Linear regression¶
This method deals with the parametric modelling of a probability
distribution for a random vector
 . It aims to measure
a type of dependence (here a linear relation) which may exist between a
component
. It aims to measure
a type of dependence (here a linear relation) which may exist between a
component  and other uncertain variables
and other uncertain variables  .
.
The principle of the multiple linear regression model is to find the
function that links the variable to other variables
 ,…,
,…, by means of a linear model:
by means of a linear model:

where  describes a random variable with zero mean
and standard deviation
describes a random variable with zero mean
and standard deviation  independent of the input variables
. For given values of ,…,,
the average forecast of is denoted by
independent of the input variables
. For given values of ,…,,
the average forecast of is denoted by  and is defined as:
and is defined as:

The estimators for the regression coefficients
 , and the
standard deviation are obtained from a sample of
, and the
standard deviation are obtained from a sample of
 , that is a set of
, that is a set of  values
values
 ,…,
,…, .
They are determined via the least-squares method:
.
They are determined via the least-squares method:
![\begin{aligned}
\left\{ \widehat{a}_0,\widehat{a}_1,\ldots,\widehat{a}_{K} \right\} = \textrm{argmin} \sum_{k=1}^n \left[ x^i_k - a_0 - \sum_{j \in \{ j_1,\ldots,j_K \} } a_j x^j_k \right]^2
\end{aligned}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScyOTYuNDMyMDY2cHQnIGhlaWdodD0nNDUuMDIwNDgxcHQnIHZpZXdCb3g9JzQ1LjgwNjM3NiAtNDUuMDIwNDc0IDI5Ni40MzIwNjYgNDUuMDIwNDgxJz4KPGRlZnM+CjxwYXRoIGlkPSdnMy03NScgZD0nTTMuNjI4Mzk0LTIuNDAyOTg5QzMuNjIyNDE2LTIuNDA4OTY2IDMuNTkyNTI4LTIuNDY4NzQyIDMuNTkyNTI4LTIuNDc0NzJTMy41OTg1MDYtMi40ODY2NzUgMy42OTQxNDctMi41NTI0MjhDNC4zMDM4NjEtMi45NzA4NTkgNS4xMTA4MzQtMy41MjA3OTcgNS40NDU1NzktMy42ODIxOTJDNS42NDg4MTctMy43Nzc4MzMgNS44MTYxODktMy44MzE2MzEgNi4wMTM0NS0zLjg0MzU4N0M2LjA3MzIyNS0zLjg0OTU2NCA2LjE1MDkzNC0zLjg1NTU0MiA2LjE1MDkzNC0zLjk5MzAyNkM2LjE1MDkzNC00LjAzNDg2OSA2LjExNTA2OC00LjA3NjcxMiA2LjA2NzI0OC00LjA3NjcxMkM1LjkzNTc0MS00LjA3NjcxMiA1Ljc2ODM2OS00LjA1ODc4IDUuNjI0OTA3LTQuMDU4NzhDNS41MzUyNDMtNC4wNTg3OCA1LjMzMjAwNS00LjA1ODc4IDUuMjQyMzQxLTQuMDY0NzU3QzUuMTcwNjEtNC4wNzA3MzUgNC45NDk0NC00LjA4MjY5IDQuODg5NjY0LTQuMDgyNjlDNC44NTM3OTgtNC4wODI2OSA0Ljc1MjE3OS00LjA4MjY5IDQuNzUyMTc5LTMuOTMzMjVDNC43NTIxNzktMy44NDk1NjQgNC44MzU4NjYtMy44NDM1ODcgNC44NTM3OTgtMy44NDM1ODdDNC45OTEyODMtMy44Mzc2MDkgNC45OTEyODMtMy43OTU3NjYgNC45OTEyODMtMy43NjU4NzhDNC45OTEyODMtMy42ODgxNjkgNC44NjU3NTMtMy41OTI1MjggNC44NDE4NDMtMy41NzQ1OTVDNC44MjM5MS0zLjU2MjY0IDQuODE3OTMzLTMuNTU2NjYzIDQuODExOTU1LTMuNTUwNjg1UzQuNzUyMTc5LTMuNTA4ODQyIDQuNzM0MjQ3LTMuNDk2ODg3TDIuMTMzOTk4LTEuNzM5NDc3TDIuNjAwMjQ5LTMuNTk4NTA2QzIuNjQ4MDctMy43OTU3NjYgMi42NjAwMjUtMy44NDM1ODcgMy4xMzgyMzItMy44NDM1ODdDMy4yNDU4MjgtMy44NDM1ODcgMy4zMjk1MTQtMy44NDM1ODcgMy4zMjk1MTQtMy45OTMwMjZDMy4zMjk1MTQtNC4wMjI5MTQgMy4zMTE1ODItNC4wODI2OSAzLjIyNzg5NS00LjA4MjY5QzMuMTAyMzY2LTQuMDgyNjkgMi45NTg5MDQtNC4wNjQ3NTcgMi44MjczOTctNC4wNjQ3NTdTMi41NTg0MDYtNC4wNTg3OCAyLjQyNjg5OS00LjA1ODc4QzIuMjg5NDE1LTQuMDU4NzggMi4xNTE5My00LjA2NDc1NyAyLjAxNDQ0Ni00LjA2NDc1N0MxLjg4MjkzOS00LjA2NDc1NyAxLjczMzQ5OS00LjA4MjY5IDEuNjAxOTkzLTQuMDgyNjlDMS41NjYxMjctNC4wODI2OSAxLjQ3MDQ4Ni00LjA4MjY5IDEuNDcwNDg2LTMuOTMzMjVDMS40NzA0ODYtMy44NDM1ODcgMS41NDgxOTQtMy44NDM1ODcgMS42NjE3NjgtMy44NDM1ODdDMS43NjkzNjUtMy44NDM1ODcgMS45MTg4MDQtMy44NDM1ODcgMi4wNDQzMzQtMy44MDE3NDNDMi4wNDQzMzQtMy43NDE5NjggMi4wNDQzMzQtMy43MDYxMDIgMi4wMjA0MjMtMy42MTA0NjFMMS4yMzczNi0uNDk2MTM5QzEuMTgzNTYyLS4yODA5NDYgMS4xNzE2MDYtLjIzOTEwMyAuNzIzMjg4LS4yMzkxMDNDLjU4NTgwMy0uMjM5MTAzIC41MDgwOTUtLjIzOTEwMyAuNTA4MDk1LS4wODk2NjRDLjUwODA5NS0uMDQxODQzIC41NDM5NiAwIC42MDk3MTQgMEMuNzM1MjQzIDAgLjg3ODcwNS0uMDE3OTMzIDEuMDEwMjEyLS4wMTc5MzNDMS4xNDc2OTYtLjAxNzkzMyAxLjI3OTIwMy0uMDIzOTEgMS40MTA3MS0uMDIzOTFDMS41NDgxOTQtLjAyMzkxIDEuNjg1Njc5LS4wMTc5MzMgMS44MjMxNjMtLjAxNzkzM0MxLjk1NDY3LS4wMTc5MzMgMi4xMDQxMSAwIDIuMjI5NjM5IDBDMi4yNzE0ODIgMCAyLjM2NzEyMyAwIDIuMzY3MTIzLS4xNDk0NEMyLjM2NzEyMy0uMjM5MTAzIDIuMjk1MzkyLS4yMzkxMDMgMi4xNjk4NjMtLjIzOTEwM0MyLjE1NzkwOC0uMjM5MTAzIDIuMDUwMzExLS4yMzkxMDMgMS45NDI3MTUtLjI1MTA1OUMxLjgyMzE2My0uMjYzMDE0IDEuNzg3Mjk4LS4yNjMwMTQgMS43ODcyOTgtLjMyODc2N0MxLjc4NzI5OC0uMzUyNjc3IDEuODI5MTQxLS41MDIxMTcgMS44NDcwNzMtLjU5MTc4MUMxLjg3Njk2MS0uNjkzNCAxLjg3Njk2MS0uNzA1MzU1IDEuOTEyODI3LS44NDg4MTdDMS45OTY1MTMtMS4xNTk2NTEgMS45OTY1MTMtMS4xNzE2MDYgMi4wNjIyNjctMS40NTg1MzFMMy4xMDIzNjYtMi4xNTc5MDhMNC4wODI2OS0uNDEyNDUzQzQuMDgyNjktLjMzNDc0NSA0LjA4MjY5LS4yNDUwODEgMy44MTM2OTktLjIzOTEwM0MzLjc0MTk2OC0uMjM5MTAzIDMuNjUyMzA0LS4yMzkxMDMgMy42NTIzMDQtLjA4OTY2NEMzLjY1MjMwNC0uMDQxODQzIDMuNjg4MTY5IDAgMy43NTM5MjMgMEMzLjkyNzI3MyAwIDQuMzY5NjE0LS4wMjM5MSA0LjU0Mjk2NC0uMDIzOTFDNC42NDQ1ODMtLjAyMzkxIDQuNzQ2MjAyLS4wMTc5MzMgNC44NDc4MjEtLjAxNzkzM1M1LjA2MzAxNCAwIDUuMTU4NjU1IDBDNS4yMjQ0MDggMCA1LjI5MDE2Mi0uMDM1ODY2IDUuMjkwMTYyLS4xNDk0NEM1LjI5MDE2Mi0uMjM5MTAzIDUuMTk0NTIxLS4yMzkxMDMgNS4xNDY3LS4yMzkxMDNDNC44MzU4NjYtLjI0NTA4MSA0Ljc4ODA0NS0uMzI4NzY3IDQuNzE2MzE0LS40NjAyNzRMMy42MjgzOTQtMi40MDI5ODlaJy8+CjxwYXRoIGlkPSdnMS01MCcgZD0nTTQuNjMwNjM1LTEuODA5MjE1QzQuNzU4MTU3LTEuODA5MjE1IDQuOTMzNDk5LTEuODA5MjE1IDQuOTMzNDk5LTEuOTkyNTI4UzQuNzU4MTU3LTIuMTc1ODQxIDQuNjMwNjM1LTIuMTc1ODQxSDEuMDc1OTY1QzEuMTc5NTc3LTMuMjgzNjg2IDIuMTA0MTEtNC4xMjg1MTggMy4zMTU1NjctNC4xMjg1MThINC42MzA2MzVDNC43NTgxNTctNC4xMjg1MTggNC45MzM0OTktNC4xMjg1MTggNC45MzM0OTktNC4zMTE4MzFTNC43NTgxNTctNC40OTUxNDMgNC42MzA2MzUtNC40OTUxNDNIMy4yOTE2NTZDMS44NTcwMzYtNC40OTUxNDMgLjcwMTM3LTMuMzc5MzI4IC43MDEzNy0xLjk5MjUyOEMuNzAxMzctLjU5Nzc1OCAxLjg2NTAwNiAuNTEwMDg3IDMuMjkxNjU2IC41MTAwODdINC42MzA2MzVDNC43NTgxNTcgLjUxMDA4NyA0LjkzMzQ5OSAuNTEwMDg3IDQuOTMzNDk5IC4zMjY3NzVTNC43NTgxNTcgLjE0MzQ2MiA0LjYzMDYzNSAuMTQzNDYySDMuMzE1NTY3QzIuMTA0MTEgLjE0MzQ2MiAxLjE3OTU3Ny0uNzAxMzcgMS4wNzU5NjUtMS44MDkyMTVINC42MzA2MzVaJy8+CjxwYXRoIGlkPSdnMS0xMDInIGQ9J00yLjQxNDk0NC00LjgyOTg4OEMyLjQxNDk0NC01LjAyOTE0MSAyLjQxNDk0NC01LjIzNjM2NCAyLjY5Mzg5OC01LjQ4MzQzN0MyLjc0OTY4OS01LjUyMzI4OCAyLjk4MDgyMi01LjcyMjU0IDMuNDc0OTY5LTUuNzU0NDIxQzMuNTcwNjEtNS43NjIzOTEgMy42MzQzNzEtNS43NjIzOTEgMy42MzQzNzEtNS44NjYwMDJDMy42MzQzNzEtNS45Nzc1ODQgMy41NTQ2Ny01Ljk3NzU4NCAzLjQ0MzA4OC01Ljk3NzU4NEMyLjU4MjMxNi01Ljk3NzU4NCAxLjgyNTE1Ni01LjU3OTA3OCAxLjgxNzE4Ni00Ljk3MzM1Vi0yLjk0MDk3MUMxLjgwMTI0NS0yLjUyNjUyNiAxLjQwMjc0LTIuMTQzOTYgLjc0OTE5MS0yLjEwNDExQy42NTM1NDktMi4wOTYxMzkgLjU4OTc4OC0yLjA5NjEzOSAuNTg5Nzg4LTEuOTkyNTI4Uy42NjE1MTktMS44ODg5MTcgLjcyNTI4LTEuODgwOTQ2QzEuNDgyNDQxLTEuODMzMTI2IDEuNzM3NDg0LTEuNDI2NjUgMS43OTMyNzUtMS4yMDM0ODdDMS44MTcxODYtMS4xMDc4NDYgMS44MTcxODYtMS4wOTE5MDUgMS44MTcxODYtLjc5NzAxMVYuODI4ODkyQzEuODE3MTg2IDEuMDgzOTM1IDEuODE3MTg2IDEuNDM0NjIgMi4zMjcyNzMgMS43Mjk1MTRDMi42Njk5ODggMS45Mjg3NjcgMy4xNjQxMzQgMS45OTI1MjggMy40NDMwODggMS45OTI1MjhDMy41NTQ2NyAxLjk5MjUyOCAzLjYzNDM3MSAxLjk5MjUyOCAzLjYzNDM3MSAxLjg4MDk0NkMzLjYzNDM3MSAxLjc3NzMzNSAzLjU2MjY0IDEuNzc3MzM1IDMuNDk4ODc5IDEuNzY5MzY1QzIuNzU3NjU5IDEuNzIxNTQ0IDIuNDk0NjQ1IDEuMzQ2OTQ5IDIuNDM4ODU0IDEuMDk5ODc1QzIuNDE0OTQ0IDEuMDIwMTc0IDIuNDE0OTQ0IDEuMDA0MjM0IDIuNDE0OTQ0IC43MjUyOFYtLjk0ODQ0M0MyLjQxNDk0NC0xLjE2MzYzNiAyLjQxNDk0NC0xLjcxMzU3NCAxLjQ5MDQxMS0xLjk5MjUyOEMyLjA4ODE2OS0yLjE3NTg0MSAyLjMxMTMzMy0yLjQ2Mjc2NSAyLjM5MTAzNC0yLjc1NzY1OUMyLjQxNDk0NC0yLjg1MzMgMi40MTQ5NDQtMi45MDkwOTEgMi40MTQ5NDQtMy4xNTYxNjRWLTQuODI5ODg4WicvPgo8cGF0aCBpZD0nZzEtMTAzJyBkPSdNMi40MTQ5NDQtNC44MTM5NDhDMi40MTQ5NDQtNS4wNDUwODEgMi40MTQ5NDQtNS4zNzk4MjYgMS45OTI1MjgtNS42NjY3NUMxLjY1Nzc4My01Ljg4OTkxMyAxLjEzMTc1Ni01Ljk3NzU4NCAuNzgxMDcxLTUuOTc3NTg0Qy42Nzc0Ni01Ljk3NzU4NCAuNTg5Nzg4LTUuOTc3NTg0IC41ODk3ODgtNS44NjYwMDJDLjU4OTc4OC01Ljc2MjM5MSAuNjYxNTE5LTUuNzYyMzkxIC43MjUyOC01Ljc1NDQyMUMxLjQ1ODUzMS01LjcwNjYgMS43Mzc0ODQtNS4zNTU5MTUgMS44MDEyNDUtNS4wNjEwMjFDMS44MTcxODYtNC45ODEzMiAxLjgxNzE4Ni00LjkyNTUyOSAxLjgxNzE4Ni00LjgxMzk0OFYtMy4xNDAyMjRDMS44MTcxODYtMi43ODk1MzkgMS44MTcxODYtMi4yNzE0ODIgMi43NDE3MTktMS45OTI1MjhDMi4yOTUzOTItMS44NTcwMzYgMS45NTI2NzctMS42MzM4NzMgMS44NDEwOTYtMS4yMjczOTdDMS44MTcxODYtMS4xMzE3NTYgMS44MTcxODYtMS4wNzU5NjUgMS44MTcxODYtLjgyODg5MlYuNjA1NzI5QzEuODE3MTg2IDEuMTM5NzI2IDEuODE3MTg2IDEuMjExNDU3IDEuNTU0MTcyIDEuNDgyNDQxQzEuNTMwMjYyIDEuNDk4MzgxIDEuMzA3MDk4IDEuNzI5NTE0IC43NDkxOTEgMS43NjkzNjVDLjY0NTU3OSAxLjc3NzMzNSAuNTg5Nzg4IDEuNzc3MzM1IC41ODk3ODggMS44ODA5NDZDLjU4OTc4OCAxLjk5MjUyOCAuNjc3NDYgMS45OTI1MjggLjc4MTA3MSAxLjk5MjUyOEMxLjY0MTg0MyAxLjk5MjUyOCAyLjQwNjk3NCAxLjYwMTk5MyAyLjQxNDk0NCAuOTg4Mjk0Vi0uNjEzNjk5QzIuNDE0OTQ0LTEuMTU1NjY2IDIuNDE0OTQ0LTEuMzM4OTc5IDIuNjU0MDQ3LTEuNTYyMTQyQzIuOTE3MDYxLTEuNzkzMjc1IDMuMjAzOTg1LTEuODU3MDM2IDMuNDc0OTY5LTEuODgwOTQ2QzMuNTc4NTgtMS44ODg5MTcgMy42MzQzNzEtMS44ODg5MTcgMy42MzQzNzEtMS45OTI1MjhTMy41NjI2NC0yLjA5NjEzOSAzLjQ5ODg3OS0yLjEwNDExQzIuNjE0MTk3LTIuMTU5OSAyLjQxNDk0NC0yLjcwMTg2OCAyLjQxNDk0NC0yLjk0MDk3MVYtNC44MTM5NDhaJy8+CjxwYXRoIGlkPSdnOC02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzgtOTcnIGQ9J000LjYxNDY5NS0zLjE5MjAzQzQuNjE0Njk1LTMuODM3NjA5IDQuNjE0Njk1LTQuMzE1ODE2IDQuMDg4NjY3LTQuNzgyMDY3QzMuNjcwMjM3LTUuMTY0NjMzIDMuMTMyMjU0LTUuMzMyMDA1IDIuNjA2MjI3LTUuMzMyMDA1QzEuNjI1OTAzLTUuMzMyMDA1IC44NzI3MjctNC42ODY0MjYgLjg3MjcyNy0zLjkwOTM0Qy44NzI3MjctMy41NjI2NCAxLjA5OTg3NS0zLjM5NTI2OCAxLjM3NDg0NC0zLjM5NTI2OEMxLjY2MTc2OC0zLjM5NTI2OCAxLjg2NTAwNi0zLjU5ODUwNiAxLjg2NTAwNi0zLjg4NTQzQzEuODY1MDA2LTQuMzc1NTkyIDEuNDM0NjItNC4zNzU1OTIgMS4yNTUyOTMtNC4zNzU1OTJDMS41MzAyNjItNC44Nzc3MDkgMi4xMDQxMS01LjA5MjkwMiAyLjU4MjMxNi01LjA5MjkwMkMzLjEzMjI1NC01LjA5MjkwMiAzLjgzNzYwOS00LjYzODYwNSAzLjgzNzYwOS0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyLTMuMDQ4NTY4IC41MjYwMjctMi4wNDQzMzQgLjUyNjAyNy0xLjEyMzc4NkMuNTI2MDI3LS4xNzkzMjggMS42MjU5MDMgLjExOTU1MiAyLjM1NTE2OCAuMTE5NTUyQzMuMTQ0MjA5IC4xMTk1NTIgMy42ODIxOTItLjM1ODY1NSAzLjkwOTM0LS45MzI1MDNDMy45NTcxNjEtLjM3MDYxIDQuMzI3NzcxIC4wNTk3NzYgNC44NDE4NDMgLjA1OTc3NkM1LjA5MjkwMiAuMDU5Nzc2IDUuNzg2MzAxLS4xMDc1OTcgNS43ODYzMDEtMS4wNjQwMVYtMS43MzM0OTlINS41MjMyODhWLTEuMDY0MDFDNS41MjMyODgtLjM4MjU2NSA1LjIzNjM2NC0uMjg2OTI0IDUuMDY4OTkxLS4yODY5MjRDNC42MTQ2OTUtLjI4NjkyNCA0LjYxNDY5NS0uOTIwNTQ4IDQuNjE0Njk1LTEuMDk5ODc1Vi0zLjE5MjAzWk0zLjgzNzYwOS0xLjY4NTY3OUMzLjgzNzYwOS0uNTE0MDcyIDIuOTY0ODgyLS4xMTk1NTIgMi40NTA4MDktLjExOTU1MkMxLjg2NTAwNi0uMTE5NTUyIDEuMzc0ODQ0LS41NDk5MzggMS4zNzQ4NDQtMS4xMjM3ODZDMS4zNzQ4NDQtMi43MDE4NjggMy40MDcyMjMtMi44NDUzMyAzLjgzNzYwOS0yLjg2OTI0Vi0xLjY4NTY3OVonLz4KPHBhdGggaWQ9J2c4LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c4LTEwNScgZD0nTTIuMDgwMTk5LTcuMzY0Mzg0QzIuMDgwMTk5LTcuNjc1MjE4IDEuODI5MTQxLTcuOTUwMTg3IDEuNDk0Mzk2LTcuOTUwMTg3QzEuMTgzNTYyLTcuOTUwMTg3IC45MjA1NDgtNy42OTkxMjggLjkyMDU0OC03LjM3NjMzOUMuOTIwNTQ4LTcuMDE3Njg0IDEuMjA3NDcyLTYuNzkwNTM1IDEuNDk0Mzk2LTYuNzkwNTM1QzEuODY1MDA2LTYuNzkwNTM1IDIuMDgwMTk5LTcuMTAxMzcgMi4wODAxOTktNy4zNjQzODRaTS40MzAzODYtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3LTQuNzk0MDIyIDEuMzAzMTEzLTQuNzIyMjkxIDEuMzAzMTEzLTQuMTM2NDg4Vi0uODg0NjgyQzEuMzAzMTEzLS4zNDY3IDEuMTcxNjA2LS4zNDY3IC4zOTQ1MjEtLjM0NjdWMEMuNzI5MjY1LS4wMjM5MSAxLjMwMzExMy0uMDIzOTEgMS42NDk4MTMtLjAyMzkxQzEuNzgxMzItLjAyMzkxIDIuNDc0NzItLjAyMzkxIDIuODgxMTk2IDBWLS4zNDY3QzIuMTA0MTEtLjM0NjcgMi4wNTYyODktLjQwNjQ3NiAyLjA1NjI4OS0uODcyNzI3Vi01LjI3MjIyOUwuNDMwMzg2LTUuMTQwNzIyWicvPgo8cGF0aCBpZD0nZzgtMTA5JyBkPSdNOC41NzE4NTYtMi45MDUxMDZDOC41NzE4NTYtNC4wMTY5MzYgOC41NzE4NTYtNC4zNTE2ODEgOC4yOTY4ODctNC43MzQyNDdDNy45NTAxODctNS4yMDA0OTggNy4zODgyOTQtNS4yNzIyMjkgNi45ODE4MTgtNS4yNzIyMjlDNS45ODk1MzktNS4yNzIyMjkgNS40ODc0MjItNC41NTQ5MTkgNS4yOTYxMzktNC4wODg2NjdDNS4xMjg3NjctNS4wMDkyMTUgNC40ODMxODgtNS4yNzIyMjkgMy43MzAwMTItNS4yNzIyMjlDMi41NzAzNjEtNS4yNzIyMjkgMi4xMTYwNjUtNC4yNzk5NSAyLjAyMDQyMy00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMLjM4MjU2NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTctNC43OTQwMjIgMS4yOTExNTgtNC43MTAzMzYgMS4yOTExNTgtNC4xMjQ1MzNWLS44ODQ2ODJDMS4yOTExNTgtLjM0NjcgMS4xNTk2NTEtLjM0NjcgLjM4MjU2NS0uMzQ2N1YwQy42OTM0LS4wMjM5MSAxLjMzODk3OS0uMDIzOTEgMS42NzM3MjQtLjAyMzkxQzIuMDIwNDIzLS4wMjM5MSAyLjY2NjAwMi0uMDIzOTEgMi45NzY4MzcgMFYtLjM0NjdDMi4yMTE3MDYtLjM0NjcgMi4wNjgyNDQtLjM0NjcgMi4wNjgyNDQtLjg4NDY4MlYtMy4xMDgzNDRDMi4wNjgyNDQtNC4zNjM2MzYgMi44OTMxNTEtNS4wMzMxMjYgMy42MzQzNzEtNS4wMzMxMjZTNC41NDI5NjQtNC40MjM0MTIgNC41NDI5NjQtMy42OTQxNDdWLS44ODQ2ODJDNC41NDI5NjQtLjM0NjcgNC40MTE0NTctLjM0NjcgMy42MzQzNzEtLjM0NjdWMEMzLjk0NTIwNS0uMDIzOTEgNC41OTA3ODUtLjAyMzkxIDQuOTI1NTI5LS4wMjM5MUM1LjI3MjIyOS0uMDIzOTEgNS45MTc4MDgtLjAyMzkxIDYuMjI4NjQzIDBWLS4zNDY3QzUuNDYzNTEyLS4zNDY3IDUuMzIwMDUtLjM0NjcgNS4zMjAwNS0uODg0NjgyVi0zLjEwODM0NEM1LjMyMDA1LTQuMzYzNjM2IDYuMTQ0OTU2LTUuMDMzMTI2IDYuODg2MTc3LTUuMDMzMTI2UzcuNzk0NzctNC40MjM0MTIgNy43OTQ3Ny0zLjY5NDE0N1YtLjg4NDY4MkM3Ljc5NDc3LS4zNDY3IDcuNjYzMjYzLS4zNDY3IDYuODg2MTc3LS4zNDY3VjBDNy4xOTcwMTEtLjAyMzkxIDcuODQyNTktLjAyMzkxIDguMTc3MzM1LS4wMjM5MUM4LjUyNDAzNS0uMDIzOTEgOS4xNjk2MTQtLjAyMzkxIDkuNDgwNDQ4IDBWLS4zNDY3QzguODgyNjktLjM0NjcgOC41ODM4MTEtLjM0NjcgOC41NzE4NTYtLjcwNTM1NVYtMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOC0xMTAnIGQ9J001LjMyMDA1LTIuOTA1MTA2QzUuMzIwMDUtNC4wMTY5MzYgNS4zMjAwNS00LjM1MTY4MSA1LjA0NTA4MS00LjczNDI0N0M0LjY5ODM4MS01LjIwMDQ5OCA0LjEzNjQ4OC01LjI3MjIyOSAzLjczMDAxMi01LjI3MjIyOUMyLjU3MDM2MS01LjI3MjIyOSAyLjExNjA2NS00LjI3OTk1IDIuMDIwNDIzLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwuMzgyNTY1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNy00Ljc5NDAyMiAxLjI5MTE1OC00LjcxMDMzNiAxLjI5MTE1OC00LjEyNDUzM1YtLjg4NDY4MkMxLjI5MTE1OC0uMzQ2NyAxLjE1OTY1MS0uMzQ2NyAuMzgyNTY1LS4zNDY3VjBDLjY5MzQtLjAyMzkxIDEuMzM4OTc5LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFDMi4wMjA0MjMtLjAyMzkxIDIuNjY2MDAyLS4wMjM5MSAyLjk3NjgzNyAwVi0uMzQ2N0MyLjIxMTcwNi0uMzQ2NyAyLjA2ODI0NC0uMzQ2NyAyLjA2ODI0NC0uODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NC00LjM2MzYzNiAyLjg5MzE1MS01LjAzMzEyNiAzLjYzNDM3MS01LjAzMzEyNlM0LjU0Mjk2NC00LjQyMzQxMiA0LjU0Mjk2NC0zLjY5NDE0N1YtLjg4NDY4MkM0LjU0Mjk2NC0uMzQ2NyA0LjQxMTQ1Ny0uMzQ2NyAzLjYzNDM3MS0uMzQ2N1YwQzMuOTQ1MjA1LS4wMjM5MSA0LjU5MDc4NS0uMDIzOTEgNC45MjU1MjktLjAyMzkxQzUuMjcyMjI5LS4wMjM5MSA1LjkxNzgwOC0uMDIzOTEgNi4yMjg2NDMgMFYtLjM0NjdDNS42MzA4ODQtLjM0NjcgNS4zMzIwMDUtLjM0NjcgNS4zMjAwNS0uNzA1MzU1Vi0yLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c4LTExNCcgZD0nTTEuOTk2NTEzLTIuNzg1NTU0QzEuOTk2NTEzLTMuOTQ1MjA1IDIuNDc0NzItNS4wMzMxMjYgMy4zOTUyNjgtNS4wMzMxMjZDMy40OTA5MDktNS4wMzMxMjYgMy41MTQ4MTktNS4wMzMxMjYgMy41NjI2NC01LjAyMTE3MUMzLjQ2Njk5OS00Ljk3MzM1IDMuMjc1NzE2LTQuOTAxNjE5IDMuMjc1NzE2LTQuNTc4ODI5QzMuMjc1NzE2LTQuMjMyMTMgMy41NTA2ODUtNC4xMDA2MjMgMy43NDE5NjgtNC4xMDA2MjNDMy45ODEwNzEtNC4xMDA2MjMgNC4yMjAxNzQtNC4yNTYwNCA0LjIyMDE3NC00LjU3ODgyOUM0LjIyMDE3NC00LjkzNzQ4NCAzLjg5NzM4NS01LjI3MjIyOSAzLjM4MzMxMy01LjI3MjIyOUMyLjM2NzEyMy01LjI3MjIyOSAyLjAyMDQyMy00LjE3MjM1NCAxLjk0ODY5Mi0zLjk0NTIwNUgxLjkzNjczN1YtNS4yNzIyMjlMLjMzNDc0NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xNDc2OTYtNC43OTQwMjIgMS4yNDMzMzctNC43MTAzMzYgMS4yNDMzMzctNC4xMjQ1MzNWLS44ODQ2ODJDMS4yNDMzMzctLjM0NjcgMS4xMTE4MzEtLjM0NjcgLjMzNDc0NS0uMzQ2N1YwQy42Njk0ODktLjAyMzkxIDEuMzI3MDI0LS4wMjM5MSAxLjY4NTY3OS0uMDIzOTFDMi4wMDg0NjgtLjAyMzkxIDIuODU3Mjg1LS4wMjM5MSAzLjEzMjI1NCAwVi0uMzQ2N0gyLjg5MzE1MUMyLjAyMDQyMy0uMzQ2NyAxLjk5NjUxMy0uNDc4MjA3IDEuOTk2NTEzLS45MDg1OTNWLTIuNzg1NTU0WicvPgo8cGF0aCBpZD0nZzQtNTgnIGQ9J00xLjYxNzkzMy0uNDM4MzU2QzEuNjE3OTMzLS43MDkzNCAxLjM5NDc3LS44ODQ2ODIgMS4xNzk1NzctLjg4NDY4MkMuOTI0NTMzLS44ODQ2ODIgLjczMzI1LS42Nzc0NiAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjE3NTM0MiAuOTU2NDEzIDAgMS4xNzE2MDYgMEMxLjQyNjY1IDAgMS42MTc5MzMtLjIwNzIyMyAxLjYxNzkzMy0uNDM4MzU2WicvPgo8cGF0aCBpZD0nZzQtNTknIGQ9J00xLjQ5MDQxMS0uMTE5NTUyQzEuNDkwNDExIC4zOTg1MDYgMS4zNzg4MjkgLjg1MjgwMiAuODg0NjgyIDEuMzQ2OTQ5Qy44NTI4MDIgMS4zNzA4NTkgLjgzNjg2MiAxLjM4NjggLjgzNjg2MiAxLjQyNjY1Qy44MzY4NjIgMS40OTA0MTEgLjkwMDYyMyAxLjUzODIzMiAuOTU2NDEzIDEuNTM4MjMyQzEuMDUyMDU1IDEuNTM4MjMyIDEuNzEzNTc0IC45MDg1OTMgMS43MTM1NzQtLjAyMzkxQzEuNzEzNTc0LS41MzM5OTggMS41MjIyOTEtLjg4NDY4MiAxLjE3MTYwNi0uODg0NjgyQy44OTI2NTMtLjg4NDY4MiAuNzMzMjUtLjY2MTUxOSAuNzMzMjUtLjQ0NjMyNkMuNzMzMjUtLjIyMzE2MyAuODg0NjgyIDAgMS4xNzk1NzcgMEMxLjM3MDg1OSAwIDEuNDkwNDExLS4xMTE1ODIgMS40OTA0MTEtLjExOTU1MlonLz4KPHBhdGggaWQ9J2c0LTc1JyBkPSdNNC4yNzk5NS0zLjIwMzk4NUM0LjI3MTk4LTMuMjE5OTI1IDQuMjMyMTMtMy4yOTk2MjYgNC4yMzIxMy0zLjMwNzU5N0M0LjIzMjEzLTMuMzIzNTM3IDQuMzY3NjIxLTMuNDE5MTc4IDQuNDQ3MzIzLTMuNDc0OTY5QzUuMDc2OTYxLTMuOTM3MjM1IDUuOTM3NzMzLTQuNTU4OTA0IDYuMjAwNzQ3LTQuNzI2Mjc2QzYuNjA3MjIzLTQuOTgxMzIgNi45MDIxMTctNS4xNDg2OTIgNy4yNjA3NzItNS4xODA1NzNDNy4zMjQ1MzMtNS4xODg1NDMgNy40MzYxMTUtNS4xOTY1MTMgNy40MzYxMTUtNS4zMzk5NzVDNy40MjgxNDQtNS4zOTU3NjYgNy4zODAzMjQtNS40NDM1ODcgNy4zMjQ1MzMtNS40NDM1ODdDNy4zMTY1NjMtNS40NDM1ODcgNy4wOTM0LTUuNDE5Njc2IDcuMDM3NjA5LTUuNDE5Njc2SDYuNzE4ODA0QzYuNTgzMzEzLTUuNDE5Njc2IDYuMzg0MDYtNS40MTk2NzYgNi4zMTIzMjktNS40Mjc2NDZDNi4yNTY1MzgtNS40Mjc2NDYgNS45NDU3MDQtNS40NDM1ODcgNS44ODk5MTMtNS40NDM1ODdTNS43MjI1NC01LjQ0MzU4NyA1LjcyMjU0LTUuMjkyMTU0QzUuNzIyNTQtNS4yODQxODQgNS43MzA1MTEtNS4xODg1NDMgNS44NTAwNjItNS4xODA1NzNDNS45MTM4MjMtNS4xNzI2MDMgNi4wNDEzNDUtNS4xNTY2NjMgNi4wNDEzNDUtNS4wNjEwMjFDNi4wNDEzNDUtNC45MzM0OTkgNS44ODE5NDMtNC43OTgwMDcgNS44NjYwMDItNC43OTAwMzdMNS44MDIyNDItNC43MzQyNDdDNS43NzgzMzEtNC43MTAzMzYgNS43NDY0NTEtNC42Nzg0NTYgNS43MDY2LTQuNjU0NTQ1TDIuNDU0Nzk1LTIuMjk1MzkyTDMuMDg0NDMzLTQuODIxOTE4QzMuMTU2MTY0LTUuMTA4ODQyIDMuMTcyMTA1LTUuMTgwNTczIDMuNzUzOTIzLTUuMTgwNTczQzMuOTEzMzI1LTUuMTgwNTczIDQuMDA4OTY2LTUuMTgwNTczIDQuMDA4OTY2LTUuMzMyMDA1QzQuMDA4OTY2LTUuMzM5OTc1IDQuMDAwOTk2LTUuNDQzNTg3IDMuODczNDc0LTUuNDQzNTg3QzMuNzIyMDQyLTUuNDQzNTg3IDMuNTMwNzYtNS40Mjc2NDYgMy4zNzkzMjgtNS40MTk2NzZIMi44NzcyMUMyLjExMjA4LTUuNDE5Njc2IDEuOTA0ODU3LTUuNDQzNTg3IDEuODQ5MDY2LTUuNDQzNTg3QzEuODA5MjE1LTUuNDQzNTg3IDEuNjg5NjY0LTUuNDQzNTg3IDEuNjg5NjY0LTUuMjkyMTU0QzEuNjg5NjY0LTUuMTgwNTczIDEuNzg1MzA1LTUuMTgwNTczIDEuOTIwNzk3LTUuMTgwNTczQzIuMTgzODExLTUuMTgwNTczIDIuNDE0OTQ0LTUuMTgwNTczIDIuNDE0OTQ0LTUuMDUzMDUxQzIuNDE0OTQ0LTUuMDIxMTcxIDIuNDA2OTc0LTUuMDEzMiAyLjM4MzA2NC00LjkwOTU4OUwxLjMxNTA2OC0uNjI5NjM5QzEuMjQzMzM3LS4zMjY3NzUgMS4yMjczOTctLjI2MzAxNCAuNjM3NjA5LS4yNjMwMTRDLjQ4NjE3Ny0uMjYzMDE0IC4zOTA1MzUtLjI2MzAxNCAuMzkwNTM1LS4xMTE1ODJDLjM5MDUzNS0uMDc5NzAxIC40MTQ0NDYgMCAuNTE4MDU3IDBDLjY2OTQ4OSAwIC44NjA3NzItLjAxNTk0IDEuMDEyMjA0LS4wMjM5MUgyLjA0MDM0OUMyLjE2Nzg3LS4wMTU5NCAyLjQzMDg4NCAwIDIuNTUwNDM2IDBDMi41OTAyODYgMCAyLjcwOTgzOCAwIDIuNzA5ODM4LS4xNDM0NjJDMi43MDk4MzgtLjI2MzAxNCAyLjYxNDE5Ny0uMjYzMDE0IDIuNDc4NzA1LS4yNjMwMTRDMi40MjI5MTQtLjI2MzAxNCAyLjMxMTMzMy0uMjYzMDE0IDIuMTc1ODQxLS4yNzg5NTRDMi4wMDg0NjgtLjI5NDg5NCAxLjk4NDU1OC0uMzEwODM0IDEuOTg0NTU4LS4zOTA1MzVDMS45ODQ1NTgtLjQzODM1NiAyLjA0MDM0OS0uNjM3NjA5IDIuMDY0MjU5LS43NjUxMzFMMi4zNjcxMjMtMS45Njg2MThMMy42NTAzMTEtMi44OTMxNTFMNC42MDY3MjUtLjkyNDUzM0M0LjYzODYwNS0uODYwNzcyIDQuNzI2Mjc2LS42ODU0MyA0Ljc1ODE1Ny0uNjEzNjk5QzQuODA1OTc4LS41MzM5OTggNC44MDU5NzgtLjUxODA1NyA0LjgwNTk3OC0uNDg2MTc3QzQuODA1OTc4LS4yNzA5ODQgNC41MTEwODMtLjI2MzAxNCA0LjQyMzQxMi0uMjYzMDE0QzQuMzQzNzExLS4yNjMwMTQgNC4yMzIxMy0uMjYzMDE0IDQuMjMyMTMtLjExMTU4MkM0LjIzMjEzLS4xMDM2MTEgNC4yNDAxIDAgNC4zNjc2MjEgMEM0LjQ0NzMyMyAwIDQuNzUwMTg3LS4wMTU5NCA0LjgyMTkxOC0uMDIzOTFINS4yODQxODRDNi4wMTc0MzUtLjAyMzkxIDUuOTkzNTI0IDAgNi4wOTcxMzYgMEM2LjEyOTAxNiAwIDYuMjQ4NTY4IDAgNi4yNDg1NjgtLjE1MTQzMkM2LjI0ODU2OC0uMjYzMDE0IDYuMTM2OTg2LS4yNjMwMTQgNi4wODkxNjYtLjI2MzAxNEM1Ljc3ODMzMS0uMjcwOTg0IDUuNjc0NzItLjMyNjc3NSA1LjU0NzE5OC0uNTk3NzU4TDQuMjc5OTUtMy4yMDM5ODVaJy8+CjxwYXRoIGlkPSdnNC0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzQtMTA2JyBkPSdNMy4yOTE2NTYtNC45NzMzNUMzLjI5MTY1Ni01LjEyNDc4MiAzLjE3MjEwNS01LjI3NjIxNCAyLjk4MDgyMi01LjI3NjIxNEMyLjc0MTcxOS01LjI3NjIxNCAyLjUzNDQ5Ni01LjA1MzA1MSAyLjUzNDQ5Ni00Ljg0NTgyOEMyLjUzNDQ5Ni00LjY5NDM5NiAyLjY1NDA0Ny00LjU0Mjk2NCAyLjg0NTMzLTQuNTQyOTY0QzMuMDg0NDMzLTQuNTQyOTY0IDMuMjkxNjU2LTQuNzY2MTI3IDMuMjkxNjU2LTQuOTczMzVaTTEuNjI1OTAzIC4zOTg1MDZDMS41MDYzNTEgLjg4NDY4MiAxLjExNTgxNiAxLjQwMjc0IC42Mjk2MzkgMS40MDI3NEMuNTAyMTE3IDEuNDAyNzQgLjM4MjU2NSAxLjM3MDg1OSAuMzY2NjI1IDEuMzYyODg5Qy42MTM2OTkgMS4yNDMzMzcgLjY0NTU3OSAxLjAyODE0NCAuNjQ1NTc5IC45NTY0MTNDLjY0NTU3OSAuNzY1MTMxIC41MDIxMTcgLjY2MTUxOSAuMzM0NzQ1IC42NjE1MTlDLjEwMzYxMSAuNjYxNTE5LS4xMTE1ODIgLjg2MDc3Mi0uMTExNTgyIDEuMTIzNzg2Qy0uMTExNTgyIDEuNDI2NjUgLjE4MzMxMyAxLjYyNTkwMyAuNjM3NjA5IDEuNjI1OTAzQzEuMTIzNzg2IDEuNjI1OTAzIDIuMDAwNDk4IDEuMzIzMDM5IDIuMjM5NjAxIC4zNjY2MjVMMi45NTY5MTItMi40ODY2NzVDMi45ODA4MjItMi41ODIzMTYgMi45OTY3NjItMi42NDYwNzcgMi45OTY3NjItMi43NjU2MjlDMi45OTY3NjItMy4yMDM5ODUgMi42NDYwNzctMy41MTQ4MTkgMi4xODM4MTEtMy41MTQ4MTlDMS4zMzg5NzktMy41MTQ4MTkgLjg0NDgzMi0yLjM5OTAwNCAuODQ0ODMyLTIuMjk1MzkyQy44NDQ4MzItMi4yMjM2NjEgLjkwMDYyMy0yLjE5MTc4MSAuOTY0Mzg0LTIuMTkxNzgxQzEuMDUyMDU1LTIuMTkxNzgxIDEuMDYwMDI1LTIuMjE1NjkxIDEuMTE1ODE2LTIuMzM1MjQzQzEuMzU0OTE5LTIuODg1MTgxIDEuNzYxMzk1LTMuMjkxNjU2IDIuMTU5OS0zLjI5MTY1NkMyLjMyNzI3My0zLjI5MTY1NiAyLjQyMjkxNC0zLjE4MDA3NSAyLjQyMjkxNC0yLjkxNzA2MUMyLjQyMjkxNC0yLjgwNTQ3OSAyLjM5OTAwNC0yLjY5Mzg5OCAyLjM3NTA5My0yLjU4MjMxNkwxLjYyNTkwMyAuMzk4NTA2WicvPgo8cGF0aCBpZD0nZzQtMTA3JyBkPSdNMi4zMjcyNzMtNS4yOTIxNTRDMi4zMzUyNDMtNS4zMDgwOTUgMi4zNTkxNTMtNS40MTE3MDYgMi4zNTkxNTMtNS40MTk2NzZDMi4zNTkxNTMtNS40NTk1MjcgMi4zMjcyNzMtNS41MzEyNTggMi4yMzE2MzEtNS41MzEyNThDMi4xOTk3NTEtNS41MzEyNTggMS45NTI2NzctNS41MDczNDcgMS43NjkzNjUtNS40OTE0MDdMMS4zMjMwMzktNS40NTk1MjdDMS4xNDc2OTYtNS40NDM1ODcgMS4wNjc5OTUtNS40MzU2MTYgMS4wNjc5OTUtNS4yOTIxNTRDMS4wNjc5OTUtNS4xODA1NzMgMS4xNzk1NzctNS4xODA1NzMgMS4yNzUyMTgtNS4xODA1NzNDMS42NTc3ODMtNS4xODA1NzMgMS42NTc3ODMtNS4xMzI3NTIgMS42NTc3ODMtNS4wNjEwMjFDMS42NTc3ODMtNS4wMzcxMTEgMS42NTc3ODMtNS4wMjExNzEgMS42MTc5MzMtNC44Nzc3MDlMLjQ4NjE3Ny0uMzQyNzE1Qy40NTQyOTYtLjIyMzE2MyAuNDU0Mjk2LS4xNzUzNDIgLjQ1NDI5Ni0uMTY3MzcyQy40NTQyOTYtLjAzMTg4IC41NjU4NzggLjA3OTcwMSAuNzE3MzEgLjA3OTcwMUMuOTg4Mjk0IC4wNzk3MDEgMS4wNTIwNTUtLjE3NTM0MiAxLjA4MzkzNS0uMjg2OTI0QzEuMTYzNjM2LS42MjE2NjkgMS4zNzA4NTktMS40NjY1MDEgMS40NTg1MzEtMS44MDEyNDVDMS44OTY4ODctMS43NTM0MjUgMi40MzA4ODQtMS42MDE5OTMgMi40MzA4ODQtMS4xNDc2OTZDMi40MzA4ODQtMS4xMDc4NDYgMi40MzA4ODQtMS4wNjc5OTUgMi40MTQ5NDQtLjk4ODI5NEMyLjM5MTAzNC0uODg0NjgyIDIuMzc1MDkzLS43NzMxMDEgMi4zNzUwOTMtLjczMzI1QzIuMzc1MDkzLS4yNjMwMTQgMi43MjU3NzggLjA3OTcwMSAzLjE4ODA0NSAuMDc5NzAxQzMuNTIyNzkgLjA3OTcwMSAzLjczMDAxMi0uMTY3MzcyIDMuODMzNjI0LS4zMTg4MDRDNC4wMjQ5MDctLjYxMzY5OSA0LjE1MjQyOC0xLjA5MTkwNSA0LjE1MjQyOC0xLjEzOTcyNkM0LjE1MjQyOC0xLjIxOTQyNyA0LjA4ODY2Ny0xLjI0MzMzNyA0LjAzMjg3Ny0xLjI0MzMzN0MzLjkzNzIzNS0xLjI0MzMzNyAzLjkyMTI5NS0xLjE5NTUxNyAzLjg4OTQxNS0xLjA1MjA1NUMzLjc4NTgwMy0uNjc3NDYgMy41Nzg1OC0uMTQzNDYyIDMuMjAzOTg1LS4xNDM0NjJDMi45OTY3NjItLjE0MzQ2MiAyLjk0ODk0MS0uMzE4ODA0IDIuOTQ4OTQxLS41MzM5OThDMi45NDg5NDEtLjYzNzYwOSAyLjk1NjkxMi0uNzMzMjUgMi45OTY3NjItLjkxNjU2M0MzLjAwNDczMi0uOTQ4NDQzIDMuMDM2NjEzLTEuMDc1OTY1IDMuMDM2NjEzLTEuMTYzNjM2QzMuMDM2NjEzLTEuODE3MTg2IDIuMjE1NjkxLTEuOTYwNjQ4IDEuODA5MjE1LTIuMDE2NDM4QzIuMTA0MTEtMi4xOTE3ODEgMi4zNzUwOTMtMi40NjI3NjUgMi40NzA3MzUtMi41NjYzNzZDMi45MDkwOTEtMi45OTY3NjIgMy4yNjc3NDYtMy4yOTE2NTYgMy42NTAzMTEtMy4yOTE2NTZDMy43NTM5MjMtMy4yOTE2NTYgMy44NDk1NjQtMy4yNjc3NDYgMy45MTMzMjUtMy4xODgwNDVDMy40ODI5MzktMy4xMzIyNTQgMy40ODI5MzktMi43NTc2NTkgMy40ODI5MzktMi43NDk2ODlDMy40ODI5MzktMi41NzQzNDYgMy42MTg0MzEtMi40NTQ3OTUgMy43OTM3NzMtMi40NTQ3OTVDNC4wMDg5NjYtMi40NTQ3OTUgNC4yNDgwNy0yLjYzMDEzNyA0LjI0ODA3LTIuOTU2OTEyQzQuMjQ4MDctMy4yMjc4OTUgNC4wNTY3ODctMy41MTQ4MTkgMy42NTgyODEtMy41MTQ4MTlDMy4xOTYwMTUtMy41MTQ4MTkgMi43ODE1NjktMy4xNjQxMzQgMi4zMjcyNzMtMi43MDk4MzhDMS44NjUwMDYtMi4yNTU1NDIgMS42NjU3NTMtMi4xNjc4NyAxLjUzODIzMi0yLjExMjA4TDIuMzI3MjczLTUuMjkyMTU0WicvPgo8cGF0aCBpZD0nZzQtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c3LTQ4JyBkPSdNMy44OTczODUtMi41NDI0NjZDMy44OTczODUtMy4zOTUyNjggMy44MDk3MTQtMy45MTMzMjUgMy41NDY3LTQuNDIzNDEyQzMuMTk2MDE1LTUuMTI0NzgyIDIuNTUwNDM2LTUuMzAwMTI1IDIuMTEyMDgtNS4zMDAxMjVDMS4xMDc4NDYtNS4zMDAxMjUgLjc0MTIyLTQuNTUwOTM0IC42Mjk2MzktNC4zMjc3NzFDLjM0MjcxNS0zLjc0NTk1MyAuMzI2Nzc1LTIuOTU2OTEyIC4zMjY3NzUtMi41NDI0NjZDLjMyNjc3NS0yLjAxNjQzOCAuMzUwNjg1LTEuMjExNDU3IC43MzMyNS0uNTczODQ4QzEuMDk5ODc1IC4wMTU5NCAxLjY4OTY2NCAuMTY3MzcyIDIuMTEyMDggLjE2NzM3MkMyLjQ5NDY0NSAuMTY3MzcyIDMuMTgwMDc1IC4wNDc4MjEgMy41Nzg1OC0uNzQxMjJDMy44NzM0NzQtMS4zMTUwNjggMy44OTczODUtMi4wMjQ0MDggMy44OTczODUtMi41NDI0NjZaTTIuMTEyMDgtLjA1NTc5MUMxLjg0MTA5Ni0uMDU1NzkxIDEuMjkxMTU4LS4xODMzMTMgMS4xMjM3ODYtMS4wMjAxNzRDMS4wMzYxMTUtMS40NzQ0NzEgMS4wMzYxMTUtMi4yMjM2NjEgMS4wMzYxMTUtMi42MzgxMDdDMS4wMzYxMTUtMy4xODgwNDUgMS4wMzYxMTUtMy43NDU5NTMgMS4xMjM3ODYtNC4xODQzMDlDMS4yOTExNTgtNC45OTcyNiAxLjkxMjgyNy01LjA3Njk2MSAyLjExMjA4LTUuMDc2OTYxQzIuMzgzMDY0LTUuMDc2OTYxIDIuOTMzMDAxLTQuOTQxNDY5IDMuMDkyNDAzLTQuMjE2MTg5QzMuMTg4MDQ1LTMuNzc3ODMzIDMuMTg4MDQ1LTMuMTgwMDc1IDMuMTg4MDQ1LTIuNjM4MTA3QzMuMTg4MDQ1LTIuMTY3ODcgMy4xODgwNDUtMS40NTA1NiAzLjA5MjQwMy0xLjAwNDIzNEMyLjkyNTAzMS0uMTY3MzcyIDIuMzc1MDkzLS4wNTU3OTEgMi4xMTIwOC0uMDU1NzkxWicvPgo8cGF0aCBpZD0nZzctNDknIGQ9J00yLjUwMjYxNS01LjA3Njk2MUMyLjUwMjYxNS01LjI5MjE1NCAyLjQ4NjY3NS01LjMwMDEyNSAyLjI3MTQ4Mi01LjMwMDEyNUMxLjk0NDcwNy00Ljk4MTMyIDEuNTIyMjkxLTQuNzkwMDM3IC43NjUxMzEtNC43OTAwMzdWLTQuNTI3MDI0Qy45ODAzMjQtNC41MjcwMjQgMS40MTA3MS00LjUyNzAyNCAxLjg3Mjk3Ni00Ljc0MjIxN1YtLjY1MzU0OUMxLjg3Mjk3Ni0uMzU4NjU1IDEuODQ5MDY2LS4yNjMwMTQgMS4wOTE5MDUtLjI2MzAxNEguODEyOTUxVjBDMS4xMzk3MjYtLjAyMzkxIDEuODI1MTU2LS4wMjM5MSAyLjE4MzgxMS0uMDIzOTFTMy4yMzU4NjYtLjAyMzkxIDMuNTYyNjQgMFYtLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNi0uMjYzMDE0IDIuNTAyNjE1LS4zNTg2NTUgMi41MDI2MTUtLjY1MzU0OVYtNS4wNzY5NjFaJy8+CjxwYXRoIGlkPSdnNy01MCcgZD0nTTIuMjQ3NTcyLTEuNjI1OTAzQzIuMzc1MDkzLTEuNzQ1NDU1IDIuNzA5ODM4LTIuMDA4NDY4IDIuODM3MzYtMi4xMjAwNUMzLjMzMTUwNy0yLjU3NDM0NiAzLjgwMTc0My0zLjAxMjcwMiAzLjgwMTc0My0zLjczNzk4M0MzLjgwMTc0My00LjY4NjQyNiAzLjAwNDczMi01LjMwMDEyNSAyLjAwODQ2OC01LjMwMDEyNUMxLjA1MjA1NS01LjMwMDEyNSAuNDIyNDE2LTQuNTc0ODQ0IC40MjI0MTYtMy44NjU1MDRDLjQyMjQxNi0zLjQ3NDk2OSAuNzMzMjUtMy40MTkxNzggLjg0NDgzMi0zLjQxOTE3OEMxLjAxMjIwNC0zLjQxOTE3OCAxLjI1OTI3OC0zLjUzODczIDEuMjU5Mjc4LTMuODQxNTk0QzEuMjU5Mjc4LTQuMjU2MDQgLjg2MDc3Mi00LjI1NjA0IC43NjUxMzEtNC4yNTYwNEMuOTk2MjY0LTQuODM3ODU4IDEuNTMwMjYyLTUuMDM3MTExIDEuOTIwNzk3LTUuMDM3MTExQzIuNjYyMDE3LTUuMDM3MTExIDMuMDQ0NTgzLTQuNDA3NDcyIDMuMDQ0NTgzLTMuNzM3OTgzQzMuMDQ0NTgzLTIuOTA5MDkxIDIuNDYyNzY1LTIuMzAzMzYyIDEuNTIyMjkxLTEuMzM4OTc5TC41MTgwNTctLjMwMjg2NEMuNDIyNDE2LS4yMTUxOTMgLjQyMjQxNi0uMTk5MjUzIC40MjI0MTYgMEgzLjU3MDYxTDMuODAxNzQzLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2LTEuMjY3MjQ4IDMuNDY2OTk5LS44Njg3NDIgMy4zNzEzNTctLjcxNzMxQzMuMzIzNTM3LS42NTM1NDkgMi43MTc4MDgtLjY1MzU0OSAyLjU5MDI4Ni0uNjUzNTQ5SDEuMTcxNjA2TDIuMjQ3NTcyLTEuNjI1OTAzWicvPgo8cGF0aCBpZD0nZzctNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2c2LTQ5JyBkPSdNMi4xNDU5NTMtMy43OTU3NjZDMi4xNDU5NTMtMy45NzUwOTMgMi4xMjIwNDItMy45NzUwOTMgMS45NDI3MTUtMy45NzUwOTNDMS41NDgxOTQtMy41OTI1MjggLjkzODQ4MS0zLjU5MjUyOCAuNzIzMjg4LTMuNTkyNTI4Vi0zLjM1OTQwMkMuODc4NzA1LTMuMzU5NDAyIDEuMjczMjI1LTMuMzU5NDAyIDEuNjMxODgtMy41MjY3NzVWLS41MDgwOTVDMS42MzE4OC0uMzEwODM0IDEuNjMxODgtLjIzMzEyNiAxLjAxNjE4OS0uMjMzMTI2SC43NTkxNTNWMEMxLjA4NzkyLS4wMjM5MSAxLjU1NDE3Mi0uMDIzOTEgMS44ODg5MTctLjAyMzkxUzIuNjg5OTEzLS4wMjM5MSAzLjAxODY4IDBWLS4yMzMxMjZIMi43NjE2NDRDMi4xNDU5NTMtLjIzMzEyNiAyLjE0NTk1My0uMzEwODM0IDIuMTQ1OTUzLS41MDgwOTVWLTMuNzk1NzY2WicvPgo8cGF0aCBpZD0nZzUtNTgnIGQ9J00yLjE5OTc1MS0uNTczODQ4QzIuMTk5NzUxLS45MjA1NDggMS45MTI4MjctMS4xNTk2NTEgMS42MjU5MDMtMS4xNTk2NTFDMS4yNzkyMDMtMS4xNTk2NTEgMS4wNDAxLS44NzI3MjcgMS4wNDAxLS41ODU4MDNDMS4wNDAxLS4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEtLjI4NjkyNCAyLjE5OTc1MS0uNTczODQ4WicvPgo8cGF0aCBpZD0nZzUtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2c1LTk3JyBkPSdNMy41OTg1MDYtMS40MjI2NjVDMy41Mzg3My0xLjIxOTQyNyAzLjUzODczLTEuMTk1NTE3IDMuMzcxMzU3LS45NjgzNjlDMy4xMDgzNDQtLjYzMzYyNCAyLjU4MjMxNi0uMTE5NTUyIDIuMDIwNDIzLS4xMTk1NTJDMS41MzAyNjItLjExOTU1MiAxLjI1NTI5My0uNTYxODkzIDEuMjU1MjkzLTEuMjY3MjQ4QzEuMjU1MjkzLTEuOTI0NzgyIDEuNjI1OTAzLTMuMjYzNzYxIDEuODUzMDUxLTMuNzY1ODc4QzIuMjU5NTI3LTQuNjAyNzQgMi44MjE0Mi01LjAzMzEyNiAzLjI4NzY3MS01LjAzMzEyNkM0LjA3NjcxMi01LjAzMzEyNiA0LjIzMjEzLTQuMDUyODAyIDQuMjMyMTMtMy45NTcxNjFDNC4yMzIxMy0zLjk0NTIwNSA0LjE5NjI2NC0zLjc4OTc4OCA0LjE4NDMwOS0zLjc2NTg3OEwzLjU5ODUwNi0xLjQyMjY2NVpNNC4zNjM2MzYtNC40ODMxODhDNC4yMzIxMy00Ljc5NDAyMiAzLjkwOTM0LTUuMjcyMjI5IDMuMjg3NjcxLTUuMjcyMjI5QzEuOTM2NzM3LTUuMjcyMjI5IC40NzgyMDctMy41MjY3NzUgLjQ3ODIwNy0xLjc1NzQxQy40NzgyMDctLjU3Mzg0OCAxLjE3MTYwNiAuMTE5NTUyIDEuOTg0NTU4IC4xMTk1NTJDMi42NDIwOTIgLjExOTU1MiAzLjIwMzk4NS0uMzk0NTIxIDMuNTM4NzMtLjc4OTA0MUMzLjY1ODI4MS0uMDgzNjg2IDQuMjIwMTc0IC4xMTk1NTIgNC41Nzg4MjkgLjExOTU1MlM1LjIyNDQwOC0uMDk1NjQxIDUuNDM5NjAxLS41MjYwMjdDNS42MzA4ODQtLjkzMjUwMyA1Ljc5ODI1Ny0xLjY2MTc2OCA1Ljc5ODI1Ny0xLjcwOTU4OUM1Ljc5ODI1Ny0xLjc2OTM2NSA1Ljc1MDQzNi0xLjgxNzE4NiA1LjY3ODcwNS0xLjgxNzE4NkM1LjU3MTEwOC0xLjgxNzE4NiA1LjU1OTE1My0xLjc1NzQxIDUuNTExMzMzLTEuNTc4MDgyQzUuMzMyMDA1LS44NzI3MjcgNS4xMDQ4NTctLjExOTU1MiA0LjYxNDY5NS0uMTE5NTUyQzQuMjY3OTk1LS4xMTk1NTIgNC4yNDQwODUtLjQzMDM4NiA0LjI0NDA4NS0uNjY5NDg5QzQuMjQ0MDg1LS45NDQ0NTggNC4yNzk5NS0xLjA3NTk2NSA0LjM4NzU0Ny0xLjU0MjIxN0M0LjQ3MTIzMy0xLjg0MTA5NiA0LjUzMTAwOS0yLjEwNDExIDQuNjI2NjUtMi40NTA4MDlDNS4wNjg5OTEtNC4yNDQwODUgNS4xNzY1ODgtNC42NzQ0NzEgNS4xNzY1ODgtNC43NDYyMDJDNS4xNzY1ODgtNC45MTM1NzQgNS4wNDUwODEtNS4wNDUwODEgNC44NjU3NTMtNS4wNDUwODFDNC40ODMxODgtNS4wNDUwODEgNC4zODc1NDctNC42MjY2NSA0LjM2MzYzNi00LjQ4MzE4OFonLz4KPHBhdGggaWQ9J2c1LTEyMCcgZD0nTTUuNjY2NzUtNC44Nzc3MDlDNS4yODQxODQtNC44MDU5NzggNS4xNDA3MjItNC41MTkwNTQgNS4xNDA3MjItNC4yOTE5MDVDNS4xNDA3MjItNC4wMDQ5ODEgNS4zNjc4Ny0zLjkwOTM0IDUuNTM1MjQzLTMuOTA5MzRDNS44OTM4OTgtMy45MDkzNCA2LjE0NDk1Ni00LjIyMDE3NCA2LjE0NDk1Ni00LjU0Mjk2NEM2LjE0NDk1Ni01LjA0NTA4MSA1LjU3MTEwOC01LjI3MjIyOSA1LjA2ODk5MS01LjI3MjIyOUM0LjMzOTcyNi01LjI3MjIyOSAzLjkzMzI1LTQuNTU0OTE5IDMuODI1NjU0LTQuMzI3NzcxQzMuNTUwNjg1LTUuMjI0NDA4IDIuODA5NDY1LTUuMjcyMjI5IDIuNTk0MjcxLTUuMjcyMjI5QzEuMzc0ODQ0LTUuMjcyMjI5IC43MjkyNjUtMy43MDYxMDIgLjcyOTI2NS0zLjQ0MzA4OEMuNzI5MjY1LTMuMzk1MjY4IC43NzcwODYtMy4zMzU0OTIgLjg2MDc3Mi0zLjMzNTQ5MkMuOTU2NDEzLTMuMzM1NDkyIC45ODAzMjQtMy40MDcyMjMgMS4wMDQyMzQtMy40NTUwNDRDMS40MTA3MS00Ljc4MjA2NyAyLjIxMTcwNi01LjAzMzEyNiAyLjU1ODQwNi01LjAzMzEyNkMzLjA5NjM4OS01LjAzMzEyNiAzLjIwMzk4NS00LjUzMTAwOSAzLjIwMzk4NS00LjI0NDA4NUMzLjIwMzk4NS0zLjk4MTA3MSAzLjEzMjI1NC0zLjcwNjEwMiAyLjk4ODc5Mi0zLjEzMjI1NEwyLjU4MjMxNi0xLjQ5NDM5NkMyLjQwMjk4OS0uNzc3MDg2IDIuMDU2Mjg5LS4xMTk1NTIgMS40MjI2NjUtLjExOTU1MkMxLjM2Mjg4OS0uMTE5NTUyIDEuMDY0MDEtLjExOTU1MiAuODEyOTUxLS4yNzQ5NjlDMS4yNDMzMzctLjM1ODY1NSAxLjMzODk3OS0uNzE3MzEgMS4zMzg5NzktLjg2MDc3MkMxLjMzODk3OS0xLjA5OTg3NSAxLjE1OTY1MS0xLjI0MzMzNyAuOTMyNTAzLTEuMjQzMzM3Qy42NDU1NzktMS4yNDMzMzcgLjMzNDc0NS0uOTkyMjc5IC4zMzQ3NDUtLjYwOTcxNEMuMzM0NzQ1LS4xMDc1OTcgLjg5NjYzOCAuMTE5NTUyIDEuNDEwNzEgLjExOTU1MkMxLjk4NDU1OCAuMTE5NTUyIDIuMzkxMDM0LS4zMzQ3NDUgMi42NDIwOTItLjgyNDkwN0MyLjgzMzM3NS0uMTE5NTUyIDMuNDMxMTMzIC4xMTk1NTIgMy44NzM0NzQgLjExOTU1MkM1LjA5MjkwMiAuMTE5NTUyIDUuNzM4NDgxLTEuNDQ2NTc1IDUuNzM4NDgxLTEuNzA5NTg5QzUuNzM4NDgxLTEuNzY5MzY1IDUuNjkwNjYtMS44MTcxODYgNS42MTg5MjktMS44MTcxODZDNS41MTEzMzMtMS44MTcxODYgNS40OTkzNzctMS43NTc0MSA1LjQ2MzUxMi0xLjY2MTc2OEM1LjE0MDcyMi0uNjA5NzE0IDQuNDQ3MzIzLS4xMTk1NTIgMy45MDkzNC0uMTE5NTUyQzMuNDkwOTA5LS4xMTk1NTIgMy4yNjM3NjEtLjQzMDM4NiAzLjI2Mzc2MS0uOTIwNTQ4QzMuMjYzNzYxLTEuMTgzNTYyIDMuMzExNTgyLTEuMzc0ODQ0IDMuNTAyODY0LTIuMTYzODg1TDMuOTIxMjk1LTMuNzg5Nzg4QzQuMTAwNjIzLTQuNTA3MDk4IDQuNTA3MDk4LTUuMDMzMTI2IDUuMDU3MDM2LTUuMDMzMTI2QzUuMDgwOTQ2LTUuMDMzMTI2IDUuNDE1NjkxLTUuMDMzMTI2IDUuNjY2NzUtNC44Nzc3MDlaJy8+CjxwYXRoIGlkPSdnMC01MCcgZD0nTTMuODk3Mzg1IDIxLjA0MTA5Nkg0LjcyMjI5MVYuMzU4NjU1SDcuODc4NDU2Vi0uNDY2MjUySDMuODk3Mzg1VjIxLjA0MTA5NlonLz4KPHBhdGggaWQ9J2cwLTUxJyBkPSdNMy4yMzk4NTEgMjEuMDQxMDk2SDQuMDY0NzU3Vi0uNDY2MjUySC4wODM2ODZWLjM1ODY1NUgzLjIzOTg1MVYyMS4wNDEwOTZaJy8+CjxwYXRoIGlkPSdnMC01MicgZD0nTTMuODk3Mzg1IDIxLjAyOTE0MUg3Ljg3ODQ1NlYyMC4yMDQyMzRINC43MjIyOTFWLS40NzgyMDdIMy44OTczODVWMjEuMDI5MTQxWicvPgo8cGF0aCBpZD0nZzAtNTMnIGQ9J00zLjIzOTg1MSAyMC4yMDQyMzRILjA4MzY4NlYyMS4wMjkxNDFINC4wNjQ3NTdWLS40NzgyMDdIMy4yMzk4NTFWMjAuMjA0MjM0WicvPgo8cGF0aCBpZD0nZzAtODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2cwLTk4JyBkPSdNMy4zMTE1ODItOC4xODkyOUw2LjU2MzM4Ny02LjcxODgwNEw2LjcwNjg0OS02Ljk4MTgxOEwzLjMyMzUzNy04Ljg5NDY0NUwtLjA1OTc3Ni02Ljk4MTgxOEwuMDcxNzMxLTYuNzE4ODA0TDMuMzExNTgyLTguMTg5MjlaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cyLTEwMicgZD0nTTMuMzgzMzEzLTcuMzc2MzM5QzMuMzgzMzEzLTcuODU0NTQ1IDMuNjk0MTQ3LTguNjE5Njc2IDQuOTk3MjYtOC43MDMzNjJDNS4wNTcwMzYtOC43MTUzMTggNS4xMDQ4NTctOC43NjMxMzggNS4xMDQ4NTctOC44MzQ4NjlDNS4xMDQ4NTctOC45NjYzNzYgNS4wMDkyMTUtOC45NjYzNzYgNC44Nzc3MDktOC45NjYzNzZDMy42ODIxOTItOC45NjYzNzYgMi41OTQyNzEtOC4zNTY2NjMgMi41ODIzMTYtNy40NzE5OFYtNC43NDYyMDJDMi41ODIzMTYtNC4yNzk5NSAyLjU4MjMxNi0zLjg5NzM4NSAyLjEwNDExLTMuNTAyODY0QzEuNjg1Njc5LTMuMTU2MTY0IDEuMjMxMzgyLTMuMTMyMjU0IC45NjgzNjktMy4xMjAyOTlDLjkwODU5My0zLjEwODM0NCAuODYwNzcyLTMuMDYwNTIzIC44NjA3NzItMi45ODg3OTJDLjg2MDc3Mi0yLjg2OTI0IC45MzI1MDMtMi44NjkyNCAxLjA1MjA1NS0yLjg1NzI4NUMxLjg0MTA5Ni0yLjgwOTQ2NSAyLjQxNDk0NC0yLjM3OTA3OCAyLjU0NjQ1MS0xLjc5MzI3NUMyLjU4MjMxNi0xLjY2MTc2OCAyLjU4MjMxNi0xLjYzNzg1OCAyLjU4MjMxNi0xLjIwNzQ3MlYxLjE1OTY1MUMyLjU4MjMxNiAxLjY2MTc2OCAyLjU4MjMxNiAyLjA0NDMzNCAzLjE1NjE2NCAyLjQ5ODYzQzMuNjIyNDE2IDIuODU3Mjg1IDQuNDExNDU3IDIuOTg4NzkyIDQuODc3NzA5IDIuOTg4NzkyQzUuMDA5MjE1IDIuOTg4NzkyIDUuMTA0ODU3IDIuOTg4NzkyIDUuMTA0ODU3IDIuODU3Mjg1QzUuMTA0ODU3IDIuNzM3NzMzIDUuMDMzMTI2IDIuNzM3NzMzIDQuOTEzNTc0IDIuNzI1Nzc4QzQuMTYwMzk5IDIuNjc3OTU4IDMuNTc0NTk1IDIuMjk1MzkyIDMuNDE5MTc4IDEuNjg1Njc5QzMuMzgzMzEzIDEuNTc4MDgyIDMuMzgzMzEzIDEuNTU0MTcyIDMuMzgzMzEzIDEuMTIzNzg2Vi0xLjM4NjhDMy4zODMzMTMtMS45MzY3MzcgMy4yODc2NzEtMi4xMzk5NzUgMi45MDUxMDYtMi41MjI1NEMyLjY1NDA0Ny0yLjc3MzU5OSAyLjMwNzM0Ny0yLjg5MzE1MSAxLjk3MjYwMy0yLjk4ODc5MkMyLjk1MjkyNy0zLjI2Mzc2MSAzLjM4MzMxMy0zLjgxMzY5OSAzLjM4MzMxMy00LjUwNzA5OFYtNy4zNzYzMzlaJy8+CjxwYXRoIGlkPSdnMi0xMDMnIGQ9J00yLjU4MjMxNiAxLjM5ODc1NUMyLjU4MjMxNiAxLjg3Njk2MSAyLjI3MTQ4MiAyLjY0MjA5MiAuOTY4MzY5IDIuNzI1Nzc4Qy45MDg1OTMgMi43Mzc3MzMgLjg2MDc3MiAyLjc4NTU1NCAuODYwNzcyIDIuODU3Mjg1Qy44NjA3NzIgMi45ODg3OTIgLjk5MjI3OSAyLjk4ODc5MiAxLjA5OTg3NSAyLjk4ODc5MkMyLjI1OTUyNyAyLjk4ODc5MiAzLjM3MTM1NyAyLjQwMjk4OSAzLjM4MzMxMyAxLjQ5NDM5NlYtMS4yMzEzODJDMy4zODMzMTMtMS42OTc2MzQgMy4zODMzMTMtMi4wODAxOTkgMy44NjE1MTktMi40NzQ3MkM0LjI3OTk1LTIuODIxNDIgNC43MzQyNDctMi44NDUzMyA0Ljk5NzI2LTIuODU3Mjg1QzUuMDU3MDM2LTIuODY5MjQgNS4xMDQ4NTctMi45MTcwNjEgNS4xMDQ4NTctMi45ODg3OTJDNS4xMDQ4NTctMy4xMDgzNDQgNS4wMzMxMjYtMy4xMDgzNDQgNC45MTM1NzQtMy4xMjAyOTlDNC4xMjQ1MzMtMy4xNjgxMiAzLjU1MDY4NS0zLjU5ODUwNiAzLjQxOTE3OC00LjE4NDMwOUMzLjM4MzMxMy00LjMxNTgxNiAzLjM4MzMxMy00LjMzOTcyNiAzLjM4MzMxMy00Ljc3MDExMlYtNy4xMzcyMzVDMy4zODMzMTMtNy42MzkzNTIgMy4zODMzMTMtOC4wMjE5MTggMi44MDk0NjUtOC40NzYyMTRDMi4zMzEyNTgtOC44NDY4MjQgMS41MDYzNTEtOC45NjYzNzYgMS4wOTk4NzUtOC45NjYzNzZDLjk5MjI3OS04Ljk2NjM3NiAuODYwNzcyLTguOTY2Mzc2IC44NjA3NzItOC44MzQ4NjlDLjg2MDc3Mi04LjcxNTMxOCAuOTMyNTAzLTguNzE1MzE4IDEuMDUyMDU1LTguNzAzMzYyQzEuODA1MjMtOC42NTU1NDIgMi4zOTEwMzQtOC4yNzI5NzYgMi41NDY0NTEtNy42NjMyNjNDMi41ODIzMTYtNy41NTU2NjYgMi41ODIzMTYtNy41MzE3NTYgMi41ODIzMTYtNy4xMDEzN1YtNC41OTA3ODVDMi41ODIzMTYtNC4wNDA4NDcgMi42Nzc5NTgtMy44Mzc2MDkgMy4wNjA1MjMtMy40NTUwNDRDMy4zMTE1ODItMy4yMDM5ODUgMy42NTgyODEtMy4wODQ0MzMgMy45OTMwMjYtMi45ODg3OTJDMy4wMTI3MDItMi43MTM4MjMgMi41ODIzMTYtMi4xNjM4ODUgMi41ODIzMTYtMS40NzA0ODZWMS4zOTg3NTVaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc0NS44MDYzNzYnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnMi0xMDInLz4KPHVzZSB4PSc1MS41MzU1NjInIHk9Jy0xOC41MzA3MjknIHhsaW5rOmhyZWY9JyNnMC05OCcvPgo8dXNlIHg9JzUxLjc4Mzk3NScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTk3Jy8+Cjx1c2UgeD0nNTcuOTI4OTE5JyB5PSctMTYuNzM3NDUxJyB4bGluazpocmVmPScjZzctNDgnLz4KPHVzZSB4PSc2Mi42NjEyMycgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTU5Jy8+Cjx1c2UgeD0nNjcuNjU2OTc3JyB5PSctMTguNTMwNzI5JyB4bGluazpocmVmPScjZzAtOTgnLz4KPHVzZSB4PSc2Ny45MDUzODknIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnNS05NycvPgo8dXNlIHg9Jzc0LjA1MDMzMycgeT0nLTE2LjczNzQ1MScgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNzguNzgyNjQ0JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzUtNTknLz4KPHVzZSB4PSc4NC4wMjY4MDMnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnNS01OCcvPgo8dXNlIHg9Jzg5LjI3MDk2MicgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTU4Jy8+Cjx1c2UgeD0nOTQuNTE1MTIxJyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzUtNTgnLz4KPHVzZSB4PSc5OS43NTkyOCcgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTU5Jy8+Cjx1c2UgeD0nMTA0Ljc1NTAyNicgeT0nLTE4LjUzMDcyOScgeGxpbms6aHJlZj0nI2cwLTk4Jy8+Cjx1c2UgeD0nMTA1LjAwMzQzOScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTk3Jy8+Cjx1c2UgeD0nMTExLjE0ODM4MycgeT0nLTE2LjczNzQ1MScgeGxpbms6aHJlZj0nI2c0LTc1Jy8+Cjx1c2UgeD0nMTE5LjM1MTA0OCcgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2cyLTEwMycvPgo8dXNlIHg9JzEyOC42NDk0NzcnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC02MScvPgo8dXNlIHg9JzE0MS4wNzQ5NTgnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC05NycvPgo8dXNlIHg9JzE0Ni45Mjc5NDgnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC0xMTQnLz4KPHVzZSB4PScxNTEuNDgwMjc0JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzgtMTAzJy8+Cjx1c2UgeD0nMTU3LjMzMzI2NCcgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c4LTEwOScvPgo8dXNlIHg9JzE2Ny4wODgyNDgnIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PScxNzAuMzM5OTA5JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzgtMTEwJy8+Cjx1c2UgeD0nMTg0LjkwMDkzNicgeT0nLTMzLjQ3NDczNScgeGxpbms6aHJlZj0nI2c0LTExMCcvPgo8dXNlIHg9JzE3OC44MzU3MjknIHk9Jy0yOS44ODgxNzknIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzE3OS43NDg4ODUnIHk9Jy00LjQyNzk2JyB4bGluazpocmVmPScjZzQtMTA3Jy8+Cjx1c2UgeD0nMTg0LjM3MDUnIHk9Jy00LjQyNzk2JyB4bGluazpocmVmPScjZzctNjEnLz4KPHVzZSB4PScxOTAuOTU3MDA3JyB5PSctNC40Mjc5NicgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nMTk4LjA5Njg0MycgeT0nLTQyLjU2MDgyNScgeGxpbms6aHJlZj0nI2cwLTUwJy8+Cjx1c2UgeD0nMTk4LjA5Njg0MycgeT0nLTIxLjA0MTMxOScgeGxpbms6aHJlZj0nI2cwLTUyJy8+Cjx1c2UgeD0nMjA2LjA2Njk3MScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTEyMCcvPgo8dXNlIHg9JzIxMi43MTkwNTgnIHk9Jy0yMy40NjY5JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nMjEyLjcxOTA1OCcgeT0nLTE1LjU3NTE5OScgeGxpbms6aHJlZj0nI2c0LTEwNycvPgo8dXNlIHg9JzIyMC40OTU0NjknIHk9Jy0xOC41MzA3MTQnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjMyLjQ1MDYyOScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTk3Jy8+Cjx1c2UgeD0nMjM4LjU5NTU3MycgeT0nLTE2LjczNzQ1MScgeGxpbms6aHJlZj0nI2c3LTQ4Jy8+Cjx1c2UgeD0nMjQ1Ljk4NDU1MicgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScyNzMuMjA2OTA4JyB5PSctMjkuODg4MTc5JyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PScyNTcuOTM5NzEyJyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnNC0xMDYnLz4KPHVzZSB4PScyNjEuODIzNzM3JyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnMS01MCcvPgo8dXNlIHg9JzI2Ny40NjkzMTQnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2cxLTEwMicvPgo8dXNlIHg9JzI3MS43MDM0OTcnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2c0LTEwNicvPgo8dXNlIHg9JzI3NS4xMjgxODUnIHk9Jy0yLjg3ODIyOScgeGxpbms6aHJlZj0nI2c2LTQ5Jy8+Cjx1c2UgeD0nMjc5LjI3OTIzJyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnNC01OScvPgo8dXNlIHg9JzI4MS42MzE1NTMnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2c0LTU4Jy8+Cjx1c2UgeD0nMjgzLjk4Mzg3NycgeT0nLTMuOTg1MTc4JyB4bGluazpocmVmPScjZzQtNTgnLz4KPHVzZSB4PScyODYuMzM2MjAxJyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnNC01OCcvPgo8dXNlIHg9JzI4OC42ODg1MjUnIHk9Jy0zLjk4NTE3OCcgeGxpbms6aHJlZj0nI2c0LTU5Jy8+Cjx1c2UgeD0nMjkxLjA0MDg0OScgeT0nLTMuOTg1MTc4JyB4bGluazpocmVmPScjZzQtMTA2Jy8+Cjx1c2UgeD0nMjk0LjQ2NTUzNicgeT0nLTIuNjQ1NzQ5JyB4bGluazpocmVmPScjZzMtNzUnLz4KPHVzZSB4PSczMDEuNTA4NTM3JyB5PSctMy45ODUxNzgnIHhsaW5rOmhyZWY9JyNnMS0xMDMnLz4KPHVzZSB4PSczMDcuNzM1MjE4JyB5PSctMTguNTMwNzE0JyB4bGluazpocmVmPScjZzUtOTcnLz4KPHVzZSB4PSczMTMuODgwMTYyJyB5PSctMTYuNzM3NDUxJyB4bGluazpocmVmPScjZzQtMTA2Jy8+Cjx1c2UgeD0nMzE4LjI2MjMxOScgeT0nLTE4LjUzMDcxNCcgeGxpbms6aHJlZj0nI2c1LTEyMCcvPgo8dXNlIHg9JzMyNC45MTQ0MDYnIHk9Jy0yNC4xOTgzMzQnIHhsaW5rOmhyZWY9JyNnNC0xMDYnLz4KPHVzZSB4PSczMjQuOTE0NDA2JyB5PSctMTUuMjAxMDM3JyB4bGluazpocmVmPScjZzQtMTA3Jy8+Cjx1c2UgeD0nMzMwLjAzNDE1NCcgeT0nLTQyLjU2MDgyNScgeGxpbms6aHJlZj0nI2cwLTUxJy8+Cjx1c2UgeD0nMzMwLjAzNDE1NCcgeT0nLTIxLjA0MTMxOScgeGxpbms6aHJlZj0nI2cwLTUzJy8+Cjx1c2UgeD0nMzM4LjAwNDI1OCcgeT0nLTM5Ljg4NDE3MicgeGxpbms6aHJlZj0nI2c3LTUwJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
In other words, the principle is to minimize the total quadratic
distance between the observations  and the linear forecast
and the linear forecast
 .
