Note
Go to the end to download the full example code
Estimate a GEV on the Port Pirie sea-levels data¶
In this example, we illustrate various techniques of extreme value modeling applied to the annual maximum sea-levels recorded in Port Pirie, north of Adelaide, south Australia, over the period 1923-1987. Readers should refer to [coles2001] to get more details.
We illustrate techniques to:
estimate a stationary and a non stationary GEV,
estimate a return level,
using:
the log-likelihood function,
the profile log-likelihood function.
First, we load the Port pirie dataset of the annual maximum sea-levels. We start by looking at them through time.
import openturns as ot
import openturns.viewer as otv
import openturns.experimental as otexp
from openturns.usecases import coles
data = coles.Coles().portpirie
print(data[:5])
graph = ot.Graph(
"Annual maximum sea-levels at Port Pirie", "year", "level (m)", True, ""
)
cloud = ot.Cloud(data[:, :2])
cloud.setColor("red")
graph.add(cloud)
graph.setIntegerXTick(True)
view = otv.View(graph)
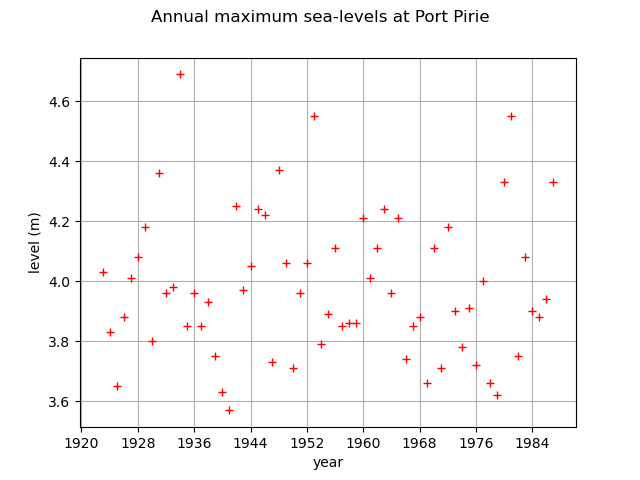
[ Year SeaLevel ]
0 : [ 1923 4.03 ]
1 : [ 1924 3.83 ]
2 : [ 1925 3.65 ]
3 : [ 1926 3.88 ]
4 : [ 1927 4.01 ]
We select the sea levels column
sample = data[:, 1]
Stationary GEV modeling via the log-likelihood function
We first assume that the dependence through time is negligible, so we first model the data as independent observations over the observation period. We estimate the parameters of the GEV distribution by maximizing the log-likelihood of the data.
factory = ot.GeneralizedExtremeValueFactory()
result_LL = factory.buildMethodOfLikelihoodMaximizationEstimator(sample)
We get the fitted GEV and its parameters of  .
.
fitted_GEV = result_LL.getDistribution()
desc = fitted_GEV.getParameterDescription()
param = fitted_GEV.getParameter()
print(", ".join([f"{p}: {value:.3f}" for p, value in zip(desc, param)]))
print("log-likelihood = ", result_LL.getLogLikelihood())
mu: 3.875, sigma: 0.198, xi: -0.050
log-likelihood = 4.339057644664945
We get the asymptotic distribution of the estimator .
In that case, the asymptotic distribution is normal.
parameterEstimate = result_LL.getParameterDistribution()
print("Asymptotic distribution of the estimator : ")
print(parameterEstimate)
Asymptotic distribution of the estimator :
Normal(mu = [3.87477,0.198054,-0.0502339], sigma = [0.0269474,0.0236136,0.132905], R = [[ 1 0.232937 -0.276996 ]
[ 0.232937 1 -0.466438 ]
[ -0.276996 -0.466438 1 ]])
We get the covariance matrix and the standard deviation of .
print("Cov matrix = \n", parameterEstimate.getCovariance())
print("Standard dev = ", parameterEstimate.getStandardDeviation())
Cov matrix =
[[ 0.000726164 0.000148224 -0.000992048 ]
[ 0.000148224 0.000557602 -0.00146386 ]
[ -0.000992048 -0.00146386 0.0176639 ]]
Standard dev = [0.0269474,0.0236136,0.132905]
We get the marginal confidence intervals of order 0.95.
order = 0.95
for i in range(3):
ci = parameterEstimate.getMarginal(i).computeBilateralConfidenceInterval(order)
print(desc[i] + ":", ci)
mu: [3.82195, 3.92759]
sigma: [0.151772, 0.244336]
xi: [-0.310724, 0.210256]
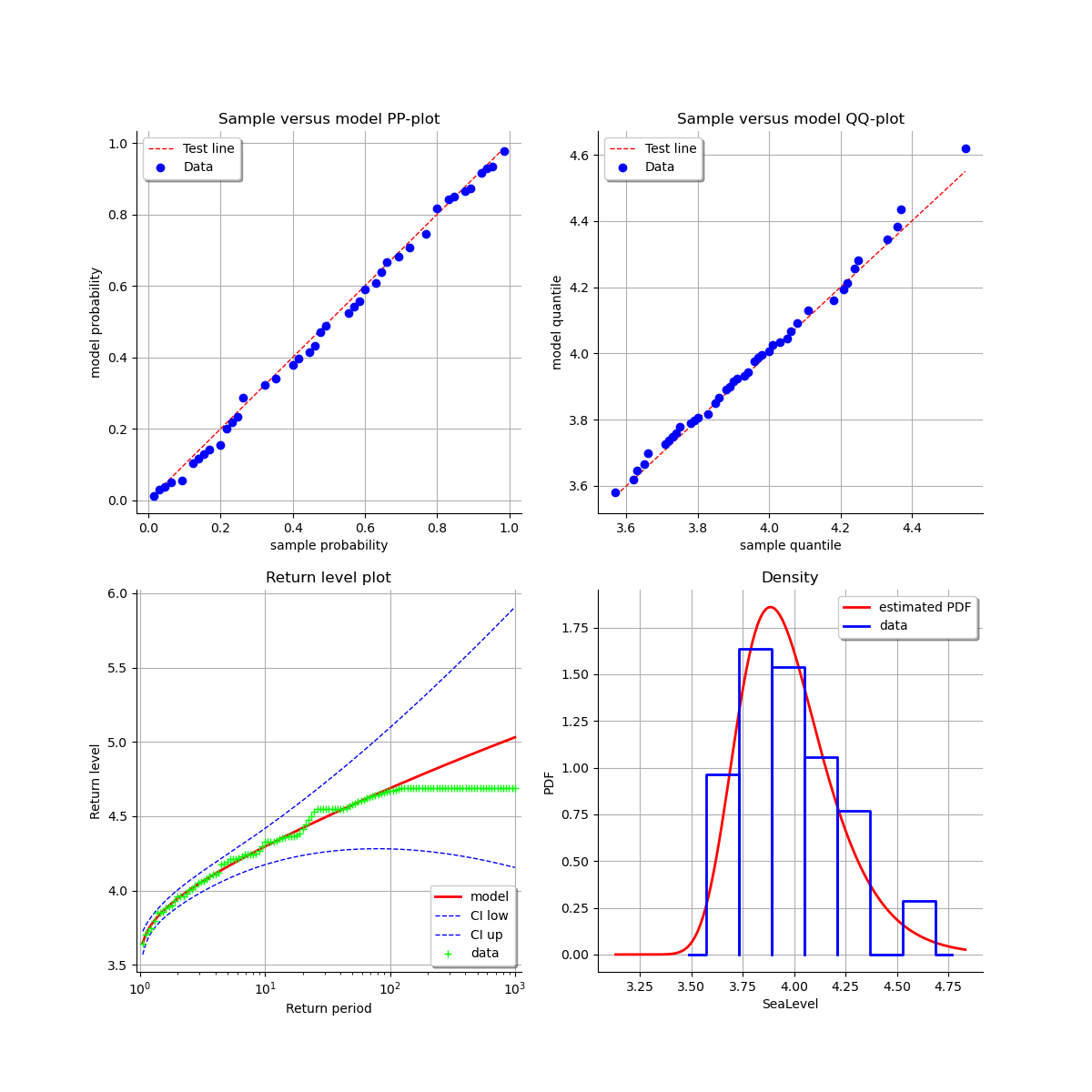
