KrigingAlgorithm¶
(Source code, png)
- class KrigingAlgorithm(*args)¶
Kriging algorithm.
Refer to Kriging.
- Parameters:
- inputSample, outputSample2-d sequence of float
The samples
 and
and  upon which the meta-model is built.
upon which the meta-model is built.- covarianceModel
CovarianceModel Covariance model used for the underlying Gaussian process assumption.
- basis
Basis, optional Functional basis to estimate the trend (universal kriging):
 .
If
.
If  , the same basis is used for each marginal output.
, the same basis is used for each marginal output.
Methods
BuildDistribution(inputSample)Recover the distribution, with metamodel performance in mind.
Accessor to the object's name.
Accessor to the joint probability density function of the physical input vector.
Accessor to the input sample.
Linear algebra method accessor.
getName()Accessor to the object's name.
getNoise()Observation noise variance accessor.
Accessor to solver used to optimize the covariance model parameters.
Accessor to the optimization bounds.
Accessor to the covariance model parameters optimization flag.
Accessor to the output sample.
Accessor to the reduced log-likelihood function that writes as argument of the covariance's model parameters.
Get the results of the metamodel computation.
Return the weights of the input sample.
hasName()Test if the object is named.
run()Compute the response surface.
setDistribution(distribution)Accessor to the joint probability density function of the physical input vector.
setMethod(method)Linear algebra method set accessor.
setName(name)Accessor to the object's name.
setNoise(noise)Observation noise variance accessor.
setOptimizationAlgorithm(solver)Accessor to the solver used to optimize the covariance model parameters.
setOptimizationBounds(optimizationBounds)Accessor to the optimization bounds.
setOptimizeParameters(optimizeParameters)Accessor to the covariance model parameters optimization flag.
Notes
We suppose we have a sample
 where
where  for all k, with
for all k, with  the model.
the model.The meta model Kriging is based on the same principles as those of the general linear model: it assumes that the sample
 is considered as the trace of a Gaussian process
is considered as the trace of a Gaussian process  on
on  . The Gaussian process is defined by:
. The Gaussian process is defined by:(1)¶

where:

with
 and
and  the trend functions.
the trend functions. is a Gaussian process of dimension p with zero mean and covariance function
is a Gaussian process of dimension p with zero mean and covariance function  (see
(see CovarianceModelfor the notations).The estimation of the all parameters (the trend coefficients
 , the scale
, the scale  and the amplitude
and the amplitude  ) are made by the
) are made by the GeneralLinearModelAlgorithmclass.The Kriging algorithm makes the general linear model interpolating on the input samples. The Kriging meta model
 is defined by:
is defined by:
where
 is the condition
is the condition  for each
for each ![k \in [1, N]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzQ5LjMyNDM4M3B0JyBoZWlnaHQ9JzExLjk1NTE2OHB0JyB2aWV3Qm94PScwIC04Ljk2NjM3NiA0OS4zMjQzODMgMTEuOTU1MTY4Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMi00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2cyLTkxJyBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJy8+CjxwYXRoIGlkPSdnMi05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjxwYXRoIGlkPSdnMC01MCcgZD0nTTYuNTUxNDMyLTIuNzQ5Njg5QzYuNzU0NjctMi43NDk2ODkgNi45Njk4NjMtMi43NDk2ODkgNi45Njk4NjMtMi45ODg3OTJTNi43NTQ2Ny0zLjIyNzg5NSA2LjU1MTQzMi0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMy00LjgyOTg4OCAzLjAwMDc0Ny01Ljk3NzU4NCA0LjY4NjQyNi01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3LTUuOTc3NTg0IDYuOTY5ODYzLTUuOTc3NTg0IDYuOTY5ODYzLTYuMjE2Njg3UzYuNzU0NjctNi40NTU3OTEgNi41NTE0MzItNi40NTU3OTFINC42NjI1MTZDMi42MTgxODItNi40NTU3OTEgLjk5MjI3OS00LjkwMTYxOSAuOTkyMjc5LTIuOTg4NzkyUzIuNjE4MTgyIC40NzgyMDcgNC42NjI1MTYgLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IC40NzgyMDcgNi45Njk4NjMgLjQ3ODIwNyA2Ljk2OTg2MyAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMtMS4xNDc2OTYgMS40ODI0NDEtMi43NDk2ODlINi41NTE0MzJaJy8+CjxwYXRoIGlkPSdnMS01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzEtNzgnIGQ9J004Ljg0NjgyNC02LjkxMDA4N0M4Ljk3ODMzMS03LjQyNDE1OSA5LjE2OTYxNC03Ljc4MjgxNCAxMC4wNzgyMDctNy44MTg2OEMxMC4xMTQwNzItNy44MTg2OCAxMC4yNTc1MzQtNy44MzA2MzUgMTAuMjU3NTM0LTguMDMzODczQzEwLjI1NzUzNC04LjE2NTM4IDEwLjE0OTkzOC04LjE2NTM4IDEwLjEwMjExNy04LjE2NTM4QzkuODYzMDE0LTguMTY1MzggOS4yNTMzLTguMTQxNDY5IDkuMDE0MTk3LTguMTQxNDY5SDguNDQwMzQ5QzguMjcyOTc2LTguMTQxNDY5IDguMDU3NzgzLTguMTY1MzggNy44OTA0MTEtOC4xNjUzOEM3LjgxODY4LTguMTY1MzggNy42NzUyMTgtOC4xNjUzOCA3LjY3NTIxOC03LjkzODIzMkM3LjY3NTIxOC03LjgxODY4IDcuNzcwODU5LTcuODE4NjggNy44NTQ1NDUtNy44MTg2OEM4LjU3MTg1Ni03Ljc5NDc3IDguNjE5Njc2LTcuNTE5ODAxIDguNjE5Njc2LTcuMzA0NjA4QzguNjE5Njc2LTcuMTk3MDExIDguNjA3NzIxLTcuMTYxMTQ2IDguNTcxODU2LTYuOTkzNzczTDcuMjIwOTIyLTEuNjAxOTkzTDQuNjYyNTE2LTcuOTYyMTQyQzQuNTc4ODI5LTguMTUzNDI1IDQuNTY2ODc0LTguMTY1MzggNC4zMDM4NjEtOC4xNjUzOEgyLjg0NTMzQzIuNjA2MjI3LTguMTY1MzggMi40OTg2My04LjE2NTM4IDIuNDk4NjMtNy45MzgyMzJDMi40OTg2My03LjgxODY4IDIuNTgyMzE2LTcuODE4NjggMi44MDk0NjUtNy44MTg2OEMyLjg2OTI0LTcuODE4NjggMy41NzQ1OTUtNy44MTg2OCAzLjU3NDU5NS03LjcxMTA4M0MzLjU3NDU5NS03LjY4NzE3MyAzLjU1MDY4NS03LjU5MTUzMiAzLjUzODczLTcuNTU1NjY2TDEuOTQ4NjkyLTEuMjE5NDI3QzEuODA1MjMtLjYzMzYyNCAxLjUxODMwNi0uMzgyNTY1IC43MjkyNjUtLjM0NjdDLjY2OTQ4OS0uMzQ2NyAuNTQ5OTM4LS4zMzQ3NDUgLjU0OTkzOC0uMTE5NTUyQy41NDk5MzggMCAuNjY5NDg5IDAgLjcwNTM1NSAwQy45NDQ0NTggMCAxLjU1NDE3Mi0uMDIzOTEgMS43OTMyNzUtLjAyMzkxSDIuMzY3MTIzQzIuNTM0NDk2LS4wMjM5MSAyLjczNzczMyAwIDIuOTA1MTA2IDBDMi45ODg3OTIgMCAzLjEyMDI5OSAwIDMuMTIwMjk5LS4yMjcxNDhDMy4xMjAyOTktLjMzNDc0NSAzLjAwMDc0Ny0uMzQ2NyAyLjk1MjkyNy0uMzQ2N0MyLjU1ODQwNi0uMzU4NjU1IDIuMTc1ODQxLS40MzAzODYgMi4xNzU4NDEtLjg2MDc3MkMyLjE3NTg0MS0uOTU2NDEzIDIuMTk5NzUxLTEuMDY0MDEgMi4yMjM2NjEtMS4xNTk2NTFMMy44Mzc2MDktNy41NTU2NjZDMy45MDkzNC03LjQzNjExNSAzLjkwOTM0LTcuNDEyMjA0IDMuOTU3MTYxLTcuMzA0NjA4TDYuODAyNDkxLS4yMTUxOTNDNi44NjIyNjctLjA3MTczMSA2Ljg4NjE3NyAwIDYuOTkzNzczIDBDNy4xMTMzMjUgMCA3LjEyNTI4LS4wMzU4NjYgNy4xNzMxMDEtLjIzOTEwM0w4Ljg0NjgyNC02LjkxMDA4N1onLz4KPHBhdGggaWQ9J2cxLTEwNycgZD0nTTMuMzU5NDAyLTcuOTk4MDA3QzMuMzcxMzU3LTguMDQ1ODI4IDMuMzk1MjY4LTguMTE3NTU5IDMuMzk1MjY4LTguMTc3MzM1QzMuMzk1MjY4LTguMjk2ODg3IDMuMjc1NzE2LTguMjk2ODg3IDMuMjUxODA2LTguMjk2ODg3QzMuMjM5ODUxLTguMjk2ODg3IDIuODA5NDY1LTguMjYxMDIxIDIuNTk0MjcxLTguMjM3MTExQzIuMzkxMDM0LTguMjI1MTU2IDIuMjExNzA2LTguMjAxMjQ1IDEuOTk2NTEzLTguMTg5MjlDMS43MDk1ODktOC4xNjUzOCAxLjYyNTkwMy04LjE1MzQyNSAxLjYyNTkwMy03LjkzODIzMkMxLjYyNTkwMy03LjgxODY4IDEuNzQ1NDU1LTcuODE4NjggMS44NjUwMDYtNy44MTg2OEMyLjQ3NDcyLTcuODE4NjggMi40NzQ3Mi03LjcxMTA4MyAyLjQ3NDcyLTcuNTkxNTMyQzIuNDc0NzItNy41NDM3MTEgMi40NzQ3Mi03LjUxOTgwMSAyLjQxNDk0NC03LjMwNDYwOEwuNzA1MzU1LS40NjYyNTJDLjY1NzUzNC0uMjg2OTI0IC42NTc1MzQtLjI2MzAxNCAuNjU3NTM0LS4xOTEyODNDLjY1NzUzNCAuMDcxNzMxIC44NjA3NzIgLjExOTU1MiAuOTgwMzI0IC4xMTk1NTJDMS4zMTUwNjggLjExOTU1MiAxLjM4NjgtLjE0MzQ2MiAxLjQ4MjQ0MS0uNTE0MDcyTDIuMDQ0MzM0LTIuNzQ5Njg5QzIuOTA1MTA2LTIuNjU0MDQ3IDMuNDE5MTc4LTIuMjk1MzkyIDMuNDE5MTc4LTEuNzIxNTQ0QzMuNDE5MTc4LTEuNjQ5ODEzIDMuNDE5MTc4LTEuNjAxOTkzIDMuMzgzMzEzLTEuNDIyNjY1QzMuMzM1NDkyLTEuMjQzMzM3IDMuMzM1NDkyLTEuMDk5ODc1IDMuMzM1NDkyLTEuMDQwMUMzLjMzNTQ5Mi0uMzQ2NyAzLjc4OTc4OCAuMTE5NTUyIDQuMzk5NTAyIC4xMTk1NTJDNC45NDk0NCAuMTE5NTUyIDUuMjM2MzY0LS4zODI1NjUgNS4zMzIwMDUtLjU0OTkzOEM1LjU4MzA2NC0uOTkyMjc5IDUuNzM4NDgxLTEuNjYxNzY4IDUuNzM4NDgxLTEuNzA5NTg5QzUuNzM4NDgxLTEuNzY5MzY1IDUuNjkwNjYtMS44MTcxODYgNS42MTg5MjktMS44MTcxODZDNS41MTEzMzMtMS44MTcxODYgNS40OTkzNzctMS43NjkzNjUgNS40NTE1NTctMS41NzgwODJDNS4yODQxODQtLjk1NjQxMyA1LjAzMzEyNi0uMTE5NTUyIDQuNDIzNDEyLS4xMTk1NTJDNC4xODQzMDktLjExOTU1MiA0LjAyODg5Mi0uMjM5MTAzIDQuMDI4ODkyLS42OTM0QzQuMDI4ODkyLS45MjA1NDggNC4wNzY3MTItMS4xODM1NjIgNC4xMjQ1MzMtMS4zNjI4ODlDNC4xNzIzNTQtMS41NzgwODIgNC4xNzIzNTQtMS41OTAwMzcgNC4xNzIzNTQtMS43MzM0OTlDNC4xNzIzNTQtMi40Mzg4NTQgMy41Mzg3My0yLjgzMzM3NSAyLjQzODg1NC0yLjk3NjgzN0MyLjg2OTI0LTMuMjM5ODUxIDMuMjk5NjI2LTMuNzA2MTAyIDMuNDY2OTk5LTMuODg1NDNDNC4xNDg0NDMtNC42NTA1NiA0LjYxNDY5NS01LjAzMzEyNiA1LjE2NDYzMy01LjAzMzEyNkM1LjQzOTYwMS01LjAzMzEyNiA1LjUxMTMzMy00Ljk2MTM5NSA1LjU5NTAxOS00Ljg4OTY2NEM1LjE1MjY3Ny00Ljg0MTg0MyA0Ljk4NTMwNS00LjUzMTAwOSA0Ljk4NTMwNS00LjI5MTkwNUM0Ljk4NTMwNS00LjAwNDk4MSA1LjIxMjQ1My0zLjkwOTM0IDUuMzc5ODI2LTMuOTA5MzRDNS43MDI2MTUtMy45MDkzNCA1Ljk4OTUzOS00LjE4NDMwOSA1Ljk4OTUzOS00LjU2Njg3NEM1Ljk4OTUzOS00LjkxMzU3NCA1LjcxNDU3LTUuMjcyMjI5IDUuMTc2NTg4LTUuMjcyMjI5QzQuNTE5MDU0LTUuMjcyMjI5IDMuOTgxMDcxLTQuODA1OTc4IDMuMTMyMjU0LTMuODQ5NTY0QzMuMDEyNzAyLTMuNzA2MTAyIDIuNTcwMzYxLTMuMjUxODA2IDIuMTI4MDItMy4wODQ0MzNMMy4zNTk0MDItNy45OTgwMDdaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PScwJyB4bGluazpocmVmPScjZzEtMTA3Jy8+Cjx1c2UgeD0nOS44MTAzMzMnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMC01MCcvPgo8dXNlIHg9JzIxLjEwMTMwMScgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTkxJy8+Cjx1c2UgeD0nMjQuMzUyOTYzJyB5PScwJyB4bGluazpocmVmPScjZzItNDknLz4KPHVzZSB4PSczMC4yMDU5NTMnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS01OScvPgo8dXNlIHg9JzM1LjQ1MDExMicgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTc4Jy8+Cjx1c2UgeD0nNDYuMDcyNzIyJyB5PScwJyB4bGluazpocmVmPScjZzItOTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) .
.(1) writes:

where
 is a matrix in
is a matrix in  and
and  .
