Maximum Likelihood Principle¶
This method deals with the parametric modeling of a probability
distribution for a random vector
 . The appropriate
probability distribution is found by using a sample of data
. The appropriate
probability distribution is found by using a sample of data
 . Such an approach
can be described in two steps as follows:
. Such an approach
can be described in two steps as follows:
Choose a probability distribution (e.g. the Normal distribution, or any other distribution available),
Find the parameter values
 that characterize the
probability distribution (e.g. the mean and standard deviation for
the Normal distribution) which best describes the sample
.
that characterize the
probability distribution (e.g. the mean and standard deviation for
the Normal distribution) which best describes the sample
.
The maximum likelihood method is used for the second step.
This method is restricted to the
case where  and continuous probability distributions.
Please note therefore that
and continuous probability distributions.
Please note therefore that  in the following
text. The maximum likelihood estimate (MLE) of is
defined as the value of which maximizes the
likelihood function
in the following
text. The maximum likelihood estimate (MLE) of is
defined as the value of which maximizes the
likelihood function  :
:

Given that  is a sample of
independent identically distributed (i.i.d) observations,
is a sample of
independent identically distributed (i.i.d) observations,
 represents the
probability of observing such a sample assuming that they are taken from
a probability distribution with parameters . In
concrete terms, the likelihood
is calculated as
follows:
represents the
probability of observing such a sample assuming that they are taken from
a probability distribution with parameters . In
concrete terms, the likelihood
is calculated as
follows:

if the distribution is continuous, with density
 .
.
For example, if we suppose that  is a Gaussian distribution
with parameters
is a Gaussian distribution
with parameters  (i.e. the mean
and standard deviation),
(i.e. the mean
and standard deviation),
![\begin{aligned}
L\left(x_1,\ldots, x_N, \vect{\theta}\right) &=& \prod_{j=1}^{N} \frac{1}{\sigma \sqrt{2\pi}} \exp \left[ -\frac{1}{2} \left( \frac{x_j-\mu}{\sigma} \right)^2 \right] \\
&=& \frac{1}{\sigma^N (2\pi)^{N/2}} \exp \left[ -\frac{1}{2\sigma^2} \sum_{j=1}^N \left( x_j-\mu \right)^2 \right]
\end{aligned}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyOTQuNDcxNjA2cHQnIGhlaWdodD0nNzguNDYxMzMycHQnIHZpZXdCb3g9JzQ3LjAzNTY4MyAtNzkuNjU2ODQ2IDI5NC40NzE2MDYgNzguNDYxMzMyJz4KPGRlZnM+CjxwYXRoIGlkPSdnMS0xOCcgZD0nTTguMzY4NjE4IDI4LjA4MjY5QzguMzY4NjE4IDI4LjAzNDg2OSA4LjM0NDcwNyAyOC4wMTA5NTkgOC4zMjA3OTcgMjcuOTc1MDkzQzcuODc4NDU2IDI3LjUzMjc1MiA3LjA3NzQ2IDI2LjczMTc1NiA2LjI3NjQ2MyAyNS40NDA1OThDNC4zNTE2ODEgMjIuMzU2MTY0IDMuNDc4OTU0IDE4LjQ3MDczNSAzLjQ3ODk1NCAxMy44Njc5OTVDMy40Nzg5NTQgMTAuNjUyMDU1IDMuOTA5MzQgNi41MDM2MTEgNS44ODE5NDMgMi45NDA5NzFDNi44MjY0MDEgMS4yNDMzMzcgNy44MDY3MjUgLjI2MzAxNCA4LjMzMjc1Mi0uMjYzMDE0QzguMzY4NjE4LS4yOTg4NzkgOC4zNjg2MTgtLjMyMjc5IDguMzY4NjE4LS4zNTg2NTVDOC4zNjg2MTgtLjQ3ODIwNyA4LjI4NDkzMi0uNDc4MjA3IDguMTE3NTU5LS40NzgyMDdTNy45MjYyNzYtLjQ3ODIwNyA3Ljc0Njk0OS0uMjk4ODc5QzMuNzQxOTY4IDMuMzQ3NDQ3IDIuNDg2Njc1IDguODIyOTE0IDIuNDg2Njc1IDEzLjg1NjA0QzIuNDg2Njc1IDE4LjU1NDQyMSAzLjU2MjY0IDIzLjI4ODY2NyA2LjU5OTI1MyAyNi44NjMyNjNDNi44MzgzNTYgMjcuMTM4MjMyIDcuMjkyNjUzIDI3LjYyODM5NCA3Ljc4MjgxNCAyOC4wNTg3OEM3LjkyNjI3NiAyOC4yMDIyNDIgNy45NTAxODcgMjguMjAyMjQyIDguMTE3NTU5IDI4LjIwMjI0MlM4LjM2ODYxOCAyOC4yMDIyNDIgOC4zNjg2MTggMjguMDgyNjlaJy8+CjxwYXRoIGlkPSdnMS0xOScgZD0nTTYuMzAwMzc0IDEzLjg2Nzk5NUM2LjMwMDM3NCA5LjE2OTYxNCA1LjIyNDQwOCA0LjQzNTM2NyAyLjE4Nzc5NiAuODYwNzcyQzEuOTQ4NjkyIC41ODU4MDMgMS40OTQzOTYgLjA5NTY0MSAxLjAwNDIzNC0uMzM0NzQ1Qy44NjA3NzItLjQ3ODIwNyAuODM2ODYyLS40NzgyMDcgLjY2OTQ4OS0uNDc4MjA3Qy41MjYwMjctLjQ3ODIwNyAuNDE4NDMxLS40NzgyMDcgLjQxODQzMS0uMzU4NjU1Qy40MTg0MzEtLjMxMDgzNCAuNDY2MjUyLS4yNjMwMTQgLjQ5MDE2Mi0uMjM5MTAzQy45MDg1OTMgLjE5MTI4MyAxLjcwOTU4OSAuOTkyMjc5IDIuNTEwNTg1IDIuMjgzNDM3QzQuNDM1MzY3IDUuMzY3ODcgNS4zMDgwOTUgOS4yNTMzIDUuMzA4MDk1IDEzLjg1NjA0QzUuMzA4MDk1IDE3LjA3MTk4IDQuODc3NzA5IDIxLjIyMDQyMyAyLjkwNTEwNiAyNC43ODMwNjRDMS45NjA2NDggMjYuNDgwNjk3IC45NjgzNjkgMjcuNDcyOTc2IC40NjYyNTIgMjcuOTc1MDkzQy40NDIzNDEgMjguMDEwOTU5IC40MTg0MzEgMjguMDQ2ODI0IC40MTg0MzEgMjguMDgyNjlDLjQxODQzMSAyOC4yMDIyNDIgLjUyNjAyNyAyOC4yMDIyNDIgLjY2OTQ4OSAyOC4yMDIyNDJDLjgzNjg2MiAyOC4yMDIyNDIgLjg2MDc3MiAyOC4yMDIyNDIgMS4wNDAxIDI4LjAyMjkxNEM1LjA0NTA4MSAyNC4zNzY1ODggNi4zMDAzNzQgMTguOTAxMTIxIDYuMzAwMzc0IDEzLjg2Nzk5NVonLz4KPHBhdGggaWQ9J2cxLTM0JyBkPSdNMy4yODc2NzEgMzUuMzc1MzQySDYuODI2NDAxVjM0LjYzNDEyMkg0LjAyODg5MlYuMjYzMDE0SDYuODI2NDAxVi0uNDc4MjA3SDMuMjg3NjcxVjM1LjM3NTM0MlonLz4KPHBhdGggaWQ9J2cxLTM1JyBkPSdNMi45MjkwMTYgMzQuNjM0MTIySC4xMzE1MDdWMzUuMzc1MzQySDMuNjcwMjM3Vi0uNDc4MjA3SC4xMzE1MDdWLjI2MzAxNEgyLjkyOTAxNlYzNC42MzQxMjJaJy8+CjxwYXRoIGlkPSdnMS04OCcgZD0nTTE1LjEzNTI0MyAxNi43MzcyMzVMMTYuNTgxODE4IDEyLjkxMTU4MkgxNi4yODI5MzlDMTUuODE2Njg3IDE0LjE1NDkxOSAxNC41NDk0NCAxNC45Njc4NyAxMy4xNzQ1OTUgMTUuMzI2NTI2QzEyLjkyMzUzNyAxNS4zODYzMDEgMTEuNzUxOTMgMTUuNjk3MTM2IDkuNDU2NTM4IDE1LjY5NzEzNkgyLjI0NzU3Mkw4LjMzMjc1MiA4LjU1OTlDOC40MTY0MzggOC40NjQyNTkgOC40NDAzNDkgOC40MjgzOTQgOC40NDAzNDkgOC4zNjg2MThDOC40NDAzNDkgOC4zNDQ3MDcgOC40NDAzNDkgOC4zMDg4NDIgOC4zNTY2NjMgOC4xODkyOUwyLjc4NTU1NCAuNTczODQ4SDkuMzM2OTg2QzEwLjkzODk3OSAuNTczODQ4IDEyLjAyNjg5OSAuNzQxMjIgMTIuMTM0NDk2IC43NjUxMzFDMTIuNzgwMDc1IC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMuNzI5MjY1IDAgLjcxNzMxIC4wMTE5NTUgLjY4MTQ0NSAuMDgzNjg2Qy42Njk0ODkgLjExOTU1MiAuNjY5NDg5IC4zNDY3IC42Njk0ODkgLjQ3ODIwN0w2Ljk5Mzc3MyA5LjEzMzc0OEwuODAwOTk2IDE2LjM5MDUzNUMuNjgxNDQ1IDE2LjUzMzk5OCAuNjgxNDQ1IDE2LjU5Mzc3MyAuNjgxNDQ1IDE2LjYwNTcyOUMuNjgxNDQ1IDE2LjczNzIzNSAuNzg5MDQxIDE2LjczNzIzNSAxLjAwNDIzNCAxNi43MzcyMzVIMTUuMTM1MjQzWicvPgo8cGF0aCBpZD0nZzEtODknIGQ9J00xNC41OTcyNiAxNi43MzcyMzVWMTYuMDkxNjU2QzEzLjAwNzIyMyAxNi4wOTE2NTYgMTIuNjM2NjEzIDE1LjU0MTcxOSAxMi42MzY2MTMgMTQuNzc2NTg4VjEuOTYwNjQ4QzEyLjYzNjYxMyAxLjE4MzU2MiAxMy4wMTkxNzggLjY0NTU3OSAxNC41OTcyNiAuNjQ1NTc5VjBILjY2OTQ4OVYuNjQ1NTc5QzIuMjU5NTI3IC42NDU1NzkgMi42MzAxMzcgMS4xOTU1MTcgMi42MzAxMzcgMS45NjA2NDhWMTQuNzc2NTg4QzIuNjMwMTM3IDE1LjU1MzY3NCAyLjI0NzU3MiAxNi4wOTE2NTYgLjY2OTQ4OSAxNi4wOTE2NTZWMTYuNzM3MjM1SDYuNDE5OTI1VjE2LjA5MTY1NkM0LjgyOTg4OCAxNi4wOTE2NTYgNC40NTkyNzggMTUuNTQxNzE5IDQuNDU5Mjc4IDE0Ljc3NjU4OFYuNjQ1NTc5SDEwLjgwNzQ3MlYxNC43NzY1ODhDMTAuODA3NDcyIDE1LjU1MzY3NCAxMC40MjQ5MDcgMTYuMDkxNjU2IDguODQ2ODI0IDE2LjA5MTY1NlYxNi43MzcyMzVIMTQuNTk3MjZaJy8+CjxwYXRoIGlkPSdnMy02MScgZD0nTTMuNzA2MTAyLTUuNjQyODM5QzMuNzUzOTIzLTUuNzU0NDIxIDMuNzUzOTIzLTUuNzcwMzYxIDMuNzUzOTIzLTUuNzk0MjcxQzMuNzUzOTIzLTUuODk3ODgzIDMuNjc0MjIyLTUuOTc3NTg0IDMuNTcwNjEtNS45Nzc1ODRDMy40NDMwODgtNS45Nzc1ODQgMy40MTEyMDgtNS44ODE5NDMgMy4zNzkzMjgtNS44MDIyNDJMLjUxODA1NyAxLjY1Nzc4M0MuNDcwMjM3IDEuNzY5MzY1IC40NzAyMzcgMS43ODUzMDUgLjQ3MDIzNyAxLjgwOTIxNUMuNDcwMjM3IDEuOTEyODI3IC41NDk5MzggMS45OTI1MjggLjY1MzU0OSAxLjk5MjUyOEMuNzgxMDcxIDEuOTkyNTI4IC44MTI5NTEgMS44OTY4ODcgLjg0NDgzMiAxLjgxNzE4NkwzLjcwNjEwMi01LjY0MjgzOVonLz4KPHBhdGggaWQ9J2czLTc4JyBkPSdNNi4zMTIzMjktNC41NzQ4NDRDNi40MDc5Ny00Ljk2NTM4IDYuNTgzMzEzLTUuMTU2NjYzIDcuMTU3MTYxLTUuMTgwNTczQzcuMjM2ODYyLTUuMTgwNTczIDcuMzAwNjIzLTUuMjI4Mzk0IDcuMzAwNjIzLTUuMzMyMDA1QzcuMzAwNjIzLTUuMzc5ODI2IDcuMjYwNzcyLTUuNDQzNTg3IDcuMTgxMDcxLTUuNDQzNTg3QzcuMTI1MjgtNS40NDM1ODcgNi45NzM4NDgtNS40MTk2NzYgNi4zODQwNi01LjQxOTY3NkM1Ljc0NjQ1MS01LjQxOTY3NiA1LjY0MjgzOS01LjQ0MzU4NyA1LjU3MTEwOC01LjQ0MzU4N0M1LjQ0MzU4Ny01LjQ0MzU4NyA1LjQxOTY3Ni01LjM1NTkxNSA1LjQxOTY3Ni01LjI5MjE1NEM1LjQxOTY3Ni01LjE4ODU0MyA1LjUyMzI4OC01LjE4MDU3MyA1LjU5NTAxOS01LjE4MDU3M0M2LjA4MTE5Ni01LjE2NDYzMyA2LjA4MTE5Ni00Ljk0OTQ0IDYuMDgxMTk2LTQuODM3ODU4QzYuMDgxMTk2LTQuNzk4MDA3IDYuMDgxMTk2LTQuNzU4MTU3IDYuMDQ5MzE1LTQuNjMwNjM1TDUuMTcyNjAzLTEuMTM5NzI2TDMuMjUxODA2LTUuMzAwMTI1QzMuMTg4MDQ1LTUuNDQzNTg3IDMuMTcyMTA1LTUuNDQzNTg3IDIuOTgwODIyLTUuNDQzNTg3SDEuOTQ0NzA3QzEuODAxMjQ1LTUuNDQzNTg3IDEuNjk3NjM0LTUuNDQzNTg3IDEuNjk3NjM0LTUuMjkyMTU0QzEuNjk3NjM0LTUuMTgwNTczIDEuNzkzMjc1LTUuMTgwNTczIDEuOTYwNjQ4LTUuMTgwNTczQzIuMDI0NDA4LTUuMTgwNTczIDIuMjYzNTEyLTUuMTgwNTczIDIuNDQ2ODI0LTUuMTMyNzUyTDEuMzc4ODI5LS44NTI4MDJDMS4yODMxODgtLjQ1NDI5NiAxLjA3NTk2NS0uMjc4OTU0IC41NDE5NjgtLjI2MzAxNEMuNDk0MTQ3LS4yNjMwMTQgLjM5ODUwNi0uMjU1MDQ0IC4zOTg1MDYtLjExMTU4MkMuMzk4NTA2LS4wNjM3NjEgLjQzODM1NiAwIC41MTgwNTcgMEMuNTQ5OTM4IDAgLjczMzI1LS4wMjM5MSAxLjMwNzA5OC0uMDIzOTFDMS45MzY3MzctLjAyMzkxIDIuMDU2Mjg5IDAgMi4xMjgwMiAwQzIuMTU5OSAwIDIuMjc5NDUyIDAgMi4yNzk0NTItLjE1MTQzMkMyLjI3OTQ1Mi0uMjQ3MDczIDIuMTkxNzgxLS4yNjMwMTQgMi4xMzU5OS0uMjYzMDE0QzEuODQ5MDY2LS4yNzA5ODQgMS42MDk5NjMtLjMxODgwNCAxLjYwOTk2My0uNTk3NzU4QzEuNjA5OTYzLS42Mzc2MDkgMS42MzM4NzMtLjc0OTE5MSAxLjYzMzg3My0uNzU3MTYxTDIuNjc3OTU4LTQuOTE3NTU5SDIuNjg1OTI4TDQuOTAxNjE5LS4xNDM0NjJDNC45NTc0MS0uMDE1OTQgNC45NjUzOCAwIDUuMDUzMDUxIDBDNS4xNjQ2MzMgMCA1LjE3MjYwMy0uMDMxODggNS4yMDQ0ODMtLjE2NzM3Mkw2LjMxMjMyOS00LjU3NDg0NFonLz4KPHBhdGggaWQ9J2czLTEwNicgZD0nTTMuMjkxNjU2LTQuOTczMzVDMy4yOTE2NTYtNS4xMjQ3ODIgMy4xNzIxMDUtNS4yNzYyMTQgMi45ODA4MjItNS4yNzYyMTRDMi43NDE3MTktNS4yNzYyMTQgMi41MzQ0OTYtNS4wNTMwNTEgMi41MzQ0OTYtNC44NDU4MjhDMi41MzQ0OTYtNC42OTQzOTYgMi42NTQwNDctNC41NDI5NjQgMi44NDUzMy00LjU0Mjk2NEMzLjA4NDQzMy00LjU0Mjk2NCAzLjI5MTY1Ni00Ljc2NjEyNyAzLjI5MTY1Ni00Ljk3MzM1Wk0xLjYyNTkwMyAuMzk4NTA2QzEuNTA2MzUxIC44ODQ2ODIgMS4xMTU4MTYgMS40MDI3NCAuNjI5NjM5IDEuNDAyNzRDLjUwMjExNyAxLjQwMjc0IC4zODI1NjUgMS4zNzA4NTkgLjM2NjYyNSAxLjM2Mjg4OUMuNjEzNjk5IDEuMjQzMzM3IC42NDU1NzkgMS4wMjgxNDQgLjY0NTU3OSAuOTU2NDEzQy42NDU1NzkgLjc2NTEzMSAuNTAyMTE3IC42NjE1MTkgLjMzNDc0NSAuNjYxNTE5Qy4xMDM2MTEgLjY2MTUxOS0uMTExNTgyIC44NjA3NzItLjExMTU4MiAxLjEyMzc4NkMtLjExMTU4MiAxLjQyNjY1IC4xODMzMTMgMS42MjU5MDMgLjYzNzYwOSAxLjYyNTkwM0MxLjEyMzc4NiAxLjYyNTkwMyAyLjAwMDQ5OCAxLjMyMzAzOSAyLjIzOTYwMSAuMzY2NjI1TDIuOTU2OTEyLTIuNDg2Njc1QzIuOTgwODIyLTIuNTgyMzE2IDIuOTk2NzYyLTIuNjQ2MDc3IDIuOTk2NzYyLTIuNzY1NjI5QzIuOTk2NzYyLTMuMjAzOTg1IDIuNjQ2MDc3LTMuNTE0ODE5IDIuMTgzODExLTMuNTE0ODE5QzEuMzM4OTc5LTMuNTE0ODE5IC44NDQ4MzItMi4zOTkwMDQgLjg0NDgzMi0yLjI5NTM5MkMuODQ0ODMyLTIuMjIzNjYxIC45MDA2MjMtMi4xOTE3ODEgLjk2NDM4NC0yLjE5MTc4MUMxLjA1MjA1NS0yLjE5MTc4MSAxLjA2MDAyNS0yLjIxNTY5MSAxLjExNTgxNi0yLjMzNTI0M0MxLjM1NDkxOS0yLjg4NTE4MSAxLjc2MTM5NS0zLjI5MTY1NiAyLjE1OTktMy4yOTE2NTZDMi4zMjcyNzMtMy4yOTE2NTYgMi40MjI5MTQtMy4xODAwNzUgMi40MjI5MTQtMi45MTcwNjFDMi40MjI5MTQtMi44MDU0NzkgMi4zOTkwMDQtMi42OTM4OTggMi4zNzUwOTMtMi41ODIzMTZMMS42MjU5MDMgLjM5ODUwNlonLz4KPHBhdGggaWQ9J2cwLTE4JyBkPSdNNi41Mzk0NzctNS44NTgwMzJDNi41Mzk0NzctNy45NjIxNDIgNS4yOTYxMzktOC4zOTI1MjggNC41NjY4NzQtOC4zOTI1MjhDMy42MjI0MTYtOC4zOTI1MjggMi40MjY4OTktNy43NzA4NTkgMS41MzAyNjItNi4xNDQ5NTZDLjkyMDU0OC01LjAyMTE3MSAuNTQ5OTM4LTMuMzk1MjY4IC41NDk5MzgtMi40MjY4OTlDLjU0OTkzOC0uNjkzNCAxLjQ1ODUzMSAuMDk1NjQxIDIuNTM0NDk2IC4wOTU2NDFDMy4zMzU0OTIgLjA5NTY0MSA0LjM4NzU0Ny0uMzcwNjEgNS4yMTI0NTMtMS41OTAwMzdDNi4yMTY2ODctMy4wNjA1MjMgNi41Mzk0NzctNC45NjEzOTUgNi41Mzk0NzctNS44NTgwMzJaTTIuMzY3MTIzLTQuNDM1MzY3QzIuNTM0NDk2LTUuMTI4NzY3IDIuODQ1MzMtNi4yMTY2ODcgMy4yMDM5ODUtNi44MzgzNTZDMy40Nzg5NTQtNy4zMjg1MTggMy45NjkxMTYtNy45NjIxNDIgNC41NDI5NjQtNy45NjIxNDJDNS4wNDUwODEtNy45NjIxNDIgNS4yNjAyNzQtNy40MzYxMTUgNS4yNjAyNzQtNi43MzA3NkM1LjI2MDI3NC01Ljk3NzU4NCA0Ljk5NzI2LTQuOTM3NDg0IDQuODY1NzUzLTQuNDM1MzY3SDIuMzY3MTIzWk00LjcyMjI5MS0zLjg2MTUxOUMzLjk4MTA3MS0uNjU3NTM0IDIuOTc2ODM3LS4zMzQ3NDUgMi41NTg0MDYtLjMzNDc0NUMyLjM5MTAzNC0uMzM0NzQ1IDIuMTM5OTc1LS4zODI1NjUgMS45NzI2MDMtLjc1MzE3NkMxLjgyOTE0MS0xLjA3NTk2NSAxLjgyOTE0MS0xLjU0MjIxNyAxLjgyOTE0MS0xLjU1NDE3MkMxLjgyOTE0MS0yLjIzNTYxNiAyLjA5MjE1NC0zLjM0NzQ0NyAyLjIyMzY2MS0zLjg2MTUxOUg0LjcyMjI5MVonLz4KPHBhdGggaWQ9J2c1LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzUtNTAnIGQ9J00yLjI0NzU3Mi0xLjYyNTkwM0MyLjM3NTA5My0xLjc0NTQ1NSAyLjcwOTgzOC0yLjAwODQ2OCAyLjgzNzM2LTIuMTIwMDVDMy4zMzE1MDctMi41NzQzNDYgMy44MDE3NDMtMy4wMTI3MDIgMy44MDE3NDMtMy43Mzc5ODNDMy44MDE3NDMtNC42ODY0MjYgMy4wMDQ3MzItNS4zMDAxMjUgMi4wMDg0NjgtNS4zMDAxMjVDMS4wNTIwNTUtNS4zMDAxMjUgLjQyMjQxNi00LjU3NDg0NCAuNDIyNDE2LTMuODY1NTA0Qy40MjI0MTYtMy40NzQ5NjkgLjczMzI1LTMuNDE5MTc4IC44NDQ4MzItMy40MTkxNzhDMS4wMTIyMDQtMy40MTkxNzggMS4yNTkyNzgtMy41Mzg3MyAxLjI1OTI3OC0zLjg0MTU5NEMxLjI1OTI3OC00LjI1NjA0IC44NjA3NzItNC4yNTYwNCAuNzY1MTMxLTQuMjU2MDRDLjk5NjI2NC00LjgzNzg1OCAxLjUzMDI2Mi01LjAzNzExMSAxLjkyMDc5Ny