Note
Go to the end to download the full example code
Posterior sampling using a PythonDistribution¶
In this example we are going to show how to do Bayesian inference using the RandomWalkMetropolisHastings algorithm
in a statistical model defined through a PythonDistribution.
This method is illustrated on a simple lifetime study test-case, which involves censored data, as described hereafter.
In the following, we assume that the lifetime  of an industrial component follows the Weibull distribution
of an industrial component follows the Weibull distribution  ,
with CDF given by
,
with CDF given by  .
.
Our goal is to estimate the model parameters  based on
a dataset of recorded failures
based on
a dataset of recorded failures  some of which
correspond to actual failures, and the remaining are right-censored.
Let
some of which
correspond to actual failures, and the remaining are right-censored.
Let  represent the nature of each
datum,
represent the nature of each
datum,  if
if  corresponds to an actual failure,
corresponds to an actual failure,
 if it is right-censored.
if it is right-censored.
Note that the likelihood of each recorded failure is given by the Weibull density:

On the other hand, the likelihood of each right-censored observation is given by:

Furthermore, assume that the prior information available on is represented by independent prior laws,
whose respective densities are denoted by  and
and 
The posterior distribution of  represents the update of the prior information on given the dataset.
Its PDF is known up to a multiplicative constant:
represents the update of the prior information on given the dataset.
Its PDF is known up to a multiplicative constant:
![\pi(\alpha, \beta | (t_1, f_1), \ldots, (t_n, f_n) ) \propto \pi(\alpha)\pi(\beta) \left(\frac{\alpha}{\beta}\right)^{\sum_i f_i}
\left(\prod_{f_i = 1} \frac{t_i}{\beta}\right)^{\alpha-1} \exp\left[-\sum_{i=1}^n\left(\frac{t_i}{\beta}\right)^\alpha\right].](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzQyMS44ODEyMzNwdCcgaGVpZ2h0PSczOC41NTU2NzNwdCcgdmlld0JveD0nMCAtMzkuNzUxMTg2IDQyMS44ODEyMzMgMzguNTU1NjczJz4KPGRlZnM+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzQtMTA1JyBkPSdNMi4wODAxOTktMy43MzAwMTJDMi4wODAxOTktMy44NzM0NzQgMS45NzI2MDMtMy45NjkxMTYgMS44MzUxMTgtMy45NjkxMTZDMS42NzM3MjQtMy45NjkxMTYgMS41MDAzNzQtMy44MTM2OTkgMS41MDAzNzQtMy42NDAzNDlDMS41MDAzNzQtMy40OTA5MDkgMS42MDc5Ny0zLjQwMTI0NSAxLjczOTQ3Ny0zLjQwMTI0NUMxLjkzMDc2LTMuNDAxMjQ1IDIuMDgwMTk5LTMuNTgwNTczIDIuMDgwMTk5LTMuNzMwMDEyWk0xLjcyMTU0NC0xLjY0MzgzNkMxLjc0NTQ1NS0xLjcwMzYxMSAxLjc5OTI1My0xLjg0NzA3MyAxLjgyMzE2My0xLjkwMDg3MkMxLjg0MTA5Ni0xLjk1NDY3IDEuODY1MDA2LTIuMDE0NDQ2IDEuODY1MDA2LTIuMTE2MDY1QzEuODY1MDA2LTIuNDUwODA5IDEuNTY2MTI3LTIuNjM2MTE1IDEuMjY3MjQ4LTIuNjM2MTE1Qy42NTc1MzQtMi42MzYxMTUgLjM2NDYzMy0xLjg0NzA3MyAuMzY0NjMzLTEuNzE1NTY3Qy4zNjQ2MzMtMS42ODU2NzkgLjM4ODU0My0xLjYzMTg4IC40NzIyMjktMS42MzE4OFMuNTczODQ4LTEuNjY3NzQ2IC41OTE3ODEtMS43MjE1NDRDLjc1OTE1My0yLjMwMTM3IDEuMDc1OTY1LTIuNDM4ODU0IDEuMjQzMzM3LTIuNDM4ODU0QzEuMzYyODg5LTIuNDM4ODU0IDEuNDA0NzMyLTIuMzYxMTQ2IDEuNDA0NzMyLTIuMjIzNjYxQzEuNDA0NzMyLTIuMTA0MTEgMS4zNjg4NjctMi4wMTQ0NDYgMS4zNTY5MTItMS45NzI2MDNMMS4wNDYwNzctMS4yMDc0NzJDLjk3NDM0Ni0xLjAzNDEyMiAuOTc0MzQ2LTEuMDIyMTY3IC44OTY2MzgtLjgxODkyOUMuODE4OTI5LS42Mzk2MDEgLjc4OTA0MS0uNTYxODkzIC43ODkwNDEtLjQ2MDI3NEMuNzg5MDQxLS4xNTU0MTcgMS4wNjQwMSAuMDU5Nzc2IDEuMzkyNzc3IC4wNTk3NzZDMS45OTY1MTMgLjA1OTc3NiAyLjI5NTM5Mi0uNzI5MjY1IDIuMjk1MzkyLS44NjA3NzJDMi4yOTUzOTItLjg3MjcyNyAyLjI4OTQxNS0uOTQ0NDU4IDIuMTgxODE4LS45NDQ0NThDMi4wOTgxMzItLjk0NDQ1OCAyLjA5MjE1NC0uOTE0NTcgMi4wNTYyODktLjgwMDk5NkMxLjk2MDY0OC0uNDk2MTM5IDEuNzE1NTY3LS4xMzc0ODQgMS40MTA3MS0uMTM3NDg0QzEuMzAzMTEzLS4xMzc0ODQgMS4yNDkzMTUtLjIwOTIxNSAxLjI0OTMxNS0uMzUyNjc3QzEuMjQ5MzE1LS40NzIyMjkgMS4yODUxODEtLjU2MTg5MyAxLjM2Mjg4OS0uNzQ3MTk4TDEuNzIxNTQ0LTEuNjQzODM2WicvPgo8cGF0aCBpZD0nZzAtODAnIGQ9J000LjEyMDU0OCA0LjEyODUxOEM0LjIxNjE4OSA0LjAyNDkwNyA0LjIxNjE4OSA0LjAwODk2NiA0LjIxNjE4OSAzLjk4NTA1NkM0LjIxNjE4OSAzLjk3NzA4NiA0LjIxNjE4OSAzLjkzNzIzNSA0LjE1MjQyOCAzLjg1NzUzNEwxLjQyNjY1IC4zNjY2MjVINC43NDIyMTdDNS43NTQ0MjEgLjM2NjYyNSA2LjM2ODEyIC40ODYxNzcgNi43MzQ3NDUgLjYwNTcyOUM3LjM4MDMyNCAuODIwOTIyIDcuOTg2MDUyIDEuMjkxMTU4IDguMjE3MTg2IDEuOTEyODI3SDguNDY0MjU5TDcuNzM4OTc5IDBILjcxNzMxQy40NzgyMDcgMCAuNDcwMjM3IC4wMDc5NyAuNDcwMjM3IC4yODY5MjRMMy41NDY3IDQuMjQwMUwuNTQ5OTM4IDcuNzMxMDA5Qy40NzgyMDcgNy44MTg2OCAuNDcwMjM3IDcuODE4NjggLjQ3MDIzNyA3Ljg1ODUzMUMuNDcwMjM3IDcuOTcwMTEyIC41NzM4NDggNy45NzAxMTIgLjcxNzMxIDcuOTcwMTEySDcuNzM4OTc5TDguNDY0MjU5IDUuOTM3NzMzSDguMjE3MTg2QzguMDI1OTAzIDYuNDg3NjcxIDcuNDgzOTM1IDcuMDY5NDg5IDYuNTE5NTUyIDcuMzE2NTYzQzUuOTUzNjc0IDcuNDYwMDI1IDUuMzc5ODI2IDcuNDgzOTM1IDQuNzk4MDA3IDcuNDgzOTM1SDEuMjQzMzM3TDQuMTIwNTQ4IDQuMTI4NTE4WicvPgo8cGF0aCBpZD0nZzUtMTEnIGQ9J000LjA2NDc1Ny0xLjExNTgxNkM0LjgwNTk3OC0xLjkyODc2NyA1LjA2ODk5MS0yLjk2NDg4MiA1LjA2ODk5MS0zLjAyODY0M0M1LjA2ODk5MS0zLjEwMDM3NCA1LjAyMTE3MS0zLjEzMjI1NCA0Ljk0OTQ0LTMuMTMyMjU0QzQuODQ1ODI4LTMuMTMyMjU0IDQuODM3ODU4LTMuMTAwMzc0IDQuNzkwMDM3LTIuOTMzMDAxQzQuNTY2ODc0LTIuMTIwMDUgNC4wODg2NjctMS40OTgzODEgNC4wNjQ3NTctMS40OTgzODFDNC4wNDg4MTctMS40OTgzODEgNC4wNDg4MTctMS42OTc2MzQgNC4wNDg4MTctMS44MjUxNTZDNC4wMzI4NzctMy4yMjc4OTUgMy4xMjQyODQtMy41MTQ4MTkgMi41ODIzMTYtMy41MTQ4MTlDMS40NTg1MzEtMy41MTQ4MTkgLjM1MDY4NS0yLjQyMjkxNCAuMzUwNjg1LTEuMjk5MTI4Qy4zNTA2ODUtLjUxMDA4NyAuOTAwNjIzIC4wNzk3MDEgMS43NDU0NTUgLjA3OTcwMUMyLjMwMzM2MiAuMDc5NzAxIDIuODkzMTUxLS4xMTk1NTIgMy41MjI3OS0uNTg5Nzg4QzMuNjk4MTMyIC4wMzk4NTEgNC4xNjAzOTkgLjA3OTcwMSA0LjMwMzg2MSAuMDc5NzAxQzQuNzU4MTU3IC4wNzk3MDEgNS4wMjExNzEtLjMyNjc3NSA1LjAyMTE3MS0uNDc4MjA3QzUuMDIxMTcxLS41NzM4NDggNC45MjU1MjktLjU3Mzg0OCA0LjkwMTYxOS0uNTczODQ4QzQuODEzOTQ4LS41NzM4NDggNC43OTgwMDctLjU0OTkzOCA0Ljc3NDA5Ny0uNDk0MTQ3QzQuNjQ2NTc1LS4xNTk0MDIgNC4zNzU1OTItLjE0MzQ2MiA0LjMzNTc0MS0uMTQzNDYyQzQuMjI0MTU5LS4xNDM0NjIgNC4wOTY2MzgtLjE0MzQ2MiA0LjA2NDc1Ny0xLjExNTgxNlpNMy40NjY5OTktLjg1MjgwMkMyLjkwMTEyMS0uMzQyNzE1IDIuMjMxNjMxLS4xNDM0NjIgMS43NjkzNjUtLjE0MzQ2MkMxLjM1NDkxOS0uMTQzNDYyIC45OTYyNjQtLjM4MjU2NSAuOTk2MjY0LTEuMDIwMTc0Qy45OTYyNjQtMS4yOTkxMjggMS4xMjM3ODYtMi4xMjAwNSAxLjQ5ODM4MS0yLjY1NDA0N0MxLjgxNzE4Ni0zLjEwMDM3NCAyLjI0NzU3Mi0zLjI5MTY1NiAyLjU3NDM0Ni0zLjI5MTY1NkMzLjAxMjcwMi0zLjI5MTY1NiAzLjI1OTc3Ni0yLjk4MDgyMiAzLjM2MzM4Ny0yLjQ5NDY0NUMzLjQ4MjkzOS0xLjk1MjY3NyAzLjQxOTE3OC0xLjMxNTA2OCAzLjQ2Njk5OS0uODUyODAyWicvPgo8cGF0aCBpZD0nZzUtMTAyJyBkPSdNMy4wNTI1NTMtMy4xNzIxMDVIMy43OTM3NzNDMy45NTMxNzYtMy4xNzIxMDUgNC4wNDg4MTctMy4xNzIxMDUgNC4wNDg4MTctMy4zMjM1MzdDNC4wNDg4MTctMy40MzUxMTggMy45NDUyMDUtMy40MzUxMTggMy44MDk3MTQtMy40MzUxMThIMy4xMDAzNzRDMy4yMjc4OTUtNC4xNTI0MjggMy4zMDc1OTctNC42MDY3MjUgMy4zODcyOTgtNC45NjUzOEMzLjQxOTE3OC01LjEwMDg3MiAzLjQ0MzA4OC01LjE4ODU0MyAzLjU2MjY0LTUuMjg0MTg0QzMuNjY2MjUyLTUuMzcxODU2IDMuNzMwMDEyLTUuMzg3Nzk2IDMuODE3Njg0LTUuMzg3Nzk2QzMuOTM3MjM1LTUuMzg3Nzk2IDQuMDY0NzU3LTUuMzYzODg1IDQuMTY4MzY5LTUuMzAwMTI1QzQuMTI4NTE4LTUuMjg0MTg0IDQuMDgwNjk3LTUuMjYwMjc0IDQuMDQwODQ3LTUuMjM2MzY0QzMuOTA1MzU1LTUuMTY0NjMzIDMuODA5NzE0LTUuMDIxMTcxIDMuODA5NzE0LTQuODYxNzY4QzMuODA5NzE0LTQuNjc4NDU2IDMuOTUzMTc2LTQuNTY2ODc0IDQuMTI4NTE4LTQuNTY2ODc0QzQuMzU5NjUxLTQuNTY2ODc0IDQuNTc0ODQ0LTQuNzY2MTI3IDQuNTc0ODQ0LTUuMDQ1MDgxQzQuNTc0ODQ0LTUuNDE5Njc2IDQuMTkyMjc5LTUuNjEwOTU5IDMuODA5NzE0LTUuNjEwOTU5QzMuNTM4NzMtNS42MTA5NTkgMy4wMzY2MTMtNS40ODM0MzcgMi43ODE1NjktNC43NTAxODdDMi43MDk4MzgtNC41NjY4NzQgMi43MDk4MzgtNC41NTA5MzQgMi40OTQ2NDUtMy40MzUxMThIMS44OTY4ODdDMS43Mzc0ODQtMy40MzUxMTggMS42NDE4NDMtMy40MzUxMTggMS42NDE4NDMtMy4yODM2ODZDMS42NDE4NDMtMy4xNzIxMDUgMS43NDU0NTUtMy4xNzIxMDUgMS44ODA5NDYtMy4xNzIxMDVIMi40NDY4MjRMMS44NzI5NzYtLjA3OTcwMUMxLjcyMTU0NCAuNzI1MjggMS42MDE5OTMgMS40MDI3NCAxLjE3OTU3NyAxLjQwMjc0QzEuMTU1NjY2IDEuNDAyNzQgLjk4ODI5NCAxLjQwMjc0IC44MzY4NjIgMS4zMDcwOThDMS4yMDM0ODcgMS4yMTk0MjcgMS4yMDM0ODcgLjg4NDY4MiAxLjIwMzQ4NyAuODc2NzEyQzEuMjAzNDg3IC42OTM0IDEuMDYwMDI1IC41ODE4MTggLjg4NDY4MiAuNTgxODE4Qy42Njk0ODkgLjU4MTgxOCAuNDM4MzU2IC43NjUxMzEgLjQzODM1NiAxLjA2Nzk5NUMuNDM4MzU2IDEuNDAyNzQgLjc4MTA3MSAxLjYyNTkwMyAxLjE3OTU3NyAxLjYyNTkwM0MxLjY2NTc1MyAxLjYyNTkwMyAyLjAwMDQ5OCAxLjExNTgxNiAyLjEwNDExIC45MTY1NjNDMi4zOTEwMzQgLjM5MDUzNSAyLjU3NDM0Ni0uNjA1NzI5IDIuNTkwMjg2LS42ODU0M0wzLjA1MjU1My0zLjE3MjEwNVonLz4KPHBhdGggaWQ9J2c1LTEwNScgZD0nTTIuMzc1MDkzLTQuOTczMzVDMi4zNzUwOTMtNS4xNDg2OTIgMi4yNDc1NzItNS4yNzYyMTQgMi4wNjQyNTktNS4yNzYyMTRDMS44NTcwMzYtNS4yNzYyMTQgMS42MjU5MDMtNS4wODQ5MzIgMS42MjU5MDMtNC44NDU4MjhDMS42MjU5MDMtNC42NzA0ODYgMS43NTM0MjUtNC41NDI5NjQgMS45MzY3MzctNC41NDI5NjRDMi4xNDM5Ni00LjU0Mjk2NCAyLjM3NTA5My00LjczNDI0NyAyLjM3NTA5My00Ljk3MzM1Wk0xLjIxMTQ1Ny0yLjA0ODMxOUwuNzgxMDcxLS45NDg0NDNDLjc0MTIyLS44Mjg4OTIgLjcwMTM3LS43MzMyNSAuNzAxMzctLjU5Nzc1OEMuNzAxMzctLjIwNzIyMyAxLjAwNDIzNCAuMDc5NzAxIDEuNDI2NjUgLjA3OTcwMUMyLjE5OTc1MSAuMDc5NzAxIDIuNTI2NTI2LTEuMDM2MTE1IDIuNTI2NTI2LTEuMTM5NzI2QzIuNTI2NTI2LTEuMjE5NDI3IDIuNDYyNzY1LTEuMjQzMzM3IDIuNDA2OTc0LTEuMjQzMzM3QzIuMzExMzMzLTEuMjQzMzM3IDIuMjk1MzkyLTEuMTg3NTQ3IDIuMjcxNDgyLTEuMTA3ODQ2QzIuMDg4MTY5LS40NzAyMzcgMS43NjEzOTUtLjE0MzQ2MiAxLjQ0MjU5LS4xNDM0NjJDMS4zNDY5NDktLjE0MzQ2MiAxLjI1MTMwOC0uMTgzMzEzIDEuMjUxMzA4LS4zOTg1MDZDMS4yNTEzMDgtLjU4OTc4OCAxLjMwNzA5OC0uNzMzMjUgMS40MTA3MS0uOTgwMzI0QzEuNDkwNDExLTEuMTk1NTE3IDEuNTcwMTEyLTEuNDEwNzEgMS42NTc3ODMtMS42MjU5MDNMMS45MDQ4NTctMi4yNzE0ODJDMS45NzY1ODgtMi40NTQ3OTUgMi4wNzIyMjktMi43MDE4NjggMi4wNzIyMjktMi44MzczNkMyLjA3MjIyOS0zLjIzNTg2NiAxLjc1MzQyNS0zLjUxNDgxOSAxLjM0Njk0OS0zLjUxNDgxOUMuNTczODQ4LTMuNTE0ODE5IC4yMzkxMDMtMi4zOTkwMDQgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMzk2MDEgLjQ5NDE0Ny0yLjMxOTMwM0MuNzE3MzEtMy4wNzY0NjMgMS4wODM5MzUtMy4yOTE2NTYgMS4zMjMwMzktMy4yOTE2NTZDMS40MzQ2Mi0zLjI5MTY1NiAxLjUxNDMyMS0zLjI1MTgwNiAxLjUxNDMyMS0zLjAyODY0M0MxLjUxNDMyMS0yLjk0ODk0MSAxLjUwNjM1MS0yLjgzNzM2IDEuNDI2NjUtMi41OTgyNTdMMS4yMTE0NTctMi4wNDgzMTlaJy8+CjxwYXRoIGlkPSdnNS0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzEtMTgnIGQ9J004LjM2ODYxOCAyOC4wODI2OUM4LjM2ODYxOCAyOC4wMzQ4NjkgOC4zNDQ3MDcgMjguMDEwOTU5IDguMzIwNzk3IDI3Ljk3NTA5M0M3Ljg3ODQ1NiAyNy41MzI3NTIgNy4wNzc0NiAyNi43MzE3NTYgNi4yNzY0NjMgMjUuNDQwNTk4QzQuMzUxNjgxIDIyLjM1NjE2NCAzLjQ3ODk1NCAxOC40NzA3MzUgMy40Nzg5NTQgMTMuODY3OTk1QzMuNDc4OTU0IDEwLjY1MjA1NSAzLjkwOTM0IDYuNTAzNjExIDUuODgxOTQzIDIuOTQwOTcxQzYuODI2NDAxIDEuMjQzMzM3IDcuODA2NzI1IC4yNjMwMTQgOC4zMzI3NTItLjI2MzAxNEM4LjM2ODYxOC0uMjk4ODc5IDguMzY4NjE4LS4zMjI3OSA4LjM2ODYxOC0uMzU4NjU1QzguMzY4NjE4LS40NzgyMDcgOC4yODQ5MzItLjQ3ODIwNyA4LjExNzU1OS0uNDc4MjA3UzcuOTI2Mjc2LS40NzgyMDcgNy43NDY5NDktLjI5ODg3OUMzLjc0MTk2OCAzLjM0NzQ0NyAyLjQ4NjY3NSA4LjgyMjkxNCAyLjQ4NjY3NSAxMy44NTYwNEMyLjQ4NjY3NSAxOC41NTQ0MjEgMy41NjI2NCAyMy4yODg2NjcgNi41OTkyNTMgMjYuODYzMjYzQzYuODM4MzU2IDI3LjEzODIzMiA3LjI5MjY1MyAyNy42MjgzOTQgNy43ODI4MTQgMjguMDU4NzhDNy45MjYyNzYgMjguMjAyMjQyIDcuOTUwMTg3IDI4LjIwMjI0MiA4LjExNzU1OSAyOC4yMDIyNDJTOC4zNjg2MTggMjguMjAyMjQyIDguMzY4NjE4IDI4LjA4MjY5WicvPgo8cGF0aCBpZD0nZzEtMTknIGQ9J002LjMwMDM3NCAxMy44Njc5OTVDNi4zMDAzNzQgOS4xNjk2MTQgNS4yMjQ0MDggNC40MzUzNjcgMi4xODc3OTYgLjg2MDc3MkMxLjk0ODY5MiAuNTg1ODAzIDEuNDk0Mzk2IC4wOTU2NDEgMS4wMDQyMzQtLjMzNDc0NUMuODYwNzcyLS40NzgyMDcgLjgzNjg2Mi0uNDc4MjA3IC42Njk0ODktLjQ3ODIwN0MuNTI2MDI3LS40NzgyMDcgLjQxODQzMS0uNDc4MjA3IC40MTg0MzEtLjM1ODY1NUMuNDE4NDMxLS4zMTA4MzQgLjQ2NjI1Mi0uMjYzMDE0IC40OTAxNjItLjIzOTEwM0MuOTA4NTkzIC4xOTEyODMgMS43MDk1ODkgLjk5MjI3OSAyLjUxMDU4NSAyLjI4MzQzN0M0LjQzNTM2NyA1LjM2Nzg3IDUuMzA4MDk1IDkuMjUzMyA1LjMwODA5NSAxMy44NTYwNEM1LjMwODA5NSAxNy4wNzE5OCA0Ljg3NzcwOSAyMS4yMjA0MjMgMi45MDUxMDYgMjQuNzgzMDY0QzEuOTYwNjQ4IDI2LjQ4MDY5NyAuOTY4MzY5IDI3LjQ3Mjk3NiAuNDY2MjUyIDI3Ljk3NTA5M0MuNDQyMzQxIDI4LjAxMDk1OSAuNDE4NDMxIDI4LjA0NjgyNCAuNDE4NDMxIDI4LjA4MjY5Qy40MTg0MzEgMjguMjAyMjQyIC41MjYwMjcgMjguMjAyMjQyIC42Njk0ODkgMjguMjAyMjQyQy44MzY4NjIgMjguMjAyMjQyIC44NjA3NzIgMjguMjAyMjQyIDEuMDQwMSAyOC4wMjI5MTRDNS4wNDUwODEgMjQuMzc2NTg4IDYuMzAwMzc0IDE4LjkwMTEyMSA2LjMwMDM3NCAxMy44Njc5OTVaJy8+CjxwYXRoIGlkPSdnMS0zMicgZD0nTTkuMDUwMDYyIDM1LjI1NTc5MUM5LjA1MDA2MiAzNS4yMTk5MjUgOS4wNTAwNjIgMzUuMTk2MDE1IDguOTc4MzMxIDM1LjExMjMyOUM3LjgzMDYzNSAzMy43MjU1MjkgNi44NzQyMjIgMzIuMTk1MjY4IDYuMTY4ODY3IDMwLjUzMzQ5OUM0LjYwMjc0IDI2Ljg3NTIxOCAzLjk4MTA3MSAyMi41OTUyNjggMy45ODEwNzEgMTcuNDU0NTQ1QzMuOTgxMDcxIDEyLjM2MTY0NCA0LjU2Njg3NCA3Ljg5MDQxMSA2LjMzNjIzOSAzLjk2OTExNkM3LjAyOTYzOSAyLjQ1MDgwOSA3LjkzODIzMiAxLjA0MDEgOS4wMDIyNDItLjI1MTA1OUM5LjAyNjE1Mi0uMjg2OTI0IDkuMDUwMDYyLS4zMTA4MzQgOS4wNTAwNjItLjM1ODY1NUM5LjA1MDA2Mi0uNDc4MjA3IDguOTY2Mzc2LS40NzgyMDcgOC43ODcwNDktLjQ3ODIwN1M4LjU4MzgxMS0uNDc4MjA3IDguNTU5OS0uNDU0Mjk2QzguNTQ3OTQ1LS40NDIzNDEgNy44MDY3MjUgLjI3NDk2OSA2Ljg3NDIyMiAxLjU5MDAzN0M0Ljc5NDAyMiA0LjUzMTAwOSAzLjc0MTk2OCA4LjA0NTgyOCAzLjIwMzk4NSAxMS42MDg0NjhDMi45MTcwNjEgMTMuNTMzMjUgMi44MjE0MiAxNS40OTM4OTggMi44MjE0MiAxNy40NDI1OUMyLjgyMTQyIDIxLjkxMzgyMyAzLjM4MzMxMyAyNi40ODA2OTcgNS4yOTYxMzkgMzAuNTY5MzY1QzYuMTQ0OTU2IDMyLjM4NjU1IDcuMjgwNjk3IDM0LjAyNDQwOCA4LjQ2NDI1OSAzNS4yNjc3NDZDOC41NzE4NTYgMzUuMzYzMzg3IDguNTgzODExIDM1LjM3NTM0MiA4Ljc4NzA0OSAzNS4zNzUzNDJDOC45NjYzNzYgMzUuMzc1MzQyIDkuMDUwMDYyIDM1LjM3NTM0MiA5LjA1MDA2MiAzNS4yNTU3OTFaJy8+CjxwYXRoIGlkPSdnMS0zMycgZD0nTTYuNjM1MTE4IDE3LjQ1NDU0NUM2LjYzNTExOCAxMi45ODMzMTMgNi4wNzMyMjUgOC40MTY0MzggNC4xNjAzOTkgNC4zMjc3NzFDMy4zMTE1ODIgMi41MTA1ODUgMi4xNzU4NDEgLjg3MjcyNyAuOTkyMjc5LS4zNzA2MUMuODg0NjgyLS40NjYyNTIgLjg3MjcyNy0uNDc4MjA3IC42Njk0ODktLjQ3ODIwN0MuNTAyMTE3LS40NzgyMDcgLjQwNjQ3Ni0uNDc4MjA3IC40MDY0NzYtLjM1ODY1NUMuNDA2NDc2LS4zMTA4MzQgLjQ1NDI5Ni0uMjUxMDU5IC40NzgyMDctLjIxNTE5M0MxLjYyNTkwMyAxLjE3MTYwNiAyLjU4MjMxNiAyLjcwMTg2OCAzLjI4NzY3MSA0LjM2MzYzNkM0Ljg1Mzc5OCA4LjAyMTkxOCA1LjQ3NTQ2NyAxMi4zMDE4NjggNS40NzU0NjcgMTcuNDQyNTlDNS40NzU0NjcgMjIuNTM1NDkyIDQuODg5NjY0IDI3LjAwNjcyNSAzLjEyMDI5OSAzMC45MjgwMkMyLjQyNjg5OSAzMi40NDYzMjYgMS41MTgzMDYgMzMuODU3MDM2IC40NTQyOTYgMzUuMTQ4MTk0Qy40NDIzNDEgMzUuMTcyMTA1IC40MDY0NzYgMzUuMjE5OTI1IC40MDY0NzYgMzUuMjU1NzkxQy40MDY0NzYgMzUuMzc1MzQyIC41MDIxMTcgMzUuMzc1MzQyIC42Njk0ODkgMzUuMzc1MzQyQy44NDg4MTcgMzUuMzc1MzQyIC44NzI3MjcgMzUuMzc1MzQyIC44OTY2MzggMzUuMzUxNDMyQy45MDg1OTMgMzUuMzM5NDc3IDEuNjQ5ODEzIDM0LjYyMjE2NyAyLjU4MjMxNiAzMy4zMDcwOThDNC42NjI1MTYgMzAuMzY2MTI3IDUuNzE0NTcgMjYuODUxMzA4IDYuMjUyNTUzIDIzLjI4ODY2N0M2LjUzOTQ3NyAyMS4zNjM4ODUgNi42MzUxMTggMTkuNDAzMjM4IDYuNjM1MTE4IDE3LjQ1NDU0NVonLz4KPHBhdGggaWQ9J2cxLTM0JyBkPSdNMy4yODc2NzEgMzUuMzc1MzQySDYuODI2NDAxVjM0LjYzNDEyMkg0LjAyODg5MlYuMjYzMDE0SDYuODI2NDAxVi0uNDc4MjA3SDMuMjg3NjcxVjM1LjM3NTM0MlonLz4KPHBhdGggaWQ9J2cxLTM1JyBkPSdNMi45MjkwMTYgMzQuNjM0MTIySC4xMzE1MDdWMzUuMzc1MzQySDMuNjcwMjM3Vi0uNDc4MjA3SC4xMzE1MDdWLjI2MzAxNEgyLjkyOTAxNlYzNC42MzQxMjJaJy8+CjxwYXRoIGlkPSdnMS04OCcgZD0nTTE1LjEzNTI0MyAxNi43MzcyMzVMMTYuNTgxODE4IDEyLjkxMTU4MkgxNi4yODI5MzlDMTUuODE2Njg3IDE0LjE1NDkxOSAxNC41NDk0NCAxNC45Njc4NyAxMy4xNzQ1OTUgMTUuMzI2NTI2QzEyLjkyMzUzNyAxNS4zODYzMDEgMTEuNzUxOTMgMTUuNjk3MTM2IDkuNDU2NTM4IDE1LjY5NzEzNkgyLjI0NzU3Mkw4LjMzMjc1MiA4LjU1OTlDOC40MTY0MzggOC40NjQyNTkgOC40NDAzNDkgOC40MjgzOTQgOC40NDAzNDkgOC4zNjg2MThDOC40NDAzNDkgOC4zNDQ3MDcgOC40NDAzNDkgOC4zMDg4NDIgOC4zNTY2NjMgOC4xODkyOUwyLjc4NTU1NCAuNTczODQ4SDkuMzM2OTg2QzEwLjkzODk3OSAuNTczODQ4IDEyLjAyNjg5OSAuNzQxMjIgMTIuMTM0NDk2IC43NjUxMzFDMTIuNzgwMDc1IC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMuNzI5MjY1IDAgLjcxNzMxIC4wMTE5NTUgLjY4MTQ0NSAuMDgzNjg2Qy42Njk0ODkgLjExOTU1MiAuNjY5NDg5IC4zNDY3IC42Njk0ODkgLjQ3ODIwN0w2Ljk5Mzc3MyA5LjEzMzc0OEwuODAwOTk2IDE2LjM5MDUzNUMuNjgxNDQ1IDE2LjUzMzk5OCAuNjgxNDQ1IDE2LjU5Mzc3MyAuNjgxNDQ1IDE2LjYwNTcyOUMuNjgxNDQ1IDE2LjczNzIzNSAuNzg5MDQxIDE2LjczNzIzNSAxLjAwNDIzNCAxNi43MzcyMzVIMTUuMTM1MjQzWicvPgo8cGF0aCBpZD0nZzEtODknIGQ9J00xNC41OTcyNiAxNi43MzcyMzVWMTYuMDkxNjU2QzEzLjAwNzIyMyAxNi4wOTE2NTYgMTIuNjM2NjEzIDE1LjU0MTcxOSAxMi42MzY2MTMgMTQuNzc2NTg4VjEuOTYwNjQ4QzEyLjYzNjYxMyAxLjE4MzU2MiAxMy4wMTkxNzggLjY0NTU3OSAxNC41OTcyNiAuNjQ1NTc5VjBILjY2OTQ4OVYuNjQ1NTc5QzIuMjU5NTI3IC42NDU1NzkgMi42MzAxMzcgMS4xOTU1MTcgMi42MzAxMzcgMS45NjA2NDhWMTQuNzc2NTg4QzIuNjMwMTM3IDE1LjU1MzY3NCAyLjI0NzU3MiAxNi4wOTE2NTYgLjY2OTQ4OSAxNi4wOTE2NTZWMTYuNzM3MjM1SDYuNDE5OTI1VjE2LjA5MTY1NkM0LjgyOTg4OCAxNi4wOTE2NTYgNC40NTkyNzggMTUuNTQxNzE5IDQuNDU5Mjc4IDE0Ljc3NjU4OFYuNjQ1NTc5SDEwLjgwNzQ3MlYxNC43NzY1ODhDMTAuODA3NDcyIDE1LjU1MzY3NCAxMC40MjQ5MDcgMTYuMDkxNjU2IDguODQ2ODI0IDE2LjA5MTY1NlYxNi43MzcyMzVIMTQuNTk3MjZaJy8+CjxwYXRoIGlkPSdnMy0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2czLTQ3JyBkPSdNOC42MzE2MzEtLjM4MjU2NUM4LjU4MzgxMS0uMzgyNTY1IDguMzkyNTI4LS4zNTg2NTUgOC4zNTY2NjMtLjM1ODY1NUM3LjQxMjIwNC0uMzU4NjU1IDYuNzc4NTgtMS4yOTExNTggNi4zNzIxMDUtMS45MTI4MjdDNi4yNTI1NTMtMi4xMTYwNjUgNS45Mjk3NjMtMi42MDYyMjcgNS43OTgyNTctMi44MDk0NjVDNi4wODUxODEtMy40NTUwNDQgNi44ODYxNzctNC45Mzc0ODQgOC4zMDg4NDItNC45Mzc0ODRDOC4zOTI1MjgtNC45Mzc0ODQgOC41MDAxMjUtNC45Mzc0ODQgOC42MzE2MzEtNC45MDE2MTlDOC42MzE2MzEtNS4yMTI0NTMgOC42MTk2NzYtNS4yMjQ0MDggOC41OTU3NjYtNS4yNDgzMTlDOC41MTIwOC01LjI3MjIyOSA4LjMzMjc1Mi01LjI4NDE4NCA4LjIyNTE1Ni01LjI4NDE4NEM2LjcwNjg0OS01LjI4NDE4NCA1LjgyMjE2Ny0zLjgyNTY1NCA1LjUzNTI0My0zLjIyNzg5NUM1LjA1NzAzNi0zLjk1NzE2MSA0Ljg4OTY2NC00LjIyMDE3NCA0LjQ0NzMyMy00LjU5MDc4NUMzLjcxODA1Ny01LjIyNDQwOCAzLjA2MDUyMy01LjI4NDE4NCAyLjc2MTY0NC01LjI4NDE4NEMxLjQzNDYyLTUuMjg0MTg0IC42Njk0ODktMy45NDUyMDUgLjY2OTQ4OS0yLjU3MDM2MUMuNjY5NDg5LTEuMjMxMzgyIDEuNDEwNzEgLjEzMTUwNyAyLjcyNTc3OCAuMTMxNTA3QzQuMjQ0MDg1IC4xMzE1MDcgNS4xMjg3NjctMS4zMjcwMjQgNS40MTU2OTEtMS45MjQ3ODJDNS44OTM4OTgtMS4xOTU1MTcgNi4wNjEyNy0uOTMyNTAzIDYuNTAzNjExLS41NjE4OTNDNy4yMzI4NzcgLjA3MTczMSA3Ljg5MDQxMSAuMTMxNTA3IDguMTg5MjkgLjEzMTUwN0M4LjMzMjc1MiAuMTMxNTA3IDguNTI0MDM1IC4xMDc1OTcgOC42MzE2MzEgLjA4MzY4NlYtLjM4MjU2NVpNNS4xNTI2NzctMi4zNDMyMTNDNC44NjU3NTMtMS42OTc2MzQgNC4wNjQ3NTctLjIxNTE5MyAyLjY0MjA5Mi0uMjE1MTkzQzEuNDgyNDQxLS4yMTUxOTMgLjkzMjUwMy0xLjQ4MjQ0MSAuOTMyNTAzLTIuNTcwMzYxQy45MzI1MDMtMy43NTM5MjMgMS42MDE5OTMtNC43OTQwMjIgMi41OTQyNzEtNC43OTQwMjJDMy41Mzg3My00Ljc5NDAyMiA0LjE3MjM1NC0zLjg2MTUxOSA0LjU3ODgyOS0zLjIzOTg1MUM0LjY5ODM4MS0zLjAzNjYxMyA1LjAyMTE3MS0yLjU0NjQ1MSA1LjE1MjY3Ny0yLjM0MzIxM1onLz4KPHBhdGggaWQ9J2czLTEwNicgZD0nTTEuOTAwODcyLTguNTM1OTlDMS45MDA4NzItOC43NTExODMgMS45MDA4NzItOC45NjYzNzYgMS42NjE3NjgtOC45NjYzNzZTMS40MjI2NjUtOC43NTExODMgMS40MjI2NjUtOC41MzU5OVYyLjU1ODQwNkMxLjQyMjY2NSAyLjc3MzU5OSAxLjQyMjY2NSAyLjk4ODc5MiAxLjY2MTc2OCAyLjk4ODc5MlMxLjkwMDg3MiAyLjc3MzU5OSAxLjkwMDg3MiAyLjU1ODQwNlYtOC41MzU5OVonLz4KPHBhdGggaWQ9J2c4LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOC00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzgtMTAxJyBkPSdNNC41Nzg4MjktMi43NzM1OTlDNC44NDE4NDMtMi43NzM1OTkgNC44NjU3NTMtMi43NzM1OTkgNC44NjU3NTMtMy4wMDA3NDdDNC44NjU3NTMtNC4yMDgyMTkgNC4yMjAxNzQtNS4zMzIwMDUgMi43NzM1OTktNS4zMzIwMDVDMS40MTA3MS01LjMzMjAwNSAuMzU4NjU1LTQuMTAwNjIzIC4zNTg2NTUtMi42MTgxODJDLjM1ODY1NS0xLjA0MDEgMS41NzgwODIgLjExOTU1MiAyLjkwNTEwNiAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNC44NjU3NTMtMS4xNzE2MDYgNC44NjU3NTMtMS40MjI2NjVDNC44NjU3NTMtMS40OTQzOTYgNC44MDU5NzgtMS41NDIyMTcgNC43MzQyNDctMS41NDIyMTdDNC42Mzg2MDUtMS41NDIyMTcgNC42MTQ2OTUtMS40ODI0NDEgNC41OTA3ODUtMS40MjI2NjVDNC4yNzk5NS0uNDE4NDMxIDMuNDc4OTU0LS4xNDM0NjIgMi45NzY4MzctLjE0MzQ2MlMxLjI2NzI0OC0uNDc4MjA3IDEuMjY3MjQ4LTIuNTQ2NDUxVi0yLjc3MzU5OUg0LjU3ODgyOVpNMS4yNzkyMDMtMy4wMDA3NDdDMS4zNzQ4NDQtNC44Nzc3MDkgMi40MjY4OTktNS4wOTI5MDIgMi43NjE2NDQtNS4wOTI5MDJDNC4wNDA4NDctNS4wOTI5MDIgNC4xMTI1NzgtMy40MDcyMjMgNC4xMjQ1MzMtMy4wMDA3NDdIMS4yNzkyMDNaJy8+CjxwYXRoIGlkPSdnOC0xMTInIGQ9J00yLjkyOTAxNiAxLjk3MjYwM0MyLjE2Mzg4NSAxLjk3MjYwMyAyLjAyMDQyMyAxLjk3MjYwMyAyLjAyMDQyMyAxLjQzNDYyVi0uNjQ1NTc5QzIuMjM1NjE2LS4zNDY3IDIuNzI1Nzc4IC4xMTk1NTIgMy40OTA5MDkgLjExOTU1MkM0Ljg2NTc1MyAuMTE5NTUyIDYuMDczMjI1LTEuMDQwMSA2LjA3MzIyNS0yLjU4MjMxNkM2LjA3MzIyNS00LjEwMDYyMyA0Ljk0OTQ0LTUuMjcyMjI5IDMuNjQ2MzI2LTUuMjcyMjI5QzIuNTk0MjcxLTUuMjcyMjI5IDIuMDMyMzc5LTQuNTE5MDU0IDEuOTk2NTEzLTQuNDcxMjMzVi01LjI3MjIyOUwuMzM0NzQ1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE3MTYwNi00Ljc5NDAyMiAxLjI0MzMzNy00LjcxMDMzNiAxLjI0MzMzNy00LjE4NDMwOVYxLjQzNDYyQzEuMjQzMzM3IDEuOTcyNjAzIDEuMTExODMxIDEuOTcyNjAzIC4zMzQ3NDUgMS45NzI2MDNWMi4zMTkzMDNDLjY0NTU3OSAyLjI5NTM5MiAxLjI5MTE1OCAyLjI5NTM5MiAxLjYyNTkwMyAyLjI5NTM5MkMxLjk3MjYwMyAyLjI5NTM5MiAyLjYxODE4MiAyLjI5NTM5MiAyLjkyOTAxNiAyLjMxOTMwM1YxLjk3MjYwM1pNMi4wMjA0MjMtMy44MTM2OTlDMi4wMjA0MjMtNC4wNDA4NDcgMi4wMjA0MjMtNC4wNTI4MDIgMi4xNTE5My00LjI0NDA4NUMyLjUxMDU4NS00Ljc4MjA2NyAzLjA5NjM4OS01LjAwOTIxNSAzLjU1MDY4NS01LjAwOTIxNUM0LjQ0NzMyMy01LjAwOTIxNSA1LjE2NDYzMy0zLjkyMTI5NSA1LjE2NDYzMy0yLjU4MjMxNkM1LjE2NDYzMy0xLjE1OTY1MSA0LjM1MTY4MS0uMTE5NTUyIDMuNDMxMTMzLS4xMTk1NTJDMy4wNjA1MjMtLjExOTU1MiAyLjcxMzgyMy0uMjc0OTY5IDIuNDc0NzItLjUwMjExN0MyLjE5OTc1MS0uNzc3MDg2IDIuMDIwNDIzLTEuMDE2MTg5IDIuMDIwNDIzLTEuMzUwOTM0Vi0zLjgxMzY5OVonLz4KPHBhdGggaWQ9J2c4LTEyMCcgZD0nTTMuMzQ3NDQ3LTIuODIxNDJDMy42OTQxNDctMy4yNzU3MTYgNC4xOTYyNjQtMy45MjEyOTUgNC40MjM0MTItNC4xNzIzNTRDNC45MTM1NzQtNC43MjIyOTEgNS40NzU0NjctNC44MDU5NzggNS44NTgwMzItNC44MDU5NzhWLTUuMTUyNjc3QzUuMzQzOTYtNS4xMjg3NjcgNS4zMjAwNS01LjEyODc2NyA0Ljg1Mzc5OC01LjEyODc2N0M0LjM5OTUwMi01LjEyODc2NyA0LjM3NTU5Mi01LjEyODc2NyAzLjc3NzgzMy01LjE1MjY3N1YtNC44MDU5NzhDMy45MzMyNS00Ljc4MjA2NyA0LjEyNDUzMy00LjcxMDMzNiA0LjEyNDUzMy00LjQzNTM2N0M0LjEyNDUzMy00LjIzMjEzIDQuMDE2OTM2LTQuMTAwNjIzIDMuOTQ1MjA1LTQuMDA0OTgxTDMuMTgwMDc1LTMuMDM2NjEzTDIuMjQ3NTcyLTQuMjY3OTk1QzIuMjExNzA2LTQuMzE1ODE2IDIuMTM5OTc1LTQuNDIzNDEyIDIuMTM5OTc1LTQuNTA3MDk4QzIuMTM5OTc1LTQuNTc4ODI5IDIuMTk5NzUxLTQuNzk0MDIyIDIuNTU4NDA2LTQuODA1OTc4Vi01LjE1MjY3N0MyLjI1OTUyNy01LjEyODc2NyAxLjY0OTgxMy01LjEyODc2NyAxLjMyNzAyNC01LjEyODc2N0MuOTMyNTAzLTUuMTI4NzY3IC45MDg1OTMtNS4xMjg3NjcgLjE3OTMyOC01LjE1MjY3N1YtNC44MDU5NzhDLjc4OTA0MS00LjgwNTk3OCAxLjAxNjE4OS00Ljc4MjA2NyAxLjI2NzI0OC00LjQ1OTI3OEwyLjY2NjAwMi0yLjYzMDEzN0MyLjY4OTkxMy0yLjYwNjIyNyAyLjczNzczMy0yLjUzNDQ5NiAyLjczNzczMy0yLjQ5ODYzUzEuODA1MjMtMS4yOTExNTggMS42ODU2NzktMS4xMzU3NDFDMS4xNTk2NTEtLjQ5MDE2MiAuNjMzNjI0LS4zNTg2NTUgLjExOTU1Mi0uMzQ2N1YwQy41NzM4NDgtLjAyMzkxIC41OTc3NTgtLjAyMzkxIDEuMTExODMxLS4wMjM5MUMxLjU2NjEyNy0uMDIzOTEgMS41OTAwMzctLjAyMzkxIDIuMTg3Nzk2IDBWLS4zNDY3QzEuOTAwODcyLS4zODI1NjUgMS44NTMwNTEtLjU2MTg5MyAxLjg1MzA1MS0uNzI5MjY1QzEuODUzMDUxLS45MjA1NDggMS45MzY3MzctMS4wMTYxODkgMi4wNTYyODktMS4xNzE2MDZDMi4yMzU2MTYtMS40MjI2NjUgMi42MzAxMzctMS45MTI4MjcgMi45MTcwNjEtMi4yODM0MzdMMy44OTczODUtMS4wMDQyMzRDNC4xMDA2MjMtLjc0MTIyIDQuMTAwNjIzLS43MTczMSA0LjEwMDYyMy0uNjQ1NTc5QzQuMTAwNjIzLS41NDk5MzggNC4wMDQ5ODEtLjM1ODY1NSAzLjY4MjE5Mi0uMzQ2N1YwQzMuOTkzMDI2LS4wMjM5MSA0LjU3ODgyOS0uMDIzOTEgNC45MTM1NzQtLjAyMzkxQzUuMzA4MDk1LS4wMjM5MSA1LjMzMjAwNS0uMDIzOTEgNi4wNDkzMTUgMFYtLjM0NjdDNS40MTU2OTEtLjM0NjcgNS4yMDA0OTgtLjM3MDYxIDQuOTEzNTc0LS43NTMxNzZMMy4zNDc0NDctMi44MjE0MlonLz4KPHBhdGggaWQ9J2c3LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzctNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2c2LTExJyBkPSdNNS41MzUyNDMtMy4wMjQ2NThDNS41MzUyNDMtNC4xODQzMDkgNC44Nzc3MDktNS4yNzIyMjkgMy42MTA0NjEtNS4yNzIyMjlDMi4wNDQzMzQtNS4yNzIyMjkgLjQ3ODIwNy0zLjU2MjY0IC40NzgyMDctMS44NjUwMDZDLjQ3ODIwNy0uODI0OTA3IDEuMTIzNzg2IC4xMTk1NTIgMi4zNDMyMTMgLjExOTU1MkMzLjA4NDQzMyAuMTE5NTUyIDMuOTY5MTE2LS4xNjczNzIgNC44MTc5MzMtLjg4NDY4MkM0Ljk4NTMwNS0uMjE1MTkzIDUuMzU1OTE1IC4xMTk1NTIgNS44Njk5ODggLjExOTU1MkM2LjUxNTU2NyAuMTE5NTUyIDYuODM4MzU2LS41NDk5MzggNi44MzgzNTYtLjcwNTM1NUM2LjgzODM1Ni0uODEyOTUxIDYuNzU0NjctLjgxMjk1MSA2LjcxODgwNC0uODEyOTUxQzYuNjIzMTYzLS44MTI5NTEgNi42MTEyMDgtLjc3NzA4NiA2LjU3NTM0Mi0uNjgxNDQ1QzYuNDY3NzQ2LS4zODI1NjUgNi4xOTI3NzctLjExOTU1MiA1LjkwNTg1My0uMTE5NTUyQzUuNTM1MjQzLS4xMTk1NTIgNS41MzUyNDMtLjg4NDY4MiA1LjUzNTI0My0xLjYxMzk0OEM2Ljc1NDY3LTMuMDcyNDc4IDcuMDQxNTk0LTQuNTc4ODI5IDcuMDQxNTk0LTQuNTkwNzg1QzcuMDQxNTk0LTQuNjk4MzgxIDYuOTQ1OTUzLTQuNjk4MzgxIDYuOTEwMDg3LTQuNjk4MzgxQzYuODAyNDkxLTQuNjk4MzgxIDYuNzkwNTM1LTQuNjYyNTE2IDYuNzQyNzE1LTQuNDQ3MzIzQzYuNTg3Mjk4LTMuOTIxMjk1IDYuMjc2NDYzLTIuOTg4NzkyIDUuNTM1MjQzLTIuMDA4NDY4Vi0zLjAyNDY1OFpNNC43ODIwNjctMS4xNzE2MDZDMy43MzAwMTItLjIyNzE0OCAyLjc4NTU1NC0uMTE5NTUyIDIuMzY3MTIzLS4xMTk1NTJDMS41MTgzMDYtLjExOTU1MiAxLjI3OTIwMy0uODcyNzI3IDEuMjc5MjAzLTEuNDM0NjJDMS4yNzkyMDMtMS45NDg2OTIgMS41NDIyMTctMy4xNjgxMiAxLjkxMjgyNy0zLjgyNTY1NEMyLjQwMjk4OS00LjY2MjUxNiAzLjA3MjQ3OC01LjAzMzEyNiAzLjYxMDQ2MS01LjAzMzEyNkM0Ljc3MDExMi01LjAzMzEyNiA0Ljc3MDExMi0zLjUxNDgxOSA0Ljc3MDExMi0yLjUxMDU4NUM0Ljc3MDExMi0yLjIxMTcwNiA0Ljc1ODE1Ny0xLjkwMDg3MiA0Ljc1ODE1Ny0xLjYwMTk5M0M0Ljc1ODE1Ny0xLjM2Mjg4OSA0Ljc3MDExMi0xLjMwMzExMyA0Ljc4MjA2Ny0xLjE3MTYwNlonLz4KPHBhdGggaWQ9J2c2LTEyJyBkPSdNNi43NjY2MjUtNi45NTc5MDhDNi43NjY2MjUtNy42NzUyMTggNi4xNTY5MTItOC40MjgzOTQgNS4wNjg5OTEtOC40MjgzOTRDMy41MjY3NzUtOC40MjgzOTQgMi41NDY0NTEtNi41Mzk0NzcgMi4yMzU2MTYtNS4yOTYxMzlMLjM0NjcgMi4xOTk3NTFDLjMyMjc5IDIuMjk1MzkyIC4zOTQ1MjEgMi4zMTkzMDMgLjQ1NDI5NiAyLjMxOTMwM0MuNTM3OTgzIDIuMzE5MzAzIC41OTc3NTggMi4zMDczNDcgLjYwOTcxNCAyLjI0NzU3MkwxLjQ0NjU3NS0xLjA5OTg3NUMxLjU2NjEyNy0uNDMwMzg2IDIuMjIzNjYxIC4xMTk1NTIgMi45MjkwMTYgLjExOTU1MkM0LjYzODYwNSAuMTE5NTUyIDYuMjUyNTUzLTEuMjE5NDI3IDYuMjUyNTUzLTMuMDAwNzQ3QzYuMjUyNTUzLTMuNDU1MDQ0IDYuMTQ0OTU2LTMuOTA5MzQgNS44OTM4OTgtNC4yOTE5MDVDNS43NTA0MzYtNC41MTkwNTQgNS41NzExMDgtNC42ODY0MjYgNS4zNzk4MjYtNC44Mjk4ODhDNi4yNDA1OTgtNS4yODQxODQgNi43NjY2MjUtNi4wMTM0NSA2Ljc2NjYyNS02Ljk1NzkwOFpNNC42ODY0MjYtNC44NDE4NDNDNC40OTUxNDMtNC43NzAxMTIgNC4zMDM4NjEtNC43NDYyMDIgNC4wNzY3MTItNC43NDYyMDJDMy45MDkzNC00Ljc0NjIwMiAzLjc1MzkyMy00LjczNDI0NyAzLjUzODczLTQuODA1OTc4QzMuNjU4MjgxLTQuODg5NjY0IDMuODM3NjA5LTQuOTEzNTc0IDQuMDg4NjY3LTQuOTEzNTc0QzQuMzAzODYxLTQuOTEzNTc0IDQuNTE5MDU0LTQuODg5NjY0IDQuNjg2NDI2LTQuODQxODQzWk02LjE0NDk1Ni03LjA2NTUwNEM2LjE0NDk1Ni02LjQwNzk3IDUuODIyMTY3LTUuNDUxNTU3IDUuMDQ1MDgxLTUuMDA5MjE1QzQuODE3OTMzLTUuMDkyOTAyIDQuNTA3MDk4LTUuMTUyNjc3IDQuMjQ0MDg1LTUuMTUyNjc3QzMuOTkzMDI2LTUuMTUyNjc3IDMuMjc1NzE2LTUuMTc2NTg4IDMuMjc1NzE2LTQuNzk0MDIyQzMuMjc1NzE2LTQuNDcxMjMzIDMuOTMzMjUtNC41MDcwOTggNC4xMzY0ODgtNC41MDcwOThDNC40NDczMjMtNC41MDcwOTggNC43MjIyOTEtNC41Nzg4MjkgNS4wMDkyMTUtNC42NjI1MTZDNS4zOTE3ODEtNC4zNTE2ODEgNS41NTkxNTMtMy45NDUyMDUgNS41NTkxNTMtMy4zNDc0NDdDNS41NTkxNTMtMi42NTQwNDcgNS4zNjc4Ny0yLjA5MjE1NCA1LjE0MDcyMi0xLjU3ODA4MkM0Ljc0NjIwMi0uNjkzNCAzLjgxMzY5OS0uMTE5NTUyIDIuOTg4NzkyLS4xMTk1NTJDMi4xMTYwNjUtLjExOTU1MiAxLjY2MTc2OC0uODEyOTUxIDEuNjYxNzY4LTEuNjI1OTAzQzEuNjYxNzY4LTEuNzMzNDk5IDEuNjYxNzY4LTEuODg4OTE3IDEuNzA5NTg5LTIuMDY4MjQ0TDIuNDg2Njc1LTUuMjEyNDUzQzIuODgxMTk2LTYuNzc4NTggMy44ODU0My04LjE4OTI5IDUuMDQ1MDgxLTguMTg5MjlDNS45MDU4NTMtOC4xODkyOSA2LjE0NDk1Ni03LjU5MTUzMiA2LjE0NDk1Ni03LjA2NTUwNFonLz4KPHBhdGggaWQ9J2c2LTI1JyBkPSdNMy4wOTYzODktNC41MDcwOThINC40NDczMjNDNC4xMjQ1MzMtMy4xNjgxMiAzLjkyMTI5NS0yLjI5NTM5MiAzLjkyMTI5NS0xLjMzODk3OUMzLjkyMTI5NS0xLjE3MTYwNiAzLjkyMTI5NSAuMTE5NTUyIDQuNDExNDU3IC4xMTk1NTJDNC42NjI1MTYgLjExOTU1MiA0Ljg3NzcwOS0uMTA3NTk3IDQuODc3NzA5LS4zMTA4MzRDNC44Nzc3MDktLjM3MDYxIDQuODc3NzA5LS4zOTQ1MjEgNC43OTQwMjItLjU3Mzg0OEM0LjQ3MTIzMy0xLjM5ODc1NSA0LjQ3MTIzMy0yLjQyNjg5OSA0LjQ3MTIzMy0yLjUxMDU4NUM0LjQ3MTIzMy0yLjU4MjMxNiA0LjQ3MTIzMy0zLjQzMTEzMyA0LjcyMjI5MS00LjUwNzA5OEg2LjA2MTI3QzYuMjE2Njg3LTQuNTA3MDk4IDYuNjExMjA4LTQuNTA3MDk4IDYuNjExMjA4LTQuODg5NjY0QzYuNjExMjA4LTUuMTUyNjc3IDYuMzg0MDYtNS4xNTI2NzcgNi4xNjg4NjctNS4xNTI2NzdIMi4yMzU2MTZDMS45NjA2NDgtNS4xNTI2NzcgMS41NTQxNzItNS4xNTI2NzcgMS4wMDQyMzQtNC41NjY4NzRDLjY5MzQtNC4yMjAxNzQgLjMxMDgzNC0zLjU4NjU1IC4zMTA4MzQtMy41MTQ4MTlTLjM3MDYxLTMuNDE5MTc4IC40NDIzNDEtMy40MTkxNzhDLjUyNjAyNy0zLjQxOTE3OCAuNTM3OTgzLTMuNDU1MDQ0IC41OTc3NTgtMy41MjY3NzVDMS4yMTk0MjctNC41MDcwOTggMS44NDEwOTYtNC41MDcwOTggMi4xMzk5NzUtNC41MDcwOThIMi44MjE0MkMyLjU1ODQwNi0zLjYxMDQ2MSAyLjI1OTUyNy0yLjU3MDM2MSAxLjI3OTIwMy0uNDc4MjA3QzEuMTgzNTYyLS4yODY5MjQgMS4xODM1NjItLjI2MzAxNCAxLjE4MzU2Mi0uMTkxMjgzQzEuMTgzNTYyIC4wNTk3NzYgMS4zOTg3NTUgLjExOTU1MiAxLjUwNjM1MSAuMTE5NTUyQzEuODUzMDUxIC4xMTk1NTIgMS45NDg2OTItLjE5MTI4MyAyLjA5MjE1NC0uNjkzNEMyLjI4MzQzNy0xLjMwMzExMyAyLjI4MzQzNy0xLjMyNzAyNCAyLjQwMjk4OS0xLjgwNTIzTDMuMDk2Mzg5LTQuNTA3MDk4WicvPgo8cGF0aCBpZD0nZzYtNTgnIGQ9J00yLjE5OTc1MS0uNTczODQ4QzIuMTk5NzUxLS45MjA1NDggMS45MTI4MjctMS4xNTk2NTEgMS42MjU5MDMtMS4xNTk2NTFDMS4yNzkyMDMtMS4xNTk2NTEgMS4wNDAxLS44NzI3MjcgMS4wNDAxLS41ODU4MDNDMS4wNDAxLS4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEtLjI4NjkyNCAyLjE5OTc1MS0uNTczODQ4WicvPgo8cGF0aCBpZD0nZzYtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2c2LTEwMicgZD0nTTUuMzMyMDA1LTQuODA1OTc4QzUuNTcxMTA4LTQuODA1OTc4IDUuNjY2NzUtNC44MDU5NzggNS42NjY3NS01LjAzMzEyNkM1LjY2Njc1LTUuMTUyNjc3IDUuNTcxMTA4LTUuMTUyNjc3IDUuMzU1OTE1LTUuMTUyNjc3SDQuMzg3NTQ3QzQuNjE0Njk1LTYuMzg0MDYgNC43ODIwNjctNy4yMzI4NzcgNC44Nzc3MDktNy42MTU0NDJDNC45NDk0NC03LjkwMjM2NiA1LjIwMDQ5OC04LjE3NzMzNSA1LjUxMTMzMy04LjE3NzMzNUM1Ljc2MjM5MS04LjE3NzMzNSA2LjAxMzQ1LTguMDY5NzM4IDYuMTMzMDAxLTcuOTYyMTQyQzUuNjY2NzUtNy45MTQzMjEgNS41MjMyODgtNy41Njc2MjEgNS41MjMyODgtNy4zNjQzODRDNS41MjMyODgtNy4xMjUyOCA1LjcwMjYxNS02Ljk4MTgxOCA1LjkyOTc2My02Ljk4MTgxOEM2LjE2ODg2Ny02Ljk4MTgxOCA2LjUyNzUyMi03LjE4NTA1NiA2LjUyNzUyMi03LjYzOTM1MkM2LjUyNzUyMi04LjE0MTQ2OSA2LjAyNTQwNS04LjQxNjQzOCA1LjQ5OTM3Ny04LjQxNjQzOEM0Ljk4NTMwNS04LjQxNjQzOCA0LjQ4MzE4OC04LjAzMzg3MyA0LjI0NDA4NS03LjU2NzYyMUM0LjAyODg5Mi03LjE0OTE5MSAzLjkwOTM0LTYuNzE4ODA0IDMuNjM0MzcxLTUuMTUyNjc3SDIuODMzMzc1QzIuNjA2MjI3LTUuMTUyNjc3IDIuNDg2Njc1LTUuMTUyNjc3IDIuNDg2Njc1LTQuOTM3NDg0QzIuNDg2Njc1LTQuODA1OTc4IDIuNTU4NDA2LTQuODA1OTc4IDIuNzk3NTA5LTQuODA1OTc4SDMuNTYyNjRDMy4zNDc0NDctMy42OTQxNDcgMi44NTcyODUtLjk5MjI3OSAyLjU4MjMxNiAuMjg2OTI0QzIuMzc5MDc4IDEuMzI3MDI0IDIuMTk5NzUxIDIuMTk5NzUxIDEuNjAxOTkzIDIuMTk5NzUxQzEuNTY2MTI3IDIuMTk5NzUxIDEuMjE5NDI3IDIuMTk5NzUxIDEuMDA0MjM0IDEuOTcyNjAzQzEuNjEzOTQ4IDEuOTI0NzgyIDEuNjEzOTQ4IDEuMzk4NzU1IDEuNjEzOTQ4IDEuMzg2OEMxLjYxMzk0OCAxLjE0NzY5NiAxLjQzNDYyIDEuMDA0MjM0IDEuMjA3NDcyIDEuMDA0MjM0Qy45NjgzNjkgMS4wMDQyMzQgLjYwOTcxNCAxLjIwNzQ3MiAuNjA5NzE0IDEuNjYxNzY4Qy42MDk3MTQgMi4xNzU4NDEgMS4xMzU3NDEgMi40Mzg4NTQgMS42MDE5OTMgMi40Mzg4NTRDMi44MjE0MiAyLjQzODg1NCAzLjMyMzUzNyAuMjUxMDU5IDMuNDU1MDQ0LS4zNDY3QzMuNjcwMjM3LTEuMjY3MjQ4IDQuMjU2MDQtNC40NDczMjMgNC4zMTU4MTYtNC44MDU5NzhINS4zMzIwMDVaJy8+CjxwYXRoIGlkPSdnNi0xMTYnIGQ9J00yLjQwMjk4OS00LjgwNTk3OEgzLjUwMjg2NEMzLjczMDAxMi00LjgwNTk3OCAzLjg0OTU2NC00LjgwNTk3OCAzLjg0OTU2NC01LjAyMTE3MUMzLjg0OTU2NC01LjE1MjY3NyAzLjc3NzgzMy01LjE1MjY3NyAzLjUzODczLTUuMTUyNjc3SDIuNDg2Njc1TDIuOTI5MDE2LTYuODk4MTMyQzIuOTc2ODM3LTcuMDY1NTA0IDIuOTc2ODM3LTcuMDg5NDE1IDIuOTc2ODM3LTcuMTczMTAxQzIuOTc2ODM3LTcuMzY0Mzg0IDIuODIxNDItNy40NzE5OCAyLjY2NjAwMi03LjQ3MTk4QzIuNTcwMzYxLTcuNDcxOTggMi4yOTUzOTItNy40MzYxMTUgMi4xOTk3NTEtNy4wNTM1NDlMMS43MzM0OTktNS4xNTI2NzdILjYwOTcxNEMuMzcwNjEtNS4xNTI2NzcgLjI2MzAxNC01LjE1MjY3NyAuMjYzMDE0LTQuOTI1NTI5Qy4yNjMwMTQtNC44MDU5NzggLjM0NjctNC44MDU5NzggLjU3Mzg0OC00LjgwNTk3OEgxLjYzNzg1OEwuODQ4ODE3LTEuNjQ5ODEzQy43NTMxNzYtMS4yMzEzODIgLjcxNzMxLTEuMTExODMxIC43MTczMS0uOTU2NDEzQy43MTczMS0uMzk0NTIxIDEuMTExODMxIC4xMTk1NTIgMS43ODEzMiAuMTE5NTUyQzIuOTg4NzkyIC4xMTk1NTIgMy42MzQzNzEtMS42MjU5MDMgMy42MzQzNzEtMS43MDk1ODlDMy42MzQzNzEtMS43ODEzMiAzLjU4NjU1LTEuODE3MTg2IDMuNTE0ODE5LTEuODE3MTg2QzMuNDkwOTA5LTEuODE3MTg2IDMuNDQzMDg4LTEuODE3MTg2IDMuNDE5MTc4LTEuNzY5MzY1QzMuNDA3MjIzLTEuNzU3NDEgMy4zOTUyNjgtMS43NDU0NTUgMy4zMTE1ODItMS41NTQxNzJDMy4wNjA1MjMtLjk1NjQxMyAyLjUxMDU4NS0uMTE5NTUyIDEuODE3MTg2LS4xMTk1NTJDMS40NTg1MzEtLjExOTU1MiAxLjQzNDYyLS40MTg0MzEgMS40MzQ2Mi0uNjgxNDQ1QzEuNDM0NjItLjY5MzQgMS40MzQ2Mi0uOTIwNTQ4IDEuNDcwNDg2LTEuMDY0MDFMMi40MDI5ODktNC44MDU5NzhaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMjUnLz4KPHVzZSB4PSc3LjA2OTI3JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxMS42MjE1OTUnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMScvPgo8dXNlIHg9JzE5LjE0MzMyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTknLz4KPHVzZSB4PScyNC4zODc0NzgnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMicvPgo8dXNlIHg9JzMxLjY1ODc0OScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2czLTEwNicvPgo8dXNlIHg9JzM0Ljk3OTYzOScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMzkuNTMxOTY1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nNDMuNzU5MTI1JyB5PSctMTUuMDU0NzUxJyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PSc0OC40OTE0NCcgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nNTMuNzM1NTk5JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTAyJy8+Cjx1c2UgeD0nNTkuNTA1NTg3JyB5PSctMTUuMDU0NzUxJyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PSc2NC4yMzc5MDInIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzY4Ljc5MDIyOCcgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nNzQuMDM0Mzg3JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTgnLz4KPHVzZSB4PSc3OS4yNzg1NDUnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OCcvPgo8dXNlIHg9Jzg0LjUyMjcwNCcgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU4Jy8+Cjx1c2UgeD0nODkuNzY2ODYzJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTknLz4KPHVzZSB4PSc5NS4wMTEwMjInIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9Jzk5LjU2MzM0OCcgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzEwMy43OTA1MDcnIHk9Jy0xNS4wNTQ3NTEnIHhsaW5rOmhyZWY9JyNnNS0xMTAnLz4KPHVzZSB4PScxMDkuNDI2ODQyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTknLz4KPHVzZSB4PScxMTQuNjcxMDAxJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTAyJy8+Cjx1c2UgeD0nMTIwLjQ0MDk4OScgeT0nLTE1LjA1NDc1MScgeGxpbms6aHJlZj0nI2c1LTExMCcvPgo8dXNlIHg9JzEyNi4wNzczMjQnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzEzMC42Mjk2NDknIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzEzOC41MDI4MDUnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnMy00NycvPgo8dXNlIHg9JzE1MS4xMjIxMzEnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0yNScvPgo8dXNlIHg9JzE1OC4xOTE0MDEnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzE2Mi43NDM3MjYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMScvPgo8dXNlIHg9JzE3MC4yNjU0NScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMTc0LjgxNzc3NicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTI1Jy8+Cjx1c2UgeD0nMTgxLjg4NzA0NicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTg2LjQzOTM3MicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTEyJy8+Cjx1c2UgeD0nMTkzLjcxMDY0MycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMjAwLjI1NTQ2NicgeT0nLTMzLjcwNDk1MScgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nMjEwLjI1MTM1MicgeT0nLTI0LjkzNTc3MicgeGxpbms6aHJlZj0nI2c2LTExJy8+CjxyZWN0IHg9JzIxMC4yNTEzNTInIHk9Jy0yMC4wNzU4OTknIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzcuNTIxNzInLz4KPHVzZSB4PScyMTAuMzc2NTg1JyB5PSctOC42NDczNTEnIHhsaW5rOmhyZWY9JyNnNi0xMicvPgo8dXNlIHg9JzIxOC45Njg1ODYnIHk9Jy0zMy43MDQ5NTEnIHhsaW5rOmhyZWY9JyNnMS0xOScvPgo8dXNlIHg9JzIyNy43Njg5NTknIHk9Jy0zNy4wMDU5MjcnIHhsaW5rOmhyZWY9JyNnMC04MCcvPgo8dXNlIHg9JzIzNi43MDc3OScgeT0nLTI4LjUzNzU5MicgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzI0MS4yODA5NDInIHk9Jy0zMS4wMjgyOTcnIHhsaW5rOmhyZWY9JyNnNS0xMDInLz4KPHVzZSB4PScyNDUuMzQ5MDYnIHk9Jy0yOS44MTMyMTknIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyNTEuMDAxNDQ4JyB5PSctMzcuMjkxNTM4JyB4bGluazpocmVmPScjZzEtMzInLz4KPHVzZSB4PScyNjEuODUzMjI1JyB5PSctMjguMjA1NDc4JyB4bGluazpocmVmPScjZzEtODknLz4KPHVzZSB4PScyNjAuNDY1OTg2JyB5PSctMi43NDUyNTknIHhsaW5rOmhyZWY9JyNnNS0xMDInLz4KPHVzZSB4PScyNjQuNTM0MTA1JyB5PSctMS41MzAxODEnIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyNjcuNjk1ODYzJyB5PSctMi43NDUyNTknIHhsaW5rOmhyZWY9JyNnNy02MScvPgo8dXNlIHg9JzI3NC4yODIzNjknIHk9Jy0yLjc0NTI1OScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nMjgxLjcwNDU2NCcgeT0nLTI0LjkzNTc3MicgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzI4NS45MzE3MjMnIHk9Jy0yMy4xNDI1MDknIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHJlY3QgeD0nMjgxLjcwNDU2NCcgeT0nLTIwLjA3NTg5OScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNy42MDg0MzEnLz4KPHVzZSB4PScyODEuODczMTUxJyB5PSctOC42NDczNTEnIHhsaW5rOmhyZWY9JyNnNi0xMicvPgo8dXNlIHg9JzI5MC41MDg1MDknIHk9Jy0zNy4yOTE1MzgnIHhsaW5rOmhyZWY9JyNnMS0zMycvPgo8dXNlIHg9JzI5OS45NzMwNDcnIHk9Jy0zNC42MTQ4ODQnIHhsaW5rOmhyZWY9JyNnNS0xMScvPgo8dXNlIHg9JzMwNS40MTE5ODcnIHk9Jy0zNC42MTQ4ODQnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMzExLjk5ODQ5MycgeT0nLTM0LjYxNDg4NCcgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nMzE4LjcyMzMwNicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTEwMScvPgo8dXNlIHg9JzMyMy45MjU5NjQnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC0xMjAnLz4KPHVzZSB4PSczMzAuMTA0MTInIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC0xMTInLz4KPHVzZSB4PSczMzguNTk5OTQnIHk9Jy0zNy4yOTE1MzgnIHhsaW5rOmhyZWY9JyNnMS0zNCcvPgo8dXNlIHg9JzM0NS41NzM4MTknIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nMzYyLjkzMDAyJyB5PSctMzEuNzkyMDM1JyB4bGluazpocmVmPScjZzUtMTEwJy8+Cjx1c2UgeD0nMzU2Ljg2NDgxMycgeT0nLTI4LjIwNTQ3OCcgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nMzU4LjY0NzIwNycgeT0nLTMuMDExMTIzJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzYxLjUzMDM0NycgeT0nLTMuMDExMTIzJyB4bGluazpocmVmPScjZzctNjEnLz4KPHVzZSB4PSczNjguMTE2ODUzJyB5PSctMy4wMTExMjMnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzM3Ni4xMjU5MjgnIHk9Jy0zMy43MDQ5NTEnIHhsaW5rOmhyZWY9JyNnMS0xOCcvPgo8dXNlIHg9JzM4Ni4xMjE4MTQnIHk9Jy0yNC45MzU3NzInIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PSczOTAuMzQ4OTc0JyB5PSctMjMuMTQyNTA5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+CjxyZWN0IHg9JzM4Ni4xMjE4MTQnIHk9Jy0yMC4wNzU4OTknIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzcuNjA4NDMxJy8+Cjx1c2UgeD0nMzg2LjI5MDQwMicgeT0nLTguNjQ3MzUxJyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PSczOTQuOTI1NzU5JyB5PSctMzMuNzA0OTUxJyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PSc0MDMuNzI2MTMyJyB5PSctMzEuMDI4Mjk3JyB4bGluazpocmVmPScjZzUtMTEnLz4KPHVzZSB4PSc0MDkuNjYzMjAzJyB5PSctMzcuMjkxNTM4JyB4bGluazpocmVmPScjZzEtMzUnLz4KPHVzZSB4PSc0MTguNjI5NTcxJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTgnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
The RandomWalkMetropolisHastings class can be used to sample from the posterior distribution. It relies on the following objects:
The prior probability density
 reflects beliefs about the possible values
of
reflects beliefs about the possible values
of  before the experimental data are considered.
before the experimental data are considered.Initial values
 of the parameters.
of the parameters.An proposal distribution used to update parameters.
