Note
Click here to download the full example code
Over-fitting and model selection¶
Introduction¶
In this notebook, we present the problem of over-fitting a model to data. We consider noisy observations of the sine function. We estimate the coefficients of the univariate polynomial based on linear least squares and show that, when the degree of the polynomial becomes too large, the overall prediction quality decreases.
This shows why and how model selection can come into play in order to select the degree of the polynomial: there is is a trade-off between fitting the data and preserving the quality of future predictions. In this example, we use cross validation as a model selection method.
References¶
Bishop Christopher M., 1995, Neural networks for pattern recognition. Figure 1.4, page 7
Compute the data¶
In this section, we generate noisy observations from the sine function.
import openturns as ot
import pylab as pl
import openturns.viewer as otv
ot.RandomGenerator.SetSeed(0)
We define the function that we are going to approximate.
g = ot.SymbolicFunction(["x"], ["sin(2*pi_*x)"])
graph = ot.Graph("Polynomial curve fitting", "x", "y", True, "topright")
# The "unknown" function
curve = g.draw(0, 1)
curve.setColors(["green"])
curve.setLegends(['"Unknown" function'])
graph.add(curve)
view = otv.View(graph)
This seems a nice, smooth function to approximate with polynomials.
def linearSample(xmin, xmax, npoints):
"""Returns a sample created from a regular grid
from xmin to xmax with npoints points."""
step = (xmax - xmin) / (npoints - 1)
rg = ot.RegularGrid(xmin, step, npoints)
vertices = rg.getVertices()
return vertices
We consider 10 observation points in the interval [0,1].
n_train = 10
x_train = linearSample(0, 1, n_train)
Assume that the observations are noisy and that the noise follows a Normal distribution with zero mean and small standard deviation.
noise = ot.Normal(0, 0.1)
noiseSample = noise.getSample(n_train)
The following computes the observation as the sum of the function value and of the noise. The couple (x_train,`y_train`) is the training set: it is used to compute the coefficients of the polynomial model.
y_train = g(x_train) + noiseSample
graph = ot.Graph("Polynomial curve fitting", "x", "y", True, "topright")
# The "unknown" function
curve = g.draw(0, 1)
curve.setColors(["green"])
graph.add(curve)
# Training set
cloud = ot.Cloud(x_train, y_train)
cloud.setPointStyle("circle")
cloud.setLegend("Observations")
graph.add(cloud)
view = otv.View(graph)
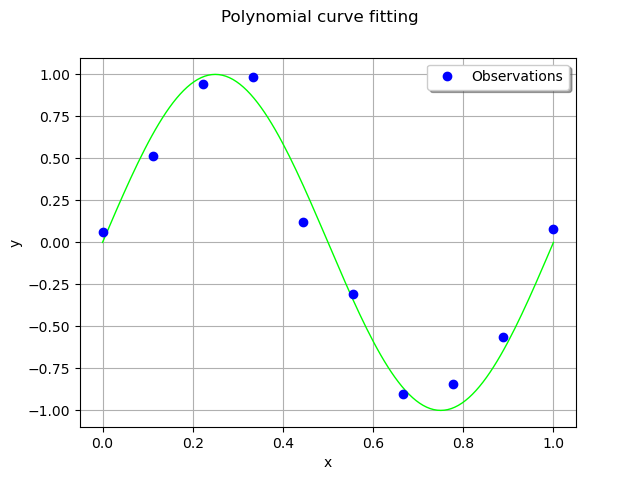
Compute the coefficients of the polynomial decomposition¶
Let  be a vector of observations.
be a vector of observations.
The polynomial model is

for any  , where
, where  is the polynomial degree and
is the polynomial degree and  is the vector of the coefficients of the model.
is the vector of the coefficients of the model.
Let  be the training sample size and let
be the training sample size and let  be the abscissas of the training set.
The design matrix
be the abscissas of the training set.
The design matrix  is
is

for  and
and  .
.
