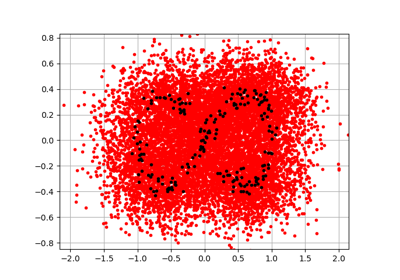
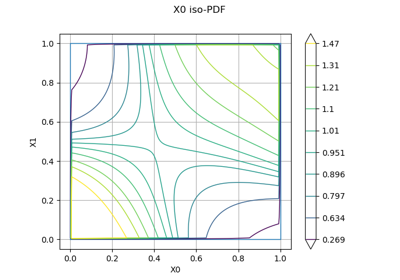
BernsteinCopulaFactory¶
- class BernsteinCopulaFactory(*args)¶
EmpiricalBernsteinCopula factory.
Methods
ComputeAMISEBinNumber(sample)Compute the optimal AMISE number of bins.
Compute the optimal log-likelihood number of bins by cross-validation.
Compute the optimal penalized Csiszar divergence number of bins.
build(*args)Build the empirical Bernstein copula.
Build the empirical Bernstein copula as a native distribution.
buildEstimator(*args)Build the distribution and the parameter distribution.
Accessor to the bootstrap size.
Accessor to the object's name.
Accessor to the known parameters indices.
Accessor to the known parameters values.
getName()Accessor to the object's name.
hasName()Test if the object is named.
setBootstrapSize(bootstrapSize)Accessor to the bootstrap size.
setKnownParameter(values, positions)Accessor to the known parameters.
setName(name)Accessor to the object's name.
See also
Notes
This class builds an
EmpiricalBernsteinCopulawhich is a non parametric fitting of the copula of a multivariate distribution.The keys of
ResourceMaprelated to the class are:the keys BernsteinCopulaFactory-MinM and BernsteinCopulaFactory-MaxM that define the range of
 in the optimization
problems computing the optimal bin number according to a specified criterion,
in the optimization
problems computing the optimal bin number according to a specified criterion,the key BernsteinCopulaFactory-BinNumberSelection that defines the criterion to compute the optimal bin number when it is not specified. The possible choices are ‘AMISE’, ‘LogLikelihood’, ‘PenalizedCsiszarDivergence’;
the key BernsteinCopulaFactory-KFraction that defines the fraction of the sample used for the validation in the method
ComputeLogLikelihoodBinNumber(),the key BernsteinCopulaFactory-SamplingSize that defines the
 parameter used in the
method
parameter used in the
method ComputePenalizedCsiszarDivergenceBinNumber().
- __init__(*args)¶
- static ComputeAMISEBinNumber(sample)¶
Compute the optimal AMISE number of bins.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample from which the optimal AMISE bin number is computed.
Notes
The bin number
is computed by minimizing the asymptotic mean integrated squared error (AMISE),
leading to:
where
 is the largest integer less than or equal to
is the largest integer less than or equal to  ,
,  the sample size and
the sample size and  the sample dimension.
the sample dimension.Note that this optimal
does not necessarily divide the sample size .
- static ComputeLogLikelihoodBinNumber(*args)¶
Compute the optimal log-likelihood number of bins by cross-validation.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample of size
from which the optimal log-likelihood bin number is computed.- kFractionint,

The fraction of the sample used for the validation.
Default value 2.
Notes
Let
 be the given sample. If
be the given sample. If  , the bin number is given by:
, the bin number is given by:
where
 is the density function of the
is the density function of the EmpiricalBernsteinCopulaassociated to the sample and the bin number
and the bin number  .
.If
 , the bin number is given by:
, the bin number is given by:
where
 and
and  .
.Note that this optimal
does not necessarily divide the sample size .
- static ComputePenalizedCsiszarDivergenceBinNumber(*args)¶
Compute the optimal penalized Csiszar divergence number of bins.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample of size
from which the optimal AMISE bin number is computed.- f
Function The function defining the Csiszar divergence of interest.
- alphafloat,

The penalization factor.
Notes
Let
be the given sample. The bin number is given by:![m = \argmin_{M\in\{1,\dots,\sampleSize\}}\left[\hat{D}_f(c^{\cE}_{M})-\dfrac{1}{\sampleSize}\sum_{\vect{x}_i\in\cE}f\left(\dfrac{1}{c^{\cE}_{M}(\vect{x}_i)}\right)\right]^2-[\rho_S(c^{\cE}_{M})-\rho_S({\cE}_{M})]^2](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzM1My44NDEwNDJwdCcgaGVpZ2h0PSczOC4xMzI0NHB0JyB2aWV3Qm94PScxNy4xMDE5MTQgLTM5LjMyNzk1NCAzNTMuODQxMDQyIDM4LjEzMjQ0Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMS0xMjAnIGQ9J002LjQwNzk3LTQuNzk0MDIyQzUuOTc3NTg0LTQuNjc0NDcxIDUuNzYyMzkxLTQuMjY3OTk1IDUuNzYyMzkxLTMuOTY5MTE2QzUuNzYyMzkxLTMuNzA2MTAyIDUuOTY1NjI5LTMuNDE5MTc4IDYuMzYwMTQ5LTMuNDE5MTc4QzYuNzc4NTgtMy40MTkxNzggNy4yMjA5MjItMy43NjU4NzggNy4yMjA5MjItNC4zNTE2ODFDNy4yMjA5MjItNC45ODUzMDUgNi41ODcyOTgtNS40MDM3MzYgNS44NTgwMzItNS40MDM3MzZDNS4xNzY1ODgtNS40MDM3MzYgNC43MzQyNDctNC44ODk2NjQgNC41Nzg4MjktNC42NzQ0NzFDNC4yNzk5NS01LjE3NjU4OCAzLjYxMDQ2MS01LjQwMzczNiAyLjkyOTAxNi01LjQwMzczNkMxLjQyMjY2NS01LjQwMzczNiAuNjA5NzE0LTMuOTMzMjUgLjYwOTcxNC0zLjUzODczQy42MDk3MTQtMy4zNzEzNTcgLjc4OTA0MS0zLjM3MTM1NyAuODk2NjM4LTMuMzcxMzU3QzEuMDQwMS0zLjM3MTM1NyAxLjEyMzc4Ni0zLjM3MTM1NyAxLjE3MTYwNi0zLjUyNjc3NUMxLjUxODMwNi00LjYxNDY5NSAyLjM3OTA3OC00Ljk3MzM1IDIuODY5MjQtNC45NzMzNUMzLjMyMzUzNy00Ljk3MzM1IDMuNTM4NzMtNC43NTgxNTcgMy41Mzg3My00LjM3NTU5MkMzLjUzODczLTQuMTQ4NDQzIDMuMzcxMzU3LTMuNDkwOTA5IDMuMjYzNzYxLTMuMDYwNTIzTDIuODU3Mjg1LTEuNDIyNjY1QzIuNjc3OTU4LS42OTM0IDIuMjQ3NTcyLS4zMzQ3NDUgMS44NDEwOTYtLjMzNDc0NUMxLjc4MTMyLS4zMzQ3NDUgMS41MDYzNTEtLjMzNDc0NSAxLjI2NzI0OC0uNTE0MDcyQzEuNjk3NjM0LS42MzM2MjQgMS45MTI4MjctMS4wNDAxIDEuOTEyODI3LTEuMzM4OTc5QzEuOTEyODI3LTEuNjAxOTkzIDEuNzA5NTg5LTEuODg4OTE3IDEuMzE1MDY4LTEuODg4OTE3Qy44OTY2MzgtMS44ODg5MTcgLjQ1NDI5Ni0xLjU0MjIxNyAuNDU0Mjk2LS45NTY0MTNDLjQ1NDI5Ni0uMzIyNzkgMS4wODc5MiAuMDk1NjQxIDEuODE3MTg2IC4wOTU2NDFDMi40OTg2MyAuMDk1NjQxIDIuOTQwOTcxLS40MTg0MzEgMy4wOTYzODktLjYzMzYyNEMzLjM5NTI2OC0uMTMxNTA3IDQuMDY0NzU3IC4wOTU2NDEgNC43NDYyMDIgLjA5NTY0MUM2LjI1MjU1MyAuMDk1NjQxIDcuMDY1NTA0LTEuMzc0ODQ0IDcuMDY1NTA0LTEuNzY5MzY1QzcuMDY1NTA0LTEuOTM2NzM3IDYuODg2MTc3LTEuOTM2NzM3IDYuNzc4NTgtMS45MzY3MzdDNi42MzUxMTgtMS45MzY3MzcgNi41NTE0MzItMS45MzY3MzcgNi41MDM2MTEtMS43ODEzMkM2LjE1NjkxMi0uNjkzNCA1LjI5NjEzOS0uMzM0NzQ1IDQuODA1OTc4LS4zMzQ3NDVDNC4zNTE2ODEtLjMzNDc0NSA0LjEzNjQ4OC0uNTQ5OTM4IDQuMTM2NDg4LS45MzI1MDNDNC4xMzY0ODgtMS4xODM1NjIgNC4yOTE5MDUtMS44MTcxODYgNC4zOTk1MDItMi4yNTk1MjdDNC40ODMxODgtMi41NzAzNjEgNC43NTgxNTctMy42OTQxNDcgNC44MTc5MzMtMy44ODU0M0M0Ljk5NzI2LTQuNjAyNzQgNS40MTU2OTEtNC45NzMzNSA1LjgzNDEyMi00Ljk3MzM1QzUuODkzODk4LTQuOTczMzUgNi4xNjg4NjctNC45NzMzNSA2LjQwNzk3LTQuNzk0MDIyWicvPgo8cGF0aCBpZD0nZzQtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnNC02OScgZD0nTTIuODU3Mjg1LTQuMzM5NzI2Qy40NjYyNTItMy4wNDg1NjggLjMzNDc0NS0xLjUwNjM1MSAuMzM0NzQ1LTEuMjE5NDI3Qy4zMzQ3NDUtLjMxMDgzNCAxLjIxOTQyNyAuMjYzMDE0IDIuMzU1MTY4IC4yNjMwMTRDNC4zNTE2ODEgLjI2MzAxNCA1Ljk1MzY3NC0xLjYyNTkwMyA1Ljk1MzY3NC0xLjg3Njk2MUM1Ljk1MzY3NC0xLjk0ODY5MiA1Ljg5Mzg5OC0xLjk2MDY0OCA1LjgzNDEyMi0xLjk2MDY0OEM1LjY5MDY2LTEuOTYwNjQ4IDUuMjM2MzY0LTEuODA1MjMgNC45NjEzOTUtMS40MzQ2MkM0LjcxMDMzNi0xLjA4NzkyIDQuMjA4MjE5LS4zOTQ1MjEgMy4xNDQyMDktLjM5NDUyMUMyLjI5NTM5Mi0uMzk0NTIxIDEuMzUwOTM0LS44MzY4NjIgMS4zNTA5MzQtMS43MzM0OTlDMS4zNTA5MzQtMi4zMTkzMDMgMi4wMjA0MjMtNC4wODg2NjcgMy45MDkzNC00LjE2MDM5OUM0LjQ3MTIzMy00LjE4NDMwOSA0Ljg4OTY2NC00LjYwMjc0IDQuODg5NjY0LTQuNzM0MjQ3QzQuODg5NjY0LTQuODA1OTc4IDQuODI5ODg4LTQuODE3OTMzIDQuNzcwMTEyLTQuODE3OTMzQzMuMDg0NDMzLTQuODg5NjY0IDIuNzQ5Njg5LTUuNzE0NTcgMi43NDk2ODktNi4xOTI3NzdDMi43NDk2ODktNi40Njc3NDYgMi45MjkwMTYtNy43NzA4NTkgNC42MDI3NC03Ljc3MDg1OUM0LjgyOTg4OC03Ljc3MDg1OSA1LjczODQ4MS03LjczNDk5NCA1LjczODQ4MS03LjExMzMyNUM1LjczODQ4MS02LjkyMjA0MiA1LjY0MjgzOS02Ljc1NDY3IDUuNTk1MDE5LTYuNjgyOTM5QzUuNTcxMTA4LTYuNjQ3MDczIDUuNTM1MjQzLTYuNTg3Mjk4IDUuNTM1MjQzLTYuNTUxNDMyQzUuNTM1MjQzLTYuNDY3NzQ2IDUuNjE4OTI5LTYuNDY3NzQ2IDUuNjU0Nzk1LTYuNDY3NzQ2QzYuMDEzNDUtNi40Njc3NDYgNi43NTQ2Ny02LjkzMzk5OCA2Ljc1NDY3LTcuNjE1NDQyQzYuNzU0NjctOC4zMjA3OTcgNS45Mjk3NjMtOC40MjgzOTQgNS4zOTE3ODEtOC40MjgzOTRDMy43NjU4NzgtOC40MjgzOTQgMS43MzM0OTktNy4xMzcyMzUgMS43MzM0OTktNS42Nzg3MDVDMS43MzM0OTktNC45NzMzNSAyLjI3MTQ4Mi00LjU0Mjk2NCAyLjg1NzI4NS00LjMzOTcyNlonLz4KPHBhdGggaWQ9J2c4LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzgtNTAnIGQ9J00yLjI0NzU3Mi0xLjYyNTkwM0MyLjM3NTA5My0xLjc0NTQ1NSAyLjcwOTgzOC0yLjAwODQ2OCAyLjgzNzM2LTIuMTIwMDVDMy4zMzE1MDctMi41NzQzNDYgMy44MDE3NDMtMy4wMTI3MDIgMy44MDE3NDMtMy43Mzc5ODNDMy44MDE3NDMtNC42ODY0MjYgMy4wMDQ3MzItNS4zMDAxMjUgMi4wMDg0NjgtNS4zMDAxMjVDMS4wNTIwNTUtNS4zMDAxMjUgLjQyMjQxNi00LjU3NDg0NCAuNDIyNDE2LTMuODY1NTA0Qy40MjI0MTYtMy40NzQ5NjkgLjczMzI1LTMuNDE5MTc4IC44NDQ4MzItMy40MTkxNzhDMS4wMTIyMDQtMy40MTkxNzggMS4yNTkyNzgtMy41Mzg3MyAxLjI1OTI3OC0zLjg0MTU5NEMxLjI1OTI3OC00LjI1NjA0IC44NjA3NzItNC4yNTYwNCAuNzY1MTMxLTQuMjU2MDRDLjk5NjI2NC00LjgzNzg1OCAxLjUzMDI2Mi01LjAzNzExMSAxLjkyMDc5Ny01LjAzNzExMUMyLjY2MjAxNy01LjAzNzExMSAzLjA0NDU4My00LjQwNzQ3MiAzLjA0NDU4My0zLjczNzk4M0MzLjA0NDU4My0yLjkwOTA5MSAyLjQ2Mjc2NS0yLjMwMzM2MiAxLjUyMjI5MS0xLjMzODk3OUwuNTE4MDU3LS4zMDI4NjRDLjQyMjQxNi0uMjE1MTkzIC40MjI0MTYtLjE5OTI1MyAuNDIyNDE2IDBIMy41NzA2MUwzLjgwMTc0My0xLjQyNjY1SDMuNTU0NjdDMy41MzA3Ni0xLjI2NzI0OCAzLjQ2Njk5OS0uODY4NzQyIDMuMzcxMzU3LS43MTczMUMzLjMyMzUzNy0uNjUzNTQ5IDIuNzE3ODA4LS42NTM1NDkgMi41OTAyODYtLjY1MzU0OUgxLjE3MTYwNkwyLjI0NzU3Mi0xLjYyNTkwM1onLz4KPHBhdGggaWQ9J2c1LTEwNScgZD0nTTIuMDgwMTk5LTMuNzMwMDEyQzIuMDgwMTk5LTMuODczNDc0IDEuOTcyNjAzLTMuOTY5MTE2IDEuODM1MTE4LTMuOTY5MTE2QzEuNjczNzI0LTMuOTY5MTE2IDEuNTAwMzc0LTMuODEzNjk5IDEuNTAwMzc0LTMuNjQwMzQ5QzEuNTAwMzc0LTMuNDkwOTA5IDEuNjA3OTctMy40MDEyNDUgMS43Mzk0NzctMy40MDEyNDVDMS45MzA3Ni0zLjQwMTI0NSAyLjA4MDE5OS0zLjU4MDU3MyAyLjA4MDE5OS0zLjczMDAxMlpNMS43MjE1NDQtMS42NDM4MzZDMS43NDU0NTUtMS43MDM2MTEgMS43OTkyNTMtMS44NDcwNzMgMS44MjMxNjMtMS45MDA4NzJDMS44NDEwOTYtMS45NTQ2NyAxLjg2NTAwNi0yLjAxNDQ0NiAxLjg2NTAwNi0yLjExNjA2NUMxLjg2NTAwNi0yLjQ1MDgwOSAxLjU2NjEyNy0yLjYzNjExNSAxLjI2NzI0OC0yLjYzNjExNUMuNjU3NTM0LTIuNjM2MTE1IC4zNjQ2MzMtMS44NDcwNzMgLjM2NDYzMy0xLjcxNTU2N0MuMzY0NjMzLTEuNjg1Njc5IC4zODg1NDMtMS42MzE4OCAuNDcyMjI5LTEuNjMxODhTLjU3Mzg0OC0xLjY2Nzc0NiAuNTkxNzgxLTEuNzIxNTQ0Qy43NTkxNTMtMi4zMDEzNyAxLjA3NTk2NS0yLjQzODg1NCAxLjI0MzMzNy0yLjQzODg1NEMxLjM2Mjg4OS0yLjQzODg1NCAxLjQwNDczMi0yLjM2MTE0NiAxLjQwNDczMi0yLjIyMzY2MUMxLjQwNDczMi0yLjEwNDExIDEuMzY4ODY3LTIuMDE0NDQ2IDEuMzU2OTEyLTEuOTcyNjAzTDEuMDQ2MDc3LTEuMjA3NDcyQy45NzQzNDYtMS4wMzQxMjIgLjk3NDM0Ni0xLjAyMjE2NyAuODk2NjM4LS44MTg5MjlDLjgxODkyOS0uNjM5NjAxIC43ODkwNDEtLjU2MTg5MyAuNzg5MDQxLS40NjAyNzRDLjc4OTA0MS0uMTU1NDE3IDEuMDY0MDEgLjA1OTc3NiAxLjM5Mjc3NyAuMDU5Nzc2QzEuOTk2NTEzIC4wNTk3NzYgMi4yOTUzOTItLjcyOTI2NSAyLjI5NTM5Mi0uODYwNzcyQzIuMjk1MzkyLS44NzI3MjcgMi4yODk0MTUtLjk0NDQ1OCAyLjE4MTgxOC0uOTQ0NDU4QzIuMDk4MTMyLS45NDQ0NTggMi4wOTIxNTQtLjkxNDU3IDIuMDU2Mjg5LS44MDA5OTZDMS45NjA2NDgtLjQ5NjEzOSAxLjcxNTU2Ny0uMTM3NDg0IDEuNDEwNzEtLjEzNzQ4NEMxLjMwMzExMy0uMTM3NDg0IDEuMjQ5MzE1LS4yMDkyMTUgMS4yNDkzMTUtLjM1MjY3N0MxLjI0OTMxNS0uNDcyMjI5IDEuMjg1MTgxLS41NjE4OTMgMS4zNjI4ODktLjc0NzE5OEwxLjcyMTU0NC0xLjY0MzgzNlonLz4KPHBhdGggaWQ9J2cwLTEyMCcgZD0nTTQuNDg3MTczLTMuMTQ4MTk0QzQuMTY4MzY5LTMuMDQ0NTgzIDQuMDMyODc3LTIuNzczNTk5IDQuMDMyODc3LTIuNTU4NDA2QzQuMDMyODc3LTIuMjU1NTQyIDQuMjY0MDEtMi4xNDM5NiA0LjQ2MzI2My0yLjE0Mzk2QzQuNzc0MDk3LTIuMTQzOTYgNS4wOTI5MDItMi4zOTEwMzQgNS4wOTI5MDItMi44MjE0MkM1LjA5MjkwMi0zLjM1NTQxNyA0LjU2Njg3NC0zLjYxMDQ2MSA0LjExMjU3OC0zLjYxMDQ2MUMzLjYyNjQwMS0zLjYxMDQ2MSAzLjM2MzM4Ny0zLjMyMzUzNyAzLjIwMzk4NS0zLjE0ODE5NEMyLjk1NjkxMi0zLjQ0MzA4OCAyLjU4MjMxNi0zLjYxMDQ2MSAyLjAyNDQwOC0zLjYxMDQ2MUMuOTQwNDczLTMuNjEwNDYxIC4zNjY2MjUtMi42NTQwNDcgLjM2NjYyNS0yLjM1OTE1M0MuMzY2NjI1LTIuMjIzNjYxIC40ODYxNzctMi4yMjM2NjEgLjU4OTc4OC0yLjIyMzY2MUMuNzU3MTYxLTIuMjIzNjYxIC43NzMxMDEtMi4yMjM2NjEgLjgyMDkyMi0yLjM4MzA2NEMxLjAyMDE3NC0yLjk2NDg4MiAxLjU3MDExMi0zLjI3NTcxNiAxLjk4NDU1OC0zLjI3NTcxNkMyLjI2MzUxMi0zLjI3NTcxNiAyLjQ3ODcwNS0zLjE3MjEwNSAyLjQ3ODcwNS0yLjg2OTI0QzIuNDc4NzA1LTIuNzI1Nzc4IDIuMzc1MDkzLTIuMzI3MjczIDIuMzExMzMzLTIuMDU2Mjg5TDIuMDU2Mjg5LTEuMDIwMTc0QzEuOTA0ODU3LS40MzAzODYgMS41NzgwODItLjI2MzAxNCAxLjMzMTAwOS0uMjYzMDE0QzEuMjk5MTI4LS4yNjMwMTQgMS4wOTk4NzUtLjI2MzAxNCAuOTQwNDczLS4zOTA1MzVDMS4yNTkyNzgtLjQ5NDE0NyAxLjM5NDc3LS43NjUxMzEgMS4zOTQ3Ny0uOTgwMzI0QzEuMzk0NzctMS4yODMxODggMS4xNjM2MzYtMS4zOTQ3NyAuOTY0Mzg0LTEuMzk0NzdDLjY1MzU0OS0xLjM5NDc3IC4zMzQ3NDUtMS4xNDc2OTYgLjMzNDc0NS0uNzE3MzFDLjMzNDc0NS0uMTgzMzEzIC44NjA3NzIgLjA3MTczMSAxLjMxNTA2OCAuMDcxNzMxQzEuODAxMjQ1IC4wNzE3MzEgMi4wNjQyNTktLjIxNTE5MyAyLjIyMzY2MS0uMzkwNTM1QzIuNDcwNzM1LS4wOTU2NDEgMi44NDUzMyAuMDcxNzMxIDMuNDAzMjM4IC4wNzE3MzFDNC40ODcxNzMgLjA3MTczMSA1LjA2MTAyMS0uODg0NjgyIDUuMDYxMDIxLTEuMTc5NTc3QzUuMDYxMDIxLTEuMzIzMDM5IDQuOTA5NTg5LTEuMzIzMDM5IDQuODM3ODU4LTEuMzIzMDM5QzQuNjU0NTQ1LTEuMzIzMDM5IDQuNjQ2NTc1LTEuMjkxMTU4IDQuNTk4NzU1LTEuMTU1NjY2QzQuNDA3NDcyLS41NzM4NDggMy44NTc1MzQtLjI2MzAxNCAzLjQ0MzA4OC0uMjYzMDE0QzMuMTY0MTM0LS4yNjMwMTQgMi45NDg5NDEtLjM2NjYyNSAyLjk0ODk0MS0uNjY5NDg5QzIuOTQ4OTQxLS44MTI5NTEgMy4wNTI1NTMtMS4yMTE0NTcgMy4xMTYzMTQtMS40ODI0NDFMMy4zNzEzNTctMi41MTg1NTVDMy41MjI3OS0zLjEwODM0NCAzLjg0OTU2NC0zLjI3NTcxNiA0LjA5NjYzOC0zLjI3NTcxNkM0LjEyODUxOC0zLjI3NTcxNiA0LjMyNzc3MS0zLjI3NTcxNiA0LjQ4NzE3My0zLjE0ODE5NFonLz4KPHBhdGggaWQ9J2czLTUwJyBkPSdNNC42MzA2MzUtMS44MDkyMTVDNC43NTgxNTctMS44MDkyMTUgNC45MzM0OTktMS44MDkyMTUgNC45MzM0OTktMS45OTI1MjhTNC43NTgxNTctMi4xNzU4NDEgNC42MzA2MzUtMi4xNzU4NDFIMS4wNzU5NjVDMS4xNzk1NzctMy4yODM2ODYgMi4xMDQxMS00LjEyODUxOCAzLjMxNTU2Ny00LjEyODUxOEg0LjYzMDYzNUM0Ljc1ODE1Ny00LjEyODUxOCA0LjkzMzQ5OS00LjEyODUxOCA0LjkzMzQ5OS00LjMxMTgzMVM0Ljc1ODE1Ny00LjQ5NTE0MyA0LjYzMDYzNS00LjQ5NTE0M0gzLjI5MTY1NkMxLjg1NzAzNi00LjQ5NTE0MyAuNzAxMzctMy4zNzkzMjggLjcwMTM3LTEuOTkyNTI4Qy43MDEzNy0uNTk3NzU4IDEuODY1MDA2IC41MTAwODcgMy4yOTE2NTYgLjUxMDA4N0g0LjYzMDYzNUM0Ljc1ODE1NyAuNTEwMDg3IDQuOTMzNDk5IC41MTAwODcgNC45MzM0OTkgLjMyNjc3NVM0Ljc1ODE1NyAuMTQzNDYyIDQuNjMwNjM1IC4xNDM0NjJIMy4zMTU1NjdDMi4xMDQxMSAuMTQzNDYyIDEuMTc5NTc3LS43MDEzNyAxLjA3NTk2NS0xLjgwOTIxNUg0LjYzMDYzNVonLz4KPHBhdGggaWQ9J2czLTY5JyBkPSdNMS45NjA2NDgtMi44OTMxNTFDLjcyNTI4LTIuMzAzMzYyIC4yMzkxMDMtMS4zNDY5NDkgLjIzOTEwMy0uODI4ODkyQy4yMzkxMDMtLjE3NTM0MiAuOTI0NTMzIC4xNjczNzIgMS42ODE2OTQgLjE2NzM3MkMzLjA4NDQzMyAuMTY3MzcyIDQuMjE2MTg5LTEuMDkxOTA1IDQuMjE2MTg5LTEuMjU5Mjc4QzQuMjE2MTg5LTEuMzA3MDk4IDQuMTc2MzM5LTEuMzIzMDM5IDQuMTQ0NDU4LTEuMzIzMDM5QzQuMDk2NjM4LTEuMzIzMDM5IDMuNzY5ODYzLTEuMjc1MjE4IDMuNTE0ODE5LS45NDA0NzNDMy4yMTk5MjUtLjU1NzkwOCAyLjgyMTQyLS4yOTQ4OTQgMi4yMzk2MDEtLjI5NDg5NEMxLjY5NzYzNC0uMjk0ODk0IC45NDg0NDMtLjUyNjAyNyAuOTQ4NDQzLTEuMTc5NTc3Qy45NDg0NDMtMS42NDE4NDMgMS40NDI1OS0yLjcyNTc3OCAyLjcyNTc3OC0yLjc2NTYyOUMzLjE1NjE2NC0yLjc4MTU2OSAzLjQyNzE0OC0zLjA4NDQzMyAzLjQyNzE0OC0zLjE2NDEzNEMzLjQyNzE0OC0zLjIxOTkyNSAzLjM3MTM1Ny0zLjIyNzg5NSAzLjMzOTQ3Ny0zLjIyNzg5NUMyLjEwNDExLTMuMjc1NzE2IDEuODg4OTE3LTMuODE3Njg0IDEuODg4OTE3LTQuMTI4NTE4QzEuODg4OTE3LTQuNDc5MjAzIDIuMTA0MTEtNS4xNDg2OTIgMy4xODAwNzUtNS4xNDg2OTJDMy4zMjM1MzctNS4xNDg2OTIgMy41MTQ4MTktNS4xMzI3NTIgMy43MTQwNzItNS4wNjEwMjFDMy44MDE3NDMtNS4wMzcxMTEgNC4wMDA5OTYtNC45NzMzNSA0LjAwMDk5Ni00LjcxMDMzNkM0LjAwMDk5Ni00LjU5MDc4NSAzLjk0NTIwNS00LjQ5NTE0MyAzLjkxMzMyNS00LjQ0NzMyM0MzLjg5NzM4NS00LjQxNTQ0MiAzLjg3MzQ3NC00LjM4MzU2MiAzLjg3MzQ3NC00LjM1MTY4MVMzLjkwNTM1NS00LjI4NzkyIDMuOTUzMTc2LTQuMjg3OTJDNC4xNzYzMzktNC4yODc5MiA0LjcxMDMzNi00LjU4MjgxNCA0LjcxMDMzNi01LjA2MTAyMUM0LjcxMDMzNi01LjU0NzE5OCA0LjA4MDY5Ny01LjYxMDk1OSAzLjc0NTk1My01LjYxMDk1OUMyLjU1ODQwNi01LjYxMDk1OSAxLjE3OTU3Ny00Ljc0MjIxNyAxLjE3OTU3Ny0zLjc3NzgzM0MxLjE3OTU3Ny0zLjQzNTExOCAxLjM4NjgtMy4wODQ0MzMgMS45NjA2NDgtMi44OTMxNTFaJy8+CjxwYXRoIGlkPSdnMy0xMDInIGQ9J00yLjQxNDk0NC00LjgyOTg4OEMyLjQxNDk0NC01LjAyOTE0MSAyLjQxNDk0NC01LjIzNjM2NCAyLjY5Mzg5OC01LjQ4MzQzN0MyLjc0OTY4OS01LjUyMzI4OCAyLjk4MDgyMi01LjcyMjU0IDMuNDc0OTY5LTUuNzU0NDIxQzMuNTcwNjEtNS43NjIzOTEgMy42MzQzNzEtNS43NjIzOTEgMy42MzQzNzEtNS44NjYwMDJDMy42MzQzNzEtNS45Nzc1ODQgMy41NTQ2Ny01Ljk3NzU4NCAzLjQ0MzA4OC01Ljk3NzU4NEMyLjU4MjMxNi01Ljk3NzU4NCAxLjgyNTE1Ni01LjU3OTA3OCAxLjgxNzE4Ni00Ljk3MzM1Vi0yLjk0MDk3MUMxLjgwMTI0NS0yLjUyNjUyNiAxLjQwMjc0LTIuMTQzOTYgLjc0OTE5MS0yLjEwNDExQy42NTM1NDktMi4wOTYxMzkgLjU4OTc4OC0yLjA5NjEzOSAuNTg5Nzg4LTEuOTkyNTI4Uy42NjE1MTktMS44ODg5MTcgLjcyNTI4LTEuODgwOTQ2QzEuNDgyNDQxLTEuODMzMTI2IDEuNzM3NDg0LTEuNDI2NjUgMS43OTMyNzUtMS4yMDM0ODdDMS44MTcxODYtMS4xMDc4NDYgMS44MTcxODYtMS4wOTE5MDUgMS44MTcxODYtLjc5NzAxMVYuODI4ODkyQzEuODE3MTg2IDEuMDgzOTM1IDEuODE3MTg2IDEuNDM0NjIgMi4zMjcyNzMgMS43Mjk1MTRDMi42Njk5ODggMS45Mjg3NjcgMy4xNjQxMzQgMS45OTI1MjggMy40NDMwODggMS45OTI1MjhDMy41NTQ2NyAxLjk5MjUyOCAzLjYzNDM3MSAxLjk5MjUyOCAzLjYzNDM3MSAxLjg4MDk0NkMzLjYzNDM3MSAxLjc3NzMzNSAzLjU2MjY0IDEuNzc3MzM1IDMuNDk4ODc5IDEuNzY5MzY1QzIuNzU3NjU5IDEuNzIxNTQ0IDIuNDk0NjQ1IDEuMzQ2OTQ5IDIuNDM4ODU0IDEuMDk5ODc1QzIuNDE0OTQ0IDEuMDIwMTc0IDIuNDE0OTQ0IDEuMDA0MjM0IDIuNDE0OTQ0IC43MjUyOFYtLjk0ODQ0M0MyLjQxNDk0NC0xLjE2MzYzNiAyLjQxNDk0NC0xLjcxMzU3NCAxLjQ5MDQxMS0xLjk5MjUyOEMyLjA4ODE2OS0yLjE3NTg0MSAyLjMxMTMzMy0yLjQ2Mjc2NSAyLjM5MTAzNC0yLjc1NzY1OUMyLjQxNDk0NC0yLjg1MzMgMi40MTQ5NDQtMi45MDkwOTEgMi40MTQ5NDQtMy4xNTYxNjRWLTQuODI5ODg4WicvPgo8cGF0aCBpZD0nZzMtMTAzJyBkPSdNMi40MTQ5NDQtNC44MTM5NDhDMi40MTQ5NDQtNS4wNDUwODEgMi40MTQ5NDQtNS4zNzk4MjYgMS45OTI1MjgtNS42NjY3NUMxLjY1Nzc4My01Ljg4OTkxMyAxLjEzMTc1Ni01Ljk3NzU4NCAuNzgxMDcxLTUuOTc3NTg0Qy42Nzc0Ni01Ljk3NzU4NCAuNTg5Nzg4LTUuOTc3NTg0IC41ODk3ODgtNS44NjYwMDJDLjU4OTc4OC01Ljc2MjM5MSAuNjYxNTE5LTUuNzYyMzkxIC43MjUyOC01Ljc1NDQyMUMxLjQ1ODUzMS01LjcwNjYgMS43Mzc0ODQtNS4zNTU5MTUgMS44MDEyNDUtNS4wNjEwMjFDMS44MTcxODYtNC45ODEzMiAxLjgxNzE4Ni00LjkyNTUyOSAxLjgxNzE4Ni00LjgxMzk0OFYtMy4xNDAyMjRDMS44MTcxODYtMi43ODk1MzkgMS44MTcxODYtMi4yNzE0ODIgMi43NDE3MTktMS45OTI1MjhDMi4yOTUzOTItMS44NTcwMzYgMS45NTI2NzctMS42MzM4NzMgMS44NDEwOTYtMS4yMjczOTdDMS44MTcxODYtMS4xMzE3NTYgMS44MTcxODYtMS4wNzU5NjUgMS44MTcxODYtLjgyODg5MlYuNjA1NzI5QzEuODE3MTg2IDEuMTM5NzI2IDEuODE3MTg2IDEuMjExNDU3IDEuNTU0MTcyIDEuNDgyNDQxQzEuNTMwMjYyIDEuNDk4MzgxIDEuMzA3MDk4IDEuNzI5NTE0IC43NDkxOTEgMS43NjkzNjVDLjY0NTU3OSAxLjc3NzMzNSAuNTg5Nzg4IDEuNzc3MzM1IC41ODk3ODggMS44ODA5NDZDLjU4OTc4OCAxLjk5MjUyOCAuNjc3NDYgMS45OTI1MjggLjc4MTA3MSAxLjk5MjUyOEMxLjY0MTg0MyAxLjk5MjUyOCAyLjQwNjk3NCAxLjYwMTk5MyAyLjQxNDk0NCAuOTg4Mjk0Vi0uNjEzNjk5QzIuNDE0OTQ0LTEuMTU1NjY2IDIuNDE0OTQ0LTEuMzM4OTc5IDIuNjU0MDQ3LTEuNTYyMTQyQzIuOTE3MDYxLTEuNzkzMjc1IDMuMjAzOTg1LTEuODU3MDM2IDMuNDc0OTY5LTEuODgwOTQ2QzMuNTc4NTgtMS44ODg5MTcgMy42MzQzNzEtMS44ODg5MTcgMy42MzQzNzEtMS45OTI1MjhTMy41NjI2NC0yLjA5NjEzOSAzLjQ5ODg3OS0yLjEwNDExQzIuNjE0MTk3LTIuMTU5OSAyLjQxNDk0NC0yLjcwMTg2OCAyLjQxNDk0NC0yLjk0MDk3MVYtNC44MTM5NDhaJy8+CjxwYXRoIGlkPSdnNi01OCcgZD0nTTEuNjE3OTMzLS40MzgzNTZDMS42MTc5MzMtLjcwOTM0IDEuMzk0NzctLjg4NDY4MiAxLjE3OTU3Ny0uODg0NjgyQy45MjQ1MzMtLjg4NDY4MiAuNzMzMjUtLjY3NzQ2IC43MzMyNS0uNDQ2MzI2Qy43MzMyNS0uMTc1MzQyIC45NTY0MTMgMCAxLjE3MTYwNiAwQzEuNDI2NjUgMCAxLjYxNzkzMy0uMjA3MjIzIDEuNjE3OTMzLS40MzgzNTZaJy8+CjxwYXRoIGlkPSdnNi01OScgZD0nTTEuNDkwNDExLS4xMTk1NTJDMS40OTA0MTEgLjM5ODUwNiAxLjM3ODgyOSAuODUyODAyIC44ODQ2ODIgMS4zNDY5NDlDLjg1MjgwMiAxLjM3MDg1OSAuODM2ODYyIDEuMzg2OCAuODM2ODYyIDEuNDI2NjVDLjgzNjg2MiAxLjQ5MDQxMSAuOTAwNjIzIDEuNTM4MjMyIC45NTY0MTMgMS41MzgyMzJDMS4wNTIwNTUgMS41MzgyMzIgMS43MTM1NzQgLjkwODU5MyAxLjcxMzU3NC0uMDIzOTFDMS43MTM1NzQtLjUzMzk5OCAxLjUyMjI5MS0uODg0NjgyIDEuMTcxNjA2LS44ODQ2ODJDLjg5MjY1My0uODg0NjgyIC43MzMyNS0uNjYxNTE5IC43MzMyNS0uNDQ2MzI2Qy43MzMyNS0uMjIzMTYzIC44ODQ2ODIgMCAxLjE3OTU3NyAwQzEuMzcwODU5IDAgMS40OTA0MTEtLjExMTU4MiAxLjQ5MDQxMS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzYtNzcnIGQ9J003LjczODk3OS00Ljc5ODAwN0M3LjgxODY4LTUuMTA4ODQyIDcuODM0NjItNS4xODA1NzMgOC4zOTI1MjgtNS4xODA1NzNDOC41NzU4NDEtNS4xODA1NzMgOC42NzE0ODItNS4xODA1NzMgOC42NzE0ODItNS4zMzIwMDVDOC42NzE0ODItNS40NDM1ODcgOC41Njc4Ny01LjQ0MzU4NyA4LjQyNDQwOC01LjQ0MzU4N0g3LjM5NjI2NEM3LjE4MTA3MS01LjQ0MzU4NyA3LjE1NzE2MS01LjQ0MzU4NyA3LjA1MzU0OS01LjI4NDE4NEw0LjA0ODgxNy0uNzMzMjVMMy4zMzk0NzctNS4yMjgzOTRDMy4zMDc1OTctNS40Mjc2NDYgMy4yOTk2MjYtNS40NDM1ODcgMy4wNjA1MjMtNS40NDM1ODdIMS45ODQ1NThDMS44NDEwOTYtNS40NDM1ODcgMS43Mzc0ODQtNS40NDM1ODcgMS43Mzc0ODQtNS4yOTIxNTRDMS43Mzc0ODQtNS4xODA1NzMgMS44NDEwOTYtNS4xODA1NzMgMS45Njg2MTgtNS4xODA1NzNDMi4yMzE2MzEtNS4xODA1NzMgMi40NjI3NjUtNS4xODA1NzMgMi40NjI3NjUtNS4wNTMwNTFDMi40NjI3NjUtNS4wMjExNzEgMi40NTQ3OTUtNS4wMTMyIDIuNDMwODg0LTQuOTA5NTg5TDEuNDE4NjgtLjg1MjgwMkMxLjMyMzAzOS0uNDU0Mjk2IDEuMTE1ODE2LS4yNzg5NTQgLjU4MTgxOC0uMjYzMDE0Qy41MzM5OTgtLjI2MzAxNCAuNDM4MzU2LS4yNTUwNDQgLjQzODM1Ni0uMTExNTgyQy40MzgzNTYtLjA2Mzc2MSAuNDc4MjA3IDAgLjU1NzkwOCAwQy41ODk3ODggMCAuNzczMTAxLS4wMjM5MSAxLjM0Njk0OS0uMDIzOTFDMS45NzY1ODgtLjAyMzkxIDIuMDk2MTM5IDAgMi4xNjc4NyAwQzIuMTk5NzUxIDAgMi4zMTkzMDMgMCAyLjMxOTMwMy0uMTUxNDMyQzIuMzE5MzAzLS4yNDcwNzMgMi4yMzE2MzEtLjI2MzAxNCAyLjE3NTg0MS0uMjYzMDE0QzEuODg4OTE3LS4yNzA5ODQgMS42NDk4MTMtLjMxODgwNCAxLjY0OTgxMy0uNTk3NzU4QzEuNjQ5ODEzLS42Mzc2MDkgMS42NzM3MjQtLjc0OTE5MSAxLjY3MzcyNC0uNzU3MTYxTDIuNzU3NjU5LTUuMDg0OTMySDIuNzY1NjI5TDMuNTM4NzMtLjIxNTE5M0MzLjU2MjY0LS4wODc2NzEgMy41NzA2MSAwIDMuNjgyMTkyIDBTMy44NDk1NjQtLjA4NzY3MSAzLjg5NzM4NS0uMTU5NDAyTDcuMTczMTAxLTUuMTQ4NjkyTDcuMTgxMDcxLTUuMTQwNzIyTDYuMDU3Mjg1LS42Mjk2MzlDNS45ODU1NTQtLjMyNjc3NSA1Ljk2OTYxNC0uMjYzMDE0IDUuMzc5ODI2LS4yNjMwMTRDNS4yMjgzOTQtLjI2MzAxNCA1LjEzMjc1Mi0uMjYzMDE0IDUuMTMyNzUyLS4xMTE1ODJDNS4xMzI3NTItLjA3OTcwMSA1LjE1NjY2MyAwIDUuMjYwMjc0IDBTNS42MDI5ODktLjAxNTk0IDUuNzE0NTctLjAyMzkxSDYuMjI0NjU4QzYuOTY1ODc4LS4wMjM5MSA3LjE1NzE2MSAwIDcuMjEyOTUxIDBDNy4yNjA3NzIgMCA3LjM3MjM1NCAwIDcuMzcyMzU0LS4xNTE0MzJDNy4zNzIzNTQtLjI2MzAxNCA3LjI2ODc0Mi0uMjYzMDE0IDcuMTMzMjUtLjI2MzAxNEM3LjEwOTM0LS4yNjMwMTQgNi45NjU4NzgtLjI2MzAxNCA2LjgzMDM4Ni0uMjc4OTU0QzYuNjYzMDE0LS4yOTQ4OTQgNi42NDcwNzMtLjMxODgwNCA2LjY0NzA3My0uMzkwNTM1QzYuNjQ3MDczLS40MzAzODYgNi42NjMwMTQtLjQ3ODIwNyA2LjY3MDk4NC0uNTE4MDU3TDcuNzM4OTc5LTQuNzk4MDA3WicvPgo8cGF0aCBpZD0nZzYtODMnIGQ9J001LjM0Nzk0NS01LjM5NTc2NkM1LjM1NTkxNS01LjQyNzY0NiA1LjM3MTg1Ni01LjQ3NTQ2NyA1LjM3MTg1Ni01LjUxNTMxOEM1LjM3MTg1Ni01LjU3MTEwOCA1LjMyNDAzNS01LjYxMDk1OSA1LjI2ODI0NC01LjYxMDk1OVM1LjE5NjUxMy01LjU5NTAxOSA1LjEwODg0Mi01LjQ5OTM3N0M1LjAyMTE3MS01LjM5NTc2NiA0LjgxMzk0OC01LjE0MDcyMiA0LjcyNjI3Ni01LjA0NTA4MUM0LjQxNTQ0Mi01LjQ5OTM3NyAzLjkxMzMyNS01LjYxMDk1OSAzLjUwNjg0OS01LjYxMDk1OUMyLjM5OTAwNC01LjYxMDk1OSAxLjQ1MDU2LTQuNjc4NDU2IDEuNDUwNTYtMy43Njk4NjNDMS40NTA1Ni0zLjMwNzU5NyAxLjY5NzYzNC0zLjAzNjYxMyAxLjczNzQ4NC0yLjk4MDgyMkMyLjAwMDQ5OC0yLjcwMTg2OCAyLjIzMTYzMS0yLjYzODEwNyAyLjgwNTQ3OS0yLjUwMjYxNUMzLjA4NDQzMy0yLjQzMDg4NCAzLjEwMDM3NC0yLjQzMDg4NCAzLjMzMTUwNy0yLjM3NTA5M1M0LjA3MjcyNy0yLjE5MTc4MSA0LjA3MjcyNy0xLjUzMDI2MkM0LjA3MjcyNy0uODM2ODYyIDMuMzg3Mjk4LS4wOTU2NDEgMi41NTA0MzYtLjA5NTY0MUMyLjAzMjM3OS0uMDk1NjQxIDEuMDgzOTM1LS4yNTUwNDQgMS4wODM5MzUtMS4yNDMzMzdDMS4wODM5MzUtMS4yNjcyNDggMS4wODM5MzUtMS40MzQ2MiAxLjEzMTc1Ni0xLjYyNTkwM0wxLjEzOTcyNi0xLjcwNTYwNEMxLjEzOTcyNi0xLjgwMTI0NSAxLjA1MjA1NS0xLjgwOTIxNSAxLjAyMDE3NC0xLjgwOTIxNUMuOTE2NTYzLTEuODA5MjE1IC45MDg1OTMtMS43NzczMzUgLjg2ODc0Mi0xLjU5NDAyMkwuNTQxOTY4LS4yOTQ4OTRDLjUxMDA4Ny0uMTc1MzQyIC40NTQyOTYgLjAzOTg1MSAuNDU0Mjk2IC4wNjM3NjFDLjQ1NDI5NiAuMTI3NTIyIC41MDIxMTcgLjE2NzM3MiAuNTU3OTA4IC4xNjczNzJTLjYyMTY2OSAuMTU5NDAyIC43MDkzNCAuMDU1NzkxTDEuMDkxOTA1LS4zOTA1