ParetoFactory¶
(Source code, png)
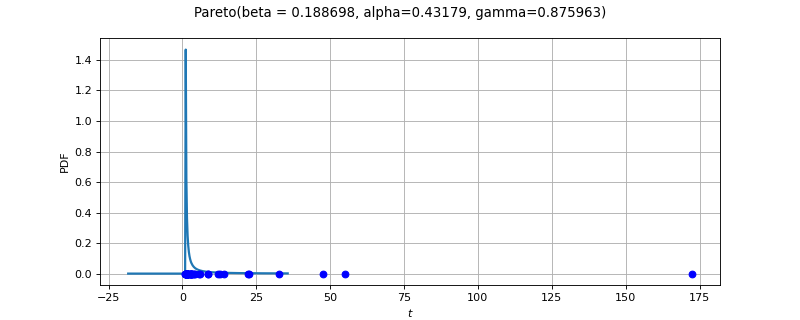
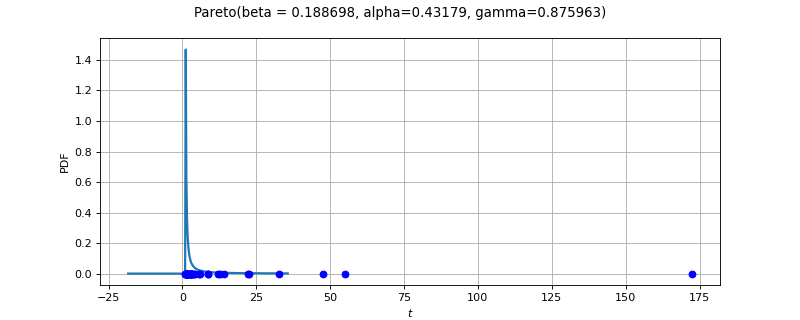
- class ParetoFactory(*args)¶
Pareto factory.
See also
Notes
Several estimators to build a Pareto distribution from a scalar sample are proposed. The default strategy is to use the least squares estimator.
Moments based estimator:
Lets denote:
 the empirical mean of the sample,
the empirical mean of the sample, its empirical variance,
its empirical variance, the empirical skewness of the sample
the empirical skewness of the sample
The estimator
 of
of
 is defined as follows :
is defined as follows :The parameter
 is solution of the equation:
is solution of the equation:
There exists a symbolic solution. If
 , then we get
, then we get  as follows:
as follows:
Maximum likelihood based estimator:
The likelihood of the sample is defined by:

The maximum likelihood based estimator
of maximizes the likelihood:
The following strategy is to be implemented soon: For a given
 , the likelihood of the sample is defined by:
, the likelihood of the sample is defined by:
We get
 which maximizes
which maximizes  :
:
We get:

Then the parameter
is obtained by maximizing the likelihood  :
:
The initial point of the optimisation problem is
 .
.Least squares estimator:
The parameter
is numerically optimized by non-linear least-squares:
where
 are computed from linear least-squares at each optimization evaluation.
are computed from linear least-squares at each optimization evaluation.When
is known and the  follow a Pareto distribution then
we use linear least-squares to solve the relation:
follow a Pareto distribution then
we use linear least-squares to solve the relation:(1)¶

And the remaining parameters are estimated with:

Methods
build(*args)Build the distribution.
buildAsPareto(*args)Estimate the distribution as native distribution.
buildEstimator(*args)Build the distribution and the parameter distribution.
buildMethodOfLeastSquares(*args)Method of least-squares.
Method of likelihood maximization.
buildMethodOfMoments(sample)Method of moments estimator.
Accessor to the bootstrap size.
Accessor to the object's name.
getName()Accessor to the object's name.
hasName()Test if the object is named.
setBootstrapSize(bootstrapSize)Accessor to the bootstrap size.
setName(name)Accessor to the object's name.
- __init__(*args)¶
- build(*args)¶
Build the distribution.
Available usages:
build()
build(sample)
build(param)
- Parameters:
- sample2-d sequence of float
Data.
- paramsequence of float
The parameters of the distribution.
- Returns:
- dist
Distribution The estimated distribution.
In the first usage, the default native distribution is built.
- dist
- buildAsPareto(*args)¶
Estimate the distribution as native distribution.
Available usages:
buildAsPareto()
buildAsPareto(sample)
buildAsPareto(param)
- buildEstimator(*args)¶
Build the distribution and the parameter distribution.
- Parameters:
- sample2-d sequence of float
Data.
- parameters
DistributionParameters Optional, the parametrization.
- Returns:
- resDist
DistributionFactoryResult The results.
- resDist
Notes
According to the way the native parameters of the distribution are estimated, the parameters distribution differs:
Moments method: the asymptotic parameters distribution is normal and estimated by Bootstrap on the initial data;
Maximum likelihood method with a regular model: the asymptotic parameters distribution is normal and its covariance matrix is the inverse Fisher information matrix;
Other methods: the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting (see
KernelSmoothing).
If another set of parameters is specified, the native parameters distribution is first estimated and the new distribution is determined from it:
if the native parameters distribution is normal and the transformation regular at the estimated parameters values: the asymptotic parameters distribution is normal and its covariance matrix determined from the inverse Fisher information matrix of the native parameters and the transformation;
in the other cases, the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting.
- buildMethodOfLeastSquares(*args)¶
Method of least-squares.
- Parameters:
- sample2-d sequence of float
Data.
- gammafloat, optional
Gamma parameter.
- Returns:
- distribution
Pareto The estimated distribution.
- distribution
Notes
Refer to
LeastSquaresDistributionFactory.
- buildMethodOfLikelihoodMaximization(sample)¶
Method of likelihood maximization.
Refer to
MaximumLikelihoodFactory.- Parameters:
- sample2-d sequence of float
Data.
- Returns:
- distribution
Pareto The estimated distribution
- distribution
- buildMethodOfMoments(sample)¶
Method of moments estimator.
- Parameters:
- sample2-d sequence of float
Data.
- Returns:
- distribution
Pareto The estimated distribution
- distribution
- getBootstrapSize()¶
Accessor to the bootstrap size.
- Returns:
- sizeint
Size of the bootstrap.
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- setBootstrapSize(bootstrapSize)¶
Accessor to the bootstrap size.
- Parameters:
- sizeint
The size of the bootstrap.
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
{kind=link}