GeneralizedExtremeValueFactory¶
(Source code, png)
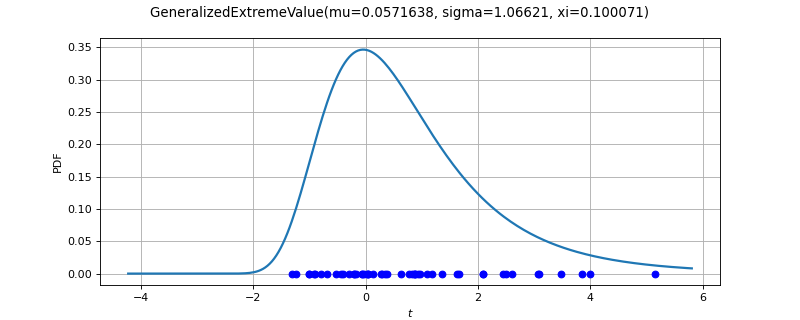
- class GeneralizedExtremeValueFactory(*args)¶
GeneralizedExtremeValue factory.
See also
Notes
Several estimators to build a GeneralizedExtremeValueFactory distribution from a scalar sample are proposed. The details are given in the methods documentation.
The following
ResourceMapentries can be used to tweak the parameters of the optimization solver involved in the different estimators:GeneralizedExtremeValueFactory-DefaultOptimizationAlgorithm
GeneralizedExtremeValueFactory-MaximumEvaluationNumber
GeneralizedExtremeValueFactory-MaximumAbsoluteError
GeneralizedExtremeValueFactory-MaximumRelativeError
GeneralizedExtremeValueFactory-MaximumObjectiveError
GeneralizedExtremeValueFactory-MaximumConstraintError
GeneralizedExtremeValueFactory-InitializationMethod
GeneralizedExtremeValueFactory-NormalizationMethod
Methods
build(*args)Estimate the distribution via maximum likelihood.
Estimate the distribution as native distribution.
buildCovariates(*args)Estimate a GEV from covariates.
buildEstimator(*args)Build the distribution and the parameter distribution.
Estimate the distribution from the
 largest order statistics.
largest order statistics.Estimate the distribution and the parameter distribution with the R-maxima method.
buildMethodOfXiProfileLikelihood(sample[, r])Estimate the distribution with the profile likelihood.
Estimate the distribution and the parameter distribution with the profile likelihood.
buildReturnLevelEstimator(result, m)Estimate a return level and its distribution from the GEV parameters.
buildReturnLevelProfileLikelihood(sample, m)Estimate a return level and its distribution with the profile likelihood.
Estimate
 and its distribution with the profile likelihood.
and its distribution with the profile likelihood.buildTimeVarying(*args)Estimate a non stationary GEV from a time-dependent parametric model.
Accessor to the bootstrap size.
Accessor to the object's name.
getName()Accessor to the object's name.
Accessor to the solver.
hasName()Test if the object is named.
setBootstrapSize(bootstrapSize)Accessor to the bootstrap size.
setName(name)Accessor to the object's name.
setOptimizationAlgorithm(solver)Accessor to the solver.
- __init__(*args)¶
- build(*args)¶
Estimate the distribution via maximum likelihood.
Available usages:
build(sample)
build(param)
- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1 from which
 are estimated.
are estimated.- paramsequence of float
The parameters of the
GeneralizedExtremeValue.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution.
- distribution
Notes
The estimation strategy described in
buildAsGeneralizedExtremeValue()is followed.
- buildAsGeneralizedExtremeValue(*args)¶
Estimate the distribution as native distribution.
Available usages:
buildAsGeneralizedExtremeValue()
buildAsGeneralizedExtremeValue(sample)
buildAsGeneralizedExtremeValue(param)
- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1 from which
are estimated.- paramsequence of float
The parameters of the
GeneralizedExtremeValue.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution as a GeneralizedExtremeValue.
In the first usage, the default GeneralizedExtremeValue distribution is built.
- distribution
Notes
The estimate maximizes the log-likelihood of the model.
- buildCovariates(*args)¶
Estimate a GEV from covariates.
- Parameters:
- sample2-d sequence of float
The block maxima grouped in a sample of size
 and one dimension.
and one dimension.- covariates2-d sequence of float
Covariates sample. A constant column is automatically added if it is not provided.
- muIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- sigmaIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- xiIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- muLink
Function, optional The
 function.
function.By default, the identity function.
- sigmaLink
Function, optional The
 function.
function.By default, the identity function.
- xiLink
Function, optional The
 function.
function.By default, the identity function.
- initializationMethodstr, optional
The initialization method for the optimization problem: Gumbel or Static.
By default, the method Gumbel (see
ResourceMap, key GeneralizedExtremeValueFactory-InitializationMethod).- normalizationMethodstr, optional
The data normalization method: CenterReduce, MinMax or None.
By default, the method MinMax (see
ResourceMap, key GeneralizedExtremeValueFactory-NormalizationMethod).
- Returns:
- result
CovariatesResult The result class.
- result
Notes
Let
 be a GEV model whose parameters depend on
be a GEV model whose parameters depend on  covariates
denoted by
covariates
denoted by  :
:
We denote by
 the values of associated to the values of the
covariates
the values of associated to the values of the
covariates  .
.For numerical reasons, it is recommended to normalize the covariates. Each covariate
 has its own normalization:
has its own normalization:
and with three ways of defining
 of the covariate :
of the covariate :the CenterReduce method where
 is the
covariate mean and
is the
covariate mean and  is the standard deviation of the covariates;
is the standard deviation of the covariates;the MinMax method where
 is the min value of the covariate
and
is the min value of the covariate
and  its range. This is the default method;
its range. This is the default method;the None method where
 and
and  : in that case, data are not
normalized.
: in that case, data are not
normalized.
Let
be the vector of parameters. Then,  depends on all the covariates
even if each component of only depends on a subset of the covariates. We
denote by
depends on all the covariates
even if each component of only depends on a subset of the covariates. We
denote by  the
the  covariates involved in the
modelling of the component
covariates involved in the
modelling of the component  .
.Each component
can be written as a function of the normalized covariates:
This relation can be written as a function of the real covariates:

where:
 is usually referred to as the inverse-link function of
the component ,
is usually referred to as the inverse-link function of
the component ,each
 .
.
To allow some parameters to remain constant, i.e. independent of the covariates (this will generally be the case for the parameter
), the library systematically
adds the constant covariate to the specified covariates.The complete vector of parameters is defined by:

where
 .
.The estimator of
 maximizes the likelihood of the model which is defined
by:
maximizes the likelihood of the model which is defined
by:
where
 denotes the GEV density function
with parameters
denotes the GEV density function
with parameters
 and evaluated at
and evaluated at  .
.Then, if none of the
 is zero, the log-likelihood is defined by:
is zero, the log-likelihood is defined by:![\ell (\vect{\beta}) = -\sum_{i=1}^{n} \left\{ \log(\sigma(\vect{y}_i)) + (1 + 1 /
\xi(\vect{y}
_i) ) \log\left[ 1+\xi(\vect{y}_i) \left( \frac{z_{\vect{y}_i} - \mu(\vect{y}_i)}
{\sigma(\vect{y}_i)}\right) \right] + \left[ 1 + \xi(\vect{y}_i) \left( \frac{
z_{\vect{y}_i}-
\mu(\vect{y}_i)}{\sigma(\vect{y}_i)} \right) \right]^{-1 / \xi(\vect{y}_i)} \right\}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc1NjEuNzYxNTI0cHQnIGhlaWdodD0nMzUuODY1ODY5cHQnIHZpZXdCb3g9JzAgLTM1Ljk1NDEyMyA1NjEuNzYxNTI0IDM1Ljg2NTg2OSc+CjxkZWZzPgo8cGF0aCBpZD0nZzMtMCcgZD0nTTUuNTcxMTA4LTEuODA5MjE1QzUuNjk4NjMtMS44MDkyMTUgNS44NzM5NzMtMS44MDkyMTUgNS44NzM5NzMtMS45OTI1MjhTNS42OTg2My0yLjE3NTg0MSA1LjU3MTEwOC0yLjE3NTg0MUgxLjAwNDIzNEMuODc2NzEyLTIuMTc1ODQxIC43MDEzNy0yLjE3NTg0MSAuNzAxMzctMS45OTI1MjhTLjg3NjcxMi0xLjgwOTIxNSAxLjAwNDIzNC0xLjgwOTIxNUg1LjU3MTEwOFonLz4KPHBhdGggaWQ9J2c1LTEwNScgZD0nTTIuMDgwMTk5LTMuNzMwMDEyQzIuMDgwMTk5LTMuODczNDc0IDEuOTcyNjAzLTMuOTY5MTE2IDEuODM1MTE4LTMuOTY5MTE2QzEuNjczNzI0LTMuOTY5MTE2IDEuNTAwMzc0LTMuODEzNjk5IDEuNTAwMzc0LTMuNjQwMzQ5QzEuNTAwMzc0LTMuNDkwOTA5IDEuNjA3OTctMy40MDEyNDUgMS43Mzk0NzctMy40MDEyNDVDMS45MzA3Ni0zLjQwMTI0NSAyLjA4MDE5OS0zLjU4MDU3MyAyLjA4MDE5OS0zLjczMDAxMlpNMS43MjE1NDQtMS42NDM4MzZDMS43NDU0NTUtMS43MDM2MTEgMS43OTkyNTMtMS44NDcwNzMgMS44MjMxNjMtMS45MDA4NzJDMS44NDEwOTYtMS45NTQ2NyAxLjg2NTAwNi0yLjAxNDQ0NiAxLjg2NTAwNi0yLjExNjA2NUMxLjg2NTAwNi0yLjQ1MDgwOSAxLjU2NjEyNy0yLjYzNjExNSAxLjI2NzI0OC0yLjYzNjExNUMuNjU3NTM0LTIuNjM2MTE1IC4zNjQ2MzMtMS44NDcwNzMgLjM2NDYzMy0xLjcxNTU2N0MuMzY0NjMzLTEuNjg1Njc5IC4zODg1NDMtMS42MzE4OCAuNDcyMjI5LTEuNjMxODhTLjU3Mzg0OC0xLjY2Nzc0NiAuNTkxNzgxLTEuNzIxNTQ0Qy43NTkxNTMtMi4zMDEzNyAxLjA3NTk2NS0yLjQzODg1NCAxLjI0MzMzNy0yLjQzODg1NEMxLjM2Mjg4OS0yLjQzODg1NCAxLjQwNDczMi0yLjM2MTE0NiAxLjQwNDczMi0yLjIyMzY2MUMxLjQwNDczMi0yLjEwNDExIDEuMzY4ODY3LTIuMDE0NDQ2IDEuMzU2OTEyLTEuOTcyNjAzTDEuMDQ2MDc3LTEuMjA3NDcyQy45NzQzNDYtMS4wMzQxMjIgLjk3NDM0Ni0xLjAyMjE2NyAuODk2NjM4LS44MTg5MjlDLjgxODkyOS0uNjM5NjAxIC43ODkwNDEtLjU2MTg5MyAuNzg5MDQxLS40NjAyNzRDLjc4OTA0MS0uMTU1NDE3IDEuMDY0MDEgLjA1OTc3NiAxLjM5Mjc3NyAuMDU5Nzc2QzEuOTk2NTEzIC4wNTk3NzYgMi4yOTUzOTItLjcyOTI2NSAyLjI5NTM5Mi0uODYwNzcyQzIuMjk1MzkyLS44NzI3MjcgMi4yODk0MTUtLjk0NDQ1OCAyLjE4MTgxOC0uOTQ0NDU4QzIuMDk4MTMyLS45NDQ0NTggMi4wOTIxNTQtLjkxNDU3IDIuMDU2Mjg5LS44MDA5OTZDMS45NjA2NDgtLjQ5NjEzOSAxLjcxNTU2Ny0uMTM3NDg0IDEuNDEwNzEtLjEzNzQ4NEMxLjMwMzExMy0uMTM3NDg0IDEuMjQ5MzE1LS4yMDkyMTUgMS4yNDkzMTUtLjM1MjY3N0MxLjI0OTMxNS0uNDcyMjI5IDEuMjg1MTgxLS41NjE4OTMgMS4zNjI4ODktLjc0NzE5OEwxLjcyMTU0NC0xLjY0MzgzNlonLz4KPHBhdGggaWQ9J2cyLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cyLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzItMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzItMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cyLTQwJyBkPSdNNS4zOTE3ODEgMjEuODQyMDkyQzUuMzkxNzgxIDIwLjUyNzAyNCA0LjQ4MzE4OCAxOC41MDY2IDIuNDAyOTg5IDE3LjQ1NDU0NUMzLjY5NDE0NyAxNi43NjExNDYgNS4yMzYzNjQgMTUuMzYyMzkxIDUuMzc5ODI2IDEzLjEyNjc3NUw1LjM5MTc4MSAxMy4wNTUwNDRWNC43NzAxMTJDNS4zOTE3ODEgMy43ODk3ODggNS4zOTE3ODEgMy41NzQ1OTUgNS40ODc0MjIgMy4xMjAyOTlDNS43MDI2MTUgMi4xNjM4ODUgNi4yNzY0NjMgLjk4MDMyNCA3Ljc5NDc3IC4wODM2ODZDNy44OTA0MTEgLjAyMzkxIDcuOTAyMzY2IC4wMTE5NTUgNy45MDIzNjYtLjIwMzIzOEM3LjkwMjM2Ni0uNDY2MjUyIDcuODkwNDExLS40NzgyMDcgNy42MjczOTctLjQ3ODIwN0M3LjQxMjIwNC0uNDc4MjA3IDcuMzg4Mjk0LS40NzgyMDcgNy4wNjU1MDQtLjI4NjkyNEM0LjM4NzU0NyAxLjIzMTM4MiA0LjIzMjEzIDMuNDU1MDQ0IDQuMjMyMTMgMy44NzM0NzRWMTIuMzczNTk5QzQuMjMyMTMgMTMuMjM0MzcxIDQuMjMyMTMgMTQuMjAyNzQgMy42MTA0NjEgMTUuMzAyNjE1QzMuMDYwNTIzIDE2LjI4MjkzOSAyLjQxNDk0NCAxNi43NzMxMDEgMS45MDA4NzIgMTcuMTE5ODAxQzEuNzMzNDk5IDE3LjIyNzM5NyAxLjcyMTU0NCAxNy4yMzkzNTIgMS43MjE1NDQgMTcuNDQyNTlDMS43MjE1NDQgMTcuNjU3NzgzIDEuNzMzNDk5IDE3LjY2OTczOCAxLjgyOTE0MSAxNy43Mjk1MTRDMi44NDUzMyAxOC4zOTkwMDQgMy45MzMyNSAxOS40NjMwMTQgNC4xOTYyNjQgMjEuNDExNzA2QzQuMjMyMTMgMjEuNjc0NzIgNC4yMzIxMyAyMS42OTg2MyA0LjIzMjEzIDIxLjg0MjA5MlYzMS4wMjM2NjFDNC4yMzIxMyAzMS45OTIwMyA0LjgyOTg4OCAzNC4wMDA0OTggNy4xMzcyMzUgMzUuMjE5OTI1QzcuNDEyMjA0IDM1LjM3NTM0MiA3LjQzNjExNSAzNS4zNzUzNDIgNy42MjczOTcgMzUuMzc1MzQyQzcuODkwNDExIDM1LjM3NTM0MiA3LjkwMjM2NiAzNS4zNjMzODcgNy45MDIzNjYgMzUuMTAwMzc0QzcuOTAyMzY2IDM0Ljg4NTE4MSA3Ljg5MDQxMSAzNC44NzMyMjUgNy44NDI1OSAzNC44NDkzMTVDNy4zMjg1MTggMzQuNTI2NTI2IDUuNzYyMzkxIDMzLjU4MjA2NyA1LjQzOTYwMSAzMS41MDE4NjhDNS4zOTE3ODEgMzEuMTkxMDM0IDUuMzkxNzgxIDMxLjE2NzEyMyA1LjM5MTc4MSAzMS4wMTE3MDZWMjEuODQyMDkyWicvPgo8cGF0aCBpZD0nZzItNDEnIGQ9J000LjIzMjEzIDMwLjEyNzAyNEM0LjIzMjEzIDMxLjEwNzM0NyA0LjIzMjEzIDMxLjMyMjU0IDQuMTM2NDg4IDMxLjc3NjgzN0MzLjkyMTI5NSAzMi43MzMyNSAzLjM0NzQ0NyAzMy45MDQ4NTcgMS44MjkxNDEgMzQuODEzNDVDMS43MzM0OTkgMzQuODczMjI1IDEuNzIxNTQ0IDM0Ljg4NTE4MSAxLjcyMTU0NCAzNS4xMDAzNzRDMS43MjE1NDQgMzUuMzc1MzQyIDEuNzMzNDk5IDM1LjM3NTM0MiAyLjAwODQ2OCAzNS4zNzUzNDJDMi4yMTE3MDYgMzUuMzc1MzQyIDIuMjM1NjE2IDM1LjM3NTM0MiAyLjU1ODQwNiAzNS4xODQwNkM1LjIzNjM2NCAzMy42NjU3NTMgNS4zOTE3ODEgMzEuNDQyMDkyIDUuMzkxNzgxIDMxLjAyMzY2MVYyMi41MjM1MzdDNS4zOTE3ODEgMjEuNjYyNzY1IDUuMzkxNzgxIDIwLjY5NDM5NiA2LjAxMzQ1IDE5LjU5NDUyMUM2LjUzOTQ3NyAxOC42NjIwMTcgNy4xNDkxOTEgMTguMTU5OSA3LjcyMzAzOSAxNy43NzczMzVDNy44OTA0MTEgMTcuNjY5NzM4IDcuOTAyMzY2IDE3LjY1Nzc4MyA3LjkwMjM2NiAxNy40NDI1OUM3LjkwMjM2NiAxNy4yODcxNzMgNy45MDIzNjYgMTcuMjI3Mzk3IDcuODU0NTQ1IDE3LjE5MTUzMkM3LjI5MjY1MyAxNi44MzI4NzcgNS43Mzg0ODEgMTUuODQwNTk4IDUuNDI3NjQ2IDEzLjQ4NTQzQzUuMzkxNzgxIDEzLjIyMjQxNiA1LjM5MTc4MSAxMy4xOTg1MDYgNS4zOTE3ODEgMTMuMDU1MDQ0VjMuODczNDc0QzUuMzkxNzgxIDIuOTA1MTA2IDQuNzk0MDIyIC44OTY2MzggMi40ODY2NzUtLjMyMjc5QzIuMjExNzA2LS40NzgyMDcgMi4xODc3OTYtLjQ3ODIwNyAyLjAwODQ2OC0uNDc4MjA3QzEuNzMzNDk5LS40NzgyMDcgMS43MjE1NDQtLjQ3ODIwNyAxLjcyMTU0NC0uMjAzMjM4QzEuNzIxNTQ0LS4wMTE5NTUgMS43MjE1NDQgLjAyMzkxIDEuODA1MjMgLjA3MTczMUM0LjA3NjcxMiAxLjQyMjY2NSA0LjIzMjEzIDMuNDE5MTc4IDQuMjMyMTMgMy44ODU0M1YxMy4wNTUwNDRDNC4yMzIxMyAxNC4zNzAxMTIgNS4xNDA3MjIgMTYuMzkwNTM1IDcuMjIwOTIyIDE3LjQ0MjU5QzUuOTI5NzYzIDE4LjEzNTk5IDQuMzg3NTQ3IDE5LjUzNDc0NSA0LjI0NDA4NSAyMS43NzAzNjFMNC4yMzIxMyAyMS44NDIwOTJWMzAuMTI3MDI0WicvPgo8cGF0aCBpZD0nZzItODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2cwLTEyMScgZD0nTTQuOTA5NTg5LTIuOTY0ODgyQzQuOTQxNDY5LTMuMDc2NDYzIDQuOTQxNDY5LTMuMDkyNDAzIDQuOTQxNDY5LTMuMTU2MTY0QzQuOTQxNDY5LTMuMzc5MzI4IDQuNzc0MDk3LTMuNTM4NzMgNC41MzQ5OTQtMy41Mzg3M0M0LjM4MzU2Mi0zLjUzODczIDQuMTIwNTQ4LTMuNDQzMDg4IDQuMDI0OTA3LTMuMTg4MDQ1QzQuMDAwOTk2LTMuMTQwMjI0IDMuOTI5MjY1LTIuODUzMyAzLjg4OTQxNS0yLjY4NTkyOEwzLjQxOTE3OC0uODEyOTUxQzMuNDExMjA4LS44MDQ5ODEgMy4wNjA1MjMtLjI2MzAxNCAyLjUxMDU4NS0uMjYzMDE0QzIuMDAwNDk4LS4yNjMwMTQgMi4wMDA0OTgtLjY3NzQ2IDIuMDAwNDk4LS44NDQ4MzJDMi4wMDA0OTgtMS4yOTkxMjggMi4yMjM2NjEtMS44NzI5NzYgMi40ODY2NzUtMi41MzQ0OTZDMi41MzQ0OTYtMi42NDYwNzcgMi41NzQzNDYtMi43NDE3MTkgMi41NzQzNDYtMi44NzcyMUMyLjU3NDM0Ni0zLjM2MzM4NyAyLjA3MjIyOS0zLjYxMDQ2MSAxLjYwMTk5My0zLjYxMDQ2MUMuNzE3MzEtMy42MTA0NjEgLjI3MDk4NC0yLjU2NjM3NiAuMjcwOTg0LTIuMzU5MTUzQy4yNzA5ODQtMi4yMjM2NjEgLjM5MDUzNS0yLjIyMzY2MSAuNDk0MTQ3LTIuMjIzNjYxQy42NDU1NzktMi4yMjM2NjEgLjY3NzQ2LTIuMjIzNjYxIC43MjUyOC0yLjM2NzEyM0MuOTQ4NDQzLTMuMTAwMzc0IDEuMzYyODg5LTMuMjc1NzE2IDEuNTU0MTcyLTMuMjc1NzE2QzEuNjAxOTkzLTMuMjc1NzE2IDEuNjg5NjY0LTMuMjc1NzE2IDEuNjg5NjY0LTMuMDkyNDAzQzEuNjg5NjY0LTIuOTI1MDMxIDEuNjE3OTMzLTIuNzQxNzE5IDEuNTYyMTQyLTIuNjE0MTk3QzEuMDkxOTA1LTEuNDc0NDcxIDEuMDkxOTA1LTEuMjAzNDg3IDEuMDkxOTA1LTEuMDA0MjM0QzEuMDkxOTA1LS4wODc2NzEgMS44ODA5NDYgLjA3MTczMSAyLjQ1NDc5NSAuMDcxNzMxQzIuODI5MzkgLjA3MTczMSAzLjEwODM0NC0uMDYzNzYxIDMuMjUxODA2LS4xNTk0MDJDMy4wNzY0NjMgLjY5MzQgMi40NDY4MjQgMS4yODMxODggMS44MzMxMjYgMS4yODMxODhDMS43NzczMzUgMS4yODMxODggMS42MDE5OTMgMS4yODMxODggMS40MDI3NCAxLjIxMTQ1N0MxLjY0MTg0MyAxLjA2Nzk5NSAxLjcyMTU0NCAuODI4ODkyIDEuNzIxNTQ0IC42Njk0ODlDMS43MjE1NDQgLjQxNDQ0NiAxLjUzMDI2MiAuMjYzMDE0IDEuMjkxMTU4IC4yNjMwMTRDLjkyNDUzMyAuMjYzMDE0IC42NjE1MTkgLjU3Mzg0OCAuNjYxNTE5IC45MDg1OTNDLjY2MTUxOSAxLjM3MDg1OSAxLjE1NTY2NiAxLjYxNzkzMyAxLjgzMzEyNiAxLjYxNzkzM0MyLjc3MzU5OSAxLjYxNzkzMyAzLjkwNTM1NSAxLjA0NDA4NSA0LjE2MDM5OSAuMDE1OTRMNC45MDk1ODktMi45NjQ4ODJaJy8+CjxwYXRoIGlkPSdnNi0yNCcgZD0nTTEuNjE3OTMzLTIuMzUxMTgzQzEuOTEyODI3LTIuMjM5NjAxIDIuMjA3NzIxLTIuMjM5NjAxIDIuMzgzMDY0LTIuMjM5NjAxQzIuNjU0MDQ3LTIuMjM5NjAxIDMuMTcyMTA1LTIuMjM5NjAxIDMuMTcyMTA1LTIuNTI2NTI2QzMuMTcyMTA1LTIuNzY1NjI5IDIuNzQxNzE5LTIuNzY1NjI5IDIuNDcwNzM1LTIuNzY1NjI5QzIuMzExMzMzLTIuNzY1NjI5IDIuMDY0MjU5LTIuNzY1NjI5IDEuNzUzNDI1LTIuNjYyMDE3QzEuNTc4MDgyLTIuODI5MzkgMS41MDYzNTEtMy4wNTI1NTMgMS41MDYzNTEtMy4yNzU3MTZDMS41MDYzNTEtMy43MjIwNDIgMS44MTcxODYtNC4yODc5MiAyLjM5OTAwNC00LjU2Njg3NEMyLjU3NDM0Ni00LjM4MzU2MiAyLjc4MTU2OS00LjM4MzU2MiAyLjk0ODk0MS00LjM4MzU2MkMzLjI1MTgwNi00LjM4MzU2MiAzLjcwNjEwMi00LjM5OTUwMiAzLjcwNjEwMi00LjY3MDQ4NkMzLjcwNjEwMi00LjkwOTU4OSAzLjI3NTcxNi00LjkwOTU4OSAyLjk5Njc2Mi00LjkwOTU4OUMyLjg2MTI3LTQuOTA5NTg5IDIuNzI1Nzc4LTQuOTA5NTg5IDIuNTAyNjE1LTQuODc3NzA5QzIuNDg2Njc1LTQuOTMzNDk5IDIuNDYyNzY1LTUuMDEzMiAyLjQ2Mjc2NS01LjExNjgxMkMyLjQ2Mjc2NS01LjIyODM5NCAyLjQ5NDY0NS01LjM2Mzg4NSAyLjQ5NDY0NS01LjM4Nzc5NkMyLjUwMjYxNS01LjM5NTc2NiAyLjUwMjYxNS01LjQyNzY0NiAyLjUwMjYxNS01LjQzNTYxNkMyLjUwMjYxNS01LjUwNzM0NyAyLjQ0NjgyNC01LjU1NTE2OCAyLjM5MTAzNC01LjU1NTE2OEMyLjIxNTY5MS01LjU1NTE2OCAyLjIxNTY5MS01LjE5NjUxMyAyLjIxNTY5MS01LjEyNDc4MkMyLjIxNTY5MS00Ljk3MzM1IDIuMjU1NTQyLTQuODM3ODU4IDIuMjYzNTEyLTQuODIxOTE4QzEuMzcwODU5LTQuNTkwNzg1IC44MjA5MjItMy45NTMxNzYgLjgyMDkyMi0zLjMyMzUzN0MuODIwOTIyLTIuOTI1MDMxIDEuMDM2MTE1LTIuNjU0MDQ3IDEuMzM4OTc5LTIuNDc4NzA1Qy40ODYxNzctMS45OTI1MjggLjE5MTI4My0xLjE4NzU0NyAuMTkxMjgzLS44MjA5MjJDLjE5MTI4My0uMDk1NjQxIC45MjQ1MzMgLjE2NzM3MiAxLjE3OTU3NyAuMjYzMDE0QzEuNjI1OTAzIC40MzAzODYgMS42NDE4NDMgLjQzMDM4NiAyLjAzMjM3OSAuNTY1ODc4QzIuMjIzNjYxIC42Mzc2MDkgMi41NDI0NjYgLjc1NzE2MSAyLjU5ODI1NyAuNzg5MDQxQzIuNzI1Nzc4IC44Njg3NDIgMi43MjU3NzggLjk4MDMyNCAyLjcyNTc3OCAxLjAyODE0NEMyLjcyNTc3OCAxLjE3MTYwNiAyLjYyMjE2NyAxLjQwMjc0IDIuMzY3MTIzIDEuNDAyNzRDMi4zMDMzNjIgMS40MDI3NCAxLjk3NjU4OCAxLjM4NjggMS42NTc3ODMgMS4xOTU1MTdDMS41NzgwODIgMS4xMzk3MjYgMS41NzAxMTIgMS4xMzE3NTYgMS41MzAyNjIgMS4xMzE3NTZDMS40NDI1OSAxLjEzMTc1NiAxLjQxODY4IDEuMjExNDU3IDEuNDE4NjggMS4yNDMzMzdDMS40MTg2OCAxLjM3MDg1OSAxLjkyODc2NyAxLjYyNTkwMyAyLjM3NTA5MyAxLjYyNTkwM0MyLjkwMTEyMSAxLjYyNTkwMyAzLjIyNzg5NSAxLjEyMzc4NiAzLjIyNzg5NSAuNzU3MTYxQzMuMjI3ODk1IC42MTM2OTkgMy4xNzIxMDUgLjQ2MjI2NyAzLjA3NjQ2MyAuMzUwNjg1QzIuOTcyODUyIC4yMzkxMDMgMi44NjkyNCAuMTk5MjUzIDIuNDIyOTE0IC4wMzk4NTFDMS43Mjk1MTQtLjIwNzIyMyAxLjIxMTQ1Ny0uMzkwNTM1IDEuMDgzOTM1LS40NjIyNjdDLjgyODg5Mi0uNTk3NzU4IC42NjE1MTktLjc4OTA0MSAuNjYxNTE5LTEuMDUyMDU1Qy42NjE1MTktMS4zNzg4MjkgLjk1NjQxMy0xLjk5MjUyOCAxLjYxNzkzMy0yLjM1MTE4M1pNMy40MDMyMzgtNC42NDY1NzVDMy4zMjM1MzctNC42MzA2MzUgMy4yNDM4MzYtNC42MDY3MjUgMi45NTY5MTItNC42MDY3MjVDMi43ODk1MzktNC42MDY3MjUgMi43NTc2NTktNC42MDY3MjUgMi42NjIwMTctNC42NTQ1NDVDMi43ODk1MzktNC42ODY0MjYgMi44NjkyNC00LjY4NjQyNiAzLjAxMjcwMi00LjY4NjQyNkMzLjIyNzg5NS00LjY4NjQyNiAzLjI4MzY4Ni00LjY3ODQ1NiAzLjQwMzIzOC00LjY1NDU0NVYtNC42NDY1NzVaTTIuODY5MjQtMi41MDI2MTVDMi43OTc1MDktMi40ODY2NzUgMi43MTc4MDgtMi40NjI3NjUgMi40MDY5NzQtMi40NjI3NjVDMi4yNTU1NDItMi40NjI3NjUgMi4xNzU4NDEtMi40NjI3NjUgMi4wNDgzMTktMi41MDI2MTVDMi4yMjM2NjEtMi41NDI0NjYgMi4zMTkzMDMtMi41NDI0NjYgMi40NjI3NjUtMi41NDI0NjZDMi42OTM4OTgtMi41NDI0NjYgMi43NTc2NTktMi41MzQ0OTYgMi44NjkyNC0yLjUxMDU4NVYtMi41MDI2MTVaJy8+CjxwYXRoIGlkPSdnNi02MScgZD0nTTMuNzA2MTAyLTUuNjQyODM5QzMuNzUzOTIzLTUuNzU0NDIxIDMuNzUzOTIzLTUuNzcwMzYxIDMuNzUzOTIzLTUuNzk0MjcxQzMuNzUzOTIzLTUuODk3ODgzIDMuNjc0MjIyLTUuOTc3NTg0IDMuNTcwNjEtNS45Nzc1ODRDMy40NDMwODgtNS45Nzc1ODQgMy40MTEyMDgtNS44ODE5NDMgMy4zNzkzMjgtNS44MDIyNDJMLjUxODA1NyAxLjY1Nzc4M0MuNDcwMjM3IDEuNzY5MzY1IC40NzAyMzcgMS43ODUzMDUgLjQ3MDIzNyAxLjgwOTIxNUMuNDcwMjM3IDEuOTEyODI3IC41NDk5MzggMS45OTI1MjggLjY1MzU0OSAxLjk5MjUyOEMuNzgxMDcxIDEuOTkyNTI4IC44MTI5NTEgMS44OTY4ODcgLjg0NDgzMiAxLjgxNzE4NkwzLjcwNjEwMi01LjY0MjgzOVonLz4KPHBhdGggaWQ9J2c2LTEwNScgZD0nTTIuMzc1MDkzLTQuOTczMzVDMi4zNzUwOTMtNS4xNDg2OTIgMi4yNDc1NzItNS4yNzYyMTQgMi4wNjQyNTktNS4yNzYyMTRDMS44NTcwMzYtNS4yNzYyMTQgMS42MjU5MDMtNS4wODQ5MzIgMS42MjU5MDMtNC44NDU4MjhDMS42MjU5MDMtNC42NzA0ODYgMS43NTM0MjUtNC41NDI5NjQgMS45MzY3MzctNC41NDI5NjRDMi4xNDM5Ni00LjU0Mjk2NCAyLjM3NTA5My00LjczNDI0NyAyLjM3NTA5My00Ljk3MzM1Wk0xLjIxMTQ1Ny0yLjA0ODMxOUwuNzgxMDcxLS45NDg0NDNDLjc0MTIyLS44Mjg4OTIgLjcwMTM3LS43MzMyNSAuNzAxMzctLjU5Nzc1OEMuNzAxMzctLjIwNzIyMyAxLjAwNDIzNCAuMDc5NzAxIDEuNDI2NjUgLjA3OTcwMUMyLjE5OTc1MSAuMDc5NzAxIDIuNTI2NTI2LTEuMDM2MTE1IDIuNTI2NTI2LTEuMTM5NzI2QzIuNTI2NTI2LTEuMjE5NDI3IDIuNDYyNzY1LTEuMjQzMzM3IDIuNDA2OTc0LTEuMjQzMzM3QzIuMzExMzMzLTEuMjQzMzM3IDIuMjk1MzkyLTEuMTg3NTQ3IDIuMjcxNDgyLTEuMTA3ODQ2QzIuMDg4MTY5LS40NzAyMzcgMS43NjEzOTUtLjE0MzQ2MiAxLjQ0MjU5LS4xNDM0NjJDMS4zNDY5NDktLjE0MzQ2MiAxLjI1MTMwOC0uMTgzMzEzIDEuMjUxMzA4LS4zOTg1MDZDMS4yNTEzMDgtLjU4OTc4OCAxLjMwNzA5OC0uNzMzMjUgMS40MTA3MS0uOTgwMzI0QzEuNDkwNDExLTEuMTk1NTE3IDEuNTcwMTEyLTEuNDEwNzEgMS42NTc3ODMtMS42MjU5MDNMMS45MDQ4NTctMi4yNzE0ODJDMS45NzY1ODgtMi40NTQ3OTUgMi4wNzIyMjktMi43MDE4NjggMi4wNzIyMjktMi44MzczNkMyLjA3MjIyOS0zLjIzNTg2NiAxLjc1MzQyNS0zLjUxNDgxOSAxLjM0Njk0OS0zLjUxNDgxOUMuNTczODQ4LTMuNTE0ODE5IC4yMzkxMDMtMi4zOTkwMDQgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMzk2MDEgLjQ5NDE0Ny0yLjMxOTMwM0MuNzE3MzEtMy4wNzY0NjMgMS4wODM5MzUtMy4yOTE2NTYgMS4zMjMwMzktMy4yOTE2NTZDMS40MzQ2Mi0zLjI5MTY1NiAxLjUxNDMyMS0zLjI1MTgwNiAxLjUxNDMyMS0zLjAyODY0M0MxLjUxNDMyMS0yLjk0ODk0MSAxLjUwNjM1MS0yLjgzNzM2IDEuNDI2NjUtMi41OTgyNTdMMS4yMTE0NTctMi4wNDgzMTlaJy8+CjxwYXRoIGlkPSdnNi0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzEtMTInIGQ9J00uMjM5MTAzIDEuOTYwNjQ4Qy4yMjcxNDggMS45ODQ1NTggLjE5MTI4MyAyLjEzOTk3NSAuMTkxMjgzIDIuMTUxOTNDLjE5MTI4MyAyLjMxOTMwMyAuMzcwNjEgMi4zMTkzMDMgLjQ3ODIwNyAyLjMxOTMwM0MuNzE3MzEgMi4zMTkzMDMgLjcxNzMxIDIuMjk1MzkyIC43ODkwNDEgMi4wNDQzMzRDLjgyNDkwNyAxLjg1MzA1MSAxLjU0MjIxNy0xLjAxNjE4OSAxLjU1NDE3Mi0xLjA0MDFDMi4wNTYyODktLjIwMzIzOCAyLjk3NjgzNyAuMTQzNDYyIDMuOTMzMjUgLjE0MzQ2MkM2LjMzNjIzOSAuMTQzNDYyIDcuNjc1MjE4LTEuNjg1Njc5IDcuNjc1MjE4LTMuMjUxODA2QzcuNjc1MjE4LTQuMDg4NjY3IDcuMzA0NjA4LTQuNTQyOTY0IDYuOTEwMDg3LTQuODQxODQzQzcuMzQwNDczLTUuMjAwNDk4IDcuODMwNjM1LTUuOTc3NTg0IDcuODMwNjM1LTYuODAyNDkxQzcuODMwNjM1LTcuODE4NjggNy4wODk0MTUtOC4zOTI1MjggNS45NjU2MjktOC4zOTI1MjhDNC4yNTYwNC04LjM5MjUyOCAyLjQ4NjY3NS03LjA2NTUwNCAyLjA1NjI4OS01LjMzMjAwNUwuMjM5MTAzIDEuOTYwNjQ4Wk01LjY1NDc5NS00Ljc5NDAyMkM1LjM2Nzg3LTQuNTkwNzg1IDUuMDY4OTkxLTQuNTkwNzg1IDQuOTAxNjE5LTQuNTkwNzg1QzQuODUzNzk4LTQuNTkwNzg1IDQuMzI3NzcxLTQuNTkwNzg1IDQuMzI3NzcxLTQuNjg2NDI2QzQuMzI3NzcxLTQuODc3NzA5IDQuOTEzNTc0LTQuODc3NzA5IDUuMDY4OTkxLTQuODc3NzA5QzUuMjg0MTg0LTQuODc3NzA5IDUuNDI3NjQ2LTQuODc3NzA5IDUuNjU0Nzk1LTQuNzk0MDIyWk02LjA2MTI3LTUuMjEyNDUzQzUuNjY2NzUtNS4zMDgwOTUgNS4zMzIwMDUtNS4zMDgwOTUgNS4xMDQ4NTctNS4zMDgwOTVDNC43MjIyOTEtNS4zMDgwOTUgMy43NTM5MjMtNS4zMDgwOTUgMy43NTM5MjMtNC42NjI1MTZDMy43NTM5MjMtNC4xNjAzOTkgNC40NzEyMzMtNC4xNjAzOTkgNC44ODk2NjQtNC4xNjAzOTlDNS4wOTI5MDItNC4xNjAzOTkgNS42MzA4ODQtNC4xNjAzOTkgNi4xNjg4NjctNC4zODc1NDdDNi4yNjQ1MDgtNC4yMDgyMTkgNi4zMDAzNzQtMy45NjkxMTYgNi4zMDAzNzQtMy43NjU4NzhDNi4zMDAzNzQtMy4zMzU0OTIgNS45ODk1MzktMS44ODg5MTcgNS42MTg5MjktMS4yNjcyNDhDNS4yNDgzMTktLjY4MTQ0NSA0LjY2MjUxNi0uMjg2OTI0IDMuOTA5MzQtLjI4NjkyNEMyLjc5NzUwOS0uMjg2OTI0IDEuODY1MDA2LS45NTY0MTMgMS44NjUwMDYtMi4wMzIzNzlDMS44NjUwMDYtMi4yNzE0ODIgMS45MjQ3ODItMi41MjI1NCAxLjk0ODY5Mi0yLjY0MjA5MkMyLjEyODAyLTMuMzQ3NDQ3IDIuNTEwNTg1LTQuOTEzNTc0IDIuNjU0MDQ3LTUuNDM5NjAxQzMuMDM2NjEzLTYuNzQyNzE1IDQuNDgzMTg4LTcuOTYyMTQyIDUuOTA1ODUzLTcuOTYyMTQyQzYuMzQ4MTk0LTcuOTYyMTQyIDYuNjExMjA4LTcuNzQ2OTQ5IDYuNjExMjA4LTcuMjgwNjk3QzYuNjExMjA4LTYuOTEwMDg3IDYuMzI0Mjg0LTUuNjc4NzA1IDYuMDYxMjctNS4yMTI0NTNaJy8+CjxwYXRoIGlkPSdnMS0xMjEnIGQ9J002Ljg5ODEzMi00LjUwNzA5OEM2Ljk1NzkwOC00LjcyMjI5MSA2Ljk1NzkwOC00Ljc0NjIwMiA2Ljk1NzkwOC00Ljc4MjA2N0M2Ljk1NzkwOC01LjA0NTA4MSA2Ljc2NjYyNS01LjMwODA5NSA2LjM5NjAxNS01LjMwODA5NUM1Ljc3NDM0Ni01LjMwODA5NSA1LjYzMDg4NC00Ljc0NjIwMiA1LjU0NzE5OC00LjQyMzQxMkw1LjIzNjM2NC0zLjE4MDA3NUM1LjA5MjkwMi0yLjYwNjIyNyA0Ljg2NTc1My0xLjY4NTY3OSA0LjczNDI0Ny0xLjE5NTUxN0M0LjY3NDQ3MS0uOTMyNTAzIDQuMzAzODYxLS42NDU1NzkgNC4yNjc5OTUtLjYyMTY2OUM0LjEzNjQ4OC0uNTM3OTgzIDMuODQ5NTY0LS4zMzQ3NDUgMy40NTUwNDQtLjMzNDc0NUMyLjc0OTY4OS0uMzM0NzQ1IDIuNzM3NzMzLS45MzI1MDMgMi43Mzc3MzMtMS4yMDc0NzJDMi43Mzc3MzMtMS45MzY3MzcgMy4xMDgzNDQtMi44NjkyNCAzLjQ0MzA4OC0zLjczMDAxMkMzLjU2MjY0LTQuMDQwODQ3IDMuNTk4NTA2LTQuMTI0NTMzIDMuNTk4NTA2LTQuMzI3NzcxQzMuNTk4NTA2LTUuMDIxMTcxIDIuOTA1MTA2LTUuNDAzNzM2IDIuMjQ3NTcyLTUuNDAzNzM2Qy45ODAzMjQtNS40MDM3MzYgLjM4MjU2NS0zLjc3NzgzMyAuMzgyNTY1LTMuNTM4NzNDLjM4MjU2NS0zLjM3MTM1NyAuNTYxODkzLTMuMzcxMzU3IC42Njk0ODktMy4zNzEzNTdDLjgxMjk1MS0zLjM3MTM1NyAuODk2NjM4LTMuMzcxMzU3IC45NDQ0NTgtMy41MjY3NzVDMS4zMzg5NzktNC44NTM3OTggMS45OTY1MTMtNC45NzMzNSAyLjE3NTg0MS00Ljk3MzM1QzIuMjU5NTI3LTQuOTczMzUgMi4zNzkwNzgtNC45NzMzNSAyLjM3OTA3OC00LjcyMjI5MUMyLjM3OTA3OC00LjQ0NzMyMyAyLjI0NzU3Mi00LjEzNjQ4OCAyLjE3NTg0MS0zLjk0NTIwNUMxLjcwOTU4OS0yLjc0OTY4OSAxLjQ1ODUzMS0yLjA2ODI0NCAxLjQ1ODUzMS0xLjQ1ODUzMUMxLjQ1ODUzMS0uMDk1NjQxIDIuNjU0MDQ3IC4wOTU2NDEgMy4zNTk0MDIgLjA5NTY0MUMzLjY1ODI4MSAuMDk1NjQxIDQuMDY0NzU3IC4wNDc4MjEgNC41MDcwOTgtLjI2MzAxNEM0LjE3MjM1NCAxLjIwNzQ3MiAzLjI3NTcxNiAxLjk4NDU1OCAyLjQ1MDgwOSAxLjk4NDU1OEMyLjI5NTM5MiAxLjk4NDU1OCAxLjk2MDY0OCAxLjk2MDY0OCAxLjcyMTU0NCAxLjgxNzE4NkMyLjEwNDExIDEuNjYxNzY4IDIuMjk1MzkyIDEuMzM4OTc5IDIuMjk1MzkyIDEuMDE2MTg5QzIuMjk1MzkyIC41ODU4MDMgMS45NDg2OTIgLjQ2NjI1MiAxLjcwOTU4OSAuNDY2MjUyQzEuMjY3MjQ4IC40NjYyNTIgLjg0ODgxNyAuODQ4ODE3IC44NDg4MTcgMS4zNzQ4NDRDLjg0ODgxNyAxLjk4NDU1OCAxLjQ4MjQ0MSAyLjQxNDk0NCAyLjQ1MDgwOSAyLjQxNDk0NEMzLjgyNTY1NCAyLjQxNDk0NCA1LjQwMzczNiAxLjQ5NDM5NiA1Ljc3NDM0NiAuMDExOTU1TDYuODk4MTMyLTQuNTA3MDk4WicvPgo8cGF0aCBpZD0nZzktNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c5LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnOS00MycgZD0nTTQuNzcwMTEyLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExLTIuNzYxNjQ0IDguNDUyMzA0LTIuNzYxNjQ0IDguNDUyMzA0LTIuOTc2ODM3QzguNDUyMzA0LTMuMjAzOTg1IDguMjQ5MDY2LTMuMjAzOTg1IDguMDY5NzM4LTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMi02LjY3MDk4NCA0Ljc3MDExMi02Ljg4NjE3NyA0LjU1NDkxOS02Ljg4NjE3N0M0LjMyNzc3MS02Ljg4NjE3NyA0LjMyNzc3MS02LjY4MjkzOSA0LjMyNzc3MS02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDLjg2MDc3Mi0zLjIwMzk4NSAuNjQ1NTc5LTMuMjAzOTg1IC42NDU1NzktMi45ODg3OTJDLjY0NTU3OS0yLjc2MTY0NCAuODQ4ODE3LTIuNzYxNjQ0IDEuMDI4MTQ0LTIuNzYxNjQ0SDQuMzI3NzcxVi41Mzc5ODNDNC4zMjc3NzEgLjcwNTM1NSA0LjMyNzc3MSAuOTIwNTQ4IDQuNTQyOTY0IC45MjA1NDhDNC43NzAxMTIgLjkyMDU0OCA0Ljc3MDExMiAuNzE3MzEgNC43NzAxMTIgLjUzNzk4M1YtMi43NjE2NDRaJy8+CjxwYXRoIGlkPSdnOS00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2c5LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnOS0xMDMnIGQ9J00xLjQyMjY2NS0yLjE2Mzg4NUMxLjk4NDU1OC0xLjc5MzI3NSAyLjQ2Mjc2NS0xLjc5MzI3NSAyLjU5NDI3MS0xLjc5MzI3NUMzLjY3MDIzNy0xLjc5MzI3NSA0LjQ3MTIzMy0yLjYwNjIyNyA0LjQ3MTIzMy0zLjUyNjc3NUM0LjQ3MTIzMy0zLjg0OTU2NCA0LjM3NTU5Mi00LjMwMzg2MSAzLjk5MzAyNi00LjY4NjQyNkM0LjQ1OTI3OC01LjE2NDYzMyA1LjAyMTE3MS01LjE2NDYzMyA1LjA4MDk0Ni01LjE2NDYzM0M1LjEyODc2Ny01LjE2NDYzMyA1LjE4ODU0My01LjE2NDYzMyA1LjIzNjM2NC01LjE0MDcyMkM1LjExNjgxMi01LjA5MjkwMiA1LjA1NzAzNi00Ljk3MzM1IDUuMDU3MDM2LTQuODQxODQzQzUuMDU3MDM2LTQuNjc0NDcxIDUuMTc2NTg4LTQuNTMxMDA5IDUuMzY3ODctNC41MzEwMDlDNS40NjM1MTItNC41MzEwMDkgNS42Nzg3MDUtNC41OTA3ODUgNS42Nzg3MDUtNC44NTM3OThDNS42Nzg3MDUtNS4wNjg5OTEgNS41MTEzMzMtNS40MDM3MzYgNS4wOTI5MDItNS40MDM3MzZDNC40NzEyMzMtNS40MDM3MzYgNC4wMDQ5ODEtNS4wMjExNzEgMy44Mzc2MDktNC44NDE4NDNDMy40Nzg5NTQtNS4xMTY4MTIgMy4wNjA1MjMtNS4yNzIyMjkgMi42MDYyMjctNS4yNzIyMjlDMS41MzAyNjItNS4yNzIyMjkgLjcyOTI2NS00LjQ1OTI3OCAuNzI5MjY1LTMuNTM4NzNDLjcyOTI2NS0yLjg1NzI4NSAxLjE0NzY5Ni0yLjQxNDk0NCAxLjI2NzI0OC0yLjMwNzM0N0MxLjEyMzc4Ni0yLjEyODAyIC45MDg1OTMtMS43ODEzMiAuOTA4NTkzLTEuMzE1MDY4Qy45MDg1OTMtLjYyMTY2OSAxLjMyNzAyNC0uMzIyNzkgMS40MjI2NjUtLjI2MzAxNEMuODcyNzI3LS4xMDc1OTcgLjMyMjc5IC4zMjI3OSAuMzIyNzkgLjk0NDQ1OEMuMzIyNzkgMS43NjkzNjUgMS40NDY1NzUgMi40NTA4MDkgMi45MTcwNjEgMi40NTA4MDlDNC4zMzk3MjYgMi40NTA4MDkgNS41MjMyODggMS44MTcxODYgNS41MjMyODggLjkyMDU0OEM1LjUyMzI4OCAuNjIxNjY5IDUuNDM5NjAxLS4wODM2ODYgNC43MjIyOTEtLjQ1NDI5NkM0LjExMjU3OC0uNzY1MTMxIDMuNTE0ODE5LS43NjUxMzEgMi40ODY2NzUtLjc2NTEzMUMxLjc1NzQxLS43NjUxMzEgMS42NzM3MjQtLjc2NTEzMSAxLjQ1ODUzMS0uOTkyMjc5QzEuMzM4OTc5LTEuMTExODMxIDEuMjMxMzgyLTEuMzM4OTc5IDEuMjMxMzgyLTEuNTkwMDM3QzEuMjMxMzgyLTEuNzkzMjc1IDEuMzAzMTEzLTEuOTk2NTEzIDEuNDIyNjY1LTIuMTYzODg1Wk0yLjYwNjIyNy0yLjA0NDMzNEMxLjU1NDE3Mi0yLjA0NDMzNCAxLjU1NDE3Mi0zLjI1MTgwNiAxLjU1NDE3Mi0zLjUyNjc3NUMxLjU1NDE3Mi0zLjc0MTk2OCAxLjU1NDE3Mi00LjIzMjEzIDEuNzU3NDEtNC41NTQ5MTlDMS45ODQ1NTgtNC45MDE2MTkgMi4zNDMyMTMtNS4wMjExNzEgMi41OTQyNzEtNS4wMjExNzFDMy42NDYzMjYtNS4wMjExNzEgMy42NDYzMjYtMy44MTM2OTkgMy42NDYzMjYtMy41Mzg3M0MzLjY0NjMyNi0zLjMyMzUzNyAzLjY0NjMyNi0yLjgzMzM3NSAzLjQ0MzA4OC0yLjUxMDU4NUMzLjIxNTk0LTIuMTYzODg1IDIuODU3Mjg1LTIuMDQ0MzM0IDIuNjA2MjI3LTIuMDQ0MzM0Wk0yLjkyOTAxNiAyLjE5OTc1MUMxLjc4MTMyIDIuMTk5NzUxIC45MDg1OTMgMS42MTM5NDggLjkwODU5MyAuOTMyNTAzQy45MDg1OTMgLjgzNjg2MiAuOTMyNTAzIC4zNzA2MSAxLjM4NjggLjA1OTc3NkMxLjY0OTgxMy0uMTA3NTk3IDEuNzU3NDEtLjEwNzU5NyAyLjU5NDI3MS0uMTA3NTk3QzMuNTg2NTUtLjEwNzU5NyA0LjkzNzQ4NC0uMTA3NTk3IDQuOTM3NDg0IC45MzI1MDNDNC45Mzc0ODQgMS42Mzc4NTggNC4wMjg4OTIgMi4xOTk3NTEgMi45MjkwMTYgMi4xOTk3NTFaJy8+CjxwYXRoIGlkPSdnOS0xMDgnIGQ9J00yLjA1NjI4OS04LjI5Njg4N0wuMzk0NTIxLTguMTY1MzhWLTcuODE4NjhDMS4yMDc0NzItNy44MTg2OCAxLjMwMzExMy03LjczNDk5NCAxLjMwMzExMy03LjE0OTE5MVYtLjg4NDY4MkMxLjMwMzExMy0uMzQ2NyAxLjE3MTYwNi0uMzQ2NyAuMzk0NTIxLS4zNDY3VjBDLjcyOTI2NS0uMDIzOTEgMS4zMTUwNjgtLjAyMzkxIDEuNjczNzI0LS4wMjM5MVMyLjYzMDEzNy0uMDIzOTEgMi45NjQ4ODIgMFYtLjM0NjdDMi4xOTk3NTEtLjM0NjcgMi4wNTYyODktLjM0NjcgMi4wNTYyODktLjg4NDY4MlYtOC4yOTY4ODdaJy8+CjxwYXRoIGlkPSdnOS0xMTEnIGQ9J001LjQ4NzQyMi0yLjU1ODQwNkM1LjQ4NzQyMi00LjEwMDYyMyA0LjMxNTgxNi01LjMzMjAwNSAyLjkyOTAxNi01LjMzMjAwNUMxLjQ5NDM5Ni01LjMzMjAwNSAuMzU4NjU1LTQuMDY0NzU3IC4zNTg2NTUtMi41NTg0MDZDLjM1ODY1NS0xLjAyODE0NCAxLjU1NDE3MiAuMTE5NTUyIDIuOTE3MDYxIC4xMTk1NTJDNC4zMjc3NzEgLjExOTU1MiA1LjQ4NzQyMi0xLjA1MjA1NSA1LjQ4NzQyMi0yLjU1ODQwNlpNMi45MjkwMTYtLjE0MzQ2MkMyLjQ4NjY3NS0uMTQzNDYyIDEuOTQ4NjkyLS4zMzQ3NDUgMS42MDE5OTMtLjkyMDU0OEMxLjI3OTIwMy0xLjQ1ODUzMSAxLjI2NzI0OC0yLjE2Mzg4NSAxLjI2NzI0OC0yLjY2NjAwMkMxLjI2NzI0OC0zLjEyMDI5OSAxLjI2NzI0OC0zLjg0OTU2NCAxLjYzNzg1OC00LjM4NzU0N0MxLjk3MjYwMy00LjkwMTYxOSAyLjQ5ODYzLTUuMDkyOTAyIDIuOTE3MDYxLTUuMDkyOTAyQzMuMzgzMzEzLTUuMDkyOTAyIDMuODg1NDMtNC44Nzc3MDkgNC4yMDgyMTktNC40MTE0NTdDNC41Nzg4MjktMy44NjE1MTkgNC41Nzg4MjktMy4xMDgzNDQgNC41Nzg4MjktMi42NjYwMDJDNC41Nzg4MjktMi4yNDc1NzIgNC41Nzg4MjktMS41MDYzNTEgNC4yNjc5OTUtLjk0NDQ1OEMzLjkzMzI1LS4zNzA2MSAzLjM4MzMxMy0uMTQzNDYyIDIuOTI5MDE2LS4xNDM0NjJaJy8+CjxwYXRoIGlkPSdnOC00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c4LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnOC00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c4LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnNC0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2c3LTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnNy0yNCcgZD0nTTMuMTIwMjk5IC4wNTk3NzZMMS44NjUwMDYtLjQ0MjM0MUMxLjU1NDE3Mi0uNTYxODkzIC44MzY4NjItLjg0ODgxNyAuODM2ODYyLTEuNTY2MTI3Qy44MzY4NjItMi41OTQyNzEgMi4wOTIxNTQtMy42MzQzNzEgMi4zNDMyMTMtMy42MzQzNzFDMi4zNjcxMjMtMy42MzQzNzEgMi40NzQ3Mi0zLjYxMDQ2MSAyLjUxMDU4NS0zLjU5ODUwNkMyLjgzMzM3NS0zLjUwMjg2NCAzLjE0NDIwOS0zLjUwMjg2NCAzLjM1OTQwMi0zLjUwMjg2NEMzLjczMDAxMi0zLjUwMjg2NCA0LjQzNTM2Ny0zLjUwMjg2NCA0LjQzNTM2Ny0zLjg0OTU2NEM0LjQzNTM2Ny00LjExMjU3OCA0LjAwNDk4MS00LjE0ODQ0MyAzLjQ5MDkwOS00LjE0ODQ0M0MzLjI1MTgwNi00LjE0ODQ0MyAyLjkyOTAxNi00LjE0ODQ0MyAyLjQ5ODYzLTQuMDA0OTgxQzIuMjExNzA2LTQuMjQ0MDg1IDIuMDkyMTU0LTQuNjI2NjUgMi4wOTIxNTQtNC45ODUzMDVDMi4wOTIxNTQtNS42NDI4MzkgMi41MjI1NC02LjU3NTM0MiAzLjQ2Njk5OS03LjAxNzY4NEMzLjY4MjE5Mi02Ljc2NjYyNSAzLjk2OTExNi02Ljc2NjYyNSA0LjIyMDE3NC02Ljc2NjYyNUM0LjUxOTA1NC02Ljc2NjYyNSA1LjI0ODMxOS02Ljc2NjYyNSA1LjI0ODMxOS03LjExMzMyNUM1LjI0ODMxOS03LjQxMjIwNCA0LjY3NDQ3MS03LjQxMjIwNCA0LjI5MTkwNS03LjQxMjIwNEM0LjA1MjgwMi03LjQxMjIwNCAzLjg3MzQ3NC03LjQxMjIwNCAzLjUzODczLTcuMzUyNDI4QzMuNDc4OTU0LTcuNDk1ODkgMy40NjY5OTktNy41MTk4MDEgMy40NjY5OTktNy43ODI4MTRDMy40NjY5OTktNy45OTgwMDcgMy41MTQ4MTktOC4xNjUzOCAzLjUxNDgxOS04LjIwMTI0NUMzLjUxNDgxOS04LjI3Mjk3NiAzLjQ1NTA0NC04LjMyMDc5NyAzLjM5NTI2OC04LjMyMDc5N0MzLjIwMzk4NS04LjMyMDc5NyAzLjIwMzk4NS03Ljg3ODQ1NiAzLjIwMzk4NS03Ljc4MjgxNEMzLjIwMzk4NS03LjYxNTQ0MiAzLjIxNTk0LTcuNDQ4MDcgMy4yODc2NzEtNy4yOTI2NTNDMS44NTMwNTEtNi44NzQyMjIgMS4yMTk0MjctNS44NTgwMzIgMS4yMTk0MjctNS4wODA5NDZDMS4yMTk0MjctNC4zNjM2MzYgMS42OTc2MzQtMy45NjkxMTYgMi4wMjA0MjMtMy43ODk3ODhDLjc4OTA0MS0zLjEyMDI5OSAuMjYzMDE0LTEuOTAwODcyIC4yNjMwMTQtMS4yNTUyOTNDLjI2MzAxNC0uMjE1MTkzIDEuMjA3NDcyIC4xNTU0MTcgMS42Mzc4NTggLjMzNDc0NUwyLjcxMzgyMyAuNzY1MTMxQzMuMDEyNzAyIC44NzI3MjcgMy41MDI4NjQgMS4wNzU5NjUgMy41ODY1NSAxLjEyMzc4NkMzLjcwNjEwMiAxLjIwNzQ3MiAzLjgwMTc0MyAxLjM1MDkzNCAzLjgwMTc0MyAxLjU0MjIxN0MzLjgwMTc0MyAxLjc5MzI3NSAzLjYxMDQ2MSAyLjE5OTc1MSAzLjE5MjAzIDIuMTk5NzUxQzMuMDEyNzAyIDIuMTk5NzUxIDIuNjE4MTgyIDIuMTUxOTMgMi4xODc3OTYgMS44MjkxNDFDMi4xMDQxMSAxLjc1NzQxIDIuMDkyMTU0IDEuNzQ1NDU1IDIuMDQ0MzM0IDEuNzQ1NDU1QzEuOTg0NTU4IDEuNzQ1NDU1IDEuOTI0NzgyIDEuNzkzMjc1IDEuOTI0NzgyIDEuODY1MDA2QzEuOTI0NzgyIDEuOTk2NTEzIDIuNTQ2NDUxIDIuNDM4ODU0IDMuMTkyMDMgMi40Mzg4NTRDMy45NTcxNjEgMi40Mzg4NTQgNC40MjM0MTIgMS42OTc2MzQgNC40MjM0MTIgMS4xODM1NjJDNC40MjM0MTIgLjgxMjk1MSA0LjIyMDE3NCAuNTE0MDcyIDMuODM3NjA5IC4zNDY3TDMuMTIwMjk5IC4wNTk3NzZaTTMuNzMwMDEyLTcuMTEzMzI1QzMuOTMzMjUtNy4xNzMxMDEgNC4xNDg0NDMtNy4xNzMxMDEgNC4zMDM4NjEtNy4xNzMxMDFDNC42OTgzODEtNy4xNzMxMDEgNC43MzQyNDctNy4xNjExNDYgNC45NzMzNS03LjEwMTM3QzQuODI5ODg4LTcuMDQxNTk0IDQuNzM0MjQ3LTcuMDA1NzI5IDQuMjMyMTMtNy4wMDU3MjlDNC4wMDQ5ODEtNy4wMDU3MjkgMy44NjE1MTktNy4wMDU3MjkgMy43MzAwMTItNy4xMTMzMjVaTTIuNzg1NTU0LTMuODM3NjA5QzMuMDcyNDc4LTMuOTA5MzQgMy4zMzU0OTItMy45MDkzNCAzLjQ3ODk1NC0zLjkwOTM0QzMuODczNDc0LTMuOTA5MzQgMy44OTczODUtMy44OTczODUgNC4xNjAzOTktMy44Mzc2MDlDNC4wMjg4OTItMy43Nzc4MzMgMy45MjEyOTUtMy43NDE5NjggMy40MDcyMjMtMy43NDE5NjhDMy4xMjAyOTktMy43NDE5NjggMy4wMDA3NDctMy43NDE5NjggMi43ODU1NTQtMy44Mzc2MDlaJy8+CjxwYXRoIGlkPSdnNy0yNycgZD0nTTYuMDczMjI1LTQuNTA3MDk4QzYuMjI4NjQzLTQuNTA3MDk4IDYuNjIzMTYzLTQuNTA3MDk4IDYuNjIzMTYzLTQuODg5NjY0QzYuNjIzMTYzLTUuMTUyNjc3IDYuMzk2MDE1LTUuMTUyNjc3IDYuMTgwODIyLTUuMTUyNjc3SDMuNTM4NzNDMS43NDU0NTUtNS4xNTI2NzcgLjQ1NDI5Ni0zLjE1NjE2NCAuNDU0Mjk2LTEuNzQ1NDU1Qy40NTQyOTYtLjcyOTI2NSAxLjExMTgzMSAuMTE5NTUyIDIuMTg3Nzk2IC4xMTk1NTJDMy41OTg1MDYgLjExOTU1MiA1LjE0MDcyMi0xLjM5ODc1NSA1LjE0MDcyMi0zLjE5MjAzQzUuMTQwNzIyLTMuNjU4MjgxIDUuMDMzMTI2LTQuMTEyNTc4IDQuNzQ2MjAyLTQuNTA3MDk4SDYuMDczMjI1Wk0yLjE5OTc1MS0uMTE5NTUyQzEuNTkwMDM3LS4xMTk1NTIgMS4xNDc2OTYtLjU4NTgwMyAxLjE0NzY5Ni0xLjQxMDcxQzEuMTQ3Njk2LTIuMTI4MDIgMS41NzgwODItNC41MDcwOTggMy4zMzU0OTItNC41MDcwOThDMy44NDk1NjQtNC41MDcwOTggNC40MjM0MTItNC4yNTYwNCA0LjQyMzQxMi0zLjMzNTQ5MkM0LjQyMzQxMi0yLjkxNzA2MSA0LjIzMjEzLTEuOTEyODI3IDMuODEzNjk5LTEuMjE5NDI3QzMuMzgzMzEzLS41MTQwNzIgMi43Mzc3MzMtLjExOTU1MiAyLjE5OTc1MS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzctNjEnIGQ9J001LjEyODc2Ny04LjUyNDAzNUM1LjEyODc2Ny04LjUzNTk5IDUuMjAwNDk4LTguNzE1MzE4IDUuMjAwNDk4LTguNzM5MjI4QzUuMjAwNDk4LTguODgyNjkgNS4wODA5NDYtOC45NjYzNzYgNC45ODUzMDUtOC45NjYzNzZDNC45MjU1MjktOC45NjYzNzYgNC44MTc5MzMtOC45NjYzNzYgNC43MjIyOTEtOC43MDMzNjJMLjcxNzMxIDIuNTQ2NDUxQy43MTczMSAyLjU1ODQwNiAuNjQ1NTc5IDIuNzM3NzMzIC42NDU1NzkgMi43NjE2NDRDLjY0NTU3OSAyLjkwNTEwNiAuNzY1MTMxIDIuOTg4NzkyIC44NjA3NzIgMi45ODg3OTJDLjkzMjUwMyAyLjk4ODc5MiAxLjA0MDEgMi45NzY4MzcgMS4xMjM3ODYgMi43MjU3NzhMNS4xMjg3NjctOC41MjQwMzVaJy8+CjxwYXRoIGlkPSdnNy05NicgZD0nTTEuMDk5ODc1LTIuMDMyMzc5Qy4zNDY3LTEuMjkxMTU4IC4xNTU0MTctMS4xMTE4MzEgLjE1NTQxNy0xLjA2NDAxUy4yMDMyMzgtLjkzMjUwMyAuMjg2OTI0LS45MzI1MDNDLjM0NjctLjkzMjUwMyAxLjAyODE0NC0xLjU5MDAzNyAxLjEyMzc4Ni0xLjY5NzYzNEMxLjE5NTUxNy0uODk2NjM4IDEuNDk0Mzk2IC4xNDM0NjIgMi40MjY4OTkgLjE0MzQ2MkMyLjkwNTEwNiAuMTQzNDYyIDMuMzM1NDkyLS4xNTU0MTcgMy41MjY3NzUtLjI5ODg3OUMzLjY4MjE5Mi0uNDE4NDMxIDQuMjU2MDQtLjkwODU5MyA0LjI1NjA0LTEuMDE2MTg5QzQuMjU2MDQtMS4wNzU5NjUgNC4xOTYyNjQtMS4xNDc2OTYgNC4xMzY0ODgtMS4xNDc2OTZDNC4wODg2NjctMS4xNDc2OTYgMy45MDkzNC0uOTY4MzY5IDMuODYxNTE5LS45MjA1NDhDMy40NDMwODgtLjUxNDA3MiAyLjkxNzA2MS0uMDk1NjQxIDIuNDM4ODU0LS4wOTU2NDFDMS43OTMyNzUtLjA5NTY0MSAxLjcwOTU4OS0xLjAyODE0NCAxLjcwOTU4OS0xLjY3MzcyNEMxLjcwOTU4OS0xLjc5MzI3NSAxLjcwOTU4OS0yLjI5NTM5MiAxLjc5MzI3NS0yLjM5MTAzNEMyLjQ5ODYzLTMuMTIwMjk5IDQuNzEwMzM2LTUuNDAzNzM2IDQuNzEwMzM2LTcuNTE5ODAxQzQuNzEwMzM2LTcuOTk4MDA3IDQuNTMxMDA5LTguNDE2NDM4IDQuMDE2OTM2LTguNDE2NDM4QzIuOTA1MTA2LTguNDE2NDM4IDEuOTM2NzM3LTUuOTUzNjc0IDEuNzY5MzY1LTUuNDk5Mzc3QzEuNzIxNTQ0LTUuMzc5ODI2IDEuMDI4MTQ0LTMuNTM4NzMgMS4wOTk4NzUtMi4wMzIzNzlaTTEuODE3MTg2LTIuNzczNTk5QzEuODI5MTQxLTIuODQ1MzMgMi4zNjcxMjMtNS45Nzc1ODQgMy4zNzEzNTctNy42NTEzMDhDMy41NzQ1OTUtNy45NzQwOTcgMy43Nzc4MzMtOC4xNzczMzUgNC4wMTY5MzYtOC4xNzczMzVDNC40MjM0MTItOC4xNzczMzUgNC40NDczMjMtNy43OTQ3NyA0LjQ0NzMyMy03LjUzMTc1NkM0LjQ0NzMyMy03LjExMzMyNSA0LjMyNzc3MS02LjAzNzM2IDMuMjg3NjcxLTQuNTMxMDA5QzIuOTc2ODM3LTQuMDg4NjY3IDIuNDk4NjMtMy40OTA5MDkgMS44MTcxODYtMi43NzM1OTlaJy8+CjxwYXRoIGlkPSdnNy0xMjInIGQ9J00xLjUxODMwNi0uOTY4MzY5QzIuMDMyMzc5LTEuNTU0MTcyIDIuNDUwODA5LTEuOTI0NzgyIDMuMDQ4NTY4LTIuNDYyNzY1QzMuNzY1ODc4LTMuMDg0NDMzIDQuMDc2NzEyLTMuMzgzMzEzIDQuMjQ0MDg1LTMuNTYyNjRDNS4wODA5NDYtNC4zODc1NDcgNS40OTkzNzctNS4wODA5NDYgNS40OTkzNzctNS4xNzY1ODhTNS40MDM3MzYtNS4yNzIyMjkgNS4zNzk4MjYtNS4yNzIyMjlDNS4yOTYxMzktNS4yNzIyMjkgNS4yNzIyMjktNS4yMjQ0MDggNS4yMTI0NTMtNS4xNDA3MjJDNC45MTM1NzQtNC42MjY2NSA0LjYyNjY1LTQuMzc1NTkyIDQuMzE1ODE2LTQuMzc1NTkyQzQuMDY0NzU3LTQuMzc1NTkyIDMuOTMzMjUtNC40ODMxODggMy43MDYxMDItNC43NzAxMTJDMy40NTUwNDQtNS4wNjg5OTEgMy4yNTE4MDYtNS4yNzIyMjkgMi45MDUxMDYtNS4yNzIyMjlDMi4wMzIzNzktNS4yNzIyMjkgMS41MDYzNTEtNC4xODQzMDkgMS41MDYzNTEtMy45MzMyNUMxLjUwNjM1MS0zLjg5NzM4NSAxLjUxODMwNi0zLjgyNTY1NCAxLjYyNTkwMy0zLjgyNTY1NEMxLjcyMTU0NC0zLjgyNTY1NCAxLjczMzQ5OS0zLjg3MzQ3NCAxLjc2OTM2NS0zLjk1NzE2MUMxLjk3MjYwMy00LjQzNTM2NyAyLjU0NjQ1MS00LjUxOTA1NCAyLjc3MzU5OS00LjUxOTA1NEMzLjAyNDY1OC00LjUxOTA1NCAzLjI2Mzc2MS00LjQzNTM2NyAzLjUxNDgxOS00LjMyNzc3MUMzLjk2OTExNi00LjEzNjQ4OCA0LjE2MDM5OS00LjEzNjQ4OCA0LjI3OTk1LTQuMTM2NDg4QzQuMzYzNjM2LTQuMTM2NDg4IDQuNDExNDU3LTQuMTM2NDg4IDQuNDcxMjMzLTQuMTQ4NDQzQzQuMDc2NzEyLTMuNjgyMTkyIDMuNDMxMTMzLTMuMTA4MzQ0IDIuODkzMTUxLTIuNjE4MTgyTDEuNjg1Njc5LTEuNTA2MzUxQy45NTY0MTMtLjc2NTEzMSAuNTE0MDcyLS4wNTk3NzYgLjUxNDA3MiAuMDIzOTFDLjUxNDA3MiAuMDk1NjQxIC41NzM4NDggLjExOTU1MiAuNjQ1NTc5IC4xMTk1NTJTLjcyOTI2NSAuMTA3NTk3IC44MTI5NTEtLjAzNTg2NkMxLjAwNDIzNC0uMzM0NzQ1IDEuMzg2OC0uNzc3MDg2IDEuODI5MTQxLS43NzcwODZDMi4wODAxOTktLjc3NzA4NiAyLjE5OTc1MS0uNjkzNCAyLjQzODg1NC0uMzk0NTIxQzIuNjY2MDAyLS4xMzE1MDcgMi44NjkyNCAuMTE5NTUyIDMuMjUxODA2IC4xMTk1NTJDNC40MjM0MTIgLjExOTU1MiA1LjA5MjkwMi0xLjM5ODc1NSA1LjA5MjkwMi0xLjY3MzcyNEM1LjA5MjkwMi0xLjcyMTU0NCA1LjA4MDk0Ni0xLjc5MzI3NSA0Ljk2MTM5NS0xLjc5MzI3NUM0Ljg2NTc1My0xLjc5MzI3NSA0Ljg1Mzc5OC0xLjc0NTQ1NSA0LjgxNzkzMy0xLjYyNTkwM0M0LjU1NDkxOS0uOTIwNTQ4IDMuODQ5NTY0LS42MzM2MjQgMy4zODMzMTMtLjYzMzYyNEMzLjEzMjI1NC0uNjMzNjI0IDIuODkzMTUxLS43MTczMSAyLjY0MjA5Mi0uODI0OTA3QzIuMTYzODg1LTEuMDE2MTg5IDIuMDMyMzc5LTEuMDE2MTg5IDEuODc2OTYxLTEuMDE2MTg5QzEuNzU3NDEtMS4wMTYxODkgMS42MjU5MDMtMS4wMTYxODkgMS41MTgzMDYtLjk2ODM2OVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy05NicvPgo8dXNlIHg9JzQuOTEyMTA2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc5LjQ2NDQzMicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyJy8+Cjx1c2UgeD0nMTcuNzU4Mjk3JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PScyNS42MzE0NTInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS02MScvPgo8dXNlIHg9JzM4LjA1NjkzMicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c0LTAnLz4KPHVzZSB4PSc1NS40MTMxMzQnIHk9Jy0yOS45NzY0MjUnIHhsaW5rOmhyZWY9JyNnNi0xMTAnLz4KPHVzZSB4PSc0OS4zNDc5MjcnIHk9Jy0yNi4zODk4NjknIHhsaW5rOmhyZWY9JyNnMi04OCcvPgo8dXNlIHg9JzUxLjEzMDMyMScgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nNTQuMDEzNDYxJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnOC02MScvPgo8dXNlIHg9JzYwLjU5OTk2NycgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PSc2OC42MDkwNDEnIHk9Jy0zNS40NzU5MjgnIHhsaW5rOmhyZWY9JyNnMi00MCcvPgo8dXNlIHg9Jzc4LjIzOTY0NCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTEwOCcvPgo8dXNlIHg9JzgxLjQ5MTMwNScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTExMScvPgo8dXNlIHg9Jzg3LjM0NDI5NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTEwMycvPgo8dXNlIHg9JzkzLjM1OTg2OScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nOTcuOTEyMTk1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzctMjcnLz4KPHVzZSB4PScxMDQuOTk0NTk5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PScxMDkuNTQ2OTI1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzEtMTIxJy8+Cjx1c2UgeD0nMTE3LjA0NjU0MScgeT0nLTEyLjIwOTY2MScgeGxpbms6aHJlZj0nI2c2LTEwNScvPgo8dXNlIHg9JzEyMC40Mjc4MTMnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzEyNC45ODAxMzknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzEzMi4xODkxMjgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzE0My45NTA0NDMnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzE0OC41MDI3NjknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00OScvPgo8dXNlIHg9JzE1Ny4wMTI0MjMnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzE2OC43NzM3MzgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00OScvPgo8dXNlIHg9JzE3NC42MjY3MjgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy02MScvPgo8dXNlIHg9JzE4MC40Nzk3MTgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy0yNCcvPgo8dXNlIHg9JzE4Ni4xNzAxNTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzE5MC43MjI0ODEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PScxOTguMjIyMDk4JyB5PSctMTIuMjA5NjYxJyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nMjAxLjYwMzM3JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PScyMDYuMTU1Njk2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PScyMTIuNzAwNTE5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTA4Jy8+Cjx1c2UgeD0nMjE1Ljk1MjE4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTExJy8+Cjx1c2UgeD0nMjIxLjgwNTE3MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTEwMycvPgo8dXNlIHg9JzIyOS44MTMyNDInIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMCcvPgo8dXNlIHg9JzIzNi4xMjI5MzknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00OScvPgo8dXNlIHg9JzI0NC42MzI1OTMnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzI1Ni4zOTM5MDgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy0yNCcvPgo8dXNlIHg9JzI2Mi4wODQzNDUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzI2Ni42MzY2NzEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PScyNzQuMTM2Mjg4JyB5PSctMTIuMjA5NjYxJyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nMjc3LjUxNzU2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PScyODQuMDYyMzgzJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMTgnLz4KPHVzZSB4PScyOTQuMDU4MjY5JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzctMTIyJy8+Cjx1c2UgeD0nMjk5LjQ5NjE2JyB5PSctMjEuNzQyNzE0JyB4bGluazpocmVmPScjZzAtMTIxJy8+Cjx1c2UgeD0nMzA0LjgyNTMxMicgeT0nLTE5LjY5NDg1MicgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzMxMS4xNDE4NjUnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnNC0wJy8+Cjx1c2UgeD0nMzIzLjA5NzAyNicgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c3LTIyJy8+Cjx1c2UgeD0nMzMwLjEzOTk5NicgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMzM0LjY5MjMyMicgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzM0Mi4xOTE5MzknIHk9Jy0yMC43MTMyMzQnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSczNDUuNTczMjExJyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzktNDEnLz4KPHJlY3QgeD0nMjk0LjA1ODI2OScgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1Ni4wNjcyNTknLz4KPHVzZSB4PSczMDguNTU3OTI3JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNy0yNycvPgo8dXNlIHg9JzMxNS42NDAzMzEnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMzIwLjE5MjY1NycgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzEtMTIxJy8+Cjx1c2UgeD0nMzI3LjY5MjI3NCcgeT0nLTQuMDA4OTk5JyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nMzMxLjA3MzU0NScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PSczNTEuMzIxMDQyJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMTknLz4KPHVzZSB4PSczNjAuMTIxNDE1JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMjEnLz4KPHVzZSB4PSczNjkuMDg3Nzc2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDMnLz4KPHVzZSB4PSczODAuODQ5MDkxJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMjAnLz4KPHVzZSB4PSczODcuMTU4Nzg4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDknLz4KPHVzZSB4PSczOTUuNjY4NDQyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDMnLz4KPHVzZSB4PSc0MDcuNDI5NzU3JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzctMjQnLz4KPHVzZSB4PSc0MTMuMTIwMTk1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc0MTcuNjcyNTInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSc0MjUuMTcyMTM3JyB5PSctMTIuMjA5NjYxJyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nNDI4LjU1MzQwOScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nNDM1LjA5ODIzMicgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cyLTE4Jy8+Cjx1c2UgeD0nNDQ1LjA5NDExOScgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c3LTEyMicvPgo8dXNlIHg9JzQ1MC41MzIwMDknIHk9Jy0yMS43NDI3MTQnIHhsaW5rOmhyZWY9JyNnMC0xMjEnLz4KPHVzZSB4PSc0NTUuODYxMTYxJyB5PSctMTkuNjk0ODUyJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nNDYyLjE3NzcxNScgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c0LTAnLz4KPHVzZSB4PSc0NzQuMTMyODc1JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzctMjInLz4KPHVzZSB4PSc0ODEuMTc1ODQ2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc0ODUuNzI4MTcxJyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzEtMTIxJy8+Cjx1c2UgeD0nNDkzLjIyNzc4OCcgeT0nLTIwLjcxMzIzNCcgeGxpbms6aHJlZj0nI2c2LTEwNScvPgo8dXNlIHg9JzQ5Ni42MDkwNicgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c5LTQxJy8+CjxyZWN0IHg9JzQ0NS4wOTQxMTknIHk9Jy0xOC4yNjAyOScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNTYuMDY3MjU5Jy8+Cjx1c2UgeD0nNDU5LjU5Mzc3NicgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzctMjcnLz4KPHVzZSB4PSc0NjYuNjc2MTgnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nNDcxLjIyODUwNicgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzEtMTIxJy8+Cjx1c2UgeD0nNDc4LjcyODEyMycgeT0nLTQuMDA4OTk5JyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nNDgyLjEwOTM5NScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PSc1MDIuMzU2ODkyJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMTknLz4KPHVzZSB4PSc1MTEuMTU3MjY1JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMjEnLz4KPHVzZSB4PSc1MTcuNDY2OTYyJyB5PSctMjkuMzQ3NTEyJyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzUyNC4wNTM0NjknIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzUyOC4yODc2NTEnIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnNi02MScvPgo8dXNlIHg9JzUzMi41MjE4MzQnIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnNi0yNCcvPgo8dXNlIHg9JzUzNi41NTUzNjknIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzUzOS44NDg2MjInIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnMC0xMjEnLz4KPHVzZSB4PSc1NDUuMTc3Nzc0JyB5PSctMjcuMjk5NjUnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc1NDguMzM5NTMyJyB5PSctMjkuMzQ3NTEyJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSc1NTIuMTMwOTE3JyB5PSctMzUuNDc1OTI4JyB4bGluazpocmVmPScjZzItNDEnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
defined on
 such that
such that  for all
for all  .
.And if any of the
is equal to 0, the log-likelihood is defined as:
The initialization of the optimization problem is crucial. Two initial points
 are proposed:
are proposed:the Gumbel initial point: in that case, we assume that the GEV is a stationary Gumbel distribution and we deduce
 from the mean
from the mean  and standard variation
and standard variation  of the data:
of the data:
 and
and  where
where
 is Euler’s constant; then we take the initial point
is Euler’s constant; then we take the initial point  . This is the default initial point;
. This is the default initial point;the Static initial point: in that case, we assume that the GEV is stationary and
is the maximum likelihood estimate resulting from that assumption.
The result class provides:
the estimator
 ,
,the asymptotic distribution of
,the parameter function
 ,
,the graphs of the parameter functions
 , where all the components of
, where all the components of
 are fixed to a reference value excepted for , for each
are fixed to a reference value excepted for , for each  ,
,the graphs of the parameter functions
 , where all the
components of are fixed to a reference value excepted for
, where all the
components of are fixed to a reference value excepted for
 , for each
, for each  ,
,the normalizing function
 ,
,the optimal log-likelihood value
,the GEV distribution at covariate
,the graphs of the quantile functions of order
 :
:  where all the components
of are fixed to a reference value excepted for , for each ,
where all the components
of are fixed to a reference value excepted for , for each ,the graphs of the quantile functions of order
:  where all the components of are fixed to a
reference value excepted for , for each .
where all the components of are fixed to a
reference value excepted for , for each .
- buildEstimator(*args)¶
Build the distribution and the parameter distribution.
- Parameters:
- sample2-d sequence of float
Data.
- parameters
DistributionParameters Optional, the parametrization.
- Returns:
- resDist
DistributionFactoryResult The results.
- resDist
Notes
According to the way the native parameters of the distribution are estimated, the parameters distribution differs:
Moments method: the asymptotic parameters distribution is normal and estimated by Bootstrap on the initial data;
Maximum likelihood method with a regular model: the asymptotic parameters distribution is normal and its covariance matrix is the inverse Fisher information matrix;
Other methods: the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting (see
KernelSmoothing).
If another set of parameters is specified, the native parameters distribution is first estimated and the new distribution is determined from it:
if the native parameters distribution is normal and the transformation regular at the estimated parameters values: the asymptotic parameters distribution is normal and its covariance matrix determined from the inverse Fisher information matrix of the native parameters and the transformation;
in the other cases, the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting.
- buildMethodOfLikelihoodMaximization(sample, r=0)¶
Estimate the distribution from the
largest order statistics.- Parameters:
- sample2-d sequence of float
Block maxima grouped in a sample of size
 and dimension
and dimension  .
.- rint,
 ,
, Number of largest order statistics taken into account among the
stored ones.By default,
 which means that all the maxima are used.
which means that all the maxima are used.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution.