.A known centered gaussian observation noise
 can be taken into account
with
can be taken into account
with setNoise():
Examples
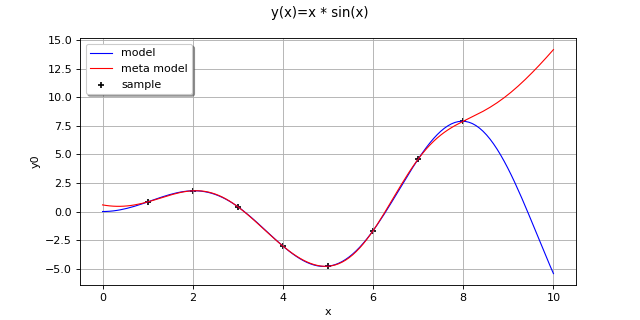
Create the model
 and the samples:
and the samples:>>> import openturns as ot >>> f = ot.SymbolicFunction(['x'], ['x * sin(x)']) >>> sampleX = [[1.0], [2.0], [3.0], [4.0], [5.0], [6.0], [7.0], [8.0]] >>> sampleY = f(sampleX)
Create the algorithm:
>>> basis = ot.Basis([ot.SymbolicFunction(['x'], ['x']), ot.SymbolicFunction(['x'], ['x^2'])]) >>> covarianceModel = ot.SquaredExponential([1.0]) >>> covarianceModel.setActiveParameter([]) >>> algo = ot.KrigingAlgorithm(sampleX, sampleY, covarianceModel, basis) >>> algo.run()
Get the resulting meta model:
>>> result = algo.getResult() >>> metamodel = result.getMetaModel()
- __init__(*args)¶
- static BuildDistribution(inputSample)¶
Recover the distribution, with metamodel performance in mind.
For each marginal, find the best 1-d continuous parametric model else fallback to the use of a nonparametric one.
The selection is done as follow:
We start with a list of all parametric models (all factories)
For each model, we estimate its parameters if feasible.
We check then if model is valid, ie if its Kolmogorov score exceeds a threshold fixed in the MetaModelAlgorithm-PValueThreshold ResourceMap key. Default value is 5%
We sort all valid models and return the one with the optimal criterion.
For the last step, the criterion might be BIC, AIC or AICC. The specification of the criterion is done through the MetaModelAlgorithm-ModelSelectionCriterion ResourceMap key. Default value is fixed to BIC. Note that if there is no valid candidate, we estimate a non-parametric model (
KernelSmoothingorHistogram). The MetaModelAlgorithm-NonParametricModel ResourceMap key allows selecting the preferred one. Default value is HistogramOne each marginal is estimated, we use the Spearman independence test on each component pair to decide whether an independent copula. In case of non independence, we rely on a
NormalCopula.- Parameters:
- sample
Sample Input sample.
- sample
- Returns:
- distribution
Distribution Input distribution.
- distribution
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getDistribution()¶
Accessor to the joint probability density function of the physical input vector.
- Returns:
- distribution
Distribution Joint probability density function of the physical input vector.
- distribution
- getInputSample()¶
Accessor to the input sample.
- Returns:
- inputSample
Sample Input sample of a model evaluated apart.
- inputSample
- getMethod()¶
Linear algebra method accessor.
- Returns:
- methodstr
Used linear algebra method.
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- getNoise()¶
Observation noise variance accessor.
- Returns:
- noisesequence of positive float
The noise variance
 of each output value.
of each output value.
- getOptimizationAlgorithm()¶
Accessor to solver used to optimize the covariance model parameters.
- Returns:
- solver
OptimizationAlgorithm Solver used to optimize the covariance model parameters.
- solver
- getOptimizationBounds()¶
Accessor to the optimization bounds.
- Returns:
- optimizationBounds
Interval The bounds used for numerical optimization of the likelihood.
- optimizationBounds
- getOptimizeParameters()¶
Accessor to the covariance model parameters optimization flag.
- Returns:
- optimizeParametersbool
Whether to optimize the covariance model parameters.
- getOutputSample()¶
Accessor to the output sample.
- Returns:
- outputSample
Sample Output sample of a model evaluated apart.
- outputSample
- getReducedLogLikelihoodFunction()¶
Accessor to the reduced log-likelihood function that writes as argument of the covariance’s model parameters.
- Returns:
- reducedLogLikelihood
Function The potentially reduced log-likelihood function.
- reducedLogLikelihood
Notes
We use the same notations as in
CovarianceModelandGeneralLinearModelAlgorithm: refers to the scale parameters and
the amplitude. We can consider three situations here:Output dimension is
 . In that case, we get the full log-likelihood function
. In that case, we get the full log-likelihood function  .
