDMuNTUwNjg1LTUuMDA5MjE1QzQuNDQ3MzIzLTUuMDA5MjE1IDUuMTY0NjMzLTMuOTIxMjk1IDUuMTY0NjMzLTIuNTgyMzE2QzUuMTY0NjMzLTEuMTU5NjUxIDQuMzUxNjgxLS4xMTk1NTIgMy40MzExMzMtLjExOTU1MkMzLjA2MDUyMy0uMTE5NTUyIDIuNzEzODIzLS4yNzQ5NjkgMi40NzQ3Mi0uNTAyMTE3QzIuMTk5NzUxLS43NzcwODYgMi4wMjA0MjMtMS4wMTYxODkgMi4wMjA0MjMtMS4zNTA5MzRWLTMuODEzNjk5WicvPgo8cGF0aCBpZD0nZzgtMTIwJyBkPSdNMy4zNDc0NDctMi44MjE0MkMzLjY5NDE0Ny0zLjI3NTcxNiA0LjE5NjI2NC0zLjkyMTI5NSA0LjQyMzQxMi00LjE3MjM1NEM0LjkxMzU3NC00LjcyMjI5MSA1LjQ3NTQ2Ny00LjgwNTk3OCA1Ljg1ODAzMi00LjgwNTk3OFYtNS4xNTI2NzdDNS4zNDM5Ni01LjEyODc2NyA1LjMyMDA1LTUuMTI4NzY3IDQuODUzNzk4LTUuMTI4NzY3QzQuMzk5NTAyLTUuMTI4NzY3IDQuMzc1NTkyLTUuMTI4NzY3IDMuNzc3ODMzLTUuMTUyNjc3Vi00LjgwNTk3OEMzLjkzMzI1LTQuNzgyMDY3IDQuMTI0NTMzLTQuNzEwMzM2IDQuMTI0NTMzLTQuNDM1MzY3QzQuMTI0NTMzLTQuMjMyMTMgNC4wMTY5MzYtNC4xMDA2MjMgMy45NDUyMDUtNC4wMDQ5ODFMMy4xODAwNzUtMy4wMzY2MTNMMi4yNDc1NzItNC4yNjc5OTVDMi4yMTE3MDYtNC4zMTU4MTYgMi4xMzk5NzUtNC40MjM0MTIgMi4xMzk5NzUtNC41MDcwOThDMi4xMzk5NzUtNC41Nzg4MjkgMi4xOTk3NTEtNC43OTQwMjIgMi41NTg0MDYtNC44MDU5NzhWLTUuMTUyNjc3QzIuMjU5NTI3LTUuMTI4NzY3IDEuNjQ5ODEzLTUuMTI4NzY3IDEuMzI3MDI0LTUuMTI4NzY3Qy45MzI1MDMtNS4xMjg3NjcgLjkwODU5My01LjEyODc2NyAuMTc5MzI4LTUuMTUyNjc3Vi00LjgwNTk3OEMuNzg5MDQxLTQuODA1OTc4IDEuMDE2MTg5LTQuNzgyMDY3IDEuMjY3MjQ4LTQuNDU5Mjc4TDIuNjY2MDAyLTIuNjMwMTM3QzIuNjg5OTEzLTIuNjA2MjI3IDIuNzM3NzMzLTIuNTM0NDk2IDIuNzM3NzMzLTIuNDk4NjNTMS44MDUyMy0xLjI5MTE1OCAxLjY4NTY3OS0xLjEzNTc0MUMxLjE1OTY1MS0uNDkwMTYyIC42MzM2MjQtLjM1ODY1NSAuMTE5NTUyLS4zNDY3VjBDLjU3Mzg0OC0uMDIzOTEgLjU5Nzc1OC0uMDIzOTEgMS4xMTE4MzEtLjAyMzkxQzEuNTY2MTI3LS4wMjM5MSAxLjU5MDAzNy0uMDIzOTEgMi4xODc3OTYgMFYtLjM0NjdDMS45MDA4NzItLjM4MjU2NSAxLjg1MzA1MS0uNTYxODkzIDEuODUzMDUxLS43MjkyNjVDMS44NTMwNTEtLjkyMDU0OCAxLjkzNjczNy0xLjAxNjE4OSAyLjA1NjI4OS0xLjE3MTYwNkMyLjIzNTYxNi0xLjQyMjY2NSAyLjYzMDEzNy0xLjkxMjgyNyAyLjkxNzA2MS0yLjI4MzQzN0wzLjg5NzM4NS0xLjAwNDIzNEM0LjEwMDYyMy0uNzQxMjIgNC4xMDA2MjMtLjcxNzMxIDQuMTAwNjIzLS42NDU1NzlDNC4xMDA2MjMtLjU0OTkzOCA0LjAwNDk4MS0uMzU4NjU1IDMuNjgyMTkyLS4zNDY3VjBDMy45OTMwMjYtLjAyMzkxIDQuNTc4ODI5LS4wMjM5MSA0LjkxMzU3NC0uMDIzOTFDNS4zMDgwOTUtLjAyMzkxIDUuMzMyMDA1LS4wMjM5MSA2LjA0OTMxNSAwVi0uMzQ2N0M1LjQxNTY5MS0uMzQ2NyA1LjIwMDQ5OC0uMzcwNjEgNC45MTM1NzQtLjc1MzE3NkwzLjM0NzQ0Ny0yLjgyMTQyWicvPgo8cGF0aCBpZD0nZzEtMTgnIGQ9J004LjM2ODYxOCAyOC4wODI2OUM4LjM2ODYxOCAyOC4wMzQ4NjkgOC4zNDQ3MDcgMjguMDEwOTU5IDguMzIwNzk3IDI3Ljk3NTA5M0M3Ljg3ODQ1NiAyNy41MzI3NTIgNy4wNzc0NiAyNi43MzE3NTYgNi4yNzY0NjMgMjUuNDQwNTk4QzQuMzUxNjgxIDIyLjM1NjE2NCAzLjQ3ODk1NCAxOC40NzA3MzUgMy40Nzg5NTQgMTMuODY3OTk1QzMuNDc4OTU0IDEwLjY1MjA1NSAzLjkwOTM0IDYuNTAzNjExIDUuODgxOTQzIDIuOTQwOTcxQzYuODI2NDAxIDEuMjQzMzM3IDcuODA2NzI1IC4yNjMwMTQgOC4zMzI3NTItLjI2MzAxNEM4LjM2ODYxOC0uMjk4ODc5IDguMzY4NjE4LS4zMjI3OSA4LjM2ODYxOC0uMzU4NjU1QzguMzY4NjE4LS40NzgyMDcgOC4yODQ5MzItLjQ3ODIwNyA4LjExNzU1OS0uNDc4MjA3UzcuOTI2Mjc2LS40NzgyMDcgNy43NDY5NDktLjI5ODg3OUMzLjc0MTk2OCAzLjM0NzQ0NyAyLjQ4NjY3NSA4LjgyMjkxNCAyLjQ4NjY3NSAxMy44NTYwNEMyLjQ4NjY3NSAxOC41NTQ0MjEgMy41NjI2NCAyMy4yODg2NjcgNi41OTkyNTMgMjYuODYzMjYzQzYuODM4MzU2IDI3LjEzODIzMiA3LjI5MjY1MyAyNy42MjgzOTQgNy43ODI4MTQgMjguMDU4NzhDNy45MjYyNzYgMjguMjAyMjQyIDcuOTUwMTg3IDI4LjIwMjI0MiA4LjExNzU1OSAyOC4yMDIyNDJTOC4zNjg2MTggMjguMjAyMjQyIDguMzY4NjE4IDI4LjA4MjY5WicvPgo8cGF0aCBpZD0nZzEtMTknIGQ9J002LjMwMDM3NCAxMy44Njc5OTVDNi4zMDAzNzQgOS4xNjk2MTQgNS4yMjQ0MDggNC40MzUzNjcgMi4xODc3OTYgLjg2MDc3MkMxLjk0ODY5MiAuNTg1ODAzIDEuNDk0Mzk2IC4wOTU2NDEgMS4wMDQyMzQtLjMzNDc0NUMuODYwNzcyLS40NzgyMDcgLjgzNjg2Mi0uNDc4MjA3IC42Njk0ODktLjQ3ODIwN0MuNTI2MDI3LS40NzgyMDcgLjQxODQzMS0uNDc4MjA3IC40MTg0MzEtLjM1ODY1NUMuNDE4NDMxLS4zMTA4MzQgLjQ2NjI1Mi0uMjYzMDE0IC40OTAxNjItLjIzOTEwM0MuOTA4NTkzIC4xOTEyODMgMS43MDk1ODkgLjk5MjI3OSAyLjUxMDU4NSAyLjI4MzQzN0M0LjQzNTM2NyA1LjM2Nzg3IDUuMzA4MDk1IDkuMjUzMyA1LjMwODA5NSAxMy44NTYwNEM1LjMwODA5NSAxNy4wNzE5OCA0Ljg3NzcwOSAyMS4yMjA0MjMgMi45MDUxMDYgMjQuNzgzMDY0QzEuOTYwNjQ4IDI2LjQ4MDY5NyAuOTY4MzY5IDI3LjQ3Mjk3NiAuNDY2MjUyIDI3Ljk3NTA5M0MuNDQyMzQxIDI4LjAxMDk1OSAuNDE4NDMxIDI4LjA0NjgyNCAuNDE4NDMxIDI4LjA4MjY5Qy40MTg0MzEgMjguMjAyMjQyIC41MjYwMjcgMjguMjAyMjQyIC42Njk0ODkgMjguMjAyMjQyQy44MzY4NjIgMjguMjAyMjQyIC44NjA3NzIgMjguMjAyMjQyIDEuMDQwMSAyOC4wMjI5MTRDNS4wNDUwODEgMjQuMzc2NTg4IDYuMzAwMzc0IDE4LjkwMTEyMSA2LjMwMDM3NCAxMy44Njc5OTVaJy8+CjxwYXRoIGlkPSdnMS0zMicgZD0nTTkuMDUwMDYyIDM1LjI1NTc5MUM5LjA1MDA2MiAzNS4yMTk5MjUgOS4wNTAwNjIgMzUuMTk2MDE1IDguOTc4MzMxIDM1LjExMjMyOUM3LjgzMDYzNSAzMy43MjU1MjkgNi44NzQyMjIgMzIuMTk1MjY4IDYuMTY4ODY3IDMwLjUzMzQ5OUM0LjYwMjc0IDI2Ljg3NTIxOCAzLjk4MTA3MSAyMi41OTUyNjggMy45ODEwNzEgMTcuNDU0NTQ1QzMuOTgxMDcxIDEyLjM2MTY0NCA0LjU2Njg3NCA3Ljg5MDQxMSA2LjMzNjIzOSAzLjk2OTExNkM3LjAyOTYzOSAyLjQ1MDgwOSA3LjkzODIzMiAxLjA0MDEgOS4wMDIyNDItLjI1MTA1OUM5LjAyNjE1Mi0uMjg2OTI0IDkuMDUwMDYyLS4zMTA4MzQgOS4wNTAwNjItLjM1ODY1NUM5LjA1MDA2Mi0uNDc4MjA3IDguOTY2Mzc2LS40NzgyMDcgOC43ODcwNDktLjQ3ODIwN1M4LjU4MzgxMS0uNDc4MjA3IDguNTU5OS0uNDU0Mjk2QzguNTQ3OTQ1LS40NDIzNDEgNy44MDY3MjUgLjI3NDk2OSA2Ljg3NDIyMiAxLjU5MDAzN0M0Ljc5NDAyMiA0LjUzMTAwOSAzLjc0MTk2OCA4LjA0NTgyOCAzLjIwMzk4NSAxMS42MDg0NjhDMi45MTcwNjEgMTMuNTMzMjUgMi44MjE0MiAxNS40OTM4OTggMi44MjE0MiAxNy40NDI1OUMyLjgyMTQyIDIxLjkxMzgyMyAzLjM4MzMxMyAyNi40ODA2OTcgNS4yOTYxMzkgMzAuNTY5MzY1QzYuMTQ0OTU2IDMyLjM4NjU1IDcuMjgwNjk3IDM0LjAyNDQwOCA4LjQ2NDI1OSAzNS4yNjc3NDZDOC41NzE4NTYgMzUuMzYzMzg3IDguNTgzODExIDM1LjM3NTM0MiA4Ljc4NzA0OSAzNS4zNzUzNDJDOC45NjYzNzYgMzUuMzc1MzQyIDkuMDUwMDYyIDM1LjM3NTM0MiA5LjA1MDA2MiAzNS4yNTU3OTFaJy8+CjxwYXRoIGlkPSdnMS0zMycgZD0nTTYuNjM1MTE4IDE3LjQ1NDU0NUM2LjYzNTExOCAxMi45ODMzMTMgNi4wNzMyMjUgOC40MTY0MzggNC4xNjAzOTkgNC4zMjc3NzFDMy4zMTE1ODIgMi41MTA1ODUgMi4xNzU4NDEgLjg3MjcyNyAuOTkyMjc5LS4zNzA2MUMuODg0NjgyLS40NjYyNTIgLjg3MjcyNy0uNDc4MjA3IC42Njk0ODktLjQ3ODIwN0MuNTAyMTE3LS40NzgyMDcgLjQwNjQ3Ni0uNDc4MjA3IC40MDY0NzYtLjM1ODY1NUMuNDA2NDc2LS4zMTA4MzQgLjQ1NDI5Ni0uMjUxMDU5IC40NzgyMDctLjIxNTE5M0MxLjYyNTkwMyAxLjE3MTYwNiAyLjU4MjMxNiAyLjcwMTg2OCAzLjI4NzY3MSA0LjM2MzYzNkM0Ljg1Mzc5OCA4LjAyMTkxOCA1LjQ3NTQ2NyAxMi4zMDE4NjggNS40NzU0NjcgMTcuNDQyNTlDNS40NzU0NjcgMjIuNTM1NDkyIDQuODg5NjY0IDI3LjAwNjcyNSAzLjEyMDI5OSAzMC45MjgwMkMyLjQyNjg5OSAzMi40NDYzMjYgMS41MTgzMDYgMzMuODU3MDM2IC40NTQyOTYgMzUuMTQ4MTk0Qy40NDIzNDEgMzUuMTcyMTA1IC40MDY0NzYgMzUuMjE5OTI1IC40MDY0NzYgMzUuMjU1NzkxQy40MDY0NzYgMzUuMzc1MzQyIC41MDIxMTcgMzUuMzc1MzQyIC42Njk0ODkgMzUuMzc1MzQyQy44NDg4MTcgMzUuMzc1MzQyIC44NzI3MjcgMzUuMzc1MzQyIC44OTY2MzggMzUuMzUxNDMyQy45MDg1OTMgMzUuMzM5NDc3IDEuNjQ5ODEzIDM0LjYyMjE2NyAyLjU4MjMxNiAzMy4zMDcwOThDNC42NjI1MTYgMzAuMzY2MTI3IDUuNzE0NTcgMjYuODUxMzA4IDYuMjUyNTUzIDIzLjI4ODY2N0M2LjUzOTQ3NyAyMS4zNjM4ODUgNi42MzUxMTggMTkuNDAzMjM4IDYuNjM1MTE4IDE3LjQ1NDU0NVonLz4KPHBhdGggaWQ9J2cxLTM0JyBkPSdNMy4yODc2NzEgMzUuMzc1MzQySDYuODI2NDAxVjM0LjYzNDEyMkg0LjAyODg5MlYuMjYzMDE0SDYuODI2NDAxVi0uNDc4MjA3SDMuMjg3NjcxVjM1LjM3NTM0MlonLz4KPHBhdGggaWQ9J2cxLTM1JyBkPSdNMi45MjkwMTYgMzQuNjM0MTIySC4xMzE1MDdWMzUuMzc1MzQySDMuNjcwMjM3Vi0uNDc4MjA3SC4xMzE1MDdWLjI2MzAxNEgyLjkyOTAxNlYzNC42MzQxMjJaJy8+CjxwYXRoIGlkPSdnMS04OCcgZD0nTTE1LjEzNTI0MyAxNi43MzcyMzVMMTYuNTgxODE4IDEyLjkxMTU4MkgxNi4yODI5MzlDMTUuODE2Njg3IDE0LjE1NDkxOSAxNC41NDk0NCAxNC45Njc4NyAxMy4xNzQ1OTUgMTUuMzI2NTI2QzEyLjkyMzUzNyAxNS4zODYzMDEgMTEuNzUxOTMgMTUuNjk3MTM2IDkuNDU2NTM4IDE1LjY5NzEzNkgyLjI0NzU3Mkw4LjMzMjc1MiA4LjU1OTlDOC40MTY0MzggOC40NjQyNTkgOC40NDAzNDkgOC40MjgzOTQgOC40NDAzNDkgOC4zNjg2MThDOC40NDAzNDkgOC4zNDQ3MDcgOC40NDAzNDkgOC4zMDg4NDIgOC4zNTY2NjMgOC4xODkyOUwyLjc4NTU1NCAuNTczODQ4SDkuMzM2OTg2QzEwLjkzODk3OSAuNTczODQ4IDEyLjAyNjg5OSAuNzQxMjIgMTIuMTM0NDk2IC43NjUxMzFDMTIuNzgwMDc1IC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMuNzI5MjY1IDAgLjcxNzMxIC4wMTE5NTUgLjY4MTQ0NSAuMDgzNjg2Qy42Njk0ODkgLjExOTU1MiAuNjY5NDg5IC4zNDY3IC42Njk0ODkgLjQ3ODIwN0w2Ljk5Mzc3MyA5LjEzMzc0OEwuODAwOTk2IDE2LjM5MDUzNUMuNjgxNDQ1IDE2LjUzMzk5