Note
Go to the end to download the full example code
Compute leave-one-out error of a polynomial chaos expansion¶
Introduction¶
In this example, we compute the design matrix of a polynomial chaos
expansion using the DesignProxy class.
Then we compute the analytical leave-one-out error using the
diagonal of the projection matrix.
To do this, we use equations from [blatman2009] page 85
(see also [blatman2011]).
In this advanced example, we use the DesignProxy
and QRMethod low level classes.
A naive implementation of this method is presented in
Polynomial chaos expansion cross-validation
using K-Fold cross-validation.
The design matrix¶
In this section, we analyze why the DesignProxy
is linked to the classical linear least squares regression problem.
Let  be the number of observations and
be the number of observations and  be the number of coefficients
of the linear model.
Let
be the number of coefficients
of the linear model.
Let  be the design matrix, i.e.
the matrix that produces the predictions of the linear regression model from
the coefficients:
be the design matrix, i.e.
the matrix that produces the predictions of the linear regression model from
the coefficients:

where  is the vector of coefficients,
is the vector of coefficients,
 is the
vector of predictions.
The linear least squares problem is:
is the
vector of predictions.
The linear least squares problem is:

The solution is given by the normal equations, i.e. the vector of coefficients is the solution of the following linear system of equations:

where  is the Gram matrix:
is the Gram matrix:

The hat matrix is the projection matrix defined by:

The hat matrix puts a hat to the vector of observations to produce the vector of predictions of the linear model:

To solve a linear least squares problem, we need to evaluate the
design matrix  , which is the primary goal of
the
, which is the primary goal of
the DesignProxy class.
Let us present some examples of situations where the design matrix
is required.
When we use the QR decomposition, we actually do not need to evaluate it in our script: the
QRMethodclass knows how to compute the solution without evaluating the Gram matrix .
.We may need the inverse Gram matrix
 sometimes, for example when we want to create
a D-optimal design.
sometimes, for example when we want to create
a D-optimal design.Finally, when we want to compute the analytical leave-one-out error, we need to compute the diagonal of the projection matrix
 .
.
For all these purposes, the DesignProxy is the tool.
The leave-one-out error¶
In this section, we show that the leave-one-error of a regression problem
can be computed using an analytical formula which depends on the hat matrix
.
We consider the physical model:

where  is the input and
is the input and  is
the output.
Consider the problem of approximating the physical model
is
the output.
Consider the problem of approximating the physical model  by the
linear model:
by the
linear model:

for any where  are the basis functions and
is a vector of parameters.
The mean squared error is ([blatman2009] eq. 4.23 page 83):
are the basis functions and
is a vector of parameters.
The mean squared error is ([blatman2009] eq. 4.23 page 83):
![\operatorname{MSE}\left(\tilde{g}\right)
= \mathbb{E}_{\vect{X}}\left[\left(g\left(\vect{X}\right) - \tilde{g}\left(\vect{X}\right) \right)^2 \right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMS4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzE3NC4yOTY2MjFwdCcgaGVpZ2h0PScxNS4xMzIyMjdwdCcgdmlld0JveD0nMTA3LjEyMzE3NSAtMTUuMTMyMjE5IDE3NC4yOTY2MjEgMTUuMTMyMjI3Jz4KPGRlZnM+CjxwYXRoIGlkPSdnNi01MCcgZD0nTTIuMjQ3NTcyLTEuNjI1OTAzQzIuMzc1MDkzLTEuNzQ1NDU1IDIuNzA5ODM4LTIuMDA4NDY4IDIuODM3MzYtMi4xMjAwNUMzLjMzMTUwNy0yLjU3NDM0NiAzLjgwMTc0My0zLjAxMjcwMiAzLjgwMTc0My0zLjczNzk4M0MzLjgwMTc0My00LjY4NjQyNiAzLjAwNDczMi01LjMwMDEyNSAyLjAwODQ2OC01LjMwMDEyNUMxLjA1MjA1NS01LjMwMDEyNSAuNDIyNDE2LTQuNTc0ODQ0IC40MjI0MTYtMy44NjU1MDRDLjQyMjQxNi0zLjQ3NDk2OSAuNzMzMjUtMy40MTkxNzggLjg0NDgzMi0zLjQxOTE3OEMxLjAxMjIwNC0zLjQxOTE3OCAxLjI1OTI3OC0zLjUzODczIDEuMjU5Mjc4LTMuODQxNTk0QzEuMjU5Mjc4LTQuMjU2MDQgLjg2MDc3Mi00LjI1NjA0IC43NjUxMzEtNC4yNTYwNEMuOTk2MjY0LTQuODM3ODU4IDEuNTMwMjYyLTUuMDM3MTExIDEuOTIwNzk3LTUuMDM3MTExQzIuNjYyMDE3LTUuMDM3MTExIDMuMDQ0NTgzLTQuNDA3NDcyIDMuMDQ0NTgzLTMuNzM3OTgzQzMuMDQ0NTgzLTIuOTA5MDkxIDIuNDYyNzY1LTIuMzAzMzYyIDEuNTIyMjkxLTEuMzM4OTc5TC41MTgwNTctLjMwMjg2NEMuNDIyNDE2LS4yMTUxOTMgLjQyMjQxNi0uMTk5MjUzIC40MjI0MTYgMEgzLjU3MDYxTDMuODAxNzQzLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2LTEuMjY3MjQ4IDMuNDY2OTk5LS44Njg3NDIgMy4zNzEzNTctLjcxNzMxQzMuMzIzNTM3LS42NTM1NDkgMi43MTc4MDgtLjY1MzU0OSAyLjU5MDI4Ni0uNjUzNTQ5SDEuMTcxNjA2TDIuMjQ3NTcyLTEuNjI1OTAzWicvPgo8cGF0aCBpZD0nZzEtODgnIGQ9J002Ljk1NzkwOC00LjcyMjI5MUw4LjUzNTk5LTYuMjc2NDYzTDkuMjc3MjEtNy4wMjk2MzlDOS43NTU0MTctNy40ODM5MzUgOS44OTg4NzktNy42MjczOTcgMTEuMTQyMjE3LTcuNjM5MzUyQzExLjM2OTM2NS03LjYzOTM1MiAxMS4zOTMyNzUtNy45NTAxODcgMTEuMzkzMjc1LTcuOTg2MDUyQzExLjM5MzI3NS04LjA1Nzc4MyAxMS4zNDU0NTUtOC4yMDEyNDUgMTEuMTU0MTcyLTguMjAxMjQ1QzEwLjczNTc0MS04LjIwMTI0NSAxMC4yODE0NDUtOC4xNjUzOCA5Ljg1MTA1OS04LjE2NTM4QzkuNTA0MzU5LTguMTY1MzggOC42NDM1ODctOC4yMDEyNDUgOC4yOTY4ODctOC4yMDEyNDVDOC4yMDEyNDUtOC4yMDEyNDUgNy45NjIxNDItOC4yMDEyNDUgNy45NjIxNDItNy44NjY1MDFDNy45NjIxNDItNy42NTEzMDggOC4xNTM0MjUtNy42MzkzNTIgOC4yNjEwMjEtNy42MzkzNTJDOC42MTk2NzYtNy42MjczOTcgOC45MzA1MTEtNy41MzE3NTYgOC45NzgzMzEtNy41MTk4MDFMNi42OTQ4OTQtNS4yNjAyNzRMNS41OTUwMTktNy41Njc2MjFDNS43MTQ1Ny03LjU5MTUzMiA2LjA4NTE4MS03LjYzOTM1MiA2LjI4ODQxOC03LjYzOTM1MkM2LjQxOTkyNS03LjYzOTM1MiA2LjYzNTExOC03LjYzOTM1MiA2LjYzNTExOC03Ljk3NDA5N0M2LjYzNTExOC04LjE0MTQ2OSA2LjUyNzUyMi04LjIwMTI0NSA2LjM3MjEwNS04LjIwMTI0NUM1Ljk2NTYyOS04LjIwMTI0NSA0Ljk2MTM5NS04LjE2NTM4IDQuNTU0OTE5LTguMTY1MzhDNC4yNzk5NS04LjE2NTM4IDQuMDA0OTgxLTguMTc3MzM1IDMuNzMwMDEyLTguMTc3MzM1UzMuMTY4MTItOC4yMDEyNDUgMi44OTMxNTEtOC4yMDEyNDVDMi43ODU1NTQtOC4yMDEyNDUgMi41NTg0MDYtOC4yMDEyNDUgMi41NTg0MDYtNy44NjY1MDFDMi41NTg0MDYtNy42MzkzNTIgMi43MTM4MjMtNy42MzkzNTIgMy4wNDg1NjgtNy42MzkzNTJDMy4yMTU5NC03LjYzOTM1MiAzLjM0NzQ0Ny03LjYzOTM1MiAzLjUxNDgxOS03LjYyNzM5N0MzLjY4MjE5Mi03LjYwMzQ4NyAzLjY5NDE0Ny03LjU5MTUzMiAzLjc2NTg3OC03LjQ0ODA3TDUuNDE1NjkxLTMuOTkzMDI2TDIuNDE0OTQ0LTEuMDI4MTQ0QzIuMTk5NzUxLS44MjQ5MDcgMS45NDg2OTItLjU3Mzg0OCAuODg0NjgyLS41NjE4OTNDLjY2OTQ4OS0uNTYxODkzIC40NjYyNTItLjU2MTg5MyAuNDY2MjUyLS4yMTUxOTNDLjQ2NjI1Mi0uMTMxNTA3IC41MjYwMjcgMCAuNzA1MzU1IDBDLjk5MjI3OSAwIDEuNzIxNTQ0LS4wMzU4NjYgMi4wMDg0NjgtLjAzNTg2NkMyLjM1NTE2OC0uMDM1ODY2IDMuMjE1OTQgMCAzLjU2MjY0IDBDMy42NTgyODEgMCAzLjg5NzM4NSAwIDMuODk3Mzg1LS4zNDY3QzMuODk3Mzg1LS41NjE4OTMgMy42ODIxOTItLjU2MTg5MyAzLjU4NjU1LS41NjE4OTNDMy4zNDc0NDctLjU2MTg5MyAzLjEwODM0NC0uNTk3NzU4IDIuODgxMTk2LS42ODE0NDVMNS42NjY3NS0zLjQ1NTA0NEw3LjAxNzY4NC0uNjMzNjI0QzcuMDA1NzI5LS42MzM2MjQgNi42MTEyMDgtLjU2MTg5MyA2LjMyNDI4NC0uNTYxODkzQzYuMjA0NzMyLS41NjE4OTMgNS45Nzc1ODQtLjU2MTg5MyA1Ljk3NzU4NC0uMjE1MTkzQzUuOTc3NTg0LS4xNzkzMjggNS45ODk1MzkgMCA2LjI0MDU5OCAwQzYuNjQ3MDczIDAgNy42NjMyNjMtLjAzNTg2NiA4LjA2OTczOC0uMDM1ODY2QzguMzQ0NzA3LS4wMzU4NjYgOC42MTk2NzYtLjAyMzkxIDguODk0NjQ1LS4wMjM5MVM5LjQ1NjUzOCAwIDkuNzMxNTA3IDBDOS44MjcxNDggMCAxMC4wNjYyNTIgMCAxMC4wNjYyNTItLjM0NjdDMTAuMDY2MjUyLS41NjE4OTMgOS44NzQ5NjktLjU2MTg5MyA5LjU4ODA0NS0uNTYxODkzQzkuNDIwNjcyLS41NjE4OTMgOS4zMDExMjEtLjU2MTg5MyA5LjEyMTc5My0uNTczODQ4QzguOTQyNDY2LS41OTc3NTggOC45MzA1MTEtLjYwOTcxNCA4Ljg0NjgyNC0uNzY1MTMxTDYuOTU3OTA4LTQuNzIyMjkxWicvPgo8cGF0aCBpZD0nZzQtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMy0yJyBkPSdNMi40MTQ5NDQgMTMuODU2MDRINC43MTAzMzZWMTMuMzc3ODMzSDIuODkzMTUxVjBINC43MTAzMzZWLS40NzgyMDdIMi40MTQ5NDRWMTMuODU2MDRaJy8+CjxwYXRoIGlkPSdnMy0zJyBkPSdNMi41NTg0MDYgMTMuODU2MDRWLS40NzgyMDdILjI2MzAxNFYwSDIuMDgwMTk5VjEzLjM3NzgzM0guMjYzMDE0VjEzLjg1NjA0SDIuNTU4NDA2WicvPgo8cGF0aCBpZD0nZzItNjknIGQ9J00zLjA5NjM4OS00LjAxNjkzNkMzLjM5NTI2OC00LjAxNjkzNiAzLjk2OTExNi00LjAxNjkzNiA0LjM4NzU0Ny0zLjc2NTg3OEM0Ljk2MTM5NS0zLjM5NTI2OCA1LjAwOTIxNS0yLjc0OTY4OSA1LjAwOTIxNS0yLjY3Nzk1OEM1LjAyMTE3MS0yLjUxMDU4NSA1LjAyMTE3MS0yLjM1NTE2OCA1LjIyNDQwOC0yLjM1NTE2OFM1LjQyNzY0Ni0yLjUyMjU0IDUuNDI3NjQ2LTIuNzM3NzMzVi01Ljk3NzU4NEM1LjQyNzY0Ni02LjE2ODg2NyA1LjQyNzY0Ni02LjM2MDE0OSA1LjIyNDQwOC02LjM2MDE0OVM1LjAwOTIxNS02LjE4MDgyMiA1LjAwOTIxNS02LjA4NTE4MUM0LjkzNzQ4NC00LjU0Mjk2NCAzLjcxODA1Ny00LjQ1OTI3OCAzLjA5NjM4OS00LjQ0NzMyM1YtNi45Njk4NjNDMy4wOTYzODktNy43NzA4NTkgMy4zMjM1MzctNy43NzA4NTkgMy42MTA0NjEtNy43NzA4NTlINC4xODQzMDlDNS43OTgyNTctNy43NzA4NTkgNi41OTkyNTMtNi45NDU5NTMgNi42NzA5ODQtNi4xMjEwNDZDNi42ODI5MzktNi4wMjU0MDUgNi42OTQ4OTQtNS44NDYwNzcgNi44ODYxNzctNS44NDYwNzdDNy4wODk0MTUtNS44NDYwNzcgNy4wODk0MTUtNi4wMzczNiA3LjA4OTQxNS02LjI0MDU5OFYtNy43OTQ3N0M3LjA4OTQxNS04LjE2NTM4IDcuMDY1NTA0LTguMTg5MjkgNi42OTQ4OTQtOC4xODkyOUguNTczODQ4Qy4zNTg2NTUtOC4xODkyOSAuMTY3MzcyLTguMTg5MjkgLjE2NzM3Mi03Ljk3NDA5N0MuMTY3MzcyLTcuNzcwODU5IC4zOTQ1MjEtNy43NzA4NTkgLjQ5MDE2Mi03Ljc3MDg1OUMxLjE3MTYwNi03Ljc3MDg1OSAxLjIxOTQyNy03LjY3NTIxOCAxLjIxOTQyNy03LjA4OTQxNVYtMS4wOTk4NzVDMS4yMTk0MjctLjUzNzk4MyAxLjE4MzU2Mi0uNDE4NDMxIC41NDk5MzgtLjQxODQzMUMuMzcwNjEtLjQxODQzMSAuMTY3MzcyLS40MTg0MzEgLjE2NzM3Mi0uMjE1MTkzQy4xNjczNzIgMCAuMzU4NjU1IDAgLjU3Mzg0OCAwSDYuOTEwMDg3QzcuMTM3MjM1IDAgNy4yNTY3ODcgMCA3LjI5MjY1My0uMTY3MzcyQzcuMzA0NjA4LS4xNzkzMjggNy42MzkzNTItMi4xNzU4NDEgNy42MzkzNTItMi4yMzU2MTZDNy42MzkzNTItMi4zNjcxMjMgNy41MzE3NTYtMi40NTA4MDkgNy40MzYxMTUtMi40NTA4MDlDNy4yNjg3NDItMi40NTA4MDkgNy4yMjA5MjItMi4yOTUzOTIgNy4yMjA5MjItMi4yODM0MzdDNy4xNDkxOTEtMS45NzI2MDMgNy4wMjk2MzktMS40NzA0ODYgNi4xNTY5MTItLjk1NjQxM0M1LjUzNTI0My0uNTg1ODAzIDQuOTI1NTI5LS40MTg0MzEgNC4yNjc5OTUtLjQxODQzMUgzLjYxMDQ2MUMzLjMyMzUzNy0uNDE4NDMxIDMuMDk2Mzg5LS40MTg0MzEgMy4wOTYzODktMS4yMTk0MjdWLTQuMDE2OTM2Wk02LjY3MDk4NC03Ljc3MDg1OVYtNy4xOTcwMTFDNi40Njc3NDYtNy40MjQxNTkgNi4yNDA1OTgtNy42MTU0NDIgNS45ODk1MzktNy43NzA4NTlINi42NzA5ODRaTTQuMzM5NzI2LTQuMjY3OTk1QzQuNTMxMDA5LTQuMzUxNjgxIDQuNzk0MDIyLTQuNTMxMDA5IDUuMDA5MjE1LTQuNzgyMDY3Vi0zLjc3NzgzM0M0LjcyMjI5MS00LjEwMDYyMyA0LjM1MTY4MS00LjI1NjA0IDQuMzM5NzI2LTQuMjU2MDRWLTQuMjY3OTk1Wk0xLjYzNzg1OC03LjExMzMyNUMxLjYzNzg1OC03LjI1Njc4NyAxLjYzNzg1OC03LjU1NTY2NiAxLjU0MjIxNy03Ljc3MDg1OUgyLjgwOTQ2NUMyLjY3Nzk1OC03LjQ5NTg5IDIuNjc3OTU4LTcuMTAxMzcgMi42Nzc5NTgtNi45OTM3NzNWLTEuMTk1NTE3QzIuNjc3OTU4LS43NjUxMzEgMi43NjE2NDQtLjUyNjAyNyAyLjgwOTQ2NS0uNDE4NDMxSDEuNTQyMjE3QzEuNjM3ODU4LS42MzM2MjQgMS42Mzc4NTgtLjkzMjUwMyAxLjYzNzg1OC0xLjA3NTk2NVYtNy4xMTMzMjVaTTYuMDg1MTgxLS40MTg0MzFWLS40MzAzODZDNi40Njc3NDYtLjYyMTY2OSA2Ljc5MDUzNS0uODcyNzI3IDcuMDI5NjM5LTEuMDg3OTJDNy4wMTc2ODQtMS4wNDAxIDYuOTMzOTk4LS41MTQwNzIgNi45MjIwNDItLjQxODQzMUg2LjA4NTE4MVonLz4KPHBhdGggaWQ9J2c1LTEwMycgZD0nTTQuMDQwODQ3LTEuNTE4MzA2QzMuOTkzMDI2LTEuMzI3MDI0IDMuOTY5MTE2LTEuMjc5MjAzIDMuODEzNjk5LTEuMDk5ODc1QzMuMzIzNTM3LS40NjYyNTIgMi44MjE0Mi0uMjM5MTAzIDIuNDUwODA5LS4yMzkxMDNDMi4wNTYyODktLjIzOTEwMyAxLjY4NTY3OS0uNTQ5OTM4IDEuNjg1Njc5LTEuMzc0ODQ0QzEuNjg1Njc5LTIuMDA4NDY4IDIuMDQ0MzM0LTMuMzQ3NDQ3IDIuMzA3MzQ3LTMuODg1NDNDMi42NTQwNDctNC41NTQ5MTkgMy4xOTIwMy01LjAzMzEyNiAzLjY5NDE0Ny01LjAzMzEyNkM0LjQ4MzE4OC01LjAzMzEyNiA0LjYzODYwNS00LjA1MjgwMiA0LjYzODYwNS0zLjk4MTA3MUw0LjYwMjc0LTMuODEzNjk5TDQuMDQwODQ3LTEuNTE4MzA2Wk00Ljc4MjA2Ny00LjQ4MzE4OEM0LjYyNjY1LTQuODI5ODg4IDQuMjkxOTA1LTUuMjcyMjI5IDMuNjk0MTQ3LTUuMjcyMjI5QzIuMzkxMDM0LTUuMjcyMjI5IC45MDg1OTMtMy42MzQzNzEgLjkwODU5My0xLjg1MzA1MUMuOTA4NTkzLS42MDk3MTQgMS42NjE3NjggMCAyLjQyNjg5OSAwQzMuMDYwNTIzIDAgMy42MjI0MTYtLjUwMjExNyAzLjgzNzYwOS0uNzQxMjJMMy41NzQ1OTUgLjMzNDc0NUMzLjQwNzIyMyAuOTkyMjc5IDMuMzM1NDkyIDEuMjkxMTU4IDIuOTA1MTA2IDEuNzA5NTg5QzIuNDE0OTQ0IDIuMTk5NzUxIDEuOTYwNjQ4IDIuMTk5NzUxIDEuNjk3NjM0IDIuMTk5NzUxQzEuMzM4OTc5IDIuMTk5NzUxIDEuMDQwMSAyLjE3NTg0MSAuNzQxMjIgMi4wODAxOTlDMS4xMjM3ODYgMS45NzI2MDMgMS4yMTk0MjcgMS42Mzc4NTggMS4yMTk0MjcgMS41MDYzNTFDMS4yMTk0MjcgMS4zMTUwNjggMS4wNzU5NjUgMS4xMjM3ODYgLjgxMjk1MSAxLjEyMzc4NkMuNTI2MDI3IDEuMTIzNzg2IC4yMTUxOTMgMS4zNjI4ODkgLjIxNTE5MyAxLjc1NzQxQy4yMTUxOTMgMi4yNDc1NzIgLjcwNTM1NSAyLjQzODg1NCAxLjcyMTU0NCAyLjQzODg1NEMzLjI2Mzc2MSAyLjQzODg1NCA0LjA2NDc1NyAxLjQ0NjU3NSA0LjIyMDE3NCAuODAwOTk2TDUuNTQ3MTk4LTQuNTU0OTE5QzUuNTgzMDY0LTQuNjk4MzgxIDUuNTgzMDY0LTQuNzIyMjkxIDUuNTgzMDY0LTQuNzQ2MjAyQzUuNTgzMDY0LTQuOTEzNTc0IDUuNDUxNTU3LTUuMDQ1MDgxIDUuMjcyMjI5LTUuMDQ1MDgxQzQuOTg1MzA1LTUuMDQ1MDgxIDQuODE3OTMzLTQuODA1OTc4IDQuNzgyMDY3LTQuNDgzMTg4WicvPgo8cGF0aCBpZD0nZzAtODgnIGQ9J000Ljk0OTQ0LTMuMDA0NzMyQzQuOTMzNDk5LTMuMDM2NjEzIDQuOTAxNjE5LTMuMDg0NDMzIDQuOTAxNjE5LTMuMTA4MzQ0UzYuMTYwODk3LTQuMjk1ODkgNi4zMDQzNTktNC40MzkzNTJDNi44NzAyMzctNC45NzMzNSA2Ljk0MTk2OC01LjA0NTA4MSA3Ljc1NDkxOS01LjA1MzA1MUM3LjkyMjI5MS01LjA2MTAyMSA3LjkzODIzMi01LjI2ODI0NCA3LjkzODIzMi01LjMwMDEyNUM3LjkzODIzMi01LjM5NTc2NiA3Ljg1ODUzMS01LjQ2NzQ5NyA3Ljc3MDg1OS01LjQ2NzQ5N0M3LjY0MzMzNy01LjQ2NzQ5NyA3LjQ4MzkzNS01LjQ1MTU1NyA3LjM0ODQ0My01LjQ0MzU4N0g2Ljg3MDIzN0M2LjE3NjgzNy01LjQ0MzU4NyA1Ljg5Nzg4My01LjQ2NzQ5NyA1Ljg1ODAzMi01LjQ2NzQ5N0M1Ljc5NDI3MS01LjQ2NzQ5NyA1LjYxODkyOS01LjQ2NzQ5NyA1LjYxODkyOS01LjIyMDQyM0M1LjYxODkyOS01LjA2MTAyMSA1Ljc3ODMzMS01LjA1MzA1MSA1LjgzNDEyMi01LjA1MzA1MVM2LjA3MzIyNS01LjAzNzExMSA2LjIxNjY4Ny00Ljk4OTI5TDQuNjYyNTE2LTMuNTMwNzZMMy44NjU1MDQtNS4wMTMyQzQuMDU2Nzg3LTUuMDUzMDUxIDQuMDgwNjk3LTUuMDUzMDUxIDQuMjQwMS01LjA1MzA1MUM0LjMyNzc3MS01LjA1MzA1MSA0LjQ4NzE3My01LjA1MzA1MSA0LjQ4NzE3My01LjMwMDEyNUM0LjQ4NzE3My01LjM4Nzc5NiA0LjQyMzQxMi01LjQ2NzQ5NyA0LjMwMzg2MS01LjQ2NzQ5N0M0LjAxNjkzNi01LjQ2NzQ5NyAzLjcyMjA0Mi01LjQ0MzU4NyAzLjQyNzE0OC01LjQ0MzU4N0gzLjEyNDI4NEMyLjI2MzUxMi01LjQ0MzU4NyAyLjA0ODMxOS01LjQ2NzQ5NyAxLjk5MjUyOC01LjQ2NzQ5N1MxLjc1MzQyNS01LjQ2NzQ5NyAxLjc1MzQyNS01LjIyMDQyM0MxLjc1MzQyNS01LjA1MzA1MSAxLjkwNDg1Ny01LjA1MzA1MSAyLjA5NjEzOS01LjA1MzA1MUMyLjIwNzcyMS01LjA1MzA1MSAyLjI4NzQyMi01LjA1MzA1MSAyLjM5OTAwNC01LjAzNzExMUMyLjQ4NjY3NS01LjAyOTE0MSAyLjQ5NDY0NS01LjAyMTE3MSAyLjU1MDQzNi00LjkyNTUyOUwzLjc2MTg5My0yLjY5Mzg5OEwxLjY4MTY5NC0uNzMzMjVDMS40MzQ2Mi0uNTAyMTE3IDEuMTIzNzg2LS40MjI0MTYgLjY0NTU3OS0uNDE0NDQ2Qy41MTgwNTctLjQxNDQ0NiAuMzY2NjI1LS40MTQ0NDYgLjM2NjYyNS0uMTY3MzcyQy4zNjY2MjUtLjA1NTc5MSAuNDYyMjY3IDAgLjUzMzk5OCAwQy42NjE1MTkgMCAuODIwOTIyLS4wMTU5NCAuOTU2NDEzLS4wMjM5MUgxLjQyNjY1QzIuMTEyMDgtLjAyMzkxIDIuNDE0OTQ0IDAgMi40NDY4MjQgMEMyLjUwMjYxNSAwIDIuNjg1OTI4IDAgMi42ODU5MjgtLjI0NzA3M0MyLjY4NTkyOC0uNDA2NDc2IDIuNTEwNTg1LS40MTQ0NDYgMi40NzA3MzUtLjQxNDQ0NkMyLjQ2Mjc2NS0uNDE0NDQ2IDIuMjQ3NTcyLS40MjI0MTYgMi4wODgxNjktLjQ3ODIwN0wzLjk5MzAyNi0yLjI3MTQ4Mkw0Ljk3MzM1LS40NTQyOTZDNC44NDU4MjgtLjQzMDM4NiA0LjcyNjI3Ni0uNDE0NDQ2IDQuNTk4NzU1LS40MTQ0NDZDNC41MjcwMjQtLjQxNDQ0NiA0LjM1MTY4MS0uNDE0NDQ2IDQuMzUxNjgxLS4xNjczNzJDNC4zNTE2ODEtLjEwMzYxMSA0LjM5OTUwMiAwIDQuNTM0OTk0IDBDNC44MjE5MTggMCA1LjExNjgxMi0uMDIzOTEgNS40MTE3MDYtLjAyMzkxSDUuNzIyNTRDNi41NTE0MzItLjAyMzkxIDYuODA2NDc2IDAgNi44NTQyOTYgMEM2LjkxMDA4NyAwIDcuMDg1NDMgMCA3LjA4NTQzLS4yNDcwNzNDNy4wODU0My0uNDE0NDQ2IDYuOTMzOTk4LS40MTQ0NDYgNi43NzQ1OTUtLjQxNDQ0NkM2LjY3MDk4NC0uNDE0NDQ2IDYuNTc1MzQyLS40MTQ0NDYgNi40NjM3NjEtLjQyMjQxNlM2LjM0NDIwOS0uNDM4MzU2IDYuMjg4NDE4LS41MzM5OThMNC45NDk0NC0zLjAwNDczMlonLz4KPHBhdGggaWQ9J2c3LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnNy00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzctNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2c3LTY5JyBkPSdNNy42MjczOTctMy4wNjA1MjNINy4zNjQzODRDNy4wNzc0Ni0xLjE5NTUxNyA2Ljc5MDUzNS0uMzQ2NyA0Ljc3MDExMi0uMzQ2N0gzLjE0NDIwOUMyLjYxODE4Mi0uMzQ2NyAyLjU5NDI3MS0uNDMwMzg2IDIuNTk0MjcxLS44MjQ5MDdWLTQuMDUyODAySDMuNjgyMTkyQzQuODI5ODg4LTQuMDUyODAyIDQuOTYxMzk1LTMuNjgyMTkyIDQuOTYxMzk1LTIuNjU0MDQ3SDUuMjI0NDA4Vi01Ljc5ODI1N0g0Ljk2MTM5NUM0Ljk2MTM5NS00Ljc3MDExMiA0LjgyOTg4OC00LjM5OTUwMiAzLjY4MjE5Mi00LjM5OTUwMkgyLjU5NDI3MVYtNy4zMTY1NjNDMi41OTQyNzEtNy43MTEwODMgMi42MTgxODItNy43OTQ3NyAzLjE0NDIwOS03Ljc5NDc3SDQuNzM0MjQ3QzYuNDkxNjU2LTcuNzk0NzcgNi44NjIyNjctNy4xOTcwMTEgNy4wNDE1OTQtNS40NzU0NjdINy4zMDQ2MDhMNi45OTM3NzMtOC4xNDE0NjlILjQ5MDE2MlYtNy43OTQ3N0guNzI5MjY1QzEuNTkwMDM3LTcuNzk0NzcgMS42MjU5MDMtNy42NzUyMTggMS42MjU5MDMtNy4yMzI4NzdWLS45MDg1OTNDMS42MjU5MDMtLjQ2NjI1MiAxLjU5MDAzNy0uMzQ2NyAuNzI5MjY1LS4zNDY3SC40OTAxNjJWMEg3LjE0OTE5MUw3LjYyNzM5Ny0zLjA2MDUyM1onLz4KPHBhdGggaWQ9J2c3LTc3JyBkPSdNMi43NDk2ODktNy45MzgyMzJDMi42NjYwMDItOC4xNjUzOCAyLjY1NDA0Ny04LjE2NTM4IDIuMzc5MDc4LTguMTY1MzhILjUyNjAyN1YtNy44MTg2OEguNzY1MTMxQzEuNjI1OTAzLTcuODE4NjggMS42NjE3NjgtNy42OTkxMjggMS42NjE3NjgtNy4yNTY3ODdWLTEuMjMxMzgyQzEuNjYxNzY4LS45MDg1OTMgMS42NjE3NjgtLjM0NjcgLjUyNjAyNy0uMzQ2N1YwQy44MzY4NjItLjAyMzkxIDEuNDcwNDg2LS4wMjM5MSAxLjgwNTIzLS4wMjM5MVMyLjc3MzU5OS0uMDIzOTEgMy4wODQ0MzMgMFYtLjM0NjdDMS45NDg2OTItLjM0NjcgMS45NDg2OTItLjkwODU5MyAxLjk0ODY5Mi0xLjIzMTM4MlYtNy43NTg5MDRIMS45NjA2NDhMNC44NDE4NDMtLjIyNzE0OEM0Ljg4OTY2NC0uMDk1NjQxIDQuOTI1NTI5IDAgNS4wNDUwODEgMEM1LjE1MjY3NyAwIDUuMTc2NTg4LS4wNTk3NzYgNS4yNDgzMTktLjIzOTEwM0w4LjE1MzQyNS03LjgxODY4SDguMTY1MzhWLS45MDg1OTNDOC4xNjUzOC0uNDY2MjUyIDguMTI5NTE0LS4zNDY3IDcuMjY4NzQyLS4zNDY3SDcuMDI5NjM5VjBDNy4zMDQ2MDgtLjAyMzkxIDguMjYxMDIxLS4wMjM5MSA4LjYwNzcyMS0uMDIzOTFTOS45MTA4MzQtLjAyMzkxIDEwLjE4NTgwMyAwVi0uMzQ2N0g5Ljk0NjdDOS4wODU5MjgtLjM0NjcgOS4wNTAwNjItLjQ2NjI1MiA5LjA1MDA2Mi0uOTA4NTkzVi03LjI1Njc4N0M5LjA1MDA2Mi03LjY5OTEyOCA5LjA4NTkyOC03LjgxODY4IDkuOTQ2Ny03LjgxODY4SDEwLjE4NTgwM1YtOC4xNjUzOEg4LjMzMjc1MkM4LjA2OTczOC04LjE2NTM4IDguMDU3NzgzLTguMTUzNDI1IDcuOTYyMTQyLTcuOTI2Mjc2TDUuMzU1OTE1LTEuMTIzNzg2TDIuNzQ5Njg5LTcuOTM4MjMyWicvPgo8cGF0aCBpZD0nZzctODMnIGQ9J00yLjQ4NjY3NS00Ljk4NTMwNUMxLjg3Njk2MS01LjE0MDcyMiAxLjMzODk3OS01LjczODQ4MSAxLjMzODk3OS02LjUwMzYxMUMxLjMzODk3OS03LjM0MDQ3MyAyLjAwODQ2OC04LjA5MzY0OSAyLjk0MDk3MS04LjA5MzY0OUM0LjkwMTYxOS04LjA5MzY0OSA1LjE2NDYzMy02LjE1NjkxMiA1LjIzNjM2NC01LjY0MjgzOUM1LjI2MDI3NC01LjQ5OTM3NyA1LjI2MDI3NC01LjQ1MTU1NyA1LjM3OTgyNi01LjQ1MTU1N0M1LjUxMTMzMy01LjQ1MTU1NyA1LjUxMTMzMy01LjUxMTMzMyA1LjUxMTMzMy01LjcyNjUyNlYtOC4xNDE0NjlDNS41MTEzMzMtOC4zNTY2NjMgNS41MTEzMzMtOC40MTY0MzggNS4zOTE3ODEtOC40MTY0MzhDNS4zNTU5MTUtOC40MTY0MzggNS4zMDgwOTUtOC40MTY0MzggNS4yMjQ0MDgtOC4yNjEwMjFMNC44Mjk4ODgtNy41MzE3NTZDNC4yNTYwNC04LjI3Mjk3NiAzLjQ2Njk5OS04LjQxNjQzOCAyLjk0MDk3MS04LjQxNjQzOEMxLjYxMzk0OC04LjQxNjQzOCAuNjQ1NTc5LTcuMzUyNDI4IC42NDU1NzktNi4xMzMwMDFDLjY0NTU3OS01LjU1OTE1MyAuODQ4ODE3LTUuMDMzMTI2IDEuMjkxMTU4LTQuNTU0OTE5QzEuNzA5NTg5LTQuMDg4NjY3IDIuMTI4MDItMy45ODEwNzEgMi45NzY4MzctMy43NjU4NzhDMy4zOTUyNjgtMy42NzAyMzcgNC4wNTI4MDItMy41MDI4NjQgNC4yMjAxNzQtMy40MzExMzNDNC43ODIwNjctMy4xNTYxNjQgNS4xNTI2NzctMi41MTA1ODUgNS4xNTI2NzctMS44NDEwOTZDNS4xNTI2NzctLjk0NDQ1OCA0LjUxOTA1NC0uMDk1NjQxIDMuNTI2Nzc1LS4wOTU2NDFDMi45ODg3OTItLjA5NTY0MSAyLjI0NzU