The least squares solution is:

In order to approximate the function with polynomials up to degree 4, we create a list of strings containing the associated monomials. We do not include a constant in the polynomial basis, as this constant term is automatically included in the model by the LinearLeastSquares class. We perform the loop from 1 up to total_degree (but the range function takes total_degree + 1 as its second input argument).
total_degree = 4
polynomialCollection = ["x^%d" % (degree) for degree in range(1, total_degree + 1)]
polynomialCollection
Out:
['x^1', 'x^2', 'x^3', 'x^4']
Given the list of strings, we create a symbolic function which computes the values of the monomials.
basis = ot.SymbolicFunction(["x"], polynomialCollection)
basis
[x]->[x^1,x^2,x^3,x^4]
designMatrix = basis(x_train)
designMatrix
| y0 | y1 | y2 | y3 | |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0.1111111 | 0.01234568 | 0.001371742 | 0.0001524158 |
| 2 | 0.2222222 | 0.04938272 | 0.01097394 | 0.002438653 |
| 3 | 0.3333333 | 0.1111111 | 0.03703704 | 0.01234568 |
| 4 | 0.4444444 | 0.1975309 | 0.0877915 | 0.03901844 |
| 5 | 0.5555556 | 0.308642 | 0.1714678 | 0.09525987 |
| 6 | 0.6666667 | 0.4444444 | 0.2962963 | 0.1975309 |
| 7 | 0.7777778 | 0.6049383 | 0.4705075 | 0.3659503 |
| 8 | 0.8888889 | 0.7901235 | 0.702332 | 0.6242951 |
| 9 | 1 | 1 | 1 | 1 |
myLeastSquares = ot.LinearLeastSquares(designMatrix, y_train)
myLeastSquares.run()
responseSurface = myLeastSquares.getMetaModel()
The couple (x_test,`y_test`) is the test set: it is used to assess the quality of the polynomial model with points that were not used for training.
n_test = 50
x_test = linearSample(0, 1, n_test)
y_test = responseSurface(basis(x_test))
graph = ot.Graph("Polynomial curve fitting", "x", "y", True, "topright")
# The "unknown" function
curve = g.draw(0, 1)
curve.setColors(["green"])
graph.add(curve)
# Training set
cloud = ot.Cloud(x_train, y_train)
cloud.setPointStyle("circle")
graph.add(cloud)
# Predictions
curve = ot.Curve(x_test, y_test)
curve.setLegend("Polynomial Degree = %d" % (total_degree))
curve.setColor("red")
graph.add(curve)
view = otv.View(graph)
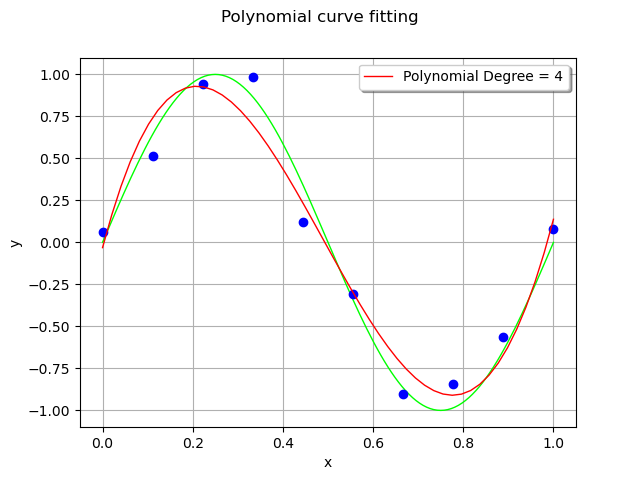
For each observation in the training set, the error is the vertical distance between the model and the observation.
