Calibration of the logistic model¶
Introduction¶
The logistic growth model is the differential equation:

for any ![t\in[t_0, t_{final}]](../../_images/math/6c0624af5c5a9d59519e525c4660b8971dced0c5.svg) , with the initial condition:
, with the initial condition:

where
 and
and  are two real parameters,
are two real parameters, is the size of the population at time
is the size of the population at time  ,
, is the initial time,
is the initial time, is the initial population at time
is the initial population at time  ,
, is the final time.
is the final time.
The  parameter sets the growth rate of the population. The
parameter sets the growth rate of the population. The  parameter acts as a competition parameter which limits the size of the population by increasing the competition between its members.
parameter acts as a competition parameter which limits the size of the population by increasing the competition between its members.
In [1], the author uses this model to simulate the growth of the U.S. population. To do this, the author uses the U.S. census data from 1790 to 1910. For this time interval, R. Pearl and L. Reed [2] computed the following values of the parameters:

Our goal is to use the logistic growth model in order to simulate the solution for a larger time interval, from 1790 to 2000:

Then we can compare the predictions of this model with the real evolution of the U.S. population.
We can prove that, if  , then the limit population is:
, then the limit population is:

In 1790, the U.S. population was 3.9 Millions inhabitants:

We can prove that the exact solution of the ordinary differential equation is:

for any .
We want to see the solution of the ordinary differential equation when uncertainties are taken into account in the parameters:
the initial U.S. population
,the parameters
and .
Indeed, Pearl and Reed [2] estimated the parameters and using the U.S. census data from 1790 to 1910 while we have the data up to 2000. Moreover, the method used by Pearl and Reed to estimate the parameters could be improved; they only used 3 dates to estimate the parameters instead of using least squares, for example. Finally, Pearl and Reed did not provide confidence intervals for the parameters and .
Normalizing the data¶
The order of magnitude of and are very different. In order to mitigate this, we consider the parameter  as the logarithm of :
as the logarithm of :

This leads to the value:

The order of magnitude of the population is  . This is why we consider the normalized population in millions:
. This is why we consider the normalized population in millions:

for any .
Let  be the initial population:
be the initial population:

Uncertainties¶
Uncertainty can be accounted for by turning , and into independent random variables  ,
,  and
and  with Gaussian distributions. From this point onward, , and respectively denote
with Gaussian distributions. From this point onward, , and respectively denote ![\mathbb{E}[Z_0]](../../_images/math/d3ade712ac6f9a863a1a5a4af9b9474e97fc408a.svg) ,
, ![\mathbb{E}[A]](../../_images/math/bb889c7ca760fadc3400de6f2c16cbd0f1290973.svg) and
and ![\mathbb{E}[C]](../../_images/math/a8222c4a25bb7d6ddd6b3e7401679c8c0988a8bf.svg) .
.
Variable |
Distribution |
|---|---|
|
gaussian, mean |
|
gaussian, mean |
|
gaussian, mean |
No particular probabilistic method was used to set these distributions. An improvement would be to use calibration methods to get a better quantification of these distributions. An improvement would be to use calibration methods to get a better quantification of these distributions.
Notes¶
This example is based on [1], chapter “First order differential equations”, page 28. The data used in [1] are from [3]. The logistic growth model was first suggested by Pierre François Verhulst near 1840. The data are from [1] for the time interval from 1790 to 1950, then from [2] for the time interval from 1960 to 2000.
Calibrating this model may require to take into account for the time dependency of the measures.
References¶
[1] Martin Braun. Differential equations and their applications, Fourth Edition. Texts in applied mathematics. Springer, 1993.
[2] Cleve Moler. Numerical Computing with Matlab. Society for Industrial Applied Mathematics, 2004.
[3] Raymond Pearl and Lowell Reed. On the rate of growth of the population of the united states since 1790 and its mathematical representation. Proceedings of the National Academy of Sciences, 1920.
