GaussianProcessRegression¶
(Source code, png)
- class GaussianProcessRegression(*args)¶
Gaussian process regression algorithm.
Warning
This class is experimental and likely to be modified in future releases. To use it, import the
openturns.experimentalsubmodule.Refer to Kriging.
- Available constructors:
GaussianProcessRegression(gprFitterResult)
GaussianProcessRegression(inputSample, outputSample, covarianceModel, trendFunction)
- Parameters:
- gprFitterResult
GaussianProcessFitterResult Result class
- inputSample, outputSample2-d sequence of float
The samples
 and
and  upon which the meta-model is built.
upon which the meta-model is built.- covarianceModel
CovarianceModel - covarianceModel
CovarianceModel Covariance model used for the underlying Gaussian process assumption.
- trendFunction
Function A trend function
- gprFitterResult
Methods
BuildDistribution(inputSample)Recover the distribution, with metamodel performance in mind.
Accessor to the object's name.
Accessor to the joint probability density function of the physical input vector.
Accessor to the input sample.
getName()Accessor to the object's name.
Accessor to the output sample.
Get the results of the metamodel computation.
Return the weights of the input sample.
hasName()Test if the object is named.
run()Compute the response surface.
setDistribution(distribution)Accessor to the joint probability density function of the physical input vector.
setName(name)Accessor to the object's name.
Notes
We suppose we have a sample
 where
where  for all k, with
for all k, with  the model.
The class allows making a gaussian process interpolating on the input samples.
the model.
The class allows making a gaussian process interpolating on the input samples.Within the first constructor, we suppose all gaussian process parameters (the trend coefficients
 , the scale
, the scale  and the amplitude
and the amplitude  ) already calibrated and the objective
is to condionning this process (the gaussian process to become interpolating over the dataset)
) already calibrated and the objective
is to condionning this process (the gaussian process to become interpolating over the dataset)Within the second constructor, we assume covariance model already calibrated. A gaussian process is fitted using
GaussianProcessFitterand the sample is considered as the trace of a this gaussian process
is considered as the trace of a this gaussian process  on
on  .
.The Gaussian process
is defined by:(1)¶

where:

with
 and
and  the trend functions.
the trend functions. is a Gaussian process of dimension p with zero mean and covariance function
is a Gaussian process of dimension p with zero mean and covariance function  (see
(see CovarianceModelfor the notations).The Gaussian Process Regression meta model
 is defined by:
is defined by:
where
 is the condition
is the condition  for each
