Note
Go to the end to download the full example code.
Example of sensitivity analyses on the wing weight model¶
This example is a brief overview of the use of the most usual sensitivity analysis techniques and how to call them:
PCC: Partial Correlation Coefficients
PRCC: Partial Rank Correlation Coefficients
SRC: Standard Regression Coefficients
SRRC: Standard Rank Regression Coefficients
Pearson coefficients
Spearman coefficients
Taylor expansion importance factors
Sobol’ indices
Rank-based estimation of Sobol’ indices
HSIC : Hilbert-Schmidt Independence Criterion
We present the methods on the WingWeight function and use the same notations.
Definition of the model¶
We load the model from the usecases module.
import openturns as ot
import openturns.experimental as otexp
import openturns.viewer as otv
from openturns.usecases.wingweight_function import WingWeightModel
from matplotlib import pylab as plt
ot.Log.Show(ot.Log.NONE)
m = WingWeightModel()
Cross cuts of the function¶
Let’s have a look on 2D cross cuts of the wing weight function. For each 2D cross cut, the other variables are fixed to the input distribution mean values. This graph allows one to have a first idea of the variations of the function in pair of dimensions. The colors of each contour plot are comparable. The number of contour levels are related to the amount of variation of the function in the corresponding coordinates.
ot.ResourceMap.SetAsBool("Contour-DefaultIsFilled", True)
ot.ResourceMap.SetAsUnsignedInteger("Contour-DefaultLevelsNumber", 50)
lowerBound = m.distributionX.getRange().getLowerBound()
upperBound = m.distributionX.getRange().getUpperBound()
grid = ot.GridLayout(m.dim - 1, m.dim - 1)
for i in range(1, m.dim):
for j in range(i):
crossCutIndices = []
crossCutReferencePoint = []
for k in range(m.dim):
if k != i and k != j:
crossCutIndices.append(k)
# Definition of the reference point
crossCutReferencePoint.append(m.distributionX.getMean()[k])
# Definition of 2D cross cut function
crossCutFunction = ot.ParametricFunction(
