Linear regression¶
This method deals with the parametric modelling of a probability
distribution for a random vector
 . It aims to measure
a type of dependence (here a linear relation) which may exist between a
component
. It aims to measure
a type of dependence (here a linear relation) which may exist between a
component  and other uncertain variables
and other uncertain variables  .
.
The principle of the multiple linear regression model is to find the
function that links the variable to other variables
 ,…,
,…, by means of a linear model:
by means of a linear model:

where  describes a random variable with zero mean
and standard deviation
describes a random variable with zero mean
and standard deviation  independent of the input variables
. For given values of ,…,,
the average forecast of is denoted by
independent of the input variables
. For given values of ,…,,
the average forecast of is denoted by  and is defined as:
and is defined as:

The estimators for the regression coefficients
 , and the
standard deviation are obtained from a sample of
, and the
standard deviation are obtained from a sample of
 , that is a set of
, that is a set of  values
values
 ,…,
,…, .
They are determined via the least-squares method:
.
They are determined via the least-squares method:
![\begin{aligned}
\left\{ \widehat{a}_0,\widehat{a}_1,\ldots,\widehat{a}_{K} \right\} = \textrm{argmin} \sum_{k=1}^n \left[ x^i_k - a_0 - \sum_{j \in \{ j_1,\ldots,j_K \} } a_j x^j_k \right]^2
\end{aligned}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyOTYuNDMyMDY2cHQnIGhlaWdodD0nNDUuMDIwNDgxcHQnIHZpZXdCb3g9JzQ1LjgwNjM3NiAtNDUuMDIwNDc0IDI5Ni40MzIwNjYgNDUuMDIwNDgxJz4KPGRlZnM+CjxwYXRoIGlkPSdnNi00OScgZD0nTTIuMTQ1OTUzLTMuNzk1NzY2QzIuMTQ1OTUzLTMuOTc1MDkzIDIuMTIyMDQyLTMuOTc1MDkzIDEuOTQyNzE1LTMuOTc1MDkzQzEuNTQ4MTk0LTMuNTkyNTI4IC45Mzg0ODEtMy41OTI1MjggLjcyMzI4OC0zLjU5MjUyOFYtMy4zNTk0MDJDLjg3ODcwNS0zLjM1OTQwMiAxLjI3MzIyNS0zLjM1OTQwMiAxLjYzMTg4LTMuNTI2Nzc1Vi0uNTA4MDk1QzEuNjMxODgtLjMxMDgzNCAxLjYzMTg4LS4yMzMxMjYgMS4wMTYxODktLjIzMzEyNkguNzU5MTUzVjBDMS4wODc5Mi0uMDIzOTEgMS41NTQxNzItLjAyMzkxIDEuODg4OTE3LS4wMjM5MVMyLjY4OTkxMy0uMDIzOTEgMy4wMTg2OCAwVi0uMjMzMTI2SDIuNzYxNjQ0QzIuMTQ1OTUzLS4yMzMxMjYgMi4xNDU5NTMtLjMxMDgzNCAyLjE0NTk1My0uNTA4MDk1Vi0zLjc5NTc2NlonLz4KPHBhdGggaWQ9J2c4LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnOC05NycgZD0nTTQuNjE0Njk1LTMuMTkyMDNDNC42MTQ2OTUtMy44Mzc2MDkgNC42MTQ2OTUtNC4zMTU4MTYgNC4wODg2NjctNC43ODIwNjdDMy42NzAyMzctNS4xNjQ2MzMgMy4xMzIyNTQtNS4zMzIwMDUgMi42MDYyMjctNS4zMzIwMDVDMS42MjU5MDMtNS4zMzIwMDUgLjg3MjcyNy00LjY4NjQyNiAuODcyNzI3LTMuOTA5MzRDLjg3MjcyNy0zLjU2MjY0IDEuMDk5ODc1LTMuMzk1MjY4IDEuMzc0ODQ0LTMuMzk1MjY4QzEuNjYxNzY4LTMuMzk1MjY4IDEuODY1MDA2LTMuNTk4NTA2IDEuODY1MDA2LTMuODg1NDNDMS44NjUwMDYtNC4zNzU1OTIgMS40MzQ2Mi00LjM3NTU5MiAxLjI1NTI5My00LjM3NTU5MkMxLjUzMDI2Mi00Ljg3NzcwOSAyLjEwNDExLTUuMDkyOTAyIDIuNTgyMzE2LTUuMDkyOTAyQzMuMTMyMjU0LTUuMDkyOTAyIDMuODM3NjA5LTQuNjM4NjA1IDMuODM3NjA5LTMuNTYyNjRWLTMuMDg0NDMzQzEuNDM0NjItMy4wNDg1NjggLjUyNjAyNy0yLjA0NDMzNCAuNTI2MDI3LTEuMTIzNzg2Qy41MjYwMjctLjE3OTMyOCAxLjYyNTkwMyAuMTE5NTUyIDIuMzU1MTY4IC4xMTk1NTJDMy4xNDQyMDkgLjExOTU1MiAzLjY4MjE5Mi0uMzU4NjU1IDMuOTA5MzQtLjkzMjUwM0MzLjk1NzE2MS0uMzcwNjEgNC4zMjc3NzEgLjA1OTc3NiA0Ljg0MTg0MyAuMDU5Nzc2QzUuMDkyOTAyIC4wNTk3NzYgNS43ODYzMDEtLjEwNzU5NyA1Ljc4NjMwMS0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OC0uMzgyNTY1IDUuMjM2MzY0LS4yODY5MjQgNS4wNjg5OTEtLjI4NjkyNEM0LjYxNDY5NS0uMjg2OTI0IDQuNjE0Njk1LS45MjA1NDggNC42MTQ2OTUtMS4wOTk4NzVWLTMuMTkyMDNaTTMuODM3NjA5LTEuNjg1Njc5QzMuODM3NjA5LS41MTQwNzIgMi45NjQ4ODItLjExOTU1MiAyLjQ1MDgwOS0uMTE5NTUyQzEuODY1MDA2LS4xMTk1NTIgMS4zNzQ4NDQtLjU0OTkzOCAxLjM3NDg0NC0xLjEyMzc4NkMxLjM3NDg0NC0yLjcwMTg2OCAzLjQwNzIyMy0yLjg0NTMzIDMuODM3NjA5LTIuODY5MjRWLTEuNjg1Njc5WicvPgo8cGF0aCBpZD0nZzgtMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzgtMTA1JyBkPSdNMi4wODAxOTktNy4zNjQzODRDMi4wODAxOTktNy42NzUyMTggMS44MjkxNDEtNy45NTAxODcgMS40OTQzOTYtNy45NTAxODdDMS4xODM1NjItNy45NTAxODcgLjkyMDU0OC03LjY5OTEyOCAuOTIwNTQ4LTcuMzc2MzM5Qy45MjA1NDgtNy4wMTc2ODQgMS4yMDc0NzItNi43OTA1MzUgMS40OTQzOTYtNi43OTA1MzVDMS44NjUwMDYtNi43OTA1MzUgMi4wODAxOTktNy4xMDEzNyAyLjA4MDE5OS03LjM2NDM4NFpNLjQzMDM4Ni01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTctNC43OTQwMjIgMS4zMDMxMTMtNC43MjIyOTEgMS4zMDMxMTMtNC4xMzY0ODhWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzAzMTEzLS4wMjM5MSAxLjY0OTgxMy0uMDIzOTFDMS43ODEzMi0uMDIzOTEgMi40NzQ3Mi0uMDIzOTEgMi44ODExOTYgMFYtLjM0NjdDMi4xMDQxMS0uMzQ2NyAyLjA1NjI4OS0uNDA2NDc2IDIuMDU2Mjg5LS44NzI3MjdWLTUuMjcyMjI5TC40MzAzODYtNS4xNDA3MjJaJy8+CjxwYXRoIGlkPSdnOC0xMDknIGQ9J004LjU3MTg1Ni0yLjkwNTEwNkM4LjU3MTg1Ni00LjAxNjkzNiA4LjU3MTg1Ni00LjM1MTY4MSA4LjI5Njg4Ny00LjczNDI0N0M3Ljk1MDE4Ny01LjIwMDQ5OCA3LjM4ODI5NC01LjI3MjIyOSA2Ljk4MTgxOC01LjI3MjIyOUM1Ljk4OTUzOS01LjI3MjIyOSA1LjQ4NzQyMi00LjU1NDkxOSA1LjI5NjEzOS00LjA4ODY2N0M1LjEyODc2Ny01LjAwOTIxNSA0LjQ4MzE4OC01LjI3MjIyOSAzLjczMDAxMi01LjI3MjIyOUMyLjU3MDM2MS01LjI3MjIyOSAyLjExNjA2NS00LjI3OTk1IDIuMDIwNDIzLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwuMzgyNTY1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNy00Ljc5NDAyMiAxLjI5MTE1OC00LjcxMDMzNiAxLjI5MTE1OC00LjEyNDUzM1YtLjg4NDY4MkMxLjI5MTE1OC0uMzQ2NyAxLjE1OTY1MS0uMzQ2NyAuMzgyNTY1LS4zNDY3VjBDLjY5MzQtLjAyMzkxIDEuMzM4OTc5LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFDMi4wMjA0MjMtLjAyMzkxIDIuNjY2MDAyLS4wMjM5MSAyLjk3NjgzNyAwVi0uMzQ2N0MyLjIxMTcwNi0uMzQ2NyAyLjA2ODI0NC0uMzQ2NyAyLjA2ODI0NC0uODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NC00LjM2MzYzNiAyLjg5MzE1MS01LjAzMzEyNiAzLjYzNDM3MS01LjAzMzEyNlM0LjU0Mjk2NC00LjQyMzQxMiA0LjU0Mjk2NC0zLjY5NDE0N1YtLjg4NDY4MkM0LjU0Mjk2NC0uMzQ2NyA0LjQxMTQ1Ny0uMzQ2NyAzLjYzNDM3MS0uMzQ2N1YwQzMuOTQ1MjA1LS4wMjM5MSA0LjU5MDc4NS0uMDIzOTEgNC45MjU1MjktLjAyMzkxQzUuMjcyMjI5LS4wMjM5MSA1LjkxNzgwOC0uMDIzOTEgNi4yMjg2NDMgMFYtLjM0NjdDNS40NjM1MTItLjM0NjcgNS4zMjAwNS0uMzQ2NyA1LjMyMDA1LS44ODQ2ODJWLTMuMTA4MzQ0QzUuMzIwMDUtNC4zNjM2MzYgNi4xNDQ5NTYtNS4wMzMxMjYgNi44ODYxNzctNS4wMzMxMjZTNy43OTQ3Ny00LjQyMzQxMiA3Ljc5NDc3LTMuNjk0MTQ3Vi0uODg0NjgyQzcuNzk0NzctLjM0NjcgNy42NjMyNjMtLjM0NjcgNi44ODYxNzctLjM0NjdWMEM3LjE5NzAxMS0uMDIzOTEgNy44NDI1OS0uMDIzOTEgOC4xNzczMzUtLjAyMzkxQzguNTI0MDM1LS4wMjM5MSA5LjE2OTYxNC0uMDIzOTEgOS40ODA0NDggMFYtLjM0NjdDOC44ODI2OS0uMzQ2NyA4LjU4MzgxMS0uMzQ2NyA4LjU3MTg1Ni0uNzA1MzU1Vi0yLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c4LTExMCcgZD0nTTUuMzIwMDUtMi45MDUxMDZDNS4zMjAwNS00LjAxNjkzNiA1LjMyMDA1LTQuMzUxNjgxIDUuMDQ1MDgxLTQuNzM0MjQ3QzQuNjk4MzgxLTUuMjAwNDk4IDQuMTM2NDg4LTUuMjcyMjI5IDMuNzMwMDEyLTUuMjcyMjI5QzIuNTcwMzYxLTUuMjcyMjI5IDIuMTE2MDY1LTQuMjc5OTUgMi4wMjA0MjMtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TC4zODI1NjUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3LTQuNzk0MDIyIDEuMjkxMTU4LTQuNzEwMzM2IDEuMjkxMTU4LTQuMTI0NTMzVi0uODg0NjgyQzEuMjkxMTU4LS4zNDY3IDEuMTU5NjUxLS4zNDY3IC4zODI1NjUtLjM0NjdWMEMuNjkzNC0uMDIzOTEgMS4zMzg5NzktLjAyMzkxIDEuNjczNzI0LS4wMjM5MUMyLjAyMDQyMy0uMDIzOTEgMi42NjYwMDItLjAyMzkxIDIuOTc2ODM3IDBWLS4zNDY3QzIuMjExNzA2LS4zNDY3IDIuMDY4MjQ0LS4zNDY3IDIuMDY4MjQ0LS44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0LTQuMzYzNjM2IDIuODkzMTUxLTUuMDMzMTI2IDMuNjM0MzcxLTUuMDMzMTI2UzQuNTQyOTY0LTQuNDIzNDEyIDQuNTQyOTY0LTMuNjk0MTQ3Vi0uODg0NjgyQzQuNTQyOTY0LS4zNDY3IDQuNDExNDU3LS4zNDY3IDMuNjM0MzcxLS4zNDY3VjBDMy45NDUyMDUtLjAyMzkxIDQuNTkwNzg1LS4wMjM5MSA0LjkyNTUyOS0uMDIzOTFDNS4yNzIyMjktLjAyMzkxIDUuOTE3ODA4LS4wMjM5MSA2LjIyODY0MyAwVi0uMzQ2N0M1LjYzMDg4NC0uMzQ2NyA1LjMzMjAwNS0uMzQ2NyA1LjMyMDA1LS43MDUzNTVWLTIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzgtMTE0JyBkPSdNMS45OTY1MTMtMi43ODU1NTRDMS45OTY1MTMtMy45NDUyMDUgMi40NzQ3Mi01LjAzMzEyNiAzLjM5NTI2OC01LjAzMzEyNkMzLjQ5MDkwOS01LjAzMzEyNiAzLjUxNDgxOS01LjAzMzEyNiAzLjU2MjY0LTUuMDIxMTcxQzMuNDY2OTk5LTQuOTczMzUgMy4yNzU3MTYtNC45MDE2MTkgMy4yNzU3MTYtNC41Nzg4MjlDMy4yNzU3MTYtNC4yMzIxMyAzLjU1MDY4NS00LjEwMDYyMyAzLjc0MTk2OC00LjEwMDYyM0MzLjk4MTA3MS00LjEwMDYyMyA0LjIyMDE3NC00LjI1NjA0IDQuMjIwMTc0LTQuNTc4ODI5QzQuMjIwMTc0LTQuOTM3NDg0IDMuODk3Mzg1LTUuMjcyMjI5IDMuMzgzMzEzLTUuMjcyMjI5QzIuMzY3MTIzLTUuMjcyMjI5IDIuMDIwNDIzLTQuMTcyMzU0IDEuOTQ4NjkyLTMuOTQ1MjA1SDEuOTM2NzM3Vi01LjI3MjIyOUwuMzM0NzQ1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE0NzY5Ni00Ljc5NDAyMiAxLjI0MzMzNy00LjcxMDMzNiAxLjI0MzMzNy00LjEyNDUzM1YtLjg4NDY4MkMxLjI0MzMzNy0uMzQ2NyAxLjExMTgzMS0uMzQ2NyAuMzM0NzQ1LS4zNDY3VjBDLjY2OTQ4OS0uMDIzOTEgMS4zMjcwMjQtLjAyMzkxIDEuNjg1Njc5LS4wMjM5MUMyLjAwODQ2OC0uMDIzOTEgMi44NTcyODUtLjAyMzkxIDMuMTMyMjU0IDBWLS4zNDY3SDIuODkzMTUxQzIuMDIwNDIzLS4zNDY3IDEuOTk2NTEzLS40NzgyMDcgMS45OTY1MTMtLjkwODU5M1YtMi43ODU1NTRaJy8+CjxwYXRoIGlkPSdnNC01OCcgZD0nTTEuNjE3OTMzLS40MzgzNTZDMS42MTc5MzMtLjcwOTM0IDEuMzk0NzctLjg4NDY4MiAxLjE3OTU3Ny0uODg0NjgyQy45MjQ1MzMtLjg4NDY4MiAuNzMzMjUtLjY3NzQ2IC43MzMyNS0uNDQ2MzI2Qy43MzMyNS0uMTc1MzQyIC45NTY0MTMgMCAxLjE3MTYwNiAwQzEuNDI2NjUgMCAxLjYxNzkzMy0uMjA3MjIzIDEuNjE3OTMzLS40MzgzNTZaJy8+CjxwYXRoIGlkPSdnNC01OScgZD0nTTEuNDkwNDExLS4xMTk1NTJDMS40OTA0MTEgLjM5ODUwNiAxLjM3ODgyOSAuODUyODAyIC44ODQ2ODIgMS4zNDY5NDlDLjg1MjgwMiAxLjM3MDg1OSAuODM2ODYyIDEuMzg2OCAuODM2ODYyIDEuNDI2NjVDLjgzNjg2MiAxLjQ5MDQxMSAuOTAwNjIzIDEuNTM4MjMyIC45NTY0MTMgMS41MzgyMzJDMS4wNTIwNTUgMS41MzgyMzIgMS43MTM1NzQgLjkwODU5MyAxLjcxMzU3NC0uMDIzOTFDMS43MTM1NzQtLjUzMzk5OCAxLjUyMjI5MS0uODg0NjgyIDEuMTcxNjA2LS44ODQ2ODJDLjg5MjY1My0uODg0NjgyIC43MzMyNS0uNjYxNTE5IC43MzMyNS0uNDQ2MzI2Qy43MzMyNS0uMjIzMTYzIC44ODQ2ODIgMCAxLjE3OTU3NyAwQzEuMzcwODU5IDAgMS40OTA0MTEtLjExMTU4MiAxLjQ5MDQxMS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzQtNzUnIGQ9J000LjI3OTk1LTMuMjAzOTg1QzQuMjcxOTgtMy4yMTk5MjUgNC4yMzIxMy0zLjI5OTYyNiA0LjIzMjEzLTMuMzA3NTk3QzQuMjMyMTMtMy4zMjM1MzcgNC4zNjc2MjEtMy40MTkxNzggNC40NDczMjMtMy40NzQ5NjlDNS4wNzY5NjEtMy45MzcyMzUgNS45Mzc3MzMtNC41NTg5MDQgNi4yMDA3NDctNC43MjYyNzZDNi42MDcyMjMtNC45ODEzMiA2LjkwMjExNy01LjE0ODY5MiA3LjI2MDc3Mi01LjE4MDU3M0M3LjMyNDUzMy01LjE4ODU0MyA3LjQzNjExNS01LjE5NjUxMyA3LjQzNjExNS01LjMzOTk3NUM3LjQyODE0NC01LjM5NTc2NiA3LjM4MDMyNC01LjQ0MzU4NyA3LjMyNDUzMy01LjQ0MzU4N0M3LjMxNjU2My01LjQ0MzU4NyA3LjA5MzQtNS40MTk2NzYgNy4wMzc2MDktNS40MTk2NzZINi43MTg4MDRDNi41ODMzMTMtNS40MTk2NzYgNi4zODQwNi01LjQxOTY3NiA2LjMxMjMyOS01LjQyNzY0NkM2LjI1NjUzOC01LjQyNzY0NiA1Ljk0NTcwNC01LjQ0MzU4NyA1Ljg4OTkxMy01LjQ0MzU4N1M1LjcyMjU0LTUuNDQzNTg3IDUuNzIyNTQtNS4yOTIxNTRDNS43MjI1NC01LjI4NDE4NCA1LjczMDUxMS01LjE4ODU0MyA1Ljg1MDA2Mi01LjE4MDU3M0M1LjkxMzgyMy01LjE3MjYwMyA2LjA0MTM0NS01LjE1NjY2MyA2LjA0MTM0NS01LjA2MTAyMUM2LjA0MTM0NS00LjkzMzQ5OSA1Ljg4MTk0My00Ljc5ODAwNyA1Ljg2NjAwMi00Ljc5MDAzN0w1LjgwMjI0Mi00LjczNDI0N0M1Ljc3ODMzMS00LjcxMDMzNiA1Ljc0NjQ1MS00LjY3ODQ1NiA1LjcwNjYtNC42NTQ1NDVMMi40NTQ3OTUtMi4yOTUzOTJMMy4wODQ0MzMtNC44MjE5MThDMy4xNTYxNjQtNS4xMDg4NDIgMy4xNzIxMDUtNS4xODA1NzMgMy43NTM5MjMtNS4xODA1NzNDMy45MTMzMjUtNS4xODA1NzMgNC4wMDg5NjYtNS4xODA1NzMgNC4wMDg5NjYtNS4zMzIwMDVDNC4wMDg5NjYtNS4zMzk5NzUgNC4wMDA5OTYtNS40NDM1ODcgMy44NzM0NzQtNS40NDM1ODdDMy43MjIwNDItNS40NDM1ODcgMy41MzA3Ni01LjQyNzY0NiAzLjM3OTMyOC01LjQxOTY3NkgyLjg3NzIxQzIuMTEyMDgtNS40MTk2NzYgMS45MDQ4NTctNS40NDM1ODcgMS44NDkwNjYtNS40NDM1ODdDMS44MDkyMTUtNS40NDM1ODcgMS42ODk2NjQtNS40NDM1ODcgMS42ODk2NjQtNS4yOTIxNTRDMS42ODk2NjQtNS4xODA1NzMgMS43ODUzMDUtNS4xODA1NzMgMS45MjA3OTctNS4xODA1NzNDMi4xODM4MTEtNS4xODA1NzMgMi40MTQ5NDQtNS4xODA1NzMgMi40MTQ5NDQtNS4wNTMwNTFDMi40MTQ5NDQtNS4wMjExNzEgMi40MDY5NzQtNS4wMTMyIDIuMzgzMDY0LTQuOTA5NTg5TDEuMzE1MDY4LS42Mjk2MzlDMS4yNDMzMzctLjMyNjc3NSAxLjIyNzM5Ny0uMjYzMDE0IC42Mzc2MDktLjI2MzAxNEMuNDg2MTc3LS4yNjMwMTQgLjM5MDUzNS0uMjYzMDE0IC4zOTA1MzUtLjExMTU4MkMuMzkwNTM1LS4wNzk3MDEgLjQxNDQ0NiAwIC41MTgwNTcgMEMuNjY5NDg5IDAgLjg2MDc3Mi0uMDE1OTQgMS4wMTIyMDQtLjAyMzkxSDIuMDQwMzQ5QzIuMTY3ODctLjAxNTk0IDIuNDMwODg0IDAgMi41NTA0MzYgMEMyLjU5MDI4NiAwIDIuNzA5ODM4IDAgMi43MDk4MzgtLjE0MzQ2MkMyLjcwOTgzOC0uMjYzMDE0IDIuNjE0MTk3LS4yNjMwMTQgMi40Nzg3MDUtLjI2MzAxNEMyLjQyMjkxNC0uMjYzMDE0IDIuMzExMzMzLS4yNjMwMTQgMi4xNzU4NDEtLjI3ODk1NEMyLjAwODQ2OC0uMjk0ODk0IDEuOTg0NTU4LS4zMTA4MzQgMS45ODQ1NTgtLjM5MDUzNUMxLjk4NDU1OC0uNDM4MzU2IDIuMDQwMzQ5LS42Mzc2MDkgMi4wNjQyNTktLjc2NTEzMUwyLjM2NzEyMy0xLjk2ODYxOEwzLjY1MDMxMS0yLjg5MzE1MUw0LjYwNjcyNS0uOTI0NTMzQzQuNjM4NjA1LS44NjA3NzIgNC43MjYyNzYtLjY4NTQzIDQuNzU4MTU3LS42MTM2OTlDNC44MDU5NzgtLjUzMzk5OCA0LjgwNTk3OC0uNTE4MDU3IDQuODA1OTc4LS40ODYxNzdDNC44MDU5NzgtLjI3MDk4NCA0LjUxMTA4My0uMjYzMDE0IDQuNDIzNDEyLS4yNjMwMTRDNC4zNDM3MTEtLjI2MzAxNCA0LjIzMjEzLS4yNjMwMTQgNC4yMzIxMy0uMTExNTgyQzQuMjMyMTMtLjEwMzYxMSA0LjI0MDEgMCA0LjM2NzYyMSAwQzQuNDQ3MzIzIDAgNC43NTAxODctLjAxNTk0IDQuODIxOTE4LS4wMjM5MUg1LjI4NDE4NEM2LjAxNzQzNS0uMDIzOTEgNS45OTM1MjQgMCA2LjA5NzEzNiAwQzYuMTI5MDE2IDAgNi4yNDg1NjggMCA2LjI0ODU2OC0uMTUxNDMyQzYuMjQ4NTY4LS4yNjMwMTQgNi4xMzY5ODYtLjI2MzAxNCA2LjA4OTE2Ni0uMjYzMDE0QzUuNzc4MzMxLS4yNzA5ODQgNS42NzQ3Mi0uMzI2Nzc1IDUuNTQ3MTk4LS41OTc3NThMNC4yNzk5NS0zLjIwMzk4NVonLz4KPHBhdGggaWQ9J2c0LTEwNScgZD0nTTIuMzc1MDkzLTQuOTczMzVDMi4zNzUwOTMtNS4xNDg2OTIgMi4yNDc1NzItNS4yNzYyMTQgMi4wNjQyNTktNS4yNzYyMTRDMS44NTcwMzYtNS4yNzYyMTQgMS42MjU5MDMtNS4wODQ5MzIgMS42MjU5MDMtNC44NDU4MjhDMS42MjU5MDMtNC42NzA0ODYgMS43NTM0MjUtNC41NDI5NjQgMS45MzY3MzctNC41NDI5NjRDMi4xNDM5Ni00LjU0Mjk2NCAyLjM3NTA5My00LjczNDI0NyAyLjM3NTA5My00Ljk3MzM1Wk0xLjIxMTQ1Ny0yLjA0ODMxOUwuNzgxMDcxLS45NDg0NDNDLjc0MTIyLS44Mjg4OTIgLjcwMTM3LS43MzMyNSAuNzAxMzctLjU5Nzc1OEMuNzAxMzctLjIwNzIyMyAxLjAwNDIzNCAuMDc5NzAxIDEuNDI2NjUgLjA3OTcwMUMyLjE5OTc1MSAuMDc5NzAxIDIuNTI2NTI2LTEuMDM2MTE1IDIuNTI2NTI2LTEuMTM5NzI2QzIuNTI2NTI2LTEuMjE5NDI3IDIuNDYyNzY1LTEuMjQzMzM3IDIuNDA2OTc0LTEuMjQzMzM3QzIuMzExMzMzLTEuMjQzMzM3IDIuMjk1MzkyLTEuMTg3NTQ3IDIuMjcxNDgyLTEuMTA3ODQ2QzIuMDg4MTY5LS40NzAyMzcgMS43NjEzOTUtLjE0MzQ2MiAxLjQ0MjU5LS4xNDM0NjJDMS4zNDY5NDktLjE0MzQ2MiAxLjI1MTMwOC0uMTgzMzEzIDEuMjUxMzA4LS4zOTg1MDZDMS4yNTEzMDgtLjU4OTc4OCAxLjMwNzA5OC0uNzMzMjUgMS40MTA3MS0uOTgwMzI0QzEuNDkwNDExLTEuMTk1NTE3IDEuNTcwMTEyLTEuNDEwNzEgMS42NTc3ODMtMS42MjU5MDNMMS45MDQ4NTctMi4yNzE0ODJDMS45NzY1ODgtMi40NTQ3OTUgMi4wNzIyMjktMi43MDE4NjggMi4wNzIyMjktMi44MzczNkMyLjA3MjIyOS0zLjIzNTg2NiAxLjc1MzQyNS0zLjUxNDgxOSAxLjM0Njk0OS0zLjUxNDgxOUMuNTczODQ4LTMuNTE0ODE5IC4yMzkxMDMtMi4zOTkwMDQgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMzk2MDEgLjQ5NDE0Ny0yLjMxOTMwM0MuNzE3MzEtMy4wNzY0NjMgMS4wODM5MzUtMy4yOTE2NTYgMS4zMjMwMzktMy4yOTE2NTZDMS40MzQ2Mi0zLjI5MTY1NiAxLjUxNDMyMS0zLjI1MTgwNiAxLjUxNDMyMS0zLjAyODY0M0MxLjUxNDMyMS0yLjk0ODk0MSAxLjUwNjM1MS0yLjgzNzM2IDEuNDI2NjUtMi41OTgyNTdMMS4yMTE0NTctMi4wNDgzMTlaJy8+CjxwYXRoIGlkPSdnNC0xMDYnIGQ9J00zLjI5MTY1Ni00Ljk3MzM1QzMuMjkxNjU2LTUuMTI0NzgyIDMuMTcyMTA1LTUuMjc2MjE0IDIuOTgwODIyLTUuMjc2MjE0QzIuNzQxNzE5LTUuMjc2MjE0IDIuNTM0NDk2LTUuMDUzMDUxIDIuNTM0NDk2LTQuODQ1ODI4QzIuNTM0NDk2LTQuNjk0Mzk2IDIuNjU0MDQ3LTQuNTQyOTY0IDIuODQ1MzMtNC41NDI5NjRDMy4wODQ0MzMtNC41NDI5NjQgMy4yOTE2NTYtNC43NjYxMjcgMy4yOTE2NTYtNC45NzMzNVpNMS42MjU5MDMgLjM5ODUwNkMxLjUwNjM1MSAuODg0NjgyIDEuMTE1ODE2IDEuNDAyNzQgLjYyOTYzOSAxLjQwMjc0Qy41MDIxMTcgMS40MDI3NCAuMzgyNTY1IDEuMzcwODU5IC4zNjY2MjUgMS4zNjI4ODlDLjYxMzY5OSAxLjI0MzMzNyAuNjQ1NTc5IDEuMDI4MTQ0IC42NDU1NzkgLjk1NjQxM0MuNjQ1NTc5IC43NjUxMzEgLjUwMjExNyAuNjYxNTE5IC4zMzQ3NDUgLjY2MTUxOUMuMTAzNjExIC42NjE1MTktLjExMTU4MiAuODYwNzcyLS4xMTE1ODIgMS4xMjM3ODZDLS4xMTE1ODIgMS40MjY2NSAuMTgzMzEzIDEuNjI1OTAzIC42Mzc2MDkgMS42MjU5MDNDMS4xMjM3ODYgMS42MjU5MDMgMi4wMDA0OTggMS4zMjMwMzkgMi4yMzk2MDEgLjM2NjYyNUwyLjk1NjkxMi0yLjQ4NjY3NUMyLjk4MDgyMi0yLjU4MjMxNiAyLjk5Njc2Mi0yLjY0NjA3NyAyLjk5Njc2Mi0yLjc2NTYyOUMyLjk5Njc2Mi0zLjIwMzk4NSAyLjY0NjA3Ny0zLjUxNDgxOSAyLjE4MzgxMS0zLjUxNDgxOUMxLjMzODk3OS0zLjUxNDgxOSAuODQ0ODMyLTIuMzk5MDA0IC44NDQ4MzItMi4yOTUzOTJDLjg0NDgzMi0yLjIyMzY2MSAuOTAwNjIzLTIuMTkxNzgxIC45NjQzODQtMi4xOTE3ODFDMS4wNTIwNTUtMi4xOTE3ODEgMS4wNjAwMjUtMi4yMTU2OTEgMS4xMTU4MTYtMi4zMzUyNDNDMS4zNTQ5MTktMi44ODUxODEgMS43NjEzOTUtMy4yOTE2NTYgMi4xNTk5LTMuMjkxNjU2QzIuMzI3MjczLTMuMjkxNjU2IDIuNDIyOTE0LTMuMTgwMDc1IDIuNDIyOTE0LTIuOTE3MDYxQzIuNDIyOTE0LTIuODA1NDc5IDIuMzk5MDA0LTIuNjkzODk4IDIuMzc1MDkzLTIuNTgyMzE2TDEuNjI1OTAzIC4zOTg1MDZaJy8+CjxwYXRoIGlkPSdnNC0xMDcnIGQ9J00yLjMyNzI3My01LjI5MjE1NEMyLjMzNTI0My01LjMwODA5NSAyLjM1OTE1My01LjQxMTcwNiAyLjM1OTE1My01LjQxOTY3NkMyLjM1OTE1My01LjQ1OTUyNyAyLjMyNzI3My01LjUzMTI1OCAyLjIzMTYzMS01LjUzMTI1OEMyLjE5OTc1MS01LjUzMTI1OCAxLjk1MjY3Ny01LjUwNzM0NyAxLjc2OTM2NS01LjQ5MTQwN0wxLjMyMzAzOS01LjQ1OTUyN0MxLjE0NzY5Ni01LjQ0MzU4NyAxLjA2Nzk5NS01LjQzNTYxNiAxLjA2Nzk5NS01LjI5MjE1NEMxLjA2Nzk5NS01LjE4MDU3MyAxLjE3OTU3Ny01LjE4MDU3MyAxLjI3NTIxOC01LjE4MDU3M0MxLjY1Nzc4My01LjE4MDU3MyAxLjY1Nzc4My01LjEzMjc1MiAxLjY1Nzc4My01LjA2MTAyMUMxLjY1Nzc4My01LjAzNzExMSAxLjY1Nzc4My01LjAyMTE3MSAxLjYxNzkzMy00Ljg3NzcwOUwuNDg2MTc3LS4zNDI3MTVDLjQ1NDI5Ni0uMjIzMTYzIC40NTQyOTYtLjE3NTM0MiAuNDU0Mjk2LS4xNjczNzJDLjQ1NDI5Ni0uMDMxODggLjU2NTg3OCAuMDc5NzAxIC43MTczMSAuMDc5NzAxQy45ODgyOTQgLjA3OTcwMSAxLjA1MjA1NS0uMTc1MzQyIDEuMDgzOTM1LS4yODY5MjRDMS4xNjM2MzYtLjYyMTY2OSAxLjM3MDg1OS0xLjQ2NjUwMSAxLjQ1ODUzMS0xLjgwMTI0NUMxLjg5Njg4Ny0xLjc1MzQyNSAyLjQzMDg4NC0xLjYwMTk5MyAyLjQzMDg4NC0xLjE0NzY5NkMyLjQzMDg4NC0xLjEwNzg0NiAyLjQzMDg4NC0xLjA2Nzk5NSAyLjQxNDk0NC0uOTg4Mjk0QzIuMzkxMDM0LS44ODQ2ODIgMi4zNzUwOTMtLjc3MzEwMSAyLjM3NTA5My0uNzMzMjVDMi4zNzUwOTMtLjI2MzAxNCAyLjcyNTc3OCAuMDc5NzAxIDMuMTg4MDQ1IC4wNzk3MDFDMy41MjI3OSAuMDc5NzAxIDMuNzMwMDEyLS4xNjczNzIgMy44MzM2MjQtLjMxODgwNEM0LjAyNDkwNy0uNjEzNjk5IDQuMTUyNDI4LTEuMDkxOTA1IDQuMTUyNDI4LTEuMTM5NzI2QzQuMTUyNDI4LTEuMjE5NDI3IDQuMDg4NjY3LTEuMjQzMzM3IDQuMDMyODc3LTEuMjQzMzM3QzMuOTM3MjM1LTEuMjQzMzM3IDMuOTIxMjk1LTEuMTk1NTE3IDMuODg5NDE1LTEuMDUyMDU1QzMuNzg1ODAzLS42Nzc0NiAzLjU3ODU4LS4xNDM0NjIgMy4yMDM5ODUtLjE0MzQ2MkMyLjk5Njc2Mi0uMTQzNDYyIDIuOTQ4OTQxLS4zMTg4MDQgMi45NDg5NDEtLjUzMzk5OEMyLjk0ODk0MS0uNjM3NjA5IDIuOTU2OTEyLS43MzMyNSAyLjk5Njc2Mi0uOTE2NTYzQzMuMDA0NzMyLS45NDg0NDMgMy4wMzY2MTMtMS4wNzU5NjUgMy4wMzY2MTMtMS4xNjM2MzZDMy4wMzY2MTMtMS44MTcxODYgMi4yMTU2OTEtMS45NjA2NDggMS44MDkyMTUtMi4wMTY0MzhDMi4xMDQxMS0yLjE5MTc4MSAyLjM3NTA5My0yLjQ2Mjc2NSAyLjQ3MDczNS0yLjU2NjM3NkMyLjkwOTA5MS0yLjk5Njc2MiAzLjI2Nzc0Ni0zLjI5MTY1NiAzLjY1MDMxMS0zLjI5MTY1NkMzLjc1MzkyMy0zLjI5MTY1NiAzLjg0OTU2NC0zLjI2Nzc0NiAzLjkxMzMyNS0zLjE4ODA0NUMzLjQ4MjkzOS0zLjEzMjI1NCAzLjQ4MjkzOS0yLjc1NzY1OSAzLjQ4MjkzOS0yLjc0OTY4OUMzLjQ4MjkzOS0yLjU3NDM0NiAzLjYxODQzMS0yLjQ1NDc5NSAzLjc5Mzc3My0yLjQ1NDc5NUM0LjAwODk2Ni0yLjQ1NDc5NSA0LjI0ODA3LTIuNjMwMTM3IDQuMjQ4MDctMi45NTY5MTJDNC4yNDgwNy0zLjIyNzg5NSA0LjA1Njc4Ny0zLjUxNDgxOSAzLjY1ODI4MS0zLjUxNDgxOUMzLjE5NjAxNS0zLjUxNDgxOSAyLjc4MTU2OS0zLjE2NDEzNCAyLjMyNzI3My0yLjcwOTgzOEMxLjg2NTAwNi0yLjI1NTU0MiAxLjY2NTc1My0yLjE2Nzg3IDEuNTM4MjMyLTIuMTEyMDhMMi4zMjcyNzMtNS4yOTIxNTRaJy8+CjxwYXRoIGlkPSdnNC0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzMtNzUnIGQ9J00zLjYyODM5NC0yLjQwMjk4OUMzLjYyMjQxNi0yLjQwODk2NiAzLjU5MjUyOC0yLjQ2ODc0MiAzLjU5MjUyOC0yLjQ3NDcyUzMuNTk4NTA2LTIuNDg2Njc1IDMuNjk0MTQ3LTIuNTUyNDI4QzQuMzAzODYxLTIuOTcwODU5IDUuMTEwODM0LTMuNTIwNzk3IDUuNDQ1NTc5LTMuNjgyMTkyQzUuNjQ4ODE3LTMuNzc3ODMzIDUuODE2MTg5LTMuODMxNjMxIDYuMDEzNDUtMy44NDM1ODdDNi4wNzMyMjUtMy44NDk1NjQgNi4xNTA5MzQtMy44NTU1NDIgNi4xNTA5MzQtMy45OTMwMjZDNi4xNTA5MzQtNC4wMzQ4NjkgNi4xMTUwNjgtNC4wNzY3MTIgNi4wNjcyNDgtNC4wNzY3MTJDNS45MzU3NDEtNC4wNzY3MTIgNS43NjgzNjktNC4wNTg3OCA1LjYyNDkwNy00LjA1ODc4QzUuNTM1MjQzLTQuMDU4NzggNS4zMzIwMDUtNC4wNTg3OCA1LjI0MjM0MS00LjA2NDc1N0M1LjE3MDYxLTQuMDcwNzM1IDQuOTQ5NDQtNC4wODI2OSA0Ljg4OTY2NC00LjA4MjY5QzQuODUzNzk4LTQuMDgyNjkgNC43NTIxNzktNC4wODI2OSA0Ljc1MjE3OS0zLjkzMzI1QzQuNzUyMTc5LTMuODQ5NTY0IDQuODM1ODY2LTMuODQzNTg3IDQuODUzNzk4LTMuODQzNTg3QzQuOTkxMjgzLTMuODM3NjA5IDQuOTkxMjgzLTMuNzk1NzY2IDQuOTkxMjgzLTMuNzY1ODc4QzQuOTkxMjgzLTMuNjg4MTY5IDQuODY1NzUzLTMuNTkyNTI4IDQuODQxODQzLTMuNTc0NTk1QzQuODIzOTEtMy41NjI2NCA0LjgxNzkzMy0zLjU1NjY2MyA0LjgxMTk1NS0zLjU1MDY4NVM0Ljc1MjE3OS0zLjUwODg0MiA0LjczNDI0Ny0zLjQ5Njg4N0wyLjEzMzk5OC0xLjczOTQ3N0wyLjYwMDI0OS0zLjU5ODUwNkMyLjY0ODA3LTMuNzk1NzY2IDIuNjYwMDI1LTMuODQzNTg3IDMuMTM4MjMyLTMuODQzNTg3QzMuMjQ1ODI4LTMuODQzNTg3IDMuMzI5NTE0LTMuODQzNTg3IDMuMzI5NTE0LTMuOTkzMDI2QzMuMzI5NTE0LTQuMDIyOTE0IDMuMzExNTgyLTQuMDgyNjkgMy4yMjc4OTUtNC4wODI2OUMzLjEwMjM2Ni00LjA4MjY5IDIuOTU4OTA0LTQuMDY0NzU3IDIuODI3Mzk3LTQuMDY0NzU3UzIuNTU4NDA2LTQuMDU4NzggMi40MjY4OTktNC4wNTg3OEMyLjI4OTQxNS00LjA1ODc4IDIuMTUxOTMtNC4wNjQ3NTcgMi4wMTQ0NDYtNC4wNjQ3NTdDMS44ODI5MzktNC4wNjQ3NTcgMS43MzM0OTktNC4wODI2OSAxLjYwMTk5My00LjA4MjY5QzEuNTY2MTI3LTQuMDgyNjkgMS40NzA0ODYtNC4wODI2OSAxLjQ3MDQ4Ni0zLjkzMzI1QzEuNDcwNDg2LTMuODQzNTg3IDEuNTQ4MTk0LTMuODQzNTg3IDEuNjYxNzY4LTMuODQzNTg3QzEuNzY5MzY1LTMuODQzNTg3IDEuOTE4ODA0LTMuODQzNTg3IDIuMDQ0MzM0LTMuODAxNzQzQzIuMDQ0MzM0LTMuNzQxOTY4IDIuMDQ0MzM0LTMuNzA2MTAyIDIuMDIwNDIzLTMuNjEwNDYxTDEuMjM3MzYtLjQ5NjEzOUMxLjE4MzU2Mi0uMjgwOTQ2IDEuMTcxNjA2LS4yMzkxMDMgLjcyMzI4OC0uMjM5MTAzQy41ODU4MDMtLjIzOTEwMyAuNTA4MDk1LS4yMzkxMDMgLjUwODA5NS0uMDg5NjY0Qy41MDgwOTUtLjA0MTg0MyAuNTQzOTYgMCAuNjA5NzE0IDBDLjczNTI0MyAwIC44Nzg3MDUtLjAxNzkzMyAxLjAxMDIxMi0uMDE3OTMzQzEuMTQ3Njk2LS4wMTc5MzMgMS4yNzkyMDMtLjAyMzkxIDEuNDEwNzEtLjAyMzkxQzEuNTQ4MTk0LS4wMjM5MSAxLjY4NTY3OS0uMDE3OTMzIDEuODIzMTYzLS4wMTc5MzNDMS45NTQ2Ny0uMDE3OTMzIDIuMTA0MTEgMCAyLjIyOTYzOSAwQzIuMjcxNDgyIDAgMi4zNjcxMjMgMCAyLjM2NzEyMy0uMTQ5NDRDMi4zNjcxMjMtLjIzOTEwMyAyLjI5NTM5Mi0uMjM5MTAzIDIuMTY5ODYzLS4yMzkxMDNDMi4xNTc5MDgtLjIzOTEwMyAyLjA1MDMxMS0uMjM5MTAzIDEuOTQyNzE1LS4yNTEwNTlDMS44MjMxNjMtLjI2MzAxNCAxLjc4NzI5OC0uMjYzMDE0IDEuNzg3Mjk4LS4zMjg3NjdDMS43ODcyOTgtLjM1MjY3NyAxLjgyOTE0MS0uNTAyMTE3IDEuODQ3MDczLS41OTE3ODFDMS44NzY5NjEtLjY5MzQgMS44NzY5NjEtLjcwNTM1NSAxLjkxMjgyNy0uODQ4ODE3QzEuOTk2NTEzLTEuMTU5NjUxIDEuOTk2NTEzLTEuMTcxNjA2IDIuMDYyMjY3LTEuNDU4NTMxTDMuMTAyMzY2LTIuMTU3OTA4TDQuMDgyNjktLjQxMjQ1M0M0LjA4MjY5LS4zMzQ3NDUgNC4wODI2OS0uMjQ1MDgxIDMuODEzNjk5LS4yMzkxMDNDMy43NDE5NjgtLjIzOTEwMyAzLjY1MjMwNC0uMjM5MTAzIDMuNjUyMzA0LS4wODk2NjRDMy42NTIzMDQtLjA0MTg0MyAzLjY4ODE2OSAwIDMuNzUzOTIzIDBDMy45MjcyNzMgMCA0LjM2OTYxNC0uMDIzOTEgNC41NDI5NjQtLjAyMzkxQzQuNjQ0NTgzLS4wMjM5MSA0Ljc0NjIwMi0uMDE3OTMzIDQuODQ3ODIxLS4wMTc5MzNTNS4wNjMwMTQgMCA1LjE1ODY1NSAwQzUuMjI0NDA4IDAgNS4yOTAxNjItLjAzNTg2NiA1LjI5MDE2Mi0uMTQ5NDRDNS4yOTAxNjItLjIzOTEwMyA1LjE5NDUyMS0uMjM5MTAzIDUuMTQ2Ny0uMjM5MTAzQzQuODM1ODY2LS4yNDUwODEgNC43ODgwNDUtLjMyODc2NyA0LjcxNjMxNC0uNDYwMjc0TDMuNjI4Mzk0LTIuNDAyOTg5WicvPgo8cGF0aCBpZD0nZzctNDgnIGQ9J00zLjg5NzM4NS0yLjU0MjQ2NkMzLjg5NzM4NS0zLjM5NTI2OCAzLjgwOTcxNC0zLjkxMzMyNSAzLjU0NjctNC40MjM0MTJDMy4xOTYwMTUtNS4xMjQ3ODIgMi41NTA0MzYtNS4zMDAxMjUgMi4xMTIwOC01LjMwMDEyNUMxLjEwNzg0Ni01LjMwMDEyNSAuNzQxMjItNC41NTA5MzQgLjYyOTYzOS00LjMyNzc3MUMuMzQyNzE1LTMuNzQ1OTUzIC4zMjY3NzUtMi45NTY5MTIgLjMyNjc3NS0yLjU0MjQ2NkMuMzI2Nzc1LTIuMDE2NDM4IC4zNTA2ODUtMS4yMTE0NTcgLjczMzI1LS41NzM4NDhDMS4wOTk4NzUgLjAxNTk0IDEuNjg5NjY0IC4xNjczNzIgMi4xMTIwOCAuMTY3MzcyQzIuNDk0NjQ1IC4xNjczNzIgMy4xODAwNzUgLjA0NzgyMSAzLjU3ODU4LS43NDEyMkMzLjg3MzQ3NC0xLjMxNTA2OCAzLjg5NzM4NS0yLjAyNDQwOCAzLjg5NzM4NS0yLjU0MjQ2NlpNMi4xMTIwOC0uMDU1NzkxQzEuODQxMDk2LS4wNTU3OTEgMS4yOTExNTgtLjE4MzMxMyAxLjEyMzc4Ni0xLjAyMDE3NEMxLjAzNjExNS0xLjQ3NDQ3MSAxLjAzNjExNS0yLjIyMzY2MSAxLjAzNjExNS0yLjYzODEwN0MxLjAzNjExNS0zLjE4ODA0NSAxLjAzNjExNS0zLjc0NTk1MyAxLjEyMzc4Ni00LjE4NDMwOUMxLjI5MTE1OC00Ljk5NzI2IDEuOTEyODI3LTUuMDc2OTYxIDIuMTEyMDgtNS4wNzY5NjFDMi4zODMwNjQtNS4wNzY5NjEgMi45MzMwMDEtNC45NDE0NjkgMy4wOTI0MDMtNC4yMTYxODlDMy4xODgwNDUtMy43Nzc4MzMgMy4xODgwNDUtMy4xODAwNzUgMy4xODgwNDUtMi42MzgxMDdDMy4xODgwNDUtMi4xNjc4NyAzLjE4ODA0NS0xLjQ1MDU2IDMuMDkyNDAzLTEuMDA0MjM0QzIuOTI1MDMxLS4xNjczNzIgMi4zNzUwOTMtLjA1NTc5MSAyLjExMjA4LS4wNTU3OTFaJy8+CjxwYXRoIGlkPSdnNy00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c3LTUwJyBkPSdNMi4yNDc1NzItMS42MjU5MDNDMi4zNzUwOTMtMS43NDU0NTUgMi43MDk4MzgtMi4wMDg0NjggMi44MzczNi0yLjEyMDA1QzMuMzMxNTA3LTIuNTc0MzQ2IDMuODAxNzQzLTMuMDEyNzAyIDMuODAxNzQzLTMuNzM3OTgzQzMuODAxNzQzLTQuNjg2NDI2IDMuMDA0NzMyLTUuMzAwMTI1IDIuMDA4NDY4LTUuMzAwMTI1QzEuMDUyMDU1LTUuMzAwMTI1IC40MjI0MTYtNC41NzQ4NDQgLjQyMjQxNi0zLjg2NTUwNEMuNDIyNDE2LTMuNDc0OTY5IC43MzMyNS0zLjQxOTE3OCAuODQ0ODMyLTMuNDE5MTc4QzEuMDEyMjA0LTMuNDE5MTc4IDEuMjU5Mjc4LTMuNTM4NzMgMS4yNTkyNzgtMy44NDE1OTRDMS4yNTkyNzgtNC4yNTYwNCAuODYwNzcyLTQuMjU2MDQgLjc2NTEzMS00LjI1NjA0Qy45OTYyNjQtNC44Mzc4NTggMS41MzAyNjItNS4wMzcxMTEgMS45MjA3OTctNS4wMzcxMTFDMi42NjIwMTctNS4wMzcxMTEgMy4wNDQ1ODMtNC40MDc0NzIgMy4wNDQ1ODMtMy43Mzc5ODNDMy4wNDQ1ODMtMi45MDkwOTEgMi40NjI3NjUtMi4zMDMzNjIgMS41MjIyOTEtMS4zMzg5NzlMLjUxODA1Ny0uMzAyODY0Qy40MjI0MTYtLjIxNTE5MyAuNDIyNDE2LS4xOTkyNTMgLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMtMS40MjY2NUgzLjU1NDY3QzMuNTMwNzYtMS4yNjcyNDggMy40NjY5OTktLjg2ODc0MiAzLjM3MTM1Ny0uNzE3MzFDMy4zMjM1MzctLjY1MzU0OSAyLjcxNzgwOC0uNjUzNTQ5IDIuNTkwMjg2LS42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzItMS42MjU5MDNaJy8+CjxwYXRoIGlkPSdnNy02MScgZD0nTTUuODI2MTUyLTIuNjU0MDQ3QzUuOTQ1NzA0LTIuNjU0MDQ3IDYuMTA1MTA2LTIuNjU0MDQ3IDYuMTA1MTA2LTIuODM3MzZTNS45MTM4MjMtMy4wMjA2NzIgNS43OTQyNzEtMy4wMjA2NzJILjc4MTA3MUMuNjYxNTE5LTMuMDIwNjcyIC40NzAyMzctMy4wMjA2NzIgLjQ3MDIzNy0yLjgzNzM2Uy42Mjk2MzktMi42NTQwNDcgLjc0OTE5MS0yLjY1NDA0N0g1LjgyNjE1MlpNNS43OTQyNzEtLjk2NDM4NEM1LjkxMzgyMy0uOTY0Mzg0IDYuMTA1MTA2LS45NjQzODQgNi4xMDUxMDYtMS4xNDc2OTZTNS45NDU3MDQtMS4zMzEwMDkgNS44MjYxNTItMS4zMzEwMDlILjc0OTE5MUMuNjI5NjM5LTEuMzMxMDA5IC40NzAyMzctMS4zMzEwMDkgLjQ3MDIzNy0xLjE0NzY5NlMuNjYxNTE5LS45NjQzODQgLjc4MTA3MS0uOTY0Mzg0SDUuNzk0MjcxWicvPgo8cGF0aCBpZD0nZzUtNTgnIGQ9J00yLjE5OTc1MS0uNTczODQ4QzIuMTk5NzUxLS45MjA1NDggMS45MTI4MjctMS4xNTk2NTEgMS42MjU5MDMtMS4xNTk2NTFDMS4yNzkyMDMtMS4xNTk2NTEgMS4wNDAxLS44NzI3MjcgMS4wNDAxLS41ODU4MDNDMS4wNDAxLS4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEtLjI4NjkyNCAyLjE5OTc1MS0uNTczODQ4WicvPgo8cGF0aCBpZD0nZzUtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2c1LTk3JyBkPSdNMy41OTg1MDYtMS40MjI2NjVDMy41Mzg3My0xLjIxOTQyNyAzLjUzODczLTEuMTk1NTE3IDMuMzcxMzU3LS45NjgzNjlDMy4xMDgzNDQtLjYzMzYyNCAyLjU4MjMxNi0uMTE5NTUyIDIuMDIwNDIzLS4xMTk1NTJDMS41MzAyNjItLjExOTU1MiAxLjI1NTI5My0uNTYxODkzIDEuMjU1MjkzLTEuMjY3MjQ4QzEuMjU1MjkzLTEuOTI0NzgyIDEuNjI1OTAzLTMuMjYzNzYxIDEuODUzMDUxLTMuNzY1ODc4QzIuMjU5NTI3LTQuNjAyNzQgMi44MjE0Mi01LjAzMzEyNiAzLjI4NzY3MS01LjAzMzEyNkM0LjA3NjcxMi01LjAzMzEyNiA0LjIzMjEzLTQuMDUyODAyIDQuMjMyMTMtMy45NTcxNjFDNC4yMzIxMy0zLjk0NTIwNSA0LjE5NjI2NC0zLjc4OTc4OCA0LjE4NDMwOS0zLjc2NTg3OEwzLjU5ODUwNi0xLjQyMjY2NVpNNC4zNjM2MzYtNC40ODMxODhDNC4yMzIxMy00Ljc5NDAyMiAzLjkwOTM0LTUuMjcyMjI5IDMuMjg3NjcxLTUuMjcyMjI5QzEuOTM2NzM3LTUuMjcyMjI5IC40NzgyMDctMy41MjY3NzUgLjQ3ODIwNy0xLjc1NzQxQy40NzgyMDctLjU3Mzg0OCAxLjE3MTYwNiAuMTE5NTUyIDEuOTg0NTU4IC4xMTk1NTJDMi42NDIwOTIgLjExOTU1MiAzLjIwMzk4NS0uMzk0NTIxIDMuNTM4NzMtLjc4OTA0MUMzLjY1ODI4MS0uMDgzNjg2IDQuMjIwMTc0IC4xMTk1NTIgNC41Nzg4MjkgLjExOTU1MlM1LjIyNDQwOC0uMDk1NjQxIDUuNDM5NjAxLS41MjYwMjdDNS42MzA4ODQtLjkzMjUwMyA1Ljc5ODI1Ny0xLjY2MTc2OCA1Ljc5ODI1Ny0xLjcwOTU4OUM1Ljc5ODI1Ny0xLjc2OTM2NSA1Ljc1MDQzNi0xLjgxNzE4NiA1LjY3ODcwNS0xLjgxNzE4NkM1LjU3MTEwOC0xLjgxNzE4NiA1LjU1OTE1My0xLjc1NzQxIDUuNTExMzMzLTEuNTc4MDgyQzUuMzMyMDA1LS44NzI3MjcgNS4xMDQ4NTctLjExOTU1MiA0LjYxNDY5NS0uMTE5NTUyQzQuMjY3OTk1LS4xMTk1NTIgNC4yNDQwODUtLjQzMDM4NiA0LjI0NDA4NS0uNjY5NDg5QzQuMjQ0MDg1LS45NDQ0NTggNC4yNzk5NS0xLjA3NTk2NSA0LjM4NzU0Ny0xLjU0MjIxN0M0LjQ3MTIzMy0xLjg0MTA5NiA0LjUzMTAwOS0yLjEwNDExIDQuNjI2NjUtMi40NTA4MDlDNS4wNjg5OTEtNC4yNDQwODUgNS4xNzY1ODgtNC42NzQ0NzEgNS4xNzY1ODgtNC43NDYyMDJDNS4xNzY1ODgtNC45MTM1NzQgNS4wNDUwODEtNS4wNDUwODEgNC44NjU3NTMtNS4wNDUwODFDNC40ODMxODgtNS4wNDUwODEgNC4zODc1NDctNC42MjY2NSA0LjM2MzYzNi00LjQ4MzE4OFonLz4KPHBhdGggaWQ9J2c1LTEyMCcgZD0nTTUuNjY2NzUtNC44Nzc3MDlDNS4yODQxODQtNC44MDU5NzggNS4xNDA3MjItNC41MTkwNTQgNS4xNDA3MjItNC4yOTE5MDVDNS4xNDA3MjItNC4wMDQ5ODEgNS4zNjc4Ny0zLjkwOTM0IDUuNTM1MjQzLTMuOTA5MzRDNS44OTM4OTgtMy45MDkzNCA2LjE0NDk1Ni00LjIyMDE3NCA2LjE0NDk1Ni00LjU0Mjk2NEM2LjE0NDk1Ni01LjA0NTA4MSA1LjU3MTEwOC01LjI3MjIyOSA1LjA2ODk5MS01LjI3MjIyOUM0LjMzOTcyNi01LjI3MjIyOSAzLjkzMzI1LTQuNTU0OTE5IDMuODI1NjU0LTQuMzI3NzcxQzMuNTUwNjg1LTUuMjI0NDA4IDIuODA5NDY1LTUuMjcyMjI5IDIuNTk0MjcxLTUuMjcyMjI5QzEuMzc0ODQ0LTUuMjcyMjI5IC43MjkyNjUtMy43MDYxMDIgLjcyOTI2NS0zLjQ0MzA4OEMuNzI5MjY1LTMuMzk1MjY4IC43NzcwODYtMy4zMzU0OTIgLjg2MDc3Mi0zLjMzNTQ5MkMuOTU2NDEzLTMuMzM1NDkyIC45ODAzMjQtMy40MDcyMjMgMS4wMDQyMzQtMy40NTUwNDRDMS40MTA3MS00Ljc4MjA2NyAyLjIxMTcwNi01LjAzMzEyNiAyLjU1ODQwNi01LjAzMzEyNkMzLjA5NjM4OS01LjAzMzEyNiAzLjIwMzk4NS00LjUzMTAwOSAzLjIwMzk4NS00LjI0NDA4NUMzLjIwMzk4NS0zLjk4MTA3MSAzLjEzMjI1NC0zLjcwNjEwMiAyLjk4ODc5Mi0zLjEzMjI1NEwyLjU4MjMxNi0xLjQ5NDM5NkMyLjQwMjk4OS0uNzc3MDg2IDIuMDU2Mjg5LS4xMTk1NTIgMS40MjI2NjUtLjExOTU1MkMxLjM2Mjg4OS0uMTE5NTUyIDEuMDY0MDEtLjExOTU1MiAuODEyOTUxLS4yNzQ5NjlDMS4yNDMzMzctLjM1ODY1NSAxLjMzODk3OS0uNzE3MzEgMS4zMzg5NzktLjg2MDc3MkMxLjMzODk3OS0xLjA5OTg3NSAxLjE1OTY1MS0xLjI0MzMzNyAuOTMyNTAzLTEuMjQzMzM3Qy42NDU1NzktMS4yNDMzMzcgLjMzNDc0NS0uOTkyMjc5IC4zMzQ3NDUtLjYwOTcxNEMuMzM0NzQ1LS4xMDc1OTcgLjg5NjYzOCAuMTE5NTUyIDEuNDEwNzEgLjExOTU1MkMxLjk4NDU1OCAuMTE5NTUyIDIuMzkxMDM0LS4zMzQ3NDUgMi42NDIwOTItLjgyNDkwN0MyLjgzMzM3NS0uMTE5NTUyIDMuNDMxMTMzIC4xMTk1NTIgMy44NzM0NzQgLjExOTU1MkM1LjA5MjkwMiAuMTE5NTUyIDUuNzM4NDgxLTEuNDQ2NTc1IDUuNzM4NDgxLTEuNzA5NTg5QzUuNzM4NDgxLTEuNzY5MzY1IDUuNjkwNjYtMS44MTcxODYgNS42MTg5MjktMS44MTcxODZDNS41MTEzMzMtMS44MTcxODYgNS40OTkzNzctMS43NTc0MSA1LjQ2MzUxMi0xLjY2MTc2OEM1LjE0MDcyMi0uNjA5NzE0IDQuNDQ3MzIzLS4xMTk1NTIgMy45MDkzNC0uMTE5NTUyQzMuNDkwOTA5LS4xMTk1NTIgMy4yNjM3NjEtLjQzMDM4NiAzLjI2Mzc2MS0uOTIwNTQ4QzMuMjYzNzYxLTEuMTgzNTYyIDMuMzExNTgyLTEuMzc0ODQ0IDMuNTAyODY0LTIuMTYzODg1TDMuOTIxMjk1LTMuNzg5Nzg4QzQuMTAwNjIzLTQuNTA3MDk4IDQuNTA3MDk4LTUuMDMzMTI2IDUuMDU3MDM2LTUuMDMzMTI2QzUuMDgwOTQ2LTUuMDMzMTI2IDUuNDE1NjkxLTUuMDMzMTI2IDUuNjY2NzUtNC44Nzc3MDlaJy8+CjxwYXRoIGlkPSdnMC01MCcgZD0nTTMuODk3Mzg1IDIxLjA0MTA5Nkg0LjcyMjI5MVYuMzU4NjU1SDcuODc4NDU2Vi0uNDY2MjUySDMuODk3Mzg1VjIxLjA0MTA5NlonLz4KPHBhdGggaWQ9J2cwLTUxJyBkPSdNMy4yMzk4NTEgMjEuMDQxMDk2SDQuMDY0NzU3Vi0uNDY2MjUySC4wODM2ODZWLjM1ODY1NUgzLjIzOTg1MVYyMS4wNDEwOTZaJy8+CjxwYXRoIGlkPSdnMC01MicgZD0nTTMuODk3Mzg1IDIxLjAyOTE0MUg3Ljg3ODQ1NlYyMC4yMDQyMzRINC43MjIyOTFWLS40NzgyMDdIMy44OTczODVWMjEuMDI5MTQxWicvPgo8cGF0aCBpZD0nZzAtNTMnIGQ9J00zLjIzOTg1MSAyMC4yMDQyMzRILjA4MzY4NlYyMS4wMjkxNDFINC4wNjQ3NTdWLS40NzgyMDdIMy4yMzk4NTFWMjAuMjA0MjM0WicvPgo8cGF0aCBpZD0nZzAtODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2cwLTk4JyBkPSdNMy4zMTE1ODItOC4xODkyOUw2LjU2MzM4Ny02LjcxODgwNEw2LjcwNjg0OS02Ljk4MTgxOEwzLjMyMzUzNy04Ljg5NDY0NUwtLjA1OTc3Ni02Ljk4MTgxOEwuMDcxNzMxLTYuNzE4ODA0TDMuMzExNTgyLTguMTg5MjlaJy8+CjxwYXRoIGlkPSdnMS01MCcgZD0nTTQuNjMwNjM1LTEuODA5MjE1QzQuNzU4MTU3LTEuODA5MjE1IDQuOTMzNDk5LTEuODA5MjE1IDQuOTMzNDk5LTEuOTkyNTI4UzQuNzU4MTU3LTIuMTc1ODQxIDQuNjMwNjM1LTIuMTc1ODQxSDEuMDc1OTY1QzEuMTc5NTc3LTMuMjgzNjg2IDIuMTA0MTEtNC4xMjg1MTggMy4zMTU1NjctNC4xMjg1MThINC42MzA2MzVDNC43NTgxNTctNC4xMjg1MTggNC45MzM0OTktNC4xMjg1MTggNC45MzM0OTktNC4zMTE4MzFTNC43NTgxNTctNC40OTUxNDMgNC42MzA2MzUtNC40OTUxNDNIMy4yOTE2NTZDMS44NTcwMzYtNC40OTUxNDMgLjcwMTM3LTMuMzc5MzI4IC43MDEzNy0xLjk5MjUyOEMuNzAxMzctLjU5Nzc1OCAxLjg2NTAwNiAuNTEwMDg3IDMuMjkxNjU2IC41MTAwODdINC42MzA2MzVDNC43NTgxNTcgLjUxMDA4NyA0LjkzMzQ5OSAuNTEwMDg3IDQuOTMzNDk5IC4zMjY3NzVTNC43NTgxNTcgLjE0MzQ2MiA0LjYzMDYzNSAuMTQzNDYySDMuMzE1NTY3QzIuMTA0MTEgLjE0MzQ2MiAxLjE3OTU3Ny0uNzAxMzcgMS4wNzU5NjUtMS44MDkyMTVINC42MzA2MzVaJy8+CjxwYXRoIGlkPSdnMS0xMDInIGQ9J00yLjQxNDk0NC00LjgyOTg4OEMyLjQxNDk0NC01LjAyOTE0MSAyLjQxNDk0NC01LjIzNjM2NCAyLjY5Mzg5OC01LjQ4MzQzN0MyLjc0OTY4OS01LjUyMzI4OCAyLjk4MDgyMi01LjcyMjU0IDMuNDc0OTY5LTUuNzU0NDIxQzMuNTcwNjEtNS43NjIzOTEgMy42MzQzNzEtNS43NjIzOTEgMy42MzQzNzEtNS44NjYwMDJDMy42MzQzNzEtNS45Nzc1ODQgMy41NTQ2Ny01Ljk3NzU4NCAzLjQ0MzA4OC01Ljk3NzU4NEMyLjU4MjMxNi01Ljk3NzU4NCAxLjgyNTE1Ni01LjU3OTA3OCAxLjgxNzE4Ni00Ljk3MzM1Vi0yLjk0MDk3MUMxLjgwMTI0NS0yLjUyNjUyNiAxLjQwMjc0LTIuMTQzOTYgLjc0OTE5MS0yLjEwNDExQy42NTM1NDktMi4wOTYxMzkgLjU4OTc4OC0yLjA5NjEzOSAuNTg5Nzg4LTEuOTkyNTI4Uy42NjE1MTktMS44ODg5MTcgLjcyNTI4LTEuODgwOTQ2QzEuNDgyNDQxLTEuODMzMTI2IDEuNzM3NDg0LTEuNDI2NjUgMS43OTMyNzUtMS4yMDM0ODdDMS44MTcxODYtMS4xMDc4NDYgMS44MTcxODYtMS4wOTE5MDUgMS44MTcxODYtLjc5NzAxMVYuODI4ODkyQzEuODE3MTg2IDEuMDgzOTM1IDEuODE3MTg2IDEuNDM0NjIgMi4zMjcyNzMgMS43Mjk1MTRDMi42Njk5ODggMS45Mjg3NjcgMy4xNjQxMzQgMS45OTI1MjggMy40NDMwODggMS45OTI1MjhDMy41NTQ2NyAxLjk5MjUyOCAzLjYzNDM3MSAxLjk5MjUyOCAzLjYzNDM3MSAxLjg4MDk0NkMzLjYzNDM3MSAxLjc3NzMzNSAzLjU2MjY0IDEuNzc3MzM1IDMuNDk4ODc5IDEuNzY5MzY1QzIuNzU3NjU5IDEuNzIxNTQ0IDIuNDk0NjQ1IDEuMzQ2OTQ5IDIuNDM4ODU0IDEuMDk5ODc1QzIuNDE0OTQ0IDEuMDIwMTc0IDIuNDE0OTQ0IDEuMDA0MjM0IDIuNDE0OTQ0IC43MjUyOFYtLjk0ODQ0M0MyLjQxNDk0NC0xLjE2MzYzNiAyLjQxNDk0NC0xLjcxMzU3NCAxLjQ5MDQxMS0xLjk5MjUyOEMyLjA4ODE2OS0yLjE3NTg0MSAyLjMxMTMzMy0yLjQ2Mjc2NSAyLjM5MTAzNC0yLjc1NzY1OUMyLjQxNDk0NC0yLjg1MzMgMi40MTQ5NDQtMi45MDkwOTEgMi40MTQ5NDQtMy4xNTYxNjRWLTQuODI5ODg4WicvPgo8cGF0aCBpZD0nZzEtMTAzJyBkPSdNMi40MTQ5NDQtNC44MTM5NDhDMi40MTQ5NDQtNS4wNDUwODEgMi40MTQ5NDQtNS4zNzk4MjYgMS45OTI1MjgtNS42NjY3NUMxLjY1Nzc4My01Ljg4OTkxMyAxLjEzMTc1Ni01Ljk3NzU4NCAuNzgxMDcxLTUuOTc3NTg0Qy42Nzc0Ni01Ljk3NzU4NCAuNTg5Nzg4LTUuOTc3NTg0IC41ODk3ODgtNS44NjYwMDJDLjU4OTc4OC01Ljc2MjM5MSAuNjYxNTE5LTUuNzYyMzkxIC43MjUyOC01Ljc1NDQyMUMxLjQ1ODUzMS01LjcwNjYgMS43Mzc0ODQtNS4zNTU5MTUgMS44MDEyNDUtNS4wNjEwMjFDMS44MTcxODYtNC45ODEzMiAxLjgxNzE4Ni00LjkyNTUyOSAxLjgxNzE4Ni00LjgxMzk0OFYtMy4xNDAyMjRDMS44MTcxODYtMi43ODk1MzkgMS44MTcxODYtMi4yNzE0ODIgMi43NDE3MTktMS45OTI1MjhDMi4yOTUzOTItMS44NTcwMzYgMS45NTI2NzctMS42MzM4NzMgMS44NDEwOTYtMS4yMjczOTdDMS44MTcxODYtMS4xMzE3NTYgMS44MTcxODYtMS4wNzU5NjUgMS44MTcxODYtLjgyODg5MlYuNjA1NzI5QzEuODE3MTg2IDEuMTM5NzI2IDEuODE3MTg2IDEuMjExNDU3IDEuNTU0MTcyIDEuNDgyNDQxQzEuNTMwMjYyIDEuNDk4MzgxIDEuMzA3MDk4IDEuNzI5NTE0IC43NDkxOTEgMS43NjkzNjVDLjY0NTU3OSAxLjc3NzMzNSAuNTg5Nzg4IDEuNzc3MzM1IC41ODk3ODggMS44ODA5NDZDLjU4OTc4OCAxLjk5MjUyOCAuNjc3NDYgMS45OTI1MjggLjc4MTA3MSAxLjk5MjUyOEMxLjY0MTg0MyAxLjk5MjUyOCAyLjQwNjk3NCAxLjYwMTk5MyAyLjQxNDk0NCAuOTg4Mjk0Vi0uNjEzNjk5QzIuNDE0OTQ0LTEuMTU1NjY2IDIuNDE0OTQ0LTEuMzM4OTc5IDIuNjU0MDQ3LTEuNTYyMTQyQzIuOTE3MDYxLTEuNzkzMjc1IDMuMjAzOTg1LTEuODU3MDM2IDMuNDc0OTY5LTEuODgwOTQ2QzMuNTc4NTgtMS44ODg5MTcgMy42MzQzNzEtMS44ODg5MTcgMy42MzQzNzEtMS45OTI1MjhTMy41NjI2NC0yLjA5NjEzOSAzLjQ5ODg3OS0yLjEwNDExQzIuNjE0MTk3LTIuMTU5OSAyLjQxNDk0NC0yLjcwMTg2OCAyLjQxNDk0NC0yLjk0MDk3MVYtNC44MTM5NDhaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cyLTEwMicgZD0nTTMuMzgzMzEzLTcuMzc2MzM5QzMuMzgzMzEzLTcuODU0NTQ1IDMuNjk0MTQ3LTguNjE5Njc2IDQuOTk3MjYtOC43MDMzNjJDNS4wNTcwMzYtOC43MTUzMTggNS4xMDQ4NTctOC43NjMxMzggNS4xMDQ4NTctOC44MzQ4NjlDNS4xMDQ4NTctOC45NjYzNzYgNS4wMDkyMTUtOC45NjYzNzYgNC44Nzc3MDktOC45NjYzNzZDMy42ODIxOTItOC45NjYzNzYgMi41OTQyNzEtOC4zNTY2NjMgMi41ODIzMTYtNy40NzE5OFYtNC43NDYyMDJDMi41ODIzMTYtNC4yNzk5NSAyLjU4MjMxNi0zLjg5NzM4NSAyLjEwNDExLTMuNTAyODY0QzEuNjg1Njc5LTMuMTU2MTY0IDEuMjMxMzgyLTMuMTMyMjU0IC45NjgzNjktMy4xMjAyOTlDLjkwODU5My0zLjEwODM0NCAuODYwNzcyLTMuMDYwNTIzIC44NjA3NzItMi45ODg3OTJDLjg2MDc3Mi0yLjg2OTI0IC45MzI1MDMtMi44NjkyNCAxLjA1MjA1NS0yLjg1NzI4NUMxLjg0MTA5Ni0yLjgwOTQ2NSAyLjQxNDk0NC0yLjM3OTA3OCAyLjU0NjQ1MS0xLjc5MzI3NUMyLjU4MjMxNi0xLjY2MTc2OCAyLjU4MjMxNi0xLjYzNzg1OCAyLjU4MjMxNi0xLjIwNzQ3MlYxLjE1OTY1MUMyLjU4MjMxNiAxLjY2MTc2OCAyLjU4MjMxNiAyLjA0NDMzNCAzLjE1NjE2NCAyLjQ5ODYzQzMuNjIyNDE2IDIuODU3Mjg1IDQuNDExNDU3IDIuOTg4NzkyIDQuODc3NzA5IDIuOTg4NzkyQzUuMDA5MjE1IDIuOTg4NzkyIDUuMTA0ODU3IDIuOTg4NzkyIDUuMTA0ODU3IDIuODU3Mjg1QzUuMTA0ODU3IDIuNzM3NzMzIDUuMDMzMTI2IDIuNzM3NzMzIDQuOTEzNTc0IDIuNzI1Nzc4QzQuMTYwMzk5IDIuNjc3OTU4IDMuNTc0NTk1IDIuMjk1MzkyIDMuNDE5MTc4IDEuNjg1Njc5QzMuMzgzMzEzIDEuNTc4MDgyIDMuMzgzMzEzIDEuNTU0MTcyIDMuMzgzMzEzIDEuMTIzNzg2Vi0xLjM4NjhDMy4zODMzMTMtMS45MzY3MzcgMy4yODc2NzEtMi4xMzk5NzUgMi45MDUxMDYtMi41MjI1NEMyLjY1NDA0Ny0yLjc3MzU5OSAyLjMwNzM0Ny0yLjg5MzE1MSAxLjk3MjYwMy0yLjk4ODc5MkMyLjk1MjkyNy0zLjI2Mzc2MSAzLjM4MzMxMy0zLjgxMzY5OSAzLjM4MzMxMy00LjUwNzA5OFYtNy4zNzYzMzlaJy8+CjxwYXRoIGlkPSdnMi0xMDMnIGQ9J00yLjU4MjMxNiAxLjM5ODc1NUMyLjU4MjMxNiAxLjg3Njk2MSAyLjI3MTQ4MiAyLjY0MjA5MiAuOTY4MzY5IDIuNzI1Nzc4Qy45MDg1OTMgMi43Mzc3MzMgLjg2MDc3MiAyLjc4NTU1NCAuODYwNzcyIDIuODU3Mjg1Qy44NjA3NzIgMi45ODg3OTIgLjk5MjI3OSAyLjk4ODc5MiAxLjA5OTg3NSAyLjk4ODc5MkMyLjI1OTUyNyAyLjk4ODc5MiAzLjM3MTM1NyAyLjQwMjk4OSAzLjM4MzMxMyAxLjQ5NDM5NlYtMS4yMzEzODJDMy4zODMzMTMtMS42OTc2MzQgMy4zODMzMTMtMi4wODAxOTkgMy44NjE1MTktMi40NzQ3MkM0LjI3OTk1LTIuODIxNDIgNC43MzQyNDctMi44NDUzMyA0Ljk5NzI2LTIuODU3Mjg1QzUuMDU3MDM2LTIuODY5MjQgNS4xMDQ4NTctMi45MTcwNjEgNS4xMDQ4NTctMi45ODg3OTJDNS4xMDQ4NTctMy4xMDgzNDQgNS4wMzMxMjYtMy4xMDgzNDQgNC45MTM1NzQtMy4xMjAyOTlDNC4xMjQ1MzMtMy4xNjgxMiAzLjU1MDY4NS0zLjU5ODUwNiAzLjQxOTE3OC00LjE4NDMwOUMzLjM4MzMxMy00LjMxNTgxNiAzLjM4MzMxMy00LjMzOTcyNiAzLjM4MzMxMy00Ljc3MDExMlYtNy4xMzcyMzVDMy4zODMzMTMtNy42MzkzNTIgMy4zODMzMTMtOC4wMjE5MTggMi44MDk0NjUtOC40NzYyMTRDMi4zMzEyNTgtOC44NDY4MjQgMS41MDYzNTEtOC45NjYzNzYgMS4wOTk4NzUtOC45NjYzNzZDLjk5MjI3OS04Ljk2NjM3NiAuODYwNzcyLTguOTY2Mzc2IC44NjA3NzItOC44MzQ4NjlDLjg2MDc3Mi04LjcxNTMxOCAuOTMyNTAzLTguNzE1MzE4IDEuMDUyMDU1LTguNzAzMzYyQzEuODA1MjMtOC42NTU1NDIgMi4zOTEwMzQtOC4yNzI5NzYgMi41NDY0NTEtNy42NjMyNjNDMi41ODIzMTYtNy41NTU2NjYgMi41ODIzMTYtNy41MzE3NTYgMi41ODIzMTYtNy4xMDEzN1YtNC41OTA3ODVDMi41ODIzMTYtNC4wNDA4NDcgMi42Nzc5NTgtMy44Mzc2MDkgMy4wNjA1MjMtMy40NTUwNDRDMy4zMTE1ODItMy4yMDM5ODUgMy42NTgyODEtMy4wODQ0MzMgMy45OTMwMjYtMi45ODg3OTJDMy4wMTI3MDItMi43MTM4MjMgMi41ODIzMTYtMi4xNjM4ODUgMi41ODIzMTYtMS40NzA0ODZWMS4zOTg3NTVaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc0NS44MDYzNzYnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnMi0xMDInLz4KPHVzZSB4PSc1MS41MzU1NjInIHk9Jy0xOC41MzA3MjknIHhsaW5rOmhyZWY9JyNnMC05OCcvPgo8dXNlIHg9JzUxLjc4Mzk3NScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTk3Jy8+Cjx1c2UgeD0nNTcuOTI4OTE5JyB5PSctMTYuNzM3NDUxJyB4bGluazpocmVmPScjZzctNDgnLz4KPHVzZSB4PSc2Mi42NjEyMycgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTU5Jy8+Cjx1c2UgeD0nNjcuNjU2OTc3JyB5PSctMTguNTMwNzI5JyB4bGluazpocmVmPScjZzAtOTgnLz4KPHVzZSB4PSc2Ny45MDUzODknIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnNS05NycvPgo8dXNlIHg9Jzc0LjA1MDMzMycgeT0nLTE2LjczNzQ1MScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNzguNzgyNjQ0JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzUtNTknLz4KPHVzZSB4PSc4NC4wMjY4MDMnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnNS01OCcvPgo8dXNlIHg9Jzg5LjI3MDk2MicgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTU4Jy8+Cjx1c2UgeD0nOTQuNTE1MTIxJyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzUtNTgnLz4KPHVzZSB4PSc5OS43NTkyOCcgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTU5Jy8+Cjx1c2UgeD0nMTA0Ljc1NTAyNicgeT0nLTE4LjUzMDcyOScgeGxpbms6aHJlZj0nI2cwLTk4Jy8+Cjx1c2UgeD0nMTA1LjAwMzQzOScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTk3Jy8+Cjx1c2UgeD0nMTExLjE0ODM4MycgeT0nLTE2LjczNzQ1MScgeGxpbms6aHJlZj0nI2c0LTc1Jy8+Cjx1c2UgeD0nMTE5LjM1MTA0OCcgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2cyLTEwMycvPgo8dXNlIHg9JzEyOC42NDk0NzcnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC02MScvPgo8dXNlIHg9JzE0MS4wNzQ5NTgnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC05NycvPgo8dXNlIHg9JzE0Ni45Mjc5NDgnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC0xMTQnLz4KPHVzZSB4PScxNTEuNDgwMjc0JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzgtMTAzJy8+Cjx1c2UgeD0nMTU3LjMzMzI2NCcgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c4LTEwOScvPgo8dXNlIHg9JzE2Ny4wODgyNDgnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PScxNzAuMzM5OTA5JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzgtMTEwJy8+Cjx1c2UgeD0nMTg0LjkwMDkzNicgeT0nLTMzLjQ3NDczNScgeGxpbms6aHJlZj0nI2c0LTExMCcvPgo8dXNlIHg9JzE3OC44MzU3MjknIHk9Jy0yOS44ODgxNzknIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzE3OS43NDg4ODUnIHk9Jy00LjQyNzk2JyB4bGluazpocmVmPScjZzQtMTA3Jy8+Cjx1c2UgeD0nMTg0LjM3MDUnIHk9Jy00LjQyNzk2JyB4bGluazpocmVmPScjZzctNjEnLz4KPHVzZSB4PScxOTAuOTU3MDA3JyB5PSctNC40Mjc5NicgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nMTk4LjA5Njg0MycgeT0nLTQyLjU2MDgyNScgeGxpbms6aHJlZj0nI2cwLTUwJy8+Cjx1c2UgeD0nMTk4LjA5Njg0MycgeT0nLTIxLjA0MTMxOScgeGxpbms6aHJlZj0nI2cwLTUyJy8+Cjx1c2UgeD0nMjA2LjA2Njk3MScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTEyMCcvPgo8dXNlIHg9JzIxMi43MTkwNTgnIHk9Jy0yMy40NjY5JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjEyLjcxOTA1OCcgeT0nLTE1LjU3NTE5OScgeGxpbms6aHJlZj0nI2c0LTEwNycvPgo8dXNlIHg9JzIyMC40OTU0NjknIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjMyLjQ1MDYyOScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTk3Jy8+Cjx1c2UgeD0nMjM4LjU5NTU3MycgeT0nLTE2LjczNzQ1MScgeGxpbms6aHJlZj0nI2c3LTQ4Jy8+Cjx1c2UgeD0nMjQ1Ljk4NDU1MicgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScyNzMuMjA2OTA4JyB5PSctMjkuODg4MTc5JyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PScyNTcuOTM5NzEyJyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnNC0xMDYnLz4KPHVzZSB4PScyNjEuODIzNzM3JyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnMS01MCcvPgo8dXNlIHg9JzI2Ny40NjkzMTQnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2cxLTEwMicvPgo8dXNlIHg9JzI3MS43MDM0OTcnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2c0LTEwNicvPgo8dXNlIHg9JzI3NS4xMjgxODUnIHk9Jy0yLjg3ODIyOScgeGxpbms6aHJlZj0nI2c2LTQ5Jy8+Cjx1c2UgeD0nMjc5LjI3OTIzJyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnNC01OScvPgo8dXNlIHg9JzI4MS42MzE1NTMnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2c0LTU4Jy8+Cjx1c2UgeD0nMjgzLjk4Mzg3NycgeT0nLTMuOTg1MTc4JyB4bGluazpocmVmPScjZzQtNTgnLz4KPHVzZSB4PScyODYuMzM2MjAxJyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnNC01OCcvPgo8dXNlIHg9JzI4OC42ODg1MjUnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2c0LTU5Jy8+Cjx1c2UgeD0nMjkxLjA0MDg0OScgeT0nLTMuOTg1MTc4JyB4bGluazpocmVmPScjZzQtMTA2Jy8+Cjx1c2UgeD0nMjk0LjQ2NTUzNicgeT0nLTIuNjQ1NzQ5JyB4bGluazpocmVmPScjZzMtNzUnLz4KPHVzZSB4PSczMDEuNTA4NTM3JyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnMS0xMDMnLz4KPHVzZSB4PSczMDcuNzM1MjE4JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzUtOTcnLz4KPHVzZSB4PSczMTMuODgwMTYyJyB5PSctMTYuNzM3NDUxJyB4bGluazpocmVmPScjZzQtMTA2Jy8+Cjx1c2UgeD0nMzE4LjI2MjMxOScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTEyMCcvPgo8dXNlIHg9JzMyNC45MTQ0MDYnIHk9Jy0yNC4xOTgzMzQnIHhsaW5rOmhyZWY9JyNnNC0xMDYnLz4KPHVzZSB4PSczMjQuOTE0NDA2JyB5PSctMTUuMjAxMDM3JyB4bGluazpocmVmPScjZzQtMTA3Jy8+Cjx1c2UgeD0nMzMwLjAzNDE1NCcgeT0nLTQyLjU2MDgyNScgeGxpbms6aHJlZj0nI2cwLTUxJy8+Cjx1c2UgeD0nMzMwLjAzNDE1NCcgeT0nLTIxLjA0MTMxOScgeGxpbms6aHJlZj0nI2cwLTUzJy8+Cjx1c2UgeD0nMzM4LjAwNDI1OCcgeT0nLTM5Ljg4NDE3MicgeGxpbms6aHJlZj0nI2c3LTUwJy8+CjwvZz4KPC9zdmc+)
In other words, the principle is to minimize the total quadratic
distance between the observations  and the linear forecast
and the linear forecast
 .
