Note
Go to the end to download the full example code
Kriging : quick-start¶
Abstract¶
In this example, we create a kriging metamodel for a function which has scalar real inputs and outputs. We show how to create the learning and the validation samples. We show how to create the kriging metamodel by choosing a trend and a covariance model. Finally, we compute the predicted kriging confidence interval using the conditional variance.
Introduction¶
We consider the sine function:

for any ![x\in[0,12]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzUwLjU3MDMzN3B0JyBoZWlnaHQ9JzExLjk1NTE2OHB0JyB2aWV3Qm94PScwIC04Ljk2NjM3NiA1MC41NzAzMzcgMTEuOTU1MTY4Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMi00OCcgZD0nTTUuMzU1OTE1LTMuODI1NjU0QzUuMzU1OTE1LTQuODE3OTMzIDUuMjk2MTM5LTUuNzg2MzAxIDQuODY1NzUzLTYuNjk0ODk0QzQuMzc1NTkyLTcuNjg3MTczIDMuNTE0ODE5LTcuOTUwMTg3IDIuOTI5MDE2LTcuOTUwMTg3QzIuMjM1NjE2LTcuOTUwMTg3IDEuMzg2OC03LjYwMzQ4NyAuOTQ0NDU4LTYuNjExMjA4Qy42MDk3MTQtNS44NTgwMzIgLjQ5MDE2Mi01LjExNjgxMiAuNDkwMTYyLTMuODI1NjU0Qy40OTAxNjItMi42NjYwMDIgLjU3Mzg0OC0xLjc5MzI3NSAxLjAwNDIzNC0uOTQ0NDU4QzEuNDcwNDg2LS4wMzU4NjYgMi4yOTUzOTIgLjI1MTA1OSAyLjkxNzA2MSAuMjUxMDU5QzMuOTU3MTYxIC4yNTEwNTkgNC41NTQ5MTktLjM3MDYxIDQuOTAxNjE5LTEuMDY0MDFDNS4zMzIwMDUtMS45NjA2NDggNS4zNTU5MTUtMy4xMzIyNTQgNS4zNTU5MTUtMy44MjU2NTRaTTIuOTE3MDYxIC4wMTE5NTVDMi41MzQ0OTYgLjAxMTk1NSAxLjc1NzQxLS4yMDMyMzggMS41MzAyNjItMS41MDYzNTFDMS4zOTg3NTUtMi4yMjM2NjEgMS4zOTg3NTUtMy4xMzIyNTQgMS4zOTg3NTUtMy45NjkxMTZDMS4zOTg3NTUtNC45NDk0NCAxLjM5ODc1NS01LjgzNDEyMiAxLjU5MDAzNy02LjUzOTQ3N0MxLjc5MzI3NS03LjM0MDQ3MyAyLjQwMjk4OS03LjcxMTA4MyAyLjkxNzA2MS03LjcxMTA4M0MzLjM3MTM1Ny03LjcxMTA4MyA0LjA2NDc1Ny03LjQzNjExNSA0LjI5MTkwNS02LjQwNzk3QzQuNDQ3MzIzLTUuNzI2NTI2IDQuNDQ3MzIzLTQuNzgyMDY3IDQuNDQ3MzIzLTMuOTY5MTE2QzQuNDQ3MzIzLTMuMTY4MTIgNC40NDczMjMtMi4yNTk1MjcgNC4zMTU4MTYtMS41MzAyNjJDNC4wODg2NjctLjIxNTE5MyAzLjMzNTQ5MiAuMDExOTU1IDIuOTE3MDYxIC4wMTE5NTVaJy8+CjxwYXRoIGlkPSdnMi00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2cyLTUwJyBkPSdNNS4yNjAyNzQtMi4wMDg0NjhINC45OTcyNkM0Ljk2MTM5NS0xLjgwNTIzIDQuODY1NzUzLTEuMTQ3Njk2IDQuNzQ2MjAyLS45NTY0MTNDNC42NjI1MTYtLjg0ODgxNyAzLjk4MTA3MS0uODQ4ODE3IDMuNjIyNDE2LS44NDg4MTdIMS40MTA3MUMxLjczMzQ5OS0xLjEyMzc4NiAyLjQ2Mjc2NS0xLjg4ODkxNyAyLjc3MzU5OS0yLjE3NTg0MUM0LjU5MDc4NS0zLjg0OTU2NCA1LjI2MDI3NC00LjQ3MTIzMyA1LjI2MDI3NC01LjY1NDc5NUM1LjI2MDI3NC03LjAyOTYzOSA0LjE3MjM1NC03Ljk1MDE4NyAyLjc4NTU1NC03Ljk1MDE4N1MuNTg1ODAzLTYuNzY2NjI1IC41ODU4MDMtNS43Mzg0ODFDLjU4NTgwMy01LjEyODc2NyAxLjExMTgzMS01LjEyODc2NyAxLjE0NzY5Ni01LjEyODc2N0MxLjM5ODc1NS01LjEyODc2NyAxLjcwOTU4OS01LjMwODA5NSAxLjcwOTU4OS01LjY5MDY2QzEuNzA5NTg5LTYuMDI1NDA1IDEuNDgyNDQxLTYuMjUyNTUzIDEuMTQ3Njk2LTYuMjUyNTUzQzEuMDQwMS02LjI1MjU1MyAxLjAxNjE4OS02LjI1MjU1MyAuOTgwMzI0LTYuMjQwNTk4QzEuMjA3NDcyLTcuMDUzNTQ5IDEuODUzMDUxLTcuNjAzNDg3IDIuNjMwMTM3LTcuNjAzNDg3QzMuNjQ2MzI2LTcuNjAzNDg3IDQuMjY3OTk1LTYuNzU0NjcgNC4yNjc5OTUtNS42NTQ3OTVDNC4yNjc5OTUtNC42Mzg2MDUgMy42ODIxOTItMy43NTM5MjMgMy4wMDA3NDctMi45ODg3OTJMLjU4NTgwMy0uMjg2OTI0VjBINC45NDk0NEw1LjI2MDI3NC0yLjAwODQ2OFonLz4KPHBhdGggaWQ9J2cyLTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnMi05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjxwYXRoIGlkPSdnMC01MCcgZD0nTTYuNTUxNDMyLTIuNzQ5Njg5QzYuNzU0NjctMi43NDk2ODkgNi45Njk4NjMtMi43NDk2ODkgNi45Njk4NjMtMi45ODg3OTJTNi43NTQ2Ny0zLjIyNzg5NSA2LjU1MTQzMi0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMy00LjgyOTg4OCAzLjAwMDc0Ny01Ljk3NzU4NCA0LjY4NjQyNi01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3LTUuOTc3NTg0IDYuOTY5ODYzLTUuOTc3NTg0IDYuOTY5ODYzLTYuMjE2Njg3UzYuNzU0NjctNi40NTU3OTEgNi41NTE0MzItNi40NTU3OTFINC42NjI1MTZDMi42MTgxODItNi40NTU3OTEgLjk5MjI3OS00LjkwMTYxOSAuOTkyMjc5LTIuOTg4NzkyUzIuNjE4MTgyIC40NzgyMDcgNC42NjI1MTYgLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IC40NzgyMDcgNi45Njk4NjMgLjQ3ODIwNyA2Ljk2OTg2MyAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMtMS4xNDc2OTYgMS40ODI0NDEtMi43NDk2ODlINi41NTE0MzJaJy8+CjxwYXRoIGlkPSdnMS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzEtMTIwJyBkPSdNNS42NjY3NS00Ljg3NzcwOUM1LjI4NDE4NC00LjgwNTk3OCA1LjE0MDcyMi00LjUxOTA1NCA1LjE0MDcyMi00LjI5MTkwNUM1LjE0MDcyMi00LjAwNDk4MSA1LjM2Nzg3LTMuOTA5MzQgNS41MzUyNDMtMy45MDkzNEM1Ljg5Mzg5OC0zLjkwOTM0IDYuMTQ0OTU2LTQuMjIwMTc0IDYuMTQ0OTU2LTQuNTQyOTY0QzYuMTQ0OTU2LTUuMDQ1MDgxIDUuNTcxMTA4LTUuMjcyMjI5IDUuMDY4OTkxLTUuMjcyMjI5QzQuMzM5NzI2LTUuMjcyMjI5IDMuOTMzMjUtNC41NTQ5MTkgMy44MjU2NTQtNC4zMjc3NzFDMy41NTA2ODUtNS4yMjQ0MDggMi44MDk0NjUtNS4yNzIyMjkgMi41OTQyNzEtNS4yNzIyMjlDMS4zNzQ4NDQtNS4yNzIyMjkgLjcyOTI2NS0zLjcwNjEwMiAuNzI5MjY1LTMuNDQzMDg4Qy43MjkyNjUtMy4zOTUyNjggLjc3NzA4Ni0zLjMzNTQ5MiAuODYwNzcyLTMuMzM1NDkyQy45NTY0MTMtMy4zMzU0OTIgLjk4MDMyNC0zLjQwNzIyMyAxLjAwNDIzNC0zLjQ1NTA0NEMxLjQxMDcxLTQuNzgyMDY3IDIuMjExNzA2LTUuMDMzMTI2IDIuNTU4NDA2LTUuMDMzMTI2QzMuMDk2Mzg5LTUuMDMzMTI2IDMuMjAzOTg1LTQuNTMxMDA5IDMuMjAzOTg1LTQuMjQ0MDg1QzMuMjAzOTg1LTMuOTgxMDcxIDMuMTMyMjU0LTMuNzA2MTAyIDIuOTg4NzkyLTMuMTMyMjU0TDIuNTgyMzE2LTEuNDk0Mzk2QzIuNDAyOTg5LS43NzcwODYgMi4wNTYyODktLjExOTU1MiAxLjQyMjY2NS0uMTE5NTUyQzEuMzYyODg5LS4xMTk1NTIgMS4wNjQwMS0uMTE5NTUyIC44MTI5NTEtLjI3NDk2OUMxLjI0MzMzNy0uMzU4NjU1IDEuMzM4OTc5LS43MTczMSAxLjMzODk3OS0uODYwNzcyQzEuMzM4OTc5LTEuMDk5ODc1IDEuMTU5NjUxLTEuMjQzMzM3IC45MzI1MDMtMS4yNDMzMzdDLjY0NTU3OS0xLjI0MzMzNyAuMzM0NzQ1LS45OTIyNzkgLjMzNDc0NS0uNjA5NzE0Qy4zMzQ3NDUtLjEwNzU5NyAuODk2NjM4IC4xMTk1NTIgMS40MTA3MSAuMTE5NTUyQzEuOTg0NTU4IC4xMTk1NTIgMi4zOTEwMzQtLjMzNDc0NSAyLjY0MjA5Mi0uODI0OTA3QzIuODMzMzc1LS4xMTk1NTIgMy40MzExMzMgLjExOTU1MiAzLjg3MzQ3NCAuMTE5NTUyQzUuMDkyOTAyIC4xMTk1NTIgNS43Mzg0ODEtMS40NDY1NzUgNS43Mzg0ODEtMS43MDk1ODlDNS43Mzg0ODEtMS43NjkzNjUgNS42OTA2Ni0xLjgxNzE4NiA1LjYxODkyOS0xLjgxNzE4NkM1LjUxMTMzMy0xLjgxNzE4NiA1LjQ5OTM3Ny0xLjc1NzQxIDUuNDYzNTEyLTEuNjYxNzY4QzUuMTQwNzIyLS42MDk3MTQgNC40NDczMjMtLjExOTU1MiAzLjkwOTM0LS4xMTk1NTJDMy40OTA5MDktLjExOTU1MiAzLjI2Mzc2MS0uNDMwMzg2IDMuMjYzNzYxLS45MjA1NDhDMy4yNjM3NjEtMS4xODM1NjIgMy4zMTE1ODItMS4zNzQ4NDQgMy41MDI4NjQtMi4xNjM4ODVMMy45MjEyOTUtMy43ODk3ODhDNC4xMDA2MjMtNC41MDcwOTggNC41MDcwOTgtNS4wMzMxMjYgNS4wNTcwMzYtNS4wMzMxMjZDNS4wODA5NDYtNS4wMzMxMjYgNS40MTU2OTEtNS4wMzMxMjYgNS42NjY3NS00Ljg3NzcwOVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS0xMjAnLz4KPHVzZSB4PSc5Ljk3MjkxNycgeT0nMCcgeGxpbms6aHJlZj0nI2cwLTUwJy8+Cjx1c2UgeD0nMjEuMjYzODg1JyB5PScwJyB4bGluazpocmVmPScjZzItOTEnLz4KPHVzZSB4PScyNC41MTU1NDYnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OCcvPgo8dXNlIHg9JzMwLjM2ODUzNicgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTU5Jy8+Cjx1c2UgeD0nMzUuNjEyNjk1JyB5PScwJyB4bGluazpocmVmPScjZzItNDknLz4KPHVzZSB4PSc0MS40NjU2ODUnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi01MCcvPgo8dXNlIHg9JzQ3LjMxODY3NScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTkzJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9NCAtLT4=) .
.
We want to create a metamodel of this function. This is why we create a sample of  observations of the function:
observations of the function:

for  , where
, where  is the i-th input and
is the i-th input and  is the corresponding output.
is the corresponding output.
We consider the seven following inputs :
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|---|---|---|---|---|---|---|---|
|
1 |
3 |
4 |
6 |
7.9 |
11 |
11.5 |

We are going to consider a kriging metamodel with:
a constant trend,
a Matern covariance model.
Creation of the metamodel¶
We begin by defining the function g as a symbolic function. Then we define the x_train variable which contains the inputs of the design of experiments of the training step. Then we compute the y_train corresponding outputs. The variable n_train is the size of the training design of experiments.
import openturns as ot
import openturns.viewer as viewer
from matplotlib import pylab as plt
ot.Log.Show(ot.Log.NONE)
g = ot.SymbolicFunction(["x"], ["sin(x)"])
x_train = ot.Sample([[x] for x in [1.0, 3.0, 4.0, 6.0, 7.9, 11.0, 11.5]])
y_train = g(x_train)
n_train = x_train.getSize()
n_train
7
In order to compare the function and its metamodel, we use a test (i.e. validation) design of experiments made of a regular grid of 100 points from 0 to 12. Then we convert this grid into a Sample and we compute the outputs of the function on this sample.
xmin = 0.0
xmax = 12.0
n_test = 100
step = (xmax - xmin) / (n_test - 1)
myRegularGrid = ot.RegularGrid(xmin, step, n_test)
x_test = myRegularGrid.getVertices()
y_test = g(x_test)
In order to observe the function and the location of the points in the input design of experiments, we define the following functions which plots the data.
def plot_data_train(x_train, y_train):
"""Plot the data (x_train,y_train) as a Cloud, in red"""
graph_train = ot.Cloud(x_train, y_train)
graph_train.setColor("red")
graph_train.setLegend("Data")
return graph_train
def plot_data_test(x_test, y_test):
"""Plot the data (x_test,y_test) as a Curve, in dashed black"""
graphF = ot.Curve(x_test, y_test)
graphF.setLegend("Exact")
graphF.setColor("black")
graphF.setLineStyle("dashed")
return graphF
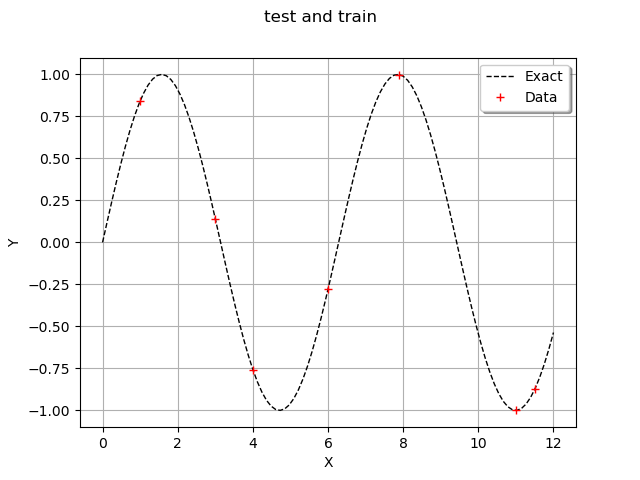
graph = ot.Graph("test and train", "", "", True, "")
graph.add(plot_data_test(x_test, y_test))
graph.add(plot_data_train(x_train, y_train))
graph.setAxes(True)
graph.setXTitle("X")
graph.setYTitle("Y")
graph.setLegendPosition("topright")
view = viewer.View(graph)
We use the ConstantBasisFactory class to define the trend and the MaternModel class to define the covariance model. This Matérn model is based on the regularity parameter  .