At last, we can validate the inference result thanks the 4 usual diagnostic plots.
validation = otexp.GeneralizedExtremeValueValidation(result_LL, sample)
graph = validation.drawDiagnosticPlot()
view = otv.View(graph)
Stationary GEV modeling via the profile log-likelihood function
Now, we use the profile log-likehood function rather than log-likehood function to estimate the parameters of the GEV.
result_PLL = factory.buildMethodOfProfileLikelihoodMaximizationEstimator(sample)
The following graph allows one to get the profile log-likelihood plot.
It also indicates the optimal value of  , the maximum profile log-likelihood and
the confidence interval for of order 0.95 (which is the default value).
, the maximum profile log-likelihood and
the confidence interval for of order 0.95 (which is the default value).
order = 0.95
result_PLL.setConfidenceLevel(order)
view = otv.View(result_PLL.drawProfileLikelihoodFunction())
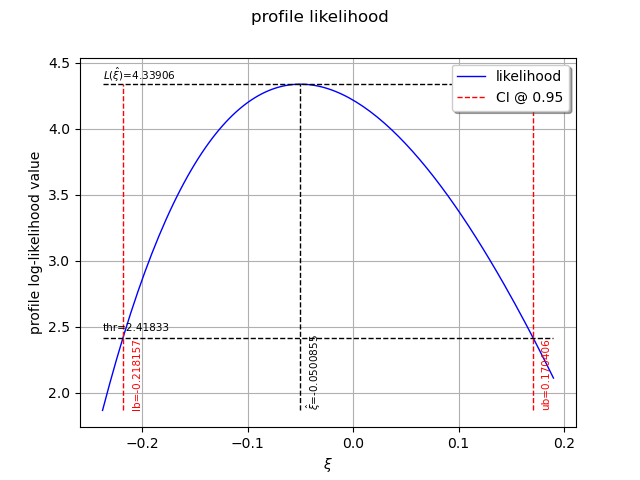
We can get the numerical values of the confidence interval: it appears to be a bit smaller with the interval obtained from the profile log-likelihood function than with the log-likelihood function. Note that if the order requested is too high, the confidence interval might not be calculated because one of its bound is out of the definition domain of the log-likelihood function.
try:
print("Confidence interval for xi = ", result_PLL.getParameterConfidenceInterval())
except Exception as ex:
print(type(ex))
pass
Confidence interval for xi = [-0.218157, 0.170406]
Return level estimate from the estimated stationary GEV
We estimate the  -block return level
-block return level  : it is computed as a particular quantile of the
GEV model estimated using the log-likelihood function. We just have to use the maximum log-likelihood
estimator built in the previous section.
: it is computed as a particular quantile of the
GEV model estimated using the log-likelihood function. We just have to use the maximum log-likelihood
estimator built in the previous section.
As the data are annual sea-levels, each block corresponds to one year: the 10-year return level
corresponds to  and the 100-year return level corresponds to
and the 100-year return level corresponds to  .
.
The method also provides the asymptotic distribution of the estimator  .
.
zm_10 = factory.buildReturnLevelEstimator(result_LL, 10.0)
return_level_10 = zm_10.getMean()
print("Maximum log-likelihood function : ")
print(f"10-year return level = {return_level_10}")
return_level_ci10 = zm_10.computeBilateralConfidenceInterval(0.95)
print(f"CI = {return_level_ci10}")
zm_100 = factory.buildReturnLevelEstimator(result_LL, 100.0)
return_level_100 = zm_100.getMean()
print(f"100-year return level = {return_level_100}")
return_level_ci100 = zm_100.computeBilateralConfidenceInterval(0.95)
print(f"CI = {return_level_ci100}")
Maximum log-likelihood function :
10-year return level = [4.29619]
CI = [4.17405, 4.41834]
100-year return level = [4.68824]
CI = [4.28031, 5.09616]
Return level estimate via the profile log-likelihood function of a stationary GEV
We can estimate the -block return level directly from the data using the profile
likelihood with respect to .
