GeneralizedParetoFactory¶
(Source code, png)

- class GeneralizedParetoFactory(*args)¶
Generalized Pareto factory.
Methods
build(*args)Build the distribution.
buildAsGeneralizedPareto(*args)Build the distribution as a GeneralizedPareto type.
buildCovariates(*args)Estimate a GPD from covariates.
buildEstimator(*args)Build the distribution and the parameter distribution.
Build the distribution based on the exponential regression estimator.
buildMethodOfLikelihoodMaximization(sample, u)Estimate the distribution with the maximum likelihood method.
Estimate the distribution and the parameter distribution with the maximum likelihood method.
buildMethodOfMoments(sample)Build the distribution based on the method of moments estimator.
Build the distribution based on the probability weighted moments estimator.
buildMethodOfXiProfileLikelihood(sample, u)Estimate the distribution with the profile likelihood.
Estimate the distribution and the parameter distribution with the profile likelihood.
buildReturnLevelEstimator(result, sample, m)Estimate a return level and its distribution from the GPD parameters.
buildReturnLevelProfileLikelihood(sample, u, m)Estimate a return level and its distribution with the profile likelihood.
Estimate
 and its distribution with the profile likelihood.
and its distribution with the profile likelihood.buildTimeVarying(*args)Estimate a non stationary GPD from a time-dependent parametric model.
drawMeanResidualLife(sample)Draw the mean residual life plot.
drawParameterThresholdStability(sample, ...)Draw the parameter threshold stability plot.
Accessor to the bootstrap size.
Accessor to the object's name.
Accessor to the known parameters indices.
Accessor to the known parameters values.
getName()Accessor to the object's name.
Accessor to the solver.
hasName()Test if the object is named.
setBootstrapSize(bootstrapSize)Accessor to the bootstrap size.
setKnownParameter(values, positions)Accessor to the known parameters.
setName(name)Accessor to the object's name.
setOptimizationAlgorithm(solver)Accessor to the solver.
See also
Notes
The following
ResourceMapentries can be used to tweak the parameters of the optimization solver involved in the different estimators:GeneralizedParetoFactory-DefaultOptimizationAlgorithm
GeneralizedParetoFactory-MaximumEvaluationNumber
GeneralizedParetoFactory-MaximumAbsoluteError
GeneralizedParetoFactory-MaximumRelativeError
GeneralizedParetoFactory-MaximumObjectiveError
GeneralizedParetoFactory-MaximumConstraintError
GeneralizedParetoFactory-InitializationMethod
GeneralizedParetoFactory-NormalizationMethod
- __init__(*args)¶
- build(*args)¶
Build the distribution.
Available usages:
build()
build(sample)
build(param)
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample from which
 are estimated.
are estimated.- paramsequence of float
The parameters of the
GeneralizedPareto.
- Returns:
- dist
Distribution The estimated GPD.
- dist
Notes
In the first usage, the default
GeneralizedParetodistribution is built.In the second usage, the chosen algorithm depends on the size of the sample compared to the
ResourceMapkey GeneralizedParetoFactory-SmallSize (see [matthys2003] for the theory):If the sample size is less or equal to GeneralizedParetoFactory-SmallSize from
ResourceMap, then the method of probability weighted moments is used. If it fails, the method of exponential regression is used.Otherwise, the first method tried is the method of exponential regression, then the method of probability weighted moments if the first one fails.
In the third usage, a
GeneralizedParetodistribution corresponding to the given parameters is built.
- buildAsGeneralizedPareto(*args)¶
Build the distribution as a GeneralizedPareto type.
Available usages:
build()
build(sample)
build(param)
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample from which
are estimated.- paramsequence of float,
A vector of parameters of the
GeneralizedPareto.
- Returns:
- dist
GeneralizedPareto The estimated GPD as a
GeneralizedPareto.In the first usage, the default GeneralizedPareto distribution is built.
- dist
Notes
The strategy described in
build()is followed.
- buildCovariates(*args)¶
Estimate a GPD from covariates.
- Parameters:
- sample2-d sequence of float
Sample drawn from a GPD.
- ufloat
The threshold.
- covariates2-d sequence of float
Covariates sample. A constant column is automatically added if none is not provided.
- sigmaIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- xiIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- sigmaLink
Function, optional The
 function.
function.By default, the identity function.
- xiLink
Function, optional The
 function.
function.By default, the identity function.
- initializationMethodstr, optional
The initialization method for the optimization problem: Generic or Static.
By default, the method Generic (see
ResourceMap, key GeneralizedParetoFactory-InitializationMethod).- normalizationMethodstr, optional
The data normalization method: CenterReduce, MinMax or None.
By default, the method MinMax (see
ResourceMap, key GeneralizedParetoFactory-NormalizationMethod).
- Returns:
- result
CovariatesResult The result class.
- result
Notes
Let
 whose excesses above the threshold
whose excesses above the threshold  follow a GPD whose parameters
follow a GPD whose parameters  depend on
depend on  covariates
denoted by
covariates
denoted by  :
:
We assume that the threshold
is known.We denote by
 the values of associated to the values of the
covariates
the values of associated to the values of the
covariates  .
.For numerical reasons, it is recommended to normalize the covariates. Each covariate
 has its own normalization:
has its own normalization:
and with three ways of defining
 of the covariate :
of the covariate :the CenterReduce method where
 is the covariate mean
and
is the covariate mean
and  is the standard deviation of the covariates;
is the standard deviation of the covariates;the MinMax method where
 is the min value of the covariate
and
is the min value of the covariate
and  its range. This is the default method. This is the default method;
its range. This is the default method. This is the default method;the None method where
 and
and  : in that case, data are not normalized.
: in that case, data are not normalized.
Let
 be the vector of parameters. Then,
be the vector of parameters. Then,  depends on all the covariates
even if each component of only depends on a subset of the covariates. We
denote by
depends on all the covariates
even if each component of only depends on a subset of the covariates. We
denote by  the
the  covariates involved in the modelling
of the component
covariates involved in the modelling
of the component  .
.Each component
can be written as a function of the normalized covariates:
This relation can be written as a function of the real covariates:

where:
 is usually referred to as the inverse-link function of the
component ,
is usually referred to as the inverse-link function of the
component ,each
 .
.
To allow some parameters to remain constant, i.e. independent of the covariates (this will generally be the case for the parameter
), the library systematically
adds the constant covariate to the specified covariates.The complete vector of parameters is defined by:

where
 .
.The estimator of
 maximizes the likelihood of the model which is defined by:
maximizes the likelihood of the model which is defined by:
where
 denotes the GPD density function with
parameters
denotes the GPD density function with
parameters
 and evaluated at
and evaluated at  .
.Then, if none of the
 is zero, the log-likelihood is defined by:
is zero, the log-likelihood is defined by:![\ell (\vect{\beta}) = -\sum_{i=1}^{n} \left\{ \log(\sigma(\vect{y}_i)) +
(1 + 1 / \xi(\vect{y}_i) ) \log\left[ 1+\xi(\vect{y}_i) \left( \frac{z_{\vect{y}_i} -
\mu(\vect{y}_i)}{\sigma(\vect{y}_i)}\right) \right] + \left[ 1 + \xi(\vect{y}_i)
\left( \frac{z_{\vect{y}_i}- \mu(\vect{y}_i)}{\sigma(\vect{y}_i)} \right) \right]^{-1 / \xi(\vect{y}_i)} \right\}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzU2MS43NjE1MjRwdCcgaGVpZ2h0PSczNS44NjU4NjlwdCcgdmlld0JveD0nMCAtMzUuOTU0MTIzIDU2MS43NjE1MjQgMzUuODY1ODY5Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMy0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzUtMTA1JyBkPSdNMi4wODAxOTktMy43MzAwMTJDMi4wODAxOTktMy44NzM0NzQgMS45NzI2MDMtMy45NjkxMTYgMS44MzUxMTgtMy45NjkxMTZDMS42NzM3MjQtMy45NjkxMTYgMS41MDAzNzQtMy44MTM2OTkgMS41MDAzNzQtMy42NDAzNDlDMS41MDAzNzQtMy40OTA5MDkgMS42MDc5Ny0zLjQwMTI0NSAxLjczOTQ3Ny0zLjQwMTI0NUMxLjkzMDc2LTMuNDAxMjQ1IDIuMDgwMTk5LTMuNTgwNTczIDIuMDgwMTk5LTMuNzMwMDEyWk0xLjcyMTU0NC0xLjY0MzgzNkMxLjc0NTQ1NS0xLjcwMzYxMSAxLjc5OTI1My0xLjg0NzA3MyAxLjgyMzE2My0xLjkwMDg3MkMxLjg0MTA5Ni0xLjk1NDY3IDEuODY1MDA2LTIuMDE0NDQ2IDEuODY1MDA2LTIuMTE2MDY1QzEuODY1MDA2LTIuNDUwODA5IDEuNTY2MTI3LTIuNjM2MTE1IDEuMjY3MjQ4LTIuNjM2MTE1Qy42NTc1MzQtMi42MzYxMTUgLjM2NDYzMy0xLjg0NzA3MyAuMzY0NjMzLTEuNzE1NTY3Qy4zNjQ2MzMtMS42ODU2NzkgLjM4ODU0My0xLjYzMTg4IC40NzIyMjktMS42MzE4OFMuNTczODQ4LTEuNjY3NzQ2IC41OTE3ODEtMS43MjE1NDRDLjc1OTE1My0yLjMwMTM3IDEuMDc1OTY1LTIuNDM4ODU0IDEuMjQzMzM3LTIuNDM4ODU0QzEuMzYyODg5LTIuNDM4ODU0IDEuNDA0NzMyLTIuMzYxMTQ2IDEuNDA0NzMyLTIuMjIzNjYxQzEuNDA0NzMyLTIuMTA0MTEgMS4zNjg4NjctMi4wMTQ0NDYgMS4zNTY5MTItMS45NzI2MDNMMS4wNDYwNzctMS4yMDc0NzJDLjk3NDM0Ni0xLjAzNDEyMiAuOTc0MzQ2LTEuMDIyMTY3IC44OTY2MzgtLjgxODkyOUMuODE4OTI5LS42Mzk2MDEgLjc4OTA0MS0uNTYxODkzIC43ODkwNDEtLjQ2MDI3NEMuNzg5MDQxLS4xNTU0MTcgMS4wNjQwMSAuMDU5Nzc2IDEuMzkyNzc3IC4wNTk3NzZDMS45OTY1MTMgLjA1OTc3NiAyLjI5NTM5Mi0uNzI5MjY1IDIuMjk1MzkyLS44NjA3NzJDMi4yOTUzOTItLjg3MjcyNyAyLjI4OTQxNS0uOTQ0NDU4IDIuMTgxODE4LS45NDQ0NThDMi4wOTgxMzItLjk0NDQ1OCAyLjA5MjE1NC0uOTE0NTcgMi4wNTYyODktLjgwMDk5NkMxLjk2MDY0OC0uNDk2MTM5IDEuNzE1NTY3LS4xMzc0ODQgMS40MTA3MS0uMTM3NDg0QzEuMzAzMTEzLS4xMzc0ODQgMS4yNDkzMTUtLjIwOTIxNSAxLjI0OTMxNS0uMzUyNjc3QzEuMjQ5MzE1LS40NzIyMjkgMS4yODUxODEtLjU2MTg5MyAxLjM2Mjg4OS0uNzQ3MTk4TDEuNzIxNTQ0LTEuNjQzODM2WicvPgo8cGF0aCBpZD0nZzAtMTIxJyBkPSdNNC45MDk1ODktMi45NjQ4ODJDNC45NDE0NjktMy4wNzY0NjMgNC45NDE0NjktMy4wOTI0MDMgNC45NDE0NjktMy4xNTYxNjRDNC45NDE0NjktMy4zNzkzMjggNC43NzQwOTctMy41Mzg3MyA0LjUzNDk5NC0zLjUzODczQzQuMzgzNTYyLTMuNTM4NzMgNC4xMjA1NDgtMy40NDMwODggNC4wMjQ5MDctMy4xODgwNDVDNC4wMDA5OTYtMy4xNDAyMjQgMy45MjkyNjUtMi44NTMzIDMuODg5NDE1LTIuNjg1OTI4TDMuNDE5MTc4LS44MTI5NTFDMy40MTEyMDgtLjgwNDk4MSAzLjA2MDUyMy0uMjYzMDE0IDIuNTEwNTg1LS4yNjMwMTRDMi4wMDA0OTgtLjI2MzAxNCAyLjAwMDQ5OC0uNjc3NDYgMi4wMDA0OTgtLjg0NDgzMkMyLjAwMDQ5OC0xLjI5OTEyOCAyLjIyMzY2MS0xLjg3Mjk3NiAyLjQ4NjY3NS0yLjUzNDQ5NkMyLjUzNDQ5Ni0yLjY0NjA3NyAyLjU3NDM0Ni0yLjc0MTcxOSAyLjU3NDM0Ni0yLjg3NzIxQzIuNTc0MzQ2LTMuMzYzMzg3IDIuMDcyMjI5LTMuNjEwNDYxIDEuNjAxOTkzLTMuNjEwNDYxQy43MTczMS0zLjYxMDQ2MSAuMjcwOTg0LTIuNTY2Mzc2IC4yNzA5ODQtMi4zNTkxNTNDLjI3MDk4NC0yLjIyMzY2MSAuMzkwNTM1LTIuMjIzNjYxIC40OTQxNDctMi4yMjM2NjFDLjY0NTU3OS0yLjIyMzY2MSAuNjc3NDYtMi4yMjM2NjEgLjcyNTI4LTIuMzY3MTIzQy45NDg0NDMtMy4xMDAzNzQgMS4zNjI4ODktMy4yNzU3MTYgMS41NTQxNzItMy4yNzU3MTZDMS42MDE5OTMtMy4yNzU3MTYgMS42ODk2NjQtMy4yNzU3MTYgMS42ODk2NjQtMy4wOTI0MDNDMS42ODk2NjQtMi45MjUwMzEgMS42MTc5MzMtMi43NDE3MTkgMS41NjIxNDItMi42MTQxOTdDMS4wOTE5MDUtMS40NzQ0NzEgMS4wOTE5MDUtMS4yMDM0ODcgMS4wOTE5MDUtMS4wMDQyMzRDMS4wOTE5MDUtLjA4NzY3MSAxLjg4MDk0NiAuMDcxNzMxIDIuNDU0Nzk1IC4wNzE3MzFDMi44MjkzOSAuMDcxNzMxIDMuMTA4MzQ0LS4wNjM3NjEgMy4yNTE4MDYtLjE1OTQwMkMzLjA3NjQ2MyAuNjkzNCAyLjQ0NjgyNCAxLjI4MzE4OCAxLjgzMzEyNiAxLjI4MzE4OEMxLjc3NzMzNSAxLjI4MzE4OCAxLjYwMTk5MyAxLjI4MzE4OCAxLjQwMjc0IDEuMjExNDU3QzEuNjQxODQzIDEuMDY3OTk1IDEuNzIxNTQ0IC44Mjg4OTIgMS43MjE1NDQgLjY2OTQ4OUMxLjcyMTU0NCAuNDE0NDQ2IDEuNTMwMjYyIC4yNjMwMTQgMS4yOTExNTggLjI2MzAxNEMuOTI0NTMzIC4yNjMwMTQgLjY2MTUxOSAuNTczODQ4IC42NjE1MTkgLjkwODU5M0MuNjYxNTE5IDEuMzcwODU5IDEuMTU1NjY2IDEuNjE3OTMzIDEuODMzMTI2IDEuNjE3OTMzQzIuNzczNTk5IDEuNjE3OTMzIDMuOTA1MzU1IDEuMDQ0MDg1IDQuMTYwMzk5IC4wMTU5NEw0LjkwOTU4OS0yLjk2NDg4MlonLz4KPHBhdGggaWQ9J2c2LTI0JyBkPSdNMS42MTc5MzMtMi4zNTExODNDMS45MTI4MjctMi4yMzk2MDEgMi4yMDc3MjEtMi4yMzk2MDEgMi4zODMwNjQtMi4yMzk2MDFDMi42NTQwNDctMi4yMzk2MDEgMy4xNzIxMDUtMi4yMzk2MDEgMy4xNzIxMDUtMi41MjY1MjZDMy4xNzIxMDUtMi43NjU2MjkgMi43NDE3MTktMi43NjU2MjkgMi40NzA3MzUtMi43NjU2MjlDMi4zMTEzMzMtMi43NjU2MjkgMi4wNjQyNTktMi43NjU2MjkgMS43NTM0MjUtMi42NjIwMTdDMS41NzgwODItMi44MjkzOSAxLjUwNjM1MS0zLjA1MjU1MyAxLjUwNjM1MS0zLjI3NTcxNkMxLjUwNjM1MS0zLjcyMjA0MiAxLjgxNzE4Ni00LjI4NzkyIDIuMzk5MDA0LTQuNTY2ODc0QzIuNTc0MzQ2LTQuMzgzNTYyIDIuNzgxNTY5LTQuMzgzNTYyIDIuOTQ4OTQxLTQuMzgzNTYyQzMuMjUxODA2LTQuMzgzNTYyIDMuNzA2MTAyLTQuMzk5NTAyIDMuNzA2MTAyLTQuNjcwNDg2QzMuNzA2MTAyLTQuOTA5NTg5IDMuMjc1NzE2LTQuOTA5NTg5IDIuOTk2NzYyLTQuOTA5NTg5QzIuODYxMjctNC45MDk1ODkgMi43MjU3NzgtNC45MDk1ODkgMi41MDI2MTUtNC44Nzc3MDlDMi40ODY2NzUtNC45MzM0OTkgMi40NjI3NjUtNS4wMTMyIDIuNDYyNzY1LTUuMTE2ODEyQzIuNDYyNzY1LTUuMjI4Mzk0IDIuNDk0NjQ1LTUuMzYzODg1IDIuNDk0NjQ1LTUuMzg3Nzk2QzIuNTAyNjE1LTUuMzk1NzY2IDIuNTAyNjE1LTUuNDI3NjQ2IDIuNTAyNjE1LTUuNDM1NjE2QzIuNTAyNjE1LTUuNTA3MzQ3IDIuNDQ2ODI0LTUuNTU1MTY4IDIuMzkxMDM0LTUuNTU1MTY4QzIuMjE1NjkxLTUuNTU1MTY4IDIuMjE1NjkxLTUuMTk2NTEzIDIuMjE1NjkxLTUuMTI0NzgyQzIuMjE1NjkxLTQuOTczMzUgMi4yNTU1NDItNC44Mzc4NTggMi4yNjM1MTItNC44MjE5MThDMS4zNzA4NTktNC41OTA3ODUgLjgyMDkyMi0zLjk1MzE3NiAuODIwOTIyLTMuMzIzNTM3Qy44MjA5MjItMi45MjUwMzEgMS4wMzYxMTUtMi42NTQwNDcgMS4zMzg5NzktMi40Nzg3MDVDLjQ4NjE3Ny0xLjk5MjUyOCAuMTkxMjgzLTEuMTg3NTQ3IC4xOTEyODMtLjgyMDkyMkMuMTkxMjgzLS4wOTU2NDEgLjkyNDUzMyAuMTY3MzcyIDEuMTc5NTc3IC4yNjMwMTRDMS42MjU5MDMgLjQzMDM4NiAxLjY0MTg0MyAuNDMwMzg2IDIuMDMyMzc5IC41NjU4NzhDMi4yMjM2NjEgLjYzNzYwOSAyLjU0MjQ2NiAuNzU3MTYxIDIuNTk4MjU3IC43ODkwNDFDMi43MjU3NzggLjg2ODc0MiAyLjcyNTc3OCAuOTgwMzI0IDIuNzI1Nzc4IDEuMDI4MTQ0QzIuNzI1Nzc4IDEuMTcxNjA2IDIuNjIyMTY3IDEuNDAyNzQgMi4zNjcxMjMgMS40MDI3NEMyLjMwMzM2MiAxLjQwMjc0IDEuOTc2NTg4IDEuMzg2OCAxLjY1Nzc4MyAxLjE5NTUxN0MxLjU3ODA4MiAxLjEzOTcyNiAxLjU3MDExMiAxLjEzMTc1NiAxLjUzMDI2MiAxLjEzMTc1NkMxLjQ0MjU5IDEuMTMxNzU2IDEuNDE4NjggMS4yMTE0NTcgMS40MTg2OCAxLjI0MzMzN0MxLjQxODY4IDEuMzcwODU5IDEuOTI4NzY3IDEuNjI1OTAzIDIuMzc1MDkzIDEuNjI1OTAzQzIuOTAxMTIxIDEuNjI1OTAzIDMuMjI3ODk1IDEuMTIzNzg2IDMuMjI3ODk1IC43NTcxNjFDMy4yMjc4OTUgLjYxMzY5OSAzLjE3MjEwNSAuNDYyMjY3IDMuMDc2NDYzIC4zNTA2ODVDMi45NzI4NTIgLjIzOTEwMyAyLjg2OTI0IC4xOTkyNTMgMi40MjI5MTQgLjAzOTg1