Note
Go to the end to download the full example code
Posterior sampling using a PythonDistribution¶
In this example we are going to show how to do Bayesian inference using the RandomWalkMetropolisHastings algorithm
in a statistical model defined through a PythonDistribution.
This method is illustrated on a simple lifetime study test-case, which involves censored data, as described hereafter.
In the following, we assume that the lifetime  of an industrial component follows the Weibull distribution
of an industrial component follows the Weibull distribution  ,
with CDF given by
,
with CDF given by  .
.
Our goal is to estimate the model parameters  based on
a dataset of recorded failures
based on
a dataset of recorded failures  some of which
correspond to actual failures, and the remaining are right-censored.
Let
some of which
correspond to actual failures, and the remaining are right-censored.
Let  represent the nature of each
datum,
represent the nature of each
datum,  if
if  corresponds to an actual failure,
corresponds to an actual failure,
 if it is right-censored.
if it is right-censored.
Note that the likelihood of each recorded failure is given by the Weibull density:

On the other hand, the likelihood of each right-censored observation is given by:

Furthermore, assume that the prior information available on is represented by independent prior laws,
whose respective densities are denoted by  and
and 
The posterior distribution of  represents the update of the prior information on given the dataset.
Its PDF is known up to a multiplicative constant:
represents the update of the prior information on given the dataset.
Its PDF is known up to a multiplicative constant:
![\pi(\alpha, \beta | (t_1, f_1), \ldots, (t_n, f_n) ) \propto \pi(\alpha)\pi(\beta) \left(\frac{\alpha}{\beta}\right)^{\sum_i f_i}
\left(\prod_{f_i = 1} \frac{t_i}{\beta}\right)^{\alpha-1} \exp\left[-\sum_{i=1}^n\left(\frac{t_i}{\beta}\right)^\alpha\right].](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMiAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc0MjEuODgxMjMzcHQnIGhlaWdodD0nMzguNTU1NjczcHQnIHZpZXdCb3g9JzAgLTM5Ljc1MTE4NiA0MjEuODgxMjMzIDM4LjU1NTY3Myc+CjxkZWZzPgo8cGF0aCBpZD0nZzItMCcgZD0nTTUuNTcxMTA4LTEuODA5MjE1QzUuNjk4NjMtMS44MDkyMTUgNS44NzM5NzMtMS44MDkyMTUgNS44NzM5NzMtMS45OTI1MjhTNS42OTg2My0yLjE3NTg0MSA1LjU3MTEwOC0yLjE3NTg0MUgxLjAwNDIzNEMuODc2NzEyLTIuMTc1ODQxIC43MDEzNy0yLjE3NTg0MSAuNzAxMzctMS45OTI1MjhTLjg3NjcxMi0xLjgwOTIxNSAxLjAwNDIzNC0xLjgwOTIxNUg1LjU3MTEwOFonLz4KPHBhdGggaWQ9J2c0LTEwNScgZD0nTTIuMDgwMTk5LTMuNzMwMDEyQzIuMDgwMTk5LTMuODczNDc0IDEuOTcyNjAzLTMuOTY5MTE2IDEuODM1MTE4LTMuOTY5MTE2QzEuNjczNzI0LTMuOTY5MTE2IDEuNTAwMzc0LTMuODEzNjk5IDEuNTAwMzc0LTMuNjQwMzQ5QzEuNTAwMzc0LTMuNDkwOTA5IDEuNjA3OTctMy40MDEyNDUgMS43Mzk0NzctMy40MDEyNDVDMS45MzA3Ni0zLjQwMTI0NSAyLjA4MDE5OS0zLjU4MDU3MyAyLjA4MDE5OS0zLjczMDAxMlpNMS43MjE1NDQtMS42NDM4MzZDMS43NDU0NTUtMS43MDM2MTEgMS43OTkyNTMtMS44NDcwNzMgMS44MjMxNjMtMS45MDA4NzJDMS44NDEwOTYtMS45NTQ2NyAxLjg2NTAwNi0yLjAxNDQ0NiAxLjg2NTAwNi0yLjExNjA2NUMxLjg2NTAwNi0yLjQ1MDgwOSAxLjU2NjEyNy0yLjYzNjExNSAxLjI2NzI0OC0yLjYzNjExNUMuNjU3NTM0LTIuNjM2MTE1IC4zNjQ2MzMtMS44NDcwNzMgLjM2NDYzMy0xLjcxNTU2N0MuMzY0NjMzLTEuNjg1Njc5IC4zODg1NDMtMS42MzE4OCAuNDcyMjI5LTEuNjMxODhTLjU3Mzg0OC0xLjY2Nzc0NiAuNTkxNzgxLTEuNzIxNTQ0Qy43NTkxNTMtMi4zMDEzNyAxLjA3NTk2NS0yLjQzODg1NCAxLjI0MzMzNy0yLjQzODg1NEMxLjM2Mjg4OS0yLjQzODg1NCAxLjQwNDczMi0yLjM2MTE0NiAxLjQwNDczMi0yLjIyMzY2MUMxLjQwNDczMi0yLjEwNDExIDEuMzY4ODY3LTIuMDE0NDQ2IDEuMzU2OTEyLTEuOTcyNjAzTDEuMDQ2MDc3LTEuMjA3NDcyQy45NzQzNDYtMS4wMzQxMjIgLjk3NDM0Ni0xLjAyMjE2NyAuODk2NjM4LS44MTg5MjlDLjgxODkyOS0uNjM5NjAxIC43ODkwNDEtLjU2MTg5MyAuNzg5MDQxLS40NjAyNzRDLjc4OTA0MS0uMTU1NDE3IDEuMDY0MDEgLjA1OTc3NiAxLjM5Mjc3NyAuMDU5Nzc2QzEuOTk2NTEzIC4wNTk3NzYgMi4yOTUzOTItLjcyOTI2NSAyLjI5NTM5Mi0uODYwNzcyQzIuMjk1MzkyLS44NzI3MjcgMi4yODk0MTUtLjk0NDQ1OCAyLjE4MTgxOC0uOTQ0NDU4QzIuMDk4MTMyLS45NDQ0NTggMi4wOTIxNTQtLjkxNDU3IDIuMDU2Mjg5LS44MDA5OTZDMS45NjA2NDgtLjQ5NjEzOSAxLjcxNTU2Ny0uMTM3NDg0IDEuNDEwNzEtLjEzNzQ4NEMxLjMwMzExMy0uMTM3NDg0IDEuMjQ5MzE1LS4yMDkyMTUgMS4yNDkzMTUtLjM1MjY3N0MxLjI0OTMxNS0uNDcyMjI5IDEuMjg1MTgxLS41NjE4OTMgMS4zNjI4ODktLjc0NzE5OEwxLjcyMTU0NC0xLjY0MzgzNlonLz4KPHBhdGggaWQ9J2cwLTgwJyBkPSdNNC4xMjA1NDggNC4xMjg1MThDNC4yMTYxODkgNC4wMjQ5MDcgNC4yMTYxODkgNC4wMDg5NjYgNC4yMTYxODkgMy45ODUwNTZDNC4yMTYxODkgMy45NzcwODYgNC4yMTYxODkgMy45MzcyMzUgNC4xNTI0MjggMy44NTc1MzRMMS40MjY2NSAuMzY2NjI1SDQuNzQyMjE3QzUuNzU0NDIxIC4zNjY2MjUgNi4zNjgxMiAuNDg2MTc3IDYuNzM0NzQ1IC42MDU3MjlDNy4zODAzMjQgLjgyMDkyMiA3Ljk4NjA1MiAxLjI5MTE1OCA4LjIxNzE4NiAxLjkxMjgyN0g4LjQ2NDI1OUw3LjczODk3OSAwSC43MTczMUMuNDc4MjA3IDAgLjQ3MDIzNyAuMDA3OTcgLjQ3MDIzNyAuMjg2OTI0TDMuNTQ2NyA0LjI0MDFMLjU0OTkzOCA3LjczMTAwOUMuNDc4MjA3IDcuODE4NjggLjQ3MDIzNyA3LjgxODY4IC40NzAyMzcgNy44NTg1MzFDLjQ3MDIzNyA3Ljk3MDExMiAuNTczODQ4IDcuOTcwMTEyIC43MTczMSA3Ljk3MDExMkg3LjczODk3OUw4LjQ2NDI1OSA1LjkzNzczM0g4LjIxNzE4NkM4LjAyNTkwMyA2LjQ4NzY3MSA3LjQ4MzkzNSA3LjA2OTQ4OSA2LjUxOTU1MiA3LjMxNjU2M0M1Ljk1MzY3NCA3LjQ2MDAyNSA1LjM3OTgyNiA3LjQ4MzkzNSA0Ljc5ODAwNyA3LjQ4MzkzNUgxLjI0MzMzN0w0LjEyMDU0OCA0LjEyODUxOFonLz4KPHBhdGggaWQ9J2c1LTExJyBkPSdNNC4wNjQ3NTctMS4xMTU4MTZDNC44MDU5NzgtMS45Mjg3NjcgNS4wNjg5OTEtMi45NjQ4ODIgNS4wNjg5OTEtMy4wMjg2NDNDNS4wNjg5OTEtMy4xMDAzNzQgNS4wMjExNzEtMy4xMzIyNTQgNC45NDk0NC0zLjEzMjI1NEM0Ljg0NTgyOC0zLjEzMjI1NCA0LjgzNzg1OC0zLjEwMDM3NCA0Ljc5MDAzNy0yLjkzMzAwMUM0LjU2Njg3NC0yLjEyMDA1IDQuMDg4NjY3LTEuNDk4MzgxIDQuMDY0NzU3LTEuNDk4MzgxQzQuMDQ4ODE3LTEuNDk4MzgxIDQuMDQ4ODE3LTEuNjk3NjM0IDQuMDQ4ODE3LTEuODI1MTU2QzQuMDMyODc3LTMuMjI3ODk1IDMuMTI0Mjg0LTMuNTE0ODE5IDIuNTgyMzE2LTMuNTE0ODE5QzEuNDU4NTMxLTMuNTE0ODE5IC4zNTA2ODUtMi40MjI5MTQgLjM1MDY4NS0xLjI5OTEyOEMuMzUwNjg1LS41MTAwODcgLjkwMDYyMyAuMDc5NzAxIDEuNzQ1NDU1IC4wNzk3MDFDMi4zMDMzNjIgLjA3OTcwMSAyLjg5MzE1MS0uMTE5NTUyIDMuNTIyNzktLjU4OTc4OEMzLjY5ODEzMiAuMDM5ODUxIDQuMTYwMzk5IC4wNzk3MDEgNC4zMDM4NjEgLjA3OTcwMUM0Ljc1ODE1NyAuMDc5NzAxIDUuMDIxMTcxLS4zMjY3NzUgNS4wMjExNzEtLjQ3ODIwN0M1LjAyMTE3MS0uNTczODQ4IDQuOTI1NTI5LS41NzM4NDggNC45MDE2MTktLjU3Mzg0OEM0LjgxMzk0OC0uNTczODQ4IDQuNzk4MDA3LS41NDk5MzggNC43NzQwOTctLjQ5NDE0N0M0LjY0NjU3NS0uMTU5NDAyIDQuMzc1NTkyLS4xNDM0NjIgNC4zMzU3NDEtLjE0MzQ2MkM0LjIyNDE1OS0uMTQzNDYyIDQuMDk2NjM4LS4xNDM0NjIgNC4wNjQ3NTctMS4xMTU4MTZaTTMuNDY2OTk5LS44NTI4MDJDMi45MDExMjEtLjM0MjcxNSAyLjIzMTYzMS0uMTQzNDYyIDEuNzY5MzY1LS4xNDM0NjJDMS4zNTQ5MTktLjE0MzQ2MiAuOTk2MjY0LS4zODI1NjUgLjk5NjI2NC0xLjAyMDE3NEMuOTk2MjY0LTEuMjk5MTI4IDEuMTIzNzg2LTIuMTIwMDUgMS40OTgzODEtMi42NTQwNDdDMS44MTcxODYtMy4xMDAzNzQgMi4yNDc1NzItMy4yOTE2NTYgMi41NzQzNDYtMy4yOTE2NTZDMy4wMTI3MDItMy4yOTE2NTYgMy4yNTk3NzYtMi45ODA4MjIgMy4zNjMzODctMi40OTQ2NDVDMy40ODI5MzktMS45NTI2NzcgMy40MTkxNzgtMS4zMTUwNjggMy40NjY5OTktLjg1MjgwMlonLz4KPHBhdGggaWQ9J2c1LTEwMicgZD0nTTMuMDUyNTUzLTMuMTcyMTA1SDMuNzkzNzczQzMuOTUzMTc2LTMuMTcyMTA1IDQuMDQ4ODE3LTMuMTcyMTA1IDQuMDQ4ODE3LTMuMzIzNTM3QzQuMDQ4ODE3LTMuNDM1MTE4IDMuOTQ1MjA1LTMuNDM1MTE4IDMuODA5NzE0LTMuNDM1MTE4SDMuMTAwMzc0QzMuMjI3ODk1LTQuMTUyNDI4IDMuMzA3NTk3LTQuNjA2NzI1IDMuMzg3Mjk4LTQuOTY1MzhDMy40MTkxNzgtNS4xMDA4NzIgMy40NDMwODgtNS4xODg1NDMgMy41NjI2NC01LjI4NDE4NEMzLjY2NjI1Mi01LjM3MTg1NiAzLjczMDAxMi01LjM4Nzc5NiAzLjgxNzY4NC01LjM4Nzc5NkMzLjkzNzIzNS01LjM4Nzc5NiA0LjA2NDc1Ny01LjM2Mzg4NSA0LjE2ODM2OS01LjMwMDEyNUM0LjEyODUxOC01LjI4NDE4NCA0LjA4MDY5Ny01LjI2MDI3NCA0LjA0MDg0Ny01LjIzNjM2NEMzLjkwNTM1NS01LjE2NDYzMyAzLjgwOTcxNC01LjAyMTE3MSAzLjgwOTcxNC00Ljg2MTc2OEMzLjgwOTcxNC00LjY3ODQ1NiAzLjk1MzE3Ni00LjU2Njg3NCA0LjEyODUxOC00LjU2Njg3NEM0LjM1OTY1MS00LjU2Njg3NCA0LjU3NDg0NC00Ljc2NjEyNyA0LjU3NDg0NC01LjA0NTA4MUM0LjU3NDg0NC01LjQxOTY3NiA0LjE5MjI3OS01LjYxMDk1OSAzLjgwOTcxNC01LjYxMDk1OUMzLjUzODczLTUuNjEwOTU5IDMuMDM2NjEzLTUuNDgzNDM3IDIuNzgxNTY5LTQuNzUwMTg3QzIuNzA5ODM4LTQuNTY2ODc0IDIuNzA5ODM4LTQuNTUwOTM0IDIuNDk0NjQ1LTMuNDM1MTE4SDEuODk2ODg3QzEuNzM3NDg0LTMuNDM1MTE4IDEuNjQxODQzLTMuNDM1MTE4IDEuNjQxODQzLTMuMjgzNjg2QzEuNjQxODQzLTMuMTcyMTA1IDEuNzQ1NDU1LTMuMTcyMTA1IDEuODgwOTQ2LTMuMTcyMTA1SDIuNDQ2ODI0TDEuODcyOTc2LS4wNzk3MDFDMS43MjE1NDQgLjcyNTI4IDEuNjAxOTkzIDEuNDAyNzQgMS4xNzk1NzcgMS40MDI3NEMxLjE1NTY2NiAxLjQwMjc0IC45ODgyOTQgMS40MDI3NCAuODM2ODYyIDEuMzA3MDk4QzEuMjAzNDg3IDEuMjE5NDI3IDEuMjAzNDg3IC44ODQ2ODIgMS4yMDM0ODcgLjg3NjcxMkMxLjIwMzQ4NyAuNjkzNCAxLjA2MDAyNSAuNTgxODE4IC44ODQ2ODIgLjU4MTgxOEMuNjY5NDg5IC41ODE4MTggLjQzODM1NiAuNzY1MTMxIC40MzgzNTYgMS4wNjc5OTVDLjQzODM1NiAxLjQwMjc0IC43ODEwNzEgMS42MjU5MDMgMS4xNzk1NzcgMS42MjU5MDNDMS42NjU3NTMgMS42MjU5MDMgMi4wMDA0OTggMS4xMTU4MTYgMi4xMDQxMSAuOTE2NTYzQzIuMzkxMDM0IC4zOTA1MzUgMi41NzQzNDYtLjYwNTcyOSAyLjU5MDI4Ni0uNjg1NDNMMy4wNTI1NTMtMy4xNzIxMDVaJy8+CjxwYXRoIGlkPSdnNS0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzUtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2cxLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cxLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzEtMzInIGQ9J005LjA1MDA2MiAzNS4yNTU3OTFDOS4wNTAwNjIgMzUuMjE5OTI1IDkuMDUwMDYyIDM1LjE5NjAxNSA4Ljk3ODMzMSAzNS4xMTIzMjlDNy44MzA2MzUgMzMuNzI1NTI5IDYuODc0MjIyIDMyLjE5NTI2OCA2LjE2ODg2NyAzMC41MzM0OTlDNC42MDI3NCAyNi44NzUyMTggMy45ODEwNzEgMjIuNTk1MjY4IDMuOTgxMDcxIDE3LjQ1NDU0NUMzLjk4MTA3MSAxMi4zNjE2NDQgNC41NjY4NzQgNy44OTA0MTEgNi4zMzYyMzkgMy45NjkxMTZDNy4wMjk2MzkgMi40NTA4MDkgNy45MzgyMzIgMS4wNDAxIDkuMDAyMjQyLS4yNTEwNTlDOS4wMjYxNTItLjI4NjkyNCA5LjA1MDA2Mi0uMzEwODM0IDkuMDUwMDYyLS4zNTg2NTVDOS4wNTAwNjItLjQ3ODIwNyA4Ljk2NjM3Ni0uNDc4MjA3IDguNzg3MDQ5LS40NzgyMDdTOC41ODM4MTEtLjQ3ODIwNyA4LjU1OTktLjQ1NDI5NkM4LjU0Nzk0NS0uNDQyMzQxIDcuODA2NzI1IC4yNzQ5NjkgNi44NzQyMjIgMS41OTAwMzdDNC43OTQwMjIgNC41MzEwMDkgMy43NDE5NjggOC4wNDU4MjggMy4yMDM5ODUgMTEuNjA4NDY4QzIuOTE3MDYxIDEzLjUzMzI1IDIuODIxNDIgMTUuNDkzODk4IDIuODIxNDIgMTcuNDQyNTlDMi44MjE0MiAyMS45MTM4MjMgMy4zODMzMTMgMjYuNDgwNjk3IDUuMjk2MTM5IDMwLjU2OTM2NUM2LjE0NDk1NiAzMi4zODY1NSA3LjI4MDY5NyAzNC4wMjQ0MDggOC40NjQyNTkgMzUuMjY3NzQ2QzguNTcxODU2IDM1LjM2MzM4NyA4LjU4MzgxMSAzNS4zNzUzNDIgOC43ODcwNDkgMzUuMzc1MzQyQzguOTY2Mzc2IDM1LjM3NTM0MiA5LjA1MDA2MiAzNS4zNzUzNDIgOS4wNTAwNjIgMzUuMjU1NzkxWicvPgo8cGF0aCBpZD0nZzEtMzMnIGQ9J002LjYzNTExOCAxNy40NTQ1NDVDNi42MzUxMTggMTIuOTgzMzEzIDYuMDczMjI1IDguNDE2NDM4IDQuMTYwMzk5IDQuMzI3NzcxQzMuMzExNTgyIDIuNTEwNTg1IDIuMTc1ODQxIC44NzI3MjcgLjk5MjI3OS0uMzcwNjFDLjg4NDY4Mi0uNDY2MjUyIC44NzI3MjctLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUwMjExNy0uNDc4MjA3IC40MDY0NzYtLjQ3ODIwNyAuNDA2NDc2LS4zNTg2NTVDLjQwNjQ3Ni0uMzEwODM0IC40NTQyOTYtLjI1MTA1OSAuNDc4MjA3LS4yMTUxOTNDMS42MjU5MDMgMS4xNzE2MDYgMi41ODIzMTYgMi43MDE4NjggMy4yODc2NzEgNC4zNjM2MzZDNC44NTM3OTggOC4wMjE5MTggNS40NzU0NjcgMTIuMzAxODY4IDUuNDc1NDY3IDE3LjQ0MjU5QzUuNDc1NDY3IDIyLjUzNTQ5MiA0Ljg4OTY2NCAyNy4wMDY3MjUgMy4xMjAyOTkgMzAuOTI4MDJDMi40MjY4OTkgMzIuNDQ2MzI2IDEuNTE4MzA2IDMzLjg1NzAzNiAuNDU0Mjk2IDM1LjE0ODE5NEMuNDQyMzQxIDM1LjE3MjEwNSAuNDA2NDc2IDM1LjIxOTkyNSAuNDA2NDc2IDM1LjI1NTc5MUMuNDA2NDc2IDM1LjM3NTM0MiAuNTAyMTE3IDM1LjM3NTM0MiAuNjY5NDg5IDM1LjM3NTM0MkMuODQ4ODE3IDM1LjM3NTM0MiAuODcyNzI3IDM1LjM3NTM0MiAuODk2NjM4IDM1LjM1MTQzMkMuOTA4NTkzIDM1LjMzOTQ3NyAxLjY0OTgxMyAzNC42MjIxNjcgMi41ODIzMTYgMzMuMzA3MDk4QzQuNjYyNTE2IDMwLjM2NjEyNyA1LjcxNDU3IDI2Ljg1MTMwOCA2LjI1MjU1MyAyMy4yODg2NjdDNi41Mzk0NzcgMjEuMzYzODg1IDYuNjM1MTE4IDE5LjQwMzIzOCA2LjYzNTExOCAxNy40NTQ1NDVaJy8+CjxwYXRoIGlkPSdnMS0zNCcgZD0nTTMuMjg3NjcxIDM1LjM3NTM0Mkg2LjgyNjQwMVYzNC42MzQxMjJINC4wMjg4OTJWLjI2MzAxNEg2LjgyNjQwMVYtLjQ3ODIwN0gzLjI4NzY3MVYzNS4zNzUzNDJaJy8+CjxwYXRoIGlkPSdnMS0zNScgZD0nTTIuOTI5MDE2IDM0LjYzNDEyMkguMTMxNTA3VjM1LjM3NTM0MkgzLjY3MDIzN1YtLjQ3ODIwN0guMTMxNTA3Vi4yNjMwMTRIMi45MjkwMTZWMzQuNjM0MTIyWicvPgo8cGF0aCBpZD0nZzEtODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2cxLTg5JyBkPSdNMTQuNTk3MjYgMTYuNzM3MjM1VjE2LjA5MTY1NkMxMy4wMDcyMjMgMTYuMDkxNjU2IDEyLjYzNjYxMyAxNS41NDE3MTkgMTIuNjM2NjEzIDE0Ljc3NjU4OFYxLjk2MDY0OEMxMi42MzY2MTMgMS4xODM1NjIgMTMuMDE5MTc4IC42NDU1NzkgMTQuNTk3MjYgLjY0NTU3OVYwSC42Njk0ODlWLjY0NTU3OUMyLjI1OTUyNyAuNjQ1NTc5IDIuNjMwMTM3IDEuMTk1NTE3IDIuNjMwMTM3IDEuOTYwNjQ4VjE0Ljc3NjU4OEMyLjYzMDEzNyAxNS41NTM2NzQgMi4yNDc1NzIgMTYuMDkxNjU2IC42Njk0ODkgMTYuMDkxNjU2VjE2LjczNzIzNUg2LjQxOTkyNVYxNi4wOTE2NTZDNC44Mjk4ODggMTYuMDkxNjU2IDQuNDU5Mjc4IDE1LjU0MTcxOSA0LjQ1OTI3OCAxNC43NzY1ODhWLjY0NTU3OUgxMC44MDc0NzJWMTQuNzc2NTg4QzEwLjgwNzQ3MiAxNS41NTM2NzQgMTAuNDI0OTA3IDE2LjA5MTY1NiA4Ljg0NjgyNCAxNi4wOTE2NTZWMTYuNzM3MjM1SDE0LjU5NzI2WicvPgo8cGF0aCBpZD0nZzMtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMy00NycgZD0nTTguNjMxNjMxLS4zODI1NjVDOC41ODM4MTEtLjM4MjU2NSA4LjM5MjUyOC0uMzU4NjU1IDguMzU2NjYzLS4zNTg2NTVDNy40MTIyMDQtLjM1ODY1NSA2Ljc3ODU4LTEuMjkxMTU4IDYuMzcyMTA1LTEuOTEyODI3QzYuMjUyNTUzLTIuMTE2MDY1IDUuOTI5NzYzLTIuNjA2MjI3IDUuNzk4MjU3LTIuODA5NDY1QzYuMDg1MTgxLTMuNDU1MDQ0IDYuODg2MTc3LTQuOTM3NDg0IDguMzA4ODQyLTQuOTM3NDg0QzguMzkyNTI4LTQuOTM3NDg0IDguNTAwMTI1LTQuOTM3NDg0IDguNjMxNjMxLTQuOTAxNjE5QzguNjMxNjMxLTUuMjEyNDUzIDguNjE5Njc2LTUuMjI0NDA4IDguNTk1NzY2LTUuMjQ4MzE5QzguNTEyMDgtNS4yNzIyMjkgOC4zMzI3NTItNS4yODQxODQgOC4yMjUxNTYtNS4yODQxODRDNi43MDY4NDktNS4yODQxODQgNS44MjIxNjctMy44MjU2NTQgNS41MzUyNDMtMy4yMjc4OTVDNS4wNTcwMzYtMy45NTcxNjEgNC44ODk2NjQtNC4yMjAxNzQgNC40NDczMjMtNC41OTA3ODVDMy43MTgwNTctNS4yMjQ0MDggMy4wNjA1MjMtNS4yODQxODQgMi43NjE2NDQtNS4yODQxODRDMS40MzQ2Mi01LjI4NDE4NCAuNjY5NDg5LTMuOTQ1MjA1IC42Njk0ODktMi41NzAzNjFDLjY2OTQ4OS0xLjIzMTM4MiAxLjQxMDcxIC4xMzE1MDcgMi43MjU3NzggLjEzMTUwN0M0LjI0NDA4NSAuMTMxNTA3IDUuMTI4NzY3LTEuMzI3MDI0IDUuNDE1NjkxLTEuOTI0NzgyQzUuODkzODk4LTEuMTk1NTE3IDYuMDYxMjctLjkzMjUwMyA2LjUwMzYxMS0uNTYxODkzQzcuMjMyODc3IC4wNzE3MzEgNy44OTA0MTEgLjEzMTUwNyA4LjE4OTI5IC4xMzE1MDdDOC4zMzI3NTIgLjEzMTUwNyA4LjUyNDAzNSAuMTA3NTk3IDguNjMxNjMxIC4wODM2ODZWLS4zODI1NjVaTTUuMTUyNjc3LTIuMzQzMjEzQzQuODY1NzUzLTEuNjk3NjM0IDQuMDY0NzU3LS4yMTUxOTMgMi42NDIwOTItLjIxNTE5M0MxLjQ4MjQ0MS0uMjE1MTkzIC45MzI1MDMtMS40ODI0NDEgLjkzMjUwMy0yLjU3MDM2MUMuOTMyNTAzLTMuNzUzOTIzIDEuNjAxOTkzLTQuNzk0MDIyIDIuNTk0MjcxLTQuNzk0MDIyQzMuNTM4NzMtNC43OTQwMjIgNC4xNzIzNTQtMy44NjE1MTkgNC41Nzg4MjktMy4yMzk4NTFDNC42OTgzODEtMy4wMzY2MTMgNS4wMjExNzEtMi41NDY0NTEgNS4xNTI2NzctMi4zNDMyMTNaJy8+CjxwYXRoIGlkPSdnMy0xMDYnIGQ9J00xLjkwMDg3Mi04LjUzNTk5QzEuOTAwODcyLTguNzUxMTgzIDEuOTAwODcyLTguOTY2Mzc2IDEuNjYxNzY4LTguOTY2Mzc2UzEuNDIyNjY1LTguNzUxMTgzIDEuNDIyNjY1LTguNTM1OTlWMi41NTg0MDZDMS40MjI2NjUgMi43NzM1OTkgMS40MjI2NjUgMi45ODg3OTIgMS42NjE3NjggMi45ODg3OTJTMS45MDA4NzIgMi43NzM1OTkgMS45MDA4NzIgMi41NTg0MDZWLTguNTM1OTlaJy8+CjxwYXRoIGlkPSdnOC00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzgtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c4LTEwMScgZD0nTTQuNTc4ODI5LTIuNzczNTk5QzQuODQxODQzLTIuNzczNTk5IDQuODY1NzUzLTIuNzczNTk5IDQuODY1NzUzLTMuMDAwNzQ3QzQuODY1NzUzLTQuMjA4MjE5IDQuMjIwMTc0LTUuMzMyMDA1IDIuNzczNTk5LTUuMzMyMDA1QzEuNDEwNzEtNS4zMzIwMDUgLjM1ODY1NS00LjEwMDYyMyAuMzU4NjU1LTIuNjE4MTgyQy4zNTg2NTUtMS4wNDAxIDEuNTc4MDgyIC4xMTk1NTIgMi45MDUxMDYgLjExOTU1MkM0LjMyNzc3MSAuMTE5NTUyIDQuODY1NzUzLTEuMTcxNjA2IDQuODY1NzUzLTEuNDIyNjY1QzQuODY1NzUzLTEuNDk0Mzk2IDQuODA1OTc4LTEuNTQyMjE3IDQuNzM0MjQ3LTEuNTQyMjE3QzQuNjM4NjA1LTEuNTQyMjE3IDQuNjE0Njk1LTEuNDgyNDQxIDQuNTkwNzg1LTEuNDIyNjY1QzQuMjc5OTUtLjQxODQzMSAzLjQ3ODk1NC0uMTQzNDYyIDIuOTc2ODM3LS4xNDM0NjJTMS4yNjcyNDgtLjQ3ODIwNyAxLjI2NzI0OC0yLjU0NjQ1MVYtMi43NzM1OTlINC41Nzg4MjlaTTEuMjc5MjAzLTMuMDAwNzQ3QzEuMzc0ODQ0LTQuODc3NzA5IDIuNDI2ODk5LTUuMDkyOTAyIDIuNzYxNjQ0LTUuMDkyOTAyQzQuMDQwODQ3LTUuMDkyOTAyIDQuMTEyNTc4LTMuNDA3