graph = ot.Graph(
"Least squares minimizes the sum of the squares of the vertical bars",
"x",
"y",
True,
"topright",
)
# Training set observations
cloud = ot.Cloud(x_train, y_train)
cloud.setPointStyle("circle")
graph.add(cloud)
# Predictions
curve = ot.Curve(x_test, y_test)
curve.setLegend("Polynomial Degree = %d" % (total_degree))
curve.setColor("red")
graph.add(curve)
# Errors
ypredicted_train = responseSurface(basis(x_train))
for i in range(n_train):
curve = ot.Curve([x_train[i], x_train[i]], [y_train[i], ypredicted_train[i]])
curve.setColor("green")
curve.setLineWidth(2)
graph.add(curve)
view = otv.View(graph)
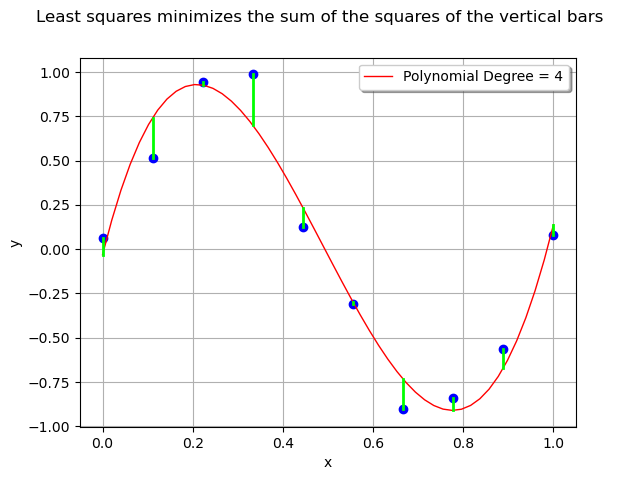
The least squares method minimizes the sum of the squared errors i.e. the sum of the squares of the lengths of the vertical segments.
We gather the previous computation in two different functions. The myPolynomialDataFitting function computes the least squares solution and myPolynomialCurveFittingGraph plots the results.
def myPolynomialDataFitting(total_degree, x_train, y_train):
"""Computes the polynomial curve fitting
with given total degree.
This is for learning purposes only: please consider a serious metamodel
for real applications, e.g. polynomial chaos or kriging."""
polynomialCollection = ["x^%d" % (degree) for degree in range(1, total_degree + 1)]
basis = ot.SymbolicFunction(["x"], polynomialCollection)
designMatrix = basis(x_train)
myLeastSquares = ot.LinearLeastSquares(designMatrix, y_train)
myLeastSquares.run()
responseSurface = myLeastSquares.getMetaModel()
return responseSurface, basis
def myPolynomialCurveFittingGraph(total_degree, x_train, y_train):
"""Returns the graphics for a polynomial curve fitting
with given total degree"""
responseSurface, basis = myPolynomialDataFitting(total_degree, x_train, y_train)
# Graphics
n_test = 100
x_test = linearSample(0, 1, n_test)
ypredicted_test = responseSurface(basis(x_test))
# Graphics
graph = ot.Graph("Polynomial curve fitting", "x", "y", True, "topright")
# The "unknown" function
curve = g.draw(0, 1)
curve.setColors(["green"])
graph.add(curve)
# Training set
cloud = ot.Cloud(x_train, y_train)
cloud.setPointStyle("circle")
cloud.setLegend("N=%d" % (x_train.getSize()))
graph.add(cloud)
# Predictions
curve = ot.Curve(x_test, ypredicted_test)
curve.setLegend("Polynomial Degree = %d" % (total_degree))
curve.setColor("red")
graph.add(curve)
return graph
In order to see the effect of the polynomial degree, we compare the polynomial fit with degrees equal to 0 (constant), 1 (linear), 3 (cubic) and 9 (enneagonic ?).