- distribution
Notes
The method estimates a GEV distribution parameterized by
from a given sample.Let us suppose we have a series of independent and identically distributed variables and that data are grouped into
blocks. In each block, the largest observations are recorded.We define the series
 for
for  where the values are sorted
in decreasing order.
where the values are sorted
in decreasing order.The estimator of
maximizes the log-likelihood built from the largest order statistics,
with defined as:If
 , then:
, then:(1)¶
![\ell(\mu, \sigma, \xi) = -nr \log \sigma - \sum_{i=1}^n \biggl[ 1 + \xi \Bigl( \frac{z_i^{(r)} - \mu }{\sigma} \Bigr) \biggr]^{-1/\xi} -\left(\dfrac{1}{\xi} +1 \right) \sum_{i=1}^n \sum_{k=1}^r \log \biggl[ 1 + \xi \Bigl( \frac{z_i^{(k)} - \mu }{\sigma} \Bigr) \biggr]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc0NjMuOTIyMTQycHQnIGhlaWdodD0nMzQuMjc4NDk5cHQnIHZpZXdCb3g9JzAgLTM1LjQ3NDAxMyA0NjMuOTIyMTQyIDM0LjI3ODQ5OSc+CjxkZWZzPgo8cGF0aCBpZD0nZzEtMCcgZD0nTTUuNTcxMTA4LTEuODA5MjE1QzUuNjk4NjMtMS44MDkyMTUgNS44NzM5NzMtMS44MDkyMTUgNS44NzM5NzMtMS45OTI1MjhTNS42OTg2My0yLjE3NTg0MSA1LjU3MTEwOC0yLjE3NTg0MUgxLjAwNDIzNEMuODc2NzEyLTIuMTc1ODQxIC43MDEzNy0yLjE3NTg0MSAuNzAxMzctMS45OTI1MjhTLjg3NjcxMi0xLjgwOTIxNSAxLjAwNDIzNC0xLjgwOTIxNUg1LjU3MTEwOFonLz4KPHBhdGggaWQ9J2c1LTQwJyBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgLjcyNTI4IDEuMzM4OTc5LS43NTcxNjEgMS4zMzg5NzktMS45OTI1MjhDMS4zMzg5NzktNC4yODc5MiAyLjI4NzQyMi01LjM2Mzg4NSAyLjY5Mzg5OC01LjczMDUxMUMyLjgwNTQ3OS01LjgzNDEyMiAyLjgxMzQ1LTUuODQyMDkyIDIuODEzNDUtNS44ODE5NDNTMi43ODE1NjktNS45Nzc1ODQgMi43MDE4NjgtNS45Nzc1ODRDMi41NzQzNDYtNS45Nzc1ODQgMi4xNzU4NDEtNS41NzExMDggMi4xMTIwOC01LjQ5OTM3N0MxLjA0NDA4NS00LjM4MzU2MiAuODIwOTIyLTIuOTQ4OTQxIC44MjA5MjItMS45OTI1MjhDLjgyMDkyMi0uMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicvPgo8cGF0aCBpZD0nZzUtNDEnIGQ9J00yLjQ2Mjc2NS0xLjk5MjUyOEMyLjQ2Mjc2NS0yLjc0OTY4OSAyLjMzNTI0My0zLjY1ODI4MSAxLjg0MTA5Ni00LjU5ODc1NUMxLjQ1MDU2LTUuMzMyMDA1IC43MjUyOC01Ljk3NzU4NCAuNTgxODE4LTUuOTc3NTg0Qy41MDIxMTctNS45Nzc1ODQgLjQ3ODIwNy01LjkyMTc5MyAuNDc4MjA3LTUuODgxOTQzQy40NzgyMDctNS44NTAwNjIgLjQ3ODIwNy01LjgzNDEyMiAuNTczODQ4LTUuNzM4NDgxQzEuNjg5NjY0LTQuNjc4NDU2IDEuOTQ0NzA3LTMuMjE5OTI1IDEuOTQ0NzA3LTEuOTkyNTI4QzEuOTQ0NzA3IC4yOTQ4OTQgLjk5NjI2NCAxLjM3ODgyOSAuNTg5Nzg4IDEuNzQ1NDU1Qy40ODYxNzcgMS44NDkwNjYgLjQ3ODIwNyAxLjg1NzAzNiAuNDc4MjA3IDEuODk2ODg3Uy41MDIxMTcgMS45OTI1MjggLjU4MTgxOCAxLjk5MjUyOEMuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgLjM5ODUwNiAyLjQ2Mjc2NS0xLjAzNjExNSAyLjQ2Mjc2NS0xLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c1LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzUtNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2cwLTE2JyBkPSdNNi4xNTY5MTIgMjAuODk3NjM0QzYuMTgwODIyIDIwLjkwOTU4OSA2LjI4ODQxOCAyMS4wMjkxNDEgNi4zMDAzNzQgMjEuMDI5MTQxSDYuNTYzMzg3QzYuNTk5MjUzIDIxLjAyOTE0MSA2LjY5NDg5NCAyMS4wMTcxODYgNi42OTQ4OTQgMjAuOTA5NTg5QzYuNjk0ODk0IDIwLjg2MTc2OCA2LjY3MDk4NCAyMC44Mzc4NTggNi42NDcwNzMgMjAuODAxOTkzQzYuMjE2Njg3IDIwLjM3MTYwNiA1LjU3MTEwOCAxOS43MTQwNzIgNC44Mjk4ODggMTguMzk5MDA0QzMuNTM4NzMgMTYuMTAzNjExIDMuMDYwNTIzIDEzLjE1MDY4NSAzLjA2MDUyMyAxMC4yODE0NDVDMy4wNjA1MjMgNC45NzMzNSA0LjU2Njg3NCAxLjg1MzA1MSA2LjY1OTAyOS0uMjYzMDE0QzYuNjk0ODk0LS4yOTg4NzkgNi42OTQ4OTQtLjMzNDc0NSA2LjY5NDg5NC0uMzU4NjU1QzYuNjk0ODk0LS40NzgyMDcgNi42MTEyMDgtLjQ3ODIwNyA2LjQ2Nzc0Ni0uNDc4MjA3QzYuMzEyMzI5LS40NzgyMDcgNi4yODg0MTgtLjQ3ODIwNyA2LjE4MDgyMi0uMzgyNTY1QzUuMDQ1MDgxIC41OTc3NTggMy43NjU4NzggMi4yNTk1MjcgMi45NDA5NzEgNC43ODIwNjdDMi40MjY4OTkgNi4zNjAxNDkgMi4xNTE5MyA4LjI4NDkzMiAyLjE1MTkzIDEwLjI2OTQ4OUMyLjE1MTkzIDEzLjEwMjg2NCAyLjY2NjAwMiAxNi4zMDY4NDkgNC41NDI5NjQgMTkuMDgwNDQ4QzQuODY1NzUzIDE5LjU0NjcgNS4zMDgwOTUgMjAuMDM2ODYyIDUuMzA4MDk1IDIwLjA0ODgxN0M1LjQyNzY0NiAyMC4xOTIyNzkgNS41OTUwMTkgMjAuMzgzNTYyIDUuNjkwNjYgMjAuNDY3MjQ4TDYuMTU2OTEyIDIwLjg5NzYzNFonLz4KPHBhdGggaWQ9J2cwLTE3JyBkPSdNNC45NzMzNSAxMC4yNjk0ODlDNC45NzMzNSA2LjgzODM1NiA0LjE3MjM1NCAzLjE5MjAzIDEuODE3MTg2IC41MDIxMTdDMS42NDk4MTMgLjMxMDgzNCAxLjIwNzQ3Mi0uMTU1NDE3IC45MjA1NDgtLjQwNjQ3NkMuODM2ODYyLS40NzgyMDcgLjgxMjk1MS0uNDc4MjA3IC42NTc1MzQtLjQ3ODIwN0MuNTM3OTgzLS40NzgyMDcgLjQzMDM4Ni0uNDc4MjA3IC40MzAzODYtLjM1ODY1NUMuNDMwMzg2LS4zMTA4MzQgLjQ3ODIwNy0uMjYzMDE0IC41MDIxMTctLjIzOTEwM0MuOTA4NTkzIC4xNzkzMjggMS41NTQxNzIgLjgzNjg2MiAyLjI5NTM5MiAyLjE1MTkzQzMuNTg2NTUgNC40NDczMjMgNC4wNjQ3NTcgNy40MDAyNDkgNC4wNjQ3NTcgMTAuMjY5NDg5QzQuMDY0NzU3IDE1LjQ1ODAzMiAyLjYzMDEzNyAxOC42MjYxNTIgLjQ3ODIwNyAyMC44MTM5NDhDLjQ1NDI5NiAyMC44Mzc4NTggLjQzMDM4NiAyMC44NzM3MjQgLjQzMDM4NiAyMC45MDk1ODlDLjQzMDM4NiAyMS4wMjkxNDEgLjUzNzk4MyAyMS4wMjkxNDEgLjY1NzUzNCAyMS4wMjkxNDFDLjgxMjk1MSAyMS4wMjkxNDEgLjgzNjg2MiAyMS4wMjkxNDEgLjk0NDQ1OCAyMC45MzM0OTlDMi4wODAxOTkgMTkuOTUzMTc2IDMuMzU5NDAyIDE4LjI5MTQwNyA0LjE4NDMwOSAxNS43Njg4NjdDNC43MTAzMzYgMTQuMTMxMDA5IDQuOTczMzUgMTIuMTk0MjcxIDQuOTczMzUgMTAuMjY5NDg5WicvPgo8cGF0aCBpZD0nZzAtMTgnIGQ9J004LjM2ODYxOCAyOC4wODI2OUM4LjM2ODYxOCAyOC4wMzQ4NjkgOC4zNDQ3MDcgMjguMDEwOTU5IDguMzIwNzk3IDI3Ljk3NTA5M0M3Ljg3ODQ1NiAyNy41MzI3NTIgNy4wNzc0NiAyNi43MzE3NTYgNi4yNzY0NjMgMjUuNDQwNTk4QzQuMzUxNjgxIDIyLjM1NjE2NCAzLjQ3ODk1NCAxOC40NzA3MzUgMy40Nzg5NTQgMTMuODY3OTk1QzMuNDc4OTU0IDEwLjY1MjA1NSAzLjkwOTM0IDYuNTAzNjExIDUuODgxOTQzIDIuOTQwOTcxQzYuODI2NDAxIDEuMjQzMzM3IDcuODA2NzI1IC4yNjMwMTQgOC4zMzI3NTItLjI2MzAxNEM4LjM2ODYxOC0uMjk4ODc5IDguMzY4NjE4LS4zMjI3OSA4LjM2ODYxOC0uMzU4NjU1QzguMzY4NjE4LS40NzgyMDcgOC4yODQ5MzItLjQ3ODIwNyA4LjExNzU1OS0uNDc4MjA3UzcuOTI2Mjc2LS40NzgyMDcgNy43NDY5NDktLjI5ODg3OUMzLjc0MTk2OCAzLjM0NzQ0NyAyLjQ4NjY3NSA4LjgyMjkxNCAyLjQ4NjY3NSAxMy44NTYwNEMyLjQ4NjY3NSAxOC41NTQ0MjEgMy41NjI2NCAyMy4yODg2NjcgNi41OTkyNTMgMjYuODYzMjYzQzYuODM4MzU2IDI3LjEzODIzMiA3LjI5MjY1MyAyNy42MjgzOTQgNy43ODI4MTQgMjguMDU4NzhDNy45MjYyNzYgMjguMjAyMjQyIDcuOTUwMTg3IDI4LjIwMjI0MiA4LjExNzU1OSAyOC4yMDIyNDJTOC4zNjg2MTggMjguMjAyMjQyIDguMzY4NjE4IDI4LjA4MjY5WicvPgo8cGF0aCBpZD0nZzAtMTknIGQ9J002LjMwMDM3NCAxMy44Njc5OTVDNi4zMDAzNzQgOS4xNjk2MTQgNS4yMjQ0MDggNC40MzUzNjcgMi4xODc3OTYgLjg2MDc3MkMxLjk0ODY5MiAuNTg1ODAzIDEuNDk0Mzk2IC4wOTU2NDEgMS4wMDQyMzQtLjMzNDc0NUMuODYwNzcyLS40NzgyMDcgLjgzNjg2Mi0uNDc4MjA3IC42Njk0ODktLjQ3ODIwN0MuNTI2MDI3LS40NzgyMDcgLjQxODQzMS0uNDc4MjA3IC40MTg0MzEtLjM1ODY1NUMuNDE4NDMxLS4zMTA4MzQgLjQ2NjI1Mi0uMjYzMDE0IC40OTAxNjItLjIzOTEwM0MuOTA4NTkzIC4xOTEyODMgMS43MDk1ODkgLjk5MjI3OSAyLjUxMDU4NSAyLjI4MzQzN0M0LjQzNTM2NyA1LjM2Nzg3IDUuMzA4MDk1IDkuMjUzMyA1LjMwODA5NSAxMy44NTYwNEM1LjMwODA5NSAxNy4wNzE5OCA0Ljg3NzcwOSAyMS4yMjA0MjMgMi45MDUxMDYgMjQuNzgzMDY0QzEuOTYwNjQ4IDI2LjQ4MDY5NyAuOTY4MzY5IDI3LjQ3Mjk3NiAuNDY2MjUyIDI3Ljk3NTA5M0MuNDQyMzQxIDI4LjAxMDk1OSAuNDE4NDMxIDI4LjA0NjgyNCAuNDE4NDMxIDI4LjA4MjY5Qy40MTg0MzEgMjguMjAyMjQyIC41MjYwMjcgMjguMjAyMjQyIC42Njk0ODkgMjguMjAyMjQyQy44MzY4NjIgMjguMjAyMjQyIC44NjA3NzIgMjguMjAyMjQyIDEuMDQwMSAyOC4wMjI5MTRDNS4wNDUwODEgMjQuMzc2NTg4IDYuMzAwMzc0IDE4LjkwMTEyMSA2LjMwMDM3NCAxMy44Njc5OTVaJy8+CjxwYXRoIGlkPSdnMC0yMCcgZD0nTTIuOTg4NzkyIDI4LjIwMjI0Mkg2LjEzMzAwMVYyNy41NDQ3MDdIMy42NDYzMjZWLjE3OTMyOEg2LjEzMzAwMVYtLjQ3ODIwN0gyLjk4ODc5MlYyOC4yMDIyNDJaJy8+CjxwYXRoIGlkPSdnMC0yMScgZD0nTTIuNjU0MDQ3IDI3LjU0NDcwN0guMTY3MzcyVjI4LjIwMjI0MkgzLjMxMTU4MlYtLjQ3ODIwN0guMTY3MzcyVi4xNzkzMjhIMi42NTQwNDdWMjcuNTQ0NzA3WicvPgo8cGF0aCBpZD0nZzAtODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2czLTI0JyBkPSdNMS42MTc5MzMtMi4zNTExODNDMS45MTI4MjctMi4yMzk2MDEgMi4yMDc3MjEtMi4yMzk2MDEgMi4zODMwNjQtMi4yMzk2MDFDMi42NTQwNDctMi4yMzk2MDEgMy4xNzIxMDUtMi4yMzk2MDEgMy4xNzIxMDUtMi41MjY1MjZDMy4xNzIxMDUtMi43NjU2MjkgMi43NDE3MTktMi43NjU2MjkgMi40NzA3MzUtMi43NjU2MjlDMi4zMTEzMzMtMi43NjU2MjkgMi4wNjQyNTktMi43NjU2MjkgMS43NTM0MjUtMi42NjIwMTdDMS41NzgwODItMi44MjkzOSAxLjUwNjM1MS0zLjA1MjU1MyAxLjUwNjM1MS0zLjI3NTcxNkMxLjUwNjM1MS0zLjcyMjA0MiAxLjgxNzE4Ni00LjI4NzkyIDIuMzk5MDA0LTQuNTY2ODc0QzIuNTc0MzQ2LTQuMzgzNTYyIDIuNzgxNTY5LTQuMzgzNTYyIDIuOTQ4OTQxLTQuMzgzNTYyQzMuMjUxODA2LTQuMzgzNTYyIDMuNzA2MTAyLTQuMzk5NTAyIDMuNzA2MTAyLTQuNjcwNDg2QzMuNzA2MTAyLTQuOTA5NTg5IDMuMjc1NzE2LTQuOTA5NTg5IDIuOTk2NzYyLTQuOTA5NTg5QzIuODYxMjctNC45MDk1ODkgMi43MjU3NzgtNC45MDk1ODkgMi41MDI2MTUtNC44Nzc3MDlDMi40ODY2NzUtNC45MzM0OTkgMi40NjI3NjUtNS4wMTMyIDIuNDYyNzY1LTUuMTE2ODEyQzIuNDYyNzY1LTUuMjI4Mzk0IDIuNDk0NjQ1LTUuMzYzODg1IDIuNDk0NjQ1LTUuMzg3Nzk2QzIuNTAyNjE1LTUuMzk1NzY2IDIuNTAyNjE1LTUuNDI3NjQ2IDIuNTAyNjE1LTUuNDM1NjE2QzIuNTAyNjE1LTUuNTA3MzQ3IDIuNDQ2ODI0LTUuNTU1MTY4IDIuMzkxMDM0LTUuNTU1MTY4QzIuMjE1NjkxLTUuNTU1MTY4IDIuMjE1NjkxLTUuMTk2NTEzIDIuMjE1NjkxLTUuMTI0NzgyQzIuMjE1NjkxLTQuOTczMzUgMi4yNTU1NDItNC44Mzc4NTggMi4yNjM1MTItNC44MjE5MThDMS4zNzA4NTktNC41OTA3ODUgLjgyMDkyMi0zLjk1MzE3NiAuODIwOTIyLTMuMzIzNTM3Qy44MjA5MjItMi45MjUwMzEgMS4wMzYxMTUtMi42NTQwNDcgMS4zMzg5NzktMi40Nzg3MDVDLjQ4NjE3Ny0xLjk5MjUyOCAuMTkxMjgzLTEuMTg3NTQ3IC4xOTEyODMtLjgyMDkyMkMuMTkxMjgzLS4wOTU2NDEgLjkyNDUzMyAuMTY3MzcyIDEuMTc5NTc3IC4yNjMwMTRDMS42MjU5MDMgLjQzMDM4NiAxLjY0MTg0MyAuNDMwMzg2IDIuMDMyMzc5IC41NjU4NzhDMi4yMjM2NjEgLjYzNzYwOSAyLjU0MjQ2NiAuNzU3MTYxIDIuNTk4MjU3IC43ODkwNDFDMi43MjU3NzggLjg2ODc0MiAyLjcyNTc3OCAuOTgwMzI0IDIuNzI1Nzc4IDEuMDI4MTQ0QzIuNzI1Nzc4IDEuMTcxNjA2IDIuNjIyMTY3IDEuNDAyNzQgMi4zNjcxMjMgMS40MDI3NEMyLjMwMzM2MiAxLjQwMjc0IDEuOTc2NTg4IDEuMzg2OCAxLjY1Nzc4MyAxLjE5NTUxN0MxLjU3ODA4MiAxLjEzOTcyNiAxLjU3MDExMiAxLjEzMTc1NiAxLjUzMDI2MiAxLjEzMTc1NkMxLjQ0MjU5IDEuMTMxNzU2IDEuNDE4NjggMS4yMTE0NTcgMS40MTg2OCAxLjI0MzMzN0MxLjQxODY4IDEuMzcwODU5IDEuOTI4NzY3IDEuNjI1OTAzIDIuMzc1MDkzIDEuNjI1OTAzQzIuOTAxMTIxIDEuNjI1OTAzIDMuMjI3ODk1IDEuMTIzNzg2IDMuMjI3ODk1IC43NTcxNjFDMy4yMjc4OTUgLjYxMzY5OSAzLjE3MjEwNSAuNDYyMjY3IDMuMDc2NDYzIC4zNTA2ODVDMi45NzI4NTIgLjIzOTEwMyAyLjg2OTI0IC4xOTkyNTMgMi40MjI5MTQgLjAzOTg1MUMxLjcyOTUxNC0uMjA3MjIzIDEuMjExNDU3LS4zOTA1MzUgMS4wODM5MzUtLjQ2MjI2N0MuODI4ODkyLS41OTc3NTggLjY2MTUxOS0uNzg5MDQxIC42NjE1MTktMS4wNTIwNTVDLjY2MTUxOS0xLjM3ODgyOSAuOTU2NDEzLTEuOTkyNTI4IDEuNjE3OTMzLTIuMzUxMTgzWk0zLjQwMzIzOC00LjY0NjU3NUMzLjMyMzUzNy00LjYzMDYzNSAzLjI0MzgzNi00LjYwNjcyNSAyLjk1NjkxMi00LjYwNjcyNUMyLjc4OTUzOS00LjYwNjcyNSAyLjc1NzY1OS00LjYwNjcyNSAyLjY2MjAxNy00LjY1NDU0NUMyLjc4OTUzOS00LjY4NjQyNiAyLjg2OTI0LTQuNjg2NDI2IDMuMDEyNzAyLTQuNjg2NDI2QzMuMjI3ODk1LTQuNjg2NDI2IDMuMjgzNjg2LTQuNjc4NDU2IDMuNDAzMjM4LTQuNjU0NTQ1Vi00LjY0NjU3NVpNMi44NjkyNC0yLjUwMjYxNUMyLjc5NzUwOS0yLjQ4NjY3NSAyLjcxNzgwOC0yLjQ2Mjc2NSAyLjQwNjk3NC0yLjQ2Mjc2NUMyLjI1NTU0Mi0yLjQ2Mjc2NSAyLjE3NTg0MS0yLjQ2Mjc2NSAyLjA0ODMxOS0yLjUwMjYxNUMyLjIyMzY2MS0yLjU0MjQ2NiAyLjMxOTMwMy0yLjU0MjQ2NiAyLjQ2Mjc2NS0yLjU0MjQ2NkMyLjY5Mzg5OC0yLjU0MjQ2NiAyLjc1NzY1OS0yLjUzNDQ5NiAyLjg2OTI0LTIuNTEwNTg1Vi0yLjUwMjYxNVonLz4KPHBhdGggaWQ9J2czLTYxJyBkPSdNMy43MDYxMDItNS42NDI4MzlDMy43NTM5MjMtNS43NTQ0MjEgMy43NTM5MjMtNS43NzAzNjEgMy43NTM5MjMtNS43OTQyNzFDMy43NTM5MjMtNS44OTc4ODMgMy42NzQyMjItNS45Nzc1ODQgMy41NzA2MS01Ljk3NzU4NEMzLjQ0MzA4OC01Ljk3NzU4NCAzLjQxMTIwOC01Ljg4MTk0MyAzLjM3OTMyOC01LjgwMjI0MkwuNTE4MDU3IDEuNjU3NzgzQy40NzAyMzcgMS43NjkzNjUgLjQ3MDIzNyAxLjc4NTMwNSAuNDcwMjM3IDEuODA5MjE1Qy40NzAyMzcgMS45MTI4MjcgLjU0OTkzOCAxLjk5MjUyOCAuNjUzNTQ5IDEuOTkyNTI4Qy43ODEwNzEgMS45OTI1MjggLjgxMjk1MSAxLjg5Njg4NyAuODQ0ODMyIDEuODE3MTg2TDMuNzA2MTAyLTUuNjQyODM5WicvPgo8cGF0aCBpZD0nZzMtMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2czLTEwNycgZD0nTTIuMzI3MjczLTUuMjkyMTU0QzIuMzM1MjQzLTUuMzA4MDk1IDIuMzU5MTUzLTUuNDExNzA2IDIuMzU5MTUzLTUuNDE5Njc2QzIuMzU5MTUzLTUuNDU5NTI3IDIuMzI3MjczLTUuNTMxMjU4IDIuMjMxNjMxLTUuNTMxMjU4QzIuMTk5NzUxLTUuNTMxMjU4IDEuOTUyNjc3LTUuNTA3MzQ3IDEuNzY5MzY1LTUuNDkxNDA3TDEuMzIzMDM5LTUuNDU5NTI3QzEuMTQ3Njk2LTUuNDQzNTg3IDEuMDY3OTk1LTUuNDM1NjE2IDEuMDY3OTk1LTUuMjkyMTU0QzEuMDY3OTk1LTUuMTgwNTczIDEuMTc5NTc3LTUuMTgwNTczIDEuMjc1MjE4LTUuMTgwNTczQzEuNjU3NzgzLTUuMTgwNTczIDEuNjU3NzgzLTUuMTMyNzUyIDEuNjU3NzgzLTUuMDYxMDIxQzEuNjU3NzgzLTUuMDM3MTExIDEuNjU3NzgzLTUuMDIxMTcxIDEuNjE3OTMzLTQuODc3NzA5TC40ODYxNzctLjM0MjcxNUMuNDU0Mjk2LS4yMjMxNjMgLjQ1NDI5Ni0uMTc1MzQyIC40NTQyOTYtLjE2NzM3MkMuNDU0Mjk2LS4wMzE4OCAuNTY1ODc4IC4wNzk3MDEgLjcxNzMxIC4wNzk3MDFDLjk4ODI5NCAuMDc5NzAxIDEuMDUyMDU1LS4xNzUzNDIgMS4wODM5MzUtLjI4NjkyNEMxLjE2MzYzNi0uNjIxNjY5IDEuMzcwODU5LTEuNDY2NTAxIDEuNDU4NTMxLTEuODAxMjQ1QzEuODk2ODg3LTEuNzUzNDI1IDIuNDMwODg0LTEuNjAxOTkzIDIuNDMwODg0LTEuMTQ3Njk2QzIuNDMwODg0LTEuMTA3ODQ2IDIuNDMwODg0LTEuMDY3OTk1IDIuNDE0OTQ0LS45ODgyOTRDMi4zOTEwMzQtLjg4NDY4MiAyLjM3NTA5My0uNzczMTAxIDIuMzc1MDkzLS43MzMyNUMyLjM3NTA5My0uMjYzMDE0IDIuNzI1Nzc4IC4wNzk3MDEgMy4xODgwNDUgLjA3OTcwMUMzLjUyMjc5IC4wNzk3MDEgMy43MzAwMTItLjE2NzM3MiAzLjgzMzYyNC0uMzE4ODA0QzQuMDI0OTA3LS42MTM2OTkgNC4xNTI0MjgtMS4wOTE5MDUgNC4xNTI0MjgtMS4xMzk3MjZDNC4xNTI0MjgtMS4yMTk0MjcgNC4wODg2NjctMS4yNDMzMzcgNC4wMzI4NzctMS4yNDMzMzdDMy45MzcyMzUtMS4yNDMzMzcgMy45MjEyOTUtMS4xOTU1MTcgMy44ODk0MTUtMS4wNTIwNTVDMy43ODU4MDMtLjY3NzQ2IDMuNTc4NTgtLjE0MzQ2MiAzLjIwMzk4NS0uMTQzNDYyQzIuOTk2NzYyLS4xNDM0NjIgMi45NDg5NDEtLjMxODgwNCAyLjk0ODk0MS0uNTMzOTk4QzIuOTQ4OTQxLS42Mzc2MDkgMi45NTY5MTItLjczMzI1IDIuOTk2NzYyLS45MTY1NjNDMy4wMDQ3MzItLjk0ODQ0MyAzLjAzNjYxMy0xLjA3NTk2NSAzLjAzNjYxMy0xLjE2MzYzNkMzLjAzNjYxMy0xLjgxNzE4NiAyLjIxNTY5MS0xLjk2MDY0OCAxLjgwOTIxNS0yLjAxNjQzOEMyLjEwNDExLTIuMTkxNzgxIDIuMzc1MDkzLTIuNDYyNzY1IDIuNDcwNzM1LTIuNTY2Mzc2QzIuOTA5MDkxLTIuOTk2NzYyIDMuMjY3NzQ2LTMuMjkxNjU2IDMuNjUwMzExLTMuMjkxNjU2QzMuNzUzOTIzLTMuMjkxNjU2IDMuODQ5NTY0LTMuMjY3NzQ2IDMuOTEzMzI1LTMuMTg4MDQ1QzMuNDgyOTM5LTMuMTMyMjU0IDMuNDgyOTM5LTIuNzU3NjU5IDMuNDgyOTM5LTIuNzQ5Njg5QzMuNDgyOTM5LTIuNTc0MzQ2IDMuNjE4NDMxLTIuNDU0Nzk1IDMuNzkzNzczLTIuNDU0Nzk1QzQuMDA4OTY2LTIuNDU0Nzk1IDQuMjQ4MDctMi42MzAxMzcgNC4yNDgwNy0yLjk1NjkxMkM0LjI0ODA3LTMuMjI3ODk1IDQuMDU2Nzg3LTMuNTE0ODE5IDMuNjU4MjgxLTMuNTE0ODE5QzMuMTk2MDE1LTMuNTE0ODE5IDIuNzgxNTY5LTMuMTY0MTM0IDIuMzI3MjczLTIuNzA5ODM4QzEuODY1MDA2LTIuMjU1NTQyIDEuNjY1NzUzLTIuMTY3ODcgMS41MzgyMzItMi4xMTIwOEwyLjMyNzI3My01LjI5MjE1NFonLz4KPHBhdGggaWQ9J2czLTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnMy0xMTQnIGQ9J00xLjUzODIzMi0xLjA5OTg3NUMxLjYyNTkwMy0xLjQ0MjU5IDEuNzEzNTc0LTEuNzg1MzA1IDEuNzkzMjc1LTIuMTM1OTlDMS44MDEyNDUtMi4xNTE5MyAxLjg1NzAzNi0yLjM4MzA2NCAxLjg2NTAwNi0yLjQyMjkxNEMxLjg4ODkxNy0yLjQ5NDY0NSAyLjA4ODE2OS0yLjgyMTQyIDIuMjk1MzkyLTMuMDIwNjcyQzIuNTUwNDM2LTMuMjUxODA2IDIuODIxNDItMy4yOTE2NTYgMi45NjQ4ODItMy4yOTE2NTZDMy4wNTI1NTMtMy4yOTE2NTYgMy4xOTYwMTUtMy4yODM2ODYgMy4zMDc1OTctMy4xODgwNDVDMi45NjQ4ODItMy4xMTYzMTQgMi45MTcwNjEtMi44MjE0MiAyLjkxNzA2MS0yLjc0OTY4OUMyLjkxNzA2MS0yLjU3NDM0NiAzLjA1MjU1My0yLjQ1NDc5NSAzLjIyNzg5NS0yLjQ1NDc5NUMzLjQ0MzA4OC0yLjQ1NDc5NSAzLjY4MjE5Mi0yLjYzMDEzNyAzLjY4MjE5Mi0yLjk0ODk0MUMzLjY4MjE5Mi0zLjIzNTg2NiAzLjQzNTExOC0zLjUxNDgxOSAyLjk4MDgyMi0zLjUxNDgxOUMyLjQzODg1NC0zLjUxNDgxOSAyLjA3MjIyOS0zLjE1NjE2NCAxLjkwNDg1Ny0yLjk0MDk3MUMxLjc0NTQ1NS0zLjUxNDgxOSAxLjIwMzQ4Ny0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzI2Nzc1LTIuNzI1Nzc4IC4yMzkxMDMtMi4zMTkzMDMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjI0MzMzNyAuMDc5NzAxIDEuMjk5MTI4LS4xNDM0NjIgMS4zNjI4ODktLjQxNDQ0NkwxLjUzODIzMi0xLjA5OTg3NVonLz4KPHBhdGggaWQ9J2cyLTAnIGQ9J003Ljg3ODQ1Ni0yLjc0OTY4OUM4LjA4MTY5NC0yLjc0OTY4OSA4LjI5Njg4Ny0yLjc0OTY4OSA4LjI5Njg4Ny0yLjk4ODc5MlM4LjA4MTY5NC0zLjIyNzg5NSA3Ljg3ODQ1Ni0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyLTMuMjI3ODk1IC45OTIyNzktMy4yMjc4OTUgLjk5MjI3OS0yLjk4ODc5MlMxLjIwNzQ3Mi0yLjc0OTY4OSAxLjQxMDcxLTIuNzQ5Njg5SDcuODc4NDU2WicvPgo8cGF0aCBpZD0nZzYtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c2LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnNi00MycgZD0nTTQuNzcwMTEyLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExLTIuNzYxNjQ0IDguNDUyMzA0LTIuNzYxNjQ0IDguNDUyMzA0LTIuOTc2ODM3QzguNDUyMzA0LTMuMjAzOTg1IDguMjQ5MDY2LTMuMjAzOTg1IDguMDY5NzM4LTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMi02LjY3MDk4NCA0Ljc3MDExMi02Ljg4NjE3NyA0LjU1NDkxOS02Ljg4NjE3N0M0LjMyNzc3MS02Ljg4NjE3NyA0LjMyNzc3MS02LjY4MjkzOSA0LjMyNzc3MS02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDLjg2MDc3Mi0zLjIwMzk4NSAuNjQ1NTc5LTMuMjAzOTg1IC42NDU1NzktMi45ODg3OTJDLjY0NTU3OS0yLjc2MTY0NCAuODQ4ODE3LTIuNzYxNjQ0IDEuMDI4MTQ0LTIuNzYxNjQ0SDQuMzI3NzcxVi41Mzc5ODNDNC4zMjc3NzEgLjcwNTM1NSA0LjMyNzc3MSAuOTIwNTQ4IDQuNTQyOTY0IC45MjA1NDhDNC43NzAxMTIgLjkyMDU0OCA0Ljc3MDExMiAuNzE3MzEgNC43NzAxMTIgLjUzNzk4M1YtMi43NjE2NDRaJy8+CjxwYXRoIGlkPSdnNi00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2c2LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnNi0xMDMnIGQ9J00xLjQyMjY2NS0yLjE2Mzg4NUMxLjk4NDU1OC0xLjc5MzI3NSAyLjQ2Mjc2NS0xLjc5MzI3NSAyLjU5NDI3MS0xLjc5MzI3NUMzLjY3MDIzNy0xLjc5MzI3NSA0LjQ3MTIzMy0yLjYwNjIyNyA0LjQ3MTIzMy0zLjUyNjc3NUM0LjQ3MTIzMy0zLjg0OTU2NCA0LjM3NTU5Mi00LjMwMzg2MSAzLjk5MzAyNi00LjY4NjQyNkM0LjQ1OTI3OC01LjE2NDYzMyA1LjAyMTE3MS01LjE2NDYzMyA1LjA4MDk0Ni01LjE2NDYzM0M1LjEyODc2Ny01LjE2NDYzMyA1LjE4ODU0My01LjE2NDYzMyA1LjIzNjM2NC01LjE0MDcyMkM1LjExNjgxMi01LjA5MjkwMiA1LjA1NzAzNi00Ljk3MzM1IDUuMDU3MDM2LTQuODQxODQzQzUuMDU3MDM2LTQuNjc0NDcxIDUuMTc2NTg4LTQuNTMxMDA5IDUuMzY3ODctNC41MzEwMDlDNS40NjM1MTItNC41MzEwMDkgNS42Nzg3MDUtNC41OTA3ODUgNS42Nzg3MDUtNC44NTM3OThDNS42Nzg3MDUtNS4wNjg5OTEgNS41MTEzMzMtNS40MDM3MzYgNS4wOTI5MDItNS40MDM3MzZDNC40NzEyMzMtNS40MDM3MzYgNC4wMDQ5ODEtNS4wMjExNzEgMy44Mzc2MDktNC44NDE4NDNDMy40Nzg5NTQtNS4xMTY4MTIgMy4wNjA1MjMtNS4yNzIyMjkgMi42MDYyMjctNS4yNzIyMjlDMS41MzAyNjItNS4yNzIyMjkgLjcyOTI2NS00LjQ1OTI3OCAuNzI5MjY1LTMuNTM4NzNDLjcyOTI2NS0yLjg1NzI4NSAxLjE0NzY5Ni0yLjQxNDk0NCAxLjI2NzI0OC0yLjMwNzM0N0MxLjEyMzc4Ni0yLjEyODAyIC45MDg1OTMtMS43ODEzMiAuOTA4NTkzLTEuMzE1MDY4Qy45MDg1OTMtLjYyMTY2OSAxLjMyNzAyNC0uMzIyNzkgMS40MjI2NjUtLjI2MzAxNEMuODcyNzI3LS4xMDc1OTcgLjMyMjc5IC4zMjI3OSAuMzIyNzkgLjk0NDQ1OEMuMzIyNzkgMS43NjkzNjUgMS40NDY1NzUgMi40NTA4MDkgMi45MTcwNjEgMi40NTA4MDlDNC4zMzk3MjYgMi40NTA4MDkgNS41MjMyODggMS44MTcxODYgNS41MjMyODggLjkyMDU0OEM1LjUyMzI4OCAuNjIxNjY5IDUuNDM5NjAxLS4wODM2ODYgNC43MjIyOTEtLjQ1NDI5NkM0LjExMjU3OC0uNzY1MTMxIDMuNTE0ODE5LS43NjUxMzEgMi40ODY2NzUtLjc2NTEzMUMxLjc1NzQxLS43NjUxMzEgMS42NzM3MjQtLjc2NTEzMSAxLjQ1ODUzMS0uOTkyMjc5QzEuMzM4OTc5LTEuMTExODMxIDEuMjMxMzgyLTEuMzM4OTc5IDEuMjMxMzgyLTEuNTkwMDM3QzEuMjMxMzgyLTEuNzkzMjc1IDEuMzAzMTEzLTEuOTk2NTEzIDEuNDIyNjY1LTIuMTYzODg1Wk0yLjYwNjIyNy0yLjA0NDMzNEMxLjU1NDE3Mi0yLjA0NDMzNCAxLjU1NDE3Mi0zLjI1MTgwNiAxLjU1NDE3Mi0zLjUyNjc3NUMxLjU1NDE3Mi0zLjc0MTk2OCAxLjU1NDE3Mi00LjIzMjEzIDEuNzU3NDEtNC41NTQ5MTlDMS45ODQ1NTgtNC45MDE2MTkgMi4zNDMyMTMtNS4wMjExNzEgMi41OTQyNzEtNS4wMjExNzFDMy42NDYzMjYtNS4wMjExNzEgMy42NDYzMjYtMy44MTM2OTkgMy42NDYzMjYtMy41Mzg3M0MzLjY0NjMyNi0zLjMyMzUzNyAzLjY0NjMyNi0yLjgzMzM3NSAzLjQ0MzA4OC0yLjUxMDU4NUMzLjIxNTk0LTIuMTYzODg1IDIuODU3Mjg1LTIuMDQ0MzM0IDIuNjA2MjI3LTIuMDQ0MzM0Wk0yLjkyOTAxNiAyLjE5OTc1MUMxLjc4MTMyIDIuMTk5NzUxIC45MDg1OTMgMS42MTM5NDggLjkwODU5MyAuOTMyNTAzQy45MDg1OTMgLjgzNjg2MiAuOTMyNTAzIC4zNzA2MSAxLjM4NjggLjA1OTc3NkMxLjY0OTgxMy0uMTA3NTk3IDEuNzU3NDEtLjEwNzU5NyAyLjU5NDI3MS0uMTA3NTk3QzMuNTg2NTUtLjEwNzU5NyA0LjkzNzQ4NC0uMTA3NTk3IDQuOTM3NDg0IC45MzI1MDNDNC45Mzc0ODQgMS42Mzc4NTggNC4wMjg4OTIgMi4xOTk3NTEgMi45MjkwMTYgMi4xOTk3NTFaJy8+CjxwYXRoIGlkPSdnNi0xMDgnIGQ9J00yLjA1NjI4OS04LjI5Njg4N0wuMzk0NTIxLTguMTY1MzhWLTcuODE4NjhDMS4yMDc0NzItNy44MTg2OCAxLjMwMzExMy03LjczNDk5NCAxLjMwMzExMy03LjE0OTE5MVYtLjg4NDY4MkMxLjMwMzExMy0uMzQ2NyAxLjE3MTYwNi0uMzQ2NyAuMzk0NTIxLS4zNDY3VjBDLjcyOTI2NS0uMDIzOTEgMS4zMTUwNjgtLjAyMzkxIDEuNjczNzI0LS4wMjM5MVMyLjYzMDEzNy0uMDIzOTEgMi45NjQ4ODIgMFYtLjM0NjdDMi4xOTk3NTEtLjM0NjcgMi4wNTYyODktLjM0NjcgMi4wNTYyODktLjg4NDY4MlYtOC4yOTY4ODdaJy8+CjxwYXRoIGlkPSdnNi0xMTEnIGQ9J001LjQ4NzQyMi0yLjU1ODQwNkM1LjQ4NzQyMi00LjEwMDYyMyA0LjMxNTgxNi01LjMzMjAwNSAyLjkyOTAxNi01LjMzMjAwNUMxLjQ5NDM5Ni01LjMzMjAwNSAuMzU4NjU1LTQuMDY0NzU3IC4zNTg2NTUtMi41NTg0MDZDLjM1ODY1NS0xLjAyODE0NCAxLjU1NDE3MiAuMTE5NTUyIDIuOTE3MDYxIC4xMTk1NTJDNC4zMjc3NzEgLjExOTU1MiA1LjQ4NzQyMi0xLjA1MjA1NSA1LjQ4NzQyMi0yLjU1ODQwNlpNMi45MjkwMTYtLjE0MzQ2MkMyLjQ4NjY3NS0uMTQzNDYyIDEuOTQ4NjkyLS4zMzQ3NDUgMS42MDE5OTMtLjkyMDU0OEMxLjI3OTIwMy0xLjQ1ODUzMSAxLjI2NzI0OC0yLjE2Mzg4NSAxLjI2NzI0OC0yLjY2NjAwMkMxLjI2NzI0OC0zLjEyMDI5OSAxLjI2NzI0OC0zLjg0OTU2NCAxLjYzNzg1OC00LjM4NzU0N0MxLjk3MjYwMy00LjkwMTYxOSAyLjQ5ODYzLTUuMDkyOTAyIDIuOTE3MDYxLTUuMDkyOTAyQzMuMzgzMzEzLTUuMDkyOTAyIDMuODg1NDMtNC44Nzc3MDkgNC4yMDgyMTktNC40MTE0NTdDNC41Nzg4MjktMy44NjE1MTkgNC41Nzg4MjktMy4xMDgzNDQgNC41Nzg4MjktMi42NjYwMDJDNC41Nzg4MjktMi4yNDc1NzIgNC41Nzg4MjktMS41MDYzNTEgNC4yNjc5OTUtLjk0NDQ1OEMzLjkzMzI1LS4zNzA2MSAzLjM4MzMxMy0uMTQzNDYyIDIuOTI5MDE2LS4xNDM0NjJaJy8+CjxwYXRoIGlkPSdnNC0yMicgZD0nTTEuNzIxNTQ0LS4yNjMwMTRDMi4wMjA0MjMgLjAxMTk1NSAyLjQ2Mjc2NSAuMTE5NTUyIDIuODY5MjQgLjExOTU1MkMzLjYzNDM3MSAuMTE5NTUyIDQuMTYwMzk5LS4zOTQ1MjEgNC40MzUzNjctLjc2NTEzMUM0LjU1NDkxOS0uMTMxNTA3IDUuMDU