Graphical goodness-of-fit tests¶
This method deals with the modelling of a probability distribution of a
random vector  . It
seeks to verify the compatibility between a sample of data
. It
seeks to verify the compatibility between a sample of data
 and a
candidate probability distribution previous chosen.
The use of graphical tools allows one to answer this question in the one
dimensional case
and a
candidate probability distribution previous chosen.
The use of graphical tools allows one to answer this question in the one
dimensional case  , and with a continuous distribution.
The QQ-plot, and henry line tests are defined in the case to
. Thus we denote
, and with a continuous distribution.
The QQ-plot, and henry line tests are defined in the case to
. Thus we denote  . The first
graphical tool provided is a QQ-plot (where “QQ” stands
for “quantile-quantile”). In the specific case of a Normal distribution,
Henry’s line may also be used.
. The first
graphical tool provided is a QQ-plot (where “QQ” stands
for “quantile-quantile”). In the specific case of a Normal distribution,
Henry’s line may also be used.
QQ-plot
A QQ-Plot is based on the notion of quantile. The
 -quantile
-quantile  of
of  , where
, where
 , is defined as follows:
, is defined as follows:

If a sample  of is
available, the quantile can be estimated empirically:
of is
available, the quantile can be estimated empirically:
the sample
is first placed in
ascending order, which gives the sample
 ;
;then, an estimate of the
-quantile is:![\begin{aligned}
\widehat{q}_{X}(\alpha) = x_{([N\alpha]+1)}
\end{aligned}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc4Ny40MjExMjJwdCcgaGVpZ2h0PScxMi44MTg2MTRwdCcgdmlld0JveD0nMTUwLjMxMTg0OSAtMTMuNDQ5NjcxIDg3LjQyMTEyMiAxMi44MTg2MTQnPgo8ZGVmcz4KPHBhdGggaWQ9J2czLTQwJyBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgLjcyNTI4IDEuMzM4OTc5LS43NTcxNjEgMS4zMzg5NzktMS45OTI1MjhDMS4zMzg5NzktNC4yODc5MiAyLjI4NzQyMi01LjM2Mzg4NSAyLjY5Mzg5OC01LjczMDUxMUMyLjgwNTQ3OS01LjgzNDEyMiAyLjgxMzQ1LTUuODQyMDkyIDIuODEzNDUtNS44ODE5NDNTMi43ODE1NjktNS45Nzc1ODQgMi43MDE4NjgtNS45Nzc1ODRDMi41NzQzNDYtNS45Nzc1ODQgMi4xNzU4NDEtNS41NzExMDggMi4xMTIwOC01LjQ5OTM3N0MxLjA0NDA4NS00LjM4MzU2MiAuODIwOTIyLTIuOTQ4OTQxIC44MjA5MjItMS45OTI1MjhDLjgyMDkyMi0uMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicvPgo8cGF0aCBpZD0nZzMtNDEnIGQ9J00yLjQ2Mjc2NS0xLjk5MjUyOEMyLjQ2Mjc2NS0yLjc0OTY4OSAyLjMzNTI0My0zLjY1ODI4MSAxLjg0MTA5Ni00LjU5ODc1NUMxLjQ1MDU2LTUuMzMyMDA1IC43MjUyOC01Ljk3NzU4NCAuNTgxODE4LTUuOTc3NTg0Qy41MDIxMTctNS45Nzc1ODQgLjQ3ODIwNy01LjkyMTc5MyAuNDc4MjA3LTUuODgxOTQzQy40NzgyMDctNS44NTAwNjIgLjQ3ODIwNy01LjgzNDEyMiAuNTczODQ4LTUuNzM4NDgxQzEuNjg5NjY0LTQuNjc4NDU2IDEuOTQ0NzA3LTMuMjE5OTI1IDEuOTQ0NzA3LTEuOTkyNTI4QzEuOTQ0NzA3IC4yOTQ4OTQgLjk5NjI2NCAxLjM3ODgyOSAuNTg5Nzg4IDEuNzQ1NDU1Qy40ODYxNzcgMS44NDkwNjYgLjQ3ODIwNyAxLjg1NzAzNiAuNDc4MjA3IDEuODk2ODg3Uy41MDIxMTcgMS45OTI1MjggLjU4MTgxOCAxLjk5MjUyOEMuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgLjM5ODUwNiAyLjQ2Mjc2NS0xLjAzNjExNSAyLjQ2Mjc2NS0xLjk5MjUyOFonLz4KPHBhdGggaWQ9J2czLTQzJyBkPSdNMy40NzQ5NjktMS44MDkyMTVINS44MTgxODJDNS45Mjk3NjMtMS44MDkyMTUgNi4xMDUxMDYtMS44MDkyMTUgNi4xMDUxMDYtMS45OTI1MjhTNS45Mjk3NjMtMi4xNzU4NDEgNS44MTgxODItMi4xNzU4NDFIMy40NzQ5NjlWLTQuNTI3MDI0QzMuNDc0OTY5LTQuNjM4NjA1IDMuNDc0OTY5LTQuODEzOTQ4IDMuMjkxNjU2LTQuODEzOTQ4UzMuMTA4MzQ0LTQuNjM4NjA1IDMuMTA4MzQ0LTQuNTI3MDI0Vi0yLjE3NTg0MUguNzU3MTYxQy42NDU1NzktMi4xNzU4NDEgLjQ3MDIzNy0yLjE3NTg0MSAuNDcwMjM3LTEuOTkyNTI4Uy42NDU1NzktMS44MDkyMTUgLjc1NzE2MS0xLjgwOTIxNUgzLjEwODM0NFYuNTQxOTY4QzMuMTA4MzQ0IC42NTM1NDkgMy4xMDgzNDQgLjgyODg5MiAzLjI5MTY1NiAuODI4ODkyUzMuNDc0OTY5IC42NTM1NDkgMy40NzQ5NjkgLjU0MTk2OFYtMS44MDkyMTVaJy8+CjxwYXRoIGlkPSdnMy00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2czLTkxJyBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicvPgo8cGF0aCBpZD0nZzMtOTMnIGQ9J00xLjM1NDkxOS01Ljk3NzU4NEguMTgzMzEzVi01LjYxMDk1OUguOTg4Mjk0VjEuNjI1OTAzSC4xODMzMTNWMS45OTI1MjhIMS4zNTQ5MTlWLTUuOTc3NTg0WicvPgo8cGF0aCBpZD0nZzQtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c0LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnNC02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzEtMTEnIGQ9J000LjA2NDc1Ny0xLjExNTgxNkM0LjgwNTk3OC0xLjkyODc2NyA1LjA2ODk5MS0yLjk2NDg4MiA1LjA2ODk5MS0zLjAyODY0M0M1LjA2ODk5MS0zLjEwMDM3NCA1LjAyMTE3MS0zLjEzMjI1NCA0Ljk0OTQ0LTMuMTMyMjU0QzQuODQ1ODI4LTMuMTMyMjU0IDQuODM3ODU4LTMuMTAwMzc0IDQuNzkwMDM3LTIuOTMzMDAxQzQuNTY2ODc0LTIuMTIwMDUgNC4wODg2NjctMS40OTgzODEgNC4wNjQ3NTctMS40OTgzODFDNC4wNDg4MTctMS40OTgzODEgNC4wNDg4MTctMS42OTc2MzQgNC4wNDg4MTctMS44MjUxNTZDNC4wMzI4NzctMy4yMjc4OTUgMy4xMjQyODQtMy41MTQ4MTkgMi41ODIzMTYtMy41MTQ4MTlDMS40NTg1MzEtMy41MTQ4MTkgLjM1MDY4NS0yLjQyMjkxNCAuMzUwNjg1LTEuMjk5MTI4Qy4zNTA2ODUtLjUxMDA4NyAuOTAwNjIzIC4wNzk3MDEgMS43NDU0NTUgLjA3OTcwMUMyLjMwMzM2MiAuMDc5NzAxIDIuODkzMTUxLS4xMTk1NTIgMy41MjI3OS0uNTg5Nzg4QzMuNjk4MTMyIC4wMzk4NTEgNC4xNjAzOTkgLjA3OTcwMSA0LjMwMzg2MSAuMDc5NzAxQzQuNzU4MTU3IC4wNzk3MDEgNS4wMjExNzEtLjMyNjc3NSA1LjAyMTE3MS0uNDc4MjA3QzUuMDIxMTcxLS41NzM4NDggNC45MjU1MjktLjU3Mzg0OCA0LjkwMTYxOS0uNTczODQ4QzQuODEzOTQ4LS41NzM4NDggNC43OTgwMDctLjU0OTkzOCA0Ljc3NDA5Ny0uNDk0MTQ3QzQuNjQ2NTc1LS4xNTk0MDIgNC4zNzU1OTItLjE0MzQ2MiA0LjMzNTc0MS0uMTQzNDYyQzQuMjI0MTU5LS4xNDM0NjIgNC4wOTY2MzgtLjE0MzQ2MiA0LjA2NDc1Ny0xLjExNTgxNlpNMy40NjY5OTktLjg1MjgwMkMyLjkwMTEyMS0uMzQyNzE1IDIuMjMxNjMxLS4xNDM0NjIgMS43NjkzNjUtLjE0MzQ2MkMxLjM1NDkxOS0uMTQzNDYyIC45OTYyNjQtLjM4MjU2NSAuOTk2MjY0LTEuMDIwMTc0Qy45OTYyNjQtMS4yOTkxMjggMS4xMjM3ODYtMi4xMjAwNSAxLjQ5ODM4MS0yLjY1NDA0N0MxLjgxNzE4Ni0zLjEwMDM3NCAyLjI0NzU3Mi0zLjI5MTY1NiAyLjU3NDM0Ni0zLjI5MTY1NkMzLjAxMjcwMi0zLjI5MTY1NiAzLjI1OTc3Ni0yLjk4MDgyMiAzLjM2MzM4Ny0yLjQ5NDY0NUMzLjQ4MjkzOS0xLjk1MjY3NyAzLjQxOTE3OC0xLjMxNTA2OCAzLjQ2Njk5OS0uODUyODAyWicvPgo8cGF0aCBpZD0nZzEtNzgnIGQ9J002LjMxMjMyOS00LjU3NDg0NEM2LjQwNzk3LTQuOTY1MzggNi41ODMzMTMtNS4xNTY2NjMgNy4xNTcxNjEtNS4xODA1NzNDNy4yMzY4NjItNS4xODA1NzMgNy4zMDA2MjMtNS4yMjgzOTQgNy4zMDA2MjMtNS4zMzIwMDVDNy4zMDA2MjMtNS4zNzk4MjYgNy4yNjA3NzItNS40NDM1ODcgNy4xODEwNzEtNS40NDM1ODdDNy4xMjUyOC01LjQ0MzU4NyA2Ljk3Mzg0OC01LjQxOTY3NiA2LjM4NDA2LTUuNDE5Njc2QzUuNzQ2NDUxLTUuNDE5Njc2IDUuNjQyODM5LTUuNDQzNTg3IDUuNTcxMTA4LTUuNDQzNTg3QzUuNDQzNTg3LTUuNDQzNTg3IDUuNDE5Njc2LTUuMzU1OTE1IDUuNDE5Njc2LTUuMjkyMTU0QzUuNDE5Njc2LTUuMTg4NTQzIDUuNTIzMjg4LTUuMTgwNTczIDUuNTk1MDE5LTUuMTgwNTczQzYuMDgxMTk2LTUuMTY0NjMzIDYuMDgxMTk2LTQuOTQ5NDQgNi4wODExOTYtNC44Mzc4NThDNi4wODExOTYtNC43OTgwMDcgNi4wODExOTYtNC43NTgxNTcgNi4wNDkzMTUtNC42MzA2MzVMNS4xNzI2MDMtMS4xMzk3MjZMMy4yNTE4MDYtNS4zMDAxMjVDMy4xODgwNDUtNS40NDM1ODcgMy4xNzIxMDUtNS40NDM1ODcgMi45ODA4MjItNS40NDM1ODdIMS45NDQ3MDdDMS44MDEyNDUtNS40NDM1ODcgMS42OTc2MzQtNS40NDM1ODcgMS42OTc2MzQtNS4yOTIxNTRDMS42OTc2MzQtNS4xODA1NzMgMS43OTMyNzUtNS4xODA1NzMgMS45NjA2NDgtNS4xODA1NzNDMi4wMjQ0MDgtNS4xODA1NzMgMi4yNjM1MTItNS4xODA1NzMgMi40NDY4MjQtNS4xMzI3NTJMMS4zNzg4MjktLjg1MjgwMkMxLjI4MzE4OC0uNDU0Mjk2IDEuMDc1OTY1LS4yNzg5NTQgLjU0MTk2OC0uMjYzMDE0Qy40OTQxNDctLjI2MzAxNCAuMzk4NTA2LS4yNTUwNDQgLjM5ODUwNi0uMTExNTgyQy4zOTg1MDYtLjA2Mzc2MSAuNDM4MzU2IDAgLjUxODA1NyAwQy41NDk5MzggMCAuNzMzMjUtLjAyMzkxIDEuMzA3MDk4LS4wMjM5MUMxLjkzNjczNy0uMDIzOTEgMi4wNTYyODkgMCAyLjEyODAyIDBDMi4xNTk5IDAgMi4yNzk0NTIgMCAyLjI3OTQ1Mi0uMTUxNDMyQzIuMjc5NDUyLS4yNDcwNzMgMi4xOTE3ODEtLjI2MzAxNCAyLjEzNTk5LS4yNjMwMTRDMS44NDkwNjYtLjI3MDk4NCAxLjYwOTk2My0uMzE4ODA0IDEuNjA5OTYzLS41OTc3NThDMS42MDk5NjMtLjYzNzYwOSAxLjYzMzg3My0uNzQ5MTkxIDEuNjMzODczLS43NTcxNjFMMi42Nzc5NTgtNC45MTc1NTlIMi42ODU5MjhMNC45MDE2MTktLjE0MzQ2MkM0Ljk1NzQxLS4wMTU5NCA0Ljk2NTM4IDAgNS4wNTMwNTEgMEM1LjE2NDYzMyAwIDUuMTcyNjAzLS4wMzE4OCA1LjIwNDQ4My0uMTY3MzcyTDYuMzEyMzI5LTQuNTc0ODQ0WicvPgo8cGF0aCBpZD0nZzEtODgnIGQ9J000LjE2MDM5OS0zLjA0NDU4M0M0LjU0Mjk2NC0zLjQzNTExOCA1LjY3NDcyLTQuNTk4NzU1IDUuODY2MDAyLTQuNzUwMTg3QzYuMjAwNzQ3LTUuMDA1MjMgNi40LTUuMTQ4NjkyIDYuOTczODQ4LTUuMTgwNTczQzcuMDIxNjY5LTUuMTg4NTQzIDcuMDg1NDMtNS4yMjgzOTQgNy4wODU0My01LjMzMjAwNUM3LjA4NTQzLTUuNDAzNzM2IDcuMDEzNjk5LTUuNDQzNTg3IDYuOTczODQ4LTUuNDQzNTg3QzYuODk0MTQ3LTUuNDQzNTg3IDYuODQ2MzI2LTUuNDE5Njc2IDYuMjI0NjU4LTUuNDE5Njc2QzUuNjI2ODk5LTUuNDE5Njc2IDUuNDExNzA2LTUuNDQzNTg3IDUuMzcxODU2LTUuNDQzNTg3QzUuMzM5OTc1LTUuNDQzNTg3IDUuMjEyNDUzLTUuNDQzNTg3IDUuMjEyNDUzLTUuMjkyMTU0QzUuMjEyNDUzLTUuMjg0MTg0IDUuMjEyNDUzLTUuMTg4NTQzIDUuMzMyMDA1LTUuMTgwNTczQzUuMzg3Nzk2LTUuMTcyNjAzIDUuNjAyOTg5LTUuMTU2NjYzIDUuNjAyOTg5LTQuOTczMzVDNS42MDI5ODktNC45MTc1NTkgNS41NzExMDgtNC44Mjk4ODggNS41MDczNDctNC43NjYxMjdMNS40ODM0MzctNC43MjYyNzZDNS40NTk1MjctNC43MDIzNjYgNS40NTk1MjctNC42ODY0MjYgNS4zNzk4MjYtNC42MTQ2OTVMNC4wNDg4MTctMy4yNjc3NDZMMy4yMzU4NjYtNC45NTc0MUMzLjM0NzQ0Ny01LjE0ODY5MiAzLjU4NjU1LTUuMTcyNjAzIDMuNjgyMTkyLTUuMTgwNTczQzMuNzIyMDQyLTUuMTgwNTczIDMuODMzNjI0LTUuMTg4NTQzIDMuODMzNjI0LTUuMzI0MDM1QzMuODMzNjI0LTUuMzk1NzY2IDMuNzc3ODMzLTUuNDQzNTg3IDMuNzA2MTAyLTUuNDQzNTg3QzMuNjI2NDAxLTUuNDQzNTg3IDMuMzIzNTM3LTUuNDI3NjQ2IDMuMjQzODM2LTUuNDI3NjQ2QzMuMTk2MDE1LTUuNDE5Njc2IDIuOTAxMTIxLTUuNDE5Njc2IDIuNzMzNzQ4LTUuNDE5Njc2QzEuOTkyNTI4LTUuNDE5Njc2IDEuODk2ODg3LTUuNDQzNTg3IDEuODI1MTU2LTUuNDQzNTg3QzEuNzkzMjc1LTUuNDQzNTg3IDEuNjY1NzUzLTUuNDQzNTg3IDEuNjY1NzUzLTUuMjkyMTU0QzEuNjY1NzUzLTUuMTgwNTczIDEuNzY5MzY1LTUuMTgwNTczIDEuODk2ODg3LTUuMTgwNTczQzIuMjk1MzkyLTUuMTgwNTczIDIuMzY3MTIzLTUuMTAwODcyIDIuNDM4ODU0LTQuOTQ5NDRMMy40OTg4NzktMi43MTc4MDhMMS44NjUwMDYtMS4wNTIwNTVDMS4zODY4LS41NzM4NDggMS4wMTIyMDQtLjI5NDg5NCAuNDQ2MzI2LS4yNjMwMTRDLjM1MDY4NS0uMjU1MDQ0IC4yNTUwNDQtLjI1NTA0NCAuMjU1MDQ0LS4xMTE1ODJDLjI1NTA0NC0uMDYzNzYxIC4yOTQ4OTQgMCAuMzc0NTk1IDBDLjQzMDM4NiAwIC41MTgwNTctLjAyMzkxIDEuMTIzNzg2LS4wMjM5MUMxLjY5NzYzNC0uMDIzOTEgMS45NDQ3MDcgMCAxLjk3NjU4OCAwQzIuMDE2NDM4IDAgMi4xMzU5OSAwIDIuMTM1OTktLjE1MTQzMkMyLjEzNTk5LS4xNjczNzIgMi4xMjgwMi0uMjU1MDQ0IDIuMDA4NDY4LS4yNjMwMTRDMS44NTcwMzYtLjI3MDk4NCAxLjc0NTQ1NS0uMzI2Nzc1IDEuNzQ1NDU1LS40NzAyMzdDMS43NDU0NTUtLjU5Nzc1OCAxLjg0MTA5Ni0uNzAxMzcgMS45NjA2NDgtLjgyMDkyMkMyLjA5NjEzOS0uOTcyMzU0IDIuNTEwNTg1LTEuMzg2OCAyLjc5NzUwOS0xLjY2NTc1M0MyLjk4MDgyMi0xLjg0OTA2NiAzLjQyNzE0OC0yLjMxMTMzMyAzLjYxMDQ2MS0yLjQ4NjY3NUw0LjUyNzAyNC0uNTgxODE4QzQuNTY2ODc0LS41MDIxMTcgNC41NjY4NzQtLjQ5NDE0NyA0LjU2Njg3NC0uNDg2MTc3QzQuNTY2ODc0LS40MTQ0NDYgNC4zOTk1MDItLjI3ODk1NCA0LjEzNjQ4OC0uMjYzMDE0QzQuMDgwNjk3LS4yNjMwMTQgMy45NzcwODYtLjI1NTA0NCAzLjk3NzA4Ni0uMTExNTgyQzMuOTc3MDg2LS4xMDM2MTEgMy45ODUwNTYgMCA0LjExMjU3OCAwQzQuMTkyMjc5IDAgNC40ODcxNzMtLjAxNTk0IDQuNTY2ODc0LS4wMjM5MUg1LjA3Njk2MUM1LjgxMDIxMi0uMDIzOTEgNS45MjE3OTMgMCA1Ljk5MzUyNCAwQzYuMDI1NDA1IDAgNi4xNDQ5NTYgMCA2LjE0NDk1Ni0uMTUxNDMyQzYuMTQ0OTU2LS4yNjMwMTQgNi4wNDEzNDUtLjI2MzAxNCA1LjkyMTc5My0uMjYzMDE0QzUuNDkxNDA3LS4yNjMwMTQgNS40NDM1ODctLjM1ODY1NSA1LjM4Nzc5Ni0uNDc4MjA3TDQuMTYwMzk5LTMuMDQ0NTgzWicvPgo8cGF0aCBpZD0nZzItMTEnIGQ9J001LjUzNTI0My0zLjAyNDY1OEM1LjUzNTI0My00LjE4NDMwOSA0Ljg3NzcwOS01LjI3MjIyOSAzLjYxMDQ2MS01LjI3MjIyOUMyLjA0NDMzNC01LjI3MjIyOSAuNDc4MjA3LTMuNTYyNjQgLjQ3ODIwNy0xLjg2NTAwNkMuNDc4MjA3LS44MjQ5MDcgMS4xMjM3ODYgLjExOTU1MiAyLjM0MzIxMyAuMTE5NTUyQzMuMDg0NDMzIC4xMTk1NTIgMy45NjkxMTYtLjE2NzM3MiA0LjgxNzkzMy0uODg0NjgyQzQuOTg1MzA1LS4yMTUxOTMgNS4zNTU5MTUgLjExOTU1MiA1Ljg2OTk4OCAuMTE5NTUyQzYuNTE1NTY3IC4xMTk1NTIgNi44MzgzNTYtLjU0OTkzOCA2LjgzODM1Ni0uNzA1MzU1QzYuODM4MzU2LS44MTI5NTEgNi43NTQ2Ny0uODEyOTUxIDYuNzE4ODA0LS44MTI5NTFDNi42MjMxNjMtLjgxMjk1MSA2LjYxMTIwOC0uNzc3MDg2IDYuNTc1MzQyLS42ODE0NDVDNi40Njc3NDYtLjM4MjU2NSA2LjE5Mjc3Ny0uMTE5NTUyIDUuOTA1ODUzLS4xMTk1NTJDNS41MzUyNDMtLjExOTU1MiA1LjUzNTI0My0uODg0NjgyIDUuNTM1MjQzLTEuNjEzOTQ4QzYuNzU0NjctMy4wNzI0NzggNy4wNDE1OTQtNC41Nzg4MjkgNy4wNDE1OTQtNC41OTA3ODVDNy4wNDE1OTQtNC42OTgzODEgNi45NDU5NTMtNC42OTgzODEgNi45MTAwODctNC42OTgzODFDNi44MDI0OTEtNC42OTgzODEgNi43OTA1MzUtNC42NjI1MTYgNi43NDI3MTUtNC40NDczMjNDNi41ODcyOTgtMy45MjEyOTUgNi4yNzY0NjMtMi45ODg3OTIgNS41MzUyNDMtMi4wMDg0NjhWLTMuMDI0NjU4Wk00Ljc4MjA2Ny0xLjE3MTYwNkMzLjczMDAxMi0uMjI3MTQ4IDIuNzg1NTU0LS4xMTk1NTIgMi4zNjcxMjMtLjExOTU1MkMxLjUxODMwNi0uMTE5NTUyIDEuMjc5MjAzLS44NzI3MjcgMS4yNzkyMDMtMS40MzQ2MkMxLjI3OTIwMy0xLjk0ODY5MiAxLjU0MjIxNy0zLjE2ODEyIDEuOTEyODI3LTMuODI1NjU0QzIuNDAyOTg5LTQuNjYyNTE2IDMuMDcyNDc4LTUuMDMzMTI2IDMuNjEwNDYxLTUuMDMzMTI2QzQuNzcwMTEyLTUuMDMzMTI2IDQuNzcwMTEyLTMuNTE0ODE5IDQuNzcwMTEyLTIuNTEwNTg1QzQuNzcwMTEyLTIuMjExNzA2IDQuNzU4MTU3LTEuOTAwODcyIDQuNzU4MTU3LTEuNjAxOTkzQzQuNzU4MTU3LTEuMzYyODg5IDQuNzcwMTEyLTEuMzAzMTEzIDQuNzgyMDY3LTEuMTcxNjA2WicvPgo8cGF0aCBpZD0nZzItMTEzJyBkPSdNNS4yNzIyMjktNS4xNTI2NzdDNS4yNzIyMjktNS4yMTI0NTMgNS4yMjQ0MDgtNS4yNjAyNzQgNS4xNjQ2MzMtNS4yNjAyNzRDNS4wNjg5OTEtNS4yNjAyNzQgNC42MDI3NC00LjgyOTg4OCA0LjM3NTU5Mi00LjQxMTQ1N0M0LjE2MDM5OS00Ljk0OTQ0IDMuNzg5Nzg4LTUuMjcyMjI5IDMuMjc1NzE2LTUuMjcyMjI5QzEuOTI0NzgyLTUuMjcyMjI5IC40NjYyNTItMy41MjY3NzUgLjQ2NjI1Mi0xLjc1NzQxQy40NjYyNTItLjU3Mzg0OCAxLjE1OTY1MSAuMTE5NTUyIDEuOTcyNjAzIC4xMTk1NTJDMi42MDYyMjcgLjExOTU1MiAzLjEzMjI1NC0uMzU4NjU1IDMuMzgzMzEzLS42MzM2MjRMMy4zOTUyNjgtLjYyMTY2OUwyLjk0MDk3MSAxLjE3MTYwNkwyLjgzMzM3NSAxLjYwMTk5M0MyLjcyNTc3OCAxLjk2MDY0OCAyLjU0NjQ1MSAxLjk2MDY0OCAxLjk4NDU1OCAxLjk3MjYwM0MxLjg1MzA1MSAxLjk3MjYwMyAxLjczMzQ5OSAxLjk3MjYwMyAxLjczMzQ5OSAyLjE5OTc1MUMxLjczMzQ5OSAyLjI4MzQzNyAxLjgwNTIzIDIuMzE5MzAzIDEuODg4OTE3IDIuMzE5MzAzQzIuMDU2Mjg5IDIuMzE5MzAzIDIuMjcxNDgyIDIuMjk1MzkyIDIuNDM4ODU0IDIuMjk1MzkySDMuNjU4MjgxQzMuODM3NjA5IDIuMjk1MzkyIDQuMDQwODQ3IDIuMzE5MzAzIDQuMjIwMTc0IDIuMzE5MzAzQzQuMjkxOTA1IDIuMzE5MzAzIDQuNDM1MzY3IDIuMzE5MzAzIDQuNDM1MzY3IDIuMDkyMTU0QzQuNDM1MzY3IDEuOTcyNjAzIDQuMzM5NzI2IDEuOTcyNjAzIDQuMTYwMzk5IDEuOTcyNjAzQzMuNTk4NTA2IDEuOTcyNjAzIDMuNTYyNjQgMS44ODg5MTcgMy41NjI2NCAxLjc5MzI3NUMzLjU2MjY0IDEuNzMzNDk5IDMuNTc0NTk1IDEuNzIxNTQ0IDMuNjEwNDYxIDEuNTY2MTI3TDUuMjcyMjI5LTUuMTUyNjc3Wk0zLjU4NjU1LTEuNDIyNjY1QzMuNTI2Nzc1LTEuMjE5NDI3IDMuNTI2Nzc1LTEuMTk1NTE3IDMuMzU5NDAyLS45NjgzNjlDMy4wOTYzODktLjYzMzYyNCAyLjU3MDM2MS0uMTE5NTUyIDIuMDA4NDY4LS4xMTk1NTJDMS41MTgzMDYtLjExOTU1MiAxLjI0MzMzNy0uNTYxODkzIDEuMjQzMzM3LTEuMjY3MjQ4QzEuMjQzMzM3LTEuOTI0NzgyIDEuNjEzOTQ4LTMuMjYzNzYxIDEuODQxMDk2LTMuNzY1ODc4QzIuMjQ3NTcyLTQuNjAyNzQgMi44MDk0NjUtNS4wMzMxMjYgMy4yNzU3MTYtNS4wMzMxMjZDNC4wNjQ3NTctNS4wMzMxMjYgNC4yMjAxNzQtNC4wNTI4MDIgNC4yMjAxNzQtMy45NTcxNjFDNC4yMjAxNzQtMy45NDUyMDUgNC4xODQzMDktMy43ODk3ODggNC4xNzIzNTQtMy43NjU4NzhMMy41ODY1NS0xLjQyMjY2NVonLz4KPHBhdGggaWQ9J2cyLTEyMCcgZD0nTTUuNjY2NzUtNC44Nzc3MDlDNS4yODQxODQtNC44MDU5NzggNS4xNDA3MjItNC41MTkwNTQgNS4xNDA3MjItNC4yOTE5MDVDNS4xNDA3MjItNC4wMDQ5ODEgNS4zNjc4Ny0zLjkwOTM0IDUuNTM1MjQzLTMuOTA5MzRDNS44OTM4OTgtMy45MDkzNCA2LjE0NDk1Ni00LjIyMDE3NCA2LjE0NDk1Ni00LjU0Mjk2NEM2LjE0NDk1Ni01LjA0NTA4MSA1LjU3MTEwOC01LjI3MjIyOSA1LjA2ODk5MS01LjI3MjIyOUM0LjMzOTcyNi01LjI3MjIyOSAzLjkzMzI1LTQuNTU0OTE5IDMuODI1NjU0LTQuMzI3NzcxQzMuNTUwNjg1LTUuMjI0NDA4IDIuODA5NDY1LTUuMjcyMjI5IDIuNTk0MjcxLTUuMjcyMjI5QzEuMzc0ODQ0LTUuMjcyMjI5IC43MjkyNjUtMy43MDYxMDIgLjcyOTI2NS0zLjQ0MzA4OEMuNzI5MjY1LTMuMzk1MjY4IC43NzcwODYtMy4zMzU0OTIgLjg2MDc3Mi0zLjMzNTQ5MkMuOTU2NDEzLTMuMzM1NDkyIC45ODAzMjQtMy40MDcyMjMgMS4wMDQyMzQtMy40NTUwNDRDMS40MTA3MS00Ljc4MjA2NyAyLjIxMTcwNi01LjAzMzEyNiAyLjU1ODQwNi01LjAzMzEyNkMzLjA5NjM4OS01LjAzMzEyNiAzLjIwMzk4NS00LjUzMTAwOSAzLjIwMzk4NS00LjI0NDA4NUMzLjIwMzk4NS0zLjk4MTA3MSAzLjEzMjI1NC0zLjcwNjEwMiAyLjk4ODc5Mi0zLjEzMjI1NEwyLjU4MjMxNi0xLjQ5NDM5NkMyLjQwMjk4OS0uNzc3MDg2IDIuMDU2Mjg5LS4xMTk1NTIgMS40MjI2NjUtLjExOTU1MkMxLjM2Mjg4OS0uMTE5NTUyIDEuMDY0MDEtLjExOTU1MiAuODEyOTUxLS4yNzQ5NjlDMS4yNDMzMzctLjM1ODY1NSAxLjMzODk3OS0uNzE3MzEgMS4zMzg5NzktLjg2MDc3MkMxLjMzODk3OS0xLjA5OTg3NSAxLjE1OTY1MS0xLjI0MzMzNyAuOTMyNTAzLTEuMjQzMzM3Qy42NDU1NzktMS4yNDMzMzcgLjMzNDc0NS0uOTkyMjc5IC4zMzQ3NDUtLjYwOTcxNEMuMzM0NzQ1LS4xMDc1OTcgLjg5NjYzOCAuMTE5NTUyIDEuNDEwNzEgLjExOTU1MkMxLjk4NDU1OCAuMTE5NTUyIDIuMzkxMDM0LS4zMzQ3NDUgMi42NDIwOTItLjgyNDkwN0MyLjgzMzM3NS0uMTE5NTUyIDMuNDMxMTMzIC4xMTk1NTIgMy44NzM0NzQgLjExOTU1MkM1LjA5MjkwMiAuMTE5NTUyIDUuNzM4NDgxLTEuNDQ2NTc1IDUuNzM4NDgxLTEuNzA5NTg5QzUuNzM4NDgxLTEuNzY5MzY1IDUuNjkwNjYtMS44MTcxODYgNS42MTg5MjktMS44MTcxODZDNS41MTEzMzMtMS44MTcxODYgNS40OTkzNzctMS43NTc0MSA1LjQ2MzUxMi0xLjY2MTc2OEM1LjE0MDcyMi0uNjA5NzE0IDQuNDQ3MzIzLS4xMTk1NTIgMy45MDkzNC0uMTE5NTUyQzMuNDkwOTA5LS4xMTk1NTIgMy4yNjM3NjEtLjQzMDM4NiAzLjI2Mzc2MS0uOTIwNTQ4QzMuMjYzNzYxLTEuMTgzNTYyIDMuMzExNTgyLTEuMzc0ODQ0IDMuNTAyODY0LTIuMTYzODg1TDMuOTIxMjk1LTMuNzg5Nzg4QzQuMTAwNjIzLTQuNTA3MDk4IDQuNTA3MDk4LTUuMDMzMTI2IDUuMDU3MDM2LTUuMDMzMTI2QzUuMDgwOTQ2LTUuMDMzMTI2IDUuNDE1NjkxLTUuMDMzMTI2IDUuNjY2NzUtNC44Nzc3MDlaJy8+CjxwYXRoIGlkPSdnMC05OCcgZD0nTTMuMzExNTgyLTguMTg5MjlMNi41NjMzODctNi43MTg4MDRMNi43MDY4NDktNi45ODE4MThMMy4zMjM1MzctOC44OTQ2NDVMLS4wNTk3NzYtNi45ODE4MThMLjA3MTczMS02LjcxODgwNEwzLjMxMTU4Mi04LjE4OTI5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMTUwLjc3NjAzNicgeT0nLTQuNDgzMzEnIHhsaW5rOmhyZWY9JyNnMC05OCcvPgo8dXNlIHg9JzE1MC4zMTE4NDknIHk9Jy00LjQ4MzI5NCcgeGxpbms6aHJlZj0nI2cyLTExMycvPgo8dXNlIHg9JzE1NS41MDIwNTcnIHk9Jy0yLjY5MDAzMScgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nMTYzLjU4NzExJyB5PSctNC40ODMyOTQnIHhsaW5rOmhyZWY9JyNnNC00MCcvPgo8dXNlIHg9JzE2OC4xMzk0MzYnIHk9Jy00LjQ4MzI5NCcgeGxpbms6aHJlZj0nI2cyLTExJy8+Cjx1c2UgeD0nMTc1LjY2MTE2JyB5PSctNC40ODMyOTQnIHhsaW5rOmhyZWY9JyNnNC00MScvPgo8dXNlIHg9JzE4My41MzQzMTUnIHk9Jy00LjQ4MzI5NCcgeGxpbms6aHJlZj0nI2c0LTYxJy8+Cjx1c2UgeD0nMTk1Ljk1OTc5NicgeT0nLTQuNDgzMjk0JyB4bGluazpocmVmPScjZzItMTIwJy8+Cjx1c2UgeD0nMjAyLjYxMTg4MycgeT0nLTIuNjIzNTg0JyB4bGluazpocmVmPScjZzMtNDAnLz4KPHVzZSB4PScyMDUuOTA1MTM2JyB5PSctMi42MjM1ODQnIHhsaW5rOmhyZWY9JyNnMy05MScvPgo8dXNlIHg9JzIwOC4yNTc0NicgeT0nLTIuNjIzNTg0JyB4bGluazpocmVmPScjZzEtNzgnLz4KPHVzZSB4PScyMTUuODI3NzY1JyB5PSctMi42MjM1ODQnIHhsaW5rOmhyZWY9JyNnMS0xMScvPgo8dXNlIHg9JzIyMS4yNjY3MDQnIHk9Jy0yLjYyMzU4NCcgeGxpbms6aHJlZj0nI2czLTkzJy8+Cjx1c2UgeD0nMjIzLjYxOTAyOCcgeT0nLTIuNjIzNTg0JyB4bGluazpocmVmPScjZzMtNDMnLz4KPHVzZSB4PScyMzAuMjA1NTM1JyB5PSctMi42MjM1ODQnIHhsaW5rOmhyZWY9JyNnMy00OScvPgo8dXNlIHg9JzIzNC40Mzk3MTgnIHk9Jy0yLjYyMzU4NCcgeGxpbms6aHJlZj0nI2czLTQxJy8+CjwvZz4KPC9zdmc+)
where ![[N\alpha]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyNC42NDc2NTdwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgMjQuNjQ3NjU3IDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtMTEnIGQ9J001LjUzNTI0My0zLjAyNDY1OEM1LjUzNTI0My00LjE4NDMwOSA0Ljg3NzcwOS01LjI3MjIyOSAzLjYxMDQ2MS01LjI3MjIyOUMyLjA0NDMzNC01LjI3MjIyOSAuNDc4MjA3LTMuNTYyNjQgLjQ3ODIwNy0xLjg2NTAwNkMuNDc4MjA3LS44MjQ5MDcgMS4xMjM3ODYgLjExOTU1MiAyLjM0MzIxMyAuMTE5NTUyQzMuMDg0NDMzIC4xMTk1NTIgMy45NjkxMTYtLjE2NzM3MiA0LjgxNzkzMy0uODg0NjgyQzQuOTg1MzA1LS4yMTUxOTMgNS4zNTU5MTUgLjExOTU1MiA1Ljg2OTk4OCAuMTE5NTUyQzYuNTE1NTY3IC4xMTk1NTIgNi44MzgzNTYtLjU0OTkzOCA2LjgzODM1Ni0uNzA1MzU1QzYuODM4MzU2LS44MTI5NTEgNi43NTQ2Ny0uODEyOTUxIDYuNzE4ODA0LS44MTI5NTFDNi42MjMxNjMtLjgxMjk1MSA2LjYxMTIwOC0uNzc3MDg2IDYuNTc1MzQyLS42ODE0NDVDNi40Njc3NDYtLjM4MjU2NSA2LjE5Mjc3Ny0uMTE5NTUyIDUuOTA1ODUzLS4xMTk1NTJDNS41MzUyNDMtLjExOTU1MiA1LjUzNTI0My0uODg0NjgyIDUuNTM1MjQzLTEuNjEzOTQ4QzYuNzU0NjctMy4wNzI0NzggNy4wNDE1OTQtNC41Nzg4MjkgNy4wNDE1OTQtNC41OTA3ODVDNy4wNDE1OTQtNC42OTgzODEgNi45NDU5NTMtNC42OTgzODEgNi45MTAwODctNC42OTgzODFDNi44MDI0OTEtNC42OTgzODEgNi43OTA1MzUtNC42NjI1MTYgNi43NDI3MTUtNC40NDczMjNDNi41ODcyOTgtMy45MjEyOTUgNi4yNzY0NjMtMi45ODg3OTIgNS41MzUyNDMtMi4wMDg0NjhWLTMuMDI0NjU4Wk00Ljc4MjA2Ny0xLjE3MTYwNkMzLjczMDAxMi0uMjI3MTQ4IDIuNzg1NTU0LS4xMTk1NTIgMi4zNjcxMjMtLjExOTU1MkMxLjUxODMwNi0uMTE5NTUyIDEuMjc5MjAzLS44NzI3MjcgMS4yNzkyMDMtMS40MzQ2MkMxLjI3OTIwMy0xLjk0ODY5MiAxLjU0MjIxNy0zLjE2ODEyIDEuOTEyODI3LTMuODI1NjU0QzIuNDAyOTg5LTQuNjYyNTE2IDMuMDcyNDc4LTUuMDMzMTI2IDMuNjEwNDYxLTUuMDMzMTI2QzQuNzcwMTEyLTUuMDMzMTI2IDQuNzcwMTEyLTMuNTE0ODE5IDQuNzcwMTEyLTIuNTEwNTg1QzQuNzcwMTEyLTIuMjExNzA2IDQuNzU4MTU3LTEuOTAwODcyIDQuNzU4MTU3LTEuNjAxOTkzQzQuNzU4MTU3LTEuMzYyODg5IDQuNzcwMTEyLTEuMzAzMTEzIDQuNzgyMDY3LTEuMTcxNjA2WicvPgo8cGF0aCBpZD0nZzAtNzgnIGQ9J004Ljg0NjgyNC02LjkxMDA4N0M4Ljk3ODMzMS03LjQyNDE1OSA5LjE2OTYxNC03Ljc4MjgxNCAxMC4wNzgyMDctNy44MTg2OEMxMC4xMTQwNzItNy44MTg2OCAxMC4yNTc1MzQtNy44MzA2MzUgMTAuMjU3NTM0LTguMDMzODczQzEwLjI1NzUzNC04LjE2NTM4IDEwLjE0OTkzOC04LjE2NTM4IDEwLjEwMjExNy04LjE2NTM4QzkuODYzMDE0LTguMTY1MzggOS4yNTMzLTguMTQxNDY5IDkuMDE0MTk3LTguMTQxNDY5SDguNDQwMzQ5QzguMjcyOTc2LTguMTQxNDY5IDguMDU3NzgzLTguMTY1MzggNy44OTA0MTEtOC4xNjUzOEM3LjgxODY4LTguMTY1MzggNy42NzUyMTgtOC4xNjUzOCA3LjY3NTIxOC03LjkzODIzMkM3LjY3NTIxOC03LjgxODY4IDcuNzcwODU5LTcuODE4NjggNy44NTQ1NDUtNy44MTg2OEM4LjU3MTg1Ni03Ljc5NDc3IDguNjE5Njc2LTcuNTE5ODAxIDguNjE5Njc2LTcuMzA0NjA4QzguNjE5Njc2LTcuMTk3MDExIDguNjA3NzIxLTcuMTYxMTQ2IDguNTcxODU2LTYuOTkzNzczTDcuMjIwOTIyLTEuNjAxOTkzTDQuNjYyNTE2LTcuOTYyMTQyQzQuNTc4ODI5LTguMTUzNDI1IDQuNTY2ODc0LTguMTY1MzggNC4zMDM4NjEtOC4xNjUzOEgyLjg0NTMzQzIuNjA2MjI3LTguMTY1MzggMi40OTg2My04LjE2NTM4IDIuNDk4NjMtNy45MzgyMzJDMi40OTg2My03LjgxODY4IDIuNTgyMzE2LTcuODE4NjggMi44MDk0NjUtNy44MTg2OEMyLjg2OTI0LTcuODE4NjggMy41NzQ1OTUtNy44MTg2OCAzLjU3NDU5NS03LjcxMTA4M0MzLjU3NDU5NS03LjY4NzE3MyAzLjU1MDY4NS03LjU5MTUzMiAzLjUzODczLTcuNTU1NjY2TDEuOTQ4NjkyLTEuMjE5NDI3QzEuODA1MjMtLjYzMzYyNCAxLjUxODMwNi0uMzgyNTY1IC43MjkyNjUtLjM0NjdDLjY2OTQ4OS0uMzQ2NyAuNTQ5OTM4LS4zMzQ3NDUgLjU0OTkzOC0uMTE5NTUyQy41NDk5MzggMCAuNjY5NDg5IDAgLjcwNTM1NSAwQy45NDQ0NTggMCAxLjU1NDE3Mi0uMDIzOTEgMS43OTMyNzUtLjAyMzkxSDIuMzY3MTIzQzIuNTM0NDk2LS4wMjM5MSAyLjczNzczMyAwIDIuOTA1MTA2IDBDMi45ODg3OTIgMCAzLjEyMDI5OSAwIDMuMTIwMjk5LS4yMjcxNDhDMy4xMjAyOTktLjMzNDc0NSAzLjAwMDc0Ny0uMzQ2NyAyLjk1MjkyNy0uMzQ2N0MyLjU1ODQwNi0uMzU4NjU1IDIuMTc1ODQxLS40MzAzODYgMi4xNzU4NDEtLjg2MDc3MkMyLjE3NTg0MS0uOTU2NDEzIDIuMTk5NzUxLTEuMDY0MDEgMi4yMjM2NjEtMS4xNTk2NTFMMy44Mzc2MDktNy41NTU2NjZDMy45MDkzNC03LjQzNjExNSAzLjkwOTM0LTcuNDEyMjA0IDMuOTU3MTYxLTcuMzA0NjA4TDYuODAyNDkxLS4yMTUxOTNDNi44NjIyNjctLjA3MTczMSA2Ljg4NjE3NyAwIDYuOTkzNzczIDBDNy4xMTMzMjUgMCA3LjEyNTI4LS4wMzU4NjYgNy4xNzMxMDEtLjIzOTEwM0w4Ljg0NjgyNC02LjkxMDA4N1onLz4KPHBhdGggaWQ9J2cxLTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnMS05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PScwJyB4bGluazpocmVmPScjZzEtOTEnLz4KPHVzZSB4PSczLjI1MTY2MScgeT0nMCcgeGxpbms6aHJlZj0nI2cwLTc4Jy8+Cjx1c2UgeD0nMTMuODc0MjcyJyB5PScwJyB4bGluazpocmVmPScjZzAtMTEnLz4KPHVzZSB4PScyMS4zOTU5OTYnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS05MycvPgo8L2c+Cjwvc3ZnPg==) denotes the integral part of
denotes the integral part of
 .
.
Thus, the  smallest value of the sample
smallest value of the sample
 is an estimate
is an estimate  of the
-quantile where
of the
-quantile where  (
( ).
).
Let us then consider the candidate probability distribution being
tested, and let us denote by  its cumulative distribution
function. An estimate of the -quantile can be also
computed from :
its cumulative distribution
function. An estimate of the -quantile can be also
computed from :

If is really the cumulative distribution function of
, then and
 should be close. Thus, graphically, the
points
should be close. Thus, graphically, the
points
 should be close to the diagonal.
should be close to the diagonal.