.
dimension = 1
basis = ot.ConstantBasisFactory(dimension).build()
# basis = ot.LinearBasisFactory(dimension).build()
basis = ot.QuadraticBasisFactory(dimension).build()
covarianceModel = ot.MaternModel([1.0] * dimension, 1.5)
algo = ot.KrigingAlgorithm(x_train, y_train, covarianceModel, basis)
algo.run()
result = algo.getResult()
print(result)
KrigingResult(covariance models=MaternModel(scale=[1.0568], amplitude=[0.872754], nu=1.5), covariance coefficients=0 : [ 0.369718 ]
1 : [ 0.473109 ]
2 : [ -1.47872 ]
3 : [ -0.45338 ]
4 : [ 1.71228 ]
5 : [ -0.967332 ]
6 : [ 0.344328 ], basis=Basis( [class=LinearEvaluation name=Unnamed center=[0] constant=[1] linear=[[ 0 ]],class=LinearEvaluation name=Unnamed center=[0] constant=[0] linear=[[ 1 ]],QuadraticEvaluation
center :
[0]
constant :
[0]
linear :
[[ 0 ]]
quadratic :
sheet #0
[[ 2 ]]
] ), trend coefficients=[0.667411,-0.117016,0.000810156])
We observe that the scale and amplitude hyper-parameters have been optimized by the run method. Then we get the metamodel with getMetaModel and evaluate the outputs of the metamodel on the test design of experiments.
krigeageMM = result.getMetaModel()
y_test_MM = krigeageMM(x_test)
The following function plots the kriging data.
def plot_data_kriging(x_test, y_test_MM):
"""Plots (x_test,y_test_MM) from the metamodel as a Curve, in blue"""
graphK = ot.Curve(x_test, y_test_MM)
graphK.setColor("blue")
graphK.setLegend("Kriging")
return graphK
graph = ot.Graph("", "", "", True, "")
graph.add(plot_data_test(x_test, y_test))
graph.add(plot_data_train(x_train, y_train))
graph.add(plot_data_kriging(x_test, y_test_MM))
graph.setAxes(True)
graph.setXTitle("X")
graph.setYTitle("Y")
graph.setLegendPosition("topright")
view = viewer.View(graph)
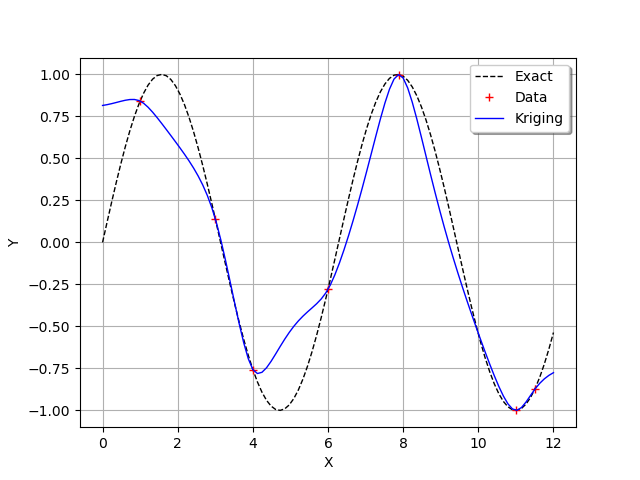
We see that the kriging metamodel is interpolating. This is what is meant by conditioning a gaussian process.
We see that, when the sine function has a strong curvature between two points which are separated by a large distance (e.g. between  and
and  ),
then the kriging metamodel is not close to the function
),
then the kriging metamodel is not close to the function  .
However, when the training points are close (e.g. between
.
However, when the training points are close (e.g. between  and
and  ) or when the function is nearly linear (e.g. between
) or when the function is nearly linear (e.g. between  and ),
then the kriging metamodel is quite accurate.
and ),
then the kriging metamodel is quite accurate.
Compute confidence bounds¶
In order to assess the quality of the metamodel, we can estimate the kriging variance and compute a 95% confidence interval associated with the conditioned gaussian process.
We begin by defining the alpha variable containing the complementary of the confidence level than we want to compute. Then we compute the quantile of the gaussian distribution corresponding to 1-alpha/2. Therefore, the confidence interval is:
![P\in\left(X\in\left[q_{\alpha/2},q_{1-\alpha/2}\right]\right)=1-\alpha.](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzE3Mi4yMTIwNjJwdCcgaGVpZ2h0PScxNC4zNDYzNDhwdCcgdmlld0JveD0nMTA4LjE2NTQ1NSAtMTQuMzQ2MzQgMTcyLjIxMjA2MiAxNC4zNDYzNDgnPgo8ZGVmcz4KPHBhdGggaWQ9J2cxLTAnIGQ9J001LjU3MTEwOC0xLjgwOTIxNUM1LjY5ODYzLTEuODA5MjE1IDUuODczOTczLTEuODA5MjE1IDUuODczOTczLTEuOTkyNTI4UzUuNjk4NjMtMi4xNzU4NDEgNS41NzExMDgtMi4xNzU4NDFIMS4wMDQyMzRDLjg3NjcxMi0yLjE3NTg0MSAuNzAxMzctMi4xNzU4NDEgLjcwMTM3LTEuOTkyNTI4Uy44NzY3MTItMS44MDkyMTUgMS4wMDQyMzQtMS44MDkyMTVINS41NzExMDhaJy8+CjxwYXRoIGlkPSdnNS00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c1LTUwJyBkPSdNMi4yNDc1NzItMS42MjU5MDNDMi4zNzUwOTMtMS43NDU0NTUgMi43MDk4MzgtMi4wMDg0NjggMi44MzczNi0yLjEyMDA1QzMuMzMxNTA3LTIuNTc0MzQ2IDMuODAxNzQzLTMuMDEyNzAyIDMuODAxNzQzLTMuNzM3OTgzQzMuODAxNzQzLTQuNjg2NDI2IDMuMDA0NzMyLTUuMzAwMTI1IDIuMDA4NDY4LTUuMzAwMTI1QzEuMDUyMDU1LTUuMzAwMTI1IC40MjI0MTYtNC41NzQ4NDQgLjQyMjQxNi0zLjg2NTUwNEMuNDIyNDE2LTMuNDc0OTY5IC43MzMyNS0zLjQxOTE3OCAuODQ0ODMyLTMuNDE5MTc4QzEuMDEyMjA0LTMuNDE5MTc4IDEuMjU5Mjc4LTMuNTM4NzMgMS4yNTkyNzgtMy44NDE1OTRDMS4