3MDM2IC4xMTk1NTIgNS40NzU0NjcgLjExOTU1MkM1LjgzNDEyMiAuMTE5NTUyIDYuMTIxMDQ2LS4wOTU2NDEgNi4zMzYyMzktLjUyNjAyN0M2LjUyNzUyMi0uOTMyNTAzIDYuNjk0ODk0LTEuNjYxNzY4IDYuNjk0ODk0LTEuNzA5NTg5QzYuNjk0ODk0LTEuNzY5MzY1IDYuNjQ3MDczLTEuODE3MTg2IDYuNTc1MzQyLTEuODE3MTg2QzYuNDY3NzQ2LTEuODE3MTg2IDYuNDU1NzkxLTEuNzU3NDEgNi40MDc5Ny0xLjU3ODA4MkM2LjIyODY0My0uODcyNzI3IDYuMDAxNDk0LS4xMTk1NTIgNS41MTEzMzMtLjExOTU1MkM1LjE2NDYzMy0uMTE5NTUyIDUuMTQwNzIyLS40MzAzODYgNS4xNDA3MjItLjY2OTQ4OUM1LjE0MDcyMi0uOTQ0NDU4IDUuMjQ4MzE5LTEuMzc0ODQ0IDUuMzMyMDA1LTEuNzMzNDk5TDUuNjY2NzUtMy4wMjQ2NThDNS43MTQ1Ny0zLjI1MTgwNiA1Ljg0NjA3Ny0zLjc4OTc4OCA1LjkwNTg1My00LjAwNDk4MUM1Ljk3NzU4NC00LjI5MTkwNSA2LjEwOTA5MS00LjgwNTk3OCA2LjEwOTA5MS00Ljg1Mzc5OEM2LjEwOTA5MS01LjAzMzEyNiA1Ljk2NTYyOS01LjE1MjY3NyA1Ljc4NjMwMS01LjE1MjY3N0M1LjY3ODcwNS01LjE1MjY3NyA1LjQyNzY0Ni01LjEwNDg1NyA1LjMzMjAwNS00Ljc0NjIwMkw0LjQ5NTE0My0xLjQyMjY2NUM0LjQzNTM2Ny0xLjE4MzU2MiA0LjQzNTM2Ny0xLjE1OTY1MSA0LjI3OTk1LS45NjgzNjlDNC4xMzY0ODgtLjc2NTEzMSAzLjY3MDIzNy0uMTE5NTUyIDIuOTE3MDYxLS4xMTk1NTJDMi4yNDc1NzItLjExOTU1MiAyLjAzMjM3OS0uNjA5NzE0IDIuMDMyMzc5LTEuMTcxNjA2QzIuMDMyMzc5LTEuNTE4MzA2IDIuMTM5OTc1LTEuOTM2NzM3IDIuMTg3Nzk2LTIuMTM5OTc1TDIuNzI1Nzc4LTQuMjkxOTA1QzIuNzg1NTU0LTQuNTE5MDU0IDIuODgxMTk2LTQuOTAxNjE5IDIuODgxMTk2LTQuOTczMzVDMi44ODExOTYtNS4xNjQ2MzMgMi43MjU3NzgtNS4yNzIyMjkgMi41NzAzNjEtNS4yNzIyMjlDMi40NjI3NjUtNS4yNzIyMjkgMi4xOTk3NTEtNS4yMzYzNjQgMi4xMDQxMS00Ljg1Mzc5OEwuMzcwNjEgMi4wNjgyNDRDLjM1ODY1NSAyLjEyODAyIC4zMzQ3NDUgMi4xOTk3NTEgLjMzNDc0NSAyLjI3MTQ4MkMuMzM0NzQ1IDIuNDUwODA5IC40NzgyMDcgMi41NzAzNjEgLjY1NzUzNCAyLjU3MDM2MUMxLjAwNDIzNCAyLjU3MDM2MSAxLjA3NTk2NSAyLjI5NTM5MiAxLjE1OTY1MSAxLjk2MDY0OEwxLjcyMTU0NC0uMjYzMDE0WicvPgo8cGF0aCBpZD0nZzQtMjQnIGQ9J00zLjEyMDI5OSAuMDU5Nzc2TDEuODY1MDA2LS40NDIzNDFDMS41NTQxNzItLjU2MTg5MyAuODM2ODYyLS44NDg4MTcgLjgzNjg2Mi0xLjU2NjEyN0MuODM2ODYyLTIuNTk0MjcxIDIuMDkyMTU0LTMuNjM0MzcxIDIuMzQzMjEzLTMuNjM0MzcxQzIuMzY3MTIzLTMuNjM0MzcxIDIuNDc0NzItMy42MTA0NjEgMi41MTA1ODUtMy41OTg1MDZDMi44MzMzNzUtMy41MDI4NjQgMy4xNDQyMDktMy41MDI4NjQgMy4zNTk0MDItMy41MDI4NjRDMy43MzAwMTItMy41MDI4NjQgNC40MzUzNjctMy41MDI4NjQgNC40MzUzNjctMy44NDk1NjRDNC40MzUzNjctNC4xMTI1NzggNC4wMDQ5ODEtNC4xNDg0NDMgMy40OTA5MDktNC4xNDg0NDNDMy4yNTE4MDYtNC4xNDg0NDMgMi45MjkwMTYtNC4xNDg0NDMgMi40OTg2My00LjAwNDk4MUMyLjIxMTcwNi00LjI0NDA4NSAyLjA5MjE1NC00LjYyNjY1IDIuMDkyMTU0LTQuOTg1MzA1QzIuMDkyMTU0LTUuNjQyODM5IDIuNTIyNTQtNi41NzUzNDIgMy40NjY5OTktNy4wMTc2ODRDMy42ODIxOTItNi43NjY2MjUgMy45NjkxMTYtNi43NjY2MjUgNC4yMjAxNzQtNi43NjY2MjVDNC41MTkwNTQtNi43NjY2MjUgNS4yNDgzMTktNi43NjY2MjUgNS4yNDgzMTktNy4xMTMzMjVDNS4yNDgzMTktNy40MTIyMDQgNC42NzQ0NzEtNy40MTIyMDQgNC4yOTE5MDUtNy40MTIyMDRDNC4wNTI4MDItNy40MTIyMDQgMy44NzM0NzQtNy40MTIyMDQgMy41Mzg3My03LjM1MjQyOEMzLjQ3ODk1NC03LjQ5NTg5IDMuNDY2OTk5LTcuNTE5ODAxIDMuNDY2OTk5LTcuNzgyODE0QzMuNDY2OTk5LTcuOTk4MDA3IDMuNTE0ODE5LTguMTY1MzggMy41MTQ4MTktOC4yMDEyNDVDMy41MTQ4MTktOC4yNzI5NzYgMy40NTUwNDQtOC4zMjA3OTcgMy4zOTUyNjgtOC4zMjA3OTdDMy4yMDM5ODUtOC4zMjA3OTcgMy4yMDM5ODUtNy44Nzg0NTYgMy4yMDM5ODUtNy43ODI4MTRDMy4yMDM5ODUtNy42MTU0NDIgMy4yMTU5NC03LjQ0ODA3IDMuMjg3NjcxLTcuMjkyNjUzQzEuODUzMDUxLTYuODc0MjIyIDEuMjE5NDI3LTUuODU4MDMyIDEuMjE5NDI3LTUuMDgwOTQ2QzEuMjE5NDI3LTQuMzYzNjM2IDEuNjk3NjM0LTMuOTY5MTE2IDIuMDIwNDIzLTMuNzg5Nzg4Qy43ODkwNDEtMy4xMjAyOTkgLjI2MzAxNC0xLjkwMDg3MiAuMjYzMDE0LTEuMjU1MjkzQy4yNjMwMTQtLjIxNTE5MyAxLjIwNzQ3MiAuMTU1NDE3IDEuNjM3ODU4IC4zMzQ3NDVMMi43MTM4MjMgLjc2NTEzMUMzLjAxMjcwMiAuODcyNzI3IDMuNTAyODY0IDEuMDc1OTY1IDMuNTg2NTUgMS4xMjM3ODZDMy43MDYxMDIgMS4yMDc0NzIgMy44MDE3NDMgMS4zNTA5MzQgMy44MDE3NDMgMS41NDIyMTdDMy44MDE3NDMgMS43OTMyNzUgMy42MTA0NjEgMi4xOTk3NTEgMy4xOTIwMyAyLjE5OTc1MUMzLjAxMjcwMiAyLjE5OTc1MSAyLjYxODE4MiAyLjE1MTkzIDIuMTg3Nzk2IDEuODI5MTQxQzIuMTA0MTEgMS43NTc0MSAyLjA5MjE1NCAxLjc0NTQ1NSAyLjA0NDMzNCAxLjc0NTQ1NUMxLjk4NDU1OCAxLjc0NTQ1NSAxLjkyNDc4MiAxLjc5MzI3NSAxLjkyNDc4MiAxLjg2NTAwNkMxLjkyNDc4MiAxLjk5NjUxMyAyLjU0NjQ1MSAyLjQzODg1NCAzLjE5MjAzIDIuNDM4ODU0QzMuOTU3MTYxIDIuNDM4ODU0IDQuNDIzNDEyIDEuNjk3NjM0IDQuNDIzNDEyIDEuMTgzNTYyQzQuNDIzNDEyIC44MTI5NTEgNC4yMjAxNzQgLjUxNDA3MiAzLjgzNzYwOSAuMzQ2N0wzLjEyMDI5OSAuMDU5Nzc2Wk0zLjczMDAxMi03LjExMzMyNUMzLjkzMzI1LTcuMTczMTAxIDQuMTQ4NDQzLTcuMTczMTAxIDQuMzAzODYxLTcuMTczMTAxQzQuNjk4MzgxLTcuMTczMTAxIDQuNzM0MjQ3LTcuMTYxMTQ2IDQuOTczMzUtNy4xMDEzN0M0LjgyOTg4OC03LjA0MTU5NCA0LjczNDI0Ny03LjAwNTcyOSA0LjIzMjEzLTcuMDA1NzI5QzQuMDA0OTgxLTcuMDA1NzI5IDMuODYxNTE5LTcuMDA1NzI5IDMuNzMwMDEyLTcuMTEzMzI1Wk0yLjc4NTU1NC0zLjgzNzYwOUMzLjA3MjQ3OC0zLjkwOTM0IDMuMzM1NDkyLTMuOTA5MzQgMy40Nzg5NTQtMy45MDkzNEMzLjg3MzQ3NC0zLjkwOTM0IDMuODk3Mzg1LTMuODk3Mzg1IDQuMTYwMzk5LTMuODM3NjA5QzQuMDI4ODkyLTMuNzc3ODMzIDMuOTIxMjk1LTMuNzQxOTY4IDMuNDA3MjIzLTMuNzQxOTY4QzMuMTIwMjk5LTMuNzQxOTY4IDMuMDAwNzQ3LTMuNzQxOTY4IDIuNzg1NTU0LTMuODM3NjA5WicvPgo8cGF0aCBpZD0nZzQtMjcnIGQ9J002LjA3MzIyNS00LjUwNzA5OEM2LjIyODY0My00LjUwNzA5OCA2LjYyMzE2My00LjUwNzA5OCA2LjYyMzE2My00Ljg4OTY2NEM2LjYyMzE2My01LjE1MjY3NyA2LjM5NjAxNS01LjE1MjY3NyA2LjE4MDgyMi01LjE1MjY3N0gzLjUzODczQzEuNzQ1NDU1LTUuMTUyNjc3IC40NTQyOTYtMy4xNTYxNjQgLjQ1NDI5Ni0xLjc0NTQ1NUMuNDU0Mjk2LS43MjkyNjUgMS4xMTE4MzEgLjExOTU1MiAyLjE4Nzc5NiAuMTE5NTUyQzMuNTk4NTA2IC4xMTk1NTIgNS4xNDA3MjItMS4zOTg3NTUgNS4xNDA3MjItMy4xOTIwM0M1LjE0MDcyMi0zLjY1ODI4MSA1LjAzMzEyNi00LjExMjU3OCA0Ljc0NjIwMi00LjUwNzA5OEg2LjA3MzIyNVpNMi4xOTk3NTEtLjExOTU1MkMxLjU5MDAzNy0uMTE5NTUyIDEuMTQ3Njk2LS41ODU4MDMgMS4xNDc2OTYtMS40MTA3MUMxLjE0NzY5Ni0yLjEyODAyIDEuNTc4MDgyLTQuNTA3MDk4IDMuMzM1NDkyLTQuNTA3MDk4QzMuODQ5NTY0LTQuNTA3MDk4IDQuNDIzNDEyLTQuMjU2MDQgNC40MjM0MTItMy4zMzU0OTJDNC40MjM0MTItMi45MTcwNjEgNC4yMzIxMy0xLjkxMjgyNyAzLjgxMzY5OS0xLjIxOTQyN0MzLjM4MzMxMy0uNTE0MDcyIDIuNzM3NzMzLS4xMTk1NTIgMi4xOTk3NTEtLjExOTU1MlonLz4KPHBhdGggaWQ9J2c0LTU5JyBkPSdNMi4zMzEyNTggLjA0NzgyMUMyLjMzMTI1OC0uNjQ1NTc5IDIuMTA0MTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yMzEzODItMS4xNTk2NTEgMS4wNDAxLS44NDg4MTcgMS4wNDAxLS41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNy0uMDQ3ODIxIDIuMDIwNDIzLS4xNTU0MTdDMi4wNDQzMzQtLjE3OTMyOCAyLjA1NjI4OS0uMTc5MzI4IDIuMDY4MjQ0LS4xNzkzMjhDMi4wOTIxNTQtLjE3OTMyOCAyLjA5MjE1NC0uMDExOTU1IDIuMDkyMTU0IC4wNDc4MjFDMi4wOTIxNTQgLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IC4wNDc4MjFaJy8+CjxwYXRoIGlkPSdnNC05NicgZD0nTTEuMDk5ODc1LTIuMDMyMzc5Qy4zNDY3LTEuMjkxMTU4IC4xNTU0MTctMS4xMTE4MzEgLjE1NTQxNy0xLjA2NDAxUy4yMDMyMzgtLjkzMjUwMyAuMjg2OTI0LS45MzI1MDNDLjM0NjctLjkzMjUwMyAxLjAyODE0NC0xLjU5MDAzNyAxLjEyMzc4Ni0xLjY5NzYzNEMxLjE5NTUxNy0uODk2NjM4IDEuNDk0Mzk2IC4xNDM0NjIgMi40MjY4OTkgLjE0MzQ2MkMyLjkwNTEwNiAuMTQzNDYyIDMuMzM1NDkyLS4xNTU0MTcgMy41MjY3NzUtLjI5ODg3OUMzLjY4MjE5Mi0uNDE4NDMxIDQuMjU2MDQtLjkwODU5MyA0LjI1NjA0LTEuMDE2MTg5QzQuMjU2MDQtMS4wNzU5NjUgNC4xOTYyNjQtMS4xNDc2OTYgNC4xMzY0ODgtMS4xNDc2OTZDNC4wODg2NjctMS4xNDc2OTYgMy45MDkzNC0uOTY4MzY5IDMuODYxNTE5LS45MjA1NDhDMy40NDMwODgtLjUxNDA3MiAyLjkxNzA2MS0uMDk1NjQxIDIuNDM4ODU0LS4wOTU2NDFDMS43OTMyNzUtLjA5NTY0MSAxLjcwOTU4OS0xLjAyODE0NCAxLjcwOTU4OS0xLjY3MzcyNEMxLjcwOTU4OS0xLjc5MzI3NSAxLjcwOTU4OS0yLjI5NTM5MiAxLjc5MzI3NS0yLjM5MTAzNEMyLjQ5ODYzLTMuMTIwMjk5IDQuNzEwMzM2LTUuNDAzNzM2IDQuNzEwMzM2LTcuNTE5ODAxQzQuNzEwMzM2LTcuOTk4MDA3IDQuNTMxMDA5LTguNDE2NDM4IDQuMDE2OTM2LTguNDE2NDM4QzIuOTA1MTA2LTguNDE2NDM4IDEuOTM2NzM3LTUuOTUzNjc0IDEuNzY5MzY1LTUuNDk5Mzc3QzEuNzIxNTQ0LTUuMzc5ODI2IDEuMDI4MTQ0LTMuNTM4NzMgMS4wOTk4NzUtMi4wMzIzNzlaTTEuODE3MTg2LTIuNzczNTk5QzEuODI5MTQxLTIuODQ1MzMgMi4zNjcxMjMtNS45Nzc1ODQgMy4zNzEzNTctNy42NTEzMDhDMy41NzQ1OTUtNy45NzQwOTcgMy43Nzc4MzMtOC4xNzczMzUgNC4wMTY5MzYtOC4xNzczMzVDNC40MjM0MTItOC4xNzczMzUgNC40NDczMjMtNy43OTQ3NyA0LjQ0NzMyMy03LjUzMTc1NkM0LjQ0NzMyMy03LjExMzMyNSA0LjMyNzc3MS02LjAzNzM2IDMuMjg3NjcxLTQuNTMxMDA5QzIuOTc2ODM3LTQuMDg4NjY3IDIuNDk4NjMtMy40OTA5MDkgMS44MTcxODYtMi43NzM1OTlaJy8+CjxwYXRoIGlkPSdnNC0xMTAnIGQ9J00yLjQ2Mjc2NS0zLjUwMjg2NEMyLjQ4NjY3NS0zLjU3NDU5NSAyLjc4NTU1NC00LjE3MjM1NCAzLjIyNzg5NS00LjU1NDkxOUMzLjUzODczLTQuODQxODQzIDMuOTQ1MjA1LTUuMDMzMTI2IDQuNDExNDU3LTUuMDMzMTI2QzQuODg5NjY0LTUuMDMzMTI2IDUuMDU3MDM2LTQuNjc0NDcxIDUuMDU3MDM2LTQuMTk2MjY0QzUuMDU3MDM2LTMuNTE0ODE5IDQuNTY2ODc0LTIuMTUxOTMgNC4zMjc3NzEtMS41MDYzNTFDNC4yMjAxNzQtMS4yMTk0MjcgNC4xNjAzOTktMS4wNjQwMSA0LjE2MDM5OS0uODQ4ODE3QzQuMTYwMzk5LS4zMTA4MzQgNC41MzEwMDkgLjExOTU1MiA1LjEwNDg1NyAuMTE5NTUyQzYuMjE2Njg3IC4xMTk1NTIgNi42MzUxMTgtMS42Mzc4NTggNi42MzUxMTgtMS43MDk1ODlDNi42MzUxMTgtMS43NjkzNjUgNi41ODcyOTgtMS44MTcxODYgNi41MTU1NjctMS44MTcxODZDNi40MDc5Ny0xLjgxNzE4NiA2LjM5NjAxNS0xLjc4MTMyIDYuMzM2MjM5LTEuNTc4MDgyQzYuMDYxMjctLjU5Nzc1OCA1LjYwNjk3NC0uMTE5NTUyIDUuMTQwNzIyLS4xMTk1NTJDNS4wMjExNzEtLjExOTU1MiA0LjgyOTg4OC0uMTMxNTA3IDQuODI5ODg4LS41MTQwNzJDNC44Mjk4ODgtLjgxMjk1MSA0Ljk2MTM5NS0xLjE3MTYwNiA1LjAzMzEyNi0xLjMzODk3OUM1LjI3MjIyOS0xLjk5NjUxMyA1Ljc3NDM0Ni0zLjMzNTQ5MiA1Ljc3NDM0Ni00LjAxNjkzNkM1Ljc3NDM0Ni00LjczNDI0NyA1LjM1NTkxNS01LjI3MjIyOSA0LjQ0NzMyMy01LjI3MjIyOUMzLjM4MzMxMy01LjI3MjIyOSAyLjgyMTQyLTQuNTE5MDU0IDIuNjA2MjI3LTQuMjIwMTc0QzIuNTcwMzYxLTQuOTAxNjE5IDIuMDgwMTk5LTUuMjcyMjI5IDEuNTU0MTcyLTUuMjcyMjI5QzEuMTcxNjA2LTUuMjcyMjI5IC45MDg1OTMtNS4wNDUwODEgLjcwNTM1NS00LjYzODYwNUMuNDkwMTYyLTQuMjA4MjE5IC4zMjI3OS0zLjQ5MDkwOSAuMzIyNzktMy40NDMwODhTLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU0OTkzOC0zLjMzNTQ5MiAuNTYxODkzLTMuMzQ3NDQ3IC42MzM2MjQtMy42MjI0MTZDLjgyNDkwNy00LjM1MTY4MSAxLjA0MDEtNS4wMzMxMjYgMS41MTgzMDYtNS4wMzMxMjZDMS43OTMyNzUtNS4wMzMxMjYgMS44ODg5MTctNC44NDE4NDMgMS44ODg5MTctNC40ODMxODhDMS44ODg5MTctNC4yMjAxNzQgMS43NjkzNjUtMy43NTM5MjMgMS42ODU2NzktMy4zODMzMTNMMS4zNTA5MzQtMi4wOTIxNTRDMS4zMDMxMTMtMS44NjUwMDYgMS4xNzE2MDYtMS4zMjcwMjQgMS4xMTE4MzEtMS4xMTE4MzFDMS4wMjgxNDQtLjgwMDk5NiAuODk2NjM4LS4yMzkxMDMgLjg5NjYzOC0uMTc5MzI4Qy44OTY2MzgtLjAxMTk1NSAxLjAyODE0NCAuMTE5NTUyIDEuMjA3NDcyIC4xMTk1NTJDMS4zNTA5MzQgLjExOTU1MiAxLjUxODMwNiAuMDQ3ODIxIDEuNjEzOTQ4LS4xMzE1MDdDMS42Mzc4NTgtLjE5MTI4MyAxLjc0NTQ1NS0uNjA5NzE0IDEuODA1MjMtLjg0ODgxN0wyLjA2ODI0NC0xLjkyNDc4MkwyLjQ2Mjc2NS0zLjUwMjg2NFonLz4KPHBhdGggaWQ9J2c0LTExNCcgZD0nTTQuNjUwNTYtNC44ODk2NjRDNC4yNzk5NS00LjgxNzkzMyA0LjA4ODY2Ny00LjU1NDkxOSA0LjA4ODY2Ny00LjI5MTkwNUM0LjA4ODY2Ny00LjAwNDk4MSA0LjMxNTgxNi0zLjkwOTM0IDQuNDgzMTg4LTMuOTA5MzRDNC44MTc5MzMtMy45MDkzNCA1LjA5MjkwMi00LjE5NjI2NCA1LjA5MjkwMi00LjU1NDkxOUM1LjA5MjkwMi00LjkzNzQ4NCA0LjcyMjI5MS01LjI3MjIyOSA0LjEyNDUzMy01LjI3MjIyOUMzLjY0NjMyNi01LjI3MjIyOSAzLjA5NjM4OS01LjA1NzAzNiAyLjU5NDI3MS00LjMyNzc3MUMyLjUxMDU4NS00Ljk2MTM5NSAyLjAzMjM3OS01LjI3MjIyOSAxLjU1NDE3Mi01LjI3MjIyOUMxLjA4NzkyLTUuMjcyMjI5IC44NDg4MTctNC45MTM1NzQgLjcwNTM1NS00LjY1MDU2Qy41MDIxMTctNC4yMjAxNzQgLjMyMjc5LTMuNTAyODY0IC4zMjI3OS0zLjQ0MzA4OEMuMzIyNzktMy4zOTUyNjggLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU0OTkzOC0zLjMzNTQ5MiAuNTYxODkzLTMuMzQ3NDQ3IC42MzM2MjQtMy42MjI0MTZDLjgxMjk1MS00LjMzOTcyNiAxLjA0MDEtNS4wMzMxMjYgMS41MTgzMDYtNS4wMzMxMjZDMS44MDUyMy01LjAzMzEyNiAxLjg4ODkxNy00LjgyOTg4OCAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjMzODk3OSAuMTE5NTUyIDEuNTY2MTI3IC4wMzU4NjYgMS42Mzc4NTgtLjIwMzIzOEMxLjY3MzcyNC0uMjk4ODc5IDIuMTE2MDY1LTIuMTA0MTEgMi4xODc3OTYtMi4zNzkwNzhDMi4yNDc1NzItMi42NDIwOTIgMi4zMTkzMDMtMi44OTMxNTEgMi4zNzkwNzgtMy4xNTYxNjRDMi40MjY4OTktMy4zMjM1MzcgMi40NzQ3Mi0zLjUxNDgxOSAyLjUxMDU4NS0zLjY3MDIzN0MyLjU0NjQ1MS0zLjc3NzgzMyAyLjg2OTI0LTQuMzYzNjM2IDMuMTY4MTItNC42MjY2NUMzLjMxMTU4Mi00Ljc1ODE1NyAzLjYyMjQxNi01LjAzMzEyNiA0LjExMjU3OC01LjAzMzEyNkM0LjMwMzg2MS01LjAzMzEyNiA0LjQ5NTE0My00Ljk5NzI2IDQuNjUwNTYtNC44ODk2NjRaJy8+CjxwYXRoIGlkPSdnNC0xMjInIGQ9J00xLjUxODMwNi0uOTY4MzY5QzIuMDMyMzc5LTEuNTU0MTcyIDIuNDUwODA5LTEuOTI0NzgyIDMuMDQ4NTY4LTIuNDYyNzY1QzMuNzY1ODc4LTMuMDg0NDMzIDQuMDc2NzEyLTMuMzgzMzEzIDQuMjQ0MDg1LTMuNTYyNjRDNS4wODA5NDYtNC4zODc1NDcgNS40OTkzNzctNS4wODA5NDYgNS40OTkzNzctNS4xNzY1ODhTNS40MDM3MzYtNS4yNzIyMjkgNS4zNzk4MjYtNS4yNzIyMjlDNS4yOTYxMzktNS4yNzIyMjkgNS4yNzIyMjktNS4yMjQ0MDggNS4yMTI0NTMtNS4xNDA3MjJDNC45MTM1NzQtNC42MjY2NSA0LjYyNjY1LTQuMzc1NTkyIDQuMzE1ODE2LTQuMzc1NTkyQzQuMDY0NzU3LTQuMzc1NTkyIDMuOTMzMjUtNC40ODMxODggMy43MDYxMDItNC43NzAxMTJDMy40NTUwNDQtNS4wNjg5OTEgMy4yNTE4MDYtNS4yNzIyMjkgMi45MDUxMDYtNS4yNzIyMjlDMi4wMzIzNzktNS4yNzIyMjkgMS41MDYzNTEtNC4xODQzMDkgMS41MDYzNTEtMy45MzMyNUMxLjUwNjM1MS0zLjg5NzM4NSAxLjUxODMwNi0zLjgyNTY1NCAxLjYyNTkwMy0zLjgyNTY1NEMxLjcyMTU0NC0zLjgyNTY1NCAxLjczMzQ5OS0zLjg3MzQ3NCAxLjc2OTM2NS0zLjk1NzE2MUMxLjk3MjYwMy00LjQzNTM2NyAyLjU0NjQ1MS00LjUxOTA1NCAyLjc3MzU5OS00LjUxOTA1NEMzLjAyNDY1OC00LjUxOTA1NCAzLjI2Mzc2MS00LjQzNTM2NyAzLjUxNDgxOS00LjMyNzc3MUMzLjk2OTExNi00LjEzNjQ4OCA0LjE2MDM5OS00LjEzNjQ4OCA0LjI3OTk1LTQuMTM2NDg4QzQuMzYzNjM2LTQuMTM2NDg4IDQuNDExNDU3LTQuMTM2NDg4IDQuNDcxMjMzLTQuMTQ4NDQzQzQuMDc2NzEyLTMuNjgyMTkyIDMuNDMxMTMzLTMuMTA4MzQ0IDIuODkzMTUxLTIuNjE4MTgyTDEuNjg1Njc5LTEuNTA2MzUxQy45NTY0MTMtLjc2NTEzMSAuNTE0MDcyLS4wNTk3NzYgLjUxNDA3MiAuMDIzOTFDLjUxNDA3MiAuMDk1NjQxIC41NzM4NDggLjExOTU1MiAuNjQ1NTc5IC4xMTk1NTJTLjcyOTI2NSAuMTA3NTk3IC44MTI5NTEtLjAzNTg2NkMxLjAwNDIzNC0uMzM0NzQ1IDEuMzg2OC0uNzc3MDg2IDEuODI5MTQxLS43NzcwODZDMi4wODAxOTktLjc3NzA4NiAyLjE5OTc1MS0uNjkzNCAyLjQzODg1NC0uMzk0NTIxQzIuNjY2MDAyLS4xMzE1MDcgMi44NjkyNCAuMTE5NTUyIDMuMjUxODA2IC4xMTk1NTJDNC40MjM0MTIgLjExOTU1MiA1LjA5MjkwMi0xLjM5ODc1NSA1LjA5MjkwMi0xLjY3MzcyNEM1LjA5MjkwMi0xLjcyMTU0NCA1LjA4MDk0Ni0xLjc5MzI3NSA0Ljk2MTM5NS0xLjc5MzI3NUM0Ljg2NTc1My0xLjc5MzI3NSA0Ljg1Mzc5OC0xLjc0NTQ1NSA0LjgxNzkzMy0xLjYyNTkwM0M0LjU1NDkxOS0uOTIwNTQ4IDMuODQ5NTY0LS42MzM2MjQgMy4zODMzMTMtLjYzMzYyNEMzLjEzMjI1NC0uNjMzNjI0IDIuODkzMTUxLS43MTczMSAyLjY0MjA5Mi0uODI0OTA3QzIuMTYzODg1LTEuMDE2MTg5IDIuMDMyMzc5LTEuMDE2MTg5IDEuODc2OTYxLTEuMDE2MTg5QzEuNzU3NDEtMS4wMTYxODkgMS42MjU5MDMtMS4wMTYxODkgMS41MTgzMDYtLjk2ODM2OVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC05NicvPgo8dXNlIHg9JzQuOTEyMTA2JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDAnLz4KPHVzZSB4PSc5LjQ2NDQzMicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c0LTIyJy8+Cjx1c2UgeD0nMTYuNTA3NDAzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtNTknLz4KPHVzZSB4PScyMS43NTE1NjInIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC0yNycvPgo8dXNlIHg9JzI4LjE4MzYzMycgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c0LTU5Jy8+Cjx1c2UgeD0nMzMuNDI3NzkyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtMjQnLz4KPHVzZSB4PSczOS4xMTgyMycgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c2LTQxJy8+Cjx1c2UgeD0nNDYuOTkxMzg1JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PSc1OS40MTY4NjYnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nNjguNzE1MzYzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtMTEwJy8+Cjx1c2UgeD0nNzUuNzAyOTY4JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtMTE0Jy8+Cjx1c2UgeD0nODMuMjk1OTM5JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtMTA4Jy8+Cjx1c2UgeD0nODYuNTQ3NjAxJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtMTExJy8+Cjx1c2UgeD0nOTIuNDAwNTkxJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtMTAzJy8+Cjx1c2UgeD0nMTAwLjQwODY2MicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c0LTI3Jy8+Cjx1c2UgeD0nMTEwLjE0NzcyOScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScxMjguMTY4MDk3JyB5PSctMzAuMjQyMjg5JyB4bGluazpocmVmPScjZzMtMTEwJy8+Cjx1c2UgeD0nMTIyLjEwMjg5JyB5PSctMjYuNjU1NzMzJyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PScxMjMuODg1Mjg0JyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnMy0xMDUnLz4KPHVzZSB4PScxMjYuNzY4NDIzJyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnNS02MScvPgo8dXNlIHg9JzEzMy4zNTQ5MycgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScxMzkuMzcxNTA3JyB5PSctMzIuMTU1MjA1JyB4bGluazpocmVmPScjZzAtMjAnLz4KPHVzZSB4PScxNDUuNjgxMjA0JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHVzZSB4PScxNTQuMTkwODU4JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDMnLz4KPHVzZSB4PScxNjUuOTUyMTczJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtMjQnLz4KPHVzZSB4PScxNzEuNjQyNjEnIHk9Jy0yOC41Njg2MTgnIHhsaW5rOmhyZWY9JyNnMC0xNicvPgo8dXNlIHg9JzE3OS45NzgwMzYnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnNC0xMjInLz4KPHVzZSB4PScxODUuOTQ4NjQzJyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzUtNDAnLz4KPHVzZSB4PScxODkuMjQxODk2JyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzMtMTE0Jy8+Cjx1c2UgeD0nMTkzLjI5ODQ5MicgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2c1LTQxJy8+Cjx1c2UgeD0nMTg1LjQxNTkyNycgeT0nLTIwLjMyMjIxNCcgeGxpbms6aHJlZj0nI2czLTEwNScvPgo8dXNlIHg9JzE5OS43NDY1NDEnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjExLjcwMTcwMScgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2c0LTIyJy8+CjxyZWN0IHg9JzE3OS45NzgwMzYnIHk9Jy0xOC41MjYxNTQnIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzM4Ljc2NjYyOCcvPgo8dXNlIHg9JzE5NS44MjAxNDgnIHk9Jy03LjA5NzYwNicgeGxpbms6aHJlZj0nI2c0LTI3Jy8+Cjx1c2UgeD0nMjE5Ljk0MDE3OCcgeT0nLTI4LjU2ODYxOCcgeGxpbms6aHJlZj0nI2cwLTE3Jy8+Cjx1c2UgeD0nMjI3LjA4MDA5JyB5PSctMzIuMTU1MjA1JyB4bGluazpocmVmPScjZzAtMjEnLz4KPHVzZSB4PScyMzMuMzg5Nzg4JyB5PSctMjkuNDc4NTUyJyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzIzOS45NzYyOTQnIHk9Jy0yOS40Nzg1NTInIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzI0NC4yMTA0NzcnIHk9Jy0yOS40Nzg1NTInIHhsaW5rOmhyZWY9JyNnMy02MScvPgo8dXNlIHg9JzI0OC40NDQ2NicgeT0nLTI5LjQ3ODU1MicgeGxpbms6aHJlZj0nI2czLTI0Jy8+Cjx1c2UgeD0nMjU1LjYzMjk5JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzI2Ny41ODgxNTEnIHk9Jy0zMi4xNTUyMDUnIHhsaW5rOmhyZWY9JyNnMC0xOCcvPgo8dXNlIHg9JzI3Ny41ODQwMzcnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnNi00OScvPgo8cmVjdCB4PScyNzcuNTg0MDM3JyB5PSctMTguNTI2MTU0JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1Ljg1Mjk5Jy8+Cjx1c2UgeD0nMjc3LjY2NTMyMScgeT0nLTcuMDk3NjA2JyB4bGluazpocmVmPScjZzQtMjQnLz4KPHVzZSB4PScyODcuMjg5MjA0JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDMnLz4KPHVzZSB4PScyOTkuMDUwNTE5JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHVzZSB4PSczMDQuOTAzNTEnIHk9Jy0zMi4xNTUyMDUnIHhsaW5rOmhyZWY9JyNnMC0xOScvPgo8dXNlIHg9JzMyMS43NjE1ODcnIHk9Jy0zMC4yNDIyODknIHhsaW5rOmhyZWY9JyNnMy0xMTAnLz4KPHVzZSB4PSczMTUuNjk2MzgnIHk9Jy0yNi42NTU3MzMnIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzMxNy40Nzg3NzQnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2czLTEwNScvPgo8dXNlIHg9JzMyMC4zNjE5MTMnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMzI2Ljk0ODQyJyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzM0MS41NjM1MDUnIHk9Jy0zMC4yNDIyODknIHhsaW5rOmhyZWY9JyNnMy0xMTQnLz4KPHVzZSB4PSczMzQuOTU3NDk0JyB5PSctMjYuNjU1NzMzJyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PSczMzUuODcwNjUnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2czLTEwNycvPgo8dXNlIHg9JzM0MC40OTIyNjYnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMzQ3LjA3ODc3MicgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PSczNTQuMjE4NjA5JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtMTA4Jy8+Cjx1c2UgeD0nMzU3LjQ3MDI3JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtMTExJy8+Cjx1c2UgeD0nMzYzLjMyMzI2JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtMTAzJy8+Cjx1c2UgeD0nMzY5LjMzODgzMycgeT0nLTMyLjE1NTIwNScgeGxpbms6aHJlZj0nI2cwLTIwJy8+Cjx1c2UgeD0nMzc1LjY0ODUzMScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c2LTQ5Jy8+Cjx1c2UgeD0nMzg0LjE1ODE4NScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c2LTQzJy8+Cjx1c2UgeD0nMzk1LjkxOTUnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC0yNCcvPgo8dXNlIHg9JzQwMS42MDk5MzcnIHk9Jy0yOC41Njg2MTgnIHhsaW5rOmhyZWY9JyNnMC0xNicvPgo8dXNlIHg9JzQwOS45NDUzNjMnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnNC0xMjInLz4KPHVzZSB4PSc0MTUuOTE1OTcnIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnNS00MCcvPgo8dXNlIHg9JzQxOS4yMDkyMjMnIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnMy0xMDcnLz4KPHVzZSB4PSc0MjMuODMwODM5JyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzUtNDEnLz4KPHVzZSB4PSc0MTUuMzgzMjU0JyB5PSctMjAuMzIyMjE0JyB4bGluazpocmVmPScjZzMtMTA1Jy8+Cjx1c2UgeD0nNDMwLjI3ODg4NycgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PSc0NDIuMjM0MDQ4JyB5PSctMjMuMzg2MDI3JyB4bGluazpocmVmPScjZzQtMjInLz4KPHJlY3QgeD0nNDA5Ljk0NTM2MycgeT0nLTE4LjUyNjE1NCcgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMzkuMzMxNjQ4Jy8+Cjx1c2UgeD0nNDI2LjA2OTk4NScgeT0nLTcuMDk3NjA2JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PSc0NTAuNDcyNTI1JyB5PSctMjguNTY4NjE4JyB4bGluazpocmVmPScjZzAtMTcnLz4KPHVzZSB4PSc0NTcuNjEyNDM3JyB5PSctMzIuMTU1MjA1JyB4bGluazpocmVmPScjZzAtMjEnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
defined on
such that  for all
for all  and
and  .