Analysis of the data¶
[1]:
import openturns as ot
import numpy as np
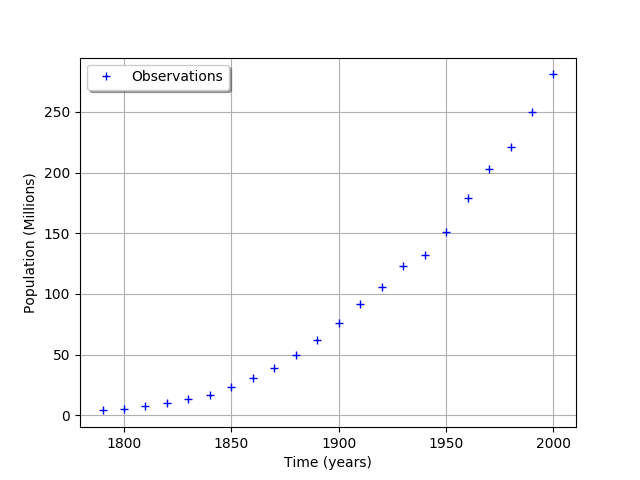
The data is based on 22 dates from 1790 to 2000.
[2]:
observedSample=ot.Sample([\
[1790,3.9], \
[1800,5.3], \
[1810,7.2], \
[1820,9.6], \
[1830,13], \
[1840,17], \
[1850,23], \
[1860,31], \
[1870,39], \
[1880,50], \
[1890,62], \
[1900,76], \
[1910,92], \
[1920,106], \
[1930,123], \
[1940,132], \
[1950,151], \
[1960,179], \
[1970,203], \
[1980,221], \
[1990,250], \
[2000,281]])
[3]:
nbobs = observedSample.getSize()
nbobs
[3]:
22
[4]:
timeObservations = observedSample[:,0]
timeObservations[0:5]
[4]:
| v0 | |
|---|---|
| 0 | 1790.0 |
| 1 | 1800.0 |
| 2 | 1810.0 |
| 3 | 1820.0 |
| 4 | 1830.0 |
[5]:
populationObservations = observedSample[:,1]
populationObservations[0:5]
[5]:
| v1 | |
|---|---|
| 0 | 3.9 |
| 1 | 5.3 |
| 2 | 7.2 |
| 3 | 9.6 |
| 4 | 13.0 |
[6]:
graph = ot.Graph('', 'Time (years)', 'Population (Millions)', True, 'topleft')
cloud = ot.Cloud(timeObservations, populationObservations)
cloud.setLegend("Observations")
graph.add(cloud)
graph
[6]:
We consider the times and populations as dimension 22 vectors. The logisticModel function takes a dimension 24 vector as input and returns a dimension 22 vector. The first 22 components of the input vector contains the dates and the remaining 2 components are and .
[7]:
def logisticModel(X):
nbdates = 22
t = [X[i] for i in range(nbdates)]
a = X[22]
c = X[23]
t0 = 1790.
y0 = 3.9e6
b = np.exp(c)
y = ot.Point(nbdates)
for i in range(nbdates):
y[i] = a*y0/(b*y0+(a-b*y0)*np.exp(-a*(t[i]-t0)))
z = y/1.e6 # Convert into millions
return z
[8]:
logisticModelPy = ot.PythonFunction(24,22,logisticModel)
The reference values of the parameters.
Because is so small with respect to , we use the logarithm.
[9]:
np.log(1.5587e-10)
[9]:
-22.581998789427587
[10]:
a=0.03134
c=-22.58
thetaPrior = [a,c]
[11]:
logisticParametric = ot.ParametricFunction(logisticModelPy,[22,23],thetaPrior)
Check that we can evaluate the parametric function.