MUMxLjcyOTUxNC0uMjA3MjIzIDEuMjExNDU3LS4zOTA1MzUgMS4wODM5MzUtLjQ2MjI2N0MuODI4ODkyLS41OTc3NTggLjY2MTUxOS0uNzg5MDQxIC42NjE1MTktMS4wNTIwNTVDLjY2MTUxOS0xLjM3ODgyOSAuOTU2NDEzLTEuOTkyNTI4IDEuNjE3OTMzLTIuMzUxMTgzWk0zLjQwMzIzOC00LjY0NjU3NUMzLjMyMzUzNy00LjYzMDYzNSAzLjI0MzgzNi00LjYwNjcyNSAyLjk1NjkxMi00LjYwNjcyNUMyLjc4OTUzOS00LjYwNjcyNSAyLjc1NzY1OS00LjYwNjcyNSAyLjY2MjAxNy00LjY1NDU0NUMyLjc4OTUzOS00LjY4NjQyNiAyLjg2OTI0LTQuNjg2NDI2IDMuMDEyNzAyLTQuNjg2NDI2QzMuMjI3ODk1LTQuNjg2NDI2IDMuMjgzNjg2LTQuNjc4NDU2IDMuNDAzMjM4LTQuNjU0NTQ1Vi00LjY0NjU3NVpNMi44NjkyNC0yLjUwMjYxNUMyLjc5NzUwOS0yLjQ4NjY3NSAyLjcxNzgwOC0yLjQ2Mjc2NSAyLjQwNjk3NC0yLjQ2Mjc2NUMyLjI1NTU0Mi0yLjQ2Mjc2NSAyLjE3NTg0MS0yLjQ2Mjc2NSAyLjA0ODMxOS0yLjUwMjYxNUMyLjIyMzY2MS0yLjU0MjQ2NiAyLjMxOTMwMy0yLjU0MjQ2NiAyLjQ2Mjc2NS0yLjU0MjQ2NkMyLjY5Mzg5OC0yLjU0MjQ2NiAyLjc1NzY1OS0yLjUzNDQ5NiAyLjg2OTI0LTIuNTEwNTg1Vi0yLjUwMjYxNVonLz4KPHBhdGggaWQ9J2c2LTYxJyBkPSdNMy43MDYxMDItNS42NDI4MzlDMy43NTM5MjMtNS43NTQ0MjEgMy43NTM5MjMtNS43NzAzNjEgMy43NTM5MjMtNS43OTQyNzFDMy43NTM5MjMtNS44OTc4ODMgMy42NzQyMjItNS45Nzc1ODQgMy41NzA2MS01Ljk3NzU4NEMzLjQ0MzA4OC01Ljk3NzU4NCAzLjQxMTIwOC01Ljg4MTk0MyAzLjM3OTMyOC01LjgwMjI0MkwuNTE4MDU3IDEuNjU3NzgzQy40NzAyMzcgMS43NjkzNjUgLjQ3MDIzNyAxLjc4NTMwNSAuNDcwMjM3IDEuODA5MjE1Qy40NzAyMzcgMS45MTI4MjcgLjU0OTkzOCAxLjk5MjUyOCAuNjUzNTQ5IDEuOTkyNTI4Qy43ODEwNzEgMS45OTI1MjggLjgxMjk1MSAxLjg5Njg4NyAuODQ0ODMyIDEuODE3MTg2TDMuNzA2MTAyLTUuNjQyODM5WicvPgo8cGF0aCBpZD0nZzYtMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2c2LTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnOC00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c4LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnOC00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c4LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnNC0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cxLTEyJyBkPSdNLjIzOTEwMyAxLjk2MDY0OEMuMjI3MTQ4IDEuOTg0NTU4IC4xOTEyODMgMi4xMzk5NzUgLjE5MTI4MyAyLjE1MTkzQy4xOTEyODMgMi4zMTkzMDMgLjM3MDYxIDIuMzE5MzAzIC40NzgyMDcgMi4zMTkzMDNDLjcxNzMxIDIuMzE5MzAzIC43MTczMSAyLjI5NTM5MiAuNzg5MDQxIDIuMDQ0MzM0Qy44MjQ5MDcgMS44NTMwNTEgMS41NDIyMTctMS4wMTYxODkgMS41NTQxNzItMS4wNDAxQzIuMDU2Mjg5LS4yMDMyMzggMi45NzY4MzcgLjE0MzQ2MiAzLjkzMzI1IC4xNDM0NjJDNi4zMzYyMzkgLjE0MzQ2MiA3LjY3NTIxOC0xLjY4NTY3OSA3LjY3NTIxOC0zLjI1MTgwNkM3LjY3NTIxOC00LjA4ODY2NyA3LjMwNDYwOC00LjU0Mjk2NCA2LjkxMDA4Ny00Ljg0MTg0M0M3LjM0MDQ3My01LjIwMDQ5OCA3LjgzMDYzNS01Ljk3NzU4NCA3LjgzMDYzNS02LjgwMjQ5MUM3LjgzMDYzNS03LjgxODY4IDcuMDg5NDE1LTguMzkyNTI4IDUuOTY1NjI5LTguMzkyNTI4QzQuMjU2MDQtOC4zOTI1MjggMi40ODY2NzUtNy4wNjU1MDQgMi4wNTYyODktNS4zMzIwMDVMLjIzOTEwMyAxLjk2MDY0OFpNNS42NTQ3OTUtNC43OTQwMjJDNS4zNjc4Ny00LjU5MDc4NSA1LjA2ODk5MS00LjU5MDc4NSA0LjkwMTYxOS00LjU5MDc4NUM0Ljg1Mzc5OC00LjU5MDc4NSA0LjMyNzc3MS00LjU5MDc4NSA0LjMyNzc3MS00LjY4NjQyNkM0LjMyNzc3MS00Ljg3NzcwOSA0LjkxMzU3NC00Ljg3NzcwOSA1LjA2ODk5MS00Ljg3NzcwOUM1LjI4NDE4NC00Ljg3NzcwOSA1LjQyNzY0Ni00Ljg3NzcwOSA1LjY1NDc5NS00Ljc5NDAyMlpNNi4wNjEyNy01LjIxMjQ1M0M1LjY2Njc1LTUuMzA4MDk1IDUuMzMyMDA1LTUuMzA4MDk1IDUuMTA0ODU3LTUuMzA4MDk1QzQuNzIyMjkxLTUuMzA4MDk1IDMuNzUzOTIzLTUuMzA4MDk1IDMuNzUzOTIzLTQuNjYyNTE2QzMuNzUzOTIzLTQuMTYwMzk5IDQuNDcxMjMzLTQuMTYwMzk5IDQuODg5NjY0LTQuMTYwMzk5QzUuMDkyOTAyLTQuMTYwMzk5IDUuNjMwODg0LTQuMTYwMzk5IDYuMTY4ODY3LTQuMzg3NTQ3QzYuMjY0NTA4LTQuMjA4MjE5IDYuMzAwMzc0LTMuOTY5MTE2IDYuMzAwMzc0LTMuNzY1ODc4QzYuMzAwMzc0LTMuMzM1NDkyIDUuOTg5NTM5LTEuODg4OTE3IDUuNjE4OTI5LTEuMjY3MjQ4QzUuMjQ4MzE5LS42ODE0NDUgNC42NjI1MTYtLjI4NjkyNCAzLjkwOTM0LS4yODY5MjRDMi43OTc1MDktLjI4NjkyNCAxLjg2NTAwNi0uOTU2NDEzIDEuODY1MDA2LTIuMDMyMzc5QzEuODY1MDA2LTIuMjcxNDgyIDEuOTI0NzgyLTIuNTIyNTQgMS45NDg2OTItMi42NDIwOTJDMi4xMjgwMi0zLjM0NzQ0NyAyLjUxMDU4NS00LjkxMzU3NCAyLjY1NDA0Ny01LjQzOTYwMUMzLjAzNjYxMy02Ljc0MjcxNSA0LjQ4MzE4OC03Ljk2MjE0MiA1LjkwNTg1My03Ljk2MjE0MkM2LjM0ODE5NC03Ljk2MjE0MiA2LjYxMTIwOC03Ljc0Njk0OSA2LjYxMTIwOC03LjI4MDY5N0M2LjYxMTIwOC02LjkxMDA4NyA2LjMyNDI4NC01LjY3ODcwNSA2LjA2MTI3LTUuMjEyNDUzWicvPgo8cGF0aCBpZD0nZzEtMTIxJyBkPSdNNi44OTgxMzItNC41MDcwOThDNi45NTc5MDgtNC43MjIyOTEgNi45NTc5MDgtNC43NDYyMDIgNi45NTc5MDgtNC43ODIwNjdDNi45NTc5MDgtNS4wNDUwODEgNi43NjY2MjUtNS4zMDgwOTUgNi4zOTYwMTUtNS4zMDgwOTVDNS43NzQzNDYtNS4zMDgwOTUgNS42MzA4ODQtNC43NDYyMDIgNS41NDcxOTgtNC40MjM0MTJMNS4yMzYzNjQtMy4xODAwNzVDNS4wOTI5MDItMi42MDYyMjcgNC44NjU3NTMtMS42ODU2NzkgNC43MzQyNDctMS4xOTU1MTdDNC42NzQ0NzEtLjkzMjUwMyA0LjMwMzg2MS0uNjQ1NTc5IDQuMjY3OTk1LS42MjE2NjlDNC4xMzY0ODgtLjUzNzk4MyAzLjg0OTU2NC0uMzM0NzQ1IDMuNDU1MDQ0LS4zMzQ3NDVDMi43NDk2ODktLjMzNDc0NSAyLjczNzczMy0uOTMyNTAzIDIuNzM3NzMzLTEuMjA3NDcyQzIuNzM3NzMzLTEuOTM2NzM3IDMuMTA4MzQ0LTIuODY5MjQgMy40NDMwODgtMy43MzAwMTJDMy41NjI2NC00LjA0MDg0NyAzLjU5ODUwNi00LjEyNDUzMyAzLjU5ODUwNi00LjMyNzc3MUMzLjU5ODUwNi01LjAyMTE3MSAyLjkwNTEwNi01LjQwMzczNiAyLjI0NzU3Mi01LjQwMzczNkMuOTgwMzI0LTUuNDAzNzM2IC4zODI1NjUtMy43Nzc4MzMgLjM4MjU2NS0zLjUzODczQy4zODI1NjUtMy4zNzEzNTcgLjU2MTg5My0zLjM3MTM1NyAuNjY5NDg5LTMuMzcxMzU3Qy44MTI5NTEtMy4zNzEzNTcgLjg5NjYzOC0zLjM3MTM1NyAuOTQ0NDU4LTMuNTI2Nzc1QzEuMzM4OTc5LTQuODUzNzk4IDEuOTk2NTEzLTQuOTczMzUgMi4xNzU4NDEtNC45NzMzNUMyLjI1OTUyNy00Ljk3MzM1IDIuMzc5MDc4LTQuOTczMzUgMi4zNzkwNzgtNC43MjIyOTFDMi4zNzkwNzgtNC40NDczMjMgMi4yNDc1NzItNC4xMzY0ODggMi4xNzU4NDEtMy45NDUyMDVDMS43MDk1ODktMi43NDk2ODkgMS40NTg1MzEtMi4wNjgyNDQgMS40NTg1MzEtMS40NTg1MzFDMS40NTg1MzEtLjA5NTY0MSAyLjY1NDA0NyAuMDk1NjQxIDMuMzU5NDAyIC4wOTU2NDFDMy42NTgyODEgLjA5NTY0MSA0LjA2NDc1NyAuMDQ3ODIxIDQuNTA3MDk4LS4yNjMwMTRDNC4xNzIzNTQgMS4yMDc0NzIgMy4yNzU3MTYgMS45ODQ1NTggMi40NTA4MDkgMS45ODQ1NThDMi4yOTUzOTIgMS45ODQ1NTggMS45NjA2NDggMS45NjA2NDggMS43MjE1NDQgMS44MTcxODZDMi4xMDQxMSAxLjY2MTc2OCAyLjI5NTM5MiAxLjMzODk3OSAyLjI5NTM5MiAxLjAxNjE4OUMyLjI5NTM5MiAuNTg1ODAzIDEuOTQ4NjkyIC40NjYyNTIgMS43MDk1ODkgLjQ2NjI1MkMxLjI2NzI0OCAuNDY2MjUyIC44NDg4MTcgLjg0ODgxNyAuODQ4ODE3IDEuMzc0ODQ0Qy44NDg4MTcgMS45ODQ1NTggMS40ODI0NDEgMi40MTQ5NDQgMi40NTA4MDkgMi40MTQ5NDRDMy44MjU2NTQgMi40MTQ5NDQgNS40MDM3MzYgMS40OTQzOTYgNS43NzQzNDYgLjAxMTk1NUw2Ljg5ODEzMi00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2cyLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cyLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzItMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzItMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cyLTQwJyBkPSdNNS4zOTE3ODEgMjEuODQyMDkyQzUuMzkxNzgxIDIwLjUyNzAyNCA0LjQ4MzE4OCAxOC41MDY2IDIuNDAyOTg5IDE3LjQ1NDU0NUMzLjY5NDE0NyAxNi43NjExNDYgNS4yMzYzNjQgMTUuMzYyMzkxIDUuMzc5ODI2IDEzLjEyNjc3NUw1LjM5MTc4MSAxMy4wNTUwNDRWNC43NzAxMTJDNS4zOTE3ODEgMy43ODk3ODggNS4zOTE3ODEgMy41NzQ1OTUgNS40ODc0MjIgMy4xMjAyOTlDNS43MDI2MTUgMi4xNjM4ODUgNi4yNzY0NjMgLjk4MDMyNCA3Ljc5NDc3IC4wODM2ODZDNy44OTA0MTEgLjAyMzkxIDcuOTAyMzY2IC4wMTE5NTUgNy45MDIzNjYtLjIwMzIzOEM3LjkwMjM2Ni0uNDY2MjUyIDcuODkwNDExLS40NzgyMDcgNy42MjczOTctLjQ3ODIwN0M3LjQxMjIwNC0uNDc4MjA3IDcuMzg4Mjk0LS40NzgyMDcgNy4wNjU1MDQtLjI4NjkyNEM0LjM4NzU0NyAxLjIzMTM4MiA0LjIzMjEzIDMuNDU1MDQ0IDQuMjMyMTMgMy44NzM0NzRWMTIuMzczNTk5QzQuMjMyMTMgMTMuMjM0MzcxIDQuMjMyMTMgMTQuMjAyNzQgMy42MTA0NjEgMTUuMzAyNjE1QzMuMDYwNTIzIDE2LjI4MjkzOSAyLjQxNDk0NCAxNi43NzMxMDEgMS45MDA4NzIgMTcuMTE5ODAxQzEuNzMzNDk5IDE3LjIyNzM5NyAxLjcyMTU0NCAxNy4yMzkzNTIgMS43MjE1NDQgMTcuNDQyNTlDMS43MjE1NDQgMTcuNjU3NzgzIDEuNzMzNDk5IDE3LjY2OTczOCAxLjgyOTE0MSAxNy43Mjk1MTRDMi44NDUzMyAxOC4zOTkwMDQgMy45MzMyNSAxOS40NjMwMTQgNC4xOTYyNjQgMjEuNDExNzA2QzQuMjMyMTMgMjEuNjc0NzIgNC4yMzIxMyAyMS42OTg2MyA0LjIzMjEzIDIxLjg0MjA5MlYzMS4wMjM2NjFDNC4yMzIxMyAzMS45OTIwMyA0LjgyOTg4OCAzNC4wMDA0OTggNy4xMzcyMzUgMzUuMjE5OTI1QzcuNDEyMjA0IDM1LjM3NTM0MiA3LjQzNjExNSAzNS4zNzUzNDIgNy42MjczOTcgMzUuMzc1MzQyQzcuODkwNDExIDM1LjM3NTM0MiA3LjkwMjM2NiAzNS4zNjMzODcgNy45MDIzNjYgMzUuMTAwMzc0QzcuOTAyMzY2IDM0Ljg4NTE4MSA3Ljg5MDQxMSAzNC44NzMyMjUgNy44NDI1OSAzNC44NDkzMTVDNy4zMjg1MTggMzQuNTI2NTI2IDUuNzYyMzkxIDMzLjU4MjA2NyA1LjQzOTYwMSAzMS41MDE4NjhDNS4zOTE3ODEgMzEuMTkxMDM0IDUuMzkxNzgxIDMxLjE2NzEyMyA1LjM5MTc4MSAzMS4wMTE3MDZWMjEuODQyMDkyWicvPgo8cGF0aCBpZD0nZzItNDEnIGQ9J000LjIzMjEzIDMwLjEyNzAyNEM0LjIzMjEzIDMxLjEwNzM0NyA0LjIzMjEzIDMxLjMyMjU0IDQuMTM2NDg4IDMxLjc3NjgzN0MzLjkyMTI5NSAzMi43MzMyNSAzLjM0NzQ0NyAzMy45MDQ4NTcgMS44MjkxNDEgMzQuODEzNDVDMS43MzM0OTkgMzQuODczMjI1IDEuNzIxNTQ0IDM0Ljg4NTE4MSAxLjcyMTU0NCAzNS4xMDAzNzRDMS43MjE1NDQgMzUuMzc1MzQyIDEuNzMzNDk5IDM1LjM3NTM0MiAyLjAwODQ2OCAzNS4zNzUzNDJDMi4yMTE3MDYgMzUuMzc1MzQyIDIuMjM1NjE2IDM1LjM3NTM0MiAyLjU1ODQwNiAzNS4xODQwNkM1LjIzNjM2NCAzMy42NjU3NTMgNS4zOTE3ODEgMzEuNDQyMDkyIDUuMzkxNzgxIDMxLjAyMzY2MVYyMi41MjM1MzdDNS4zOTE3ODEgMjEuNjYyNzY1IDUuMzkxNzgxIDIwLjY5NDM5NiA2LjAxMzQ1IDE5LjU5NDUyMUM2LjUzOTQ3NyAxOC42NjIwMTcgNy4xNDkxOTEgMTguMTU5OSA3LjcyMzAzOSAxNy43NzczMzVDNy44OTA0MTEgMTcuNjY5NzM4IDcuOTAyMzY2IDE3LjY1Nzc4MyA3LjkwMjM2NiAxNy40NDI1OUM3LjkwMjM2NiAxNy4yODcxNzMgNy45MDIzNjYgMTcuMjI3Mzk3IDcuODU0NTQ1IDE3LjE5MTUzMkM3LjI5MjY1MyAxNi44MzI4NzcgNS43Mzg0ODEgMTUuODQwNTk4IDUuNDI3NjQ2IDEzLjQ4NTQzQzUuMzkxNzgxIDEzLjIyMjQxNiA1LjM5MTc4MSAxMy4xOTg1MDYgNS4zOTE3ODEgMTMuMDU1MDQ0VjMuODczNDc0QzUuMzkxNzgxIDIuOTA1MTA2IDQuNzk0MDIyIC44OTY2MzggMi40ODY2NzUtLjMyMjc5QzIuMjExNzA2LS40NzgyMDcgMi4xODc3OTYtLjQ3ODIwNyAyLjAwODQ2OC0uNDc4MjA3QzEuNzMzNDk5LS40NzgyMDcgMS43MjE1NDQtLjQ3ODIwNyAxLjcyMTU0NC0uMjAzMjM4QzEuNzIxNTQ0LS4wMTE5NTUgMS43MjE1NDQgLjAyMzkxIDEuODA1MjMgLjA3MTczMUM0LjA3NjcxMiAxLjQyMjY2NSA0LjIzMjEzIDMuNDE5MTc4IDQuMjMyMTMgMy44ODU0M1YxMy4wNTUwNDRDNC4yMzIxMyAxNC4zNzAxMTIgNS4xNDA3MjIgMTYuMzkwNTM1IDcuMjIwOTIyIDE3LjQ0MjU5QzUuOTI5NzYzIDE4LjEzNTk5IDQuMzg3NTQ3IDE5LjUzNDc0NSA0LjI0NDA4NSAyMS43NzAzNjFMNC4yMzIxMyAyMS44NDIwOTJWMzAuMTI3MDI0WicvPgo8cGF0aCBpZD0nZzItODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2c5LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOS00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzktNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzktNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnOS02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzktMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzktMTA4JyBkPSdNMi4wNTYyODktOC4yOTY4ODdMLjM5NDUyMS04LjE2NTM4Vi03LjgxODY4QzEuMjA3NDcyLTcuODE4NjggMS4zMDMxMTMtNy43MzQ5OTQgMS4zMDMxMTMtNy4xNDkxOTFWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzE1MDY4LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFTMi42MzAxMzctLjAyMzkxIDIuOTY0ODgyIDBWLS4zNDY3QzIuMTk5NzUxLS4zNDY3IDIuMDU2Mjg5LS4zNDY3IDIuMDU2Mjg5LS44ODQ2ODJWLTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzktMTExJyBkPSdNNS40ODc0MjItMi41NTg0MDZDNS40ODc0MjItNC4xMDA2MjMgNC4zMTU4MTYtNS4zMzIwMDUgMi45MjkwMTYtNS4zMzIwMDVDMS40OTQzOTYtNS4zMzIwMDUgLjM1ODY1NS00LjA2NDc1NyAuMzU4NjU1LTIuNTU4NDA2Qy4zNTg2NTUtMS4wMjgxNDQgMS41NTQxNzIgLjExOTU1MiAyLjkxNzA2MSAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNS40ODc0MjItMS4wNTIwNTUgNS40ODc0MjItMi41NTg0MDZaTTIuOTI5MDE2LS4xNDM0NjJDMi40ODY2NzUtLjE0MzQ2MiAxLjk0ODY5Mi0uMzM0NzQ1IDEuNjAxOTkzLS45MjA1NDhDMS4yNzkyMDMtMS40NTg1MzEgMS4yNjcyNDgtMi4xNjM4ODUgMS4yNjcyNDgtMi42NjYwMDJDMS4yNjcyNDgtMy4xMjAyOTkgMS4yNjcyNDgtMy44NDk1NjQgMS42Mzc4NTgtNC4zODc1NDdDMS45NzI2MDMtNC45MDE2MTkgMi40OTg2My01LjA5MjkwMiAyLjkxNzA2MS01LjA5MjkwMkMzLjM4MzMxMy01LjA5MjkwMiAzLjg4NTQzLTQuODc3NzA5IDQuMjA4MjE5LTQuNDExNDU3QzQuNTc4ODI5LTMuODYxNTE5IDQuNTc4ODI5LTMuMTA4MzQ0IDQuNTc4ODI5LTIuNjY2MDAyQzQuNTc4ODI5LTIuMjQ3NTcyIDQuNTc4ODI5LTEuNTA2MzUxIDQuMjY3OTk1LS45NDQ0NThDMy45MzMyNS0uMzcwNjEgMy4zODMzMTMtLjE0MzQ2MiAyLjkyOTAxNi0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzctMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2c3LTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2c3LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNy02MScgZD0nTTUuMTI4NzY3LTguNTI0MDM1QzUuMTI4NzY3LTguNTM1OTkgNS4yMDA0OTgtOC43MTUzMTggNS4yMDA0OTgtOC43MzkyMjhDNS4yMDA0OTgtOC44ODI2OSA1LjA4MDk0Ni04Ljk2NjM3NiA0Ljk4NTMwNS04Ljk2NjM3NkM0LjkyNTUyOS04Ljk2NjM3NiA0LjgxNzkzMy04Ljk2NjM3NiA0LjcyMjI5MS04LjcwMzM2MkwuNzE3MzEgMi41NDY0NTFDLjcxNzMxIDIuNTU4NDA2IC42NDU1NzkgMi43Mzc3MzMgLjY0NTU3OSAyLjc2MTY0NEMuNjQ1NTc5IDIuOTA1MTA2IC43NjUxMzEgMi45ODg3OTIgLjg2MDc3MiAyLjk4ODc5MkMuOTMyNTAzIDIuOTg4NzkyIDEuMDQwMSAyLjk3NjgzNyAxLjEyMzc4NiAyLjcyNTc3OEw1LjEyODc2Ny04LjUyNDAzNVonLz4KPHBhdGggaWQ9J2c3LTk2JyBkPSdNMS4wOTk4NzUtMi4wMzIzNzlDLjM0NjctMS4yOTExNTggLjE1NTQxNy0xLjExMTgzMSAuMTU1NDE3LTEuMDY0MDFTLjIwMzIzOC0uOTMyNTAzIC4yODY5MjQtLjkzMjUwM0MuMzQ2Ny0uOTMyNTAzIDEuMDI4MTQ0LTEuNTkwMDM3IDEuMTIzNzg2LTEuNjk3NjM0QzEuMTk1NTE3LS44OTY2MzggMS40OTQzOTYgLjE0MzQ2MiAyLjQyNjg5OSAuMTQzNDYyQzIuOTA1MTA2IC4xNDM0NjIgMy4zMzU0OTItLjE1NTQxNyAzLjUyNjc3NS0uMjk4ODc5QzMuNjgyMTkyLS40MTg0MzEgNC4yNTYwNC0uOTA4NTkzIDQuMjU2MDQtMS4wMTYxODlDNC4yNTYwNC0xLjA3NTk2NSA0LjE5NjI2NC0xLjE0NzY5NiA0LjEzNjQ4OC0xLjE0NzY5NkM0LjA4ODY2Ny0xLjE0NzY5NiAzLjkwOTM0LS45NjgzNjkgMy44NjE1MTktLjkyMDU0OEMzLjQ0MzA4OC0uNTE0MDcyIDIuOTE3MDYxLS4wOTU2NDEgMi40Mzg4NTQtLjA5NTY0MUMxLjc5MzI3NS0uMDk1NjQxIDEuNzA5NTg5LTEuMDI4MTQ0IDEuNzA5NTg5LTEuNjczNzI0QzEuNzA5NTg5LTEuNzkzMjc1IDEuNzA5NTg5LTIuMjk1MzkyIDEuNzkzMjc1LTIuMzkxMDM0QzIuNDk4NjMtMy4xMjAyOTkgNC43MTAzMzYtNS40MDM3MzYgNC43MTAzMzYtNy41MTk4MDFDNC43MTAzMzYtNy45OTgwMDcgNC41MzEwMDktOC40MTY0MzggNC4wMTY5MzYtOC40MTY0MzhDMi45MDUxMDYtOC40MTY0MzggMS45MzY3MzctNS45NTM2NzQgMS43NjkzNjUtNS40OTkzNzdDMS43MjE1NDQtNS4zNzk4MjYgMS4wMjgxNDQtMy41Mzg3MyAxLjA5OTg3NS0yLjAzMjM3OVpNMS44MTcxODYtMi43NzM1OTlDMS44MjkxNDEtMi44NDUzMyAyLjM2NzEyMy01Ljk3NzU4NCAzLjM3MTM1Ny03LjY1MTMwOEMzLjU3NDU5NS03Ljk3NDA5NyAzLjc3NzgzMy04LjE3NzMzNSA0LjAxNjkzNi04LjE3NzMzNUM0LjQyMzQxMi04LjE3NzMzNSA0LjQ0NzMyMy03Ljc5NDc3IDQuNDQ3MzIzLTcuNTMxNzU2QzQuNDQ3MzIzLTcuMTEzMzI1IDQuMzI3NzcxLTYuMDM3MzYgMy4yODc2NzEtNC41MzEwMDlDMi45NzY4MzctNC4wODg2NjcgMi40OTg2My0zLjQ5MDkwOSAxLjgxNzE4Ni0yLjc3MzU5OVonLz4KPHBhdGggaWQ9J2c3LTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTk2Jy8+Cjx1c2UgeD0nNC45MTIxMDYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzkuNDY0NDMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzEtMTInLz4KPHVzZSB4PScxNy43NTgyOTcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzI1LjYzMTQ1MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTYxJy8+Cjx1c2UgeD0nMzguMDU2OTMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzQtMCcvPgo8dXNlIHg9JzU1LjQxMzEzNCcgeT0nLTI5Ljk3NjQyNScgeGxpbms6aHJlZj0nI2c2LTExMCcvPgo8dXNlIHg9JzQ5LjM0NzkyNycgeT0nLTI2LjM4OTg2OScgeGxpbms6aHJlZj0nI2cyLTg4Jy8+Cjx1c2UgeD0nNTEuMTMwMzIxJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSc1NC4wMTM0NjEnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2c4LTYxJy8+Cjx1c2UgeD0nNjAuNTk5OTY3JyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzY4LjYwOTA0MScgeT0nLTM1LjQ3NTkyOCcgeGxpbms6aHJlZj0nI2cyLTQwJy8+Cjx1c2UgeD0nNzguMjM5NjQ0