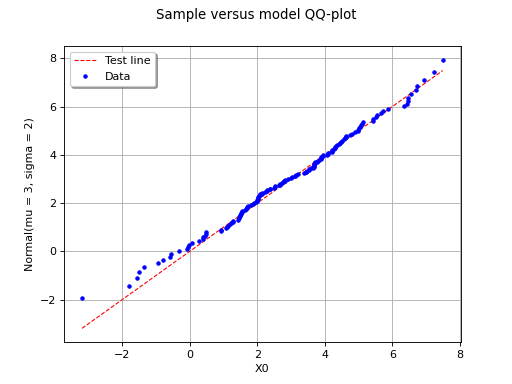
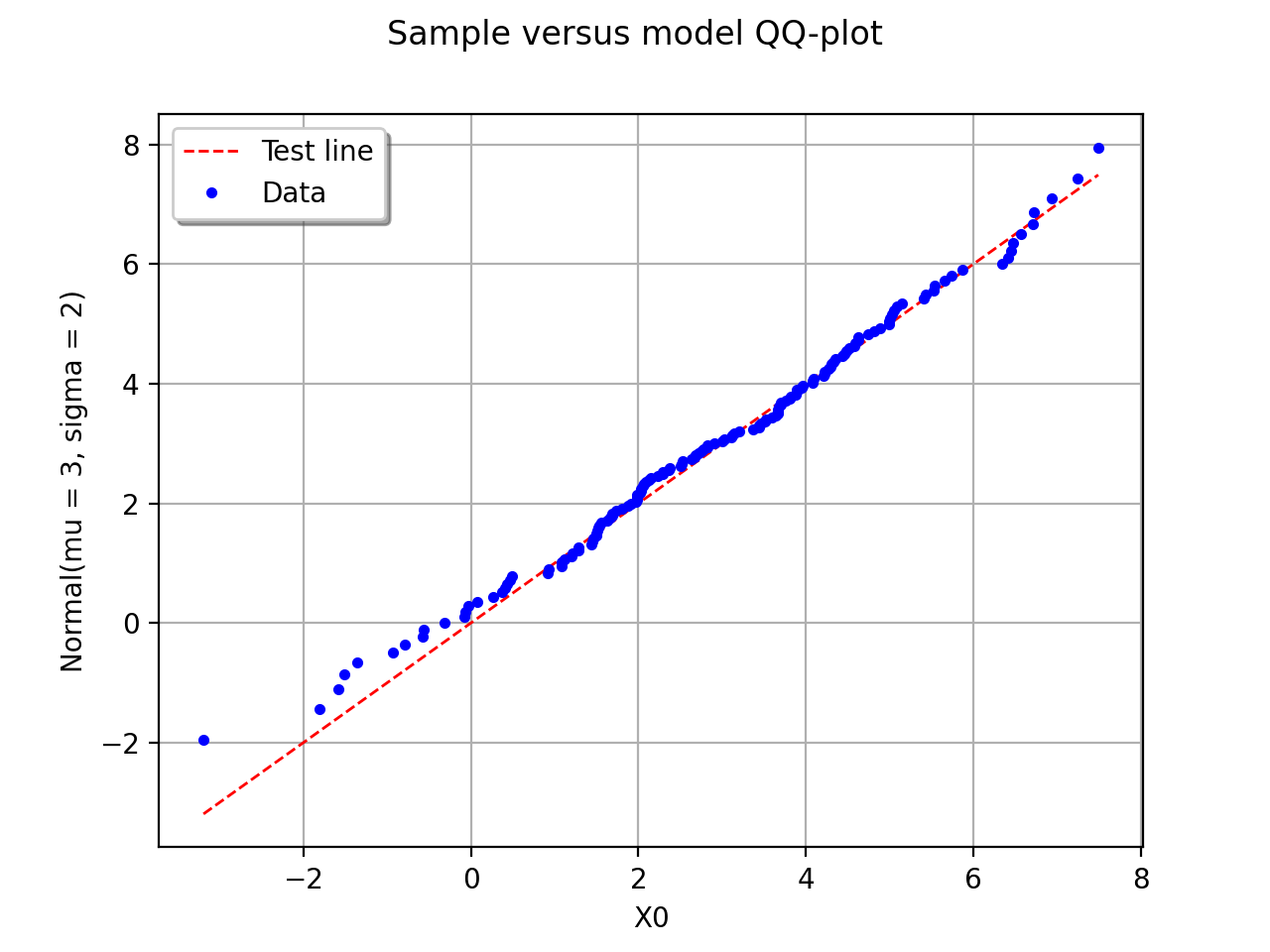
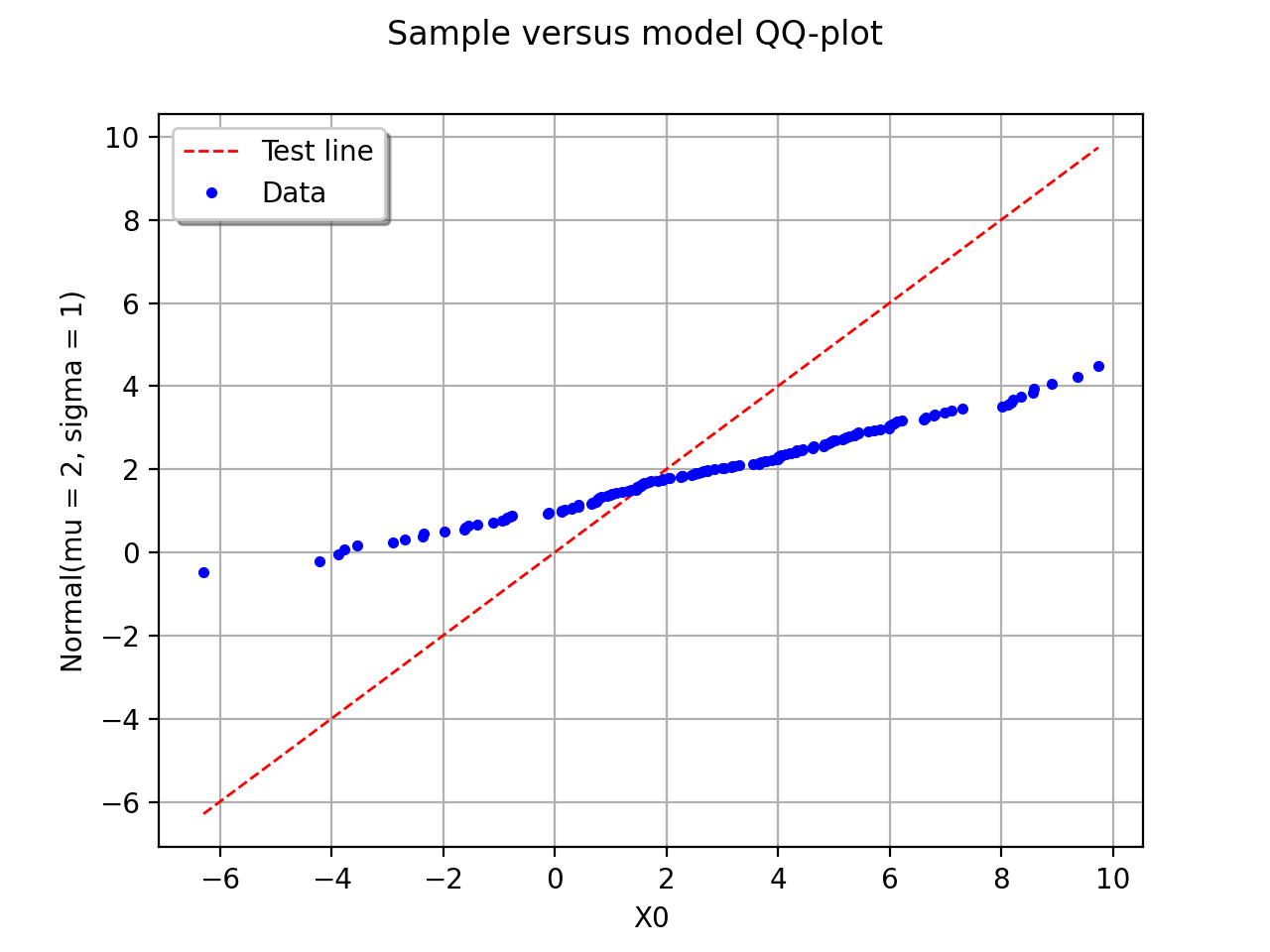
The following figure illustrates the principle of a QQ-plot with a
sample of size  . Note that the unit of the two axis is that
of the variable studied; the quantiles determined via
are called here “value of
. Note that the unit of the two axis is that
of the variable studied; the quantiles determined via
are called here “value of  ”. In this example, the
points remain close to the diagonal and the hypothesis “ is the
cumulative distribution function of ” does not seem irrelevant,
even if a more quantitative analysis (see for instance ) should be
carried out to confirm this.
”. In this example, the
points remain close to the diagonal and the hypothesis “ is the
cumulative distribution function of ” does not seem irrelevant,
even if a more quantitative analysis (see for instance ) should be
carried out to confirm this.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
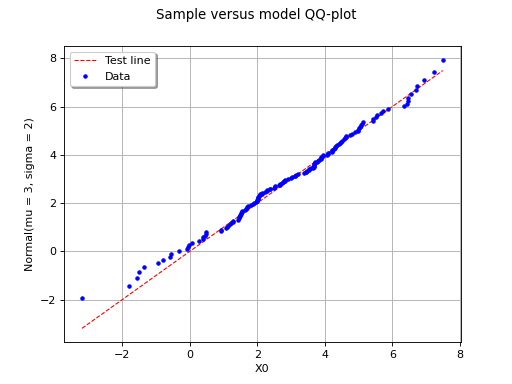
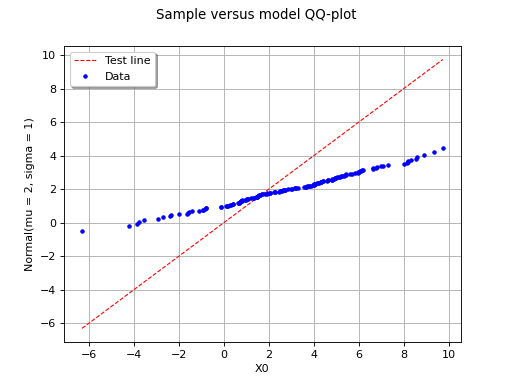
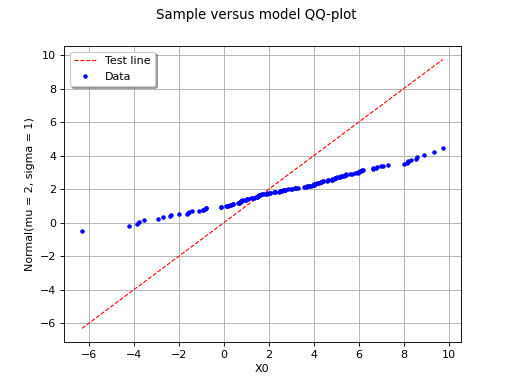
In this second example, the candidate distribution function is clearly irrelevant.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Henry’s line
This second graphical tool is only relevant if the candidate
distribution function being tested is gaussian. It also uses the ordered
sample introduced for
the QQ-plot, and the empirical cumulative distribution function
 presented in .
presented in .
By definition,

Then, let us denote by  the cumulative distribution
function of a Normal distribution with mean 0 and standard deviation 1.
The quantity
the cumulative distribution
function of a Normal distribution with mean 0 and standard deviation 1.
The quantity  is defined as follows:
is defined as follows:

If is distributed according to a normal probability
distribution with mean  and standard-deviation
and standard-deviation
 , then the points
, then the points
 should be close to the line defined by
should be close to the line defined by  .
This comes from a property of a normal distribution: it the distribution
of is really
.
This comes from a property of a normal distribution: it the distribution
of is really  , then the distribution of
, then the distribution of
 is
is  .
.
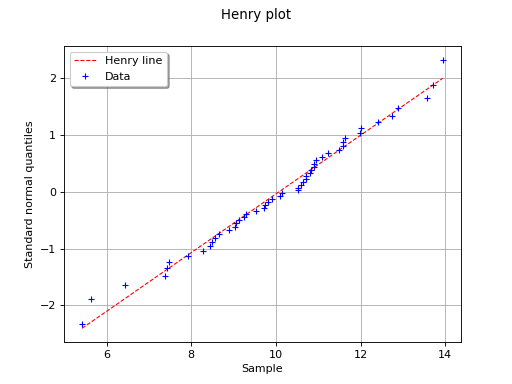
The following figure illustrates the principle of Henry’s graphical test
with a sample of size . Note that only the unit of the
horizontal axis is that of the variable studied. In this
example, the points remain close to a line and the hypothesis “the
distribution function of is a Gaussian one” does not seem
irrelevant, even if a more quantitative analysis (see for instance )
should be carried out to confirm this.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
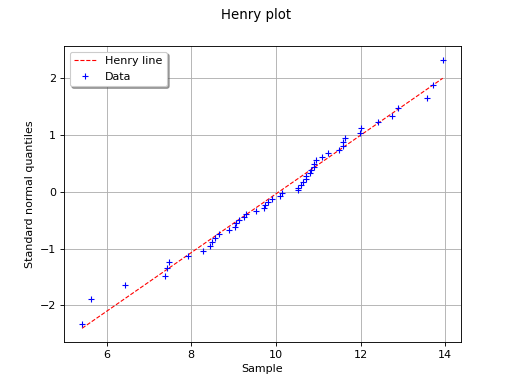
In this example the test validates the hypothesis of a gaussian distribution.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
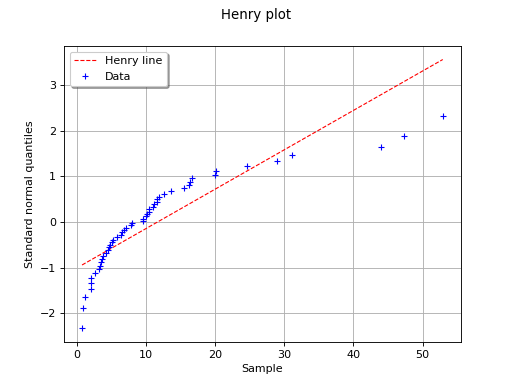
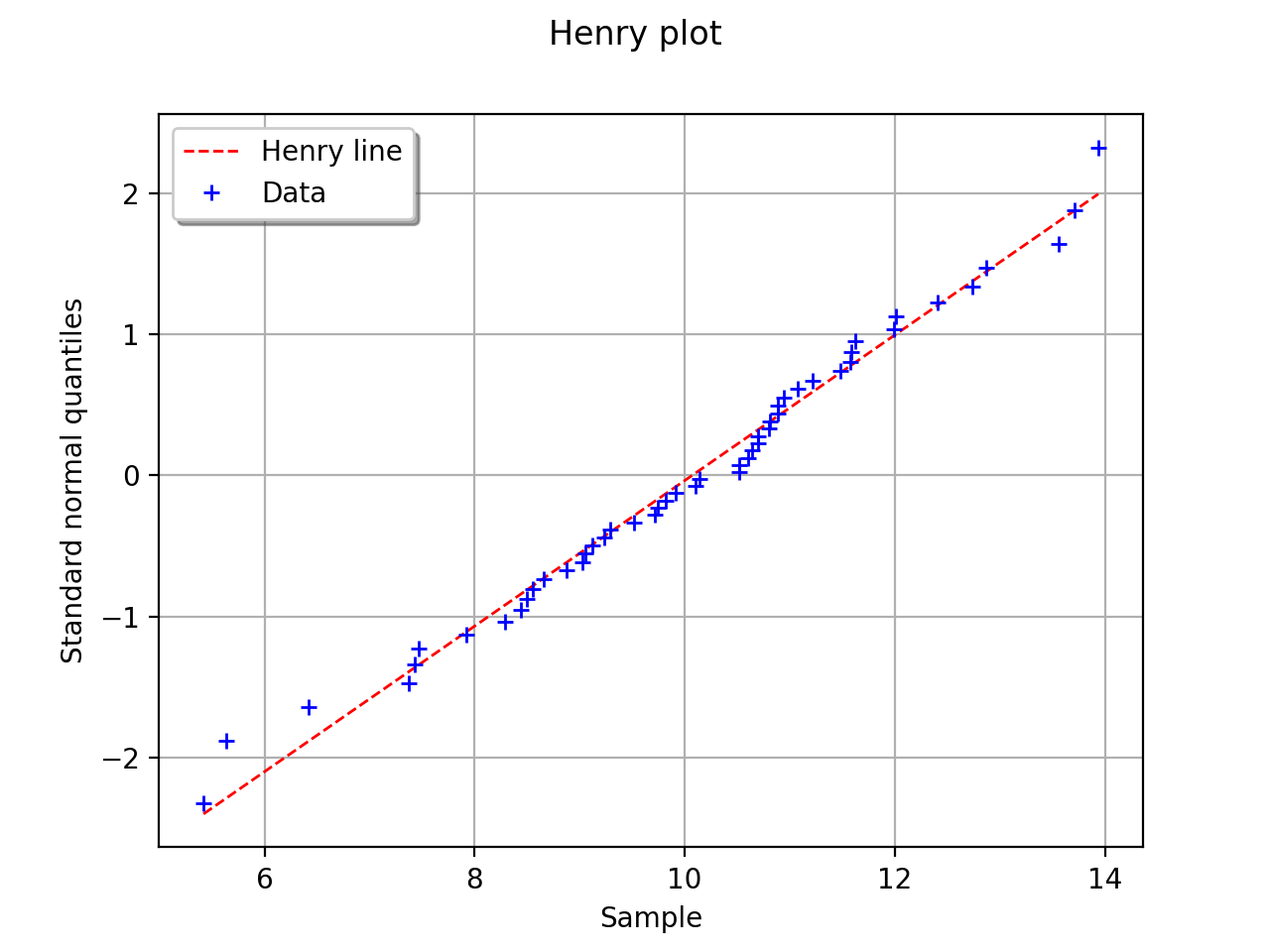
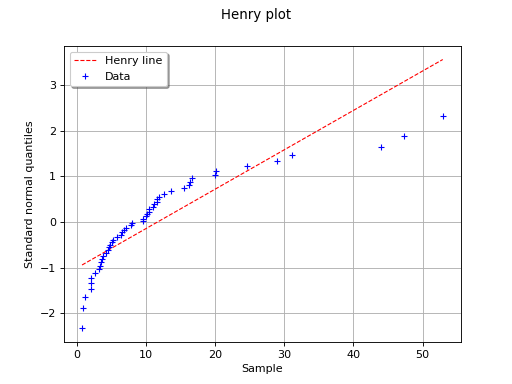
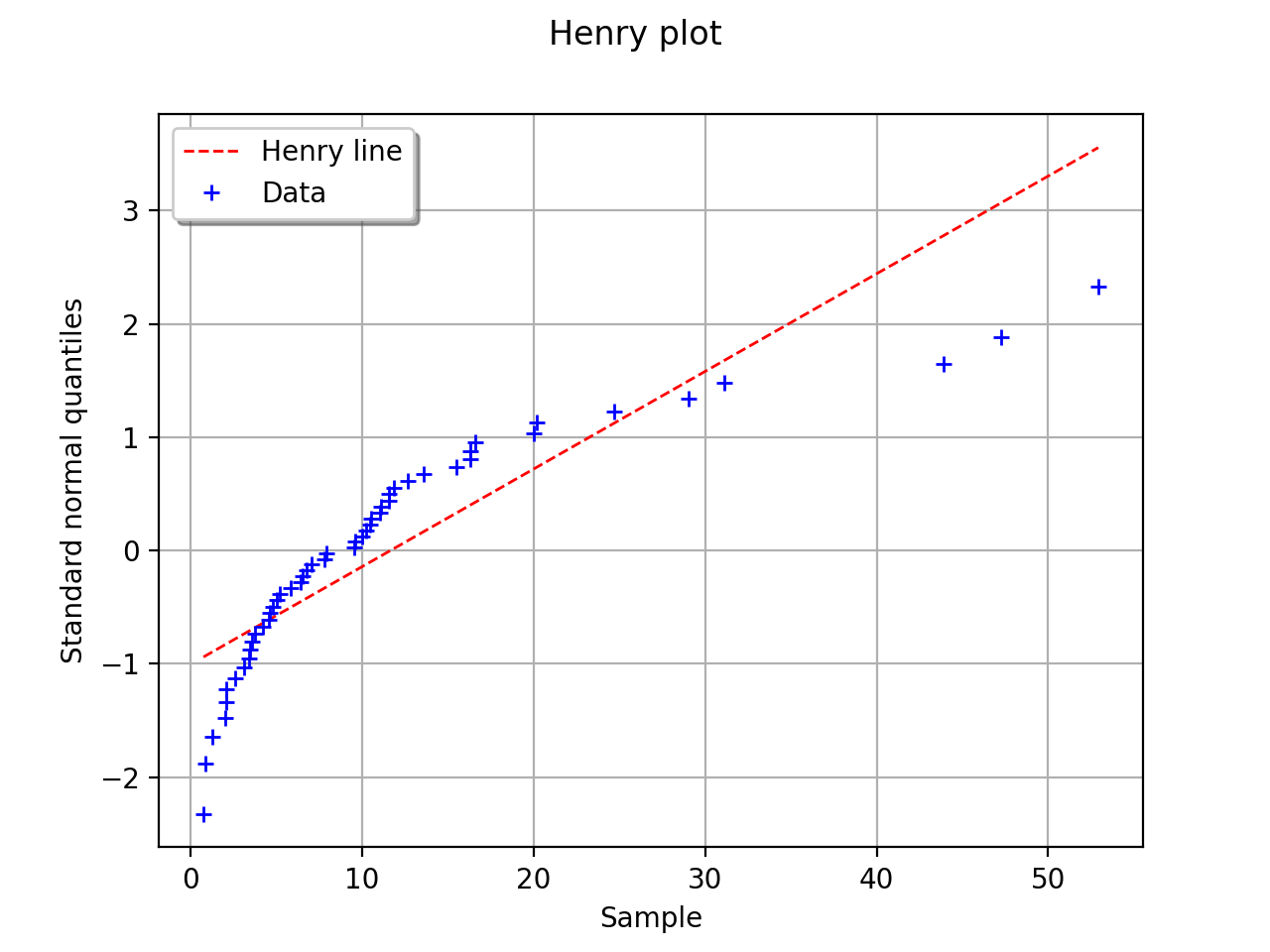
In this second example, the hypothesis of a gaussian distribution seems
far less relevant because of the behavior for small values of
.
Kendall plot
In the bivariate case, the Kendall Plot test enables to validate the choice of a specific copula model or to verify that two samples share the same copula model.
Let  be a bivariate random vector which copula is
noted
be a bivariate random vector which copula is
noted  .
Let
.
Let  be a sample of
.
be a sample of
.