for each ![k \in [1, \sampleSize]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzQ1LjY4OTM3OXB0JyBoZWlnaHQ9JzExLjk1NTE2OHB0JyB2aWV3Qm94PScwIC04Ljk2NjM3NiA0NS42ODkzNzkgMTEuOTU1MTY4Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMi00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2cyLTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnMi05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjxwYXRoIGlkPSdnMC01MCcgZD0nTTYuNTUxNDMyLTIuNzQ5Njg5QzYuNzU0NjctMi43NDk2ODkgNi45Njk4NjMtMi43NDk2ODkgNi45Njk4NjMtMi45ODg3OTJTNi43NTQ2Ny0zLjIyNzg5NSA2LjU1MTQzMi0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMy00LjgyOTg4OCAzLjAwMDc0Ny01Ljk3NzU4NCA0LjY4NjQyNi01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3LTUuOTc3NTg0IDYuOTY5ODYzLTUuOTc3NTg0IDYuOTY5ODYzLTYuMjE2Njg3UzYuNzU0NjctNi40NTU3OTEgNi41NTE0MzItNi40NTU3OTFINC42NjI1MTZDMi42MTgxODItNi40NTU3OTEgLjk5MjI3OS00LjkwMTYxOSAuOTkyMjc5LTIuOTg4NzkyUzIuNjE4MTgyIC40NzgyMDcgNC42NjI1MTYgLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IC40NzgyMDcgNi45Njk4NjMgLjQ3ODIwNyA2Ljk2OTg2MyAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMtMS4xNDc2OTYgMS40ODI0NDEtMi43NDk2ODlINi41NTE0MzJaJy8+CjxwYXRoIGlkPSdnMS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzEtMTA3JyBkPSdNMy4zNTk0MDItNy45OTgwMDdDMy4zNzEzNTctOC4wNDU4MjggMy4zOTUyNjgtOC4xMTc1NTkgMy4zOTUyNjgtOC4xNzczMzVDMy4zOTUyNjgtOC4yOTY4ODcgMy4yNzU3MTYtOC4yOTY4ODcgMy4yNTE4MDYtOC4yOTY4ODdDMy4yMzk4NTEtOC4yOTY4ODcgMi44MDk0NjUtOC4yNjEwMjEgMi41OTQyNzEtOC4yMzcxMTFDMi4zOTEwMzQtOC4yMjUxNTYgMi4yMTE3MDYtOC4yMDEyNDUgMS45OTY1MTMtOC4xODkyOUMxLjcwOTU4OS04LjE2NTM4IDEuNjI1OTAzLTguMTUzNDI1IDEuNjI1OTAzLTcuOTM4MjMyQzEuNjI1OTAzLTcuODE4NjggMS43NDU0NTUtNy44MTg2OCAxLjg2NTAwNi03LjgxODY4QzIuNDc0NzItNy44MTg2OCAyLjQ3NDcyLTcuNzExMDgzIDIuNDc0NzItNy41OTE1MzJDMi40NzQ3Mi03LjU0MzcxMSAyLjQ3NDcyLTcuNTE5ODAxIDIuNDE0OTQ0LTcuMzA0NjA4TC43MDUzNTUtLjQ2NjI1MkMuNjU3NTM0LS4yODY5MjQgLjY1NzUzNC0uMjYzMDE0IC42NTc1MzQtLjE5MTI4M0MuNjU3NTM0IC4wNzE3MzEgLjg2MDc3MiAuMTE5NTUyIC45ODAzMjQgLjExOTU1MkMxLjMxNTA2OCAuMTE5NTUyIDEuMzg2OC0uMTQzNDYyIDEuNDgyNDQxLS41MTQwNzJMMi4wNDQzMzQtMi43NDk2ODlDMi45MDUxMDYtMi42NTQwNDcgMy40MTkxNzgtMi4yOTUzOTIgMy40MTkxNzgtMS43MjE1NDRDMy40MTkxNzgtMS42NDk4MTMgMy40MTkxNzgtMS42MDE5OTMgMy4zODMzMTMtMS40MjI2NjVDMy4zMzU0OTItMS4yNDMzMzcgMy4zMzU0OTItMS4wOTk4NzUgMy4zMzU0OTItMS4wNDAxQzMuMzM1NDkyLS4zNDY3IDMuNzg5Nzg4IC4xMTk1NTIgNC4zOTk1MDIgLjExOTU1MkM0Ljk0OTQ0IC4xMTk1NTIgNS4yMzYzNjQtLjM4MjU2NSA1LjMzMjAwNS0uNTQ5OTM4QzUuNTgzMDY0LS45OTIyNzkgNS43Mzg0ODEtMS42NjE3NjggNS43Mzg0ODEtMS43MDk1ODlDNS43Mzg0ODEtMS43NjkzNjUgNS42OTA2Ni0xLjgxNzE4NiA1LjYxODkyOS0xLjgxNzE4NkM1LjUxMTMzMy0xLjgxNzE4NiA1LjQ5OTM3Ny0xLjc2OTM2NSA1LjQ1MTU1Ny0xLjU3ODA4MkM1LjI4NDE4NC0uOTU2NDEzIDUuMDMzMTI2LS4xMTk1NTIgNC40MjM0MTItLjExOTU1MkM0LjE4NDMwOS0uMTE5NTUyIDQuMDI4ODkyLS4yMzkxMDMgNC4wMjg4OTItLjY5MzRDNC4wMjg4OTItLjkyMDU0OCA0LjA3NjcxMi0xLjE4MzU2MiA0LjEyNDUzMy0xLjM2Mjg4OUM0LjE3MjM1NC0xLjU3ODA4MiA0LjE3MjM1NC0xLjU5MDAzNyA0LjE3MjM1NC0xLjczMzQ5OUM0LjE3MjM1NC0yLjQzODg1NCAzLjUzODczLTIuODMzMzc1IDIuNDM4ODU0LTIuOTc2ODM3QzIuODY5MjQtMy4yMzk4NTEgMy4yOTk2MjYtMy43MDYxMDIgMy40NjY5OTktMy44ODU0M0M0LjE0ODQ0My00LjY1MDU2IDQuNjE0Njk1LTUuMDMzMTI2IDUuMTY0NjMzLTUuMDMzMTI2QzUuNDM5NjAxLTUuMDMzMTI2IDUuNTExMzMzLTQuOTYxMzk1IDUuNTk1MDE5LTQuODg5NjY0QzUuMTUyNjc3LTQuODQxODQzIDQuOTg1MzA1LTQuNTMxMDA5IDQuOTg1MzA1LTQuMjkxOTA1QzQuOTg1MzA1LTQuMDA0OTgxIDUuMjEyNDUzLTMuOTA5MzQgNS4zNzk4MjYtMy45MDkzNEM1LjcwMjYxNS0zLjkwOTM0IDUuOTg5NTM5LTQuMTg0MzA5IDUuOTg5NTM5LTQuNTY2ODc0QzUuOTg5NTM5LTQuOTEzNTc0IDUuNzE0NTctNS4yNzIyMjkgNS4xNzY1ODgtNS4yNzIyMjlDNC41MTkwNTQtNS4yNzIyMjkgMy45ODEwNzEtNC44MDU5NzggMy4xMzIyNTQtMy44NDk1NjRDMy4wMTI3MDItMy43MDYxMDIgMi41NzAzNjEtMy4yNTE4MDYgMi4xMjgwMi0zLjA4NDQzM0wzLjM1OTQwMi03Ljk5ODAwN1onLz4KPHBhdGggaWQ9J2cxLTExMCcgZD0nTTIuNDYyNzY1LTMuNTAyODY0QzIuNDg2Njc1LTMuNTc0NTk1IDIuNzg1NTU0LTQuMTcyMzU0IDMuMjI3ODk1LTQuNTU0OTE5QzMuNTM4NzMtNC44NDE4NDMgMy45NDUyMDUtNS4wMzMxMjYgNC40MTE0NTctNS4wMzMxMjZDNC44ODk2NjQtNS4wMzMxMjYgNS4wNTcwMzYtNC42NzQ0NzEgNS4wNTcwMzYtNC4xOTYyNjRDNS4wNTcwMzYtMy41MTQ4MTkgNC41NjY4NzQtMi4xNTE5MyA0LjMyNzc3MS0xLjUwNjM1MUM0LjIyMDE3NC0xLjIxOTQyNyA0LjE2MDM5OS0xLjA2NDAxIDQuMTYwMzk5LS44NDg4MTdDNC4xNjAzOTktLjMxMDgzNCA0LjUzMTAwOSAuMTE5NTUyIDUuMTA0ODU3IC4xMTk1NTJDNi4yMTY2ODcgLjExOTU1MiA2LjYzNTExOC0xLjYzNzg1OCA2LjYzNTExOC0xLjcwOTU4OUM2LjYzNTExOC0xLjc2OTM2NSA2LjU4NzI5OC0xLjgxNzE4NiA2LjUxNTU2Ny0xLjgxNzE4NkM2LjQwNzk3LTEuODE3MTg2IDYuMzk2MDE1LTEuNzgxMzIgNi4zMzYyMzktMS41NzgwODJDNi4wNjEyNy0uNTk3NzU4IDUuNjA2OTc0LS4xMTk1NTIgNS4xNDA3MjItLjExOTU1MkM1LjAyMTE3MS0uMTE5NTUyIDQuODI5ODg4LS4xMzE1MDcgNC44Mjk4ODgtLjUxNDA3MkM0LjgyOTg4OC0uODEyOTUxIDQuOTYxMzk1LTEuMTcxNjA2IDUuMDMzMTI2LTEuMzM4OTc5QzUuMjcyMjI5LTEuOTk2NTEzIDUuNzc0MzQ2LTMuMzM1NDkyIDUuNzc0MzQ2LTQuMDE2OTM2QzUuNzc0MzQ2LTQuNzM0MjQ3IDUuMzU1OTE1LTUuMjcyMjI5IDQuNDQ3MzIzLTUuMjcyMjI5QzMuMzgzMzEzLTUuMjcyMjI5IDIuODIxNDItNC41MTkwNTQgMi42MDYyMjctNC4yMjAxNzRDMi41NzAzNjEtNC45MDE2MTkgMi4wODAxOTktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4xNzE2MDYtNS4yNzIyMjkgLjkwODU5My01LjA0NTA4MSAuNzA1MzU1LTQuNjM4NjA1Qy40OTAxNjItNC4yMDgyMTkgLjMyMjc5LTMuNDkwOTA5IC4zMjI3OS0zLjQ0MzA4OFMuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODI0OTA3LTQuMzUxNjgxIDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjc5MzI3NS01LjAzMzEyNiAxLjg4ODkxNy00Ljg0MTg0MyAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjM1MDkzNCAuMTE5NTUyIDEuNTE4MzA2IC4wNDc4MjEgMS42MTM5NDgtLjEzMTUwN0MxLjYzNzg1OC0uMTkxMjgzIDEuNzQ1NDU1LS42MDk3MTQgMS44MDUyMy0uODQ4ODE3TDIuMDY4MjQ0LTEuOTI0NzgyTDIuNDYyNzY1LTMuNTAyODY0WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTEwNycvPgo8dXNlIHg9JzkuODEwMzMzJyB5PScwJyB4bGluazpocmVmPScjZzAtNTAnLz4KPHVzZSB4PScyMS4xMDEzMDEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi05MScvPgo8dXNlIHg9JzI0LjM1Mjk2MycgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTQ5Jy8+Cjx1c2UgeD0nMzAuMjA1OTUzJyB5PScwJyB4bGluazpocmVmPScjZzEtNTknLz4KPHVzZSB4PSczNS40NTAxMTInIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS0xMTAnLz4KPHVzZSB4PSc0Mi40Mzc3MTgnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi05MycvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTQgLS0+) .