m.model, crossCutIndices, crossCutReferencePoint
)
crossCutLowerBound = [lowerBound[j], lowerBound[i]]
crossCutUpperBound = [upperBound[j], upperBound[i]]
# Get and customize the contour plot
graph = crossCutFunction.draw(crossCutLowerBound, crossCutUpperBound)
graph.setTitle("")
contour = graph.getDrawable(0).getImplementation()
contour.setVmin(176.0)
contour.setVmax(363.0)
contour.setColorBarPosition("") # suppress colorbar of each plot
contour.setColorMap("hsv")
graph.setDrawable(contour, 0)
graph.setXTitle("")
graph.setYTitle("")
graph.setTickLocation(ot.GraphImplementation.TICKNONE)
graph.setGrid(False)
# Creation of axes title
if j == 0:
graph.setYTitle(m.distributionX.getDescription()[i])
if i == 9:
graph.setXTitle(m.distributionX.getDescription()[j])
grid.setGraph(i - 1, j, graph)
# Get View object to manipulate the underlying figure
v = otv.View(grid)
fig = v.getFigure()
fig.set_size_inches(12, 12) # reduce the size
# Setup a large colorbar
axes = v.getAxes()
colorbar = fig.colorbar(
v.getSubviews()[6][2].getContourSets()[0], ax=axes[:, -1], fraction=0.3
)
fig.subplots_adjust(top=1.0, bottom=0.0, left=0.0, right=1.0)
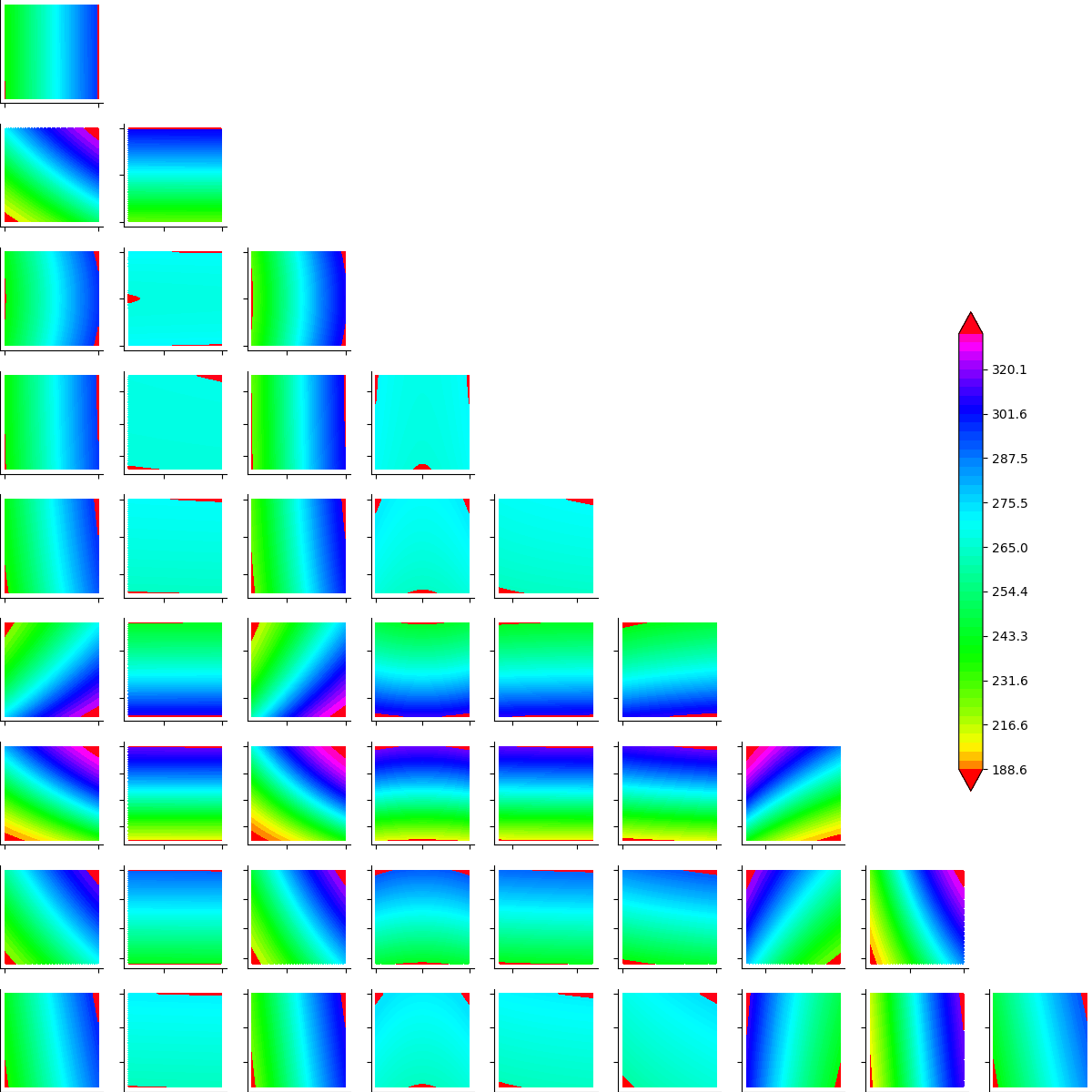
We can see that the variables  seem to be influent on the wing weight whereas
seem to be influent on the wing weight whereas  have less influence on the function.
have less influence on the function.
Data generation¶
We create the input and output data for the estimation of the different sensitivity coefficients and we get the input variables description:
inputNames = m.distributionX.getDescription()
size = 500
inputDesign = m.distributionX.getSample(size)
outputDesign = m.model(inputDesign)
Let’s estimate the PCC, PRCC, SRC, SRRC, Pearson and Spearman coefficients, display and analyze them.
We create a CorrelationAnalysis model.
corr_analysis = ot.CorrelationAnalysis(inputDesign, outputDesign)
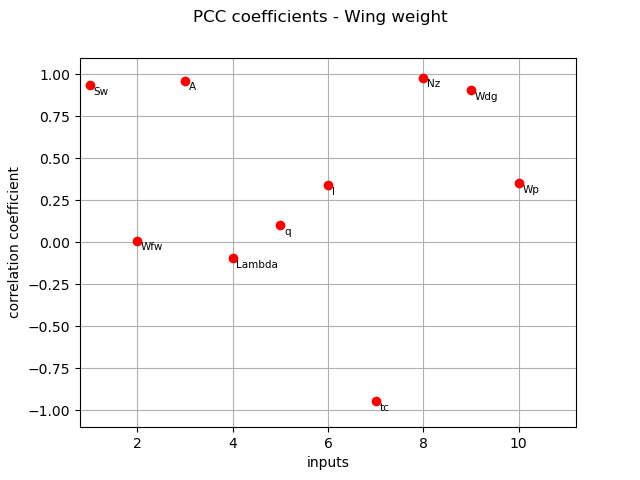
PCC coefficients¶
We compute here PCC coefficients using the CorrelationAnalysis.