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTA4Jy8+Cjx1c2UgeD0nODEuNDkxMzA1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTExJy8+Cjx1c2UgeD0nODcuMzQ0Mjk2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTAzJy8+Cjx1c2UgeD0nOTMuMzU5ODY5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc5Ny45MTIxOTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy0yNycvPgo8dXNlIHg9JzEwNC45OTQ1OTknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzEwOS41NDY5MjUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PScxMTcuMDQ2NTQxJyB5PSctMTIuMjA5NjYxJyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nMTIwLjQyNzgxMycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMTI0Ljk4MDEzOScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMTMyLjE4OTEyOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nMTQzLjk1MDQ0MycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMTQ4LjUwMjc2OScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQ5Jy8+Cjx1c2UgeD0nMTU3LjAxMjQyMycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nMTY4Ljc3MzczOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQ5Jy8+Cjx1c2UgeD0nMTc0LjYyNjcyOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nMTgwLjQ3OTcxOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTI0Jy8+Cjx1c2UgeD0nMTg2LjE3MDE1NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMTkwLjcyMjQ4MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzE5OC4yMjIwOTgnIHk9Jy0xMi4yMDk2NjEnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PScyMDEuNjAzMzcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzIwNi4xNTU2OTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzIxMi43MDA1MTknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS0xMDgnLz4KPHVzZSB4PScyMTUuOTUyMTgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS0xMTEnLz4KPHVzZSB4PScyMjEuODA1MTcxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTAzJy8+Cjx1c2UgeD0nMjI5LjgxMzI0MicgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cyLTIwJy8+Cjx1c2UgeD0nMjM2LjEyMjkzOScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQ5Jy8+Cjx1c2UgeD0nMjQ0LjYzMjU5MycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nMjU2LjM5MzkwOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTI0Jy8+Cjx1c2UgeD0nMjYyLjA4NDM0NScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMjY2LjYzNjY3MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzI3NC4xMzYyODgnIHk9Jy0xMi4yMDk2NjEnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PScyNzcuNTE3NTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzI4NC4wNjIzODMnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0xOCcvPgo8dXNlIHg9JzI5NC4wNTgyNjknIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnNy0xMjInLz4KPHVzZSB4PScyOTkuNDk2MTYnIHk9Jy0yMS43NDI3MTQnIHhsaW5rOmhyZWY9JyNnMC0xMjEnLz4KPHVzZSB4PSczMDQuODI1MzEyJyB5PSctMTkuNjk0ODUyJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzExLjE0MTg2NScgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c0LTAnLz4KPHVzZSB4PSczMjMuMDk3MDI2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzctMjInLz4KPHVzZSB4PSczMzAuMTM5OTk2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSczMzQuNjkyMzIyJyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzEtMTIxJy8+Cjx1c2UgeD0nMzQyLjE5MTkzOScgeT0nLTIwLjcxMzIzNCcgeGxpbms6aHJlZj0nI2c2LTEwNScvPgo8dXNlIHg9JzM0NS41NzMyMTEnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8cmVjdCB4PScyOTQuMDU4MjY5JyB5PSctMTguMjYwMjknIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzU2LjA2NzI1OScvPgo8dXNlIHg9JzMwOC41NTc5MjcnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c3LTI3Jy8+Cjx1c2UgeD0nMzE1LjY0MDMzMScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSczMjAuMTkyNjU3JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSczMjcuNjkyMjc0JyB5PSctNC4wMDg5OTknIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSczMzEuMDczNTQ1JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzM1MS4zMjEwNDInIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0xOScvPgo8dXNlIHg9JzM2MC4xMjE0MTUnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMScvPgo8dXNlIHg9JzM2OS4wODc3NzYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzM4MC44NDkwOTEnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMCcvPgo8dXNlIHg9JzM4Ny4xNTg3ODgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00OScvPgo8dXNlIHg9JzM5NS42Njg0NDInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzQwNy40Mjk3NTcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy0yNCcvPgo8dXNlIHg9JzQxMy4xMjAxOTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzQxNy42NzI1MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzQyNS4xNzIxMzcnIHk9Jy0xMi4yMDk2NjEnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSc0MjguNTUzNDA5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PSc0MzUuMDk4MjMyJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMTgnLz4KPHVzZSB4PSc0NDUuMDk0MTE5JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzctMTIyJy8+Cjx1c2UgeD0nNDUwLjUzMjAwOScgeT0nLTIxLjc0MjcxNCcgeGxpbms6aHJlZj0nI2cwLTEyMScvPgo8dXNlIHg9JzQ1NS44NjExNjEnIHk9Jy0xOS42OTQ4NTInIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0NjIuMTc3NzE1JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzQtMCcvPgo8dXNlIHg9JzQ3NC4xMzI4NzUnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnNy0yMicvPgo8dXNlIHg9JzQ4MS4xNzU4NDYnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzQ4NS43MjgxNzEnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSc0OTMuMjI3Nzg4JyB5PSctMjAuNzEzMjM0JyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nNDk2LjYwOTA2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzktNDEnLz4KPHJlY3QgeD0nNDQ1LjA5NDExOScgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1Ni4wNjcyNTknLz4KPHVzZSB4PSc0NTkuNTkzNzc2JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNy0yNycvPgo8dXNlIHg9JzQ2Ni42NzYxOCcgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc0NzEuMjI4NTA2JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSc0NzguNzI4MTIzJyB5PSctNC4wMDg5OTknIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSc0ODIuMTA5Mzk1JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzUwMi4zNTY4OTInIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0xOScvPgo8dXNlIHg9JzUxMS4xNTcyNjUnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMScvPgo8dXNlIHg9JzUxNy40NjY5NjInIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nNTI0LjA1MzQ2OScgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nNTI4LjI4NzY1MScgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c2LTYxJy8+Cjx1c2UgeD0nNTMyLjUyMTgzNCcgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c2LTI0Jy8+Cjx1c2UgeD0nNTM2LjU1NTM2OScgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nNTM5Ljg0ODYyMicgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2cwLTEyMScvPgo8dXNlIHg9JzU0NS4xNzc3NzQnIHk9Jy0yNy4yOTk2NScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzU0OC4zMzk1MzInIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzU1Mi4xMzA5MTcnIHk9Jy0zNS40NzU5MjgnIHhsaW5rOmhyZWY9JyNnMi00MScvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
defined on
 such that
such that  for all
for all  .
.And if any of the
is equal to 0, the log-likelihood is defined as:
The initialization of the optimization problem is crucial. Two initial points
 are proposed:
are proposed:the Generic initial point: in that case, we assume that the GPD is stationary and
 is the estimate resulting from the method
is the estimate resulting from the method
buildAsGeneralizedPareto()which follows the strategy described in the methodbuild(). This is the default initial point;the Static initial point: in that case, we still assume that the GPD is stationary and
is the maximum likelihood estimate.
The result class provides:
the estimator
 ,
,the asymptotic distribution of
,the parameter function
 ,
,the graphs of the parameter functions
 , where all the components of
, where all the components of
 are fixed to a reference value excepted for , for each
are fixed to a reference value excepted for , for each  ,
,the graphs of the parameter functions
 , where all the
components of are fixed to a reference value excepted for
, where all the
components of are fixed to a reference value excepted for
 , for each
, for each  ,
,the normalizing function
 ,
,the optimal log-likelihood value
,the GEV distribution at covariate
,the graphs of the quantile functions of order
 :
:  where all
the components of are fixed to a reference value excepted for , for each ,
where all
the components of are fixed to a reference value excepted for , for each ,the graphs of the quantile functions of order
:  where
all the components of are fixed to a
reference value excepted for , for each .
where
all the components of are fixed to a
reference value excepted for , for each .
- buildEstimator(*args)¶
Build the distribution and the parameter distribution.
- Parameters:
- sample2-d sequence of float
Data.
- parameters
DistributionParameters Optional, the parametrization.
- Returns:
- resDist
DistributionFactoryResult The results.
- resDist
Notes
According to the way the native parameters of the distribution are estimated, the parameters distribution differs:
Moments method: the asymptotic parameters distribution is normal and estimated by Bootstrap on the initial data;
Maximum likelihood method with a regular model: the asymptotic parameters distribution is normal and its covariance matrix is the inverse Fisher information matrix;
Other methods: the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting (see
KernelSmoothing).
If another set of parameters is specified, the native parameters distribution is first estimated and the new distribution is determined from it:
if the native parameters distribution is normal and the transformation regular at the estimated parameters values: the asymptotic parameters distribution is normal and its covariance matrix determined from the inverse Fisher information matrix of the native parameters and the transformation;
in the other cases, the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting.
- buildMethodOfExponentialRegression(sample)¶
Build the distribution based on the exponential regression estimator.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample from which
are estimated.
- Returns:
- dist
GeneralizedPareto The estimated GPD.
- dist
Notes
Lets denote:
 for
for 
Then we estimate
 using:
using:(1)¶

Where
 maximizes:
maximizes:(2)¶

under the constraint
 .
.
- buildMethodOfLikelihoodMaximization(sample, u)¶
Estimate the distribution with the maximum likelihood method.
- Parameters:
- sample2-d sequence of float
Sample drawn from
 .
.- ufloat
Given threshold value.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution of
 .
.
- distribution
Notes
Let
be a random variable whose excesses above follow
a GPD parameterized by . We assume
that is known.Let
 be a sample drawn from . We define the excesses above by:
be a sample drawn from . We define the excesses above by:
for all
 .
.The maximum likelihood estimator of
maximizes the log-likelihood defined by:If
 :
:(3)¶

defined on
such that  for all .
for all .If
 :
:(4)¶

- buildMethodOfLikelihoodMaximizationEstimator(sample, u)¶
Estimate the distribution and the parameter distribution with the maximum likelihood method.
- Parameters:
- sample2-d sequence of float
Sample drawn from
.- ufloat
Given threshold value.
- Returns:
- result
DistributionFactoryLikelihoodResult The result class.
- result
Notes
Let
be a random variable whose excesses above follow
a GPD parameterized by . We assume
that is known.The estimator
is defined using the profile log-likelihood as detailed in
buildMethodOfLikelihoodMaximization().The result class produced by the method provides:
the GPD distribution associated to
 ,
,the asymptotic distribution of
.
- buildMethodOfMoments(sample)¶
Build the distribution based on the method of moments estimator.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample from which
are estimated.
- Returns:
- dist
GeneralizedPareto The estimated GPD.
- dist
Notes
Lets denote:
 the empirical
mean of the sample,
the empirical
mean of the sample, its empirical variance.
its empirical variance.
Then, we estimate
 using:
using:(5)¶

This estimator is well-defined only if
 , otherwise the second moment does not exist.
, otherwise the second moment does not exist.
- buildMethodOfProbabilityWeightedMoments(sample)¶
Build the distribution based on the probability weighted moments estimator.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample from which
are estimated.
- Returns:
- dist
GeneralizedPareto The estimated GPD.
- dist
Notes
Lets denote:
 the sample sorted in ascending order
the sample sorted in ascending order

Then we estimate
using:(6)¶

This estimator is well-defined only if
 , otherwise the first moment does not exist.
, otherwise the first moment does not exist.
- buildMethodOfXiProfileLikelihood(sample, u)¶
Estimate the distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
Sample drawn from
.- ufloat
Given threshold value.
- Returns:
- distribution
GeneralizedPareto The estimated GPD.
- distribution
Notes
Let
be a random variable whose excesses above follow
a GPD parameterized by . We assume
that is known.The estimator
is defined using a nested numerical optimization of the log-likelihood:
where
 is detailed in equations (3) and (4).
is detailed in equations (3) and (4).The estimator is given by:

- buildMethodOfXiProfileLikelihoodEstimator(sample, u)¶
Estimate the distribution and the parameter distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
Sample drawn from
.- ufloat
Given threshold value.
- Returns:
- result
ProfileLikelihoodResult The result class.
- result
Notes
Let
be a random variable whose excesses above follow
a GPD parameterized by . We assume
that is known.The estimator
is defined in buildMethodOfXiProfileLikelihood().The result class produced by the method provides:
the GPD distribution associated to
,the asymptotic distribution of
,the profile log-likelihood function
 ,
,the optimal profile log-likelihood value
 ,
,confidence intervals of level
 of .
of .