result_zm_10_PLL = factory.buildReturnLevelProfileLikelihoodEstimator(sample, 10.0)
zm_10_PLL = result_zm_10_PLL.getParameter()
print(f"10-year return level (profile) = {zm_10_PLL}")
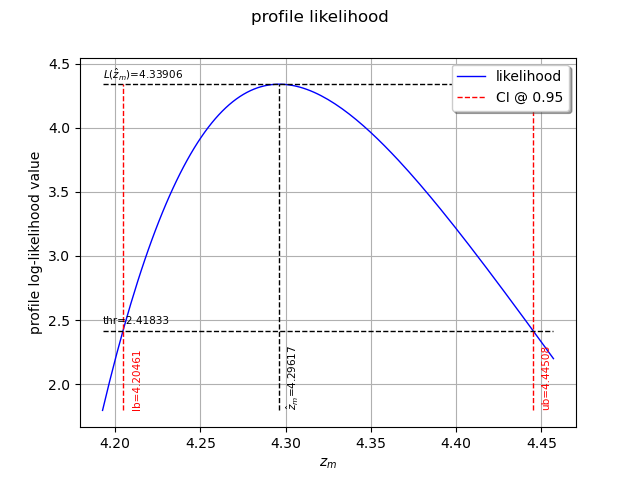
10-year return level (profile) = 4.296169941103285
We can get the confidence interval of : once more, it appears to be a bit smaller
than the interval obtained from the log-likelihood function.
result_zm_10_PLL.setConfidenceLevel(0.95)
return_level_ci10 = result_zm_10_PLL.getParameterConfidenceInterval()
print("Maximum profile log-likelihood function : ")
print(f"CI={return_level_ci10}")
Maximum profile log-likelihood function :
CI=[4.20461, 4.44508]
We can also plot the profile log-likelihood function and get the confidence interval, the optimal value
of and its confidence interval.
view = otv.View(result_zm_10_PLL.drawProfileLikelihoodFunction())
Non stationary GEV modeling via the log-likelihood function
Now, we want to see whether it is necessary to model the time dependence over the observation period.
We have to define the functional basis for each parameter of the GEV model. Even if we have
the possibility to affect a time-varying model to each of the 3 parameters  ,
it is strongly recommended not to vary the parameter .
,
it is strongly recommended not to vary the parameter .
We suppose that  is linear with time, and that the other parameters remain constant.
is linear with time, and that the other parameters remain constant.
For numerical reasons, it is strongly recommended to normalize all the data as follows:

where:
the CenterReduce method where
 is the mean time stamps
and
is the mean time stamps
and  is the standard deviation of the time stamps;
is the standard deviation of the time stamps;the MinMax method where
 is the initial time and
is the initial time and  the final time;
the final time;the None method where
 and
and  : in that case, data are not normalized.
: in that case, data are not normalized.

constant = ot.SymbolicFunction(["t"], ["1.0"])
basis_lin = ot.Basis([constant, ot.SymbolicFunction(["t"], ["t"])])
basis_cst = ot.Basis([constant])
# basis for mu, sigma, xi
basis_coll = [basis_lin, basis_cst, basis_cst]
We need to get the time stamps (in years here).
timeStamps = data[:, 0]
We can now estimate the list of coefficients  using
the log-likelihood of the data.
We test the 3 normalizing methods and both initial points in order to evaluate their impact on the results.
We can see that:
using
the log-likelihood of the data.
We test the 3 normalizing methods and both initial points in order to evaluate their impact on the results.
We can see that:
both normalization methods lead to the same result for
 ,
,  and
and  (note that
(note that  depends on the normalization function),
depends on the normalization function),both initial points lead to the same result when the data have been normalized,
it is very important to normalize all the data: if not, the result strongly depends on the initial point and it differs from the result obtained with normalized data. The results are not optimal in that case since the associated log-likelihood are much smaller than those obtained with normalized data.
initiPoint_list = list()
initiPoint_list.append("Gumbel")
initiPoint_list.append("Static")
normMethod_list = list()
normMethod_list.append("MinMax")
normMethod_list.append("CenterReduce")
normMethod_list.append("None")
print("Linear mu(t) model: ")
for normMeth in normMethod_list:
for initPoint in initiPoint_list:
print("normMeth, initPoint = ", normMeth, initPoint)
# The ot.Function() is the identity function.
result = factory.buildTimeVarying(
sample, timeStamps, basis_coll, ot.Function(), initPoint, normMeth
)
beta = result.getOptimalParameter()
print("beta1, beta2, beta3, beta4 = ", beta)
print("Max log-likelihood = ", result.getLogLikelihood())
Linear mu(t) model:
normMeth, initPoint = MinMax Gumbel
beta1, beta2, beta3, beta4 = [3.88617,-0.0226606,0.197965,-0.050304]
Max log-likelihood = 4.375105790428855
normMeth, initPoint = MinMax Static
beta1, beta2, beta3, beta4 = [3.88616,-0.022621,0.197965,-0.0504251]
Max log-likelihood = 4.375106565819115
normMeth, initPoint = CenterReduce Gumbel
beta1, beta2, beta3, beta4 = [3.87484,-0.00671465,0.197963,-0.0503351]
Max log-likelihood = 4.375106360823884
normMeth, initPoint = CenterReduce Static
beta1, beta2, beta3, beta4 = [3.87484,-0.00670763,0.197954,-0.0503005]
Max log-likelihood = 4.375105770154065
normMeth, initPoint = None Gumbel
beta1, beta2, beta3, beta4 = [3.89541,-1.63808e-05,0.197743,0.100071]
Max log-likelihood = 3.3473631512726687
normMeth, initPoint = None Static
beta1, beta2, beta3, beta4 = [3.87477,-3.43115e-10,0.198052,-0.0502339]
Max log-likelihood = 4.339057650029008
According to the previous results, we choose the MinMax normalization method and the Gumbel initial point. This initial point is cheaper than the Static one as it requires no optimization computation.
result_NonStatLL = factory.buildTimeVarying(sample, timeStamps, basis_coll)
beta = result_NonStatLL.getOptimalParameter()
print("beta1, beta2, beta3, beta_4 = ", beta)
print(f"mu(t) = {beta[0]:.4f} + {beta[1]:.4f} * tau")
print(f"sigma = {beta[2]:.4f}")
print(f"xi = {beta[3]:.4f}")
beta1, beta2, beta3, beta_4 = [3.88617,-0.0226606,0.197965,-0.050304]
mu(t) = 3.8862 + -0.0227 * tau
sigma = 0.1980
xi = -0.0503
We get the asymptotic distribution of  to compute some confidence intervals of
the estimates, for example of order
to compute some confidence intervals of
the estimates, for example of order  .