MjIzIDQuMTI0NTMzLTMuMDAwNzQ3SDEuMjc5MjAzWicvPgo8cGF0aCBpZD0nZzgtMTEyJyBkPSdNMi45MjkwMTYgMS45NzI2MDNDMi4xNjM4ODUgMS45NzI2MDMgMi4wMjA0MjMgMS45NzI2MDMgMi4wMjA0MjMgMS40MzQ2MlYtLjY0NTU3OUMyLjIzNTYxNi0uMzQ2NyAyLjcyNTc3OCAuMTE5NTUyIDMuNDkwOTA5IC4xMTk1NTJDNC44NjU3NTMgLjExOTU1MiA2LjA3MzIyNS0xLjA0MDEgNi4wNzMyMjUtMi41ODIzMTZDNi4wNzMyMjUtNC4xMDA2MjMgNC45NDk0NC01LjI3MjIyOSAzLjY0NjMyNi01LjI3MjIyOUMyLjU5NDI3MS01LjI3MjIyOSAyLjAzMjM3OS00LjUxOTA1NCAxLjk5NjUxMy00LjQ3MTIzM1YtNS4yNzIyMjlMLjMzNDc0NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xNzE2MDYtNC43OTQwMjIgMS4yNDMzMzctNC43MTAzMzYgMS4yNDMzMzctNC4xODQzMDlWMS40MzQ2MkMxLjI0MzMzNyAxLjk3MjYwMyAxLjExMTgzMSAxLjk3MjYwMyAuMzM0NzQ1IDEuOTcyNjAzVjIuMzE5MzAzQy42NDU1NzkgMi4yOTUzOTIgMS4yOTExNTggMi4yOTUzOTIgMS42MjU5MDMgMi4yOTUzOTJDMS45NzI2MDMgMi4yOTUzOTIgMi42MTgxODIgMi4yOTUzOTIgMi45MjkwMTYgMi4zMTkzMDNWMS45NzI2MDNaTTIuMDIwNDIzLTMuODEzNjk5QzIuMDIwNDIzLTQuMDQwODQ3IDIuMDIwNDIzLTQuMDUyODAyIDIuMTUxOTMtNC4yNDQwODVDMi41MTA1ODUtNC43ODIwNjcgMy4wOTYzODktNS4wMDkyMTUgMy41NTA2ODUtNS4wMDkyMTVDNC40NDczMjMtNS4wMDkyMTUgNS4xNjQ2MzMtMy45MjEyOTUgNS4xNjQ2MzMtMi41ODIzMTZDNS4xNjQ2MzMtMS4xNTk2NTEgNC4zNTE2ODEtLjExOTU1MiAzLjQzMTEzMy0uMTE5NTUyQzMuMDYwNTIzLS4xMTk1NTIgMi43MTM4MjMtLjI3NDk2OSAyLjQ3NDcyLS41MDIxMTdDMi4xOTk3NTEtLjc3NzA4NiAyLjAyMDQyMy0xLjAxNjE4OSAyLjAyMDQyMy0xLjM1MDkzNFYtMy44MTM2OTlaJy8+CjxwYXRoIGlkPSdnOC0xMjAnIGQ9J00zLjM0NzQ0Ny0yLjgyMTQyQzMuNjk0MTQ3LTMuMjc1NzE2IDQuMTk2MjY0LTMuOTIxMjk1IDQuNDIzNDEyLTQuMTcyMzU0QzQuOTEzNTc0LTQuNzIyMjkxIDUuNDc1NDY3LTQuODA1OTc4IDUuODU4MDMyLTQuODA1OTc4Vi01LjE1MjY3N0M1LjM0Mzk2LTUuMTI4NzY3IDUuMzIwMDUtNS4xMjg3NjcgNC44NTM3OTgtNS4xMjg3NjdDNC4zOTk1MDItNS4xMjg3NjcgNC4zNzU1OTItNS4xMjg3NjcgMy43Nzc4MzMtNS4xNTI2NzdWLTQuODA1OTc4QzMuOTMzMjUtNC43ODIwNjcgNC4xMjQ1MzMtNC43MTAzMzYgNC4xMjQ1MzMtNC40MzUzNjdDNC4xMjQ1MzMtNC4yMzIxMyA0LjAxNjkzNi00LjEwMDYyMyAzLjk0NTIwNS00LjAwNDk4MUwzLjE4MDA3NS0zLjAzNjYxM0wyLjI0NzU3Mi00LjI2Nzk5NUMyLjIxMTcwNi00LjMxNTgxNiAyLjEzOTk3NS00LjQyMzQxMiAyLjEzOTk3NS00LjUwNzA5OEMyLjEzOTk3NS00LjU3ODgyOSAyLjE5OTc1MS00Ljc5NDAyMiAyLjU1ODQwNi00LjgwNTk3OFYtNS4xNTI2NzdDMi4yNTk1MjctNS4xMjg3NjcgMS42NDk4MTMtNS4xMjg3NjcgMS4zMjcwMjQtNS4xMjg3NjdDLjkzMjUwMy01LjEyODc2NyAuOTA4NTkzLTUuMTI4NzY3IC4xNzkzMjgtNS4xNTI2NzdWLTQuODA1OTc4Qy43ODkwNDEtNC44MDU5NzggMS4wMTYxODktNC43ODIwNjcgMS4yNjcyNDgtNC40NTkyNzhMMi42NjYwMDItMi42MzAxMzdDMi42ODk5MTMtMi42MDYyMjcgMi43Mzc3MzMtMi41MzQ0OTYgMi43Mzc3MzMtMi40OTg2M1MxLjgwNTIzLTEuMjkxMTU4IDEuNjg1Njc5LTEuMTM1NzQxQzEuMTU5NjUxLS40OTAxNjIgLjYzMzYyNC0uMzU4NjU1IC4xMTk1NTItLjM0NjdWMEMuNTczODQ4LS4wMjM5MSAuNTk3NzU4LS4wMjM5MSAxLjExMTgzMS0uMDIzOTFDMS41NjYxMjctLjAyMzkxIDEuNTkwMDM3LS4wMjM5MSAyLjE4Nzc5NiAwVi0uMzQ2N0MxLjkwMDg3Mi0uMzgyNTY1IDEuODUzMDUxLS41NjE4OTMgMS44NTMwNTEtLjcyOTI2NUMxLjg1MzA1MS0uOTIwNTQ4IDEuOTM2NzM3LTEuMDE2MTg5IDIuMDU2Mjg5LTEuMTcxNjA2QzIuMjM1NjE2LTEuNDIyNjY1IDIuNjMwMTM3LTEuOTEyODI3IDIuOTE3MDYxLTIuMjgzNDM3TDMuODk3Mzg1LTEuMDA0MjM0QzQuMTAwNjIzLS43NDEyMiA0LjEwMDYyMy0uNzE3MzEgNC4xMDA2MjMtLjY0NTU3OUM0LjEwMDYyMy0uNTQ5OTM4IDQuMDA0OTgxLS4zNTg2NTUgMy42ODIxOTItLjM0NjdWMEMzLjk5MzAyNi0uMDIzOTEgNC41Nzg4MjktLjAyMzkxIDQuOTEzNTc0LS4wMjM5MUM1LjMwODA5NS0uMDIzOTEgNS4zMzIwMDUtLjAyMzkxIDYuMDQ5MzE1IDBWLS4zNDY3QzUuNDE1NjkxLS4zNDY3IDUuMjAwNDk4LS4zNzA2MSA0LjkxMzU3NC0uNzUzMTc2TDMuMzQ3NDQ3LTIuODIxNDJaJy8+CjxwYXRoIGlkPSdnNy00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c3LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnNi0xMScgZD0nTTUuNTM1MjQzLTMuMDI0NjU4QzUuNTM1MjQzLTQuMTg0MzA5IDQuODc3NzA5LTUuMjcyMjI5IDMuNjEwNDYxLTUuMjcyMjI5QzIuMDQ0MzM0LTUuMjcyMjI5IC40NzgyMDctMy41NjI2NCAuNDc4MjA3LTEuODY1MDA2Qy40NzgyMDctLjgyNDkwNyAxLjEyMzc4NiAuMTE5NTUyIDIuMzQzMjEzIC4xMTk1NTJDMy4wODQ0MzMgLjExOTU1MiAzLjk2OTExNi0uMTY3MzcyIDQuODE3OTMzLS44ODQ2ODJDNC45ODUzMDUtLjIxNTE5MyA1LjM1NTkxNSAuMTE5NTUyIDUuODY5OTg4IC4xMTk1NTJDNi41MTU1NjcgLjExOTU1MiA2LjgzODM1Ni0uNTQ5OTM4IDYuODM4MzU2LS43MDUzNTVDNi44MzgzNTYtLjgxMjk1MSA2Ljc1NDY3LS44MTI5NTEgNi43MTg4MDQtLjgxMjk1MUM2LjYyMzE2My0uODEyOTUxIDYuNjExMjA4LS43NzcwODYgNi41NzUzNDItLjY4MTQ0NUM2LjQ2Nzc0Ni0uMzgyNTY1IDYuMTkyNzc3LS4xMTk1NTIgNS45MDU4NTMtLjExOTU1MkM1LjUzNTI0My0uMTE5NTUyIDUuNTM1MjQzLS44ODQ2ODIgNS41MzUyNDMtMS42MTM5NDhDNi43NTQ2Ny0zLjA3MjQ3OCA3LjA0MTU5NC00LjU3ODgyOSA3LjA0MTU5NC00LjU5MDc4NUM3LjA0MTU5NC00LjY5ODM4MSA2Ljk0NTk1My00LjY5ODM4MSA2LjkxMDA4Ny00LjY5ODM4MUM2LjgwMjQ5MS00LjY5ODM4MSA2Ljc5MDUzNS00LjY2MjUxNiA2Ljc0MjcxNS00LjQ0NzMyM0M2LjU4NzI5OC0zLjkyMTI5NSA2LjI3NjQ2My0yLjk4ODc5MiA1LjUzNTI0My0yLjAwODQ2OFYtMy4wMjQ2NThaTTQuNzgyMDY3LTEuMTcxNjA2QzMuNzMwMDEyLS4yMjcxNDggMi43ODU1NTQtLjExOTU1MiAyLjM2NzEyMy0uMTE5NTUyQzEuNTE4MzA2LS4xMTk1NTIgMS4yNzkyMDMtLjg3MjcyNyAxLjI3OTIwMy0xLjQzNDYyQzEuMjc5MjAzLTEuOTQ4NjkyIDEuNTQyMjE3LTMuMTY4MTIgMS45MTI4MjctMy44MjU2NTRDMi40MDI5ODktNC42NjI1MTYgMy4wNzI0NzgtNS4wMzMxMjYgMy42MTA0NjEtNS4wMzMxMjZDNC43NzAxMTItNS4wMzMxMjYgNC43NzAxMTItMy41MTQ4MTkgNC43NzAxMTItMi41MTA1ODVDNC43NzAxMTItMi4yMTE3MDYgNC43NTgxNTctMS45MDA4NzIgNC43NTgxNTctMS42MDE5OTNDNC43NTgxNTctMS4zNjI4ODkgNC43NzAxMTItMS4zMDMxMTMgNC43ODIwNjctMS4xNzE2MDZaJy8+CjxwYXRoIGlkPSdnNi0xMicgZD0nTTYuNzY2NjI1LTYuOTU3OTA