Additionnaly we want to define the likelihood term defined by these objects:
The conditional density
 will be defined as a
will be defined as a PythonDistribution.The sample of observations acting as the parameters of the conditional density
Set up the PythonDistribution¶
The censured Weibuill likelihood is outside the usual catalog of probability distributions in OpenTURNS, hence we need to define it using the PythonDistribution class.
import numpy as np
import openturns as ot
from openturns.viewer import View
ot.Log.Show(ot.Log.NONE)
ot.RandomGenerator.SetSeed(123)
The following methods must be defined:
getRange: required for conversion to the
DistributionformatcomputeLogPDF: used by
RandomWalkMetropolisHastingsto evaluate the posterior densitysetParameter used by
RandomWalkMetropolisHastingsto test new parameter values
Note
We formally define a bivariate distribution on the  couple, even though
couple, even though  has no distribution (it is simply a covariate).
This is not an issue, since the sole purpose of this
has no distribution (it is simply a covariate).
This is not an issue, since the sole purpose of this PythonDistribution object is to pass the likelihood calculation over to RandomWalkMetropolisHastings.
class CensoredWeibull(ot.PythonDistribution):
"""
Right-censored Weibull log-PDF calculation
Each data point x is assumed 2D, with:
x[0]: observed functioning time
x[1]: nature of x[0]:
if x[1]=0: x[0] is a censoring time
if x[1]=1: x[0] is a time-to failure
"""
def __init__(self, beta=5000.0, alpha=2.0):
super(CensoredWeibull, self).__init__(2)
self.beta = beta
self.alpha = alpha
def getRange(self):
return ot.Interval([0, 0], [1, 1], [True] * 2, [False, True])
def computeLogPDF(self, x):
if not (self.alpha > 0.0 and self.beta > 0.0):
return -np.inf
log_pdf = -((x[0] / self.beta) ** self.alpha)
log_pdf += (self.alpha - 1) * np.log(x[0] / self.beta) * x[1]
log_pdf += np.log(self.alpha / self.beta) * x[1]
return log_pdf
def setParameter(self, parameter):
self.beta = parameter[0]
self.alpha = parameter[1]
def getParameter(self):
return [self.beta, self.alpha]
Convert to Distribution
conditional = ot.Distribution(CensoredWeibull())
Observations, prior, initial point and proposal distributions¶
Define the observations
Tobs = np.array([4380, 1791, 1611, 1291, 6132, 5694, 5296, 4818, 4818, 4380])
fail = np.array([True] * 4 + [False] * 6)
x = ot.Sample(np.vstack((Tobs, fail)).T)
Define a uniform prior distribution for  and a Gamma prior distribution for
and a Gamma prior distribution for  .
.
alpha_min, alpha_max = 0.5, 3.8
a_beta, b_beta = 2, 2e-4
priorCopula = ot.IndependentCopula(2) # prior independence
priorMarginals = [] # prior marginals
priorMarginals.append(ot.Gamma(a_beta, b_beta)) # Gamma prior for beta
priorMarginals.append(ot.Uniform(alpha_min, alpha_max)) # uniform prior for alpha
prior = ot.ComposedDistribution(priorMarginals, priorCopula)
prior.setDescription(["beta", "alpha"])
We select prior means as the initial point of the Metropolis-Hastings algorithm.
initialState = [a_beta / b_beta, 0.5 * (alpha_max - alpha_min)]
For our random walk proposal distributions, we choose normal steps, with standard deviation equal to roughly  of the prior range (for the uniform prior)
or standard deviation (for the normal prior).
of the prior range (for the uniform prior)
or standard deviation (for the normal prior).
proposal = []
proposal.append(ot.Normal(0.0, 0.1 * np.sqrt(a_beta / b_beta ** 2)))
proposal.append(ot.Normal(0.0, 0.1 * (alpha_max - alpha_min)))
proposal = ot.ComposedDistribution(proposal)
Sample from the posterior distribution¶
sampler = ot.RandomWalkMetropolisHastings(prior, initialState, proposal)
sampler.setLikelihood(conditional, x)
sampleSize = 10000
sample = sampler.getSample(sampleSize)
# compute acceptance rate
print("Acceptance rate: %s" % (sampler.getAcceptanceRate()))
Acceptance rate: 0.3347
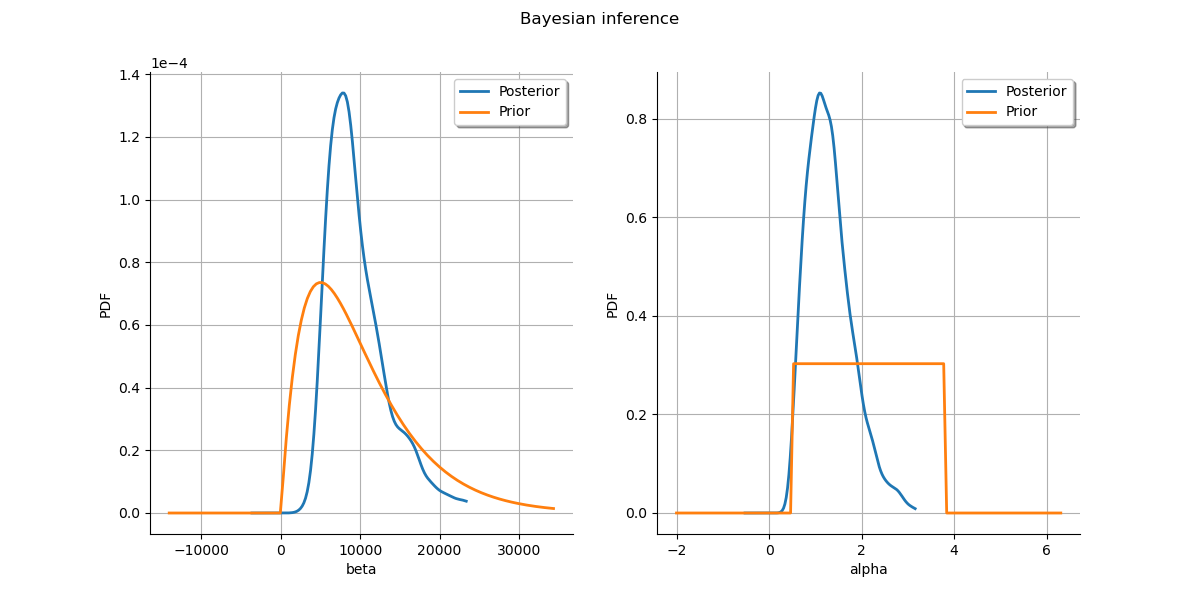
Plot prior to posterior marginal plots.
kernel = ot.KernelSmoothing()
posterior = kernel.build(sample)
grid = ot.GridLayout(1, 2)
grid.setTitle("Bayesian inference")
for parameter_index in range(2):
graph = posterior.getMarginal(parameter_index).drawPDF()
priorGraph = prior.getMarginal(parameter_index).drawPDF()
graph.add(priorGraph)
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
graph.setLegends(["Posterior", "Prior"])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
Define an improper prior¶
Now, define an improper prior:

logpdf = ot.SymbolicFunction(["beta", "alpha"], ["-log(beta)"])
support = ot.Interval([0] * 2, [1] * 2)
support.setFiniteUpperBound([False] * 2)
Sample from the posterior distribution
sampler2 = ot.RandomWalkMetropolisHastings(logpdf, support, initialState, proposal)
sampler2.setLikelihood(conditional, x)
sample2 = sampler2.getSample(1000)
print("Acceptance rate: %s" % (sampler2.getAcceptanceRate()))
Acceptance rate: 0.37
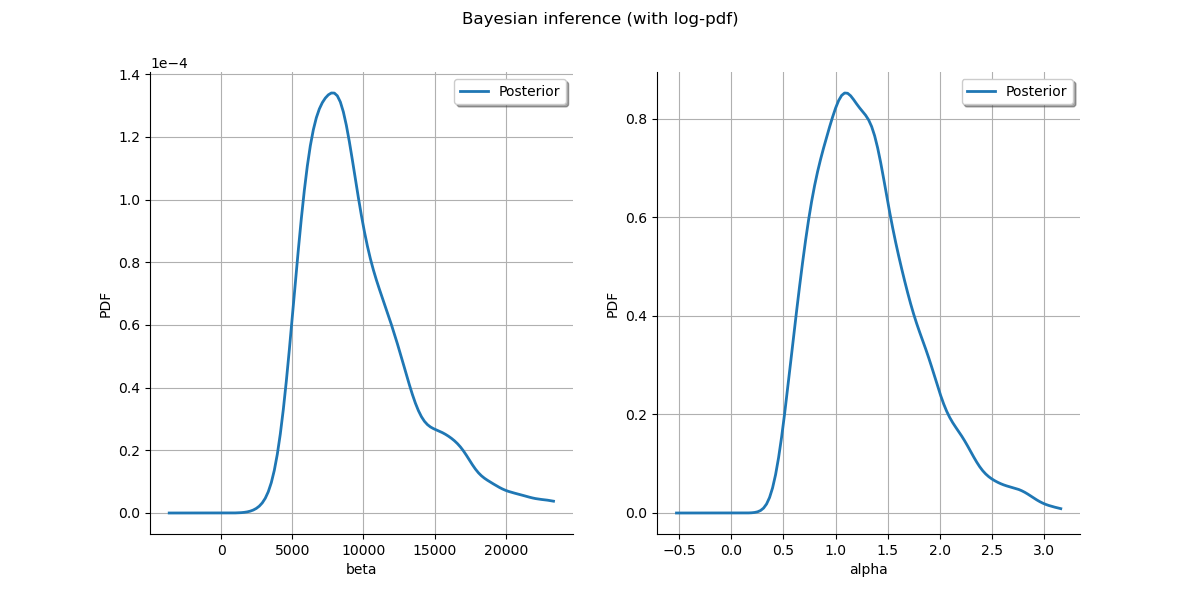
Plot posterior marginal plots only as prior cannot be drawn meaningfully.
kernel = ot.KernelSmoothing()
posterior = kernel.build(sample)
grid = ot.GridLayout(1, 2)
grid.setTitle("Bayesian inference (with log-pdf)")
for parameter_index in range(2):
graph = posterior.getMarginal(parameter_index).drawPDF()
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
graph.setLegends(["Posterior"])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
View.ShowAll()
Total running time of the script: (0 minutes 5.505 seconds)