MzVDMS4yNzUyMTgtLjE1MTQzMiAxLjcyOTUxNCAuMTY3MzcyIDIuNTM0NDk2IC4xNjczNzJDMy42OTAxNjIgLjE2NzM3MiA0LjYzODYwNS0uODc2NzEyIDQuNjM4NjA1LTEuODMzMTI2QzQuNjM4NjA1LTIuMTk5NzUxIDQuNTE5MDU0LTIuNDg2Njc1IDQuMzAzODYxLTIuNzA5ODM4QzQuMDY0NzU3LTIuOTcyODUyIDMuODAxNzQzLTMuMDM2NjEzIDMuNDI3MTQ4LTMuMTMyMjU0QzMuMTk2MDE1LTMuMTg4MDQ1IDIuODg1MTgxLTMuMjU5Nzc2IDIuNzAxODY4LTMuMzA3NTk3QzIuNDYyNzY1LTMuMzYzMzg3IDIuMDE2NDM4LTMuNTIyNzkgMi4wMTY0MzgtNC4wODA2OTdDMi4wMTY0MzgtNC43MDIzNjYgMi42ODU5MjgtNS4zNzE4NTYgMy40OTg4NzktNS4zNzE4NTZDNC4yMTYxODktNS4zNzE4NTYgNC43MTAzMzYtNC45OTcyNiA0LjcxMDMzNi00LjEzNjQ4OEM0LjcxMDMzNi0zLjk0NTIwNSA0LjY3ODQ1Ni0zLjc3NzgzMyA0LjY3ODQ1Ni0zLjc0NTk1M0M0LjY3ODQ1Ni0zLjY1MDMxMSA0Ljc1MDE4Ny0zLjYzNDM3MSA0LjgwNTk3OC0zLjYzNDM3MUM0LjkwMTYxOS0zLjYzNDM3MSA0LjkwOTU4OS0zLjY2NjI1MiA0Ljk0MTQ2OS0zLjc5Mzc3M0w1LjM0Nzk0NS01LjM5NTc2NlonLz4KPHBhdGggaWQ9J2c2LTEwMicgZD0nTTMuMDUyNTUzLTMuMTcyMTA1SDMuNzkzNzczQzMuOTUzMTc2LTMuMTcyMTA1IDQuMDQ4ODE3LTMuMTcyMTA1IDQuMDQ4ODE3LTMuMzIzNTM3QzQuMDQ4ODE3LTMuNDM1MTE4IDMuOTQ1MjA1LTMuNDM1MTE4IDMuODA5NzE0LTMuNDM1MTE4SDMuMTAwMzc0QzMuMjI3ODk1LTQuMTUyNDI4IDMuMzA3NTk3LTQuNjA2NzI1IDMuMzg3Mjk4LTQuOTY1MzhDMy40MTkxNzgtNS4xMDA4NzIgMy40NDMwODgtNS4xODg1NDMgMy41NjI2NC01LjI4NDE4NEMzLjY2NjI1Mi01LjM3MTg1NiAzLjczMDAxMi01LjM4Nzc5NiAzLjgxNzY4NC01LjM4Nzc5NkMzLjkzNzIzNS01LjM4Nzc5NiA0LjA2NDc1Ny01LjM2Mzg4NSA0LjE2ODM2OS01LjMwMDEyNUM0LjEyODUxOC01LjI4NDE4NCA0LjA4MDY5Ny01LjI2MDI3NCA0LjA0MDg0Ny01LjIzNjM2NEMzLjkwNTM1NS01LjE2NDYzMyAzLjgwOTcxNC01LjAyMTE3MSAzLjgwOTcxNC00Ljg2MTc2OEMzLjgwOTcxNC00LjY3ODQ1NiAzLjk1MzE3Ni00LjU2Njg3NCA0LjEyODUxOC00LjU2Njg3NEM0LjM1OTY1MS00LjU2Njg3NCA0LjU3NDg0NC00Ljc2NjEyNyA0LjU3NDg0NC01LjA0NTA4MUM0LjU3NDg0NC01LjQxOTY3NiA0LjE5MjI3OS01LjYxMDk1OSAzLjgwOTcxNC01LjYxMDk1OUMzLjUzODczLTUuNjEwOTU5IDMuMDM2NjEzLTUuNDgzNDM3IDIuNzgxNTY5LTQuNzUwMTg3QzIuNzA5ODM4LTQuNTY2ODc0IDIuNzA5ODM4LTQuNTUwOTM0IDIuNDk0NjQ1LTMuNDM1MTE4SDEuODk2ODg3QzEuNzM3NDg0LTMuNDM1MTE4IDEuNjQxODQzLTMuNDM1MTE4IDEuNjQxODQzLTMuMjgzNjg2QzEuNjQxODQzLTMuMTcyMTA1IDEuNzQ1NDU1LTMuMTcyMTA1IDEuODgwOTQ2LTMuMTcyMTA1SDIuNDQ2ODI0TDEuODcyOTc2LS4wNzk3MDFDMS43MjE1NDQgLjcyNTI4IDEuNjAxOTkzIDEuNDAyNzQgMS4xNzk1NzcgMS40MDI3NEMxLjE1NTY2NiAxLjQwMjc0IC45ODgyOTQgMS40MDI3NCAuODM2ODYyIDEuMzA3MDk4QzEuMjAzNDg3IDEuMjE5NDI3IDEuMjAzNDg3IC44ODQ2ODIgMS4yMDM0ODcgLjg3NjcxMkMxLjIwMzQ4NyAuNjkzNCAxLjA2MDAyNSAuNTgxODE4IC44ODQ2ODIgLjU4MTgxOEMuNjY5NDg5IC41ODE4MTggLjQzODM1NiAuNzY1MTMxIC40MzgzNTYgMS4wNjc5OTVDLjQzODM1NiAxLjQwMjc0IC43ODEwNzEgMS42MjU5MDMgMS4xNzk1NzcgMS42MjU5MDNDMS42NjU3NTMgMS42MjU5MDMgMi4wMDA0OTggMS4xMTU4MTYgMi4xMDQxMSAuOTE2NTYzQzIuMzkxMDM0IC4zOTA1MzUgMi41NzQzNDYtLjYwNTcyOSAyLjU5MDI4Ni0uNjg1NDNMMy4wNTI1NTMtMy4xNzIxMDVaJy8+CjxwYXRoIGlkPSdnNi0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzYtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2cyLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cyLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzItMzQnIGQ9J00zLjI4NzY3MSAzNS4zNzUzNDJINi44MjY0MDFWMzQuNjM0MTIySDQuMDI4ODkyVi4yNjMwMTRINi44MjY0MDFWLS40NzgyMDdIMy4yODc2NzFWMzUuMzc1MzQyWicvPgo8cGF0aCBpZD0nZzItMzUnIGQ9J00yLjkyOTAxNiAzNC42MzQxMjJILjEzMTUwN1YzNS4zNzUzNDJIMy42NzAyMzdWLS40NzgyMDdILjEzMTUwN1YuMjYzMDE0SDIuOTI5MDE2VjM0LjYzNDEyMlonLz4KPHBhdGggaWQ9J2cyLTg4JyBkPSdNMTUuMTM1MjQzIDE2LjczNzIzNUwxNi41ODE4MTggMTIuOTExNTgySDE2LjI4MjkzOUMxNS44MTY2ODcgMTQuMTU0OTE5IDE0LjU0OTQ0IDE0Ljk2Nzg3IDEzLjE3NDU5NSAxNS4zMjY1MjZDMTIuOTIzNTM3IDE1LjM4NjMwMSAxMS43NTE5MyAxNS42OTcxMzYgOS40NTY1MzggMTUuNjk3MTM2SDIuMjQ3NTcyTDguMzMyNzUyIDguNTU5OUM4LjQxNjQzOCA4LjQ2NDI1OSA4LjQ0MDM0OSA4LjQyODM5NCA4LjQ0MDM0OSA4LjM2ODYxOEM4LjQ0MDM0OSA4LjM0NDcwNyA4LjQ0MDM0OSA4LjMwODg0MiA4LjM1NjY2MyA4LjE4OTI5TDIuNzg1NTU0IC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IC41NzM4NDggMTIuMDI2ODk5IC43NDEyMiAxMi4xMzQ0OTYgLjc2NTEzMUMxMi43ODAwNzUgLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0Qy43MjkyNjUgMCAuNzE3MzEgLjAxMTk1NSAuNjgxNDQ1IC4wODM2ODZDLjY2OTQ4OSAuMTE5NTUyIC42Njk0ODkgLjM0NjcgLjY2OTQ4OSAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TC44MDA5OTYgMTYuMzkwNTM1Qy42ODE0NDUgMTYuNTMzOTk4IC42ODE0NDUgMTYuNTkzNzczIC42ODE0NDUgMTYuNjA1NzI5Qy42ODE0NDUgMTYuNzM3MjM1IC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJy8+CjxwYXRoIGlkPSdnOS00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzktNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c5LTQ5JyBkPSdNMy40NDMwODgtNy42NjMyNjNDMy40NDMwODgtNy45MzgyMzIgMy40NDMwODgtNy45NTAxODcgMy4yMDM5ODUtNy45NTAxODdDMi45MTcwNjEtNy42MjczOTcgMi4zMTkzMDMtNy4xODUwNTYgMS4wODc5Mi03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODktNi44MzgzNTYgMS45NjA2NDgtNi44MzgzNTYgMi42MTgxODItNy4xNDkxOTFWLS45MjA1NDhDMi42MTgxODItLjQ5MDE2MiAyLjU4MjMxNi0uMzQ2NyAxLjUzMDI2Mi0uMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTEgMy4wMzY2MTMtLjAyMzkxUzQuNTc4ODI5LS4wMjM5MSA0LjkwMTYxOSAwVi0uMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NC0uMzQ2NyAzLjQ0MzA4OC0uNDkwMTYyIDMuNDQzMDg4LS45MjA1NDhWLTcuNjYzMjYzWicvPgo8cGF0aCBpZD0nZzktNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2c5LTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnOS05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjxwYXRoIGlkPSdnOS05NCcgZD0nTTIuOTI5MDE2LTguMjk2ODg3TDEuMzYyODg5LTYuNjcwOTg0TDEuNTU0MTcyLTYuNDkxNjU2TDIuOTE3MDYxLTcuNzIzMDM5TDQuMjkxOTA1LTYuNDkxNjU2TDQuNDgzMTg4LTYuNjcwOTg0TDIuOTI5MDE2LTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzktOTcnIGQ9J000LjYxNDY5NS0zLjE5MjAzQzQuNjE0Njk1LTMuODM3NjA5IDQuNjE0Njk1LTQuMzE1ODE2IDQuMDg4NjY3LTQuNzgyMDY3QzMuNjcwMjM3LTUuMTY0NjMzIDMuMTMyMjU0LTUuMzMyMDA1IDIuNjA2MjI3LTUuMzMyMDA1QzEuNjI1OTAzLTUuMzMyMDA1IC44NzI3MjctNC42ODY0MjYgLjg3MjcyNy0zLjkwOTM0Qy44NzI3MjctMy41NjI2NCAxLjA5OTg3NS0zLjM5NTI2OCAxLjM3NDg0NC0zLjM5NTI2OEMxLjY2MTc2OC0zLjM5NTI2OCAxLjg2NTAwNi0zLjU5ODUwNiAxLjg2NTAwNi0zLjg4NTQzQzEuODY1MDA2LTQuMzc1NTkyIDEuNDM0NjItNC4zNzU1OTIgMS4yNTUyOTMtNC4zNzU1OTJDMS41MzAyNjItNC44Nzc3MDkgMi4xMDQxMS01LjA5MjkwMiAyLjU4MjMxNi01LjA5MjkwMkMzLjEzMjI1NC01LjA5MjkwMiAzLjgzNzYwOS00LjYzODYwNSAzLjgzNzYwOS0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyLTMuMDQ4NTY4IC41MjYwMjctMi4wNDQzMzQgLjUyNjAyNy0xLjEyMzc4NkMuNTI2MDI3LS4xNzkzMjggMS42MjU5MDMgLjExOTU1MiAyLjM1NTE2OCAuMTE5NTUyQzMuMTQ0MjA5IC4xMTk1NTIgMy42ODIxOTItLjM1ODY1NSAzLjkwOTM0LS45MzI1MDNDMy45NTcxNjEtLjM3MDYxIDQuMzI3NzcxIC4wNTk3NzYgNC44NDE4NDMgLjA1OTc3NkM1LjA5MjkwMiAuMDU5Nzc2IDUuNzg2MzAxLS4xMDc1OTcgNS43ODYzMDEtMS4wNjQwMVYtMS43MzM0OTlINS41MjMyODhWLTEuMDY0MDFDNS41MjMyODgtLjM4MjU2NSA1LjIzNjM2NC0uMjg2OTI0IDUuMDY4OTkxLS4yODY5MjRDNC42MTQ2OTUtLjI4NjkyNCA0LjYxNDY5NS0uOTIwNTQ4IDQuNjE0Njk1LTEuMDk5ODc1Vi0zLjE5MjAzWk0zLjgzNzYwOS0xLjY4NTY3OUMzLjgzNzYwOS0uNTE0MDcyIDIuOTY0ODgyLS4xMTk1NTIgMi40NTA4MDktLjExOTU1MkMxLjg2NTAwNi0uMTE5NTUyIDEuMzc0ODQ0LS41NDk5MzggMS4zNzQ4NDQtMS4xMjM3ODZDMS4zNzQ4NDQtMi43MDE4NjggMy40MDcyMjMtMi44NDUzMyAzLjgzNzYwOS0yLjg2OTI0Vi0xLjY4NTY3OVonLz4KPHBhdGggaWQ9J2c5LTEwMycgZD0nTTEuNDIyNjY1LTIuMTYzODg1QzEuOTg0NTU4LTEuNzkzMjc1IDIuNDYyNzY1LTEuNzkzMjc1IDIuNTk0MjcxLTEuNzkzMjc1QzMuNjcwMjM3LTEuNzkzMjc1IDQuNDcxMjMzLTIuNjA2MjI3IDQuNDcxMjMzLTMuNTI2Nzc1QzQuNDcxMjMzLTMuODQ5NTY0IDQuMzc1NTkyLTQuMzAzODYxIDMuOTkzMDI2LTQuNjg2NDI2QzQuNDU5Mjc4LTUuMTY0NjMzIDUuMDIxMTcxLTUuMTY0NjMzIDUuMDgwOTQ2LTUuMTY0NjMzQzUuMTI4NzY3LTUuMTY0NjMzIDUuMTg4NTQzLTUuMTY0NjMzIDUuMjM2MzY0LTUuMTQwNzIyQzUuMTE2ODEyLTUuMDkyOTAyIDUuMDU3MDM2LTQuOTczMzUgNS4wNTcwMzYtNC44NDE4NDNDNS4wNTcwMzYtNC42NzQ0NzEgNS4xNzY1ODgtNC41MzEwMDkgNS4zNjc4Ny00LjUzMTAwOUM1LjQ2MzUxMi00LjUzMTAwOSA1LjY3ODcwNS00LjU5MDc4NSA1LjY3ODcwNS00Ljg1Mzc5OEM1LjY3ODcwNS01LjA2ODk5MSA1LjUxMTMzMy01LjQwMzczNiA1LjA5MjkwMi01LjQwMzczNkM0LjQ3MTIzMy01LjQwMzczNiA0LjAwNDk4MS01LjAyMTE3MSAzLjgzNzYwOS00Ljg0MTg0M0MzLjQ3ODk1NC01LjExNjgxMiAzLjA2MDUyMy01LjI3MjIyOSAyLjYwNjIyNy01LjI3MjIyOUMxLjUzMDI2Mi01LjI3MjIyOSAuNzI5MjY1LTQuNDU5Mjc4IC43MjkyNjUtMy41Mzg3M0MuNzI5MjY1LTIuODU3Mjg1IDEuMTQ3Njk2LTIuNDE0OTQ0IDEuMjY3MjQ4LTIuMzA3MzQ3QzEuMTIzNzg2LTIuMTI4MDIgLjkwODU5My0xLjc4MTMyIC45MDg1OTMtMS4zMTUwNjhDLjkwODU5My0uNjIxNjY5IDEuMzI3MDI0LS4zMjI3OSAxLjQyMjY2NS0uMjYzMDE0Qy44NzI3MjctLjEwNzU5NyAuMzIyNzkgLjMyMjc5IC4zMjI3OSAuOTQ0NDU4Qy4zMjI3OSAxLjc2OTM2NSAxLjQ0NjU3NSAyLjQ1MDgwOSAyLjkxNzA2MSAyLjQ1MDgwOUM0LjMzOTcyNiAyLjQ1MDgwOSA1LjUyMzI4OCAxLjgxNzE4NiA1LjUyMzI4OCAuOTIwNTQ4QzUuNTIzMjg4IC42MjE2NjkgNS40Mzk2MDEtLjA4MzY4NiA0LjcyMjI5MS0uNDU0Mjk2QzQuMTEyNTc4LS43NjUxMzEgMy41MTQ4MTktLjc2NTEzMSAyLjQ4NjY3NS0uNzY1MTMxQzEuNzU3NDEtLjc2NTEzMSAxLjY3MzcyNC0uNzY1MTMxIDEuNDU4NTMxLS45OTIyNzlDMS4zMzg5NzktMS4xMTE4MzEgMS4yMzEzODItMS4zMzg5NzkgMS4yMzEzODItMS41OTAwMzdDMS4yMzEzODItMS43OTMyNzUgMS4zMDMxMTMtMS45OTY1MTMgMS40MjI2NjUtMi4xNjM4ODVaTTIuNjA2MjI3LTIuMDQ0MzM0QzEuNTU0MTcyLTIuMDQ0MzM0IDEuNTU0MTcyLTMuMjUxODA2IDEuNTU0MTcyLTMuNTI2Nzc1QzEuNTU0MTcyLTMuNzQxOTY4IDEuNTU0MTcyLTQuMjMyMTMgMS43NTc0MS00LjU1NDkxOUMxLjk4NDU1OC00LjkwMTYxOSAyLjM0MzIxMy01LjAyMTE3MSAyLjU5NDI3MS01LjAyMTE3MUMzLjY0NjMyNi01LjAyMTE3MSAzLjY0NjMyNi0zLjgxMzY5OSAzLjY0NjMyNi0zLjUzODczQzMuNjQ2MzI2LTMuMzIzNTM3IDMuNjQ2MzI2LTIuODMzMzc1IDMuNDQzMDg4LTIuNTEwNTg1QzMuMjE1OTQtMi4xNjM4ODUgMi44NTcyODUtMi4wNDQzMzQgMi42MDYyMjctMi4wNDQzMzRaTTIuOTI5MDE2IDIuMTk5NzUxQzEuNzgxMzIgMi4xOTk3NTEgLjkwODU5MyAxLjYxMzk0OCAuOTA4NTkzIC45MzI1MDNDLjkwODU5MyAuODM2ODYyIC45MzI1MDMgLjM3MDYxIDEuMzg2OCAuMDU5Nzc2QzEuNjQ5ODEzLS4xMDc1OTcgMS43NTc0MS0uMTA3NTk3IDIuNTk0MjcxLS4xMDc1OTdDMy41ODY1NS0uMTA3NTk3IDQuOTM3NDg0LS4xMDc1OTcgNC45Mzc0ODQgLjkzMjUwM0M0LjkzNzQ4NCAxLjYzNzg1OCA0LjAyODg5MiAyLjE5OTc1MSAyLjkyOTAxNiAyLjE5OTc1MVonLz4KPHBhdGggaWQ9J2c5LTEwNScgZD0nTTIuMDgwMTk5LTcuMzY0Mzg0QzIuMDgwMTk5LTcuNjc1MjE4IDEuODI5MTQxLTcuOTUwMTg3IDEuNDk0Mzk2LTcuOTUwMTg3QzEuMTgzNTYyLTcuOTUwMTg3IC45MjA1NDgtNy42OTkxMjggLjkyMDU0OC03LjM3NjMzOUMuOTIwNTQ4LTcuMDE3Njg0IDEuMjA3NDcyLTYuNzkwNTM1IDEuNDk0Mzk2LTYuNzkwNTM1QzEuODY1MDA2LTYuNzkwNTM1IDIuMDgwMTk5LTcuMTAxMzcgMi4wODAxOTktNy4zNjQzODRaTS40MzAzODYtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3LTQuNzk0MDIyIDEuMzAzMTEzLTQuNzIyMjkxIDEuMzAzMTEzLTQuMTM2NDg4Vi0uODg0NjgyQzEuMzAzMTEzLS4zNDY3IDEuMTcxNjA2LS4zNDY3IC4zOTQ1MjEtLjM0NjdWMEMuNzI5MjY1LS4wMjM5MSAxLjMwMzExMy0uMDIzOTEgMS42NDk4MTMtLjAyMzkxQzEuNzgxMzItLjAyMzkxIDIuNDc0NzItLjAyMzkxIDIuODgxMTk2IDBWLS4zNDY3QzIuMTA0MTEtLjM0NjcgMi4wNTYyODktLjQwNjQ3NiAyLjA1NjI4OS0uODcyNzI3Vi01LjI3MjIyOUwuNDMwMzg2LTUuMTQwNzIyWicvPgo8cGF0aCBpZD0nZzktMTA5JyBkPSdNOC41NzE4NTYtMi45MDUxMDZDOC41NzE4NTYtNC4wMTY5MzYgOC41NzE4NTYtNC4zNTE2ODEgOC4yOTY4ODctNC43MzQyNDdDNy45NTAxODctNS4yMDA0OTggNy4zODgyOTQtNS4yNzIyMjkgNi45ODE4MTgtNS4yNzIyMjlDNS45ODk1MzktNS4yNzIyMjkgNS40ODc0MjItNC41NTQ5MTkgNS4yOTYxMzktNC4wODg2NjdDNS4xMjg3NjctNS4wMDkyMTUgNC40ODMxODgtNS4yNzIyMjkgMy43MzAwMTItNS4yNzIyMjlDMi41NzAzNjEtNS4yNzIyMjkgMi4xMTYwNjUtNC4yNzk5NSAyLjAyMDQyMy00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMLjM4MjU2NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTctNC43OTQwMjIgMS4yOTExNTgtNC43MTAzMzYgMS4yOTExNTgtNC4xMjQ1MzNWLS44ODQ2ODJDMS4yOTExNTgtLjM0NjcgMS4xNTk2NTEtLjM0NjcgLjM4MjU2NS0uMzQ2N1YwQy42OTM0LS4wMjM5MSAxLjMzODk3OS0uMDIzOTEgMS42NzM3MjQtLjAyMzkxQzIuMDIwNDIzLS4wMjM5MSAyLjY2NjAwMi0uMDIzOTEgMi45NzY4MzcgMFYtLjM0NjdDMi4yMTE3MDYtLjM0NjcgMi4wNjgyNDQtLjM0NjcgMi4wNjgyNDQtLjg4NDY4MlYtMy4xMDgzNDRDMi4wNjgyNDQtNC4zNjM2MzYgMi44OTMxNTEtNS4wMzMxMjYgMy42MzQzNzEtNS4wMzMxMjZTNC41NDI5NjQtNC40MjM0MTIgNC41NDI5NjQtMy42OTQxNDdWLS44ODQ2ODJDNC41NDI5NjQtLjM0NjcgNC40MTE0NTctLjM0NjcgMy42MzQzNzEtLjM0NjdWMEMzLjk0NTIwNS0uMDIzOTEgNC41OTA3ODUtLjAyMzkxIDQuOTI1NTI5LS4wMjM5MUM1LjI3MjIyOS0uMDIzOTEgNS45MTc4MDgtLjAyMzkxIDYuMjI4NjQzIDBWLS4zNDY3QzUuNDYzNTEyLS4zNDY3IDUuMzIwMDUtLjM0NjcgNS4zMjAwNS0uODg0NjgyVi0zLjEwODM0NEM1LjMyMDA1LTQuMzYzNjM2IDYuMTQ0OTU2LTUuMDMzMTI2IDYuODg2MTc3LTUuMDMzMTI2UzcuNzk0NzctNC40MjM0MTIgNy43OTQ3Ny0zLjY5NDE0N1YtLjg4NDY4MkM3Ljc5NDc3LS4zNDY3IDcuNjYzMjYzLS4zNDY3IDYuODg2MTc3LS4zNDY3VjBDNy4xOTcwMTEtLjAyMzkxIDcuODQyNTktLjAyMzkxIDguMTc3MzM1LS4wMjM5MUM4LjUyNDAzNS0uMDIzOTEgOS4xNjk2MTQtLjAyMzkxIDkuNDgwNDQ4IDBWLS4zNDY3QzguODgyNjktLjM0NjcgOC41ODM4MTEtLjM0NjcgOC41NzE4NTYtLjcwNTM1NVYtMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOS0xMTAnIGQ9J001LjMyMDA1LTIuOTA1MTA2QzUuMzIwMDUtNC4wMTY5MzYgNS4zMjAwNS00LjM1MTY4MSA1LjA0NTA4MS00LjczNDI0N0M0LjY5ODM4MS01LjIwMDQ5OCA0LjEzNjQ4OC01LjI3MjIyOSAzLjczMDAxMi01LjI3MjIyOUMyLjU3MDM2MS01LjI3MjIyOSAyLjExNjA2NS00LjI3OTk1IDIuMDIwNDIzLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwuMzgyNTY1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNy00Ljc5NDAyMiAxLjI5MTE1OC00LjcxMDMzNiAxLjI5MTE1OC00LjEyNDUzM1YtLjg4NDY4MkMxLjI5MTE1OC0uMzQ2NyAxLjE1OTY1MS0uMzQ2NyAuMzgyNTY1LS4zNDY3VjBDLjY5MzQtLjAyMzkxIDEuMzM4OTc5LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFDMi4wMjA0MjMtLjAyMzkxIDIuNjY2MDAyLS4wMjM5MSAyLjk3NjgzNyAwVi0uMzQ2N0MyLjIxMTcwNi0uMzQ2NyAyLjA2ODI0NC0uMzQ2NyAyLjA2ODI0NC0uODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NC00LjM2MzYzNiAyLjg5MzE1MS01LjAzMzEyNiAzLjYzNDM3MS01LjAzMzEyNlM0LjU0Mjk2NC00LjQyMzQxMiA0LjU0Mjk2NC0zLjY5NDE0N1YtLjg4NDY4MkM0LjU0Mjk2NC0uMzQ2NyA0LjQxMTQ1Ny0uMzQ2NyAzLjYzNDM3MS0uMzQ2N1YwQzMuOTQ1MjA1LS4wMjM5MSA0LjU5MDc4NS0uMDIzOTEgNC45MjU1MjktLjAyMzkxQzUuMjcyMjI5LS4wMjM5MSA1LjkxNzgwOC0uMDIzOTEgNi4yMjg2NDMgMFYtLjM0NjdDNS42MzA4ODQtLjM0NjcgNS4zMzIwMDUtLjM0NjcgNS4zMjAwNS0uNzA1MzU1Vi0yLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c5LTExNCcgZD0nTTEuOTk2NTEzLTIuNzg1NTU0QzEuOTk2NTEzLTMuOTQ1MjA1IDIuNDc0NzItNS4wMzMxMjYgMy4zOTUyNjgtNS4wMzMxMjZDMy40OTA5MDktNS4wMzMxMjYgMy41MTQ4MTktNS4wMzMxMjYgMy41NjI2NC01LjAyMTE3MUMzLjQ2Njk5OS00Ljk3MzM1IDMuMjc1NzE2LTQuOTAxNjE5IDMuMjc1NzE2LTQuNTc4ODI5QzMuMjc1NzE2LTQuMjMyMTMgMy41NTA2ODUtNC4xMDA2MjMgMy43NDE5NjgtNC4xMDA2MjNDMy45ODEwNzEtNC4xMDA2MjMgNC4yMjAxNzQtNC4yNTYwNCA0LjIyMDE3NC00LjU3ODgyOUM0LjIyMDE3NC00LjkzNzQ4NCAzLjg5NzM4NS01LjI3MjIyOSAzLjM4MzMxMy01LjI3MjIyOUMyLjM2NzEyMy01LjI3MjIyOSAyLjAyMDQyMy00LjE3MjM1NCAxLjk0ODY5Mi0zLjk0NTIwNUgxLjkzNjczN1YtNS4yNzIyMjlMLjMzNDc0NS01LjE0MDcyMlYtNC43OTQwMjJDMS4xNDc2OTYtNC43OTQwMjIgMS4yNDMzMzctNC43MTAzMzYgMS4yNDMzMzctNC4xMjQ1MzNWLS44ODQ2ODJDMS4yNDMzMzctLjM0NjcgMS4xMTE4MzEtLjM0NjcgLjMzNDc0NS0uMzQ2N1YwQy42Njk0ODktLjAyMzkxIDEuMzI3MDI0LS4wMjM5MSAxLjY4NTY3OS0uMDIzOTFDMi4wMDg0NjgtLjAyMzkxIDIuODU3Mjg1LS4wMjM5MSAzLjEzMjI1NCAwVi0uMzQ2N0gyLjg5MzE1MUMyLjAyMDQyMy0uMzQ2NyAxLjk5NjUxMy0uNDc4MjA3IDEuOTk2NTEzLS45MDg1OTNWLTIuNzg1NTU0WicvPgo8cGF0aCBpZD0nZzctMjYnIGQ9J00uMzcwNjEgMi4wNjgyNDRDLjM1ODY1NSAyLjEyODAyIC4zMzQ3NDUgMi4xOTk3NTEgLjMzNDc0NSAyLjI3MTQ4MkMuMzM0NzQ1IDIuNDUwODA5IC40NzgyMDcgMi41NzAzNjEgLjY1NzUzNCAyLjU3MDM2MVMxLjAwNDIzNCAyLjQ1MDgwOSAxLjA3NTk2NSAyLjI4MzQzN0MxLjEyMzc4NiAyLjE3NTg0MSAxLjQ1ODUzMSAuNzQxMjIgMS44NDEwOTYtLjcyOTI2NUMyLjA4MDE5OS0uMTMxNTA3IDIuNTIyNTQgLjExOTU1MiAyLjk4ODc5MiAuMTE5NTUyQzQuMzM5NzI2IC4xMTk1NTIgNS44Njk5ODgtMS41NTQxNzIgNS44Njk5ODgtMy4zNTk0MDJDNS44Njk5ODgtNC42Mzg2MDUgNS4wOTI5MDItNS4yNzIyMjkgNC4yNjc5OTUtNS4yNzIyMjlDMy4yMTU5NC01LjI3MjIyOSAxLjkzNjczNy00LjE4NDMwOSAxLjU0MjIxNy0yLjU5NDI3MUwuMzcwNjEgMi4wNjgyNDRaTTIuOTc2ODM3LS4xMTk1NTJDMi4xNjM4ODUtLjExOTU1MiAxLjk2MDY0OC0xLjA2NDAxIDEuOTYwNjQ4LTEuMjA3NDcyQzEuOTYwNjQ4LTEuMjc5MjAzIDIuMjU5NTI3LTIuNDE0OTQ0IDIuMjk1MzkyLTIuNTk0MjcxQzIuOTA1MTA2LTQuOTczMzUgNC4wNzY3MTItNS4wMzMxMjYgNC4yNTYwNC01LjAzMzEyNkM0Ljc5NDAyMi01LjAzMzEyNiA1LjA5MjkwMi00LjU0Mjk2NCA1LjA5MjkwMi0zLjgzNzYwOUM1LjA5MjkwMi0zLjIyNzg5NSA0Ljc3MDExMi