01LjAzNzExMUMyLjY2MjAxNy01LjAzNzExMSAzLjA0NDU4My00LjQwNzQ3MiAzLjA0NDU4My0zLjczNzk4M0MzLjA0NDU4My0yLjkwOTA5MSAyLjQ2Mjc2NS0yLjMwMzM2MiAxLjUyMjI5MS0xLjMzODk3OUwuNTE4MDU3LS4zMDI4NjRDLjQyMjQxNi0uMjE1MTkzIC40MjI0MTYtLjE5OTI1MyAuNDIyNDE2IDBIMy41NzA2MUwzLjgwMTc0My0xLjQyNjY1SDMuNTU0NjdDMy41MzA3Ni0xLjI2NzI0OCAzLjQ2Njk5OS0uODY4NzQyIDMuMzcxMzU3LS43MTczMUMzLjMyMzUzNy0uNjUzNTQ5IDIuNzE3ODA4LS42NTM1NDkgMi41OTAyODYtLjY1MzU0OUgxLjE3MTYwNkwyLjI0NzU3Mi0xLjYyNTkwM1onLz4KPHBhdGggaWQ9J2c1LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnNi00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzYtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c2LTQ5JyBkPSdNMy40NDMwODgtNy42NjMyNjNDMy40NDMwODgtNy45MzgyMzIgMy40NDMwODgtNy45NTAxODcgMy4yMDM5ODUtNy45NTAxODdDMi45MTcwNjEtNy42MjczOTcgMi4zMTkzMDMtNy4xODUwNTYgMS4wODc5Mi03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODktNi44MzgzNTYgMS45NjA2NDgtNi44MzgzNTYgMi42MTgxODItNy4xNDkxOTFWLS45MjA1NDhDMi42MTgxODItLjQ5MDE2MiAyLjU4MjMxNi0uMzQ2NyAxLjUzMDI2Mi0uMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTEgMy4wMzY2MTMtLjAyMzkxUzQuNTc4ODI5LS4wMjM5MSA0LjkwMTYxOSAwVi0uMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NC0uMzQ2NyAzLjQ0MzA4OC0uNDkwMTYyIDMuNDQzMDg4LS45MjA1NDhWLTcuNjYzMjYzWicvPgo8cGF0aCBpZD0nZzYtNTAnIGQ9J001LjI2MDI3NC0yLjAwODQ2OEg0Ljk5NzI2QzQuOTYxMzk1LTEuODA1MjMgNC44NjU3NTMtMS4xNDc2OTYgNC43NDYyMDItLjk1NjQxM0M0LjY2MjUxNi0uODQ4ODE3IDMuOTgxMDcxLS44NDg4MTcgMy42MjI0MTYtLjg0ODgxN0gxLjQxMDcxQzEuNzMzNDk5LTEuMTIzNzg2IDIuNDYyNzY1LTEuODg4OTE3IDIuNzczNTk5LTIuMTc1ODQxQzQuNTkwNzg1LTMuODQ5NTY0IDUuMjYwMjc0LTQuNDcxMjMzIDUuMjYwMjc0LTUuNjU0Nzk1QzUuMjYwMjc0LTcuMDI5NjM5IDQuMTcyMzU0LTcuOTUwMTg3IDIuNzg1NTU0LTcuOTUwMTg3Uy41ODU4MDMtNi43NjY2MjUgLjU4NTgwMy01LjczODQ4MUMuNTg1ODAzLTUuMTI4NzY3IDEuMTExODMxLTUuMTI4NzY3IDEuMTQ3Njk2LTUuMTI4NzY3QzEuMzk4NzU1LTUuMTI4NzY3IDEuNzA5NTg5LTUuMzA4MDk1IDEuNzA5NTg5LTUuNjkwNjZDMS43MDk1ODktNi4wMjU0MDUgMS40ODI0NDEtNi4yNTI1NTMgMS4xNDc2OTYtNi4yNTI1NTNDMS4wNDAxLTYuMjUyNTUzIDEuMDE2MTg5LTYuMjUyNTUzIC45ODAzMjQtNi4yNDA1OThDMS4yMDc0NzItNy4wNTM1NDkgMS44NTMwNTEtNy42MDM0ODcgMi42MzAxMzctNy42MDM0ODdDMy42NDYzMjYtNy42MDM0ODcgNC4yNjc5OTUtNi43NTQ2NyA0LjI2Nzk5NS01LjY1NDc5NUM0LjI2Nzk5NS00LjYzODYwNSAzLjY4MjE5Mi0zLjc1MzkyMyAzLjAwMDc0Ny0yLjk4ODc5MkwuNTg1ODAzLS4yODY5MjRWMEg0Ljk0OTQ0TDUuMjYwMjc0LTIuMDA4NDY4WicvPgo8cGF0aCBpZD0nZzYtNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2c2LTEwMScgZD0nTTQuNTc4ODI5LTIuNzczNTk5QzQuODQxODQzLTIuNzczNTk5IDQuODY1NzUzLTIuNzczNTk5IDQuODY1NzUzLTMuMDAwNzQ3QzQuODY1NzUzLTQuMjA4MjE5IDQuMjIwMTc0LTUuMzMyMDA1IDIuNzczNTk5LTUuMzMyMDA1QzEuNDEwNzEtNS4zMzIwMDUgLjM1ODY1NS00LjEwMDYyMyAuMzU4NjU1LTIuNjE4MTgyQy4zNTg2NTUtMS4wNDAxIDEuNTc4MDgyIC4xMTk1NTIgMi45MDUxMDYgLjExOTU1MkM0LjMyNzc3MSAuMTE5NTUyIDQuODY1NzUzLTEuMTcxNjA2IDQuODY1NzUzLTEuNDIyNjY1QzQuODY1NzUzLTEuNDk0Mzk2IDQuODA1OTc4LTEuNTQyMjE3IDQuNzM0MjQ3LTEuNTQyMjE3QzQuNjM4NjA1LTEuNTQyMjE3IDQuNjE0Njk1LTEuNDgyNDQxIDQuNTkwNzg1LTEuNDIyNjY1QzQuMjc5OTUtLjQxODQzMSAzLjQ3ODk1NC0uMTQzNDYyIDIuOTc2ODM3LS4xNDM0NjJTMS4yNjcyNDgtLjQ3ODIwNyAxLjI2NzI0OC0yLjU0NjQ1MVYtMi43NzM1OTlINC41Nzg4MjlaTTEuMjc5MjAzLTMuMDAwNzQ3QzEuMzc0ODQ0LTQuODc3NzA5IDIuNDI2ODk5LTUuMDkyOTAyIDIuNzYxNjQ0LTUuMDkyOTAyQzQuMDQwODQ3LTUuMDkyOTAyIDQuMTEyNTc4LTMuNDA3MjIzIDQuMTI0NTMzLTMuMDAwNzQ3SDEuMjc5MjAzWicvPgo8cGF0aCBpZD0nZzYtMTEyJyBkPSdNMi45MjkwMTYgMS45NzI2MDNDMi4xNjM4ODUgMS45NzI2MDMgMi4wMjA0MjMgMS45NzI2MDMgMi4wMjA0MjMgMS40MzQ2MlYtLjY0NTU3OUMyLjIzNTYxNi0uMzQ2NyAyLjcyNTc3OCAuMTE5NTUyIDMuNDkwOTA5IC4xMTk1NTJDNC44NjU3NTMgLjExOTU1MiA2LjA3MzIyNS0xLjA0MDEgNi4wNzMyMjUtMi41ODIzMTZDNi4wNzMyMjUtNC4xMDA2MjMgNC45NDk0NC01LjI3MjIyOSAzLjY0NjMyNi01LjI3MjIyOUMyLjU5NDI3MS01LjI3MjIyOSAyLjAzMjM3OS00LjUxOTA1NCAxLjk5NjUxMy00LjQ3MTIzM1YtNS4yNzIyMjlMLjMzNDc0NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xNzE2MDYtNC43OTQwMjIgMS4yNDMzMzctNC43MTAzMzYgMS4yNDMzMzctNC4xODQzMDlWMS40MzQ2MkMxLjI0MzMzNyAxLjk3MjYwMyAxLjExMTgzMSAxLjk3MjYwMyAuMzM0NzQ1IDEuOTcyNjAzVjIuMzE5MzAzQy42NDU1NzkgMi4yOTUzOTIgMS4yOTExNTggMi4yOTUzOTIgMS42MjU5MDMgMi4yOTUzOTJDMS45NzI2MDMgMi4yOTUzOTIgMi42MTgxODIgMi4yOTUzOTIgMi45MjkwMTYgMi4zMTkzMDNWMS45