We note:
![\begin{aligned}
\forall i \geq 1, \displaystyle H_i = \frac{1}{n-1} Card \left\{ j \in [1,N], j \neq i, \, | \, x^j_1 \leq x^i_1 \mbox{ and } x^j_2 \leq x^i_2 \right \}
\end{aligned}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSczMzQuODI1ODU0cHQnIGhlaWdodD0nMjQuOTg5MTM1cHQnIHZpZXdCb3g9JzI2Ljg1ODU3IC0yNC45ODkxMjcgMzM0LjgyNTg1NCAyNC45ODkxMzUnPgo8ZGVmcz4KPHBhdGggaWQ9J2c0LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzQtNTAnIGQ9J00yLjI0NzU3Mi0xLjYyNTkwM0MyLjM3NTA5My0xLjc0NTQ1NSAyLjcwOTgzOC0yLjAwODQ2OCAyLjgzNzM2LTIuMTIwMDVDMy4zMzE1MDctMi41NzQzNDYgMy44MDE3NDMtMy4wMTI3MDIgMy44MDE3NDMtMy43Mzc5ODNDMy44MDE3NDMtNC42ODY0MjYgMy4wMDQ3MzItNS4zMDAxMjUgMi4wMDg0NjgtNS4zMDAxMjVDMS4wNTIwNTUtNS4zMDAxMjUgLjQyMjQxNi00LjU3NDg0NCAuNDIyNDE2LTMuODY1NTA0Qy40MjI0MTYtMy40NzQ5NjkgLjczMzI1LTMuNDE5MTc4IC44NDQ4MzItMy40MTkxNzhDMS4wMTIyMDQtMy40MTkxNzggMS4yNTkyNzgtMy41Mzg3MyAxLjI1OTI3OC0zLjg0MTU5NEMxLjI1OTI3OC00LjI1NjA0IC44NjA3NzItNC4yNTYwNCAuNzY1MTMxLTQuMjU2MDRDLjk5NjI2NC00LjgzNzg1OCAxLjUzMDI2Mi01LjAzNzExMSAxLjkyMDc5Ny01LjAzNzExMUMyLjY2MjAxNy01LjAzNzExMSAzLjA0NDU4My00LjQwNzQ3MiAzLjA0NDU4My0zLjczNzk4M0MzLjA0NDU4My0yLjkwOTA5MSAyLjQ2Mjc2NS0yLjMwMzM2MiAxLjUyMjI5MS0xLjMzODk3OUwuNTE4MDU3LS4zMDI4NjRDLjQyMjQxNi0uMjE1MTkzIC40MjI0MTYtLjE5OTI1MyAuNDIyNDE2IDBIMy41NzA2MUwzLjgwMTc0My0xLjQyNjY1SDMuNTU0NjdDMy41MzA3Ni0xLjI2NzI0OCAzLjQ2Njk5OS0uODY4NzQyIDMuMzcxMzU3LS43MTczMUMzLjMyMzUzNy0uNjUzNTQ5IDIuNzE3ODA4LS42NTM1NDkgMi41OTAyODYtLjY1MzU0OUgxLjE3MTYwNkwyLjI0NzU3Mi0xLjYyNTkwM1onLz4KPHBhdGggaWQ9J2c1LTQ5JyBkPSdNMy40NDMwODgtNy42NjMyNjNDMy40NDMwODgtNy45MzgyMzIgMy40NDMwODgtNy45NTAxODcgMy4yMDM5ODUtNy45NTAxODdDMi45MTcwNjEtNy42MjczOTcgMi4zMTkzMDMtNy4xODUwNTYgMS4wODc5Mi03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODktNi44MzgzNTYgMS45NjA2NDgtNi44MzgzNTYgMi42MTgxODItNy4xNDkxOTFWLS45MjA1NDhDMi42MTgxODItLjQ5MDE2MiAyLjU4MjMxNi0uMzQ2NyAxLjUzMDI2Mi0uMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTEgMy4wMzY2MTMtLjAyMzkxUzQuNTc4ODI5LS4wMjM5MSA0LjkwMTYxOSAwVi0uMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NC0uMzQ2NyAzLjQ0MzA4OC0uNDkwMTYyIDMuNDQzMDg4LS45MjA1NDhWLTcuNjYzMjYzWicvPgo8cGF0aCBpZD0nZzUtNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2c1LTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnNS05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjxwYXRoIGlkPSdnNS05NycgZD0nTTQuNjE0Njk1LTMuMTkyMDNDNC42MTQ2OTUtMy44Mzc2MDkgNC42MTQ2OTUtNC4zMTU4MTYgNC4wODg2NjctNC43ODIwNjdDMy42NzAyMzctNS4xNjQ2MzMgMy4xMzIyNTQtNS4zMzIwMDUgMi42MDYyMjctNS4zMzIwMDVDMS42MjU5MDMtNS4zMzIwMDUgLjg3MjcyNy00LjY4NjQyNiAuODcyNzI3LTMuOTA5MzRDLjg3MjcyNy0zLjU2MjY0IDEuMDk5ODc1LTMuMzk1MjY4IDEuMzc0ODQ0LTMuMzk1MjY4QzEuNjYxNzY4LTMuMzk1MjY4IDEuODY1MDA2LTMuNTk4NTA2IDEuODY1MDA2LTMuODg1NDNDMS44NjUwMDYtNC4zNzU1OTIgMS40MzQ2Mi00LjM3NTU5MiAxLjI1NTI5My00LjM3NTU5MkMxLjUzMDI2Mi00Ljg3NzcwOSAyLjEwNDExLTUuMDkyOTAyIDIuNTgyMzE2LTUuMDkyOTAyQzMuMTMyMjU0LTUuMDkyOTAyIDMuODM3NjA5LTQuNjM4NjA1IDMuODM3NjA5LTMuNTYyNjRWLTMuMDg0NDMzQzEuNDM0NjItMy4wNDg1NjggLjUyNjAyNy0yLjA0NDMzNCAuNTI2MDI3LTEuMTIzNzg2Qy41MjYwMjctLjE3OTMyOCAxLjYyNTkwMyAuMTE5NTUyIDIuMzU1MTY4IC4xMTk1NTJDMy4xNDQyMDkgLjExOTU1MiAzLjY4MjE5Mi0uMzU4NjU1IDMuOTA5MzQtLjkzMjUwM0MzLjk1NzE2MS0uMzcwNjEgNC4zMjc3NzEgLjA1OTc3NiA0Ljg0MTg0MyAuMDU5Nzc2QzUuMDkyOTAyIC4wNTk3NzYgNS43ODYzMDEtLjEwNzU5NyA1Ljc4NjMwMS0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OC0uMzgyNTY1IDUuMjM2MzY0LS4yODY5MjQgNS4wNjg5OTEtLjI4NjkyNEM0LjYxNDY5NS0uMjg2OTI0IDQuNjE0Njk1LS45MjA1NDggNC42MTQ2OTUtMS4wOTk4NzVWLTMuMTkyMDNaTTMuODM3NjA5LTEuNjg1Njc5QzMuODM3NjA5LS41MTQwNzIgMi45NjQ4ODItLjExOTU1MiAyLjQ1MDgwOS0uMTE5NTUyQzEuODY1MDA2LS4xMTk1NTIgMS4zNzQ4NDQtLjU0OTkzOCAxLjM3NDg0NC0xLjEyMzc4NkMxLjM3NDg0NC0yLjcwMTg2OCAzLjQwNzIyMy0yLjg0NTMzIDMuODM3NjA5LTIuODY5MjRWLTEuNjg1Njc5WicvPgo8cGF0aCBpZD0nZzUtMTAwJyBkPSdNMy41ODY1NS04LjE2NTM4Vi03LjgxODY4QzQuMzk5NTAyLTcuODE4NjggNC40OTUxNDMtNy43MzQ5OTQgNC40OTUxNDMtNy4xNDkxOTFWLTQuNTA3MDk4QzQuMjQ0MDg1LTQuODUzNzk4IDMuNzMwMDEyLTUuMjcyMjI5IDMuMDAwNzQ3LTUuMjcyMjI5QzEuNjEzOTQ4LTUuMjcyMjI5IC40MTg0MzEtNC4xMDA2MjMgLjQxODQzMS0yLjU3MDM2MUMuNDE4NDMxLTEuMDUyMDU1IDEuNTU0MTcyIC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNzc3ODMzIC4xMTk1NTIgNC4zMDM4NjEtLjQ3ODIwNyA0LjQ3MTIzMy0uNzA1MzU1Vi4xMTk1NTJMNi4xNTY5MTIgMFYtLjM0NjdDNS4zNDM5Ni0uMzQ2NyA1LjI0ODMxOS0uNDMwMzg2IDUuMjQ4MzE5LTEuMDE2MTg5Vi04LjI5Njg4N0wzLjU4NjU1LTguMTY1MzhaTTQuNDcxMjMzLTEuMzk4NzU1QzQuNDcxMjMzLTEuMTgzNTYyIDQuNDcxMjMzLTEuMTQ3Njk2IDQuMzAzODYxLS44ODQ2ODJDNC4wMTY5MzYtLjQ2NjI1MiAzLjUyNjc3NS0uMTE5NTUyIDIuOTI5MDE2LS4xMTk1NTJDMi42MTgxODItLjExOTU1MiAxLjMyNzAyNC0uMjM5MTAzIDEuMzI3MDI0LTIuNTU4NDA2QzEuMzI3MDI0LTMuNDE5MTc4IDEuNDcwNDg2LTMuODk3Mzg1IDEuNzMzNDk5LTQuMjkxOTA1QzEuOTcyNjAzLTQuNjYyNTE2IDIuNDUwODA5LTUuMDMzMTI2IDMuMDQ4NTY4LTUuMDMzMTI2QzMuNzg5Nzg4LTUuMDMzMTI2IDQuMjA4MjE5LTQuNDk1MTQzIDQuMzI3NzcxLTQuMzAzODYxQzQuNDcxMjMzLTQuMTAwNjIzIDQuNDcxMjMzLTQuMDc2NzEyIDQuNDcxMjMzLTMuODYxNTE5Vi0xLjM5ODc1NVonLz4KPHBhdGggaWQ9J2c1LTExMCcgZD0nTTUuMzIwMDUtMi45MDUxMDZDNS4zMjAwNS00LjAxNjkzNiA1LjMyMDA1LTQuMzUxNjgxIDUuMDQ1MDgxLTQuNzM0MjQ3QzQuNjk4MzgxLTUuMjAwNDk4IDQuMTM2NDg4LTUuMjcyMjI5IDMuNzMwMDEyLTUuMjcyMjI5QzIuNTcwMzYxLTUuMjcyMjI5IDIuMTE2MDY1LTQuMjc5OTUgMi4wMjA0MjMtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TC4zODI1NjUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3LTQuNzk0MDIyIDEuMjkxMTU4LTQuNzEwMzM2IDEuMjkxMTU4LTQuMTI0NTMzVi0uODg0NjgyQzEuMjkxMTU4LS4zNDY3IDEuMTU5NjUxLS4zNDY3IC4zODI1NjUtLjM0NjdWMEMuNjkzNC0uMDIzOTEgMS4zMzg5NzktLjAyMzkxIDEuNjczNzI0LS4wMjM5MUMyLjAyMDQyMy0uMDIzOTEgMi42NjYwMDItLjAyMzkxIDIuOTc2ODM3IDBWLS4zNDY3QzIuMjExNzA2LS4zNDY3IDIuMDY4MjQ0LS4zNDY3IDIuMDY4MjQ0LS44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0LTQuMzYzNjM2IDIuODkzMTUxLTUuMDMzMTI2IDMuNjM0MzcxLTUuMDMzMTI2UzQuNTQyOTY0LTQuNDIzNDEyIDQuNTQyOTY0LTMuNjk0MTQ3Vi0uODg0NjgyQzQuNTQyOTY0LS4zNDY3IDQuNDExNDU3LS4zNDY3IDMuNjM0MzcxLS4zNDY3VjBDMy45NDUyMDUtLjAyMzkxIDQuNTkwNzg1LS4wMjM5MSA0LjkyNTUyOS0uMDIzOTFDNS4yNzIyMjktLjAyMzkxIDUuOTE3ODA4LS4wMjM5MSA2LjIyODY0MyAwVi0uMzQ2N0M1LjYzMDg4NC0uMzQ2NyA1LjMzMjAwNS0uMzQ2NyA1LjMyMDA1LS43MDUzNTVWLTIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzAtOCcgZD0nTTMuMDcyNDc4IDQuNzcwMTEyQzMuMDcyNDc4IDUuNjA2OTc0IDIuNjU0MDQ3IDYuMDYxMjcgMS40NDY1NzUgNi41Mzk0NzdDMS4zODY4IDYuNTYzMzg3IDEuMzUwOTM0IDYuNjExMjA4IDEuMzUwOTM0IDYuNjgyOTM5QzEuMzUwOTM0IDYuNzc4NTggMS4zNzQ4NDQgNi44MTQ0NDYgMS40NzA0ODYgNi44NTAzMTFDMy4wNzI0NzggNy40NzE5OCAzLjA3MjQ3OCA4LjExNzU1OSAzLjA3MjQ3OCA4Ljc4NzA0OVYxMi4wODY2NzVDMy4wODQ0MzMgMTIuNDA5NDY1IDMuMjYzNzYxIDEyLjg1MTgwNiAzLjc4OTc4OCAxMy4yMTA0NjFDNC4zNzU1OTIgMTMuNjA0OTgxIDUuMzQzOTYgMTMuODU2MDQgNS40NTE1NTcgMTMuODU2MDRDNS41NzExMDggMTMuODU2MDQgNS42MDY5NzQgMTMuODA4MjE5IDUuNjA2OTc0IDEzLjcwMDYyM1M1LjU4MzA2NCAxMy41ODEwNzEgNS40MDM3MzYgMTMuNTIxMjk1QzUuMDU3MDM2IDEzLjM4OTc4OCA0LjEyNDUzMyAxMy4wMTkxNzggMy45MzMyNSAxMi4yODk5MTNDMy44OTczODUgMTIuMTQ2NDUxIDMuODk3Mzg1IDEyLjEyMjU0IDMuODk3Mzg1IDExLjY4MDE5OVY4Ljc1MTE4M0MzLjg5NzM4NSA4LjEyOTUxNCAzLjg5NzM4NSA3LjI1Njc4NyAxLjk0ODY5MiA2LjY5NDg5NEMzLjg5NzM4NSA2LjA5NzEzNiAzLjg5NzM4NSA1LjI4NDE4NCAzLjg5NzM4NSA0LjYxNDY5NVYxLjY4NTY3OUMzLjg5NzM4NSAxLjAyODE0NCAzLjg5NzM4NSAuNDA2NDc2IDUuNTIzMjg4LS4xOTEyODNDNS42MDY5NzQtLjIxNTE5MyA1LjYwNjk3NC0uMjk4ODc5IDUuNjA2OTc0LS4zMjI3OUM1LjYwNjk3NC0uNDMwMzg2IDUuNTcxMTA4LS40NzgyMDcgNS40NTE1NTctLjQ3ODIwN0M1LjM2Nzg3LS40NzgyMDcgMy42ODIxOTItLjA5NTY0MSAzLjI2Mzc2MSAuNjkzNEMzLjA3MjQ3OCAxLjA1MjA1NSAzLjA3MjQ3OCAxLjE1OTY1MSAzLjA3MjQ3OCAxLjY3MzcyNFY0Ljc3MDExMlonLz4KPHBhdGggaWQ9J2cwLTknIGQ9J00zLjg5NzM4NSA4LjYwNzcyMUMzLjg5NzM4NSA4LjIxMzIgMy44OTczODUgNy40NzE5OCA1LjQyNzY0NiA2Ljg2MjI2N0M1LjU4MzA2NCA2LjgwMjQ5MSA1LjYwNjk3NCA2LjgwMjQ5MSA1LjYwNjk3NCA2LjY4MjkzOUM1LjYwNjk3NCA2LjY1OTAyOSA1LjYwNjk3NCA2LjU3NTM0MiA1LjUyMzI4OCA2LjU1MTQzMkMzLjg5NzM4NSA1LjkxNzgwOCAzLjg5NzM4NSA1LjI3MjIyOSAzLjg5NzM4NSA0LjU5MDc4NVYxLjI5MTE1OEMzLjg3MzQ3NCAuNjQ1NTc5IDMuMzQ3NDQ3IC4yNzQ5NjkgMy4xNTYxNjQgLjE0MzQ2MkMyLjY0MjA5Mi0uMjAzMjM4IDEuNjM3ODU4LS40NzgyMDcgMS41MDYzNTEtLjQ3ODIwN0MxLjM4NjgtLjQ3ODIwNyAxLjM1MDkzNC0uNDE4NDMxIDEuMzUwOTM0LS4zMjI3OUMxLjM1MDkzNC0uMjE1MTkzIDEuNDEwNzEtLjE5MTI4MyAxLjQ5NDM5Ni0uMTY3MzcyQzMuMDcyNDc4IC40MzAzODYgMy4wNzI0NzggMS4wMjgxNDQgMy4wNzI0NzggMS42OTc2MzRWNC42MjY2NUMzLjA3MjQ3OCA1LjI4NDE4NCAzLjA3MjQ3OCA2LjA5NzEzNiA1LjAwOTIxNSA2LjY4MjkzOUMzLjA3MjQ3OCA3LjMyODUxOCAzLjA3MjQ3OCA4LjAyMTkxOCAzLjA3MjQ3OCA4Ljc2MzEzOFYxMS42OTIxNTRDMy4wNzI0NzggMTIuMzEzODIzIDMuMDcyNDc4IDEyLjk0NzQ0NyAxLjU0MjIxNyAxMy41MjEyOTVDMS4zOTg3NTUgMTMuNTgxMDcxIDEuMzUwOTM0IDEzLjU5MzAyNiAxLjM1MDkzNCAxMy43MDA2MjNDMS4zNTA5MzQgMTMuNzk2MjY0IDEuMzg2OCAxMy44NTYwNCAxLjUwNjM1MSAxMy44NTYwNEMxLjUxODMwNiAxMy44NTYwNCAzLjA5NjM4OSAxMy41NTcxNjEgMy42NTgyODEgMTIuNzY4MTJDMy44OTczODUgMTIuNDIxNDIgMy44OTczODUgMTIuMTU4NDA2IDMuODk3Mzg1IDExLjcwNDExVjguNjA3NzIxWicvPgo8cGF0aCBpZD0nZzMtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2czLTY3JyBkPSdNOC45MzA1MTEtOC4zMDg4NDJDOC45MzA1MTEtOC40MTY0MzggOC44NDY4MjQtOC40MTY0MzggOC44MjI5MTQtOC40MTY0MzhTOC43NTExODMtOC40MTY0MzggOC42NTU1NDItOC4yOTY4ODdMNy44MzA2MzUtNy4yOTI2NTNDNy40MTIyMDQtOC4wMDk5NjMgNi43NTQ2Ny04LjQxNjQzOCA1Ljg1ODAzMi04LjQxNjQzOEMzLjI3NTcxNi04LjQxNjQzOCAuNTk3NzU4LTUuNzk4MjU3IC41OTc3NTgtMi45ODg3OTJDLjU5Nzc1OC0uOTkyMjc5IDEuOTk2NTEzIC4yNTEwNTkgMy43NDE5NjggLjI1MTA1OUM0LjY5ODM4MSAuMjUxMDU5IDUuNTM1MjQzLS4xNTU0MTcgNi4yMjg2NDMtLjc0MTIyQzcuMjY4NzQyLTEuNjEzOTQ4IDcuNTc5NTc3LTIuNzczNTk5IDcuNTc5NTc3LTIuODY5MjRDNy41Nzk1NzctMi45NzY4MzcgNy40ODM5MzUtMi45NzY4MzcgNy40NDgwNy0yLjk3NjgzN0M3LjM0MDQ3My0yLjk3NjgzNyA3LjMyODUxOC0yLjkwNTEwNiA3LjMwNDYwOC0yLjg1NzI4NUM2Ljc1NDY3LS45OTIyNzkgNS4xNDA3MjItLjA5NTY0MSAzLjk0NTIwNS0uMDk1NjQxQzIuNjc3OTU4LS4wOTU2NDEgMS41NzgwODItLjkwODU5MyAxLjU3ODA4Mi0yLjYwNjIyN0MxLjU3ODA4Mi0yLjk4ODc5MiAxLjY5NzYzNC01LjA2ODk5MSAzLjA0ODU2OC02LjYzNTExOEMzLjcwNjEwMi03LjQwMDI0OSA0LjgyOTg4OC04LjA2OTczOCA1Ljk2NTYyOS04LjA2OTczOEM3LjI4MDY5Ny04LjA2OTczOCA3Ljg2NjUwMS02Ljk4MTgxOCA3Ljg2NjUwMS01Ljc2MjM5MUM3Ljg2NjUwMS01LjQ1MTU1NyA3LjgzMDYzNS01LjE4ODU0MyA3LjgzMDYzNS01LjE0MDcyMkM3LjgzMDYzNS01LjAzMzEyNiA3Ljk1MDE4Ny01LjAzMzEyNiA3Ljk4NjA1Mi01LjAzMzEyNkM4LjExNzU1OS01LjAzMzEyNiA4LjEyOTUxNC01LjA0NTA4MSA4LjE3NzMzNS01LjI2MDI3NEw4LjkzMDUxMS04LjMwODg0MlonLz4KPHBhdGggaWQ9J2czLTcyJyBkPSdNOC45NDI0NjYtNy4yOTI2NTNDOS4wNTAwNjItNy42OTkxMjggOS4wNzM5NzMtNy44MTg2OCA5LjkyMjc5LTcuODE4NjhDMTAuMTM3OTgzLTcuODE4NjggMTAuMjU3NTM0LTcuODE4NjggMTAuMjU3NTM0LTguMDMzODczQzEwLjI1NzUzNC04LjE2NTM4IDEwLjE0OTkzOC04LjE2NTM4IDEwLjA3ODIwNy04LjE2NTM4QzkuODYzMDE0LTguMTY1MzggOS42MTE5NTUtOC4xNDE0NjkgOS4zODQ4MDctOC4xNDE0NjlINy45NzQwOTdDNy43NDY5NDktOC4xNDE0NjkgNy40OTU4OS04LjE2NTM4IDcuMjY4NzQyLTguMTY1MzhDNy4xODUwNTYtOC4xNjUzOCA3LjA0MTU5NC04LjE2NTM4IDcuMDQxNTk0LTcuOTM4MjMyQzcuMDQxNTk0LTcuODE4NjggNy4xMjUyOC03LjgxODY4IDcuMzUyNDI4LTcuODE4NjhDOC4wNjk3MzgtNy44MTg2OCA4LjA2OTczOC03LjcyMzAzOSA4LjA2OTczOC03LjU5MTUzMkM4LjA2OTczOC03LjU2NzYyMSA4LjA2OTczOC03LjQ5NTg5IDguMDIxOTE4LTcuMzE2NTYzTDcuMjkyNjUzLTQuNDIzNDEySDMuNjgyMTkyTDQuMzk5NTAyLTcuMjkyNjUzQzQuNTA3MDk4LTcuNjk5MTI4IDQuNTMxMDA5LTcuODE4NjggNS4zNzk4MjYtNy44MTg2OEM1LjU5NTAxOS03LjgxODY4IDUuNzE0NTctNy44MTg2OCA1LjcxNDU3LTguMDMzODczQzUuNzE0NTctOC4xNjUzOCA1LjYwNjk3NC04LjE2NTM4IDUuNTM1MjQzLTguMTY1MzhDNS4zMjAwNS04LjE2NTM4IDUuMDY4OTkxLTguMTQxNDY5IDQuODQxODQzLTguMTQxNDY5SDMuNDMxMTMzQzMuMjAzOTg1LTguMTQxNDY5IDIuOTUyOTI3LTguMTY1MzggMi43MjU3NzgtOC4xNjUzOEMyLjY0MjA5Mi04LjE2NTM4IDIuNDk4NjMtOC4xNjUzOCAyLjQ5ODYzLTcuOTM4MjMyQzIuNDk4NjMtNy44MTg2OCAyLjU4MjMxNi03LjgxODY4IDIuODA5NDY1LTcuODE4NjhDMy41MjY3NzUtNy44MTg2OCAzLjUyNjc3NS03LjcyMzAzOSAzLjUyNjc3NS03LjU5MTUzMkMzLjUyNjc3NS03LjU2NzYyMSAzLjUyNjc3NS03LjQ5NTg5IDMuNDc4OTU0LTcuMzE2NTYzTDEuODY1MDA2LS44ODQ2ODJDMS43NTc0MS0uNDY2MjUyIDEuNzMzNDk5LS4zNDY3IC45MDg1OTMtLjM0NjdDLjYzMzYyNC0uMzQ2NyAuNTQ5OTM4LS4zNDY3IC41NDk5MzgtLjExOTU1MkMuNTQ5OTM4IDAgLjY4MTQ0NSAwIC43MTczMSAwQy45MzI1MDMgMCAxLjE4MzU2Mi0uMDIzOTEgMS40MTA3MS0uMDIzOTFIMi44MjE0MkMzLjA0ODU2OC0uMDIzOTEgMy4yOTk2MjYgMCAzLjUyNjc3NSAwQzMuNjIyNDE2IDAgMy43NTM5MjMgMCAzLjc1MzkyMy0uMjI3MTQ4QzMuNzUzOTIzLS4zNDY3IDMuNjQ2MzI2LS4zNDY3IDMuNDY2OTk5LS4zNDY3QzIuNzM3NzMzLS4zNDY3IDIuNzM3NzMzLS40NDIzNDEgMi43Mzc3MzMtLjU2MTg5M0MyLjczNzczMy0uNTczODQ4IDIuNzM3NzMzLS42NTc1MzQgMi43NjE2NDQtLjc1MzE3NkwzLjU4NjU1LTQuMDc2NzEySDcuMjA4OTY2QzcuMDA1NzI5LTMuMjg3NjcxIDYuMzk2MDE1LS43ODkwNDEgNi4zNzIxMDUtLjcxNzMxQzYuMjQwNTk4LS4zNTg2NTUgNi4wNDkzMTUtLjM1ODY1NSA1LjM0Mzk2LS4zNDY3QzUuMjAwNDk4LS4zNDY3IDUuMDkyOTAyLS4zNDY3IDUuMDkyOTAyLS4xMTk1NTJDNS4wOTI5MDIgMCA1LjIyNDQwOCAwIDUuMjYwMjc0IDBDNS40NzU0NjcgMCA1LjcyNjUyNi0uMDIzOTEgNS45NTM2NzQtLjAyMzkxSDcuMzY0Mzg0QzcuNTkxNTMyLS4wMjM5MSA3Ljg0MjU5IDAgOC4wNjk3MzggMEM4LjE2NTM4IDAgOC4yOTY4ODcgMCA4LjI5Njg4Ny0uMjI3MTQ4QzguMjk2ODg3LS4zNDY3IDguMTg5MjktLjM0NjcgOC4wMDk5NjMtLjM0NjdDNy4yODA2OTctLjM0NjcgNy4yODA2OTctLjQ0MjM0MSA3LjI4MDY5Ny0uNTYxODkzQzcuMjgwNjk3LS41NzM4NDggNy4yODA2OTctLjY1NzUzNCA3LjMwNDYwOC0uNzUzMTc2TDguOTQyNDY2LTcuMjkyNjUzWicvPgo8cGF0aCBpZD0nZzMtNzgnIGQ9J004Ljg0NjgyNC02LjkxMDA4N0M4Ljk3ODMzMS03LjQyNDE1OSA5LjE2OTYxNC03Ljc4MjgxNCAxMC4wNzgyMDctNy44MTg2OEMxMC4xMTQwNzItNy44MTg2OCAxMC4yNTc1MzQtNy44MzA2MzUgMTAuMjU3NTM0LTguMDMzODczQzEwLjI1NzUzNC04LjE2NTM4IDEwLjE0OTkzOC04LjE2NTM4IDEwLjEwMjExNy04LjE2NTM4QzkuODYzMDE0LTguMTY1MzggOS4yNTMzLTguMTQxNDY5IDkuMDE0MTk3LTguMTQxNDY5SDguNDQwMzQ5QzguMjcyOTc2LTguMTQxNDY5IDguMDU3NzgzLTguMTY1MzggNy44OTA0MTEtOC4xNjUzOEM3LjgxODY4LTguMTY1MzggNy42NzUyMTgtOC4xNjUzOCA3LjY3NTIxOC03LjkzODIzMkM3LjY3NTIxOC03LjgxODY4IDcuNzcwODU5LTcuODE4NjggNy44NTQ1NDUtNy44MTg2OEM4LjU3MTg1Ni03Ljc5NDc3IDguNjE5Njc2LTcuNTE5ODAxIDguNjE5Njc2LTcuMzA0NjA4QzguNjE5Njc2LTcuMTk3MDExIDguNjA3NzIxLTcuMTYxMTQ2IDguNTcxODU2LTYuOTkzNzczTDcuMjIwOTIyLTEuNjAxOTkzTDQuNjYyNTE2LTcuOTYyMTQyQzQuNTc4ODI5LTguMTUzNDI1IDQuNTY2ODc0LTguMTY1MzggNC4zMDM4NjEtOC4xNjUzOEgyLjg0NTMzQzIuNjA2MjI3LTguMTY1MzggMi40OTg2My04LjE2NTM4IDIuNDk4NjMtNy45MzgyMzJDMi40OTg2My03LjgxODY4IDIuNTgyMzE2LTcuODE4NjggMi44MDk0NjUtNy44MTg2OEMyLjg2OTI0LTcuODE4NjggMy41NzQ1OTUtNy44MTg2OCAzLjU3NDU5NS03LjcxMTA4M0MzLjU3NDU5NS03LjY4NzE3MyAzLjU1MDY4NS03LjU5MTUzMiAzLjUzODczLTcuNTU1NjY2TDEuOTQ4NjkyLTEuMjE5NDI3QzEuODA1MjMtLjYzMzYyNCAxLjUxODMwNi0uMzgyNTY1IC43MjkyNjUtLjM0NjdDLjY2OTQ4OS0uMzQ2NyAuNTQ5OTM4LS4zMzQ3NDUgLjU0OTkzOC0uMTE5NTUyQy41NDk5MzggMCAuNjY5NDg5IDAgLjcwNTM1NSAwQy45NDQ0NTggMCAxLjU1NDE3Mi0uMDIzOTEgMS43OTMyNzUtLjAyMzkxSDIuMzY3MTIzQzIuNTM0NDk2LS4wMjM5MSAyLjczNzczMyAwIDIuOTA1MTA2IDBDMi45ODg3OTIgMCAzLjEyMDI5OSAwIDMuMTIwMjk5LS4yMjcxNDhDMy4xMjAyOTktLjMzNDc0NSAzLjAwMDc0Ny0uMzQ2NyAyLjk1MjkyNy0uMzQ2N0MyLjU1ODQwNi0uMzU4NjU1IDIuMTc1ODQxLS40MzAzODYgMi4xNzU4NDEtLjg2MDc3MkMyLjE3NTg0MS0uOTU2NDEzIDIuMTk5NzUxLTEuMDY0MDEgMi4yMjM2NjEtMS4xNTk2NTFMMy44Mzc2MDktNy41NTU2NjZDMy45MDkzNC03LjQzNjExNSAzLjkwOTM0LTcuNDEyMjA0IDMuOTU3MTYxLTcuMzA0NjA4TDYuODAyNDkxLS4yMTUxOTNDNi44NjIyNjctLjA3MTczMSA2Ljg4NjE3NyAwIDYuOTkzNzczIDBDNy4xMTMzMjUgMCA3LjEyNTI4LS4wMzU4NjYgNy4xNzMxMDEtLjIzOTEwM0w4Ljg0NjgyNC02LjkxMDA4N1onLz4KPHBhdGggaWQ9J2czLTk3JyBkPSdNMy41OTg1MDYtMS40MjI2NjVDMy41Mzg3My0xLjIxOTQyNyAzLjUzODczLTEuMTk1NTE3IDMuMzcxMzU3LS45NjgzNjlDMy4xMDgzNDQtLjYzMzYyNCAyLjU4MjMxNi0uMTE5NTUyIDIuMDIwNDIzLS4xMTk1NTJDMS41MzAyNjItLjExOTU1MiAxLjI1NTI5My0uNTYxODkzIDEuMjU1MjkzLTEuMjY3MjQ4QzEuMjU1MjkzLTEuOTI0NzgyIDEuNjI1OTAzLTMuMjYzNzYxIDEuODUzMDUxLTMuNzY1ODc4QzIuMjU5NTI3LTQuNjAyNzQgMi44MjE0Mi01LjAzMzEyNiAzLjI4NzY3MS01LjAzMzEyNkM0LjA3NjcxMi01LjAzMzEyNiA0LjIzMjEzLTQuMDUyODAyIDQuMjMyMTMtMy45NTcxNjFDNC4yMzIxMy0zLjk0NTIwNSA0LjE5NjI2NC0zLjc4OTc4OCA0LjE4NDMwOS0zLjc2NTg3OEwzLjU5ODUwNi0xLjQyMjY2NVpNNC4zNjM2MzYtNC40ODMxODhDNC4yMzIxMy00Ljc5NDAyMiAzLjkwOTM0LTUuMjcyMjI5IDMuMjg3NjcxLTUuMjcyMjI5QzEuOTM2NzM3LTUuMjcyMjI5IC40NzgyMDctMy41MjY3NzUgLjQ3ODIwNy0xLjc1NzQxQy40NzgyMDctLjU3Mzg0OCAxLjE3MTYwNiAuMTE5NTUyIDEuOTg0NTU4IC4xMTk1NTJDMi42NDIwOTIgLjExOTU1MiAzLjIwMzk4NS0uMzk0NTIxIDMuNTM4NzMtLjc4OTA0MUMzLjY1ODI4MS0uMDgzNjg2IDQuMjIwMTc0IC4xMTk1NTIgNC41Nzg4MjkgLjExOTU1MlM1LjIyNDQwOC0uMDk1NjQxIDUuNDM5NjAxLS41MjYwMjdDNS42MzA4ODQtLjkzMjUwMyA1Ljc5ODI1Ny0xLjY2MTc2OCA1Ljc5ODI1Ny0xLjcwOTU4OUM1Ljc5ODI1Ny0xLjc2OTM2NSA1Ljc1MDQzNi0xLjgxNzE4NiA1LjY3ODcwNS0xLjgxNzE4NkM1LjU3MTEwOC0xLjgxNzE4NiA1LjU1OTE1My0xLjc1NzQxIDUuNTExMzMzLTEuNTc4MDgyQzUuMzMyMDA1LS44NzI3MjcgNS4xMDQ4NTctLjExOTU1MiA0LjYxNDY5NS0uMTE5NTUyQzQuMjY3OTk1LS4xMTk1NTIgNC4yNDQwODUtLjQzMDM4NiA0LjI0NDA4NS0uNjY5NDg5QzQuMjQ0MDg1LS45NDQ0NTggNC4yNzk5NS0xLjA3NTk2NSA0LjM4NzU0Ny0xLjU0MjIxN0M0LjQ3MTIzMy0xLjg0MTA5NiA0LjUzMTAwOS0yLjEwNDExIDQuNjI2NjUtMi40NTA4MDlDNS4wNjg5OTEtNC4yNDQwODUgNS4xNzY1ODgtNC42NzQ0NzEgNS4xNzY1ODgtNC43NDYyMDJDNS4xNzY1ODgtNC45MTM1NzQgNS4wNDUwODEtNS4wNDUwODEgNC44NjU3NTMtNS4wNDUwODFDNC40ODMxODgtNS4wNDUwODEgNC4zODc1NDctNC42MjY2NSA0LjM2MzYzNi00LjQ4MzE4OFonLz4KPHBhdGggaWQ9J2czLTEwMCcgZD0nTTYuMDEzNDUtNy45OTgwMDdDNi4wMjU0MDUtOC4wNDU4MjggNi4wNDkzMTUtOC4xMTc1NTkgNi4wNDkzMTUtOC4xNzczMzVDNi4wNDkzMTUtOC4yOTY4ODcgNS45Mjk3NjMtOC4yOTY4ODcgNS45MDU4NTMtOC4yOTY4ODdDNS44OTM4OTgtOC4yOTY4ODcgNS4zMDgwOTUtOC4yNDkwNjYgNS4yNDgzMTktOC4yMzcxMTFDNS4wNDUwODEtOC4yMjUxNTYgNC44NjU3NTMtOC4yMDEyNDUgNC42NTA1Ni04LjE4OTI5QzQuMzUxNjgxLTguMTY1MzggNC4yNjc5OTUtOC4xNTM0MjUgNC4yNjc5OTUtNy45MzgyMzJDNC4yNjc5OTUtNy44MTg2OCA0LjM2MzYzNi03LjgxODY4IDQuNTMxMDA5LTcuODE4NjhDNS4xMTY4MTItNy44MTg2OCA1LjEyODc2Ny03LjcxMTA4MyA1LjEyODc2Ny03LjU5MTUzMkM1LjEyODc2Ny03LjUxOTgwMSA1LjEwNDg1Ny03LjQyNDE1OSA1LjA5MjkwMi03LjM4ODI5NEw0LjM2MzYzNi00LjQ4MzE4OEM0LjIzMjEzLTQuNzk0MDIyIDMuOTA5MzQtNS4yNzIyMjkgMy4yODc2NzEtNS4yNzIyMjlDMS45MzY3MzctNS4yNzIyMjkgLjQ3ODIwNy0zLjUyNjc3NSAuNDc4MjA3LTEuNzU3NDFDLjQ3ODIwNy0uNTczODQ4IDEuMTcxNjA2IC4xMTk1NTIgMS45ODQ1NTggLjExOTU1MkMyLjY0MjA5MiAuMTE5NTUyIDMuMjAzOTg1LS4zOTQ1MjEgMy41Mzg3My0uNzg5MDQxQzMuNjU4MjgxLS4wODM2ODYgNC4yMjAxNzQgLjExOTU1MiA0LjU3ODgyOSAuMTE5NTUyUzUuMjI0NDA4LS4wOTU2NDEgNS40Mzk2MDEtLjUyNjAyN0M1LjYzMDg4NC0uOTMyNTAzIDUuNzk4MjU3LTEuNjYxNzY4IDUuNzk4MjU3LTEuNzA5NTg5QzUuNzk4MjU3LTEuNzY5MzY1IDUuNzUwNDM2LTEuODE3MTg2IDUuNjc4NzA1LTEuODE3MTg2QzUuNTcxMTA4LTEuODE3MTg2IDUuNTU5MTUzLTEuNzU3NDEgNS41MTEzMzMtMS41NzgwODJDNS4zMzIwMDUtLjg3MjcyNyA1LjEwNDg1Ny0uMTE5NTUyIDQuNjE0Njk1LS4xMTk1NTJDNC4yNjc5OTUtLjExOTU1MiA0LjI0NDA4NS0uNDMwMzg2IDQuMjQ0MDg1LS42Njk0ODlDNC4yNDQwODUtLjcxNzMxIDQuMjQ0MDg1LS45NjgzNjkgNC4zMjc3NzEtMS4zMDMxMTNMNi4wMTM0NS03Ljk5ODAwN1pNMy41OTg1MDYtMS40MjI2NjVDMy41Mzg3My0xLjIxOTQyNyAzLjUzODczLTEuMTk1NTE3IDMuMzcxMzU3LS45NjgzNjlDMy4xMDgzNDQtLjYzMzYyNCAyLjU4MjMxNi0uMTE5NTUyIDIuMDIwNDIzLS4xMTk1NTJDMS41MzAyNjItLjExOTU1MiAxLjI1NTI5My0uNTYxODkzIDEuMjU1MjkzLTEuMjY3MjQ4QzEuMjU1MjkzLTEuOTI0NzgyIDEuNjI1OTAzLTMuMjYzNzYxIDEuODUzMDUxLTMuNzY1ODc4QzIuMjU5NTI3LTQuNjAyNzQgMi44MjE0Mi01LjAzMzEyNiAzLjI4NzY3MS01LjAzMzEyNkM0LjA3NjcxMi01LjAzMzEyNiA0LjIzMjEzLTQuMDUyODAyIDQuMjMyMTMtMy45NTcxNjFDNC4yMzIxMy0zLjk0NTIwNSA0LjE5NjI2NC0zLjc4OTc4OCA0LjE4NDMwOS0zLjc2NTg3OEwzLjU5ODUwNi0xLjQyMjY2NVonLz4KPHBhdGggaWQ9J2czLTEwNScgZD0nTTMuMzgzMzEzLTEuNzA5NTg5QzMuMzgzMzEzLTEuNzY5MzY1IDMuMzM1NDkyLTEuODE3MTg2IDMuMjYzNzYxLTEuODE3MTg2QzMuMTU2MTY0LTEuODE3MTg2IDMuMTQ0MjA5LTEuNzgxMzIgMy4wODQ0MzMtMS41NzgwODJDMi43NzM1OTktLjQ5MDE2MiAyLjI4MzQzNy0uMTE5NTUyIDEuODg4OTE3LS4xMTk1NTJDMS43NDU0NTUtLjExOTU1MiAxLjU3ODA4Mi0uMTU1NDE3IDEuNTc4MDgyLS41MTQwNzJDMS41NzgwODItLjgzNjg2MiAxLjcyMTU0NC0xLjE5NTUxNyAxLjg1MzA1MS0xLjU1NDE3MkwyLjY4OTkxMy0zLjc3NzgzM0MyLjcyNTc3OC0zLjg3MzQ3NCAyLjgwOTQ2NS00LjA4ODY2NyAyLjgwOTQ2NS00LjMxNTgxNkMyLjgwOTQ2NS00LjgxNzkzMyAyLjQ1MDgwOS01LjI3MjIyOSAxLjg2NTAwNi01LjI3MjIyOUMuNzY1MTMxLTUuMjcyMjI5IC4zMjI3OS0zLjUzODczIC4zMjI3OS0zLjQ0MzA4OEMuMzIyNzktMy4zOTUyNjggLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU2MTg5My0zLjMzNTQ5MiAuNTczODQ4LTMuMzgzMzEzIC42MjE2NjktMy41NTA2ODVDLjkwODU5My00LjU1NDkxOSAxLjM2Mjg4OS01LjAzMzEyNiAxLjgyOTE0MS01LjAzMzEyNkMxLjkzNjczNy01LjAzMzEyNiAyLjEzOTk3NS01LjAyMTE3MSAyLjEzOTk3NS00LjYzODYwNUMyLjEzOTk3NS00LjMyNzc3MSAxLjk4NDU1OC0zLjkzMzI1IDEuODg4OTE3LTMuNjcwMjM3TDEuMDUyMDU1LTEuNDQ2NTc1Qy45ODAzMjQtMS4yNTUyOTMgLjkwODU5My0xLjA2NDAxIC45MDg1OTMtLjg0ODgxN0MuOTA4NTkzLS4zMTA4MzQgMS4yNzkyMDMgLjExOTU1MiAxLjg1MzA1MSAuMTE5NTUyQzIuOTUyOTI3IC4xMTk1NTIgMy4zODMzMTMtMS42MjU5MDMgMy4zODMzMTMtMS43MDk1ODlaTTMuMjg3NjcxLTcuNDYwMDI1QzMuMjg3NjcxLTcuNjM5MzUyIDMuMTQ0MjA5LTcuODU0NTQ1IDIuODgxMTk2LTcuODU0NTQ1QzIuNjA2MjI3LTcuODU0NTQ1IDIuMjk1MzkyLTcuNTkxNTMyIDIuMjk1MzkyLTcuMjgwNjk3QzIuMjk1MzkyLTYuOTgxODE4IDIuNTQ2NDUxLTYuODg2MTc3IDIuNjg5OTEzLTYuODg2MTc3QzMuMDEyNzAyLTYuODg2MTc3IDMuMjg3NjcxLTcuMTk3MDExIDMuMjg3NjcxLTcuNDYwMDI1WicvPgo8cGF0aCBpZD0nZzMtMTA2JyBkPSdNNC4xODQzMDktMy43ODk3ODhDNC4yMzIxMy0zLjk4MTA3MSA0LjIzMjEzLTQuMTQ4NDQzIDQuMjMyMTMtNC4xOTYyNjRDNC4yMzIxMy00Ljg4OTY2NCAzLjcxODA1Ny01LjI3MjIyOSAzLjE4MDA3NS01LjI3MjIyOUMxLjk3MjYwMy01LjI3MjIyOSAxLjMyNzAyNC0zLjUyNjc3NSAxLjMyNzAyNC0zLjQ0MzA4OEMxLjMyNzAyNC0zLjM4MzMxMyAxLjM3NDg0NC0zLjMzNTQ5MiAxLjQ0NjU3NS0zLjMzNTQ5MkMxLjU0MjIxNy0zLjMzNTQ5MiAxLjU1NDE3Mi0zLjM4MzMxMyAxLjYxMzk0OC0zLjUwMjg2NEMyLjA5MjE1NC00LjY2MjUxNiAyLjY4OTkxMy01LjAzMzEyNiAzLjE0NDIwOS01LjAzMzEyNkMzLjM5NTI2OC01LjAzMzEyNiAzLjUyNjc3NS00LjkwMTYxOSAzLjUyNjc3NS00LjQ4MzE4OEMzLjUyNjc3NS00LjE5NjI2NCAzLjQ5MDkwOS00LjA3NjcxMiAzLjQ0MzA4OC0zLjg2MTUxOUwyLjMwNzM0NyAuNjQ1NTc5QzIuMDgwMTk5IDEuNTMwMjYyIDEuNTE4MzA2IDIuMTk5NzUxIC44NjA3NzIgMi4xOTk3NTFDLjgxMjk1MSAyLjE5OTc1MSAuNTYxODkzIDIuMTk5NzUxIC4zMzQ3NDUgMi4wODAxOTlDLjYyMTY2OSAyLjAyMDQyMyAuODQ4ODE3IDEuNzkzMjc1IC44NDg4MTcgMS41MDYzNTFDLjg0ODgxNyAxLjMxNTA2OCAuNzA1MzU1IDEuMTIzNzg2IC40NDIzNDEgMS4xMjM3ODZDLjEzMTUwNyAxLjEyMzc4Ni0uMTU1NDE3IDEuMzg2OC0uMTU1NDE3IDEuNzQ1NDU1Qy0uMTU1NDE3IDIuMjM1NjE2IC4zNzA2MSAyLjQzODg1NCAuODYwNzcyIDIuNDM4ODU0QzEuNjg1Njc5IDIuNDM4ODU0IDIuNzczNTk5IDEuODI5MTQxIDMuMDcyNDc4IC42MzM2MjRMNC4xODQzMDktMy43ODk3ODhaTTQuNjc0NDcxLTcuNDYwMDI1QzQuNjc0NDcxLTcuNzU4OTA0IDQuNDIzNDEyLTcuODU0NTQ1IDQuMjc5OTUtNy44NTQ1NDVDMy45NTcxNjEtNy44NTQ1NDUgMy42ODIxOTItNy41NDM3MTEgMy42ODIxOTItNy4yODA2OTdDMy42ODIxOTItNy4xMDEzNyAzLjgyNTY1NC02Ljg4NjE3NyA0LjA4ODY2Ny02Ljg4NjE3N0M0LjM2MzYzNi02Ljg4NjE3NyA0LjY3NDQ3MS03LjE0OTE5MSA0LjY3NDQ3MS03LjQ2MDAyNVonLz4KPHBhdGggaWQ9J2czLTExMCcgZD0nTTIuNDYyNzY1LTMuNTAyODY0QzIuNDg2Njc1LTMuNTc0NTk1IDIuNzg1NTU0LTQuMTcyMzU0IDMuMjI3ODk1LTQuNTU0OTE5QzMuNTM4NzMtNC44NDE4NDMgMy45NDUyMDUtNS4wMzMxMjYgNC40MTE0NTctNS4wMzMxMjZDNC44ODk2NjQtNS4wMzMxMjYgNS4wNTcwMzYtNC42NzQ0NzEgNS4wNTcwMzYtNC4xOTYyNjRDNS4wNTcwMzYtMy41MTQ4MTkgNC41NjY4NzQtMi4xNTE5MyA0LjMyNzc3MS0xLjUwNjM1MUM0LjIyMDE3NC0xLjIxOTQyNyA0LjE2MDM5OS0xLjA2NDAxIDQuMTYwMzk5LS44NDg4MTdDNC4xNjAzOTktLjMxMDgzNCA0LjUzMTAwOSAuMTE5NTUyIDUuMTA0ODU3IC4xMTk1NTJDNi4yMTY2ODcgLjExOTU1MiA2LjYzNTExOC0xLjYzNzg1OCA2LjYzNTExOC0xLjcwOTU4OUM2LjYzNTExOC0xLjc2OTM2NSA2LjU4NzI5OC0xLjgxNzE4NiA2LjUxNTU2Ny0xLjgxNzE4NkM2LjQwNzk3LTEuODE3MTg2IDYuMzk2MDE1LTEuNzgxMzIgNi4zMzYyMzktMS41NzgwODJDNi4wNjEyNy0uNTk3NzU4IDUuNjA2OTc0LS4xMTk1NTIgNS4xNDA3MjItLjExOTU1MkM1LjAyMTE3MS0uMTE5NTUyIDQuODI5ODg4LS4xMzE1MDcgNC44Mjk4ODgtLjUxNDA3MkM0LjgyOTg4OC0uODEyOTUxIDQuOTYxMzk1LTEuMTcxNjA2IDUuMDMzMTI2LTEuMzM4OTc5QzUuMjcyMjI5LTEuOTk2NTEzIDUuNzc0MzQ2LTMuMzM1NDkyIDUuNzc0MzQ2LTQuMDE2OTM2QzUuNzc0MzQ2LTQuNzM0MjQ3IDUuMzU1OTE1LTUuMjcyMjI5IDQuNDQ3MzIzLTUuMjcyMjI5QzMuMzgzMzEzLTUuMjcyMjI5IDIuODIxNDItNC41MTkwNTQgMi42MDYyMjctNC4yMjAxNzRDMi41NzAzNjEtNC45MDE2MTkgMi4wODAxOTktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4xNzE2MDYtNS4yNzIyMjkgLjkwODU5My01LjA0NTA4MSAuNzA1MzU1LTQuNjM4NjA1Qy40OTAxNjItNC4yMDgyMTkgLjMyMjc5LTMuNDkwOTA5IC4zMjI3OS0zLjQ0MzA4OFMuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODI0OTA3LTQuMzUxNjgxIDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjc5MzI3NS01LjAzMzEyNiAxLjg4ODkxNy00Ljg0MTg0MyAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjM1MDkzNCAuMTE5NTUyIDEuNTE4MzA2IC4wNDc4MjEgMS42MTM5NDgtLjEzMTUwN0MxLjYzNzg1OC0uMTkxMjgzIDEuNzQ1NDU1LS42MDk3MTQgMS44MDUyMy0uODQ4ODE3TDIuMDY4MjQ0LTEuOTI0NzgyTDIuNDYyNzY1LTMuNTAyODY0WicvPgo8cGF0aCBpZD0nZzMtMTE0JyBkPSdNNC42NTA1Ni00Ljg4OTY2NEM0LjI3OTk1LTQuODE3OTMzIDQuMDg4NjY3LTQuNTU0OTE5IDQuMDg4NjY3LTQuMjkxOTA1QzQuMDg4NjY3LTQuMDA0OTgxIDQuMzE1ODE2LTMuOTA5MzQgNC40ODMxODgtMy45MDkzNEM0LjgxNzkzMy0zLjkwOTM0IDUuMDkyOTAyLTQuMTk2MjY0IDUuMDkyOTAyLTQuNTU0OTE5QzUuMDkyOTAyLTQuOTM3NDg0IDQuNzIyMjkxLTUuMjcyMjI5IDQuMTI0NTMzLTUuMjcyMjI5QzMuNjQ2MzI2LTUuMjcyMjI5IDMuMDk2Mzg5LTUuMDU3MDM2IDIuNTk0MjcxLTQuMzI3NzcxQzIuNTEwNTg1LTQuOTYxMzk1IDIuMDMyMzc5LTUuMjcyMjI5IDEuNTU0MTcyLTUuMjcyMjI5QzEuMDg3OTItNS4yNzIyMjkgLjg0ODgxNy00LjkxMzU3NCAuNzA1MzU1LTQuNjUwNTZDLjUwMjExNy00LjIyMDE3NCAuMzIyNzktMy41MDI4NjQgLjMyMjc5LTMuNDQzMDg4Qy4zMjI3OS0zLjM5NTI2OCAuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODEyOTUxLTQuMzM5NzI2IDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjgwNTIzLTUuMDMzMTI2IDEuODg4OTE3LTQuODI5ODg4IDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzM4OTc5IC4xMTk1NTIgMS41NjYxMjcgLjAzNTg2NiAxLjYzNzg1OC0uMjAzMjM4QzEuNjczNzI0LS4yOTg4NzkgMi4xMTYwNjUtMi4xMDQxMSAyLjE4Nzc5Ni0yLjM3OTA3OEMyLjI0NzU3Mi0yLjY0MjA5MiAyLjMxOTMwMy0yLjg5MzE1MSAyLjM3OTA3OC0zLjE1NjE2NEMyLjQyNjg5OS0zLjMyMzUzNyAyLjQ3NDcyLTMuNTE0ODE5IDIuNTEwNTg1LTMuNjcwMjM3QzIuNTQ2NDUxLTMuNzc3ODMzIDIuODY5MjQtNC4zNjM2MzYgMy4xNjgxMi00LjYyNjY1QzMuMzExNTgyLTQuNzU4MTU3IDMuNjIyNDE2LTUuMDMzMTI2IDQuMTEyNTc4LTUuMDMzMTI2QzQuMzAzODYxLTUuMDMzMTI2IDQuNDk1MTQzLTQuOTk3MjYgNC42NTA1Ni00Ljg4OTY2NFonLz4KPHBhdGggaWQ9J2czLTEyMCcgZD0nTTUuNjY2NzUtNC44Nzc3MDlDNS4yODQxODQtNC44MDU5NzggNS4xNDA3MjItNC41MTkwNTQgNS4xNDA3MjItNC4yOTE5