[12]:
populationPredicted = logisticParametric(timeObservations.asPoint())
populationPredicted
[12]:
[3.9,5.29757,7.17769,9.69198,13.0277,17.4068,23.0769,30.2887,39.2561,50.0977,62.7691,77.0063,92.311,108.001,123.322,137.59,150.3,161.184,170.193,177.442,183.144,187.55]#22
[13]:
graph = ot.Graph('', 'Time (years)', 'Population (Millions)', True, 'topleft')
# Observations
cloud = ot.Cloud(timeObservations, populationObservations)
cloud.setLegend("Observations")
cloud.setColor("blue")
graph.add(cloud)
# Predictions
cloud = ot.Cloud(timeObservations.asPoint(), populationPredicted)
cloud.setLegend("Predictions")
cloud.setColor("green")
graph.add(cloud)
graph
[13]:
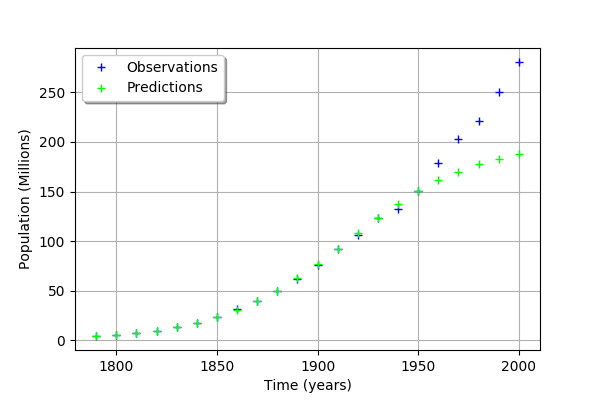
We see that the fit is not good: the observations continue to grow after 1950, while the growth of the prediction seem to fade.
A visualisation class¶
[14]:
"""
A graphics class to analyze the results of calibration.
"""
import pylab as pl
import openturns as ot
import openturns.viewer as otv
class CalibrationAnalysis:
def __init__(self,calibrationResult,model,inputObservations,outputObservations):
"""
Plots the prior and posterior distribution of the calibrated parameter theta.
Parameters
----------
calibrationResult : :class:`~openturns.calibrationResult`
The result of a calibration.
model : 2-d sequence of float
The function to calibrate.
inputObservations : :class:`~openturns.Sample`
The sample of input values of the model linked to the observations.
outputObservations : 2-d sequence of float
The sample of output values of the model linked to the observations.
"""
self.model = model
self.outputAtPrior = None
self.outputAtPosterior = None
self.calibrationResult = calibrationResult
self.observationColor = "blue"
self.priorColor = "red"
self.posteriorColor = "green"
self.inputObservations = inputObservations
self.outputObservations = outputObservations
self.unitlength = 6 # inch
# Compute yAtPrior
meanPrior = calibrationResult.getParameterPrior().getMean()
model.setParameter(meanPrior)
self.outputAtPrior=model(inputObservations)
# Compute yAtPosterior
meanPosterior = calibrationResult.getParameterPosterior().getMean()
model.setParameter(meanPosterior)
self.outputAtPosterior=model(inputObservations)
return None
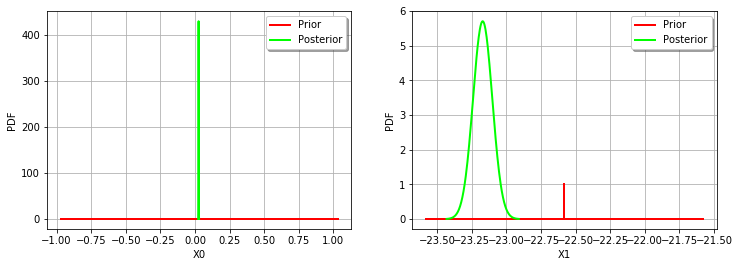
def drawParameterDistributions(self):
"""
Plots the prior and posterior distribution of the calibrated parameter theta.
"""
thetaPrior = self.calibrationResult.getParameterPrior()
thetaDescription = thetaPrior.getDescription()
thetaPosterior = self.calibrationResult.getParameterPosterior()
thetaDim = thetaPosterior.getDimension()
fig = pl.figure(figsize=(12, 4))
for i in range(thetaDim):
graph = ot.Graph("",thetaDescription[i],"PDF",True,"topright")
# Prior distribution
thetaPrior_i = thetaPrior.getMarginal(i)
priorPDF = thetaPrior_i.drawPDF()
priorPDF.setColors([self.priorColor])
priorPDF.setLegends(["Prior"])
graph.add(priorPDF)
# Posterior distribution
thetaPosterior_i = thetaPosterior.getMarginal(i)
postPDF = thetaPosterior_i.drawPDF()
postPDF.setColors([self.posteriorColor])
postPDF.setLegends(["Posterior"])
graph.add(postPDF)
'''
If the prior is a Dirac, set the vertical axis bounds to the posterior.