.
dist_beta = result_NonStatLL.getParameterDistribution()
condifence_level = 0.95
for i in range(beta.getSize()):
lower_bound = dist_beta.getMarginal(i).computeQuantile((1 - condifence_level) / 2)[
0
]
upper_bound = dist_beta.getMarginal(i).computeQuantile((1 + condifence_level) / 2)[
0
]
print(
"Conf interval for beta_"
+ str(i + 1)
+ " = ["
+ str(lower_bound)
+ "; "
+ str(upper_bound)
+ "]"
)
Conf interval for beta_1 = [3.7819583640787644; 3.9903750475017206]
Conf interval for beta_2 = [-0.20104854264857375; 0.15572739670269614]
Conf interval for beta_3 = [0.15133300361567922; 0.24459658323613762]
Conf interval for beta_4 = [-0.31559228144843376; 0.21498422872842005]
You can get the expression of the normalizing function  :
:
normFunc = result_NonStatLL.getNormalizationFunction()
print("Function tau(t): ", normFunc)
print("c = ", normFunc.getEvaluation().getImplementation().getCenter()[0])
print("1/d = ", normFunc.getEvaluation().getImplementation().getLinear()[0, 0])
Function tau(t): class=LinearFunction name=Unnamed implementation=class=LinearEvaluation name=Unnamed center=[1923] constant=[0] linear=[[ 0.015625 ]]
c = 1923.0
1/d = 0.015625
You can get the function  where
where
 .
.
functionTheta = result_NonStatLL.getParameterFunction()
In order to compare different modelings, we get the optimal log-likelihood of the data for both stationary and non stationary models. The difference seems to be non significant enough, which means that the non stationary model does not really improve the quality of the modeling.
print("Max log-likelihood: ")
print("Stationary model = ", result_LL.getLogLikelihood())
print("Non stationary linear mu(t) model = ", result_NonStatLL.getLogLikelihood())
Max log-likelihood:
Stationary model = 4.339057644664945
Non stationary linear mu(t) model = 4.375105790428855
In order to draw some diagnostic plots similar to those drawn in the stationary case, we refer to the
following result: if  is a non stationary GEV model parametrized by
is a non stationary GEV model parametrized by  ,
then the standardized variables
,
then the standardized variables  defined by:
defined by:
![\hat{Z}_t = \dfrac{1}{\xi(t)} \log \left[1+ \xi(t)\left( \dfrac{Z_t-\mu(t)}{\sigma(t)} \right)\right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzE4OC4yODUxMDRwdCcgaGVpZ2h0PScyOC42OTI2OTVwdCcgdmlld0JveD0nMTAwLjEyODkyNiAtMjguNjkyNjg4IDE4OC4yODUxMDQgMjguNjkyNjk1Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMS0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cwLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cwLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzAtMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzAtMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cyLTExNicgZD0nTTEuNzYxMzk1LTMuMTcyMTA1SDIuNTQyNDY2QzIuNjkzODk4LTMuMTcyMTA1IDIuNzg5NTM5LTMuMTcyMTA1IDIuNzg5NTM5LTMuMzIzNTM3QzIuNzg5NTM5LTMuNDM1MTE4IDIuNjg1OTI4LTMuNDM1MTE4IDIuNTUwNDM2LTMuNDM1MTE4SDEuODI1MTU2TDIuMTEyMDgtNC41NjY4NzRDMi4xNDM5Ni00LjY4NjQyNiAyLjE0Mzk2LTQuNzI2Mjc2IDIuMTQzOTYtNC43MzQyNDdDMi4xNDM5Ni00LjkwMTYxOSAyLjAxNjQzOC00Ljk4MTMyIDEuODgwOTQ2LTQuOTgxMzJDMS42MDk5NjMtNC45ODEzMiAxLjU1NDE3Mi00Ljc2NjEyNyAxLjQ2NjUwMS00LjQwNzQ3MkwxLjIxOTQyNy0zLjQzNTExOEguNDU0Mjk2Qy4zMDI4NjQtMy40MzUxMTggLjE5OTI1My0zLjQzNTExOCAuMTk5MjUzLTMuMjgzNjg2Qy4xOTkyNTMtMy4xNzIxMDUgLjMwMjg2NC0zLjE3MjEwNSAuNDM4MzU2LTMuMTcyMTA1SDEuMTU1NjY2TC42Nzc0Ni0xLjI1OTI3OEMuNjI5NjM5LTEuMDYwMDI1IC41NTc5MDgtLjc4MTA3MSAuNTU3OTA4LS42Njk0ODlDLjU1NzkwOC0uMTkxMjgzIC45NDg0NDMgLjA3OTcwMSAxLjM3MDg1OSAuMDc5NzAxQzIuMjIzNjYxIC4wNzk3MDEgMi43MDk4MzgtMS4wNDQwODUgMi43MDk4MzgtMS4xMzk3MjZDMi43MDk4MzgtMS4yMjczOTcgMi42MzgxMDctMS4yNDMzMzcgMi41OTAyODYtMS4yNDMzMzdDMi41MDI2MTUtMS4yNDMzMzcgMi40OTQ2NDUtMS4yMTE0NTcgMi40Mzg4NTQtMS4wOTE5MDVDMi4yNzk0NTItLjcwOTM0IDEuODgwOTQ2LS4xNDM0NjIgMS4zOTQ3Ny0uMTQzNDYyQzEuMjI3Mzk3LS4xNDM0NjIgMS4xMzE3NTYtLjI1NTA0NCAxLjEzMTc1Ni0uNTE4MDU3QzEuMTMxNzU2LS42Njk0ODkgMS4xNTU2NjYtLjc1NzE2MSAxLjE3OTU3Ny0uODYwNzcyTDEuNzYxMzk1LTMuMTcyMTA1WicvPgo8cGF0aCBpZD0nZzMtMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2czLTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2czLTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnMy05MCcgZD0nTTguMzY4NjE4LTcuNzk0NzdDOC40NDAzNDktNy44Nzg0NTYgOC41MDAxMjUtNy45NTAxODcgOC41MDAxMjUtOC4wNjk3MzhDOC41MDAxMjUtOC4xNTM0MjUgOC40ODgxNjktOC4xNjUzOCA4LjIxMzItOC4xNjUzOEgzLjI3NTcxNkMzLjAwMDc0Ny04LjE2NTM4IDIuOTg4NzkyLTguMTUzNDI1IDIuOTE3MDYxLTcuOTM4MjMyTDIuMjU5NTI3LTUuNzg2MzAxQzIuMjIzNjYxLTUuNjY2NzUgMi4yMjM2NjEtNS42NDI4MzkgMi4yMjM2NjEtNS42MTg5MjlDMi4yMjM2NjEtNS41NzExMDggMi4yNTk1MjctNS40OTkzNzcgMi4zNDMyMTMtNS40OTkzNzdDMi40Mzg4NTQtNS40OTkzNzcgMi40NjI3NjUtNS41NDcxOTggMi41MTA1ODUtNS43MDI2MTVDMi45NTI5MjctNi45OTM3NzMgMy41Mzg3My03LjgxODY4IDUuNDI3NjQ2LTcuODE4NjhINy4zODgyOTRMLjgzNjg2Mi0uNDA2NDc2Qy43MjkyNjUtLjI3NDk2OSAuNjgxNDQ1LS4yMjcxNDggLjY4MTQ0NS0uMDk1NjQxQy42ODE0NDUgMCAuNzQxMjIgMCAuOTY4MzY5IDBINi4wNzMyMjVDNi4zNDgxOTQgMCA2LjM2MDE0OS0uMDExOTU1IDYuNDMxODgtLjIyNzE0OEw3LjI2ODc0Mi0yLjg2OTI0QzcuMjgwNjk3LTIuOTA1MTA2IDcuMzA0NjA4LTIuOTg4NzkyIDcuMzA0NjA4LTMuMDM2NjEzQzcuMzA0NjA4LTMuMDk2Mzg5IDcuMjU2Nzg3LTMuMTU2MTY0IDcuMTg1MDU2LTMuMTU2MTY0QzcuMDg5NDE1LTMuMTU2MTY0IDcuMDc3NDYtMy4xNDQyMDkgNi45ODE4MTgtMi44NDUzM0M2LjQ3OTcwMS0xLjMwMzExMyA1Ljk1MzY3NC0uMzcwNjEgMy44NzM0NzQtLjM3MDYxSDEuODA1MjNMOC4zNjg2MTgtNy43OTQ3N1onLz4KPHBhdGggaWQ9J2czLTExNicgZD0nTTIuNDAyOTg5LTQuODA1OTc4SDMuNTAyODY0QzMuNzMwMDEyLTQuODA1OTc4IDMuODQ5NTY0LTQuODA1OTc4IDMuODQ5NTY0LTUuMDIxMTcxQzMuODQ5NTY0LTUuMTUyNjc3IDMuNzc3ODMzLTUuMTUyNjc3IDMuNTM4NzMtNS4xNTI2NzdIMi40ODY2NzVMMi45MjkwMTYtNi44OTgxMzJDMi45NzY4MzctNy4wNjU1MDQgMi45NzY4MzctNy4wODk0MTUgMi45NzY4MzctNy4xNzMxMDFDMi45NzY4MzctNy4zNjQzODQgMi44MjE0Mi03LjQ3MTk4IDIuNjY2MDAyLTcuNDcxOThDMi41NzAzNjEtNy40NzE5OCAyLjI5NTM5Mi03LjQzNjExNSAyLjE5OTc1MS03LjA1MzU0OUwxLjczMzQ5OS01LjE1MjY3N0guNjA5NzE0Qy4zNzA2MS01LjE1MjY3NyAuMjYzMDE0LTUuMTUyNjc3IC4yNjMwMTQtNC45MjU1MjlDLjI2MzAxNC00LjgwNTk3OCAuMzQ2Ny00LjgwNTk3OCAuNTczODQ4LTQuODA1OTc4SDEuNjM3ODU4TC44NDg4MTctMS42NDk4MTNDLjc1MzE3Ni0xLjIzMTM4MiAuNzE3MzEtMS4xMTE4MzEgLjcxNzMxLS45NTY0MTNDLjcxNzMxLS4zOTQ1MjEgMS4xMTE4MzEgLjExOTU1MiAxLjc4MTMyIC4xMTk1NTJDMi45ODg3OTIgLjExOTU1MiAzLjYzNDM3MS0xLjYyNTkwMyAzLjYzNDM3MS0xLjcwOTU4OUMzLjYzNDM3MS0xLjc4MTMyIDMuNTg2NTUtMS44MTcxODYgMy41MTQ4MTktMS44MTcxODZDMy40OTA5MDktMS44MTcxODYgMy40NDMwODgtMS44MTcxODYgMy40MTkxNzgtMS43NjkzNjVDMy40MDcyMjMtMS43NTc0MSAzLjM5NTI2OC0xLjc0NTQ1NSAzLjMxMTU4Mi0xLjU1NDE3MkMzLjA2MDUyMy0uOTU2NDEzIDIuNTEwNTg1LS4xMTk1NTIgMS44MTcxODYtLjExOTU1MkMxLjQ1ODUzMS0uMTE5NTUyIDEuNDM0NjItLjQxODQzMSAxLjQzNDYyLS42ODE0NDVDMS40MzQ2Mi0uNjkzNCAxLjQzNDYyLS45MjA1NDggMS40NzA0ODYtMS4wNjQwMUwyLjQwMjk4OS00LjgwNTk3OFonLz4KPHBhdGggaWQ9J2c0LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnNC00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzQtNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzQtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnNC02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzQtOTQnIGQ9J00yLjkyOTAxNi04LjI5Njg4N0wxLjM2Mjg4OS02LjY3MDk4NEwxLjU1NDE3Mi02LjQ5MTY1NkwyLjkxNzA2MS03LjcyMzAzOUw0LjI5MTkwNS02LjQ5MTY1Nkw0LjQ4MzE4OC02LjY3MDk4NEwyLjkyOTAxNi04LjI5Njg4N1onLz4KPHBhdGggaWQ9J2c0LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c0LTEwOCcgZD0nTTIuMDU2Mjg5LTguMjk2ODg3TC4zOTQ1MjEtOC4xNjUzOFYtNy44MTg2OEMxLjIwNzQ3Mi03LjgxODY4IDEuMzAzMTEzLTcuNzM0OTk0IDEuMzAzMTEzLTcuMTQ5MTkxVi0uODg0NjgyQzEuMzAzMTEzLS4zNDY3IDEuMTcxNjA2LS4zNDY3IC4zOTQ1MjEtLjM0NjdWMEMuNzI5MjY1LS4wMjM5MSAxLjMxNTA2OC0uMDIzOTEgMS42NzM3MjQtLjAyMzkxUzIuNjMwMTM3LS4wMjM5MSAyLjk2NDg4MiAwVi0uMzQ2N0MyLjE5OTc1MS0uMzQ2NyAyLjA1NjI4OS0uMzQ2NyAyLjA1NjI4OS0uODg0NjgyVi04LjI5Njg4N1onLz4KPHBhdGggaWQ9J2c0LTExMScgZD0nTTUuNDg3NDIyLTIuNTU4NDA2QzUuNDg3NDIyLTQuMTAwNjIzIDQuMzE1ODE2LTUuMzMyMDA1IDIuOTI5MDE2LTUuMzMyMDA1QzEuNDk0Mzk2LTUuMzMyMDA1IC4zNTg2NTUtNC4wNjQ3NTcgLjM1ODY1NS0yLjU1ODQwNkMuMzU4NjU1LTEuMDI4MTQ0IDEuNTU0MTcyIC4xMTk1NTIgMi45MTcwNjEgLjExOTU1MkM0LjMyNzc3MSAuMTE5NTUyIDUuNDg3NDIyLTEuMDUyMDU1IDUuNDg3NDIyLTIuNTU4NDA2Wk0yLjkyOTAxNi0uMTQzNDYyQzIuNDg2Njc1LS4xNDM0NjIgMS45NDg2OTItLjMzNDc0NSAxLjYwMTk5My0uOTIwNTQ4QzEuMjc5MjAzLTEuNDU4NTMxIDEuMjY3MjQ4LTIuMTYzODg1IDEuMjY3MjQ4LTIuNjY2MDAyQzEuMjY3MjQ4LTMuMTIwMjk5IDEuMjY3MjQ4LTMuODQ5NTY0IDEuNjM3ODU4LTQuMzg3NTQ3QzEuOTcyNjAzLTQuOTAxNjE5IDIuNDk4NjMtNS4wOTI5MDIgMi45MTcwNjEtNS4wOTI5MDJDMy4zODMzMTMtNS4wOTI5MDIgMy44ODU0My00Ljg3NzcwOSA0LjIwODIxOS00LjQxMTQ1N0M0LjU3ODgyOS0zLjg2MTUxOSA0LjU3ODgyOS0zLjEwODM0NCA0LjU3ODgyOS0yLjY2NjAwMkM0LjU3ODgyOS0yLjI0NzU3MiA0LjU3ODgyOS0xLjUwNjM1MSA0LjI2Nzk5NS0uOTQ0NDU4QzMuOTMzMjUtLjM3MDYxIDMuMzgzMzEzLS4xNDM0NjIgMi45MjkwMTYtLjE0MzQ2MlonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzEwMi42MTMzMzgnIHk9Jy0xNC4zNzk1NDgnIHhsaW5rOmhyZWY9JyNnNC05NCcvPgo8dXNlIHg9JzEwMC4xMjg5MjYnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnMy05MCcvPgo8dXNlIHg9JzEwOC4xNDExODInIHk9Jy05LjU2NDI5MycgeGxpbms6aHJlZj0nI2cyLTExNicvPgo8dXNlIHg9JzExNS4wMTgxNicgeT0nLTExLjM1NzU1NicgeGxpbms6aHJlZj