0yLjA0NDMzNCA0LjU2Njg3NC0xLjU0MjIxN0M0LjIwODIxOS0uNzE3MzEgMy41ODY1NS0uMTE5NTUyIDIuOTc2ODM3LS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNy02OCcgZD0nTTEuODc2OTYxLS44ODQ2ODJDMS43NjkzNjUtLjQ2NjI1MiAxLjc0NTQ1NS0uMzQ2NyAuOTA4NTkzLS4zNDY3Qy42ODE0NDUtLjM0NjcgLjU2MTg5My0uMzQ2NyAuNTYxODkzLS4xMzE1MDdDLjU2MTg5MyAwIC42MzM2MjQgMCAuODcyNzI3IDBINC42NjI1MTZDNy4wNzc0NiAwIDkuNDMyNjI4LTIuNDk4NjMgOS40MzI2MjgtNS4xNjQ2MzNDOS40MzI2MjgtNi44ODYxNzcgOC40MDQ0ODMtOC4xNjUzOCA2LjY5NDg5NC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3LTguMTY1MzggMi41MjI1NC04LjE2NTM4IDIuNTIyNTQtNy45MzgyMzJDMi41MjI1NC03LjgxODY4IDIuNjMwMTM3LTcuODE4NjggMi44MDk0NjUtNy44MTg2OEMzLjUzODczLTcuODE4NjggMy41Mzg3My03LjcyMzAzOSAzLjUzODczLTcuNTkxNTMyQzMuNTM4NzMtNy41Njc2MjEgMy41Mzg3My03LjQ5NTg5IDMuNDkwOTA5LTcuMzE2NTYzTDEuODc2OTYxLS44ODQ2ODJaTTQuMzk5NTAyLTcuMzUyNDI4QzQuNTA3MDk4LTcuNzk0NzcgNC41NTQ5MTktNy44MTg2OCA1LjAyMTE3MS03LjgxODY4SDYuMzM2MjM5QzcuNDYwMDI1LTcuODE4NjggOC40ODgxNjktNy4yMDg5NjYgOC40ODgxNjktNS41NTkxNTNDOC40ODgxNjktNC45NjEzOTUgOC4yNDkwNjYtMi44ODExOTYgNy4wODk0MTUtMS41NjYxMjdDNi43NTQ2Ny0xLjE3MTYwNiA1Ljg0NjA3Ny0uMzQ2NyA0LjQ3MTIzMy0uMzQ2N0gzLjEwODM0NEMyLjk0MDk3MS0uMzQ2NyAyLjkxNzA2MS0uMzQ2NyAyLjg0NTMzLS4zNTg2NTVDMi43MTM4MjMtLjM3MDYxIDIuNzAxODY4LS4zOTQ1MjEgMi43MDE4NjgtLjQ5MDE2MkMyLjcwMTg2OC0uNTczODQ4IDIuNzI1Nzc4LS42NDU1NzkgMi43NDk2ODktLjc1MzE3Nkw0LjM5OTUwMi03LjM1MjQyOFonLz4KPHBhdGggaWQ9J2c3LTk5JyBkPSdNNC42NzQ0NzEtNC40OTUxNDNDNC40NDczMjMtNC40OTUxNDMgNC4zMzk3MjYtNC40OTUxNDMgNC4xNzIzNTQtNC4zNTE2ODFDNC4xMDA2MjMtNC4yOTE5MDUgMy45NjkxMTYtNC4xMTI1NzggMy45NjkxMTYtMy45MjEyOTVDMy45NjkxMTYtMy42ODIxOTIgNC4xNDg0NDMtMy41Mzg3MyA0LjM3NTU5Mi0zLjUzODczQzQuNjYyNTE2LTMuNTM4NzMgNC45ODUzMDUtMy43Nzc4MzMgNC45ODUzMDUtNC4yNTYwNEM0Ljk4NTMwNS00LjgyOTg4OCA0LjQzNTM2Ny01LjI3MjIyOSAzLjYxMDQ2MS01LjI3MjIyOUMyLjA0NDMzNC01LjI3MjIyOSAuNDc4MjA3LTMuNTYyNjQgLjQ3ODIwNy0xLjg2NTAwNkMuNDc4MjA3LS44MjQ5MDcgMS4xMjM3ODYgLjExOTU1MiAyLjM0MzIxMyAuMTE5NTUyQzMuOTY5MTE2IC4xMTk1NTIgNC45OTcyNi0xLjE0NzY5NiA0Ljk5NzI2LTEuMzAzMTEzQzQuOTk3MjYtMS4zNzQ4NDQgNC45MjU1MjktMS40MzQ2MiA0Ljg3NzcwOS0xLjQzNDYyQzQuODQxODQzLTEuNDM0NjIgNC44Mjk4ODgtMS40MjI2NjUgNC43MjIyOTEtMS4zMTUwNjhDMy45NTcxNjEtLjI5ODg3OSAyLjgyMTQyLS4xMTk1NTIgMi4zNjcxMjMtLjExOTU1MkMxLjU0MjIxNy0uMTE5NTUyIDEuMjc5MjAzLS44MzY4NjIgMS4yNzkyMDMtMS40MzQ2MkMxLjI3OTIwMy0xLjg1MzA1MSAxLjQ4MjQ0MS0zLjAxMjcwMiAxLjkxMjgyNy0zLjgyNTY1NEMyLjIyMzY2MS00LjM4NzU0NyAyLjg2OTI0LTUuMDMzMTI2IDMuNjIyNDE2LTUuMDMzMTI2QzMuNzc3ODMzLTUuMDMzMTI2IDQuNDM1MzY3LTUuMDA5MjE1IDQuNjc0NDcxLTQuNDk1MTQzWicvPgo8cGF0aCBpZD0nZzctMTAyJyBkPSdNNS4zMzIwMDUtNC44MDU5NzhDNS41NzExMDgtNC44MDU5NzggNS42NjY3NS00LjgwNTk3OCA1LjY2Njc1LTUuMDMzMTI2QzUuNjY2NzUtNS4xNTI2NzcgNS41NzExMDgtNS4xNTI2NzcgNS4zNTU5MTUtNS4xNTI2NzdINC4zODc1NDdDNC42MTQ2OTUtNi4zODQwNiA0Ljc4MjA2Ny03LjIzMjg3NyA0Ljg3NzcwOS03LjYxNTQ0MkM0Ljk0OTQ0LTcuOTAyMzY2IDUuMjAwNDk4LTguMTc3MzM1IDUuNTExMzMzLTguMTc3MzM1QzUuNzYyMzkxLTguMTc3MzM1IDYuMDEzNDUtOC4wNjk3MzggNi4xMzMwMDEtNy45NjIxNDJDNS42NjY3NS03LjkxNDMyMSA1LjUyMzI4OC03LjU2NzYyMSA1LjUyMzI4OC03LjM2NDM4NEM1LjUyMzI4OC03LjEyNTI4IDUuNzAyNjE1LTYuOTgxODE4IDUuOTI5NzYzLTYuOTgxODE4QzYuMTY4ODY3LTYuOTgxODE4IDYuNTI3NTIyLTcuMTg1MDU2IDYuNTI3NTIyLTcuNjM5MzUyQzYuNTI3NTIyLTguMTQxNDY5IDYuMDI1NDA1LTguNDE2NDM4IDUuNDk5Mzc3LTguNDE2NDM4QzQuOTg1MzA1LTguNDE2NDM4IDQuNDgzMTg4LTguMDMzODczIDQuMjQ0MDg1LTcuNTY3NjIxQzQuMDI4ODkyLTcuMTQ5MTkxIDMuOTA5MzQtNi43MTg4MDQgMy42MzQzNzEtNS4xNTI2NzdIMi44MzMzNzVDMi42MDYyMjctNS4xNTI2NzcgMi40ODY2NzUtNS4xNTI2NzcgMi40ODY2NzUtNC45Mzc0ODRDMi40ODY2NzUtNC44MDU5NzggMi41NTg0MDYtNC44MDU5NzggMi43OTc1MDktNC44MDU5NzhIMy41NjI2NEMzLjM0NzQ0Ny0zLjY5NDE0NyAyLjg1NzI4NS0uOTkyMjc5IDIuNTgyMzE2IC4yODY5MjRDMi4zNzkwNzggMS4zMjcwMjQgMi4xOTk3NTEgMi4xOTk3NTEgMS42MDE5OTMgMi4xOTk3NTFDMS41NjYxMjcgMi4xOTk3NTEgMS4yMTk0MjcgMi4xOTk3NTEgMS4wMDQyMzQgMS45NzI2MDNDMS42MTM5NDggMS45MjQ3ODIgMS42MTM5NDggMS4zOTg3NTUgMS42MTM5NDggMS4zODY4QzEuNjEzOTQ4IDEuMTQ3Njk2IDEuNDM0NjIgMS4wMDQyMzQgMS4yMDc0NzIgMS4wMDQyMzRDLjk2ODM2OSAxLjAwNDIzNCAuNjA5NzE0IDEuMjA3NDcyIC42MDk3MTQgMS42NjE3NjhDLjYwOTcxNCAyLjE3NTg0MSAxLjEzNTc0MSAyLjQzODg1NCAxLjYwMTk5MyAyLjQzODg1NEMyLjgyMTQyIDIuNDM4ODU0IDMuMzIzNTM3IC4yNTEwNTkgMy40NTUwNDQtLjM0NjdDMy42NzAyMzctMS4yNjcyNDggNC4yNTYwNC00LjQ0NzMyMyA0LjMxNTgxNi00LjgwNTk3OEg1LjMzMjAwNVonLz4KPHBhdGggaWQ9J2c3LTEwOScgZD0nTTIuNDYyNzY1LTMuNTAyODY0QzIuNDg2Njc1LTMuNTc0NTk1IDIuNzg1NTU0LTQuMTcyMzU0IDMuMjI3ODk1LTQuNTU0OTE5QzMuNTM4NzMtNC44NDE4NDMgMy45NDUyMDUtNS4wMzMxMjYgNC40MTE0NTctNS4wMzMxMjZDNC44ODk2NjQtNS4wMzMxMjYgNS4wNTcwMzYtNC42NzQ0NzEgNS4wNTcwMzYtNC4xOTYyNjRDNS4wNTcwMzYtNC4xMjQ1MzMgNS4wNTcwMzYtMy44ODU0MyA0LjkxMzU3NC0zLjMyMzUzN0w0LjYxNDY5NS0yLjA5MjE1NEM0LjUxOTA1NC0xLjczMzQ5OSA0LjI5MTkwNS0uODQ4ODE3IDQuMjY3OTk1LS43MTczMUM0LjIyMDE3NC0uNTM3OTgzIDQuMTQ4NDQzLS4yMjcxNDggNC4xNDg0NDMtLjE3OTMyOEM0LjE0ODQ0My0uMDExOTU1IDQuMjc5OTUgLjExOTU1MiA0LjQ1OTI3OCAuMTE5NTUyQzQuODE3OTMzIC4xMTk1NTIgNC44Nzc3MDktLjE1NTQxNyA0Ljk4NTMwNS0uNTg1ODAzTDUuNzAyNjE1LTMuNDQzMDg4QzUuNzI2NTI2LTMuNTM4NzMgNi4zNDgxOTQtNS4wMzMxMjYgNy42NjMyNjMtNS4wMzMxMjZDOC4xNDE0NjktNS4wMzMxMjYgOC4zMDg4NDItNC42NzQ0NzEgOC4zMDg4NDItNC4xOTYyNjRDOC4zMDg4NDItMy41MjY3NzUgNy44NDI1OS0yLjIyMzY2MSA3LjU3OTU3Ny0xLjUwNjM1MUM3LjQ3MTk4LTEuMjE5NDI3IDcuNDEyMjA0LTEuMDY0MDEgNy40MTIyMDQtLjg0ODgxN0M3LjQxMjIwNC0uMzEwODM0IDcuNzgyODE0IC4xMTk1NTIgOC4zNTY2NjMgLjExOTU1MkM5LjQ2ODQ5MyAuMTE5NTUyIDkuODg2OTI0LTEuNjM3ODU4IDkuODg2OTI0LTEuNzA5NTg5QzkuODg2OTI0LTEuNzY5MzY1IDkuODM5MTAzLTEuODE3MTg2IDkuNzY3MzcyLTEuODE3MTg2QzkuNjU5Nzc2LTEuODE3MTg2IDkuNjQ3ODIxLTEuNzgxMzIgOS41ODgwNDUtMS41NzgwODJDOS4zMTMwNzYtLjYyMTY2OSA4Ljg3MDczNS0uMTE5NTUyIDguMzkyNTI4LS4xMTk1NTJDOC4yNzI5NzYtLjExOTU1MiA4LjA4MTY5NC0uMTMxNTA3IDguMDgxNjk0LS41MTQwNzJDOC4wODE2OTQtLjgyNDkwNyA4LjIyNTE1Ni0xLjIwNzQ3MiA4LjI3Mjk3Ni0xLjMzODk3OUM4LjQ4ODE2OS0xLjkxMjgyNyA5LjAyNjE1Mi0zLjMyMzUzNyA5LjAyNjE1Mi00LjAxNjkzNkM5LjAyNjE1Mi00LjczNDI0NyA4LjYwNzcyMS01LjI3MjIyOSA3LjY5OTEyOC01LjI3MjIyOUM2Ljg5ODEzMi01LjI3MjIyOSA2LjI1MjU1My00LjgxNzkzMyA1Ljc3NDM0Ni00LjExMjU3OEM1LjczODQ4MS00Ljc1ODE1NyA1LjM0Mzk2LTUuMjcyMjI5IDQuNDQ3MzIzLTUuMjcyMjI5QzMuMzgzMzEzLTUuMjcyMjI5IDIuODIxNDItNC41MTkwNTQgMi42MDYyMjctNC4yMjAxNzRDMi41NzAzNjEtNC45MDE2MTkgMi4wODAxOTktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4yMDc0NzItNS4yNzIyMjkgLjkzMjUwMy01LjEwNDg1NyAuNzA1MzU1LTQuNjUwNTZDLjQ5MDE2Mi00LjIyMDE3NCAuMzIyNzktMy40OTA5MDkgLjMyMjc5LTMuNDQzMDg4Uy4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NDk5MzgtMy4zMzU0OTIgLjU2MTg5My0zLjM0NzQ0NyAuNjMzNjI0LTMuNjIyNDE2Qy44MTI5NTEtNC4zMjc3NzEgMS4wNDAxLTUuMDMzMTI2IDEuNTE4MzA2LTUuMDMzMTI2QzEuNzkzMjc1LTUuMDMzMTI2IDEuODg4OTE3LTQuODQxODQzIDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzUwOTM0IC4xMTk1NTIgMS41MTgzMDYgLjA0NzgyMSAxLjYxMzk0OC0uMTMxNTA3QzEuNjM3ODU4LS4xOTEyODMgMS43NDU0NTUtLjYwOTcxNCAxLjgwNTIzLS44NDg4MTdMMi4wNjgyNDQtMS45MjQ3ODJMMi40NjI3NjUtMy41MDI4NjRaJy8+CjxwYXRoIGlkPSdnNy0xMTAnIGQ9J00yLjQ2Mjc2NS0zLjUwMjg2NEMyLjQ4NjY3NS0zLjU3NDU5NSAyLjc4NTU1NC00LjE3MjM1NCAzLjIyNzg5NS00LjU1NDkxOUMzLjUzODczLTQuODQxODQzIDMuOTQ1MjA1LTUuMDMzMTI2IDQuNDExNDU3LTUuMDMzMTI2QzQuODg5NjY0LTUuMDMzMTI2IDUuMDU3MDM2LTQuNjc0NDcxIDUuMDU3MDM2LTQuMTk2MjY0QzUuMDU3MDM2LTMuNTE0ODE5IDQuNTY2ODc0LTIuMTUxOTMgNC4zMjc3NzEtMS41MDYzNTFDNC4yMjAxNzQtMS4yMTk0MjcgNC4xNjAzOTktMS4wNjQwMSA0LjE2MDM5OS0uODQ4ODE3QzQuMTYwMzk5LS4zMTA4MzQgNC41MzEwMDkgLjExOTU1MiA1LjEwNDg1NyAuMTE5NTUyQzYuMjE2Njg3IC4xMTk1NTIgNi42MzUxMTgtMS42Mzc4NTggNi42MzUxMTgtMS43MDk1ODlDNi42MzUxMTgtMS43NjkzNjUgNi41ODcyOTgtMS44MTcxODYgNi41MTU1NjctMS44MTcxODZDNi40MDc5Ny0xLjgxNzE4NiA2LjM5NjAxNS0xLjc4MTMyIDYuMzM2MjM5LTEuNTc4MDgyQzYuMDYxMjctLjU5Nzc1OCA1LjYwNjk3NC0uMTE5NTUyIDUuMTQwNzIyLS4xMTk1NTJDNS4wMjExNzEtLjExOTU1MiA0LjgyOTg4OC0uMTMxNTA3IDQuODI5ODg4LS41MTQwNzJDNC44Mjk4ODgtLjgxMjk1MSA0Ljk2MTM5NS0xLjE3MTYwNiA1LjAzMzEyNi0xLjMzODk3OUM1LjI3MjIyOS0xLjk5NjUxMyA1Ljc3NDM0Ni0zLjMzNTQ5MiA1Ljc3NDM0Ni00LjAxNjkzNkM1Ljc3NDM0Ni00LjczNDI0NyA1LjM1NTkxNS01LjI3MjIyOSA0LjQ0NzMyMy01LjI3MjIyOUMzLjM4MzMxMy01LjI3MjIyOSAyLjgyMTQyLTQuNTE5MDU0IDIuNjA2MjI3LTQuMjIwMTc0QzIuNTcwMzYxLTQuOTAxNjE5IDIuMDgwMTk5LTUuMjcyMjI5IDEuNTU0MTcyLTUuMjcyMjI5QzEuMTcxNjA2LTUuMjcyMjI5IC45MDg1OTMtNS4wNDUwODEgLjcwNTM1NS00LjYzODYwNUMuNDkwMTYyLTQuMjA4MjE5IC4zMjI3OS0zLjQ5MDkwOSAuMzIyNzktMy40NDMwODhTLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU0OTkzOC0zLjMzNTQ5MiAuNTYxODkzLTMuMzQ3NDQ3IC42MzM2MjQtMy42MjI0MTZDLjgyNDkwNy00LjM1MTY4MSAxLjA0MDEtNS4wMzMxMjYgMS41MTgzMDYtNS4wMzMxMjZDMS43OTMyNzUtNS4wMzMxMjYgMS44ODg5MTctNC44NDE4NDMgMS44ODg5MTctNC40ODMxODhDMS44ODg5MTctNC4yMjAxNzQgMS43NjkzNjUtMy43NTM5MjMgMS42ODU2NzktMy4zODMzMTNMMS4zNTA5MzQtMi4wOTIxNTRDMS4zMDMxMTMtMS44NjUwMDYgMS4xNzE2MDYtMS4zMjcwMjQgMS4xMTE4MzEtMS4xMTE4MzFDMS4wMjgxNDQtLjgwMDk5NiAuODk2NjM4LS4yMzkxMDMgLjg5NjYzOC0uMTc5MzI4Qy44OTY2MzgtLjAxMTk1NSAxLjAyODE0NCAuMTE5NTUyIDEuMjA3NDcyIC4xMTk1NTJDMS4zNTA5MzQgLjExOTU1MiAxLjUxODMwNiAuMDQ3ODIxIDEuNjEzOTQ4LS4xMzE1MDdDMS42Mzc4NTgtLjE5MTI4MyAxLjc0NTQ1NS0uNjA5NzE0IDEuODA1MjMtLjg0ODgxN0wyLjA2ODI0NC0xLjkyNDc4MkwyLjQ2Mjc2NS0zLjUwMjg2NFonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzE3LjEwMTkxNCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c3LTEwOScvPgo8dXNlIHg9JzMwLjY2MjAxJyB5PSctMTYuNDI0NzgxJyB4bGluazpocmVmPScjZzktNjEnLz4KPHVzZSB4PSc0Ny4zMTgxNzgnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnOS05NycvPgo8dXNlIHg9JzUzLjE3MTE2OCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTExNCcvPgo8dXNlIHg9JzU3LjcyMzQ5NCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTEwMycvPgo8dXNlIHg9JzYzLjU3NjQ4NCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTEwOScvPgo8dXNlIHg9JzczLjMzMTQ2OCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTEwNScvPgo8dXNlIHg9Jzc2LjU4MzEyOScgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTExMCcvPgo8dXNlIHg9JzQzLjA4NzQ5MScgeT0nLTYuMTMwMDczJyB4bGluazpocmVmPScjZzYtNzcnLz4KPHVzZSB4PSc1Mi4wNjkxOTEnIHk9Jy02LjEzMDA3MycgeGxpbms6aHJlZj0nI2czLTUwJy8+Cjx1c2UgeD0nNTcuNzE0NzY4JyB5PSctNi4xMzAwNzMnIHhsaW5rOmhyZWY9JyNnMy0xMDInLz4KPHVzZSB4PSc2MS45NDg5NTEnIHk9Jy02LjEzMDA3MycgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nNjYuMTgzMTMzJyB5PSctNi4xMzAwNzMnIHhsaW5rOmhyZWY9JyNnNi01OScvPgo8dXNlIHg9JzY4LjUzNTQ1NycgeT0nLTYuMTMwMDczJyB4bGluazpocmVmPScjZzYtNTgnLz4KPHVzZSB4PSc3MC44ODc3ODEnIHk9Jy02LjEzMDA3MycgeGxpbms6aHJlZj0nI2c2LTU4Jy8+Cjx1c2UgeD0nNzMuMjQwMTA1JyB5PSctNi4xMzAwNzMnIHhsaW5rOmhyZWY9JyNnNi01OCcvPgo8dXNlIHg9Jzc1LjU5MjQyOScgeT0nLTYuMTMwMDczJyB4bGluazpocmVmPScjZzYtNTknLz4KPHVzZSB4PSc3Ny45NDQ3NTInIHk9Jy02LjEzMDA3MycgeGxpbms6aHJlZj0nI2c2LTExMCcvPgo8dXNlIHg9JzgzLjA4Mjk1NScgeT0nLTYuMTMwMDczJyB4bGluazpocmVmPScjZzMtMTAzJy8+Cjx1c2UgeD0nODkuMzA5NjM1JyB5PSctMzYuODY4MzA1JyB4bGluazpocmVmPScjZzItMzQnLz4KPHVzZSB4PSc5OS4wMjk1OTQnIHk9Jy0xOS40NDY3NzQnIHhsaW5rOmhyZWY9JyNnOS05NCcvPgo8dXNlIHg9Jzk2LjI4MzUxNCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c3LTY4Jy8+Cjx1c2UgeD0nMTA2LjAwMjgyMycgeT0nLTE0LjYzMTUxOCcgeGxpbms6aHJlZj0nI2c2LTEwMicvPgo8dXNlIHg9JzExMS40NDc3MTcnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzExNi4wMDAwNDMnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnNy05OScvPgo8dXNlIHg9JzEyMS4wMzgwMzInIHk9Jy0yMS4zNjA5NjcnIHhsaW5rOmhyZWY9JyNnMy02OScvPgo8dXNlIHg9JzEyMS4wMzgwMzInIHk9Jy0xMy40NjkyNjYnIHhsaW5rOmhyZWY9JyNnNi03NycvPgo8dXNlIHg9JzEzMC41MTc4NjMnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzEzNy43MjY4NTInIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnNC0wJy8+Cjx1c2UgeD0nMTUxLjQ0NDg0MicgeT0nLTI0LjUxMjU0JyB4bGluazpocmVmPScjZzktNDknLz4KPHJlY3QgeD0nMTUwLjg3NzUyNycgeT0nLTE5LjY1MjY2NycgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNi45ODc2MDYnLz4KPHVzZSB4PScxNTAuODc3NTI3JyB5PSctOC4yMjQxMTknIHhsaW5rOmhyZWY9JyNnNy0xMTAnLz4KPHVzZSB4PScxNjIuMTg3Mjg4JyB5PSctMjcuNzgyMjQ1JyB4bGluazpocmVmPScjZzItODgnLz4KPHVzZSB4PScxNjEuMDUzMTQ0JyB5PSctMi40MTA1OTInIHhsaW5rOmhyZWY9JyNnMC0xMjAnLz4KPHVzZSB4PScxNjYuNjIzOTQzJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PScxNjkuNzg1NzAxJyB5PSctMi40MTA1OTInIHhsaW5rOmhyZWY9JyNnMy01MCcvPgo8dXNlIHg9JzE3NS40MzEyNzgnIHk9Jy0yLjQxMDU5MicgeGxpbms6aHJlZj0nI2czLTY5Jy8+Cjx1c2UgeD0nMTgyLjU4MjUzMScgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c3LTEwMicvPgo8dXNlIHg9JzE5MS42MjE0NjUnIHk9Jy0zMy4yODE3MTgnIHhsaW5rOmhyZWY9JyNnMi0xOCcvPgo8dXNlIHg9JzIxNi4xMzIxMicgeT0nLTI0LjUxMjU0JyB4bGluazpocmVmPScjZzktNDknLz4KPHJlY3QgeD0nMjAxLjYxNzM1MicgeT0nLTE5LjY1MjY2NycgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMzQuODgyNTEyJy8+Cjx1c2UgeD0nMjAxLjYxNzM1MicgeT0nLTguMTc1ODA3JyB4bGluazpocmVmPScjZzctOTknLz4KPHVzZSB4PScyMDYuNjU1MzQnIHk9Jy0xMi4yOTM2ODEnIHhsaW5rOmhyZWY9JyNnMy02OScvPgo8dXNlIHg9JzIwNi42NTUzNCcgeT0nLTQuOTM0Njk2JyB4bGluazpocmVmPScjZzYtNzcnLz4KPHVzZSB4PScyMTYuMTM1MTcyJyB5PSctOC4xNzU4MDcnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzIyMC42ODc0OTgnIHk9Jy04LjE3NTgwNycgeGxpbms6aHJlZj0nI2cxLTEyMCcvPgo8dXNlIHg9JzIyOC41NjYyNzcnIHk9Jy02LjM4MjU0NCcgeGxpbms6aHJlZj0nI2c2LTEwNScvPgo8dXNlIHg9JzIzMS45NDc1NDknIHk9Jy04LjE3NTgwNycgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMjM3LjY5NTM3NycgeT0nLTMzLjI4MTcxOCcgeGxpbms6aHJlZj0nI2cyLTE5Jy8+Cjx1c2UgeD0nMjQ2LjQ5NTc1JyB5PSctMzYuODY4MzA1JyB4bGluazpocmVmPScjZzItMzUnLz4KPHVzZSB4PScyNTMuNDY5NjA5JyB5PSctMzQuMTkxNjUxJyB4bGluazpocmVmPScjZzgtNTAnLz4KPHVzZSB4PScyNjAuODU4NTg4JyB5PSctMTYuNDI0NzgxJyB4bGluazpocmVmPScjZzQtMCcvPgo8dXNlIHg9JzI3Mi44MTM3NDgnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnOS05MScvPgo8dXNlIHg9JzI3Ni4wNjU0MDknIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnNy0yNicvPgo8dXNlIHg9JzI4Mi4xMDMxMzUnIHk9Jy0xNC42MzE1MTgnIHhsaW5rOmhyZWY9JyNnNi04MycvPgo8dXNlIHg9JzI4OC4xOTcwMTMnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzI5Mi43NDkzMzknIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnNy05OScvPgo8dXNlIHg9JzI5Ny43ODczMjcnIHk9Jy0yMS4zNjA5NjcnIHhsaW5rOmhyZWY9JyNnMy02OScvPgo8dXNlIHg9JzI5Ny43ODczMjcnIHk9Jy0xMy40NjkyNjYnIHhsaW5rOmhyZWY9JyNnNi03NycvPgo8dXNlIHg9JzMwNy4yNjcxNTknIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzMxNC40NzYxNDgnIHk9Jy0xNi40MjQ3ODEnIHhsaW5rOmhyZWY9JyNnNC0wJy8+Cjx1c2UgeD0nMzI2LjQzMTMwOScgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c3LTI2Jy8+Cjx1c2UgeD0nMzMyLjQ2OTAzNScgeT0nLTE0LjYzMTUxOCcgeGxpbms6aHJlZj0nI2c2LTgzJy8+Cjx1c2UgeD0nMzM4LjU2MjkxMicgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMzQzLjExNTIzOCcgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c0LTY5Jy8+Cjx1c2UgeD0nMzQ5LjQyNDk1NScgeT0nLTE0LjYzMTUxOCcgeGxpbms6aHJlZj0nI2c2LTc3Jy8+Cjx1c2UgeD0nMzU4LjkwNDc4NicgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMzYzLjQ1NzExMicgeT0nLTE2LjQyNDc4MScgeGxpbms6aHJlZj0nI2c5LTkzJy8+Cjx1c2UgeD0nMzY2LjcwODc3MycgeT0nLTIxLjM2MDk2NycgeGxpbms6aHJlZj0nI2c4LTUwJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
where
is the density function of the EmpiricalBernsteinCopulaassociated to the sample and the bin number ,  a
Monte Carlo estimate of the Csiszar
a
Monte Carlo estimate of the Csiszar  divergence,
divergence,  the exact Spearman correlation of the empirical
Bernstein copula and
the exact Spearman correlation of the empirical
Bernstein copula and  the empirical Spearman correlation of the sample
the empirical Spearman correlation of the sample  .