MDVDNS4xNDA3MjItNC4wMDQ5ODEgNS4zNjc4Ny0zLjkwOTM0IDUuNTM1MjQzLTMuOTA5MzRDNS44OTM4OTgtMy45MDkzNCA2LjE0NDk1Ni00LjIyMDE3NCA2LjE0NDk1Ni00LjU0Mjk2NEM2LjE0NDk1Ni01LjA0NTA4MSA1LjU3MTEwOC01LjI3MjIyOSA1LjA2ODk5MS01LjI3MjIyOUM0LjMzOTcyNi01LjI3MjIyOSAzLjkzMzI1LTQuNTU0OTE5IDMuODI1NjU0LTQuMzI3NzcxQzMuNTUwNjg1LTUuMjI0NDA4IDIuODA5NDY1LTUuMjcyMjI5IDIuNTk0MjcxLTUuMjcyMjI5QzEuMzc0ODQ0LTUuMjcyMjI5IC43MjkyNjUtMy43MDYxMDIgLjcyOTI2NS0zLjQ0MzA4OEMuNzI5MjY1LTMuMzk1MjY4IC43NzcwODYtMy4zMzU0OTIgLjg2MDc3Mi0zLjMzNTQ5MkMuOTU2NDEzLTMuMzM1NDkyIC45ODAzMjQtMy40MDcyMjMgMS4wMDQyMzQtMy40NTUwNDRDMS40MTA3MS00Ljc4MjA2NyAyLjIxMTcwNi01LjAzMzEyNiAyLjU1ODQwNi01LjAzMzEyNkMzLjA5NjM4OS01LjAzMzEyNiAzLjIwMzk4NS00LjUzMTAwOSAzLjIwMzk4NS00LjI0NDA4NUMzLjIwMzk4NS0zLjk4MTA3MSAzLjEzMjI1NC0zLjcwNjEwMiAyLjk4ODc5Mi0zLjEzMjI1NEwyLjU4MjMxNi0xLjQ5NDM5NkMyLjQwMjk4OS0uNzc3MDg2IDIuMDU2Mjg5LS4xMTk1NTIgMS40MjI2NjUtLjExOTU1MkMxLjM2Mjg4OS0uMTE5NTUyIDEuMDY0MDEtLjExOTU1MiAuODEyOTUxLS4yNzQ5NjlDMS4yNDMzMzctLjM1ODY1NSAxLjMzODk3OS0uNzE3MzEgMS4zMzg5NzktLjg2MDc3MkMxLjMzODk3OS0xLjA5OTg3NSAxLjE1OTY1MS0xLjI0MzMzNyAuOTMyNTAzLTEuMjQzMzM3Qy42NDU1NzktMS4yNDMzMzcgLjMzNDc0NS0uOTkyMjc5IC4zMzQ3NDUtLjYwOTcxNEMuMzM0NzQ1LS4xMDc1OTcgLjg5NjYzOCAuMTE5NTUyIDEuNDEwNzEgLjExOTU1MkMxLjk4NDU1OCAuMTE5NTUyIDIuMzkxMDM0LS4zMzQ3NDUgMi42NDIwOTItLjgyNDkwN0MyLjgzMzM3NS0uMTE5NTUyIDMuNDMxMTMzIC4xMTk1NTIgMy44NzM0NzQgLjExOTU1MkM1LjA5MjkwMiAuMTE5NTUyIDUuNzM4NDgxLTEuNDQ2NTc1IDUuNzM4NDgxLTEuNzA5NTg5QzUuNzM4NDgxLTEuNzY5MzY1IDUuNjkwNjYtMS44MTcxODYgNS42MTg5MjktMS44MTcxODZDNS41MTEzMzMtMS44MTcxODYgNS40OTkzNzctMS43NTc0MSA1LjQ2MzUxMi0xLjY2MTc2OEM1LjE0MDcyMi0uNjA5NzE0IDQuNDQ3MzIzLS4xMTk1NTIgMy45MDkzNC0uMTE5NTUyQzMuNDkwOTA5LS4xMTk1NTIgMy4yNjM3NjEtLjQzMDM4NiAzLjI2Mzc2MS0uOTIwNTQ4QzMuMjYzNzYxLTEuMTgzNTYyIDMuMzExNTgyLTEuMzc0ODQ0IDMuNTAyODY0LTIuMTYzODg1TDMuOTIxMjk1LTMuNzg5Nzg4QzQuMTAwNjIzLTQuNTA3MDk4IDQuNTA3MDk4LTUuMDMzMTI2IDUuMDU3MDM2LTUuMDMzMTI2QzUuMDgwOTQ2LTUuMDMzMTI2IDUuNDE1NjkxLTUuMDMzMTI2IDUuNjY2NzUtNC44Nzc3MDlaJy8+CjxwYXRoIGlkPSdnMi0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzItMTA2JyBkPSdNMy4yOTE2NTYtNC45NzMzNUMzLjI5MTY1Ni01LjEyNDc4MiAzLjE3MjEwNS01LjI3NjIxNCAyLjk4MDgyMi01LjI3NjIxNEMyLjc0MTcxOS01LjI3NjIxNCAyLjUzNDQ5Ni01LjA1MzA1MSAyLjUzNDQ5Ni00Ljg0NTgyOEMyLjUzNDQ5Ni00LjY5NDM5NiAyLjY1NDA0Ny00LjU0Mjk2NCAyLjg0NTMzLTQuNTQyOTY0QzMuMDg0NDMzLTQuNTQyOTY0IDMuMjkxNjU2LTQuNzY2MTI3IDMuMjkxNjU2LTQuOTczMzVaTTEuNjI1OTAzIC4zOTg1MDZDMS41MDYzNTEgLjg4NDY4MiAxLjExNTgxNiAxLjQwMjc0IC42Mjk2MzkgMS40MDI3NEMuNTAyMTE3IDEuNDAyNzQgLjM4MjU2NSAxLjM3MDg1OSAuMzY2NjI1IDEuMzYyODg5Qy42MTM2OTkgMS4yNDMzMzcgLjY0NTU3OSAxLjAyODE0NCAuNjQ1NTc5IC45NTY0MTNDLjY0NTU3OSAuNzY1MTMxIC41MDIxMTcgLjY2MTUxOSAuMzM0NzQ1IC42NjE1MTlDLjEwMzYxMSAuNjYxNTE5LS4xMTE1ODIgLjg2MDc3Mi0uMTExNTgyIDEuMTIzNzg2Qy0uMTExNTgyIDEuNDI2NjUgLjE4MzMxMyAxLjYyNTkwMyAuNjM3NjA5IDEuNjI1OTAzQzEuMTIzNzg2IDEuNjI1OTAzIDIuMDAwNDk4IDEuMzIzMDM5IDIuMjM5NjAxIC4zNjY2MjVMMi45NTY5MTItMi40ODY2NzVDMi45ODA4MjItMi41ODIzMTYgMi45OTY3NjItMi42NDYwNzcgMi45OTY3NjItMi43NjU2MjlDMi45OTY3NjItMy4yMDM5ODUgMi42NDYwNzctMy41MTQ4MTkgMi4xODM4MTEtMy41MTQ4MTlDMS4zMzg5NzktMy41MTQ4MTkgLjg0NDgzMi0yLjM5OTAwNCAuODQ0ODMyLTIuMjk1MzkyQy44NDQ4MzItMi4yMjM2NjEgLjkwMDYyMy0yLjE5MTc4MSAuOTY0Mzg0LTIuMTkxNzgxQzEuMDUyMDU1LTIuMTkxNzgxIDEuMDYwMDI1LTIuMjE1NjkxIDEuMTE1ODE2LTIuMzM1MjQzQzEuMzU0OTE5LTIuODg1MTgxIDEuNzYxMzk1LTMuMjkxNjU2IDIuMTU5OS0zLjI5MTY1NkMyLjMyNzI3My0zLjI5MTY1NiAyLjQyMjkxNC0zLjE4MDA3NSAyLjQyMjkxNC0yLjkxNzA2MUMyLjQyMjkxNC0yLjgwNTQ3OSAyLjM5OTAwNC0yLjY5Mzg5OCAyLjM3NTA5My0yLjU4MjMxNkwxLjYyNTkwMyAuMzk4NTA2WicvPgo8cGF0aCBpZD0nZzEtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMS0yMCcgZD0nTTguMDY5NzM4LTcuMTAxMzdDOC4yMDEyNDUtNy4xNjExNDYgOC4yOTY4ODctNy4yMjA5MjIgOC4yOTY4ODctNy4zNjQzODRDOC4yOTY4ODctNy40OTU4OSA4LjIwMTI0NS03LjYwMzQ4NyA4LjA1Nzc4My03LjYwMzQ4N0M3Ljk5ODAwNy03LjYwMzQ4NyA3Ljg5MDQxMS03LjU1NTY2NiA3Ljg0MjU5LTcuNTMxNzU2TDEuMjMxMzgyLTQuNDExNDU3QzEuMDI4MTQ0LTQuMzE1ODE2IC45OTIyNzktNC4yMzIxMyAuOTkyMjc5LTQuMTM2NDg4Qy45OTIyNzktNC4wMjg4OTIgMS4wNjQwMS0zLjk0NTIwNSAxLjIzMTM4Mi0zLjg3MzQ3NEw3Ljg0MjU5LS43NjUxMzFDNy45OTgwMDctLjY4MTQ0NSA4LjAyMTkxOC0uNjgxNDQ1IDguMDU3NzgzLS42ODE0NDVDOC4xODkyOS0uNjgxNDQ1IDguMjk2ODg3LS43ODkwNDEgOC4yOTY4ODctLjkyMDU0OEM4LjI5Njg4Ny0xLjAyODE0NCA4LjI0OTA2Ni0xLjA5OTg3NSA4LjA0NTgyOC0xLjE5NTUxN0wxLjc5MzI3NS00LjEzNjQ4OEw4LjA2OTczOC03LjEwMTM3Wk03Ljg3ODQ1NiAxLjYzNzg1OEM4LjA4MTY5NCAxLjYzNzg1OCA4LjI5Njg4NyAxLjYzNzg1OCA4LjI5Njg4NyAxLjM5ODc1NVM4LjA0NTgyOCAxLjE1OTY1MSA3Ljg2NjUwMSAxLjE1OTY1MUgxLjQyMjY2NUMxLjI0MzMzNyAxLjE1OTY1MSAuOTkyMjc5IDEuMTU5NjUxIC45OTIyNzkgMS4zOTg3NTVTMS4yMDc0NzIgMS42Mzc4NTggMS40MTA3MSAxLjYzNzg1OEg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cxLTIxJyBkPSdNOC4wNTc3ODMtMy44NzM0NzRDOC4yMjUxNTYtMy45NDUyMDUgOC4yOTY4ODctNC4wMjg4OTIgOC4yOTY4ODctNC4xMzY0ODhDOC4yOTY4ODctNC4yNTYwNCA4LjI0OTA2Ni00LjMyNzc3MSA4LjA1Nzc4My00LjQxMTQ1N0wxLjQ3MDQ4Ni03LjUxOTgwMUMxLjMwMzExMy03LjYwMzQ4NyAxLjI1NTI5My03LjYwMzQ4NyAxLjIzMTM4Mi03LjYwMzQ4N0MxLjA4NzkyLTcuNjAzNDg3IC45OTIyNzktNy40OTU4OSAuOTkyMjc5LTcuMzY0Mzg0Qy45OTIyNzktNy4yMjA5MjIgMS4wODc5Mi03LjE2MTE0NiAxLjIxOTQyNy03LjEwMTM3TDcuNDk1ODktNC4xNDg0NDNMMS4yNDMzMzctMS4xOTU1MTdDMS4wMDQyMzQtMS4wODc5MiAuOTkyMjc5LS45OTIyNzkgLjk5MjI3OS0uOTIwNTQ4Qy45OTIyNzktLjc4OTA0MSAxLjA5OTg3NS0uNjgxNDQ1IDEuMjMxMzgyLS42ODE0NDVDMS4yNjcyNDgtLjY4MTQ0NSAxLjI5MTE1OC0uNjgxNDQ1IDEuNDQ2NTc1LS43NjUxMzFMOC4wNTc3ODMtMy44NzM0NzRaTTcuODc4NDU2IDEuNjM3ODU4QzguMDgxNjk0IDEuNjM3ODU4IDguMjk2ODg3IDEuNjM3ODU4IDguMjk2ODg3IDEuMzk4NzU1UzguMDQ1ODI4IDEuMTU5NjUxIDcuODY2NTAxIDEuMTU5NjUxSDEuNDIyNjY1QzEuMjQzMzM3IDEuMTU5NjUxIC45OTIyNzkgMS4xNTk2NTEgLjk5MjI3OSAxLjM5ODc1NVMxLjIwNzQ3MiAxLjYzNzg1OCAxLjQxMDcxIDEuNjM3ODU4SDcuODc4NDU2WicvPgo8cGF0aCBpZD0nZzEtNTAnIGQ9J002LjU1MTQzMi0yLjc0OTY4OUM2Ljc1NDY3LTIuNzQ5Njg5IDYuOTY5ODYzLTIuNzQ5Njg5IDYuOTY5ODYzLTIuOTg4NzkyUzYuNzU0NjctMy4yMjc4OTUgNi41NTE0MzItMy4yMjc4OTVIMS40ODI0NDFDMS42MjU5MDMtNC44Mjk4ODggMy4wMDA3NDctNS45Nzc1ODQgNC42ODY0MjYtNS45Nzc1ODRINi41NTE0MzJDNi43NTQ2Ny01Ljk3NzU4NCA2Ljk2OTg2My01Ljk3NzU4NCA2Ljk2OTg2My02LjIxNjY4N1M2Ljc1NDY3LTYuNDU1NzkxIDYuNTUxNDMyLTYuNDU1NzkxSDQuNjYyNTE2QzIuNjE4MTgyLTYuNDU1NzkxIC45OTIyNzktNC45MDE2MTkgLjk5MjI3OS0yLjk4ODc5MlMyLjYxODE4MiAuNDc4MjA3IDQuNjYyNTE2IC40NzgyMDdINi41NTE0MzJDNi43NTQ2NyAuNDc4MjA3IDYuOTY5ODYzIC40NzgyMDcgNi45Njk4NjMgLjIzOTEwM1M2Ljc1NDY3IDAgNi41NTE0MzIgMEg0LjY4NjQyNkMzLjAwMDc0NyAwIDEuNjI1OTAzLTEuMTQ3Njk2IDEuNDgyNDQxLTIuNzQ5Njg5SDYuNTUxNDMyWicvPgo8cGF0aCBpZD0nZzEtNTQnIGQ9J003LjUzMTc1Ni04LjA5MzY0OUM3LjYyNzM5Ny04LjI2MTAyMSA3LjYyNzM5Ny04LjI4NDkzMiA3LjYyNzM5Ny04LjMyMDc5N0M3LjYyNzM5Ny04LjQwNDQ4MyA3LjU1NTY2Ni04LjU1OTkgNy4zODgyOTQtOC41NTk5QzcuMjQ0ODMyLTguNTU5OSA3LjIwODk2Ni04LjQ4ODE2OSA3LjEyNTI4LTguMzIwNzk3TDEuNzU3NDEgMi4xMTYwNjVDMS42NjE3NjggMi4yODM0MzcgMS42NjE3NjggMi4zMDczNDcgMS42NjE3NjggMi4zNDMyMTNDMS42NjE3NjggMi40Mzg4NTQgMS43NDU0NTUgMi41ODIzMTYgMS45MDA4NzIgMi41ODIzMTZDMi4wNDQzMzQgMi41ODIzMTYgMi4wODAxOTkgMi41MTA1ODUgMi4xNjM4ODUgMi4zNDMyMTNMNy41MzE3NTYtOC4wOTM2NDlaJy8+CjxwYXRoIGlkPSdnMS01NicgZD0nTTYuNTg3Mjk4LTcuODQyNTlDNi42NDcwNzMtNy45NzQwOTcgNi42NDcwNzMtNy45OTgwMDcgNi42NDcwNzMtOC4wNTc3ODNDNi42NDcwNzMtOC4xNzczMzUgNi41NTE0MzItOC4yOTY4ODcgNi40MDc5Ny04LjI5Njg4N0M2LjI1MjU1My04LjI5Njg4NyA2LjE4MDgyMi04LjE1MzQyNSA2LjEzMzAwMS04LjAyMTkxOEw1LjE0MDcyMi01LjM5MTc4MUgxLjUwNjM1MUwuNTE0MDcyLTguMDIxOTE4Qy40NTQyOTYtOC4xODkyOSAuMzk0NTIxLTguMjk2ODg3IC4yMzkxMDMtOC4yOTY4ODdDLjExOTU1Mi04LjI5Njg4NyAwLTguMTc3MzM1IDAtOC4wNTc3ODNDMC04LjAzMzg3MyAwLTguMDA5OTYzIC4wNzE3MzEtNy44NDI1OUwzLjA0ODU2OC0uMDExOTU1QzMuMTA4MzQ0IC4xNTU0MTcgMy4xNjgxMiAuMjYzMDE0IDMuMzIzNTM3IC4yNjMwMTRDMy40OTA5MDkgLjI2MzAxNCAzLjUzODczIC4xMzE1MDcgMy41ODY1NSAuMDExOTU1TDYuNTg3Mjk4LTcuODQyNTlaTTEuNjk3NjM0LTQuOTEzNTc0SDQuOTQ5NDRMMy4zMjM1MzctLjY1NzUzNEwxLjY5NzYzNC00LjkxMzU3NFonLz4KPHBhdGggaWQ9J2cxLTEwNicgZD0nTTEuOTAwODcyLTguNTM1OTlDMS45MDA4NzItOC43NTExODMgMS45MDA4NzItOC45NjYzNzYgMS42NjE3NjgtOC45NjYzNzZTMS40MjI2NjUtOC43NTExODMgMS40MjI2NjUtOC41MzU5OVYyLjU1ODQwNkMxLjQyMjY2NSAyLjc3MzU5OSAxLjQyMjY2NSAyLjk4ODc5MiAxLjY2MTc2OCAyLjk4ODc5MlMxLjkwMDg3MiAyLjc3MzU5OSAxLjkwMDg3MiAyLjU1ODQwNlYtOC41MzU5OVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzI2Ljg1ODU3JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMS01NicvPgo8dXNlIHg9JzMzLjUwMDM1JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMy0xMDUnLz4KPHVzZSB4PSc0MC44MTQ2MTInIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2cxLTIxJy8+Cjx1c2UgeD0nNTMuNDMzOTM4JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzU5LjI4NjkyOCcgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtNTknLz4KPHVzZSB4PSc2NC41MzEwODcnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2czLTcyJy8+Cjx1c2UgeD0nNzQuMjMwMDY4JyB5PSctNy40MDM2NjMnIHhsaW5rOmhyZWY9JyNnMi0xMDUnLz4KPHVzZSB4PSc4MC45MzIxNjknIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMTA1LjM1Mjg3NCcgeT0nLTE3LjI4NDY4NScgeGxpbms6aHJlZj0nI2c1LTQ5Jy8+CjxyZWN0IHg9Jzk0LjU1MzE2MycgeT0nLTEyLjQyNDgxMicgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMjcuNDUyNDEyJy8+Cjx1c2UgeD0nOTQuNTUzMTYzJyB5PSctLjk5NjI2NCcgeGxpbms6aHJlZj0nI2czLTExMCcvPgo8dXNlIHg9JzEwNC4xOTc0MzMnIHk9Jy0uOTk2MjY0JyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzExNi4xNTI1OTMnIHk9Jy0uOTk2MjY0JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScxMjMuMjAxMDg5JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMy02NycvPgo8dXNlIHg9JzEzMi40MzQ3MDInIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2czLTk3Jy8+Cjx1c2UgeD0nMTM4LjU3OTY0NicgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtMTE0Jy8+Cjx1c2UgeD0nMTQ0LjE4MDExOScgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtMTAwJy8+Cjx1c2UgeD0nMTUyLjI1NTMxJyB5PSctMTguODgwNjknIHhsaW5rOmhyZWY9JyNnMC04Jy8+Cjx1c2UgeD0nMTU5LjIyOTE4OCcgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtMTA2Jy8+Cjx1c2UgeD0nMTY4LjA2NTUxMycgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzEtNTAnLz4KPHVzZSB4PScxNzkuMzU2NDgxJyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnNS05MScvPgo8dXNlIHg9JzE4Mi42MDgxNDInIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2c1LTQ5Jy8+Cjx1c2UgeD0nMTg4LjQ2MTEzMycgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtNTknLz4KPHVzZSB4PScxOTMuNzA1MjkyJyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMy03OCcvPgo8dXNlIHg9JzIwNC4zMjc5MDInIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2c1LTkzJy8+Cjx1c2UgeD0nMjA3LjU3OTU2MycgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtNTknLz4KPHVzZSB4PScyMTIuODIzNzIyJyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PScyMjEuNjYwMDQ3JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMS01NCcvPgo8dXNlIHg9JzIyMS42NjAwNDcnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMjM0LjA4NTUyOCcgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtMTA1Jy8+Cjx1c2UgeD0nMjM4LjA3ODk2JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnMy01OScvPgo8dXNlIHg9JzI0NS4zMTU2MTYnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2cxLTEwNicvPgo8dXNlIHg9JzI1MC42MjkwMDQnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2czLTEyMCcvPgo8dXNlIHg9JzI1Ny4yODEwOTEnIHk9Jy0xNC44NjQ1NDYnIHhsaW5rOmhyZWY9JyNnMi0xMDYnLz4KPHVzZSB4PScyNTcuMjgxMDkxJyB5PSctNi4yNjU3NDknIHhsaW5rOmhyZWY9JyNnNC00OScvPgo8dXNlIHg9JzI2NS4zMzQyMzYnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2cxLTIwJy8+Cjx1c2UgeD0nMjc3Ljk1MzU2MicgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtMTIwJy8+Cjx1c2UgeD0nMjg0LjYwNTY0OScgeT0nLTE0LjEzMzExMicgeGxpbms6aHJlZj0nI2cyLTEwNScvPgo8dXNlIHg9JzI4NC42MDU2NDknIHk9Jy02LjI0MTQxMScgeGxpbms6aHJlZj0nI2c0LTQ5Jy8+Cjx1c2UgeD0nMjkzLjIzOTk1NycgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzUtOTcnLz4KPHVzZSB4PScyOTkuMDkyOTQ4JyB5PSctOS4xOTY5MjYnIHhsaW5rOmhyZWY9JyNnNS0xMTAnLz4KPHVzZSB4PSczMDUuNTk2MjcnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2c1LTEwMCcvPgo8dXNlIHg9JzMxNi4wMDE1ODYnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2czLTEyMCcvPgo8dXNlIHg9JzMyMi42NTM2NzMnIHk9Jy0xNC44NjQ1NDYnIHhsaW5rOmhyZWY9JyNnMi0xMDYnLz4KPHVzZSB4PSczMjIuNjUzNjczJyB5PSctNi4yNjU3NDknIHhsaW5rOmhyZWY9JyNnNC01MCcvPgo8dXNlIHg9JzMzMC43MDY4MTgnIHk9Jy05LjE5NjkyNicgeGxpbms6aHJlZj0nI2cxLTIwJy8+Cjx1c2UgeD0nMzQzLjMyNjE0NCcgeT0nLTkuMTk2OTI2JyB4bGluazpocmVmPScjZzMtMTIwJy8+Cjx1c2UgeD0nMzQ5Ljk3ODIzMScgeT0nLTE0LjEzMzExMicgeGxpbms6aHJlZj0nI2cyLTEwNScvPgo8dXNlIHg9JzM0OS45NzgyMzEnIHk9Jy02LjI0MTQxMScgeGxpbms6aHJlZj0nI2c0LTUwJy8+Cjx1c2UgeD0nMzU0LjcxMDU0NicgeT0nLTE4Ljg4MDY5JyB4bGluazpocmVmPScjZzAtOScvPgo8L2c+Cjwvc3ZnPg==)
and  the ordered statistics of
the ordered statistics of
 .