3Mi0uMjI3MTQ4IDEuNjYxNzY4LS43NDEyMkMuOTY4MzY5LTEuMzYyODg5IC45MjA1NDgtMi4yMjM2NjEgLjkwODU5My0yLjYxODE4MkMuODk2NjM4LTIuNzEzODIzIC44MDA5OTYtMi43MTM4MjMgLjc3NzA4Ni0yLjcxMzgyM0MuNjQ1NTc5LTIuNzEzODIzIC42NDU1NzktMi42NTQwNDcgLjY0NTU3OS0yLjQzODg1NFYtLjAyMzkxQy42NDU1NzkgLjE5MTI4MyAuNjQ1NTc5IC4yNTEwNTkgLjc2NTEzMSAuMjUxMDU5Qy44MzY4NjIgLjI1MTA1OSAuODQ4ODE3IC4yMjcxNDggLjkzMjUwMyAuMDgzNjg2Qy45ODAzMjQtLjAxMTk1NSAxLjIzMTM4Mi0uNDU0Mjk2IDEuMzI3MDI0LS42MzM2MjRDMS43NTc0MS0uMTU1NDE3IDIuNTEwNTg1IC4yNTEwNTkgMy41Mzg3MyAuMjUxMDU5QzQuODc3NzA5IC4yNTEwNTkgNS44NDYwNzctLjg4NDY4MiA1Ljg0NjA3Ny0yLjE5OTc1MUM1Ljg0NjA3Ny0yLjkyOTAxNiA1LjU3MTEwOC0zLjQ2Njk5OSA1LjI0ODMxOS0zLjg2MTUxOUM0LjgwNTk3OC00LjM5OTUwMiA0LjI2Nzk5NS00LjUzMTAwOSAzLjgwMTc0My00LjY1MDU2TDIuNDg2Njc1LTQuOTg1MzA1WicvPgo8cGF0aCBpZD0nZzctMTI2JyBkPSdNNC42OTgzODEtNy45MzgyMzJDNC4zNTE2ODEtNy41OTE1MzIgNC4xMDA2MjMtNy4zNTI0MjggMy43MTgwNTctNy4zNTI0MjhDMy41Mzg3My03LjM1MjQyOCAzLjM3MTM1Ny03LjM4ODI5NCAzLjAwMDc0Ny03LjYzOTM1MkMyLjc2MTY0NC03Ljc4MjgxNCAyLjUyMjU0LTcuOTM4MjMyIDIuMjQ3NTcyLTcuOTM4MjMyQzEuODA1MjMtNy45MzgyMzIgMS41NDIyMTctNy42MzkzNTIgLjk4MDMyNC03LjAxNzY4NEwxLjE0NzY5Ni02Ljg1MDMxMUMxLjQ5NDM5Ni03LjE5NzAxMSAxLjc0NTQ1NS03LjQzNjExNSAyLjEyODAyLTcuNDM2MTE1QzIuMzA3MzQ3LTcuNDM2MTE1IDIuNDc0NzItNy40MDAyNDkgMi44NDUzMy03LjE0OTE5MUMzLjA4NDQzMy03LjAwNTcyOSAzLjMyMzUzNy02Ljg1MDMxMSAzLjU5ODUwNi02Ljg1MDMxMUM0LjA0MDg0Ny02Ljg1MDMxMSA0LjMwMzg2MS03LjE0OTE5MSA0Ljg2NTc1My03Ljc3MDg1OUw0LjY5ODM4MS03LjkzODIzMlonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzEwNy4xMjMxNzUnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c3LTc3Jy8+Cjx1c2UgeD0nMTE3Ljg0OTUxOScgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctODMnLz4KPHVzZSB4PScxMjQuMzUyODQxJyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNy02OScvPgo8dXNlIHg9JzEzNC4zMDk4MycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctNDAnLz4KPHVzZSB4PScxMzkuMjc3OTU1JyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNy0xMjYnLz4KPHVzZSB4PScxMzguODYyMTU2JyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNS0xMDMnLz4KPHVzZSB4PScxNDQuODk2NDEyJyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNy00MScvPgo8dXNlIHg9JzE1Mi43Njk1NjcnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nMTY1LjE5NTA0OCcgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzItNjknLz4KPHVzZSB4PScxNzMuMTY1MTg3JyB5PSctMi4zOTExMTknIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzE4NC4yMzc1NzInIHk9Jy0xMy44NjgxNDUnIHhsaW5rOmhyZWY9JyNnMy0yJy8+Cjx1c2UgeD0nMTg5LjIxODkwNycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctNDAnLz4KPHVzZSB4PScxOTMuNzcxMjMzJyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNS0xMDMnLz4KPHVzZSB4PScyMDEuNzk3OTg3JyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNy00MCcvPgo8dXNlIHg9JzIwNi4zNTAzMTMnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nMjE4LjYwNDI4NycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctNDEnLz4KPHVzZSB4PScyMjUuODEzMjc2JyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnNC0wJy8+Cjx1c2UgeD0nMjM4LjE4NDIzNicgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctMTI2Jy8+Cjx1c2UgeD0nMjM3Ljc2ODQzNycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzUtMTAzJy8+Cjx1c2UgeD0nMjQ1Ljc5NTE5MScgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctNDAnLz4KPHVzZSB4PScyNTAuMzQ3NTE3JyB5PSctNC4xODQzODInIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzI2Mi42MDE0OTEnIHk9Jy00LjE4NDM4MicgeGxpbms6aHJlZj0nI2c3LTQxJy8+Cjx1c2UgeD0nMjY3LjE1MzgxNycgeT0nLTQuMTg0MzgyJyB4bGluazpocmVmPScjZzctNDEnLz4KPHVzZSB4PScyNzEuNzA2MTM1JyB5PSctOS45OTU5MTcnIHhsaW5rOmhyZWY9JyNnNi01MCcvPgo8dXNlIHg9JzI3Ni40Mzg0NScgeT0nLTEzLjg2ODE0NScgeGxpbms6aHJlZj0nI2czLTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
The leave-one-out error is an estimator of the mean squared error. Let:

be independent observations of the input random vector  and
let
and
let  be the corresponding
observations of the output of the physical model:
be the corresponding
observations of the output of the physical model:

for  .
Let
.
Let  be the vector of observations:
be the vector of observations:

Consider the following set of inputs, let aside the  -th input:
-th input:

for  .
Let
.
Let  be the vector of
observations, let aside the -th observation:
be the vector of
observations, let aside the -th observation:

for .
Let  the metamodel built on the data set
the metamodel built on the data set  .
The leave-one-out error is:
.
The leave-one-out error is:

The leave-one-out error is sometimes referred to as predicted residual sum of squares (PRESS) or jacknife error. In the next section, we show how this estimator can be computed analytically, using the hat matrix.
The analytical leave-one-out error¶
One limitation of the previous equation is that we must train
different surrogate models, which can be long in some situations.
To overcome this limitation, we can use the following equations.
Let  design matrix ([blatman2009] eq. 4.32 page 85):
design matrix ([blatman2009] eq. 4.32 page 85):

for and  .
The matrix
.
The matrix  is mathematically equal to the
matrix presented earlier in the present document.
Let
is mathematically equal to the
matrix presented earlier in the present document.
Let  be the projection matrix:
be the projection matrix:

It can be proved that ([blatman2009] eq. 4.33 page 85):