.If
 , then:
, then:(2)¶
![\ell(\mu, \sigma, \xi) = -nr \log \sigma - \sum_{i=1}^n \exp \biggl[ - \Bigl( \frac{z_i^{(r)} - \mu }{\sigma} \Bigr) \biggr] - \sum_{i=1}^n \sum_{k=1}^r \Bigl( \frac{z_i^{(k)} - \mu }{\sigma} \Bigr)](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSczNDMuNzQ3NTcycHQnIGhlaWdodD0nMzQuMjc4NDk5cHQnIHZpZXdCb3g9JzIyLjM5NzcxMyAtMzUuNDc0MDEzIDM0My43NDc1NzIgMzQuMjc4NDk5Jz4KPGRlZnM+CjxwYXRoIGlkPSdnNC00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c0LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnNC00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c0LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnMC0xNicgZD0nTTYuMTU2OTEyIDIwLjg5NzYzNEM2LjE4MDgyMiAyMC45MDk1ODkgNi4yODg0MTggMjEuMDI5MTQxIDYuMzAwMzc0IDIxLjAyOTE0MUg2LjU2MzM4N0M2LjU5OTI1MyAyMS4wMjkxNDEgNi42OTQ4OTQgMjEuMDE3MTg2IDYuNjk0ODk0IDIwLjkwOTU4OUM2LjY5NDg5NCAyMC44NjE3NjggNi42NzA5ODQgMjAuODM3ODU4IDYuNjQ3MDczIDIwLjgwMTk5M0M2LjIxNjY4NyAyMC4zNzE2MDYgNS41NzExMDggMTkuNzE0MDcyIDQuODI5ODg4IDE4LjM5OTAwNEMzLjUzODczIDE2LjEwMzYxMSAzLjA2MDUyMyAxMy4xNTA2ODUgMy4wNjA1MjMgMTAuMjgxNDQ1QzMuMDYwNTIzIDQuOTczMzUgNC41NjY4NzQgMS44NTMwNTEgNi42NTkwMjktLjI2MzAxNEM2LjY5NDg5NC0uMjk4ODc5IDYuNjk0ODk0LS4zMzQ3NDUgNi42OTQ4OTQtLjM1ODY1NUM2LjY5NDg5NC0uNDc4MjA3IDYuNjExMjA4LS40NzgyMDcgNi40Njc3NDYtLjQ3ODIwN0M2LjMxMjMyOS0uNDc4MjA3IDYuMjg4NDE4LS40NzgyMDcgNi4xODA4MjItLjM4MjU2NUM1LjA0NTA4MSAuNTk3NzU4IDMuNzY1ODc4IDIuMjU5NTI3IDIuOTQwOTcxIDQuNzgyMDY3QzIuNDI2ODk5IDYuMzYwMTQ5IDIuMTUxOTMgOC4yODQ5MzIgMi4xNTE5MyAxMC4yNjk0ODlDMi4xNTE5MyAxMy4xMDI4NjQgMi42NjYwMDIgMTYuMzA2ODQ5IDQuNTQyOTY0IDE5LjA4MDQ0OEM0Ljg2NTc1MyAxOS41NDY3IDUuMzA4MDk1IDIwLjAzNjg2MiA1LjMwODA5NSAyMC4wNDg4MTdDNS40Mjc2NDYgMjAuMTkyMjc5IDUuNTk1MDE5IDIwLjM4MzU2MiA1LjY5MDY2IDIwLjQ2NzI0OEw2LjE1NjkxMiAyMC44OTc2MzRaJy8+CjxwYXRoIGlkPSdnMC0xNycgZD0nTTQuOTczMzUgMTAuMjY5NDg5QzQuOTczMzUgNi44MzgzNTYgNC4xNzIzNTQgMy4xOTIwMyAxLjgxNzE4NiAuNTAyMTE3QzEuNjQ5ODEzIC4zMTA4MzQgMS4yMDc0NzItLjE1NTQxNyAuOTIwNTQ4LS40MDY0NzZDLjgzNjg2Mi0uNDc4MjA3IC44MTI5NTEtLjQ3ODIwNyAuNjU3NTM0LS40NzgyMDdDLjUzNzk4My0uNDc4MjA3IC40MzAzODYtLjQ3ODIwNyAuNDMwMzg2LS4zNTg2NTVDLjQzMDM4Ni0uMzEwODM0IC40NzgyMDctLjI2MzAxNCAuNTAyMTE3LS4yMzkxMDNDLjkwODU5MyAuMTc5MzI4IDEuNTU0MTcyIC44MzY4NjIgMi4yOTUzOTIgMi4xNTE5M0MzLjU4NjU1IDQuNDQ3MzIzIDQuMDY0NzU3IDcuNDAwMjQ5IDQuMDY0NzU3IDEwLjI2OTQ4OUM0LjA2NDc1NyAxNS40NTgwMzIgMi42MzAxMzcgMTguNjI2MTUyIC40NzgyMDcgMjAuODEzOTQ4Qy40NTQyOTYgMjAuODM3ODU4IC40MzAzODYgMjAuODczNzI0IC40MzAzODYgMjAuOTA5NTg5Qy40MzAzODYgMjEuMDI5MTQxIC41Mzc5ODMgMjEuMDI5MTQxIC42NTc1MzQgMjEuMDI5MTQxQy44MTI5NTEgMjEuMDI5MTQxIC44MzY4NjIgMjEuMDI5MTQxIC45NDQ0NTggMjAuOTMzNDk5QzIuMDgwMTk5IDE5Ljk1MzE3NiAzLjM1OTQwMiAxOC4yOTE0MDcgNC4xODQzMDkgMTUuNzY4ODY3QzQuNzEwMzM2IDE0LjEzMTAwOSA0Ljk3MzM1IDEyLjE5NDI3MSA0Ljk3MzM1IDEwLjI2OTQ4OVonLz4KPHBhdGggaWQ9J2cwLTIwJyBkPSdNMi45ODg3OTIgMjguMjAyMjQySDYuMTMzMDAxVjI3LjU0NDcwN0gzLjY0NjMyNlYuMTc5MzI4SDYuMTMzMDAxVi0uNDc4MjA3SDIuOTg4NzkyVjI4LjIwMjI0MlonLz4KPHBhdGggaWQ9J2cwLTIxJyBkPSdNMi42NTQwNDcgMjcuNTQ0NzA3SC4xNjczNzJWMjguMjAyMjQySDMuMzExNTgyVi0uNDc4MjA3SC4xNjczNzJWLjE3OTMyOEgyLjY1NDA0N1YyNy41NDQ3MDdaJy8+CjxwYXRoIGlkPSdnMC04OCcgZD0nTTE1LjEzNTI0MyAxNi43MzcyMzVMMTYuNTgxODE4IDEyLjkxMTU4MkgxNi4yODI5MzlDMTUuODE2Njg3IDE0LjE1NDkxOSAxNC41NDk0NCAxNC45Njc4NyAxMy4xNzQ1OTUgMTUuMzI2NTI2QzEyLjkyMzUzNyAxNS4zODYzMDEgMTEuNzUxOTMgMTUuNjk3MTM2IDkuNDU2NTM4IDE1LjY5NzEzNkgyLjI0NzU3Mkw4LjMzMjc1MiA4LjU1OTlDOC40MTY0MzggOC40NjQyNTkgOC40NDAzNDkgOC40MjgzOTQgOC40NDAzNDkgOC4zNjg2MThDOC40NDAzNDkgOC4zNDQ3MDcgOC40NDAzNDkgOC4zMDg4NDIgOC4zNTY2NjMgOC4xODkyOUwyLjc4NTU1NCAuNTczODQ4SDkuMzM2OTg2QzEwLjkzODk3OSAuNTczODQ4IDEyLjAyNjg5OSAuNzQxMjIgMTIuMTM0NDk2IC43NjUxMzFDMTIuNzgwMDc1IC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMuNzI5MjY1IDAgLjcxNzMxIC4wMTE5NTUgLjY4MTQ0NSAuMDgzNjg2Qy42Njk0ODkgLjExOTU1MiAuNjY5NDg5IC4zNDY3IC42Njk0ODkgLjQ3ODIwN0w2Ljk5Mzc3MyA5LjEzMzc0OEwuODAwOTk2IDE2LjM5MDUzNUMuNjgxNDQ1IDE2LjUzMzk5OCAuNjgxNDQ1IDE2LjU5Mzc3MyAuNjgxNDQ1IDE2LjYwNTcyOUMuNjgxNDQ1IDE2LjczNzIzNSAuNzg5MDQxIDE2LjczNzIzNSAxLjAwNDIzNCAxNi43MzcyMzVIMTUuMTM1MjQzWicvPgo8cGF0aCBpZD0nZzEtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnNS00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzUtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c1LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnNS0xMDEnIGQ9J000LjU3ODgyOS0yLjc3MzU5OUM0Ljg0MTg0My0yLjc3MzU5OSA0Ljg2NTc1My0yLjc3MzU5OSA0Ljg2NTc1My0zLjAwMDc0N0M0Ljg2NTc1My00LjIwODIxOSA0LjIyMDE3NC01LjMzMjAwNSAyLjc3MzU5OS01LjMzMjAwNUMxLjQxMDcxLTUuMzMyMDA1IC4zNTg2NTUtNC4xMDA2MjMgLjM1ODY1NS0yLjYxODE4MkMuMzU4NjU1LTEuMDQwMSAxLjU3ODA4MiAuMTE5NTUyIDIuOTA1MTA2IC4xMTk1NTJDNC4zMjc3NzEgLjExOTU1MiA0Ljg2NTc1My0xLjE3MTYwNiA0Ljg2NTc1My0xLjQyMjY2NUM0Ljg2NTc1My0xLjQ5NDM5NiA0LjgwNTk3OC0xLjU0MjIxNyA0LjczNDI0Ny0xLjU0MjIxN0M0LjYzODYwNS0xLjU0MjIxNyA0LjYxNDY5NS0xLjQ4MjQ0MSA0LjU5MDc4NS0xLjQyMjY2NUM0LjI3OTk1LS40MTg0MzEgMy40Nzg5NTQtLjE0MzQ2MiAyLjk3NjgzNy0uMTQzNDYyUzEuMjY3MjQ4LS40NzgyMDcgMS4yNjcyNDgtMi41NDY0NTFWLTIuNzczNTk5SDQuNTc4ODI5Wk0xLjI3OTIwMy0zLjAwMDc0N0MxLjM3NDg0NC00Ljg3NzcwOSAyLjQyNjg5OS01LjA5MjkwMiAyLjc2MTY0NC01LjA5MjkwMkM0LjA0MDg0Ny01LjA5MjkwMiA0LjExMjU3OC0zLjQwNzIyMyA0LjEyNDUzMy0zLjAwMDc0N0gxLjI3OTIwM1onLz4KPHBhdGggaWQ9J2c1LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c1LTEwOCcgZD0nTTIuMDU2Mjg5LTguMjk2ODg3TC4zOTQ1MjEtOC4xNjUzOFYtNy44MTg2OEMxLjIwNzQ3Mi03LjgxODY4IDEuMzAzMTEzLTcuNzM0OTk0IDEuMzAzMTEzLTcuMTQ5MTkxVi0uODg0NjgyQzEuMzAzMTEzLS4zNDY3IDEuMTcxNjA2LS4zNDY3IC4zOTQ1MjEtLjM0NjdWMEMuNzI5MjY1LS4wMjM5MSAxLjMxNTA2OC0uMDIzOTEgMS42NzM3MjQtLjAyMzkxUzIuNjMwMTM3LS4wMjM5MSAyLjk2NDg4MiAwVi0uMzQ2N0MyLjE5OTc1MS0uMzQ2NyAyLjA1NjI4OS0uMzQ2NyAyLjA1NjI4OS0uODg0NjgyVi04LjI5Njg4N1onLz4KPHBhdGggaWQ9J2c1LTExMScgZD0nTTUuNDg3NDIyLTIuNTU4NDA2QzUuNDg3NDIyLTQuMTAwNjIzIDQuMzE1ODE2LTUuMzMyMDA1IDIuOTI5MDE2LTUuMzMyMDA1QzEuNDk0Mzk2LTUuMzMyMDA1IC4zNTg2NTUtNC4wNjQ3NTcgLjM1ODY1NS0yLjU1ODQwNkMuMzU4NjU1LTEuMDI4MTQ0IDEuNTU0MTcyIC4xMTk1NTIgMi45MTcwNjEgLjExOTU1MkM0LjMyNzc3MSAuMTE5NTUyIDUuNDg3NDIyLTEuMDUyMDU1IDUuNDg3NDIyLTIuNTU4NDA2Wk0yLjkyOTAxNi0uMTQzNDYyQzIuNDg2Njc1LS4xNDM0NjIgMS45NDg2OTItLjMzNDc0NSAxLjYwMTk5My0uOTIwNTQ4QzEuMjc5MjAzLTEuNDU4NTMxIDEuMjY3MjQ4LTIuMTYzODg1IDEuMjY3MjQ4LTIuNjY2MDAyQzEuMjY3MjQ4LTMuMTIwMjk5IDEuMjY3MjQ4LTMuODQ5NTY0IDEuNjM3ODU4LTQuMzg3NTQ3QzEuOTcyNjAzLTQuOTAxNjE5IDIuNDk4NjMtNS4wOTI5MDIgMi45MTcwNjEtNS4wOTI5MDJDMy4zODMzMTMtNS4wOTI5MDIgMy44ODU0My00Ljg3NzcwOSA0LjIwODIxOS00LjQxMTQ1N0M0LjU3ODgyOS0zLjg2MTUxOSA0LjU3ODgyOS0zLjEwODM0NCA0LjU3ODgyOS0yLjY2NjAwMkM0LjU3ODgyOS0yLjI0NzU3MiA0LjU3ODgyOS0xLjUwNjM1MSA0LjI2Nzk5NS0uOTQ0NDU4QzMuOTMzMjUtLjM3MDYxIDMuMzgzMzEzLS4xNDM0NjIgMi45MjkwMTYtLjE0MzQ2MlonLz4KPHBhdGggaWQ9J2c1LTExMicgZD0nTTIuOTI5MDE2IDEuOTcyNjAzQzIuMTYzODg1IDEuOTcyNjAzIDIuMDIwNDIzIDEuOTcyNjAzIDIuMDIwNDIzIDEuNDM0NjJWLS42NDU1NzlDMi4yMzU2MTYtLjM0NjcgMi43MjU3NzggLjExOTU1MiAzLjQ5MDkwOSAuMTE5NTUyQzQuODY1NzUzIC4xMTk1NTIgNi4wNzMyMjUtMS4wNDAxIDYuMDczMjI1LTIuNTgyMzE2QzYuMDczMjI1LTQuMTAwNjIzIDQuOTQ5NDQtNS4yNzIyMjkgMy42NDYzMjYtNS4yNzIyMjlDMi41OTQyNzEtNS4yNzIyMjkgMi4wMzIzNzktNC41MTkwNTQgMS45OTY1MTMtNC40NzEyMzNWLTUuMjcyMjI5TC4zMzQ3NDUtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTcxNjA2LTQuNzk0MDIyIDEuMjQzMzM3LTQuNzEwMzM2IDEuMjQzMzM3LTQuMTg0MzA5VjEuNDM0NjJDMS4yNDMzMzcgMS45NzI2MDMgMS4xMTE4MzEgMS45NzI2MDMgLjMzNDc0NSAxLjk3MjYwM1YyLjMxOTMwM0MuNjQ1NTc5IDIuMjk1MzkyIDEuMjkxMTU4IDIuMjk1MzkyIDEuNjI1OTAzIDIuMjk1MzkyQzEuOTcyNjAzIDIuMjk1MzkyIDIuNjE4MTgyIDIuMjk1MzkyIDIuOTI5MDE2IDIuMzE5MzAzVjEuOTcyNjAzWk0yLjAyMDQyMy0zLjgxMzY5OUMyLjAyMDQyMy00LjA0MDg0NyAyLjAyMDQyMy00LjA1MjgwMiAyLjE1MTkzLTQuMjQ0MDg1QzIuNTEwNTg1LTQuNzgyMDY3IDMuMDk2Mzg5LTUuMDA5MjE1IDMuNTUwNjg1LTUuMDA5MjE1QzQuNDQ3MzIzLTUuMDA5MjE1IDUuMTY0NjMzLTMuOTIxMjk1IDUuMTY0NjMzLTIuNTgyMzE2QzUuMTY0NjMzLTEuMTU5NjUxIDQuMzUxNjgxLS4xMTk1NTIgMy40MzExMzMtLjExOTU1MkMzLjA2MDUyMy0uMTE5NTUyIDIuNzEzODIzLS4yNzQ5NjkgMi40NzQ3Mi0uNTAyMTE3QzIuMTk5NzUxLS43NzcwODYgMi4wMjA0MjMtMS4wMTYxODkgMi4wMjA0MjMtMS4zNTA5MzRWLTMuODEzNjk5WicvPgo8cGF0aCBpZD0nZzUtMTIwJyBkPSdNMy4zNDc0NDctMi44MjE0MkMzLjY5NDE0Ny0zLjI3NTcxNiA0LjE5NjI2NC0zLjkyMTI5NSA0LjQyMzQxMi00LjE3MjM1NEM0LjkxMzU3NC00LjcyMjI5MSA1LjQ3NTQ2Ny00LjgwNTk3OCA1Ljg1ODAzMi00LjgwNTk3OFYtNS4xNTI2NzdDNS4zNDM5Ni01LjEyODc2NyA1LjMyMDA1LTUuMTI4NzY3IDQuODUzNzk4LTUuMTI4NzY3QzQuMzk5NTAyLTUuMTI4NzY3IDQuMzc1NTkyLTUuMTI4NzY3IDMuNzc3ODMzLTUuMTUyNjc3Vi00LjgwNTk3OEMzLjkzMzI1LTQuNzgyMDY3IDQuMTI0NTMzLTQuNzEwMzM2IDQuMTI0NTMzLTQuNDM1MzY3QzQuMTI0NTMzLTQuMjMyMTMgNC4wMTY5MzYtNC4xMDA2MjMgMy45NDUyMDUtNC4wMDQ5ODFMMy4xODAwNzUtMy4wMzY2MTNMMi4yNDc1NzItNC4yNjc5OTVDMi4yMTE3MDYtNC4zMTU4MTYgMi4xMzk5NzUtNC40MjM0MTIgMi4xMzk5NzUtNC41MDcwOThDMi4xMzk5NzUtNC41Nzg4MjkgMi4xOTk3NTEtNC43OTQwMjIgMi41NTg0MDYtNC44MDU5NzhWLTUuMTUyNjc3QzIuMjU5NTI3LTUuMTI4NzY3IDEuNjQ5ODEzLTUuMTI4NzY3IDEuMzI3MDI0LTUuMTI4NzY3Qy45MzI1MDMtNS4xMjg3NjcgLjkwODU5My01LjEyODc2NyAuMTc5MzI4LTUuMTUyNjc3Vi00LjgwNTk3OEMuNzg5MDQxLTQuODA1OTc4IDEuMDE2MTg5LTQuNzgyMDY3IDEuMjY3MjQ4LTQuNDU5Mjc4TDIuNjY2MDAyLTIuNjMwMTM3QzIuNjg5OTEzLTIuNjA2MjI3IDIuNzM3NzMzLTIuNTM0NDk2IDIuNzM3NzMzLTIuNDk4NjNTMS44MDUyMy0xLjI5MTE1OCAxLjY4NTY3OS0xLjEzNTc0MUMxLjE1OTY1MS0uNDkwMTYyIC42MzM2MjQtLjM1ODY1NSAuMTE5NTUyLS4zNDY3VjBDLjU3Mzg0OC0uMDIzOTEgLjU5Nzc1OC0uMDIzOTEgMS4xMTE4MzEtLjAyMzkxQzEuNTY2MTI3LS4wMjM5MSAxLjU5MDAzNy0uMDIzOTEgMi4xODc3OTYgMFYtLjM0NjdDMS45MDA4NzItLjM4MjU2NSAxLjg1MzA1MS0uNTYxODkzIDEuODUzMDUxLS43MjkyNjVDMS44NTMwNTEtLjkyMDU0OCAxLjkzNjczNy0xLjAxNjE4OSAyLjA1NjI4OS0xLjE3MTYwNkMyLjIzNTYxNi0xLjQyMjY2NSAyLjYzMDEzNy0xLjkxMjgyNyAyLjkxNzA2MS0yLjI4MzQzN0wzLjg5NzM4NS0xLjAwNDIzNEM0LjEwMDYyMy0uNzQxMjIgNC4xMDA2MjMtLjcxNzMxIDQuMTAwNjIzLS42NDU1NzlDNC4xMDA2MjMtLjU0OTkzOCA0LjAwNDk4MS0uMzU4NjU1IDMuNjgyMTkyLS4zNDY3VjBDMy45OTMwMjYtLjAyMzkxIDQuNTc4ODI5LS4wMjM5MSA0LjkxMzU3NC0uMDIzOTFDNS4zMDgwOTUtLjAyMzkxIDUuMzMyMDA1LS4wMjM5MSA2LjA0OTMxNSAwVi0uMzQ2N0M1LjQxNTY5MS0uMzQ2NyA1LjIwMDQ5OC0uMzcwNjEgNC45MTM1NzQtLjc1MzE3NkwzLjM0NzQ0Ny0yLjgyMTQyWicvPgo8cGF0aCBpZD0nZzItMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2cyLTEwNycgZD0nTTIuMzI3MjczLTUuMjkyMTU0QzIuMzM1MjQzLTUuMzA4MDk1IDIuMzU5MTUzLTUuNDExNzA2IDIuMzU5MTUzLTUuNDE5Njc2QzIuMzU5MTUzLTUuNDU5NTI3IDIuMzI3MjczLTUuNTMxMjU4IDIuMjMxNjMxLTUuNTMxMjU4QzIuMTk5NzUxLTUuNTMxMjU4IDEuOTUyNjc3LTUuNTA3MzQ3IDEuNzY5MzY1LTUuNDkxNDA3TDEuMzIzMDM5LTUuNDU5NTI3QzEuMTQ3Njk2LTUuNDQzNTg3IDEuMDY3OTk1LTUuNDM1NjE2IDEuMDY3OTk1LTUuMjkyMTU0QzEuMDY3OTk1LTUuMTgwNTczIDEuMTc5NTc3LTUuMTgwNTczIDEuMjc1MjE4LTUuMTgwNTczQzEuNjU3NzgzLTUuMTgwNTczIDEuNjU3NzgzLTUuMTMyNzUyIDEuNjU3NzgzLTUuMDYxMDIxQzEuNjU3NzgzLTUuMDM3MTExIDEuNjU3NzgzLTUuMDIxMTcxIDEuNjE3OTMzLTQuODc3NzA5TC40ODYxNzctLjM0MjcxNUMuNDU0Mjk2LS4yMjMxNjMgLjQ1NDI5Ni0uMTc1MzQyIC40NTQyOTYtLjE2NzM3MkMuNDU0Mjk2LS4wMzE4OCAuNTY1ODc4IC4wNzk3MDEgLjcxNzMxIC4wNzk3MDFDLjk4ODI5NCAuMDc5NzAxIDEuMDUyMDU1LS4xNzUzNDIgMS4wODM5MzUtLjI4NjkyNEMxLjE2MzYzNi0uNjIxNjY5IDEuMzcwODU5LTEuNDY2NTAxIDEuNDU4NTMxLTEuODAxMjQ1QzEuODk2ODg3LTEuNzUzNDI1IDIuNDMwODg0LTEuNjAxOTkzIDIuNDMwODg0LTEuMTQ3Njk2QzIuNDMwODg0LTEuMTA3ODQ2IDIuNDMwODg0LTEuMDY3OTk1IDIuNDE0OTQ0LS45ODgyOTRDMi4zOTEwMzQtLjg4NDY4MiAyLjM3NTA5My0uNzczMTAxIDIuMzc1MDkzLS43MzMyNUMyLjM3NTA5My0uMjYzMDE0IDIuNzI1Nzc4IC4wNzk3MDEgMy4xODgwNDUgLjA3OTcwMUMzLjUyMjc5IC4wNzk3MDEgMy43MzAwMTItLjE2NzM3MiAzLjgzMzYyNC0uMzE4ODA0QzQuMDI0OTA3LS42MTM2OTkgNC4xNTI0MjgtMS4wOTE5MDUgNC4xNTI0MjgtMS4xMzk3MjZDNC4xNTI0MjgtMS4yMTk0MjcgNC4wODg2NjctMS4yNDMzMzcgNC4wMzI4NzctMS4yNDMzMzdDMy45MzcyMzUtMS4yNDMzMzcgMy45MjEyOTUtMS4xOTU1MTcgMy44ODk0MTUtMS4wNTIwNTVDMy43ODU4MDMtLjY3NzQ2IDMuNTc4NTgtLjE0MzQ2MiAzLjIwMzk4NS0uMTQzNDYyQzIuOTk2NzYyLS4xNDM0NjIgMi45NDg5NDEtLjMxODgwNCAyLjk0ODk0MS0uNTMzOTk4QzIuOTQ4OTQxLS42Mzc2MDkgMi45NTY5MTItLjczMzI1IDIuOTk2NzYyLS45MTY1NjNDMy4wMDQ3MzItLjk0ODQ0MyAzLjAzNjYxMy0xLjA3NTk2NSAzLjAzNjYxMy0xLjE2MzYzNkMzLjAzNjYxMy0xLjgxNzE4NiAyLjIxNTY5MS0xLjk2MDY0OCAxLjgwOTIxNS0yLjAxNjQzOEMyLjEwNDExLTIuMTkxNzgxIDIuMzc1MDkzLTIuNDYyNzY1IDIuNDcwNzM1LTIuNTY2Mzc2QzIuOTA5MDkxLTIuOTk2NzYyIDMuMjY3NzQ2LTMuMjkxNjU2IDMuNjUwMzExLTMuMjkxNjU2QzMuNzUzOTIzLTMuMjkxNjU2IDMuODQ5NTY0LTMuMjY3NzQ2IDMuOTEzMzI1LTMuMTg4MDQ1QzMuNDgyOTM5LTMuMTMyMjU0IDMuNDgyOTM5LTIuNzU3NjU5IDMuNDgyOTM5LTIuNzQ5Njg5QzMuNDgyOTM5LTIuNTc0MzQ2IDMuNjE4NDMxLTIuNDU0Nzk1IDMuNzkzNzczLTIuNDU0Nzk1QzQuMDA4OTY2LTIuNDU0Nzk1IDQuMjQ4MDctMi42MzAxMzcgNC4yNDgwNy0yLjk1NjkxMkM0LjI0ODA3LTMuMjI3ODk1IDQuMDU2Nzg3LTMuNTE0ODE5IDMuNjU4MjgxLTMuNTE0ODE5QzMuMTk2MDE1LTMuNTE0ODE5IDIuNzgxNTY5LTMuMTY0MTM0IDIuMzI3MjczLTIuNzA5ODM4QzEuODY1MDA2LTIuMjU1NTQyIDEuNjY1NzUzLTIuMTY3ODcgMS41MzgyMzItMi4xMTIwOEwyLjMyNzI3My01LjI5MjE1NFonLz4KPHBhdGggaWQ9J2cyLTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnMi0xMTQnIGQ9J00xLjUzODIzMi0xLjA5OTg3NUMxLjYyNTkwMy0xLjQ0MjU5IDEuNzEzNTc0LTEuNzg1MzA1IDEuNzkzMjc1LTIuMTM1OTlDMS44MDEyNDUtMi4xNTE5MyAxLjg1NzAzNi0yLjM4MzA2NCAxLjg2NTAwNi0yLjQyMjkxNEMxLjg4ODkxNy0yLjQ5NDY0NSAyLjA4ODE2OS0yLjgyMTQyIDIuMjk1MzkyLTMuMDIwNjcyQzIuNTUwNDM2LTMuMjUxODA2IDIuODIxNDItMy4yOTE2NTYgMi45NjQ4ODItMy4yOTE2NTZDMy4wNTI1NTMtMy4yOTE2NTYgMy4xOTYwMTUtMy4yODM2ODYgMy4zMDc1OTctMy4xODgwNDVDMi45NjQ4ODItMy4xMTYzMTQgMi45MTcwNjEtMi44MjE0MiAyLjkxNzA2MS0yLjc0OTY4OUMyLjkxNzA2MS0yLjU3NDM0NiAzLjA1MjU1My0yLjQ1NDc5NSAzLjIyNzg5NS0yLjQ1NDc5NUMzLjQ0MzA4OC0yLjQ1NDc5NSAzLjY4MjE5Mi0yLjYzMDEzNyAzLjY4MjE5Mi0yLjk0ODk0MUMzLjY4MjE5Mi0zLjIzNTg2NiAzLjQzNTExOC0zLjUxNDgxOSAyLjk4MDgyMi0zLjUxNDgxOUMyLjQzODg1NC0zLjUxNDgxOSAyLjA3MjIyOS0zLjE1NjE2NCAxLjkwNDg1Ny0yLjk0MDk3MUMxLjc0NTQ1NS0zLjUxNDgxOSAxLjIwMzQ4Ny0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzI2Nzc1LTIuNzI1Nzc4IC4yMzkxMDMtMi4zMTkzMDMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjI0MzMzNyAuMDc5NzAxIDEuMjk5MTI4LS4xNDM0NjIgMS4zNjI4ODktLjQxNDQ0NkwxLjUzODIzMi0xLjA5OTg3NVonLz4KPHBhdGggaWQ9J2czLTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnMy0yNCcgZD0nTTMuMTIwMjk5IC4wNTk3NzZMMS44NjUwMDYtLjQ0MjM0MUMxLjU1NDE3Mi0uNTYxODkzIC44MzY4NjItLjg0ODgxNyAuODM2ODYyLTEuNTY2MTI3Qy44MzY4NjItMi41OTQyNzEgMi4wOTIxNTQtMy42MzQzNzEgMi4zNDMyMTMtMy42MzQzNzFDMi4zNjcxMjMtMy42MzQzNzEgMi40NzQ3Mi0zLjYxMDQ2MSAyLjUxMDU4NS0zLjU5ODUwNkMyLjgzMzM3NS0zLjUwMjg2NCAzLjE0NDIwOS0zLjUwMjg2NCAzLjM1OTQwMi0zLjUwMjg2NEMzLjczMDAxMi0zLjUwMjg2NCA0LjQzNTM2Ny0zLjUwMjg2NCA0LjQzNTM2Ny0zLjg0OTU2NEM0LjQzNTM2Ny00LjExMjU3OCA0LjAwNDk4MS00LjE0ODQ0MyAzLjQ5MDkwOS00LjE0ODQ0M0MzLjI1MTgwNi00LjE0ODQ0MyAyLjkyOTAxNi00LjE0ODQ0MyAyLjQ5ODYzLTQuMDA0OTgxQzIuMjExNzA2LTQuMjQ0MDg1IDIuMDkyMTU0LTQuNjI2NjUgMi4wOTIxNTQtNC45ODUzMDVDMi4wOTIxNTQtNS42NDI4MzkgMi41MjI1NC02LjU3NTM0MiAzLjQ2Njk5OS03LjAxNzY4NEMzLjY4MjE5Mi02Ljc2NjYyNSAzLjk2OTExNi02Ljc2NjYyNSA0LjIyMDE3NC02Ljc2NjYyNUM0LjUxOTA1NC02Ljc2NjYyNSA1LjI0ODMxOS02Ljc2NjYyNSA1LjI0ODMxOS03LjExMzMyNUM1LjI0ODMxOS03LjQxMjIwNCA0LjY3NDQ3MS03LjQxMjIwNCA0LjI5MTkwNS03LjQxMjIwNEM0LjA1MjgwMi03LjQxMjIwNCAzLjg3MzQ3NC03LjQxMjIwNCAzLjUzODczLTcuMzUyNDI4QzMuNDc4OTU0LTcuNDk1ODkgMy40NjY5OTktNy41MTk4MDEgMy40NjY5OTktNy43ODI4MTRDMy40NjY5OTktNy45OTgwMDcgMy41MTQ4MTktOC4xNjUzOCAzLjUxNDgxOS04LjIwMTI0NUMzLjUxNDgxOS04LjI3Mjk3NiAzLjQ1NTA0NC04LjMyMDc5NyAzLjM5NTI2OC04LjMyMDc5N0MzLjIwMzk4NS04LjMyMDc5NyAzLjIwMzk4NS03Ljg3ODQ1NiAzLjIwMzk4NS03Ljc4MjgxNEMzLjIwMzk4NS03LjYxNTQ0MiAzLjIxNTk0LTcuNDQ4MDcgMy4yODc2NzEtNy4yOTI2NTNDMS44NTMwNTEtNi44NzQyMjIgMS4yMTk0MjctNS44NTgwMzIgMS4yMTk0MjctNS4wODA5NDZDMS4yMTk0MjctNC4zNjM2MzYgMS42OTc2MzQtMy45NjkxMTYgMi4wMjA0MjMtMy43ODk3ODhDLjc4OTA0MS0zLjEyMDI5OSAuMjYzMDE0LTEuOTAwODcyIC4yNjMwMTQtMS4yNTUyOTNDLjI2MzAxNC0uMjE1MTkzIDEuMjA3NDcyIC4xNTU0MTcgMS42Mzc4NTggLjMzNDc0NUwyLjcxMzgyMyAuNzY1MTMxQzMuMDEyNzAyIC44NzI3MjcgMy41MDI4NjQgMS4wNzU5NjUgMy41ODY1NSAxLjEyMzc4NkMzLjcwNjEwMiAxLjIwNzQ3MiAzLjgwMTc0MyAxLjM1MDkzNCAzLjgwMTc0MyAxLjU0MjIxN0MzLjgwMTc0MyAxLjc5MzI3NSAzLjYxMDQ2MSAyLjE5OTc1MSAzLjE5MjAzIDIuMTk5NzUxQzMuMDEyNzAyIDIuMTk5NzUxIDIuNjE4MTgyIDIuMTUxOTMgMi4xODc3OTYgMS44MjkxNDFDMi4xMDQxMSAxLjc1NzQxIDIuMDkyMTU0IDEuNzQ1NDU1IDIuMDQ0MzM0IDEuNzQ1NDU1QzEuOTg0NTU4IDEuNzQ1NDU1IDEuOTI0NzgyIDEuNzkzMjc1IDEuOTI0NzgyIDEuODY1MDA2QzEuOTI0NzgyIDEuOTk2NTEzIDIuNTQ2NDUxIDIuNDM4ODU0IDMuMTkyMDMgMi40Mzg4NTRDMy45NTcxNjEgMi40Mzg4NTQgNC40MjM0MTIgMS42OTc2MzQgNC40MjM0MTIgMS4xODM1NjJDNC40MjM0MTIgLjgxMjk1MSA0LjIyMDE3NCAuNTE0MDcyIDMuODM3NjA5IC4zNDY3TDMuMTIwMjk5IC4wNTk3NzZaTTMuNzMwMDEyLTcuMTEzMzI1QzMuOTMzMjUtNy4xNzMxMDEgNC4xNDg0NDMtNy4xNzMxMDEgNC4zMDM4NjEtNy4xNzMxMDFDNC42OTgzODEtNy4xNzMxMDEgNC43MzQyNDctNy4xNjExNDYgNC45NzMzNS03LjEwMTM3QzQuODI5ODg4LTcuMDQxNTk0IDQuNzM0MjQ3LTcuMDA1NzI5IDQuMjMyMTMtNy4wMDU3MjlDNC4wMDQ5ODEtNy4wMDU3MjkgMy44NjE1MTktNy4wMDU3MjkgMy43MzAwMTItNy4xMTMzMjVaTTIuNzg1NTU0LTMuODM3NjA5QzMuMDcyNDc4LTMuOTA5MzQgMy4zMzU0OTItMy45MDkzNCAzLjQ3ODk1NC0zLjkwOTM0QzMuODczNDc0LTMuOTA5MzQgMy44OTczODUtMy44OTczODUgNC4xNjAzOTktMy44Mzc2MDlDNC4wMjg4OTItMy43Nzc4MzMgMy45MjEyOTUtMy43NDE5NjggMy40MDcyMjMtMy43NDE5NjhDMy4xMjAyOTktMy43NDE5NjggMy4wMDA3NDctMy43NDE5NjggMi43ODU1NTQtMy44Mzc2MDlaJy8+CjxwYXRoIGlkPSdnMy0yNycgZD0nTTYuMDczMjI1LTQuNTA3MDk4QzYuMjI4NjQzLTQuNTA3MDk4IDYuNjIzMTYzLTQuNTA3MDk4IDYuNjIzMTYzLTQuODg5NjY0QzYuNjIzMTYzLTUuMTUyNjc3IDYuMzk2MDE1LTUuMTUyNjc3IDYuMTgwODIyLTUuMTUyNjc3SDMuNTM4NzNDMS43NDU0NTUtNS4xNTI2NzcgLjQ1NDI5Ni0zLjE1NjE2NCAuNDU0Mjk2LTEuNzQ1NDU1Qy40NTQyOTYtLjcyOTI2NSAxLjExMTgzMSAuMTE5NTUyIDIuMTg3Nzk2IC4xMTk1NTJDMy41OTg1MDYgLjExOTU1MiA1LjE0MDcyMi0xLjM5ODc1NSA1LjE0MDcyMi0zLjE5MjAzQzUuMTQwNzIyLTMuNjU4MjgxIDUuMDMzMTI2LTQuMTEyNTc4IDQuNzQ2MjAyLTQuNTA3MDk4SDYuMDczMjI1Wk0yLjE5OTc1MS0uMTE5NTUyQzEuNTkwMDM3LS4xMTk1NTIgMS4xNDc2OTYtLjU4NTgwMyAxLjE0NzY5Ni0xLjQxMDcxQzEuMTQ3Njk2LTIuMTI4MDIgMS41NzgwODItNC41MDcwOTggMy4zMzU0OTItNC41MDcwOThDMy44NDk1NjQtNC41MDcwOTggNC40MjM0MTItNC4yNTYwNCA0LjQyMzQxMi0zLjMzNTQ5MkM0LjQyMzQxMi0yLjkxNzA2MSA0LjIzMjEzLTEuOTEyODI3IDMuODEzNjk5LTEuMjE5NDI3QzMuMzgzMzEzLS41MTQwNzIgMi43Mzc3MzMtLjExOTU1MiAyLjE5OTc1MS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzMtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2czLTk2JyBkPSdNMS4wOTk4NzUtMi4wMzIzNzlDLjM0NjctMS4yOTExNTggLjE1NTQxNy0xLjExMTgzMSAuMTU1NDE3LTEuMDY0MDFTLjIwMzIzOC0uOTMyNTAzIC4yODY5MjQtLjkzMjUwM0MuMzQ2Ny0uOTMyNTAzIDEuMDI4MTQ0LTEuNTkwMDM3IDEuMTIzNzg2LTEuNjk3NjM0QzEuMTk1NTE3LS44OTY2MzggMS40OTQzOTYgLjE0MzQ2MiAyLjQyNjg5OSAuMTQzNDYyQzIuOTA1MTA2IC4xNDM0NjIgMy4zMzU0OTItLjE1NTQxNyAzLjUyNjc3NS0uMjk4ODc5QzMuNjgyMTkyLS40MTg0MzEgNC4yNTYwNC0uOTA4NTkzIDQuMjU2MDQtMS4wMTYxODlDNC4yNTYwNC0xLjA3NTk2NSA0LjE5NjI2NC0xLjE0NzY5NiA0LjEzNjQ4OC0xLjE0NzY5NkM0LjA4ODY2Ny0xLjE0NzY5NiAzLjkwOTM0LS45NjgzNjkgMy44NjE1MTktLjkyMDU0OEMzLjQ0MzA4OC0uNTE0MDcyIDIuOTE3MDYxLS4wOTU2NDEgMi40Mzg4NTQtLjA5NTY0MUMxLjc5MzI3NS0uMDk1NjQxIDEuNzA5NTg5LTEuMDI4MTQ0IDEuNzA5NTg5LTEuNjczNzI0QzEuNzA5NTg5LTEuNzkzMjc1IDEuNzA5NTg5LTIuMjk1MzkyIDEuNzkzMjc1LTIuMzkxMDM0QzIuNDk4NjMtMy4xMjAyOTkgNC43MTAzMzYtNS40MDM3MzYgNC43MTAzMzYtNy41MTk4MDFDNC43MTAzMzYtNy45OTgwMDcgNC41MzEwMDktOC40MTY0MzggNC4wMTY5MzYtOC40MTY0MzhDMi45MDUxMDYtOC40MTY0MzggMS45MzY3MzctNS45NTM2NzQgMS43NjkzNjUtNS40OTkzNzdDMS43MjE1NDQtNS4zNzk4MjYgMS4wMjgxNDQtMy41Mzg3MyAxLjA5OTg3NS0yLjAzMjM3OVpNMS44MTcxODYtMi43NzM1OTlDMS44MjkxNDEtMi44NDUzMyAyLjM2NzEyMy01Ljk3NzU4NCAzLjM3MTM1Ny03LjY1MTMwOEMzLjU3NDU5NS03Ljk3NDA5NyAzLjc3NzgzMy04LjE3NzMzNSA0LjAxNjkzNi04LjE3NzMzNUM0LjQyMzQxMi04LjE3NzMzNSA0LjQ0NzMyMy03Ljc5NDc3IDQuNDQ3MzIzLTcuNTMxNzU2QzQuNDQ3MzIzLTcuMTEzMzI1IDQuMzI3NzcxLTYuMDM3MzYgMy4yODc2NzEtNC41MzEwMDlDMi45NzY4MzctNC4wODg2NjcgMi40OTg2My0zLjQ5MDkwOSAxLjgxNzE4Ni0yLjc3MzU5OVonLz4KPHBhdGggaWQ9J2czLTExMCcgZD0nTTIuNDYyNzY1LTMuNTAyODY0QzIuNDg2Njc1LTMuNTc0NTk1IDIuNzg1NTU0LTQuMTcyMzU0IDMuMjI3ODk1LTQuNTU0OTE5QzMuNTM4NzMtNC44NDE4NDMgMy45NDUyMDUtNS4wMzMxMjYgNC40MTE0NTctNS4wMzMxMjZDNC44ODk2NjQtNS4wMzMxMjYgNS4wNTcwMzYtNC42NzQ0NzEgNS4wNTcwMzYtNC4xOTYyNjRDNS4wNTcwMzYtMy41MTQ4MTkgNC41NjY4NzQtMi4xNTE5MyA0LjMyNzc3MS0xLjUwNjM1MUM0LjIyMDE3NC0xLjIxOTQyNyA0LjE2MDM5OS0xLjA2NDAxIDQuMTYwMzk5LS44NDg4MTdDNC4xNjAzOTktLjMxMDgzNCA0LjUzMTAwOSAuMTE5NTUyIDUuMTA0ODU3IC4xMTk1NTJDNi4yMTY2ODcgLjExOTU1MiA2LjYzNTExOC0xLjYzNzg1OCA2LjYzNTExOC0xLjcwOTU4OUM2LjYzNTExOC0xLjc2OTM2NSA2LjU4NzI5OC0xLjgxNzE4NiA2LjUxNTU2Ny0xLjgxNzE4NkM2LjQwNzk3LTEuODE3MTg2IDYuMzk2MDE1LTEuNzgxMzIgNi4zMzYyMzktMS41NzgwODJDNi4wNjEyNy0uNTk3NzU4IDUuNjA2OTc0LS4xMTk1NTIgNS4xNDA3MjItLjExOTU1MkM1LjAyMTE3MS0uMTE5NTUyIDQuODI5ODg4LS4xMzE1MDcgNC44Mjk4ODgtLjUxNDA3MkM0LjgyOTg4OC0uODEyOTUxIDQuOTYxMzk1LTEuMTcxNjA2IDUuMDMzMTI2LTEuMzM4OTc5QzUuMjcyMjI5LTEuOTk2NTEzIDUuNzc0MzQ2LTMuMzM1NDkyIDUuNzc0MzQ2LTQuMDE2OTM2QzUuNzc0MzQ2LTQuNzM0MjQ3IDUuMzU1OTE1LTUuMjcyMjI5IDQuNDQ3MzIzLTUuMjcyMjI5QzMuMzgzMzEzLTUuMjcyMjI5IDIuODIxNDItNC41MTkwNTQgMi42MDYyMjctNC4yMjAxNzRDMi41NzAzNjEtNC45MDE2MTkgMi4wODAxOTktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4xNzE2MDYtNS4yNzIyMjkgLjkwODU5My01LjA0NTA4MSAuNzA1MzU1LTQuNjM4NjA1Qy40OTAxNjItNC4yMDgyMTkgLjMyMjc5LTMuNDkwOTA5IC4zMjI3OS0zLjQ0MzA4OFMuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODI0OTA3LTQuMzUxNjgxIDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjc5MzI3NS01LjAzMzEyNiAxLjg4ODkxNy00Ljg0MTg0MyAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjM1MDkzNCAuMTE5NTUyIDEuNTE4MzA2IC4wNDc4MjEgMS42MTM5NDgtLjEzMTUwN0MxLjYzNzg1OC0uMTkxMjgzIDEuNzQ1NDU1LS42MDk3MTQgMS44MDUyMy0uODQ4ODE3TDIuMDY4MjQ0LTEuOTI0NzgyTDIuNDYyNzY1LTMuNTAyODY0WicvPgo8cGF0aCBpZD0nZzMtMTE0JyBkPSdNNC42NTA1Ni00Ljg4OTY2NEM0LjI3OTk1LTQuODE3OTMzIDQuMDg4NjY3LTQuNTU0OTE5IDQuMDg4NjY3LTQuMjkxOTA1QzQuMDg4NjY3LTQuMDA0OTgxIDQuMzE1ODE2LTMuOTA5MzQgNC40ODMxODgtMy45MDkzNEM0LjgxNzkzMy0zLjkwOTM0IDUuMDkyOTAyLTQuMTk2MjY0IDUuMDkyOTAyLTQuNTU0OTE5QzUuMDkyOTAyLTQuOTM3NDg0IDQuNzIyMjkxLTUuMjcyMjI5IDQuMTI0NTMzLTUuMjcyMjI5QzMuNjQ2MzI2LTUuMjcyMjI5IDMuMDk2Mzg5LTUuMDU3MDM2IDIuNTk0MjcxLTQuMzI3NzcxQzIuNTEwNTg1LTQuOTYxMzk1IDIuMDMyMzc5LTUuMjcyMjI5IDEuNTU0MTcyLTUuMjcyMjI5QzEuMDg3OTItNS4yNzIyMjkgLjg0ODgxNy00LjkxMzU3NCAuNzA1MzU1LTQuNjUwNTZDLjUwMjExNy00LjIyMDE3NCAuMzIyNzktMy41MDI4NjQgLjMyMjc5LTMuNDQzMDg4Qy4zMjI3OS0zLjM5NTI2OCAuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODEyOTUxLTQuMzM5NzI2IDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjgwNTIzLTUuMDMzMTI2IDEuODg4OTE3LTQuODI5ODg4IDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzM4OTc5IC4xMTk1NTIgMS41NjYxMjcgLjAzNTg2NiAxLjYzNzg1OC0uMjAzMjM4QzEuNjczNzI0LS4yOTg4NzkgMi4xMTYwNjUtMi4xMDQxMSAyLjE4Nzc5Ni0yLjM3OTA3OEMyLjI0NzU3Mi0yLjY0MjA5MiAyLjMxOTMwMy0yLjg5MzE1MSAyLjM3OTA3OC0zLjE1NjE2NEMyLjQyNjg5OS0zLjMyMzUzNyAyLjQ3NDcyLTMuNTE0ODE5IDIuNTEwNTg1LTMuNjcwMjM3QzIuNTQ2NDUxLTMuNzc3ODMzIDIuODY5MjQtNC4zNjM2MzYgMy4xNjgxMi00LjYyNjY1QzMuMzExNTgyLTQuNzU4MTU3IDMuNjIyNDE2LTUuMDMzMTI2IDQuMTEyNTc4LTUuMDMzMTI2QzQuMzAzODYxLTUuMDMzMTI2IDQuNDk1MTQzLTQuOTk3MjYgNC42NTA1Ni00Ljg4OTY2NFonLz4KPHBhdGggaWQ9J2czLTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMjIuMzk3NzEzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtOTYnLz4KPHVzZSB4PScyNy4zMDk4MicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c1LTQwJy8+Cjx1c2UgeD0nMzEuODYyMTQ1JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtMjInLz4KPHVzZSB4PSczOC45MDUxMTYnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy01OScvPgo8dXNlIHg9JzQ0LjE0OTI3NScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2czLTI3Jy8+Cjx1c2UgeD0nNTAuNTgxMzQ3JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtNTknLz4KPHVzZSB4PSc1NS44MjU1MDUnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy0yNCcvPgo8dXNlIHg9JzYxLjUxNTk0MycgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c1LTQxJy8+Cjx1c2UgeD0nNjkuMzg5MDk4JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtNjEnLz4KPHVzZSB4PSc4MS44MTQ1NzknIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nOTEuMTEzMDc2JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtMTEwJy8+Cjx1c2UgeD0nOTguMTAwNjgyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtMTE0Jy8+Cjx1c2UgeD0nMTA1LjY5MzY1MycgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c1LTEwOCcvPgo8dXNlIHg9JzEwOC45NDUzMTQnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNS0xMTEnLz4KPHVzZSB4PScxMTQuNzk4MzA0JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtMTAzJy8+Cjx1c2UgeD0nMTIyLjgwNjM3NScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2czLTI3Jy8+Cjx1c2UgeD0nMTMyLjU0NTQ0MycgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2cxLTAnLz4KPHVzZSB4PScxNTAuNTY1ODEnIHk9Jy0zMC4yNDIyODknIHhsaW5rOmhyZWY9JyNnMi0xMTAnLz4KPHVzZSB4PScxNDQuNTAwNjAzJyB5PSctMjYuNjU1NzMzJyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PScxNDYuMjgyOTk3JyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnMi0xMDUnLz4KPHVzZSB4PScxNDkuMTY2MTM3JyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnNC02MScvPgo8dXNlIHg9JzE1NS43NTI2NDMnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2c0LTQ5Jy8+Cjx1c2UgeD0nMTYzLjc2MTcxOCcgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c1LTEwMScvPgo8dXNlIHg9JzE2OC45NjQzNzYnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNS0xMjAnLz4KPHVzZSB4PScxNzUuMTQyNTMyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtMTEyJy8+Cjx1c2UgeD0nMTgxLjY0NTg1NCcgeT0nLTMyLjE1NTIwNScgeGxpbms6aHJlZj0nI2cwLTIwJy8+Cjx1c2UgeD0nMTg3Ljk1NTU1MicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2cxLTAnLz4KPHVzZSB4PScxOTcuMjU0MDQ5JyB5PSctMjguNTY4NjE4JyB4bGluazpocmVmPScjZzAtMTYnLz4KPHVzZSB4PScyMDUuNTg5NDc1JyB5PSctMjMuMzg2MDI3JyB4bGluazpocmVmPScjZzMtMTIyJy8+Cjx1c2UgeD0nMjExLjU2MDA4MScgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2c0LTQwJy8+Cjx1c2UgeD0nMjE0Ljg1MzMzNScgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2cyLTExNCcvPgo8dXNlIHg9JzIxOC45MDk5MycgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2c0LTQxJy8+Cjx1c2UgeD0nMjExLjAyNzM2NScgeT0nLTIwLjMyMjIxNCcgeGxpbms6aHJlZj0nI2cyLTEwNScvPgo8dXNlIHg9JzIyNS4zNTc5NzknIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nMjM3LjMxMzE0JyB5PSctMjMuMzg2MDI3JyB4bGluazpocmVmPScjZzMtMjInLz4KPHJlY3QgeD0nMjA1LjU4OTQ3NScgeT0nLTE4LjUyNjE1NCcgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMzguNzY2NjI4Jy8+Cjx1c2UgeD0nMjIxLjQzMTU4NycgeT0nLTcuMDk3NjA2JyB4bGluazpocmVmPScjZzMtMjcnLz4KPHVzZSB4PScyNDUuNTUxNjE2JyB5PSctMjguNTY4NjE4JyB4bGluazpocmVmPScjZzAtMTcnLz4KPHVzZSB4PScyNTIuNjkxNTI5JyB5PSctMzIuMTU1MjA1JyB4bGluazpocmVmPScjZzAtMjEnLz4KPHVzZSB4PScyNjEuNjU3ODknIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nMjc5LjY3ODI1NycgeT0nLTMwLjI0MjI4OScgeGxpbms6aHJlZj0nI2cyLTExMCcvPgo8dXNlIHg9JzI3My42MTMwNScgeT0nLTI2LjY1NTczMycgeGxpbms6aHJlZj0nI2cwLTg4Jy8+Cjx1c2UgeD0nMjc1LjM5NTQ0NCcgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzItMTA1Jy8+Cjx1c2UgeD0nMjc4LjI3ODU4NCcgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzQtNjEnLz4KPHVzZSB4PScyODQuODY1MDknIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2c0LTQ5Jy8+Cjx1c2UgeD0nMjk5LjQ4MDE3NScgeT0nLTMwLjI0MjI4OScgeGxpbms6aHJlZj0nI2cyLTExNCcvPgo8dXNlIHg9JzI5Mi44NzQxNjUnIHk9Jy0yNi42NTU3MzMnIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzI5My43ODczMicgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzItMTA3Jy8+Cjx1c2UgeD0nMjk4LjQwODkzNicgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzQtNjEnLz4KPHVzZSB4PSczMDQuOTk1NDQzJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNC00OScvPgo8dXNlIHg9JzMxMC4xNDI3ODEnIHk9Jy0yOC41Njg2MTgnIHhsaW5rOmhyZWY9JyNnMC0xNicvPgo8dXNlIHg9JzMxOC40NzgyMDcnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnMy0xMjInLz4KPHVzZSB4PSczMjQuNDQ4ODE0JyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzQtNDAnLz4KPHVzZSB4PSczMjcuNzQyMDY3JyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzItMTA3Jy8+Cjx1c2UgeD0nMzMyLjM2MzY4MycgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2c0LTQxJy8+Cjx1c2UgeD0nMzIzLjkxNjA5OCcgeT0nLTIwLjMyMjIxNCcgeGxpbms6aHJlZj0nI2cyLTEwNScvPgo8dXNlIHg9JzMzOC44MTE3MzEnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nMzUwLjc2Njg5MicgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2czLTIyJy8+CjxyZWN0IHg9JzMxOC40NzgyMDcnIHk9Jy0xOC41MjYxNTQnIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzM5LjMzMTY0OCcvPgo8dXNlIHg9JzMzNC42MDI4MjknIHk9Jy03LjA5NzYwNicgeGxpbms6aHJlZj0nI2czLTI3Jy8+Cjx1c2UgeD0nMzU5LjAwNTM2OScgeT0nLTI4LjU2ODYxOCcgeGxpbms6aHJlZj0nI2cwLTE3Jy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
- buildMethodOfLikelihoodMaximizationEstimator(sample, r=0)¶
Estimate the distribution and the parameter distribution with the R-maxima method.