yNTkyNzgtNC4yNTYwNCAuODYwNzcyLTQuMjU2MDQgLjc2NTEzMS00LjI1NjA0Qy45OTYyNjQtNC44Mzc4NTggMS41MzAyNjItNS4wMzcxMTEgMS45MjA3OTctNS4wMzcxMTFDMi42NjIwMTctNS4wMzcxMTEgMy4wNDQ1ODMtNC40MDc0NzIgMy4wNDQ1ODMtMy43Mzc5ODNDMy4wNDQ1ODMtMi45MDkwOTEgMi40NjI3NjUtMi4zMDMzNjIgMS41MjIyOTEtMS4zMzg5NzlMLjUxODA1Ny0uMzAyODY0Qy40MjI0MTYtLjIxNTE5MyAuNDIyNDE2LS4xOTkyNTMgLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMtMS40MjY2NUgzLjU1NDY3QzMuNTMwNzYtMS4yNjcyNDggMy40NjY5OTktLjg2ODc0MiAzLjM3MTM1Ny0uNzE3MzFDMy4zMjM1MzctLjY1MzU0OSAyLjcxNzgwOC0uNjUzNTQ5IDIuNTkwMjg2LS42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzItMS42MjU5MDNaJy8+CjxwYXRoIGlkPSdnNi00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2c2LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnMy0xMScgZD0nTTQuMDY0NzU3LTEuMTE1ODE2QzQuODA1OTc4LTEuOTI4NzY3IDUuMDY4OTkxLTIuOTY0ODgyIDUuMDY4OTkxLTMuMDI4NjQzQzUuMDY4OTkxLTMuMTAwMzc0IDUuMDIxMTcxLTMuMTMyMjU0IDQuOTQ5NDQtMy4xMzIyNTRDNC44NDU4MjgtMy4xMzIyNTQgNC44Mzc4NTgtMy4xMDAzNzQgNC43OTAwMzctMi45MzMwMDFDNC41NjY4NzQtMi4xMjAwNSA0LjA4ODY2Ny0xLjQ5ODM4MSA0LjA2NDc1Ny0xLjQ5ODM4MUM0LjA0ODgxNy0xLjQ5ODM4MSA0LjA0ODgxNy0xLjY5NzYzNCA0LjA0ODgxNy0xLjgyNTE1NkM0LjAzMjg3Ny0zLjIyNzg5NSAzLjEyNDI4NC0zLjUxNDgxOSAyLjU4MjMxNi0zLjUxNDgxOUMxLjQ1ODUzMS0zLjUxNDgxOSAuMzUwNjg1LTIuNDIyOTE0IC4zNTA2ODUtMS4yOTkxMjhDLjM1MDY4NS0uNTEwMDg3IC45MDA2MjMgLjA3OTcwMSAxLjc0NTQ1NSAuMDc5NzAxQzIuMzAzMzYyIC4wNzk3MDEgMi44OTMxNTEtLjExOTU1MiAzLjUyMjc5LS41ODk3ODhDMy42OTgxMzIgLjAzOTg1MSA0LjE2MDM5OSAuMDc5NzAxIDQuMzAzODYxIC4wNzk3MDFDNC43NTgxNTcgLjA3OTcwMSA1LjAyMTE3MS0uMzI2Nzc1IDUuMDIxMTcxLS40NzgyMDdDNS4wMjExNzEtLjU3Mzg0OCA0LjkyNTUyOS0uNTczODQ4IDQuOTAxNjE5LS41NzM4NDhDNC44MTM5NDgtLjU3Mzg0OCA0Ljc5ODAwNy0uNTQ5OTM4IDQuNzc0MDk3LS40OTQxNDdDNC42NDY1NzUtLjE1OTQwMiA0LjM3NTU5Mi0uMTQzNDYyIDQuMzM1NzQxLS4xNDM0NjJDNC4yMjQxNTktLjE0MzQ2MiA0LjA5NjYzOC0uMTQzNDYyIDQuMDY0NzU3LTEuMTE1ODE2Wk0zLjQ2Njk5OS0uODUyODAyQzIuOTAxMTIxLS4zNDI3MTUgMi4yMzE2MzEtLjE0MzQ2MiAxLjc2OTM2NS0uMTQzNDYyQzEuMzU0OTE5LS4xNDM0NjIgLjk5NjI2NC0uMzgyNTY1IC45OTYyNjQtMS4wMjAxNzRDLjk5NjI2NC0xLjI5OTEyOCAxLjEyMzc4Ni0yLjEyMDA1IDEuNDk4MzgxLTIuNjU0MDQ3QzEuODE3MTg2LTMuMTAwMzc0IDIuMjQ3NTcyLTMuMjkxNjU2IDIuNTc0MzQ2LTMuMjkxNjU2QzMuMDEyNzAyLTMuMjkxNjU2IDMuMjU5Nzc2LTIuOTgwODIyIDMuMzYzMzg3LTIuNDk0NjQ1QzMuNDgyOTM5LTEuOTUyNjc3IDMuNDE5MTc4LTEuMzE1MDY4IDMuNDY2OTk5LS44NTI4MDJaJy8+CjxwYXRoIGlkPSdnMy02MScgZD0nTTMuNzA2MTAyLTUuNjQyODM5QzMuNzUzOTIzLTUuNzU0NDIxIDMuNzUzOTIzLTUuNzcwMzYxIDMuNzUzOTIzLTUuNzk0MjcxQzMuNzUzOTIzLTUuODk3ODgzIDMuNjc0MjIyLTUuOTc3NTg0IDMuNTcwNjEtNS45Nzc1ODRDMy40NDMwODgtNS45Nzc1ODQgMy40MTEyMDgtNS44ODE5NDMgMy4zNzkzMjgtNS44MDIyNDJMLjUxODA1NyAxLjY1Nzc4M0MuNDcwMjM3IDEuNzY5MzY1IC40NzAyMzcgMS43ODUzMDUgLjQ3MDIzNyAxLjgwOTIxNUMuNDcwMjM3IDEuOTEyODI3IC41NDk5MzggMS45OTI1MjggLjY1MzU0OSAxLjk5MjUyOEMuNzgxMDcxIDEuOTkyNTI4IC44MTI5NTEgMS44OTY4ODcgLjg0NDgzMiAxLjgxNzE4NkwzLjcwNjEwMi01LjY0MjgzOVonLz4KPHBhdGggaWQ9J2cwLTAnIGQ9J000LjkzNzQ4NCAxMy43MzY0ODhDNC45Mzc0ODQgMTMuNjg4NjY3IDQuOTEzNTc0IDEzLjY2NDc1NyA0Ljg4OTY2NCAxMy42Mjg4OTJDNC4zMzk3MjYgMTMuMDQzMDg4IDMuNTI2Nzc1IDEyLjA3NDcyIDMuMDI0NjU4IDEwLjEyNjAyN0MyLjc0OTY4OSA5LjAzODEwNyAyLjY0MjA5MiA3LjgwNjcyNSAyLjY0MjA5MiA2LjY5NDg5NEMyLjY0MjA5MiAzLjU1MDY4NSAzLjM5NTI2OCAxLjM1MDkzNCA0LjgyOTg4OC0uMjAzMjM4QzQuOTM3NDg0LS4zMTA4MzQgNC45Mzc0ODQtLjMzNDc0NSA0LjkzNzQ4NC0uMzU4NjU1QzQuOTM3NDg0LS40NzgyMDcgNC44NDE4NDMtLjQ3ODIwNyA0Ljc5NDAyMi0uNDc4MjA3QzQuNjE0Njk1LS40NzgyMDcgMy45NjkxMTYgLjIzOTEwMyAzLjgxMzY5OSAuNDE4NDMxQzIuNTk0MjcxIDEuODY1MDA2IDEuODE3MTg2IDQuMDE2OTM2IDEuODE3MTg2IDYuNjgyOTM5QzEuODE3MTg2IDguMzgwNTczIDIuMTE2MDY1IDEwLjc4MzU2MiAzLjY4MjE5MiAxMi44MDM5ODVDMy44MDE3NDMgMTIuOTQ3NDQ3IDQuNTc4ODI5IDEzLjg1NjA0IDQuNzk0MDIyIDEzLjg1NjA0QzQuODQxODQzIDEzLjg1NjA0IDQuOTM3NDg0IDEzLjg1NjA0IDQuOTM3NDg0IDEzLjczNjQ4OFonLz4KPHBhdGggaWQ9J2cwLTEnIGQ9J00zLjY0NjMyNiA2LjY5NDg5NEMzLjY0NjMyNiA0Ljk5NzI2IDMuMzQ3NDQ3IDIuNTk0MjcxIDEuNzgxMzIgLjU3Mzg0OEMxLjY2MTc2OCAuNDMwMzg2IC44ODQ2ODItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjYwOTcxNC0uNDc4MjA3IC41MjYwMjctLjQ1NDI5NiAuNTI2MDI3LS4zNTg2NTVDLjUyNjAyNy0uMzEwODM0IC41NDk5MzgtLjI3NDk2OSAuNTk3NzU4LS4yMzkxMDNDMS4xNzE2MDYgLjM4MjU2NSAxLjk0ODY5MiAxLjM1MDkzNCAyLjQzODg1NCAzLjI1