pcc_indices = corr_analysis.computePCC()
print(pcc_indices)
[0.934554,0.0104727,0.962365,-0.0924538,0.102948,0.341098,-0.944522,0.979969,0.90616,0.351184]#10
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
pcc_indices, inputNames, "PCC coefficients - Wing weight"
)
view = otv.View(graph)
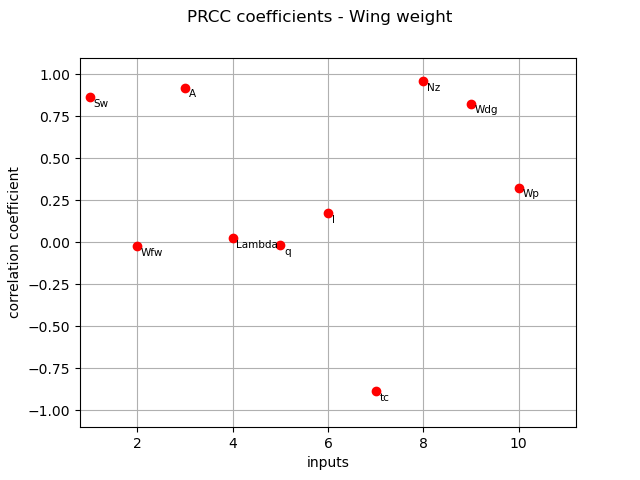
PRCC coefficients¶
We compute here PRCC coefficients using the CorrelationAnalysis.
prcc_indices = corr_analysis.computePRCC()
print(prcc_indices)
[0.86627,-0.0214398,0.921994,0.0255119,-0.0154478,0.173707,-0.887035,0.957783,0.825807,0.32514]#10
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
prcc_indices, inputNames, "PRCC coefficients - Wing weight"
)
view = otv.View(graph)
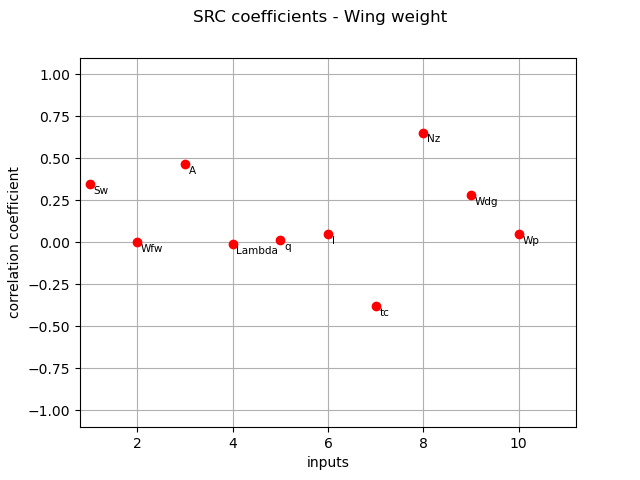
SRC coefficients¶
We compute here SRC coefficients using the CorrelationAnalysis.
src_indices = corr_analysis.computeSRC()
print(src_indices)
[0.346856,0.00137014,0.464381,-0.012191,0.0135906,0.047704,-0.377673,0.653557,0.28188,0.0491583]#10
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
src_indices, inputNames, "SRC coefficients - Wing weight"
)
view = otv.View(graph)
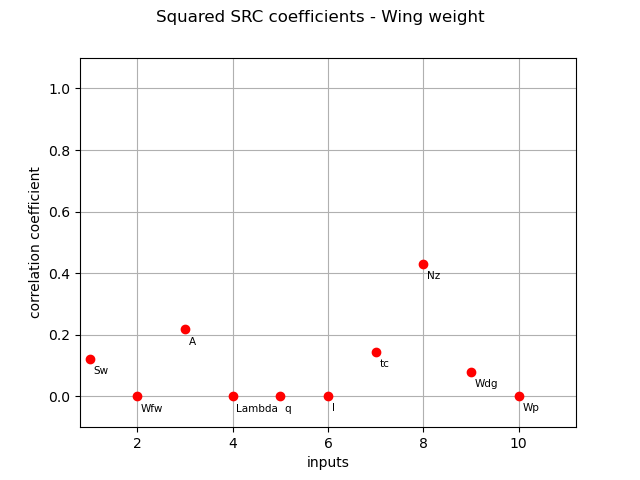
Normalized squared SRC coefficients (coefficients are made to sum to 1) :
squared_src_indices = corr_analysis.computeSquaredSRC(True)
print(squared_src_indices)
[0.121498,1.89582e-06,0.217781,0.000150088,0.000186529,0.00229815,0.144046,0.431357,0.0802415,0.00244041]#10
And their associated graph:
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
squared_src_indices, inputNames, "Squared SRC coefficients - Wing weight"
)
view = otv.View(graph)
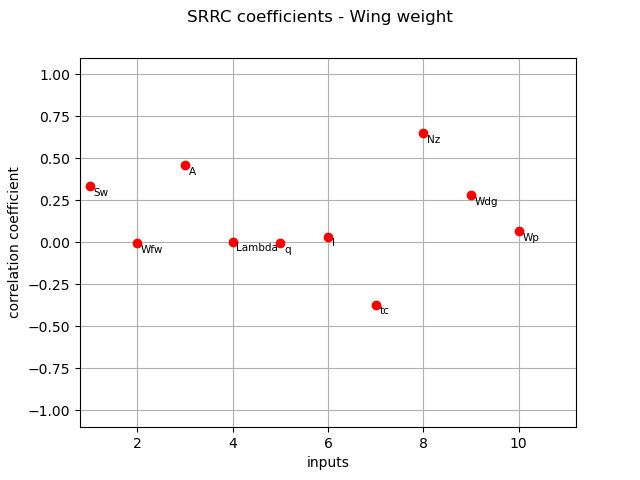
SRRC coefficients¶
We compute here SRRC coefficients using the CorrelationAnalysis.