Otherwise, the Dirac set to [0,1], where the 1 can be much larger
than the maximum PDF of the posterior.
'''
if (thetaPrior_i.getName()=="Dirac"):
# The vertical (PDF) bounds of the posterior
postbb = postPDF.getBoundingBox()
pdf_upper = postbb.getUpperBound()[1]
pdf_lower = postbb.getLowerBound()[1]
# Set these bounds to the graph
bb = graph.getBoundingBox()
graph_upper = bb.getUpperBound()
graph_upper[1] = pdf_upper
bb.setUpperBound(graph_upper)
graph_lower = bb.getLowerBound()
graph_lower[1] = pdf_lower
bb.setLowerBound(graph_lower)
graph.setBoundingBox(bb)
# Add it to the graphics
ax = fig.add_subplot(1, thetaDim, i+1)
_ = otv.View(graph, figure=fig, axes=[ax])
return fig
def drawObservationsVsPredictions(self):
"""
Plots the output of the model depending
on the output observations before and after calibration.
"""
ySize = self.outputObservations.getSize()
yDim = self.outputObservations.getDimension()
graph = ot.Graph("","Observations","Predictions",True,"topleft")
# Plot the diagonal
if (yDim==1):
graph = self._drawObservationsVsPredictions1Dimension(self.outputObservations,self.outputAtPrior,self.outputAtPosterior)
elif (ySize==1):
outputObservations = ot.Sample(self.outputObservations[0],1)
outputAtPrior = ot.Sample(self.outputAtPrior[0],1)
outputAtPosterior = ot.Sample(self.outputAtPosterior[0],1)
graph = self._drawObservationsVsPredictions1Dimension(outputObservations,outputAtPrior,outputAtPosterior)
else:
fig = pl.figure(figsize=(self.unitlength*yDim, self.unitlength))
for i in range(yDim):
outputObservations = self.outputObservations[:,i]
outputAtPrior = self.outputAtPrior[:,i]
outputAtPosterior = self.outputAtPosterior[:,i]
graph = self._drawObservationsVsPredictions1Dimension(outputObservations,outputAtPrior,outputAtPosterior)
ax = fig.add_subplot(1, yDim, i+1)
_ = otv.View(graph, figure=fig, axes=[ax])
return graph
def _drawObservationsVsPredictions1Dimension(self,outputObservations,outputAtPrior,outputAtPosterior):
"""
Plots the output of the model depending
on the output observations before and after calibration.
Can manage only 1D samples.
"""
yDim = outputObservations.getDimension()
ydescription = outputObservations.getDescription()
xlabel = "%s Observations" % (ydescription[0])
ylabel = "%s Predictions" % (ydescription[0])
graph = ot.Graph("",xlabel,ylabel,True,"topleft")
# Plot the diagonal
if (yDim==1):
curve = ot.Curve(outputObservations, outputObservations)
curve.setColor(self.observationColor)
graph.add(curve)
else:
raise TypeError('Output observations are not 1D.')
# Plot the predictions before
yPriorDim = outputAtPrior.getDimension()
if (yPriorDim==1):
cloud = ot.Cloud(outputObservations, outputAtPrior)
cloud.setColor(self.priorColor)
cloud.setLegend("Prior")
graph.add(cloud)
else:
raise TypeError('Output prior predictions are not 1D.')
# Plot the predictions after
yPosteriorDim = outputAtPosterior.getDimension()
if (yPosteriorDim==1):
cloud = ot.Cloud(outputObservations, outputAtPosterior)
cloud.setColor(self.posteriorColor)
cloud.setLegend("Posterior")
graph.add(cloud)
else:
raise TypeError('Output posterior predictions are not 1D.')
return graph
def drawResiduals(self):
"""
Plot the distribution of the residuals and
the distribution of the observation errors.