- buildReturnLevelEstimator(result, sample, m, theta=1.0)¶
Estimate a return level and its distribution from the GPD parameters.
- Parameters:
- result
DistributionFactoryResult Likelihood estimation result obtained to estimate the GPD
 .
.- sample2-d sequence of float
The initial data from which the clusters (if any) have been extracted. If the data are independent, sample is the sample used to get result.
- mfloat
The return period expressed in terms of number of observations.
- thetafloat, optional
The extremal index defined in (9).
Default value is 1.
- result
- Returns:
- distribution
Distribution The asymptotic distribution of
 .
.
- distribution
Notes
Let
 a random variable whose excesses above the threshold
follow a Generalized Pareto distribution
a random variable whose excesses above the threshold
follow a Generalized Pareto distribution
 . We assume that is known.
. We assume that is known.The
 -observation return level
-observation return level  is the level exceeded on
average once every observations.
The -observation return level can be translated into the annual-scale: if there
are
is the level exceeded on
average once every observations.
The -observation return level can be translated into the annual-scale: if there
are  observations per year, then the
observations per year, then the  -year return level
corresponds to the -observation return level where
-year return level
corresponds to the -observation return level where  .
.The
-observation return level is defined as a particular quantile of :If
:(7)¶
![z_m = u + \frac{\sigma}{\xi}\left[(m \zeta_u \theta)^{\xi} - 1 \right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzEzMi4zMTY0NTRwdCcgaGVpZ2h0PScyMy43NjA0MDFwdCcgdmlld0JveD0nMTI4LjExMzI2NCAtMjMuNzYwMzkgMTMyLjMxNjQ1NCAyMy43NjA0MDEnPgo8ZGVmcz4KPHBhdGggaWQ9J2cwLTInIGQ9J00yLjQxNDk0NCAxMy44NTYwNEg0LjcxMDMzNlYxMy4zNzc4MzNIMi44OTMxNTFWMEg0LjcxMDMzNlYtLjQ3ODIwN0gyLjQxNDk0NFYxMy44NTYwNFonLz4KPHBhdGggaWQ9J2cwLTMnIGQ9J00yLjU1ODQwNiAxMy44NTYwNFYtLjQ3ODIwN0guMjYzMDE0VjBIMi4wODAxOTlWMTMuMzc3ODMzSC4yNjMwMTRWMTMuODU2MDRIMi41NTg0MDZaJy8+CjxwYXRoIGlkPSdnNC00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzQtNDEnIGQ9J00zLjM3MTM1Ny0yLjk3NjgzN0MzLjM3MTM1Ny0zLjg4NTQzIDMuMjUxODA2LTUuMzY3ODcgMi41ODIzMTYtNi43NTQ2N0MxLjg3Njk2MS04LjE4OTI5IC44OTY2MzgtOC45NjYzNzYgLjc2NTEzMS04Ljk2NjM3NkMuNzE3MzEtOC45NjYzNzYgLjY1NzUzNC04Ljk0MjQ2NiAuNjU3NTM0LTguODcwNzM1Qy42NTc1MzQtOC44MzQ4NjkgLjY1NzUzNC04LjgxMDk1OSAuODYwNzcyLTguNjA3NzIxQzIuMDU2Mjg5LTcuNDAwMjQ5IDIuNzI1Nzc4LTUuNDI3NjQ2IDIuNzI1Nzc4LTIuOTg4NzkyQzIuNzI1Nzc4LS42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgLjc3NzA4NiAyLjczNzczM0MuNjU3NTM0IDIuODQ1MzMgLjY1NzUzNCAyLjg2OTI0IC42NTc1MzQgMi45MDUxMDZDLjY1NzUzNCAyLjk3NjgzNyAuNzE3MzEgMy4wMDA3NDcgLjc2NTEzMSAzLjAwMDc0N0MuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IC45NjgzNjlDMy4wOTYzODktLjI1MTA1OSAzLjM3MTM1Ny0xLjU0MjIxNyAzLjM3MTM1Ny0yLjk3NjgzN1onLz4KPHBhdGggaWQ9J2c0LTQzJyBkPSdNNC43NzAxMTItMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEtMi43NjE2NDQgOC40NTIzMDQtMi43NjE2NDQgOC40NTIzMDQtMi45NzY4MzdDOC40NTIzMDQtMy4yMDM5ODUgOC4yNDkwNjYtMy4yMDM5ODUgOC4wNjk3MzgtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyLTYuNjcwOTg0IDQuNzcwMTEyLTYuODg2MTc3IDQuNTU0OTE5LTYuODg2MTc3QzQuMzI3NzcxLTYuODg2MTc3IDQuMzI3NzcxLTYuNjgyOTM5IDQuMzI3NzcxLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMuODYwNzcyLTMuMjAzOTg1IC42NDU1NzktMy4yMDM5ODUgLjY0NTU3OS0yLjk4ODc5MkMuNjQ1NTc5LTIuNzYxNjQ0IC44NDg4MTctMi43NjE2NDQgMS4wMjgxNDQtMi43NjE2NDRINC4zMjc3NzFWLjUzNzk4M0M0LjMyNzc3MSAuNzA1MzU1IDQuMzI3NzcxIC45MjA1NDggNC41NDI5NjQgLjkyMDU0OEM0Ljc3MDExMiAuOTIwNTQ4IDQuNzcwMTEyIC43MTczMSA0Ljc3MDExMiAuNTM3OTgzVi0yLjc2MTY0NFonLz4KPHBhdGggaWQ9J2c0LTQ5JyBkPSdNMy40NDMwODgtNy42NjMyNjNDMy40NDMwODgtNy45MzgyMzIgMy40NDMwODgtNy45NTAxODcgMy4yMDM5ODUtNy45NTAxODdDMi45MTcwNjEtNy42MjczOTcgMi4zMTkzMDMtNy4xODUwNTYgMS4wODc5Mi03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODktNi44MzgzNTYgMS45NjA2NDgtNi44MzgzNTYgMi42MTgxODItNy4xNDkxOTFWLS45MjA1NDhDMi42MTgxODItLjQ5MDE2MiAyLjU4MjMxNi0uMzQ2NyAxLjUzMDI2Mi0uMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxLS4wMjM5MSAyLjY0MjA5Mi0uMDIzOTEgMy4wMzY2MTMtLjAyMzkxUzQuNTc4ODI5LS4wMjM5MSA0LjkwMTYxOSAwVi0uMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NC0uMzQ2NyAzLjQ0MzA4OC0uNDkwMTYyIDMuNDQzMDg4LS45MjA1NDhWLTcuNjYzMjYzWicvPgo8cGF0aCBpZD0nZzQtNjEnIGQ9J004LjA2OTczOC0zLjg3MzQ3NEM4LjIzNzExMS0zLjg3MzQ3NCA4LjQ1MjMwNC0zLjg3MzQ3NCA4LjQ1MjMwNC00LjA4ODY2N0M4LjQ1MjMwNC00LjMxNTgxNiA4LjI0OTA2Ni00LjMxNTgxNiA4LjA2OTczOC00LjMxNTgxNkgxLjAyODE0NEMuODYwNzcyLTQuMzE1ODE2IC42NDU1NzktNC4zMTU4MTYgLjY0NTU3OS00LjEwMDYyM0MuNjQ1NTc5LTMuODczNDc0IC44NDg4MTctMy44NzM0NzQgMS4wMjgxNDQtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4LTEuNjQ5ODEzQzguMjM3MTExLTEuNjQ5ODEzIDguNDUyMzA0LTEuNjQ5ODEzIDguNDUyMzA0LTEuODY1MDA2QzguNDUyMzA0LTIuMDkyMTU0IDguMjQ5MDY2LTIuMDkyMTU0IDguMDY5NzM4LTIuMDkyMTU0SDEuMDI4MTQ0Qy44NjA3NzItMi4wOTIxNTQgLjY0NTU3OS0yLjA5MjE1NCAuNjQ1NTc5LTEuODc2OTYxQy42NDU1NzktMS42NDk4MTMgLjg0ODgxNy0xLjY0OTgxMyAxLjAyODE0NC0xLjY0OTgxM0g4LjA2OTczOFonLz4KPHBhdGggaWQ9J2cyLTI0JyBkPSdNMS42MTc5MzMtMi4zNTExODNDMS45MTI4MjctMi4yMzk2MDEgMi4yMDc3MjEtMi4yMzk2MDEgMi4zODMwNjQtMi4yMzk2MDFDMi42NTQwNDctMi4yMzk2MDEgMy4xNzIxMDUtMi4yMzk2MDEgMy4xNzIxMDUtMi41MjY1MjZDMy4xNzIxMDUtMi43NjU2MjkgMi43NDE3MTktMi43NjU2MjkgMi40NzA3MzUtMi43NjU2MjlDMi4zMTEzMzMtMi43NjU2MjkgMi4wNjQyNTktMi43NjU2MjkgMS43NTM0MjUtMi42NjIwMTdDMS41NzgwODItMi44MjkzOSAxLjUwNjM1MS0zLjA1MjU1MyAxLjUwNjM1MS0zLjI3NTcxNkMxLjUwNjM1MS0zLjcyMjA0MiAxLjgxNzE4Ni00LjI4NzkyIDIuMzk5MDA0LTQuNTY2ODc0QzIuNTc0MzQ2LTQuMzgzNTYyIDIuNzgxNTY5LTQuMzgzNTYyIDIuOTQ4OTQxLTQuMzgzNTYyQzMuMjUxODA2LTQuMzgzNTYyIDMuNzA2MTAyLTQuMzk5NTAyIDMuNzA2MTAyLTQuNjcwNDg2QzMuNzA2MTAyLTQuOTA5NTg5IDMuMjc1NzE2LTQuOTA5NTg5IDIuOTk2NzYyLTQuOTA5NTg5QzIuODYxMjctNC45MDk1ODkgMi43MjU3NzgtNC45MDk1ODkgMi41MDI2MTUtNC44Nzc3MDlDMi40ODY2NzUtNC45MzM0OTkgMi40NjI3NjUtNS4wMTMyIDIuNDYyNzY1LTUuMTE2ODEyQzIuNDYyNzY1LTUuMjI4Mzk0IDIuNDk0NjQ1LTUuMzYzODg1IDIuNDk0NjQ1LTUuMzg3Nzk2QzIuNTAyNjE1LTUuMzk1NzY2IDIuNTAyNjE1LTUuNDI3NjQ2IDIuNTAyNjE1LTUuNDM1NjE2QzIuNTAyNjE1LTUuNTA3MzQ3IDIuNDQ2ODI0LTUuNTU1MTY4IDIuMzkxMDM0LTUuNTU1MTY4QzIuMjE1NjkxLTUuNTU1MTY4IDIuMjE1NjkxLTUuMTk2NTEzIDIuMjE1NjkxLTUuMTI0NzgyQzIuMjE1NjkxLTQuOTczMzUgMi4yNTU1NDItNC44Mzc4NTggMi4yNjM1MTItNC44MjE5MThDMS4zNzA4NTktNC41OTA3ODUgLjgyMDkyMi0zLjk1MzE3NiAuODIwOTIyLTMuMzIzNTM3Qy44MjA5MjItMi45MjUwMzEgMS4wMzYxMTUtMi42NTQwNDcgMS4zMzg5NzktMi40Nzg3MDVDLjQ4NjE3Ny0xLjk5MjUyOCAuMTkxMjgzLTEuMTg3NTQ3IC4xOTEyODMtLjgyMDkyMkMuMTkxMjgzLS4wOTU2NDEgLjkyNDUzMyAuMTY3MzcyIDEuMTc5NTc3IC4yNjMwMTRDMS42MjU5MDMgLjQzMDM4NiAxLjY0MTg0MyAuNDMwMzg2IDIuMDMyMzc5IC41NjU4NzhDMi4yMjM2NjEgLjYzNzYwOSAyLjU0MjQ2NiAuNzU3MTYxIDIuNTk4MjU3IC43ODkwNDFDMi43MjU3NzggLjg2ODc0MiAyLjcyNTc3OCAuOTgwMzI0IDIuNzI1Nzc4IDEuMDI4MTQ0QzIuNzI1Nzc4IDEuMTcxNjA2IDIuNjIyMTY3IDEuNDAyNzQgMi4zNjcxMjMgMS40MDI3NEMyLjMwMzM2MiAxLjQwMjc0IDEuOTc2NTg4IDEuMzg2OCAxLjY1Nzc4MyAxLjE5NTUxN0MxLjU3ODA4MiAxLjEzOTcyNiAxLjU3MDExMiAxLjEzMTc1NiAxLjUzMDI2MiAxLjEzMTc1NkMxLjQ0MjU5IDEuMTMxNzU2IDEuNDE4NjggMS4yMTE0NTcgMS40MTg2OCAxLjI0MzMzN0MxLjQxODY4IDEuMzcwODU5IDEuOTI4NzY3IDEuNjI1OTAzIDIuMzc1MDkzIDEuNjI1OTAzQzIuOTAxMTIxIDEuNjI1OTAzIDMuMjI3ODk1IDEuMTIzNzg2IDMuMjI3ODk1IC43NTcxNjFDMy4yMjc4OTUgLjYxMzY5OSAzLjE3MjEwNSAuNDYyMjY3IDMuMDc2NDYzIC4zNTA2ODVDMi45NzI4NTIgLjIzOTEwMyAyLjg2OTI0IC4xOTkyNTMgMi40MjI5MTQgLjAzOTg1MUMxLjcyOTUxNC0uMjA3MjIzIDEuMjExNDU3LS4zOTA1MzUgMS4wODM5MzUtLjQ2MjI2N0MuODI4ODkyLS41OTc3NTggLjY2MTUxOS0uNzg5MDQxIC42NjE1MTktMS4wNTIwNTVDLjY2MTUxOS0xLjM3ODgyOSAuOTU2NDEzLTEuOTkyNTI4IDEuNjE3OTMzLTIuMzUxMTgzWk0zLjQwMzIzOC00LjY0NjU3NUMzLjMyMzUzNy00LjYzMDYzNSAzLjI0MzgzNi00LjYwNjcyNSAyLjk1NjkxMi00LjYwNjcyNUMyLjc4OTUzOS00LjYwNjcyNSAyLjc1NzY1OS00LjYwNjcyNSAyLjY2MjAxNy00LjY1NDU0NUMyLjc4OTUzOS00LjY4NjQyNiAyLjg2OTI0LTQuNjg2NDI2IDMuMDEyNzAyLTQuNjg2NDI2QzMuMjI3ODk1LTQuNjg2NDI2IDMuMjgzNjg2LTQuNjc4NDU2IDMuNDAzMjM4LTQuNjU0NTQ1Vi00LjY0NjU3NVpNMi44NjkyNC0yLjUwMjYxNUMyLjc5NzUwOS0yLjQ4NjY3NSAyLjcxNzgwOC0yLjQ2Mjc2NSAyLjQwNjk3NC0yLjQ2Mjc2NUMyLjI1NTU0Mi0yLjQ2Mjc2NSAyLjE3NTg0MS0yLjQ2Mjc2NSAyLjA0ODMxOS0yLjUwMjYxNUMyLjIyMzY2MS0yLjU0MjQ2NiAyLjMxOTMwMy0yLjU0MjQ2NiAyLjQ2Mjc2NS0yLjU0MjQ2NkMyLjY5Mzg5OC0yLjU0MjQ2NiAyLjc1NzY1OS0yLjUzNDQ5NiAyLjg2OTI0LTIuNTEwNTg1Vi0yLjUwMjYxNVonLz4KPHBhdGggaWQ9J2cyLTEwOScgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS43NDU0NTUtMS45Mjg3NjcgMS43OTMyNzUtMi4xMjAwNSAxLjgwOTIxNS0yLjE5OTc1MUMxLjgyNTE1Ni0yLjIzOTYwMSAyLjA4ODE2OS0yLjc1NzY1OSAyLjQzODg1NC0zLjAyMDY3MkMyLjcwOTgzOC0zLjIyNzg5NSAyLjk3Mjg1Mi0zLjI5MTY1NiAzLjE5NjAxNS0zLjI5MTY1NkMzLjQ5MDkwOS0zLjI5MTY1NiAzLjY1MDMxMS0zLjExNjMxNCAzLjY1MDMxMS0yLjc0OTY4OUMzLjY1MDMxMS0yLjU1ODQwNiAzLjYwMjQ5MS0yLjM3NTA5MyAzLjUxNDgxOS0yLjAxNjQzOEMzLjQ1OTAyOS0xLjgwOTIxNSAzLjMyMzUzNy0xLjI3NTIxOCAzLjI3NTcxNi0xLjA2MDAyNUwzLjE1NjE2NC0uNTgxODE4QzMuMTE2MzE0LS40NDYzMjYgMy4wNjA1MjMtLjIwNzIyMyAzLjA2MDUyMy0uMTY3MzcyQzMuMDYwNTIzIC4wMTU5NCAzLjIxMTk1NSAuMDc5NzAxIDMuMzE1NTY3IC4wNzk3MDFDMy40NTkwMjkgLjA3OTcwMSAzLjU3ODU4LS4wMTU5NCAzLjYzNDM3MS0uMTExNTgyQzMuNjU4MjgxLS4xNTk0MDIgMy43MjIwNDItLjQzMDM4NiAzLjc2MTg5My0uNTk3NzU4TDMuOTQ1MjA1LTEuMzA3MDk4QzMuOTY5MTE2LTEuNDI2NjUgNC4wNDg4MTctMS43Mjk1MTQgNC4wNzI3MjctMS44NDkwNjZDNC4xODQzMDktMi4yNzk0NTIgNC4xODQzMDktMi4yODc0MjIgNC4zNjc2MjEtMi41NTA0MzZDNC42MzA2MzUtMi45NDA5NzEgNS4wMDUyMy0zLjI5MTY1NiA1LjUzOTIyOC0zLjI5MTY1NkM1LjgyNjE1Mi0zLjI5MTY1NiA1Ljk5MzUyNC0zLjEyNDI4NCA1Ljk5MzUyNC0yLjc0OTY4OUM1Ljk5MzUyNC0yLjMxMTMzMyA1LjY1ODc4LTEuMzk0NzcgNS41MDczNDctMS4wMTIyMDRDNS40Mjc2NDYtLjgwNDk4MSA1LjQwMzczNi0uNzQ5MTkxIDUuNDAzNzM2LS41OTc3NThDNS40MDM3MzYtLjE0MzQ2MiA1Ljc3ODMzMSAuMDc5NzAxIDYuMTIxMDQ2IC4wNzk3MDFDNi45MDIxMTcgLjA3OTcwMSA3LjIyODg5Mi0xLjAzNjExNSA3LjIyODg5Mi0xLjEzOTcyNkM3LjIyODg5Mi0xLjIxOTQyNyA3LjE2NTEzMS0xLjI0MzMzNyA3LjEwOTM0LTEuMjQzMzM3QzcuMDEzNjk5LTEuMjQzMzM3IDYuOTk3NzU4LTEuMTg3NTQ3IDYuOTczODQ4LTEuMTA3ODQ2QzYuNzgyNTY1LS40NDYzMjYgNi40NDc4MjEtLjE0MzQ2MiA2LjE0NDk1Ni0uMTQzNDYyQzYuMDE3NDM1LS4xNDM0NjIgNS45NTM2NzQtLjIyMzE2MyA1Ljk1MzY3NC0uNDA2NDc2UzYuMDE3NDM1LS43NjUxMzEgNi4wOTcxMzYtLjk2NDM4NEM2LjIxNjY4Ny0xLjI2NzI0OCA2LjU2NzM3Mi0yLjE4MzgxMSA2LjU2NzM3Mi0yLjYzMDEzN0M2LjU2NzM3Mi0zLjIyNzg5NSA2LjE1MjkyNy0zLjUxNDgxOSA1LjU3OTA3OC0zLjUxNDgxOUM1LjAyOTE0MS0zLjUxNDgxOSA0LjU3NDg0NC0zLjIyNzg5NSA0LjIxNjE4OS0yLjczMzc0OEM0LjE1MjQyOC0zLjM3MTM1NyAzLjY0MjM0MS0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjg2MTI3LTMuNTE0ODE5IDIuMzc1MDkzLTMuMzg3Mjk4IDEuOTM2NzM3LTIuODEzNDVDMS44ODA5NDYtMy4yOTE2NTYgMS40OTgzODEtMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjg0NDgzMi0zLjUxNDgxOSAuNjQ1NTc5LTMuMzQ3NDQ3IC41MTAwODctMy4wNzY0NjNDLjMxODgwNC0yLjcwMTg2OCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzItMTE3JyBkPSdNMi45ODg3OTItLjg2ODc0MkMyLjk0ODk0MS0uNzE3MzEgMi41NzQzNDYtLjE0MzQ2MiAyLjA0MDM0OS0uMTQzNDYyQzEuNjQ5ODEzLS4xNDM0NjIgMS41MTQzMjEtLjQzMDM4NiAxLjUxNDMyMS0uNzg5MDQxQzEuNTE0MzIxLTEuMjU5Mjc4IDEuNzkzMjc1LTEuOTc2NTg4IDEuOTY4NjE4LTIuNDIyOTE0QzIuMDQ4MzE5LTIuNjIyMTY3IDIuMDcyMjI5LTIuNjkzODk4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yNzU3MTYgMS43MjE1NDQtMy41MTQ4MTkgMS4zNTQ5MTktMy41MTQ4MTlDLjU2NTg3OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzkxMDM0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcwMTM3LTMuMDI4NjQzIDEuMDUyMDU1LTMuMjkxNjU2IDEuMzMxMDA