where  is the diagonal of the hat matrix
for .
The goal of this example is to show how to implement the previous equation
using the
is the diagonal of the hat matrix
for .
The goal of this example is to show how to implement the previous equation
using the DesignProxy class.
import openturns as ot
import openturns.viewer as otv
import numpy as np
from openturns.usecases import ishigami_function
Create the polynomial chaos model¶
We load the Ishigami model.
im = ishigami_function.IshigamiModel()
Create a training sample.
nTrain = 100
xTrain = im.distributionX.getSample(nTrain)
yTrain = im.model(xTrain)
Create the chaos.
def ComputeSparseLeastSquaresFunctionalChaos(
inputTrain,
outputTrain,
multivariateBasis,
basisSize,
distribution,
sparse=True,
):
if sparse:
selectionAlgorithm = ot.LeastSquaresMetaModelSelectionFactory()
else:
selectionAlgorithm = ot.PenalizedLeastSquaresAlgorithmFactory()
projectionStrategy = ot.LeastSquaresStrategy(
inputTrain, outputTrain, selectionAlgorithm
)
adaptiveStrategy = ot.FixedStrategy(multivariateBasis, basisSize)
chaosAlgorithm = ot.FunctionalChaosAlgorithm(
inputTrain, outputTrain, distribution, adaptiveStrategy, projectionStrategy
)
chaosAlgorithm.run()
chaosResult = chaosAlgorithm.getResult()
return chaosResult
multivariateBasis = ot.OrthogonalProductPolynomialFactory([im.X1, im.X2, im.X3])
totalDegree = 5
enumerateFunction = multivariateBasis.getEnumerateFunction()
basisSize = enumerateFunction.getBasisSizeFromTotalDegree(totalDegree)
print("Basis size = ", basisSize)
sparse = False # For full PCE and comparison with analytical LOO error
chaosResult = ComputeSparseLeastSquaresFunctionalChaos(
xTrain,
yTrain,
multivariateBasis,
basisSize,
im.distributionX,
sparse,
)
Basis size = 56
The DesignProxy¶
The DesignProxy class provides methods used to create the objects necessary to solve
the least squares problem.
More precisely, it provides the computeDesign()
method that we need to evaluate the design matrix.
In many cases we do not need that matrix, but the Gram matrix (or its inverse).
The DesignProxy class is needed by a least squares solver,
e.g. QRMethod that knows how to actually compute the coefficients.
Another class is the Basis class which manages a set of
functions as the functional basis for the decomposition.
This basis is required by the constructor of the DesignProxy because it defines
the columns of the matrix.
In order to create that basis, we use the getReducedBasis() method,
because the model selection (such as LARS for example)
may have selected functions which best predict the output.
This may reduce the number of coefficients to estimate and
improve their accuracy.
This is important here, because it defines the number of
columns in the design matrix.
reducedBasis = chaosResult.getReducedBasis() # As a result of the model selection
transformation = (
chaosResult.getTransformation()
) # As a result of the input distribution
zTrain = transformation(
xTrain
) # Map from the physical input into the transformed input
We can now create the design.
designProxy = ot.DesignProxy(zTrain, reducedBasis)
To actually evaluate the design matrix, we can specify the columns that we need to evaluate. This can be useful when we perform model selection, because not all columns are always needed. This can lead to CPU and memory savings. In our case, we evaluate all the columns, which corresponds to evaluate all the functions in the basis.
reducedBasisSize = reducedBasis.getSize()
print("Reduced basis size = ", reducedBasisSize)
allIndices = range(reducedBasisSize)
designMatrix = designProxy.computeDesign(allIndices)
print("Design matrix : ", designMatrix.getNbRows(), " x ", designMatrix.getNbColumns())
Reduced basis size = 56
Design matrix : 100 x 56
Solve the least squares problem.
lsqMethod = ot.QRMethod(designProxy, allIndices)
betaHat = lsqMethod.solve(yTrain.asPoint())
Compute the inverse of the Gram matrix.
inverseGram = lsqMethod.getGramInverse()
print("Inverse Gram : ", inverseGram.getNbRows(), "x", inverseGram.getNbColumns())
Inverse Gram : 56 x 56
Compute the raw leave-one-out error¶
In this section, we show how to compute the raw leave-one-out error using the naive formula. To do this, we could use implement the :class:~openturns.KFoldSplitter` class with K = N. Since this would complicate the script and obscure its purpose, we implement the leave-one-out method naively.
Compute leave-one-out error
predictionsLOO = ot.Sample(nTrain, 1)
residuals = ot.Point(nTrain)
for j in range(nTrain):
indicesLOO = list(range(nTrain))
indicesLOO.pop(j)
xTrainLOO = xTrain[indicesLOO]
yTrainLOO = yTrain[indicesLOO]
xj = xTrain[j]
yj = yTrain[j]
chaosResultLOO = ComputeSparseLeastSquaresFunctionalChaos(
xTrainLOO,
yTrainLOO,
multivariateBasis,
basisSize,
im.distributionX,
sparse,
)
metamodelLOO = chaosResultLOO.getMetaModel()
predictionsLOO[j] = metamodelLOO(xj)
residuals[j] = (yj - predictionsLOO[j])[0]
mseLOO = residuals.normSquare() / nTrain
print("mseLOO = ", mseLOO)
mseLOO = 14.59699017622131
For each point in the training sample, we plot the predicted leave-one-out output prediction depending on the observed output.
graph = ot.Graph("Leave-one-out validation", "Observation", "LOO prediction", True)
cloud = ot.Cloud(yTrain, predictionsLOO)
graph.add(cloud)
curve = ot.Curve(yTrain, yTrain)
graph.add(curve)
graph.setColors(ot.Drawable().BuildDefaultPalette(2))
view = otv.View(graph)
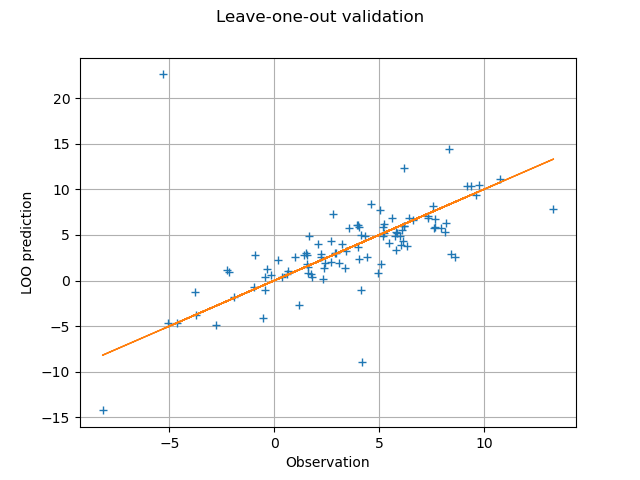
In the previous method, we must pay attention to the fact that
the comparison that we are going to make is not necessarily
valid if we use the LARS selection method,
because this may lead to a different active basis for each leave-one-out
sample.
One limitation of the previous script is that it can be relatively long when the sample size increases or when the size of the functional basis increases. In the next section, we use the analytical formula: this can leads to significant time savings in some cases.
Compute the analytical leave-one-out error¶
Get the diagonal of the projection matrix.
This is a Point.
diagonalH = lsqMethod.getHDiag()
print("diagonalH : ", diagonalH.getDimension())
diagonalH : 100
Compute the metamodel predictions.
metamodel = chaosResult.getMetaModel()
yHat = metamodel(xTrain)
Compute the residuals.
residuals = yTrain.asPoint() - yHat.asPoint()
Compute the analytical leave-one-out error: perform elementwise division and exponentiation
delta = np.array(residuals) / (1.0 - np.array(diagonalH))
squaredDelta = delta**2
leaveOneOutMSE = ot.Sample.BuildFromPoint(squaredDelta).computeMean()[0]
print("MSE LOO = ", leaveOneOutMSE)
relativeLOOError = leaveOneOutMSE / yTrain.computeVariance()[0]
q2LeaveOneOut = 1.0 - relativeLOOError
print("Q2 LOO = ", q2LeaveOneOut)
MSE LOO = 14.59699017622175
Q2 LOO = 0.005926129084500298
We see that the MSE leave-one-out error is equal to the naive LOO error. The numerical differences between the two values are the consequences of the rounding errors in the numerical evaluation of the hat matrix.
otv.View.ShowAll()