0nI2c0LTYxJy8+Cjx1c2UgeD0nMTM1LjIyMzc5MicgeT0nLTE5LjQ0NTMxNCcgeGxpbms6aHJlZj0nI2c0LTQ5Jy8+CjxyZWN0IHg9JzEyOC42MzkxNTUnIHk9Jy0xNC41ODU0NDEnIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzE5LjAyMjI0OScvPgo8dXNlIHg9JzEyOC42MzkxNTUnIHk9Jy0zLjE1Njg5MycgeGxpbms6aHJlZj0nI2czLTI0Jy8+Cjx1c2UgeD0nMTM0LjMyOTU5MicgeT0nLTMuMTU2ODkzJyB4bGluazpocmVmPScjZzQtNDAnLz4KPHVzZSB4PScxMzguODgxOTE4JyB5PSctMy4xNTY4OTMnIHhsaW5rOmhyZWY9JyNnMy0xMTYnLz4KPHVzZSB4PScxNDMuMTA5MDc4JyB5PSctMy4xNTY4OTMnIHhsaW5rOmhyZWY9JyNnNC00MScvPgo8dXNlIHg9JzE1MC44NDk0MTUnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnNC0xMDgnLz4KPHVzZSB4PScxNTQuMTAxMDc2JyB5PSctMTEuMzU3NTU2JyB4bGluazpocmVmPScjZzQtMTExJy8+Cjx1c2UgeD0nMTU5Ljk1NDA2NicgeT0nLTExLjM1NzU1NicgeGxpbms6aHJlZj0nI2c0LTEwMycvPgo8dXNlIHg9JzE2Ny45NjIxMzcnIHk9Jy0yOC4yMTQ0OTMnIHhsaW5rOmhyZWY9JyNnMC0yMCcvPgo8dXNlIHg9JzE3NC4yNzE4MzUnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnNC00OScvPgo8dXNlIHg9JzE4Mi43ODE0ODgnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnNC00MycvPgo8dXNlIHg9JzE5NC41NDI4MDMnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnMy0yNCcvPgo8dXNlIHg9JzIwMC4yMzMyNDEnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnNC00MCcvPgo8dXNlIHg9JzIwNC43ODU1NjcnIHk9Jy0xMS4zNTc1NTYnIHhsaW5rOmhyZWY9JyNnMy0xMTYnLz4KPHVzZSB4PScyMDkuMDEyNzI2JyB5PSctMTEuMzU3NTU2JyB4bGluazpocmVmPScjZzQtNDEnLz4KPHVzZSB4PScyMTUuNTU3NTUnIHk9Jy0yOC4yMTQ0OTMnIHhsaW5rOmhyZWY9JyNnMC0xOCcvPgo8dXNlIHg9JzIyNS41NTM0MzYnIHk9Jy0xOS40NDUzMTQnIHhsaW5rOmhyZWY9JyNnMy05MCcvPgo8dXNlIHg9JzIzMy41NjU2OTEnIHk9Jy0xNy42NTIwNTEnIHhsaW5rOmhyZWY9JyNnMi0xMTYnLz4KPHVzZSB4PScyMzkuNzc4NTA4JyB5PSctMTkuNDQ1MzE0JyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzI1MS43MzM2NjgnIHk9Jy0xOS40NDUzMTQnIHhsaW5rOmhyZWY9JyNnMy0yMicvPgo8dXNlIHg9JzI1OC43NzY2MzknIHk9Jy0xOS40NDUzMTQnIHhsaW5rOmhyZWY9JyNnNC00MCcvPgo8dXNlIHg9JzI2My4zMjg5NjUnIHk9Jy0xOS40NDUzMTQnIHhsaW5rOmhyZWY9JyNnMy0xMTYnLz4KPHVzZSB4PScyNjcuNTU2MTI0JyB5PSctMTkuNDQ1MzE0JyB4bGluazpocmVmPScjZzQtNDEnLz4KPHJlY3QgeD0nMjI1LjU1MzQzNicgeT0nLTE0LjU4NTQ0MScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNDYuNTU1MDAyJy8+Cjx1c2UgeD0nMjM4LjYyMzgzNycgeT0nLTMuMTU2ODkzJyB4bGluazpocmVmPScjZzMtMjcnLz4KPHVzZSB4PScyNDUuNzA2MjQxJyB5PSctMy4xNTY4OTMnIHhsaW5rOmhyZWY9JyNnNC00MCcvPgo8dXNlIHg9JzI1MC4yNTg1NjcnIHk9Jy0zLjE1Njg5MycgeGxpbms6aHJlZj0nI2czLTExNicvPgo8dXNlIHg9JzI1NC40ODU3MjcnIHk9Jy0zLjE1Njg5MycgeGxpbms6aHJlZj0nI2c0LTQxJy8+Cjx1c2UgeD0nMjczLjMwMzk1MicgeT0nLTI4LjIxNDQ5MycgeGxpbms6aHJlZj0nI2cwLTE5Jy8+Cjx1c2UgeD0nMjgyLjEwNDMyNScgeT0nLTI4LjIxNDQ5MycgeGxpbms6aHJlZj0nI2cwLTIxJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
have the standard Gumbel distribution which is the GEV model with  .
.
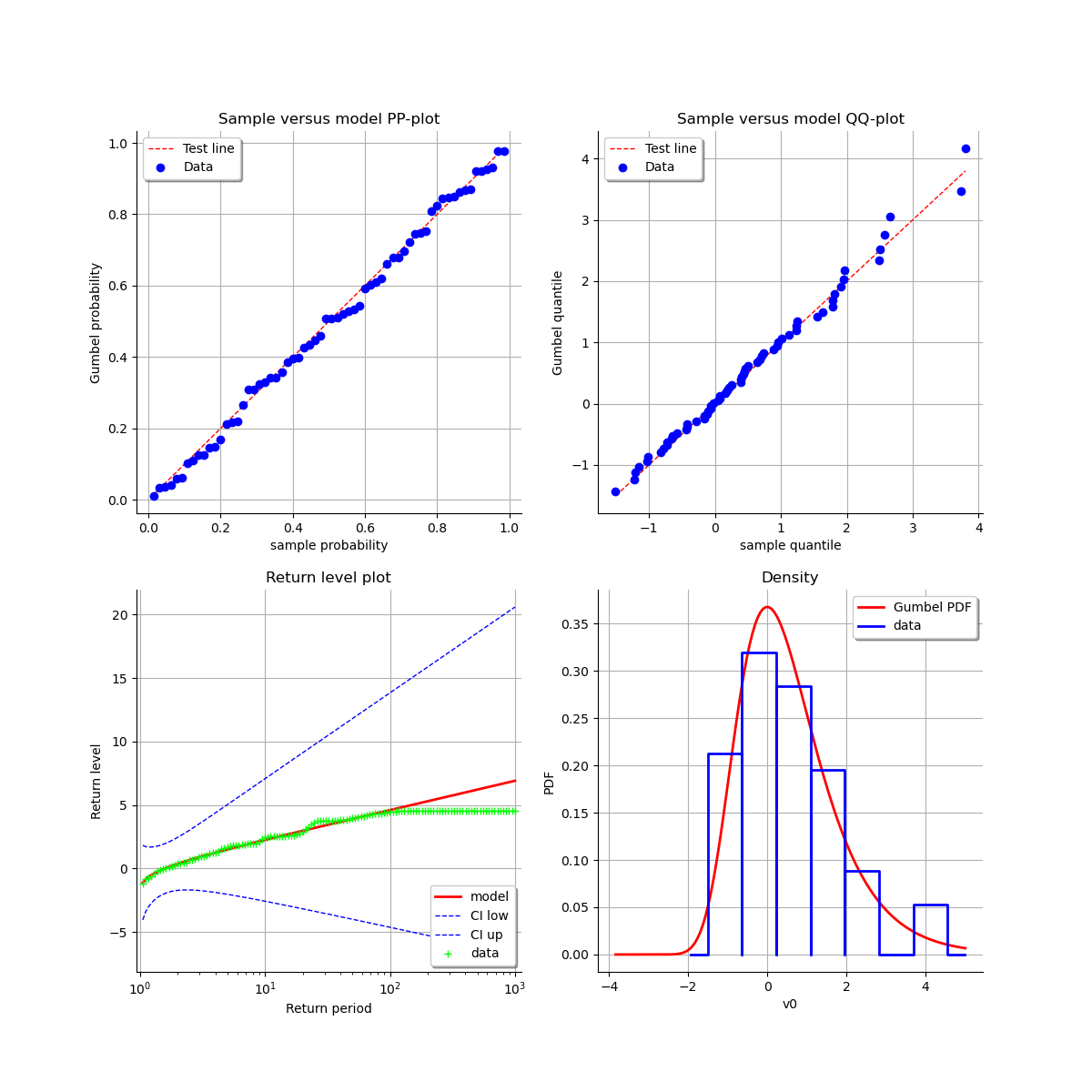
As a result, we can validate the inference result thanks the 4 usual diagnostic plots:
the probability-probability pot,
the quantile-quantile pot,
the return level plot,
the data histogram and the desnity of the fitted model.