fig = pl.figure(figsize=(12, 9))
_ = fig.suptitle("Polynomial curve fitting")
ax_1 = fig.add_subplot(2, 2, 1)
_ = ot.viewer.View(
myPolynomialCurveFittingGraph(0, x_train, y_train), figure=fig, axes=[ax_1]
)
ax_2 = fig.add_subplot(2, 2, 2)
_ = ot.viewer.View(
myPolynomialCurveFittingGraph(1, x_train, y_train), figure=fig, axes=[ax_2]
)
ax_3 = fig.add_subplot(2, 2, 3)
_ = ot.viewer.View(
myPolynomialCurveFittingGraph(3, x_train, y_train), figure=fig, axes=[ax_3]
)
ax_4 = fig.add_subplot(2, 2, 4)
_ = ot.viewer.View(
myPolynomialCurveFittingGraph(9, x_train, y_train), figure=fig, axes=[ax_4]
)
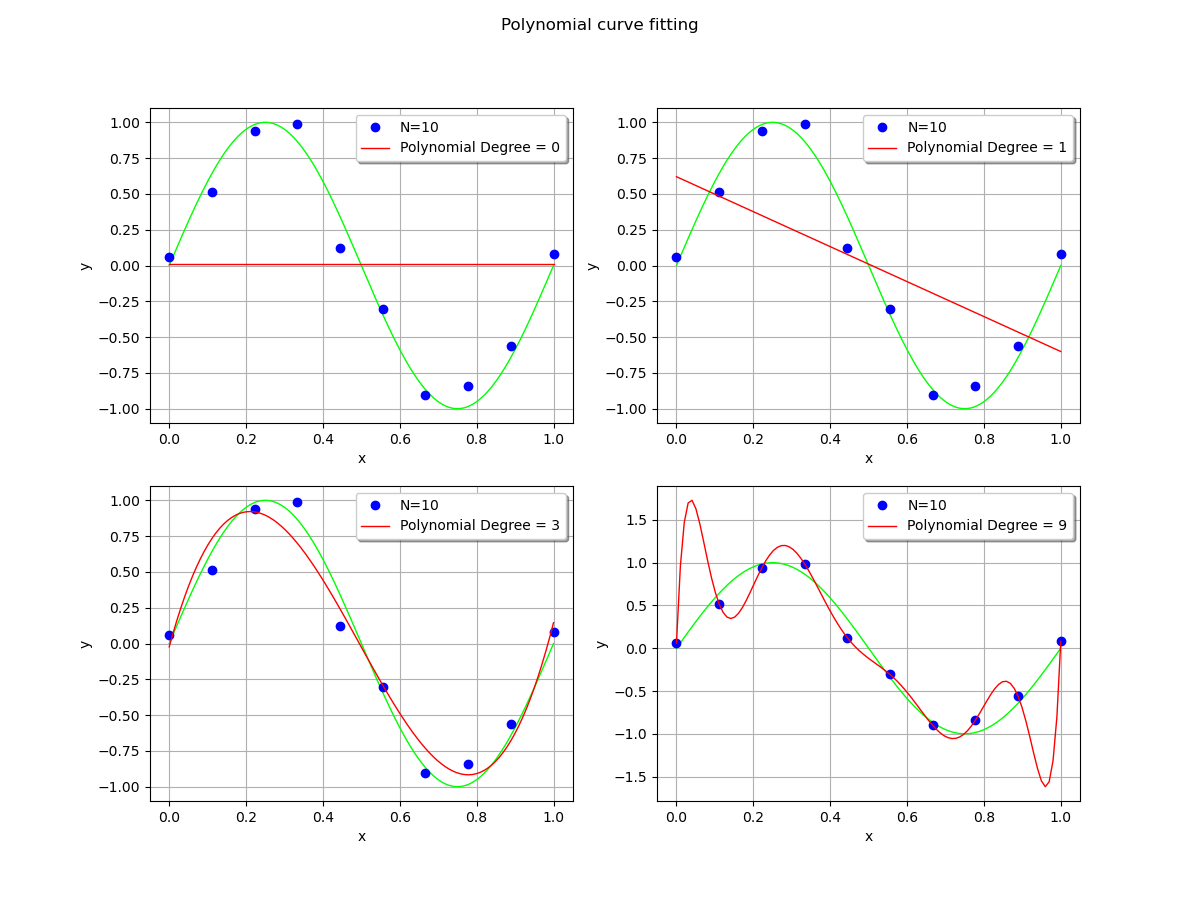
When the polynomial degree is low, the fit is satisfying. The polynomial is close to the observations, although there is still some residual error.
However, when the polynomial degree is high, it produces large oscillations which significantly deviate from the true function. This is overfitting. This is a pity, given the fact that the polynomial exactly interpolates the observations: the residuals are zeroed.
If the locations of the x abscissas could be changed, then the oscillations could be made smaller. This is the method used in gaussian quadrature, where the nodes of interpolation are made closer on the left and right bounds. In our situation, we make the asssumption that these abscissas cannot be changed: the most obvious choice is to limit the degree of the polynomial. Another possibility is to include a regularization into the least squares solution.
Root mean squared error¶
In order to assess the quality of the polynomial fit, we create a second dataset, the test set and compare the value of the polynomial with the test observations.
sqrt = ot.SymbolicFunction(["x"], ["sqrt(x)"])
In order to see how close the model is to the observations, we compute the root mean square error.