"""
ySize = self.outputObservations.getSize()
yDim = self.outputObservations.getDimension()
yPriorSize = self.outputAtPrior.getSize()
yPriorDim = self.outputAtPrior.getDimension()
if (yDim==1):
observationsError = self.calibrationResult.getObservationsError()
graph = self._drawResiduals1Dimension(self.outputObservations,self.outputAtPrior,self.outputAtPosterior,observationsError)
elif (ySize==1):
outputObservations = ot.Sample(self.outputObservations[0],1)
outputAtPrior = ot.Sample(self.outputAtPrior[0],1)
outputAtPosterior = ot.Sample(self.outputAtPosterior[0],1)
observationsError = self.calibrationResult.getObservationsError()
# In this case, we cannot draw observationsError ; just
# pass the required input argument, but it is not actually used.
graph = self._drawResiduals1Dimension(outputObservations,outputAtPrior,outputAtPosterior,observationsError)
else:
observationsError = self.calibrationResult.getObservationsError()
fig = pl.figure(figsize=(self.unitlength*yDim, self.unitlength))
for i in range(yDim):
outputObservations = self.outputObservations[:,i]
outputAtPrior = self.outputAtPrior[:,i]
outputAtPosterior = self.outputAtPosterior[:,i]
observationsErrorYi = observationsError.getMarginal(i)
graph = self._drawResiduals1Dimension(outputObservations,outputAtPrior,outputAtPosterior,observationsErrorYi)
ax = fig.add_subplot(1, yDim, i+1)
_ = otv.View(graph, figure=fig, axes=[ax])
return graph
def _drawResiduals1Dimension(self,outputObservations,outputAtPrior,outputAtPosterior,observationsError):
"""
Plot the distribution of the residuals and
the distribution of the observation errors.
Can manage only 1D samples.
"""
ydescription = outputObservations.getDescription()
xlabel = "%s Residuals" % (ydescription[0])
graph = ot.Graph("Residuals analysis",xlabel,"Probability distribution function",True,"topright")
yDim = outputObservations.getDimension()
yPriorDim = outputAtPrior.getDimension()
yPosteriorDim = outputAtPrior.getDimension()
if (yDim==1) and (yPriorDim==1) :
posteriorResiduals = outputObservations - outputAtPrior
kernel = ot.KernelSmoothing()
fittedDist = kernel.build(posteriorResiduals)
residualPDF = fittedDist.drawPDF()
residualPDF.setColors([self.priorColor])
residualPDF.setLegends(["Prior"])
graph.add(residualPDF)
else:
raise TypeError('Output prior observations are not 1D.')
if (yDim==1) and (yPosteriorDim==1) :
posteriorResiduals = outputObservations - outputAtPosterior
kernel = ot.KernelSmoothing()
fittedDist = kernel.build(posteriorResiduals)
residualPDF = fittedDist.drawPDF()
residualPDF.setColors([self.posteriorColor])
residualPDF.setLegends(["Posterior"])
graph.add(residualPDF)
else:
raise TypeError('Output posterior observations are not 1D.')
# Plot the distribution of the observation errors
if (observationsError.getDimension()==1):
# In the other case, we just do not plot
obserrgraph = observationsError.drawPDF()
obserrgraph.setColors([self.observationColor])
obserrgraph.setLegends(["Observation errors"])
graph.add(obserrgraph)
return graph
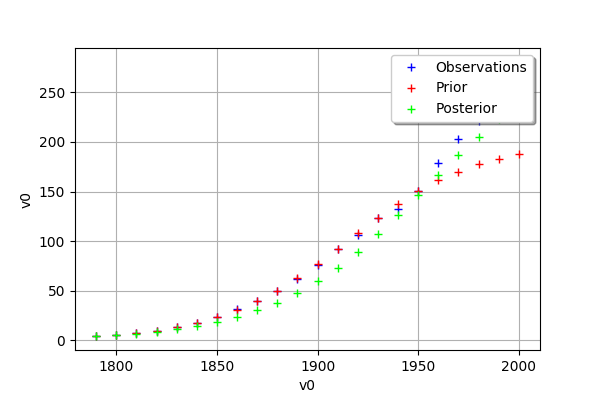
def drawObservationsVsInputs(self):
"""
Plots the observed output of the model depending
on the observed input before and after calibration.
