A flood model¶
Introduction¶
The following figure presents a dyke protecting industrial facilities. When the river level exceeds the dyke height, flooding occurs. The model is based on a crude simplification of the 1D hydrodynamical equations of Saint-Venant under the assumptions of uniform and constant flow rate and large rectangular sections. This model was first introduced in [deRocquigny2006], and then used in [Limbourg2010], [deRocquigny2012], [iooss2015], [baudin2015].
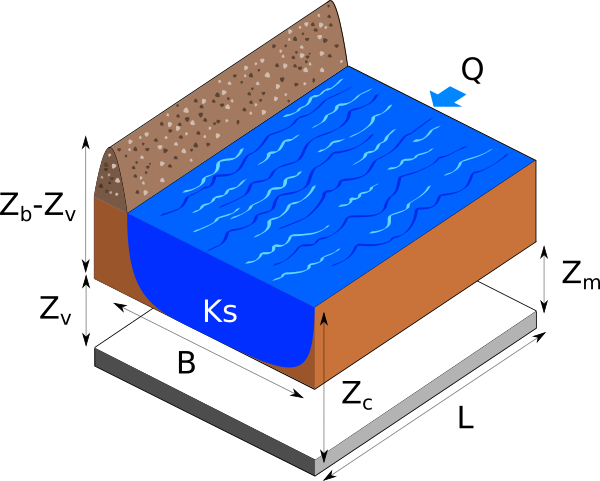
Figure 1. Flooding section.¶
Height independent random variables are considered:
: flow rate
;
: Strickler
;
: downstream height
;
: upstream height
: river width
: river length
: altitude of the river banks
: height of the dyke
When the Strickler coefficient increases, the riverbed generates less friction.
The altitude of the dyke is:

The slope  of the river is assumed to be close to zero, which implies:
of the river is assumed to be close to zero, which implies:

if  .
The water depth is ([deRocquigny2012] eq. 3.2 page 79) :
.
The water depth is ([deRocquigny2012] eq. 3.2 page 79) :

for any  .
The flood altitude is:
.
The flood altitude is:

The altitude of the surface of the water is greater than the altitude of the top of the dyke (i.e. there is a flood) if ([deRocquigny2012] eq. 3.3 page 79):

is greater than zero.
The following figure presents the model with more details.
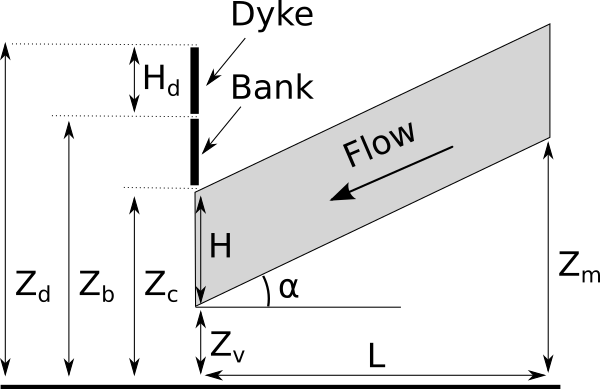
Figure 2. Flooding section detail.¶
The cost  can be decomposed into the building of the dyke and
the cost of the flood ([iooss2015] eq. 5.3 page 103):
can be decomposed into the building of the dyke and
the cost of the flood ([iooss2015] eq. 5.3 page 103):

where the cost of the dyke is:

and the cost of the flood is:

We assume that the 8 inputs have the following distributions. We consider 2 different set of hypotheses.
In the hypothesis where
is low, then its distribution
is uniform in the interval ![[2, 4]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNiAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyMy40NTM0NjJwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgMjMuNDUzNDYyIDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2cxLTUwJyBkPSdNNS4yNjAyNzQtMi4wMDg0NjhINC45OTcyNkM0Ljk2MTM5NS0xLjgwNTIzIDQuODY1NzUzLTEuMTQ3Njk2IDQuNzQ2MjAyLS45NTY0MTNDNC42NjI1MTYtLjg0ODgxNyAzLjk4MTA3MS0uODQ4ODE3IDMuNjIyNDE2LS44NDg4MTdIMS40MTA3MUMxLjczMzQ5OS0xLjEyMzc4NiAyLjQ2Mjc2NS0xLjg4ODkxNyAyLjc3MzU5OS0yLjE3NTg0MUM0LjU5MDc4NS0zLjg0OTU2NCA1LjI2MDI3NC00LjQ3MTIzMyA1LjI2MDI3NC01LjY1NDc5NUM1LjI2MDI3NC03LjAyOTYzOSA0LjE3MjM1NC03Ljk1MDE4NyAyLjc4NTU1NC03Ljk1MDE4N1MuNTg1ODAzLTYuNzY2NjI1IC41ODU4MDMtNS43Mzg0ODFDLjU4NTgwMy01LjEyODc2NyAxLjExMTgzMS01LjEyODc2NyAxLjE0NzY5Ni01LjEyODc2N0MxLjM5ODc1NS01LjEyODc2NyAxLjcwOTU4OS01LjMwODA5NSAxLjcwOTU4OS01LjY5MDY2QzEuNzA5NTg5LTYuMDI1NDA1IDEuNDgyNDQxLTYuMjUyNTUzIDEuMTQ3Njk2LTYuMjUyNTUzQzEuMDQwMS02LjI1MjU1MyAxLjAxNjE4OS02LjI1MjU1MyAuOTgwMzI0LTYuMjQwNTk4QzEuMjA3NDcyLTcuMDUzNTQ5IDEuODUzMDUxLTcuNjAzNDg3IDIuNjMwMTM3LTcuNjAzNDg3QzMuNjQ2MzI2LTcuNjAzNDg3IDQuMjY3OTk1LTYuNzU0NjcgNC4yNjc5OTUtNS42NTQ3OTVDNC4yNjc5OTUtNC42Mzg2MDUgMy42ODIxOTItMy43NTM5MjMgMy4wMDA3NDctMi45ODg3OTJMLjU4NTgwMy0uMjg2OTI0VjBINC45NDk0NEw1LjI2MDI3NC0yLjAwODQ2OFonLz4KPHBhdGggaWQ9J2cxLTUyJyBkPSdNNC4zMTU4MTYtNy43ODI4MTRDNC4zMTU4MTYtOC4wMDk5NjMgNC4zMTU4MTYtOC4wNjk3MzggNC4xNDg0NDMtOC4wNjk3MzhDNC4wNTI4MDItOC4wNjk3MzggNC4wMTY5MzYtOC4wNjk3MzggMy45MjEyOTUtNy45MjYyNzZMLjMyMjc5LTIuMzQzMjEzVi0xLjk5NjUxM0gzLjQ2Njk5OVYtLjkwODU5M0MzLjQ2Njk5OS0uNDY2MjUyIDMuNDQzMDg4LS4zNDY3IDIuNTcwMzYxLS4zNDY3SDIuMzMxMjU4VjBDMi42MDYyMjctLjAyMzkxIDMuNTUwNjg1LS4wMjM5MSAzLjg4NTQzLS4wMjM5MVM1LjE3NjU4OC0uMDIzOTEgNS40NTE1NTcgMFYtLjM0NjdINS4yMTI0NTNDNC4zNTE2ODEtLjM0NjcgNC4zMTU4MTYtLjQ2NjI1MiA0LjMxNTgxNi0uOTA4NTkzVi0xLjk5NjUxM0g1LjUyMzI4OFYtMi4zNDMyMTNINC4zMTU4MTZWLTcuNzgyODE0Wk0zLjUyNjc3NS02Ljg1MDMxMVYtMi4zNDMyMTNILjYyMTY2OUwzLjUyNjc3NS02Ljg1MDMxMVonLz4KPHBhdGggaWQ9J2cxLTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnMS05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PScwJyB4bGluazpocmVmPScjZzEtOTEnLz4KPHVzZSB4PSczLjI1MTY2MScgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTUwJy8+Cjx1c2UgeD0nOS4xMDQ2NTInIHk9JzAnIHhsaW5rOmhyZWY9JyNnMC01OScvPgo8dXNlIHg9JzE0LjM0ODgxJyB5PScwJyB4bGluazpocmVmPScjZzEtNTInLz4KPHVzZSB4PScyMC4yMDE4MDEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS05MycvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTQgLS0+) .
.In the hypothesis where
is high, then its distribution