First, we create a degree 4 polynomial which fits the data.
total_degree = 4
responseSurface, basis = myPolynomialDataFitting(total_degree, x_train, y_train)
Then we create a test set, with the same method as before.
def createDataset(n):
x = linearSample(0, 1, n)
noiseSample = noise.getSample(n)
y = g(x) + noiseSample
return x, y
n_test = 100
x_test, y_test = createDataset(n_test)
On this test set, we evaluate the polynomial.
ypredicted_test = responseSurface(basis(x_test))
The vector of residuals is the vector of the differences between the observations and the predictions.
residuals = y_test.asPoint() - ypredicted_test.asPoint()
The normSquare method computes the square of the Euclidian norm (i.e. the 2-norm). We divide this by the test sample size (so as to compare the error for different sample sizes) and compute the square root of the result (so that the result has the same unit as y).
RMSE = sqrt([residuals.normSquare() / n_test])[0]
RMSE
Out:
0.1446476675291092
The following function gathers the RMSE computation to make the experiment easier.
def computeRMSE(responseSurface, basis, x, y):
ypredicted = responseSurface(basis(x))
residuals = y.asPoint() - ypredicted.asPoint()
RMSE = sqrt([residuals.normSquare() / n_test])[0]
return RMSE
maximum_degree = 10
RMSE_train = ot.Sample(maximum_degree, 1)
RMSE_test = ot.Sample(maximum_degree, 1)
for total_degree in range(maximum_degree):
responseSurface, basis = myPolynomialDataFitting(total_degree, x_train, y_train)
RMSE_train[total_degree, 0] = computeRMSE(responseSurface, basis, x_train, y_train)
RMSE_test[total_degree, 0] = computeRMSE(responseSurface, basis, x_test, y_test)
degreeSample = ot.Sample([[i] for i in range(maximum_degree)])
graph = ot.Graph("Root mean square error", "Degree", "RMSE", True, "topright")
# Train
cloud = ot.Curve(degreeSample, RMSE_train)
cloud.setColor("blue")
cloud.setLegend("Train")
cloud.setPointStyle("circle")
graph.add(cloud)
# Test
cloud = ot.Curve(degreeSample, RMSE_test)
cloud.setColor("red")
cloud.setLegend("Test")
cloud.setPointStyle("circle")
graph.add(cloud)
view = otv.View(graph)
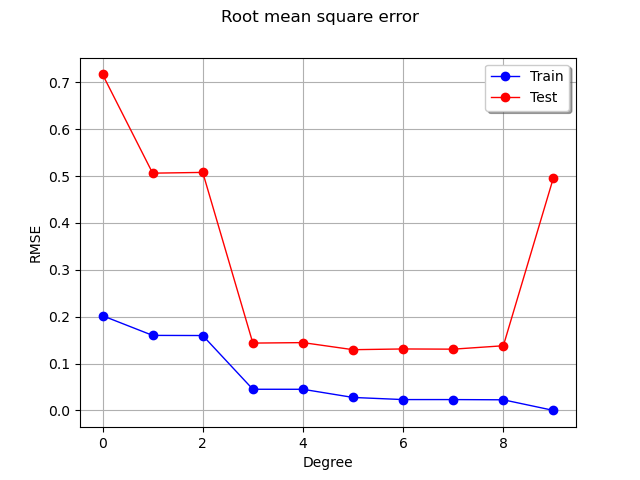
We see that the RMSE on the train set continuously decreases, reaching zero when the polynomial degree is so that the number of coefficients is equal to the train dataset sample size. In this extreme situation, the least squares solution is equivalent to solving a linear system of equations: this leads to a zero residual.
On the test set however, the RMSE decreases, reaches a flat region, then increases dramatically when the degree is equal to 9. Hence, limiting the polynomial degree limits overfitting.