MTgwNkMyLjcxMzgyMyA0LjMzOTcyNiAyLjgyMTQyIDUuNTcxMTA4IDIuODIxNDIgNi42ODI5MzlDMi44MjE0MiA3Ljg5MDQxMSAyLjcxMzgyMyA5LjEwOTgzOCAyLjQwMjk4OSAxMC4yODE0NDVDMS45NDg2OTIgMTEuOTU1MTY4IDEuMjQzMzM3IDEyLjkxMTU4MiAuNjMzNjI0IDEzLjU4MTA3MUMuNTI2MDI3IDEzLjY4ODY2NyAuNTI2MDI3IDEzLjcxMjU3OCAuNTI2MDI3IDEzLjczNjQ4OEMuNTI2MDI3IDEzLjgzMjEzIC42MDk3MTQgMTMuODU2MDQgLjY2OTQ4OSAxMy44NTYwNEMuODQ4ODE3IDEzLjg1NjA0IDEuNTA2MzUxIDEzLjEyNjc3NSAxLjY0OTgxMyAxMi45NTk0MDJDMi44NjkyNCAxMS41MTI4MjcgMy42NDYzMjYgOS4zNjA4OTcgMy42NDYzMjYgNi42OTQ4OTRaJy8+CjxwYXRoIGlkPSdnMC0yJyBkPSdNMi40MTQ5NDQgMTMuODU2MDRINC43MTAzMzZWMTMuMzc3ODMzSDIuODkzMTUxVjBINC43MTAzMzZWLS40NzgyMDdIMi40MTQ5NDRWMTMuODU2MDRaJy8+CjxwYXRoIGlkPSdnMC0zJyBkPSdNMi41NTg0MDYgMTMuODU2MDRWLS40NzgyMDdILjI2MzAxNFYwSDIuMDgwMTk5VjEzLjM3NzgzM0guMjYzMDE0VjEzLjg1NjA0SDIuNTU4NDA2WicvPgo8cGF0aCBpZD0nZzItMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMi01MCcgZD0nTTYuNTUxNDMyLTIuNzQ5Njg5QzYuNzU0NjctMi43NDk2ODkgNi45Njk4NjMtMi43NDk2ODkgNi45Njk4NjMtMi45ODg3OTJTNi43NTQ2Ny0zLjIyNzg5NSA2LjU1MTQzMi0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMy00LjgyOTg4OCAzLjAwMDc0Ny01Ljk3NzU4NCA0LjY4NjQyNi01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3LTUuOTc3NTg0IDYuOTY5ODYzLTUuOTc3NTg0IDYuOTY5ODYzLTYuMjE2Njg3UzYuNzU0NjctNi40NTU3OTEgNi41NTE0MzItNi40NTU3OTFINC42NjI1MTZDMi42MTgxODItNi40NTU3OTEgLjk5MjI3OS00LjkwMTYxOSAuOTkyMjc5LTIuOTg4NzkyUzIuNjE4MTgyIC40NzgyMDcgNC42NjI1MTYgLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IC40NzgyMDcgNi45Njk4NjMgLjQ3ODIwNyA2Ljk2OTg2MyAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMtMS4xNDc2OTYgMS40ODI0NDEtMi43NDk2ODlINi41NTE0MzJaJy8+CjxwYXRoIGlkPSdnNC0xMScgZD0nTTUuNTM1MjQzLTMuMDI0NjU4QzUuNTM1MjQzLTQuMTg0MzA5IDQuODc3NzA5LTUuMjcyMjI5IDMuNjEwNDYxLTUuMjcyMjI5QzIuMDQ0MzM0LTUuMjcyMjI5IC40NzgyMDctMy41NjI2NCAuNDc4MjA3LTEuODY1MDA2Qy40NzgyMDctLjgyNDkwNyAxLjEyMzc4NiAuMTE5NTUyIDIuMzQzMjEzIC4xMTk1NTJDMy4wODQ0MzMgLjExOTU1MiAzLjk2OTExNi0uMTY3MzcyIDQuODE3OTMzLS44ODQ2ODJDNC45ODUzMDUtLjIxNTE5MyA1LjM1NTkxNSAuMTE5NTUyIDUuODY5OTg4IC4xMTk1NTJDNi41MTU1NjcgLjExOTU1MiA2LjgzODM1Ni0uNTQ5OTM4IDYuODM4MzU2LS43MDUzNTVDNi44MzgzNTYtLjgxMjk1MSA2Ljc1NDY3LS44MTI5NTEgNi43MTg4MDQtLjgxMjk1MUM2LjYyMzE2My0uODEyOTUxIDYuNjExMjA4LS43NzcwODYgNi41NzUzNDItLjY4MTQ0NUM2LjQ2Nzc0Ni0uMzgyNTY1IDYuMTkyNzc3LS4xMTk1NTIgNS45MDU4NTMtLjExOTU1MkM1LjUzNTI0My0uMTE5NTUyIDUuNTM1MjQzLS44ODQ2ODIgNS41MzUyNDMtMS42MTM5NDhDNi43NTQ2Ny0zLjA3MjQ3OCA3LjA0MTU5NC00LjU3ODgyOSA3LjA0MTU5NC00LjU5MDc4NUM3LjA0MTU5NC00LjY5ODM4MSA2Ljk0NTk1My00LjY5ODM4MSA2LjkxMDA4Ny00LjY5ODM4MUM2LjgwMjQ5MS00LjY5ODM4MSA2Ljc5MDUzNS00LjY2MjUxNiA2Ljc0MjcxNS00LjQ0NzMyM0M2LjU4NzI5OC0zLjkyMTI5NSA2LjI3NjQ2My0yLjk4ODc5MiA1LjUzNTI0My0yLjAwODQ2OFYtMy4wMjQ2NThaTTQuNzgyMDY3LTEuMTcxNjA2QzMuNzMwMDEyLS4yMjcxNDggMi43ODU1NTQtLjExOTU1MiAyLjM2NzEyMy0uMTE5NTUyQzEuNTE4MzA2LS4xMTk1NTIgMS4yNzkyMDMtLjg3MjcyNyAxLjI3OTIwMy0xLjQzNDYyQzEuMjc5MjAzLTEuOTQ4NjkyIDEuNTQyMjE3LTMuMTY4MTIgMS45MTI4MjctMy44MjU2NTRDMi40MDI5ODktNC42NjI1MTYgMy4wNzI0NzgtNS4wMzMxMjYgMy42MTA0NjEtNS4wMzMxMjZDNC43NzAxMTItNS4wMzMxMjYgNC43NzAxMTItMy41MTQ4MTkgNC43NzAxMTItMi41MTA1ODVDNC43NzAxMTItMi4yMTE3MDYgNC43NTgxNTctMS45MDA4NzIgNC43NTgxNTctMS42MDE5OTNDNC43NTgxNTctMS4zNjI4ODkgNC43NzAxMTItMS4zMDMxMTMgNC43ODIwNjctMS4xNzE2MDZaJy8+CjxwYXRoIGlkPSdnNC01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnNC01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzQtODAnIGQ9J00zLjUzODczLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExLTMuODAxNzQzIDguODQ2ODI0LTUuMDIxMTcxIDguODQ2ODI0LTYuMzg0MDZDOC44NDY4MjQtNy4zMTY1NjMgOC4wNTc3ODMtOC4xNjUzOCA2LjU1MTQzMi04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3LTguMTY1MzggMi41MjI1NC04LjE2NTM4IDIuNTIyNTQtNy45MzgyMzJDMi41MjI1NC03LjgxODY4IDIuNjMwMTM3LTcuODE4NjggMi44MDk0NjUtNy44MTg2OEMzLjUzODczLTcuODE4NjggMy41Mzg3My03LjcyMzAzOSAzLjUzODczLTcuNTkxNTMyQzMuNTM4NzMtNy41Njc2MjEgMy41Mzg3My03LjQ5NTg5IDMuNDkwOTA5LTcuMzE2NTYzTDEuODc2OTYxLS44ODQ2ODJDMS43NjkzNjUtLjQ2NjI1MiAxLjc0NTQ1NS0uMzQ2NyAuOTA4NTkzLS4zNDY3Qy42ODE0NDUtLjM0NjcgLjU2MTg5My0uMzQ2NyAuNTYxODkzLS4xMzE1MDdDLjU2MTg5MyAwIC42Njk0ODkgMCAuNzQxMjIgMEMuOTY4MzY5IDAgMS4yMDc0NzItLjAyMzkxIDEuNDM0NjItLjAyMzkxSDIuODMzMzc1QzMuMDYwNTIzLS4wMjM5MSAzLjMxMTU4MiAwIDMuNTM4NzMgMEMzLjYzNDM3MSAwIDMuNzY1ODc4IDAgMy43NjU4NzgtLjIyNzE0OEMzLjc2NTg3OC0uMzQ2NyAzLjY1ODI4MS0uMzQ2NyAzLjQ3ODk1NC0uMzQ2N0MyLjc2MTY0NC0uMzQ2NyAyLjc0OTY4OS0uNDMwMzg2IDIuNzQ5Njg5LS41NDk5MzhDMi43NDk2ODktLjYwOTcxNCAyLjc2MTY0NC0uNjkzNCAyLjc3MzU5OS0uNzUzMTc2TDMuNTM4NzMtMy44MDE3NDNaTTQuMzk5NTAyLTcuMzUyNDI4QzQuNTA3MDk4LTcuNzk0NzcgNC41NTQ5MTktNy44MTg2OCA1LjAyMTE3MS03LjgxODY4SDYuMjA0NzMyQzcuMTAxMzctNy44MTg2OCA3Ljg0MjU5LTcuNTMxNzU2IDcuODQyNTktNi42MzUxMThDNy44NDI1OS02LjMyNDI4NCA3LjY4NzE3My01LjMwODA5NSA3LjEzNzIzNS00Ljc1ODE1N0M2LjkzMzk5OC00LjU0Mjk2NCA2LjM2MDE0OS00LjA4ODY2NyA1LjI3MjIyOS00LjA4ODY2N0gzLjU4NjU1TDQuMzk5NTAyLTcuMzUyNDI4WicvPgo8cGF0aCBpZD0nZzQtODgnIGQ9J001LjY3ODcwNS00Ljg1Mzc5OEw0LjU1NDkxOS03LjQ3MTk4QzQuNzEwMzM2LTcuNzU4OTA0IDUuMDY4OTkxLTcuODA2NzI1IDUuMjEyNDUzLTcuODE4NjhDNS4yODQxODQtNy44MTg2OCA1LjQxNTY5MS03LjgzMDYzNSA1LjQxNTY5MS04LjAzMzg3M0M1LjQxNTY5MS04LjE2NTM4IDUuMzA4MDk1LTguMTY1MzggNS4yMzYzNjQtOC4xNjUzOEM1LjAzMzEyNi04LjE2NTM4IDQuNzk0MDIyLTguMTQxNDY5IDQuNTkwNzg1LTguMTQxNDY5SDMuODk3Mzg1QzMuMTY4MTItOC4xNDE0NjkgMi42NDIwOTItOC4xNjUzOCAyLjYzMDEzNy04LjE2NTM4QzIuNTM0NDk2LTguMTY1MzggMi40MTQ5NDQtOC4xNjUzOCAyLjQxNDk0NC03LjkzODIzMkMyLjQxNDk0NC03LjgxODY4IDIuNTIyNTQtNy44MTg2OCAyLjY3Nzk1OC03LjgxODY4QzMuMzcxMzU3LTcuODE4NjggMy40MTkxNzgtNy42OTkxMjggMy41Mzg3My03LjQxMjIwNEw0Ljk2MTM5NS00LjA4ODY2N0wyLjM2NzEyMy0xLjMxNTA2OEMxLjkzNjczNy0uODQ4ODE3IDEuNDIyNjY1LS4zOTQ1MjEgLjUzNzk4My0uMzQ2N0MuMzk0NTIxLS4zMzQ3NDUgLjI5ODg3OS0uMzM0NzQ1IC4yOTg4NzktLjExOTU1MkMuMjk4ODc5LS4wODM2ODYgLjMxMDgzNCAwIC40NDIzNDEgMEMuNjA5NzE0IDAgLjc4OTA0MS0uMDIzOTEgLjk1NjQxMy0uMDIzOTFIMS41MTgzMDZDMS45MDA4NzItLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEtLjIxNTE5M0MyLjkxNzA2MS0uMzM0NzQ1IDIuODMzMzc1LS4zNDY3IDIuNzYxNjQ0LS4zNDY3QzIuNTIyNTQtLjM3MDYxIDIuMzY3MTIzLS41MDIxMTcgMi4zNjcxMjMtLjY5MzRDMi4zNjcxMjMtLjg5NjYzOCAyLjUxMDU4NS0xLjA0MDEgMi44NTcyODUtMS4zOTg3NTVMMy45MjEyOTUtMi41NTg0MDZDNC4xODQzMDktMi44MzMzNzUgNC44MTc5MzMtMy41MjY3NzUgNS4wODA5NDYtMy43ODk3ODhMNi4zMzYyMzktLjg0ODgxN0M2LjM0ODE5NC0uODI0OTA3IDYuMzk2MDE1LS43MDUzNTUgNi4zOTYwMTUtLjY5MzRDNi4zOTYwMTUtLjU4NTgwMyA2LjEzMzAwMS0uMzcwNjEgNS43NTA0MzYtLjM0NjdDNS42Nzg3MDUtLjM0NjcgNS41NDcxOTgtLjMzNDc0NSA1LjU0NzE5OC0uMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2Ny0uMDIzOTEgNi4zNzIxMDUtLjAyMzkxSDcuNjg3MTczQzcuOTAyMzY2LS4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1LS4yMjcxNDhDOC41NDc5NDUtLjM0NjcgOC40MjgzOTQtLjM0NjcgOC4zMjA3OTctLjM0NjdDNy42MDM0ODctLjM1ODY1NSA3LjU3OTU3Ny0uNDE4NDMxIDcuMzc2MzM5LS44NjA3NzJMNS43OTgyNTctNC41NjY4NzRMNy4zMTY1NjMtNi4xOTI3NzdDNy40MzYxMTUtNi4zMTIzMjkgNy43MTEwODMtNi42MTEyMDggNy44MTg2OC02LjczMDc2QzguMzMyNzUyLTcuMjY4NzQyIDguODEwOTU5LTcuNzU4OTA0IDkuNzc5MzI4LTcuODE4NjhDOS44OTg4NzktNy44MzA2MzUgMTAuMDE4NDMxLTcuODMwNjM1IDEwLjAxODQzMS04LjAzMzg3M0MxMC4wMTg0MzEtOC4xNjUzOCA5LjkxMDgzNC04LjE2NTM4IDkuODYzMDE0LTguMTY1MzhDOS42OTU2NDEtOC4xNjUzOCA5LjUxNjMxNC04LjE0MTQ2OSA5LjM0ODk0MS04LjE0MTQ2OUg4Ljc5OTAwNEM4LjQxNjQzOC04LjE0MTQ2OSA3Ljk5ODAwNy04LjE2NTM4IDcuNjI3Mzk3LTguMTY1MzhDNy41NDM3MTEtOC4xNjUzOCA3LjQwMDI0OS04LjE2NTM4IDcuNDAwMjQ5LTcuOTUwMTg3QzcuNDAwMjQ5LTcuODMwNjM1IDcuNDgzOTM1LTcuODE4NjggNy41NTU2NjYtNy44MTg2OEM3Ljc0Njk0OS03Ljc5NDc3IDcuOTUwMTg3LTcuNjk5MTI4IDcuOTUwMTg3LTcuNDcxOThMNy45MzgyMzItNy40NDgwN0M3LjkyNjI3Ni03LjM2NDM4NCA3LjkwMjM2Ni03LjI0NDgzMiA3Ljc3MDg1OS03LjEwMTM3TDUuNjc4NzA1LTQuODUzNzk4WicvPgo8cGF0aCBpZD0nZzQtMTEzJyBkPSdNNS4yNzIyMjktNS4xNTI2NzdDNS4yNzIyMjktNS4yMTI0NTMgNS4yMjQ0MDgtNS4yNjAyNzQgNS4xNjQ2MzMtNS4yNjAyNzRDNS4wNjg5OTEtNS4yNjAyNzQgNC42MDI3NC00LjgyOTg4OCA0LjM3NTU5Mi00LjQxMTQ1N0M0LjE2MDM5OS00Ljk0OTQ0IDMuNzg5Nzg4LTUuMjcyMjI5IDMuMjc1NzE2LTUuMjcyMjI5QzEuOTI0NzgyLTUuMjcyMjI5IC40NjYyNTItMy41MjY3NzUgLjQ2NjI1Mi0xLjc1NzQxQy40NjYyNTItLjU3Mzg0OCAxLjE1OTY1MSAuMTE5NTUyIDEuOTcyNjAzIC4xMTk1NTJDMi42MDYyMjcgLjExOTU1MiAzLjEzMjI1NC0uMzU4NjU1IDMuMzgzMzEzLS42MzM2MjRMMy4zOTUyNjgtLjYyMTY2OUwyLjk0MDk3MSAxLjE3MTYwNkwyLjgzMzM3NSAxLjYwMTk5M0MyLjcyNTc3OCAxLjk2MDY0OCAyLjU0NjQ1MSAxLjk2MDY0OCAxLjk4NDU1OCAxLjk3MjYwM0MxLjg1MzA1MSAxLjk3MjYwMyAxLjczMzQ5OSAxLjk3MjYwMyAxLjczMzQ5OSAyLjE5OTc1MUMxLjczMzQ5OSAyLjI4MzQzNyAxLjgwNTIzIDIuMzE5MzAzIDEuODg4OTE3IDIuMzE5MzAzQzIuMDU2Mjg5IDIuMzE5MzAzIDIuMjcxNDgyIDIuMjk1MzkyIDIuNDM4ODU0IDIuMjk1MzkySDMuNjU4MjgxQzMuODM3NjA5IDIuMjk1MzkyIDQuMDQwODQ3IDIuMzE5MzAzIDQuMjIwMTc0IDIuMzE5MzAzQzQuMjkxOTA1IDIuMzE5MzAzIDQuNDM1MzY3IDIuMzE5MzAzIDQuNDM1MzY3IDIuMDkyMTU0QzQuNDM1MzY3IDEuOTcyNjAzIDQuMzM5NzI2IDEuOTcyNjAzIDQuMTYwMzk5IDEuOTcyNjAzQzMuNTk4NTA2IDEuOTcyNjAzIDMuNTYyNjQgMS44ODg5MTcgMy41NjI2NCAxLjc5MzI3NUMzLjU2MjY0IDEuNzMzNDk5IDMuNTc0NTk1IDEuNzIxNTQ0IDMuNjEwNDYxIDEuNTY2MTI3TDUuMjcyMjI5LTUuMTUyNjc3Wk0zLjU4NjU1LTEuNDIyNjY1QzMuNTI2Nzc1LTEuMjE5NDI3IDMuNTI2Nzc1LTEuMTk1NTE3IDMuMzU5NDAyLS45NjgzNjlDMy4wOTYzODktLjYzMzYyNCAyLjU3MDM2MS0uMTE5NTUyIDIuMDA4NDY4LS4xMTk1NTJDMS41MTgzMDYtLjExOTU1MiAxLjI0MzMzNy0uNTYxODkzIDEuMjQzMzM3LTEuMjY3MjQ4QzEuMjQzMzM3LTEuOTI0NzgyIDEuNjEzOTQ4LTMuMjYzNzYxIDEuODQxMDk2LTMuNzY1ODc4QzIuMjQ3NTcyLTQuNjAyNzQgMi44MDk0NjUtNS4wMzMxMjYgMy4yNzU3MTYtNS4wMzMxMjZDNC4wNjQ3NTctNS4wMzMxMjYgNC4yMjAxNzQtNC4wNTI4MDIgNC4yMjAxNzQtMy45NTcxNjFDNC4yMjAxNzQtMy45NDUyMDUgNC4xODQzMDktMy43ODk3ODggNC4xNzIzNTQtMy43NjU4NzhMMy41ODY1NS0xLjQyMjY2NVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzEwOC4xNjU0NTUnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c0LTgwJy8+Cjx1c2UgeD0nMTIwLjY1NzM4MycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzItNTAnLz4KPHVzZSB4PScxMzEuOTQ4MzUxJyB5PSctMTMuODY4MTQ1JyB4bGluazpocmVmPScjZzAtMCcvPgo8dXNlIHg9JzEzNy40Mjc4MzMnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c0LTg4Jy8+Cjx1c2UgeD0nMTUxLjQwMzc3MScgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzItNTAnLz4KPHVzZSB4PScxNjIuNjk0NzM5JyB5PSctMTMuODY4MTQ1JyB4bGluazpocmVmPScjZzAtMicvPgo8dXNlIHg9JzE2Ny42NzYwNzQnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c0LTExMycvPgo8dXNlIHg9JzE3Mi44NjYyODInIHk9Jy0yLjMyNDY3MicgeGxpbms6aHJlZj0nI2czLTExJy8+Cjx1c2UgeD0nMTc4LjMwNTIyMScgeT0nLTIuMzI0NjcyJyB4bGluazpocmVmPScjZzMtNjEnLz4KPHVzZSB4PScxODIuNTM5NDA0JyB5PSctMi4zMjQ2NzInIHhsaW5rOmhyZWY9JyNnNS01MCcvPgo8dXNlIHg9JzE4Ny4yNzE3MTknIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c0LTU5Jy8+Cjx1c2UgeD0nMTkyLjUxNTg3OCcgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzQtMTEzJy8+Cjx1c2UgeD0nMTk3LjcwNjA4NScgeT0nLTIuMzI0NjcyJyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScyMDEuOTQwMjY4JyB5PSctMi4zMjQ2NzInIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nMjA4LjUyNjc3NScgeT0nLTIuMzI0NjcyJyB4bGluazpocmVmPScjZzMtMTEnLz4KPHVzZSB4PScyMTMuOTY1NzE0JyB5PSctMi4zMjQ2NzInIHhsaW5rOmhyZWY9JyNnMy02MScvPgo8dXNlIHg9JzIxOC4xOTk4OTcnIHk9Jy0yLjMyNDY3MicgeGxpbms6aHJlZj0nI2c1LTUwJy8+Cjx1c2UgeD0nMjIyLjkzMjIxMicgeT0nLTEzLjg2ODE0NScgeGxpbms6aHJlZj0nI2cwLTMnLz4KPHVzZSB4PScyMjcuOTEzNTQ3JyB5PSctMTMuODY4MTQ1JyB4bGluazpocmVmPScjZzAtMScvPgo8dXNlIHg9JzIzNi43MTM4MzYnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c2LTYxJy8+Cjx1c2UgeD0nMjQ5LjEzOTMxNycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzYtNDknLz4KPHVzZSB4PScyNTcuNjQ4OTcxJyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjY5LjYwNDEzMScgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzQtMTEnLz4KPHVzZSB4PScyNzcuMTI1ODU1JyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNC01OCcvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
alpha = 0.05
def computeQuantileAlpha(alpha):
bilateralCI = ot.Normal().computeBilateralConfidenceInterval(1 - alpha)
return bilateralCI.getUpperBound()[0]
quantileAlpha = computeQuantileAlpha(alpha)
print("alpha=%f" % (alpha))
print("Quantile alpha=%f" % (quantileAlpha))
alpha=0.050000
Quantile alpha=1.959964
In order to compute the kriging error, we can consider the conditional variance. The getConditionalCovariance method returns the covariance matrix covGrid evaluated at each points in the given sample. Then we can use the diagonal coefficients in order to get the marginal conditional kriging variance. Since this is a variance, we use the square root in order to compute the standard deviation. However, some coefficients in the diagonal are very close to zero and nonpositive, which leads to an exception of the sqrt function. This is why we add an epsilon on the diagonal (nugget factor), which prevents this issue.