.(1) writes:

where
 is a matrix in
is a matrix in  and
and  .
.Examples
Create the model
 and the samples:
and the samples:>>> import openturns as ot >>> import openturns.experimental as otexp >>> g = ot.SymbolicFunction(['x'], ['x * sin(x)']) >>> sampleX = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0], [7.0], [8.0]] >>> sampleY = g(sampleX)
Create the algorithm:
>>> basis = ot.Basis([ot.SymbolicFunction(['x'], ['x']), ot.SymbolicFunction(['x'], ['x^2'])]) >>> covarianceModel = ot.SquaredExponential([1.0]) >>> covarianceModel.setActiveParameter([]) >>> fit_algo = otexp.GaussianProcessFitter(sampleX, sampleY, covarianceModel, basis) >>> fit_algo.run()
Get the resulting meta model:
>>> fit_result = fit_algo.getResult() >>> algo = otexp.GaussianProcessRegression(fit_result) >>> algo.run() >>> result = algo.getResult() >>> metamodel = result.getMetaModel()
- __init__(*args)¶
- static BuildDistribution(inputSample)¶
Recover the distribution, with metamodel performance in mind.
For each marginal, find the best 1-d continuous parametric model else fallback to the use of a nonparametric one.
The selection is done as follow:
We start with a list of all parametric models (all factories)
For each model, we estimate its parameters if feasible.
We check then if model is valid, ie if its Kolmogorov score exceeds a threshold fixed in the MetaModelAlgorithm-PValueThreshold ResourceMap key. Default value is 5%
We sort all valid models and return the one with the optimal criterion.
For the last step, the criterion might be BIC, AIC or AICC. The specification of the criterion is done through the MetaModelAlgorithm-ModelSelectionCriterion ResourceMap key. Default value is fixed to BIC. Note that if there is no valid candidate, we estimate a non-parametric model (
KernelSmoothingorHistogram). The MetaModelAlgorithm-NonParametricModel ResourceMap key allows selecting the preferred one. Default value is HistogramOne each marginal is estimated, we use the Spearman independence test on each component pair to decide whether an independent copula. In case of non independence, we rely on a
NormalCopula.- Parameters:
- sample
Sample Input sample.
- sample
- Returns:
- distribution
Distribution Input distribution.
- distribution
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getDistribution()¶
Accessor to the joint probability density function of the physical input vector.
- Returns:
- distribution
Distribution Joint probability density function of the physical input vector.
- distribution
- getInputSample()¶
Accessor to the input sample.
- Returns:
- inputSample
Sample Input sample of a model evaluated apart.
- inputSample
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- getOutputSample()¶
Accessor to the output sample.
- Returns:
- outputSample
Sample Output sample of a model evaluated apart.
- outputSample
- getResult()¶
Get the results of the metamodel computation.
- Returns:
- result
GaussianProcessRegressionResult Structure containing all the results obtained after computation and created by the method
run().
- result
- getWeights()¶
Return the weights of the input sample.
- Returns:
- weightssequence of float
The weights of the points in the input sample.
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- run()¶
Compute the response surface.
Notes
It computes the kriging response surface and creates a
GaussianProcessRegressionResultstructure containing all the results.
- setDistribution(distribution)¶
Accessor to the joint probability density function of the physical input vector.
- Parameters:
- distribution
Distribution Joint probability density function of the physical input vector.
- distribution
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
Examples using the class¶
Gaussian Process Regression : cantilever beam model
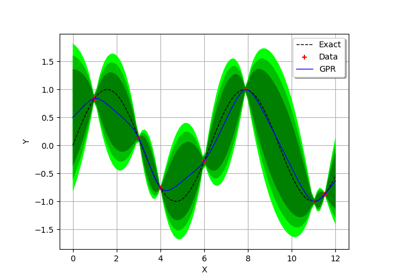
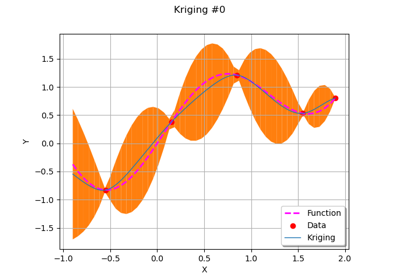
{kind=link}