.The parameter
is controlled by the BernsteinCopulaFactory-SamplingSize key in ResourceMap.Note that this optimal
does not necessarily divide the sample size .
- build(*args)¶
Build the empirical Bernstein copula.
Available usages:
build()
build(sample)
build(sample, m)
build(sample, method, f)
- Parameters:
- sample2-d sequence of float, of dimension
The sample of size
 from which the copula is estimated.
from which the copula is estimated.- methodstr
The name of the bin number selection method. Possible choices are AMISE, LogLikelihood and PenalizedCsiszarDivergence.
Default is LogLikelihood.
- f
Function The function defining the Csiszar divergence of interest used by the PenalizedCsiszarDivergence method.
Default is Function().
- mint,:math:1 leq m leq sampleSize,
The bin number, i.e. the number of sub-intervals in which all the edges of the unit cube
![[0, 1]^d](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzI3LjgxMDc3OXB0JyBoZWlnaHQ9JzEyLjg2MjAzcHQnIHZpZXdCb3g9JzAgLTkuODczMjM4IDI3LjgxMDc3OSAxMi44NjIwMyc+CjxkZWZzPgo8cGF0aCBpZD0nZzAtMTAwJyBkPSdNNC4yODc5Mi01LjI5MjE1NEM0LjI5NTg5LTUuMzA4MDk1IDQuMzE5ODAxLTUuNDExNzA2IDQuMzE5ODAxLTUuNDE5Njc2QzQuMzE5ODAxLTUuNDU5NTI3IDQuMjg3OTItNS41MzEyNTggNC4xOTIyNzktNS41MzEyNThDNC4xNjAzOTktNS41MzEyNTggMy45MTMzMjUtNS41MDczNDcgMy43MzAwMTItNS40OTE0MDdMMy4yODM2ODYtNS40NTk1MjdDMy4xMDgzNDQtNS40NDM1ODcgMy4wMjg2NDMtNS40MzU2MTYgMy4wMjg2NDMtNS4yOTIxNTRDMy4wMjg2NDMtNS4xODA1NzMgMy4xNDAyMjQtNS4xODA1NzMgMy4yMzU4NjYtNS4xODA1NzNDMy42MTg0MzEtNS4xODA1NzMgMy42MTg0MzEtNS4xMzI3NTIgMy42MTg0MzEtNS4wNjEwMjFDMy42MTg0MzEtNS4wMTMyIDMuNTU0NjctNC43NTAxODcgMy41MTQ4MTktNC41OTA3ODVMMy4xMjQyODQtMy4wMzY2MTNDMy4wNTI1NTMtMy4xNzIxMDUgMi44MjE0Mi0zLjUxNDgxOSAyLjMzNTI0My0zLjUxNDgxOUMxLjM4NjgtMy41MTQ4MTkgLjM0MjcxNS0yLjQwNjk3NCAuMzQyNzE1LTEuMjI3Mzk3Qy4zNDI3MTUtLjM5ODUwNiAuODc2NzEyIC4wNzk3MDEgMS40OTA0MTEgLjA3OTcwMUMyLjAwMDQ5OCAuMDc5NzAxIDIuNDM4ODU0LS4zMjY3NzUgMi41ODIzMTYtLjQ4NjE3N0MyLjcyNTc3OCAuMDYzNzYxIDMuMjY3NzQ2IC4wNzk3MDEgMy4zNjMzODcgLjA3OTcwMUMzLjczMDAxMiAuMDc5NzAxIDMuOTEzMzI1LS4yMjMxNjMgMy45NzcwODYtLjM1ODY1NUM0LjEzNjQ4OC0uNjQ1NTc5IDQuMjQ4MDctMS4xMDc4NDYgNC4yNDgwNy0xLjEzOTcyNkM0LjI0ODA3LTEuMTg3NTQ3IDQuMjE2MTg5LTEuMjQzMzM3IDQuMTIwNTQ4LTEuMjQzMzM3UzQuMDA4OTY2LTEuMTk1NTE3IDMuOTYxMTQ2LS45OTYyNjRDMy44NDk1NjQtLjU1NzkwOCAzLjY5ODEzMi0uMTQzNDYyIDMuMzg3Mjk4LS4xNDM0NjJDMy4yMDM5ODUtLjE0MzQ2MiAzLjEzMjI1NC0uMjk0ODk0IDMuMTMyMjU0LS41MTgwNTdDMy4xMzIyNTQtLjY2OTQ4OSAzLjE1NjE2NC0uNzU3MTYxIDMuMTgwMDc1LS44NjA3NzJMNC4yODc5Mi01LjI5MjE1NFpNMi41ODIzMTYtLjg2MDc3MkMyLjE4MzgxMS0uMzEwODM0IDEuNzY5MzY1LS4xNDM0NjIgMS41MTQzMjEtLjE0MzQ2MkMxLjE0NzY5Ni0uMTQzNDYyIC45NjQzODQtLjQ3ODIwNyAuOTY0Mzg0LS44OTI2NTNDLjk2NDM4NC0xLjI2NzI0OCAxLjE3OTU3Ny0yLjEyMDA1IDEuMzU0OTE5LTIuNDcwNzM1QzEuNTg2MDUyLTIuOTU2OTEyIDEuOTc2NTg4LTMuMjkxNjU2IDIuMzQzMjEzLTMuMjkxNjU2QzIuODYxMjctMy4yOTE2NTYgMy4wMTI3MDItMi43MDk4MzggMy4wMTI3MDItMi42MTQxOTdDMy4wMTI3MDItMi41ODIzMTYgMi44MTM0NS0xLjgwMTI0NSAyLjc2NTYyOS0xLjU5NDAyMkMyLjY2MjAxNy0xLjIxOTQyNyAyLjY2MjAxNy0xLjIwMzQ4NyAyLjU4MjMxNi0uODYwNzcyWicvPgo8cGF0aCBpZD0nZzEtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2cyLTQ4JyBkPSdNNS4zNTU5MTUtMy44MjU2NTRDNS4zNTU5MTUtNC44MTc5MzMgNS4yOTYxMzktNS43ODYzMDEgNC44NjU3NTMtNi42OTQ4OTRDNC4zNzU1OTItNy42ODcxNzMgMy41MTQ4MTktNy45NTAxODcgMi45MjkwMTYtNy45NTAxODdDMi4yMzU2MTYtNy45NTAxODcgMS4zODY4LTcuNjAzNDg3IC45NDQ0NTgtNi42MTEyMDhDLjYwOTcxNC01Ljg1ODAzMiAuNDkwMTYyLTUuMTE2ODEyIC40OTAxNjItMy44MjU2NTRDLjQ5MDE2Mi0yLjY2NjAwMiAuNTczODQ4LTEuNzkzMjc1IDEuMDA0MjM0LS45NDQ0NThDMS40NzA0ODYtLjAzNTg2NiAyLjI5NTM5MiAuMjUxMDU5IDIuOTE3MDYxIC4yNTEwNTlDMy45NTcxNjEgLjI1MTA1OSA0LjU1NDkxOS0uMzcwNjEgNC45MDE2MTktMS4wNjQwMUM1LjMzMjAwNS0xLjk2MDY0OCA1LjM1NTkxNS0zLjEzMjI1NCA1LjM1NTkxNS0zLjgyNTY1NFpNMi45MTcwNjEgLjAxMTk1NUMyLjUzNDQ5NiAuMDExOTU1IDEuNzU3NDEtLjIwMzIzOCAxLjUzMDI2Mi0xLjUwNjM1MUMxLjM5ODc1NS0yLjIyMzY2MSAxLjM5ODc1NS0zLjEzMjI1NCAxLjM5ODc1NS0zLjk2OTExNkMxLjM5ODc1NS00Ljk0OTQ0IDEuMzk4NzU1LTUuODM0MTIyIDEuNTkwMDM3LTYuNTM5NDc3QzEuNzkzMjc1LTcuMzQwNDczIDIuNDAyOTg5LTcuNzExMDgzIDIuOTE3MDYxLTcuNzExMDgzQzMuMzcxMzU3LTcuNzExMDgzIDQuMDY0NzU3LTcuNDM2MTE1IDQuMjkxOTA1LTYuNDA3OTdDNC40NDczMjMtNS43MjY1MjYgNC40NDczMjMtNC43ODIwNjcgNC40NDczMjMtMy45NjkxMTZDNC40NDczMjMtMy4xNjgxMiA0LjQ0NzMyMy0yLjI1OTUyNyA0LjMxNTgxNi0xLjUzMDI2MkM0LjA4ODY2Ny0uMjE1MTkzIDMuMzM1NDkyIC4wMTE5NTUgMi45MTcwNjEgLjAxMTk1NVonLz4KPHBhdGggaWQ9J2cyLTQ5JyBkPSdNMy40NDMwODgtNy42NjMyNjNDMy40NDMwODgtNy45MzgyMzIgMy40NDMwODgtNy45NTAxODcgMy4yMDM5ODUtNy45NTAxODdDMi45MTcwNjEtNy42MjczOTcgMi4zMTkzMDMtNy4xODUwNTYgMS4wODc5Mi03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODktNi44MzgzNTYgMS45NjA2NDgtNi44MzgzNTYgMi42MTgxODItNy4xNDkxOTFWLS45MjA1NDhDMi42MTgxODItLjQ5MDE2MiAyLjU4MjMxNi0uMzQ2NyAxLjUzMDI2Mi0uMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTEgMy4wMzY2MTMtLjAyMzkxUzQuNTc4ODI5LS4wMjM5MSA0LjkwMTYxOSAwVi0uMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NC0uMzQ2NyAzLjQ0MzA4OC0uNDkwMTYyIDMuNDQzMDg4LS45MjA1NDhWLTcuNjYzMjYzWicvPgo8cGF0aCBpZD0nZzItOTEnIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonLz4KPHBhdGggaWQ9J2cyLTkzJyBkPSdNMS44NTMwNTEtOC45NjYzNzZILjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUguMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi05MScvPgo8dXNlIHg9JzMuMjUxNjYxJyB5PScwJyB4bGluazpocmVmPScjZzItNDgnLz4KPHVzZSB4PSc5LjEwNDY1MicgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTU5Jy8+Cjx1c2UgeD0nMTQuMzQ4ODEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi00OScvPgo8dXNlIHg9JzIwLjIwMTgwMScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTkzJy8+Cjx1c2UgeD0nMjMuNDUzNDYyJyB5PSctNC4zMzg0MzcnIHhsaW5rOmhyZWY9JyNnMC0xMDAnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) are regularly partitioned.
are regularly partitioned.Default value is the value computed from the default bin number selection method.
- sample2-d sequence of float, of dimension
- Returns:
- copula
Distribution The empirical Bernstein copula as a generic distribution.
- copula
Notes
If the bin number
is specified and does not divide the sample size , then a part of the sample is
removed for the result to be a copula. See EmpiricalBernsteinCopula.
- buildAsEmpiricalBernsteinCopula(*args)¶
Build the empirical Bernstein copula as a native distribution.
Available usages:
buildAsEmpiricalBernsteinCopula()
buildAsEmpiricalBernsteinCopula(sample)
buildAsEmpiricalBernsteinCopula(sample, m)
buildAsEmpiricalBernsteinCopula(sample, method, f)
- Parameters:
- sample2-d sequence of float, of dimension d
The sample of size
from which the copula is estimated.- methodstr
The name of the bin number selection method. Possible choices are AMISE, LogLikelihood and PenalizedCsiszarDivergence.
Default is LogLikelihood.
- f
Function The function defining the Csiszar divergence of interest used by the PenalizedCsiszarDivergence method.
Default is Function().
- mint,
 ,
, The bin number, i.e. the number of sub-intervals in which all the edges of the unit cube
are regularly partitioned.Default value is the value computed from the default bin number selection method.
- Returns:
- copula
EmpiricalBernsteinCopula The empirical Bernstein copula as a native distribution.
- copula
Notes
If the bin number
is specified and does not divide the sample size , then a part of the sample is
removed for the result to be a copula a copula. See EmpiricalBernsteinCopula.
- buildEstimator(*args)¶
Build the distribution and the parameter distribution.
- Parameters:
- sample2-d sequence of float
Data.
- parameters
DistributionParameters Optional, the parametrization.
- Returns:
- resDist
DistributionFactoryResult The results.
- resDist
Notes
According to the way the native parameters of the distribution are estimated, the parameters distribution differs:
Moments method: the asymptotic parameters distribution is normal and estimated by Bootstrap on the initial data;
Maximum likelihood method with a regular model: the asymptotic parameters distribution is normal and its covariance matrix is the inverse Fisher information matrix;
Other methods: the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting (see
KernelSmoothing).
If another set of parameters is specified, the native parameters distribution is first estimated and the new distribution is determined from it:
if the native parameters distribution is normal and the transformation regular at the estimated parameters values: the asymptotic parameters distribution is normal and its covariance matrix determined from the inverse Fisher information matrix of the native parameters and the transformation;
in the other cases, the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting.
- getBootstrapSize()¶
Accessor to the bootstrap size.
- Returns:
- sizeint
Size of the bootstrap.
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getKnownParameterIndices()¶
Accessor to the known parameters indices.
- Returns:
- indices
Indices Indices of the known parameters.
- indices
- getKnownParameterValues()¶
Accessor to the known parameters values.
- Returns:
- values
Point Values of known parameters.
- values
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- setBootstrapSize(bootstrapSize)¶
Accessor to the bootstrap size.
- Parameters:
- sizeint
The size of the bootstrap.
- setKnownParameter(values, positions)¶
Accessor to the known parameters.
- Parameters:
- valuessequence of float
Values of known parameters.
- positionssequence of int
Indices of known parameters.
Examples
When a subset of the parameter vector is known, the other parameters only have to be estimated from data.
In the following example, we consider a sample and want to fit a
Betadistribution. We assume that the and
and  parameters are known beforehand.
In this case, we set the third parameter (at index 2) to -1
and the fourth parameter (at index 3) to 1.
parameters are known beforehand.
In this case, we set the third parameter (at index 2) to -1
and the fourth parameter (at index 3) to 1.>>> import openturns as ot >>> ot.RandomGenerator.SetSeed(0) >>> distribution = ot.Beta(2.3, 2.2, -1.0, 1.0) >>> sample = distribution.getSample(10) >>> factory = ot.BetaFactory() >>> # set (a,b) out of (r, t, a, b) >>> factory.setKnownParameter([-1.0, 1.0], [2, 3]) >>> inf_distribution = factory.build(sample)
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.