srrc_indices = corr_analysis.computeSRRC()
print(srrc_indices)
[0.335959,-0.00411943,0.458295,0.00491644,-0.00297807,0.0340243,-0.370397,0.649178,0.282764,0.0661544]#10
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
srrc_indices, inputNames, "SRRC coefficients - Wing weight"
)
view = otv.View(graph)
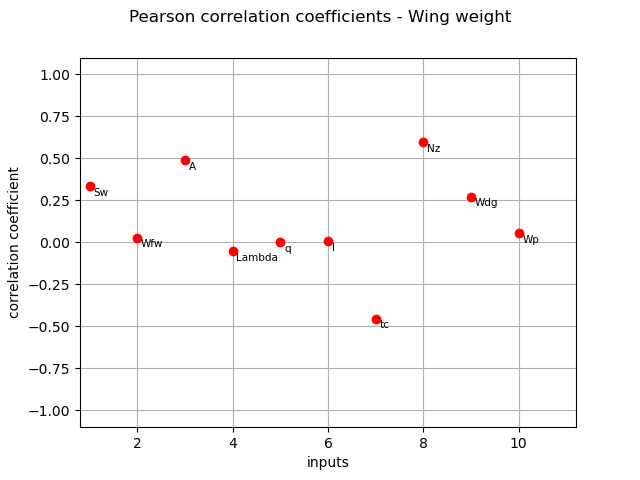
Pearson coefficients¶
We compute here the Pearson  coefficients using the
coefficients using the CorrelationAnalysis.
pearson_correlation = corr_analysis.computeLinearCorrelation()
print(pearson_correlation)
[0.332935,0.0283844,0.487791,-0.0500682,0.00344846,0.00567923,-0.453345,0.595607,0.272408,0.0562576]#10
title_pearson_graph = "Pearson correlation coefficients - Wing weight"
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
pearson_correlation, inputNames, title_pearson_graph
)
view = otv.View(graph)
Spearman coefficients¶
We compute here the Spearman  coefficients using the
coefficients using the CorrelationAnalysis.
spearman_correlation = corr_analysis.computeSpearmanCorrelation()
print(spearman_correlation)
[0.32268,0.0244834,0.482812,-0.0305156,-0.0137379,-0.00473234,-0.44607,0.596487,0.271809,0.0719404]#10
title_spearman_graph = "Spearman correlation coefficients - Wing weight"
graph = ot.SobolIndicesAlgorithm.DrawCorrelationCoefficients(
spearman_correlation, inputNames, title_spearman_graph
)
view = otv.View(graph)
plt.show()
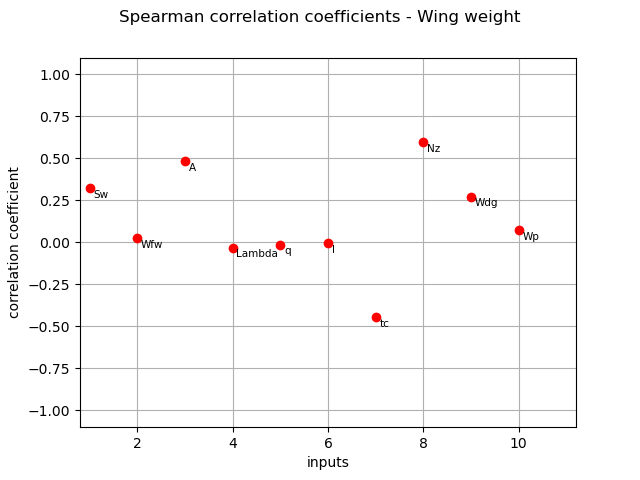
The different computed correlation estimators show that the variables  seem to be the most correlated with the wing weight in absolute value.
Pearson and Spearman coefficients do not reveal any linear nor monotonic correlation as no coefficients are equal to +/- 1.
Coefficients about
seem to be the most correlated with the wing weight in absolute value.
Pearson and Spearman coefficients do not reveal any linear nor monotonic correlation as no coefficients are equal to +/- 1.
Coefficients about  are negative revealing a negative correlation with the wing weight, that is consistent with the model expression.
are negative revealing a negative correlation with the wing weight, that is consistent with the model expression.
Taylor expansion importance factors¶
We compute here the Taylor expansion importance factors using TaylorExpansionMoments.
We create a distribution-based RandomVector.
X = ot.RandomVector(m.distributionX)
We create a composite RandomVector Y from X and m.model.
Y = ot.CompositeRandomVector(m.model, X)
We create a Taylor expansion method to approximate moments.
taylor = ot.TaylorExpansionMoments(Y)
We get the importance factors.
print(taylor.getImportanceFactors())
[Sw : 0.130315, Wfw : 2.94004e-06, A : 0.228153, Lambda : 0, q : 8.25053e-05, l : 0.00180269, tc : 0.135002, Nz : 0.412794, Wdg : 0.0883317, Wp : 0.00351621]
We draw the importance factors
graph = taylor.drawImportanceFactors()
graph.setTitle("Taylor expansion imporfance factors - Wing weight")
view = otv.View(graph)
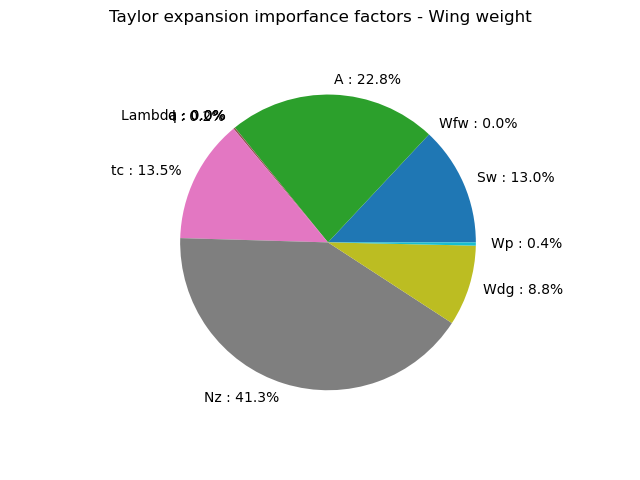
The Taylor expansion importance factors is consistent with the previous estimators as seem to be the most influent variables.
To analyze the relevance of the previous indices, a Sobol’ analysis is now carried out.
Sobol’ indices¶
We compute the Sobol’ indices from both sampling approach and Polynomial Chaos Expansion.
sizeSobol = 1000
sie = ot.SobolIndicesExperiment(m.distributionX, sizeSobol)
inputDesignSobol = sie.generate()
inputNames = m.distributionX.getDescription()
inputDesignSobol.setDescription(inputNames)
inputDesignSobol.getSize()
12000
We see that 12000 function evaluations are required to estimate the first order and total Sobol’ indices.
Then, we evaluate the outputs corresponding to this design of experiments.
outputDesignSobol = m.model(inputDesignSobol)
We estimate the Sobol’ indices with the SaltelliSensitivityAlgorithm.
sensitivityAnalysis = ot.SaltelliSensitivityAlgorithm(
inputDesignSobol, outputDesignSobol, sizeSobol
)
The getFirstOrderIndices and getTotalOrderIndices methods respectively return estimates of all first order and total Sobol’ indices.
print("First order indices:", sensitivityAnalysis.getFirstOrderIndices())
First order indices: [0.129315,0.00380685,0.209507,0.0046623,0.00408488,0.00341787,0.156257,0.350255,0.08197,0.00719791]#10
print("Total order indices:", sensitivityAnalysis.getTotalOrderIndices())
Total order indices: [0.13956,-0.000147514,0.195328,0.00112719,0.000281449,0.00453793,0.123365,0.429118,0.0985793,0.0130993]#10
The draw method produces the following graph. The vertical bars represent the 95% confidence intervals of the estimates.
graph = sensitivityAnalysis.draw()
graph.setTitle("Sobol indices with Saltelli - wing weight")
view = otv.View(graph)
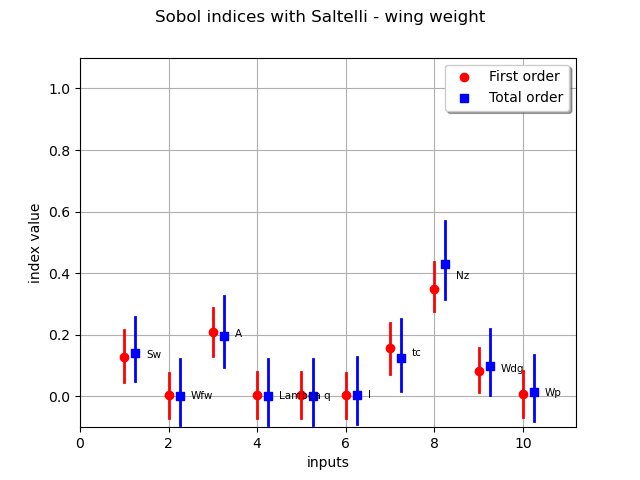
We see that several Sobol’ indices are negative, that is inconsistent with the theory. Therefore, a larger number of samples is required to get consistent indices
sizeSobol = 10000
sie = ot.SobolIndicesExperiment(m.distributionX, sizeSobol)
inputDesignSobol = sie.generate()
inputNames = m.distributionX.getDescription()
inputDesignSobol.setDescription(inputNames)
inputDesignSobol.getSize()
outputDesignSobol = m.model(inputDesignSobol)
sensitivityAnalysis = ot.SaltelliSensitivityAlgorithm(
inputDesignSobol, outputDesignSobol, sizeSobol
)
sensitivityAnalysis.getFirstOrderIndices()
sensitivityAnalysis.getTotalOrderIndices()
graph = sensitivityAnalysis.draw()
graph.setTitle("Sobol indices with Saltelli - wing weight")
view = otv.View(graph)
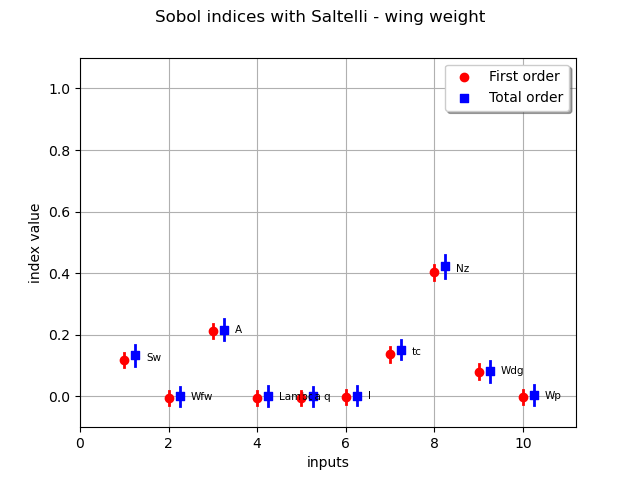
It improves the accuracy of the estimation but, for very low indices, Saltelli scheme is not accurate since several confidence intervals provide negative lower bounds.
Now, we estimate the Sobol’ indices using Polynomial Chaos Expansion. We create a Functional Chaos Expansion.
sizePCE = 800
inputDesignPCE = m.distributionX.getSample(sizePCE)
outputDesignPCE = m.model(inputDesignPCE)
algo = ot.FunctionalChaosAlgorithm(inputDesignPCE, outputDesignPCE, m.distributionX)
algo.run()
result = algo.getResult()
print(result.getResiduals())
print(result.getRelativeErrors())
[0.000334975]
[3.83943e-08]
The relative errors are low : this indicates that the PCE model has good accuracy. Then, we exploit the surrogate model to compute the Sobol’ indices.
sensitivityAnalysis = ot.FunctionalChaosSobolIndices(result)
sensitivityAnalysis
firstOrder = [sensitivityAnalysis.getSobolIndex(i) for i in range(m.dim)]
totalOrder = [sensitivityAnalysis.getSobolTotalIndex(i) for i in range(m.dim)]
graph = ot.SobolIndicesAlgorithm.DrawSobolIndices(inputNames, firstOrder, totalOrder)
graph.setTitle("Sobol indices by Polynomial Chaos Expansion - wing weight")
view = otv.View(graph)
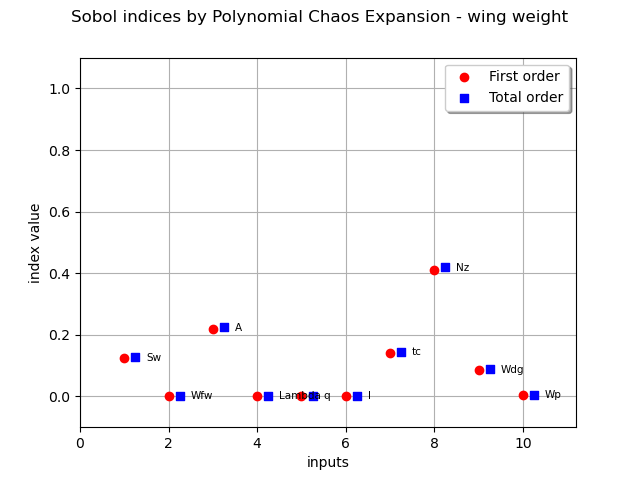
Furthermore, first order Sobol’ indices can also been estimated in a data-driven way using a rank-based sensitivity algorithm. In such a way, the estimation of sensitivity indices does not involve any surrogate model.
sizeRankSobol = 800
inputDesignRankSobol = m.distributionX.getSample(sizeRankSobol)
outputDesignankSobol = m.model(inputDesignRankSobol)
myRankSobol = otexp.RankSobolSensitivityAlgorithm(
inputDesignRankSobol, outputDesignankSobol
)
indicesrankSobol = myRankSobol.getFirstOrderIndices()
print("First order indices:", indicesrankSobol)
graph = myRankSobol.draw()
graph.setTitle("Sobol indices by rank-based estimation - wing weight")
view = otv.View(graph)
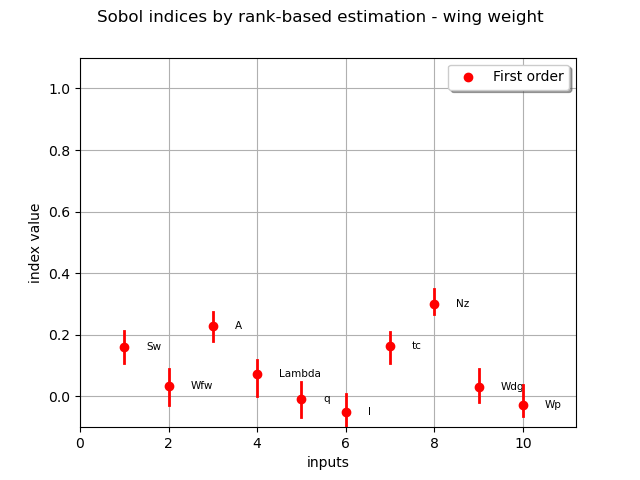
First order indices: [0.161955,0.0324797,0.228436,0.0726432,-0.00801005,-0.0498924,0.1633,0.299647,0.0310078,-0.0271989]#10
The Sobol’ indices confirm the previous analyses, in terms of ranking of the most influent variables.
We also see that five variables have a quasi null total Sobol’ indices, that indicates almost no influence on the wing weight.
There is no discrepancy between first order and total Sobol’ indices, that indicates no or very low interaction between the variables in the variance of the output.
As the most important variables act only through decoupled first degree contributions, the hypothesis of a linear dependence between the input variables and the weight is legitimate.
This explains why both squared SRC and Taylor give the exact same results even if the first one is based on a  linear approximation
and the second one is based on a linear expansion around the mean value of the input variables.
linear approximation
and the second one is based on a linear expansion around the mean value of the input variables.
HSIC indices¶
We then estimate the HSIC indices using a data-driven approach.
sizeHSIC = 250
inputDesignHSIC = m.distributionX.getSample(sizeHSIC)
outputDesignHSIC = m.model(inputDesignHSIC)
covarianceModelCollection = []
for i in range(m.dim):
Xi = inputDesignHSIC.getMarginal(i)
inputCovariance = ot.SquaredExponential(1)
inputCovariance.setScale(Xi.computeStandardDeviation())
covarianceModelCollection.append(inputCovariance)
We define a covariance kernel associated to the output variable.
outputCovariance = ot.SquaredExponential(1)
outputCovariance.setScale(outputDesignHSIC.computeStandardDeviation())
covarianceModelCollection.append(outputCovariance)
In this paragraph, we perform the analysis on the raw data: that is the global HSIC estimator.
estimatorType = ot.HSICUStat()
We now build the HSIC estimator:
globHSIC = ot.HSICEstimatorGlobalSensitivity(
covarianceModelCollection, inputDesignHSIC, outputDesignHSIC, estimatorType
)
We get the R2-HSIC indices:
R2HSICIndices = globHSIC.getR2HSICIndices()
print("\n Global HSIC analysis")
print("R2-HSIC Indices: ", R2HSICIndices)
Global HSIC analysis
R2-HSIC Indices: [0.0769851,-0.00448428,0.193184,-0.00490769,-0.00259878,0.00087629,0.0929111,0.35137,0.0367247,0.0147795]#10
and the HSIC indices:
HSICIndices = globHSIC.getHSICIndices()
print("HSIC Indices: ", HSICIndices)
HSIC Indices: [0.00707653,-0.000408212,0.0174873,-0.000446765,-0.000234775,7.91858e-05,0.00858646,0.0314256,0.00329501,0.00132732]#10
The p-value by permutation.
pvperm = globHSIC.getPValuesPermutation()
print("p-value (permutation): ", pvperm)
p-value (permutation): [0,0.752475,0,0.792079,0.564356,0.336634,0,0,0,0.029703]#10
We have an asymptotic estimate of the value for this estimator.
pvas = globHSIC.getPValuesAsymptotic()
print("p-value (asymptotic): ", pvas)
p-value (asymptotic): [7.51129e-09,0.784923,3.32161e-21,0.816713,0.613181,0.354752,2.75678e-10,5.49328e-35,0.000130914,0.0247993]#10
We vizualise the results.
graph1 = globHSIC.drawHSICIndices()
view1 = otv.View(graph1)
graph2 = globHSIC.drawPValuesAsymptotic()
view2 = otv.View(graph2)
graph3 = globHSIC.drawR2HSICIndices()
view3 = otv.View(graph3)
graph4 = globHSIC.drawPValuesPermutation()
view4 = otv.View(graph4)
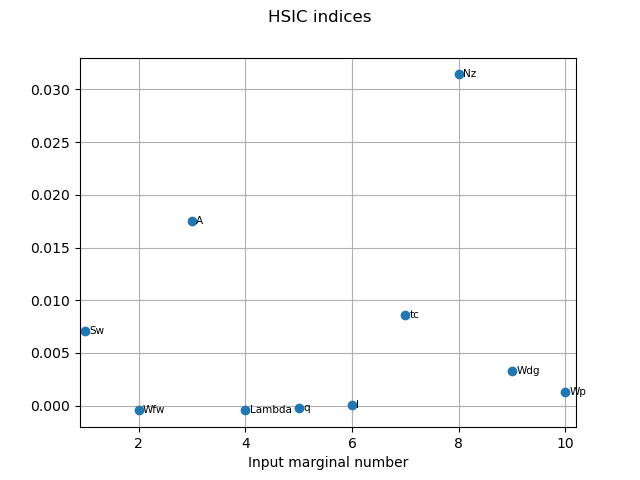
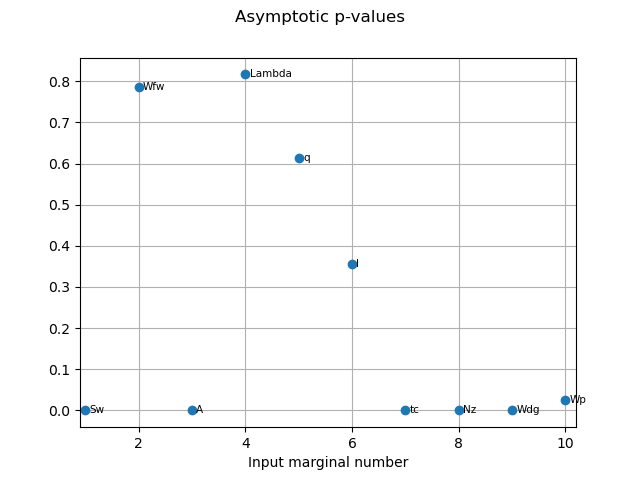
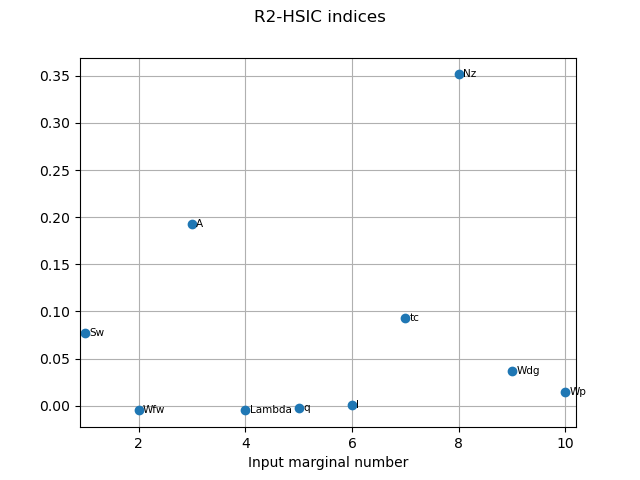
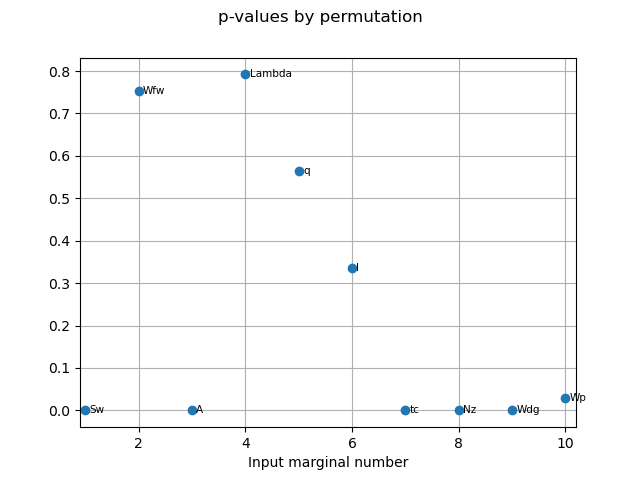
The HSIC indices go in the same way as the other estimators in terms the most influent variables.
The variables  seem to be independent to the output as the corresponding p-values are high.
We can also see that the asymptotic p-values and p-values estimated by permutation are quite similar.
seem to be independent to the output as the corresponding p-values are high.
We can also see that the asymptotic p-values and p-values estimated by permutation are quite similar.
Reset default settings
ot.ResourceMap.Reload()
Total running time of the script: (0 minutes 10.980 seconds)