OCAuNjgxNDQ1IDE2LjU5Mzc3MyAuNjgxNDQ1IDE2LjYwNTcyOUMuNjgxNDQ1IDE2LjczNzIzNSAuNzg5MDQxIDE2LjczNzIzNSAxLjAwNDIzNCAxNi43MzcyMzVIMTUuMTM1MjQzWicvPgo8cGF0aCBpZD0nZzEtODknIGQ9J00xNC41OTcyNiAxNi43MzcyMzVWMTYuMDkxNjU2QzEzLjAwNzIyMyAxNi4wOTE2NTYgMTIuNjM2NjEzIDE1LjU0MTcxOSAxMi42MzY2MTMgMTQuNzc2NTg4VjEuOTYwNjQ4QzEyLjYzNjYxMyAxLjE4MzU2MiAxMy4wMTkxNzggLjY0NTU3OSAxNC41OTcyNiAuNjQ1NTc5VjBILjY2OTQ4OVYuNjQ1NTc5QzIuMjU5NTI3IC42NDU1NzkgMi42MzAxMzcgMS4xOTU1MTcgMi42MzAxMzcgMS45NjA2NDhWMTQuNzc2NTg4QzIuNjMwMTM3IDE1LjU1MzY3NCAyLjI0NzU3MiAxNi4wOTE2NTYgLjY2OTQ4OSAxNi4wOTE2NTZWMTYuNzM3MjM1SDYuNDE5OTI1VjE2LjA5MTY1NkM0LjgyOTg4OCAxNi4wOTE2NTYgNC40NTkyNzggMTUuNTQxNzE5IDQuNDU5Mjc4IDE0Ljc3NjU4OFYuNjQ1NTc5SDEwLjgwNzQ3MlYxNC43NzY1ODhDMTAuODA3NDcyIDE1LjU1MzY3NCAxMC40MjQ5MDcgMTYuMDkxNjU2IDguODQ2ODI0IDE2LjA5MTY1NlYxNi43MzcyMzVIMTQuNTk3MjZaJy8+CjxwYXRoIGlkPSdnNi0xMScgZD0nTTUuNTM1MjQzLTMuMDI0NjU4QzUuNTM1MjQzLTQuMTg0MzA5IDQuODc3NzA5LTUuMjcyMjI5IDMuNjEwNDYxLTUuMjcyMjI5QzIuMDQ0MzM0LTUuMjcyMjI5IC40NzgyMDctMy41NjI2NCAuNDc4MjA3LTEuODY1MDA2Qy40NzgyMDctLjgyNDkwNyAxLjEyMzc4NiAuMTE5NTUyIDIuMzQzMjEzIC4xMTk1NTJDMy4wODQ0MzMgLjExOTU1MiAzLjk2OTExNi0uMTY3MzcyIDQuODE3OTMzLS44ODQ2ODJDNC45ODUzMDUtLjIxNTE5MyA1LjM1NTkxNSAuMTE5NTUyIDUuODY5OTg4IC4xMTk1NTJDNi41MTU1NjcgLjExOTU1MiA2LjgzODM1Ni0uNTQ5OTM4IDYuODM4MzU2LS43MDUzNTVDNi44MzgzNTYtLjgxMjk1MSA2Ljc1NDY3LS44MTI5NTEgNi43MTg4MDQtLjgxMjk1MUM2LjYyMzE2My0uODEyOTUxIDYuNjExMjA4LS43NzcwODYgNi41NzUzNDItLjY4MTQ0NUM2LjQ2Nzc0Ni0uMzgyNTY1IDYuMTkyNzc3LS4xMTk1NTIgNS45MDU4NTMtLjExOTU1MkM1LjUzNTI0My0uMTE5NTUyIDUuNTM1MjQzLS44ODQ2ODIgNS41MzUyNDMtMS42MTM5NDhDNi43NTQ2Ny0zLjA3MjQ3OCA3LjA0MTU5NC00LjU3ODgyOSA3LjA0MTU5NC00LjU5MDc4NUM3LjA0MTU5NC00LjY5ODM4MSA2Ljk0NTk1My00LjY5ODM4MSA2LjkxMDA4Ny00LjY5ODM4MUM2LjgwMjQ5MS00LjY5ODM4MSA2Ljc5MDUzNS00LjY2MjUxNiA2Ljc0MjcxNS00LjQ0NzMyM0M2LjU4NzI5OC0zLjkyMTI5NSA2LjI3NjQ2My0yLjk4ODc5MiA1LjUzNTI0My0yLjAwODQ2OFYtMy4wMjQ2NThaTTQuNzgyMDY3LTEuMTcxNjA2QzMuNzMwMDEyLS4yMjcxNDggMi43ODU1NTQtLjExOTU1MiAyLjM2NzEyMy0uMTE5NTUyQzEuNTE4MzA2LS4xMTk1NTIgMS4yNzkyMDMtLjg3MjcyNyAxLjI3OTIwMy0xLjQzNDYyQzEuMjc5MjAzLTEuOTQ4NjkyIDEuNTQyMjE3LTMuMTY4MTIgMS45MTI4MjctMy44MjU2NTRDMi40MDI5ODktNC42NjI1MTYgMy4wNzI0NzgtNS4wMzMxMjYgMy42MTA0NjEtNS4wMzMxMjZDNC43NzAxMTItNS4wMzMxMjYgNC43NzAxMTItMy41MTQ4MTkgNC43NzAxMTItMi41MTA1ODVDNC43NzAxMTItMi4yMTE3MDYgNC43NTgxNTctMS45MDA4NzIgNC43NTgxNTctMS42MDE5OTNDNC43NTgxNTctMS4zNjI4ODkgNC43NzAxMTItMS4zMDMxMTMgNC43ODIwNjctMS4xNzE2MDZaJy8+CjxwYXRoIGlkPSdnNi0xMicgZD0nTTYuNzY2NjI1LTYuOTU3OTA4QzYuNzY2NjI1LTcuNjc1MjE4IDYuMTU2OTEyLTguNDI4Mzk0IDUuMDY4OTkxLTguNDI4Mzk0QzMuNTI2Nzc1LTguNDI4Mzk0IDIuNTQ2NDUxLTYuNTM5NDc3IDIuMjM1NjE2LTUuMjk2MTM5TC4zNDY3IDIuMTk5NzUxQy4zMjI3OSAyLjI5NTM5MiAuMzk0NTIxIDIuMzE5MzAzIC40NTQyOTYgMi4zMTkzMDNDLjUzNzk4MyAyLjMxOTMwMyAuNTk3NzU4IDIuMzA3MzQ3IC42MDk3MTQgMi4yNDc1NzJMMS40NDY1NzUtMS4wOTk4NzVDMS41NjYxMjctLjQzMDM4NiAyLjIyMzY2MSAuMTE5NTUyIDIuOTI5MDE2IC4xMTk1NTJDNC42Mzg2MDUgLjExOTU1MiA2LjI1MjU1My0xLjIxOTQyNyA2LjI1MjU1My0zLjAwMDc0N0M2LjI1MjU1My0zLjQ1NTA0NCA2LjE0NDk1Ni0zLjkwOTM0IDUuODkzODk4LTQuMjkxOTA1QzUuNzUwNDM2LTQuNTE5MDU0IDUuNTcxMTA4LTQuNjg2NDI2IDUuMzc5ODI2LTQuODI5ODg4QzYuMjQwNTk4LTUuMjg0MTg0IDYuNzY2NjI1LTYuMDEzNDUgNi43NjY2MjUtNi45NTc5MDhaTTQuNjg2NDI2LTQuODQxODQzQzQuNDk1MTQzLTQuNzcwMTEyIDQuMzAzODYxLTQuNzQ2MjAyIDQuMDc2NzEyLTQuNzQ2MjAyQzMuOTA5MzQtNC43NDYyMDIgMy43NTM5MjMtNC43MzQyNDcgMy41Mzg3My00LjgwNTk3OEMzLjY1ODI4MS00Ljg4OTY2NCAzLjgzNzYwOS00LjkxMzU3NCA0LjA4ODY2Ny00LjkxMzU3NEM0LjMwMzg2MS00LjkxMzU3NCA0LjUxOTA1NC00Ljg4OTY2NCA0LjY4NjQyNi00Ljg0MTg0M1pNNi4xNDQ5NTYtNy4wNjU1MDRDNi4xNDQ5NTYtNi40MDc5NyA1LjgyMjE2Ny01LjQ1MTU1NyA1LjA0NTA4MS01LjAwOTIxNUM0LjgxNzkzMy01LjA5MjkwMiA0LjUwNzA5OC01LjE1MjY3NyA0LjI0NDA4NS01LjE1MjY3N0MzLjk5MzAyNi01LjE1MjY3NyAzLjI3NTcxNi01LjE3NjU4OCAzLjI3NTcxNi00Ljc5NDAyMkMzLjI3NTcxNi00LjQ3MTIzMyAzLjkzMzI1LTQuNTA3MDk4IDQuMTM2NDg4LTQuNTA3MDk4QzQuNDQ3MzIzLTQuNTA3MDk4IDQuNzIyMjkxLTQuNTc4ODI5IDUuMDA5MjE1LTQuNjYyNTE2QzUuMzkxNzgxLTQuMzUxNjgxIDUuNTU5MTUzLTMuOTQ1MjA1IDUuNTU5MTUzLTMuMzQ3NDQ3QzUuNTU5MTUzLTIuNjU0MDQ3IDUuMzY3ODctMi4wOTIxNTQgNS4xNDA3MjItMS41NzgwODJDNC43NDYyMDItLjY5MzQgMy44MTM2OTktLjExOTU1MiAyLjk4ODc5Mi0uMTE5NTUyQzIuMTE2MDY1LS4xMTk1NTIgMS42NjE3NjgtLjgxMjk1MSAxLjY2MTc2OC0xLjYyNTkwM0MxLjY2MTc2OC0xLjczMzQ5OSAxLjY2MTc2OC0xLjg4ODkxNyAxLjcwOTU4OS0yLjA2ODI0NEwyLjQ4NjY3NS01LjIxMjQ1M0MyLjg4MTE5Ni02Ljc3ODU4IDMuODg1NDMtOC4xODkyOSA1LjA0NTA4MS04LjE4OTI5QzUuOTA1ODUzLTguMTg5MjkgNi4xNDQ5NTYtNy41OTE1MzIgNi4xNDQ5NTYtNy4wNjU1MDRaJy8+CjxwYXRoIGlkPSdnNi0yNScgZD0nTTMuMDk2Mzg5LTQuNTA3MDk4SDQuNDQ3MzIzQzQuMTI0NTMzLTMuMTY4MTIgMy45MjEyOTUtMi4yOTUzOTIgMy45MjEyOTUtMS4zMzg5NzlDMy45MjEyOTUtMS4xNzE2MDYgMy45MjEyOTUgLjExOTU1MiA0LjQxMTQ1NyAuMTE5NTUyQzQuNjYyNTE2IC4xMTk1NTIgNC44Nzc3MDktLjEwNzU5NyA0Ljg3NzcwOS0uMzEwODM0QzQuODc3NzA5LS4zNzA2MSA0Ljg3NzcwOS0uMzk0NTIxIDQuNzk0MDIyLS41NzM4NDhDNC40NzEyMzMtMS4zOTg3NTUgNC40NzEyMzMtMi40MjY4OTkgNC40NzEyMzMtMi41MTA1ODVDNC40NzEyMzMtMi41ODIzMTYgNC40NzEyMzMtMy40MzExMzMgNC43MjIyOTEtNC41MDcwOThINi4wNjEyN0M2LjIxNjY4Ny00LjUwNzA5OCA2LjYxMTIwOC00LjUwNzA5OCA2LjYxMTIwOC00Ljg4OTY2NEM2LjYxMTIwOC01LjE1MjY3NyA2LjM4NDA2LTUuMTUyNjc3IDYuMTY4ODY3LTUuMTUyNjc3SDIuMjM1NjE2QzEuOTYwNjQ4LTUuMTUyNjc3IDEuNTU0MTcyLTUuMTUyNjc3IDEuMDA0MjM0LTQuNTY2ODc0Qy42OTM0LTQuMjIwMTc0IC4zMTA4MzQtMy41ODY1NSAuMzEwODM0LTMuNTE0ODE5Uy4zNzA2MS0zLjQxOTE3OCAuNDQyMzQxLTMuNDE5MTc4Qy41MjYwMjctMy40MTkxNzggLjUzNzk4My0zLjQ1NTA0NCAuNTk3NzU4LTMuNTI2Nzc1QzEuMjE5NDI3LTQuNTA3MDk4IDEuODQxMDk2LTQuNTA3MDk4IDIuMTM5OTc1LTQuNTA3MDk4SDIuODIxNDJDMi41NTg0MDYtMy42MTA0NjEgMi4yNTk1MjctMi41NzAzNjEgMS4yNzkyMDMtLjQ3ODIwN0MxLjE4MzU2Mi0uMjg2OTI0IDEuMTgzNTYyLS4yNjMwMTQgMS4xODM1NjItLjE5MTI4M0MxLjE4MzU2MiAuMDU5Nzc2IDEuMzk4NzU1IC4xMTk1NTIgMS41MDYzNTEgLjExOTU1MkMxLjg1MzA1MSAuMTE5NTUyIDEuOTQ4NjkyLS4xOTEyODMgMi4wOTIxNTQtLjY5MzRDMi4yODM0MzctMS4zMDMxMTMgMi4yODM0MzctMS4zMjcwMjQgMi40MDI5ODktMS44MDUyM0wzLjA5NjM4OS00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c2LTU4JyBkPSdNMi4xOTk3NTEtLjU3Mzg0OEMyLjE5OTc1MS0uOTIwNTQ4IDEuOTEyODI3LTEuMTU5NjUxIDEuNjI1OTAzLTEuMTU5NjUxQzEuMjc5MjAzLTEuMTU5NjUxIDEuMDQwMS0uODcyNzI3IDEuMDQwMS0uNTg1ODAzQzEuMDQwMS0uMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxLS4yODY5MjQgMi4xOTk3NTEtLjU3Mzg0OFonLz4KPHBhdGggaWQ9J2c2LTU5JyBkPSdNMi4zMzEyNTggLjA0NzgyMUMyLjMzMTI1OC0uNjQ1NTc5IDIuMTA0MTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yMzEzODItMS4xNTk2NTEgMS4wNDAxLS44NDg4MTcgMS4wNDAxLS41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNy0uMDQ3ODIxIDIuMDIwNDIzLS4xNTU0MTdDMi4wNDQzMzQtLjE3OTMyOCAyLjA1NjI4OS0uMTc5MzI4IDIuMDY4MjQ0LS4xNzkzMjhDMi4wOTIxNTQtLjE3OTMyOCAyLjA5MjE1NC0uMDExOTU1IDIuMDkyMTU0IC4wNDc4MjFDMi4wOTIxNTQgLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IC4wNDc4MjFaJy8+CjxwYXRoIGlkPSdnNi0xMDInIGQ9J001LjMzMjAwNS00LjgwNTk3OEM1LjU3MTEwOC00LjgwNTk3OCA1LjY2Njc1LTQuODA1OTc4IDUuNjY2NzUtNS4wMzMxMjZDNS42NjY3NS01LjE1MjY3NyA1LjU3MTEwOC01LjE1MjY3NyA1LjM1NTkxNS01LjE1MjY3N0g0LjM4NzU0N0M0LjYxNDY5NS02LjM4NDA2IDQuNzgyMDY3LTcuMjMyODc3IDQuODc3NzA5LTcuNjE1NDQyQzQuOTQ5NDQtNy45MDIzNjYgNS4yMDA0OTgtOC4xNzczMzUgNS41MTEzMzMtOC4xNzczMzVDNS43NjIzOTEtOC4xNzczMzUgNi4wMTM0NS04LjA2OTczOCA2LjEzMzAwMS03Ljk2MjE0MkM1LjY2Njc1LTcuOTE0MzIxIDUuNTIzMjg4LTcuNTY3NjIxIDUuNTIzMjg4LTcuMzY0Mzg0QzUuNTIzMjg4LTcuMTI1MjggNS43MDI2MTUtNi45ODE4MTggNS45Mjk3NjMtNi45ODE4MThDNi4xNjg4NjctNi45ODE4MTggNi41Mjc1MjItNy4xODUwNTYgNi41Mjc1MjItNy42MzkzNTJDNi41Mjc1MjItOC4xNDE0NjkgNi4wMjU0MDUtOC40MTY0MzggNS40OTkzNzctOC40MTY0MzhDNC45ODUzMDUtOC40MTY0MzggNC40ODMxODgtOC4wMzM4NzMgNC4yNDQwODUtNy41Njc2MjFDNC4wMjg4OTItNy4xNDkxOTEgMy45MDkzNC02LjcxODgwNCAzLjYzNDM3MS01LjE1MjY3N0gyLjgzMzM3NUMyLjYwNjIyNy01LjE1MjY3NyAyLjQ4NjY3NS01LjE1MjY3NyAyLjQ4NjY3NS00LjkzNzQ4NEMyLjQ4NjY3NS00LjgwNTk3OCAyLjU1ODQwNi00LjgwNTk3OCAyLjc5NzUwOS00LjgwNTk3OEgzLjU2MjY0QzMuMzQ3NDQ3LTMuNjk0MTQ3IDIuODU3Mjg1LS45OTIyNzkgMi41ODIzMTYgLjI4NjkyNEMyLjM3OTA3OCAxLjMyNzAyNCAyLjE5OTc1MSAyLjE5OTc1MSAxLjYwMTk5MyAyLjE5OTc1MUMxLjU2NjEyNyAyLjE5OTc1MSAxLjIxOTQyNyAyLjE5OTc1MSAxLjAwNDIzNCAxLjk3MjYwM0MxLjYxMzk0OCAxLjkyNDc4MiAxLjYxMzk0OCAxLjM5ODc1NSAxLjYxMzk0OCAxLjM4NjhDMS42MTM5NDggMS4xNDc2OTYgMS40MzQ2MiAxLjAwNDIzNCAxLjIwNzQ3MiAxLjAwNDIzNEMuOTY4MzY5IDEuMDA0MjM0IC42MDk3MTQgMS4yMDc0NzIgLjYwOTcxNCAxLjY2MTc2OEMuNjA5NzE0IDIuMTc1ODQxIDEuMTM1NzQxIDIuNDM4ODU0IDEuNjAxOTkzIDIuNDM4ODU0QzIuODIxNDIgMi40Mzg4NTQgMy4zMjM1MzcgLjI1MTA1OSAzLjQ1NTA0NC0uMzQ2N0MzLjY3MDIzNy0xLjI2NzI0OCA0LjI1NjA0LTQuNDQ3MzIzIDQuMzE1ODE2LTQuODA1OTc4SDUuMzMyMDA1WicvPgo8cGF0aCBpZD0nZzYtMTE2JyBkPSdNMi40MDI5ODktNC44MDU5NzhIMy41MDI4NjRDMy43MzAwMTItNC44MDU5NzggMy44NDk1NjQtNC44MDU5NzggMy44NDk1NjQtNS4wMjExNzFDMy44NDk1NjQtNS4xNTI2NzcgMy43Nzc4MzMtNS4xNTI2NzcgMy41Mzg3My01LjE1MjY3N0gyLjQ4NjY3NUwyLjkyOTAxNi02Ljg5ODEzMkMyLjk3NjgzNy03LjA2NTUwNCAyLjk3NjgzNy03LjA4OTQxNSAyLjk3NjgzNy03LjE3MzEwMUMyLjk3NjgzNy03LjM2NDM4NCAyLjgyMTQyLTcuNDcxOTggMi42NjYwMDItNy40NzE5OEMyLjU3MDM2MS03LjQ3MTk4IDIuMjk1MzkyLTcuNDM2MTE1IDIuMTk5NzUxLTcuMDUzNTQ5TDEuNzMzNDk5LTUuMTUyNjc3SC42MDk3MTRDLjM3MDYxLTUuMTUyNjc3IC4yNjMwMTQtNS4xNTI2NzcgLjI2MzAxNC00LjkyNTUyOUMuMjYzMDE0LTQuODA1OTc4IC4zNDY3LTQuODA1OTc4IC41NzM4NDgtNC44MDU5NzhIMS42Mzc4NThMLjg0ODgxNy0xLjY0OTgxM0MuNzUzMTc2LTEuMjMxMzgyIC43MTczMS0xLjExMTgzMSAuNzE3MzEtLjk1NjQxM0MuNzE3MzEtLjM5NDUyMSAxLjExMTgzMSAuMTE5NTUyIDEuNzgxMzIgLjExOTU1MkMyLjk4ODc5MiAuMTE5NTUyIDMuNjM0MzcxLTEuNjI1OTAzIDMuNjM0MzcxLTEuNzA5NTg5QzMuNjM0MzcxLTEuNzgxMzIgMy41ODY1NS0xLjgxNzE4NiAzLjUxNDgxOS0xLjgxNzE4NkMzLjQ5MDkwOS0xLjgxNzE4NiAzLjQ0MzA4OC0xLjgxNzE4NiAzLjQxOTE3OC0xLjc2OTM2NUMzLjQwNzIyMy0xLjc1NzQxIDMuMzk1MjY4LTEuNzQ1NDU1IDMuMzExNTgyLTEuNTU0MTcyQzMuMDYwNTIzLS45NTY0MTMgMi41MTA1ODUtLjExOTU1MiAxLjgxNzE4Ni0uMTE5NTUyQzEuNDU4NTMxLS4xMTk1NTIgMS40MzQ2Mi0uNDE4NDMxIDEuNDM0NjItLjY4MTQ0NUMxLjQzNDYyLS42OTM0IDEuNDM0NjItLjkyMDU0OCAxLjQ3MDQ4Ni0xLjA2NDAxTDIuNDAyOTg5LTQuODA1OTc4WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTI1Jy8+Cjx1c2UgeD0nNy4wNjkyNycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTEuNjIxNTk1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTEnLz4KPHVzZSB4PScxOS4xNDMzMicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nMjQuMzg3NDc4JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PSczMS42NTg3NDknIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PSczNC45Nzk2MzknIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzM5LjUzMTk2NScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzQzLjc1OTEyNScgeT0nLTE1LjA1NDc1MScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNDguNDkxNDQnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9JzUzLjczNTU5OScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTEwMicvPgo8dXNlIHg9JzU5LjUwNTU4NycgeT0nLTE1LjA1NDc1MScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNjQuMjM3OTAyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSc2OC43OTAyMjgnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9Jzc0LjAzNDM4NycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU4Jy8+Cjx1c2UgeD0nNzkuMjc4NTQ1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTgnLz4KPHVzZSB4PSc4NC41MjI3MDQnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OCcvPgo8dXNlIHg9Jzg5Ljc2Njg2MycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nOTUuMDExMDIyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc5OS41NjMzNDgnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScxMDMuNzkwNTA3JyB5PSctMTUuMDU0NzUxJyB4bGluazpocmVmPScjZzUtMTEwJy8+Cjx1c2UgeD0nMTA5LjQyNjg0MicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nMTE0LjY3MTAwMScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTEwMicvPgo8dXNlIHg9JzEyMC40NDA5ODknIHk9Jy0xNS4wNTQ3NTEnIHhsaW5rOmhyZWY9JyNnNS0xMTAnLz4KPHVzZSB4PScxMjYuMDc3MzI0JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScxMzAuNjI5NjQ5JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScxMzguNTAyODA1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzMtNDcnLz4KPHVzZSB4PScxNTEuMTIyMTMxJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMjUnLz4KPHVzZSB4PScxNTguMTkxNDAxJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxNjIuNzQzNzI2JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTEnLz4KPHVzZSB4PScxNzAuMjY1NDUnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzE3NC44MTc3NzYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0yNScvPgo8dXNlIHg9JzE4MS44ODcwNDYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzE4Ni40MzkzNzInIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMicvPgo8dXNlIHg9JzE5My43MTA2NDMnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzIwMC4yNTU0NjYnIHk9Jy0zMy43MDQ5NTEnIHhsaW5rOmhyZWY9JyNnMS0xOCcvPgo8dXNlIHg9JzIxMC4yNTEzNTInIHk9Jy0yNC45MzU3NzInIHhsaW5rOmhyZWY9JyNnNi0xMScvPgo8cmVjdCB4PScyMTAuMjUxMzUyJyB5PSctMjAuMDc1ODk5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc3LjUyMTcyJy8+Cjx1c2UgeD0nMjEwLjM3NjU4NScgeT0nLTguNjQ3MzUxJyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PScyMTguOTY4NTg2JyB5PSctMzMuNzA0OTUxJyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PScyMjcuNzY4OTU5JyB5PSctMzcuMDA1OTI3JyB4bGluazpocmVmPScjZzAtODAnLz4KPHVzZSB4PScyMzYuNzA3NzknIHk9Jy0yOC41Mzc1OTInIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyNDEuMjgwOTQyJyB5PSctMzEuMDI4Mjk3JyB4bGluazpocmVmPScjZzUtMTAyJy8+Cjx1c2UgeD0nMjQ1LjM0OTA2JyB5PSctMjkuODEzMjE5JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjUxLjAwMTQ0OCcgeT0nLTM3LjI5MTUzOCcgeGxpbms6aHJlZj0nI2cxLTMyJy8+Cjx1c2UgeD0nMjYxLjg1MzIyNScgeT0nLTI4LjIwNTQ3OCcgeGxpbms6aHJlZj0nI2cxLTg5Jy8+Cjx1c2UgeD0nMjYwLjQ2NTk4NicgeT0nLTIuNzQ1MjU5JyB4bGluazpocmVmPScjZzUtMTAyJy8+Cjx1c2UgeD0nMjY0LjUzNDEwNScgeT0nLTEuNTMwMTgxJyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjY3LjY5NTg2MycgeT0nLTIuNzQ1MjU5JyB4bGluazpocmVmPScjZzctNjEnLz4KPHVzZSB4PScyNzQuMjgyMzY5JyB5PSctMi43NDUyNTknIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzI4MS43MDQ1NjQnIHk9Jy0yNC45MzU3NzInIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScyODUuOTMxNzIzJyB5PSctMjMuMTQyNTA5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+CjxyZWN0IHg9JzI4MS43MDQ1NjQnIHk9Jy0yMC4wNzU4OTknIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzcuNjA4NDMxJy8+Cjx1c2UgeD0nMjgxLjg3MzE1MScgeT0nLTguNjQ3MzUxJyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PScyOTAuNTA4NTA5JyB5PSctMzcuMjkxNTM4JyB4bGluazpocmVmPScjZzEtMzMnLz4KPHVzZSB4PScyOTkuOTczMDQ3JyB5PSctMzQuNjE0ODg0JyB4bGluazpocmVmPScjZzUtMTEnLz4KPHVzZSB4PSczMDUuNDExOTg3JyB5PSctMzQuNjE0ODg0JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzMxMS45OTg0OTMnIHk9Jy0zNC42MTQ4ODQnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzMxOC43MjMzMDYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PSczMjMuOTI1OTY0JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtMTIwJy8+Cjx1c2UgeD0nMzMwLjEwNDEyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtMTEyJy8+Cjx1c2UgeD0nMzM4LjU5OTk0JyB5PSctMzcuMjkxNTM4JyB4bGluazpocmVmPScjZzEtMzQnLz4KPHVzZSB4PSczNDUuNTczODE5JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzM2Mi45MzAwMicgeT0nLTMxLjc5MjAzNScgeGxpbms6aHJlZj0nI2c1LTExMCcvPgo8dXNlIHg9JzM1Ni44NjQ4MTMnIHk9Jy0yOC4yMDU0NzgnIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzM1OC42NDcyMDcnIHk9Jy0zLjAxMTEyMycgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzM2MS41MzAzNDcnIHk9Jy0zLjAxMTEyMycgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nMzY4LjExNjg1MycgeT0nLTMuMDExMTIzJyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PSczNzYuMTI1OTI4JyB5PSctMzMuNzA0OTUxJyB4bGluazpocmVmPScjZzEtMTgnLz4KPHVzZSB4PSczODYuMTIxODE0JyB5PSctMjQuOTM1NzcyJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMzkwLjM0ODk3NCcgeT0nLTIzLjE0MjUwOScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8cmVjdCB4PSczODYuMTIxODE0JyB5PSctMjAuMDc1ODk5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc3LjYwODQzMScvPgo8dXNlIHg9JzM4Ni4yOTA0MDInIHk9Jy04LjY0NzM1MScgeGxpbms6aHJlZj0nI2c2LTEyJy8+Cjx1c2UgeD0nMzk0LjkyNTc1OScgeT0nLTMzLjcwNDk1MScgeGxpbms6aHJlZj0nI2cxLTE5Jy8+Cjx1c2UgeD0nNDAzLjcyNjEzMicgeT0nLTMxLjAyODI5NycgeGxpbms6aHJlZj0nI2c1LTExJy8+Cjx1c2UgeD0nNDA5LjY2MzIwMycgeT0nLTM3LjI5MTUzOCcgeGxpbms6aHJlZj0nI2cxLTM1Jy8+Cjx1c2UgeD0nNDE4LjYyOTU3MScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU4Jy8+CjwvZz4KPC9zdmc+)
The RandomWalkMetropolisHastings class can be used to sample from the posterior distribution. It relies on the following objects:
The prior probability density
 reflects beliefs about the possible values
of
reflects beliefs about the possible values
of  before the experimental data are considered.
before the experimental data are considered.Initial values
 of the parameters.
of the parameters.An proposal distribution used to update parameters.
Additionnaly we want to define the likelihood term defined by these objects:
The conditional density
 will be defined as a
will be defined as a PythonDistribution.The sample of observations acting as the parameters of the conditional density
Set up the PythonDistribution¶
The censured Weibuill likelihood is outside the usual catalog of probability distributions in OpenTURNS, hence we need to define it using the PythonDistribution class.
import numpy as np
import openturns as ot
from openturns.viewer import View
ot.Log.Show(ot.Log.NONE)
ot.RandomGenerator.SetSeed(123)
The following methods must be defined:
getRange: required for conversion to the
DistributionformatcomputeLogPDF: used by
RandomWalkMetropolisHastingsto evaluate the posterior densitysetParameter used by
RandomWalkMetropolisHastingsto test new parameter values
Note
We formally define a bivariate distribution on the  couple, even though
couple, even though  has no distribution (it is simply a covariate).
This is not an issue, since the sole purpose of this
has no distribution (it is simply a covariate).
This is not an issue, since the sole purpose of this PythonDistribution object is to pass the likelihood calculation over to RandomWalkMetropolisHastings.
class CensoredWeibull(ot.PythonDistribution):
"""
Right-censored Weibull log-PDF calculation
Each data point x is assumed 2D, with:
x[0]: observed functioning time
x[1]: nature of x[0]:
if x[1]=0: x[0] is a censoring time
if x[1]=1: x[0] is a time-to failure
"""
def __init__(self, beta=5000.0, alpha=2.0):
super(CensoredWeibull, self).__init__(2)
self.beta = beta
self.alpha = alpha
def getRange(self):
return ot.Interval([0, 0], [1, 1], [True] * 2, [False, True])
def computeLogPDF(self, x):
if not (self.alpha > 0.0 and self.beta > 0.0):
return -np.inf
log_pdf = -((x[0] / self.beta) ** self.alpha)
log_pdf += (self.alpha - 1) * np.log(x[0] / self.beta) * x[1]
log_pdf += np.log(self.alpha / self.beta) * x[1]
return log_pdf
def setParameter(self, parameter):
self.beta = parameter[0]
self.alpha = parameter[1]
def getParameter(self):
return [self.beta, self.alpha]
Convert to Distribution
conditional = ot.Distribution(CensoredWeibull())
Observations, prior, initial point and proposal distributions¶
Define the observations
Tobs = np.array([4380, 1791, 1611, 1291, 6132, 5694, 5296, 4818, 4818, 4380])
fail = np.array([True] * 4 + [False] * 6)
x = ot.Sample(np.vstack((Tobs, fail)).T)
Define a uniform prior distribution for  and a Gamma prior distribution for
and a Gamma prior distribution for  .