"""
xSize = self.inputObservations.getSize()
ySize = self.outputObservations.getSize()
xDim = self.inputObservations.getDimension()
yDim = self.outputObservations.getDimension()
xdescription = self.inputObservations.getDescription()
ydescription = self.outputObservations.getDescription()
# Observations
if (xDim==1) and (yDim==1):
graph = self._drawObservationsVsInputs1Dimension(self.inputObservations,self.outputObservations,self.outputAtPrior,self.outputAtPosterior)
elif (xSize==1) and (ySize==1):
inputObservations = ot.Sample(self.inputObservations[0],1)
outputObservations = ot.Sample(self.outputObservations[0],1)
outputAtPrior = ot.Sample(self.outputAtPrior[0],1)
outputAtPosterior = ot.Sample(self.outputAtPosterior[0],1)
graph = self._drawObservationsVsInputs1Dimension(inputObservations,outputObservations,outputAtPrior,outputAtPosterior)
else:
fig = pl.figure(figsize=(xDim*self.unitlength, yDim*self.unitlength))
for i in range(xDim):
for j in range(yDim):
k = xDim * j + i
inputObservations = self.inputObservations[:,i]
outputObservations = self.outputObservations[:,j]
outputAtPrior = self.outputAtPrior[:,j]
outputAtPosterior = self.outputAtPosterior[:,j]
graph = self._drawObservationsVsInputs1Dimension(inputObservations,outputObservations,outputAtPrior,outputAtPosterior)
ax = fig.add_subplot(yDim, xDim, k+1)
_ = otv.View(graph, figure=fig, axes=[ax])
return graph
def _drawObservationsVsInputs1Dimension(self,inputObservations,outputObservations,outputAtPrior,outputAtPosterior):
"""
Plots the observed output of the model depending
on the observed input before and after calibration.
Can manage only 1D samples.
"""
xDim = inputObservations.getDimension()
if (xDim!=1):
raise TypeError('Input observations are not 1D.')
yDim = outputObservations.getDimension()
xdescription = inputObservations.getDescription()
ydescription = outputObservations.getDescription()
graph = ot.Graph("",xdescription[0],ydescription[0],True,"topright")
# Observations
if (yDim==1):
cloud = ot.Cloud(inputObservations,outputObservations)
cloud.setColor(self.observationColor)
cloud.setLegend("Observations")
graph.add(cloud)
else:
raise TypeError('Output observations are not 1D.')
# Model outputs before calibration
yPriorDim = outputAtPrior.getDimension()
if (yPriorDim==1):
cloud = ot.Cloud(inputObservations,outputAtPrior)
cloud.setColor(self.priorColor)
cloud.setLegend("Prior")
graph.add(cloud)
else:
raise TypeError('Output prior predictions are not 1D.')
# Model outputs after calibration
yPosteriorDim = outputAtPosterior.getDimension()
if (yPosteriorDim==1):
cloud = ot.Cloud(inputObservations,outputAtPosterior)
cloud.setColor(self.posteriorColor)
cloud.setLegend("Posterior")
graph.add(cloud)
else:
raise TypeError('Output posterior predictions are not 1D.')
return graph
Calibration with linear least squares¶
[15]:
timeObservationsVector = ot.Sample(timeObservations.asPoint(),nbobs)
timeObservationsVector
[15]:
| v0 | v1 | v2 | v3 | v4 | v5 | v6 | v7 | v8 | v9 | v10 | v11 | v12 | v13 | v14 | v15 | v16 | v17 | v18 | v19 | v20 | v21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1790.0 | 1800.0 | 1810.0 | 1820.0 | 1830.0 | 1840.0 | 1850.0 | 1860.0 | 1870.0 | 1880.0 | 1890.0 | 1900.0 | 1910.0 | 1920.0 | 1930.0 | 1940.0 | 1950.0 | 1960.0 | 1970.0 | 1980.0 | 1990.0 | 2000.0 |
[16]:
populationObservationsVector = ot.Sample(populationObservations.asPoint(),nbobs)
populationObservationsVector
[16]:
| v0 | v1 | v2 | v3 | v4 | v5 | v6 | v7 | v8 | v9 | v10 | v11 | v12 | v13 | v14 | v15 | v16 | v17 | v18 | v19 | v20 | v21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3.9 | 5.3 | 7.2 | 9.6 | 13.0 | 17.0 | 23.0 | 31.0 | 39.0 | 50.0 | 62.0 | 76.0 | 92.0 | 106.0 | 123.0 | 132.0 | 151.0 | 179.0 | 203.0 | 221.0 | 250.0 | 281.0 |
The reference values of the parameters.