sqrt = ot.SymbolicFunction(["x"], ["sqrt(x)"])
epsilon = ot.Sample(n_test, [1.0e-8])
conditionalVariance = result.getConditionalMarginalVariance(x_test) + epsilon
conditionalSigma = sqrt(conditionalVariance)
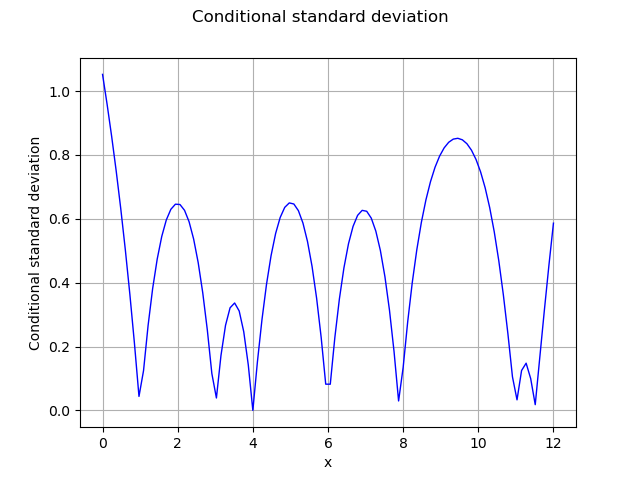
The following figure presents the conditional standard deviation depending on  .
.
graph = ot.Graph(
"Conditional standard deviation", "x", "Conditional standard deviation", True, ""
)
curve = ot.Curve(x_test, conditionalSigma)
graph.add(curve)
view = viewer.View(graph)
We now compute the bounds of the confidence interval. For this purpose we define a small function computeBoundsConfidenceInterval :
def computeBoundsConfidenceInterval(quantileAlpha):
dataLower = [
[y_test_MM[i, 0] - quantileAlpha * conditionalSigma[i, 0]]
for i in range(n_test)
]
dataUpper = [
[y_test_MM[i, 0] + quantileAlpha * conditionalSigma[i, 0]]
for i in range(n_test)
]
dataLower = ot.Sample(dataLower)
dataUpper = ot.Sample(dataUpper)
return dataLower, dataUpper
In order to create the graphics containing the bounds of the confidence interval, we use the Polygon. This will create a colored surface associated to the confidence interval. In order to do this, we create the nodes of the polygons at the lower level vLow and at the upper level vUp. Then we assemble these nodes to create the polygons. That is what we do inside the plot_kriging_bounds function.
def plot_kriging_bounds(dataLower, dataUpper, n_test, color=[120, 1.0, 1.0]):
"""
From two lists containing the lower and upper bounds of the region,
create a PolygonArray.
Default color is green given by HSV values in color list.
"""
vLow = [[x_test[i, 0], dataLower[i, 0]] for i in range(n_test)]
vUp = [[x_test[i, 0], dataUpper[i, 0]] for i in range(n_test)]
myHSVColor = ot.Polygon.ConvertFromHSV(color[0], color[1], color[2])
polyData = [[vLow[i], vLow[i + 1], vUp[i + 1], vUp[i]] for i in range(n_test - 1)]
polygonList = [
ot.Polygon(polyData[i], myHSVColor, myHSVColor) for i in range(n_test - 1)
]
boundsPoly = ot.PolygonArray(polygonList)
return boundsPoly
We define two small lists to draw three different confidence intervals (defined by the alpha value) :
alphas = [0.05, 0.1, 0.2]
# three different green colors defined by HSV values
mycolors = [[120, 1.0, 1.0], [120, 1.0, 0.75], [120, 1.0, 0.5]]
We are ready to display all the previous information and the three confidence intervals we want.
sphinx_gallery_thumbnail_number = 4
graph = ot.Graph("", "", "", True, "")
graph.add(plot_data_test(x_test, y_test))
graph.add(plot_data_train(x_train, y_train))
graph.add(plot_data_kriging(x_test, y_test_MM))
# Now we loop over the different values :
for idx, v in enumerate(alphas):
quantileAlpha = computeQuantileAlpha(v)
vLow, vUp = computeBoundsConfidenceInterval(quantileAlpha)
boundsPoly = plot_kriging_bounds(vLow, vUp, n_test, mycolors[idx])
boundsPoly.setLegend(" %d%% bounds" % ((1.0 - v) * 100))
graph.add(boundsPoly)
graph.setAxes(True)
graph.setXTitle("X")
graph.setYTitle("Y")
graph.setLegendPosition("topright")
view = viewer.View(graph)
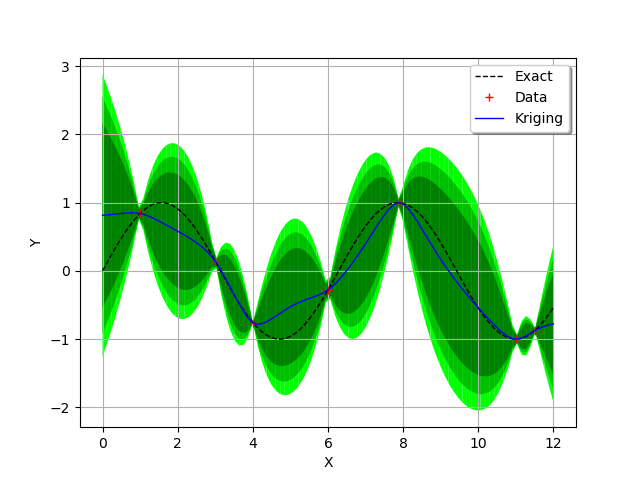
We see that the confidence intervals are small in the regions where two
consecutive training points are close to each other
(e.g. between and ) and large when the two points
are not (e.g. between  and ) or when the curvature
of the function is large (between and ).
and ) or when the curvature
of the function is large (between and ).
plt.show()
References¶
Metamodeling with Gaussian processes, Bertrand Iooss, EDF R&D, 2014, www.gdr-mascotnum.fr/media/sssamo14_iooss.pdf