.
The statistic  is defined by:
is defined by:
(1)¶
where  is the cumulative density function of
is the cumulative density function of
 . We can show that this is the cumulative density function
of the random variate
. We can show that this is the cumulative density function
of the random variate  when
when  and
and  are
independent and follow
are
independent and follow  distributions.
distributions.
 samples of size
samples of size
 from the bivariate copula , in order to have
realizations of the statistics
from the bivariate copula , in order to have
realizations of the statistics
 and have an estimation of
and have an estimation of
![W_i = E[H_{(i)}], \forall i \leq N](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScxMDguMTU3NTA4cHQnIGhlaWdodD0nMTIuODE4NjE0cHQnIHZpZXdCb3g9JzAgLTguOTY2Mzc2IDEwOC4xNTc1MDggMTIuODE4NjE0Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMC0yMCcgZD0nTTguMDY5NzM4LTcuMTAxMzdDOC4yMDEyNDUtNy4xNjExNDYgOC4yOTY4ODctNy4yMjA5MjIgOC4yOTY4ODctNy4zNjQzODRDOC4yOTY4ODctNy40OTU4OSA4LjIwMTI0NS03LjYwMzQ4NyA4LjA1Nzc4My03LjYwMzQ4N0M3Ljk5ODAwNy03LjYwMzQ4NyA3Ljg5MDQxMS03LjU1NTY2NiA3Ljg0MjU5LTcuNTMxNzU2TDEuMjMxMzgyLTQuNDExNDU3QzEuMDI4MTQ0LTQuMzE1ODE2IC45OTIyNzktNC4yMzIxMyAuOTkyMjc5LTQuMTM2NDg4Qy45OTIyNzktNC4wMjg4OTIgMS4wNjQwMS0zLjk0NTIwNSAxLjIzMTM4Mi0zLjg3MzQ3NEw3Ljg0MjU5LS43NjUxMzFDNy45OTgwMDctLjY4MTQ0NSA4LjAyMTkxOC0uNjgxNDQ1IDguMDU3NzgzLS42ODE0NDVDOC4xODkyOS0uNjgxNDQ1IDguMjk2ODg3LS43ODkwNDEgOC4yOTY4ODctLjkyMDU0OEM4LjI5Njg4Ny0xLjAyODE0NCA4LjI0OTA2Ni0xLjA5OTg3NSA4LjA0NTgyOC0xLjE5NTUxN0wxLjc5MzI3NS00LjEzNjQ4OEw4LjA2OTczOC03LjEwMTM3Wk03Ljg3ODQ1NiAxLjYzNzg1OEM4LjA4MTY5NCAxLjYzNzg1OCA4LjI5Njg4NyAxLjYzNzg1OCA4LjI5Njg4NyAxLjM5ODc1NVM4LjA0NTgyOCAxLjE1OTY1MSA3Ljg2NjUwMSAxLjE1OTY1MUgxLjQyMjY2NUMxLjI0MzMzNyAxLjE1OTY1MSAuOTkyMjc5IDEuMTU5NjUxIC45OTIyNzkgMS4zOTg3NTVTMS4yMDc0NzIgMS42Mzc4NTggMS40MTA3MSAxLjYzNzg1OEg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cwLTU2JyBkPSdNNi41ODcyOTgtNy44NDI1OUM2LjY0NzA3My03Ljk3NDA5NyA2LjY0NzA3My03Ljk5ODAwNyA2LjY0NzA3My04LjA1Nzc4M0M2LjY0NzA3My04LjE3NzMzNSA2LjU1MTQzMi04LjI5Njg4NyA2LjQwNzk3LTguMjk2ODg3QzYuMjUyNTUzLTguMjk2ODg3IDYuMTgwODIyLTguMTUzNDI1IDYuMTMzMDAxLTguMDIxOTE4TDUuMTQwNzIyLTUuMzkxNzgxSDEuNTA2MzUxTC41MTQwNzItOC4wMjE5MThDLjQ1NDI5Ni04LjE4OTI5IC4zOTQ1MjEtOC4yOTY4ODcgLjIzOTEwMy04LjI5Njg4N0MuMTE5NTUyLTguMjk2ODg3IDAtOC4xNzczMzUgMC04LjA1Nzc4M0MwLTguMDMzODczIDAtOC4wMDk5NjMgLjA3MTczMS03Ljg0MjU5TDMuMDQ4NTY4LS4wMTE5NTVDMy4xMDgzNDQgLjE1NTQxNyAzLjE2ODEyIC4yNjMwMTQgMy4zMjM1MzcgLjI2MzAxNEMzLjQ5MDkwOSAuMjYzMDE0IDMuNTM4NzMgLjEzMTUwNyAzLjU4NjU1IC4wMTE5NTVMNi41ODcyOTgtNy44NDI1OVpNMS42OTc2MzQtNC45MTM1NzRINC45NDk0NEwzLjMyMzUzNy0uNjU3NTM0TDEuNjk3NjM0LTQuOTEzNTc0WicvPgo8cGF0aCBpZD0nZzMtNDAnIGQ9J00yLjY1NDA0NyAxLjk5MjUyOEMyLjcxNzgwOCAxLjk5MjUyOCAyLjgxMzQ1IDEuOTkyNTI4IDIuODEzNDUgMS44OTY4ODdDMi44MTM0NSAxLjg2NTAwNiAyLjgwNTQ3OSAxLjg1NzAzNiAyLjcwMTg2OCAxLjc1MzQyNUMxLjYwOTk2MyAuNzI1MjggMS4zMzg5NzktLjc1NzE2MSAxLjMzODk3OS0xLjk5MjUyOEMxLjMzODk3OS00LjI4NzkyIDIuMjg3NDIyLTUuMzYzODg1IDIuNjkzODk4LTUuNzMwNTExQzIuODA1NDc5LTUuODM0MTIyIDIuODEzNDUtNS44NDIwOTIgMi44MTM0NS01Ljg4MTk0M1MyLjc4MTU2OS01Ljk3NzU4NCAyLjcwMTg2OC01Ljk3NzU4NEMyLjU3NDM0Ni01Ljk3NzU4NCAyLjE3NTg0MS01LjU3MTEwOCAyLjExMjA4LTUuNDk5Mzc3QzEuMDQ0MDg1LTQuMzgzNTYyIC44MjA5MjItMi45NDg5NDEgLjgyMDkyMi0xLjk5MjUyOEMuODIwOTIyLS4yMDcyMjMgMS41NzAxMTIgMS4yMjczOTcgMi42NTQwNDcgMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnMy00MScgZD0nTTIuNDYyNzY1LTEuOTkyNTI4QzIuNDYyNzY1LTIuNzQ5Njg5IDIuMzM1MjQzLTMuNjU4MjgxIDEuODQxMDk2LTQuNTk4NzU1QzEuNDUwNTYtNS4zMzIwMDUgLjcyNTI4LTUuOTc3NTg0IC41ODE4MTgtNS45Nzc1ODRDLjUwMjExNy01Ljk3NzU4NCAuNDc4MjA3LTUuOTIxNzkzIC40NzgyMDctNS44ODE5NDNDLjQ3ODIwNy01Ljg1MDA2MiAuNDc4MjA3LTUuODM0MTIyIC41NzM4NDgtNS43Mzg0ODFDMS42ODk2NjQtNC42Nzg0NTYgMS45NDQ3MDctMy4yMTk5MjUgMS45NDQ3MDctMS45OTI1MjhDMS45NDQ3MDcgLjI5NDg5NCAuOTk2MjY0IDEuMzc4ODI5IC41ODk3ODggMS43NDU0NTVDLjQ4NjE3NyAxLjg0OTA2NiAuNDc4MjA3IDEuODU3MDM2IC40NzgyMDcgMS44OTY4ODdTLjUwMjExNyAxLjk5MjUyOCAuNTgxODE4IDEuOTkyNTI4Qy43MDkzNCAxLjk5MjUyOCAxLjEwNzg0NiAxLjU4NjA1MiAxLjE3MTYwNiAxLjUxNDMyMUMyLjIzOTYwMSAuMzk4NTA2IDIuNDYyNzY1LTEuMDM2MTE1IDIuNDYyNzY1LTEuOTkyNTI4WicvPgo8cGF0aCBpZD0nZzEtMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2c0LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnNC05MScgZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicvPgo8cGF0aCBpZD0nZzQtOTMnIGQ9J00xLjg1MzA1MS04Ljk2NjM3NkguMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicvPgo8cGF0aCBpZD0nZzItNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2cyLTY5JyBkPSdNOC4zMDg4NDItMi43NzM1OTlDOC4zMjA3OTctMi44MDk0NjUgOC4zNTY2NjMtMi44OTMxNTEgOC4zNTY2NjMtMi45NDA5NzFDOC4zNTY2NjMtMy4wMDA3NDcgOC4zMDg4NDItMy4wNjA1MjMgOC4yMzcxMTEtMy4wNjA1MjNDOC4xODkyOS0zLjA2MDUyMyA4LjE2NTM4LTMuMDQ4NTY4IDguMTI5NTE0LTMuMDEyNzAyQzguMTA1NjA0LTMuMDAwNzQ3IDguMTA1NjA0LTIuOTc2ODM3IDcuOTk4MDA3LTIuNzM3NzMzQzcuMjkyNjUzLTEuMDY0MDEgNi43Nzg1OC0uMzQ2NyA0Ljg2NTc1My0uMzQ2N0gzLjEyMDI5OUMyLjk1MjkyNy0uMzQ2NyAyLjkyOTAxNi0uMzQ2NyAyLjg1NzI4NS0uMzU4NjU1QzIuNzI1Nzc4LS4zNzA2MSAyLjcxMzgyMy0uMzk0NTIxIDIuNzEzODIzLS40OTAxNjJDMi43MTM4MjMtLjU3Mzg0OCAyLjczNzczMy0uNjQ1NTc5IDIuNzYxNjQ0LS43NTMxNzZMMy41ODY1NS00LjA1MjgwMkg0Ljc3MDExMkM1LjcwMjYxNS00LjA1MjgwMiA1Ljc3NDM0Ni0zLjg0OTU2NCA1Ljc3NDM0Ni0zLjQ5MDkwOUM1Ljc3NDM0Ni0zLjM3MTM1NyA1Ljc3NDM0Ni0zLjI2Mzc2MSA1LjY5MDY2LTIuOTA1MTA2QzUuNjY2NzUtMi44NTcyODUgNS42NTQ3OTUtMi44MDk0NjUgNS42NTQ3OTUtMi43NzM1OTlDNS42NTQ3OTUtMi42ODk5MTMgNS43MTQ1Ny0yLjY1NDA0NyA1Ljc4NjMwMS0yLjY1NDA0N0M1Ljg5Mzg5OC0yLjY1NDA0NyA1LjkwNTg1My0yLjczNzczMyA1Ljk1MzY3NC0yLjkwNTEwNkw2LjYzNTExOC01LjY3ODcwNUM2LjYzNTExOC01LjczODQ4MSA2LjU4NzI5OC01Ljc5ODI1NyA2LjUxNTU2Ny01Ljc5ODI1N0M2LjQwNzk3LTUuNzk4MjU3IDYuMzk2MDE1LTUuNzUwNDM2IDYuMzQ4MTk0LTUuNTgzMDY0QzYuMTA5MDkxLTQuNjYyNTE2IDUuODY5OTg4LTQuMzk5NTAyIDQuODA1OTc4LTQuMzk5NTAySDMuNjcwMjM3TDQuNDExNDU3LTcuMzQwNDczQzQuNTE5MDU0LTcuNzU4OTA0IDQuNTQyOTY0LTcuNzk0NzcgNS4wMzMxMjYtNy43OTQ3N0g2Ljc0MjcxNUM4LjIxMzItNy43OTQ3NyA4LjUxMjA4LTcuNDAwMjQ5IDguNTEyMDgtNi40OTE2NTZDOC41MTIwOC02LjQ3OTcwMSA4LjUxMjA4LTYuMTQ0OTU2IDguNDY0MjU5LTUuNzUwNDM2QzguNDUyMzA0LTUuNzAyNjE1IDguNDQwMzQ5LTUuNjMwODg0IDguNDQwMzQ5LTUuNjA2OTc0QzguNDQwMzQ5LTUuNTExMzMzIDguNTAwMTI1LTUuNDc1NDY3IDguNTcxODU2LTUuNDc1NDY3QzguNjU1NTQyLTUuNDc1NDY3IDguNzAzMzYyLTUuNTIzMjg4IDguNzI3MjczLTUuNzM4NDgxTDguOTc4MzMxLTcuODMwNjM1QzguOTc4MzMxLTcuODY2NTAxIDkuMDAyMjQyLTcuOTg2MDUyIDkuMDAyMjQyLTguMDA5OTYzQzkuMDAyMjQyLTguMTQxNDY5IDguODk0NjQ1LTguMTQxNDY5IDguNjc5NDUyLTguMTQxNDY5SDIuODQ1MzNDMi42MTgxODItOC4xNDE0NjkgMi40OTg2My04LjE0MTQ2OSAyLjQ5ODYzLTcuOTI2Mjc2QzIuNDk4NjMtNy43OTQ3NyAyLjU4MjMxNi03Ljc5NDc3IDIuNzg1NTU0LTcuNzk0NzdDMy41MjY3NzUtNy43OTQ3NyAzLjUyNjc3NS03LjcxMTA4MyAzLjUyNjc3NS03LjU3OTU3N0MzLjUyNjc3NS03LjUxOTgwMSAzLjUxNDgxOS03LjQ3MTk4IDMuNDc4OTU0LTcuMzQwNDczTDEuODY1MDA2LS44ODQ2ODJDMS43NTc0MS0uNDY2MjUyIDEuNzMzNDk5LS4zNDY3IC44OTY2MzgtLjM0NjdDLjY2OTQ4OS0uMzQ2NyAuNTQ5OTM4LS4zNDY3IC41NDk5MzgtLjEzMTUwN0MuNTQ5OTM4IDAgLjYyMTY2OSAwIC44NjA3NzIgMEg2Ljg2MjI2N0M3LjEyNTI4IDAgNy4xMzcyMzUtLjAxMTk1NSA3LjIyMDkyMi0uMjAzMjM4TDguMzA4ODQyLTIuNzczNTk5WicvPgo8cGF0aCBpZD0nZzItNzInIGQ9J004Ljk0MjQ2Ni03LjI5MjY1M0M5LjA1MDA2Mi03LjY5OTEyOCA5LjA3Mzk3My03LjgxODY4IDkuOTIyNzktNy44MTg2OEMxMC4xMzc5ODMtNy44MTg2OCAxMC4yNTc1MzQtNy44MTg2OCAxMC4yNTc1MzQtOC4wMzM4NzNDMTAuMjU3NTM0LTguMTY1MzggMTAuMTQ5OTM4LTguMTY1MzggMTAuMDc4MjA3LTguMTY1MzhDOS44NjMwMTQtOC4xNjUzOCA5LjYxMTk1NS04LjE0MTQ2OSA5LjM4NDgwNy04LjE0MTQ2OUg3Ljk3NDA5N0M3Ljc0Njk0OS04LjE0MTQ2OSA3LjQ5NTg5LTguMTY1MzggNy4yNjg3NDItOC4xNjUzOEM3LjE4NTA1Ni04LjE2NTM4IDcuMDQxNTk0LTguMTY1MzggNy4wNDE1OTQtNy45MzgyMzJDNy4wNDE1OTQtNy44MTg2OCA3LjEyNTI4LTcuODE4NjggNy4zNTI0MjgtNy44MTg2OEM4LjA2OTczOC03LjgxODY4IDguMDY5NzM4LTcuNzIzMDM5IDguMDY5NzM4LTcuNTkxNTMyQzguMDY5NzM4LTcuNTY3NjIxIDguMDY5NzM4LTcuNDk1ODkgOC4wMjE5MTgtNy4zMTY1NjNMNy4yOTI2NTMtNC40MjM0MTJIMy42ODIxOTJMNC4zOTk1MDItNy4yOTI2NTNDNC41MDcwOTgtNy42OTkxMjggNC41MzEwMDktNy44MTg2OCA1LjM3OTgyNi03LjgxODY4QzUuNTk1MDE5LTcuODE4NjggNS43MTQ1Ny03LjgxODY4IDUuNzE0NTctOC4wMzM4NzNDNS43MTQ1Ny04LjE2NTM4IDUuNjA2OTc0LTguMTY1MzggNS41MzUyNDMtOC4xNjUzOEM1LjMyMDA1LTguMTY1MzggNS4wNjg5OTEtOC4xNDE0NjkgNC44NDE4NDMtOC4xNDE0NjlIMy40MzExMzNDMy4yMDM5ODUtOC4xNDE0NjkgMi45NTI5MjctOC4xNjUzOCAyLjcyNTc3OC04LjE2NTM4QzIuNjQyMDkyLTguMTY1MzggMi40OTg2My04LjE2NTM4IDIuNDk4NjMtNy45MzgyMzJDMi40OTg2My03LjgxODY4IDIuNTgyMzE2LTcuODE4NjggMi44MDk0NjUtNy44MTg2OEMzLjUyNjc3NS03LjgxODY4IDMuNTI2Nzc1LTcuNzIzMDM5IDMuNTI2Nzc1LTcuNTkxNTMyQzMuNTI2Nzc1LTcuNTY3NjIxIDMuNTI2Nzc1LTcuNDk1ODkgMy40Nzg5NTQtNy4zMTY1NjNMMS44NjUwMDYtLjg4NDY4MkMxLjc1NzQxLS40NjYyNTIgMS43MzM0OTktLjM0NjcgLjkwODU5My0uMzQ2N0MuNjMzNjI0LS4zNDY3IC41NDk5MzgtLjM0NjcgLjU0OTkzOC0uMTE5NTUyQy41NDk5MzggMCAuNjgxNDQ1IDAgLjcxNzMxIDBDLjkzMjUwMyAwIDEuMTgzNTYyLS4wMjM5MSAxLjQxMDcxLS4wMjM5MUgyLjgyMTQyQzMuMDQ4NTY4LS4wMjM5MSAzLjI5OTYyNiAwIDMuNTI2Nzc1IDBDMy42MjI0MTYgMCAzLjc1MzkyMyAwIDMuNzUzOTIzLS4yMjcxNDhDMy43NTM5MjMtLjM0NjcgMy42NDYzMjYtLjM0NjcgMy40NjY5OTktLjM0NjdDMi43Mzc3MzMtLjM0NjcgMi43Mzc3MzMtLjQ0MjM0MSAyLjczNzczMy0uNTYxODkzQzIuNzM3NzMzLS41NzM4NDggMi43Mzc3MzMtLjY1NzUzNCAyLjc2MTY0NC0uNzUzMTc2TDMuNTg2NTUtNC4wNzY3MTJINy4yMDg5NjZDNy4wMDU3MjktMy4yODc2NzEgNi4zOTYwMTUtLjc4OTA0MSA2LjM3MjEwNS0uNzE3MzFDNi4yNDA1OTgtLjM1ODY1NSA2LjA0OTMxNS0uMzU4NjU1IDUuMzQzOTYtLjM0NjdDNS4yMDA0OTgtLjM0NjcgNS4wOTI5MDItLjM0NjcgNS4wOTI5MDItLjExOTU1MkM1LjA5MjkwMiAwIDUuMjI0NDA4IDAgNS4yNjAyNzQgMEM1LjQ3NTQ2NyAwIDUuNzI2NTI2LS4wMjM5MSA1Ljk1MzY3NC0uMDIzOTFINy4zNjQzODRDNy41OTE1MzItLjAyMzkxIDcuODQyNTkgMCA4LjA2OTczOCAwQzguMTY1MzggMCA4LjI5Njg4NyAwIDguMjk2ODg3LS4yMjcxNDhDOC4yOTY4ODctLjM0NjcgOC4xODkyOS0uMzQ2NyA4LjAwOTk2My0uMzQ2N0M3LjI4MDY5Ny0uMzQ2NyA3LjI4MDY5Ny0uNDQyMzQxIDcuMjgwNjk3LS41NjE4OTNDNy4yODA2OTctLjU3Mzg0OCA3LjI4MDY5Ny0uNjU3NTM0IDcuMzA0NjA4LS43NTMxNzZMOC45NDI0NjYtNy4yOTI2NTNaJy8+CjxwYXRoIGlkPSdnMi03OCcgZD0nTTguODQ2ODI0LTYuOTEwMDg3QzguOTc4MzMxLTcuNDI0MTU5IDkuMTY5NjE0LTcuNzgyODE0IDEwLjA3ODIwNy03LjgxODY4QzEwLjExNDA3Mi03LjgxODY4IDEwLjI1NzUzNC03LjgzMDYzNSAxMC4yNTc1MzQtOC4wMzM4NzNDMTAuMjU3NTM0LTguMTY1MzggMTAuMTQ5OTM4LTguMTY1MzggMTAuMTAyMTE3LTguMTY1MzhDOS44NjMwMTQtOC4xNjUzOCA5LjI1MzMtOC4xNDE0NjkgOS4wMTQxOTctOC4xNDE0NjlIOC40NDAzNDlDOC4yNzI5NzYtOC4xNDE0NjkgOC4wNTc3ODMtOC4xNjUzOCA3Ljg5MDQxMS04LjE2NTM4QzcuODE4NjgtOC4xNjUzOCA3LjY3NTIxOC04LjE2NTM4IDcuNjc1MjE4LTcuOTM4MjMyQzcuNjc1MjE4LTcuODE4NjggNy43NzA4NTktNy44MTg2OCA3Ljg1NDU0NS03LjgxODY4QzguNTcxODU2LTcuNzk0NzcgOC42MTk2NzYtNy41MTk4MDEgOC42MTk2NzYtNy4zMDQ2MDhDOC42MTk2NzYtNy4xOTcwMTEgOC42MDc3MjEtNy4xNjExNDYgOC41NzE4NTYtNi45OTM3NzNMNy4yMjA5MjItMS42MDE5OTNMNC42NjI1MTYtNy45NjIxNDJDNC41Nzg4MjktOC4xNTM0MjUgNC41NjY4NzQtOC4xNjUzOCA0LjMwMzg2MS04LjE2NTM4SDIuODQ1MzNDMi42MDYyMjctOC4xNjUzOCAyLjQ5ODYzLTguMTY1MzggMi40OTg2My03LjkzODIzMkMyLjQ5ODYzLTcuODE4NjggMi41ODIzMTYtNy44MTg2OCAyLjgwOTQ2NS03LjgxODY4QzIuODY5MjQtNy44MTg2OCAzLjU3NDU5NS03LjgxODY4IDMuNTc0NTk1LTcuNzExMDgzQzMuNTc0NTk1LTcuNjg3MTczIDMuNTUwNjg1LTcuNTkxNTMyIDMuNTM4NzMtNy41NTU2NjZMMS45NDg2OTItMS4yMTk0MjdDMS44MDUyMy0uNjMzNjI0IDEuNTE4MzA2LS4zODI1NjUgLjcyOTI2NS0uMzQ2N0MuNjY5NDg5LS4zNDY3IC41NDk5MzgtLjMzNDc0NSAuNTQ5OTM4LS4xMTk1NTJDLjU0OTkzOCAwIC42Njk0ODkgMCAuNzA1MzU1IDBDLjk0NDQ1OCAwIDEuNTU0MTcyLS4wMjM5MSAxLjc5MzI3NS0uMDIzOTFIMi4zNjcxMjNDMi41MzQ0OTYtLjAyMzkxIDIuNzM3NzMzIDAgMi45MDUxMDYgMEMyLjk4ODc5MiAwIDMuMTIwMjk5IDAgMy4xMjAyOTktLjIyNzE0OEMzLjEyMDI5OS0uMzM0NzQ1IDMuMDAwNzQ3LS4zNDY3IDIuOTUyOTI3LS4zNDY3QzIuNTU4NDA2LS4zNTg2NTUgMi4xNzU4NDEtLjQzMDM4NiAyLjE3NTg0MS0uODYwNzcyQzIuMTc1ODQxLS45NTY0MTMgMi4xOTk3NTEtMS4wNjQwMSAyLjIyMzY2MS0xLjE1OTY1MUwzLjgzNzYwOS03LjU1NTY2NkMzLjkwOTM0LTcuNDM2MTE1IDMuOTA5MzQtNy40MTIyMDQgMy45NTcxNjEtNy4zMDQ2MDhMNi44MDI0OTEtLjIxNTE5M0M2Ljg2MjI2Ny0uMDcxNzMxIDYuODg2MTc3IDAgNi45OTM3NzMgMEM3LjExMzMyNSAwIDcuMTI1MjgtLjAzNTg2NiA3LjE3MzEwMS0uMjM5MTAzTDguODQ2ODI0LTYuOTEwMDg3WicvPgo8cGF0aCBpZD0nZzItODcnIGQ9J00xMC43OTU1MTctNi44MzgzNTZDMTEuMDcwNDg2LTcuMzA0NjA4IDExLjMzMzQ5OS03Ljc0Njk0OSAxMi4wNTA4MDktNy44MTg2OEMxMi4xNTg0MDYtNy44MzA2MzUgMTIuMjY2MDAyLTcuODQyNTkgMTIuMjY2MDAyLTguMDMzODczQzEyLjI2NjAwMi04LjE2NTM4IDEyLjE1ODQwNi04LjE2NTM4IDEyLjEyMjU0LTguMTY1MzhDMTIuMDk4NjMtOC4xNjUzOCAxMi4wMTQ5NDQtOC4xNDE0NjkgMTEuMjI1OTAzLTguMTQxNDY5QzEwLjg2NzI0OC04LjE0MTQ2OSAxMC40OTY2MzgtOC4xNjUzOCAxMC4xNDk5MzgtOC4xNjUzOEMxMC4wNzgyMDctOC4xNjUzOCA5LjkzNDc0NS04LjE2NTM4IDkuOTM0NzQ1LTcuOTM4MjMyQzkuOTM0NzQ1LTcuODMwNjM1IDEwLjAzMDM4Ni03LjgxODY4IDEwLjEwMjExNy03LjgxODY4QzEwLjM0MTIyLTcuODA2NzI1IDEwLjcyMzc4Ni03LjczNDk5NCAxMC43MjM3ODYtNy4zNjQzODRDMTAuNzIzNzg2LTcuMjA4OTY2IDEwLjY3NTk2NS03LjEyNTI4IDEwLjU1NjQxMy02LjkyMjA0Mkw3LjI5MjY1My0xLjIwNzQ3Mkw2Ljg2MjI2Ny03LjQzNjExNUM2Ljg2MjI2Ny03LjU3OTU3NyA2Ljk5Mzc3My03LjgwNjcyNSA3LjY2MzI2My03LjgxODY4QzcuODE4NjgtNy44MTg2OCA3LjkzODIzMi03LjgxODY4IDcuOTM4MjMyLTguMDQ1ODI4QzcuOTM4MjMyLTguMTY1MzggNy44MTg2OC04LjE2NTM4IDcuNzU4OTA0LTguMTY1MzhDNy4zNDA0NzMtOC4xNjUzOCA2Ljg5ODEzMi04LjE0MTQ2OSA2LjQ2Nzc0Ni04LjE0MTQ2OUg1Ljg0NjA3N0M1LjY2Njc1LTguMTQxNDY5IDUuNDUxNTU3LTguMTY1MzggNS4yNzIyMjktOC4xNjUzOEM1LjIwMDQ5OC04LjE2NTM4IDUuMDU3MDM2LTguMTY1MzggNS4wNTcwMzYtNy45MzgyMzJDNS4wNTcwMzYtNy44MTg2OCA1LjE0MDcyMi03LjgxODY4IDUuMzQzOTYtNy44MTg2OEM1Ljg5Mzg5OC03LjgxODY4IDUuODkzODk4LTcuODA2NzI1IDUuOTQxNzE5LTcuMDc3NDZMNS45Nzc1ODQtNi42NDcwNzNMMi44ODExOTYtMS4yMDc0NzJMMi40Mzg4NTQtNy4zNzYzMzlDMi40Mzg4NTQtNy41MDc4NDYgMi40Mzg4NTQtNy44MDY3MjUgMy4yNTE4MDYtNy44MTg2OEMzLjM4MzMxMy03LjgxODY4IDMuNTE0ODE5LTcuODE4NjggMy41MTQ4MTktOC4wMzM4NzNDMy41MTQ4MTktOC4xNjUzOCAzLjQwNzIyMy04LjE2NTM4IDMuMzM1NDkyLTguMTY1MzhDMi45MTcwNjEtOC4xNjUzOCAyLjQ3NDcyLTguMTQxNDY5IDIuMDQ0MzM0LTguMTQxNDY5SDEuNDIyNjY1QzEuMjQzMzM3LTguMTQxNDY5IDEuMDI4MTQ0LTguMTY1MzggLjg0ODgxNy04LjE2NTM4Qy43NzcwODYtOC4xNjUzOCAuNjMzNjI0LTguMTY1MzggLjYzMzYyNC03LjkzODIzMkMuNjMzNjI0LTcuODE4NjggLjcyOTI2NS03LjgxODY4IC44OTY2MzgtNy44MTg2OEMxLjQ1ODUzMS03LjgxODY4IDEuNDcwNDg2LTcuNzQ2OTQ5IDEuNDk0Mzk2LTcuMzY0Mzg0TDIuMDIwNDIzLS4wMjM5MUMyLjAzMjM3OSAuMTc5MzI4IDIuMDQ0MzM0IC4yNTEwNTkgMi4xODc3OTYgLjI1MTA1OUMyLjMwNzM0NyAuMjUxMDU5IDIuMzMxMjU4IC4yMDMyMzggMi40Mzg4NTQgLjAyMzkxTDYuMDAxNDk0LTYuMjA0NzMyTDYuNDQzODM2LS4wMjM5MUM2LjQ1NTc5MSAuMTc5MzI4IDYuNDY3NzQ2IC4yNTEwNTkgNi42MTEyMDggLjI1MTA1OUM2LjczMDc2IC4yNTEwNTkgNi43NjY2MjUgLjE5MTI4MyA2Ljg2MjI2NyAuMDIzOTFMMTAuNzk1NTE3LTYuODM4MzU2WicvPgo8cGF0aCBpZD0nZzItMTA1JyBkPSdNMy4zODMzMTMtMS43MDk1ODlDMy4zODMzMTMtMS43NjkzNjUgMy4zMzU0OTItMS44MTcxODYgMy4yNjM3NjEtMS44MTcxODZDMy4xNTYxNjQtMS44MTcxODYgMy4xNDQyMDktMS43ODEzMiAzLjA4NDQzMy0xLjU3ODA4MkMyLjc3MzU5OS0uNDkwMTYyIDIuMjgzNDM3LS4xMTk1NTIgMS44ODg5MTctLjExOTU1MkMxLjc0NTQ1NS0uMTE5NTUyIDEuNTc4MDgyLS4xNTU0MTcgMS41NzgwODItLjUxNDA3MkMxLjU3ODA4Mi0uODM2ODYyIDEuNzIxNTQ0LTEuMTk1NTE3IDEuODUzMDUxLTEuNTU0MTcyTDIuNjg5OTEzLTMuNzc3ODMzQzIuNzI1Nzc4LTMuODczNDc0IDIuODA5NDY1LTQuMDg4NjY3IDIuODA5NDY1LTQuMzE1ODE2QzIuODA5NDY1LTQuODE3OTMzIDIuNDUwODA5LTUuMjcyMjI5IDEuODY1MDA2LTUuMjcyMjI5Qy43NjUxMzEtNS4yNzIyMjkgLjMyMjc5LTMuNTM4NzMgLjMyMjc5LTMuNDQzMDg4Qy4zMjI3OS0zLjM5NTI2OCAuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTYxODkzLTMuMzM1NDkyIC41NzM4NDgtMy4zODMzMTMgLjYyMTY2OS0zLjU1MDY4NUMuOTA4NTkzLTQuNTU0OTE5IDEuMzYyODg5LTUuMDMzMTI2IDEuODI5MTQxLTUuMDMzMTI2QzEuOTM2NzM3LTUuMDMzMTI2IDIuMTM5OTc1LTUuMDIxMTcxIDIuMTM5OTc1LTQuNjM4NjA1QzIuMTM5OTc1LTQuMzI3NzcxIDEuOTg0NTU4LTMuOTMzMjUgMS44ODg5MTctMy42NzAyMzdMMS4wNTIwNTUtMS40NDY1NzVDLjk4MDMyNC0xLjI1NTI5MyAuOTA4NTkzLTEuMDY0MDEgLjkwODU5My0uODQ4ODE3Qy45MDg1OTMtLjMxMDgzNCAxLjI3OTIwMyAuMTE5NTUyIDEuODUzMDUxIC4xMTk1NTJDMi45NTI5MjcgLjExOTU1MiAzLjM4MzMxMy0xLjYyNTkwMyAzLjM4MzMxMy0xLjcwOTU4OVpNMy4yODc2NzEtNy40NjAwMjVDMy4yODc2NzEtNy42MzkzNTIgMy4xNDQyMDktNy44NTQ1NDUgMi44ODExOTYtNy44NTQ1NDVDMi42MDYyMjctNy44NTQ1NDUgMi4yOTUzOTItNy41OTE1MzIgMi4yOTUzOTItNy4yODA2OTdDMi4yOTUzOTItNi45ODE4MTggMi41NDY0NTEtNi44ODYxNzcgMi42ODk5MTMtNi44ODYxNzdDMy4wMTI3MDItNi44ODYxNzcgMy4yODc2NzEtNy4xOTcwMTEgMy4yODc2NzEtNy40NjAwMjVaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PScwJyB4bGluazpocmVmPScjZzItODcnLz4KPHVzZSB4PScxMS4wNTE1MScgeT0nMS43OTMyNjMnIHhsaW5rOmhyZWY9JyNnMS0xMDUnLz4KPHVzZSB4PScxNy43NTM2MTEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnNC02MScvPgo8dXNlIHg9JzMwLjE3OTA5MScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTY5Jy8+Cjx1c2UgeD0nMzkuNTQ1Mjg2JyB5PScwJyB4bGluazpocmVmPScjZzQtOTEnLz4KPHVzZSB4PSc0Mi43OTY5NDcnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi03MicvPgo8dXNlIHg9JzUyLjQ5NTkyNycgeT0nMS44NTk3MScgeGxpbms6aHJlZj0nI2czLTQwJy8+Cjx1c2UgeD0nNTUuNzg5MTgxJyB5PScxLjg1OTcxJyB4bGluazpocmVmPScjZzEtMTA1Jy8+Cjx1c2UgeD0nNTguNjcyMzInIHk9JzEuODU5NzEnIHhsaW5rOmhyZWY9JyNnMy00MScvPgo8dXNlIHg9JzYyLjQ2MzcwNicgeT0nMCcgeGxpbms6aHJlZj0nI2c0LTkzJy8+Cjx1c2UgeD0nNjUuNzE1MzY3JyB5PScwJyB4bGluazpocmVmPScjZzItNTknLz4KPHVzZSB4PSc3MC45NTk1MjYnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMC01NicvPgo8dXNlIHg9Jzc3LjYwMTMwNicgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTEwNScvPgo8dXNlIHg9Jzg0LjkxNTU2OCcgeT0nMCcgeGxpbms6aHJlZj0nI2cwLTIwJy8+Cjx1c2UgeD0nOTcuNTM0ODk0JyB5PScwJyB4bGluazpocmVmPScjZzItNzgnLz4KPC9nPgo8L3N2Zz4=) .
. .
If the points are one the first diagonal, the copula model is
validated.
.
If the points are one the first diagonal, the copula model is
validated. respectively
associated to the first and second sample. Note that the two samples
must have the same size.
respectively
associated to the first and second sample. Note that the two samples
must have the same size.(Source code, png, hires.png, pdf)
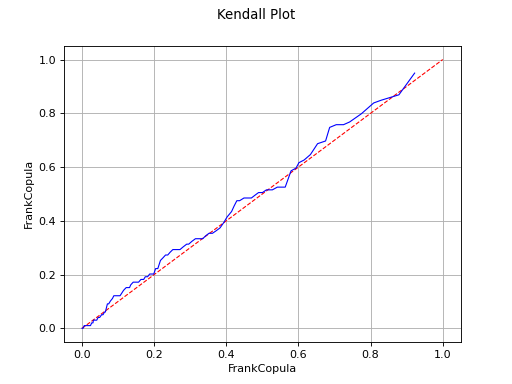{kind=link}
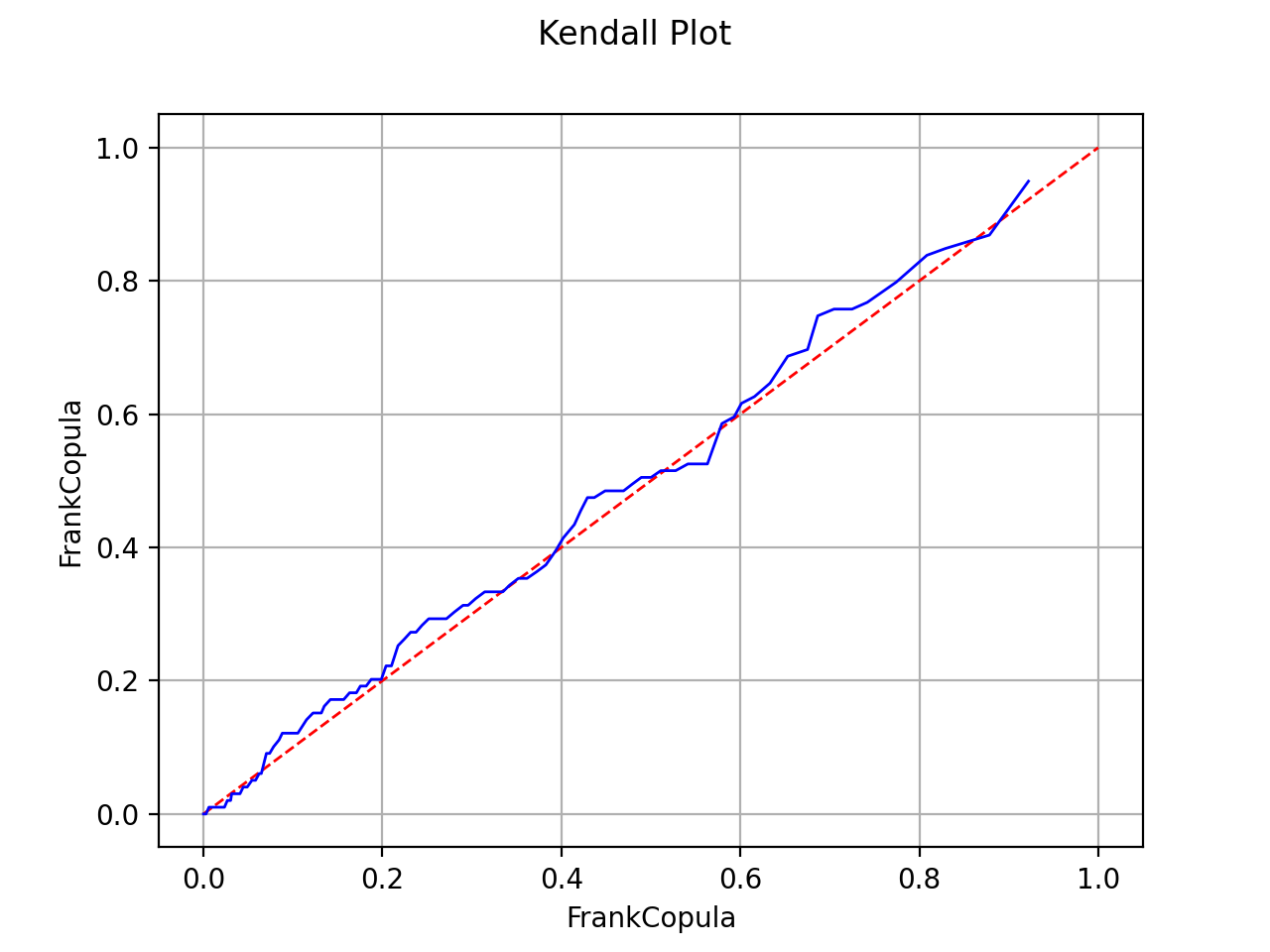{kind=link}
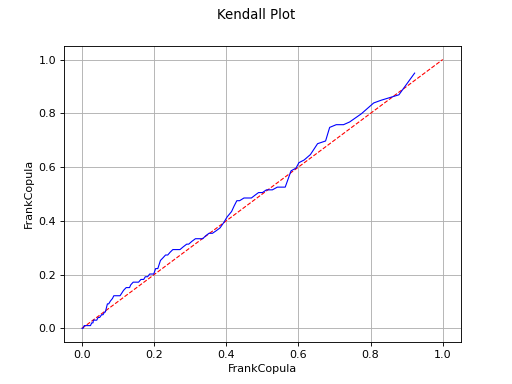
The Kendall Plot test validates the use of the Frank copula for a sample.
(Source code, png, hires.png, pdf)
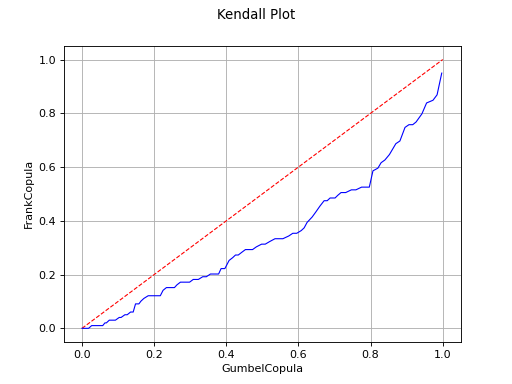{kind=link}
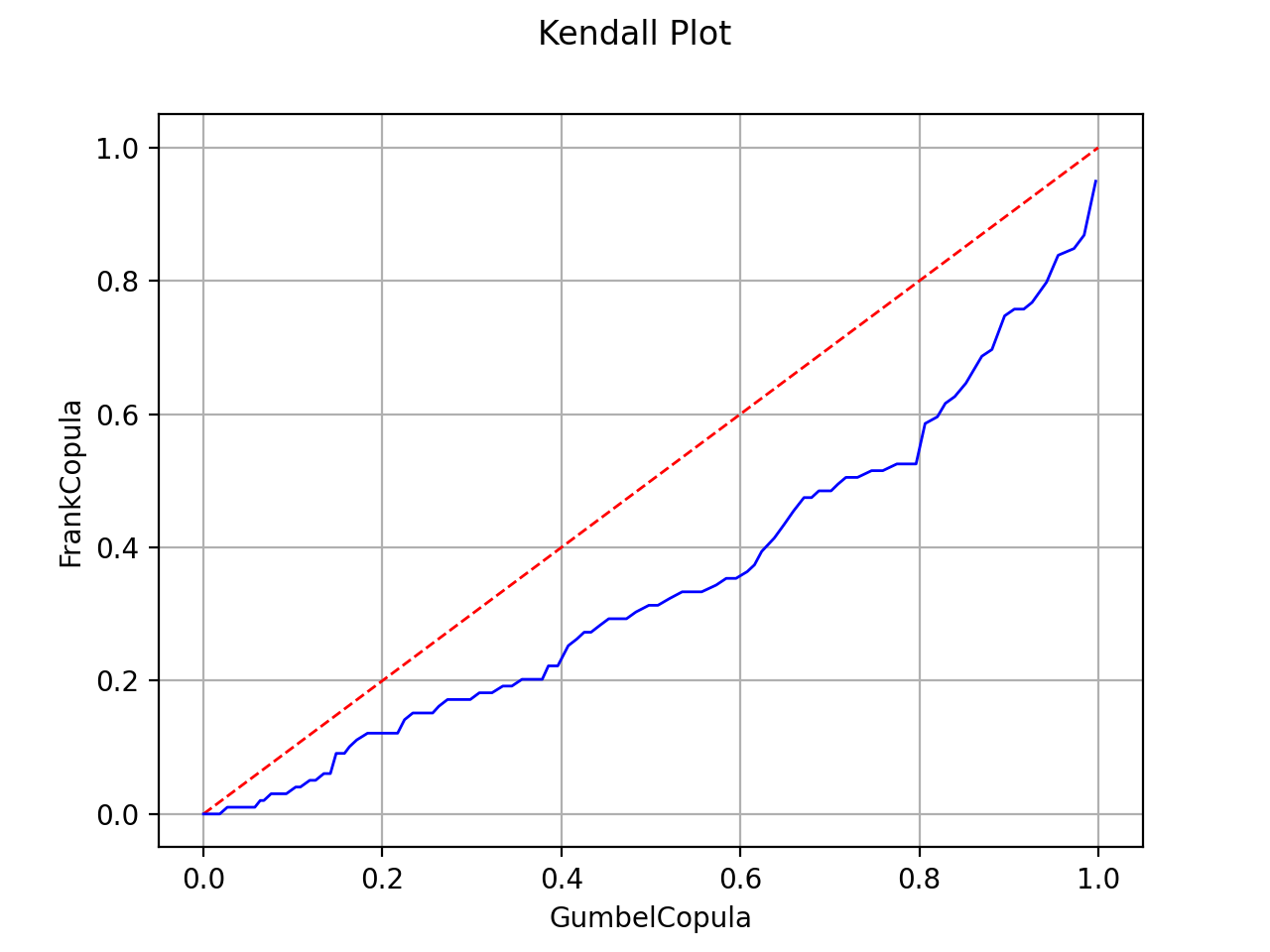{kind=link}
The Kendall Plot test invalidates the use of the Frank copula for a sample.
Remark: In the case where you want to test a sample with respect to a specific copula, if the size of the sample is superior to 500, we recommend to use the second form of the Kendall plot test: generate a sample of the proper size from your copula and then test both samples. This way of doing is more efficient.