NzI2MDNaTTIuMDIwNDIzLTMuODEzNjk5QzIuMDIwNDIzLTQuMDQwODQ3IDIuMDIwNDIzLTQuMDUyODAyIDIuMTUxOTMtNC4yNDQwODVDMi41MTA1ODUtNC43ODIwNjcgMy4wOTYzODktNS4wMDkyMTUgMy41NTA2ODUtNS4wMDkyMTVDNC40NDczMjMtNS4wMDkyMTUgNS4xNjQ2MzMtMy45MjEyOTUgNS4xNjQ2MzMtMi41ODIzMTZDNS4xNjQ2MzMtMS4xNTk2NTEgNC4zNTE2ODEtLjExOTU1MiAzLjQzMTEzMy0uMTE5NTUyQzMuMDYwNTIzLS4xMTk1NTIgMi43MTM4MjMtLjI3NDk2OSAyLjQ3NDcyLS41MDIxMTdDMi4xOTk3NTEtLjc3NzA4NiAyLjAyMDQyMy0xLjAxNjE4OSAyLjAyMDQyMy0xLjM1MDkzNFYtMy44MTM2OTlaJy8+CjxwYXRoIGlkPSdnNi0xMjAnIGQ9J00zLjM0NzQ0Ny0yLjgyMTQyQzMuNjk0MTQ3LTMuMjc1NzE2IDQuMTk2MjY0LTMuOTIxMjk1IDQuNDIzNDEyLTQuMTcyMzU0QzQuOTEzNTc0LTQuNzIyMjkxIDUuNDc1NDY3LTQuODA1OTc4IDUuODU4MDMyLTQuODA1OTc4Vi01LjE1MjY3N0M1LjM0Mzk2LTUuMTI4NzY3IDUuMzIwMDUtNS4xMjg3NjcgNC44NTM3OTgtNS4xMjg3NjdDNC4zOTk1MDItNS4xMjg3NjcgNC4zNzU1OTItNS4xMjg3NjcgMy43Nzc4MzMtNS4xNTI2NzdWLTQuODA1OTc4QzMuOTMzMjUtNC43ODIwNjcgNC4xMjQ1MzMtNC43MTAzMzYgNC4xMjQ1MzMtNC40MzUzNjdDNC4xMjQ1MzMtNC4yMzIxMyA0LjAxNjkzNi00LjEwMDYyMyAzLjk0NTIwNS00LjAwNDk4MUwzLjE4MDA3NS0zLjAzNjYxM0wyLjI0NzU3Mi00LjI2Nzk5NUMyLjIxMTcwNi00LjMxNTgxNiAyLjEzOTk3NS00LjQyMzQxMiAyLjEzOTk3NS00LjUwNzA5OEMyLjEzOTk3NS00LjU3ODgyOSAyLjE5OTc1MS00Ljc5NDAyMiAyLjU1ODQwNi00LjgwNTk3OFYtNS4xNTI2NzdDMi4yNTk1MjctNS4xMjg3NjcgMS42NDk4MTMtNS4xMjg3NjcgMS4zMjcwMjQtNS4xMjg3NjdDLjkzMjUwMy01LjEyODc2NyAuOTA4NTkzLTUuMTI4NzY3IC4xNzkzMjgtNS4xNTI2NzdWLTQuODA1OTc4Qy43ODkwNDEtNC44MDU5NzggMS4wMTYxODktNC43ODIwNjcgMS4yNjcyNDgtNC40NTkyNzhMMi42NjYwMDItMi42MzAxMzdDMi42ODk5MTMtMi42MDYyMjcgMi43Mzc3MzMtMi41MzQ0OTYgMi43Mzc3MzMtMi40OTg2M1MxLjgwNTIzLTEuMjkxMTU4IDEuNjg1Njc5LTEuMTM1NzQxQzEuMTU5NjUxLS40OTAxNjIgLjYzMzYyNC0uMzU4NjU1IC4xMTk1NTItLjM0NjdWMEMuNTczODQ4LS4wMjM5MSAuNTk3NzU4LS4wMjM5MSAxLjExMTgzMS0uMDIzOTFDMS41NjYxMjctLjAyMzkxIDEuNTkwMDM3LS4wMjM5MSAyLjE4Nzc5NiAwVi0uMzQ2N0MxLjkwMDg3Mi0uMzgyNTY1IDEuODUzMDUxLS41NjE4OTMgMS44NTMwNTEtLjcyOTI2NUMxLjg1MzA1MS0uOTIwNTQ4IDEuOTM2NzM3LTEuMDE2MTg5IDIuMDU2Mjg5LTEuMTcxNjA2QzIuMjM1NjE2LTEuNDIyNjY1IDIuNjMwMTM3LTEuOTEyODI3IDIuOTE3MDYxLTIuMjgzNDM3TDMuODk3Mzg1LTEuMDA0MjM0QzQuMTAwNjIzLS43NDEyMiA0LjEwMDYyMy0uNzE3MzEgNC4xMDA2MjMtLjY0NTU3OUM0LjEwMDYyMy0uNTQ5OTM4IDQuMDA0OTgxLS4zNTg2NTUgMy42ODIxOTItLjM0NjdWMEMzLjk5MzAyNi0uMDIzOTEgNC41Nzg4MjktLjAyMzkxIDQuOTEzNTc0LS4wMjM5MUM1LjMwODA5NS0uMDIzOTEgNS4zMzIwMDUtLjAyMzkxIDYuMDQ5MzE1IDBWLS4zNDY3QzUuNDE1NjkxLS4zNDY3IDUuMjAwNDk4LS4zNzA2MSA0LjkxMzU3NC0uNzUzMTc2TDMuMzQ3NDQ3LTIuODIxNDJaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cyLTExMicgZD0nTTQuNjUwNTYgMTAuMjIxNjY5TDIuNTQ2NDUxIDUuNTcxMTA4QzIuNDYyNzY1IDUuMzc5ODI2IDIuNDAyOTg5IDUuMzc5ODI2IDIuMzY3MTIzIDUuMzc5ODI2QzIuMzU1MTY4IDUuMzc5ODI2IDIuMjk1MzkyIDUuMzc5ODI2IDIuMTYzODg1IDUuNDc1NDY3TDEuMDI4MTQ0IDYuMzM2MjM5Qy44NzI3MjcgNi40NTU3OTEgLjg3MjcyNyA2LjQ5MTY1NiAuODcyNzI3IDYuNTI3NTIyQy44NzI3MjcgNi41ODcyOTggLjkwODU5MyA2LjY1OTAyOSAuOTkyMjc5IDYuNjU5MDI5QzEuMDY0MDEgNi42NTkwMjkgMS4yNjcyNDggNi40OTE2NTYgMS4zOTg3NTUgNi4zOTYwMTVDMS40NzA0ODYgNi4zMzYyMzkgMS42NDk4MTMgNi4yMDQ3MzIgMS43ODEzMiA2LjEwOTA5MUw0LjEzNjQ4OCAxMS4yODU2NzlDNC4yMjAxNzQgMTEuNDc2OTYxIDQuMjc5OTUgMTEuNDc2OTYxIDQuMzg3NTQ3IDExLjQ3Njk2MUM0LjU2Njg3NCAxMS40NzY5NjEgNC42MDI3NCAxMS40MDUyMyA0LjY4NjQyNiAxMS4yMzc4NThMMTAuMTE0MDcyIDBDMTAuMTk3NzU4LS4xNjczNzIgMTAuMTk3NzU4LS4yMTUxOTMgMTAuMTk3NzU4LS4yMzkxMDNDMTAuMTk3NzU4LS4zNTg2NTUgMTAuMTAyMTE3LS40NzgyMDcgOS45NTg2NTUtLjQ3ODIwN0M5Ljg2MzAxNC0uNDc4MjA3IDkuNzc5MzI4LS40MTg0MzEgOS42ODM2ODYtLjIyNzE0OEw0LjY1MDU2IDEwLjIyMTY2OVonLz4KPHBhdGggaWQ9J2c0LTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnNC0yNScgZD0nTTMuMDk2Mzg5LTQuNTA3MDk4SDQuNDQ3MzIzQzQuMTI0NTMzLTMuMTY4MTIgMy45MjEyOTUtMi4yOTUzOTIgMy45MjEyOTUtMS4zMzg5NzlDMy45MjEyOTUtMS4xNzE2MDYgMy45MjEyOTUgLjExOTU1MiA0LjQxMTQ1NyAuMTE5NTUyQzQuNjYyNTE2IC4xMTk1NTIgNC44Nzc3MDktLjEwNzU5NyA0Ljg3NzcwOS0uMzEwODM0QzQuODc3NzA5LS4zNzA2MSA0Ljg3NzcwOS0uMzk0NTIxIDQuNzk0MDIyLS41NzM4NDhDNC40NzEyMzMtMS4zOTg3NTUgNC40NzEyMzMtMi40MjY4OTkgNC40NzEyMzMtMi41MTA1ODVDNC40NzEyMzMtMi41ODIzMTYgNC40NzEyMzMtMy40MzExMzMgNC43MjIyOTEtNC41MDcwOThINi4wNjEyN0M2LjIxNjY4Ny00LjUwNzA5OCA2LjYxMTIwOC00LjUwNzA5OCA2LjYxMTIwOC00Ljg4OTY2NEM2LjYxMTIwOC01LjE1MjY3NyA2LjM4NDA2LTUuMTUyNjc3IDYuMTY4