Note
Go to the end to download the full example code
Linear Regression with interval-censored observations¶
1. Model formulation¶
We consider the following linear model:

where the observation vector  is modeled as
the sum of:
is modeled as
the sum of:
a linear part, with an
 design matrix
design matrix  and unknown regression coefficients
and unknown regression coefficients  ,
,a Gaussian error term
 ,
,
where  represents a known precision (inverse variance) matrix
for measurement errors,
and
represents a known precision (inverse variance) matrix
for measurement errors,
and  an unknown precision parameter
quantifying the variability of the observed phenomenon.
an unknown precision parameter
quantifying the variability of the observed phenomenon.
1.1. Likelihood of the linear regression model¶
The above linear regression model can thus be written:

We then have the following likelihood:

where  is the Mahalanobis distance between
and
is the Mahalanobis distance between
and  with covariance matrice
with covariance matrice  :
:

1.2. Interval Censorship¶
We now assume that, instead of observing directly the
 as described above, we only have access to
discretized values
as described above, we only have access to
discretized values  , where
, where
 is a grid length and
is a grid length and  means that
means that
 .
.
1.3. Remarks¶
The presence of a composite matrix
 makes
estimation more complex than with a spherical one
makes
estimation more complex than with a spherical one
 since we would then have explicit (closed-form)
maximum likelihood estimators, and also conjugate priors leading to
explicit full joint posterior distributions.
since we would then have explicit (closed-form)
maximum likelihood estimators, and also conjugate priors leading to
explicit full joint posterior distributions.Another difficulty is the presence of censored data, since the likelihood is no more available in closed-form. As we will see, this can be overcome thanks to Bayesian inference.
Heteroscedastic linear modeling under interval censorship as formulated above was originally motivated by an industrial case-study in seismology, wherein the
 correspond to the observed
intensity of an earthquake in a distant site, and explanatory
variables
correspond to the observed
intensity of an earthquake in a distant site, and explanatory
variables  are derived from the epicentral distance to the
earthquake’s source as well as its characteristics (magnitude,
depth). But it can also arise in many different contexts, as soon as
observations are available with known statistical precisions (hence
the heteroscedasticity) and limited numerical accuracy (hence the
censorship).
are derived from the epicentral distance to the
earthquake’s source as well as its characteristics (magnitude,
depth). But it can also arise in many different contexts, as soon as
observations are available with known statistical precisions (hence
the heteroscedasticity) and limited numerical accuracy (hence the
censorship).
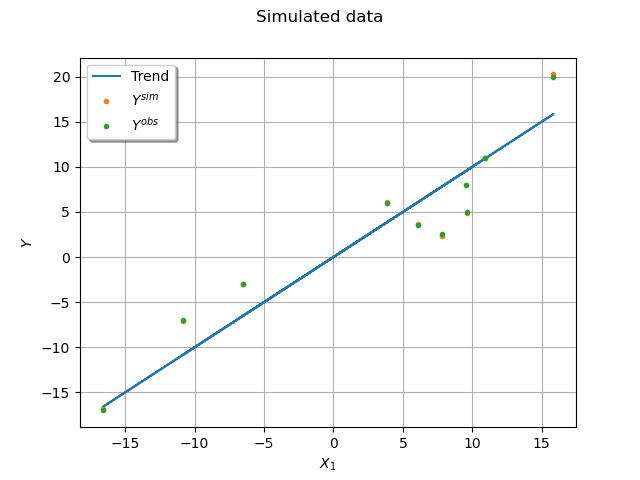
1.4 Simulate the dataset¶
import openturns as ot
from openturns.viewer import View
import numpy as np
ot.Log.Show(ot.Log.NONE)
ot.RandomGenerator.SetSeed(1)
n = 10
delta = 0.5
Build the design matrix
X = ot.Sample([[1.0]] * n)
X.stack(ot.Normal(0.0, 10.0).getSample(n))
Make the precision matrix a diagonal matrix and sample
its diagonal coefficients from an Exponential distribution.
Q = np.ones((n, 1)) + ot.Exponential().getSample(n)
Choose values for the parameters  and .
and .
theta_true = np.array([[0.0], [1.0]])
p = len(theta_true)
tau_true = 0.1
First sample uncensored, and then censored observation data.
mean_true = np.dot(X, theta_true).ravel()
std_true = np.sqrt(1.0 / tau_true + 1.0 / Q).ravel()
Y_sim = mean_true + [x[0] for x in ot.Normal().getSample(n)] * std_true
Yobs_sim = np.round(Y_sim / delta) * delta
Plot the simulated dataset.
graph = ot.Graph("Simulated data", "$X_1$", "$Y$", True, "topleft", 16)
cloud_obs = ot.Cloud(X[:, 1].asPoint(), Yobs_sim)
cloud_obs.setPointStyle("bullet")
cloud_sim = ot.Cloud(X[:, 1].asPoint(), Y_sim)
cloud_sim.setPointStyle("bullet")
curve = ot.Curve(X[:, 1].asPoint(), mean_true)
curve.setLineWidth(1.5)
graph.add(curve)
graph.add(cloud_sim)
graph.add(cloud_obs)
graph.setLegends(["Trend", "$Y^{sim}$", "$Y^{obs}$"])
graph.setColors(ot.Drawable.BuildDefaultPalette(3))
_ = View(graph)
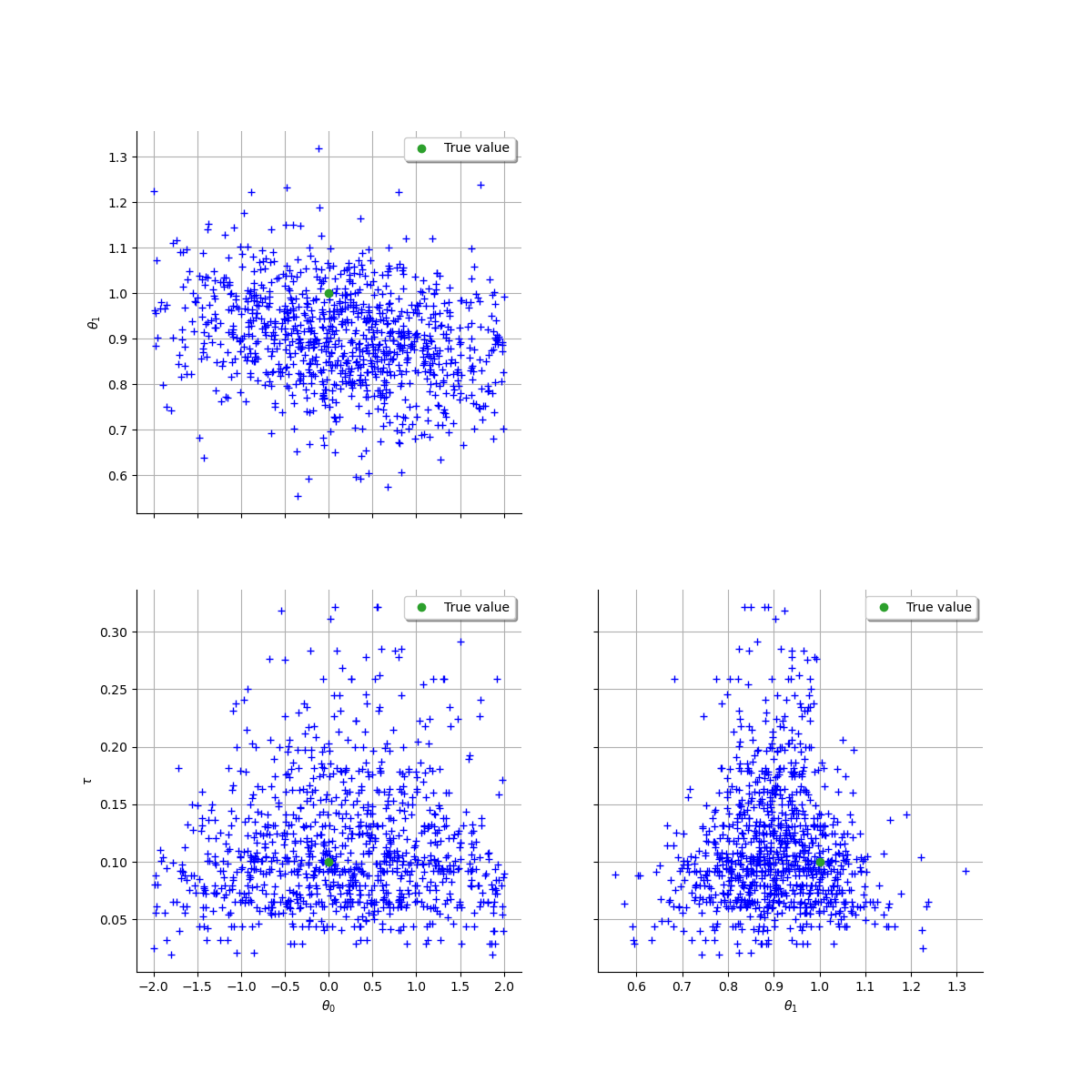
2. Bayesian Inference¶
2.1. Choice of a prior law¶
We use the standard Normal-Gamma prior for and
:

where all parameters are assumed a priori independent if not stated otherwise.
Furthermore, a default choice for the hyperparameters consists in having all prior variances go to infinity, equivalent to the degenerate case:

But the resulting prior is improper. Hence, posterior propriety needs to be proven first.
A simpler solution is to ensure prior (hence posterior) propriety by
imposing bounds  on all parameters following:
on all parameters following:

where inequalites are taken componentwise. When all hyperparameters go to
 as described above, the prior converges to a product of
uniform distributions.
as described above, the prior converges to a product of
uniform distributions.
We will use this product of univariate uniforms as a prior in the following. As discussed above, there is no simple way to obtain the posterior distribution, justifying the use of Monte-Carlo Markov chain techniques, as described hereafter.
lower = (Yobs_sim.ravel() - delta).tolist()
upper = (Yobs_sim.ravel() + delta).tolist()
# Global support of the joint distribution: theta, tau, outputs
support = ot.Interval([-2.0] * p + [1e-4] + lower, [2.0] * p + [1e1] + upper)
prior = ot.ComposedDistribution(
[ot.Uniform(-2.0, 2.0), ot.Uniform(-2.0, 2.0), ot.Uniform(1e-4, 1e1)]
)
# Initialize to true value
initial_state = theta_true[:, 0].tolist() + [tau_true] + Y_sim.ravel().tolist()
initial_state = ot.Point(initial_state)
2.2. Posterior sampling¶
The solution we advocate consists in sampling from the joint posterior
distribution of all uncertain parameters, including the vector of
continuous intensities  seen here as a latent variable.
Indeed, adding to the vector of sampled variables yields a
posterior density which is available in closed form, up to an unknown
multiplicative factor
seen here as a latent variable.
Indeed, adding to the vector of sampled variables yields a
posterior density which is available in closed form, up to an unknown
multiplicative factor

This allows one to perform the following Metropolis within Gibbs sampling
scheme, wherein the pre-defined blocks of variables
 are updated in turn, according to their
conditional posterior density, or to a Markov kernel targeting it, as
described in the following.
are updated in turn, according to their
conditional posterior density, or to a Markov kernel targeting it, as
described in the following.
2.2.1. Updating ¶

hence the latent variables are updated by simply simulating
independent univariate truncated normals.
Step 1 : Create associated RandomVector
marginals_trunc = [
ot.TruncatedNormal(Yobs_sim[i], 1.0, lower[i], upper[i]) for i in range(len(X))
]
trunc_cond_Y = ot.ComposedDistribution(marginals_trunc)
RV_Y = ot.RandomVector(trunc_cond_Y)
Step 2 : Link function, giving the parameters of the univariate truncated normals in function of the chain’s current state
gen_params = np.array(trunc_cond_Y.getParameter())
def py_link_function_y(x):
"""
link function for Y conditional density
Input
x: vector with length (p + 1 + n), containing the current state of (theta, tau, Y)
Output
params: vector with length 4*n, corresponding to mean, std, a and b, for each component of Y
Notes
a and b represent the upper and lower bounds for the truncated normals
"""
theta = [x[i] for i in range(p)]
tau = x[p]
# compute conditional mean and standard deviates
mean = np.dot(X, theta)
std = np.sqrt(1.0 / tau + 1.0 / Q)
# inject values in blueprint
params = gen_params.copy()
params[::4] = mean
params[1::4] = std.ravel()
return params
2.2.2. Updating ¶
 Due to the
partial conjugacy of the conditional prior
Due to the
partial conjugacy of the conditional prior  this is explicit, and given by the following box-constrained
multivariate normal:
this is explicit, and given by the following box-constrained
multivariate normal:

with

or equivalently, thanks to the matrix Woodsbury identity:

By having all hyperparameters go to  we obtain the following
simplified form:
we obtain the following
simplified form:

Explicit simulation from a box-constrained multivariate normal can be done with a simple rejection sampling scheme:
Step 1 : Create associated RandomVector
class BoxConstrainedNormal(ot.PythonRandomVector):
"""
Multivariate normal distribution
under box constraints
"""
def __init__(
self, d=2, mu=np.zeros(2), Sigma=np.eye(2), r=np.zeros(2), s=np.ones(2)
):
for x in mu, Sigma, r, s:
if len(x) != d:
print("expectation or bound does not have size %s" % d)
raise ValueError
if Sigma.shape != (d, d):
print("covariance matrix not have dimensions (%s,%s)" % (d, d))
raise ValueError
super(BoxConstrainedNormal, self).__init__(d)
self.mu = mu
self.Sigma = Sigma
self.r = r
self.s = s
self.interval = ot.Interval(r, s)
def setParameter(self, parameter):
d = self.getDimension()
self.mu = np.array(parameter[:d])
self.Sigma = np.array(parameter[d: d + d * d]).reshape(d, d)
self.r = np.array(parameter[-2 * d: -d])
self.s = np.array(parameter[-d:])
self.interval = ot.Interval(self.r, self.s)
def getParameter(self):
return np.concatenate(
[self.mu.ravel(), self.Sigma.ravel(), self.r.ravel(), self.s.ravel()]
)
def getRealization(self):
accept = False
proposaldist = ot.Normal(self.mu, ot.CovarianceMatrix(self.Sigma))
while not accept:
proposal = proposaldist.getRealization()
accept = self.interval.contains(proposal)
return proposal
RV_theta = ot.RandomVector(BoxConstrainedNormal())
Step 2 : Link function, giving the parameters of the box-constrained normal in function of and values
def py_link_function_theta(x):
tau = x[p]
Y = [x[i] for i in range(p + 1, len(x))]
# conditional mean and variance
# for diagonal Q
Itilde_inv = 1.0 / (1.0 + tau / Q)
Xtilde = Itilde_inv * X
Sigma_n = np.linalg.inv(np.dot(Xtilde.T, X)) / tau
mu_n = np.dot(Xtilde.T, Y)
mu_n = tau * np.dot(Sigma_n, mu_n)
# extract parameters in correct order (coherent with getParameter() method of RV_theta)
return np.concatenate(
[
mu_n.ravel(),
Sigma_n.ravel(),
support.getLowerBound()[:p],
support.getUpperBound()[:p],
]
)
2.2.3. Updating ¶
 is proportional to:
is proportional to:

Hence, can be updated using the Random-walk
Metropolis-Hastings algorithm.
Step 1 : compute tau’s conditional posterior density, up to a multiplicative factor
def marginals_Y(theta, tau):
mu = np.dot(X, theta).ravel()
sigma = np.sqrt(1.0 / tau + 1.0 / Q).ravel()
return [ot.Normal(mu[i], sigma[i]) for i in range(len(X))]
def py_log_density(x):
theta = [x[i] for i in range(p)]
tau = x[p]
Y = [x[p + 1 + i] for i in range(len(X))]
ld = ot.ComposedDistribution(marginals_Y(theta, tau)).computeLogPDF(Y)
return [ld]
Step 2 : define the proposal distribution
proposal_tau = ot.Normal(0.0, 1e-1)
2.3. Initialization¶
To avoid all numerical problems, it is better to provide the algorithm
with a starting point not too far from the posterior mode. To this end,
we propose to set  for simplicity, then solve the
following optimization problem
for simplicity, then solve the
following optimization problem
![\widehat\theta,\widehat\tau = \arg\max_{\vect{\theta},\tau} \pi(\vect{\theta},\tau|\vect{Y}^{obs},\vect{Y}=\vect{Y}^{obs})
= \arg\max_{\theta\in[\vect{\theta}_{\min};\vect{\theta}_{\max}]
\tau\in[\tau_{\min};\tau_{\max}]} \mathcal N(\vect{Y}^{obs}|\vect{\theta} \mat{X}; \tau^{-1} \mat{I}_n + \mat{Q}^{-1}).](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzQ3NC45OTM5NDZwdCcgaGVpZ2h0PScyMS43NTE3NjdwdCcgdmlld0JveD0nMCAtMjIuOTQ3MjgxIDQ3NC45OTM5NDYgMjEuNzUxNzY3Jz4KPGRlZnM+CjxwYXRoIGlkPSdnNy05NycgZD0nTTIuODM5MzUyLTEuNzgxMzJDMi44MzkzNTItMi4zMzcyMzUgMi4yNzE0ODItMi42NjYwMDIgMS42MDE5OTMtMi42NjYwMDJDMS4zMTUwNjgtMi42NjYwMDIgLjYwOTcxNC0yLjYzNjExNSAuNjA5NzE0LTIuMTMzOTk4Qy42MDk3MTQtMS45NzI2MDMgLjcxNzMxLTEuODQxMDk2IC45MDI2MTUtMS44NDEwOTZDMS4wNzU5NjUtMS44NDEwOTYgMS4xODk1MzktMS45NzI2MDMgMS4xODk1MzktMi4xMjgwMkMxLjE4OTUzOS0yLjIzNTYxNiAxLjE0MTcxOS0yLjMzNzIzNSAxLjAzNDEyMi0yLjM4NTA1NkMxLjIzMTM4Mi0yLjQ3NDcyIDEuNTMwMjYyLTIuNDc0NzIgMS41OTAwMzctMi40NzQ3MkMyLjAxNDQ0Ni0yLjQ3NDcyIDIuMzQzMjEzLTIuMjIzNjYxIDIuMzQzMjEzLTEuNzY5MzY1Vi0xLjYxMzk0OEMyLjA2ODI0NC0xLjYwMTk5MyAxLjU5MDAzNy0xLjU5MDAzNyAxLjE1MzY3NC0xLjQzNDYyQy43NTkxNTMtMS4yOTcxMzYgLjM4MjU2NS0xLjAyODE0NCAuMzgyNTY1LS42Mjc2NDZDLjM4MjU2NS0uMDk1NjQxIDEuMDE2MTg5IC4wNTk3NzYgMS40ODI0NDEgLjA1OTc3NkMxLjk4NDU1OCAuMDU5Nzc2IDIuMjgzNDM3LS4xOTEyODMgMi40MTQ5NDQtLjQxODQzMUMyLjQ1Njc4Ny0uMTA3NTk3IDIuNjU0MDQ3IC4wMjk4ODggMi44NjMyNjMgLjAyOTg4OEMyLjg4NzE3MyAuMDI5ODg4IDMuNTI2Nzc1IC4wMjk4ODggMy41MjY3NzUtLjUzNzk4M1YtLjg2Njc1SDMuMzA1NjA0Vi0uNTQ5OTM4QzMuMzA1NjA0LS40OTAxNjIgMy4zMDU2MDQtLjIyMTE3MSAzLjA3MjQ3OC0uMjIxMTcxUzIuODM5MzUyLS40OTAxNjIgMi44MzkzNTItLjU0OTkzOFYtMS43ODEzMlpNMi4zNDMyMTMtLjg0ODgxN0MyLjM0MzIxMy0uMjI3MTQ4IDEuNzI3NTIyLS4xMzE1MDcgMS41MzYyMzktLjEzMTUwN0MxLjIxMzQ1LS4xMzE1MDcgLjkwODU5My0uMzI4NzY3IC45MDg1OTMtLjYyNzY0NkMuOTA4NTkzLS45NjIzOTEgMS4yMzEzODItMS4zOTg3NTUgMi4zNDMyMTMtMS40MzQ2MlYtLjg0ODgxN1onLz4KPHBhdGggaWQ9J2c3LTEwNScgZD0nTTEuMzU2OTEyLTMuNjgyMTkyQzEuMzU2OTEyLTMuODYxNTE5IDEuMjA3NDcyLTQuMDQwODQ3IC45OTgyNTctNC4wNDA4NDdDLjgxMjk1MS00LjA0MDg0NyAuNjM5NjAxLTMuODk3Mzg1IC42Mzk2MDEtMy42ODIxOTJTLjgxMjk1MS0zLjMyMzUzNyAuOTk4MjU3LTMuMzIzNTM3QzEuMjA3NDcyLTMuMzIzNTM3IDEuMzU2OTEyLTMuNTAyODY0IDEuMzU2OTEyLTMuNjgyMTkyWk0uNDA2NDc2LTIuNTcwMzYxVi0yLjMzNzIzNUMuODAwOTk2LTIuMzM3MjM1IC44NTQ3OTUtMi4yOTUzOTIgLjg1NDc5NS0yLjAwMjQ5MVYtLjQ5MDE2MkMuODU0Nzk1LS4yMzMxMjYgLjc5NTAxOS0uMjMzMTI2IC4zODI1NjUtLjIzMzEyNlYwQy41NTU5MTUtLjAxMTk1NSAxLjAyMjE2Ny0uMDIzOTEgMS4wODE5NDMtLjAyMzkxUzEuNTk2MDE1LS4wMTE5NTUgMS43NTE0MzIgMFYtLjIzMzEyNkMxLjM4MDgyMi0uMjMzMTI2IDEuMzI3MDI0LS4yMzMxMjYgMS4zMjcwMjQtLjQ4NDE4NFYtMi42MzYxMTVMLjQwNjQ3Ni0yLjU3MDM2MVonLz4KPHBhdGggaWQ9J2c3LTEwOScgZD0nTTUuMjA2NDc2LTEuODA1MjNDNS4yMDY0NzYtMi40MTQ5NDQgNC44NDc4MjEtMi42MzYxMTUgNC4yNjIwMTctMi42MzYxMTVDMy43MDYxMDItMi42MzYxMTUgMy4zNzczMzUtMi4zMTkzMDMgMy4yNDU4MjgtMi4wOTIxNTRDMy4xMDgzNDQtMi42MzYxMTUgMi40OTg2My0yLjYzNjExNSAyLjMzMTI1OC0yLjYzNjExNUMxLjc4NzI5OC0yLjYzNjExNSAxLjQ1MjU1My0yLjMzNzIzNSAxLjMwOTA5MS0yLjA4NjE3N0gxLjMwMzExM1YtMi42MzYxMTVMLjM3NjU4OC0yLjU3MDM2MVYtMi4zMzcyMzVDLjc5NTAxOS0yLjMzNzIzNSAuODQ4ODE3LTIuMjk1MzkyIC44NDg4MTctMi4wMDI0OTFWLS40OTAxNjJDLjg0ODgxNy0uMjMzMTI2IC43ODkwNDEtLjIzMzEyNiAuMzc2NTg4LS4yMzMxMjZWMEMuNDE4NDMxLS4wMDU5NzggLjgyNDkwNy0uMDIzOTEgMS4wOTM4OTgtLjAyMzkxUzEuNzU3NDEtLjAwNTk3OCAxLjgxNzE4NiAwVi0uMjMzMTI2QzEuNDA0NzMyLS4yMzMxMjYgMS4zNDQ5NTYtLjIzMzEyNiAxLjM0NDk1Ni0uNDkwMTYyVi0xLjU0MjIxN0MxLjM0NDk1Ni0yLjE5OTc1MSAxLjkxMjgyNy0yLjQ0NDgzMiAyLjI3NzQ2LTIuNDQ0ODMyQzIuNjg5OTEzLTIuNDQ0ODMyIDIuNzc5NTc3LTIuMTg3Nzk2IDIuNzc5NTc3LTEuODE3MTg2Vi0uNDkwMTYyQzIuNzc5NTc3LS4yMzMxMjYgMi43MTk4MDEtLjIzMzEyNiAyLjMwNzM0Ny0uMjMzMTI2VjBDMi4zNDkxOTEtLjAwNTk3OCAyLjc1NTY2Ni0uMDIzOTEgMy4wMjQ2NTgtLjAyMzkxUzMuNjg4MTY5LS4wMDU5NzggMy43NDc5NDUgMFYtLjIzMzEyNkMzLjMzNTQ5Mi0uMjMzMTI2IDMuMjc1NzE2LS4yMzMxMjYgMy4yNzU3MTYtLjQ5MDE2MlYtMS41NDIyMTdDMy4yNzU3MTYtMi4xOTk3NTEgMy44NDM1ODctMi40NDQ4MzIgNC4yMDgyMTktMi40NDQ4MzJDNC42MjA2NzItMi40NDQ4MzIgNC43MTAzMzYtMi4xODc3OTYgNC43MTAzMzYtMS44MTcxODZWLS40OTAxNjJDNC43MTAzMzYtLjIzMzEyNiA0LjY1MDU2LS4yMzMxMjYgNC4yMzgxMDctLjIzMzEyNlYwQzQuMjc5OTUtLjAwNTk3OCA0LjY4NjQyNi0uMDIzOTEgNC45NTU0MTctLjAyMzkxUzUuNjE4OTI5LS4wMDU5NzggNS42Nzg3MDUgMFYtLjIzMzEyNkM1LjI2NjI1Mi0uMjMzMTI2IDUuMjA2NDc2LS4yMzMxMjYgNS4yMDY0NzYtLjQ5MDE2MlYtMS44MDUyM1onLz4KPHBhdGggaWQ9J2c3LTExMCcgZD0nTTMuMjY5NzM4LTEuODA1MjNDMy4yNjk3MzgtMi4zOTEwMzQgMi45MzQ5OTQtMi42MzYxMTUgMi4zMzEyNTgtMi42MzYxMTVDMS44MDUyMy0yLjYzNjExNSAxLjQ3NjQ2My0yLjM2MTE0NiAxLjMwMzExMy0yLjA3NDIyMlYtMi42MzYxMTVMLjM3NjU4OC0yLjU3MDM2MVYtMi4zMzcyMzVDLjc5NTAxOS0yLjMzNzIzNSAuODQ4ODE3LTIuMjk1MzkyIC44NDg4MTctMi4wMDI0OTFWLS40OTAxNjJDLjg0ODgxNy0uMjMzMTI2IC43ODkwNDEtLjIzMzEyNiAuMzc2NTg4LS4yMzMxMjZWMEMuNDE4NDMxLS4wMDU5NzggLjgyNDkwNy0uMDIzOTEgMS4wOTM4OTgtLjAyMzkxUzEuNzU3NDEtLjAwNTk3OCAxLjgxNzE4NiAwVi0uMjMzMTI2QzEuNDA0NzMyLS4yMzMxMjYgMS4zNDQ5NTYtLjIzMzEyNiAxLjM0NDk1Ni0uNDkwMTYyVi0xLjU0MjIxN0MxLjM0NDk1Ni0yLjE5OTc1MSAxLjkwNjg0OS0yLjQ0NDgzMiAyLjI3NzQ2LTIuNDQ0ODMyQzIuNjc3OTU4LTIuNDQ0ODMyIDIuNzczNTk5LTIuMTkzNzczIDIuNzczNTk5LTEuODIzMTYzVi0uNDkwMTYyQzIuNzczNTk5LS4yMzMxMjYgMi43MTM4MjMtLjIzMzEyNiAyLjMwMTM3LS4yMzMxMjZWMEMyLjM0MzIxMy0uMDA1OTc4IDIuNzQ5Njg5LS4wMjM5MSAzLjAxODY4LS4wMjM5MVMzLjY4MjE5Mi0uMDA1OTc4IDMuNzQxOTY4IDBWLS4yMzMxMjZDMy4zMjk1MTQtLjIzMzEyNiAzLjI2OTczOC0uMjMzMTI2IDMuMjY5NzM4LS40OTAxNjJWLTEuODA1MjNaJy8+CjxwYXRoIGlkPSdnNy0xMjAnIGQ9J00yLjEyMjA0Mi0xLjM5ODc1NUwyLjcxMzgyMy0yLjAyMDQyM0MzLjAyNDY1OC0yLjMxOTMwMyAzLjM1MzQyNS0yLjM0MzIxMyAzLjUxNDgxOS0yLjM0MzIxM1YtMi41NzYzMzlDMy40MzcxMTEtMi41NzAzNjEgMy4xNzQwOTctMi41NTI0MjggMi45ODI4MTQtMi41NTI0MjhDMi43Njc2MjEtMi41NTI0MjggMi40MDI5ODktMi41NzAzNjEgMi4zNjcxMjMtMi41NzYzMzlWLTIuMzQzMjEzQzIuNDM4ODU0LTIuMzMxMjU4IDIuNDg2Njc1LTIuMjgzNDM3IDIuNDg2Njc1LTIuMjExNzA2QzIuNDg2Njc1LTIuMTEwMDg3IDIuNDM4ODU0LTIuMDYyMjY3IDIuMjY1NTA0LTEuODY1MDA2TDEuOTcyNjAzLTEuNTYwMTQ5TDEuNDU4NTMxLTIuMTE2MDY1QzEuMzk4NzU1LTIuMTc1ODQxIDEuMzkyNzc3LTIuMTg3Nzk2IDEuMzkyNzc3LTIuMjIzNjYxQzEuMzkyNzc3LTIuMzEzMzI1IDEuNDg4NDE4LTIuMzQzMjEzIDEuNTU0MTcyLTIuMzQzMjEzVi0yLjU3NjMzOUMxLjQxMDcxLTIuNTY0Mzg0IC45OTgyNTctMi41NTI0MjggLjg1NDc5NS0yLjU1MjQyOEMuNzQxMjItMi41NTI0MjggLjM3NjU4OC0yLjU2NDM4NCAuMjQ1MDgxLTIuNTc2MzM5Vi0yLjM0MzIxM0MuNTg1ODAzLTIuMzQzMjEzIC42OTkzNzctMi4zMzEyNTggLjg0ODgxNy0yLjE2OTg2M0wxLjYzMTg4LTEuMzIxMDQ2QzEuNjczNzI0LTEuMjc5MjAzIDEuNjc5NzAxLTEuMjczMjI1IDEuNjc5NzAxLTEuMjYxMjdDMS42Nzk3MDEtMS4yNDMzMzcgMS4xNDE3MTktLjY5MzQgMS4wNzU5NjUtLjYyNzY0NkMuOTIwNTQ4LS40NjYyNTIgLjY5OTM3Ny0uMjM5MTAzIC4yMDkyMTUtLjIzMzEyNlYwQy4yODY5MjQtLjAwNTk3OCAuNTQ5OTM4LS4wMjM5MSAuNzQxMjItLjAyMzkxQy44MjQ5MDctLjAyMzkxIDEuMjMxMzgyLS4wMTE5NTUgMS4zNjI4ODkgMFYtLjIzMzEyNkMxLjI4NTE4MS0uMjM5MTAzIDEuMjQzMzM3LS4yODY5MjQgMS4yNDMzMzctLjM2NDYzM0MxLjI0MzMzNy0uNDY2MjUyIDEuMzE1MDY4LS41NDM5NiAxLjM0NDk1Ni0uNTc5ODI2QzEuNTAwMzc0LS43NTkxNTMgMS42Njc3NDYtLjkzMjUwMyAxLjgzNTExOC0xLjA5OTg3NUwyLjM2NzEyMy0uNTI2MDI3QzIuNDg2Njc1LS4zOTQ1MjEgMi40ODY2NzUtLjM4MjU2NSAyLjQ4NjY3NS0uMzUyNjc3QzIuNDg2Njc1LS4yOTI5MDIgMi40MzI4NzctLjIzMzEyNiAyLjMyNTI4LS4yMzMxMjZWMEMyLjUyMjU0LS4wMTE5NTUgMi45NzY4MzctLjAyMzkxIDMuMDI0NjU4LS4wMjM5MUMzLjI0NTgyOC0uMDIzOTEgMy41NTY2NjMtLjAwNTk3OCAzLjYzNDM3MSAwVi0uMjMzMTI2QzMuMzM1NDkyLS4yMzMxMjYgMy4xODYwNTItLjIzMzEyNiAzLjAyNDY1OC0uNDEyNDUzTDIuMTIyMDQyLTEuMzk4NzU1WicvPgo8cGF0aCBpZD0nZzEtMTgnIGQ9J002LjUzOTQ3Ny01Ljg1ODAzMkM2LjUzOTQ3Ny03Ljk2MjE0MiA1LjI5NjEzOS04LjM5MjUyOCA0LjU2Njg3NC04LjM5MjUyOEMzLjYyMjQxNi04LjM5MjUyOCAyLjQyNjg5OS03Ljc3MDg1OSAxLjUzMDI2Mi02LjE0NDk1NkMuOTIwNTQ4LTUuMDIxMTcxIC41NDk5MzgtMy4zOTUyNjggLjU0OTkzOC0yLjQyNjg5OUMuNTQ5OTM4LS42OTM0IDEuNDU4NTMxIC4wOTU2NDEgMi41MzQ0OTYgLjA5NTY0MUMzLjMzNTQ5MiAuMDk1NjQxIDQuMzg3NTQ3LS4zNzA2MSA1LjIxMjQ1My0xLjU5MDAzN0M2LjIxNjY4Ny0zLjA2MDUyMyA2LjUzOTQ3Ny00Ljk2MTM5NSA2LjUzOTQ3Ny01Ljg1ODAzMlpNMi4zNjcxMjMtNC40MzUzNjdDMi41MzQ0OTYtNS4xMjg3NjcgMi44NDUzMy02LjIxNjY4NyAzLjIwMzk4NS02LjgzODM1NkMzLjQ3ODk1NC03LjMyODUxOCAzLjk2OTExNi03Ljk2MjE0MiA0LjU0Mjk2NC03Ljk2MjE0MkM1LjA0NTA4MS03Ljk2MjE0MiA1LjI2MDI3NC03LjQzNjExNSA1LjI2MDI3NC02LjczMDc2QzUuMjYwMjc0LTUuOTc3NTg0IDQuOTk3MjYtNC45Mzc0ODQgNC44NjU3NTMtNC40MzUzNjdIMi4zNjcxMjNaTTQuNzIyMjkxLTMuODYxNTE5QzMuOTgxMDcxLS42NTc1MzQgMi45NzY4MzctLjMzNDc0NSAyLjU1ODQwNi0uMzM0NzQ1QzIuMzkxMDM0LS4zMzQ3NDUgMi4xMzk5NzUtLjM4MjU2NSAxLjk3MjYwMy0uNzUzMTc2QzEuODI5MTQxLTEuMDc1OTY1IDEuODI5MTQxLTEuNTQyMjE3IDEuODI5MTQxLTEuNTU0MTcyQzEuODI5MTQxLTIuMjM1NjE2IDIuMDkyMTU0LTMuMzQ3NDQ3IDIuMjIzNjYxLTMuODYxNTE5SDQuNzIyMjkxWicvPgo8cGF0aCBpZD0nZzEtNzMnIGQ9J001LjI3MjIyOS03LjM4ODI5NEM1LjMyMDA1LTcuNTkxNTMyIDUuMzMyMDA1LTcuNjAzNDg3IDUuNTcxMTA4LTcuNjI3Mzk3QzUuNzUwNDM2LTcuNjM5MzUyIDUuOTA1ODUzLTcuNjM5MzUyIDYuMDg1MTgxLTcuNjM5MzUySDYuMzM2MjM5QzYuNTg3Mjk4LTcuNjM5MzUyIDYuNTk5MjUzLTcuNjUxMzA4IDYuNjU5MDI5LTcuNjk5MTI4QzYuNzMwNzYtNy43NDY5NDkgNi43NjY2MjUtNy45MTQzMjEgNi43NjY2MjUtNy45ODYwNTJDNi43NjY2MjUtOC4xMjk1MTQgNi42NDcwNzMtOC4yMDEyNDUgNi41MDM2MTEtOC4yMDEyNDVDNi4yMDQ3MzItOC4yMDEyNDUgNS44OTM4OTgtOC4xNzczMzUgNS41OTUwMTktOC4xNzczMzVDNS4yODQxODQtOC4xNzczMzUgNC45NjEzOTUtOC4xNjUzOCA0LjYzODYwNS04LjE2NTM4QzQuMzAzODYxLTguMTY1MzggMy45NjkxMTYtOC4xNzczMzUgMy42NDYzMjYtOC4xNzczMzVDMy4zMzU0OTItOC4xNzczMzUgMy4wMTI3MDItOC4yMDEyNDUgMi43MTM4MjMtOC4yMDEyNDVDMi41ODIzMTYtOC4yMDEyNDUgMi4zNjcxMjMtOC4yMDEyNDUgMi4zNjcxMjMtNy44NTQ1NDVDMi4zNjcxMjMtNy42MzkzNTIgMi41NTg0MDYtNy42MzkzNTIgMi43NzM1OTktNy42MzkzNTJIMy4wMjQ2NThDMy4xMzIyNTQtNy42MzkzNTIgMy40MTkxNzgtNy42MjczOTcgMy42NTgyODEtNy42MTU0NDJMMS45NDg2OTItLjgwMDk5NkMxLjkwMDg3Mi0uNjA5NzE0IDEuODg4OTE3LS41OTc3NTggMS42NjE3NjgtLjU4NTgwM0MxLjUxODMwNi0uNTYxODkzIDEuMzAzMTEzLS41NjE4OTMgMS4xNDc2OTYtLjU2MTg5M0guODk2NjM4Qy42NTc1MzQtLjU2MTg5MyAuNDU0Mjk2LS41NjE4OTMgLjQ1NDI5Ni0uMjE1MTkzQy40NTQyOTYtLjA1OTc3NiAuNTg1ODAzIDAgLjcxNzMxIDBDMS4wMTYxODkgMCAxLjMyNzAyNC0uMDIzOTEgMS42MjU5MDMtLjAyMzkxQzEuOTQ4NjkyLS4wMjM5MSAyLjI3MTQ4Mi0uMDM1ODY2IDIuNTk0MjcxLS4wMzU4NjZDMi45MjkwMTYtLjAzNTg2NiAzLjI1MTgwNi0uMDIzOTEgMy41ODY1NS0uMDIzOTFDMy44OTczODUtLjAyMzkxIDQuMjA4MjE5IDAgNC41MDcwOTggMEM0LjYyNjY1IDAgNC44NjU3NTMgMCA0Ljg2NTc1My0uMzQ2N0M0Ljg2NTc1My0uNTYxODkzIDQuNjYyNTE2LS41NjE4OTMgNC40NTkyNzgtLjU2MTg5M0g0LjIwODIxOUM0LjEyNDUzMy0uNTYxODkzIDMuNzMwMDEyLS41NzM4NDggMy41NzQ1OTUtLjU4NTgwM0w1LjI3MjIyOS03LjM4ODI5NFonLz4KPHBhdGggaWQ9J2cxLTgxJyBkPSdNNS4zMDgwOTUgLjY4MTQ0NUM1LjMwODA5NSAxLjI5MTE1OCA1LjM5MTc4MSAyLjMxOTMwMyA2LjQ2Nzc0NiAyLjMxOTMwM0M3Ljk1MDE4NyAyLjMxOTMwMyA4LjYzMTYzMSAuMjUxMDU5IDguNjMxNjMxIDBDOC42MzE2MzEtLjExOTU1MiA4LjUzNTk5LS4yMTUxOTMgOC40MTY0MzgtLjIxNTE5M0M4LjI3Mjk3Ni0uMjE1MTkzIDguMjI1MTU2LS4wOTU2NDEgOC4yMDEyNDUtLjAzNTg2NkM3Ljk3NDA5NyAuNTYxODkzIDcuMDg5NDE1IC41NjE4OTMgNi45Njk4NjMgLjU2MTg5M0M2LjcwNjg0OSAuNTYxODkzIDYuMzk2MDE1IC41NjE4OTMgNi4wOTcxMzYtLjEzMTUwN0M4Ljk5MDI4Ni0xLjE5NTUxNyA5Ljc0MzQ2Mi0zLjk1NzE2MSA5Ljc0MzQ2Mi01LjMyMDA1QzkuNzQzNDYyLTcuMzUyNDI4IDguMzMyNzUyLTguNDA0NDgzIDYuMjY0NTA4LTguNDA0NDgzQzIuNTcwMzYxLTguNDA0NDgzIC42MzM2MjQtNS4yMzYzNjQgLjYzMzYyNC0yLjg0NTMzQy42MzM2MjQtLjc1MzE3NiAyLjEyODAyIC4yMDMyMzggNC4xMjQ1MzMgLjIwMzIzOEM0LjI2Nzk5NSAuMjAzMjM4IDQuNzEwMzM2IC4yMDMyMzggNS4zMDgwOTUgLjA4MzY4NlYuNjgxNDQ1Wk0zLjIwMzk4NS0uNTE0MDcyQzIuNDYyNzY1LS44NzI3MjcgMi4yMjM2NjEtMS42MDE5OTMgMi4yMjM2NjEtMi40MDI5ODlDMi4yMjM2NjEtMy4wODQ0MzMgMi41NTg0MDYtNS4yNjAyNzQgMy41ODY1NS02LjU5OTI1M0M0LjM1MTY4MS03LjU3OTU3NyA1LjM2Nzg3LTcuOTI2Mjc2IDYuMTQ0OTU2LTcuOTI2Mjc2QzcuMTczMTAxLTcuOTI2Mjc2IDguMTUzNDI1LTcuMzUyNDI4IDguMTUzNDI1LTUuNzc0MzQ2QzguMTUzNDI1LTUuNjkwNjYgNy45OTgwMDctMi4wMzIzNzkgNS44NTgwMzItLjc1MzE3NkM1LjYxODkyOS0xLjMzODk3OSA1LjI5NjEzOS0xLjg1MzA1MSA0LjU2Njg3NC0xLjg1MzA1MUMzLjkwOTM0LTEuODUzMDUxIDMuMTkyMDMtMS4zMzg5NzkgMy4xOTIwMy0uNjY5NDg5QzMuMTkyMDMtLjU3Mzg0OCAzLjE5MjAzLS41NjE4OTMgMy4yMDM5ODUtLjUxNDA3MlpNNS4yOTYxMzktLjQ2NjI1MkM1LjIxMjQ1My0uNDMwMzg2IDQuNzM0MjQ3LS4yNzQ5NjkgNC4yNDQwODUtLjI3NDk2OUM0LjAyODg5Mi0uMjc0OTY5IDMuNjIyNDE2LS4yNzQ5NjkgMy42MjI0MTYtLjY2OTQ4OUMzLjYyMjQxNi0xLjA1MjA1NSA0LjA4ODY2Ny0xLjQyMjY2NSA0LjU3ODgyOS0xLjQyMjY2NUM0Ljg4OTY2NC0xLjQyMjY2NSA1LjI3MjIyOS0xLjMzODk3OSA1LjI5NjEzOS0uNDY2MjUyWicvPgo8cGF0aCBpZD0nZzEtODgnIGQ9J002Ljk1NzkwOC00LjcyMjI5MUw4LjUzNTk5LTYuMjc2NDYzTDkuMjc3MjEtNy4wMjk2MzlDOS43NTU0MTctNy40ODM5MzUgOS44OTg4NzktNy42MjczOTcgMTEuMTQyMjE3LTcuNjM5MzUyQzExLjM2OTM2NS03LjYzOTM1MiAxMS4zOTMyNzUtNy45NTAxODcgMTEuMzkzMjc1LTcuOTg2MDUyQzExLjM5MzI3NS04LjA1Nzc4MyAxMS4zNDU0NTUtOC4yMDEyNDUgMTEuMTU0MTcyLTguMjAxMjQ1QzEwLjczNTc0MS04LjIwMTI0NSAxMC4yODE0NDUtOC4xNjUzOCA5Ljg1MTA1OS04LjE2NTM4QzkuNTA0MzU5LTguMTY1MzggOC42NDM1ODctOC4yMDEyNDUgOC4yOTY4ODctOC4yMDEyNDVDOC4yMDEyNDUtOC4yMDEyNDUgNy45NjIxNDItOC4yMDEyNDUgNy45NjIxNDItNy44NjY1MDFDNy45NjIxNDItNy42NTEzMDggOC4xNTM0MjUtNy42MzkzNTIgOC4yNjEwMjEtNy42MzkzNTJDOC42MTk2NzYtNy42MjczOTcgOC45MzA1MTEtNy41MzE3NTYgOC45NzgzMzEtNy41MTk4MDFMNi42OTQ4OTQtNS4yNjAyNzRMNS41OTUwMTktNy41Njc2MjFDNS43MTQ1Ny03LjU5MTUzMiA2LjA4NTE4MS03LjYzOTM1MiA2LjI4ODQxOC03LjYzOTM1MkM2LjQxOTkyNS03LjYzOTM1MiA2LjYzNTExOC03LjYzOTM1MiA2LjYzNTExOC03Ljk3NDA5N0M2LjYzNTExOC04LjE0MTQ2OSA2LjUyNzUyMi04LjIwMTI0NSA2LjM3MjEwNS04LjIwMTI0NUM1Ljk2NTYyOS04LjIwMTI0NSA0Ljk2MTM5NS04LjE2NTM4IDQuNTU0OTE5LTguMTY1MzhDNC4yNzk5NS04LjE2NTM4IDQuMDA0OTgxLTguMTc3MzM1IDMuNzMwMDEyLTguMTc3MzM1UzMuMTY4MTItOC4yMDEyNDUgMi44OTMxNTEtOC4yMDEyNDVDMi43ODU1NTQtOC4yMDEyNDUgMi41NTg0MDYtOC4yMDEyNDUgMi41NTg0MDYtNy44NjY1MDFDMi41NTg0MDYtNy42MzkzNTIgMi43MTM4MjMtNy42MzkzNTIgMy4wNDg1NjgtNy42MzkzNTJDMy4yMTU5NC03LjYzOTM1MiAzLjM0NzQ0Ny03LjYzOTM1MiAzLjUxNDgxOS03LjYyNzM5N0MzLjY4MjE5Mi03LjYwMzQ4NyAzLjY5NDE0Ny03LjU5MTUzMiAzLjc2NTg3OC03LjQ0ODA3TDUuNDE1NjkxLTMuOTkzMDI2TDIuNDE0OTQ0LTEuMDI4MTQ0QzIuMTk5NzUxLS44MjQ5MDcgMS45NDg2OTItLjU3Mzg0OCAuODg0NjgyLS41NjE4OTNDLjY2OTQ4OS0uNTYxODkzIC40NjYyNTItLjU2MTg5MyAuNDY2MjUyLS4yMTUxOTNDLjQ2NjI1Mi0uMTMxNTA3IC41MjYwMjcgMCAuNzA1MzU1IDBDLjk5MjI3OSAwIDEuNzIxNTQ0LS4wMzU4NjYgMi4wMDg0NjgtLjAzNTg2NkMyLjM1NTE2OC0uMDM1ODY2IDMuMjE1OTQgMCAzLjU2MjY0IDBDMy42NTgyODEgMCAzLjg5NzM4NSAwIDMuODk3Mzg1LS4zNDY3QzMuODk3Mzg1LS41NjE4OTMgMy42ODIxOTItLjU2MTg5MyAzLjU4NjU1LS41NjE4OTNDMy4zNDc0NDctLjU2MTg5MyAzLjEwODM0NC0uNTk3NzU4IDIuODgxMTk2LS42ODE0NDVMNS42NjY3NS0zLjQ1NTA0NEw3LjAxNzY4NC0uNjMzNjI0QzcuMDA1NzI5LS42MzM2MjQgNi42MTEyMDgtLjU2MTg5MyA2LjMyNDI4NC0uNTYxODkzQzYuMjA0NzMyLS41NjE4OTMgNS45Nzc1ODQtLjU2MTg5MyA1Ljk3NzU4NC0uMjE1MTkzQzUuOTc3NTg0LS4xNzkzMjggNS45ODk1MzkgMCA2LjI0MDU5OCAwQzYuNjQ3MDczIDAgNy42NjMyNjMtLjAzNTg2NiA4LjA2OTczOC0uMDM1ODY2QzguMzQ0NzA3LS4wMzU4NjYgOC42MTk2NzYtLjAyMzkxIDguODk0NjQ1LS4wMjM5MVM5LjQ1NjUzOCAwIDkuNzMxNTA3IDBDOS44MjcxNDggMCAxMC4wNjYyNTIgMCAxMC4wNjYyNTItLjM0NjdDMTAuMDY2MjUyLS41NjE4OTMgOS44NzQ5NjktLjU2MTg5MyA5LjU4ODA0NS0uNTYxODkzQzkuNDIwNjcyLS41NjE4OTMgOS4zMDExMjEtLjU2MTg5MyA5LjEyMTc5My0uNTczODQ4QzguOTQyNDY2LS41OTc3NTggOC45MzA1MTEtLjYwOTcxNCA4Ljg0NjgyNC0uNzY1MTMxTDYuOTU3OTA4LTQuNzIyMjkxWicvPgo8cGF0aCBpZD0nZzEtODknIGQ9J004Ljc3NTA5My03LjE3MzEwMUM5LjAzODEwNy03LjQ0ODA3IDkuMzEzMDc2LTcuNjI3Mzk3IDEwLjExNDA3Mi03LjYzOTM1MkMxMC4yNDU1NzktNy42MzkzNTIgMTAuNDYwNzcyLTcuNjM5MzUyIDEwLjQ2MDc3Mi03Ljk4NjA1MkMxMC40NjA3NzItOC4wNTc3ODMgMTAuNDAwOTk2LTguMjAxMjQ1IDEwLjI0NTU3OS04LjIwMTI0NUM5Ljg5ODg3OS04LjIwMTI0NSA5LjUwNDM1OS04LjE2NTM4IDkuMTQ1NzA0LTguMTY1MzhDOC43MDMzNjItOC4xNjUzOCA4LjI0OTA2Ni04LjIwMTI0NSA3LjgxODY4LTguMjAxMjQ1QzcuNzM0OTk0LTguMjAxMjQ1IDcuNDk1ODktOC4yMDEyNDUgNy40OTU4OS03Ljg1NDU0NUM3LjQ5NTg5LTcuNjM5MzUyIDcuNjk5MTI4LTcuNjM5MzUyIDcuODE4NjgtNy42MzkzNTJTOC4xNzczMzUtNy42MTU0NDIgOC4zNTY2NjMtNy41NTU2NjZMNS4xMTY4MTItNC4wODg2NjdMMy41ODY1NS03LjU5MTUzMkMzLjkyMTI5NS03LjYzOTM1MiAzLjkzMzI1LTcuNjM5MzUyIDQuMjU2MDQtNy42MzkzNTJDNC40NTkyNzgtNy42MzkzNTIgNC42NjI1MTYtNy42NTEzMDggNC42NjI1MTYtNy45ODYwNTJDNC42NjI1MTYtOC4xNDE0NjkgNC41MzEwMDktOC4yMDEyNDUgNC4zOTk1MDItOC4yMDEyNDVDMy45OTMwMjYtOC4yMDEyNDUgMi45NTI5MjctOC4xNjUzOCAyLjU0NjQ1MS04LjE2NTM4QzIuMjcxNDgyLTguMTY1MzggMS45ODQ1NTgtOC4xNzczMzUgMS43MjE1NDQtOC4xNzczMzVDMS40MzQ2Mi04LjE3NzMzNSAxLjEzNTc0MS04LjIwMTI0NSAuODYwNzcyLTguMjAxMjQ1Qy43NDEyMi04LjIwMTI0NSAuNTI2MDI3LTguMjAxMjQ1IC41MjYwMjctNy44NTQ1NDVDLjUyNjAyNy03LjYzOTM1MiAuNjkzNC03LjYzOTM1MiAxLjAxNjE4OS03LjYzOTM1MkMxLjE3MTYwNi03LjYzOTM1MiAxLjMxNTA2OC03LjYzOTM1MiAxLjQ4MjQ0MS03LjYyNzM5N0MxLjYyNTkwMy03LjYwMzQ4NyAxLjY0OTgxMy03LjYwMzQ4NyAxLjcyMTU0NC03LjQ0ODA3TDMuNTM4NzMtMy4yNzU3MTZMMi45MTcwNjEtLjgxMjk1MUMyLjg2OTI0LS42MDk3MTQgMi44NTcyODUtLjU5Nzc1OCAyLjY0MjA5Mi0uNTg1ODAzQzIuNDM4ODU0LS41NjE4OTMgMi4yMzU2MTYtLjU2MTg5MyAyLjAyMDQyMy0uNTYxODkzQzEuNjYxNzY4LS41NjE4OTMgMS42Mzc4NTgtLjU2MTg5MyAxLjU5MDAzNy0uNTE0MDcyQzEuNTE4MzA2LS40NTQyOTYgMS40NzA0ODYtLjI5ODg3OSAxLjQ3MDQ4Ni0uMjE1MTkzQzEuNDcwNDg2LS4xOTEyODMgMS40ODI0NDEgMCAxLjczMzQ5OSAwQzIuMDMyMzc5IDAgMi4zNDMyMTMtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MUMyLjkyOTAxNi0uMDIzOTEgMy4yMjc4OTUtLjAzNTg2NiAzLjUxNDgxOS0uMDM1ODY2QzMuOTIxMjk1LS4wMzU4NjYgNC45Mzc0ODQgMCA1LjM0Mzk2IDBDNS40NTE1NTcgMCA1LjY5MDY2IDAgNS42OTA2Ni0uMzQ2N0M1LjY5MDY2LS41NjE4OTMgNS41MjMyODgtLjU2MTg5MyA1LjE4ODU0My0uNTYxODkzQzQuOTM3NDg0LS41NjE4OTMgNC43MTAzMzYtLjU3Mzg0OCA0LjQ1OTI3OC0uNTg1ODAzTDUuMTI4NzY3LTMuMjc1NzE2TDguNzc1MDkzLTcuMTczMTAxWicvPgo8cGF0aCBpZD0nZzUtMTgnIGQ9J00zLjgxNzY4NC0zLjkxMzMyNUMzLjgxNzY4NC00LjkwOTU4OSAzLjQzNTExOC01LjYxMDk1OSAyLjc3MzU5OS01LjYxMDk1OUMxLjU4NjA1Mi01LjYxMDk1OSAuMzUwNjg1LTMuMzk1MjY4IC4zNTA2ODUtMS42MTc5MzNDLjM1MDY4NS0uODUyODAyIC42MTM2OTkgLjA3OTcwMSAxLjQwMjc0IC4wNzk3MDFDMi41NjYzNzYgLjA3OTcwMSAzLjgxNzY4NC0yLjA4MDE5OSAzLjgxNzY4NC0zLjkxMzMyNVpNMS4yNDMzMzctMi45MDExMjFDMS42MTc5MzMtNC41MTEwODMgMi4yNzE0ODItNS4zODc3OTYgMi43NjU2MjktNS4zODc3OTZDMy4yNDM4MzYtNS4zODc3OTYgMy4yNDM4MzYtNC41MzQ5OTQgMy4yNDM4MzYtNC4zODM1NjJDMy4yNDM4MzYtMy45MzcyMzUgMy4xMDAzNzQtMy4yOTE2NTYgMy4wMDQ3MzItMi45MDExMjFIMS4yNDMzMzdaTTIuOTMzMDAxLTIuNjMwMTM3QzIuNTU4NDA2LTEuMDI4MTQ0IDEuOTA0ODU3LS4xNDM0NjIgMS40MTA3MS0uMTQzNDYyQy45ODAzMjQtLjE0MzQ2MiAuOTMyNTAzLS43ODEwNzEgLjkzMjUwMy0xLjE0NzY5NkMuOTMyNTAzLTEuNjQ5ODEzIDEuMDgzOTM1LTIuMjk1MzkyIDEuMTcxNjA2LTIuNjMwMTM3SDIuOTMzMDAxWicvPgo8cGF0aCBpZD0nZzUtMjgnIGQ9J00yLjUwMjYxNS0yLjkwOTA5MUgzLjkyOTI2NUM0LjA1Njc4Ny0yLjkwOTA5MSA0LjE0NDQ1OC0yLjkwOTA5MSA0LjIyNDE1OS0yLjk3Mjg1MkM0LjMxOTgwMS0zLjA2MDUyMyA0LjM0MzcxMS0zLjE2NDEzNCA0LjM0MzcxMS0zLjIxMTk1NUM0LjM0MzcxMS0zLjQzNTExOCA0LjE0NDQ1OC0zLjQzNTExOCA0LjAwODk2Ni0zLjQzNTExOEgxLjYwMTk5M0MxLjQzNDYyLTMuNDM1MTE4IDEuMTMxNzU2LTMuNDM1MTE4IC43NDEyMi0zLjA1MjU1M0MuNDU0Mjk2LTIuNzY1NjI5IC4yMzExMzMtMi4zOTkwMDQgLjIzMTEzMy0yLjM0MzIxM0MuMjMxMTMzLTIuMjcxNDgyIC4yODY5MjQtMi4yNDc1NzIgLjM1MDY4NS0yLjI0NzU3MkMuNDMwMzg2LTIuMjQ3NTcyIC40NDYzMjYtMi4yNzE0ODIgLjQ5NDE0Ny0yLjMzNTI0M0MuODg0NjgyLTIuOTA5MDkxIDEuMzU0OTE5LTIuOTA5MDkxIDEuNTM4MjMyLTIuOTA5MDkxSDIuMjIzNjYxTDEuNTM4MjMyLS43MDEzN0MxLjQ4MjQ0MS0uNTE4MDU3IDEuMzc4ODI5LS4xOTEyODMgMS4zNzg4MjktLjE1MTQzMkMxLjM3ODgyOSAuMDMxODggMS41NDYyMDIgLjA5NTY0MSAxLjY0MTg0MyAuMDk1NjQxQzEuOTM2NzM3IC4wOTU2NDEgMS45ODQ1NTgtLjE4MzMxMyAyLjAwODQ2OC0uMzAyODY0TDIuNTAyNjE1LTIuOTA5MDkxWicvPgo8cGF0aCBpZD0nZzUtNTknIGQ9J00xLjQ5MDQxMS0uMTE5NTUyQzEuNDkwNDExIC4zOTg1MDYgMS4zNzg4MjkgLjg1MjgwMiAuODg0NjgyIDEuMzQ2OTQ5Qy44NTI4MDIgMS4zNzA4NTkgLjgzNjg2MiAxLjM4NjggLjgzNjg2MiAxLjQyNjY1Qy44MzY4NjIgMS40OTA0MTEgLjkwMDYyMyAxLjUzODIzMiAuOTU2NDEzIDEuNTM4MjMyQzEuMDUyMDU1IDEuNTM4MjMyIDEuNzEzNTc0IC45MDg1OTMgMS43MTM1NzQtLjAyMzkxQzEuNzEzNTc0LS41MzM5OTggMS41MjIyOTEtLjg4NDY4MiAxLjE3MTYwNi0uODg0NjgyQy44OTI2NTMtLjg4NDY4MiAuNzMzMjUtLjY2MTUxOSAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjIyMzE2MyAuODg0NjgyIDAgMS4xNzk1NzcgMEMxLjM3MDg1OSAwIDEuNDkwNDExLS4xMTE1ODIgMS40OTA0MTEtLjExOTU1MlonLz4KPHBhdGggaWQ9J2c1LTk4JyBkPSdNMS45NDQ3MDctNS4yOTIxNTRDMS45NTI2NzctNS4zMDgwOTUgMS45NzY1ODgtNS40MTE3MDYgMS45NzY1ODgtNS40MTk2NzZDMS45NzY1ODgtNS40NTk1MjcgMS45NDQ3MDctNS41MzEyNTggMS44NDkwNjYtNS41MzEyNThDMS44MTcxODYtNS41MzEyNTggMS41NzAxMTItNS41MDczNDcgMS4zODY4LTUuNDkxNDA3TC45NDA0NzMtNS40NTk1MjdDLjc2NTEzMS01LjQ0MzU4NyAuNjg1NDMtNS40MzU2MTYgLjY4NTQzLTUuMjkyMTU0Qy42ODU0My01LjE4MDU3MyAuNzk3MDExLTUuMTgwNTczIC44OTI2NTMtNS4xODA1NzNDMS4yNzUyMTgtNS4xODA1NzMgMS4yNzUyMTgtNS4xMzI3NTIgMS4yNzUyMTgtNS4wNjEwMjFDMS4yNzUyMTgtNS4wMTMyIDEuMTk1NTE3LTQuNjk0Mzk2IDEuMTQ3Njk2LTQuNTExMDgzTC40NTQyOTYtMS43Mzc0ODRDLjM5MDUzNS0xLjQ2NjUwMSAuMzkwNTM1LTEuMzQ2OTQ5IC4zOTA1MzUtMS4yMTE0NTdDLjM5MDUzNS0uMzkwNTM1IC44OTI2NTMgLjA3OTcwMSAxLjUwNjM1MSAuMDc5NzAxQzIuNDg2Njc1IC4wNzk3MDEgMy41MDY4NDktMS4wNTIwNTUgMy41MDY4NDktMi4yMDc3MjFDMy41MDY4NDktMi45OTY3NjIgMi45OTY3NjItMy41MTQ4MTkgMi4zNTkxNTMtMy41MTQ4MTlDMS45MTI4MjctMy41MTQ4MTkgMS41NzAxMTItMy4yMjc4OTUgMS4zOTQ3Ny0zLjA3NjQ2M0wxLjk0NDcwNy01LjI5MjE1NFpNMS41MDYzNTEtLjE0MzQ2MkMxLjIxOTQyNy0uMTQzNDYyIC45MzI1MDMtLjM2NjYyNSAuOTMyNTAzLS45NDg0NDNDLjkzMjUwMy0xLjE2MzYzNiAuOTY0Mzg0LTEuMzYyODg5IDEuMDYwMDI1LTEuNzQ1NDU1QzEuMTE1ODE2LTEuOTc2NTg4IDEuMTcxNjA2LTIuMTk5NzUxIDEuMjM1MzY3LTIuNDMwODg0QzEuMjc1MjE4LTIuNTc0MzQ2IDEuMjc1MjE4LTIuNTkwMjg2IDEuMzcwODU5LTIuNzA5ODM4QzEuNjQxODQzLTMuMDQ0NTgzIDIuMDAwNDk4LTMuMjkxNjU2IDIuMzM1MjQzLTMuMjkxNjU2QzIuNzMzNzQ4LTMuMjkxNjU2IDIuODg1MTgxLTIuOTAxMTIxIDIuODg1MTgxLTIuNTQyNDY2QzIuODg1MTgxLTIuMjQ3NTcyIDIuNzA5ODM4LTEuMzk0NzcgMi40NzA3MzUtLjkyNDUzM0MyLjI2MzUxMi0uNDk0MTQ3IDEuODgwOTQ2LS4xNDM0NjIgMS41MDYzNTEtLjE0MzQ2MlonLz4KPHBhdGggaWQ9J2c1LTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnNS0xMTEnIGQ9J00zLjk2OTExNi0yLjEzNTk5QzMuOTY5MTE2LTIuOTE3MDYxIDMuNDExMjA4LTMuNTE0ODE5IDIuNTgyMzE2LTMuNTE0ODE5QzEuNDUwNTYtMy41MTQ4MTkgLjM1MDY4NS0yLjQxNDk0NCAuMzUwNjg1LTEuMjk5MTI4Qy4zNTA2ODUtLjQ4NjE3NyAuOTI0NTMzIC4wNzk3MDEgMS43Mzc0ODQgLjA3OTcwMUMyLjg3NzIxIC4wNzk3MDEgMy45NjkxMTYtMS4wMzYxMTUgMy45NjkxMTYtMi4xMzU5OVpNMS43NDU0NTUtLjE0MzQ2MkMxLjQ2NjUwMS0uMTQzNDYyIC45OTYyNjQtLjI4NjkyNCAuOTk2MjY0LTEuMDIwMTc0Qy45OTYyNjQtMS4zNDY5NDkgMS4xNDc2OTYtMi4yMDc3MjEgMS41MzAyNjItMi43MDE4NjhDMS45MjA3OTctMy4yMDM5ODUgMi4zNTkxNTMtMy4yOTE2NTYgMi41NzQzNDYtMy4yOTE2NTZDMi45MDExMjEtMy4yOTE2NTYgMy4zMjM1MzctMy4wOTI0MDMgMy4zMjM1MzctMi40MjI5MTRDMy4zMjM1MzctMi4xMDQxMSAzLjE4MDA3NS0xLjM0Njk0OSAyLjg3NzIxLS44Njg3NDJDMi41ODIzMTYtLjQxNDQ0NiAyLjE0Mzk2LS4xNDM0NjIgMS43NDU0NTUtLjE0MzQ2MlonLz4KPHBhdGggaWQ9J2c1LTExNScgZD0nTTMuMjExOTU1LTIuOTk2NzYyQzMuMDI4NjQzLTIuOTY0ODgyIDIuODYxMjctMi44MjE0MiAyLjg2MTI3LTIuNjIyMTY3QzIuODYxMjctMi40Nzg3MDUgMi45NTY5MTItMi4zNzUwOTMgMy4xMzIyNTQtMi4zNzUwOTNDMy4yNTE4MDYtMi4zNzUwOTMgMy40OTg4NzktMi40NjI3NjUgMy40OTg4NzktMi44MjE0MkMzLjQ5ODg3OS0zLjMxNTU2NyAyLjk4MDgyMi0zLjUxNDgxOSAyLjQ4NjY3NS0zLjUxNDgxOUMxLjQxODY4LTMuNTE0ODE5IDEuMDgzOTM1LTIuNzU3NjU5IDEuMDgzOTM1LTIuMzUxMTgzQzEuMDgzOTM1LTIuMjcxNDgyIDEuMDgzOTM1LTEuOTg0NTU4IDEuMzc4ODI5LTEuNzYxMzk1QzEuNTYyMTQyLTEuNjE3OTMzIDEuNjk3NjM0LTEuNTk0MDIyIDIuMTEyMDgtMS41MTQzMjFDMi4zOTEwMzQtMS40NTg1MzEgMi44NDUzMy0xLjM3ODgyOSAyLjg0NTMzLS45NjQzODRDMi44NDUzMy0uNzU3MTYxIDIuNjkzODk4LS40OTQxNDcgMi40NzA3MzUtLjM0MjcxNUMyLjE3NTg0MS0uMTUxNDMyIDEuNzg1MzA1LS4xNDM0NjIgMS42NTc3ODMtLjE0MzQ2MkMxLjQ2NjUwMS0uMTQzNDYyIC45MjQ1MzMtLjE3NTM0MiAuNzI1MjgtLjQ5NDE0N0MxLjEzMTc1Ni0uNTEwMDg3IDEuMTg3NTQ3LS44MzY4NjIgMS4xODc1NDctLjkzMjUwM0MxLjE4NzU0Ny0xLjE3MTYwNiAuOTcyMzU0LTEuMjI3Mzk3IC44NzY3MTItMS4yMjczOTdDLjc0OTE5MS0xLjIyNzM5NyAuNDIyNDE2LTEuMTMxNzU2IC40MjI0MTYtLjY5MzRDLjQyMjQxNi0uMjIzMTYzIC45MTY1NjMgLjA3OTcwMSAxLjY1Nzc4MyAuMDc5NzAxQzMuMDQ0NTgzIC4wNzk3MDEgMy4zMzk0NzctLjkwMDYyMyAzLjMzOTQ3Ny0xLjIzNTM2N0MzLjMzOTQ3Ny0xLjk1MjY3NyAyLjU1ODQwNi0yLjEwNDExIDIuMjYzNTEyLTIuMTU5OUMxLjg4MDk0Ni0yLjIzMTYzMSAxLjU3MDExMi0yLjI4NzQyMiAxLjU3MDExMi0yLjYyMjE2N0MxLjU3MDExMi0yLjc2NTYyOSAxLjcwNTYwNC0zLjI5MTY1NiAyLjQ3ODcwNS0zLjI5MTY1NkMyLjc4MTU2OS0zLjI5MTY1NiAzLjA5MjQwMy0zLjIwMzk4NSAzLjIxMTk1NS0yLjk5Njc2MlonLz4KPHBhdGggaWQ9J2cwLTE4JyBkPSdNNC41OTA3ODUtMy44NTc1MzRDNC41OTA3ODUtNS4yMjA0MjMgMy43ODU4MDMtNS42MDI5ODkgMy4xNjQxMzQtNS42MDI5ODlDMi41OTgyNTctNS42MDI5ODkgMS44MzMxMjYtNS4yODQxODQgMS4yMzUzNjctNC4zOTk1MDJDLjU0OTkzOC0zLjM3OTMyOCAuMzkwNTM1LTIuMTIwMDUgLjM5MDUzNS0xLjY2NTc1M0MuMzkwNTM1LS40ODYxNzcgMS4wMzYxMTUgLjA3MTczMSAxLjgyNTE1NiAuMDcxNzMxQzIuMzM1MjQzIC4wNzE3MzEgMy4wNDQ1ODMtLjE4MzMxMyAzLjY0MjM0MS0uOTgwMzI0QzQuMzU5NjUxLTEuOTI4NzY3IDQuNTkwNzg1LTMuMjM1ODY2IDQuNTkwNzg1LTMuODU3NTM0Wk0xLjY1Nzc4My0yLjk3Mjg1MkMxLjgxNzE4Ni0zLjYxODQzMSAxLjk3NjU4OC00LjE0NDQ1OCAyLjI2MzUxMi00LjYwNjcyNUMyLjQ1NDc5NS00LjkxNzU1OSAyLjc5NzUwOS01LjI2ODI0NCAzLjE0ODE5NC01LjI2ODI0NEMzLjU2MjY0LTUuMjY4MjQ0IDMuNjc0MjIyLTQuNzk4MDA3IDMuNjc0MjIyLTQuNDE1NDQyQzMuNjc0MjIyLTMuOTkzMDI2IDMuNTU0NjctMy40ODI5MzkgMy40MzUxMTgtMi45NzI4NTJIMS42NTc3ODNaTTMuMzMxNTA3LTIuNTU4NDA2QzMuMjAzOTg1LTIuMDcyMjI5IDMuMDQ0NTgzLTEuNDc0NDcxIDIuNzg5NTM5LTEuMDQ0MDg1QzIuNDcwNzM1LS40OTQxNDcgMi4xMjAwNS0uMjYzMDE0IDEuODMzMTI2LS4yNjMwMTRDMS41NzAxMTItLjI2MzAxNCAxLjMxNTA2OC0uNDYyMjY3IDEuMzE1MDY4LTEuMTIzNzg2QzEuMzE1MDY4LTEuNTc4MDgyIDEuNDI2NjUtMi4wNDAzNDkgMS41NTQxNzItMi41NTg0MDZIMy4zMzE1MDdaJy8+CjxwYXRoIGlkPSdnOS00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzktNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c5LTQzJyBkPSdNNC43NzAxMTItMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEtMi43NjE2NDQgOC40NTIzMDQtMi43NjE2NDQgOC40NTIzMDQtMi45NzY4MzdDOC40NTIzMDQtMy4yMDM5ODUgOC4yNDkwNjYtMy4yMDM5ODUgOC4wNjk3MzgtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyLTYuNjcwOTg0IDQuNzcwMTEyLTYuODg2MTc3IDQuNTU0OTE5LTYuODg2MTc3QzQuMzI3NzcxLTYuODg2MTc3IDQuMzI3NzcxLTYuNjgyOTM5IDQuMzI3NzcxLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMuODYwNzcyLTMuMjAzOTg1IC42NDU1NzktMy4yMDM5ODUgLjY0NTU3OS0yLjk4ODc5MkMuNjQ1NTc5LTIuNzYxNjQ0IC44NDg4MTctMi43NjE2NDQgMS4wMjgxNDQtMi43NjE2NDRINC4zMjc3NzFWLjUzNzk4M0M0LjMyNzc3MSAuNzA1MzU1IDQuMzI3NzcxIC45MjA1NDggNC41NDI5NjQgLjkyMDU0OEM0Ljc3MDExMiAuOTIwNTQ4IDQuNzcwMTEyIC43MTczMSA0Ljc3MDExMiAuNTM3OTgzVi0yLjc2MTY0NFonLz4KPHBhdGggaWQ9J2c5LTU5JyBkPSdNMi4xOTk3NTEtNC41Nzg4MjlDMi4xOTk3NTEtNC45MDE2MTkgMS45MjQ3ODItNS4xNTI2NzcgMS42MjU5MDMtNS4xNTI2NzdDMS4yNzkyMDMtNS4xNTI2NzcgMS4wNDAxLTQuODc3NzA5IDEuMDQwMS00LjU3ODgyOUMxLjA0MDEtNC4yMjAxNzQgMS4zMzg5NzktMy45OTMwMjYgMS42MTM5NDgtMy45OTMwMjZDMS45MzY3MzctMy45OTMwMjYgMi4xOTk3NTEtNC4yNDQwODUgMi4xOTk3NTEtNC41Nzg4MjlaTTEuOTk2NTEzLS4xMTk1NTJDMS45OTY1MTMgLjI5ODg3OSAxLjk5NjUxMyAxLjE0NzY5NiAxLjI2NzI0OCAyLjA0NDMzNEMxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjM5ODc1NSAyLjMwNzM0NyAyLjIzNTYxNiAxLjQyMjY2NSAyLjIzNTYxNiAuMDIzOTFDMi4yMzU2MTYtLjQxODQzMSAyLjE5OTc1MS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjI2NzI0OC0xLjE1OTY1MSAxLjA0MDEtLjg5NjYzOCAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjI2MzAxNCAxLjI2NzI0OCAwIDEuNjI1OTAzIDBDMS44NTMwNTEgMCAxLjkzNjczNy0uMDcxNzMxIDEuOTk2NTEzLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnOS02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzktOTcnIGQ9J000LjYxNDY5NS0zLjE5MjAzQzQuNjE0Njk1LTMuODM3NjA5IDQuNjE0Njk1LTQuMzE1ODE2IDQuMDg4NjY3LTQuNzgyMDY3QzMuNjcwMjM3LTUuMTY0NjMzIDMuMTMyMjU0LTUuMzMyMDA1IDIuNjA2MjI3LTUuMzMyMDA1QzEuNjI1OTAzLTUuMzMyMDA1IC44NzI3MjctNC42ODY0MjYgLjg3MjcyNy0zLjkwOTM0Qy44NzI3MjctMy41NjI2NCAxLjA5OTg3NS0zLjM5NTI2OCAxLjM3NDg0NC0zLjM5NTI2OEMxLjY2MTc2OC0zLjM5NTI2OCAxLjg2NTAwNi0zLjU5ODUwNiAxLjg2NTAwNi0zLjg4NTQzQzEuODY1MDA2LTQuMzc1NTkyIDEuNDM0NjItNC4zNzU1OTIgMS4yNTUyOTMtNC4zNzU1OTJDMS41MzAyNjItNC44Nzc3MDkgMi4xMDQxMS01LjA5MjkwMiAyLjU4MjMxNi01LjA5MjkwMkMzLjEzMjI1NC01LjA5MjkwMiAzLjgzNzYwOS00LjYzODYwNSAzLjgzNzYwOS0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyLTMuMDQ4NTY4IC41MjYwMjctMi4wNDQzMzQgLjUyNjAyNy0xLjEyMzc4NkMuNTI2MDI3LS4xNzkzMjggMS42MjU5MDMgLjExOTU1MiAyLjM1NTE2OCAuMTE5NTUyQzMuMTQ0MjA5IC4xMTk1NTIgMy42ODIxOTItLjM1ODY1NSAzLjkwOTM0LS45MzI1MDNDMy45NTcxNjEtLjM3MDYxIDQuMzI3NzcxIC4wNTk3NzYgNC44NDE4NDMgLjA1OTc3NkM1LjA5MjkwMiAuMDU5Nzc2IDUuNzg2MzAxLS4xMDc1OTcgNS43ODYzMDEtMS4wNjQwMVYtMS43MzM0OTlINS41MjMyODhWLTEuMDY0MDFDNS41MjMyODgtLjM4MjU2NSA1LjIzNjM2NC0uMjg2OTI0IDUuMDY4OTkxLS4yODY5MjRDNC42MTQ2OTUtLjI4NjkyNCA0LjYxNDY5NS0uOTIwNTQ4IDQuNjE0Njk1LTEuMDk5ODc1Vi0zLjE5MjAzWk0zLjgzNzYwOS0xLjY4NTY3OUMzLjgzNzYwOS0uNTE0MDcyIDIuOTY0ODgyLS4xMTk1NTIgMi40NTA4MDktLjExOTU1MkMxLjg2NTAwNi0uMTE5NTUyIDEuMzc0ODQ0LS41NDk5MzggMS4zNzQ4NDQtMS4xMjM3ODZDMS4zNzQ4NDQtMi43MDE4NjggMy40MDcyMjMtMi44NDUzMyAzLjgzNzYwOS0yLjg2OTI0Vi0xLjY4NTY3OVonLz4KPHBhdGggaWQ9J2c5LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c5LTEwOScgZD0nTTguNTcxODU2LTIuOTA1MTA2QzguNTcxODU2LTQuMDE2OTM2IDguNTcxODU2LTQuMzUxNjgxIDguMjk2ODg3LTQuNzM0MjQ3QzcuOTUwMTg3LTUuMjAwNDk4IDcuMzg4Mjk0LTUuMjcyMjI5IDYuOTgxODE4LTUuMjcyMjI5QzUuOTg5NTM5LTUuMjcyMjI5IDUuNDg3NDIyLTQuNTU0OTE5IDUuMjk2MTM5LTQuMDg4NjY3QzUuMTI4NzY3LTUuMDA5MjE1IDQuNDgzMTg4LTUuMjcyMjI5IDMuNzMwMDEyLTUuMjcyMjI5QzIuNTcwMzYxLTUuMjcyMjI5IDIuMTE2MDY1LTQuMjc5OTUgMi4wMjA0MjMtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TC4zODI1NjUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3LTQuNzk0MDIyIDEuMjkxMTU4LTQuNzEwMzM2IDEuMjkxMTU4LTQuMTI0NTMzVi0uODg0NjgyQzEuMjkxMTU4LS4zNDY3IDEuMTU5NjUxLS4zNDY3IC4zODI1NjUtLjM0NjdWMEMuNjkzNC0uMDIzOTEgMS4zMzg5NzktLjAyMzkxIDEuNjczNzI0LS4wMjM5MUMyLjAyMDQyMy0uMDIzOTEgMi42NjYwMDItLjAyMzkxIDIuOTc2ODM3IDBWLS4zNDY3QzIuMjExNzA2LS4zNDY3IDIuMDY4MjQ0LS4zNDY3IDIuMDY4MjQ0LS44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0LTQuMzYzNjM2IDIuODkzMTUxLTUuMDMzMTI2IDMuNjM0MzcxLTUuMDMzMTI2UzQuNTQyOTY0LTQuNDIzNDEyIDQuNTQyOTY0LTMuNjk0MTQ3Vi0uODg0NjgyQzQuNTQyOTY0LS4zNDY3IDQuNDExNDU3LS4zNDY3IDMuNjM0MzcxLS4zNDY3VjBDMy45NDUyMDUtLjAyMzkxIDQuNTkwNzg1LS4wMjM5MSA0LjkyNTUyOS0uMDIzOTFDNS4yNzIyMjktLjAyMzkxIDUuOTE3ODA4LS4wMjM5MSA2LjIyODY0MyAwVi0uMzQ2N0M1LjQ2MzUxMi0uMzQ2NyA1LjMyMDA1LS4zNDY3IDUuMzIwMDUtLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNS00LjM2MzYzNiA2LjE0NDk1Ni01LjAzMzEyNiA2Ljg4NjE3Ny01LjAzMzEyNlM3Ljc5NDc3LTQuNDIzNDEyIDcuNzk0NzctMy42OTQxNDdWLS44ODQ2ODJDNy43OTQ3Ny0uMzQ2NyA3LjY2MzI2My0uMzQ2NyA2Ljg4NjE3Ny0uMzQ2N1YwQzcuMTk3MDExLS4wMjM5MSA3Ljg0MjU5LS4wMjM5MSA4LjE3NzMzNS0uMDIzOTFDOC41MjQwMzUtLjAyMzkxIDkuMTY5NjE0LS4wMjM5MSA5LjQ4MDQ0OCAwVi0uMzQ2N0M4Ljg4MjY5LS4zNDY3IDguNTgzODExLS4zNDY3IDguNTcxODU2LS43MDUzNTVWLTIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzktMTE0JyBkPSdNMS45OTY1MTMtMi43ODU1NTRDMS45OTY1MTMtMy45NDUyMDUgMi40NzQ3Mi01LjAzMzEyNiAzLjM5NTI2OC01LjAzMzEyNkMzLjQ5MDkwOS01LjAzMzEyNiAzLjUxNDgxOS01LjAzMzEyNiAzLjU2MjY0LTUuMDIxMTcxQzMuNDY2OTk5LTQuOTczMzUgMy4yNzU3MTYtNC45MDE2MTkgMy4yNzU3MTYtNC41Nzg4MjlDMy4yNzU3MTYtNC4yMzIxMyAzLjU1MDY4NS00LjEwMDYyMyAzLjc0MTk2OC00LjEwMDYyM0MzLjk4MTA3MS00LjEwMDYyMyA0LjIyMDE3NC00LjI1NjA0IDQuMjIwMTc0LTQuNTc4ODI5QzQuMjIwMTc0LTQuOTM3NDg0IDMuODk3Mzg1LTUuMjcyMjI5IDMuMzgzMzEzLTUuMjcyMjI5QzIuMzY3MTIzLTUuMjcyMjI5IDIuMDIwNDIzLTQuMTcyMzU0IDEuOTQ4NjkyLTMuOTQ1MjA1SDEuOTM2NzM3Vi01LjI3MjIyOUwuMzM0NzQ1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE0NzY5Ni00Ljc5NDAyMiAxLjI0MzMzNy00LjcxMDMzNiAxLjI0MzMzNy00LjEyNDUzM1YtLjg4NDY4MkMxLjI0MzMzNy0uMzQ2NyAxLjExMTgzMS0uMzQ2NyAuMzM0NzQ1LS4zNDY3VjBDLjY2OTQ4OS0uMDIzOTEgMS4zMjcwMjQtLjAyMzkxIDEuNjg1Njc5LS4wMjM5MUMyLjAwODQ2OC0uMDIzOTEgMi44NTcyODUtLjAyMzkxIDMuMTMyMjU0IDBWLS4zNDY3SDIuODkzMTUxQzIuMDIwNDIzLS4zNDY3IDEuOTk2NTEzLS40NzgyMDcgMS45OTY1MTMtLjkwODU5M1YtMi43ODU1NTRaJy8+CjxwYXRoIGlkPSdnOS0xMjAnIGQ9J00zLjM0NzQ0Ny0yLjgyMTQyQzMuNjk0MTQ3LTMuMjc1NzE2IDQuMTk2MjY0LTMuOTIxMjk1IDQuNDIzNDEyLTQuMTcyMzU0QzQuOTEzNTc0LTQuNzIyMjkxIDUuNDc1NDY3LTQuODA1OTc4IDUuODU4MDMyLTQuODA1OTc4Vi01LjE1MjY3N0M1LjM0Mzk2LTUuMTI4NzY3IDUuMzIwMDUtNS4xMjg3NjcgNC44NTM3OTgtNS4xMjg3NjdDNC4zOTk1MDItNS4xMjg3NjcgNC4zNzU1OTItNS4xMjg3NjcgMy43Nzc4MzMtNS4xNTI2NzdWLTQuODA1OTc4QzMuOTMzMjUtNC43ODIwNjcgNC4xMjQ1MzMtNC43MTAzMzYgNC4xMjQ1MzMtNC40MzUzNjdDNC4xMjQ1MzMtNC4yMzIxMyA0LjAxNjkzNi00LjEwMDYyMyAzLjk0NTIwNS00LjAwNDk4MUwzLjE4MDA3NS0zLjAzNjYxM0wyLjI0NzU3Mi00LjI2Nzk5NUMyLjIxMTcwNi00LjMxNTgxNiAyLjEzOTk3NS00LjQyMzQxMiAyLjEzOTk3NS00LjUwNzA5OEMyLjEzOTk3NS00LjU3ODgyOSAyLjE5OTc1MS00Ljc5NDAyMiAyLjU1ODQwNi00LjgwNTk3OFYtNS4xNTI2NzdDMi4yNTk1MjctNS4xMjg3NjcgMS42NDk4MTMtNS4xMjg3NjcgMS4zMjcwMjQtNS4xMjg3NjdDLjkzMjUwMy01LjEyODc2NyAuOTA4NTkzLTUuMTI4NzY3IC4xNzkzMjgtNS4xNTI2NzdWLTQuODA1OTc4Qy43ODkwNDEtNC44MDU5NzggMS4wMTYxODktNC43ODIwNjcgMS4yNjcyNDgtNC40NTkyNzhMMi42NjYwMDItMi42MzAxMzdDMi42ODk5MTMtMi42MDYyMjcgMi43Mzc3MzMtMi41MzQ0OTYgMi43Mzc3MzMtMi40OTg2M1MxLjgwNTIzLTEuMjkxMTU4IDEuNjg1Njc5LTEuMTM1NzQxQzEuMTU5NjUxLS40OTAxNjIgLjYzMzYyNC0uMzU4NjU1IC4xMTk1NTItLjM0NjdWMEMuNTczODQ4LS4wMjM5MSAuNTk3NzU4LS4wMjM5MSAxLjExMTgzMS0uMDIzOTFDMS41NjYxMjctLjAyMzkxIDEuNTkwMDM3LS4wMjM5MSAyLjE4Nzc5NiAwVi0uMzQ2N0MxLjkwMDg3Mi0uMzgyNTY1IDEuODUzMDUxLS41NjE4OTMgMS44NTMwNTEtLjcyOTI2NUMxLjg1MzA1MS0uOTIwNTQ4IDEuOTM2NzM3LTEuMDE2MTg5IDIuMDU2Mjg5LTEuMTcxNjA2QzIuMjM1NjE2LTEuNDIyNjY1IDIuNjMwMTM3LTEuOTEyODI3IDIuOTE3MDYxLTIuMjgzNDM3TDMuODk3Mzg1LTEuMDA0MjM0QzQuMTAwNjIzLS43NDEyMiA0LjEwMDYyMy0uNzE3MzEgNC4xMDA2MjMtLjY0NTU3OUM0LjEwMDYyMy0uNTQ5OTM4IDQuMDA0OTgxLS4zNTg2NTUgMy42ODIxOTItLjM0NjdWMEMzLjk5MzAyNi0uMDIzOTEgNC41Nzg4MjktLjAyMzkxIDQuOTEzNTc0LS4wMjM5MUM1LjMwODA5NS0uMDIzOTEgNS4zMzIwMDUtLjAyMzkxIDYuMDQ5MzE1IDBWLS4zNDY3QzUuNDE1NjkxLS4zNDY3IDUuMjAwNDk4LS4zNzA2MSA0LjkxMzU3NC0uNzUzMTc2TDMuMzQ3NDQ3LTIuODIxNDJaJy8+CjxwYXRoIGlkPSdnMy0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzMtNTAnIGQ9J000LjYzMDYzNS0xLjgwOTIxNUM0Ljc1ODE1Ny0xLjgwOTIxNSA0LjkzMzQ5OS0xLjgwOTIxNSA0LjkzMzQ5OS0xLjk5MjUyOFM0Ljc1ODE1Ny0yLjE3NTg0MSA0LjYzMDYzNS0yLjE3NTg0MUgxLjA3NTk2NUMxLjE3OTU3Ny0zLjI4MzY4NiAyLjEwNDExLTQuMTI4NTE4IDMuMzE1NTY3LTQuMTI4NTE4SDQuNjMwNjM1QzQuNzU4MTU3LTQuMTI4NTE4IDQuOTMzNDk5LTQuMTI4NTE4IDQuOTMzNDk5LTQuMzExODMxUzQuNzU4MTU3LTQuNDk1MTQzIDQuNjMwNjM1LTQuNDk1MTQzSDMuMjkxNjU2QzEuODU3MDM2LTQuNDk1MTQzIC43MDEzNy0zLjM3OTMyOCAuNzAxMzctMS45OTI1MjhDLjcwMTM3LS41OTc3NTggMS44NjUwMDYgLjUxMDA4NyAzLjI5MTY1NiAuNTEwMDg3SDQuNjMwNjM1QzQuNzU4MTU3IC41MTAwODcgNC45MzM0OTkgLjUxMDA4NyA0LjkzMzQ5OSAuMzI2Nzc1UzQuNzU4MTU3IC4xNDM0NjIgNC42MzA2MzUgLjE0MzQ2MkgzLjMxNTU2N0MyLjEwNDExIC4xNDM0NjIgMS4xNzk1NzctLjcwMTM3IDEuMDc1OTY1LTEuODA5MjE1SDQuNjMwNjM1WicvPgo8cGF0aCBpZD0nZzYtMTgnIGQ9J001LjI5NjEzOS02LjAxMzQ1QzUuMjk2MTM5LTcuMjMyODc3IDQuOTEzNTc0LTguNDE2NDM4IDMuOTMzMjUtOC40MTY0MzhDMi4yNTk1MjctOC40MTY0MzggLjQ3ODIwNy00LjkxMzU3NCAuNDc4MjA3LTIuMjgzNDM3Qy40NzgyMDctMS43MzM0OTkgLjU5Nzc1OCAuMTE5NTUyIDEuODUzMDUxIC4xMTk1NTJDMy40Nzg5NTQgLjExOTU1MiA1LjI5NjEzOS0zLjI5OTYyNiA1LjI5NjEzOS02LjAxMzQ1Wk0xLjY3MzcyNC00LjMyNzc3MUMxLjg1MzA1MS01LjAzMzEyNiAyLjEwNDExLTYuMDM3MzYgMi41ODIzMTYtNi44ODYxNzdDMi45NzY4MzctNy42MDM0ODcgMy4zOTUyNjgtOC4xNzczMzUgMy45MjEyOTUtOC4xNzczMzVDNC4zMTU4MTYtOC4xNzczMzUgNC41Nzg4MjktNy44NDI1OSA0LjU3ODgyOS02LjY5NDg5NEM0LjU3ODgyOS02LjI2NDUwOCA0LjU0Mjk2NC01LjY2Njc1IDQuMTk2MjY0LTQuMzI3NzcxSDEuNjczNzI0Wk00LjExMjU3OC0zLjk2OTExNkMzLjgxMzY5OS0yLjc5NzUwOSAzLjU2MjY0LTIuMDQ0MzM0IDMuMTMyMjU0LTEuMjkxMTU4QzIuNzg1NTU0LS42ODE0NDUgMi4zNjcxMjMtLjExOTU1MiAxLjg2NTAwNi0uMTE5NTUyQzEuNDk0Mzk2LS4xMTk1NTIgMS4xOTU1MTctLjQwNjQ3NiAxLjE5NTUxNy0xLjU5MDAzN0MxLjE5NTUxNy0yLjM2NzEyMyAxLjM4NjgtMy4xODAwNzUgMS41NzgwODItMy45NjkxMTZINC4xMTI1NzhaJy8+CjxwYXRoIGlkPSdnNi0yNScgZD0nTTMuMDk2Mzg5LTQuNTA3MDk4SDQuNDQ3MzIzQzQuMTI0NTMzLTMuMTY4MTIgMy45MjEyOTUtMi4yOTUzOTIgMy45MjEyOTUtMS4zMzg5NzlDMy45MjEyOTUtMS4xNzE2MDYgMy45MjEyOTUgLjExOTU1MiA0LjQxMTQ1NyAuMTE5NTUyQzQuNjYyNTE2IC4xMTk1NTIgNC44Nzc3MDktLjEwNzU5NyA0Ljg3NzcwOS0uMzEwODM0QzQuODc3NzA5LS4zNzA2MSA0Ljg3NzcwOS0uMzk0NTIxIDQuNzk0MDIyLS41NzM4NDhDNC40NzEyMzMtMS4zOTg3NTUgNC40NzEyMzMtMi40MjY4OTkgNC40NzEyMzMtMi41MTA1ODVDNC40NzEyMzMtMi41ODIzMTYgNC40NzEyMzMtMy40MzExMzMgNC43MjIyOTEtNC41MDcwOThINi4wNjEyN0M2LjIxNjY4Ny00LjUwNzA5OCA2LjYxMTIwOC00LjUwNzA5OCA2LjYxMTIwOC00Ljg4OTY2NEM2LjYxMTIwOC01LjE1MjY3NyA2LjM4NDA2LTUuMTUyNjc3IDYuMTY4ODY3LTUuMTUyNjc3SDIuMjM1NjE2QzEuOTYwNjQ4LTUuMTUyNjc3IDEuNTU0MTcyLTUuMTUyNjc3IDEuMDA0MjM0LTQuNTY2ODc0Qy42OTM0LTQuMjIwMTc0IC4zMTA4MzQtMy41ODY1NSAuMzEwODM0LTMuNTE0ODE5Uy4zNzA2MS0zLjQxOTE3OCAuNDQyMzQxLTMuNDE5MTc4Qy41MjYwMjctMy40MTkxNzggLjUzNzk4My0zLjQ1NTA0NCAuNTk3NzU4LTMuNTI2Nzc1QzEuMjE5NDI3LTQuNTA3MDk4IDEuODQxMDk2LTQuNTA3MDk4IDIuMTM5OTc1LTQuNTA3MDk4SDIuODIxNDJDMi41NTg0MDYtMy42MTA0NjEgMi4yNTk1MjctMi41NzAzNjEgMS4yNzkyMDMtLjQ3ODIwN0MxLjE4MzU2Mi0uMjg2OTI0IDEuMTgzNTYyLS4yNjMwMTQgMS4xODM1NjItLjE5MTI4M0MxLjE4MzU2MiAuMDU5Nzc2IDEuMzk4NzU1IC4xMTk1NTIgMS41MDYzNTEgLjExOTU1MkMxLjg1MzA1MSAuMTE5NTUyIDEuOTQ4NjkyLS4xOTEyODMgMi4wOTIxNTQtLjY5MzRDMi4yODM0MzctMS4zMDMxMTMgMi4yODM0MzctMS4zMjcwMjQgMi40MDI5ODktMS44MDUyM0wzLjA5NjM4OS00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c2LTI4JyBkPSdNMy40MzExMzMtNC41MDcwOThINS40MTU2OTFDNS41NzExMDgtNC41MDcwOTggNS45NjU2MjktNC41MDcwOTggNS45NjU2MjktNC44ODk2NjRDNS45NjU2MjktNS4xNTI2NzcgNS43Mzg0ODEtNS4xNTI2NzcgNS41MjMyODgtNS4xNTI2NzdIMi4yMzU2MTZDMS45NjA2NDgtNS4xNTI2NzcgMS41NTQxNzItNS4xNTI2NzcgMS4wMDQyMzQtNC41NjY4NzRDLjY5MzQtNC4yMjAxNzQgLjMxMDgzNC0zLjU4NjU1IC4zMTA4MzQtMy41MTQ4MTlTLjM3MDYxLTMuNDE5MTc4IC40NDIzNDEtMy40MTkxNzhDLjUyNjAyNy0zLjQxOTE3OCAuNTM3OTgzLTMuNDU1MDQ0IC41OTc3NTgtMy41MjY3NzVDMS4yMTk0MjctNC41MDcwOTggMS44NDEwOTYtNC41MDcwOTggMi4xMzk5NzUtNC41MDcwOThIMy4xMzIyNTRMMS44ODg5MTctLjQwNjQ3NkMxLjgyOTE0MS0uMjI3MTQ4IDEuODI5MTQxLS4yMDMyMzggMS44MjkxNDEtLjE2NzM3MkMxLjgyOTE0MS0uMDM1ODY2IDEuOTEyODI3IC4xMzE1MDcgMi4xNTE5MyAuMTMxNTA3QzIuNTIyNTQgLjEzMTUwNyAyLjU4MjMxNi0uMTkxMjgzIDIuNjE4MTgyLS4zNzA2MUwzLjQzMTEzMy00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c2LTU4JyBkPSdNMi4xOTk3NTEtLjU3Mzg0OEMyLjE5OTc1MS0uOTIwNTQ4IDEuOTEyODI3LTEuMTU5NjUxIDEuNjI1OTAzLTEuMTU5NjUxQzEuMjc5MjAzLTEuMTU5NjUxIDEuMDQwMS0uODcyNzI3IDEuMDQwMS0uNTg1ODAzQzEuMDQwMS0uMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxLS4yODY5MjQgMi4xOTk3NTEtLjU3Mzg0OFonLz4KPHBhdGggaWQ9J2c2LTU5JyBkPSdNMi4zMzEyNTggLjA0NzgyMUMyLjMzMTI1OC0uNjQ1NTc5IDIuMTA0MTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yMzEzODItMS4xNTk2NTEgMS4wNDAxLS44NDg4MTcgMS4wNDAxLS41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNy0uMDQ3ODIxIDIuMDIwNDIzLS4xNTU0MTdDMi4wNDQzMzQtLjE3OTMyOCAyLjA1NjI4OS0uMTc5MzI4IDIuMDY4MjQ0LS4xNzkzMjhDMi4wOTIxNTQtLjE3OTMyOCAyLjA5MjE1NC0uMDExOTU1IDIuMDkyMTU0IC4wNDc4MjFDMi4wOTIxNTQgLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IC4wNDc4MjFaJy8+CjxwYXRoIGlkPSdnOC00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c4LTU5JyBkPSdNMS42MTc5MzMtMi45ODg3OTJDMS42MTc5MzMtMy4yNTk3NzYgMS40MDI3NC0zLjQzNTExOCAxLjE3OTU3Ny0zLjQzNTExOEMuOTA4NTkzLTMuNDM1MTE4IC43MzMyNS0zLjIxOTkyNSAuNzMzMjUtMi45OTY3NjJDLjczMzI1LTIuNzI1Nzc4IC45NDg0NDMtMi41NTA0MzYgMS4xNzE2MDYtMi41NTA0MzZDMS40NDI1OS0yLjU1MDQzNiAxLjYxNzkzMy0yLjc2NTYyOSAxLjYxNzkzMy0yLjk4ODc5MlpNMS40MTg2OC0uMDYzNzYxQzEuNDE4NjggLjQ1NDI5NiAxLjI1MTMwOCAuOTE2NTYzIC45MDA2MjMgMS4zMTUwNjhDLjg1MjgwMiAxLjM3ODgyOSAuODM2ODYyIDEuMzg2OCAuODM2ODYyIDEuNDI2NjVDLjgzNjg2MiAxLjQ5ODM4MSAuOTA4NTkzIDEuNTQ2MjAyIC45NDg0NDMgMS41NDYyMDJDMS4wNTIwNTUgMS41NDYyMDIgMS42NDE4NDMgLjkwMDYyMyAxLjY0MTg0My0uMDQ3ODIxQzEuNjQxODQzLS4zMTA4MzQgMS42MDk5NjMtLjg4NDY4MiAxLjE3MTYwNi0uODg0NjgyQy45MDg1OTMtLjg4NDY4MiAuNzMzMjUtLjY3NzQ2IC43MzMyNS0uNDQ2MzI2Qy43MzMyNS0uMjA3MjIzIC45MDA2MjMgMCAxLjE3OTU3NyAwQzEuMzE1MDY4IDAgMS4zNjI4ODktLjAyMzkxIDEuNDE4NjgtLjA2Mzc2MVonLz4KPHBhdGggaWQ9J2c4LTkxJyBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicvPgo8cGF0aCBpZD0nZzgtOTMnIGQ9J00xLjM1NDkxOS01Ljk3NzU4NEguMTgzMzEzVi01LjYxMDk1OUguOTg4Mjk0VjEuNjI1OTAzSC4xODMzMTNWMS45OTI1MjhIMS4zNTQ5MTlWLTUuOTc3NTg0WicvPgo8cGF0aCBpZD0nZzQtNzgnIGQ9J00zLjY1ODI4MS02Ljg2MjI2N0MzLjg3MzQ3NC02LjI0MDU5OCA0LjEzNjQ4OC01LjM0Mzk2IDQuNjc0NDcxLTMuODczNDc0QzUuNDI3NjQ2LTEuODQxMDk2IDUuNzYyMzkxLTEuMDk5ODc1IDYuNDkxNjU2IC4wMzU4NjZDNi42NTkwMjkgLjI4NjkyNCA2LjY3MDk4NCAuMjk4ODc5IDYuNzc4NTggLjI5ODg3OUM2Ljk0NTk1MyAuMjk4ODc5IDcuMTk3MDExIC4xNTU0MTcgNy4zMjg1MTggLjA1OTc3NkM3LjQ5NTg5LS4wOTU2NDEgNy41MDc4NDYtLjEwNzU5NyA3LjYzOTM1Mi0uNjkzNEM4LjM1NjY2My0zLjgzNzYwOSA5LjI2NTI1NS03LjExMzMyNSA5LjUwNDM1OS03LjY2MzI2M0M5LjUxNjMxNC03LjY4NzE3MyA5Ljc1NTQxNy04LjE0MTQ2OSAxMS4yMjU5MDMtOC4xNjUzOEMxMS40NjUwMDYtOC4xNzczMzUgMTEuNjkyMTU0LTguODEwOTU5IDExLjY5MjE1NC05LjA3Mzk3M0MxMS42OTIxNTQtOS4yNjUyNTUgMTEuNjIwNDIzLTkuMjY1MjU1IDExLjQ1MzA1MS05LjI2NTI1NUMxMC4yNTc1MzQtOS4yNjUyNTUgOS43MTk1NTItOC43NjMxMzggOS41NzYwOS04LjYwNzcyMUM5LjI0MTM0NS04LjE3NzMzNSA4Ljk1NDQyMS03LjMwNDYwOCA4LjQwNDQ4My01LjMwODA5NUM3Ljk4NjA1Mi0zLjc3NzgzMyA3LjYwMzQ4Ny0yLjIyMzY2MSA3LjIzMjg3Ny0uNjgxNDQ1QzYuNTc1MzQyLTEuNjczNzI0IDYuMjA0NzMyLTIuNjE4MTgyIDUuNjMwODg0LTQuMTYwMzk5QzQuOTk3MjYtNS44NTgwMzIgNC42MTQ2OTUtNy4xMDEzNyA0LjI5MTkwNS04LjE3NzMzNUM0LjIyMDE3NC04LjQxNjQzOCA0LjIwODIxOS04LjQyODM5NCA0LjEwMDYyMy04LjQyODM5NEM0LjA3NjcxMi04LjQyODM5NCAzLjgzNzYwOS04LjQyODM5NCAzLjQ5MDkwOS04LjE0MTQ2OUMzLjM3MTM1Ny04LjAzMzg3MyAzLjM1OTQwMi03LjkyNjI3NiAzLjM0NzQ0Ny03Ljc5NDc3QzMuMDEyNzAyLTQuNjE0Njk1IDEuODg4OTE3LTEuNDcwNDg2IDEuNTY2MTI3LS44OTY2MzhDMS40NzA0ODYtLjcxNzMxIDEuMzI3MDI0LS41MDIxMTcgMS4wODc5Mi0uNTAyMTE3Qy45NjgzNjktLjUwMjExNyAuNTAyMTE3LS41NjE4OTMgLjE5MTI4My0uODQ4ODE3Qy4xMzE1MDctLjg5NjYzOCAuMTA3NTk3LS44OTY2MzggLjA5NTY0MS0uODk2NjM4Qy0uMDk1NjQxLS44OTY2MzgtLjM0NjctLjI5ODg3OS0uMzQ2Ny0uMDExOTU1Qy0uMzQ2NyAuMzU4NjU1IC4zODI1NjUgLjU5Nzc1OCAuNzE3MzEgLjU5Nzc1OEMxLjQ4MjQ0MSAuNTk3NzU4IDIuMDkyMTU0LTEuMDg3OTIgMi4yODM0MzctMS42Mzc4NThDMy4wNjA1MjMtMy44MDE3NDMgMy40MzExMzMtNS41ODMwNjQgMy42NTgyODEtNi44NjIyNjdaJy8+CjxwYXRoIGlkPSdnNC0xMDYnIGQ9J00xLjkwMDg3Mi04LjUzNTk5QzEuOTAwODcyLTguNzUxMTgzIDEuOTAwODcyLTguOTY2Mzc2IDEuNjYxNzY4LTguOTY2Mzc2UzEuNDIyNjY1LTguNzUxMTgzIDEuNDIyNjY1LTguNTM1OTlWMi41NTg0MDZDMS40MjI2NjUgMi43NzM1OTkgMS40MjI2NjUgMi45ODg3OTIgMS42NjE3NjggMi45ODg3OTJTMS45MDA4NzIgMi43NzM1OTkgMS45MDA4NzIgMi41NTg0MDZWLTguNTM1OTlaJy8+CjxwYXRoIGlkPSdnMi05OCcgZD0nTTMuMzExNTgyLTguMTg5MjlMNi41NjMzODctNi43MTg4MDRMNi43MDY4NDktNi45ODE4MThMMy4zMjM1MzctOC44OTQ2NDVMLS4wNTk3NzYtNi45ODE4MThMLjA3MTczMS02LjcxODgwNEwzLjMxMTU4Mi04LjE4OTI5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nLjU0NDc4NicgeT0nLTE0LjMxMjk4JyB4bGluazpocmVmPScjZzItOTgnLz4KPHVzZSB4PScwJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzYtMTgnLz4KPHVzZSB4PSc1Ljc4MDM0MScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nMTEuMjM4MjUyJyB5PSctMTEuMTU4MTY5JyB4bGluazpocmVmPScjZzItOTgnLz4KPHVzZSB4PScxMS4wMjQ1JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzYtMjgnLz4KPHVzZSB4PScyMC43NjQyNjcnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS02MScvPgo8dXNlIHg9JzMzLjE4OTc0NycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTk3Jy8+Cjx1c2UgeD0nMzkuMDQyNzM4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTE0Jy8+Cjx1c2UgeD0nNDMuNTk1MDYzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTAzJy8+Cjx1c2UgeD0nNTEuNjAzMTM0JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTA5Jy8+Cjx1c2UgeD0nNjEuMzU4MTE4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktOTcnLz4KPHVzZSB4PSc2Ny4yMTExMDgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS0xMjAnLz4KPHVzZSB4PSc1Ni40ODMyNzEnIHk9Jy0zLjYzMDgyNCcgeGxpbms6aHJlZj0nI2cwLTE4Jy8+Cjx1c2UgeD0nNjEuNDc4NDU1JyB5PSctMy42MzA4MjQnIHhsaW5rOmhyZWY9JyNnNS01OScvPgo8dXNlIHg9JzYzLjgzMDc3OScgeT0nLTMuNjMwODI0JyB4bGluazpocmVmPScjZzUtMjgnLz4KPHVzZSB4PSc3NS4zODE3NjInIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNi0yNScvPgo8dXNlIHg9JzgyLjQ1MTAzMicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nODcuMDAzMzU4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzEtMTgnLz4KPHVzZSB4PSc5NC4xMDE2OTMnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9Jzk5LjM0NTg1MicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTI4Jy8+Cjx1c2UgeD0nMTA1Ljc2NDc5MycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c0LTEwNicvPgo8dXNlIHg9JzEwOS4wODU2ODMnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMS04OScvPgo8dXNlIHg9JzEyMC4yMDU1NzQnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNS0xMTEnLz4KPHVzZSB4PScxMjQuMjk4NjI0JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtOTgnLz4KPHVzZSB4PScxMjcuOTIxMjA5JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtMTE1Jy8+Cjx1c2UgeD0nMTMyLjMzNTI1OScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nMTM3LjU3OTQxOCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTg5Jy8+Cjx1c2UgeD0nMTUyLjAyMDEzOCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTYxJy8+Cjx1c2UgeD0nMTY0LjQ0NTYxOScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTg5Jy8+Cjx1c2UgeD0nMTc1LjU2NTUxJyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtMTExJy8+Cjx1c2UgeD0nMTc5LjY1ODU2JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtOTgnLz4KPHVzZSB4PScxODMuMjgxMTQ0JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzUtMTE1Jy8+Cjx1c2UgeD0nMTg3LjY5NTE5NScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMTk1LjU2ODM1JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktNjEnLz4KPHVzZSB4PScyMDcuOTkzODMxJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktOTcnLz4KPHVzZSB4PScyMTMuODQ2ODIxJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTE0Jy8+Cjx1c2UgeD0nMjE4LjM5OTE0NycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTEwMycvPgo8dXNlIHg9JzI2Ny45OTY1MTInIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOS0xMDknLz4KPHVzZSB4PScyNzcuNzUxNDk2JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktOTcnLz4KPHVzZSB4PScyODMuNjA0NDg2JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktMTIwJy8+Cjx1c2UgeD0nMjI2LjQwNzIxOCcgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzUtMTgnLz4KPHVzZSB4PScyMzAuNTkyOTUyJyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnMy01MCcvPgo8dXNlIHg9JzIzNi4yMzg1MjknIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c4LTkxJy8+Cjx1c2UgeD0nMjM4LjU5MDg1MycgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzAtMTgnLz4KPHVzZSB4PScyNDMuNTg2MDM3JyB5PSctMS44OTY4NDgnIHhsaW5rOmhyZWY9JyNnNy0xMDknLz4KPHVzZSB4PScyNDkuNTYzNTU5JyB5PSctMS44OTY4NDgnIHhsaW5rOmhyZWY9JyNnNy0xMDUnLz4KPHVzZSB4PScyNTEuNjY2NzU4JyB5PSctMS44OTY4NDgnIHhsaW5rOmhyZWY9JyNnNy0xMTAnLz4KPHVzZSB4PScyNTYuMjA1MjM1JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnOC01OScvPgo8dXNlIHg9JzI1OC41NTc1NTgnIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2cwLTE4Jy8+Cjx1c2UgeD0nMjYzLjU1Mjc0MicgeT0nLTIuMTkxNzc4JyB4bGluazpocmVmPScjZzctMTA5Jy8+Cjx1c2UgeD0nMjY5LjUzMDI2NCcgeT0nLTIuMTkxNzc4JyB4bGluazpocmVmPScjZzctOTcnLz4KPHVzZSB4PScyNzMuMTgzMTg5JyB5PSctMi4xOTE3NzgnIHhsaW5rOmhyZWY9JyNnNy0xMjAnLz4KPHVzZSB4PScyNzcuNTI3OTM5JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnOC05MycvPgo8dXNlIHg9JzI3OS44ODAyNjInIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c1LTI4Jy8+Cjx1c2UgeD0nMjg0LjU1ODYxMScgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzMtNTAnLz4KPHVzZSB4PScyOTAuMjA0MTg4JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnOC05MScvPgo8dXNlIHg9JzI5Mi41NTY1MTInIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c1LTI4Jy8+Cjx1c2UgeD0nMjk2LjMxNDY5NycgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzctMTA5Jy8+Cjx1c2UgeD0nMzAyLjI5MjIxOCcgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzctMTA1Jy8+Cjx1c2UgeD0nMzA0LjM5NTQxNycgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzctMTEwJy8+Cjx1c2UgeD0nMzA4LjkzMzg5NCcgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzgtNTknLz4KPHVzZSB4PSczMTEuMjg2MjE3JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNS0yOCcvPgo8dXNlIHg9JzMxNS4wNDQ0MDInIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c3LTEwOScvPgo8dXNlIHg9JzMyMS4wMjE5MjMnIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c3LTk3Jy8+Cjx1c2UgeD0nMzI0LjY3NDg0OScgeT0nLTIuMTkxNzc4JyB4bGluazpocmVmPScjZzctMTIwJy8+Cjx1c2UgeD0nMzI5LjAxOTU5OCcgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzgtOTMnLz4KPHVzZSB4PSczMzMuMzY0NDInIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNC03OCcvPgo8dXNlIHg9JzM0NC45MzUyMycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMzQ5LjQ4NzU1NicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTg5Jy8+Cjx1c2UgeD0nMzYwLjYwNzQ0NycgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c1LTExMScvPgo8dXNlIHg9JzM2NC43MDA0OTYnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNS05OCcvPgo8dXNlIHg9JzM2OC4zMjMwODEnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNS0xMTUnLz4KPHVzZSB4PSczNzIuNzM3MTMxJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzQtMTA2Jy8+Cjx1c2UgeD0nMzc2LjA1ODAyMScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nMzgzLjE1NjM1NycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nMzk1LjQxMDMzMScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c5LTU5Jy8+Cjx1c2UgeD0nNDAwLjY1NDQ5JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzYtMjgnLz4KPHVzZSB4PSc0MDcuMDczNDMxJyB5PSctMTYuMDk0MzQnIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nNDEzLjY1OTkzOCcgeT0nLTE2LjA5NDM0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PSc0MTguMzkyMjUzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzEtNzMnLz4KPHVzZSB4PSc0MjUuNDMyNDg3JyB5PSctOS4zNjQ4OTEnIHhsaW5rOmhyZWY9JyNnNS0xMTAnLz4KPHVzZSB4PSc0MzMuNzI1NDg1JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktNDMnLz4KPHVzZSB4PSc0NDUuNDg2OCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2cxLTgxJy8+Cjx1c2UgeD0nNDU1Ljg3MTEzNycgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PSc0NjIuNDU3NjQ0JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PSc0NjcuMTg5OTU5JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PSc0NzEuNzQyMjg1JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzYtNTgnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
Note that the unconstrained optimization over for fixed
is explicit, since:

But we have shown that the conditional posterior density of
is Gaussian. Hence the unconstrained conditional
posterior mode (and mean) is given by:

If this point does not respect the constraints, then we simply project each component unto the constrained space.
Hence the following 1D problem remains to be solved:
![\widehat\tau = \arg\max_{\tau\in[\tau_{\min};\tau_{\max}]} \mathcal N(\vect{Y}^{obs}|\vect{\mu}_n(\tau) \mat{X}; \tau^{-1} \mat{I}_n + \mat{Q}^{-1}).](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzI1OC4yMTY1OXB0JyBoZWlnaHQ9JzIwLjU0NTE3OHB0JyB2aWV3Qm94PSc2NS4xNjMxODUgLTIxLjc0MDY5MiAyNTguMjE2NTkgMjAuNTQ1MTc4Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMC0yMicgZD0nTTMuMjg3NjcxLTMuOTY5MTE2QzMuMzU5NDAyLTQuMjc5OTUgMy40OTA5MDktNC43OTQwMjIgMy40OTA5MDktNC44Nzc3MDlDMy40OTA5MDktNS4xMjg3NjcgMy4yOTk2MjYtNS40MDM3MzYgMi45MjkwMTYtNS40MDM3MzZDMi4zMDczNDctNS40MDM3MzYgMi4xNTE5My00LjgwNTk3OCAyLjExNjA2NS00LjY2MjUxNkwuNTI2MDI3IDEuNjg1Njc5Qy40NzgyMDcgMS44NzY5NjEgLjQ3ODIwNyAxLjk0ODY5MiAuNDc4MjA3IDEuOTk2NTEzQy40NzgyMDcgMi4zNzkwNzggLjc4OTA0MSAyLjUyMjU0IDEuMDQwMSAyLjUyMjU0QzEuMjY3MjQ4IDIuNTIyNTQgMS41OTAwMzcgMi4zOTEwMzQgMS43NTc0MSAyLjA1NjI4OUMxLjgyOTE0MSAxLjkxMjgyNyAyLjIyMzY2MSAuMjc0OTY5IDIuMzA3MzQ3LS4wOTU2NDFDMi43OTc1MDkgLjA5NTY0MSAzLjMzNTQ5MiAuMDk1NjQxIDMuNDkwOTA5IC4wOTU2NDFDMy44OTczODUgLjA5NTY0MSA0LjQ0NzMyMyAuMDIzOTEgNS4xNjQ2MzMtLjYyMTY2OUM1LjQ1MTU1Ny0uMDcxNzMxIDYuMTIxMDQ2IC4wOTU2NDEgNi41NjMzODcgLjA5NTY0MVM3LjM1MjQyOC0uMTU1NDE3IDcuNjAzNDg3LS41ODU4MDNDNy45MDIzNjYtMS4wNjQwMSA4LjA1Nzc4My0xLjcwOTU4OSA4LjA1Nzc4My0xLjc2OTM2NUM4LjA1Nzc4My0xLjkzNjczNyA3Ljg3ODQ1Ni0xLjkzNjczNyA3Ljc3MDg1OS0xLjkzNjczN0M3LjYzOTM1Mi0xLjkzNjczNyA3LjU5MTUzMi0xLjkzNjczNyA3LjUzMTc1Ni0xLjg3Njk2MUM3LjUwNzg0Ni0xLjg1MzA1MSA3LjUwNzg0Ni0xLjgyOTE0MSA3LjQzNjExNS0xLjUzMDI2MkM3LjE5NzAxMS0uNTczODQ4IDYuOTIyMDQyLS4zMzQ3NDUgNi42MjMxNjMtLjMzNDc0NUM2LjQ5MTY1Ni0uMzM0NzQ1IDYuMzQ4MTk0LS4zODI1NjUgNi4zNDgxOTQtLjc3NzA4NkM2LjM0ODE5NC0uOTgwMzI0IDYuMzk2MDE1LTEuMTcxNjA2IDYuNTE1NTY3LTEuNjQ5ODEzTDYuODI2NDAxLTIuODY5MjRDNi44ODYxNzctMy4xMzIyNTQgNy4wMDU3MjktMy42MjI0MTYgNy4wODk0MTUtMy45NDUyMDVDNy4xNjExNDYtNC4yMjAxNzQgNy4yODA2OTctNC42OTgzODEgNy4yODA2OTctNC43ODIwNjdDNy4yODA2OTctNS4wMzMxMjYgNy4wODk0MTUtNS4zMDgwOTUgNi43MTg4MDQtNS4zMDgwOTVDNi40Nzk3MDEtNS4zMDgwOTUgNi4wNjEyNy01LjE2NDYzMyA1LjkyOTc2My00LjY3NDQ3MUw1LjEwNDg1Ny0xLjM2Mjg4OUM1LjA1NzAzNi0xLjE0NzY5NiA0Ljg1Mzc5OC0uOTQ0NDU4IDQuNjM4NjA1LS43NjUxMzFDNC4yNTYwNC0uNDQyMzQxIDMuODk3Mzg1LS4zMzQ3NDUgMy41NzQ1OTUtLjMzNDc0NUMyLjc2MTY0NC0uMzM0NzQ1IDIuNjg5OTEzLS45MjA1NDggMi42ODk5MTMtMS4yNzkyMDNDMi42ODk5MTMtMS42MDE5OTMgMi43NjE2NDQtMS44ODg5MTcgMi44MDk0NjUtMi4xMDQxMUwzLjI4NzY3MS0zLjk2OTExNlonLz4KPHBhdGggaWQ9J2cwLTczJyBkPSdNNS4yNzIyMjktNy4zODgyOTRDNS4zMjAwNS03LjU5MTUzMiA1LjMzMjAwNS03LjYwMzQ4NyA1LjU3MTEwOC03LjYyNzM5N0M1Ljc1MDQzNi03LjYzOTM1MiA1LjkwNTg1My03LjYzOTM1MiA2LjA4NTE4MS03LjYzOTM1Mkg2LjMzNjIzOUM2LjU4NzI5OC03LjYzOTM1MiA2LjU5OTI1My03LjY1MTMwOCA2LjY1OTAyOS03LjY5OTEyOEM2LjczMDc2LTcuNzQ2OTQ5IDYuNzY2NjI1LTcuOTE0MzIxIDYuNzY2NjI1LTcuOTg2MDUyQzYuNzY2NjI1LTguMTI5NTE0IDYuNjQ3MDczLTguMjAxMjQ1IDYuNTAzNjExLTguMjAxMjQ1QzYuMjA0NzMyLTguMjAxMjQ1IDUuODkzODk4LTguMTc3MzM1IDUuNTk1MDE5LTguMTc3MzM1QzUuMjg0MTg0LTguMTc3MzM1IDQuOTYxMzk1LTguMTY1MzggNC42Mzg2MDUtOC4xNjUzOEM0LjMwMzg2MS04LjE2NTM4IDMuOTY5MTE2LTguMTc3MzM1IDMuNjQ2MzI2LTguMTc3MzM1QzMuMzM1NDkyLTguMTc3MzM1IDMuMDEyNzAyLTguMjAxMjQ1IDIuNzEzODIzLTguMjAxMjQ1QzIuNTgyMzE2LTguMjAxMjQ1IDIuMzY3MTIzLTguMjAxMjQ1IDIuMzY3MTIzLTcuODU0NTQ1QzIuMzY3MTIzLTcuNjM5MzUyIDIuNTU4NDA2LTcuNjM5MzUyIDIuNzczNTk5LTcuNjM5MzUySDMuMDI0NjU4QzMuMTMyMjU0LTcuNjM5MzUyIDMuNDE5MTc4LTcuNjI3Mzk3IDMuNjU4MjgxLTcuNjE1NDQyTDEuOTQ4NjkyLS44MDA5OTZDMS45MDA4NzItLjYwOTcxNCAxLjg4ODkxNy0uNTk3NzU4IDEuNjYxNzY4LS41ODU4MDNDMS41MTgzMDYtLjU2MTg5MyAxLjMwMzExMy0uNTYxODkzIDEuMTQ3Njk2LS41NjE4OTNILjg5NjYzOEMuNjU3NTM0LS41NjE4OTMgLjQ1NDI5Ni0uNTYxODkzIC40NTQyOTYtLjIxNTE5M0MuNDU0Mjk2LS4wNTk3NzYgLjU4NTgwMyAwIC43MTczMSAwQzEuMDE2MTg5IDAgMS4zMjcwMjQtLjAyMzkxIDEuNjI1OTAzLS4wMjM5MUMxLjk0ODY5Mi0uMDIzOTEgMi4yNzE0ODItLjAzNTg2NiAyLjU5NDI3MS0uMDM1ODY2QzIuOTI5MDE2LS4wMzU4NjYgMy4yNTE4MDYtLjAyMzkxIDMuNTg2NTUtLjAyMzkxQzMuODk3Mzg1LS4wMjM5MSA0LjIwODIxOSAwIDQuNTA3MDk4IDBDNC42MjY2NSAwIDQuODY1NzUzIDAgNC44NjU3NTMtLjM0NjdDNC44NjU3NTMtLjU2MTg5MyA0LjY2MjUxNi0uNTYxODkzIDQuNDU5Mjc4LS41NjE4OTNINC4yMDgyMTlDNC4xMjQ1MzMtLjU2MTg5MyAzLjczMDAxMi0uNTczODQ4IDMuNTc0NTk1LS41ODU4MDNMNS4yNzIyMjktNy4zODgyOTRaJy8+CjxwYXRoIGlkPSdnMC04MScgZD0nTTUuMzA4MDk1IC42ODE0NDVDNS4zMDgwOTUgMS4yOTExNTggNS4zOTE3ODEgMi4zMTkzMDMgNi40Njc3NDYgMi4zMTkzMDNDNy45NTAxODcgMi4zMTkzMDMgOC42MzE2MzEgLjI1MTA1OSA4LjYzMTYzMSAwQzguNjMxNjMxLS4xMTk1NTIgOC41MzU5OS0uMjE1MTkzIDguNDE2NDM4LS4yMTUxOTNDOC4yNzI5NzYtLjIxNTE5MyA4LjIyNTE1Ni0uMDk1NjQxIDguMjAxMjQ1LS4wMzU4NjZDNy45NzQwOTcgLjU2MTg5MyA3LjA4OTQxNSAuNTYxODkzIDYuOTY5ODYzIC41NjE4OTNDNi43MDY4NDkgLjU2MTg5MyA2LjM5NjAxNSAuNTYxODkzIDYuMDk3MTM2LS4xMzE1MDdDOC45OTAyODYtMS4xOTU1MTcgOS43NDM0NjItMy45NTcxNjEgOS43NDM0NjItNS4zMjAwNUM5Ljc0MzQ2Mi03LjM1MjQyOCA4LjMzMjc1Mi04LjQwNDQ4MyA2LjI2NDUwOC04LjQwNDQ4M0MyLjU3MDM2MS04LjQwNDQ4MyAuNjMzNjI0LTUuMjM2MzY0IC42MzM2MjQtMi44NDUzM0MuNjMzNjI0LS43NTMxNzYgMi4xMjgwMiAuMjAzMjM4IDQuMTI0NTMzIC4yMDMyMzhDNC4yNjc5OTUgLjIwMzIzOCA0LjcxMDMzNiAuMjAzMjM4IDUuMzA4MDk1IC4wODM2ODZWLjY4MTQ0NVpNMy4yMDM5ODUtLjUxNDA3MkMyLjQ2Mjc2NS0uODcyNzI3IDIuMjIzNjYxLTEuNjAxOTkzIDIuMjIzNjYxLTIuNDAyOTg5QzIuMjIzNjYxLTMuMDg0NDMzIDIuNTU4NDA2LTUuMjYwMjc0IDMuNTg2NTUtNi41OTkyNTNDNC4zNTE2ODEtNy41Nzk1NzcgNS4zNjc4Ny03LjkyNjI3NiA2LjE0NDk1Ni03LjkyNjI3NkM3LjE3MzEwMS03LjkyNjI3NiA4LjE1MzQyNS03LjM1MjQyOCA4LjE1MzQyNS01Ljc3NDM0NkM4LjE1MzQyNS01LjY5MDY2IDcuOTk4MDA3LTIuMDMyMzc5IDUuODU4MDMyLS43NTMxNzZDNS42MTg5MjktMS4zMzg5NzkgNS4yOTYxMzktMS44NTMwNTEgNC41NjY4NzQtMS44NTMwNTFDMy45MDkzNC0xLjg1MzA1MSAzLjE5MjAzLTEuMzM4OTc5IDMuMTkyMDMtLjY2OTQ4OUMzLjE5MjAzLS41NzM4NDggMy4xOTIwMy0uNTYxODkzIDMuMjAzOTg1LS41MTQwNzJaTTUuMjk2MTM5LS40NjYyNTJDNS4yMTI0NTMtLjQzMDM4NiA0LjczNDI0Ny0uMjc0OTY5IDQuMjQ0MDg1LS4yNzQ5NjlDNC4wMjg4OTItLjI3NDk2OSAzLjYyMjQxNi0uMjc0OTY5IDMuNjIyNDE2LS42Njk0ODlDMy42MjI0MTYtMS4wNTIwNTUgNC4wODg2NjctMS40MjI2NjUgNC41Nzg4MjktMS40MjI2NjVDNC44ODk2NjQtMS40MjI2NjUgNS4yNzIyMjktMS4zMzg5NzkgNS4yOTYxMzktLjQ2NjI1MlonLz4KPHBhdGggaWQ9J2cwLTg4JyBkPSdNNi45NTc5MDgtNC43MjIyOTFMOC41MzU5OS02LjI3NjQ2M0w5LjI3NzIxLTcuMDI5NjM5QzkuNzU1NDE3LTcuNDgzOTM1IDkuODk4ODc5LTcuNjI3Mzk3IDExLjE0MjIxNy03LjYzOTM1MkMxMS4zNjkzNjUtNy42MzkzNTIgMTEuMzkzMjc1LTcuOTUwMTg3IDExLjM5MzI3NS03Ljk4NjA1MkMxMS4zOTMyNzUtOC4wNTc3ODMgMTEuMzQ1NDU1LTguMjAxMjQ1IDExLjE1NDE3Mi04LjIwMTI0NUMxMC43MzU3NDEtOC4yMDEyNDUgMTAuMjgxNDQ1LTguMTY1MzggOS44NTEwNTktOC4xNjUzOEM5LjUwNDM1OS04LjE2NTM4IDguNjQzNTg3LTguMjAxMjQ1IDguMjk2ODg3LTguMjAxMjQ1QzguMjAxMjQ1LTguMjAxMjQ1IDcuOTYyMTQyLTguMjAxMjQ1IDcuOTYyMTQyLTcuODY2NTAxQzcuOTYyMTQyLTcuNjUxMzA4IDguMTUzNDI1LTcuNjM5MzUyIDguMjYxMDIxLTcuNjM5MzUyQzguNjE5Njc2LTcuNjI3Mzk3IDguOTMwNTExLTcuNTMxNzU2IDguOTc4MzMxLTcuNTE5ODAxTDYuNjk0ODk0LTUuMjYwMjc0TDUuNTk1MDE5LTcuNTY3NjIxQzUuNzE0NTctNy41OTE1MzIgNi4wODUxODEtNy42MzkzNTIgNi4yODg0MTgtNy42MzkzNTJDNi40MTk5MjUtNy42MzkzNTIgNi42MzUxMTgtNy42MzkzNTIgNi42MzUxMTgtNy45NzQwOTdDNi42MzUxMTgtOC4xNDE0NjkgNi41Mjc1MjItOC4yMDEyNDUgNi4zNzIxMDUtOC4yMDEyNDVDNS45NjU2MjktOC4yMDEyNDUgNC45NjEzOTUtOC4xNjUzOCA0LjU1NDkxOS04LjE2NTM4QzQuMjc5OTUtOC4xNjUzOCA0LjAwNDk4MS04LjE3NzMzNSAzLjczMDAxMi04LjE3NzMzNVMzLjE2ODEyLTguMjAxMjQ1IDIuODkzMTUxLTguMjAxMjQ1QzIuNzg1NTU0LTguMjAxMjQ1IDIuNTU4NDA2LTguMjAxMjQ1IDIuNTU4NDA2LTcuODY2NTAxQzIuNTU4NDA2LTcuNjM5MzUyIDIuNzEzODIzLTcuNjM5MzUyIDMuMDQ4NTY4LTcuNjM5MzUyQzMuMjE1OTQtNy42MzkzNTIgMy4zNDc0NDctNy42MzkzNTIgMy41MTQ4MTktNy42MjczOTdDMy42ODIxOTItNy42MDM0ODcgMy42OTQxNDctNy41OTE1MzIgMy43NjU4NzgtNy40NDgwN0w1LjQxNTY5MS0zLjk5MzAyNkwyLjQxNDk0NC0xLjAyODE0NEMyLjE5OTc1MS0uODI0OTA3IDEuOTQ4NjkyLS41NzM4NDggLjg4NDY4Mi0uNTYxODkzQy42Njk0ODktLjU2MTg5MyAuNDY2MjUyLS41NjE4OTMgLjQ2NjI1Mi0uMjE1MTkzQy40NjYyNTItLjEzMTUwNyAuNTI2MDI3IDAgLjcwNTM1NSAwQy45OTIyNzkgMCAxLjcyMTU0NC0uMDM1ODY2IDIuMDA4NDY4LS4wMzU4NjZDMi4zNTUxNjgtLjAzNTg2NiAzLjIxNTk0IDAgMy41NjI2NCAwQzMuNjU4MjgxIDAgMy44OTczODUgMCAzLjg5NzM4NS0uMzQ2N0MzLjg5NzM4NS0uNTYxODkzIDMuNjgyMTkyLS41NjE4OTMgMy41ODY1NS0uNTYxODkzQzMuMzQ3NDQ3LS41NjE4OTMgMy4xMDgzNDQtLjU5Nzc1OCAyLjg4MTE5Ni0uNjgxNDQ1TDUuNjY2NzUtMy40NTUwNDRMNy4wMTc2ODQtLjYzMzYyNEM3LjAwNTcyOS0uNjMzNjI0IDYuNjExMjA4LS41NjE4OTMgNi4zMjQyODQtLjU2MTg5M0M2LjIwNDczMi0uNTYxODkzIDUuOTc3NTg0LS41NjE4OTMgNS45Nzc1ODQtLjIxNTE5M0M1Ljk3NzU4NC0uMTc5MzI4IDUuOTg5NTM5IDAgNi4yNDA1OTggMEM2LjY0NzA3MyAwIDcuNjYzMjYzLS4wMzU4NjYgOC4wNjk3MzgtLjAzNTg2NkM4LjM0NDcwNy0uMDM1ODY2IDguNjE5Njc2LS4wMjM5MSA4Ljg5NDY0NS0uMDIzOTFTOS40NTY1MzggMCA5LjczMTUwNyAwQzkuODI3MTQ4IDAgMTAuMDY2MjUyIDAgMTAuMDY2MjUyLS4zNDY3QzEwLjA2NjI1Mi0uNTYxODkzIDkuODc0OTY5LS41NjE4OTMgOS41ODgwNDUtLjU2MTg5M0M5LjQyMDY3Mi0uNTYxODkzIDkuMzAxMTIxLS41NjE4OTMgOS4xMjE3OTMtLjU3Mzg0OEM4Ljk0MjQ2Ni0uNTk3NzU4IDguOTMwNTExLS42MDk3MTQgOC44NDY4MjQtLjc2NTEzMUw2Ljk1NzkwOC00LjcyMjI5MVonLz4KPHBhdGggaWQ9J2cwLTg5JyBkPSdNOC43NzUwOTMtNy4xNzMxMDFDOS4wMzgxMDctNy40NDgwNyA5LjMxMzA3Ni03LjYyNzM5NyAxMC4xMTQwNzItNy42MzkzNTJDMTAuMjQ1NTc5LTcuNjM5MzUyIDEwLjQ2MDc3Mi03LjYzOTM1MiAxMC40NjA3NzItNy45ODYwNTJDMTAuNDYwNzcyLTguMDU3NzgzIDEwLjQwMDk5Ni04LjIwMTI0NSAxMC4yNDU1NzktOC4yMDEyNDVDOS44OTg4NzktOC4yMDEyNDUgOS41MDQzNTktOC4xNjUzOCA5LjE0NTcwNC04LjE2NTM4QzguNzAzMzYyLTguMTY1MzggOC4yNDkwNjYtOC4yMDEyNDUgNy44MTg2OC04LjIwMTI0NUM3LjczNDk5NC04LjIwMTI0NSA3LjQ5NTg5LTguMjAxMjQ1IDcuNDk1ODktNy44NTQ1NDVDNy40OTU4OS03LjYzOTM1MiA3LjY5OTEyOC03LjYzOTM1MiA3LjgxODY4LTcuNjM5MzUyUzguMTc3MzM1LTcuNjE1NDQyIDguMzU2NjYzLTcuNTU1NjY2TDUuMTE2ODEyLTQuMDg4NjY3TDMuNTg2NTUtNy41OTE1MzJDMy45MjEyOTUtNy42MzkzNTIgMy45MzMyNS03LjYzOTM1MiA0LjI1NjA0LTcuNjM5MzUyQzQuNDU5Mjc4LTcuNjM5MzUyIDQuNjYyNTE2LTcuNjUxMzA4IDQuNjYyNTE2LTcuOTg2MDUyQzQuNjYyNTE2LTguMTQxNDY5IDQuNTMxMDA5LTguMjAxMjQ1IDQuMzk5NTAyLTguMjAxMjQ1QzMuOTkzMDI2LTguMjAxMjQ1IDIuOTUyOTI3LTguMTY1MzggMi41NDY0NTEtOC4xNjUzOEMyLjI3MTQ4Mi04LjE2NTM4IDEuOTg0NTU4LTguMTc3MzM1IDEuNzIxNTQ0LTguMTc3MzM1QzEuNDM0NjItOC4xNzczMzUgMS4xMzU3NDEtOC4yMDEyNDUgLjg2MDc3Mi04LjIwMTI0NUMuNzQxMjItOC4yMDEyNDUgLjUyNjAyNy04LjIwMTI0NSAuNTI2MDI3LTcuODU0NTQ1Qy41MjYwMjctNy42MzkzNTIgLjY5MzQtNy42MzkzNTIgMS4wMTYxODktNy42MzkzNTJDMS4xNzE2MDYtNy42MzkzNTIgMS4zMTUwNjgtNy42MzkzNTIgMS40ODI0NDEtNy42MjczOTdDMS42MjU5MDMtNy42MDM0ODcgMS42NDk4MTMtNy42MDM0ODcgMS43MjE1NDQtNy40NDgwN0wzLjUzODczLTMuMjc1NzE2TDIuOTE3MDYxLS44MTI5NTFDMi44NjkyNC0uNjA5NzE0IDIuODU3Mjg1LS41OTc3NTggMi42NDIwOTItLjU4NTgwM0MyLjQzODg1NC0uNTYxODkzIDIuMjM1NjE2LS41NjE4OTMgMi4wMjA0MjMtLjU2MTg5M0MxLjY2MTc2OC0uNTYxODkzIDEuNjM3ODU4LS41NjE4OTMgMS41OTAwMzctLjUxNDA3MkMxLjUxODMwNi0uNDU0Mjk2IDEuNDcwNDg2LS4yOTg4NzkgMS40NzA0ODYtLjIxNTE5M0MxLjQ3MDQ4Ni0uMTkxMjgzIDEuNDgyNDQxIDAgMS43MzM0OTkgMEMyLjAzMjM3OSAwIDIuMzQzMjEzLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTFDMi45MjkwMTYtLjAyMzkxIDMuMjI3ODk1LS4wMzU4NjYgMy41MTQ4MTktLjAzNTg2NkMzLjkyMTI5NS0uMDM1ODY2IDQuOTM3NDg0IDAgNS4zNDM5NiAwQzUuNDUxNTU3IDAgNS42OTA2NiAwIDUuNjkwNjYtLjM0NjdDNS42OTA2Ni0uNTYxODkzIDUuNTIzMjg4LS41NjE4OTMgNS4xODg1NDMtLjU2MTg5M0M0LjkzNzQ4NC0uNTYxODkzIDQuNzEwMzM2LS41NzM4NDggNC40NTkyNzgtLjU4NTgwM0w1LjEyODc2Ny0zLjI3NTcxNkw4Ljc3NTA5My03LjE3MzEwMVonLz4KPHBhdGggaWQ9J2czLTc4JyBkPSdNMy42NTgyODEtNi44NjIyNjdDMy44NzM0NzQtNi4yNDA1OTggNC4xMzY0ODgtNS4zNDM5NiA0LjY3NDQ3MS0zLjg3MzQ3NEM1LjQyNzY0Ni0xLjg0MTA5NiA1Ljc2MjM5MS0xLjA5OTg3NSA2LjQ5MTY1NiAuMDM1ODY2QzYuNjU5MDI5IC4yODY5MjQgNi42NzA5ODQgLjI5ODg3OSA2Ljc3ODU4IC4yOTg4NzlDNi45NDU5NTMgLjI5ODg3OSA3LjE5NzAxMSAuMTU1NDE3IDcuMzI4NTE4IC4wNTk3NzZDNy40OTU4OS0uMDk1NjQxIDcuNTA3ODQ2LS4xMDc1OTcgNy42MzkzNTItLjY5MzRDOC4zNTY2NjMtMy44Mzc2MDkgOS4yNjUyNTUtNy4xMTMzMjUgOS41MDQzNTktNy42NjMyNjNDOS41MTYzMTQtNy42ODcxNzMgOS43NTU0MTctOC4xNDE0NjkgMTEuMjI1OTAzLTguMTY1MzhDMTEuNDY1MDA2LTguMTc3MzM1IDExLjY5MjE1NC04LjgxMDk1OSAxMS42OTIxNTQtOS4wNzM5NzNDMTEuNjkyMTU0LTkuMjY1MjU1IDExLjYyMDQyMy05LjI2NTI1NSAxMS40NTMwNTEtOS4yNjUyNTVDMTAuMjU3NTM0LTkuMjY1MjU1IDkuNzE5NTUyLTguNzYzMTM4IDkuNTc2MDktOC42MDc3MjFDOS4yNDEzNDUtOC4xNzczMzUgOC45NTQ0MjEtNy4zMDQ2MDggOC40MDQ0ODMtNS4zMDgwOTVDNy45ODYwNTItMy43Nzc4MzMgNy42MDM0ODctMi4yMjM2NjEgNy4yMzI4NzctLjY4MTQ0NUM2LjU3NTM0Mi0xLjY3MzcyNCA2LjIwNDczMi0yLjYxODE4MiA1LjYzMDg4NC00LjE2MDM5OUM0Ljk5NzI2LTUuODU4MDMyIDQuNjE0Njk1LTcuMTAxMzcgNC4yOTE5MDUtOC4xNzczMzVDNC4yMjAxNzQtOC40MTY0MzggNC4yMDgyMTktOC40MjgzOTQgNC4xMDA2MjMtOC40MjgzOTRDNC4wNzY3MTItOC40MjgzOTQgMy44Mzc2MDktOC40MjgzOTQgMy40OTA5MDktOC4xNDE0NjlDMy4zNzEzNTctOC4wMzM4NzMgMy4zNTk0MDItNy45MjYyNzYgMy4zNDc0NDctNy43OTQ3N0MzLjAxMjcwMi00LjYxNDY5NSAxLjg4ODkxNy0xLjQ3MDQ4NiAxLjU2NjEyNy0uODk2NjM4QzEuNDcwNDg2LS43MTczMSAxLjMyNzAyNC0uNTAyMTE3IDEuMDg3OTItLjUwMjExN0MuOTY4MzY5LS41MDIxMTcgLjUwMjExNy0uNTYxODkzIC4xOTEyODMtLjg0ODgxN0MuMTMxNTA3LS44OTY2MzggLjEwNzU5Ny0uODk2NjM4IC4wOTU2NDEtLjg5NjYzOEMtLjA5NTY0MS0uODk2NjM4LS4zNDY3LS4yOTg4NzktLjM0NjctLjAxMTk1NUMtLjM0NjcgLjM1ODY1NSAuMzgyNTY1IC41OTc3NTggLjcxNzMxIC41OTc3NThDMS40ODI0NDEgLjU5Nzc1OCAyLjA5MjE1NC0xLjA4NzkyIDIuMjgzNDM3LTEuNjM3ODU4QzMuMDYwNTIzLTMuODAxNzQzIDMuNDMxMTMzLTUuNTgzMDY0IDMuNjU4MjgxLTYuODYyMjY3WicvPgo8cGF0aCBpZD0nZzMtMTA2JyBkPSdNMS45MDA4NzItOC41MzU5OUMxLjkwMDg3Mi04Ljc1MTE4MyAxLjkwMDg3Mi04Ljk2NjM3NiAxLjY2MTc2OC04Ljk2NjM3NlMxLjQyMjY2NS04Ljc1MTE4MyAxLjQyMjY2NS04LjUzNTk5VjIuNTU4NDA2QzEuNDIyNjY1IDIuNzczNTk5IDEuNDIyNjY1IDIuOTg4NzkyIDEuNjYxNzY4IDIuOTg4NzkyUzEuOTAwODcyIDIuNzczNTk5IDEuOTAwODcyIDIuNTU4NDA2Vi04LjUzNTk5WicvPgo8cGF0aCBpZD0nZzctNDknIGQ9J00yLjUwMjYxNS01LjA3Njk2MUMyLjUwMjYxNS01LjI5MjE1NCAyLjQ4NjY3NS01LjMwMDEyNSAyLjI3MTQ4Mi01LjMwMDEyNUMxLjk0NDcwNy00Ljk4MTMyIDEuNTIyMjkxLTQuNzkwMDM3IC43NjUxMzEtNC43OTAwMzdWLTQuNTI3MDI0Qy45ODAzMjQtNC41MjcwMjQgMS40MTA3MS00LjUyNzAyNCAxLjg3Mjk3Ni00Ljc0MjIxN1YtLjY1MzU0OUMxLjg3Mjk3Ni0uMzU4NjU1IDEuODQ5MDY2LS4yNjMwMTQgMS4wOTE5MDUtLjI2MzAxNEguODEyOTUxVjBDMS4xMzk3MjYtLjAyMzkxIDEuODI1MTU2LS4wMjM5MSAyLjE4MzgxMS0uMDIzOTFTMy4yMzU4NjYtLjAyMzkxIDMuNTYyNjQgMFYtLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNi0uMjYzMDE0IDIuNTAyNjE1LS4zNTg2NTUgMi41MDI2MTUtLjY1MzU0OVYtNS4wNzY5NjFaJy8+CjxwYXRoIGlkPSdnNy01OScgZD0nTTEuNjE3OTMzLTIuOTg4NzkyQzEuNjE3OTMzLTMuMjU5Nzc2IDEuNDAyNzQtMy40MzUxMTggMS4xNzk1NzctMy40MzUxMThDLjkwODU5My0zLjQzNTExOCAuNzMzMjUtMy4yMTk5MjUgLjczMzI1LTIuOTk2NzYyQy43MzMyNS0yLjcyNTc3OCAuOTQ4NDQzLTIuNTUwNDM2IDEuMTcxNjA2LTIuNTUwNDM2QzEuNDQyNTktMi41NTA0MzYgMS42MTc5MzMtMi43NjU2MjkgMS42MTc5MzMtMi45ODg3OTJaTTEuNDE4NjgtLjA2Mzc2MUMxLjQxODY4IC40NTQyOTYgMS4yNTEzMDggLjkxNjU2MyAuOTAwNjIzIDEuMzE1MDY4Qy44NTI4MDIgMS4zNzg4MjkgLjgzNjg2MiAxLjM4NjggLjgzNjg2MiAxLjQyNjY1Qy44MzY4NjIgMS40OTgzODEgLjkwODU5MyAxLjU0NjIwMiAuOTQ4NDQzIDEuNTQ2MjAyQzEuMDUyMDU1IDEuNTQ2MjAyIDEuNjQxODQzIC45MDA2MjMgMS42NDE4NDMtLjA0NzgyMUMxLjY0MTg0My0uMzEwODM0IDEuNjA5OTYzLS44ODQ2ODIgMS4xNzE2MDYtLjg4NDY4MkMuOTA4NTkzLS44ODQ2ODIgLjczMzI1LS42Nzc0NiAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjIwNzIyMyAuOTAwNjIzIDAgMS4xNzk1NzcgMEMxLjMxNTA2OCAwIDEuMzYyODg5LS4wMjM5MSAxLjQxODY4LS4wNjM3NjFaJy8+CjxwYXRoIGlkPSdnNy05MScgZD0nTTIuMTU5OSAxLjk5MjUyOFYxLjYyNTkwM0gxLjM1NDkxOVYtNS42MTA5NTlIMi4xNTk5Vi01Ljk3NzU4NEguOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonLz4KPHBhdGggaWQ9J2c3LTkzJyBkPSdNMS4zNTQ5MTktNS45Nzc1ODRILjE4MzMxM1YtNS42MTA5NTlILjk4ODI5NFYxLjYyNTkwM0guMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonLz4KPHBhdGggaWQ9J2cyLTAnIGQ9J001LjU3MTEwOC0xLjgwOTIxNUM1LjY5ODYzLTEuODA5MjE1IDUuODczOTczLTEuODA5MjE1IDUuODczOTczLTEuOTkyNTI4UzUuNjk4NjMtMi4xNzU4NDEgNS41NzExMDgtMi4xNzU4NDFIMS4wMDQyMzRDLjg3NjcxMi0yLjE3NTg0MSAuNzAxMzctMi4xNzU4NDEgLjcwMTM3LTEuOTkyNTI4Uy44NzY3MTItMS44MDkyMTUgMS4wMDQyMzQtMS44MDkyMTVINS41NzExMDhaJy8+CjxwYXRoIGlkPSdnMi01MCcgZD0nTTQuNjMwNjM1LTEuODA5MjE1QzQuNzU4MTU3LTEuODA5MjE1IDQuOTMzNDk5LTEuODA5MjE1IDQuOTMzNDk5LTEuOTkyNTI4UzQuNzU4MTU3LTIuMTc1ODQxIDQuNjMwNjM1LTIuMTc1ODQxSDEuMDc1OTY1QzEuMTc5NTc3LTMuMjgzNjg2IDIuMTA0MTEtNC4xMjg1MTggMy4zMTU1NjctNC4xMjg1MThINC42MzA2MzVDNC43NTgxNTctNC4xMjg1MTggNC45MzM0OTktNC4xMjg1MTggNC45MzM0OTktNC4zMTE4MzFTNC43NTgxNTctNC40OTUxNDMgNC42MzA2MzUtNC40OTUxNDNIMy4yOTE2NTZDMS44NTcwMzYtNC40OTUxNDMgLjcwMTM3LTMuMzc5MzI4IC43MDEzNy0xLjk5MjUyOEMuNzAxMzctLjU5Nzc1OCAxLjg2NTAwNiAuNTEwMDg3IDMuMjkxNjU2IC41MTAwODdINC42MzA2MzVDNC43NTgxNTcgLjUxMDA4NyA0LjkzMzQ5OSAuNTEwMDg3IDQuOTMzNDk5IC4zMjY3NzVTNC43NTgxNTcgLjE0MzQ2MiA0LjYzMDYzNSAuMTQzNDYySDMuMzE1NTY3QzIuMTA0MTEgLjE0MzQ2MiAxLjE3OTU3Ny0uNzAxMzcgMS4wNzU5NjUtMS44MDkyMTVINC42MzA2MzVaJy8+CjxwYXRoIGlkPSdnOC00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzgtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c4LTQzJyBkPSdNNC43NzAxMTItMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEtMi43NjE2NDQgOC40NTIzMDQtMi43NjE2NDQgOC40NTIzMDQtMi45NzY4MzdDOC40NTIzMDQtMy4yMDM5ODUgOC4yNDkwNjYtMy4yMDM5ODUgOC4wNjk3MzgtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyLTYuNjcwOTg0IDQuNzcwMTEyLTYuODg2MTc3IDQuNTU0OTE5LTYuODg2MTc3QzQuMzI3NzcxLTYuODg2MTc3IDQuMzI3NzcxLTYuNjgyOTM5IDQuMzI3NzcxLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMuODYwNzcyLTMuMjAzOTg1IC42NDU1NzktMy4yMDM5ODUgLjY0NTU3OS0yLjk4ODc5MkMuNjQ1NTc5LTIuNzYxNjQ0IC44NDg4MTctMi43NjE2NDQgMS4wMjgxNDQtMi43NjE2NDRINC4zMjc3NzFWLjUzNzk4M0M0LjMyNzc3MSAuNzA1MzU1IDQuMzI3NzcxIC45MjA1NDggNC41NDI5NjQgLjkyMDU0OEM0Ljc3MDExMiAuOTIwNTQ4IDQuNzcwMTEyIC43MTczMSA0Ljc3MDExMiAuNTM3OTgzVi0yLjc2MTY0NFonLz4KPHBhdGggaWQ9J2c4LTU5JyBkPSdNMi4xOTk3NTEtNC41Nzg4MjlDMi4xOTk3NTEtNC45MDE2MTkgMS45MjQ3ODItNS4xNTI2NzcgMS42MjU5MDMtNS4xNTI2NzdDMS4yNzkyMDMtNS4xNTI2NzcgMS4wNDAxLTQuODc3NzA5IDEuMDQwMS00LjU3ODgyOUMxLjA0MDEtNC4yMjAxNzQgMS4zMzg5NzktMy45OTMwMjYgMS42MTM5NDgtMy45OTMwMjZDMS45MzY3MzctMy45OTMwMjYgMi4xOTk3NTEtNC4yNDQwODUgMi4xOTk3NTEtNC41Nzg4MjlaTTEuOTk2NTEzLS4xMTk1NTJDMS45OTY1MTMgLjI5ODg3OSAxLjk5NjUxMyAxLjE0NzY5NiAxLjI2NzI0OCAyLjA0NDMzNEMxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjM5ODc1NSAyLjMwNzM0NyAyLjIzNTYxNiAxLjQyMjY2NSAyLjIzNTYxNiAuMDIzOTFDMi4yMzU2MTYtLjQxODQzMSAyLjE5OTc1MS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjI2NzI0OC0xLjE1OTY1MSAxLjA0MDEtLjg5NjYzOCAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjI2MzAxNCAxLjI2NzI0OCAwIDEuNjI1OTAzIDBDMS44NTMwNTEgMCAxLjkzNjczNy0uMDcxNzMxIDEuOTk2NTEzLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnOC02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzgtOTcnIGQ9J000LjYxNDY5NS0zLjE5MjAzQzQuNjE0Njk1LTMuODM3NjA5IDQuNjE0Njk1LTQuMzE1ODE2IDQuMDg4NjY3LTQuNzgyMDY3QzMuNjcwMjM3LTUuMTY0NjMzIDMuMTMyMjU0LTUuMzMyMDA1IDIuNjA2MjI3LTUuMzMyMDA1QzEuNjI1OTAzLTUuMzMyMDA1IC44NzI3MjctNC42ODY0MjYgLjg3MjcyNy0zLjkwOTM0Qy44NzI3MjctMy41NjI2NCAxLjA5OTg3NS0zLjM5NTI2OCAxLjM3NDg0NC0zLjM5NTI2OEMxLjY2MTc2OC0zLjM5NTI2OCAxLjg2NTAwNi0zLjU5ODUwNiAxLjg2NTAwNi0zLjg4NTQzQzEuODY1MDA2LTQuMzc1NTkyIDEuNDM0NjItNC4zNzU1OTIgMS4yNTUyOTMtNC4zNzU1OTJDMS41MzAyNjItNC44Nzc3MDkgMi4xMDQxMS01LjA5MjkwMiAyLjU4MjMxNi01LjA5MjkwMkMzLjEzMjI1NC01LjA5MjkwMiAzLjgzNzYwOS00LjYzODYwNSAzLjgzNzYwOS0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyLTMuMDQ4NTY4IC41MjYwMjctMi4wNDQzMzQgLjUyNjAyNy0xLjEyMzc4NkMuNTI2MDI3LS4xNzkzMjggMS42MjU5MDMgLjExOTU1MiAyLjM1NTE2OCAuMTE5NTUyQzMuMTQ0MjA5IC4xMTk1NTIgMy42ODIxOTItLjM1ODY1NSAzLjkwOTM0LS45MzI1MDNDMy45NTcxNjEtLjM3MDYxIDQuMzI3NzcxIC4wNTk3NzYgNC44NDE4NDMgLjA1OTc3NkM1LjA5MjkwMiAuMDU5Nzc2IDUuNzg2MzAxLS4xMDc1OTcgNS43ODYzMDEtMS4wNjQwMVYtMS43MzM0OTlINS41MjMyODhWLTEuMDY0MDFDNS41MjMyODgtLjM4MjU2NSA1LjIzNjM2NC0uMjg2OTI0IDUuMDY4OTkxLS4yODY5MjRDNC42MTQ2OTUtLjI4NjkyNCA0LjYxNDY5NS0uOTIwNTQ4IDQuNjE0Njk1LTEuMDk5ODc1Vi0zLjE5MjAzWk0zLjgzNzYwOS0xLjY4NTY3OUMzLjgzNzYwOS0uNTE0MDcyIDIuOTY0ODgyLS4xMTk1NTIgMi40NTA4MDktLjExOTU1MkMxLjg2NTAwNi0uMTE5NTUyIDEuMzc0ODQ0LS41NDk5MzggMS4zNzQ4NDQtMS4xMjM3ODZDMS4zNzQ4NDQtMi43MDE4NjggMy40MDcyMjMtMi44NDUzMyAzLjgzNzYwOS0yLjg2OTI0Vi0xLjY4NTY3OVonLz4KPHBhdGggaWQ9J2c4LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c4LTEwOScgZD0nTTguNTcxODU2LTIuOTA1MTA2QzguNTcxODU2LTQuMDE2OTM2IDguNTcxODU2LTQuMzUxNjgxIDguMjk2ODg3LTQuNzM0MjQ3QzcuOTUwMTg3LTUuMjAwNDk4IDcuMzg4Mjk0LTUuMjcyMjI5IDYuOTgxODE4LTUuMjcyMjI5QzUuOTg5NTM5LTUuMjcyMjI5IDUuNDg3NDIyLTQuNTU0OTE5IDUuMjk2MTM5LTQuMDg4NjY3QzUuMTI4NzY3LTUuMDA5MjE1IDQuNDgzMTg4LTUuMjcyMjI5IDMuNzMwMDEyLTUuMjcyMjI5QzIuNTcwMzYxLTUuMjcyMjI5IDIuMTE2MDY1LTQuMjc5OTUgMi4wMjA0MjMtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TC4zODI1NjUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3LTQuNzk0MDIyIDEuMjkxMTU4LTQuNzEwMzM2IDEuMjkxMTU4LTQuMTI0NTMzVi0uODg0NjgyQzEuMjkxMTU4LS4zNDY3IDEuMTU5NjUxLS4zNDY3IC4zODI1NjUtLjM0NjdWMEMuNjkzNC0uMDIzOTEgMS4zMzg5NzktLjAyMzkxIDEuNjczNzI0LS4wMjM5MUMyLjAyMDQyMy0uMDIzOTEgMi42NjYwMDItLjAyMzkxIDIuOTc2ODM3IDBWLS4zNDY3QzIuMjExNzA2LS4zNDY3IDIuMDY4MjQ0LS4zNDY3IDIuMDY4MjQ0LS44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0LTQuMzYzNjM2IDIuODkzMTUxLTUuMDMzMTI2IDMuNjM0MzcxLTUuMDMzMTI2UzQuNTQyOTY0LTQuNDIzNDEyIDQuNTQyOTY0LTMuNjk0MTQ3Vi0uODg0NjgyQzQuNTQyOTY0LS4zNDY3IDQuNDExNDU3LS4zNDY3IDMuNjM0MzcxLS4zNDY3VjBDMy45NDUyMDUtLjAyMzkxIDQuNTkwNzg1LS4wMjM5MSA0LjkyNTUyOS0uMDIzOTFDNS4yNzIyMjktLjAyMzkxIDUuOTE3ODA4LS4wMjM5MSA2LjIyODY0MyAwVi0uMzQ2N0M1LjQ2MzUxMi0uMzQ2NyA1LjMyMDA1LS4zNDY3IDUuMzIwMDUtLjg4NDY4MlYtMy4xMDgzNDRDNS4zMjAwNS00LjM2MzYzNiA2LjE0NDk1Ni01LjAzMzEyNiA2Ljg4NjE3Ny01LjAzMzEyNlM3Ljc5NDc3LTQuNDIzNDEyIDcuNzk0NzctMy42OTQxNDdWLS44ODQ2ODJDNy43OTQ3Ny0uMzQ2NyA3LjY2MzI2My0uMzQ2NyA2Ljg4NjE3Ny0uMzQ2N1YwQzcuMTk3MDExLS4wMjM5MSA3Ljg0MjU5LS4wMjM5MSA4LjE3NzMzNS0uMDIzOTFDOC41MjQwMzUtLjAyMzkxIDkuMTY5NjE0LS4wMjM5MSA5LjQ4MDQ0OCAwVi0uMzQ2N0M4Ljg4MjY5LS4zNDY3IDguNTgzODExLS4zNDY3IDguNTcxODU2LS43MDUzNTVWLTIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzgtMTE0JyBkPSdNMS45OTY1MTMtMi43ODU1NTRDMS45OTY1MTMtMy45NDUyMDUgMi40NzQ3Mi01LjAzMzEyNiAzLjM5NTI2OC01LjAzMzEyNkMzLjQ5MDkwOS01LjAzMzEyNiAzLjUxNDgxOS01LjAzMzEyNiAzLjU2MjY0LTUuMDIxMTcxQzMuNDY2OTk5LTQuOTczMzUgMy4yNzU3MTYtNC45MDE2MTkgMy4yNzU3MTYtNC41Nzg4MjlDMy4yNzU3MTYtNC4yMzIxMyAzLjU1MDY4NS00LjEwMDYyMyAzLjc0MTk2OC00LjEwMDYyM0MzLjk4MTA3MS00LjEwMDYyMyA0LjIyMDE3NC00LjI1NjA0IDQuMjIwMTc0LTQuNTc4ODI5QzQuMjIwMTc0LTQuOTM3NDg0IDMuODk3Mzg1LTUuMjcyMjI5IDMuMzgzMzEzLTUuMjcyMjI5QzIuMzY3MTIzLTUuMjcyMjI5IDIuMDIwNDIzLTQuMTcyMzU0IDEuOTQ4NjkyLTMuOTQ1MjA1SDEuOTM2NzM3Vi01LjI3MjIyOUwuMzM0NzQ1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE0NzY5Ni00Ljc5NDAyMiAxLjI0MzMzNy00LjcxMDMzNiAxLjI0MzMzNy00LjEyNDUzM1YtLjg4NDY4MkMxLjI0MzMzNy0uMzQ2NyAxLjExMTgzMS0uMzQ2NyAuMzM0NzQ1LS4zNDY3VjBDLjY2OTQ4OS0uMDIzOTEgMS4zMjcwMjQtLjAyMzkxIDEuNjg1Njc5LS4wMjM5MUMyLjAwODQ2OC0uMDIzOTEgMi44NTcyODUtLjAyMzkxIDMuMTMyMjU0IDBWLS4zNDY3SDIuODkzMTUxQzIuMDIwNDIzLS4zNDY3IDEuOTk2NTEzLS40NzgyMDcgMS45OTY1MTMtLjkwODU5M1YtMi43ODU1NTRaJy8+CjxwYXRoIGlkPSdnOC0xMjAnIGQ9J00zLjM0NzQ0Ny0yLjgyMTQyQzMuNjk0MTQ3LTMuMjc1NzE2IDQuMTk2MjY0LTMuOTIxMjk1IDQuNDIzNDEyLTQuMTcyMzU0QzQuOTEzNTc0LTQuNzIyMjkxIDUuNDc1NDY3LTQuODA1OTc4IDUuODU4MDMyLTQuODA1OTc4Vi01LjE1MjY3N0M1LjM0Mzk2LTUuMTI4NzY3IDUuMzIwMDUtNS4xMjg3NjcgNC44NTM3OTgtNS4xMjg3NjdDNC4zOTk1MDItNS4xMjg3NjcgNC4zNzU1OTItNS4xMjg3NjcgMy43Nzc4MzMtNS4xNTI2NzdWLTQuODA1OTc4QzMuOTMzMjUtNC43ODIwNjcgNC4xMjQ1MzMtNC43MTAzMzYgNC4xMjQ1MzMtNC40MzUzNjdDNC4xMjQ1MzMtNC4yMzIxMyA0LjAxNjkzNi00LjEwMDYyMyAzLjk0NTIwNS00LjAwNDk4MUwzLjE4MDA3NS0zLjAzNjYxM0wyLjI0NzU3Mi00LjI2Nzk5NUMyLjIxMTcwNi00LjMxNTgxNiAyLjEzOTk3NS00LjQyMzQxMiAyLjEzOTk3NS00LjUwNzA5OEMyLjEzOTk3NS00LjU3ODgyOSAyLjE5OTc1MS00Ljc5NDAyMiAyLjU1ODQwNi00LjgwNTk3OFYtNS4xNTI2NzdDMi4yNTk1MjctNS4xMjg3NjcgMS42NDk4MTMtNS4xMjg3NjcgMS4zMjcwMjQtNS4xMjg3NjdDLjkzMjUwMy01LjEyODc2NyAuOTA4NTkzLTUuMTI4NzY3IC4xNzkzMjgtNS4xNTI2NzdWLTQuODA1OTc4Qy43ODkwNDEtNC44MDU5NzggMS4wMTYxODktNC43ODIwNjcgMS4yNjcyNDgtNC40NTkyNzhMMi42NjYwMDItMi42MzAxMzdDMi42ODk5MTMtMi42MDYyMjcgMi43Mzc3MzMtMi41MzQ0OTYgMi43Mzc3MzMtMi40OTg2M1MxLjgwNTIzLTEuMjkxMTU4IDEuNjg1Njc5LTEuMTM1NzQxQzEuMTU5NjUxLS40OTAxNjIgLjYzMzYyNC0uMzU4NjU1IC4xMTk1NTItLjM0NjdWMEMuNTczODQ4LS4wMjM5MSAuNTk3NzU4LS4wMjM5MSAxLjExMTgzMS0uMDIzOTFDMS41NjYxMjctLjAyMzkxIDEuNTkwMDM3LS4wMjM5MSAyLjE4Nzc5NiAwVi0uMzQ2N0MxLjkwMDg3Mi0uMzgyNTY1IDEuODUzMDUxLS41NjE4OTMgMS44NTMwNTEtLjcyOTI2NUMxLjg1MzA1MS0uOTIwNTQ4IDEuOTM2NzM3LTEuMDE2MTg5IDIuMDU2Mjg5LTEuMTcxNjA2QzIuMjM1NjE2LTEuNDIyNjY1IDIuNjMwMTM3LTEuOTEyODI3IDIuOTE3MDYxLTIuMjgzNDM3TDMuODk3Mzg1LTEuMDA0MjM0QzQuMTAwNjIzLS43NDEyMiA0LjEwMDYyMy0uNzE3MzEgNC4xMDA2MjMtLjY0NTU3OUM0LjEwMDYyMy0uNTQ5OTM4IDQuMDA0OTgxLS4zNTg2NTUgMy42ODIxOTItLjM0NjdWMEMzLjk5MzAyNi0uMDIzOTEgNC41Nzg4MjktLjAyMzkxIDQuOTEzNTc0LS4wMjM5MUM1LjMwODA5NS0uMDIzOTEgNS4zMzIwMDUtLjAyMzkxIDYuMDQ5MzE1IDBWLS4zNDY3QzUuNDE1NjkxLS4zNDY3IDUuMjAwNDk4LS4zNzA2MSA0LjkxMzU3NC0uNzUzMTc2TDMuMzQ3NDQ3LTIuODIxNDJaJy8+CjxwYXRoIGlkPSdnNi05NycgZD0nTTIuODM5MzUyLTEuNzgxMzJDMi44MzkzNTItMi4zMzcyMzUgMi4yNzE0ODItMi42NjYwMDIgMS42MDE5OTMtMi42NjYwMDJDMS4zMTUwNjgtMi42NjYwMDIgLjYwOTcxNC0yLjYzNjExNSAuNjA5NzE0LTIuMTMzOTk4Qy42MDk3MTQtMS45NzI2MDMgLjcxNzMxLTEuODQxMDk2IC45MDI2MTUtMS44NDEwOTZDMS4wNzU5NjUtMS44NDEwOTYgMS4xODk1MzktMS45NzI2MDMgMS4xODk1MzktMi4xMjgwMkMxLjE4OTUzOS0yLjIzNTYxNiAxLjE0MTcxOS0yLjMzNzIzNSAxLjAzNDEyMi0yLjM4NTA1NkMxLjIzMTM4Mi0yLjQ3NDcyIDEuNTMwMjYyLTIuNDc0NzIgMS41OTAwMzctMi40NzQ3MkMyLjAxNDQ0Ni0yLjQ3NDcyIDIuMzQzMjEzLTIuMjIzNjYxIDIuMzQzMjEzLTEuNzY5MzY1Vi0xLjYxMzk0OEMyLjA2ODI0NC0xLjYwMTk5MyAxLjU5MDAzNy0xLjU5MDAzNyAxLjE1MzY3NC0xLjQzNDYyQy43NTkxNTMtMS4yOTcxMzYgLjM4MjU2NS0xLjAyODE0NCAuMzgyNTY1LS42Mjc2NDZDLjM4MjU2NS0uMDk1NjQxIDEuMDE2MTg5IC4wNTk3NzYgMS40ODI0NDEgLjA1OTc3NkMxLjk4NDU1OCAuMDU5Nzc2IDIuMjgzNDM3LS4xOTEyODMgMi40MTQ5NDQtLjQxODQzMUMyLjQ1Njc4Ny0uMTA3NTk3IDIuNjU0MDQ3IC4wMjk4ODggMi44NjMyNjMgLjAyOTg4OEMyLjg4NzE3MyAuMDI5ODg4IDMuNTI2Nzc1IC4wMjk4ODggMy41MjY3NzUtLjUzNzk4M1YtLjg2Njc1SDMuMzA1NjA0Vi0uNTQ5OTM4QzMuMzA1NjA0LS40OTAxNjIgMy4zMDU2MDQtLjIyMTE3MSAzLjA3MjQ3OC0uMjIxMTcxUzIuODM5MzUyLS40OTAxNjIgMi44MzkzNTItLjU0OTkzOFYtMS43ODEzMlpNMi4zNDMyMTMtLjg0ODgxN0MyLjM0MzIxMy0uMjI3MTQ4IDEuNzI3NTIyLS4xMzE1MDcgMS41MzYyMzktLjEzMTUwN0MxLjIxMzQ1LS4xMzE1MDcgLjkwODU5My0uMzI4NzY3IC45MDg1OTMtLjYyNzY0NkMuOTA4NTkzLS45NjIzOTEgMS4yMzEzODItMS4zOTg3NTUgMi4zNDMyMTMtMS40MzQ2MlYtLjg0ODgxN1onLz4KPHBhdGggaWQ9J2c2LTEwNScgZD0nTTEuMzU2OTEyLTMuNjgyMTkyQzEuMzU2OTEyLTMuODYxNTE5IDEuMjA3NDcyLTQuMDQwODQ3IC45OTgyNTctNC4wNDA4NDdDLjgxMjk1MS00LjA0MDg0NyAuNjM5NjAxLTMuODk3Mzg1IC42Mzk2MDEtMy42ODIxOTJTLjgxMjk1MS0zLjMyMzUzNyAuOTk4MjU3LTMuMzIzNTM3QzEuMjA3NDcyLTMuMzIzNTM3IDEuMzU2OTEyLTMuNTAyODY0IDEuMzU2OTEyLTMuNjgyMTkyWk0uNDA2NDc2LTIuNTcwMzYxVi0yLjMzNzIzNUMuODAwOTk2LTIuMzM3MjM1IC44NTQ3OTUtMi4yOTUzOTIgLjg1NDc5NS0yLjAwMjQ5MVYtLjQ5MDE2MkMuODU0Nzk1LS4yMzMxMjYgLjc5NTAxOS0uMjMzMTI2IC4zODI1NjUtLjIzMzEyNlYwQy41NTU5MTUtLjAxMTk1NSAxLjAyMjE2Ny0uMDIzOTEgMS4wODE5NDMtLjAyMzkxUzEuNTk2MDE1LS4wMTE5NTUgMS43NTE0MzIgMFYtLjIzMzEyNkMxLjM4MDgyMi0uMjMzMTI2IDEuMzI3MDI0LS4yMzMxMjYgMS4zMjcwMjQtLjQ4NDE4NFYtMi42MzYxMTVMLjQwNjQ3Ni0yLjU3MDM2MVonLz4KPHBhdGggaWQ9J2c2LTEwOScgZD0nTTUuMjA2NDc2LTEuODA1MjNDNS4yMDY0NzYtMi40MTQ5NDQgNC44NDc4MjEtMi42MzYxMTUgNC4yNjIwMTctMi42MzYxMTVDMy43MDYxMDItMi42MzYxMTUgMy4zNzczMzUtMi4zMTkzMDMgMy4yNDU4MjgtMi4wOTIxNTRDMy4xMDgzNDQtMi42MzYxMTUgMi40OTg2My0yLjYzNjExNSAyLjMzMTI1OC0yLjYzNjExNUMxLjc4NzI5OC0yLjYzNjExNSAxLjQ1MjU1My0yLjMzNzIzNSAxLjMwOTA5MS0yLjA4NjE3N0gxLjMwMzExM1YtMi42MzYxMTVMLjM3NjU4OC0yLjU3MDM2MVYtMi4zMzcyMzVDLjc5NTAxOS0yLjMzNzIzNSAuODQ4ODE3LTIuMjk1MzkyIC44NDg4MTctMi4wMDI0OTFWLS40OTAxNjJDLjg0ODgxNy0uMjMzMTI2IC43ODkwNDEtLjIzMzEyNiAuMzc2NTg4LS4yMzMxMjZWMEMuNDE4NDMxLS4wMDU5NzggLjgyNDkwNy0uMDIzOTEgMS4wOTM4OTgtLjAyMzkxUzEuNzU3NDEtLjAwNTk3OCAxLjgxNzE4NiAwVi0uMjMzMTI2QzEuNDA0NzMyLS4yMzMxMjYgMS4zNDQ5NTYtLjIzMzEyNiAxLjM0NDk1Ni0uNDkwMTYyVi0xLjU0MjIxN0MxLjM0NDk1Ni0yLjE5OTc1MSAxLjkxMjgyNy0yLjQ0NDgzMiAyLjI3NzQ2LTIuNDQ0ODMyQzIuNjg5OTEzLTIuNDQ0ODMyIDIuNzc5NTc3LTIuMTg3Nzk2IDIuNzc5NTc3LTEuODE3MTg2Vi0uNDkwMTYyQzIuNzc5NTc3LS4yMzMxMjYgMi43MTk4MDEtLjIzMzEyNiAyLjMwNzM0Ny0uMjMzMTI2VjBDMi4zNDkxOTEtLjAwNTk3OCAyLjc1NTY2Ni0uMDIzOTEgMy4wMjQ2NTgtLjAyMzkxUzMuNjg4MTY5LS4wMDU5NzggMy43NDc5NDUgMFYtLjIzMzEyNkMzLjMzNTQ5Mi0uMjMzMTI2IDMuMjc1NzE2LS4yMzMxMjYgMy4yNzU3MTYtLjQ5MDE2MlYtMS41NDIyMTdDMy4yNzU3MTYtMi4xOTk3NTEgMy44NDM1ODctMi40NDQ4MzIgNC4yMDgyMTktMi40NDQ4MzJDNC42MjA2NzItMi40NDQ4MzIgNC43MTAzMzYtMi4xODc3OTYgNC43MTAzMzYtMS44MTcxODZWLS40OTAxNjJDNC43MTAzMzYtLjIzMzEyNiA0LjY1MDU2LS4yMzMxMjYgNC4yMzgxMDctLjIzMzEyNlYwQzQuMjc5OTUtLjAwNTk3OCA0LjY4NjQyNi0uMDIzOTEgNC45NTU0MTctLjAyMzkxUzUuNjE4OTI5LS4wMDU5NzggNS42Nzg3MDUgMFYtLjIzMzEyNkM1LjI2NjI1Mi0uMjMzMTI2IDUuMjA2NDc2LS4yMzMxMjYgNS4yMDY0NzYtLjQ5MDE2MlYtMS44MDUyM1onLz4KPHBhdGggaWQ9J2c2LTExMCcgZD0nTTMuMjY5NzM4LTEuODA1MjNDMy4yNjk3MzgtMi4zOTEwMzQgMi45MzQ5OTQtMi42MzYxMTUgMi4zMzEyNTgtMi42MzYxMTVDMS44MDUyMy0yLjYzNjExNSAxLjQ3NjQ2My0yLjM2MTE0NiAxLjMwMzExMy0yLjA3NDIyMlYtMi42MzYxMTVMLjM3NjU4OC0yLjU3MDM2MVYtMi4zMzcyMzVDLjc5NTAxOS0yLjMzNzIzNSAuODQ4ODE3LTIuMjk1MzkyIC44NDg4MTctMi4wMDI0OTFWLS40OTAxNjJDLjg0ODgxNy0uMjMzMTI2IC43ODkwNDEtLjIzMzEyNiAuMzc2NTg4LS4yMzMxMjZWMEMuNDE4NDMxLS4wMDU5NzggLjgyNDkwNy0uMDIzOTEgMS4wOTM4OTgtLjAyMzkxUzEuNzU3NDEtLjAwNTk3OCAxLjgxNzE4NiAwVi0uMjMzMTI2QzEuNDA0NzMyLS4yMzMxMjYgMS4zNDQ5NTYtLjIzMzEyNiAxLjM0NDk1Ni0uNDkwMTYyVi0xLjU0MjIxN0MxLjM0NDk1Ni0yLjE5OTc1MSAxLjkwNjg0OS0yLjQ0NDgzMiAyLjI3NzQ2LTIuNDQ0ODMyQzIuNjc3OTU4LTIuNDQ0ODMyIDIuNzczNTk5LTIuMTkzNzczIDIuNzczNTk5LTEuODIzMTYzVi0uNDkwMTYyQzIuNzczNTk5LS4yMzMxMjYgMi43MTM4MjMtLjIzMzEyNiAyLjMwMTM3LS4yMzMxMjZWMEMyLjM0MzIxMy0uMDA1OTc4IDIuNzQ5Njg5LS4wMjM5MSAzLjAxODY4LS4wMjM5MVMzLjY4MjE5Mi0uMDA1OTc4IDMuNzQxOTY4IDBWLS4yMzMxMjZDMy4zMjk1MTQtLjIzMzEyNiAzLjI2OTczOC0uMjMzMTI2IDMuMjY5NzM4LS40OTAxNjJWLTEuODA1MjNaJy8+CjxwYXRoIGlkPSdnNi0xMjAnIGQ9J00yLjEyMjA0Mi0xLjM5ODc1NUwyLjcxMzgyMy0yLjAyMDQyM0MzLjAyNDY1OC0yLjMxOTMwMyAzLjM1MzQyNS0yLjM0MzIxMyAzLjUxNDgxOS0yLjM0MzIxM1YtMi41NzYzMzlDMy40MzcxMTEtMi41NzAzNjEgMy4xNzQwOTctMi41NTI0MjggMi45ODI4MTQtMi41NTI0MjhDMi43Njc2MjEtMi41NTI0MjggMi40MDI5ODktMi41NzAzNjEgMi4zNjcxMjMtMi41NzYzMzlWLTIuMzQzMjEzQzIuNDM4ODU0LTIuMzMxMjU4IDIuNDg2Njc1LTIuMjgzNDM3IDIuNDg2Njc1LTIuMjExNzA2QzIuNDg2Njc1LTIuMTEwMDg3IDIuNDM4ODU0LTIuMDYyMjY3IDIuMjY1NTA0LTEuODY1MDA2TDEuOTcyNjAzLTEuNTYwMTQ5TDEuNDU4NTMxLTIuMTE2MDY1QzEuMzk4NzU1LTIuMTc1ODQxIDEuMzkyNzc3LTIuMTg3Nzk2IDEuMzkyNzc3LTIuMjIzNjYxQzEuMzkyNzc3LTIuMzEzMzI1IDEuNDg4NDE4LTIuMzQzMjEzIDEuNTU0MTcyLTIuMzQzMjEzVi0yLjU3NjMzOUMxLjQxMDcxLTIuNTY0Mzg0IC45OTgyNTctMi41NTI0MjggLjg1NDc5NS0yLjU1MjQyOEMuNzQxMjItMi41NTI0MjggLjM3NjU4OC0yLjU2NDM4NCAuMjQ1MDgxLTIuNTc2MzM5Vi0yLjM0MzIxM0MuNTg1ODAzLTIuMzQzMjEzIC42OTkzNzctMi4zMzEyNTggLjg0ODgxNy0yLjE2OTg2M0wxLjYzMTg4LTEuMzIxMDQ2QzEuNjczNzI0LTEuMjc5MjAzIDEuNjc5NzAxLTEuMjczMjI1IDEuNjc5NzAxLTEuMjYxMjdDMS42Nzk3MDEtMS4yNDMzMzcgMS4xNDE3MTktLjY5MzQgMS4wNzU5NjUtLjYyNzY0NkMuOTIwNTQ4LS40NjYyNTIgLjY5OTM3Ny0uMjM5MTAzIC4yMDkyMTUtLjIzMzEyNlYwQy4yODY5MjQtLjAwNTk3OCAuNTQ5OTM4LS4wMjM5MSAuNzQxMjItLjAyMzkxQy44MjQ5MDctLjAyMzkxIDEuMjMxMzgyLS4wMTE5NTUgMS4zNjI4ODkgMFYtLjIzMzEyNkMxLjI4NTE4MS0uMjM5MTAzIDEuMjQzMzM3LS4yODY5MjQgMS4yNDMzMzctLjM2NDYzM0MxLjI0MzMzNy0uNDY2MjUyIDEuMzE1MDY4LS41NDM5NiAxLjM0NDk1Ni0uNTc5ODI2QzEuNTAwMzc0LS43NTkxNTMgMS42Njc3NDYtLjkzMjUwMyAxLjgzNTExOC0xLjA5OTg3NUwyLjM2NzEyMy0uNTI2MDI3QzIuNDg2Njc1LS4zOTQ1MjEgMi40ODY2NzUtLjM4MjU2NSAyLjQ4NjY3NS0uMzUyNjc3QzIuNDg2Njc1LS4yOTI5MDIgMi40MzI4NzctLjIzMzEyNiAyLjMyNTI4LS4yMzMxMjZWMEMyLjUyMjU0LS4wMTE5NTUgMi45NzY4MzctLjAyMzkxIDMuMDI0NjU4LS4wMjM5MUMzLjI0NTgyOC0uMDIzOTEgMy41NTY2NjMtLjAwNTk3OCAzLjYzNDM3MSAwVi0uMjMzMTI2QzMuMzM1NDkyLS4yMzMxMjYgMy4xODYwNTItLjIzMzEyNiAzLjAyNDY1OC0uNDEyNDUzTDIuMTIyMDQyLTEuMzk4NzU1WicvPgo8cGF0aCBpZD0nZzUtMjgnIGQ9J00zLjQzMTEzMy00LjUwNzA5OEg1LjQxNTY5MUM1LjU3MTEwOC00LjUwNzA5OCA1Ljk2NTYyOS00LjUwNzA5OCA1Ljk2NTYyOS00Ljg4OTY2NEM1Ljk2NTYyOS01LjE1MjY3NyA1LjczODQ4MS01LjE1MjY3NyA1LjUyMzI4OC01LjE1MjY3N0gyLjIzNTYxNkMxLjk2MDY0OC01LjE1MjY3NyAxLjU1NDE3Mi01LjE1MjY3NyAxLjAwNDIzNC00LjU2Njg3NEMuNjkzNC00LjIyMDE3NCAuMzEwODM0LTMuNTg2NTUgLjMxMDgzNC0zLjUxNDgxOVMuMzcwNjEtMy40MTkxNzggLjQ0MjM0MS0zLjQxOTE3OEMuNTI2MDI3LTMuNDE5MTc4IC41Mzc5ODMtMy40NTUwNDQgLjU5Nzc1OC0zLjUyNjc3NUMxLjIxOTQyNy00LjUwNzA5OCAxLjg0MTA5Ni00LjUwNzA5OCAyLjEzOTk3NS00LjUwNzA5OEgzLjEzMjI1NEwxLjg4ODkxNy0uNDA2NDc2QzEuODI5MTQxLS4yMjcxNDggMS44MjkxNDEtLjIwMzIzOCAxLjgyOTE0MS0uMTY3MzcyQzEuODI5MTQxLS4wMzU4NjYgMS45MTI4MjcgLjEzMTUwNyAyLjE1MTkzIC4xMzE1MDdDMi41MjI1NCAuMTMxNTA3IDIuNTgyMzE2LS4xOTEyODMgMi42MTgxODItLjM3MDYxTDMuNDMxMTMzLTQuNTA3MDk4WicvPgo8cGF0aCBpZD0nZzUtNTgnIGQ9J00yLjE5OTc1MS0uNTczODQ4QzIuMTk5NzUxLS45MjA1NDggMS45MTI4MjctMS4xNTk2NTEgMS42MjU5MDMtMS4xNTk2NTFDMS4yNzkyMDMtMS4xNTk2NTEgMS4wNDAxLS44NzI3MjcgMS4wNDAxLS41ODU4MDNDMS4wNDAxLS4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEtLjI4NjkyNCAyLjE5OTc1MS0uNTczODQ4WicvPgo8cGF0aCBpZD0nZzQtMjgnIGQ9J00yLjUwMjYxNS0yLjkwOTA5MUgzLjkyOTI2NUM0LjA1Njc4Ny0yLjkwOTA5MSA0LjE0NDQ1OC0yLjkwOTA5MSA0LjIyNDE1OS0yLjk3Mjg1MkM0LjMxOTgwMS0zLjA2MDUyMyA0LjM0MzcxMS0zLjE2NDEzNCA0LjM0MzcxMS0zLjIxMTk1NUM0LjM0MzcxMS0zLjQzNTExOCA0LjE0NDQ1OC0zLjQzNTExOCA0LjAwODk2Ni0zLjQzNTExOEgxLjYwMTk5M0MxLjQzNDYyLTMuNDM1MTE4IDEuMTMxNzU2LTMuNDM1MTE4IC43NDEyMi0zLjA1MjU1M0MuNDU0Mjk2LTIuNzY1NjI5IC4yMzExMzMtMi4zOTkwMDQgLjIzMTEzMy0yLjM0MzIxM0MuMjMxMTMzLTIuMjcxNDgyIC4yODY5MjQtMi4yNDc1NzIgLjM1MDY4NS0yLjI0NzU3MkMuNDMwMzg2LTIuMjQ3NTcyIC40NDYzMjYtMi4yNzE0ODIgLjQ5NDE0Ny0yLjMzNTI0M0MuODg0NjgyLTIuOTA5MDkxIDEuMzU0OTE5LTIuOTA5MDkxIDEuNTM4MjMyLTIuOTA5MDkxSDIuMjIzNjYxTDEuNTM4MjMyLS43MDEzN0MxLjQ4MjQ0MS0uNTE4MDU3IDEuMzc4ODI5LS4xOTEyODMgMS4zNzg4MjktLjE1MTQzMkMxLjM3ODgyOSAuMDMxODggMS41NDYyMDIgLjA5NTY0MSAxLjY0MTg0MyAuMDk1NjQxQzEuOTM2NzM3IC4wOTU2NDEgMS45ODQ1NTgtLjE4MzMxMyAyLjAwODQ2OC0uMzAyODY0TDIuNTAyNjE1LTIuOTA5MDkxWicvPgo8cGF0aCBpZD0nZzQtOTgnIGQ9J00xLjk0NDcwNy01LjI5MjE1NEMxLjk1MjY3Ny01LjMwODA5NSAxLjk3NjU4OC01LjQxMTcwNiAxLjk3NjU4OC01LjQxOTY3NkMxLjk3NjU4OC01LjQ1OTUyNyAxLjk0NDcwNy01LjUzMTI1OCAxLjg0OTA2Ni01LjUzMTI1OEMxLjgxNzE4Ni01LjUzMTI1OCAxLjU3MDExMi01LjUwNzM0NyAxLjM4NjgtNS40OTE0MDdMLjk0MDQ3My01LjQ1OTUyN0MuNzY1MTMxLTUuNDQzNTg3IC42ODU0My01LjQzNTYxNiAuNjg1NDMtNS4yOTIxNTRDLjY4NTQzLTUuMTgwNTczIC43OTcwMTEtNS4xODA1NzMgLjg5MjY1My01LjE4MDU3M0MxLjI3NTIxOC01LjE4MDU3MyAxLjI3NTIxOC01LjEzMjc1MiAxLjI3NTIxOC01LjA2MTAyMUMxLjI3NTIxOC01LjAxMzIgMS4xOTU1MTctNC42OTQzOTYgMS4xNDc2OTYtNC41MTEwODNMLjQ1NDI5Ni0xLjczNzQ4NEMuMzkwNTM1LTEuNDY2NTAxIC4zOTA1MzUtMS4zNDY5NDkgLjM5MDUzNS0xLjIxMTQ1N0MuMzkwNTM1LS4zOTA1MzUgLjg5MjY1MyAuMDc5NzAxIDEuNTA2MzUxIC4wNzk3MDFDMi40ODY2NzUgLjA3OTcwMSAzLjUwNjg0OS0xLjA1MjA1NSAzLjUwNjg0OS0yLjIwNzcyMUMzLjUwNjg0OS0yLjk5Njc2MiAyLjk5Njc2Mi0zLjUxNDgxOSAyLjM1OTE1My0zLjUxNDgxOUMxLjkxMjgyNy0zLjUxNDgxOSAxLjU3MDExMi0zLjIyNzg5NSAxLjM5NDc3LTMuMDc2NDYzTDEuOTQ0NzA3LTUuMjkyMTU0Wk0xLjUwNjM1MS0uMTQzNDYyQzEuMjE5NDI3LS4xNDM0NjIgLjkzMjUwMy0uMzY2NjI1IC45MzI1MDMtLjk0ODQ0M0MuOTMyNTAzLTEuMTYzNjM2IC45NjQzODQtMS4zNjI4ODkgMS4wNjAwMjUtMS43NDU0NTVDMS4xMTU4MTYtMS45NzY1ODggMS4xNzE2MDYtMi4xOTk3NTEgMS4yMzUzNjctMi40MzA4ODRDMS4yNzUyMTgtMi41NzQzNDYgMS4yNzUyMTgtMi41OTAyODYgMS4zNzA4NTktMi43MDk4MzhDMS42NDE4NDMtMy4wNDQ1ODMgMi4wMDA0OTgtMy4yOTE2NTYgMi4zMzUyNDMtMy4yOTE2NTZDMi43MzM3NDgtMy4yOTE2NTYgMi44ODUxODEtMi45MDExMjEgMi44ODUxODEtMi41NDI0NjZDMi44ODUxODEtMi4yNDc1NzIgMi43MDk4MzgtMS4zOTQ3NyAyLjQ3MDczNS0uOTI0NTMzQzIuMjYzNTEyLS40OTQxNDcgMS44ODA5NDYtLjE0MzQ2MiAxLjUwNjM1MS0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzQtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c0LTExMScgZD0nTTMuOTY5MTE2LTIuMTM1OTlDMy45NjkxMTYtMi45MTcwNjEgMy40MTEyMDgtMy41MTQ4MTkgMi41ODIzMTYtMy41MTQ4MTlDMS40NTA1Ni0zLjUxNDgxOSAuMzUwNjg1LTIuNDE0OTQ0IC4zNTA2ODUtMS4yOTkxMjhDLjM1MDY4NS0uNDg2MTc3IC45MjQ1MzMgLjA3OTcwMSAxLjczNzQ4NCAuMDc5NzAxQzIuODc3MjEgLjA3OTcwMSAzLjk2OTExNi0xLjAzNjExNSAzLjk2OTExNi0yLjEzNTk5Wk0xLjc0NTQ1NS0uMTQzNDYyQzEuNDY2NTAxLS4xNDM0NjIgLjk5NjI2NC0uMjg2OTI0IC45OTYyNjQtMS4wMjAxNzRDLjk5NjI2NC0xLjM0Njk0OSAxLjE0NzY5Ni0yLjIwNzcyMSAxLjUzMDI2Mi0yLjcwMTg2OEMxLjkyMDc5Ny0zLjIwMzk4NSAyLjM1OTE1My0zLjI5MTY1NiAyLjU3NDM0Ni0zLjI5MTY1NkMyLjkwMTEyMS0zLjI5MTY1NiAzLjMyMzUzNy0zLjA5MjQwMyAzLjMyMzUzNy0yLjQyMjkxNEMzLjMyMzUzNy0yLjEwNDExIDMuMTgwMDc1LTEuMzQ2OTQ5IDIuODc3MjEtLjg2ODc0MkMyLjU4MjMxNi0uNDE0NDQ2IDIuMTQzOTYtLjE0MzQ2MiAxLjc0NTQ1NS0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzQtMTE1JyBkPSdNMy4yMTE5NTUtMi45OTY3NjJDMy4wMjg2NDMtMi45NjQ4ODIgMi44NjEyNy0yLjgyMTQyIDIuODYxMjctMi42MjIxNjdDMi44NjEyNy0yLjQ3ODcwNSAyLjk1NjkxMi0yLjM3NTA5MyAzLjEzMjI1NC0yLjM3NTA5M0MzLjI1MTgwNi0yLjM3NTA5MyAzLjQ5ODg3OS0yLjQ2Mjc2NSAzLjQ5ODg3OS0yLjgyMTQyQzMuNDk4ODc5LTMuMzE1NTY3IDIuOTgwODIyLTMuNTE0ODE5IDIuNDg2Njc1LTMuNTE0ODE5QzEuNDE4NjgtMy41MTQ4MTkgMS4wODM5MzUtMi43NTc2NTkgMS4wODM5MzUtMi4zNTExODNDMS4wODM5MzUtMi4yNzE0ODIgMS4wODM5MzUtMS45ODQ1NTggMS4zNzg4MjktMS43NjEzOTVDMS41NjIxNDItMS42MTc5MzMgMS42OTc2MzQtMS41OTQwMjIgMi4xMTIwOC0xLjUxNDMyMUMyLjM5MTAzNC0xLjQ1ODUzMSAyLjg0NTMzLTEuMzc4ODI5IDIuODQ1MzMtLjk2NDM4NEMyLjg0NTMzLS43NTcxNjEgMi42OTM4OTgtLjQ5NDE0NyAyLjQ3MDczNS0uMzQyNzE1QzIuMTc1ODQxLS4xNTE0MzIgMS43ODUzMDUtLjE0MzQ2MiAxLjY1Nzc4My0uMTQzNDYyQzEuNDY2NTAxLS4xNDM0NjIgLjkyNDUzMy0uMTc1MzQyIC43MjUyOC0uNDk0MTQ3QzEuMTMxNzU2LS41MTAwODcgMS4xODc1NDctLjgzNjg2MiAxLjE4NzU0Ny0uOTMyNTAzQzEuMTg3NTQ3LTEuMTcxNjA2IC45NzIzNTQtMS4yMjczOTcgLjg3NjcxMi0xLjIyNzM5N0MuNzQ5MTkxLTEuMjI3Mzk3IC40MjI0MTYtMS4xMzE3NTYgLjQyMjQxNi0uNjkzNEMuNDIyNDE2LS4yMjMxNjMgLjkxNjU2MyAuMDc5NzAxIDEuNjU3NzgzIC4wNzk3MDFDMy4wNDQ1ODMgLjA3OTcwMSAzLjMzOTQ3Ny0uOTAwNjIzIDMuMzM5NDc3LTEuMjM1MzY3QzMuMzM5NDc3LTEuOTUyNjc3IDIuNTU4NDA2LTIuMTA0MTEgMi4yNjM1MTItMi4xNTk5QzEuODgwOTQ2LTIuMjMxNjMxIDEuNTcwMTEyLTIuMjg3NDIyIDEuNTcwMTEyLTIuNjIyMTY3QzEuNTcwMTEyLTIuNzY1NjI5IDEuNzA1NjA0LTMuMjkxNjU2IDIuNDc4NzA1LTMuMjkxNjU2QzIuNzgxNTY5LTMuMjkxNjU2IDMuMDkyNDAzLTMuMjAzOTg1IDMuMjExOTU1LTIuOTk2NzYyWicvPgo8cGF0aCBpZD0nZzEtOTgnIGQ9J00zLjMxMTU4Mi04LjE4OTI5TDYuNTYzMzg3LTYuNzE4ODA0TDYuNzA2ODQ5LTYuOTgxODE4TDMuMzIzNTM3LTguODk0NjQ1TC0uMDU5Nzc2LTYuOTgxODE4TC4wNzE3MzEtNi43MTg4MDRMMy4zMTE1ODItOC4xODkyOVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzY1LjM3NjkzNycgeT0nLTExLjE1ODE2OScgeGxpbms6aHJlZj0nI2cxLTk4Jy8+Cjx1c2UgeD0nNjUuMTYzMTg1JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzUtMjgnLz4KPHVzZSB4PSc3NC45MDI5NTInIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC02MScvPgo8dXNlIHg9Jzg3LjMyODQzMycgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTk3Jy8+Cjx1c2UgeD0nOTMuMTgxNDIzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtMTE0Jy8+Cjx1c2UgeD0nOTcuNzMzNzQ5JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtMTAzJy8+Cjx1c2UgeD0nMTIwLjU5NDU4NCcgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTEwOScvPgo8dXNlIHg9JzEzMC4zNDk1NjgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC05NycvPgo8dXNlIHg9JzEzNi4yMDI1NTgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC0xMjAnLz4KPHVzZSB4PScxMDUuNzQxODInIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c0LTI4Jy8+Cjx1c2UgeD0nMTEwLjQyMDE2OCcgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzItNTAnLz4KPHVzZSB4PScxMTYuMDY1NzQ1JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNy05MScvPgo8dXNlIHg9JzExOC40MTgwNjknIHk9Jy0zLjE4ODA0MicgeGxpbms6aHJlZj0nI2c0LTI4Jy8+Cjx1c2UgeD0nMTIyLjE3NjI1NCcgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzYtMTA5Jy8+Cjx1c2UgeD0nMTI4LjE1Mzc3NScgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nMTMwLjI1Njk3NCcgeT0nLTEuODk2ODQ4JyB4bGluazpocmVmPScjZzYtMTEwJy8+Cjx1c2UgeD0nMTM0Ljc5NTQ1MScgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzctNTknLz4KPHVzZSB4PScxMzcuMTQ3Nzc1JyB5PSctMy4xODgwNDInIHhsaW5rOmhyZWY9JyNnNC0yOCcvPgo8dXNlIHg9JzE0MC45MDU5NTknIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c2LTEwOScvPgo8dXNlIHg9JzE0Ni44ODM0ODEnIHk9Jy0yLjE5MTc3OCcgeGxpbms6aHJlZj0nI2c2LTk3Jy8+Cjx1c2UgeD0nMTUwLjUzNjQwNicgeT0nLTIuMTkxNzc4JyB4bGluazpocmVmPScjZzYtMTIwJy8+Cjx1c2UgeD0nMTU0Ljg4MTE1NicgeT0nLTMuMTg4MDQyJyB4bGluazpocmVmPScjZzctOTMnLz4KPHVzZSB4PScxNTkuMjI1OTc3JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzMtNzgnLz4KPHVzZSB4PScxNzAuNzk2Nzg3JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxNzUuMzQ5MTEzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzAtODknLz4KPHVzZSB4PScxODYuNDY5MDA0JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzQtMTExJy8+Cjx1c2UgeD0nMTkwLjU2MjA1MycgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c0LTk4Jy8+Cjx1c2UgeD0nMTk0LjE4NDYzOCcgeT0nLTE2LjIwNTg5MScgeGxpbms6aHJlZj0nI2c0LTExNScvPgo8dXNlIHg9JzE5OC41OTg2ODgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PScyMDEuOTE5NTc4JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzAtMjInLz4KPHVzZSB4PScyMTAuMzgyMjU5JyB5PSctOC4zMzU0MTEnIHhsaW5rOmhyZWY9JyNnNC0xMTAnLz4KPHVzZSB4PScyMTYuMDE4NTkzJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScyMjAuNTcwOTE5JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzUtMjgnLz4KPHVzZSB4PScyMjYuOTg5ODYnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzIzMS41NDIxODYnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzI0My43OTYxNicgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c4LTU5Jy8+Cjx1c2UgeD0nMjQ5LjA0MDMxOScgeT0nLTExLjE1ODE1NCcgeGxpbms6aHJlZj0nI2c1LTI4Jy8+Cjx1c2UgeD0nMjU1LjQ1OTI2JyB5PSctMTYuMDk0MzQnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjYyLjA0NTc2NycgeT0nLTE2LjA5NDM0JyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PScyNjYuNzc4MDgyJyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzAtNzMnLz4KPHVzZSB4PScyNzMuODE4MzE2JyB5PSctOS4zNjQ4OTEnIHhsaW5rOmhyZWY9JyNnNC0xMTAnLz4KPHVzZSB4PScyODIuMTExMzE0JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzgtNDMnLz4KPHVzZSB4PScyOTMuODcyNjI5JyB5PSctMTEuMTU4MTU0JyB4bGluazpocmVmPScjZzAtODEnLz4KPHVzZSB4PSczMDQuMjU2OTY3JyB5PSctMTYuMjA1ODkxJyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzMxMC44NDM0NzMnIHk9Jy0xNi4yMDU4OTEnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzMxNS41NzU3ODgnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzMyMC4xMjgxMTQnIHk9Jy0xMS4xNTgxNTQnIHhsaW5rOmhyZWY9JyNnNS01OCcvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
The optimal value of is then given by:

def mu_n(tau):
x = ot.Point(initial_state)
x[p] = tau
# trick: posterior conditional mean is computed by the link function
return py_link_function_theta(x)[:p]
# optimization criterion
def log_cond_tau_post(tau):
x = ot.Point(initial_state)
x[p] = tau
# replace theta by its conditional posterior mean
x[:p] = py_link_function_theta(x)[:p]
# compute log conditional posterior of tau
ll = py_log_density(x)[0]
return ll
1D optimization
def func(X):
return [-log_cond_tau_post(X[0])]
problem = ot.OptimizationProblem(ot.PythonFunction(1, 1, func))
problem.setBounds(ot.Interval([1e-4], [1e4]))
solver = ot.TNC(problem)
solver.setStartingPoint([1.0])
solver.run()
tauhat = solver.getResult().getOptimalPoint()[0]
print("tauhat =", tauhat)
# inject result in initialState vector
x = ot.Point(initial_state)
x[:p] = mu_n(tauhat)
x[p] = tauhat
tauhat = 0.10077295009614318
Final step : create a MetropolisHastings object for each block
initialState = x
mi_Y = [i for i in range(p + 1, p + 1 + n)]
link_function_y = ot.PythonFunction(len(x), 4 * n, py_link_function_y)
rvmh_Y = ot.RandomVectorMetropolisHastings(RV_Y, initialState, mi_Y, link_function_y)
mi_theta = [i for i in range(p)]
link_function_theta = ot.PythonFunction(len(x), p + (p + 2) * p, py_link_function_theta)
rvmh_theta = ot.RandomVectorMetropolisHastings(
RV_theta, initialState, mi_theta, link_function_theta
)
log_pdf_tau = ot.PythonFunction(len(x), 1, py_log_density)
rwmh_tau = ot.RandomWalkMetropolisHastings(
log_pdf_tau, support, initialState, proposal_tau, [p]
)
# Now, assemble the blocks to create a Gibbs algorithm:
gibbs = ot.Gibbs([rvmh_Y, rvmh_theta, rwmh_tau])
Launch Algorithm
sampleSize = 1000
# Joint posterior density sample
sample = gibbs.getSample(sampleSize)
# compute acceptance rate
tau_post = np.array(sample[:, p]).ravel()
acc_rate = (tau_post[1:] != tau_post[:-1]).mean()
print("Acceptance rate: %s" % acc_rate)
Acceptance rate: 0.32732732732732733
Plot posterior distribution marginals
# extract interest parameters
post_sample = sample.getMarginal([i for i in range(p + 1)])
post_sample.setDescription(["$\\theta_0$", "$\\theta_1$", "$\\tau$"])
posterior = ot.KernelSmoothing().build(post_sample)
posterior = ot.TruncatedDistribution(posterior, prior.getRange())
grid = ot.GridLayout(1, 3)
grid.setTitle("Bayesian inference")
xlabs = [r"$\theta_0$", r"$\theta_1$", r"$\tau$"]
p_true = [theta_true[0][0], theta_true[1][0], tau_true]
for parameter_index in range(3):
graph = posterior.getMarginal(parameter_index).drawPDF()
bbox = graph.getBoundingBox()
bound = bbox.getUpperBound()[1]
prior_pdf = prior.getMarginal(parameter_index).drawPDF()
graph.add(prior_pdf)
curve_true = ot.Curve([p_true[parameter_index]] * 2, [0.0, bound])
graph.add(curve_true)
graph.setColors(ot.Drawable.BuildDefaultPalette(3))
graph.setLegends(["Posterior", "Prior", "True value"])
graph.setXTitle(xlabs[parameter_index])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
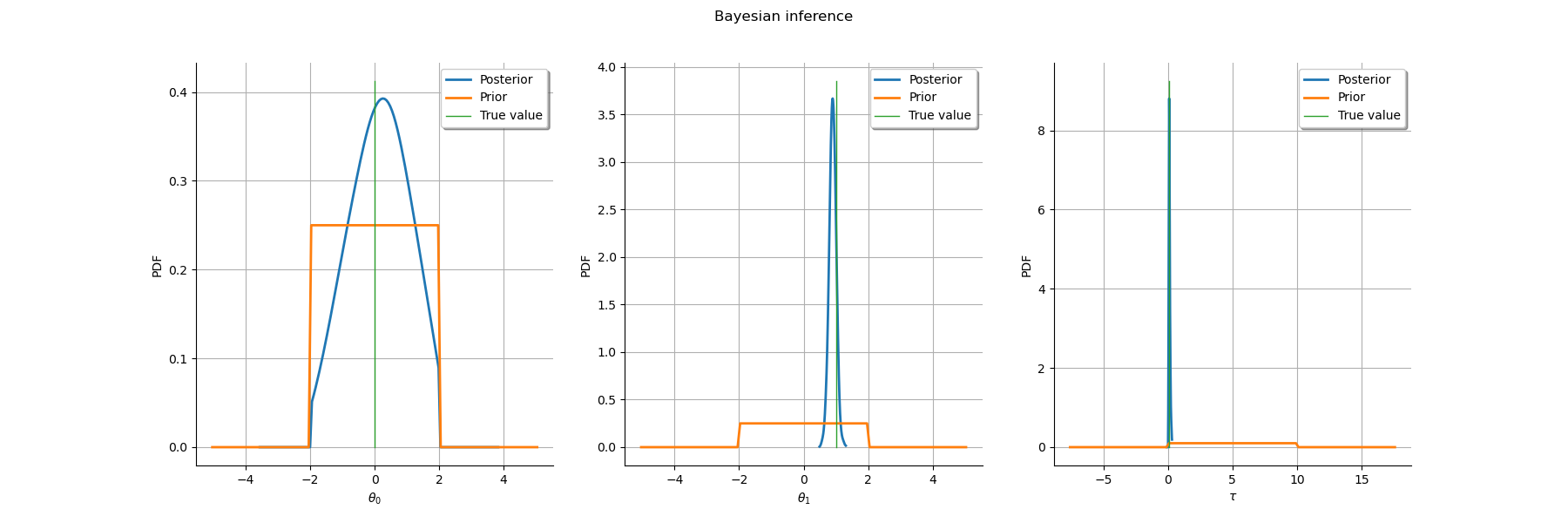
Draw pairplots of the posterior sample.
# sphinx_gallery_thumbnail_number = 3
grid = ot.VisualTest.DrawPairs(post_sample)
graph = grid.getGraph(0, 0)
pt = ot.Cloud(theta_true.T, "#2ca02c", "circle", "True value")
graph.add(pt)
grid.setGraph(0, 0, graph)
graph = grid.getGraph(1, 0)
pt = ot.Cloud([[theta_true[0, 0], tau_true]], "#2ca02c", "circle", "True value")
graph.add(pt)
grid.setGraph(1, 0, graph)
graph = grid.getGraph(1, 1)
pt = ot.Cloud([[theta_true[1, 0], tau_true]], "#2ca02c", "circle", "True value")
graph.add(pt)
grid.setGraph(1, 1, graph)
_ = View(grid)
View.ShowAll()