- Parameters:
- sampleM2-d sequence of float
Block maxima grouped in a sample of size
and dimension .- rint, , optional
Number of order statistics taken into account among the
stored ones.By default,
which means that all the maxima are used.
- Returns:
- result
DistributionFactoryLikelihoodResult The result class.
- result
Notes
The method estimates a GEV distribution parameterized by
from a given sample.The estimator
 is defined using the profile log-likelihood as detailed in
is defined using the profile log-likelihood as detailed in
buildMethodOfLikelihoodMaximization().The result class produced by the method provides:
the GEV distribution associated to
 ,
,the asymptotic distribution of
.
- buildMethodOfXiProfileLikelihood(sample, r=0)¶
Estimate the distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
Block maxima grouped in a sample of size
and dimension .- rint, ,
Number of largest order statistics taken into account among the
stored ones.By default,
which means that all the maxima are used.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution.
- distribution
Notes
The method estimates a GEV distribution parameterized by
from a given sample.The estimator
is defined using a nested numerical optimization of the log-likelihood:
where
 is detailed in equations (1) and (2) with
is detailed in equations (1) and (2) with  .
.If
then:
The starting point of the optimization is initialized from the probability weighted moments method, see [diebolt2008].
- buildMethodOfXiProfileLikelihoodEstimator(sample, r=0)¶
Estimate the distribution and the parameter distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
Block maxima grouped in a sample of size
and dimension .- rint, ,
Number of largest order statistics taken into account among the
stored ones.
The block maxima sample of dimension 1 from which
are estimated.By default,
which means that all the maxima are used.
- Returns:
- result
ProfileLikelihoodResult The result class.
- result
Notes
The method estimates a GEV distribution parameterized by
from a given sample.The estimator
is defined in buildMethodOfXiProfileLikelihood().The result class produced by the method provides:
the GEV distribution associated to
,the asymptotic distribution of
,the profile log-likelihood function
 ,
,the optimal profile log-likelihood value
 ,
,confidence intervals of level
 of .
of .
- buildReturnLevelEstimator(result, m)¶
Estimate a return level and its distribution from the GEV parameters.
- Parameters:
- result
DistributionFactoryResult Likelihood estimation result of a
GeneralizedExtremeValue- mfloat
The return period expressed in terms of number of blocks.
- result
- Returns:
- distribution
Distribution The asymptotic distribution of
 .
.
- distribution
Notes
Let
 be a random variable which follows a GEV distribution parameterized by
.
be a random variable which follows a GEV distribution parameterized by
.The
-block return level  is the level exceeded on average once every
blocks.
The -block return level can be translated into the annual-scale: if there
are
is the level exceeded on average once every
blocks.
The -block return level can be translated into the annual-scale: if there
are  blocks per year, then the
blocks per year, then the  -year return level
corresponds to the -bock return level where
-year return level
corresponds to the -bock return level where  .
.The
-block return level is defined as the quantile of order  of the GEV
distribution:
of the GEV
distribution:If
:(3)¶
![z_m = \mu - \frac{\sigma}{\xi} \left[ 1- (-\log(1-p))^{-\xi}\right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPScxNzQuNzk5NzMycHQnIGhlaWdodD0nMjMuNzYwNDAxcHQnIHZpZXdCb3g9JzEwNi44NzE2MzEgLTIzLjc2MDM5IDE3NC43OTk3MzIgMjMuNzYwNDAxJz4KPGRlZnM+CjxwYXRoIGlkPSdnMS0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzAtMicgZD0nTTIuNDE0OTQ0IDEzLjg1NjA0SDQuNzEwMzM2VjEzLjM3NzgzM0gyLjg5MzE1MVYwSDQuNzEwMzM2Vi0uNDc4MjA3SDIuNDE0OTQ0VjEzLjg1NjA0WicvPgo8cGF0aCBpZD0nZzAtMycgZD0nTTIuNTU4NDA2IDEzLjg1NjA0Vi0uNDc4MjA3SC4yNjMwMTRWMEgyLjA4MDE5OVYxMy4zNzc4MzNILjI2MzAxNFYxMy44NTYwNEgyLjU1ODQwNlonLz4KPHBhdGggaWQ9J2cyLTAnIGQ9J003Ljg3ODQ1Ni0yLjc0OTY4OUM4LjA4MTY5NC0yLjc0OTY4OSA4LjI5Njg4Ny0yLjc0OTY4OSA4LjI5Njg4Ny0yLjk4ODc5MlM4LjA4MTY5NC0zLjIyNzg5NSA3Ljg3ODQ1Ni0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyLTMuMjI3ODk1IC45OTIyNzktMy4yMjc4OTUgLjk5MjI3OS0yLjk4ODc5MlMxLjIwNzQ3Mi0yLjc0OTY4OSAxLjQxMDcxLTIuNzQ5Njg5SDcuODc4NDU2WicvPgo8cGF0aCBpZD0nZzUtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c1LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnNS00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2c1LTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnNS0xMDMnIGQ9J00xLjQyMjY2NS0yLjE2Mzg4NUMxLjk4NDU1OC0xLjc5MzI3NSAyLjQ2Mjc2NS0xLjc5MzI3NSAyLjU5NDI3MS0xLjc5MzI3NUMzLjY3MDIzNy0xLjc5MzI3NSA0LjQ3MTIzMy0yLjYwNjIyNyA0LjQ3MTIzMy0zLjUyNjc3NUM0LjQ3MTIzMy0zLjg0OTU2NCA0LjM3NTU5Mi00LjMwMzg2MSAzLjk5MzAyNi00LjY4NjQyNkM0LjQ1OTI3OC01LjE2NDYzMyA1LjAyMTE3MS01LjE2NDYzMyA1LjA4MDk0Ni01LjE2NDYzM0M1LjEyODc2Ny01LjE2NDYzMyA1LjE4ODU0My01LjE2NDYzMyA1LjIzNjM2NC01LjE0MDcyMkM1LjExNjgxMi01LjA5MjkwMiA1LjA1NzAzNi00Ljk3MzM1IDUuMDU3MDM2LTQuODQxODQzQzUuMDU3MDM2LTQuNjc0NDcxIDUuMTc2NTg4LTQuNTMxMDA5IDUuMzY3ODctNC41MzEwMDlDNS40NjM1MTItNC41MzEwMDkgNS42Nzg3MDUtNC41OTA3ODUgNS42Nzg3MDUtNC44NTM3OThDNS42Nzg3MDUtNS4wNjg5OTEgNS41MTEzMzMtNS40MDM3MzYgNS4wOTI5MDItNS40MDM3MzZDNC40NzEyMzMtNS40MDM3MzYgNC4wMDQ5ODEtNS4wMjExNzEgMy44Mzc2MDktNC44NDE4NDNDMy40Nzg5NTQtNS4xMTY4MTIgMy4wNjA1MjMtNS4yNzIyMjkgMi42MDYyMjctNS4yNzIyMjlDMS41MzAyNjItNS4yNzIyMjkgLjcyOTI2NS00LjQ1OTI3OCAuNzI5MjY1LTMuNTM4NzNDLjcyOTI2NS0yLjg1NzI4NSAxLjE0NzY5Ni0yLjQxNDk0NCAxLjI2NzI0OC0yLjMwNzM0N0MxLjEyMzc4Ni0yLjEyODAyIC45MDg1OTMtMS43ODEzMiAuOTA4NTkzLTEuMzE1MDY4Qy45MDg1OTMtLjYyMTY2OSAxLjMyNzAyNC0uMzIyNzkgMS40MjI2NjUtLjI2MzAxNEMuODcyNzI3LS4xMDc1OTcgLjMyMjc5IC4zMjI3OSAuMzIyNzkgLjk0NDQ1OEMuMzIyNzkgMS43NjkzNjUgMS40NDY1NzUgMi40NTA4MDkgMi45MTcwNjEgMi40NTA4MDlDNC4zMzk3MjYgMi40NTA4MDkgNS41MjMyODggMS44MTcxODYgNS41MjMyODggLjkyMDU0OEM1LjUyMzI4OCAuNjIxNjY5IDUuNDM5NjAxLS4wODM2ODYgNC43MjIyOTEtLjQ1NDI5NkM0LjExMjU3OC0uNzY1MTMxIDMuNTE0ODE5LS43NjUxMzEgMi40ODY2NzUtLjc2NTEzMUMxLjc1NzQxLS43NjUxMzEgMS42NzM3MjQtLjc2NTEzMSAxLjQ1ODUzMS0uOTkyMjc5QzEuMzM4OTc5LTEuMTExODMxIDEuMjMxMzgyLTEuMzM4OTc5IDEuMjMxMzgyLTEuNTkwMDM3QzEuMjMxMzgyLTEuNzkzMjc1IDEuMzAzMTEzLTEuOTk2NTEzIDEuNDIyNjY1LTIuMTYzODg1Wk0yLjYwNjIyNy0yLjA0NDMzNEMxLjU1NDE3Mi0yLjA0NDMzNCAxLjU1NDE3Mi0zLjI1MTgwNiAxLjU1NDE3Mi0zLjUyNjc3NUMxLjU1NDE3Mi0zLjc0MTk2OCAxLjU1NDE3Mi00LjIzMjEzIDEuNzU3NDEtNC41NTQ5MTlDMS45ODQ1NTgtNC45MDE2MTkgMi4zNDMyMTMtNS4wMjExNzEgMi41OTQyNzEtNS4wMjExNzFDMy42NDYzMjYtNS4wMjExNzEgMy42NDYzMjYtMy44MTM2OTkgMy42NDYzMjYtMy41Mzg3M0MzLjY0NjMyNi0zLjMyMzUzNyAzLjY0NjMyNi0yLjgzMzM3NSAzLjQ0MzA4OC0yLjUxMDU4NUMzLjIxNTk0LTIuMTYzODg1IDIuODU3Mjg1LTIuMDQ0MzM0IDIuNjA2MjI3LTIuMDQ0MzM0Wk0yLjkyOTAxNiAyLjE5OTc1MUMxLjc4MTMyIDIuMTk5NzUxIC45MDg1OTMgMS42MTM5NDggLjkwODU5MyAuOTMyNTAzQy45MDg1OTMgLjgzNjg2MiAuOTMyNTAzIC4zNzA2MSAxLjM4NjggLjA1OTc3NkMxLjY0OTgxMy0uMTA3NTk3IDEuNzU3NDEtLjEwNzU5NyAyLjU5NDI3MS0uMTA3NTk3QzMuNTg2NTUtLjEwNzU5NyA0LjkzNzQ4NC0uMTA3NTk3IDQuOTM3NDg0IC45MzI1MDNDNC45Mzc0ODQgMS42Mzc4NTggNC4wMjg4OTIgMi4xOTk3NTEgMi45MjkwMTYgMi4xOTk3NTFaJy8+CjxwYXRoIGlkPSdnNS0xMDgnIGQ9J00yLjA1NjI4OS04LjI5Njg4N0wuMzk0NTIxLTguMTY1MzhWLTcuODE4NjhDMS4yMDc0NzItNy44MTg2OCAxLjMwMzExMy03LjczNDk5NCAxLjMwMzExMy03LjE0OTE5MVYtLjg4NDY4MkMxLjMwMzExMy0uMzQ2NyAxLjE3MTYwNi0uMzQ2NyAuMzk0NTIxLS4zNDY3VjBDLjcyOTI2NS0uMDIzOTEgMS4zMTUwNjgtLjAyMzkxIDEuNjczNzI0LS4wMjM5MVMyLjYzMDEzNy0uMDIzOTEgMi45NjQ4ODIgMFYtLjM0NjdDMi4xOTk3NTEtLjM0NjcgMi4wNTYyODktLjM0NjcgMi4wNTYyODktLjg4NDY4MlYtOC4yOTY4ODdaJy8+CjxwYXRoIGlkPSdnNS0xMTEnIGQ9J001LjQ4NzQyMi0yLjU1ODQwNkM1LjQ4NzQyMi00LjEwMDYyMyA0LjMxNTgxNi01LjMzMjAwNSAyLjkyOTAxNi01LjMzMjAwNUMxLjQ5NDM5Ni01LjMzMjAwNSAuMzU4NjU1LTQuMDY0NzU3IC4zNTg2NTUtMi41NTg0MDZDLjM1ODY1NS0xLjAyODE0NCAxLjU1NDE3MiAuMTE5NTUyIDIuOTE3MDYxIC4xMTk1NTJDNC4zMjc3NzEgLjExOTU1MiA1LjQ4NzQyMi0xLjA1MjA1NSA1LjQ4NzQyMi0yLjU1ODQwNlpNMi45MjkwMTYtLjE0MzQ2MkMyLjQ4NjY3NS0uMTQzNDYyIDEuOTQ4NjkyLS4zMzQ3NDUgMS42MDE5OTMtLjkyMDU0OEMxLjI3OTIwMy0xLjQ1ODUzMSAxLjI2NzI0OC0yLjE2Mzg4NSAxLjI2NzI0OC0yLjY2NjAwMkMxLjI2NzI0OC0zLjEyMDI5OSAxLjI2NzI0OC0zLjg0OTU2NCAxLjYzNzg1OC00LjM4NzU0N0MxLjk3MjYwMy00LjkwMTYxOSAyLjQ5ODYzLTUuMDkyOTAyIDIuOTE3MDYxLTUuMDkyOTAyQzMuMzgzMzEzLTUuMDkyOTAyIDMuODg1NDMtNC44Nzc3MDkgNC4yMDgyMTktNC40MTE0NTdDNC41Nzg4MjktMy44NjE1MTkgNC41Nzg4MjktMy4xMDgzNDQgNC41Nzg4MjktMi42NjYwMDJDNC41Nzg4MjktMi4yNDc1NzIgNC41Nzg4MjktMS41MDYzNTEgNC4yNjc5OTUtLjk0NDQ1OEMzLjkzMzI1LS4zNzA2MSAzLjM4MzMxMy0uMTQzNDYyIDIuOTI5MDE2LS4xNDM0NjJaJy8+CjxwYXRoIGlkPSdnMy0yNCcgZD0nTTEuNjE3OTMzLTIuMzUxMTgzQzEuOTEyODI3LTIuMjM5NjAxIDIuMjA3NzIxLTIuMjM5NjAxIDIuMzgzMDY0LTIuMjM5NjAxQzIuNjU0MDQ3LTIuMjM5NjAxIDMuMTcyMTA1LTIuMjM5NjAxIDMuMTcyMTA1LTIuNTI2NTI2QzMuMTcyMTA1LTIuNzY1NjI5IDIuNzQxNzE5LTIuNzY1NjI5IDIuNDcwNzM1LTIuNzY1NjI5QzIuMzExMzMzLTIuNzY1NjI5IDIuMDY0MjU5LTIuNzY1NjI5IDEuNzUzNDI1LTIuNjYyMDE3QzEuNTc4MDgyLTIuODI5MzkgMS41MDYzNTEtMy4wNTI1NTMgMS41MDYzNTEtMy4yNzU3MTZDMS41MDYzNTEtMy43MjIwNDIgMS44MTcxODYtNC4yODc5MiAyLjM5OTAwNC00LjU2Njg3NEMyLjU3NDM0Ni00LjM4MzU2MiAyLjc4MTU2OS00LjM4MzU2MiAyLjk0ODk0MS00LjM4MzU2MkMzLjI1MTgwNi00LjM4MzU2MiAzLjcwNjEwMi00LjM5OTUwMiAzLjcwNjEwMi00LjY3MDQ4NkMzLjcwNjEwMi00LjkwOTU4OSAzLjI3NTcxNi00LjkwOTU4OSAyLjk5Njc2Mi00LjkwOTU4OUMyLjg2MTI3LTQuOTA5NTg5IDIuNzI1Nzc4LTQuOTA5NTg5IDIuNTAyNjE1LTQuODc3NzA5QzIuNDg2Njc1LTQuOTMzNDk5IDIuNDYyNzY1LTUuMDEzMiAyLjQ2Mjc2NS01LjExNjgxMkMyLjQ2Mjc2NS01LjIyODM5NCAyLjQ5NDY0NS01LjM2Mzg4NSAyLjQ5NDY0NS01LjM4Nzc5NkMyLjUwMjYxNS01LjM5NTc2NiAyLjUwMjYxNS01LjQyNzY0NiAyLjUwMjYxNS01LjQzNTYxNkMyLjUwMjYxNS01LjUwNzM0NyAyLjQ0NjgyNC01LjU1NTE2OCAyLjM5MTAzNC01LjU1NTE2OEMyLjIxNTY5MS01LjU1NTE2OCAyLjIxNTY5MS01LjE5NjUxMyAyLjIxNTY5MS01LjEyNDc4MkMyLjIxNTY5MS00Ljk3MzM1IDIuMjU1NTQyLTQuODM3ODU4IDIuMjYzNTEyLTQuODIxOTE4QzEuMzcwODU5LTQuNTkwNzg1IC44MjA5MjItMy45NTMxNzYgLjgyMDkyMi0zLjMyMzUzN0MuODIwOTIyLTIuOTI1MDMxIDEuMDM2MTE1LTIuNjU0MDQ3IDEuMzM4OTc5LTIuNDc4NzA1Qy40ODYxNzctMS45OTI1MjggLjE5MTI4My0xLjE4NzU0NyAuMTkxMjgzLS44MjA5MjJDLjE5MTI4My0uMDk1NjQxIC45MjQ1MzMgLjE2NzM3MiAxLjE3OTU3NyAuMjYzMDE0QzEuNjI1OTAzIC40MzAzODYgMS42NDE4NDMgLjQzMDM4NiAyLjAzMjM3OSAuNTY1ODc4QzIuMjIzNjYxIC42Mzc2MDkgMi41NDI0NjYgLjc1NzE2MSAyLjU5ODI1NyAuNzg5MDQxQzIuNzI1Nzc4IC44Njg3NDIgMi43MjU3NzggLjk4MDMyNCAyLjcyNTc3OCAxLjAyODE0NEMyLjcyNTc3OCAxLjE3MTYwNiAyLjYyMjE2NyAxLjQwMjc0IDIuMzY3MTIzIDEuNDAyNzRDMi4zMDMzNjIgMS40MDI3NCAxLjk3NjU4OCAxLjM4NjggMS42NTc3ODMgMS4xOTU1MTdDMS41NzgwODIgMS4xMzk3MjYgMS41NzAxMTIgMS4xMzE3NTYgMS41MzAyNjIgMS4xMzE3NTZDMS40NDI1OSAxLjEzMTc1NiAxLjQxODY4IDEuMjExNDU3IDEuNDE4NjggMS4yNDMzMzdDMS40MTg2OCAxLjM3MDg1OSAxLjkyODc2NyAxLjYyNTkwMyAyLjM3NTA5MyAxLjYyNTkwM0MyLjkwMTEyMSAxLjYyNTkwMyAzLjIyNzg5NSAxLjEyMzc4NiAzLjIyNzg5NSAuNzU3MTYxQzMuMjI3ODk1IC42MTM2OTkgMy4xNzIxMDUgLjQ2MjI2NyAzLjA3NjQ2MyAuMzUwNjg1QzIuOTcyODUyIC4yMzkxMDMgMi44NjkyNCAuMTk5MjUzIDIuNDIyOTE0IC4wMzk4NTFDMS43Mjk1MTQtLjIwNzIyMyAxLjIxMTQ1Ny0uMzkwNTM1IDEuMDgzOTM1LS40NjIyNjdDLjgyODg5Mi0uNTk3NzU4IC42NjE1MTktLjc4OTA0MSAuNjYxNTE5LTEuMDUyMDU1Qy42NjE1MTktMS4zNzg4MjkgLjk1NjQxMy0xLjk5MjUyOCAxLjYxNzkzMy0yLjM1MTE4M1pNMy40MDMyMzgtNC42NDY1NzVDMy4zMjM1MzctNC42MzA2MzUgMy4yNDM4MzYtNC42MDY3MjUgMi45NTY5MTItNC42MDY3MjVDMi43ODk1MzktNC42MDY3MjUgMi43NTc2NTktNC42MDY3MjUgMi42NjIwMTctNC42NTQ1NDVDMi43ODk1MzktNC42ODY0MjYgMi44NjkyNC00LjY4NjQyNiAzLjAxMjcwMi00LjY4NjQyNkMzLjIyNzg5NS00LjY4NjQyNiAzLjI4MzY4Ni00LjY3ODQ1NiAzLjQwMzIzOC00LjY1NDU0NVYtNC42NDY1NzVaTTIuODY5MjQtMi41MDI2MTVDMi43OTc1MDktMi40ODY2NzUgMi43MTc4MDgtMi40NjI3NjUgMi40MDY5NzQtMi40NjI3NjVDMi4yNTU1NDItMi40NjI3NjUgMi4xNzU4NDEtMi40NjI3NjUgMi4wNDgzMTktMi41MDI2MTVDMi4yMjM2NjEtMi41NDI0NjYgMi4zMTkzMDMtMi41NDI0NjYgMi40NjI3NjUtMi41NDI0NjZDMi42OTM4OTgtMi41NDI0NjYgMi43NTc2NTktMi41MzQ0OTYgMi44NjkyNC0yLjUxMDU4NVYtMi41MDI2MTVaJy8+CjxwYXRoIGlkPSdnMy0xMDknIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuNzQ1NDU1LTEuOTI4NzY3IDEuNzkzMjc1LTIuMTIwMDUgMS44MDkyMTUtMi4xOTk3NTFDMS44MjUxNTYtMi4yMzk2MDEgMi4wODgxNjktMi43NTc2NTkgMi40Mzg4NTQtMy4wMjA2NzJDMi43MDk4MzgtMy4yMjc4OTUgMi45NzI4NTItMy4yOTE2NTYgMy4xOTYwMTUtMy4yOTE2NTZDMy40OTA5MDktMy4yOTE2NTYgMy42NTAzMTEtMy4xMTYzMTQgMy42NTAzMTEtMi43NDk2ODlDMy42NTAzMTEtMi41NTg0MDYgMy42MDI0OTEtMi4zNzUwOTMgMy41MTQ4MTktMi4wMTY0MzhDMy40NTkwMjktMS44MDkyMTUgMy4zMjM1MzctMS4yNzUyMTggMy4yNzU3MTYtMS4wNjAwMjVMMy4xNTYxNjQtLjU4MTgxOEMzLjExNjMxNC0uNDQ2MzI2IDMuMDYwNTIzLS4yMDcyMjMgMy4wNjA1MjMtLjE2NzM3MkMzLjA2MDUyMyAuMDE1OTQgMy4yMTE5NTUgLjA3OTcwMSAzLjMxNTU2NyAuMDc5NzAxQzMuNDU5MDI5IC4wNzk3MDEgMy41Nzg1OC0uMDE1OTQgMy42MzQzNzEtLjExMTU4MkMzLjY1ODI4MS0uMTU5NDAyIDMuNzIyMDQyLS40MzAzODYgMy43NjE4OTMtLjU5Nzc1OEwzLjk0NTIwNS0xLjMwNzA5OEMzLjk2OTExNi0xLjQyNjY1IDQuMDQ4ODE3LTEuNzI5NTE0IDQuMDcyNzI3LTEuODQ5MDY2QzQuMTg0MzA5LTIuMjc5NDUyIDQuMTg0MzA5LTIuMjg3NDIyIDQuMzY3NjIxLTIuNTUwNDM2QzQuNjMwNjM1LTIuOTQwOTcxIDUuMDA1MjMtMy4yOTE2NTYgNS41MzkyMjgtMy4yOTE2NTZDNS44MjYxNTItMy4yOTE2NTYgNS45OTM1MjQtMy4xMjQyODQgNS45OTM1MjQtMi43NDk2ODlDNS45OTM1MjQtMi4zMTEzMzMgNS42NTg3OC0xLjM5NDc3IDUuNTA3MzQ3LTEuMDEyMjA0QzUuNDI3NjQ2LS44MDQ5ODEgNS40MDM3MzYtLjc0OTE5MSA1LjQwMzczNi0uNTk3NzU4QzUuNDAzNzM2LS4xNDM0NjIgNS43NzgzMzEgLjA3OTcwMSA2LjEyMTA0NiAuMDc5NzAxQzYuOTAyMTE3IC4wNzk3MDEgNy4yMjg4OTItMS4wMzYxMTUgNy4yMjg4OTItMS4xMzk3MjZDNy4yMjg4OTItMS4yMTk0MjcgNy4xNjUxMzEtMS4yNDMzMzcgNy4xMDkzNC0xLjI0MzMzN0M3LjAxMzY5OS0xLjI0MzMzNyA2Ljk5Nzc1OC0xLjE4NzU0NyA2Ljk3Mzg0OC0xLjEwNzg0NkM2Ljc4MjU2NS0uNDQ2MzI2IDYuNDQ3ODIxLS4xNDM0NjIgNi4xNDQ5NTYtLjE0MzQ2MkM2LjAxNzQzNS0uMTQzNDYyIDUuOTUzNjc0LS4yMjMxNjMgNS45NTM2NzQtLjQwNjQ3NlM2LjAxNzQzNS0uNzY1MTMxIDYuMDk3MTM2LS45NjQzODRDNi4yMTY2ODctMS4yNjcyNDggNi41NjczNzItMi4xODM4MTEgNi41NjczNzItMi42MzAxMzdDNi41NjczNzItMy4yMjc4OTUgNi4xNTI5MjctMy41MTQ4MTkgNS41NzkwNzgtMy41MTQ4MTlDNS4wMjkxNDEtMy41MTQ4MTkgNC41NzQ4NDQtMy4yMjc4OTUgNC4yMTYxODktMi43MzM3NDhDNC4xNTI0MjgtMy4zNzEzNTcgMy42NDIzNDEtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi44NjEyNy0zLjUxNDgxOSAyLjM3NTA5My0zLjM4NzI5OCAxLjkzNjczNy0yLjgxMzQ1QzEuODgwOTQ2LTMuMjkxNjU2IDEuNDk4MzgxLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44NDQ4MzItMy41MTQ4MTkgLjY0NTU3OS0zLjM0NzQ0NyAuNTEwMDg3LTMuMDc2NDYzQy4zMTg4MDQtMi43MDE4NjggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c0LTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnNC0yNCcgZD0nTTMuMTIwMjk5IC4wNTk3NzZMMS44NjUwMDYtLjQ0MjM0MUMxLjU1NDE3Mi0uNTYxODkzIC44MzY4NjItLjg0ODgxNyAuODM2ODYyLTEuNTY2MTI3Qy44MzY4NjItMi41OTQyNzEgMi4wOTIxNTQtMy42MzQzNzEgMi4zNDMyMTMtMy42MzQzNzFDMi4zNjcxMjMtMy42MzQzNzEgMi40NzQ3Mi0zLjYxMDQ2MSAyLjUxMDU4NS0zLjU5ODUwNkMyLjgzMzM3NS0zLjUwMjg2NCAzLjE0NDIwOS0zLjUwMjg2NCAzLjM1OTQwMi0zLjUwMjg2NEMzLjczMDAxMi0zLjUwMjg2NCA0LjQzNTM2Ny0zLjUwMjg2NCA0LjQzNTM2Ny0zLjg0OTU2NEM0LjQzNTM2Ny00LjExMjU3OCA0LjAwNDk4MS00LjE0ODQ0MyAzLjQ5MDkwOS00LjE0ODQ0M0MzLjI1MTgwNi00LjE0ODQ0MyAyLjkyOTAxNi00LjE0ODQ0MyAyLjQ5ODYzLTQuMDA0OTgxQzIuMjExNzA2LTQuMjQ0MDg1IDIuMDkyMTU0LTQuNjI2NjUgMi4wOTIxNTQtNC45ODUzMDVDMi4wOTIxNTQtNS42NDI4MzkgMi41MjI1NC02LjU3NTM0MiAzLjQ2Njk5OS03LjAxNzY4NEMzLjY4MjE5Mi02Ljc2NjYyNSAzLjk2OTExNi02Ljc2NjYyNSA0LjIyMDE3NC02Ljc2NjYyNUM0LjUxOTA1NC02Ljc2NjYyNSA1LjI0ODMxOS02Ljc2NjYyNSA1LjI0ODMxOS03LjExMzMyNUM1LjI0ODMxOS03LjQxMjIwNCA0LjY3NDQ3MS03LjQxMjIwNCA0LjI5MTkwNS03LjQxMjIwNEM0LjA1MjgwMi03LjQxMjIwNCAzLjg3MzQ3NC03LjQxMjIwNCAzLjUzODczLTcuMzUyNDI4QzMuNDc4OTU0LTcuNDk1ODkgMy40NjY5OTktNy41MTk4MDEgMy40NjY5OTktNy43ODI4MTRDMy40NjY5OTktNy45OTgwMDcgMy41MTQ4MTktOC4xNjUzOCAzLjUxNDgxOS04LjIwMTI0NUMzLjUxNDgxOS04LjI3Mjk3NiAzLjQ1NTA0NC04LjMyMDc5NyAzLjM5NTI2OC04LjMyMDc5N0MzLjIwMzk4NS04LjMyMDc5NyAzLjIwMzk4NS03Ljg3ODQ1NiAzLjIwMzk4NS03Ljc4MjgxNEMzLjIwMzk4NS03LjYxNTQ0MiAzLjIxNTk0LTcuNDQ4MDcgMy4yODc2NzEtNy4yOTI2NTNDMS44NTMwNTEtNi44NzQyMjIgMS4yMTk0MjctNS44NTgwMzIgMS4yMTk0MjctNS4wODA5NDZDMS4yMTk0MjctNC4zNjM2MzYgMS42OTc2MzQtMy45NjkxMTYgMi4wMjA0MjMtMy43ODk3ODhDLjc4OTA0MS0zLjEyMDI5OSAuMjYzMDE0LTEuOTAwODcyIC4yNjMwMTQtMS4yNTUyOTNDLjI2MzAxNC0uMjE1MTkzIDEuMjA3NDcyIC4xNTU0MTcgMS42Mzc4NTggLjMzNDc0NUwyLjcxMzgyMyAuNzY1MTMxQzMuMDEyNzAyIC44NzI3MjcgMy41MDI4NjQgMS4wNzU5NjUgMy41ODY1NSAxLjEyMzc4NkMzLjcwNjEwMiAxLjIwNzQ3MiAzLjgwMTc0MyAxLjM1MDkzNCAzLjgwMTc0MyAxLjU0MjIxN0MzLjgwMTc0MyAxLjc5MzI3NSAzLjYxMDQ2MSAyLjE5OTc1MSAzLjE5MjAzIDIuMTk5NzUxQzMuMDEyNzAyIDIuMTk5NzUxIDIuNjE4MTgyIDIuMTUxOTMgMi4xODc3OTYgMS44MjkxNDFDMi4xMDQxMSAxLjc1NzQxIDIuMDkyMTU0IDEuNzQ1NDU1IDIuMDQ0MzM0IDEuNzQ1NDU1QzEuOTg0NTU4IDEuNzQ1NDU1IDEuOTI0NzgyIDEuNzkzMjc1IDEuOTI0NzgyIDEuODY1MDA2QzEuOTI0NzgyIDEuOTk2NTEzIDIuNTQ2NDUxIDIuNDM4ODU0IDMuMTkyMDMgMi40Mzg4NTRDMy45NTcxNjEgMi40Mzg4NTQgNC40MjM0MTIgMS42OTc2MzQgNC40MjM0MTIgMS4xODM1NjJDNC40MjM0MTIgLjgxMjk1MSA0LjIyMDE3NCAuNTE0MDcyIDMuODM3NjA5IC4zNDY3TDMuMTIwMjk5IC4wNTk3NzZaTTMuNzMwMDEyLTcuMTEzMzI1QzMuOTMzMjUtNy4xNzMxMDEgNC4xNDg0NDMtNy4xNzMxMDEgNC4zMDM4NjEtNy4xNzMxMDFDNC42OTgzODEtNy4xNzMxMDEgNC43MzQyNDctNy4xNjExNDYgNC45NzMzNS03LjEwMTM3QzQuODI5ODg4LTcuMDQxNTk0IDQuNzM0MjQ3LTcuMDA1NzI5IDQuMjMyMTMtNy4wMDU3MjlDNC4wMDQ5ODEtNy4wMDU3MjkgMy44NjE1MTktNy4wMDU3MjkgMy43MzAwMTItNy4xMTMzMjVaTTIuNzg1NTU0LTMuODM3NjA5QzMuMDcyNDc4LTMuOTA5MzQgMy4zMzU0OTItMy45MDkzNCAzLjQ3ODk1NC0zLjkwOTM0QzMuODczNDc0LTMuOTA5MzQgMy44OTczODUtMy44OTczODUgNC4xNjAzOTktMy44Mzc2MDlDNC4wMjg4OTItMy43Nzc4MzMgMy45MjEyOTUtMy43NDE5NjggMy40MDcyMjMtMy43NDE5NjhDMy4xMjAyOTktMy43NDE5NjggMy4wMDA3NDctMy43NDE5NjggMi43ODU1NTQtMy44Mzc2MDlaJy8+CjxwYXRoIGlkPSdnNC0yNycgZD0nTTYuMDczMjI1LTQuNTA3MDk4QzYuMjI4NjQzLTQuNTA3MDk4IDYuNjIzMTYzLTQuNTA3MDk4IDYuNjIzMTYzLTQuODg5NjY0QzYuNjIzMTYzLTUuMTUyNjc3IDYuMzk2MDE1LTUuMTUyNjc3IDYuMTgwODIyLTUuMTUyNjc3SDMuNTM4NzNDMS43NDU0NTUtNS4xNTI2NzcgLjQ1NDI5Ni0zLjE1NjE2NCAuNDU0Mjk2LTEuNzQ1NDU1Qy40NTQyOTYtLjcyOTI2NSAxLjExMTgzMSAuMTE5NTUyIDIuMTg3Nzk2IC4xMTk1NTJDMy41OTg1MDYgLjExOTU1MiA1LjE0MDcyMi0xLjM5ODc1NSA1LjE0MDcyMi0zLjE5MjAzQzUuMTQwNzIyLTMuNjU4MjgxIDUuMDMzMTI2LTQuMTEyNTc4IDQuNzQ2MjAyLTQuNTA3MDk4SDYuMDczMjI1Wk0yLjE5OTc1MS0uMTE5NTUyQzEuNTkwMDM3LS4xMTk1NTIgMS4xNDc2OTYtLjU4NTgwMyAxLjE0NzY5Ni0xLjQxMDcxQzEuMTQ3Njk2LTIuMTI4MDIgMS41NzgwODItNC41MDcwOTggMy4zMzU0OTItNC41MDcwOThDMy44NDk1NjQtNC41MDcwOTggNC40MjM0MTItNC4yNTYwNCA0LjQyMzQxMi0zLjMzNTQ5MkM0LjQyMzQxMi0yLjkxNzA2MSA0LjIzMjEzLTEuOTEyODI3IDMuODEzNjk5LTEuMjE5NDI3QzMuMzgzMzEzLS41MTQwNzIgMi43Mzc3MzMtLjExOTU1MiAyLjE5OTc1MS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzQtMTEyJyBkPSdNLjUxNDA3MiAxLjUxODMwNkMuNDMwMzg2IDEuODc2OTYxIC4zODI1NjUgMS45NzI2MDMtLjEwNzU5NyAxLjk3MjYwM0MtLjI1MTA1OSAxLjk3MjYwMy0uMzcwNjEgMS45NzI2MDMtLjM3MDYxIDIuMTk5NzUxQy0uMzcwNjEgMi4yMjM2NjEtLjM1ODY1NSAyLjMxOTMwMy0uMjI3MTQ4IDIuMzE5MzAzQy0uMDcxNzMxIDIuMzE5MzAzIC4wOTU2NDEgMi4yOTUzOTIgLjI1MTA1OSAyLjI5NTM5MkguNzY1MTMxQzEuMDE2MTg5IDIuMjk1MzkyIDEuNjI1OTAzIDIuMzE5MzAzIDEuODc2OTYxIDIuMzE5MzAzQzEuOTQ4NjkyIDIuMzE5MzAzIDIuMDkyMTU0IDIuMzE5MzAzIDIuMDkyMTU0IDIuMTA0MTFDMi4wOTIxNTQgMS45NzI2MDMgMi4wMDg0NjggMS45NzI2MDMgMS44MDUyMyAxLjk3MjYwM0MxLjI1NTI5MyAxLjk3MjYwMyAxLjIxOTQyNyAxLjg4ODkxNyAxLjIxOTQyNyAxLjc5MzI3NUMxLjIxOTQyNyAxLjY0OTgxMyAxLjc1NzQxLS40MDY0NzYgMS44MjkxNDEtLjY4MTQ0NUMxLjk2MDY0OC0uMzQ2NyAyLjI4MzQzNyAuMTE5NTUyIDIuOTA1MTA2IC4xMTk1NTJDNC4yNTYwNCAuMTE5NTUyIDUuNzE0NTctMS42Mzc4NTggNS43MTQ1Ny0zLjM5NTI2OEM1LjcxNDU3LTQuNDk1MTQzIDUuMDkyOTAyLTUuMjcyMjI5IDQuMTk2MjY0LTUuMjcyMjI5QzMuNDMxMTMzLTUuMjcyMjI5IDIuNzg1NTU0LTQuNTMxMDA5IDIuNjU0MDQ3LTQuMzYzNjM2QzIuNTU4NDA2LTQuOTYxMzk1IDIuMDkyMTU0LTUuMjcyMjI5IDEuNjEzOTQ4LTUuMjcyMjI5QzEuMjY3MjQ4LTUuMjcyMjI5IC45OTIyNzktNS4xMDQ4NTcgLjc2NTEzMS00LjY1MDU2Qy41NDk5MzgtNC4yMjAxNzQgLjM4MjU2NS0zLjQ5MDkwOSAuMzgyNTY1LTMuNDQzMDg4Uy40MzAzODYtMy4zMzU0OTIgLjUxNDA3Mi0zLjMzNTQ5MkMuNjA5NzE0LTMuMzM1NDkyIC42MjE2NjktMy4zNDc0NDcgLjY5MzQtMy42MjI0MTZDLjg3MjcyNy00LjMyNzc3MSAxLjA5OTg3NS01LjAzMzEyNiAxLjU3ODA4Mi01LjAzMzEyNkMxLjg1MzA1MS01LjAzMzEyNiAxLjk0ODY5Mi00Ljg0MTg0MyAxLjk0ODY5Mi00LjQ4MzE4OEMxLjk0ODY5Mi00LjE5NjI2NCAxLjkxMjgyNy00LjA3NjcxMiAxLjg2NTAwNi0zLjg2MTUxOUwuNTE0MDcyIDEuNTE4MzA2Wk0yLjU4MjMxNi0zLjczMDAxMkMyLjY2NjAwMi00LjA2NDc1NyAzLjAwMDc0Ny00LjQxMTQ1NyAzLjE5MjAzLTQuNTc4ODI5QzMuMzIzNTM3LTQuNjk4MzgxIDMuNzE4MDU3LTUuMDMzMTI2IDQuMTcyMzU0LTUuMDMzMTI2QzQuNjk4MzgxLTUuMDMzMTI2IDQuOTM3NDg0LTQuNTA3MDk4IDQuOTM3NDg0LTMuODg1NDNDNC45Mzc0ODQtMy4zMTE1ODIgNC42MDI3NC0xLjk2MDY0OCA0LjMwMzg2MS0xLjMzODk3OUM0LjAwNDk4MS0uNjkzNCAzLjQ1NTA0NC0uMTE5NTUyIDIuOTA1MTA2LS4xMTk1NTJDMi4wOTIxNTQtLjExOTU1MiAxLjk2MDY0OC0xLjE0NzY5NiAxLjk2MDY0OC0xLjE5NTUxN0MxLjk2MDY0OC0xLjIzMTM4MiAxLjk4NDU1OC0xLjMyNzAyNCAxLjk5NjUxMy0xLjM4NjhMMi41ODIzMTYtMy43MzAwMTJaJy8+CjxwYXRoIGlkPSdnNC0xMjInIGQ9J00xLjUxODMwNi0uOTY4MzY5QzIuMDMyMzc5LTEuNTU0MTcyIDIuNDUwODA5LTEuOTI0NzgyIDMuMDQ4NTY4LTIuNDYyNzY1QzMuNzY1ODc4LTMuMDg0NDMzIDQuMDc2NzEyLTMuMzgzMzEzIDQuMjQ0MDg1LTMuNTYyNjRDNS4wODA5NDYtNC4zODc1NDcgNS40OTkzNzctNS4wODA5NDYgNS40OTkzNzctNS4xNzY1ODhTNS40MDM3MzYtNS4yNzIyMjkgNS4zNzk4MjYtNS4yNzIyMjlDNS4yOTYxMzktNS4yNzIyMjkgNS4yNzIyMjktNS4yMjQ0MDggNS4yMTI0NTMtNS4xNDA3MjJDNC45MTM1NzQtNC42MjY2NSA0LjYyNjY1LTQuMzc1NTkyIDQuMzE1ODE2LTQuMzc1NTkyQzQuMDY0NzU3LTQuMzc1NTkyIDMuOTMzMjUtNC40ODMxODggMy43MDYxMDItNC43NzAxMTJDMy40NTUwNDQtNS4wNjg5OTEgMy4yNTE4MDYtNS4yNzIyMjkgMi45MDUxMDYtNS4yNzIyMjlDMi4wMzIzNzktNS4yNzIyMjkgMS41MDYzNTEtNC4xODQzMDkgMS41MDYzNTEtMy45MzMyNUMxLjUwNjM1MS0zLjg5NzM4NSAxLjUxODMwNi0zLjgyNTY1NCAxLjYyNTkwMy0zLjgyNTY1NEMxLjcyMTU0NC0zLjgyNTY1NCAxLjczMzQ5OS0zLjg3MzQ3NCAxLjc2OTM2NS0zLjk1NzE2MUMxLjk3MjYwMy00LjQzNTM2NyAyLjU0NjQ1MS00LjUxOTA1NCAyLjc3MzU5OS00LjUxOTA1NEMzLjAyNDY1OC00LjUxOTA1NCAzLjI2Mzc2MS00LjQzNTM2NyAzLjUxNDgxOS00LjMyNzc3MUMzLjk2OTExNi00LjEzNjQ4OCA0LjE2MDM5OS00LjEzNjQ4OCA0LjI3OTk1LTQuMTM2NDg4QzQuMzYzNjM2LTQuMTM2NDg4IDQuNDExNDU3LTQuMTM2NDg4IDQuNDcxMjMzLTQuMTQ4NDQzQzQuMDc2NzEyLTMuNjgyMTkyIDMuNDMxMTMzLTMuMTA4MzQ0IDIuODkzMTUxLTIuNjE4MTgyTDEuNjg1Njc5LTEuNTA2MzUxQy45NTY0MTMtLjc2NTEzMSAuNTE0MDcyLS4wNTk3NzYgLjUxNDA3MiAuMDIzOTFDLjUxNDA3MiAuMDk1NjQxIC41NzM4NDggLjExOTU1MiAuNjQ1NTc5IC4xMTk1NTJTLjcyOTI2NSAuMTA3NTk3IC44MTI5NTEtLjAzNTg2NkMxLjAwNDIzNC0uMzM0NzQ1IDEuMzg2OC0uNzc3MDg2IDEuODI5MTQxLS43NzcwODZDMi4wODAxOTktLjc3NzA4NiAyLjE5OTc1MS0uNjkzNCAyLjQzODg1NC0uMzk0NTIxQzIuNjY2MDAyLS4xMzE1MDcgMi44NjkyNCAuMTE5NTUyIDMuMjUxODA2IC4xMTk1NTJDNC40MjM0MTIgLjExOTU1MiA1LjA5MjkwMi0xLjM5ODc1NSA1LjA5MjkwMi0xLjY3MzcyNEM1LjA5MjkwMi0xLjcyMTU0NCA1LjA4MDk0Ni0xLjc5MzI3NSA0Ljk2MTM5NS0xLjc5MzI3NUM0Ljg2NTc1My0xLjc5MzI3NSA0Ljg1Mzc5OC0xLjc0NTQ1NSA0LjgxNzkzMy0xLjYyNTkwM0M0LjU1NDkxOS0uOTIwNTQ4IDMuODQ5NTY0LS42MzM2MjQgMy4zODMzMTMtLjYzMzYyNEMzLjEzMjI1NC0uNjMzNjI0IDIuODkzMTUxLS43MTczMSAyLjY0MjA5Mi0uODI0OTA3QzIuMTYzODg1LTEuMDE2MTg5IDIuMDMyMzc5LTEuMDE2MTg5IDEuODc2OTYxLTEuMDE2MTg5QzEuNzU3NDEtMS4wMTYxODkgMS42MjU5MDMtMS4wMTYxODkgMS41MTgzMDYtLjk2ODM2OVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzEwNi44NzE2MzEnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNC0xMjInLz4KPHVzZSB4PScxMTIuMzA5NTIyJyB5PSctOC43MzE5OTUnIHhsaW5rOmhyZWY9JyNnMy0xMDknLz4KPHVzZSB4PScxMjMuNjE5MDA5JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtNjEnLz4KPHVzZSB4PScxMzYuMDQ0NDknIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNC0yMicvPgo8dXNlIHg9JzE0NS43NDQxMjQnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMTU4Ljg5NDc5OCcgeT0nLTE4LjYxMzAxNycgeGxpbms6aHJlZj0nI2c0LTI3Jy8+CjxyZWN0IHg9JzE1OC44OTQ3OTgnIHk9Jy0xMy43NTMxNDQnIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzcuMDgyNDA0Jy8+Cjx1c2UgeD0nMTU5LjU5MDc4MicgeT0nLTIuMzI0NTk2JyB4bGluazpocmVmPScjZzQtMjQnLz4KPHVzZSB4PScxNjkuMTY1MjE0JyB5PSctMjAuMjA5MDIxJyB4bGluazpocmVmPScjZzAtMicvPgo8dXNlIHg9JzE3NC4xNDY1NDknIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzE4Mi42NTYyMDMnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMTk0LjYxMTM2MycgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c1LTQwJy8+Cjx1c2UgeD0nMTk5LjE2MzY4OScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScyMTAuNDU0Njg0JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtMTA4Jy8+Cjx1c2UgeD0nMjEzLjcwNjM0NScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c1LTExMScvPgo8dXNlIHg9JzIxOS41NTkzMzUnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS0xMDMnLz4KPHVzZSB4PScyMjUuNTc0OTA5JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtNDAnLz4KPHVzZSB4PScyMzAuMTI3MjM0JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtNDknLz4KPHVzZSB4PScyMzguNjM2ODg4JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzI1MC41OTIwNDknIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNC0xMTInLz4KPHVzZSB4PScyNTYuNDY3MTkyJyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtNDEnLz4KPHVzZSB4PScyNjEuMDE5NTE3JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtNDEnLz4KPHVzZSB4PScyNjUuNTcxODQzJyB5PSctMTUuNDYxNDQ0JyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzI3Mi4xNTgzNScgeT0nLTE1LjQ2MTQ0NCcgeGxpbms6aHJlZj0nI2czLTI0Jy8+Cjx1c2UgeD0nMjc2LjY5MDAxNicgeT0nLTIwLjIwOTAyMScgeGxpbms6aHJlZj0nI2cwLTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
If
:(4)¶

The estimator
of is deduced from the estimator
of .The asymptotic distribution of
 is obtained by the Delta method from the asymptotic distribution of
. It is a normal distribution with mean and variance:
is obtained by the Delta method from the asymptotic distribution of
. It is a normal distribution with mean and variance:
where
 and
and  is the asymptotic covariance of .