.Output dimension is 1 and the GeneralLinearModelAlgorithm-UseAnalyticalAmplitudeEstimate key of
ResourceMapis set to True. The amplitude parameter of the covariance model is in the active set of parameters and thus we get the reduced
log-likelihood function  .
.Output dimension is 1 and the GeneralLinearModelAlgorithm-UseAnalyticalAmplitudeEstimate key of
ResourceMapis set to False. In that case, we get the full log-likelihood.
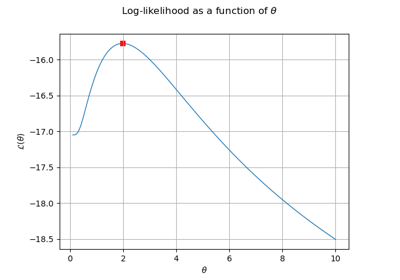
The reduced log-likelihood function may be useful for some pre/postprocessing: vizualisation of the maximizer, use of an external optimizers to maximize the reduced log-likelihood etc.
Examples
Create the model
and the samples:>>> import openturns as ot >>> f = ot.SymbolicFunction(['x0'], ['x0 * sin(x0)']) >>> inputSample = ot.Sample([[1.0], [3.0], [5.0], [6.0], [7.0], [8.0]]) >>> outputSample = f(inputSample)
Create the algorithm:
>>> basis = ot.ConstantBasisFactory().build() >>> covarianceModel = ot.SquaredExponential(1) >>> algo = ot.KrigingAlgorithm(inputSample, outputSample, covarianceModel, basis) >>> algo.run()
Get the reduced log-likelihood function:
>>> reducedLogLikelihoodFunction = algo.getReducedLogLikelihoodFunction()
- getResult()¶
Get the results of the metamodel computation.
- Returns:
- result
KrigingResult Structure containing all the results obtained after computation and created by the method
run().
- result
- getWeights()¶
Return the weights of the input sample.
- Returns:
- weightssequence of float
The weights of the points in the input sample.
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- run()¶
Compute the response surface.
Notes
It computes the kriging response surface and creates a
KrigingResultstructure containing all the results.
- setDistribution(distribution)¶
Accessor to the joint probability density function of the physical input vector.
- Parameters:
- distribution
Distribution Joint probability density function of the physical input vector.
- distribution
- setMethod(method)¶
Linear algebra method set accessor.
- Parameters:
- methodstr
Used linear algebra method. Value should be LAPACK or HMAT
Notes
The setter update the implementation and require new evaluation. We might also use the ResourceMap key to set the method when instantiating the algorithm. For that purpose, we can use ResourceMap.SetAsString(GeneralLinearModelAlgorithm-LinearAlgebra, key) with key being HMAT or LAPACK.
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
- setNoise(noise)¶
Observation noise variance accessor.
- Parameters:
- noisesequence of positive float
The noise variance
of each output value.
- setOptimizationAlgorithm(solver)¶
Accessor to the solver used to optimize the covariance model parameters.
- Parameters:
- solver
OptimizationAlgorithm Solver used to optimize the covariance model parameters.
- solver
Examples
Create the model
and the samples:>>> import openturns as ot >>> input_data = ot.Uniform(-1.0, 2.0).getSample(10) >>> model = ot.SymbolicFunction(['x'], ['x-1+sin(pi_*x/(1+0.25*x^2))']) >>> output_data = model(input_data)
Create the Kriging algorithm with the optimizer option:
>>> basis = ot.Basis([ot.SymbolicFunction(['x'], ['0.0'])]) >>> thetaInit = 1.0 >>> covariance = ot.GeneralizedExponential([thetaInit], 2.0) >>> bounds = ot.Interval(1e-2,1e2) >>> algo = ot.KrigingAlgorithm(input_data, output_data, covariance, basis) >>> algo.setOptimizationBounds(bounds)
- setOptimizationBounds(optimizationBounds)¶
Accessor to the optimization bounds.