4QzYuNzY2NjI1LTcuNjc1MjE4IDYuMTU2OTEyLTguNDI4Mzk0IDUuMDY4OTkxLTguNDI4Mzk0QzMuNTI2Nzc1LTguNDI4Mzk0IDIuNTQ2NDUxLTYuNTM5NDc3IDIuMjM1NjE2LTUuMjk2MTM5TC4zNDY3IDIuMTk5NzUxQy4zMjI3OSAyLjI5NTM5MiAuMzk0NTIxIDIuMzE5MzAzIC40NTQyOTYgMi4zMTkzMDNDLjUzNzk4MyAyLjMxOTMwMyAuNTk3NzU4IDIuMzA3MzQ3IC42MDk3MTQgMi4yNDc1NzJMMS40NDY1NzUtMS4wOTk4NzVDMS41NjYxMjctLjQzMDM4NiAyLjIyMzY2MSAuMTE5NTUyIDIuOTI5MDE2IC4xMTk1NTJDNC42Mzg2MDUgLjExOTU1MiA2LjI1MjU1My0xLjIxOTQyNyA2LjI1MjU1My0zLjAwMDc0N0M2LjI1MjU1My0zLjQ1NTA0NCA2LjE0NDk1Ni0zLjkwOTM0IDUuODkzODk4LTQuMjkxOTA1QzUuNzUwNDM2LTQuNTE5MDU0IDUuNTcxMTA4LTQuNjg2NDI2IDUuMzc5ODI2LTQuODI5ODg4QzYuMjQwNTk4LTUuMjg0MTg0IDYuNzY2NjI1LTYuMDEzNDUgNi43NjY2MjUtNi45NTc5MDhaTTQuNjg2NDI2LTQuODQxODQzQzQuNDk1MTQzLTQuNzcwMTEyIDQuMzAzODYxLTQuNzQ2MjAyIDQuMDc2NzEyLTQuNzQ2MjAyQzMuOTA5MzQtNC43NDYyMDIgMy43NTM5MjMtNC43MzQyNDcgMy41Mzg3My00LjgwNTk3OEMzLjY1ODI4MS00Ljg4OTY2NCAzLjgzNzYwOS00LjkxMzU3NCA0LjA4ODY2Ny00LjkxMzU3NEM0LjMwMzg2MS00LjkxMzU3NCA0LjUxOTA1NC00Ljg4OTY2NCA0LjY4NjQyNi00Ljg0MTg0M1pNNi4xNDQ5NTYtNy4wNjU1MDRDNi4xNDQ5NTYtNi40MDc5NyA1LjgyMjE2Ny01LjQ1MTU1NyA1LjA0NTA4MS01LjAwOTIxNUM0LjgxNzkzMy01LjA5MjkwMiA0LjUwNzA5OC01LjE1MjY3NyA0LjI0NDA4NS01LjE1MjY3N0MzLjk5MzAyNi01LjE1MjY3NyAzLjI3NTcxNi01LjE3NjU4OCAzLjI3NTcxNi00Ljc5NDAyMkMzLjI3NTcxNi00LjQ3MTIzMyAzLjkzMzI1LTQuNTA3MDk4IDQuMTM2NDg4LTQuNTA3MDk4QzQuNDQ3MzIzLTQuNTA3MDk4IDQuNzIyMjkxLTQuNTc4ODI5IDUuMDA5MjE1LTQuNjYyNTE2QzUuMzkxNzgxLTQuMzUxNjgxIDUuNTU5MTUzLTMuOTQ1MjA1IDUuNTU5MTUzLTMuMzQ3NDQ3QzUuNTU5MTUzLTIuNjU0MDQ3IDUuMzY3ODctMi4wOTIxNTQgNS4xNDA3MjItMS41NzgwODJDNC43NDYyMDItLjY5MzQgMy44MTM2OTktLjExOTU1MiAyLjk4ODc5Mi0uMTE5NTUyQzIuMTE2MDY1LS4xMTk1NTIgMS42NjE3NjgtLjgxMjk1MSAxLjY2MTc2OC0xLjYyNTkwM0MxLjY2MTc2OC0xLjczMzQ5OSAxLjY2MTc2OC0xLjg4ODkxNyAxLjcwOTU4OS0yLjA2ODI0NEwyLjQ4NjY3NS01LjIxMjQ1M0MyLjg4MTE5Ni02Ljc3ODU4IDMuODg1NDMtOC4xODkyOSA1LjA0NTA4MS04LjE4OTI5QzUuOTA1ODUzLTguMTg5MjkgNi4xNDQ5NTYtNy41OTE1MzIgNi4xNDQ5NTYtNy4wNjU1MDRaJy8+CjxwYXRoIGlkPSdnNi0yNScgZD0nTTMuMDk2Mzg5LTQuNTA3MDk4SDQuNDQ3MzIzQzQuMTI0NTMzLTMuMTY4MTIgMy45MjEyOTUtMi4yOTUzOTIgMy45MjEyOTUtMS4zMzg5NzlDMy45MjEyOTUtMS4xNzE2MDYgMy45MjEyOTUgLjExOTU1MiA0LjQxMTQ1NyAuMTE5NTUyQzQuNjYyNTE2IC4xMTk1NTIgNC44Nzc3MDktLjEwNzU5NyA0Ljg3NzcwOS0uMzEwODM0QzQuODc3NzA5LS4zNzA2MSA0Ljg3NzcwOS0uMzk0NTIxIDQuNzk0MDIyLS41NzM4NDhDNC40NzEyMzMtMS4zOTg3NTUgNC40NzEyMzMtMi40MjY4OTkgNC40NzEyMzMtMi41MTA1ODVDNC40NzEyMzMtMi41ODIzMTYgNC40NzEyMzMtMy40MzExMzMgNC43MjIyOTEtNC41MDcwOThINi4wNjEyN0M2LjIxNjY4Ny00LjUwNzA5OCA2LjYxMTIwOC00LjUwNzA5OCA2LjYxMTIwOC00Ljg4OTY2NEM2LjYxMTIwOC01LjE1MjY3NyA2LjM4NDA2LTUuMTUyNjc3IDYuMTY4ODY3LTUuMTUyNjc3SDIuMjM1NjE2QzEuOTYwNjQ4LTUuMTUyNjc3IDEuNTU0MTcyLTUuMTUyNjc3IDEuMDA0MjM0LTQuNTY2ODc0Qy42OTM0LTQuMjIwMTc0IC4zMTA4MzQtMy41ODY1NSAuMzEwODM0LTMuNTE0ODE5Uy4zNzA2MS0zLjQxOTE3OCAuNDQyMzQxLTMuNDE5MTc4Qy41MjYwMjctMy40MTkxNzggLjUzNzk4My0zLjQ1NTA0NCAuNTk3NzU4LTMuNTI2Nzc1QzEuMjE5NDI3LTQuNTA3MDk4IDEuODQxMDk2LTQuNTA3MDk4IDIuMTM5OTc1LTQuNTA3MDk4SDIuODIxNDJDMi41NTg0MDYtMy42MTA0NjEgMi4yNTk1MjctMi41NzAzNjEgMS4yNzkyMDMtLjQ3ODIwN0MxLjE4MzU2Mi0uMjg2OTI0IDEuMTgzNTYyLS4yNjMwMTQgMS4xODM1NjItLjE5MTI4M0MxLjE4MzU2MiAuMDU5Nzc2IDEuMzk4NzU1IC4xMTk1NTIgMS41MDYzNTEgLjExOTU1MkMxLjg1MzA1MSAuMTE5NTUyIDEuOTQ4NjkyLS4xOTEyODMgMi4wOTIxNTQtLjY5MzRDMi4yODM0MzctMS4zMDMxMTMgMi4yODM0MzctMS4zMjcwMjQgMi40MDI5ODktMS44MDUyM0wzLjA5NjM4OS00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2c2LTU4JyBkPSdNMi4xOTk3NTEtLjU3Mzg0OEMyLjE5OTc1MS0uOTIwNTQ4IDEuOTEyODI3LTEuMTU5NjUxIDEuNjI1OTAzLTEuMTU5NjUxQzEuMjc5MjAzLTEuMTU5NjUxIDEuMDQwMS0uODcyNzI3IDEuMDQwMS0uNTg1ODAzQzEuMDQwMS0uMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxLS4yODY5MjQgMi4xOTk3NTEtLjU3Mzg0OFonLz4KPHBhdGggaWQ9J2c2LTU5JyBkPSdNMi4zMzEyNTggLjA0NzgyMUMyLjMzMTI1OC0uNjQ1NTc5IDIuMTA0MTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yMzEzODItMS4xNTk2NTEgMS4wNDAxLS44NDg4MTcgMS4wNDAxLS41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNy0uMDQ3ODIxIDIuMDIwNDIzLS4xNTU0MTdDMi4wNDQzMzQtLjE3OTMyOCAyLjA1NjI4OS0uMTc5MzI4IDIuMDY4MjQ0LS4xNzkzMjhDMi4wOTIxNTQtLjE3OTMyOCAyLjA5MjE1NC0uMDExOTU1IDIuMDkyMTU0IC4wNDc4MjFDMi4wOTIxNTQgLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IC4wNDc4MjFaJy8+CjxwYXRoIGlkPSdnNi0xMDInIGQ9J001LjMzMjAwNS00LjgwNTk3OEM1LjU3MTEwOC00LjgwNTk3OCA1LjY2Njc1LTQuODA1OTc4IDUuNjY2NzUtNS4wMzMxMjZDNS42NjY3NS01LjE1MjY3NyA1LjU3MTEwOC01LjE1MjY3NyA1LjM1NTkxNS01LjE1MjY3N0g0LjM4NzU0N0M0LjYxNDY5NS02LjM4NDA2IDQuNzgyMDY3LTcuMjMyODc3IDQuODc3NzA5LTcuNjE1NDQyQzQuOTQ5NDQtNy45MDIzNjYgNS4yMDA0OTgtOC4xNzczMzUgNS41MTEzMzMtOC4xNzczMzVDNS43NjIzOTEtOC4xNzczMzUgNi4wMTM0NS04LjA2OTczOCA2LjEzMzAwMS03Ljk2MjE0MkM1LjY2Njc1LTcuOTE0MzIxIDUuNTIzMjg4LTcuNTY3NjIxIDUuNTIzMjg4LTcuMzY0Mzg0QzUuNTIzMjg4LTcuMTI1MjggNS43MDI2MTUtNi45ODE4MTggNS45Mjk3NjMtNi45ODE4MThDNi4xNjg4NjctNi45ODE4MTggNi41Mjc1MjItNy4xODUwNTYgNi41Mjc1MjItNy42MzkzNTJDNi41Mjc1MjItOC4xNDE0NjkgNi4wMjU0MDUtOC40MTY0MzggNS40OTkzNzctOC40MTY0MzhDNC45ODUzMDUtOC40MTY0MzggNC40ODMxODgtOC4wMzM4NzMgNC4yNDQwODUtNy41Njc2MjFDNC4wMjg4OTItNy4xNDkxOTEgMy45MDkzNC02LjcxODgwNCAzLjYzNDM3MS01LjE1MjY3N0gyLjgzMzM3NUMyLjYwNjIyNy01LjE1MjY3NyAyLjQ4NjY3NS01LjE1MjY3NyAyLjQ4NjY3NS00LjkzNzQ4NEMyLjQ4NjY3NS00LjgwNTk3OCAyLjU1ODQwNi00LjgwNTk3OCAyLjc5NzUwOS00LjgwNTk3OEgzLjU2MjY0QzMuMzQ3NDQ3LTMuNjk0MTQ3IDIuODU3Mjg1LS45OTIyNzkgMi41ODIzMTYgLjI4NjkyNEMyLjM3OTA3OCAxLjMyNzAyNCAyLjE5OTc1MSAyLjE5OTc1MSAxLjYwMTk5MyAyLjE5OTc1MUMxLjU2NjEyNyAyLjE5OTc1MSAxLjIxOTQyNyAyLjE5OTc1MSAxLjAwNDIzNCAxLjk3MjYwM0MxLjYxMzk0OCAxLjkyNDc4MiAxLjYxMzk0OCAxLjM5ODc1NSAxLjYxMzk0OCAxLjM4NjhDMS42MTM5NDggMS4xNDc2OTYgMS40MzQ2MiAxLjAwNDIzNCAxLjIwNzQ3MiAxLjAwNDIzNEMuOTY4MzY5IDEuMDA0MjM0IC42MDk3MTQgMS4yMDc0NzIgLjYwOTcxNCAxLjY2MTc2OEMuNjA5NzE0IDIuMTc1ODQxIDEuMTM1NzQxIDIuNDM4ODU0IDEuNjAxOTkzIDIuNDM4ODU0QzIuODIxNDIgMi40Mzg4NTQgMy4zMjM1MzcgLjI1MTA1OSAzLjQ1NTA0NC0uMzQ2N0MzLjY3MDIzNy0xLjI2NzI0OCA0LjI1NjA0LTQuNDQ3MzIzIDQuMzE1ODE2LTQuODA1OTc4SDUuMzMyMDA1WicvPgo8cGF0aCBpZD0nZzYtMTE2JyBkPSdNMi40MDI5ODktNC44MDU5NzhIMy41MDI4NjRDMy43MzAwMTItNC44MDU5NzggMy44NDk1NjQtNC44MDU5NzggMy44NDk1NjQtNS4wMjExNzFDMy44NDk1NjQtNS4xNTI2NzcgMy43Nzc4MzMtNS4xNTI2NzcgMy41Mzg3My01LjE1MjY3N0gyLjQ4NjY3NUwyLjkyOTAxNi02Ljg5ODEzMkMyLjk3NjgzNy03LjA2NTUwNCAyLjk3NjgzNy03LjA4OTQxNSAyLjk3NjgzNy03LjE3MzEwMUMyLjk3NjgzNy03LjM2NDM4NCAyLjgyMTQyLTcuNDcxOTggMi42NjYwMDItNy40NzE5OEMyLjU3MDM2MS03LjQ3MTk4IDIuMjk1MzkyLTcuNDM2MTE1IDIuMTk5NzUxLTcuMDUzNTQ5TDEuNzMzNDk5LTUuMTUyNjc3SC42MDk3MTRDLjM3MDYxLTUuMTUyNjc3IC4yNjMwMTQtNS4xNTI2NzcgLjI2MzAxNC00LjkyNTUyOUMuMjYzMDE0LTQuODA1OTc4IC4zNDY3LTQuODA1OTc4IC41NzM4NDgtNC44MDU5NzhIMS42Mzc4NThMLjg0ODgxNy0xLjY0OTgxM0MuNzUzMTc2LTEuMjMxMzgyIC43MTczMS0xLjExMTgzMSAuNzE3MzEtLjk1NjQxM0MuNzE3MzEtLjM5NDUyMSAxLjExMTgzMSAuMTE5NTUyIDEuNzgxMzIgLjExOTU1MkMyLjk4ODc5MiAuMTE5NTUyIDMuNjM0MzcxLTEuNjI1OTAzIDMuNjM0MzcxLTEuNzA5NTg5QzMuNjM0MzcxLTEuNzgxMzIgMy41ODY1NS0xLjgxNzE4NiAzLjUxNDgxOS0xLjgxNzE4NkMzLjQ5MDkwOS0xLjgxNzE4NiAzLjQ0MzA4OC0xLjgxNzE4NiAzLjQxOTE3OC0xLjc2OTM2NUMzLjQwNzIyMy0xLjc1NzQxIDMuMzk1MjY4LTEuNzQ1NDU1IDMuMzExNTgyLTEuNTU0MTcyQzMuMDYwNTIzLS45NTY0MTMgMi41MTA1ODUtLjExOTU1MiAxLjgxNzE4Ni0uMTE5NTUyQzEuNDU4NTMxLS4xMTk1NTIgMS40MzQ2Mi0uNDE4NDMxIDEuNDM0NjItLjY4MTQ0NUMxLjQzNDYyLS42OTM0IDEuNDM0NjItLjkyMDU0OCAxLjQ3MDQ4Ni0xLjA2NDAxTDIuNDAyOTg5LTQuODA1OTc4WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTI1Jy8+Cjx1c2UgeD0nNy4wNjkyNycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTEuNjIxNTk1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTEnLz4KPHVzZSB4PScxOS4xNDMzMicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nMjQuMzg3NDc4JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PSczMS42NTg3NDknIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnMy0xMDYnLz4KPHVzZSB4PSczNC45Nzk2MzknIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzM5LjUzMTk2NScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzQzLjc1OTEyNScgeT0nLTE1LjA1NDc1MScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNDguNDkxNDQnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9JzUzLjczNTU5OScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTEwMicvPgo8dXNlIHg9JzU5LjUwNTU4NycgeT0nLTE1LjA1NDc1MScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNjQuMjM3OTAyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSc2OC43OTAyMjgnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9Jzc0LjAzNDM4NycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU4Jy8+Cjx1c2UgeD0nNzkuMjc4NTQ1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtNTgnLz4KPHVzZSB4PSc4NC41MjI3MDQnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi01OCcvPgo8dXNlIHg9Jzg5Ljc2Njg2MycgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nOTUuMDExMDIyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc5OS41NjMzNDgnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScxMDMuNzkwNTA3JyB5PSctMTUuMDU0NzUxJyB4bGluazpocmVmPScjZzUtMTEwJy8+Cjx1c2UgeD0nMTA5LjQyNjg0MicgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU5Jy8+Cjx1c2UgeD0nMTE0LjY3MTAwMScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTEwMicvPgo8dXNlIHg9JzEyMC40NDA5ODknIHk9Jy0xNS4wNTQ3NTEnIHhsaW5rOmhyZWY9JyNnNS0xMTAnLz4KPHVzZSB4PScxMjYuMDc3MzI0JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScxMzAuNjI5NjQ5JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScxMzguNTAyODA1JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzMtNDcnLz4KPHVzZSB4PScxNTEuMTIyMTMxJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMjUnLz4KPHVzZSB4PScxNTguMTkxNDAxJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxNjIuNzQzNzI2JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzYtMTEnLz4KPHVzZSB4PScxNzAuMjY1NDUnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzE3NC44MTc3NzYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0yNScvPgo8dXNlIHg9JzE4MS44ODcwNDYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzE4Ni40MzkzNzInIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnNi0xMicvPgo8dXNlIHg9JzE5My43MTA2NDMnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzIwMC4yNTU0NjYnIHk9Jy0zMy43MDQ5NTEnIHhsaW5rOmhyZWY9JyNnMS0xOCcvPgo8dXNlIHg9JzIxMC4yNTEzNTInIHk9Jy0yNC45MzU3NzInIHhsaW5rOmhyZWY9JyNnNi0xMScvPgo8cmVjdCB4PScyMTAuMjUxMzUyJyB5PSctMjAuMDc1ODk5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc3LjUyMTcyJy8+Cjx1c2UgeD0nMjEwLjM3NjU4NScgeT0nLTguNjQ3MzUxJyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PScyMTguOTY4NTg2JyB5PSctMzMuNzA0OTUxJyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PScyMjcuNzY4OTU5JyB5PSctMzcuMDA1OTI3JyB4bGluazpocmVmPScjZzAtODAnLz4KPHVzZSB4PScyMzYuNzA3NzknIHk9Jy0yOC41Mzc1OTInIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyNDEuMjgwOTQyJyB5PSctMzEuMDI4Mjk3JyB4bGluazpocmVmPScjZzUtMTAyJy8+Cjx1c2UgeD0nMjQ1LjM0OTA2JyB5PSctMjkuODEzMjE5JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjUxLjAwMTQ0OCcgeT0nLTM3LjI5MTUzOCcgeGxpbms6aHJlZj0nI2cxLTMyJy8+Cjx1c2UgeD0nMjYxLjg1MzIyNScgeT0nLTI4LjIwNTQ3OCcgeGxpbms6aHJlZj0nI2cxLTg5Jy8+Cjx1c2UgeD0nMjYwLjQ2NTk4NicgeT0nLTIuNzQ1MjU5JyB4bGluazpocmVmPScjZzUtMTAyJy8+Cjx1c2UgeD0nMjY0LjUzNDEwNScgeT0nLTEuNTMwMTgxJyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjY3LjY5NTg2MycgeT0nLTIuNzQ1MjU5JyB4bGluazpocmVmPScjZzctNjEnLz4KPHVzZSB4PScyNzQuMjgyMzY5JyB5PSctMi43NDUyNTknIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzI4MS43MDQ1NjQnIHk9Jy0yNC45MzU3NzInIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScyODUuOTMxNzIzJyB5PSctMjMuMTQyNTA5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+CjxyZWN0IHg9JzI4MS43MDQ1NjQnIHk9Jy0yMC4wNzU4OTknIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzcuNjA4NDMxJy8+Cjx1c2UgeD0nMjgxLjg3MzE1MScgeT0nLTguNjQ3MzUxJyB4bGluazpocmVmPScjZzYtMTInLz4KPHVzZSB4PScyOTAuNTA4NTA5JyB5PSctMzcuMjkxNTM4JyB4bGluazpocmVmPScjZzEtMzMnLz4KPHVzZSB4PScyOTkuOTczMDQ3JyB5PSctMzQuNjE0ODg0JyB4bGluazpocmVmPScjZzUtMTEnLz4KPHVzZSB4PSczMDUuNDExOTg3JyB5PSctMzQuNjE0ODg0JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzMxMS45OTg0OTMnIHk9Jy0zNC42MTQ4ODQnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzMxOC43MjMzMDYnIHk9Jy0xNi44NDgwMTQnIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PSczMjMuOTI1OTY0JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtMTIwJy8+Cjx1c2UgeD0nMzMwLjEwNDEyJyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzgtMTEyJy8+Cjx1c2UgeD0nMzM4LjU5OTk0JyB5PSctMzcuMjkxNTM4JyB4bGluazpocmVmPScjZzEtMzQnLz4KPHVzZSB4PSczNDUuNTczODE5JyB5PSctMTYuODQ4MDE0JyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzM2Mi45MzAwMicgeT0nLTMxLjc5MjAzNScgeGxpbms6aHJlZj0nI2c1LTExMCcvPgo8dXNlIHg9JzM1Ni44NjQ4MTMnIHk9Jy0yOC4yMDU0NzgnIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzM1OC42NDcyMDcnIHk9Jy0zLjAxMTEyMycgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzM2MS41MzAzNDcnIHk9Jy0zLjAxMTEyMycgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nMzY4LjExNjg1MycgeT0nLTMuMDExMTIzJyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PSczNzYuMTI1OTI4JyB5PSctMzMuNzA0OTUxJyB4bGluazpocmVmPScjZzEtMTgnLz4KPHVzZSB4PSczODYuMTIxODE0JyB5PSctMjQuOTM1NzcyJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMzkwLjM0ODk3NCcgeT0nLTIzLjE0MjUwOScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8cmVjdCB4PSczODYuMTIxODE0JyB5PSctMjAuMDc1ODk5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc3LjYwODQzMScvPgo8dXNlIHg9JzM4Ni4yOTA0MDInIHk9Jy04LjY0NzM1MScgeGxpbms6aHJlZj0nI2c2LTEyJy8+Cjx1c2UgeD0nMzk0LjkyNTc1OScgeT0nLTMzLjcwNDk1MScgeGxpbms6aHJlZj0nI2cxLTE5Jy8+Cjx1c2UgeD0nNDAzLjcyNjEzMicgeT0nLTMxLjAyODI5NycgeGxpbms6aHJlZj0nI2c1LTExJy8+Cjx1c2UgeD0nNDA5LjY2MzIwMycgeT0nLTM3LjI5MTUzOCcgeGxpbms6aHJlZj0nI2cxLTM1Jy8+Cjx1c2UgeD0nNDE4LjYyOTU3MScgeT0nLTE2Ljg0ODAxNCcgeGxpbms6aHJlZj0nI2c2LTU4Jy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
The RandomWalkMetropolisHastings class can be used to sample from the posterior distribution. It relies on the following objects:
The prior probability density
 reflects beliefs about the possible values
of
reflects beliefs about the possible values
of  before the experimental data are considered.
before the experimental data are considered.Initial values
 of the parameters.
of the parameters.An proposal distribution used to update parameters.
Additionally we want to define the likelihood term defined by these objects:
The conditional density
 will be defined as a
will be defined as a PythonDistribution.The sample of observations acting as the parameters of the conditional density
Set up the PythonDistribution¶
The censured Weibull likelihood is outside the usual catalog of probability distributions,
hence we need to define it using the PythonDistribution class.
import numpy as np
import openturns as ot
from openturns.viewer import View
ot.Log.Show(ot.Log.NONE)
ot.RandomGenerator.SetSeed(123)
The following methods must be defined:
getRange: required for conversion to the
DistributionformatcomputeLogPDF: used by
RandomWalkMetropolisHastingsto evaluate the posterior densitysetParameter used by
RandomWalkMetropolisHastingsto test new parameter values
Note
We formally define a bivariate distribution on the  couple, even though
couple, even though  has no distribution (it is simply a covariate).