is uniform in the interval ![[7, 9]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNiAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyMy40NTM0NjJwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgMjMuNDUzNDYyIDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2cxLTU1JyBkPSdNNS42Nzg3MDUtNy40MjQxNTlWLTcuNjk5MTI4SDIuNzk3NTA5QzEuMzUwOTM0LTcuNjk5MTI4IDEuMzI3MDI0LTcuODU0NTQ1IDEuMjc5MjAzLTguMDgxNjk0SDEuMDE2MTg5TC42NDU1NzktNS42OTA2NkguOTA4NTkzQy45NDQ0NTgtNS45MDU4NTMgMS4wNTIwNTUtNi42NDcwNzMgMS4yMDc0NzItNi43Nzg1OEMxLjMwMzExMy02Ljg1MDMxMSAyLjE5OTc1MS02Ljg1MDMxMSAyLjM2NzEyMy02Ljg1MDMxMUg0LjkwMTYxOUwzLjYzNDM3MS01LjAzMzEyNkMzLjMxMTU4Mi00LjU2Njg3NCAyLjEwNDExLTIuNjA2MjI3IDIuMTA0MTEtLjM1ODY1NUMyLjEwNDExLS4yMjcxNDggMi4xMDQxMSAuMjUxMDU5IDIuNTk0MjcxIC4yNTEwNTlDMy4wOTYzODkgLjI1MTA1OSAzLjA5NjM4OS0uMjE1MTkzIDMuMDk2Mzg5LS4zNzA2MVYtLjk2ODM2OUMzLjA5NjM4OS0yLjc0OTY4OSAzLjM4MzMxMy00LjEzNjQ4OCAzLjk0NTIwNS00LjkzNzQ4NEw1LjY3ODcwNS03LjQyNDE1OVonLz4KPHBhdGggaWQ9J2cxLTU3JyBkPSdNNC4zNzU1OTItMy40Nzg5NTRDNC4zNzU1OTItLjY1NzUzNCAzLjEyMDI5OS0uMDcxNzMxIDIuNDAyOTg5LS4wNzE3MzFDMi4xMTYwNjUtLjA3MTczMSAxLjQ4MjQ0MS0uMTA3NTk3IDEuMTgzNTYyLS41MjYwMjdIMS4yNTUyOTNDMS4zMzg5NzktLjUwMjExNyAxLjc2OTM2NS0uNTczODQ4IDEuNzY5MzY1LTEuMDE2MTg5QzEuNzY5MzY1LTEuMjc5MjAzIDEuNTkwMDM3LTEuNTA2MzUxIDEuMjc5MjAzLTEuNTA2MzUxUy43NzcwODYtMS4zMDMxMTMgLjc3NzA4Ni0uOTkyMjc5Qy43NzcwODYtLjI1MTA1OSAxLjM3NDg0NCAuMjUxMDU5IDIuNDE0OTQ0IC4yNTEwNTlDMy45MDkzNCAuMjUxMDU5IDUuMzU1OTE1LTEuMzM4OTc5IDUuMzU1OTE1LTMuOTMzMjVDNS4zNTU5MTUtNy4xNDkxOTEgNC4wMTY5MzYtNy45NTAxODcgMi45NjQ4ODItNy45NTAxODdDMS42NDk4MTMtNy45NTAxODcgLjQ5MDE2Mi02Ljg1MDMxMSAuNDkwMTYyLTUuMjcyMjI5UzEuNjAxOTkzLTIuNjE4MTgyIDIuNzk3NTA5LTIuNjE4MTgyQzMuNjgyMTkyLTIuNjE4MTgyIDQuMTM2NDg4LTMuMjYzNzYxIDQuMzc1NTkyLTMuODczNDc0Vi0zLjQ3ODk1NFpNMi44NDUzMy0yLjg1NzI4NUMyLjA5MjE1NC0yLjg1NzI4NSAxLjc2OTM2NS0zLjQ2Njk5OSAxLjY2MTc2OC0zLjY5NDE0N0MxLjQ3MDQ4Ni00LjE0ODQ0MyAxLjQ3MDQ4Ni00LjcyMjI5MSAxLjQ3MDQ4Ni01LjI2MDI3NEMxLjQ3MDQ4Ni01LjkyOTc2MyAxLjQ3MDQ4Ni02LjUwMzYxMSAxLjc4MTMyLTYuOTkzNzczQzEuOTk2NTEzLTcuMzE2NTYzIDIuMzE5MzAzLTcuNjYzMjYzIDIuOTY0ODgyLTcuNjYzMjYzQzMuNjQ2MzI2LTcuNjYzMjYzIDMuOTkzMDI2LTcuMDY1NTA0IDQuMTEyNTc4LTYuNzkwNTM1QzQuMzUxNjgxLTYuMjA0NzMyIDQuMzUxNjgxLTUuMTg4NTQzIDQuMzUxNjgxLTUuMDA5MjE1QzQuMzUxNjgxLTQuMDA0OTgxIDMuODk3Mzg1LTIuODU3Mjg1IDIuODQ1MzMtMi44NTcyODVaJy8+CjxwYXRoIGlkPSdnMS05MScgZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicvPgo8cGF0aCBpZD0nZzEtOTMnIGQ9J00xLjg1MzA1MS04Ljk2NjM3NkguMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTkxJy8+Cjx1c2UgeD0nMy4yNTE2NjEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS01NScvPgo8dXNlIHg9JzkuMTA0NjUyJyB5PScwJyB4bGluazpocmVmPScjZzAtNTknLz4KPHVzZSB4PScxNC4zNDg4MScgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTU3Jy8+Cjx1c2UgeD0nMjAuMjAxODAxJyB5PScwJyB4bGluazpocmVmPScjZzEtOTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) .
This is the hypothesis used in [iooss2015].
.
This is the hypothesis used in [iooss2015].
Input variable |
Distribution |
|---|---|
|
Gumbel(mode=1013, scale=558), |
|
Normal(mu=30.0, sigma=7.5), |
|
Uniform(a=49, b=51) |
|
Uniform(a=54, b=56) |
|
Triangular(min=295, mode=300, max=305) |
|
Triangular(min=4990, mode=5000, max=5010) |
|
Triangular(min=55, mode=55.5, max=56) |
|
Uniform(min=2, max=4) |
Table 1. Distribution of the input random variables in the scenario where is low.
Input variable |
Distribution |
|---|---|
|
Uniform(min=7, max=9) |
Table 2. Distribution of the input random variables in the scenario where is high.
The other variables have the same distribution.
Moreover, we assume that the input random variables are independent.
We want to estimate the flood probability:

The results depend on the hypothesis chosen for .
If
is low, then  (with coefficient of variation lower than 0.01).
In this case, the model is mostly additive.
(with coefficient of variation lower than 0.01).
In this case, the model is mostly additive.If
is high, then  (with coefficient of variation lower than 0.01).
In this case, the model for has interactions, mainly for ,
, and .
The model is mostly additive for
(with coefficient of variation lower than 0.01).
In this case, the model for has interactions, mainly for ,
, and .
The model is mostly additive for  and
and  .
.
Analysis of the model¶
The next figure presents the river height depending on the flowrate
when the other parameters are set to their mean values.
We see that the river height as a power model shape which is a property
of the Manning-Strickler model.
(Source code, svg)

The next figure plots the cost depending on the overflow
in the default scenario where the dyke height is low.
It makes use of a Quasi Monte Carlo sample of size  .
.
(Source code, svg)

The next figure plots the cost depending on the dyke height
when the other parameters are set to their mean values.
We notice that the cost first decreases because the flooding cost decreases
when the dyke height increases.
Then the cost increases because cost of the dyke increases when the
dyke height increases.
(Source code, svg)

The next figure presents the distribution of the three outputs in the
default scenario where the height of the dyke is low.
It is based on a Monte-Carlo sample of size  and uses
the histogram to estimate the density of the output of the model.
and uses
the histogram to estimate the density of the output of the model.
(Source code, svg)

The next figure presents the distribution of the three outputs in the scenario where the height of the dyke is high.
(Source code, svg)

The next figure presents the Sobol’ indices of the three outputs in the
scenario where the height of the dyke is low.
We estimate the Sobol’ indices from sampling, using a root sample
size equal to  and the Sobol’ low discrepancy sequence.
and the Sobol’ low discrepancy sequence.
(Source code, svg)

The next figure presents the Sobol’ indices of the three outputs in the scenario where the height of the dyke is high.
(Source code, svg)

The next figure presents the Sobol’ indices of the height model output
with four inputs  only.
This is a simpler model that leads to a simplified analysis.
only.
This is a simpler model that leads to a simplified analysis.
(Source code, svg)