- Parameters:
- optimizationBounds
Interval The bounds used for numerical optimization of the likelihood.
- optimizationBounds
Notes
See
GeneralLinearModelAlgorithmclass for more details, particularlysetOptimizationBounds().
- setOptimizeParameters(optimizeParameters)¶
Accessor to the covariance model parameters optimization flag.
- Parameters:
- optimizeParametersbool
Whether to optimize the covariance model parameters.
Examples using the class¶
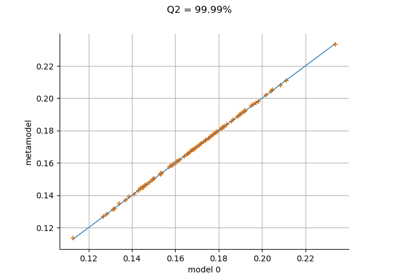

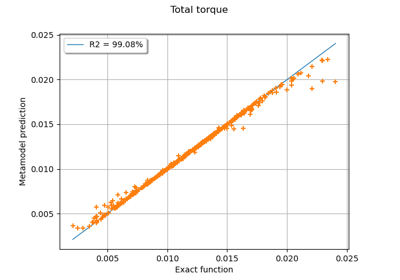
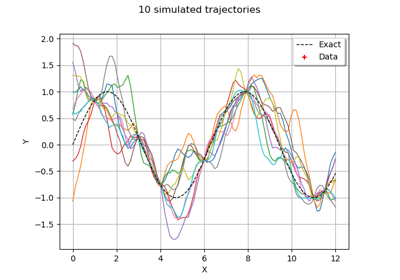
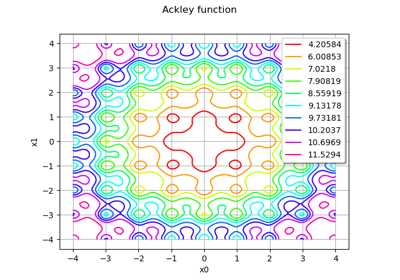
Example of multi output Kriging on the fire satellite model
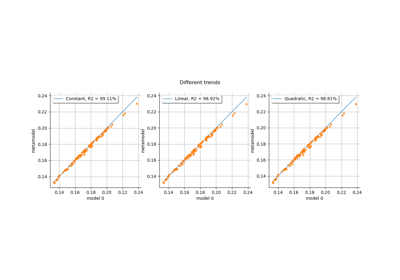
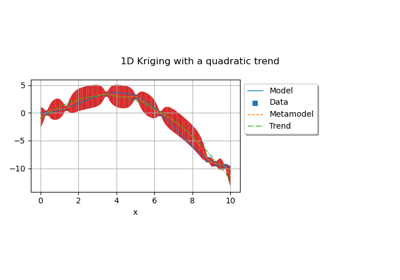
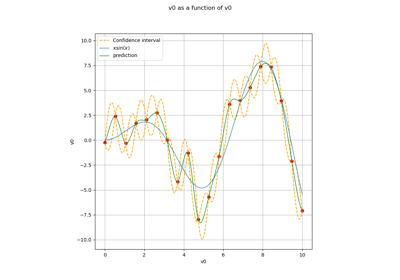
Kriging: choose a polynomial trend on the beam model
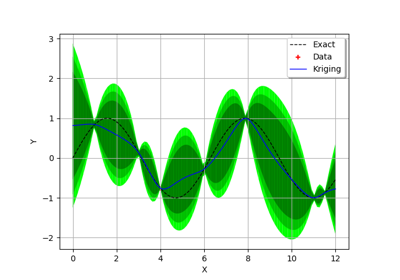

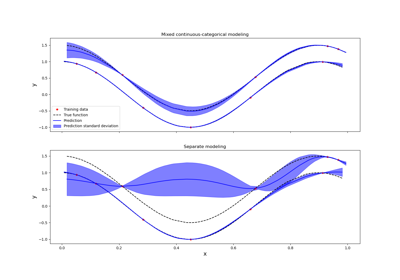
Kriging: metamodel with continuous and categorical variables
{kind=link}