.
Some estimated coefficient  may be close to
zero, which may indicate that the variable
may be close to
zero, which may indicate that the variable  does not
bring valuable information to forecast . A classical statistical
test to identify such situations is available: Fisher’s test.
For each estimated coefficient , an important
characteristic is the so-called “
does not
bring valuable information to forecast . A classical statistical
test to identify such situations is available: Fisher’s test.
For each estimated coefficient , an important
characteristic is the so-called “ -value” of Fisher’s test. The
coefficient is said to be “significant” if and only if
-value” of Fisher’s test. The
coefficient is said to be “significant” if and only if
 is greater than a value
is greater than a value
 chosen by the user (typically 5% or 10%). The higher the
-value, the more significant the coefficient.
chosen by the user (typically 5% or 10%). The higher the
-value, the more significant the coefficient.
Another important characteristic of the adjusted linear model is the
coefficient of determination  . This quantity indicates the
part of the variance of that is explained by the linear
model:
. This quantity indicates the
part of the variance of that is explained by the linear
model:

where  denotes the empirical mean of the sample
denotes the empirical mean of the sample
 .
.
Thus,  . A value close to 1 indicates a good fit
of the linear model, whereas a value close to 0 indicates that the
linear model does not provide a relevant forecast. A statistical test
allows one to detect significant values of . Again, a
-value is provided: the higher the -value, the more
significant the coefficient of determination.
. A value close to 1 indicates a good fit
of the linear model, whereas a value close to 0 indicates that the
linear model does not provide a relevant forecast. A statistical test
allows one to detect significant values of . Again, a
-value is provided: the higher the -value, the more
significant the coefficient of determination.
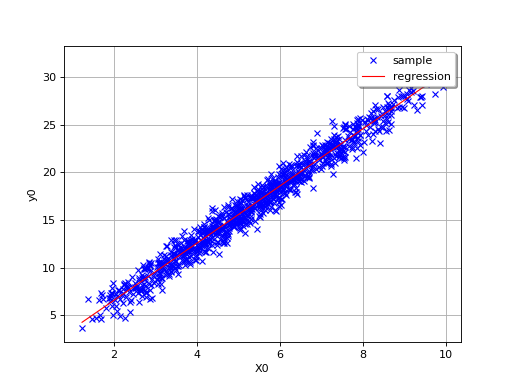
By definition, the multiple regression model is only relevant for linear
relationships, as in the following simple example where
 .
.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
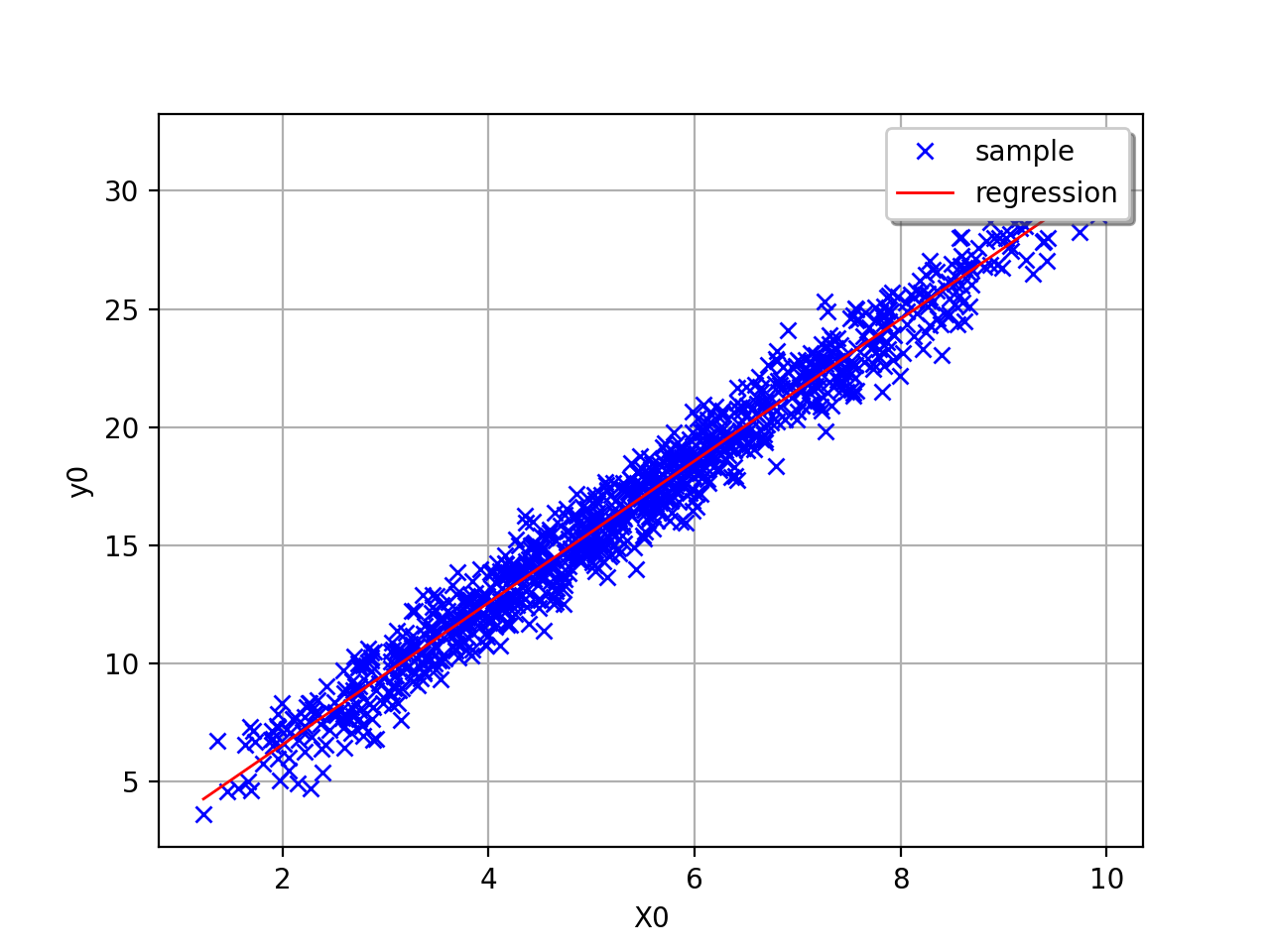
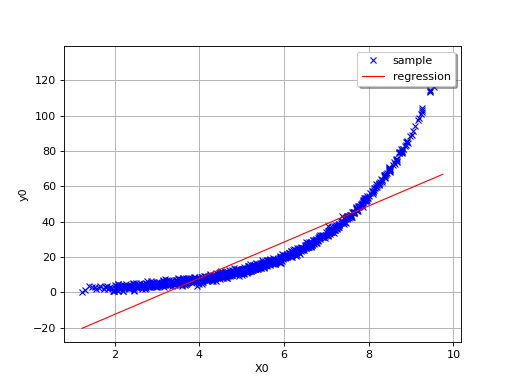
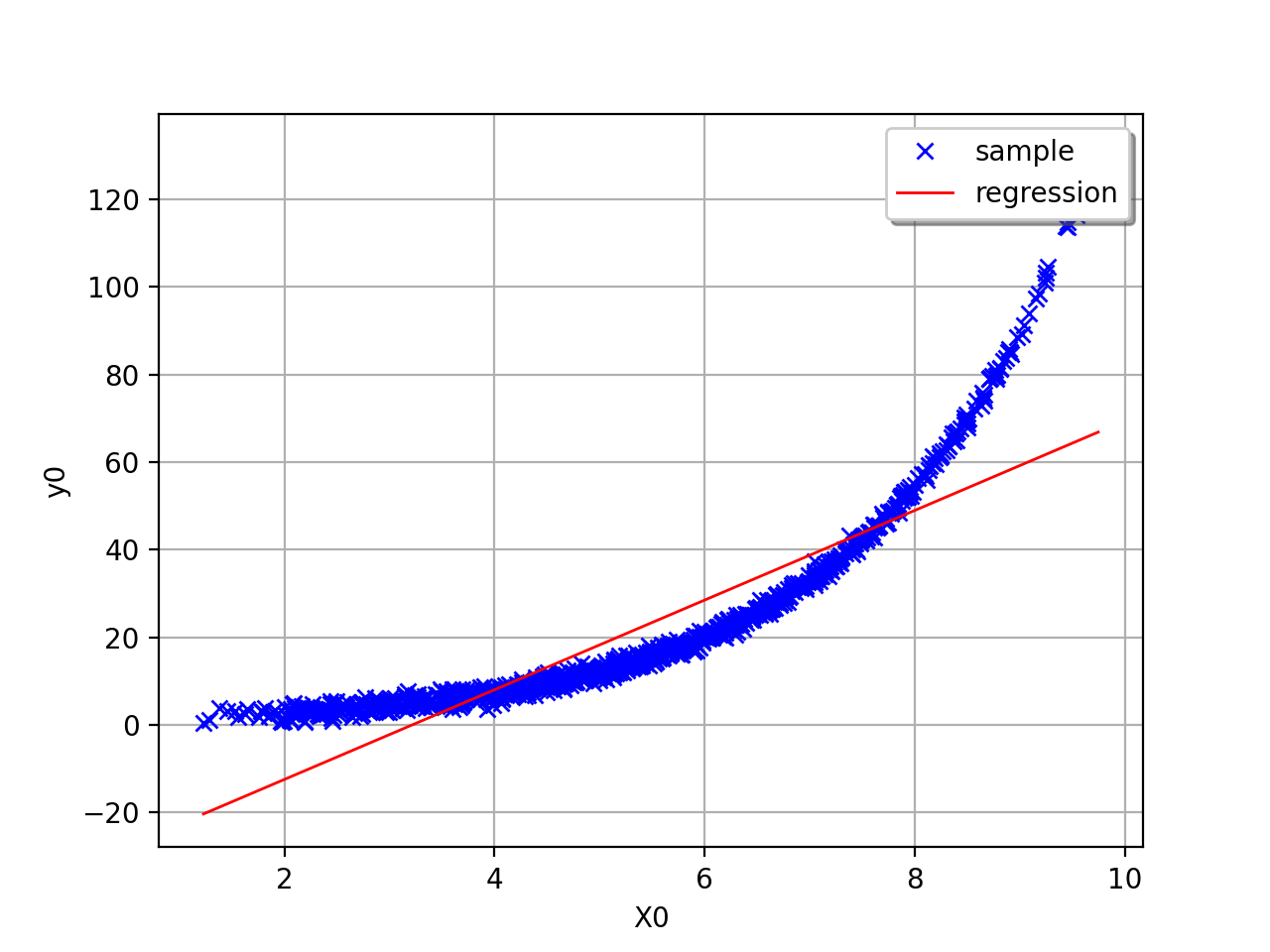
In this second example (still in dimension 1), the linear model is not
relevant because of the exponential shape of the relation. But a linear
approach would be useful on the transformed problem
 . In other words, what is important is
that the relationships between and the variables
,…, is linear with respect to the
regression coefficients
. In other words, what is important is
that the relationships between and the variables
,…, is linear with respect to the
regression coefficients  .