is the asymptotic covariance of .
- buildReturnLevelProfileLikelihood(sample, m)¶
Estimate a return level and its distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1.
- Returns:
- distribution
Normal The asymptotic distribution of
.
- distribution
Notes
Let
be a random variable which follows a GEV distribution parameterized by
.The
-return level is defined in buildReturnLevelEstimator().The estimator is defined using a nested numerical optimization of the log-likelihood:

where
 is the log-likelihood detailed in (1) and (2) with and where we substitued
for using equations (3) or (4).
is the log-likelihood detailed in (1) and (2) with and where we substitued
for using equations (3) or (4).The estimator
of is defined by:
The asymptotic distribution of
is normal.The starting point of the optimization is initialized from the regular maximum likelihood method.
- buildReturnLevelProfileLikelihoodEstimator(sample, m)¶
Estimate
and its distribution with the profile likelihood.- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1.
- mfloat
The return period expressed in terms of number of blocks.
- Returns:
- result
ProfileLikelihoodResult The result class.
- result
Notes
Let
be a random variable which follows a GEV distribution parameterized by
.The
-block return level is defined in buildReturnLevelEstimator(). The profile log-likelihood is defined in
is defined in buildReturnLevelProfileLikelihood().The estimator of
 is defined by:
is defined by:
The result class produced by the method provides:
the GEV distribution associated to
,the asymptotic distribution of
,the profile log-likelihood function
 ,
,the optimal profile log-likelihood value
 ,
,confidence intervals of level
of .
- buildTimeVarying(*args)¶
Estimate a non stationary GEV from a time-dependent parametric model.
- Parameters:
- sample2-d sequence of float
The block maxima grouped in a sample of size
and one dimension.- timeStamps2-d sequence of float
Values of
 .
.- basis
Basis Functional basis respectively for
 ,
,  and
and  .
.- muIndicessequence of int, optional
Indices of basis terms considered for parameter
- sigmaIndicessequence of int, optional
Indices of basis terms considered for parameter
- xiIndicessequence of int, optional
Indices of basis terms considered for parameter
- muLink
Function, optional The
function.By default, the identity function.
- sigmaLink
Function, optional The
function.By default, the identity function.
- xiLink
Function, optional The
function.By default, the identity function.
- initializationMethodstr, optional
The initialization method for the optimization problem: Gumbel or Static.
By default, the method Gumbel (see
ResourceMap, key GeneralizedExtremeValueFactory-InitializationMethod).- normalizationMethodstr, optional
The data normalization method: CenterReduce, MinMax or None.
By default, the method MinMax (see
ResourceMap, key GeneralizedExtremeValueFactory-NormalizationMethod).
- Returns:
- result
TimeVaryingResult The result class.
- result
Notes
Let
 be a non stationary GEV distribution:
be a non stationary GEV distribution:
We denote by
 the values of
on the time stamps
the values of
on the time stamps  .
.For numerical reasons, it is recommended to normalize the time stamps. The following mapping is applied:

and with three ways of defining
 :
:the CenterReduce method where
 is the mean time
stamps
and
is the mean time
stamps
and  is the standard deviation of the time stamps;
is the standard deviation of the time stamps;the MinMax method where
 is the first time and
is the first time and  the
range of the time stamps. This is the default method;
the
range of the time stamps. This is the default method;the None method where
 and
and  : in that case, data are not
normalized.
: in that case, data are not
normalized.
If we denote by
is a component of ,
then can be written as a function of :
where:
 is the size of the functional basis involved in the modelling of
,
is the size of the functional basis involved in the modelling of
,- is usually referred to as the inverse-link function of
the parameter ,
each
 is a scalar function
is a scalar function  ,
,each
 .
.
We denote by
 ,
,  and
and  the size of the functional basis of
, and respectively. We denote by
the size of the functional basis of
, and respectively. We denote by
 the complete vector of parameters.
the complete vector of parameters.The estimator of
maximizes the likelihood of the non stationary model which is defined by:
where
 denotes the GEV density function with parameters
denotes the GEV density function with parameters
 evaluated at
evaluated at  .
.Then, if none of the
 is zero, the log-likelihood is defined by:
is zero, the log-likelihood is defined by:![\ell (\vect{\beta}) = -\sum_{i=1}^{n} \left\{ \log(\sigma(t_i)) + (1 + 1 / \xi(t_i) ) \log\left[ 1+\xi(t_i) \left( \frac{z_{t_i} - \mu(t_i)}{\sigma(t_i)}\right) \right] + \left[ 1 + \xi(t_i) \left( \frac{z_{t_i}- \mu(t_i)}{\sigma(t_i)} \right) \right]^{-1 / \xi(t_i)} \right\}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMyAtLT4KPHN2ZyB2ZXJzaW9uPScxLjEnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnIHdpZHRoPSc1MzUuMzEzMzg3cHQnIGhlaWdodD0nMzUuODY1ODY5cHQnIHZpZXdCb3g9JzAgLTM1Ljk1NDEyMyA1MzUuMzEzMzg3IDM1Ljg2NTg2OSc+CjxkZWZzPgo8cGF0aCBpZD0nZzItMCcgZD0nTTUuNTcxMTA4LTEuODA5MjE1QzUuNjk4NjMtMS44MDkyMTUgNS44NzM5NzMtMS44MDkyMTUgNS44NzM5NzMtMS45OTI1MjhTNS42OTg2My0yLjE3NTg0MSA1LjU3MTEwOC0yLjE3NTg0MUgxLjAwNDIzNEMuODc2NzEyLTIuMTc1ODQxIC43MDEzNy0yLjE3NTg0MSAuNzAxMzctMS45OTI1MjhTLjg3NjcxMi0xLjgwOTIxNSAxLjAwNDIzNC0xLjgwOTIxNUg1LjU3MTEwOFonLz4KPHBhdGggaWQ9J2c0LTEwNScgZD0nTTIuMDgwMTk5LTMuNzMwMDEyQzIuMDgwMTk5LTMuODczNDc0IDEuOTcyNjAzLTMuOTY5MTE2IDEuODM1MTE4LTMuOTY5MTE2QzEuNjczNzI0LTMuOTY5MTE2IDEuNTAwMzc0LTMuODEzNjk5IDEuNTAwMzc0LTMuNjQwMzQ5QzEuNTAwMzc0LTMuNDkwOTA5IDEuNjA3OTctMy40MDEyNDUgMS43Mzk0NzctMy40MDEyNDVDMS45MzA3Ni0zLjQwMTI0NSAyLjA4MDE5OS0zLjU4MDU3MyAyLjA4MDE5OS0zLjczMDAxMlpNMS43MjE1NDQtMS42NDM4MzZDMS43NDU0NTUtMS43MDM2MTEgMS43OTkyNTMtMS44NDcwNzMgMS44MjMxNjMtMS45MDA4NzJDMS44NDEwOTYtMS45NTQ2NyAxLjg2NTAwNi0yLjAxNDQ0NiAxLjg2NTAwNi0yLjExNjA2NUMxLjg2NTAwNi0yLjQ1MDgwOSAxLjU2NjEyNy0yLjYzNjExNSAxLjI2NzI0OC0yLjYzNjExNUMuNjU3NTM0LTIuNjM2MTE1IC4zNjQ2MzMtMS44NDcwNzMgLjM2NDYzMy0xLjcxNTU2N0MuMzY0NjMzLTEuNjg1Njc5IC4zODg1NDMtMS42MzE4OCAuNDcyMjI5LTEuNjMxODhTLjU3Mzg0OC0xLjY2Nzc0NiAuNTkxNzgxLTEuNzIxNTQ0Qy43NTkxNTMtMi4zMDEzNyAxLjA3NTk2NS0yLjQzODg1NCAxLjI0MzMzNy0yLjQzODg1NEMxLjM2Mjg4OS0yLjQzODg1NCAxLjQwNDczMi0yLjM2MTE0NiAxLjQwNDczMi0yLjIyMzY2MUMxLjQwNDczMi0yLjEwNDExIDEuMzY4ODY3LTIuMDE0NDQ2IDEuMzU2OTEyLTEuOTcyNjAzTDEuMDQ2MDc3LTEuMjA3NDcyQy45NzQzNDYtMS4wMzQxMjIgLjk3NDM0Ni0xLjAyMjE2NyAuODk2NjM4LS44MTg5MjlDLjgxODkyOS0uNjM5NjAxIC43ODkwNDEtLjU2MTg5MyAuNzg5MDQxLS40NjAyNzRDLjc4OTA0MS0uMTU1NDE3IDEuMDY0MDEgLjA1OTc3NiAxLjM5Mjc3NyAuMDU5Nzc2QzEuOTk2NTEzIC4wNTk3NzYgMi4yOTUzOTItLjcyOTI2NSAyLjI5NTM5Mi0uODYwNzcyQzIuMjk1MzkyLS44NzI3MjcgMi4yODk0MTUtLjk0NDQ1OCAyLjE4MTgxOC0uOTQ0NDU4QzIuMDk4MTMyLS45NDQ0NTggMi4wOTIxNTQtLjkxNDU3IDIuMDU2Mjg5LS44MDA5OTZDMS45NjA2NDgtLjQ5NjEzOSAxLjcxNTU2Ny0uMTM3NDg0IDEuNDEwNzEtLjEzNzQ4NEMxLjMwMzExMy0uMTM3NDg0IDEuMjQ5MzE1LS4yMDkyMTUgMS4yNDkzMTUtLjM1MjY3N0MxLjI0OTMxNS0uNDcyMjI5IDEuMjg1MTgxLS41NjE4OTMgMS4zNjI4ODktLjc0NzE5OEwxLjcyMTU0NC0xLjY0MzgzNlonLz4KPHBhdGggaWQ9J2c3LTQwJyBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgLjcyNTI4IDEuMzM4OTc5LS43NTcxNjEgMS4zMzg5NzktMS45OTI1MjhDMS4zMzg5NzktNC4yODc5MiAyLjI4NzQyMi01LjM2Mzg4NSAyLjY5Mzg5OC01LjczMDUxMUMyLjgwNTQ3OS01LjgzNDEyMiAyLjgxMzQ1LTUuODQyMDkyIDIuODEzNDUtNS44ODE5NDNTMi43ODE1NjktNS45Nzc1ODQgMi43MDE4NjgtNS45Nzc1ODRDMi41NzQzNDYtNS45Nzc1ODQgMi4xNzU4NDEtNS41NzExMDggMi4xMTIwOC01LjQ5OTM3N0MxLjA0NDA4NS00LjM4MzU2MiAuODIwOTIyLTIuOTQ4OTQxIC44MjA5MjItMS45OTI1MjhDLjgyMDkyMi0uMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicvPgo8cGF0aCBpZD0nZzctNDEnIGQ9J00yLjQ2Mjc2NS0xLjk5MjUyOEMyLjQ2Mjc2NS0yLjc0OTY4OSAyLjMzNTI0My0zLjY1ODI4MSAxLjg0MTA5Ni00LjU5ODc1NUMxLjQ1MDU2LTUuMzMyMDA1IC43MjUyOC01Ljk3NzU4NCAuNTgxODE4LTUuOTc3NTg0Qy41MDIxMTctNS45Nzc1ODQgLjQ3ODIwNy01LjkyMTc5MyAuNDc4MjA3LTUuODgxOTQzQy40NzgyMDctNS44NTAwNjIgLjQ3ODIwNy01LjgzNDEyMiAuNTczODQ4LTUuNzM4NDgxQzEuNjg5NjY0LTQuNjc4NDU2IDEuOTQ0NzA3LTMuMjE5OTI1IDEuOTQ0NzA3LTEuOTkyNTI4QzEuOTQ0NzA3IC4yOTQ4OTQgLjk5NjI2NCAxLjM3ODgyOSAuNTg5Nzg4IDEuNzQ1NDU1Qy40ODYxNzcgMS44NDkwNjYgLjQ3ODIwNyAxLjg1NzAzNiAuNDc4MjA3IDEuODk2ODg3Uy41MDIxMTcgMS45OTI1MjggLjU4MTgxOCAxLjk5MjUyOEMuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgLjM5ODUwNiAyLjQ2Mjc2NS0xLjAzNjExNSAyLjQ2Mjc2NS0xLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c3LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzctNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2cxLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cxLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzEtMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzEtMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cxLTQwJyBkPSdNNS4zOTE3ODEgMjEuODQyMDkyQzUuMzkxNzgxIDIwLjUyNzAyNCA0LjQ4MzE4OCAxOC41MDY2IDIuNDAyOTg5IDE3LjQ1NDU0NUMzLjY5NDE0NyAxNi43NjExNDYgNS4yMzYzNjQgMTUuMzYyMzkxIDUuMzc5ODI2IDEzLjEyNjc3NUw1LjM5MTc4MSAxMy4wNTUwNDRWNC43NzAxMTJDNS4zOTE3ODEgMy43ODk3ODggNS4zOTE3ODEgMy41NzQ1OTUgNS40ODc0MjIgMy4xMjAyOTlDNS43MDI2MTUgMi4xNjM4ODUgNi4yNzY0NjMgLjk4MDMyNCA3Ljc5NDc3IC4wODM2ODZDNy44OTA0MTEgLjAyMzkxIDcuOTAyMzY2IC4wMTE5NTUgNy45MDIzNjYtLjIwMzIzOEM3LjkwMjM2Ni0uNDY2MjUyIDcuODkwNDExLS40NzgyMDcgNy42MjczOTctLjQ3ODIwN0M3LjQxMjIwNC0uNDc4MjA3IDcuMzg4Mjk0LS40NzgyMDcgNy4wNjU1MDQtLjI4NjkyNEM0LjM4NzU0NyAxLjIzMTM4MiA0LjIzMjEzIDMuNDU1MDQ0IDQuMjMyMTMgMy44NzM0NzRWMTIuMzczNTk5QzQuMjMyMTMgMTMuMjM0MzcxIDQuMjMyMTMgMTQuMjAyNzQgMy42MTA0NjEgMTUuMzAyNjE1QzMuMDYwNTIzIDE2LjI4MjkzOSAyLjQxNDk0NCAxNi43NzMxMDEgMS45MDA4NzIgMTcuMTE5ODAxQzEuNzMzNDk5IDE3LjIyNzM5NyAxLjcyMTU0NCAxNy4yMzkzNTIgMS43MjE1NDQgMTcuNDQyNTlDMS43MjE1NDQgMTcuNjU3NzgzIDEuNzMzNDk5IDE3LjY2OTczOCAxLjgyOTE0MSAxNy43Mjk1MTRDMi44NDUzMyAxOC4zOTkwMDQgMy45MzMyNSAxOS40NjMwMTQgNC4xOTYyNjQgMjEuNDExNzA2QzQuMjMyMTMgMjEuNjc0NzIgNC4yMzIxMyAyMS42OTg2MyA0LjIzMjEzIDIxLjg0MjA5MlYzMS4wMjM2NjFDNC4yMzIxMyAzMS45OTIwMyA0LjgyOTg4OCAzNC4wMDA0OTggNy4xMzcyMzUgMzUuMjE5OTI1QzcuNDEyMjA0IDM1LjM3NTM0MiA3LjQzNjExNSAzNS4zNzUzNDIgNy42MjczOTcgMzUuMzc1MzQyQzcuODkwNDExIDM1LjM3NTM0MiA3LjkwMjM2NiAzNS4zNjMzODcgNy45MDIzNjYgMzUuMTAwMzc0QzcuOTAyMzY2IDM0Ljg4NTE4MSA3Ljg5MDQxMSAzNC44NzMyMjUgNy44NDI1OSAzNC44NDkzMTVDNy4zMjg1MTggMzQuNTI2NTI2IDUuNzYyMzkxIDMzLjU4MjA2NyA1LjQzOTYwMSAzMS41MDE4NjhDNS4zOTE3ODEgMzEuMTkxMDM0IDUuMzkxNzgxIDMxLjE2NzEyMyA1LjM5MTc4MSAzMS4wMTE3MDZWMjEuODQyMDkyWicvPgo8cGF0aCBpZD0nZzEtNDEnIGQ9J000LjIzMjEzIDMwLjEyNzAyNEM0LjIzMjEzIDMxLjEwNzM0NyA0LjIzMjEzIDMxLjMyMjU0IDQuMTM2NDg4IDMxLjc3NjgzN0MzLjkyMTI5NSAzMi43MzMyNSAzLjM0NzQ0NyAzMy45MDQ4NTcgMS44MjkxNDEgMzQuODEzNDVDMS43MzM0OTkgMzQuODczMjI1IDEuNzIxNTQ0IDM0Ljg4NTE4MSAxLjcyMTU0NCAzNS4xMDAzNzRDMS43MjE1NDQgMzUuMzc1MzQyIDEuNzMzNDk5IDM1LjM3NTM0MiAyLjAwODQ2OCAzNS4zNzUzNDJDMi4yMTE3MDYgMzUuMzc1MzQyIDIuMjM1NjE2IDM1LjM3NTM0MiAyLjU1ODQwNiAzNS4xODQwNkM1LjIzNjM2NCAzMy42NjU3NTMgNS4zOTE3ODEgMzEuNDQyMDkyIDUuMzkxNzgxIDMxLjAyMzY2MVYyMi41MjM1MzdDNS4zOTE3ODEgMjEuNjYyNzY1IDUuMzkxNzgxIDIwLjY5NDM5NiA2LjAxMzQ1IDE5LjU5NDUyMUM2LjUzOTQ3NyAxOC42NjIwMTcgNy4xNDkxOTEgMTguMTU5OSA3LjcyMzAzOSAxNy43NzczMzVDNy44OTA0MTEgMTcuNjY5NzM4IDcuOTAyMzY2IDE3LjY1Nzc4MyA3LjkwMjM2NiAxNy40NDI1OUM3LjkwMjM2NiAxNy4yODcxNzMgNy45MDIzNjYgMTcuMjI3Mzk3IDcuODU0NTQ1IDE3LjE5MTUzMkM3LjI5MjY1MyAxNi44MzI4NzcgNS43Mzg0ODEgMTUuODQwNTk4IDUuNDI3NjQ2IDEzLjQ4NTQzQzUuMzkxNzgxIDEzLjIyMjQxNiA1LjM5MTc4MSAxMy4xOTg1MDYgNS4zOTE3ODEgMTMuMDU1MDQ0VjMuODczNDc0QzUuMzkxNzgxIDIuOTA1MTA2IDQuNzk0MDIyIC44OTY2MzggMi40ODY2NzUtLjMyMjc5QzIuMjExNzA2LS40NzgyMDcgMi4xODc3OTYtLjQ3ODIwNyAyLjAwODQ2OC0uNDc4MjA3QzEuNzMzNDk5LS40NzgyMDcgMS43MjE1NDQtLjQ3ODIwNyAxLjcyMTU0NC0uMjAzMjM4QzEuNzIxNTQ0LS4wMTE5NTUgMS43MjE1NDQgLjAyMzkxIDEuODA1MjMgLjA3MTczMUM0LjA3NjcxMiAxLjQyMjY2NSA0LjIzMjEzIDMuNDE5MTc4IDQuMjMyMTMgMy44ODU0M1YxMy4wNTUwNDRDNC4yMzIxMyAxNC4zNzAxMTIgNS4xNDA3MjIgMTYuMzkwNTM1IDcuMjIwOTIyIDE3LjQ0MjU5QzUuOTI5NzYzIDE4LjEzNTk5IDQuMzg3NTQ3IDE5LjUzNDc0NSA0LjI0NDA4NSAyMS43NzAzNjFMNC4yMzIxMyAyMS44NDIwOTJWMzAuMTI3MDI0WicvPgo8cGF0aCBpZD0nZzEtODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2c1LTI0JyBkPSdNMS42MTc5MzMtMi4zNTExODNDMS45MTI4MjctMi4yMzk2MDEgMi4yMDc3MjEtMi4yMzk2MDEgMi4zODMwNjQtMi4yMzk2MDFDMi42NTQwNDctMi4yMzk2MDEgMy4xNzIxMDUtMi4yMzk2MDEgMy4xNzIxMDUtMi41MjY1MjZDMy4xNzIxMDUtMi43NjU2MjkgMi43NDE3MTktMi43NjU2MjkgMi40NzA3MzUtMi43NjU2MjlDMi4zMTEzMzMtMi43NjU2MjkgMi4wNjQyNTktMi43NjU2MjkgMS43NTM0MjUtMi42NjIwMTdDMS41NzgwODItMi44MjkzOSAxLjUwNjM1MS0zLjA1MjU1MyAxLjUwNjM1MS0zLjI3NTcxNkMxLjUwNjM1MS0zLjcyMjA0MiAxLjgxNzE4Ni00LjI4NzkyIDIuMzk5MDA0LTQuNTY2ODc0QzIuNTc0MzQ2LTQuMzgzNTYyIDIuNzgxNTY5LTQuMzgzNTYyIDIuOTQ4OTQxLTQuMzgzNTYyQzMuMjUxODA2LTQuMzgzNTYyIDMuNzA2MTAyLTQuMzk5NTAyIDMuNzA2MTAyLTQuNjcwNDg2QzMuNzA2MTAyLTQuOTA5NTg5IDMuMjc1NzE2LTQuOTA5NTg5IDIuOTk2NzYyLTQuOTA5NTg5QzIuODYxMjctNC45MDk1ODkgMi43MjU3NzgtNC45MDk1ODkgMi41MDI2MTUtNC44Nzc3MDlDMi40ODY2NzUtNC45MzM0OTkgMi40NjI3NjUtNS4wMTMyIDIuNDYyNzY1LTUuMTE2ODEyQzIuNDYyNzY1LTUuMjI4Mzk0IDIuNDk0NjQ1LTUuMzYzODg1IDIuNDk0NjQ1LTUuMzg3Nzk2QzIuNTAyNjE1LTUuMzk1NzY2IDIuNTAyNjE1LTUuNDI3NjQ2IDIuNTAyNjE1LTUuNDM1NjE2QzIuNTAyNjE1LTUuNTA3MzQ3IDIuNDQ2ODI0LTUuNTU1MTY4IDIuMzkxMDM0LTUuNTU1MTY4QzIuMjE1NjkxLTUuNTU1MTY4IDIuMjE1NjkxLTUuMTk2NTEzIDIuMjE1NjkxLTUuMTI0NzgyQzIuMjE1NjkxLTQuOTczMzUgMi4yNTU1NDItNC44Mzc4NTggMi4yNjM1MTItNC44MjE5MThDMS4zNzA4NTktNC41OTA3ODUgLjgyMDkyMi0zLjk1MzE3NiAuODIwOTIyLTMuMzIzNTM3Qy44MjA5MjItMi45MjUwMzEgMS4wMzYxMTUtMi42NTQwNDcgMS4zMzg5NzktMi40Nzg3MDVDLjQ4NjE3Ny0xLjk5MjUyOCAuMTkxMjgzLTEuMTg3NTQ3IC4xOTEyODMtLjgyMDkyMkMuMTkxMjgzLS4wOTU2NDEgLjkyNDUzMyAuMTY3MzcyIDEuMTc5NTc3IC4yNjMwMTRDMS42MjU5MDMgLjQzMDM4NiAxLjY0MTg0MyAuNDMwMzg2IDIuMDMyMzc5IC41NjU4NzhDMi4yMjM2NjEgLjYzNzYwOSAyLjU0MjQ2NiAuNzU3MTYxIDIuNTk4MjU3IC43ODkwNDFDMi43MjU3NzggLjg2ODc0MiAyLjcyNTc3OCAuOTgwMzI0IDIuNzI1Nzc4IDEuMDI4MTQ0QzIuNzI1Nzc4IDEuMTcxNjA2IDIuNjIyMTY3IDEuNDAyNzQgMi4zNjcxMjMgMS40MDI3NEMyLjMwMzM2MiAxLjQwMjc0IDEuOTc2NTg4IDEuMzg2OCAxLjY1Nzc4MyAxLjE5NTUxN0MxLjU3ODA4MiAxLjEzOTcyNiAxLjU3MDExMiAxLjEzMTc1NiAxLjUzMDI2MiAxLjEzMTc1NkMxLjQ0MjU5IDEuMTMxNzU2IDEuNDE4NjggMS4yMTE0NTcgMS40MTg2OCAxLjI0MzMzN0MxLjQxODY4IDEuMzcwODU5IDEuOTI4NzY3IDEuNjI1OTAzIDIuMzc1MDkzIDEuNjI1OTAzQzIuOTAxMTIxIDEuNjI1OTAzIDMuMjI3ODk1IDEuMTIzNzg2IDMuMjI3ODk1IC43NTcxNjFDMy4yMjc4OTUgLjYxMzY5OSAzLjE3MjEwNSAuNDYyMjY3IDMuMDc2NDYzIC4zNTA2ODVDMi45NzI4NTIgLjIzOTEwMyAyLjg2OTI0IC4xOTkyNTMgMi40MjI5MTQgLjAzOTg1MUMxLjcyOTUxNC0uMjA3MjIzIDEuMjExNDU3LS4zOTA1MzUgMS4wODM5MzUtLjQ2MjI2N0MuODI4ODkyLS41OTc3NTggLjY2MTUxOS0uNzg5MDQxIC42NjE1MTktMS4wNTIwNTVDLjY2MTUxOS0xLjM3ODgyOSAuOTU2NDEzLTEuOTkyNTI4IDEuNjE3OTMzLTIuMzUxMTgzWk0zLjQwMzIzOC00LjY0NjU3NUMzLjMyMzUzNy00LjYzMDYzNSAzLjI0MzgzNi00LjYwNjcyNSAyLjk1NjkxMi00LjYwNjcyNUMyLjc4OTUzOS00LjYwNjcyNSAyLjc1NzY1OS00LjYwNjcyNSAyLjY2MjAxNy00LjY1NDU0NUMyLjc4OTUzOS00LjY4NjQyNiAyLjg2OTI0LTQuNjg2NDI2IDMuMDEyNzAyLTQuNjg2NDI2QzMuMjI3ODk1LTQuNjg2NDI2IDMuMjgzNjg2LTQuNjc4NDU2IDMuNDAzMjM4LTQuNjU0NTQ1Vi00LjY0NjU3NVpNMi44NjkyNC0yLjUwMjYxNUMyLjc5NzUwOS0yLjQ4NjY3NSAyLjcxNzgwOC0yLjQ2Mjc2NSAyLjQwNjk3NC0yLjQ2Mjc2NUMyLjI1NTU0Mi0yLjQ2Mjc2NSAyLjE3NTg0MS0yLjQ2Mjc2NSAyLjA0ODMxOS0yLjUwMjYxNUMyLjIyMzY2MS0yLjU0MjQ2NiAyLjMxOTMwMy0yLjU0MjQ2NiAyLjQ2Mjc2NS0yLjU0MjQ2NkMyLjY5Mzg5OC0yLjU0MjQ2NiAyLjc1NzY1OS0yLjUzNDQ5NiAyLjg2OTI0LTIuNTEwNTg1Vi0yLjUwMjYxNVonLz4KPHBhdGggaWQ9J2c1LTYxJyBkPSdNMy43MDYxMDItNS42NDI4MzlDMy43NTM5MjMtNS43NTQ0MjEgMy43NTM5MjMtNS43NzAzNjEgMy43NTM5MjMtNS43OTQyNzFDMy43NTM5MjMtNS44OTc4ODMgMy42NzQyMjItNS45Nzc1ODQgMy41NzA2MS01Ljk3NzU4NEMzLjQ0MzA4OC01Ljk3NzU4NCAzLjQxMTIwOC01Ljg4MTk0MyAzLjM3OTMyOC01LjgwMjI0MkwuNTE4MDU3IDEuNjU3NzgzQy40NzAyMzcgMS43NjkzNjUgLjQ3MDIzNyAxLjc4NTMwNSAuNDcwMjM3IDEuODA5MjE1Qy40NzAyMzcgMS45MTI4MjcgLjU0OTkzOCAxLjk5MjUyOCAuNjUzNTQ5IDEuOTkyNTI4Qy43ODEwNzEgMS45OTI1MjggLjgxMjk1MSAxLjg5Njg4NyAuODQ0ODMyIDEuODE3MTg2TDMuNzA2MTAyLTUuNjQyODM5WicvPgo8cGF0aCBpZD0nZzUtMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2c1LTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnNS0xMTYnIGQ9J00xLjc2MTM5NS0zLjE3MjEwNUgyLjU0MjQ2NkMyLjY5Mzg5OC0zLjE3MjEwNSAyLjc4OTUzOS0zLjE3MjEwNSAyLjc4OTUzOS0zLjMyMzUzN0MyLjc4OTUzOS0zLjQzNTExOCAyLjY4NTkyOC0zLjQzNTExOCAyLjU1MDQzNi0zLjQzNTExOEgxLjgyNTE1NkwyLjExMjA4LTQuNTY2ODc0QzIuMTQzOTYtNC42ODY0MjYgMi4xNDM5Ni00LjcyNjI3NiAyLjE0Mzk2LTQuNzM0MjQ3QzIuMTQzOTYtNC45MDE2MTkgMi4wMTY0MzgtNC45ODEzMiAxLjg4MDk0Ni00Ljk4MTMyQzEuNjA5OTYzLTQuOTgxMzIgMS41NTQxNzItNC43NjYxMjcgMS40NjY1MDEtNC40MDc0NzJMMS4yMTk0MjctMy40MzUxMThILjQ1NDI5NkMuMzAyODY0LTMuNDM1MTE4IC4xOTkyNTMtMy40MzUxMTggLjE5OTI1My0zLjI4MzY4NkMuMTk5MjUzLTMuMTcyMTA1IC4zMDI4NjQtMy4xNzIxMDUgLjQzODM1Ni0zLjE3MjEwNUgxLjE1NTY2NkwuNjc3NDYtMS4yNTkyNzhDLjYyOTYzOS0xLjA2MDAyNSAuNTU3OTA4LS43ODEwNzEgLjU1NzkwOC0uNjY5NDg5Qy41NTc5MDgtLjE5MTI4MyAuOTQ4NDQzIC4wNzk3MDEgMS4zNzA4NTkgLjA3OTcwMUMyLjIyMzY2MSAuMDc5NzAxIDIuNzA5ODM4LTEuMDQ0MDg1IDIuNzA5ODM4LTEuMTM5NzI2QzIuNzA5ODM4LTEuMjI3Mzk3IDIuNjM4MTA3LTEuMjQzMzM3IDIuNTkwMjg2LTEuMjQzMzM3QzIuNTAyNjE1LTEuMjQzMzM3IDIuNDk0NjQ1LTEuMjExNDU3IDIuNDM4ODU0LTEuMDkxOTA1QzIuMjc5NDUyLS43MDkzNCAxLjg4MDk0Ni0uMTQzNDYyIDEuMzk0NzctLjE0MzQ2MkMxLjIyNzM5Ny0uMTQzNDYyIDEuMTMxNzU2LS4yNTUwNDQgMS4xMzE3NTYtLjUxODA1N0MxLjEzMTc1Ni0uNjY5NDg5IDEuMTU1NjY2LS43NTcxNjEgMS4xNzk1NzctLjg2MDc3MkwxLjc2MTM5NS0zLjE3MjEwNVonLz4KPHBhdGggaWQ9J2czLTAnIGQ9J003Ljg3ODQ1Ni0yLjc0OTY4OUM4LjA4MTY5NC0yLjc0OTY4OSA4LjI5Njg4Ny0yLjc0OTY4OSA4LjI5Njg4Ny0yLjk4ODc5MlM4LjA4MTY5NC0zLjIyNzg5NSA3Ljg3ODQ1Ni0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyLTMuMjI3ODk1IC45OTIyNzktMy4yMjc4OTUgLjk5MjI3OS0yLjk4ODc5MlMxLjIwNzQ3Mi0yLjc0OTY4OSAxLjQxMDcxLTIuNzQ5Njg5SDcuODc4NDU2WicvPgo8cGF0aCBpZD0nZzAtMTInIGQ9J00uMjM5MTAzIDEuOTYwNjQ4Qy4yMjcxNDggMS45ODQ1NTggLjE5MTI4MyAyLjEzOTk3NSAuMTkxMjgzIDIuMTUxOTNDLjE5MTI4MyAyLjMxOTMwMyAuMzcwNjEgMi4zMTkzMDMgLjQ3ODIwNyAyLjMxOTMwM0MuNzE3MzEgMi4zMTkzMDMgLjcxNzMxIDIuMjk1MzkyIC43ODkwNDEgMi4wNDQzMzRDLjgyNDkwNyAxLjg1MzA1MSAxLjU0MjIxNy0xLjAxNjE4OSAxLjU1NDE3Mi0xLjA0MDFDMi4wNTYyODktLjIwMzIzOCAyLjk3NjgzNyAuMTQzNDYyIDMuOTMzMjUgLjE0MzQ2MkM2LjMzNjIzOSAuMTQzNDYyIDcuNjc1MjE4LTEuNjg1Njc5IDcuNjc1MjE4LTMuMjUxODA2QzcuNjc1MjE4LTQuMDg4NjY3IDcuMzA0NjA4LTQuNTQyOTY0IDYuOTEwMDg3LTQuODQxODQzQzcuMzQwNDczLTUuMjAwNDk4IDcuODMwNjM1LTUuOTc3NTg0IDcuODMwNjM1LTYuODAyNDkxQzcuODMwNjM1LTcuODE4NjggNy4wODk0MTUtOC4zOTI1MjggNS45NjU2MjktOC4zOTI1MjhDNC4yNTYwNC04LjM5MjUyOCAyLjQ4NjY3NS03LjA2NTUwNCAyLjA1NjI4OS01LjMzMjAwNUwuMjM5MTAzIDEuOTYwNjQ4Wk01LjY1NDc5NS00Ljc5NDAyMkM1LjM2Nzg3LTQuNTkwNzg1IDUuMDY4OTkxLTQuNTkwNzg1IDQuOTAxNjE5LTQuNTkwNzg1QzQuODUzNzk4LTQuNTkwNzg1IDQuMzI3NzcxLTQuNTkwNzg1IDQuMzI3NzcxLTQuNjg2NDI2QzQuMzI3NzcxLTQuODc3NzA5IDQuOTEzNTc0LTQuODc3NzA5IDUuMDY4OTkxLTQuODc3NzA5QzUuMjg0MTg0LTQuODc3NzA5IDUuNDI3NjQ2LTQuODc3NzA5IDUuNjU0Nzk1LTQuNzk0MDIyWk02LjA2MTI3LTUuMjEyNDUzQzUuNjY2NzUtNS4zMDgwOTUgNS4zMzIwMDUtNS4zMDgwOTUgNS4xMDQ4NTctNS4zMDgwOTVDNC43MjIyOTEtNS4zMDgwOTUgMy43NTM5MjMtNS4zMDgwOTUgMy43NTM5MjMtNC42NjI1MTZDMy43NTM5MjMtNC4xNjAzOTkgNC40NzEyMzMtNC4xNjAzOTkgNC44ODk2NjQtNC4xNjAzOTlDNS4wOTI5MDItNC4xNjAzOTkgNS42MzA4ODQtNC4xNjAzOTkgNi4xNjg4NjctNC4zODc1NDdDNi4yNjQ1MDgtNC4yMDgyMTkgNi4zMDAzNzQtMy45NjkxMTYgNi4zMDAzNzQtMy43NjU4NzhDNi4zMDAzNzQtMy4zMzU0OTIgNS45ODk1MzktMS44ODg5MTcgNS42MTg5MjktMS4yNjcyNDhDNS4yNDgzMTktLjY4MTQ0NSA0LjY2MjUxNi0uMjg2OTI0IDMuOTA5MzQtLjI4NjkyNEMyLjc5NzUwOS0uMjg2OTI0IDEuODY1MDA2LS45NTY0MTMgMS44NjUwMDYtMi4wMzIzNzlDMS44NjUwMDYtMi4yNzE0ODIgMS45MjQ3ODItMi41MjI1NCAxLjk0ODY5Mi0yLjY0MjA5MkMyLjEyODAyLTMuMzQ3NDQ3IDIuNTEwNTg1LTQuOTEzNTc0IDIuNjU0MDQ3LTUuNDM5NjAxQzMuMDM2NjEzLTYuNzQyNzE1IDQuNDgzMTg4LTcuOTYyMTQyIDUuOTA1ODUzLTcuOTYyMTQyQzYuMzQ4MTk0LTcuOTYyMTQyIDYuNjExMjA4LTcuNzQ2OTQ5IDYuNjExMjA4LTcuMjgwNjk3QzYuNjExMjA4LTYuOTEwMDg3IDYuMzI0Mjg0LTUuNjc4NzA1IDYuMDYxMjctNS4yMTI0NTNaJy8+CjxwYXRoIGlkPSdnOC00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzgtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c4LTQzJyBkPSdNNC43NzAxMTItMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEtMi43NjE2NDQgOC40NTIzMDQtMi43NjE2NDQgOC40NTIzMDQtMi45NzY4MzdDOC40NTIzMDQtMy4yMDM5ODUgOC4yNDkwNjYtMy4yMDM5ODUgOC4wNjk3MzgtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyLTYuNjcwOTg0IDQuNzcwMTEyLTYuODg2MTc3IDQuNTU0OTE5LTYuODg2MTc3QzQuMzI3NzcxLTYuODg2MTc3IDQuMzI3NzcxLTYuNjgyOTM5IDQuMzI3NzcxLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMuODYwNzcyLTMuMjAzOTg1IC42NDU1NzktMy4yMDM5ODUgLjY0NTU3OS0yLjk4ODc5MkMuNjQ1NTc5LTIuNzYxNjQ0IC44NDg4MTctMi43NjE2NDQgMS4wMjgxNDQtMi43NjE2NDRINC4zMjc3NzFWLjUzNzk4M0M0LjMyNzc3MSAuNzA1MzU1IDQuMzI3NzcxIC45MjA1NDggNC41NDI5NjQgLjkyMDU0OEM0Ljc3MDExMiAuOTIwNTQ4IDQuNzcwMTEyIC43MTczMSA0Ljc3MDExMiAuNTM3OTgzVi0yLjc2MTY0NFonLz4KPHBhdGggaWQ9J2c4LTQ5JyBkPSdNMy40NDMwODgtNy42NjMyNjNDMy40NDMwODgtNy45MzgyMzIgMy40NDMwODgtNy45NTAxODcgMy4yMDM5ODUtNy45NTAxODdDMi45MTcwNjEtNy42MjczOTcgMi4zMTkzMDMtNy4xODUwNTYgMS4wODc5Mi03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODktNi44MzgzNTYgMS45NjA2NDgtNi44MzgzNTYgMi42MTgxODItNy4xNDkxOTFWLS45MjA1NDhDMi42MTgxODItLjQ5MDE2MiAyLjU4MjMxNi0uMzQ2NyAxLjUzMDI2Mi0uMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTEgMy4wMzY2MTMtLjAyMzkxUzQuNTc4ODI5LS4wMjM5MSA0LjkwMTYxOSAwVi0uMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NC0uMzQ2NyAzLjQ0MzA4OC0uNDkwMTYyIDMuNDQzMDg4LS45MjA1NDhWLTcuNjYzMjYzWicvPgo8cGF0aCBpZD0nZzgtNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2c4LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c4LTEwOCcgZD0nTTIuMDU2Mjg5LTguMjk2ODg3TC4zOTQ1MjEtOC4xNjUzOFYtNy44MTg2OEMxLjIwNzQ3Mi03LjgxODY4IDEuMzAzMTEzLTcuNzM0OTk0IDEuMzAzMTEzLTcuMTQ5MTkxVi0uODg0NjgyQzEuMzAzMTEzLS4zNDY3IDEuMTcxNjA2LS4zNDY3IC4zOTQ1MjEtLjM0NjdWMEMuNzI5MjY1LS4wMjM5MSAxLjMxNTA2OC0uMDIzOTEgMS42NzM3MjQtLjAyMzkxUzIuNjMwMTM3LS4wMjM5MSAyLjk2NDg4MiAwVi0uMzQ2N0MyLjE5OTc1MS0uMzQ2NyAyLjA1NjI4OS0uMzQ2NyAyLjA1NjI4OS0uODg0NjgyVi04LjI5Njg4N1onLz4KPHBhdGggaWQ9J2c4LTExMScgZD0nTTUuNDg3NDIyLTIuNTU4NDA2QzUuNDg3NDIyLTQuMTAwNjIzIDQuMzE1ODE2LTUuMzMyMDA1IDIuOTI5MDE2LTUuMzMyMDA1QzEuNDk0Mzk2LTUuMzMyMDA1IC4zNTg2NTUtNC4wNjQ3NTcgLjM1ODY1NS0yLjU1ODQwNkMuMzU4NjU1LTEuMDI4MTQ0IDEuNTU0MTcyIC4xMTk1NTIgMi45MTcwNjEgLjExOTU1MkM0LjMyNzc3MSAuMTE5NTUyIDUuNDg3NDIyLTEuMDUyMDU1IDUuNDg3NDIyLTIuNTU4NDA2Wk0yLjkyOTAxNi0uMTQzNDYyQzIuNDg2Njc1LS4xNDM0NjIgMS45NDg2OTItLjMzNDc0NSAxLjYwMTk5My0uOTIwNTQ4QzEuMjc5MjAzLTEuNDU4NTMxIDEuMjY3MjQ4LTIuMTYzODg1IDEuMjY3MjQ4LTIuNjY2MDAyQzEuMjY3MjQ4LTMuMTIwMjk5IDEuMjY3MjQ4LTMuODQ5NTY0IDEuNjM3ODU4LTQuMzg3NTQ3QzEuOTcyNjAzLTQuOTAxNjE5IDIuNDk4NjMtNS4wOTI5MDIgMi45MTcwNjEtNS4wOTI5MDJDMy4zODMzMTMtNS4wOTI5MDIgMy44ODU0My00Ljg3NzcwOSA0LjIwODIxOS00LjQxMTQ1N0M0LjU3ODgyOS0zLjg2MTUxOSA0LjU3ODgyOS0zLjEwODM0NCA0LjU3ODgyOS0yLjY2NjAwMkM0LjU3ODgyOS0yLjI0NzU3MiA0LjU3ODgyOS0xLjUwNjM1MSA0LjI2Nzk5NS0uOTQ0NDU4QzMuOTMzMjUtLjM3MDYxIDMuMzgzMzEzLS4xNDM0NjIgMi45MjkwMTYtLjE0MzQ2MlonLz4KPHBhdGggaWQ9J2c2LTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnNi0yNCcgZD0nTTMuMTIwMjk5IC4wNTk3NzZMMS44NjUwMDYtLjQ0MjM0MUMxLjU1NDE3Mi0uNTYxODkzIC44MzY4NjItLjg0ODgxNyAuODM2ODYyLTEuNTY2MTI3Qy44MzY4NjItMi41OTQyNzEgMi4wOTIxNTQtMy42MzQzNzEgMi4zNDMyMTMtMy42MzQzNzFDMi4zNjcxMjMtMy42MzQzNzEgMi40NzQ3Mi0zLjYxMDQ2MSAyLjUxMDU4NS0zLjU5ODUwNkMyLjgzMzM3NS0zLjUwMjg2NCAzLjE0NDIwOS0zLjUwMjg2NCAzLjM1OTQwMi0zLjUwMjg2NEMzLjczMDAxMi0zLjUwMjg2NCA0LjQzNTM2Ny0zLjUwMjg2NCA0LjQzNTM2Ny0zLjg0OTU2NEM0LjQzNTM2Ny00LjExMjU3OCA0LjAwNDk4MS00LjE0ODQ0MyAzLjQ5MDkwOS00LjE0ODQ0M0MzLjI1MTgwNi00LjE0ODQ0MyAyLjkyOTAxNi00LjE0ODQ0MyAyLjQ5ODYzLTQuMDA0OTgxQzIuMjExNzA2LTQuMjQ0MDg1IDIuMDkyMTU0LTQuNjI2NjUgMi4wOTIxNTQtNC45ODUzMDVDMi4wOTIxNTQtNS42NDI4MzkgMi41MjI1NC02LjU3NTM0MiAzLjQ2Njk5OS03LjAxNzY4NEMzLjY4MjE5Mi02Ljc2NjYyNSAzLjk2OTExNi02Ljc2NjYyNSA0LjIyMDE3NC02Ljc2NjYyNUM0LjUxOTA1NC02Ljc2NjYyNSA1LjI0ODMxOS02Ljc2NjYyNSA1LjI0ODMxOS03LjExMzMyNUM1LjI0ODMxOS03LjQxMjIwNCA0LjY3NDQ3MS03LjQxMjIwNCA0LjI5MTkwNS03LjQxMjIwNEM0LjA1MjgwMi03LjQxMjIwNCAzLjg3MzQ3NC03LjQxMjIwNCAzLjUzODczLTcuMzUyNDI4QzMuNDc4OTU0LTcuNDk1ODkgMy40NjY5OTktNy41MTk4MDEgMy40NjY5OTktNy43ODI4MTRDMy40NjY5OTktNy45OTgwMDcgMy41MTQ4MTktOC4xNjUzOCAzLjUxNDgxOS04LjIwMTI0NUMzLjUxNDgxOS04LjI3Mjk3NiAzLjQ1NTA0NC04LjMyMDc5NyAzLjM5NTI2OC04LjMyMDc5N0MzLjIwMzk4NS04LjMyMDc5NyAzLjIwMzk4NS03Ljg3ODQ1NiAzLjIwMzk4NS03Ljc4MjgxNEMzLjIwMzk4NS03LjYxNTQ0MiAzLjIxNTk0LTcuNDQ4MDcgMy4yODc2NzEtNy4yOTI2NTNDMS44NTMwNTEtNi44NzQyMjIgMS4yMTk0MjctNS44NTgwMzIgMS4yMTk0MjctNS4wODA5NDZDMS4yMTk0MjctNC4zNjM2MzYgMS42OTc2MzQtMy45NjkxMTYgMi4wMjA0MjMtMy43ODk3ODhDLjc4OTA0MS0zLjEyMDI5OSAuMjYzMDE0LTEuOTAwODcyIC4yNjMwMTQtMS4yNTUyOTNDLjI2MzAxNC0uMjE1MTkzIDEuMjA3NDcyIC4xNTU0MTcgMS42Mzc4NTggLjMzNDc0NUwyLjcxMzgyMyAuNzY1MTMxQzMuMDEyNzAyIC44NzI3MjcgMy41MDI4NjQgMS4wNzU5NjUgMy41ODY1NSAxLjEyMzc4NkMzLjcwNjEwMiAxLjIwNzQ3MiAzLjgwMTc0MyAxLjM1MDkzNCAzLjgwMTc0MyAxLjU0MjIxN0MzLjgwMTc0MyAxLjc5MzI3NSAzLjYxMDQ2MSAyLjE5OTc1MSAzLjE5MjAzIDIuMTk5NzUxQzMuMDEyNzAyIDIuMTk5NzUxIDIuNjE4MTgyIDIuMTUxOTMgMi4xODc3OTYgMS44MjkxNDFDMi4xMDQxMSAxLjc1NzQxIDIuMDkyMTU0IDEuNzQ1NDU1IDIuMDQ0MzM0IDEuNzQ1NDU1QzEuOTg0NTU4IDEuNzQ1NDU1IDEuOTI0NzgyIDEuNzkzMjc1IDEuOTI0NzgyIDEuODY1MDA2QzEuOTI0NzgyIDEuOTk2NTEzIDIuNTQ2NDUxIDIuNDM4ODU0IDMuMTkyMDMgMi40Mzg4NTRDMy45NTcxNjEgMi40Mzg4NTQgNC40MjM0MTIgMS42OTc2MzQgNC40MjM0MTIgMS4xODM1NjJDNC40MjM0MTIgLjgxMjk1MSA0LjIyMDE3NCAuNTE0MDcyIDMuODM3NjA5IC4zNDY3TDMuMTIwMjk5IC4wNTk3NzZaTTMuNzMwMDEyLTcuMTEzMzI1QzMuOTMzMjUtNy4xNzMxMDEgNC4xNDg0NDMtNy4xNzMxMDEgNC4zMDM4NjEtNy4xNzMxMDFDNC42OTgzODEtNy4xNzMxMDEgNC43MzQyNDctNy4xNjExNDYgNC45NzMzNS03LjEwMTM3QzQuODI5ODg4LTcuMDQxNTk0IDQuNzM0MjQ3LTcuMDA1NzI5IDQuMjMyMTMtNy4wMDU3MjlDNC4wMDQ5ODEtNy4wMDU3MjkgMy44NjE1MTktNy4wMDU3MjkgMy43MzAwMTItNy4xMTMzMjVaTTIuNzg1NTU0LTMuODM3NjA5QzMuMDcyNDc4LTMuOTA5MzQgMy4zMzU0OTItMy45MDkzNCAzLjQ3ODk1NC0zLjkwOTM0QzMuODczNDc0LTMuOTA5MzQgMy44OTczODUtMy44OTczODUgNC4xNjAzOTktMy44Mzc2MDlDNC4wMjg4OTItMy43Nzc4MzMgMy45MjEyOTUtMy43NDE5NjggMy40MDcyMjMtMy43NDE5NjhDMy4xMjAyOTktMy43NDE5NjggMy4wMDA3NDctMy43NDE5NjggMi43ODU1NTQtMy44Mzc2MDlaJy8+CjxwYXRoIGlkPSdnNi0yNycgZD0nTTYuMDczMjI1LTQuNTA3MDk4QzYuMjI4NjQzLTQuNTA3MDk4IDYuNjIzMTYzLTQuNTA3MDk4IDYuNjIzMTYzLTQuODg5NjY0QzYuNjIzMTYzLTUuMTUyNjc3IDYuMzk2MDE1LTUuMTUyNjc3IDYuMTgwODIyLTUuMTUyNjc3SDMuNTM4NzNDMS43NDU0NTUtNS4xNTI2NzcgLjQ1NDI5Ni0zLjE1NjE2NCAuNDU0Mjk2LTEuNzQ1NDU1Qy40NTQyOTYtLjcyOTI2NSAxLjExMTgzMSAuMTE5NTUyIDIuMTg3Nzk2IC4xMTk1NTJDMy41OTg1MDYgLjExOTU1MiA1LjE0MDcyMi0xLjM5ODc1NSA1LjE0MDcyMi0zLjE5MjAzQzUuMTQwNzIyLTMuNjU4MjgxIDUuMDMzMTI2LTQuMTEyNTc4IDQuNzQ2MjAyLTQuNTA3MDk4SDYuMDczMjI1Wk0yLjE5OTc1MS0uMTE5NTUyQzEuNTkwMDM3LS4xMTk1NTIgMS4xNDc2OTYtLjU4NTgwMyAxLjE0NzY5Ni0xLjQxMDcxQzEuMTQ3Njk2LTIuMTI4MDIgMS41NzgwODItNC41MDcwOTggMy4zMzU0OTItNC41MDcwOThDMy44NDk1NjQtNC41MDcwOTggNC40MjM0MTItNC4yNTYwNCA0LjQyMzQxMi0zLjMzNTQ5MkM0LjQyMzQxMi0yLjkxNzA2MSA0LjIzMjEzLTEuOTEyODI3IDMuODEzNjk5LTEuMjE5NDI3QzMuMzgzMzEzLS41MTQwNzIgMi43Mzc3MzMtLjExOTU1MiAyLjE5OTc1MS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzYtNjEnIGQ9J001LjEyODc2Ny04LjUyNDAzNUM1LjEyODc2Ny04LjUzNTk5IDUuMjAwNDk4LTguNzE1MzE4IDUuMjAwNDk4LTguNzM5MjI4QzUuMjAwNDk4LTguODgyNjkgNS4wODA5NDYtOC45NjYzNzYgNC45ODUzMDUtOC45NjYzNzZDNC45MjU1MjktOC45NjYzNzYgNC44MTc5MzMtOC45NjYzNzYgNC43MjIyOTEtOC43MDMzNjJMLjcxNzMxIDIuNTQ2NDUxQy43MTczMSAyLjU1ODQwNiAuNjQ1NTc5IDIuNzM3NzMzIC42NDU1NzkgMi43NjE2NDRDLjY0NTU3OSAyLjkwNTEwNiAuNzY1MTMxIDIuOTg4NzkyIC44NjA3NzIgMi45ODg3OTJDLjkzMjUwMyAyLjk4ODc5MiAxLjA0MDEgMi45NzY4MzcgMS4xMjM3ODYgMi43MjU3NzhMNS4xMjg3NjctOC41MjQwMzVaJy8+CjxwYXRoIGlkPSdnNi05NicgZD0nTTEuMDk5ODc1LTIuMDMyMzc5Qy4zNDY3LTEuMjkxMTU4IC4xNTU0MTctMS4xMTE4MzEgLjE1NTQxNy0xLjA2NDAxUy4yMDMyMzgtLjkzMjUwMyAuMjg2OTI0LS45MzI1MDNDLjM0NjctLjkzMjUwMyAxLjAyODE0NC0xLjU5MDAzNyAxLjEyMzc4Ni0xLjY5NzYzNEMxLjE5NTUxNy0uODk2NjM4IDEuNDk0Mzk2IC4xNDM0NjIgMi40MjY4OTkgLjE0MzQ2MkMyLjkwNTEwNiAuMTQzNDYyIDMuMzM1NDkyLS4xNTU0MTcgMy41MjY3NzUtLjI5ODg3OUMzLjY4MjE5Mi0uNDE4NDMxIDQuMjU2MDQtLjkwODU5MyA0LjI1NjA0LTEuMDE2MTg5QzQuMjU2MDQtMS4wNzU5NjUgNC4xOTYyNjQtMS4xNDc2OTYgNC4xMzY0ODgtMS4xNDc2OTZDNC4wODg2NjctMS4xNDc2OTYgMy45MDkzNC0uOTY4MzY5IDMuODYxNTE5LS45MjA1NDhDMy40NDMwODgtLjUxNDA3MiAyLjkxNzA2MS0uMDk1NjQxIDIuNDM4ODU0LS4wOTU2NDFDMS43OTMyNzUtLjA5NTY0MSAxLjcwOTU4OS0xLjAyODE0NCAxLjcwOTU4OS0xLjY3MzcyNEMxLjcwOTU4OS0xLjc5MzI3NSAxLjcwOTU4OS0yLjI5NTM5MiAxLjc5MzI3NS0yLjM5MTAzNEMyLjQ5ODYzLTMuMTIwMjk5IDQuNzEwMzM2LTUuNDAzNzM2IDQuNzEwMzM2LTcuNTE5ODAxQzQuNzEwMzM2LTcuOTk4MDA3IDQuNTMxMDA5LTguNDE2NDM4IDQuMDE2OTM2LTguNDE2NDM4QzIuOTA1MTA2LTguNDE2NDM4IDEuOTM2NzM3LTUuOTUzNjc0IDEuNzY5MzY1LTUuNDk5Mzc3QzEuNzIxNTQ0LTUuMzc5ODI2IDEuMDI4MTQ0LTMuNTM4NzMgMS4wOTk4NzUtMi4wMzIzNzlaTTEuODE3MTg2LTIuNzczNTk5QzEuODI5MTQxLTIuODQ1MzMgMi4zNjcxMjMtNS45Nzc1ODQgMy4zNzEzNTctNy42NTEzMDhDMy41NzQ1OTUtNy45NzQwOTcgMy43Nzc4MzMtOC4xNzczMzUgNC4wMTY5MzYtOC4xNzczMzVDNC40MjM0MTItOC4xNzczMzUgNC40NDczMjMtNy43OTQ3NyA0LjQ0NzMyMy03LjUzMTc1NkM0LjQ0NzMyMy03LjExMzMyNSA0LjMyNzc3MS02LjAzNzM2IDMuMjg3NjcxLTQuNTMxMDA5QzIuOTc2ODM3LTQuMDg4NjY3IDIuNDk4NjMtMy40OTA5MDkgMS44MTcxODYtMi43NzM1OTlaJy8+CjxwYXRoIGlkPSdnNi0xMTYnIGQ9J00yLjQwMjk4OS00LjgwNTk3OEgzLjUwMjg2NEMzLjczMDAxMi00LjgwNTk3OCAzLjg0OTU2NC00LjgwNTk3OCAzLjg0OTU2NC01LjAyMTE3MUMzLjg0OTU2NC01LjE1MjY3NyAzLjc3NzgzMy01LjE1MjY3NyAzLjUzODczLTUuMTUyNjc3SDIuNDg2Njc1TDIuOTI5MDE2LTYuODk4MTMyQzIuOTc2ODM3LTcuMDY1NTA0IDIuOTc2ODM3LTcuMDg5NDE1IDIuOTc2ODM3LTcuMTczMTAxQzIuOTc2ODM3LTcuMzY0Mzg0IDIuODIxNDItNy40NzE5OCAyLjY2NjAwMi03LjQ3MTk4QzIuNTcwMzYxLTcuNDcxOTggMi4yOTUzOTItNy40MzYxMTUgMi4xOTk3NTEtNy4wNTM1NDlMMS43MzM0OTktNS4xNTI2NzdILjYwOTcxNEMuMzcwNjEtNS4xNTI2NzcgLjI2MzAxNC01LjE1MjY3NyAuMjYzMDE0LTQuOTI1NTI5Qy4yNjMwMTQtNC44MDU5NzggLjM0NjctNC44MDU5NzggLjU3Mzg0OC00LjgwNTk3OEgxLjYzNzg1OEwuODQ4ODE3LTEuNjQ5ODEzQy43NTMxNzYtMS4yMzEzODIgLjcxNzMxLTEuMTExODMxIC43MTczMS0uOTU2NDEzQy43MTczMS0uMzk0NTIxIDEuMTExODMxIC4xMTk1NTIgMS43ODEzMiAuMTE5NTUyQzIuOTg4NzkyIC4xMTk1NTIgMy42MzQzNzEtMS42MjU5MDMgMy42MzQzNzEtMS43MDk1ODlDMy42MzQzNzEtMS43ODEzMiAzLjU4NjU1LTEuODE3MTg2IDMuNTE0ODE5LTEuODE3MTg2QzMuNDkwOTA5LTEuODE3MTg2IDMuNDQzMDg4LTEuODE3MTg2IDMuNDE5MTc4LTEuNzY5MzY1QzMuNDA3MjIzLTEuNzU3NDEgMy4zOTUyNjgtMS43NDU0NTUgMy4zMTE1ODItMS41NTQxNzJDMy4wNjA1MjMtLjk1NjQxMyAyLjUxMDU4NS0uMTE5NTUyIDEuODE3MTg2LS4xMTk1NTJDMS40NTg1MzEtLjExOTU1MiAxLjQzNDYyLS40MTg0MzEgMS40MzQ2Mi0uNjgxNDQ1QzEuNDM0NjItLjY5MzQgMS40MzQ2Mi0uOTIwNTQ4IDEuNDcwNDg2LTEuMDY0MDFMMi40MDI5ODktNC44MDU5NzhaJy8+CjxwYXRoIGlkPSdnNi0xMjInIGQ9J00xLjUxODMwNi0uOTY4MzY5QzIuMDMyMzc5LTEuNTU0MTcyIDIuNDUwODA5LTEuOTI0NzgyIDMuMDQ4NTY4LTIuNDYyNzY1QzMuNzY1ODc4LTMuMDg0NDMzIDQuMDc2NzEyLTMuMzgzMzEzIDQuMjQ0MDg1LTMuNTYyNjRDNS4wODA5NDYtNC4zODc1NDcgNS40OTkzNzctNS4wODA5NDYgNS40OTkzNzctNS4xNzY1ODhTNS40MDM3MzYtNS4yNzIyMjkgNS4zNzk4MjYtNS4yNzIyMjlDNS4yOTYxMzktNS4yNzIyMjkgNS4yNzIyMjktNS4yMjQ0MDggNS4yMTI0NTMtNS4xNDA3MjJDNC45MTM1NzQtNC42MjY2NSA0LjYyNjY1LTQuMzc1NTkyIDQuMzE1ODE2LTQuMzc1NTkyQzQuMDY0NzU3LTQuMzc1NTkyIDMuOTMzMjUtNC40ODMxODggMy43MDYxMDItNC43NzAxMTJDMy40NTUwNDQtNS4wNjg5OTEgMy4yNTE4MDYtNS4yNzIyMjkgMi45MDUxMDYtNS4yNzIyMjlDMi4wMzIzNzktNS4yNzIyMjkgMS41MDYzNTEtNC4xODQzMDkgMS41MDYzNTEtMy45MzMyNUMxLjUwNjM1MS0zLjg5NzM4NSAxLjUxODMwNi0zLjgyNTY1NCAxLjYyNTkwMy0zLjgyNTY1NEMxLjcyMTU0NC0zLjgyNTY1NCAxLjczMzQ5OS0zLjg3MzQ3NCAxLjc2OTM2NS0zLjk1NzE2MUMxLjk3MjYwMy00LjQzNTM2NyAyLjU0NjQ1MS00LjUxOTA1NCAyLjc3MzU5OS00LjUxOTA1NEMzLjAyNDY1OC00LjUxOTA1NCAzLjI2Mzc2MS00LjQzNTM2NyAzLjUxNDgxOS00LjMyNzc3MUMzLjk2OTExNi00LjEzNjQ4OCA0LjE2MDM5OS00LjEzNjQ4OCA0LjI3OTk1LTQuMTM2NDg4QzQuMzYzNjM2LTQuMTM2NDg4IDQuNDExNDU3LTQuMTM2NDg4IDQuNDcxMjMzLTQuMTQ4NDQzQzQuMDc2NzEyLTMuNjgyMTkyIDMuNDMxMTMzLTMuMTA4MzQ0IDIuODkzMTUxLTIuNjE4MTgyTDEuNjg1Njc5LTEuNTA2MzUxQy45NTY0MTMtLjc2NTEzMSAuNTE0MDcyLS4wNTk3NzYgLjUxNDA3MiAuMDIzOTFDLjUxNDA3MiAuMDk1NjQxIC41NzM4NDggLjExOTU1MiAuNjQ1NTc5IC4xMTk1NTJTLjcyOTI2NSAuMTA3NTk3IC44MTI5NTEtLjAzNTg2NkMxLjAwNDIzNC0uMzM0NzQ1IDEuMzg2OC0uNzc3MDg2IDEuODI5MTQxLS43NzcwODZDMi4wODAxOTktLjc3NzA4NiAyLjE5OTc1MS0uNjkzNCAyLjQzODg1NC0uMzk0NTIxQzIuNjY2MDAyLS4xMzE1MDcgMi44NjkyNCAuMTE5NTUyIDMuMjUxODA2IC4xMTk1NTJDNC40MjM0MTIgLjExOTU1MiA1LjA5MjkwMi0xLjM5ODc1NSA1LjA5MjkwMi0xLjY3MzcyNEM1LjA5MjkwMi0xLjcyMTU0NCA1LjA4MDk0Ni0xLjc5MzI3NSA0Ljk2MTM5NS0xLjc5MzI3NUM0Ljg2NTc1My0xLjc5MzI3NSA0Ljg1Mzc5OC0xLjc0NTQ1NSA0LjgxNzkzMy0xLjYyNTkwM0M0LjU1NDkxOS0uOTIwNTQ4IDMuODQ5NTY0LS42MzM2MjQgMy4zODMzMTMtLjYzMzYyNEMzLjEzMjI1NC0uNjMzNjI0IDIuODkzMTUxLS43MTczMSAyLjY0MjA5Mi0uODI0OTA3QzIuMTYzODg1LTEuMDE2MTg5IDIuMDMyMzc5LTEuMDE2MTg5IDEuODc2OTYxLTEuMDE2MTg5QzEuNzU3NDEtMS4wMTYxODkgMS42MjU5MDMtMS4wMTYxODkgMS41MTgzMDYtLjk2ODM2OVonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi05NicvPgo8dXNlIHg9JzQuOTEyMTA2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc5LjQ2NDQzMicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cwLTEyJy8+Cjx1c2UgeD0nMTcuNzU4Mjk3JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScyNS42MzE0NTInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC02MScvPgo8dXNlIHg9JzM4LjA1NjkzMicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PSc1NS40MTMxMzQnIHk9Jy0yOS45NzY0MjUnIHhsaW5rOmhyZWY9JyNnNS0xMTAnLz4KPHVzZSB4PSc0OS4zNDc5MjcnIHk9Jy0yNi4zODk4NjknIHhsaW5rOmhyZWY9JyNnMS04OCcvPgo8dXNlIHg9JzUxLjEzMDMyMScgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nNTQuMDEzNDYxJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNy02MScvPgo8dXNlIHg9JzYwLjU5OTk2NycgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzctNDknLz4KPHVzZSB4PSc2OC42MDkwNDEnIHk9Jy0zNS40NzU5MjgnIHhsaW5rOmhyZWY9JyNnMS00MCcvPgo8dXNlIHg9Jzc4LjIzOTY0NCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTEwOCcvPgo8dXNlIHg9JzgxLjQ5MTMwNScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTExMScvPgo8dXNlIHg9Jzg3LjM0NDI5NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTEwMycvPgo8dXNlIHg9JzkzLjM1OTg2OScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nOTcuOTEyMTk1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMjcnLz4KPHVzZSB4PScxMDQuOTk0NTk5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxMDkuNTQ2OTI1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMTEzLjc3NDA4NCcgeT0nLTEzLjIzOTE0MScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzExNy4xNTUzNTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzEyMS43MDc2ODInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzEyOC45MTY2NzEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MycvPgo8dXNlIHg9JzE0MC42Nzc5ODYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzE0NS4yMzAzMTInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzE1My43Mzk5NjUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MycvPgo8dXNlIHg9JzE2NS41MDEyOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nMTcxLjM1NDI3MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c2LTYxJy8+Cjx1c2UgeD0nMTc3LjIwNzI2MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c2LTI0Jy8+Cjx1c2UgeD0nMTgyLjg5NzY5OCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTg3LjQ1MDAyNCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzE5MS42NzcxODQnIHk9Jy0xMy4yMzkxNDEnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PScxOTUuMDU4NDU1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScxOTkuNjEwNzgxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PScyMDYuMTU1NjA1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTA4Jy8+Cjx1c2UgeD0nMjA5LjQwNzI2NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTExMScvPgo8dXNlIHg9JzIxNS4yNjAyNTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC0xMDMnLz4KPHVzZSB4PScyMjMuMjY4MzI3JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMjAnLz4KPHVzZSB4PScyMjkuNTc4MDI0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PScyMzguMDg3Njc4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDMnLz4KPHVzZSB4PScyNDkuODQ4OTkzJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMjQnLz4KPHVzZSB4PScyNTUuNTM5NDMxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScyNjAuMDkxNzU2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMjY0LjMxODkxNicgeT0nLTEzLjIzOTE0MScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzI2Ny43MDAxODgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzI3NC4yNDUwMTEnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0xOCcvPgo8dXNlIHg9JzI4NC4yNDA4OTcnIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnNi0xMjInLz4KPHVzZSB4PScyODkuNjc4Nzg4JyB5PSctMjEuMzI2OScgeGxpbms6aHJlZj0nI2c1LTExNicvPgo8dXNlIHg9JzI5Mi43MzY4MDknIHk9Jy0yMC4xMTE4MjEnIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PScyOTkuMDUzMzYyJyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzMxMS4wMDg1MjMnIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnNi0yMicvPgo8dXNlIHg9JzMxOC4wNTE0OTMnIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzMyMi42MDM4MTknIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PSczMjYuODMwOTc5JyB5PSctMjEuMzI2OScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzMzMC4yMTIyNScgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c4LTQxJy8+CjxyZWN0IHg9JzI4NC4yNDA4OTcnIHk9Jy0xOC4yNjAyOScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNTAuNTIzNjcxJy8+Cjx1c2UgeD0nMjk3LjYwNDk5NycgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzYtMjcnLz4KPHVzZSB4PSczMDQuNjg3NDAxJyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzMwOS4yMzk3MjcnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzMxMy40NjY4ODcnIHk9Jy01LjAzODQ3OScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzMxNi44NDgxNTgnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMzM1Ljk2MDA4MicgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cxLTE5Jy8+Cjx1c2UgeD0nMzQ0Ljc2MDQ1NScgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cxLTIxJy8+Cjx1c2UgeD0nMzUzLjcyNjgxNicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMzY1LjQ4ODEzMScgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cxLTIwJy8+Cjx1c2UgeD0nMzcxLjc5NzgyOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nMzgwLjMwNzQ4MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMzkyLjA2ODc5NycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c2LTI0Jy8+Cjx1c2UgeD0nMzk3Ljc1OTIzNCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nNDAyLjMxMTU2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nNDA2LjUzODcyJyB5PSctMTMuMjM5MTQxJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nNDA5LjkxOTk5MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nNDE2LjQ2NDgxNScgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nNDI2LjQ2MDcwMScgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTEyMicvPgo8dXNlIHg9JzQzMS44OTg1OTInIHk9Jy0yMS4zMjY5JyB4bGluazpocmVmPScjZzUtMTE2Jy8+Cjx1c2UgeD0nNDM0Ljk1NjYxMycgeT0nLTIwLjExMTgyMScgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzQ0MS4yNzMxNjYnIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nNDUzLjIyODMyNycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTIyJy8+Cjx1c2UgeD0nNDYwLjI3MTI5NycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nNDY0LjgyMzYyMycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzQ2OS4wNTA3ODInIHk9Jy0yMS4zMjY5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nNDcyLjQzMjA1NCcgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c4LTQxJy8+CjxyZWN0IHg9JzQyNi40NjA3MDEnIHk9Jy0xOC4yNjAyOScgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNTAuNTIzNjcxJy8+Cjx1c2UgeD0nNDM5LjgyNDgwMScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzYtMjcnLz4KPHVzZSB4PSc0NDYuOTA3MjA1JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzQ1MS40NTk1MzEnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzQ1NS42ODY2OScgeT0nLTUuMDM4NDc5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nNDU5LjA2Nzk2MicgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSc0NzguMTc5ODg2JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PSc0ODYuOTgwMjU5JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMjEnLz4KPHVzZSB4PSc0OTMuMjg5OTU2JyB5PSctMjkuMjEyNjg4JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzQ5OS44NzY0NjMnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzUwNC4xMTA2NDYnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnNS02MScvPgo8dXNlIHg9JzUwOC4zNDQ4MjgnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnNS0yNCcvPgo8dXNlIHg9JzUxMi4zNzgzNjMnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnNy00MCcvPgo8dXNlIHg9JzUxNS42NzE2MTYnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnNS0xMTYnLz4KPHVzZSB4PSc1MTguNzI5NjM3JyB5PSctMjcuOTk3NjA5JyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nNTIxLjg5MTM5NScgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c3LTQxJy8+Cjx1c2UgeD0nNTI1LjY4Mjc4JyB5PSctMzUuNDc1OTI4JyB4bGluazpocmVmPScjZzEtNDEnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
defined on
such that  for all .
for all .And if any of the
is equal to 0, the log-likelihood is defined as:
The initialization of the optimization problem is crucial. Two initial points
are proposed:the Gumbel initial point: in that case, we assume that the GEV is a stationary Gumbel distribution and we deduce
from the empirical mean and the empirical standard variation
of the data:
and where
is Euler’s constant; then we take the initial point . This is the default initial point;the Static initial point: in that case, we assume that the GEV is stationary and
is the maximum likelihood estimate resulting from that assumption.
The result class produced by the method provides:
the estimator
,the asymptotic distribution of
,the parameter functions
 ,
,the normalizing function
 ,
,the optimal log-likelihood value
,the GEV distribution at time
,the quantile functions of order
:  .
.
- getBootstrapSize()¶
Accessor to the bootstrap size.
- Returns:
- sizeint
Size of the bootstrap.
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- getOptimizationAlgorithm()¶
Accessor to the solver.
- Returns:
- solver
OptimizationAlgorithm The solver used for numerical optimization of the moments.
- solver
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- setBootstrapSize(bootstrapSize)¶
Accessor to the bootstrap size.
- Parameters:
- sizeint
The size of the bootstrap.
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
- setOptimizationAlgorithm(solver)¶
Accessor to the solver.
- Parameters:
- solver
OptimizationAlgorithm The solver used for numerical optimization of the moments.
- solver
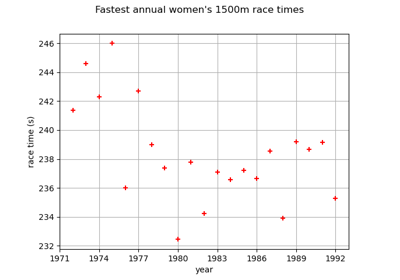
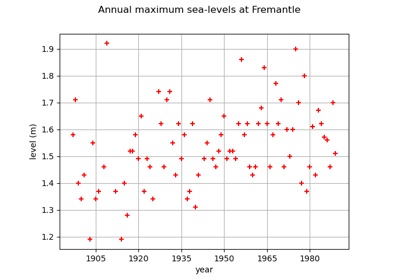
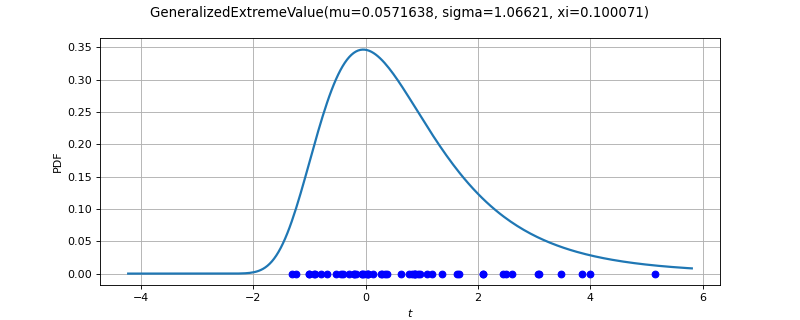{kind=link}