Analysis of the calibration problem¶
In this section, we analyse why calibrating the parameters of this model may raise some difficulties.
First, the slope only depends on the difference  .
This is why and cannot be identified at the same time.
In algebraic terms, there is an infinite number of couples
.
This is why and cannot be identified at the same time.
In algebraic terms, there is an infinite number of couples  which
generate the same difference .
which
generate the same difference .
Second, the denominator of the expression of involves the product
 .
In algebraic terms, there is an infinite number of couples
.
In algebraic terms, there is an infinite number of couples  which
generate the same product
which
generate the same product  .
This is why either or can be identified separately,
but not at the same time.
This shows that only one parameter can be identified.
.
This is why either or can be identified separately,
but not at the same time.
This shows that only one parameter can be identified.
Hence, calibrating this model requires some regularization which can be done by Bayesian methods.
References¶
API documentation¶
- class FloodModel(trueKs=30.0, trueZv=50.0, trueZm=55.0, distributionHdLow=True)
Data class for the flood model.
- Parameters:
- Lfloat, optional
Length of the river. The default is 5000.0.
- Bfloat, optional
Width of the river. The default is 300.0.
- trueKsfloat, optional
The true value of the Ks parameter. The default is 30.0.
- trueZvfloat, optional
The true value of the Zv parameter. The default is 50.0.
- trueZmfloat, optional
The true value of the Zm parameter. The default is 55.0.
- distributionHdLowbool, optional
If True, then the distribution of Hd is uniform in [2, 4] i.e the dyke is relatively low. Otherwise, the distribution of Hd is uniform in [7, 9] i.e the dyke is relatively high. The default is True.
- Attributes:
- dimint
The dimension of the problem: dim=4
- Q
TruncatedDistribution ot.TruncatedDistribution(ot.Gumbel(558.0, 1013.0), 0.0, ot.TruncatedDistribution.LOWER)
- Ks
TruncatedDistribution ot.TruncatedDistribution(ot.Normal(30.0, 7.5), 0.0, ot.TruncatedDistribution.LOWER)
- Zv
Uniform ot.Uniform(49.0, 51.0)
- Zm
Uniform ot.Uniform(54.0, 56.0)
- B
Uniform Triangular(295.0, 300.0, 305.0)
- L
Uniform ot.Triangular(4990.0, 5000.0, 5010.0)
- Hd
Uniform ot.Uniform(54.0, 56.0)
- Zb
Uniform The distribution depends on distributionHdLow.
- model
ParametricFunction The flood model. The function has input dimension 8 and output dimension 3. More precisely, we have
 and
and
 .
.- distribution
JointDistribution The joint distribution of the input parameters.
- data
Sample of size 10 and dimension 2 A data set which contains noisy observations of the flow rate (column 0) and the height (column 1).
Methods
getHeightModel([L, B, Zb, Hd])Return the height model with corresponding input distribution
Examples
>>> from openturns.usecases import flood_model >>> # Load the flood model >>> fm = flood_model.FloodModel() >>> print(fm.data[:5]) [ Q ($m^3/s$) H (m) ] 0 : [ 130 0.59 ] 1 : [ 530 1.33 ] 2 : [ 960 2.03 ] 3 : [ 1400 2.72 ] 4 : [ 1830 2.83 ] >>> print("Inputs:", fm.model.getInputDescription()) Inputs: [Q, Ks, Zv, Zm, B, L, Zb, Hd] >>> print("Output:", fm.model.getOutputDescription()) Output: [H, S, C]
Get the height model.
>>> heightInputDistribution, heightModel = fm.getHeightModel() >>> print("Inputs:", heightModel.getInputDescription()) Inputs: [Q,Ks,Zv,Zm] >>> print("Outputs:", heightModel.getOutputDescription()) Outputs: [H]
Get the flooding model with high Hd scenario.
>>> fm = flood_model.FloodModel(distributionHdLow=False)
- getHeightModel(L=5000.0, B=300.0, Zb=55.5, Hd=3.0)
Return the height model with corresponding input distribution
- Parameters:
- Lfloat, optional
The value of the river length. The default is 5000.0.
- Bfloat, optional
The value of the river width. The default is 300.0.
- Zbfloat, optional
The level (altitude) of the bank. The default is 55.5.
- Hdfloat, optional
The height of the dyke. The default is 3.0.
- Returns:
- heightInputDistribution
Distribution The joint input distribution of (Q, Ks, Zv, Zm).
- heightModel
Function The function with (Q, Ks, Zv, Zm) as input and (H) as output.
- heightInputDistribution
Examples based on this use case¶


Calibrate a parametric model: a quick-start guide to calibration






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}