.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
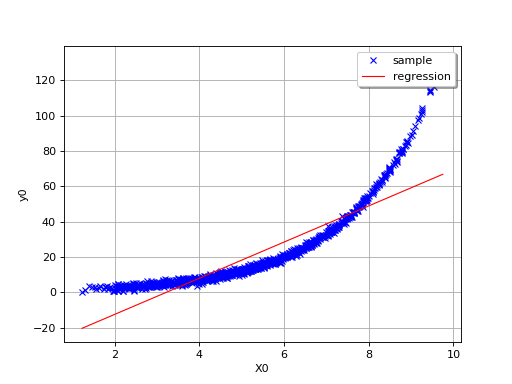
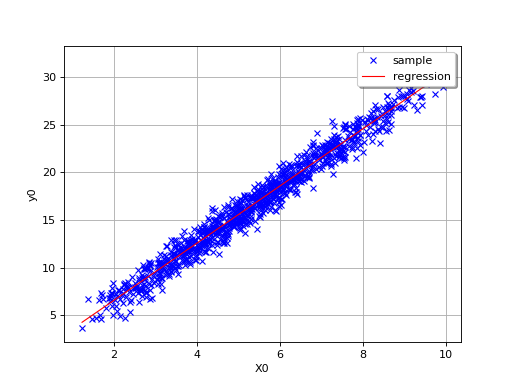
The value of is a good indication of the goodness-of fit of
the linear model. However, several other verifications have to be
carried out before concluding that the linear model is satisfactory. For
instance, one has to pay attentions to the “residuals”
 of the regression:
of the regression:

A residual is thus equal to the difference between the observed value
of and the average forecast provided by the linear model. A
key-assumption for the robustness of the model is that the
characteristics of the residuals do not depend on the value of
 : the mean value should be close
to 0 and the standard deviation should be constant. Thus, plotting the
residuals versus these variables can fruitful.
: the mean value should be close
to 0 and the standard deviation should be constant. Thus, plotting the
residuals versus these variables can fruitful.
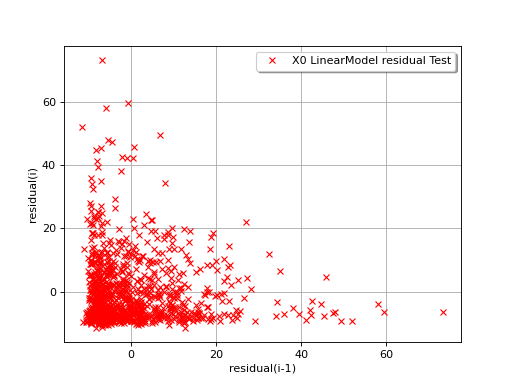
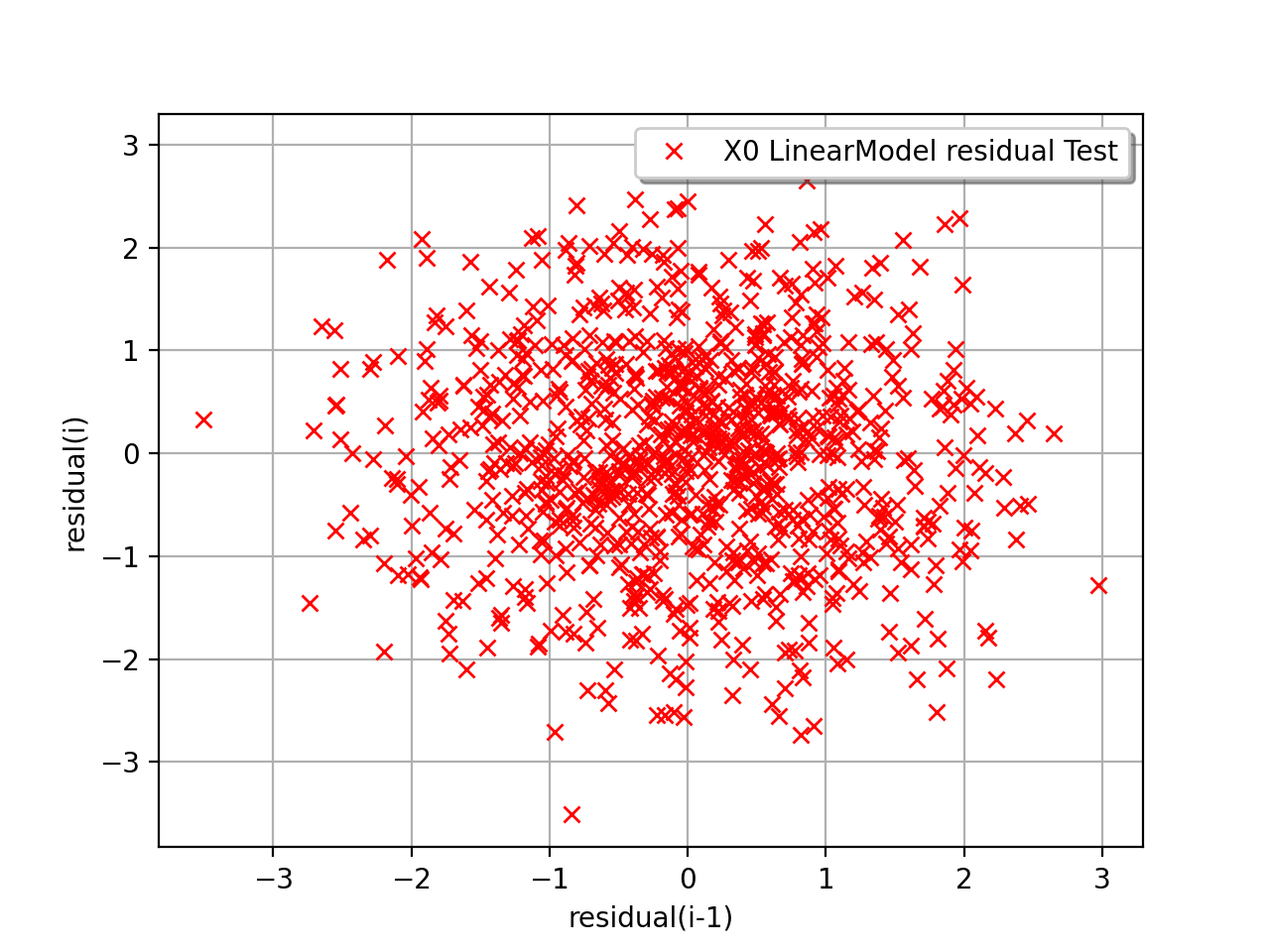
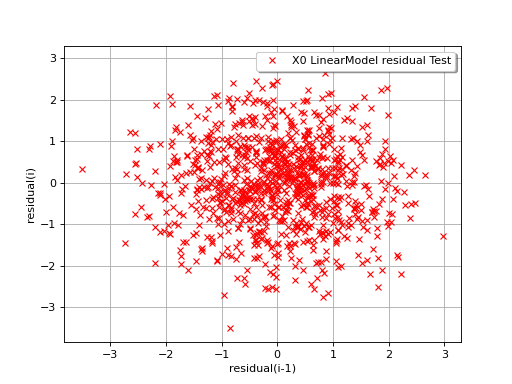
In the following example, the behavior of the residuals is satisfactory: no particular trend can be detected neither in the mean nor in he standard deviation.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
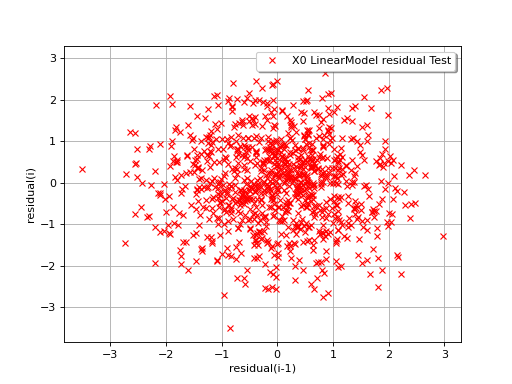
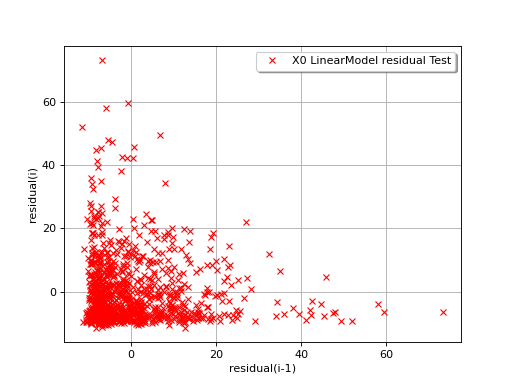
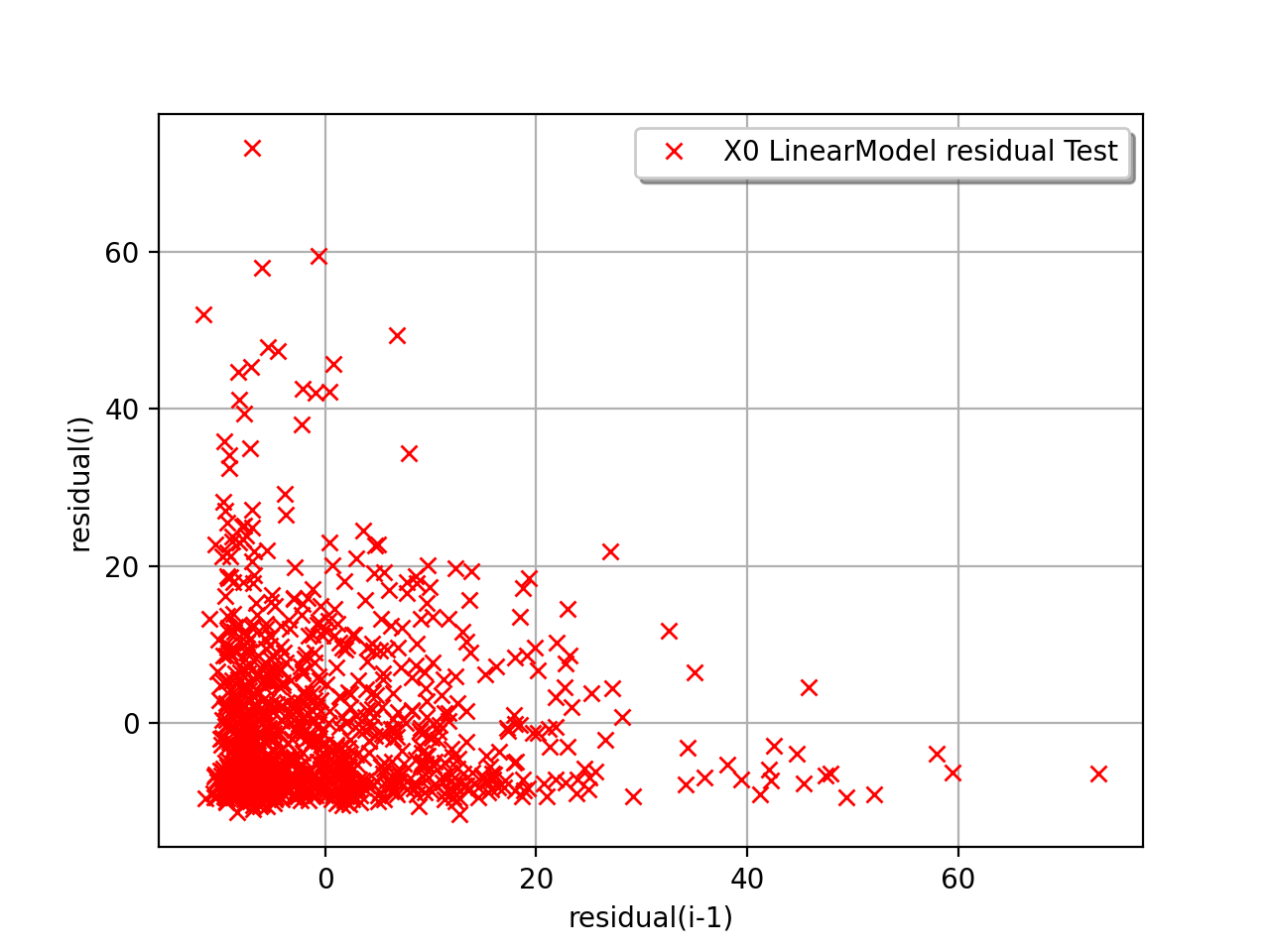
The next example illustrates a less favorable situation: the mean value
of the residuals seems to be close to 0 but the standard deviation tends
to increase with  . In such a situation, the linear model should
be abandoned, or at least used very cautiously.
. In such a situation, the linear model should
be abandoned, or at least used very cautiously.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}