[17]:
a=0.03134
c=-22.58
thetaPrior = ot.Point([a,c])
[18]:
logisticParametric = ot.ParametricFunction(logisticModelPy,[22,23],thetaPrior)
Check that we can evaluate the parametric function.
[19]:
populationPredicted = logisticParametric(timeObservationsVector)
populationPredicted
[19]:
| y0 | y1 | y2 | y3 | y4 | y5 | y6 | y7 | y8 | y9 | y10 | y11 | y12 | y13 | y14 | y15 | y16 | y17 | y18 | y19 | y20 | y21 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3.9 | 5.297570993588737 | 7.177694331049029 | 9.691976509075118 | 13.027688360176668 | 17.406816257931556 | 23.07690645223348 | 30.288701735679773 | 39.25606261502755 | 50.0976684188684 | 62.7690708585206 | 77.00630247912245 | 92.3110280836433 | 108.00087305198232 | 123.32228287684865 | 137.589851663471 | 150.30028422484065 | 161.18428958748135 | 170.1930026645712 | 177.44218514254803 | 183.14425780833 | 187.5496464703368 |
Calibration¶
[20]:
algo = ot.LinearLeastSquaresCalibration(logisticParametric, timeObservationsVector, populationObservationsVector, thetaPrior)
[21]:
algo.run()
[22]:
calibrationResult = algo.getResult()
[23]:
thetaMAP = calibrationResult.getParameterMAP()
thetaMAP
[23]:
[0.0265958,-23.1714]
[24]:
thetaPosterior = calibrationResult.getParameterPosterior()
thetaPosterior.computeBilateralConfidenceIntervalWithMarginalProbability(0.95)[0]
[24]:
[0.0246465, 0.028545]
[-23.3182, -23.0247]
[25]:
mypcr = CalibrationAnalysis(calibrationResult,logisticParametric, timeObservationsVector, populationObservationsVector)
[26]:
mypcr.drawObservationsVsInputs()
[26]:
[27]:
mypcr.drawObservationsVsPredictions()
[27]:
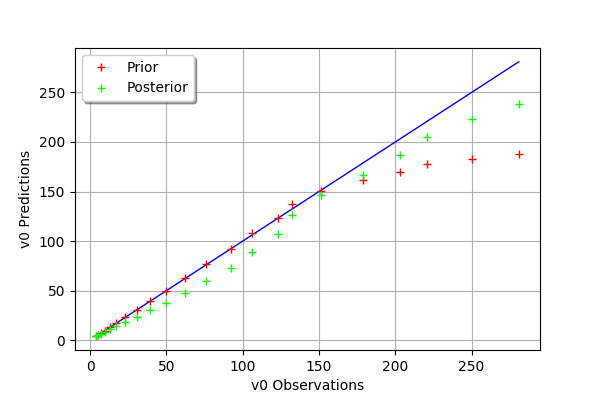
[28]:
mypcr.drawResiduals()
[28]:
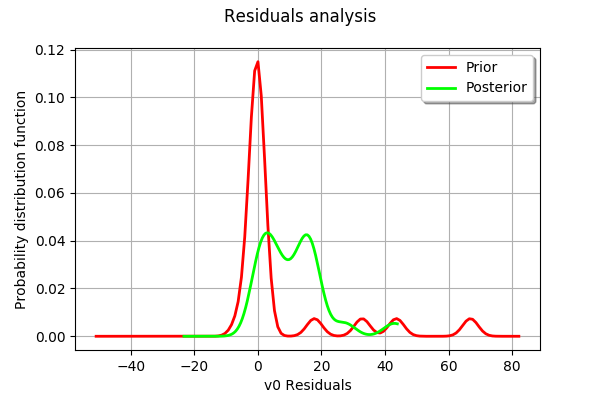
[29]:
_ = mypcr.drawParameterDistributions()