Increasing the training set¶
We wonder what happens when the training dataset size is increased.
total_degree = 9
fig = pl.figure(figsize=(12, 9))
_ = fig.suptitle("Polynomial curve fitting")
#
ax_1 = fig.add_subplot(2, 2, 1)
n_train = 11
x_train, y_train = createDataset(n_train)
_ = ot.viewer.View(
myPolynomialCurveFittingGraph(total_degree, x_train, y_train),
figure=fig,
axes=[ax_1],
)
#
n_train = 100
x_train, y_train = createDataset(n_train)
ax_2 = fig.add_subplot(2, 2, 2)
_ = ot.viewer.View(
myPolynomialCurveFittingGraph(total_degree, x_train, y_train),
figure=fig,
axes=[ax_2],
)
pl.show()
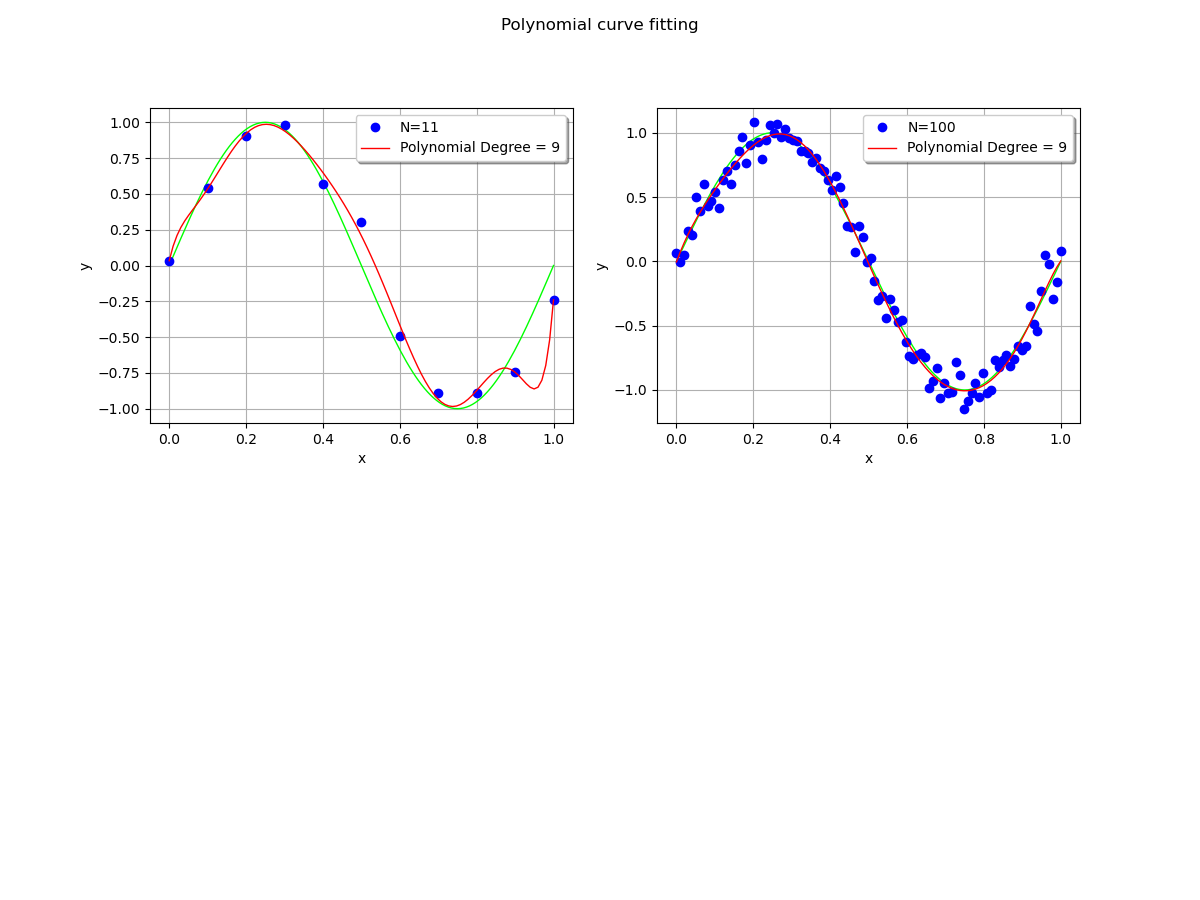
We see that the polynomial oscillates with a dataset with size 11, but does not with the larger dataset: increasing the training dataset mitigates the oscillations.
Total running time of the script: ( 0 minutes 0.903 seconds)