5LTMuMjkxNjU2QzEuNDUwNTYtMy4yOTE2NTYgMS41MjIyOTEtMy4yMTE5NTUgMS41MjIyOTEtMy4wMjg2NDNTMS40NTA1Ni0yLjY2MjAxNyAxLjM0Njk0OS0yLjM4MzA2NEMxLjAxMjIwNC0xLjUzODIzMiAuOTQwNDczLTEuMTk1NTE3IC45NDA0NzMtLjkwODU5M0MuOTQwNDczLS4xMjc1MjIgMS41MzAyNjIgLjA3OTcwMSAyLjAwMDQ5OCAuMDc5NzAxQzIuNTk4MjU3IC4wNzk3MDEgMi45NjQ4ODItLjM5ODUwNiAyLjk5Njc2Mi0uNDM4MzU2QzMuMTI0Mjg0LS4wNjM3NjEgMy40ODI5MzkgLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuMTQ0NDU4IC4wNzk3MDEgNC4zMjc3NzEtLjIzOTEwMyA0LjM4MzU2Mi0uMzU4NjU1QzQuNTQyOTY0LS42NDU1NzkgNC42NTQ1NDUtMS4xMDc4NDYgNC42NTQ1NDUtMS4xMzk3MjZDNC42NTQ1NDUtMS4xODc1NDcgNC42MjI2NjUtMS4yNDMzMzcgNC41MjcwMjQtMS4yNDMzMzdTNC40MTU0NDItMS4yMDM0ODcgNC4zNjc2MjEtLjk5NjI2NEM0LjI2NDAxLS41OTc3NTggNC4xMjA1NDgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjEwNDYxLS4xNDM0NjIgMy41Mzg3My0uMjk0ODk0IDMuNTM4NzMtLjUxODA1N0MzLjUzODczLS42NTM1NDkgMy42MTA0NjEtLjkyNDUzMyAzLjY1ODI4MS0xLjEyMzc4NlMzLjgyNTY1NC0xLjgwMTI0NSAzLjg1NzUzNC0xLjk0NDcwN0w0LjAxNjkzNi0yLjU1MDQzNkM0LjA2NDc1Ny0yLjc2NTYyOSA0LjE2MDM5OS0zLjE0MDIyNCA0LjE2MDM5OS0zLjE4ODA0NUM0LjE2MDM5OS0zLjM4NzI5OCA0LjAwMDk5Ni0zLjQzNTExOCAzLjkwNTM1NS0zLjQzNTExOEMzLjc5Mzc3My0zLjQzNTExOCAzLjYxODQzMS0zLjM2MzM4NyAzLjU2MjY0LTMuMTcyMTA1TDIuOTg4NzkyLS44Njg3NDJaJy8+CjxwYXRoIGlkPSdnMS0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2czLTE2JyBkPSdNMi4yNTk1MjctLjU4NTgwM0MxLjU1NDE3Mi0uODYwNzcyIDEuMTQ3Njk2LTEuMzk4NzU1IDEuMTQ3Njk2LTIuMjk1MzkyQzEuMTQ3Njk2LTMuOTMzMjUgMi4zNTUxNjgtNi4xMjEwNDYgMy44MjU2NTQtNi45Njk4NjNDNC4wNDA4NDctNi43NjY2MjUgNC4zMTU4MTYtNi43NjY2MjUgNC41NDI5NjQtNi43NjY2MjVDNC44NDE4NDMtNi43NjY2MjUgNS41NzExMDgtNi43NjY2MjUgNS41NzExMDgtNy4xMTMzMjVDNS41NzExMDgtNy40MDAyNDkgNS4wMzMxMjYtNy40MTIyMDQgNC42NTA1Ni03LjQxMjIwNEM0LjQxMTQ1Ny03LjQxMjIwNCA0LjIwODIxOS03LjQxMjIwNCAzLjg5NzM4NS03LjI4MDY5N0MzLjgyNTY1NC03LjQzNjExNSAzLjc4OTc4OC03LjYwMzQ4NyAzLjc4OTc4OC03Ljc4MjgxNEMzLjc4OTc4OC03Ljk5ODAwNyAzLjgzNzYwOS04LjE2NTM4IDMuODM3NjA5LTguMjAxMjQ1QzMuODM3NjA5LTguMjcyOTc2IDMuNzc3ODMzLTguMzIwNzk3IDMuNzE4MDU3LTguMzIwNzk3QzMuNTI2Nzc1LTguMzIwNzk3IDMuNTI2Nzc1LTcuODc4NDU2IDMuNTI2Nzc1LTcuNzgyODE0QzMuNTI2Nzc1LTcuNjc1MjE4IDMuNTI2Nzc1LTcuNDI0MTU5IDMuNjcwMjM3LTcuMTczMTAxQzIuMjgzNDM3LTYuNDU1NzkxIC41Mzc5ODMtNC4yMjAxNzQgLjUzNzk4My0xLjk4NDU1OEMuNTM3OTgzLS4zNDY3IDEuNjI1OTAzIC4wMzU4NjYgMi4yNDc1NzIgLjI1MTA1OUMyLjQwMjk4OSAuMjk4ODc5IDIuNzg1NTU0IC40MzAzODYgMi45NDA5NzEgLjQ5MDE2MkMzLjQzMTEzMyAuNjU3NTM0IDMuODk3Mzg1IC44MTI5NTEgMy44OTczODUgMS4zODY4QzMuODk3Mzg1IDEuNzMzNDk5IDMuNjQ2MzI2IDIuMTk5NzUxIDMuMjAzOTg1IDIuMTk5NzUxQzIuOTY0ODgyIDIuMTk5NzUxIDIuNjQyMDkyIDIuMTE2MDY1IDIuMzQzMjEzIDEuODE3MTg2QzIuMjk1MzkyIDEuNzY5MzY1IDIuMjcxNDgyIDEuNzQ1NDU1IDIuMjExNzA2IDEuNzQ1NDU1QzIuMTE2MDY1IDEuNzQ1NDU1IDIuMDkyMTU0IDEuODQxMDk2IDIuMDkyMTU0IDEuODY1MDA2QzIuMDkyMTU0IDEuOTg0NTU4IDIuNjA2MjI3IDIuNDM4ODU0IDMuMjAzOTg1IDIuNDM4ODU0QzMuOTY5MTE2IDIuNDM4ODU0IDQuNDk1MTQzIDEuNjM3ODU4IDQuNDk1MTQzIDEuMDE2MTg5QzQuNDk1MTQzIC4xNzkzMjggMy44MDE3NDMtLjA1OTc3NiAzLjM1OTQwMi0uMjAzMjM4TDIuMjU5NTI3LS41ODU4MDNaTTQuMDg4NjY3LTcuMDg5NDE1QzQuMjY3OTk1LTcuMTczMTAxIDQuNDM1MzY3LTcuMTczMTAxIDQuNjM4NjA1LTcuMTczMTAxQzUuMDIxMTcxLTcuMTczMTAxIDUuMDU3MDM2LTcuMTYxMTQ2IDUuMjk2MTM5LTcuMTAxMzdDNS4xNTI2NzctNy4wNDE1OTQgNS4wNTcwMzYtNy4wMDU3MjkgNC41NTQ5MTktNy4wMDU3MjlDNC4zMDM4NjEtNy4wMDU3MjkgNC4yMjAxNzQtNy4wMDU3MjkgNC4wODg2NjctNy4wODk0MTVaJy8+CjxwYXRoIGlkPSdnMy0xOCcgZD0nTTUuMjk2MTM5LTYuMDEzNDVDNS4yOTYxMzktNy4yMzI4NzcgNC45MTM1NzQtOC40MTY0MzggMy45MzMyNS04LjQxNjQzOEMyLjI1OTUyNy04LjQxNjQzOCAuNDc4MjA3LTQuOTEzNTc0IC40NzgyMDctMi4yODM0MzdDLjQ3ODIwNy0xLjczMzQ5OSAuNTk3NzU4IC4xMTk1NTIgMS44NTMwNTEgLjExOTU1MkMzLjQ3ODk1NCAuMTE5NTUyIDUuMjk2MTM5LTMuMjk5NjI2IDUuMjk2MTM5LTYuMDEzNDVaTTEuNjczNzI0LTQuMzI3NzcxQzEuODUzMDUxLTUuMDMzMTI2IDIuMTA0MTEtNi4wMzczNiAyLjU4MjMxNi02Ljg4NjE3N0MyLjk3NjgzNy03LjYwMzQ4NyAzLjM5NTI2OC04LjE3NzMzNSAzLjkyMTI5NS04LjE3NzMzNUM0LjMxNTgxNi04LjE3NzMzNSA0LjU3ODgyOS03Ljg0MjU5IDQuNTc4ODI5LTYuNjk0ODk0QzQuNTc4ODI5LTYuMjY0NTA4IDQuNTQyOTY0LTUuNjY2NzUgNC4xOTYyNjQtNC4zMjc3NzFIMS42NzM3MjRaTTQuMTEyNTc4LTMuOTY5MTE2QzMuODEzNjk5LTIuNzk3NTA5IDMuNTYyNjQtMi4wNDQzMzQgMy4xMzIyNTQtMS4yOTExNThDMi43ODU1NTQtLjY4MTQ0NSAyLjM2NzEyMy0uMTE5NTUyIDEuODY1MDA2LS4xMTk1NTJDMS40OTQzOTYtLjExOTU1MiAxLjE5NTUxNy0uNDA2NDc2IDEuMTk1NTE3LTEuNTkwMDM3QzEuMTk1NTE3LTIuMzY3MTIzIDEuMzg2OC0zLjE4MDA3NSAxLjU3ODA4Mi0zLjk2OTExNkg0LjExMjU3OFonLz4KPHBhdGggaWQ9J2czLTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2czLTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnMy0xMDknIGQ9J00yLjQ2Mjc2NS0zLjUwMjg2NEMyLjQ4NjY3NS0zLjU3NDU5NSAyLjc4NTU1NC00LjE3MjM1NCAzLjIyNzg5NS00LjU1NDkxOUMzLjUzODczLTQuODQxODQzIDMuOTQ1MjA1LTUuMDMzMTI2IDQuNDExNDU3LTUuMDMzMTI2QzQuODg5NjY0LTUuMDMzMTI2IDUuMDU3MDM2LTQuNjc0NDcxIDUuMDU3MDM2LTQuMTk2MjY0QzUuMDU3MDM2LTQuMTI0NTMzIDUuMDU3MDM2LTMuODg1NDMgNC45MTM1NzQtMy4zMjM1MzdMNC42MTQ2OTUtMi4wOTIxNTRDNC41MTkwNTQtMS43MzM0OTkgNC4yOTE5MDUtLjg0ODgxNyA0LjI2Nzk5NS0uNzE3MzFDNC4yMjAxNzQtLjUzNzk4MyA0LjE0ODQ0My0uMjI3MTQ4IDQuMTQ4NDQzLS4xNzkzMjhDNC4xNDg0NDMtLjAxMTk1NSA0LjI3OTk1IC4xMTk1NTIgNC40NTkyNzggLjExOTU1MkM0LjgxNzkzMyAuMTE5NTUyIDQuODc3NzA5LS4xNTU0MTcgNC45ODUzMDUtLjU4NTgwM0w1LjcwMjYxNS0zLjQ0MzA4OEM1LjcyNjUyNi0zLjUzODczIDYuMzQ4MTk0LTUuMDMzMTI2IDcuNjYzMjYzLTUuMDMzMTI2QzguMTQxNDY5LTUuMDMzMTI2IDguMzA4ODQyLTQuNjc0NDcxIDguMzA4ODQyLTQuMTk2MjY0QzguMzA4ODQyLTMuNTI2Nzc1IDcuODQyNTktMi4yMjM2NjEgNy41Nzk1NzctMS41MDYzNTFDNy40NzE5OC0xLjIxOTQyNyA3LjQxMjIwNC0xLjA2NDAxIDcuNDEyMjA0LS44NDg4MTdDNy40MTIyMDQtLjMxMDgzNCA3Ljc4MjgxNCAuMTE5NTUyIDguMzU2NjYzIC4xMTk1NTJDOS40Njg0OTMgLjExOTU1MiA5Ljg4NjkyNC0xLjYzNzg1OCA5Ljg4NjkyNC0xLjcwOTU4OUM5Ljg4NjkyNC0xLjc2OTM2NSA5LjgzOTEwMy0xLjgxNzE4NiA5Ljc2NzM3Mi0xLjgxNzE4NkM5LjY1OTc3Ni0xLjgxNzE4NiA5LjY0NzgyMS0xLjc4MTMyIDkuNTg4MDQ1LTEuNTc4MDgyQzkuMzEzMDc2LS42MjE2NjkgOC44NzA3MzUtLjExOTU1MiA4LjM5MjUyOC0uMTE5NTUyQzguMjcyOTc2LS4xMTk1NTIgOC4wODE2OTQtLjEzMTUwNyA4LjA4MTY5NC0uNTE0MDcyQzguMDgxNjk0LS44MjQ5MDcgOC4yMjUxNTYtMS4yMDc0NzIgOC4yNzI5NzYtMS4zMzg5NzlDOC40ODgxNjktMS45MTI4MjcgOS4wMjYxNTItMy4zMjM1MzcgOS4wMjYxNTItNC4wMTY5MzZDOS4wMjYxNTItNC43MzQyNDcgOC42MDc3MjEtNS4yNzIyMjkgNy42OTkxMjgtNS4yNzIyMjlDNi44OTgxMzItNS4yNzIyMjkgNi4yNTI1NTMtNC44MTc5MzMgNS43NzQzNDYtNC4xMTI1NzhDNS43Mzg0ODEtNC43NTgxNTcgNS4zNDM5Ni01LjI3MjIyOSA0LjQ0NzMyMy01LjI3MjIyOUMzLjM4MzMxMy01LjI3MjIyOSAyLjgyMTQyLTQuNTE5MDU0IDIuNjA2MjI3LTQuMjIwMTc0QzIuNTcwMzYxLTQuOTAxNjE5IDIuMDgwMTk5LTUuMjcyMjI5IDEuNTU0MTcyLTUuMjcyMjI5QzEuMjA3NDcyLTUuMjcyMjI5IC45MzI1MDMtNS4xMDQ4NTcgLjcwNTM1NS00LjY1MDU2Qy40OTAxNjItNC4yMjAxNzQgLjMyMjc5LTMuNDkwOTA5IC4zMjI3OS0zLjQ0MzA4OFMuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODEyOTUxLTQuMzI3NzcxIDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjc5MzI3NS01LjAzMzEyNiAxLjg4ODkxNy00Ljg0MTg0MyAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjM1MDkzNCAuMTE5NTUyIDEuNTE4MzA2IC4wNDc4MjEgMS42MTM5NDgtLjEzMTUwN0MxLjYzNzg1OC0uMTkxMjgzIDEuNzQ1NDU1LS42MDk3MTQgMS44MDUyMy0uODQ4ODE3TDIuMDY4MjQ0LTEuOTI0NzgyTDIuNDYyNzY1LTMuNTAyODY0WicvPgo8cGF0aCBpZD0nZzMtMTE3JyBkPSdNNC4wNzY3MTItLjY5MzRDNC4yMzIxMy0uMDIzOTEgNC44MDU5NzggLjExOTU1MiA1LjA5MjkwMiAuMTE5NTUyQzUuNDc1NDY3IC4xMTk1NTIgNS43NjIzOTEtLjEzMTUwNyA1Ljk1MzY3NC0uNTM3OTgzQzYuMTU2OTEyLS45NjgzNjkgNi4zMTIzMjktMS42NzM3MjQgNi4zMTIzMjktMS43MDk1ODlDNi4zMTIzMjktMS43NjkzNjUgNi4yNjQ1MDgtMS44MTcxODYgNi4xOTI3NzctMS44MTcxODZDNi4wODUxODEtMS44MTcxODYgNi4wNzMyMjUtMS43NTc0MSA2LjAyNTQwNS0xLjU3ODA4MkM1LjgxMDIxMi0uNzUzMTc2IDUuNTk1MDE5LS4xMTk1NTIgNS4xMTY4MTItLjExOTU1MkM0Ljc1ODE1Ny0uMTE5NTUyIDQuNzU4MTU3LS41MTQwNzIgNC43NTgxNTctLjY2OTQ4OUM0Ljc1ODE1Ny0uOTQ0NDU4IDQuNzk0MDIyLTEuMDY0MDEgNC45MTM1NzQtMS41NjYxMjdDNC45OTcyNi0xLjg4ODkxNyA1LjA4MDk0Ni0yLjIxMTcwNiA1LjE1MjY3Ny0yLjU0NjQ1MUw1LjY0MjgzOS00LjQ5NTE0M0M1LjcyNjUyNi00Ljc5NDAyMiA1LjcyNjUyNi00LjgxNzkzMyA1LjcyNjUyNi00Ljg1Mzc5OEM1LjcyNjUyNi01LjAzMzEyNiA1LjU4MzA2NC01LjE1MjY3NyA1LjQwMzczNi01LjE1MjY3N0M1LjA1NzAzNi01LjE1MjY3NyA0Ljk3MzM1LTQuODUzNzk4IDQuOTAxNjE5LTQuNTU0OTE5QzQuNzgyMDY3LTQuMDg4NjY3IDQuMTM2NDg4LTEuNTE4MzA2IDQuMDUyODAyLTEuMDk5ODc1QzQuMDQwODQ3LTEuMDk5ODc1IDMuNTc0NTk1LS4xMTk1NTIgMi43MDE4NjgtLjExOTU1MkMyLjA4MDE5OS0uMTE5NTUyIDEuOTYwNjQ4LS42NTc1MzQgMS45NjA2NDgtMS4wOTk4NzVDMS45NjA2NDgtMS43ODEzMiAyLjI5NTM5Mi0yLjczNzczMyAyLjYwNjIyNy0zLjUzODczQzIuNzQ5Njg5LTMuOTIxMjk1IDIuODA5NDY1LTQuMDc2NzEyIDIuODA5NDY1LTQuMzE1ODE2QzIuODA5NDY1LTQuODI5ODg4IDIuNDM4ODU0LTUuMjcyMjI5IDEuODY1MDA2LTUuMjcyMjI5Qy43NjUxMzEtNS4yNzIyMjkgLjMyMjc5LTMuNTM4NzMgLjMyMjc5LTMuNDQzMDg4Qy4zMjI3OS0zLjM5NTI2OCAuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTYxODkzLTMuMzM1NDkyIC41NzM4NDgtMy4zODMzMTMgLjYyMTY2OS0zLjU1MDY4NUMuOTA4NTkzLTQuNTc4ODI5IDEuMzc0ODQ0LTUuMDMzMTI2IDEuODI5MTQxLTUuMDMzMTI2QzEuOTQ4NjkyLTUuMDMzMTI2IDIuMTM5OTc1LTUuMDIxMTcxIDIuMTM5OTc1LTQuNjM4NjA1QzIuMTM5OTc1LTQuMzI3NzcxIDIuMDA4NDY4LTMuOTgxMDcxIDEuODI5MTQxLTMuNTI2Nzc1QzEuMzAzMTEzLTIuMTA0MTEgMS4yNDMzMzctMS42NDk4MTMgMS4yNDMzMzctMS4yOTExNThDMS4yNDMzMzctLjA3MTczMSAyLjE2Mzg4NSAuMTE5NTUyIDIuNjU0MDQ3IC4xMTk1NTJDMy40MTkxNzggLjExOTU1MiAzLjgzNzYwOS0uNDA2NDc2IDQuMDc2NzEyLS42OTM0WicvPgo8cGF0aCBpZD0nZzMtMTIyJyBkPSdNMS41MTgzMDYtLjk2ODM2OUMyLjAzMjM3OS0xLjU1NDE3MiAyLjQ1MDgwOS0xLjkyNDc4MiAzLjA0ODU2OC0yLjQ2Mjc2NUMzLjc2NTg3OC0zLjA4NDQzMyA0LjA3NjcxMi0zLjM4MzMxMyA0LjI0NDA4NS0zLjU2MjY0QzUuMDgwOTQ2LTQuMzg3NTQ3IDUuNDk5Mzc3LTUuMDgwOTQ2IDUuNDk5Mzc3LTUuMTc2NTg4UzUuNDAzNzM2LTUuMjcyMjI5IDUuMzc5ODI2LTUuMjcyMjI5QzUuMjk2MTM5LTUuMjcyMjI5IDUuMjcyMjI5LTUuMjI0NDA4IDUuMjEyNDUzLTUuMTQwNzIyQzQuOTEzNTc0LTQuNjI2NjUgNC42MjY2NS00LjM3NTU5MiA0LjMxNTgxNi00LjM3NTU5MkM0LjA2NDc1Ny00LjM3NTU5MiAzLjkzMzI1LTQuNDgzMTg4IDMuNzA2MTAyLTQuNzcwMTEyQzMuNDU1MDQ0LTUuMDY4OTkxIDMuMjUxODA2LTUuMjcyMjI5IDIuOTA1MTA2LTUuMjcyMjI5QzIuMDMyMzc5LTUuMjcyMjI5IDEuNTA2MzUxLTQuMTg0MzA5IDEuNTA2MzUxLTMuOTMzMjVDMS41MDYzNTEtMy44OTczODUgMS41MTgzMDYtMy44MjU2NTQgMS42MjU5MDMtMy44MjU2NTRDMS43MjE1NDQtMy44MjU2NTQgMS43MzM0OTktMy44NzM0NzQgMS43NjkzNjUtMy45NTcxNjFDMS45NzI2MDMtNC40MzUzNjcgMi41NDY0NTEtNC41MTkwNTQgMi43NzM1OTktNC41MTkwNTRDMy4wMjQ2NTgtNC41MTkwNTQgMy4yNjM3NjEtNC40MzUzNjcgMy41MTQ4MTktNC4zMjc3NzFDMy45NjkxMTYtNC4xMzY0ODggNC4xNjAzOTktNC4xMzY0ODggNC4yNzk5NS00LjEzNjQ4OEM0LjM2MzYzNi00LjEzNjQ4OCA0LjQxMTQ1Ny00LjEzNjQ4OCA0LjQ3MTIzMy00LjE0ODQ0M0M0LjA3NjcxMi0zLjY4MjE5MiAzLjQzMTEzMy0zLjEwODM0NCAyLjg5MzE1MS0yLjYxODE4MkwxLjY4NTY3OS0xLjUwNjM1MUMuOTU2NDEzLS43NjUxMzEgLjUxNDA3Mi0uMDU5Nzc2IC41MTQwNzIgLjAyMzkxQy41MTQwNzIgLjA5NTY0MSAuNTczODQ4IC4xMTk1NTIgLjY0NTU3OSAuMTE5NTUyUy43MjkyNjUgLjEwNzU5NyAuODEyOTUxLS4wMzU4NjZDMS4wMDQyMzQtLjMzNDc0NSAxLjM4NjgtLjc3NzA4NiAxLjgyOTE0MS0uNzc3MDg2QzIuMDgwMTk5LS43NzcwODYgMi4xOTk3NTEtLjY5MzQgMi40Mzg4NTQtLjM5NDUyMUMyLjY2NjAwMi0uMTMxNTA3IDIuODY5MjQgLjExOTU1MiAzLjI1MTgwNiAuMTE5NTUyQzQuNDIzNDEyIC4xMTk1NTIgNS4wOTI5MDItMS4zOTg3NTUgNS4wOTI5MDItMS42NzM3MjRDNS4wOTI5MDItMS43MjE1NDQgNS4wODA5NDYtMS43OTMyNzUgNC45NjEzOTUtMS43OTMyNzVDNC44NjU3NTMtMS43OTMyNzUgNC44NTM3OTgtMS43NDU0NTUgNC44MTc5MzMtMS42MjU5MDNDNC41NTQ5MTktLjkyMDU0OCAzLjg0OTU2NC0uNjMzNjI0IDMuMzgzMzEzLS42MzM2MjRDMy4xMzIyNTQtLjYzMzYyNCAyLjg5MzE1MS0uNzE3MzEgMi42NDIwOTItLjgyNDkwN0MyLjE2Mzg4NS0xLjAxNjE4OSAyLjAzMjM3OS0xLjAxNjE4OSAxLjg3Njk2MS0xLjAxNjE4OUMxLjc1NzQxLTEuMDE2MTg5IDEuNjI1OTAzLTEuMDE2MTg5IDEuNTE4MzA2LS45NjgzNjlaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScxMjguMTEzMjY0JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzMtMTIyJy8+Cjx1c2UgeD0nMTMzLjU1MTE1NScgeT0nLTguNzMxOTk1JyB4bGluazpocmVmPScjZzItMTA5Jy8+Cjx1c2UgeD0nMTQ0Ljg2MDY0MicgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c0LTYxJy8+Cjx1c2UgeD0nMTU3LjI4NjEyMycgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2czLTExNycvPgo8dXNlIHg9JzE2Ni42MDUyMjYnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNC00MycvPgo8dXNlIHg9JzE3OS41NjIwNTUnIHk9Jy0xOC42MTMwMTcnIHhsaW5rOmhyZWY9JyNnMy0yNycvPgo8cmVjdCB4PScxNzkuNTYyMDU1JyB5PSctMTMuNzUzMTQ0JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc3LjA4MjQwNCcvPgo8dXNlIHg9JzE4MC4yNTgwMzgnIHk9Jy0yLjMyNDU5NicgeGxpbms6aHJlZj0nI2czLTI0Jy8+Cjx1c2UgeD0nMTg5LjgzMjQ3JyB5PSctMjAuMjA5MDIxJyB4bGluazpocmVmPScjZzAtMicvPgo8dXNlIHg9JzE5NC44MTM4MDYnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNC00MCcvPgo8dXNlIHg9JzE5OS4zNjYxMzEnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnMy0xMDknLz4KPHVzZSB4PScyMDkuNjA1Mzk4JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzMtMTYnLz4KPHVzZSB4PScyMTQuNzE4MTIyJyB5PSctOC43MzE5OTUnIHhsaW5rOmhyZWY9JyNnMi0xMTcnLz4KPHVzZSB4PScyMjAuMTE5MjI1JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzMtMTgnLz4KPHVzZSB4PScyMjUuODk5NTY1JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzQtNDEnLz4KPHVzZSB4PScyMzAuNDUxODkxJyB5PSctMTUuNDYxNDQ0JyB4bGluazpocmVmPScjZzItMjQnLz4KPHVzZSB4PScyMzcuNjQwMjIxJyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzI0OS41OTUzODInIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNC00OScvPgo8dXNlIHg9JzI1NS40NDgzNzInIHk9Jy0yMC4yMDkwMjEnIHhsaW5rOmhyZWY9JyNnMC0zJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9MCAtLT4=)