.
alpha_min, alpha_max = 0.5, 3.8
a_beta, b_beta = 2, 2e-4
priorCopula = ot.IndependentCopula(2) # prior independence
priorMarginals = [] # prior marginals
priorMarginals.append(ot.Gamma(a_beta, b_beta)) # Gamma prior for beta
priorMarginals.append(ot.Uniform(alpha_min, alpha_max)) # uniform prior for alpha
prior = ot.ComposedDistribution(priorMarginals, priorCopula)
prior.setDescription(["beta", "alpha"])
We select prior means as the initial point of the Metropolis-Hastings algorithm.
initialState = [a_beta / b_beta, 0.5 * (alpha_max - alpha_min)]
For our random walk proposal distributions, we choose normal steps, with standard deviation equal to roughly  of the prior range (for the uniform prior) or standard deviation (for the normal prior).
of the prior range (for the uniform prior) or standard deviation (for the normal prior).
proposal = []
proposal.append(ot.Normal(0.0, 0.1 * np.sqrt(a_beta / b_beta**2)))
proposal.append(ot.Normal(0.0, 0.1 * (alpha_max - alpha_min)))
proposal = ot.ComposedDistribution(proposal)
Sample from the posterior distribution¶
sampler = ot.RandomWalkMetropolisHastings(prior, initialState, proposal)
sampler.setLikelihood(conditional, x)
sampleSize = 10000
sample = sampler.getSample(sampleSize)
# compute acceptance rate
print("Acceptance rate: %s" % (sampler.getAcceptanceRate()))
Acceptance rate: 0.7194
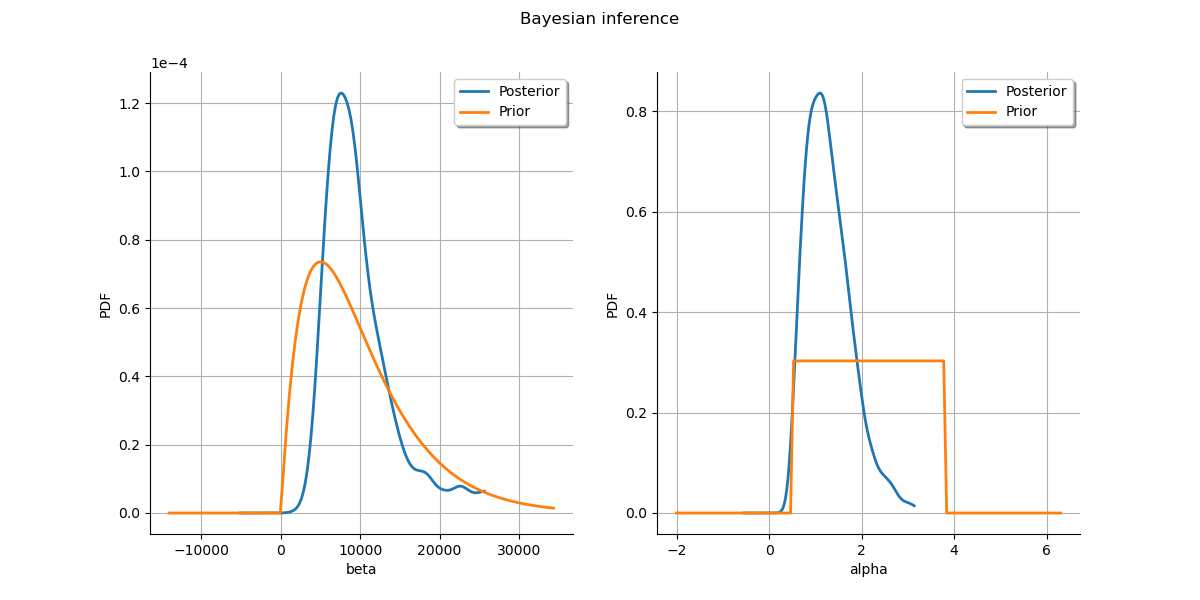
Plot prior to posterior marginal plots.
kernel = ot.KernelSmoothing()
posterior = kernel.build(sample)
grid = ot.GridLayout(1, 2)
grid.setTitle("Bayesian inference")
for parameter_index in range(2):
graph = posterior.getMarginal(parameter_index).drawPDF()
priorGraph = prior.getMarginal(parameter_index).drawPDF()
graph.add(priorGraph)
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
graph.setLegends(["Posterior", "Prior"])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
Define an improper prior¶
Now, define an improper prior:

logpdf = ot.SymbolicFunction(["beta", "alpha"], ["-log(beta)"])
support = ot.Interval([0] * 2, [1] * 2)
support.setFiniteUpperBound([False] * 2)
Sample from the posterior distribution
sampler2 = ot.RandomWalkMetropolisHastings(logpdf, support, initialState, proposal)
sampler2.setLikelihood(conditional, x)
sample2 = sampler2.getSample(1000)
print("Acceptance rate: %s" % (sampler2.getAcceptanceRate()))
Acceptance rate: 0.729
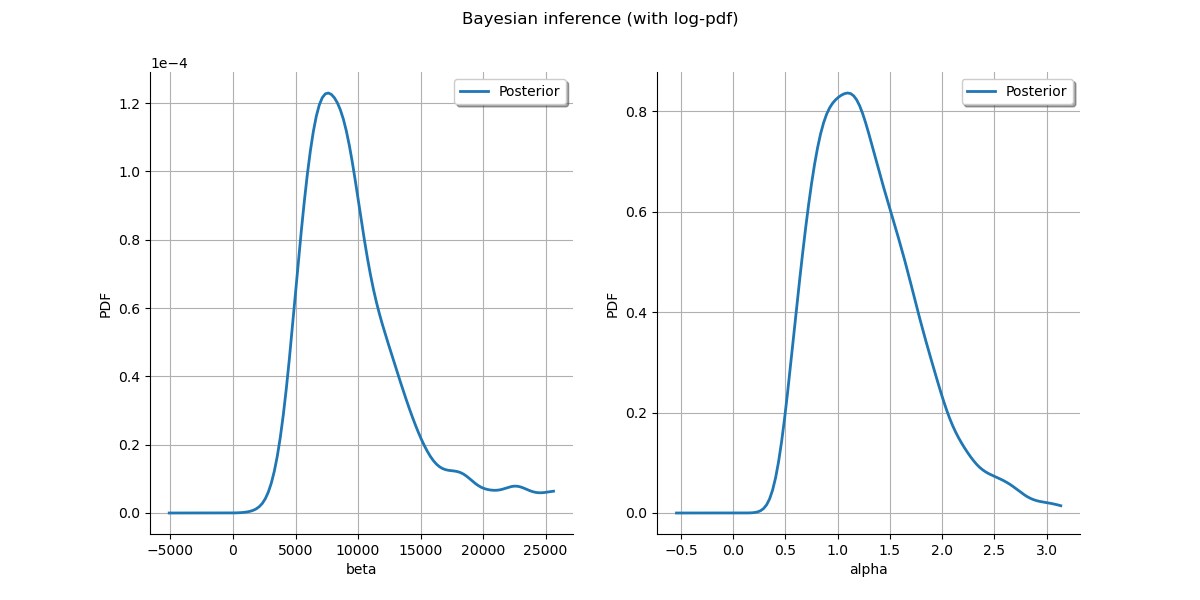
Plot posterior marginal plots only as prior cannot be drawn meaningfully.
kernel = ot.KernelSmoothing()
posterior = kernel.build(sample)
grid = ot.GridLayout(1, 2)
grid.setTitle("Bayesian inference (with log-pdf)")
for parameter_index in range(2):
graph = posterior.getMarginal(parameter_index).drawPDF()
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
graph.setLegends(["Posterior"])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
View.ShowAll()
Total running time of the script: ( 0 minutes 7.261 seconds)