.
Some estimated coefficient  may be close to
zero, which may indicate that the variable
may be close to
zero, which may indicate that the variable  does not
bring valuable information to forecast . A classical statistical
test to identify such situations is available: Fisher’s test.
For each estimated coefficient , an important
characteristic is the so-called “
does not
bring valuable information to forecast . A classical statistical
test to identify such situations is available: Fisher’s test.
For each estimated coefficient , an important
characteristic is the so-called “ -value” of Fisher’s test. The
coefficient is said to be “significant” if and only if
-value” of Fisher’s test. The
coefficient is said to be “significant” if and only if
 is greater than a value
is greater than a value
 chosen by the user (typically 5% or 10%). The higher the
-value, the more significant the coefficient.
chosen by the user (typically 5% or 10%). The higher the
-value, the more significant the coefficient.
Another important characteristic of the adjusted linear model is the
coefficient of determination  . This quantity indicates the
part of the variance of that is explained by the linear
model:
. This quantity indicates the
part of the variance of that is explained by the linear
model:

where  denotes the empirical mean of the sample
denotes the empirical mean of the sample
 .
.
Thus,  . A value close to 1 indicates a good fit
of the linear model, whereas a value close to 0 indicates that the
linear model does not provide a relevant forecast. A statistical test
allows one to detect significant values of . Again, a
-value is provided: the higher the -value, the more
significant the coefficient of determination.
. A value close to 1 indicates a good fit
of the linear model, whereas a value close to 0 indicates that the
linear model does not provide a relevant forecast. A statistical test
allows one to detect significant values of . Again, a
-value is provided: the higher the -value, the more
significant the coefficient of determination.
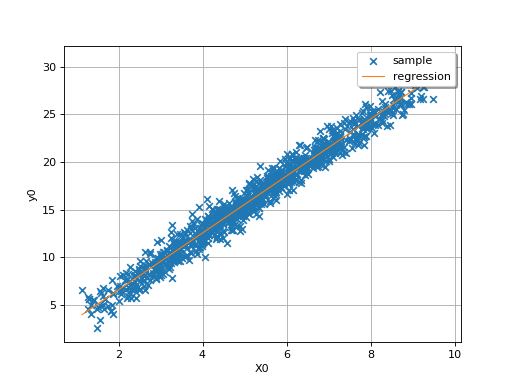
By definition, the multiple regression model is only relevant for linear
relationships, as in the following simple example where
 .
.
(Source code, png)
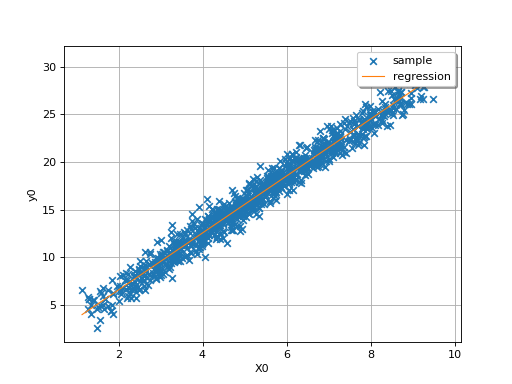{kind=link}
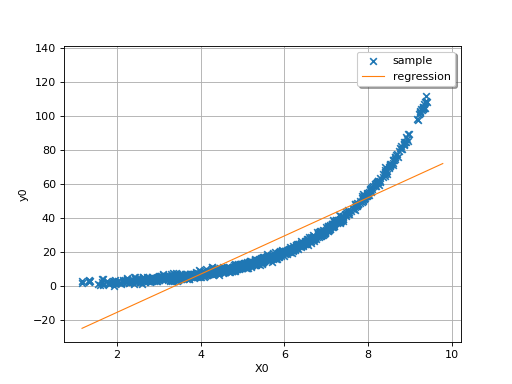
In this second example (still in dimension 1), the linear model is not
relevant because of the exponential shape of the relation. But a linear
approach would be useful on the transformed problem
 . In other words, what is important is
that the relationships between and the variables
,…, is linear with respect to the
regression coefficients
. In other words, what is important is
that the relationships between and the variables
,…, is linear with respect to the
regression coefficients  .
.
(Source code, png)
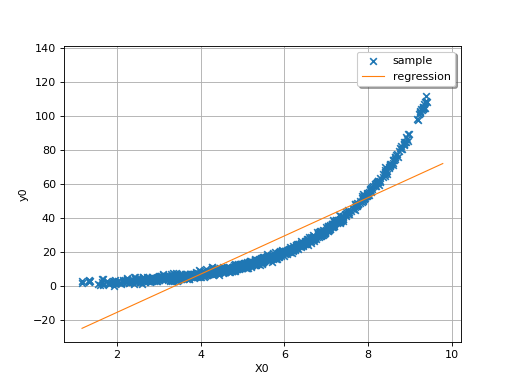{kind=link}
The value of is a good indication of the goodness-of fit of
the linear model. However, several other verifications have to be
carried out before concluding that the linear model is satisfactory. For
instance, one has to pay attentions to the “residuals”
 of the regression:
of the regression:

A residual is thus equal to the difference between the observed value
of and the average forecast provided by the linear model. A
key-assumption for the robustness of the model is that the
characteristics of the residuals do not depend on the value of
 : the mean value should be close
to 0 and the standard deviation should be constant. Thus, plotting the
residuals versus these variables can fruitful.
: the mean value should be close
to 0 and the standard deviation should be constant. Thus, plotting the
residuals versus these variables can fruitful.
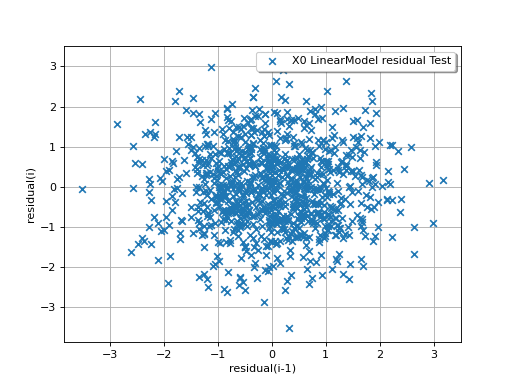
In the following example, the behavior of the residuals is satisfactory: no particular trend can be detected neither in the mean nor in he standard deviation.
(Source code, png)
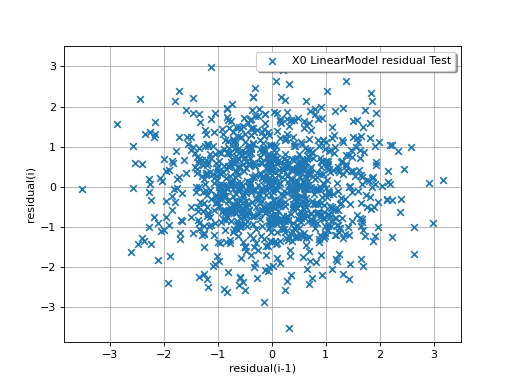{kind=link}
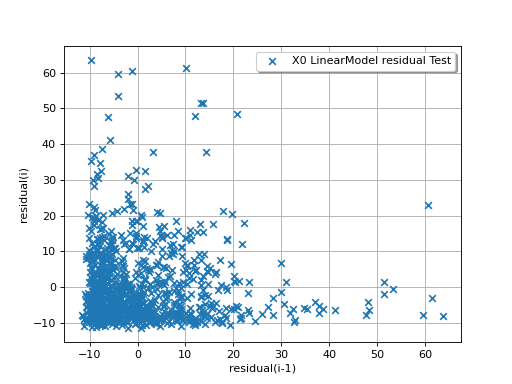
The next example illustrates a less favorable situation: the mean value
of the residuals seems to be close to 0 but the standard deviation tends
to increase with  . In such a situation, the linear model should
be abandoned, or at least used very cautiously.
. In such a situation, the linear model should
be abandoned, or at least used very cautiously.
(Source code, png)
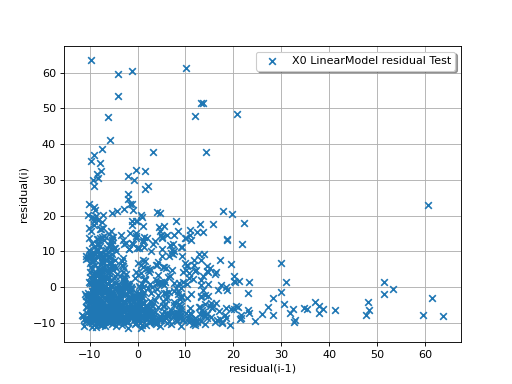{kind=link}
The analysis of a linear regression model is presented in Regression analysis.