using the transformed data compared to the Gumbel model. We can see that the adequation seems similar to the graph of the stationary model.
graph = result_NonStatLL.drawDiagnosticPlot()
view = otv.View(graph)
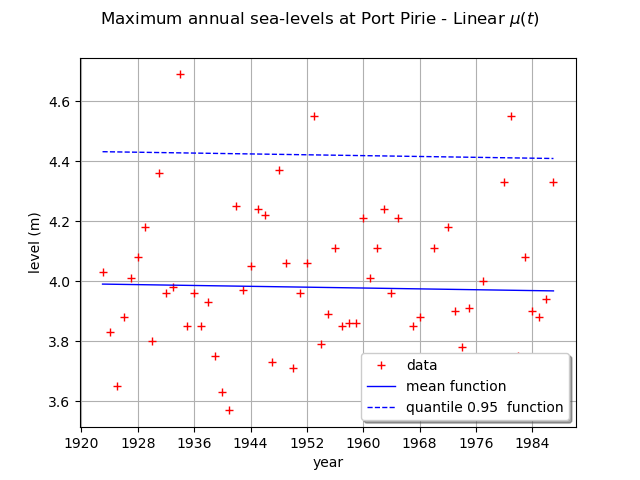
We can draw the mean function  . Be careful, it is not the function
. Be careful, it is not the function
 . As a matter of fact, the mean is defined for
. As a matter of fact, the mean is defined for  only and in that case,
for
only and in that case,
for  , we have:
, we have:

and for  , we have:
, we have:

where  is the Euler constant.
is the Euler constant.
We can also draw the function  where
where  is the quantile of
order
is the quantile of
order  of the GEV distribution at time
of the GEV distribution at time  .
Here,
.
Here,  is a linear function and the other parameters are constant, so the mean and the quantile
functions are also linear functions.
is a linear function and the other parameters are constant, so the mean and the quantile
functions are also linear functions.
graph = ot.Graph(
r"Maximum annual sea-levels at Port Pirie - Linear $\mu(t)$",
"year",
"level (m)",
True,
"",
)
graph.setIntegerXTick(True)
# data
cloud = ot.Cloud(data[:, :2])
cloud.setColor("red")
graph.add(cloud)
# mean function
meandata = [
result_NonStatLL.getDistribution(t).getMean()[0] for t in data[:, 0].asPoint()
]
curve_meanPoints = ot.Curve(data[:, 0].asPoint(), meandata)
graph.add(curve_meanPoints)
# quantile function
graphQuantile = result_NonStatLL.drawQuantileFunction(0.95)
drawQuant = graphQuantile.getDrawable(0)
drawQuant = graphQuantile.getDrawable(0)
drawQuant.setLineStyle("dashed")
graph.add(drawQuant)
graph.setLegends(["data", "mean function", "quantile 0.95 function"])
graph.setLegendPosition("bottomright")
view = otv.View(graph)
At last, we can test the validity of the stationary model  relative to the model with time varying parameters
relative to the model with time varying parameters  . The
model is parametrized
by
. The
model is parametrized
by  and the model is parametrized
by
and the model is parametrized
by  : so we have
: so we have  .
.
We use the Likelihood Ratio test. The null hypothesis is the stationary model .
The Type I error  is taken equal to 0.05.
is taken equal to 0.05.
This test confirms that there is no evidence of a linear trend for .
llh_LL = result_LL.getLogLikelihood()
llh_NonStatLL = result_NonStatLL.getLogLikelihood()
modelM0_Nb_param = 3
modelM1_Nb_param = 4
resultLikRatioTest = ot.HypothesisTest.LikelihoodRatioTest(
modelM0_Nb_param, llh_LL, modelM1_Nb_param, llh_NonStatLL, 0.05
)
accepted = resultLikRatioTest.getBinaryQualityMeasure()
print(
f"Hypothesis H0 (stationary model) vs H1 (linear mu(t) model): accepted ? = {accepted}"
)
Hypothesis H0 (stationary model) vs H1 (linear mu(t) model): accepted ? = True
We detail the statistics of the Likelihood Ratio test: the deviance statistics
 follows a
follows a  distribution.
The model is rejected if the deviance statistics estimated on the data is greater than
the threshold
distribution.
The model is rejected if the deviance statistics estimated on the data is greater than
the threshold  or if the p-value is less than the Type I error
or if the p-value is less than the Type I error  .
.
print(f"Dp={resultLikRatioTest.getStatistic():.2f}")
print(f"alpha={resultLikRatioTest.getThreshold():.2f}")
print(f"p-value={resultLikRatioTest.getPValue():.2f}")
Dp=0.07
alpha=0.05
p-value=0.79
otv.View.ShowAll()
Total running time of the script: (0 minutes 2.055 seconds)