ODY3LTUuMTUyNjc3SDIuMjM1NjE2QzEuOTYwNjQ4LTUuMTUyNjc3IDEuNTU0MTcyLTUuMTUyNjc3IDEuMDA0MjM0LTQuNTY2ODc0Qy42OTM0LTQuMjIwMTc0IC4zMTA4MzQtMy41ODY1NSAuMzEwODM0LTMuNTE0ODE5Uy4zNzA2MS0zLjQxOTE3OCAuNDQyMzQxLTMuNDE5MTc4Qy41MjYwMjctMy40MTkxNzggLjUzNzk4My0zLjQ1NTA0NCAuNTk3NzU4LTMuNTI2Nzc1QzEuMjE5NDI3LTQuNTA3MDk4IDEuODQxMDk2LTQuNTA3MDk4IDIuMTM5OTc1LTQuNTA3MDk4SDIuODIxNDJDMi41NTg0MDYtMy42MTA0NjEgMi4yNTk1MjctMi41NzAzNjEgMS4yNzkyMDMtLjQ3ODIwN0MxLjE4MzU2Mi0uMjg2OTI0IDEuMTgzNTYyLS4yNjMwMTQgMS4xODM1NjItLjE5MTI4M0MxLjE4MzU2MiAuMDU5Nzc2IDEuMzk4NzU1IC4xMTk1NTIgMS41MDYzNTEgLjExOTU1MkMxLjg1MzA1MSAuMTE5NTUyIDEuOTQ4NjkyLS4xOTEyODMgMi4wOTIxNTQtLjY5MzRDMi4yODM0MzctMS4zMDMxMTMgMi4yODM0MzctMS4zMjcwMjQgMi40MDI5ODktMS44MDUyM0wzLjA5NjM4OS00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c0LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNC01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnNC01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzQtNzYnIGQ9J000LjM4NzU0Ny03LjI0NDgzMkM0LjQ5NTE0My03LjY5OTEyOCA0LjUzMTAwOS03LjgxODY4IDUuNTgzMDY0LTcuODE4NjhDNS45MDU4NTMtNy44MTg2OCA1Ljk4OTUzOS03LjgxODY4IDUuOTg5NTM5LTguMDQ1ODI4QzUuOTg5NTM5LTguMTY1MzggNS44NTgwMzItOC4xNjUzOCA1LjgxMDIxMi04LjE2NTM4QzUuNTcxMTA4LTguMTY1MzggNS4yOTYxMzktOC4xNDE0NjkgNS4wNTcwMzYtOC4xNDE0NjlIMy40NTUwNDRDMy4yMjc4OTUtOC4xNDE0NjkgMi45NjQ4ODItOC4xNjUzOCAyLjczNzczMy04LjE2NTM4QzIuNjQyMDkyLTguMTY1MzggMi41MTA1ODUtOC4xNjUzOCAyLjUxMDU4NS03LjkzODIzMkMyLjUxMDU4NS03LjgxODY4IDIuNjE4MTgyLTcuODE4NjggMi43OTc1MDktNy44MTg2OEMzLjUyNjc3NS03LjgxODY4IDMuNTI2Nzc1LTcuNzIzMDM5IDMuNTI2Nzc1LTcuNTkxNTMyQzMuNTI2Nzc1LTcuNTY3NjIxIDMuNTI2Nzc1LTcuNDk1ODkgMy40Nzg5NTQtNy4zMTY1NjNMMS44NjUwMDYtLjg4NDY4MkMxLjc1NzQxLS40NjYyNTIgMS43MzM0OTktLjM0NjcgLjg5NjYzOC0uMzQ2N0MuNjY5NDg5LS4zNDY3IC41NDk5MzgtLjM0NjcgLjU0OTkzOC0uMTMxNTA3Qy41NDk5MzggMCAuNjIxNjY5IDAgLjg2MDc3MiAwSDYuMjE2Njg3QzYuNDc5NzAxIDAgNi40OTE2NTYtLjAxMTk1NSA2LjU3NTM0Mi0uMjI3MTQ4TDcuNDk1ODktMi43NzM1OTlDNy41MTk4MDEtMi44MzMzNzUgNy41NDM3MTEtMi45MDUxMDYgNy41NDM3MTEtMi45NDA5NzFDNy41NDM3MTEtMy4wMTI3MDIgNy40ODM5MzUtMy4wNjA1MjMgNy40MjQxNTktMy4wNjA1MjNDNy40MTIyMDQtMy4wNjA1MjMgNy4zNTI0MjgtMy4wNjA1MjMgNy4zMjg1MTgtMy4wMTI3MDJDNy4zMDQ2MDgtMy4wMDA3NDcgNy4zMDQ2MDgtMi45NzY4MzcgNy4yMDg5NjYtMi43NDk2ODlDNi44MjY0MDEtMS42OTc2MzQgNi4yODg0MTgtLjM0NjcgNC4yNjc5OTUtLjM0NjdIMy4xMjAyOTlDMi45NTI5MjctLjM0NjcgMi45MjkwMTYtLjM0NjcgMi44NTcyODUtLjM1ODY1NUMyLjcyNTc3OC0uMzcwNjEgMi43MTM4MjMtLjM5NDUyMSAyLjcxMzgyMy0uNDkwMTYyQzIuNzEzODIzLS41NzM4NDggMi43Mzc3MzMtLjY0NTU3OSAyLjc2MTY0NC0uNzUzMTc2TDQuMzg3NTQ3LTcuMjQ0ODMyWicvPgo8cGF0aCBpZD0nZzQtMTIwJyBkPSdNNS42NjY3NS00Ljg3NzcwOUM1LjI4NDE4NC00LjgwNTk3OCA1LjE0MDcyMi00LjUxOTA1NCA1LjE0MDcyMi00LjI5MTkwNUM1LjE0MDcyMi00LjAwNDk4MSA1LjM2Nzg3LTMuOTA5MzQgNS41MzUyNDMtMy45MDkzNEM1Ljg5Mzg5OC0zLjkwOTM0IDYuMTQ0OTU2LTQuMjIwMTc0IDYuMTQ0OTU2LTQuNTQyOTY0QzYuMTQ0OTU2LTUuMDQ1MDgxIDUuNTcxMTA4LTUuMjcyMjI5IDUuMDY4OTkxLTUuMjcyMjI5QzQuMzM5NzI2LTUuMjcyMjI5IDMuOTMzMjUtNC41NTQ5MTkgMy44MjU2NTQtNC4zMjc3NzFDMy41NTA2ODUtNS4yMjQ0MDggMi44MDk0NjUtNS4yNzIyMjkgMi41OTQyNzEtNS4yNzIyMjlDMS4zNzQ4NDQtNS4yNzIyMjkgLjcyOTI2NS0zLjcwNjEwMiAuNzI5MjY1LTMuNDQzMDg4Qy43MjkyNjUtMy4zOTUyNjggLjc3NzA4Ni0zLjMzNTQ5MiAuODYwNzcyLTMuMzM1NDkyQy45NTY0MTMtMy4zMzU0OTIgLjk4MDMyNC0zLjQwNzIyMyAxLjAwNDIzNC0zLjQ1NTA0NEMxLjQxMDcxLTQuNzgyMDY3IDIuMjExNzA2LTUuMDMzMTI2IDIuNTU4NDA2LTUuMDMzMTI2QzMuMDk2Mzg5LTUuMDMzMTI2IDMuMjAzOTg1LTQuNTMxMDA5IDMuMjAzOTg1LTQuMjQ0MDg1QzMuMjAzOTg1LTMuOTgxMDcxIDMuMTMyMjU0LTMuNzA2MTAyIDIuOTg4NzkyLTMuMTMyMjU0TDIuNTgyMzE2LTEuNDk0Mzk2QzIuNDAyOTg5LS43NzcwODYgMi4wNTYyODktLjExOTU1MiAxLjQyMjY2NS0uMTE5NTUyQzEuMzYyODg5LS4xMTk1NTIgMS4wNjQwMS0uMTE5NTUyIC44MTI5NTEtLjI3NDk2OUMxLjI0MzMzNy0uMzU4NjU1IDEuMzM4OTc5LS43MTczMSAxLjMzODk3OS0uODYwNzcyQzEuMzM4OTc5LTEuMDk5ODc1IDEuMTU5NjUxLTEuMjQzMzM3IC45MzI1MDMtMS4yNDMzMzdDLjY0NTU3OS0xLjI0MzMzNyAuMzM0NzQ1LS45OTIyNzkgLjMzNDc0NS0uNjA5NzE0Qy4zMzQ3NDUtLjEwNzU5NyAuODk2NjM4IC4xMTk1NTIgMS40MTA3MSAuMTE5NTUyQzEuOTg0NTU4IC4xMTk1NTIgMi4zOTEwMzQtLjMzNDc0NSAyLjY0MjA5Mi0uODI0OTA3QzIuODMzMzc1LS4xMTk1NTIgMy40MzExMzMgLjExOTU1MiAzLjg3MzQ3NCAuMTE5NTUyQzUuMDkyOTAyIC4xMTk1NTIgNS43Mzg0ODEtMS40NDY1NzUgNS43Mzg0ODEtMS43MDk1ODlDNS43Mzg0ODEtMS43NjkzNjUgNS42OTA2Ni0xLjgxNzE4NiA1LjYxODkyOS0xLjgxNzE4NkM1LjUxMTMzMy0xLjgxNzE4NiA1LjQ5OTM3Ny0xLjc1NzQxIDUuNDYzNTEyLTEuNjYxNzY4QzUuMTQwNzIyLS42MDk3MTQgNC40NDczMjMtLjExOTU1MiAzLjkwOTM0LS4xMTk1NTJDMy40OTA5MDktLjExOTU1MiAzLjI2Mzc2MS0uNDMwMzg2IDMuMjYzNzYxLS45MjA1NDhDMy4yNjM3NjEtMS4xODM1NjIgMy4zMTE1ODItMS4zNzQ4NDQgMy41MDI4NjQtMi4xNjM4ODVMMy45MjEyOTUtMy43ODk3ODhDNC4xMDA2MjMtNC41MDcwOTggNC41MDcwOTgtNS4wMzMxMjYgNS4wNTcwMzYtNS4wMzMxMjZDNS4wODA5NDYtNS4wMzMxMjYgNS40MTU2OTEtNS4wMzMxMjYgNS42NjY3NS00Ljg3NzcwOVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzQ3LjAzNTY4MycgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c0LTc2Jy8+Cjx1c2UgeD0nNTYuOTkyNjg3JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtNDAnLz4KPHVzZSB4PSc2MS41NDUwMTMnIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC0xMjAnLz4KPHVzZSB4PSc2OC4xOTcxJyB5PSctNTYuOTQxODY0JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PSc3Mi45Mjk0MTUnIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC01OScvPgo8dXNlIHg9Jzc4LjE3MzU3MycgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c0LTU4Jy8+Cjx1c2UgeD0nODMuNDE3NzMyJyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzQtNTgnLz4KPHVzZSB4PSc4OC42NjE4OTEnIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC01OCcvPgo8dXNlIHg9JzkzLjkwNjA1JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzQtNTknLz4KPHVzZSB4PSc5OS4xNTAyMDknIHk9Jy01OC43MzUxMjcnIHhsaW5rOmhyZWY9JyNnNC0xMjAnLz4KPHVzZSB4PScxMDUuODAyMjk2JyB5PSctNTYuOTQxODY0JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxMTMuODcwNzMzJyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzQtNTknLz4KPHVzZSB4PScxMTkuMTE0ODkyJyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzAtMTgnLz4KPHVzZSB4PScxMjYuMjEzMjI4JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtNDEnLz4KPHVzZSB4PScxMzQuMDg2Mzc5JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScxODIuOTY4MjEyJyB5PSctNzMuNjc5MTQ4JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxNzkuMTE1MzInIHk9Jy03MC4wOTI1OTEnIHhsaW5rOmhyZWY9JyNnMS04OScvPgo8dXNlIHg9JzE3OS40MDEwMDcnIHk9Jy00NC44OTgyMzYnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PScxODMuMjg1MDMyJyB5PSctNDQuODk4MjM2JyB4bGluazpocmVmPScjZzUtNjEnLz4KPHVzZSB4PScxODkuODcxNTM5JyB5PSctNDQuODk4MjM2JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScyMDkuNjM2NTkyJyB5PSctNjYuODIyODg1JyB4bGluazpocmVmPScjZzYtNDknLz4KPHJlY3QgeD0nMTk3LjU3OTQyJyB5PSctNjEuOTYzMDEyJyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPScyOS45NjczMzQnLz4KPHVzZSB4PScxOTcuNTc5NDInIHk9Jy00OS4yMDQzMjQnIHhsaW5rOmhyZWY9JyNnNC0yNycvPgo8dXNlIHg9JzIwNC42NjE4MjQnIHk9Jy01OS4wOTM4ODknIHhsaW5rOmhyZWY9JyNnMi0xMTInLz4KPHJlY3QgeD0nMjE0LjYyNDQ5NScgeT0nLTU5LjU3MjA3NicgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMTIuOTIyMjYnLz4KPHVzZSB4PScyMTQuNjI0NDk1JyB5PSctNDkuMjA0MzI0JyB4bGluazpocmVmPScjZzYtNTAnLz4KPHVzZSB4PScyMjAuNDc3NDg1JyB5PSctNDkuMjA0MzI0JyB4bGluazpocmVmPScjZzQtMjUnLz4KPHVzZSB4PScyMzAuNzM0NzY2JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzYtMTAxJy8+Cjx1c2UgeD0nMjM1LjkzNzQyNCcgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c2LTEyMCcvPgo8dXNlIHg9JzI0Mi4xMTU1OCcgeT0nLTU4LjczNTEyNycgeGxpbms6aHJlZj0nI2c2LTExMicvPgo8dXNlIHg9JzI1MC42MTE0JyB5PSctNzkuMTc4NjUxJyB4bGluazpocmVmPScjZzEtMzQnLz4KPHVzZSB4PScyNTcuNTg1Mjc5JyB5PSctNTguNzM1MTI3JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzI2OC4wNzkyOScgeT0nLTY2LjgyMjg4NScgeGxpbms6aHJlZj0nI2c2LTQ5Jy8+CjxyZWN0IHg9JzI2OC4wNzkyOScgeT0nLTYxLjk2MzAxMicgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNS44NTI5OScvPgo8dXNlIHg9JzI2OC4wNzkyOScgeT0nLTUwLjUzNDQ2NCcgeGxpbms6aHJlZj0nI2c2LTUwJy8+Cjx1c2UgeD0nMjc3LjEyMDI5MScgeT0nLTc1LjU5MjA2NCcgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nMjg3LjExNjE3OCcgeT0nLTY2LjgyMjg4NScgeGxpbms6aHJlZj0nI2c0LTEyMCcvPgo8dXNlIHg9JzI5My43NjgyNjUnIHk9Jy02NS4wMjk2MjInIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PSczMDAuODA3MDg1JyB5PSctNjYuODIyODg1JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzMxMi43NjIyNDYnIHk9Jy02Ni44MjI4ODUnIHhsaW5rOmhyZWY9JyNnNC0yMicvPgo8cmVjdCB4PScyODcuMTE2MTc4JyB5PSctNjEuOTYzMDEyJyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSczMi42ODkwMzEnLz4KPHVzZSB4PScyOTkuOTE5NDk5JyB5PSctNTAuNTM0NDY0JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PSczMjEuMDAwNzIzJyB5PSctNzUuNTkyMDY0JyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PSczMjkuODAxMDk1JyB5PSctNzIuOTE1NDEnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzMzNC41MzM0MScgeT0nLTc5LjE3ODY1MScgeGxpbms6aHJlZj0nI2cxLTM1Jy8+Cjx1c2UgeD0nMTM0LjA4NjM3OScgeT0nLTE2LjU4MjE1JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScxNzcuOTI3MTE4JyB5PSctMjQuNjY5OTA4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHJlY3QgeD0nMTU0LjM0OTE4NCcgeT0nLTE5LjgxMDAzNScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNTMuMDA4ODU4Jy8+Cjx1c2UgeD0nMTU0LjM0OTE4NCcgeT0nLTguMzgxNDg4JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PScxNjEuNDMxNTg4JyB5PSctMTEuODM1MTk2JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxNjkuNTAwMDI2JyB5PSctOC4zODE0ODgnIHhsaW5rOmhyZWY9JyNnNi00MCcvPgo8dXNlIHg9JzE3NC4wNTIzNTEnIHk9Jy04LjM4MTQ4OCcgeGxpbms6aHJlZj0nI2c2LTUwJy8+Cjx1c2UgeD0nMTc5LjkwNTM0MicgeT0nLTguMzgxNDg4JyB4bGluazpocmVmPScjZzQtMjUnLz4KPHVzZSB4PScxODYuOTc0NjExJyB5PSctOC4zODE0ODgnIHhsaW5rOmhyZWY9JyNnNi00MScvPgo8dXNlIHg9JzE5MS41MjY5MzcnIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnMy03OCcvPgo8dXNlIHg9JzE5OC4zOTE1NDUnIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnMy02MScvPgo8dXNlIHg9JzIwMi42MjU3MjgnIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzIxMC41NDYwNTQnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c2LTEwMScvPgo8dXNlIHg9JzIxNS43NDg3MTInIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c2LTEyMCcvPgo8dXNlIHg9JzIyMS45MjY4NjgnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c2LTExMicvPgo8dXNlIHg9JzIzMC40MjI2ODknIHk9Jy0zNy4wMjU2NzQnIHhsaW5rOmhyZWY9JyNnMS0zNCcvPgo8dXNlIHg9JzIzNy4zOTY1NjcnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScyNTMuNzk3OTQ1JyB5PSctMjQuNjY5OTA4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHJlY3QgeD0nMjQ3Ljg5MDU3OCcgeT0nLTE5LjgxMDAzNScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMTcuNjY3NzA5Jy8+Cjx1c2UgeD0nMjQ3Ljg5MDU3OCcgeT0nLTguMzgxNDg4JyB4bGluazpocmVmPScjZzYtNTAnLz4KPHVzZSB4PScyNTMuNzQzNTY4JyB5PSctOC4zODE0ODgnIHhsaW5rOmhyZWY9JyNnNC0yNycvPgo8dXNlIHg9JzI2MC44MjU5NzInIHk9Jy0xMS44MzUxOTYnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzI3My41OTU0NTQnIHk9Jy0zMS41MjYxNzEnIHhsaW5rOmhyZWY9JyNnMy03OCcvPgo8dXNlIHg9JzI2OC43NDYyOTgnIHk9Jy0yNy45Mzk2MTQnIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzI3MC4wMjgyNDknIHk9Jy0yLjc0NTI1OScgeGxpbms6aHJlZj0nI2czLTEwNicvPgo8dXNlIHg9JzI3My45MTIyNzQnIHk9Jy0yLjc0NTI1OScgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMjgwLjQ5ODc4MScgeT0nLTIuNzQ1MjU5JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScyODguMDA3NDEzJyB5PSctMTYuNTgyMTUnIHhsaW5rOmhyZWY9JyNnNi00MCcvPgo8dXNlIHg9JzI5Mi41NTk3MzgnIHk9Jy0xNi41ODIxNScgeGxpbms6aHJlZj0nI2c0LTEyMCcvPgo8dXNlIHg9JzI5OS4yMTE4MjYnIHk9Jy0xNC43ODg4ODcnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PSczMDYuMjUwNjQ2JyB5PSctMTYuNTgyMTUnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMzE4LjIwNTgwNycgeT0nLTE2LjU4MjE1JyB4bGluazpocmVmPScjZzQtMjInLz4KPHVzZSB4PSczMjUuMjQ4Nzc3JyB5PSctMTYuNTgyMTUnIHhsaW5rOmhyZWY9JyNnNi00MScvPgo8dXNlIHg9JzMyOS44MDEwOTUnIHk9Jy0yMi4zOTM2ODUnIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzMzNC41MzM0MScgeT0nLTM3LjAyNTY3NCcgeGxpbms6aHJlZj0nI2cxLTM1Jy8+CjwvZz4KPC9zdmc+)
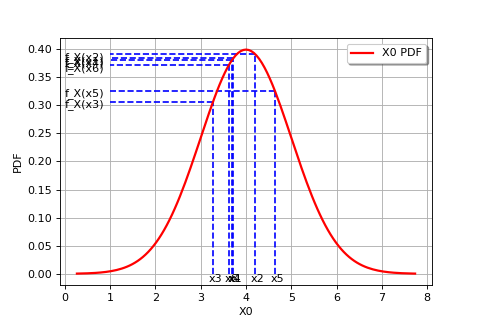
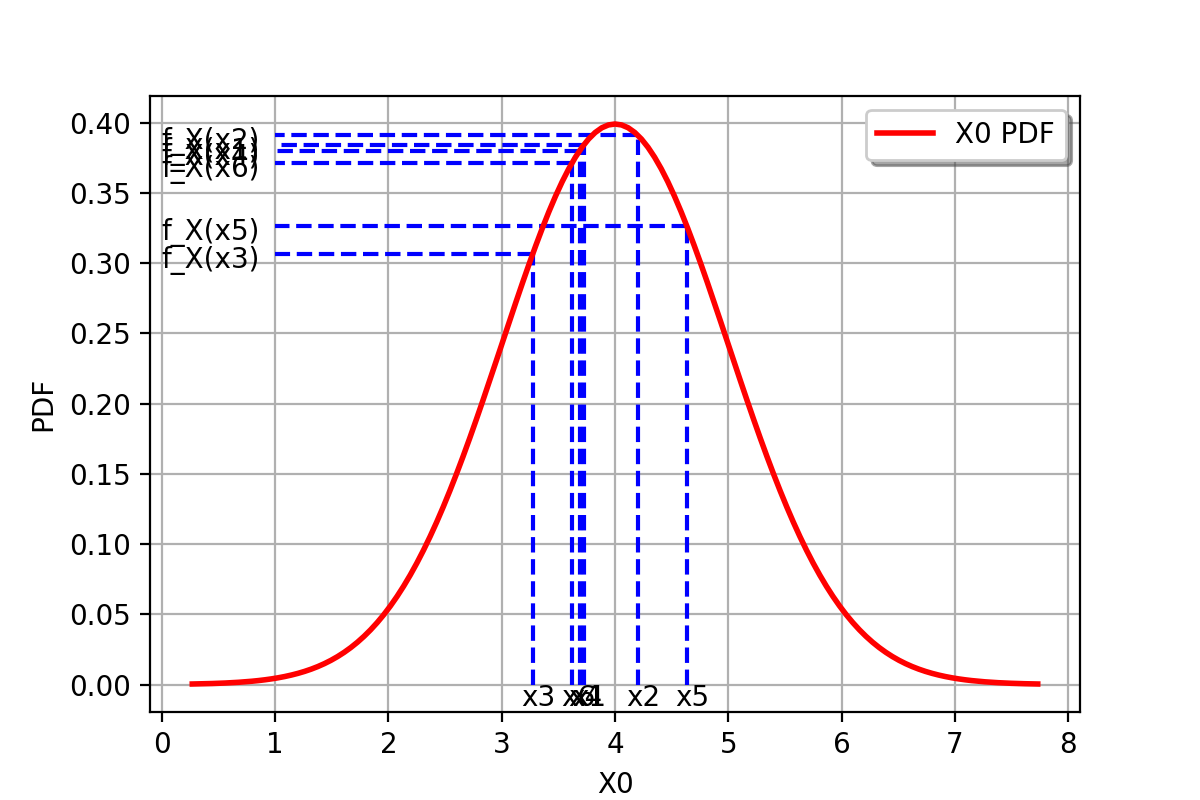
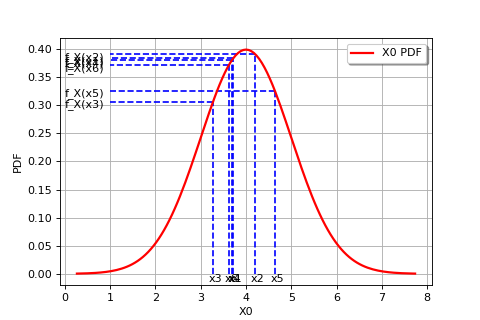
The following figure graphically illustrates the maximum likelihood method, in the particular case of a Gaussian probability distribution.
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
In general, in order to maximize the likelihood function classical optimization algorithms (e.g. gradient type) can be used. The Gaussian distribution case is an exception to this, as the maximum likelihood estimators are obtained analytically:
