Chaos basis enumeration strategies¶
The functional chaos expansion allows one to obtain an explicit
representation of the random response  of the
model under consideration. More precisely, the response is cast
as a converging series featuring an orthonormal basis. For
computational purpose, it is necessary though to retain a finite
number of terms by truncating the expansion. First of all, a specific
strategy for enumerating the infinite PC series has to be defined.
This is the scope of the current section.
of the
model under consideration. More precisely, the response is cast
as a converging series featuring an orthonormal basis. For
computational purpose, it is necessary though to retain a finite
number of terms by truncating the expansion. First of all, a specific
strategy for enumerating the infinite PC series has to be defined.
This is the scope of the current section.
Given an input random vector  with prescribed
probability density function (PDF)
with prescribed
probability density function (PDF)  , it is
possible to build up a functional chaos multivariate basis
, it is
possible to build up a functional chaos multivariate basis
 by tensorization of univariate
functions associated to each marginal input variable.
by tensorization of univariate
functions associated to each marginal input variable.
We define the multi-indices associated to the marginal degrees of the univariate marginal functions:

The component  defines the marginal degree of the univariate
basis term associated to the variable
defines the marginal degree of the univariate
basis term associated to the variable  .
For
.
For  , let
, let  be a univariate basis term of marginal degree depending on the i-th standardized variable
be a univariate basis term of marginal degree depending on the i-th standardized variable  .
Then, the multivariate basis term
.
Then, the multivariate basis term  is defined by the product:
is defined by the product:

for any  .
.
Let us first define the length of any multi-index  by
by

When the multi-index represents the marginal degrees of a polynomial, the length of the multi-index is the total degree of the polynomial.
An enumeration rule is a method to explore this basis.
It is defined by an enumeration function  from
from  to
to  ,
which creates a one-to-one mapping between an integer
,
which creates a one-to-one mapping between an integer  and a multi-index
and a multi-index  .
.
Mathematically speaking, it is a bijective enumeration function defined by:

Linear enumeration strategy¶
A natural choice to sort the PC basis (i.e. the multi-indices ) is the
lexicographical order with a constraint of increasing total degree.
The linear enumeration function  is a function:
is a function:

for  such that:
such that:

Furthermore, for any  and any
and any  , we say that:
, we say that:

if either (i) the length of  is strictly lower than
is strictly lower than  i.e.:
i.e.:

or (ii) the length of equal to the length of i.e.

and there exists  such that:
such that:

The conditions (i) and (ii) ensure that the mapping implies a strict order on the set .
The condition (i) states that the two multi-indices  and
and  are not on the same strata.
are not on the same strata.
The condition (ii) states that, if the two multi-indices and are on the same strata,
then at least one of the component (denoted by  in the definition) is different while the previous components are equal.
in the definition) is different while the previous components are equal.
Such an enumeration strategy is illustrated in a two-dimensional case
(i.e.  ) in the figure below:
) in the figure below:
(Source code, png, hires.png, pdf)
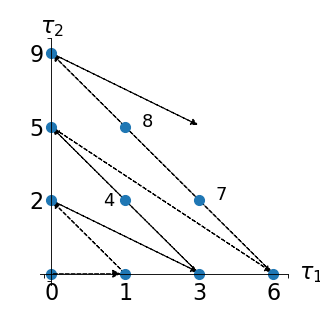
This corresponds to the following enumeration of the multi-indices:
|
|
|
|---|---|---|
|
|
0 |
|
|
1 |
|
|
1 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
3 |
|
|
3 |
|
|
3 |
|
|
3 |






















Hyperbolic enumeration strategy¶
The hyperbolic truncation strategy is inspired by the so-called
sparsity-of-effects principle, which states that most models are
principally governed by main effects and low-order interactions.
Accordingly, one wishes to define an enumeration strategy which first
selects those multi-indices related to main effects, i.e. with a
reasonably small number of nonzero components, prior to selecting
those associated with higher-order interactions.
For any real number  in
in ![(0,1]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuMTMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyNC43NTQxMjZwdCcgaGVpZ2h0PScxMS45NTUxNjhwdCcgdmlld0JveD0nMCAtOC45NjYzNzYgMjQuNzU0MTI2IDExLjk1NTE2OCc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2cxLTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnMS00OCcgZD0nTTUuMzU1OTE1LTMuODI1NjU0QzUuMzU1OTE1LTQuODE3OTMzIDUuMjk2MTM5LTUuNzg2MzAxIDQuODY1NzUzLTYuNjk0ODk0QzQuMzc1NTkyLTcuNjg3MTczIDMuNTE0ODE5LTcuOTUwMTg3IDIuOTI5MDE2LTcuOTUwMTg3QzIuMjM1NjE2LTcuOTUwMTg3IDEuMzg2OC03LjYwMzQ4NyAuOTQ0NDU4LTYuNjExMjA4Qy42MDk3MTQtNS44NTgwMzIgLjQ5MDE2Mi01LjExNjgxMiAuNDkwMTYyLTMuODI1NjU0Qy40OTAxNjItMi42NjYwMDIgLjU3Mzg0OC0xLjc5MzI3NSAxLjAwNDIzNC0uOTQ0NDU4QzEuNDcwNDg2LS4wMzU4NjYgMi4yOTUzOTIgLjI1MTA1OSAyLjkxNzA2MSAuMjUxMDU5QzMuOTU3MTYxIC4yNTEwNTkgNC41NTQ5MTktLjM3MDYxIDQuOTAxNjE5LTEuMDY0MDFDNS4zMzIwMDUtMS45NjA2NDggNS4zNTU5MTUtMy4xMzIyNTQgNS4zNTU5MTUtMy44MjU2NTRaTTIuOTE3MDYxIC4wMTE5NTVDMi41MzQ0OTYgLjAxMTk1NSAxLjc1NzQxLS4yMDMyMzggMS41MzAyNjItMS41MDYzNTFDMS4zOTg3NTUtMi4yMjM2NjEgMS4zOTg3NTUtMy4xMzIyNTQgMS4zOTg3NTUtMy45NjkxMTZDMS4zOTg3NTUtNC45NDk0NCAxLjM5ODc1NS01LjgzNDEyMiAxLjU5MDAzNy02LjUzOTQ3N0MxLjc5MzI3NS03LjM0MDQ3MyAyLjQwMjk4OS03LjcxMTA4MyAyLjkxNzA2MS03LjcxMTA4M0MzLjM3MTM1Ny03LjcxMTA4MyA0LjA2NDc1Ny03LjQzNjExNSA0LjI5MTkwNS02LjQwNzk3QzQuNDQ3MzIzLTUuNzI2NTI2IDQuNDQ3MzIzLTQuNzgyMDY3IDQuNDQ3MzIzLTMuOTY5MTE2QzQuNDQ3MzIzLTMuMTY4MTIgNC40NDczMjMtMi4yNTk1MjcgNC4zMTU4MTYtMS41MzAyNjJDNC4wODg2NjctLjIxNTE5MyAzLjMzNTQ5MiAuMDExOTU1IDIuOTE3MDYxIC4wMTE5NTVaJy8+CjxwYXRoIGlkPSdnMS00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2cxLTkzJyBkPSdNMS44NTMwNTEtOC45NjYzNzZILjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUguMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS00MCcvPgo8dXNlIHg9JzQuNTUyMzI2JyB5PScwJyB4bGluazpocmVmPScjZzEtNDgnLz4KPHVzZSB4PScxMC40MDUzMTYnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMC01OScvPgo8dXNlIHg9JzE1LjY0OTQ3NScgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTQ5Jy8+Cjx1c2UgeD0nMjEuNTAyNDY1JyB5PScwJyB4bGluazpocmVmPScjZzEtOTMnLz4KPC9nPgo8L3N2Zz4=) , one defines the
-hyperbolic norm (or -norm for short) of a
multi-index by:
, one defines the
-hyperbolic norm (or -norm for short) of a
multi-index by:

Strictly speaking,  is not properly a norm but
rather a quasi-norm since it does not satisfy the triangular
inequality. However this abuse of language will be used in the
following. Note that the case
is not properly a norm but
rather a quasi-norm since it does not satisfy the triangular
inequality. However this abuse of language will be used in the
following. Note that the case  corresponds to the
definition of the total degree.
corresponds to the
definition of the total degree.
Let  be a real positive number. One defines the set of
multi-indices with -norm not greater than as
follows:
be a real positive number. One defines the set of
multi-indices with -norm not greater than as
follows:
(1)¶

Moreover, one defines the front of  by:
by:

where  is a multi-index with a unit
is a multi-index with a unit  -entry
and zero
-entry
and zero  -entries,
-entries,  .
.
The idea consists in exploring the space by progressively
increasing the -norm of its elements. In this purpose, one
wants to construct an enumeration function that relies upon (1) the
bijection defined in the previous paragraph and (2) an
appropriate increasing sequence  that tends
to infinity. Such a sequence can be used to define a specific
partition of into strata
that tends
to infinity. Such a sequence can be used to define a specific
partition of into strata  .
Precisely, the enumeration of the multi-indices is achieved by sorting
the elements of
.
Precisely, the enumeration of the multi-indices is achieved by sorting
the elements of  in ascending order of the
-norm, and then by sorting the possible elements having the
same -norm using the bijection . Several examples
of partition are given in the sequel.
Partition based on the total degree. We can simply define the
sequence as the set of natural integers
. Thus we build up a sequence
of strata as follows:
in ascending order of the
-norm, and then by sorting the possible elements having the
same -norm using the bijection . Several examples
of partition are given in the sequel.
Partition based on the total degree. We can simply define the
sequence as the set of natural integers
. Thus we build up a sequence
of strata as follows:

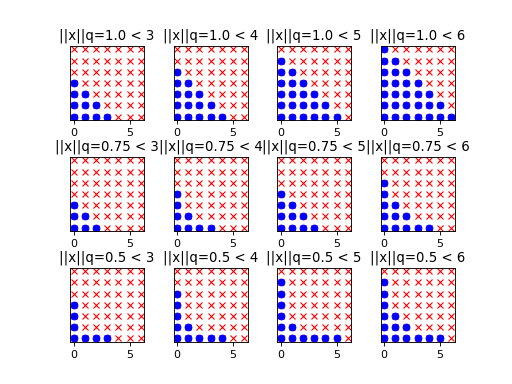
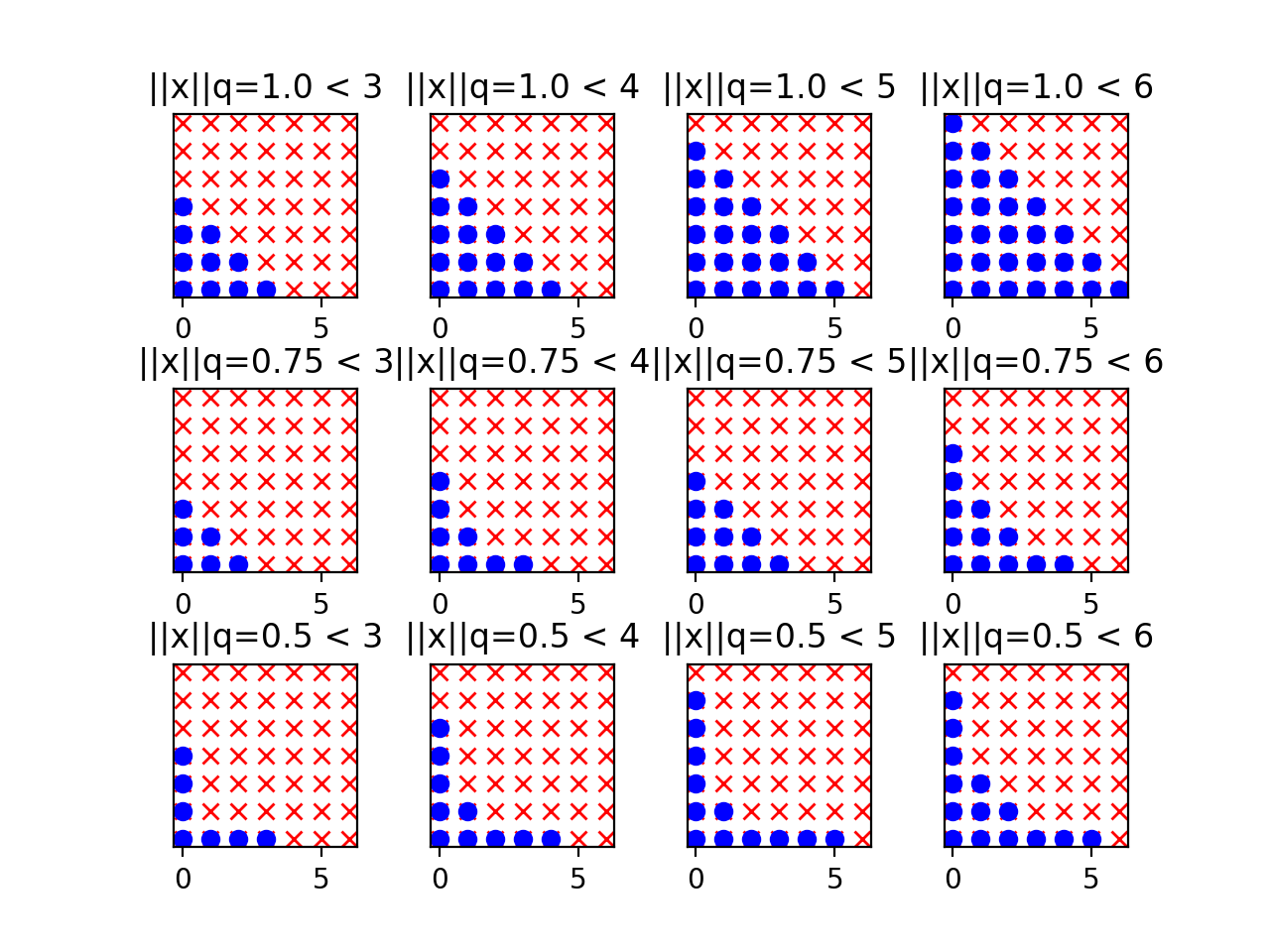
The progressive exploration of is depicted in the
two-dimensional case for various values of the parameter :
(Source code, png, hires.png, pdf)
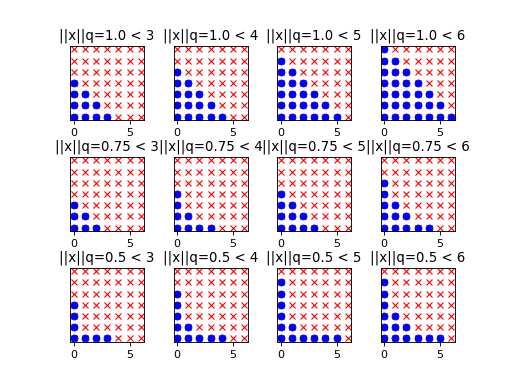
As expected, the hyperbolic norms penalize the indices associated with
high-order interactions all the more since is low. Note that
setting equal to 1 corresponds to the usual linear
enumeration strategy. Then the retained basis terms are located under
a straight line, hence the label linear enumeration strategy. In
contrast, when  , the retained basis terms are
located under an hyperbola, hence the name hyperbolic enumeration
strategy.
Partition based on disjoint fronts. Instead of considering the
sequence of natural integers, we define the sequence
recursively by:
, the retained basis terms are
located under an hyperbola, hence the name hyperbolic enumeration
strategy.
Partition based on disjoint fronts. Instead of considering the
sequence of natural integers, we define the sequence
recursively by:

In other words,  is the infimum of the real numbers
for which the new front contains only element which do
not belong to the former one. Hence the sequence of strata:
is the infimum of the real numbers
for which the new front contains only element which do
not belong to the former one. Hence the sequence of strata:

Note that this partition of is finer than the one based
on total degrees, since the cardinality of the strata is smaller.
Anisotropic hyperbolic enumeration strategy¶
One might also consider enumeration strategies based on an anisotropic hyperbolic norm defined by:

where the  ’s are real positive numbers. This would lead
to first select the basis terms depending on a specific subset
of input variables.
’s are real positive numbers. This would lead
to first select the basis terms depending on a specific subset
of input variables.
In this setup, it is also possible to explore the space of
the multi-indices by partitioning it according to one of the two
schemes outlined in the previous paragraph (it is only necessary to
replace the isotropic -norm in (1) with the
 -anisotropic one).
We may also build up an alternative partition related to the partial
degree of the most important variable, i.e. the one associated to the
smallest weight . Then the sequence
is equal to and the sets
are defined by:
-anisotropic one).
We may also build up an alternative partition related to the partial
degree of the most important variable, i.e. the one associated to the
smallest weight . Then the sequence
is equal to and the sets
are defined by:

If strata with larger cardinalities are of interest, one may rather
consider the partial degree of the least significant variable, i.e.
the one associated with the greatest weight . To this
end, the index  in the previous formula has to be defined
by:
in the previous formula has to be defined
by:

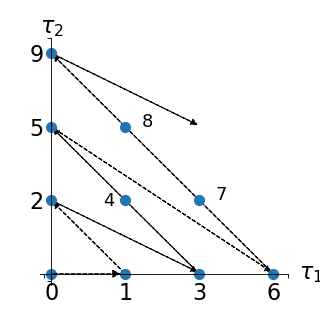
Infinity norm enumeration strategy¶
One might also consider an enumeration strategies based on the infinite norm:

This corresponds to the following enumeration of the multi-indices:
|
|
|
|---|---|---|
|
|
0 |
|
|
1 |
|
|
1 |
|
|
1 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
3 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}