This is not an issue, since the sole purpose of this
has no distribution (it is simply a covariate).
This is not an issue, since the sole purpose of this PythonDistribution object is to pass
the likelihood calculation over to RandomWalkMetropolisHastings.
class CensoredWeibull(ot.PythonDistribution):
"""
Right-censored Weibull log-PDF calculation
Each data point x is assumed 2D, with:
x[0]: observed functioning time
x[1]: nature of x[0]:
if x[1]=0: x[0] is a censoring time
if x[1]=1: x[0] is a time-to failure
"""
def __init__(self, beta=5000.0, alpha=2.0):
super(CensoredWeibull, self).__init__(2)
self.beta = beta
self.alpha = alpha
def getRange(self):
return ot.Interval([0, 0], [1, 1], [True] * 2, [False, True])
def computeLogPDF(self, x):
if not (self.alpha > 0.0 and self.beta > 0.0):
return -np.inf
log_pdf = -((x[0] / self.beta) ** self.alpha)
log_pdf += (self.alpha - 1) * np.log(x[0] / self.beta) * x[1]
log_pdf += np.log(self.alpha / self.beta) * x[1]
return log_pdf
def setParameter(self, parameter):
self.beta = parameter[0]
self.alpha = parameter[1]
def getParameter(self):
return [self.beta, self.alpha]
Convert to Distribution
conditional = ot.Distribution(CensoredWeibull())
Observations, prior, initial point and proposal distributions¶
Define the observations
Tobs = np.array([4380, 1791, 1611, 1291, 6132, 5694, 5296, 4818, 4818, 4380])
fail = np.array([True] * 4 + [False] * 6)
x = ot.Sample(np.vstack((Tobs, fail)).T)
Define a uniform prior distribution for  and a Gamma prior distribution for
and a Gamma prior distribution for  .
.
alpha_min, alpha_max = 0.5, 3.8
a_beta, b_beta = 2, 2e-4
priorCopula = ot.IndependentCopula(2) # prior independence
priorMarginals = [] # prior marginals
priorMarginals.append(ot.Gamma(a_beta, b_beta)) # Gamma prior for beta
priorMarginals.append(ot.Uniform(alpha_min, alpha_max)) # uniform prior for alpha
prior = ot.ComposedDistribution(priorMarginals, priorCopula)
prior.setDescription(["beta", "alpha"])
We select prior means as the initial point of the Metropolis-Hastings algorithm.
initialState = [a_beta / b_beta, 0.5 * (alpha_max - alpha_min)]
For our random walk proposal distributions, we choose normal steps, with standard deviation equal to roughly  of the prior range (for the uniform prior)
or standard deviation (for the normal prior).
of the prior range (for the uniform prior)
or standard deviation (for the normal prior).
proposal = []
proposal.append(ot.Normal(0.0, 0.1 * np.sqrt(a_beta / b_beta**2)))
proposal.append(ot.Normal(0.0, 0.1 * (alpha_max - alpha_min)))
proposal = ot.ComposedDistribution(proposal)
Sample from the posterior distribution¶
sampler = ot.RandomWalkMetropolisHastings(prior, initialState, proposal)
sampler.setLikelihood(conditional, x)
sampleSize = 10000
sample = sampler.getSample(sampleSize)
# compute acceptance rate
print("Acceptance rate: %s" % (sampler.getAcceptanceRate()))
Acceptance rate: 0.3347
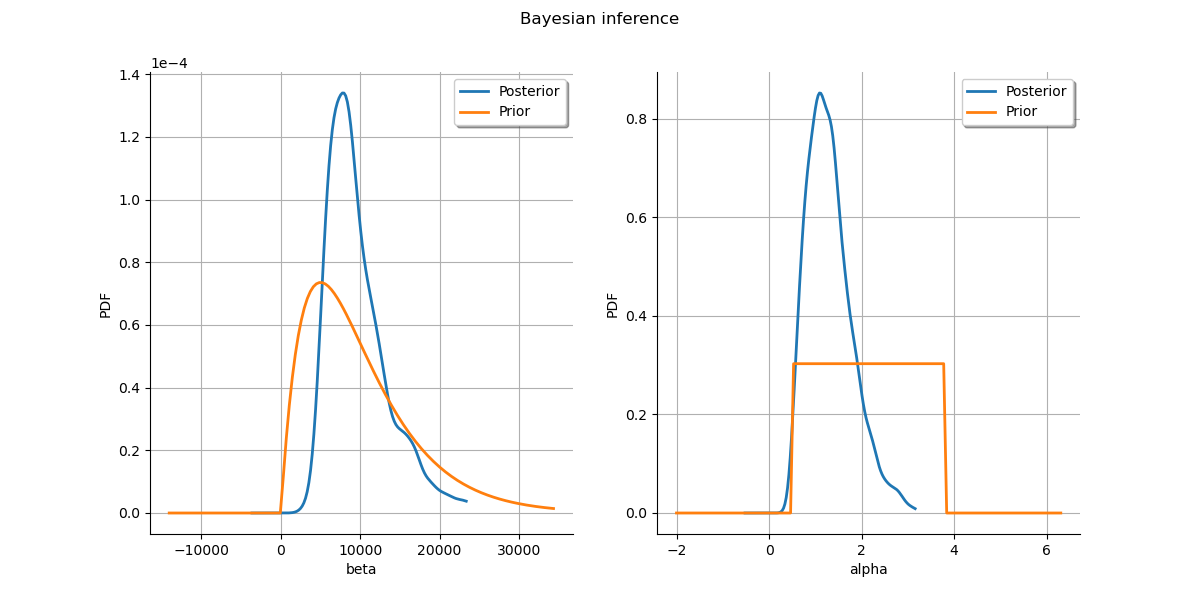
Plot prior to posterior marginal plots.
kernel = ot.KernelSmoothing()
posterior = kernel.build(sample)
grid = ot.GridLayout(1, 2)
grid.setTitle("Bayesian inference")
for parameter_index in range(2):
graph = posterior.getMarginal(parameter_index).drawPDF()
priorGraph = prior.getMarginal(parameter_index).drawPDF()
graph.add(priorGraph)
graph.setColors(ot.Drawable.BuildDefaultPalette(2))
graph.setLegends(["Posterior", "Prior"])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
Define an improper prior¶
Now, define an improper prior:

logpdf = ot.SymbolicFunction(["beta", "alpha"], ["-log(beta)"])
support = ot.Interval([0] * 2, [1] * 2)
support.setFiniteUpperBound([False] * 2)
Sample from the posterior distribution
sampler2 = ot.RandomWalkMetropolisHastings(logpdf, support, initialState, proposal)
sampler2.setLikelihood(conditional, x)
sample2 = sampler2.getSample(1000)
print("Acceptance rate: %s" % (sampler2.getAcceptanceRate()))
Acceptance rate: 0.37
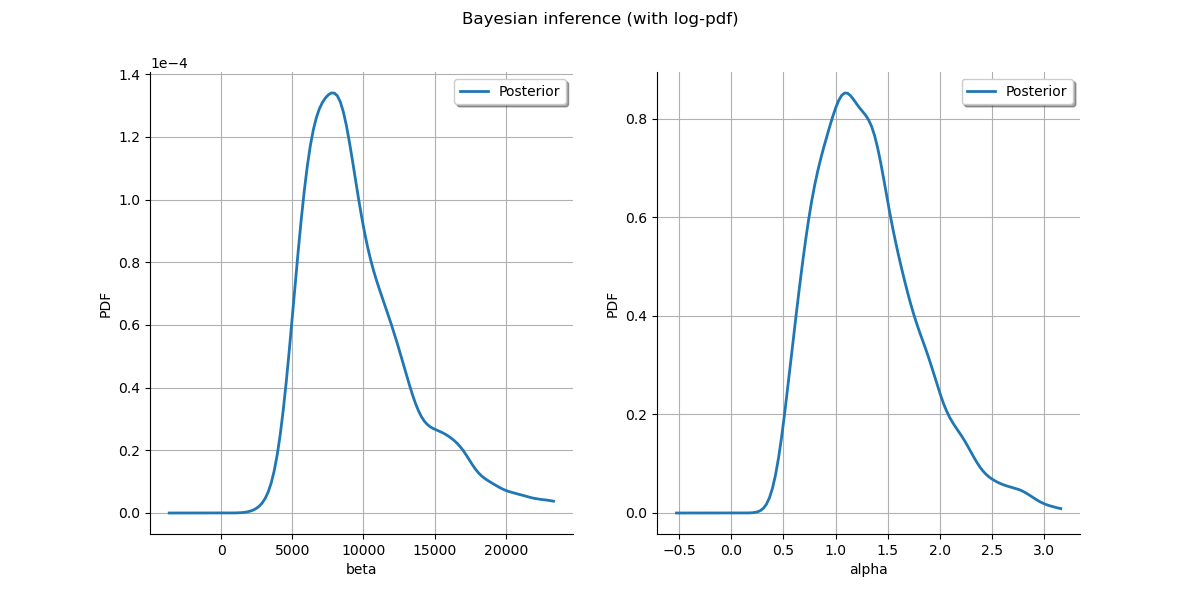
Plot posterior marginal plots only as prior cannot be drawn meaningfully.
kernel = ot.KernelSmoothing()
posterior = kernel.build(sample)
grid = ot.GridLayout(1, 2)
grid.setTitle("Bayesian inference (with log-pdf)")
for parameter_index in range(2):
graph = posterior.getMarginal(parameter_index).drawPDF()
graph.setLegends(["Posterior"])
grid.setGraph(0, parameter_index, graph)
_ = View(grid)
View.ShowAll()
Total running time of the script: (0 minutes 5.575 seconds)