If
:(8)¶

with
 the probability of an exceedance of
and
the probability of an exceedance of
and  the extremal index. Denoting the number of observations by
the extremal index. Denoting the number of observations by
 , the number of exceedances of the threshold by
, the number of exceedances of the threshold by
 and the number of clusters obtained above by
and the number of clusters obtained above by
 , then and are estimated by:
, then and are estimated by:(9)¶

If the data are independent, no clustering is performed and
 .
.The estimator
of is deduced from the estimator
 of
of  of the GPD.
of the GPD.The asymptotic distribution of
is obtained by the Delta method from the asymptotic distribution of
 . It is a normal distribution with mean and variance:
. It is a normal distribution with mean and variance:
where
 and
and  is the asymptotic covariance of
is the asymptotic covariance of  .
.
- buildReturnLevelProfileLikelihood(sample, u, m, theta=1.0)¶
Estimate a return level and its distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
A sample of dimension 1.
- ufloat
The threshold.
- mfloat
The return period expressed in terms of number of observations.
- thetafloat, optional
The extremal index defined in (9).
Default value is 1.
- Returns:
- distribution
Normal The asymptotic distribution of
.
- distribution
Notes
Let
a random variable whose excesses above the threshold
follow a Generalized Pareto distribution
. We assume that is known.The return level
is defined in buildReturnLevelEstimator().The estimator
of is defined using a nested numerical optimization of the log-likelihood:
where
 is the log-likelihood detailed in (3) and (4)
where we substitued
for using equations (7) or (8).
is the log-likelihood detailed in (3) and (4)
where we substitued
for using equations (7) or (8).Then
is defined by:
The asymptotic distribution of
is normal.The starting point of the optimization is initialized from the regular maximum likelihood method.
- buildReturnLevelProfileLikelihoodEstimator(sample, u, m, theta=1.0)¶
Estimate
and its distribution with the profile likelihood.- Parameters:
- sample2-d sequence of float
A sample of dimension 1.
- ufloat
The threshold.
- mfloat
The return period expressed in terms of number of observations.
- thetafloat, optional
When clustering is performed, this is the ratio
 of number
of clusters over number of exceedances, otherwise defaults to 1.
of number
of clusters over number of exceedances, otherwise defaults to 1.
- Returns:
- result
ProfileLikelihoodResult The result class.
- result
Notes
Let
a random variable whose excesses above the threshold
follow a Generalized Pareto distribution
. We assume that is known.The return level
is defined in buildReturnLevelEstimator(). The profile log-likelihood is defined in
is defined in
buildReturnLevelProfileLikelihood().The result class produced by the method provides:
the GPD distribution associated to
 ,
,the asymptotic distribution of
,the profile log-likelihood function
 ,
,the optimal profile log-likelihood value
 ,
,confidence intervals of level
of .
- buildTimeVarying(*args)¶
Estimate a non stationary GPD from a time-dependent parametric model.
- Parameters:
- sample2-d sequence of float
Sample drawn from
 .
.- ufloat
The threshold.
- timeStamps2-d sequence of float
Values of
 .
.- basis
Basis Functional basis.
- sigmaIndicessequence of int, optional
Indices of basis terms considered for parameter
.- xiIndicessequence of int, optional
Indices of basis terms considered for parameter
.- sigmaLink
Function, optional The
function.By default, the identity function.
- xiLink
Function, optional The
function.By default, the identity function.
- initializationMethodstr, optional
The initialization method for the optimization problem: Generic or Static.
By default, the method Generic (see
ResourceMap, key GeneralizedParetoFactory-InitializationMethod).- normalizationMethodstr, optional
The data normalization method: CenterReduce, MinMax or None.
By default, the method MinMax (see
ResourceMap, key GeneralizedParetoFactory-NormalizationMethod).
- Returns:
- result
TimeVaryingResult The result class.
- result
Notes
Let
be a non stationary random variable whose excesses above the threshold follow a GPD. We assume that is known:
We denote by
 the values of
on the time stamps
the values of
on the time stamps  .
.For numerical reasons, it is recommended to normalize the time stamps. The following mapping is applied:

and with three ways of defining
 :
:the CenterReduce method where
 is the mean
time stamps
and
is the mean
time stamps
and  is the standard deviation of the time stamps;
is the standard deviation of the time stamps;the MinMax method where
 is the first time and
is the first time and  the
range of the time stamps. This is the default method;
the
range of the time stamps. This is the default method;the None method where
 and
and  : in that case, data are not
normalized.
: in that case, data are not
normalized.
If we denote by
is a component of ,
then can be written as a function of :
where:
 is the size of the functional basis involved in the modelling of
,
is the size of the functional basis involved in the modelling of
,- is usually referred to as the inverse-link function of
the parameter ,
each
 is a scalar function
is a scalar function  ,
,each
 .
.
We denote by
 and
and  the size of the functional basis of
and respectively. We denote by
the size of the functional basis of
and respectively. We denote by
 the complete vector of parameters.
the complete vector of parameters.The estimator of
maximizes the likelihood of the non stationary model which is defined by:
where
 denotes the GPD density function with parameters
denotes the GPD density function with parameters
 evaluated at
evaluated at  .
.Then, if none of the
 is zero, the log-likelihood is defined by:
is zero, the log-likelihood is defined by:![\ell (\vect{\beta}) = -\sum_{i=1}^{n} \left\{ \log(\sigma(t_i)) + (1 + 1 / \xi(t_i) )
\log\left[ 1+\xi(t_i) \left( \frac{z_{t_i} - \mu(t_i)}{\sigma(t_i)}\right) \right] + \left[ 1 +
\xi(t_i) \left( \frac{z_{t_i}- \mu(t_i)}{\sigma(t_i)} \right) \right]^{-1 / \xi(t_i)} \right\}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzUzNS4zMTMzODdwdCcgaGVpZ2h0PSczNS44NjU4NjlwdCcgdmlld0JveD0nMCAtMzUuOTU0MTIzIDUzNS4zMTMzODcgMzUuODY1ODY5Jz4KPGRlZnM+CjxwYXRoIGlkPSdnNC0xMDUnIGQ9J00yLjA4MDE5OS0zLjczMDAxMkMyLjA4MDE5OS0zLjg3MzQ3NCAxLjk3MjYwMy0zLjk2OTExNiAxLjgzNTExOC0zLjk2OTExNkMxLjY3MzcyNC0zLjk2OTExNiAxLjUwMDM3NC0zLjgxMzY5OSAxLjUwMDM3NC0zLjY0MDM0OUMxLjUwMDM3NC0zLjQ5MDkwOSAxLjYwNzk3LTMuNDAxMjQ1IDEuNzM5NDc3LTMuNDAxMjQ1QzEuOTMwNzYtMy40MDEyNDUgMi4wODAxOTktMy41ODA1NzMgMi4wODAxOTktMy43MzAwMTJaTTEuNzIxNTQ0LTEuNjQzODM2QzEuNzQ1NDU1LTEuNzAzNjExIDEuNzk5MjUzLTEuODQ3MDczIDEuODIzMTYzLTEuOTAwODcyQzEuODQxMDk2LTEuOTU0NjcgMS44NjUwMDYtMi4wMTQ0NDYgMS44NjUwMDYtMi4xMTYwNjVDMS44NjUwMDYtMi40NTA4MDkgMS41NjYxMjctMi42MzYxMTUgMS4yNjcyNDgtMi42MzYxMTVDLjY1NzUzNC0yLjYzNjExNSAuMzY0NjMzLTEuODQ3MDczIC4zNjQ2MzMtMS43MTU1NjdDLjM2NDYzMy0xLjY4NTY3OSAuMzg4NTQzLTEuNjMxODggLjQ3MjIyOS0xLjYzMTg4Uy41NzM4NDgtMS42Njc3NDYgLjU5MTc4MS0xLjcyMTU0NEMuNzU5MTUzLTIuMzAxMzcgMS4wNzU5NjUtMi40Mzg4NTQgMS4yNDMzMzctMi40Mzg4NTRDMS4zNjI4ODktMi40Mzg4NTQgMS40MDQ3MzItMi4zNjExNDYgMS40MDQ3MzItMi4yMjM2NjFDMS40MDQ3MzItMi4xMDQxMSAxLjM2ODg2Ny0yLjAxNDQ0NiAxLjM1NjkxMi0xLjk3MjYwM0wxLjA0NjA3Ny0xLjIwNzQ3MkMuOTc0MzQ2LTEuMDM0MTIyIC45NzQzNDYtMS4wMjIxNjcgLjg5NjYzOC0uODE4OTI5Qy44MTg5MjktLjYzOTYwMSAuNzg5MDQxLS41NjE4OTMgLjc4OTA0MS0uNDYwMjc0Qy43ODkwNDEtLjE1NTQxNyAxLjA2NDAxIC4wNTk3NzYgMS4zOTI3NzcgLjA1OTc3NkMxLjk5NjUxMyAuMDU5Nzc2IDIuMjk1MzkyLS43MjkyNjUgMi4yOTUzOTItLjg2MDc3MkMyLjI5NTM5Mi0uODcyNzI3IDIuMjg5NDE1LS45NDQ0NTggMi4xODE4MTgtLjk0NDQ1OEMyLjA5ODEzMi0uOTQ0NDU4IDIuMDkyMTU0LS45MTQ1NyAyLjA1NjI4OS0uODAwOTk2QzEuOTYwNjQ4LS40OTYxMzkgMS43MTU1NjctLjEzNzQ4NCAxLjQxMDcxLS4xMzc0ODRDMS4zMDMxMTMtLjEzNzQ4NCAxLjI0OTMxNS0uMjA5MjE1IDEuMjQ5MzE1LS4zNTI2NzdDMS4yNDkzMTUtLjQ3MjIyOSAxLjI4NTE4MS0uNTYxODkzIDEuMzYyODg5LS43NDcxOThMMS43MjE1NDQtMS42NDM4MzZaJy8+CjxwYXRoIGlkPSdnNy00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c3LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnNy00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c3LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnMS0xOCcgZD0nTTguMzY4NjE4IDI4LjA4MjY5QzguMzY4NjE4IDI4LjAzNDg2OSA4LjM0NDcwNyAyOC4wMTA5NTkgOC4zMjA3OTcgMjcuOTc1MDkzQzcuODc4NDU2IDI3LjUzMjc1MiA3LjA3NzQ2IDI2LjczMTc1NiA2LjI3NjQ2MyAyNS40NDA1OThDNC4zNTE2ODEgMjIuMzU2MTY0IDMuNDc4OTU0IDE4LjQ3MDczNSAzLjQ3ODk1NCAxMy44Njc5OTVDMy40Nzg5NTQgMTAuNjUyMDU1IDMuOTA5MzQgNi41MDM2MTEgNS44ODE5NDMgMi45NDA5NzFDNi44MjY0MDEgMS4yNDMzMzcgNy44MDY3MjUgLjI2MzAxNCA4LjMzMjc1Mi0uMjYzMDE0QzguMzY4NjE4LS4yOTg4NzkgOC4zNjg2MTgtLjMyMjc5IDguMzY4NjE4LS4zNTg2NTVDOC4zNjg2MTgtLjQ3ODIwNyA4LjI4NDkzMi0uNDc4MjA3IDguMTE3NTU5LS40NzgyMDdTNy45MjYyNzYtLjQ3ODIwNyA3Ljc0Njk0OS0uMjk4ODc5QzMuNzQxOTY4IDMuMzQ3NDQ3IDIuNDg2Njc1IDguODIyOTE0IDIuNDg2Njc1IDEzLjg1NjA0QzIuNDg2Njc1IDE4LjU1NDQyMSAzLjU2MjY0IDIzLjI4ODY2NyA2LjU5OTI1MyAyNi44NjMyNjNDNi44MzgzNTYgMjcuMTM4MjMyIDcuMjkyNjUzIDI3LjYyODM5NCA3Ljc4MjgxNCAyOC4wNTg3OEM3LjkyNjI3NiAyOC4yMDIyNDIgNy45NTAxODcgMjguMjAyMjQyIDguMTE3NTU5IDI4LjIwMjI0MlM4LjM2ODYxOCAyOC4yMDIyNDIgOC4zNjg2MTggMjguMDgyNjlaJy8+CjxwYXRoIGlkPSdnMS0xOScgZD0nTTYuMzAwMzc0IDEzLjg2Nzk5NUM2LjMwMDM3NCA5LjE2OTYxNCA1LjIyNDQwOCA0LjQzNTM2NyAyLjE4Nzc5NiAuODYwNzcyQzEuOTQ4NjkyIC41ODU4MDMgMS40OTQzOTYgLjA5NTY0MSAxLjAwNDIzNC0uMzM0NzQ1Qy44NjA3NzItLjQ3ODIwNyAuODM2ODYyLS40NzgyMDcgLjY2OTQ4OS0uNDc4MjA3Qy41MjYwMjctLjQ3ODIwNyAuNDE4NDMxLS40NzgyMDcgLjQxODQzMS0uMzU4NjU1Qy40MTg0MzEtLjMxMDgzNCAuNDY2MjUyLS4yNjMwMTQgLjQ5MDE2Mi0uMjM5MTAzQy45MDg1OTMgLjE5MTI4MyAxLjcwOTU4OSAuOTkyMjc5IDIuNTEwNTg1IDIuMjgzNDM3QzQuNDM1MzY3IDUuMzY3ODcgNS4zMDgwOTUgOS4yNTMzIDUuMzA4MDk1IDEzLjg1NjA0QzUuMzA4MDk1IDE3LjA3MTk4IDQuODc3NzA5IDIxLjIyMDQyMyAyLjkwNTEwNiAyNC43ODMwNjRDMS45NjA2NDggMjYuNDgwNjk3IC45NjgzNjkgMjcuNDcyOTc2IC40NjYyNTIgMjcuOTc1MDkzQy40NDIzNDEgMjguMDEwOTU5IC40MTg0MzEgMjguMDQ2ODI0IC40MTg0MzEgMjguMDgyNjlDLjQxODQzMSAyOC4yMDIyNDIgLjUyNjAyNyAyOC4yMDIyNDIgLjY2OTQ4OSAyOC4yMDIyNDJDLjgzNjg2MiAyOC4yMDIyNDIgLjg2MDc3MiAyOC4yMDIyNDIgMS4wNDAxIDI4LjAyMjkxNEM1LjA0NTA4MSAyNC4zNzY1ODggNi4zMDAzNzQgMTguOTAxMTIxIDYuMzAwMzc0IDEzLjg2Nzk5NVonLz4KPHBhdGggaWQ9J2cxLTIwJyBkPSdNMi45ODg3OTIgMjguMjAyMjQySDYuMTMzMDAxVjI3LjU0NDcwN0gzLjY0NjMyNlYuMTc5MzI4SDYuMTMzMDAxVi0uNDc4MjA3SDIuOTg4NzkyVjI4LjIwMjI0MlonLz4KPHBhdGggaWQ9J2cxLTIxJyBkPSdNMi42NTQwNDcgMjcuNTQ0NzA3SC4xNjczNzJWMjguMjAyMjQySDMuMzExNTgyVi0uNDc4MjA3SC4xNjczNzJWLjE3OTMyOEgyLjY1NDA0N1YyNy41NDQ3MDdaJy8+CjxwYXRoIGlkPSdnMS00MCcgZD0nTTUuMzkxNzgxIDIxLjg0MjA5MkM1LjM5MTc4MSAyMC41MjcwMjQgNC40ODMxODggMTguNTA2NiAyLjQwMjk4OSAxNy40NTQ1NDVDMy42OTQxNDcgMTYuNzYxMTQ2IDUuMjM2MzY0IDE1LjM2MjM5MSA1LjM3OTgyNiAxMy4xMjY3NzVMNS4zOTE3ODEgMTMuMDU1MDQ0VjQuNzcwMTEyQzUuMzkxNzgxIDMuNzg5Nzg4IDUuMzkxNzgxIDMuNTc0NTk1IDUuNDg3NDIyIDMuMTIwMjk5QzUuNzAyNjE1IDIuMTYzODg1IDYuMjc2NDYzIC45ODAzMjQgNy43OTQ3NyAuMDgzNjg2QzcuODkwNDExIC4wMjM5MSA3LjkwMjM2NiAuMDExOTU1IDcuOTAyMzY2LS4yMDMyMzhDNy45MDIzNjYtLjQ2NjI1MiA3Ljg5MDQxMS0uNDc4MjA3IDcuNjI3Mzk3LS40NzgyMDdDNy40MTIyMDQtLjQ3ODIwNyA3LjM4ODI5NC0uNDc4MjA3IDcuMDY1NTA0LS4yODY5MjRDNC4zODc1NDcgMS4yMzEzODIgNC4yMzIxMyAzLjQ1NTA0NCA0LjIzMjEzIDMuODczNDc0VjEyLjM3MzU5OUM0LjIzMjEzIDEzLjIzNDM3MSA0LjIzMjEzIDE0LjIwMjc0IDMuNjEwNDYxIDE1LjMwMjYxNUMzLjA2MDUyMyAxNi4yODI5MzkgMi40MTQ5NDQgMTYuNzczMTAxIDEuOTAwODcyIDE3LjExOTgwMUMxLjczMzQ5OSAxNy4yMjczOTcgMS43MjE1NDQgMTcuMjM5MzUyIDEuNzIxNTQ0IDE3LjQ0MjU5QzEuNzIxNTQ0IDE3LjY1Nzc4MyAxLjczMzQ5OSAxNy42Njk3MzggMS44MjkxNDEgMTcuNzI5NTE0QzIuODQ1MzMgMTguMzk5MDA0IDMuOTMzMjUgMTkuNDYzMDE0IDQuMTk2MjY0IDIxLjQxMTcwNkM0LjIzMjEzIDIxLjY3NDcyIDQuMjMyMTMgMjEuNjk4NjMgNC4yMzIxMyAyMS44NDIwOTJWMzEuMDIzNjYxQzQuMjMyMTMgMzEuOTkyMDMgNC44Mjk4ODggMzQuMDAwNDk4IDcuMTM3MjM1IDM1LjIxOTkyNUM3LjQxMjIwNCAzNS4zNzUzNDIgNy40MzYxMTUgMzUuMzc1MzQyIDcuNjI3Mzk3IDM1LjM3NTM0MkM3Ljg5MDQxMSAzNS4zNzUzNDIgNy45MDIzNjYgMzUuMzYzMzg3IDcuOTAyMzY2IDM1LjEwMDM3NEM3LjkwMjM2NiAzNC44ODUxODEgNy44OTA0MTEgMzQuODczMjI1IDcuODQyNTkgMzQuODQ5MzE1QzcuMzI4NTE4IDM0LjUyNjUyNiA1Ljc2MjM5MSAzMy41ODIwNjcgNS40Mzk2MDEgMzEuNTAxODY4QzUuMzkxNzgxIDMxLjE5MTAzNCA1LjM5MTc4MSAzMS4xNjcxMjMgNS4zOTE3ODEgMzEuMDExNzA2VjIxLjg0MjA5MlonLz4KPHBhdGggaWQ9J2cxLTQxJyBkPSdNNC4yMzIxMyAzMC4xMjcwMjRDNC4yMzIxMyAzMS4xMDczNDcgNC4yMzIxMyAzMS4zMjI1NCA0LjEzNjQ4OCAzMS43NzY4MzdDMy45MjEyOTUgMzIuNzMzMjUgMy4zNDc0NDcgMzMuOTA0ODU3IDEuODI5MTQxIDM0LjgxMzQ1QzEuNzMzNDk5IDM0Ljg3MzIyNSAxLjcyMTU0NCAzNC44ODUxODEgMS43MjE1NDQgMzUuMTAwMzc0QzEuNzIxNTQ0IDM1LjM3NTM0MiAxLjczMzQ5OSAzNS4zNzUzNDIgMi4wMDg0NjggMzUuMzc1MzQyQzIuMjExNzA2IDM1LjM3NTM0MiAyLjIzNTYxNiAzNS4zNzUzNDIgMi41NTg0MDYgMzUuMTg0MDZDNS4yMzYzNjQgMzMuNjY1NzUzIDUuMzkxNzgxIDMxLjQ0MjA5MiA1LjM5MTc4MSAzMS4wMjM2NjFWMjIuNTIzNTM3QzUuMzkxNzgxIDIxLjY2Mjc2NSA1LjM5MTc4MSAyMC42OTQzOTYgNi4wMTM0NSAxOS41OTQ1MjFDNi41Mzk0NzcgMTguNjYyMDE3IDcuMTQ5MTkxIDE4LjE1OTkgNy43MjMwMzkgMTcuNzc3MzM1QzcuODkwNDExIDE3LjY2OTczOCA3LjkwMjM2NiAxNy42NTc3ODMgNy45MDIzNjYgMTcuNDQyNTlDNy45MDIzNjYgMTcuMjg3MTczIDcuOTAyMzY2IDE3LjIyNzM5NyA3Ljg1NDU0NSAxNy4xOTE1MzJDNy4yOTI2NTMgMTYuODMyODc3IDUuNzM4NDgxIDE1Ljg0MDU5OCA1LjQyNzY0NiAxMy40ODU0M0M1LjM5MTc4MSAxMy4yMjI0MTYgNS4zOTE3ODEgMTMuMTk4NTA2IDUuMzkxNzgxIDEzLjA1NTA0NFYzLjg3MzQ3NEM1LjM5MTc4MSAyLjkwNTEwNiA0Ljc5NDAyMiAuODk2NjM4IDIuNDg2Njc1LS4zMjI3OUMyLjIxMTcwNi0uNDc4MjA3IDIuMTg3Nzk2LS40NzgyMDcgMi4wMDg0NjgtLjQ3ODIwN0MxLjczMzQ5OS0uNDc4MjA3IDEuNzIxNTQ0LS40NzgyMDcgMS43MjE1NDQtLjIwMzIzOEMxLjcyMTU0NC0uMDExOTU1IDEuNzIxNTQ0IC4wMjM5MSAxLjgwNTIzIC4wNzE3MzFDNC4wNzY3MTIgMS40MjI2NjUgNC4yMzIxMyAzLjQxOTE3OCA0LjIzMjEzIDMuODg1NDNWMTMuMDU1MDQ0QzQuMjMyMTMgMTQuMzcwMTEyIDUuMTQwNzIyIDE2LjM5MDUzNSA3LjIyMDkyMiAxNy40NDI1OUM1LjkyOTc2MyAxOC4xMzU5OSA0LjM4NzU0NyAxOS41MzQ3NDUgNC4yNDQwODUgMjEuNzcwMzYxTDQuMjMyMTMgMjEuODQyMDkyVjMwLjEyNzAyNFonLz4KPHBhdGggaWQ9J2cxLTg4JyBkPSdNMTUuMTM1MjQzIDE2LjczNzIzNUwxNi41ODE4MTggMTIuOTExNTgySDE2LjI4MjkzOUMxNS44MTY2ODcgMTQuMTU0OTE5IDE0LjU0OTQ0IDE0Ljk2Nzg3IDEzLjE3NDU5NSAxNS4zMjY1MjZDMTIuOTIzNTM3IDE1LjM4NjMwMSAxMS43NTE5MyAxNS42OTcxMzYgOS40NTY1MzggMTUuNjk3MTM2SDIuMjQ3NTcyTDguMzMyNzUyIDguNTU5OUM4LjQxNjQzOCA4LjQ2NDI1OSA4LjQ0MDM0OSA4LjQyODM5NCA4LjQ0MDM0OSA4LjM2ODYxOEM4LjQ0MDM0OSA4LjM0NDcwNyA4LjQ0MDM0OSA4LjMwODg0MiA4LjM1NjY2MyA4LjE4OTI5TDIuNzg1NTU0IC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IC41NzM4NDggMTIuMDI2ODk5IC43NDEyMiAxMi4xMzQ0OTYgLjc2NTEzMUMxMi43ODAwNzUgLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0Qy43MjkyNjUgMCAuNzE3MzEgLjAxMTk1NSAuNjgxNDQ1IC4wODM2ODZDLjY2OTQ4OSAuMTE5NTUyIC42Njk0ODkgLjM0NjcgLjY2OTQ4OSAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TC44MDA5OTYgMTYuMzkwNTM1Qy42ODE0NDUgMTYuNTMzOTk4IC42ODE0NDUgMTYuNTkzNzczIC42ODE0NDUgMTYuNjA1NzI5Qy42ODE0NDUgMTYuNzM3MjM1IC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzUtMjQnIGQ9J00xLjYxNzkzMy0yLjM1MTE4M0MxLjkxMjgyNy0yLjIzOTYwMSAyLjIwNzcyMS0yLjIzOTYwMSAyLjM4MzA2NC0yLjIzOTYwMUMyLjY1NDA0Ny0yLjIzOTYwMSAzLjE3MjEwNS0yLjIzOTYwMSAzLjE3MjEwNS0yLjUyNjUyNkMzLjE3MjEwNS0yLjc2NTYyOSAyLjc0MTcxOS0yLjc2NTYyOSAyLjQ3MDczNS0yLjc2NTYyOUMyLjMxMTMzMy0yLjc2NTYyOSAyLjA2NDI1OS0yLjc2NTYyOSAxLjc1MzQyNS0yLjY2MjAxN0MxLjU3ODA4Mi0yLjgyOTM5IDEuNTA2MzUxLTMuMDUyNTUzIDEuNTA2MzUxLTMuMjc1NzE2QzEuNTA2MzUxLTMuNzIyMDQyIDEuODE3MTg2LTQuMjg3OTIgMi4zOTkwMDQtNC41NjY4NzRDMi41NzQzNDYtNC4zODM1NjIgMi43ODE1NjktNC4zODM1NjIgMi45NDg5NDEtNC4zODM1NjJDMy4yNTE4MDYtNC4zODM1NjIgMy43MDYxMDItNC4zOTk1MDIgMy43MDYxMDItNC42NzA0ODZDMy43MDYxMDItNC45MDk1ODkgMy4yNzU3MTYtNC45MDk1ODkgMi45OTY3NjItNC45MDk1ODlDMi44NjEyNy00LjkwOTU4OSAyLjcyNTc3OC00LjkwOTU4OSAyLjUwMjYxNS00Ljg3NzcwOUMyLjQ4NjY3NS00LjkzMzQ5OSAyLjQ2Mjc2NS01LjAxMzIgMi40NjI3NjUtNS4xMTY4MTJDMi40NjI3NjUtNS4yMjgzOTQgMi40OTQ2NDUtNS4zNjM4ODUgMi40OTQ2NDUtNS4zODc3OTZDMi41MDI2MTUtNS4zOTU3NjYgMi41MDI2MTUtNS40Mjc2NDYgMi41MDI2MTUtNS40MzU2MTZDMi41MDI2MTUtNS41MDczNDcgMi40NDY4MjQtNS41NTUxNjggMi4zOTEwMzQtNS41NTUxNjhDMi4yMTU2OTEtNS41NTUxNjggMi4yMTU2OTEtNS4xOTY1MTMgMi4yMTU2OTEtNS4xMjQ3ODJDMi4yMTU2OTEtNC45NzMzNSAyLjI1NTU0Mi00LjgzNzg1OCAyLjI2MzUxMi00LjgyMTkxOEMxLjM3MDg1OS00LjU5MDc4NSAuODIwOTIyLTMuOTUzMTc2IC44MjA5MjItMy4zMjM1MzdDLjgyMDkyMi0yLjkyNTAzMSAxLjAzNjExNS0yLjY1NDA0NyAxLjMzODk3OS0yLjQ3ODcwNUMuNDg2MTc3LTEuOTkyNTI4IC4xOTEyODMtMS4xODc1NDcgLjE5MTI4My0uODIwOTIyQy4xOTEyODMtLjA5NTY0MSAuOTI0NTMzIC4xNjczNzIgMS4xNzk1NzcgLjI2MzAxNEMxLjYyNTkwMyAuNDMwMzg2IDEuNjQxODQzIC40MzAzODYgMi4wMzIzNzkgLjU2NTg3OEMyLjIyMzY2MSAuNjM3NjA5IDIuNTQyNDY2IC43NTcxNjEgMi41OTgyNTcgLjc4OTA0MUMyLjcyNTc3OCAuODY4NzQyIDIuNzI1Nzc4IC45ODAzMjQgMi43MjU3NzggMS4wMjgxNDRDMi43MjU3NzggMS4xNzE2MDYgMi42MjIxNjcgMS40MDI3NCAyLjM2NzEyMyAxLjQwMjc0QzIuMzAzMzYyIDEuNDAyNzQgMS45NzY1ODggMS4zODY4IDEuNjU3NzgzIDEuMTk1NTE3QzEuNTc4MDgyIDEuMTM5NzI2IDEuNTcwMTEyIDEuMTMxNzU2IDEuNTMwMjYyIDEuMTMxNzU2QzEuNDQyNTkgMS4xMzE3NTYgMS40MTg2OCAxLjIxMTQ1NyAxLjQxODY4IDEuMjQzMzM3QzEuNDE4NjggMS4zNzA4NTkgMS45Mjg3NjcgMS42MjU5MDMgMi4zNzUwOTMgMS42MjU5MDNDMi45MDExMjEgMS42MjU5MDMgMy4yMjc4OTUgMS4xMjM3ODYgMy4yMjc4OTUgLjc1NzE2MUMzLjIyNzg5NSAuNjEzNjk5IDMuMTcyMTA1IC40NjIyNjcgMy4wNzY0NjMgLjM1MDY4NUMyLjk3Mjg1MiAuMjM5MTAzIDIuODY5MjQgLjE5OTI1MyAyLjQyMjkxNCAuMDM5ODUxQzEuNzI5NTE0LS4yMDcyMjMgMS4yMTE0NTctLjM5MDUzNSAxLjA4MzkzNS0uNDYyMjY3Qy44Mjg4OTItLjU5Nzc1OCAuNjYxNTE5LS43ODkwNDEgLjY2MTUxOS0xLjA1MjA1NUMuNjYxNTE5LTEuMzc4ODI5IC45NTY0MTMtMS45OTI1MjggMS42MTc5MzMtMi4zNTExODNaTTMuNDAzMjM4LTQuNjQ2NTc1QzMuMzIzNTM3LTQuNjMwNjM1IDMuMjQzODM2LTQuNjA2NzI1IDIuOTU2OTEyLTQuNjA2NzI1QzIuNzg5NTM5LTQuNjA2NzI1IDIuNzU3NjU5LTQuNjA2NzI1IDIuNjYyMDE3LTQuNjU0NTQ1QzIuNzg5NTM5LTQuNjg2NDI2IDIuODY5MjQtNC42ODY0MjYgMy4wMTI3MDItNC42ODY0MjZDMy4yMjc4OTUtNC42ODY0MjYgMy4yODM2ODYtNC42Nzg0NTYgMy40MDMyMzgtNC42NTQ1NDVWLTQuNjQ2NTc1Wk0yLjg2OTI0LTIuNTAyNjE1QzIuNzk3NTA5LTIuNDg2Njc1IDIuNzE3ODA4LTIuNDYyNzY1IDIuNDA2OTc0LTIuNDYyNzY1QzIuMjU1NTQyLTIuNDYyNzY1IDIuMTc1ODQxLTIuNDYyNzY1IDIuMDQ4MzE5LTIuNTAyNjE1QzIuMjIzNjYxLTIuNTQyNDY2IDIuMzE5MzAzLTIuNTQyNDY2IDIuNDYyNzY1LTIuNTQyNDY2QzIuNjkzODk4LTIuNTQyNDY2IDIuNzU3NjU5LTIuNTM0NDk2IDIuODY5MjQtMi41MTA1ODVWLTIuNTAyNjE1WicvPgo8cGF0aCBpZD0nZzUtNjEnIGQ9J00zLjcwNjEwMi01LjY0MjgzOUMzLjc1MzkyMy01Ljc1NDQyMSAzLjc1MzkyMy01Ljc3MDM2MSAzLjc1MzkyMy01Ljc5NDI3MUMzLjc1MzkyMy01Ljg5Nzg4MyAzLjY3NDIyMi01Ljk3NzU4NCAzLjU3MDYxLTUuOTc3NTg0QzMuNDQzMDg4LTUuOTc3NTg0IDMuNDExMjA4LTUuODgxOTQzIDMuMzc5MzI4LTUuODAyMjQyTC41MTgwNTcgMS42NTc3ODNDLjQ3MDIzNyAxLjc2OTM2NSAuNDcwMjM3IDEuNzg1MzA1IC40NzAyMzcgMS44MDkyMTVDLjQ3MDIzNyAxLjkxMjgyNyAuNTQ5OTM4IDEuOTkyNTI4IC42NTM1NDkgMS45OTI1MjhDLjc4MTA3MSAxLjk5MjUyOCAuODEyOTUxIDEuODk2ODg3IC44NDQ4MzIgMS44MTcxODZMMy43MDYxMDItNS42NDI4MzlaJy8+CjxwYXRoIGlkPSdnNS0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzUtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c1LTExNicgZD0nTTEuNzYxMzk1LTMuMTcyMTA1SDIuNTQyNDY2QzIuNjkzODk4LTMuMTcyMTA1IDIuNzg5NTM5LTMuMTcyMTA1IDIuNzg5NTM5LTMuMzIzNTM3QzIuNzg5NTM5LTMuNDM1MTE4IDIuNjg1OTI4LTMuNDM1MTE4IDIuNTUwNDM2LTMuNDM1MTE4SDEuODI1MTU2TDIuMTEyMDgtNC41NjY4NzRDMi4xNDM5Ni00LjY4NjQyNiAyLjE0Mzk2LTQuNzI2Mjc2IDIuMTQzOTYtNC43MzQyNDdDMi4xNDM5Ni00LjkwMTYxOSAyLjAxNjQzOC00Ljk4MTMyIDEuODgwOTQ2LTQuOTgxMzJDMS42MDk5NjMtNC45ODEzMiAxLjU1NDE3Mi00Ljc2NjEyNyAxLjQ2NjUwMS00LjQwNzQ3MkwxLjIxOTQyNy0zLjQzNTExOEguNDU0Mjk2Qy4zMDI4NjQtMy40MzUxMTggLjE5OTI1My0zLjQzNTExOCAuMTk5MjUzLTMuMjgzNjg2Qy4xOTkyNTMtMy4xNzIxMDUgLjMwMjg2NC0zLjE3MjEwNSAuNDM4MzU2LTMuMTcyMTA1SDEuMTU1NjY2TC42Nzc0Ni0xLjI1OTI3OEMuNjI5NjM5LTEuMDYwMDI1IC41NTc5MDgtLjc4MTA3MSAuNTU3OTA4LS42Njk0ODlDLjU1NzkwOC0uMTkxMjgzIC45NDg0NDMgLjA3OTcwMSAxLjM3MDg1OSAuMDc5NzAxQzIuMjIzNjYxIC4wNzk3MDEgMi43MDk4MzgtMS4wNDQwODUgMi43MDk4MzgtMS4xMzk3MjZDMi43MDk4MzgtMS4yMjczOTcgMi42MzgxMDctMS4yNDMzMzcgMi41OTAyODYtMS4yNDMzMzdDMi41MDI2MTUtMS4yNDMzMzcgMi40OTQ2NDUtMS4yMTE0NTcgMi40Mzg4NTQtMS4wOTE5MDVDMi4yNzk0NTItLjcwOTM0IDEuODgwOTQ2LS4xNDM0NjIgMS4zOTQ3Ny0uMTQzNDYyQzEuMjI3Mzk3LS4xNDM0NjIgMS4xMzE3NTYtLjI1NTA0NCAxLjEzMTc1Ni0uNTE4MDU3QzEuMTMxNzU2LS42Njk0ODkgMS4xNTU2NjYtLjc1NzE2MSAxLjE3OTU3Ny0uODYwNzcyTDEuNzYxMzk1LTMuMTcyMTA1WicvPgo8cGF0aCBpZD0nZzMtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMC0xMicgZD0nTS4yMzkxMDMgMS45NjA2NDhDLjIyNzE0OCAxLjk4NDU1OCAuMTkxMjgzIDIuMTM5OTc1IC4xOTEyODMgMi4xNTE5M0MuMTkxMjgzIDIuMzE5MzAzIC4zNzA2MSAyLjMxOTMwMyAuNDc4MjA3IDIuMzE5MzAzQy43MTczMSAyLjMxOTMwMyAuNzE3MzEgMi4yOTUzOTIgLjc4OTA0MSAyLjA0NDMzNEMuODI0OTA3IDEuODUzMDUxIDEuNTQyMjE3LTEuMDE2MTg5IDEuNTU0MTcyLTEuMDQwMUMyLjA1NjI4OS0uMjAzMjM4IDIuOTc2ODM3IC4xNDM0NjIgMy45MzMyNSAuMTQzNDYyQzYuMzM2MjM5IC4xNDM0NjIgNy42NzUyMTgtMS42ODU2NzkgNy42NzUyMTgtMy4yNTE4MDZDNy42NzUyMTgtNC4wODg2NjcgNy4zMDQ2MDgtNC41NDI5NjQgNi45MTAwODctNC44NDE4NDNDNy4zNDA0NzMtNS4yMDA0OTggNy44MzA2MzUtNS45Nzc1ODQgNy44MzA2MzUtNi44MDI0OTFDNy44MzA2MzUtNy44MTg2OCA3LjA4OTQxNS04LjM5MjUyOCA1Ljk2NTYyOS04LjM5MjUyOEM0LjI1NjA0LTguMzkyNTI4IDIuNDg2Njc1LTcuMDY1NTA0IDIuMDU2Mjg5LTUuMzMyMDA1TC4yMzkxMDMgMS45NjA2NDhaTTUuNjU0Nzk1LTQuNzk0MDIyQzUuMzY3ODctNC41OTA3ODUgNS4wNjg5OTEtNC41OTA3ODUgNC45MDE2MTktNC41OTA3ODVDNC44NTM3OTgtNC41OTA3ODUgNC4zMjc3NzEtNC41OTA3ODUgNC4zMjc3NzEtNC42ODY0MjZDNC4zMjc3NzEtNC44Nzc3MDkgNC45MTM1NzQtNC44Nzc3MDkgNS4wNjg5OTEtNC44Nzc3MDlDNS4yODQxODQtNC44Nzc3MDkgNS40Mjc2NDYtNC44Nzc3MDkgNS42NTQ3OTUtNC43OTQwMjJaTTYuMDYxMjctNS4yMTI0NTNDNS42NjY3NS01LjMwODA5NSA1LjMzMjAwNS01LjMwODA5NSA1LjEwNDg1Ny01LjMwODA5NUM0LjcyMjI5MS01LjMwODA5NSAzLjc1MzkyMy01LjMwODA5NSAzLjc1MzkyMy00LjY2MjUxNkMzLjc1MzkyMy00LjE2MDM5OSA0LjQ3MTIzMy00LjE2MDM5OSA0Ljg4OTY2NC00LjE2MDM5OUM1LjA5MjkwMi00LjE2MDM5OSA1LjYzMDg4NC00LjE2MDM5OSA2LjE2ODg2Ny00LjM4NzU0N0M2LjI2NDUwOC00LjIwODIxOSA2LjMwMDM3NC0zLjk2OTExNiA2LjMwMDM3NC0zLjc2NTg3OEM2LjMwMDM3NC0zLjMzNTQ5MiA1Ljk4OTUzOS0xLjg4ODkxNyA1LjYxODkyOS0xLjI2NzI0OEM1LjI0ODMxOS0uNjgxNDQ1IDQuNjYyNTE2LS4yODY5MjQgMy45MDkzNC0uMjg2OTI0QzIuNzk3NTA5LS4yODY5MjQgMS44NjUwMDYtLjk1NjQxMyAxLjg2NTAwNi0yLjAzMjM3OUMxLjg2NTAwNi0yLjI3MTQ4MiAxLjkyNDc4Mi0yLjUyMjU0IDEuOTQ4NjkyLTIuNjQyMDkyQzIuMTI4MDItMy4zNDc0NDcgMi41MTA1ODUtNC45MTM1NzQgMi42NTQwNDctNS40Mzk2MDFDMy4wMzY2MTMtNi43NDI3MTUgNC40ODMxODgtNy45NjIxNDIgNS45MDU4NTMtNy45NjIxNDJDNi4zNDgxOTQtNy45NjIxNDIgNi42MTEyMDgtNy43NDY5NDkgNi42MTEyMDgtNy4yODA2OTdDNi42MTEyMDgtNi45MTAwODcgNi4zMjQyODQtNS42Nzg3MDUgNi4wNjEyNy01LjIxMjQ1M1onLz4KPHBhdGggaWQ9J2c4LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOC00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzgtNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzgtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnOC02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzgtMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzgtMTA4JyBkPSdNMi4wNTYyODktOC4yOTY4ODdMLjM5NDUyMS04LjE2NTM4Vi03LjgxODY4QzEuMjA3NDcyLTcuODE4NjggMS4zMDMxMTMtNy43MzQ5OTQgMS4zMDMxMTMtNy4xNDkxOTFWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzE1MDY4LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFTMi42MzAxMzctLjAyMzkxIDIuOTY0ODgyIDBWLS4zNDY3QzIuMTk5NzUxLS4zNDY3IDIuMDU2Mjg5LS4zNDY3IDIuMDU2Mjg5LS44ODQ2ODJWLTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzgtMTExJyBkPSdNNS40ODc0MjItMi41NTg0MDZDNS40ODc0MjItNC4xMDA2MjMgNC4zMTU4MTYtNS4zMzIwMDUgMi45MjkwMTYtNS4zMzIwMDVDMS40OTQzOTYtNS4zMzIwMDUgLjM1ODY1NS00LjA2NDc1NyAuMzU4NjU1LTIuNTU4NDA2Qy4zNTg2NTUtMS4wMjgxNDQgMS41NTQxNzIgLjExOTU1MiAyLjkxNzA2MSAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNS40ODc0MjItMS4wNTIwNTUgNS40ODc0MjItMi41NTg0MDZaTTIuOTI5MDE2LS4xNDM0NjJDMi40ODY2NzUtLjE0MzQ2MiAxLjk0ODY5Mi0uMzM0NzQ1IDEuNjAxOTkzLS45MjA1NDhDMS4yNzkyMDMtMS40NTg1MzEgMS4yNjcyNDgtMi4xNjM4ODUgMS4yNjcyNDgtMi42NjYwMDJDMS4yNjcyNDgtMy4xMjAyOTkgMS4yNjcyNDgtMy44NDk1NjQgMS42Mzc4NTgtNC4zODc1NDdDMS45NzI2MDMtNC45MDE2MTkgMi40OTg2My01LjA5MjkwMiAyLjkxNzA2MS01LjA5MjkwMkMzLjM4MzMxMy01LjA5MjkwMiAzLjg4NTQzLTQuODc3NzA5IDQuMjA4MjE5LTQuNDExNDU3QzQuNTc4ODI5LTMuODYxNTE5IDQuNTc4ODI5LTMuMTA4MzQ0IDQuNTc4ODI5LTIuNjY2MDAyQzQuNTc4ODI5LTIuMjQ3NTcyIDQuNTc4ODI5LTEuNTA2MzUxIDQuMjY3OTk1LS45NDQ0NThDMy45MzMyNS0uMzcwNjEgMy4zODMzMTMtLjE0MzQ2MiAyLjkyOTAxNi0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzYtMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2c2LTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2c2LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNi02MScgZD0nTTUuMTI4NzY3LTguNTI0MDM1QzUuMTI4NzY3LTguNTM1OTkgNS4yMDA0OTgtOC43MTUzMTggNS4yMDA0OTgtOC43MzkyMjhDNS4yMDA0OTgtOC44ODI2OSA1LjA4MDk0Ni04Ljk2NjM3NiA0Ljk4NTMwNS04Ljk2NjM3NkM0LjkyNTUyOS04Ljk2NjM3NiA0LjgxNzkzMy04Ljk2NjM3NiA0LjcyMjI5MS04LjcwMzM2MkwuNzE3MzEgMi41NDY0NTFDLjcxNzMxIDIuNTU4NDA2IC42NDU1NzkgMi43Mzc3MzMgLjY0NTU3OSAyLjc2MTY0NEMuNjQ1NTc5IDIuOTA1MTA2IC43NjUxMzEgMi45ODg3OTIgLjg2MDc3MiAyLjk4ODc5MkMuOTMyNTAzIDIuOTg4NzkyIDEuMDQwMSAyLjk3NjgzNyAxLjEyMzc4NiAyLjcyNTc3OEw1LjEyODc2Ny04LjUyNDAzNVonLz4KPHBhdGggaWQ9J2c2LTk2JyBkPSdNMS4wOTk4NzUtMi4wMzIzNzlDLjM0NjctMS4yOTExNTggLjE1NTQxNy0xLjExMTgzMSAuMTU1NDE3LTEuMDY0MDFTLjIwMzIzOC0uOTMyNTAzIC4yODY5MjQtLjkzMjUwM0MuMzQ2Ny0uOTMyNTAzIDEuMDI4MTQ0LTEuNTkwMDM3IDEuMTIzNzg2LTEuNjk3NjM0QzEuMTk1NTE3LS44OTY2MzggMS40OTQzOTYgLjE0MzQ2MiAyLjQyNjg5OSAuMTQzNDYyQzIuOTA1MTA2IC4xNDM0NjIgMy4zMzU0OTItLjE1NTQxNyAzLjUyNjc3NS0uMjk4ODc5QzMuNjgyMTkyLS40MTg0MzEgNC4yNTYwNC0uOTA4NTkzIDQuMjU2MDQtMS4wMTYxODlDNC4yNTYwNC0xLjA3NTk2NSA0LjE5NjI2NC0xLjE0NzY5NiA0LjEzNjQ4OC0xLjE0NzY5NkM0LjA4ODY2Ny0xLjE0NzY5NiAzLjkwOTM0LS45NjgzNjkgMy44NjE1MTktLjkyMDU0OEMzLjQ0MzA4OC0uNTE0MDcyIDIuOTE3MDYxLS4wOTU2NDEgMi40Mzg4NTQtLjA5NTY0MUMxLjc5MzI3NS0uMDk1NjQxIDEuNzA5NTg5LTEuMDI4MTQ0IDEuNzA5NTg5LTEuNjczNzI0QzEuNzA5NTg5LTEuNzkzMjc1IDEuNzA5NTg5LTIuMjk1MzkyIDEuNzkzMjc1LTIuMzkxMDM0QzIuNDk4NjMtMy4xMjAyOTkgNC43MTAzMzYtNS40MDM3MzYgNC43MTAzMzYtNy41MTk4MDFDNC43MTAzMzYtNy45OTgwMDcgNC41MzEwMDktOC40MTY0MzggNC4wMTY5MzYtOC40MTY0MzhDMi45MDUxMDYtOC40MTY0MzggMS45MzY3MzctNS45NTM2NzQgMS43NjkzNjUtNS40OTkzNzdDMS43MjE1NDQtNS4zNzk4MjYgMS4wMjgxNDQtMy41Mzg3MyAxLjA5OTg3NS0yLjAzMjM3OVpNMS44MTcxODYtMi43NzM1OTlDMS44MjkxNDEtMi44NDUzMyAyLjM2NzEyMy01Ljk3NzU4NCAzLjM3MTM1Ny03LjY1MTMwOEMzLjU3NDU5NS03Ljk3NDA5NyAzLjc3NzgzMy04LjE3NzMzNSA0LjAxNjkzNi04LjE3NzMzNUM0LjQyMzQxMi04LjE3NzMzNSA0LjQ0NzMyMy03Ljc5NDc3IDQuNDQ3MzIzLTcuNTMxNzU2QzQuNDQ3MzIzLTcuMTEzMzI1IDQuMzI3NzcxLTYuMDM3MzYgMy4yODc2NzEtNC41MzEwMDlDMi45NzY4MzctNC4wODg2NjcgMi40OTg2My0zLjQ5MDkwOSAxLjgxNzE4Ni0yLjc3MzU5OVonLz4KPHBhdGggaWQ9J2c2LTExNicgZD0nTTIuNDAyOTg5LTQuODA1OTc4SDMuNTAyODY0QzMuNzMwMDEyLTQuODA1OTc4IDMuODQ5NTY0LTQuODA1OTc4IDMuODQ5NTY0LTUuMDIxMTcxQzMuODQ5NTY0LTUuMTUyNjc3IDMuNzc3ODMzLTUuMTUyNjc3IDMuNTM4NzMtNS4xNTI2NzdIMi40ODY2NzVMMi45MjkwMTYtNi44OTgxMzJDMi45NzY4MzctNy4wNjU1MDQgMi45NzY4MzctNy4wODk0MTUgMi45NzY4MzctNy4xNzMxMDFDMi45NzY4MzctNy4zNjQzODQgMi44MjE0Mi03LjQ3MTk4IDIuNjY2MDAyLTcuNDcxOThDMi41NzAzNjEtNy40NzE5OCAyLjI5NTM5Mi03LjQzNjExNSAyLjE5OTc1MS03LjA1MzU0OUwxLjczMzQ5OS01LjE1MjY3N0guNjA5NzE0Qy4zNzA2MS01LjE1MjY3NyAuMjYzMDE0LTUuMTUyNjc3IC4yNjMwMTQtNC45MjU1MjlDLjI2MzAxNC00LjgwNTk3OCAuMzQ2Ny00LjgwNTk3OCAuNTczODQ4LTQuODA1OTc4SDEuNjM3ODU4TC44NDg4MTctMS42NDk4MTNDLjc1MzE3Ni0xLjIzMTM4MiAuNzE3MzEtMS4xMTE4MzEgLjcxNzMxLS45NTY0MTNDLjcxNzMxLS4zOTQ1MjEgMS4xMTE4MzEgLjExOTU1MiAxLjc4MTMyIC4xMTk1NTJDMi45ODg3OTIgLjExOTU1MiAzLjYzNDM3MS0xLjYyNTkwMyAzLjYzNDM3MS0xLjcwOTU4OUMzLjYzNDM3MS0xLjc4MTMyIDMuNTg2NTUtMS44MTcxODYgMy41MTQ4MTktMS44MTcxODZDMy40OTA5MDktMS44MTcxODYgMy40NDMwODgtMS44MTcxODYgMy40MTkxNzgtMS43NjkzNjVDMy40MDcyMjMtMS43NTc0MSAzLjM5NTI2OC0xLjc0NTQ1NSAzLjMxMTU4Mi0xLjU1NDE3MkMzLjA2MDUyMy0uOTU2NDEzIDIuNTEwNTg1LS4xMTk1NTIgMS44MTcxODYtLjExOTU1MkMxLjQ1ODUzMS0uMTE5NTUyIDEuNDM0NjItLjQxODQzMSAxLjQzNDYyLS42ODE0NDVDMS40MzQ2Mi0uNjkzNCAxLjQzNDYyLS45MjA1NDggMS40NzA0ODYtMS4wNjQwMUwyLjQwMjk4OS00LjgwNTk3OFonLz4KPHBhdGggaWQ9J2c2LTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c2LTk2Jy8+Cjx1c2UgeD0nNC45MTIxMDYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzkuNDY0NDMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzAtMTInLz4KPHVzZSB4PScxNy43NTgyOTcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzI1LjYzMTQ1MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTYxJy8+Cjx1c2UgeD0nMzguMDU2OTMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzU1LjQxMzEzNCcgeT0nLTI5Ljk3NjQyNScgeGxpbms6aHJlZj0nI2c1LTExMCcvPgo8dXNlIHg9JzQ5LjM0NzkyNycgeT0nLTI2LjM4OTg2OScgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nNTEuMTMwMzIxJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc1NC4wMTM0NjEnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nNjAuNTk5OTY3JyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzY4LjYwOTA0MScgeT0nLTM1LjQ3NTkyOCcgeGxpbms6aHJlZj0nI2cxLTQwJy8+Cjx1c2UgeD0nNzguMjM5NjQ0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTA4Jy8+Cjx1c2UgeD0nODEuNDkxMzA1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTExJy8+Cjx1c2UgeD0nODcuMzQ0Mjk2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTAzJy8+Cjx1c2UgeD0nOTMuMzU5ODY5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc5Ny45MTIxOTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0yNycvPgo8dXNlIHg9JzEwNC45OTQ1OTknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzEwOS41NDY5MjUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScxMTMuNzc0MDg0JyB5PSctMTMuMjM5MTQxJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMTE3LjE1NTM1NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMTIxLjcwNzY4MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMTI4LjkxNjY3MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMTQwLjY3Nzk4NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTQ1LjIzMDMxMicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nMTUzLjczOTk2NScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMTY1LjUwMTI4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PScxNzEuMzU0MjcxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScxNzcuMjA3MjYxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMjQnLz4KPHVzZSB4PScxODIuODk3Njk4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxODcuNDUwMDI0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMTkxLjY3NzE4NCcgeT0nLTEzLjIzOTE0MScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzE5NS4wNTg0NTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzE5OS42MTA3ODEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzIwNi4xNTU2MDUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC0xMDgnLz4KPHVzZSB4PScyMDkuNDA3MjY2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTExJy8+Cjx1c2UgeD0nMjE1LjI2MDI1NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTEwMycvPgo8dXNlIHg9JzIyMy4yNjgzMjcnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0yMCcvPgo8dXNlIHg9JzIyOS41NzgwMjQnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzIzOC4wODc2NzgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MycvPgo8dXNlIHg9JzI0OS44NDg5OTMnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0yNCcvPgo8dXNlIHg9JzI1NS41Mzk0MzEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzI2MC4wOTE3NTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScyNjQuMzE4OTE2JyB5PSctMTMuMjM5MTQxJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMjY3LjcwMDE4OCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMjc0LjI0NTAxMScgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nMjg0LjI0MDg5NycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTEyMicvPgo8dXNlIHg9JzI4OS42Nzg3ODgnIHk9Jy0yMS4zMjY5JyB4bGluazpocmVmPScjZzUtMTE2Jy8+Cjx1c2UgeD0nMjkyLjczNjgwOScgeT0nLTIwLjExMTgyMScgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzI5OS4wNTMzNjInIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nMzExLjAwODUyMycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTIyJy8+Cjx1c2UgeD0nMzE4LjA1MTQ5MycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMzIyLjYwMzgxOScgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzMyNi44MzA5NzknIHk9Jy0yMS4zMjY5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzMwLjIxMjI1JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHJlY3QgeD0nMjg0LjI0MDg5NycgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1MC41MjM2NzEnLz4KPHVzZSB4PScyOTcuNjA0OTk3JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNi0yNycvPgo8dXNlIHg9JzMwNC42ODc0MDEnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMzA5LjIzOTcyNycgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMzEzLjQ2Njg4NycgeT0nLTUuMDM4NDc5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzE2Ljg0ODE1OCcgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSczMzUuOTYwMDgyJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PSczNDQuNzYwNDU1JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMjEnLz4KPHVzZSB4PSczNTMuNzI2ODE2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDMnLz4KPHVzZSB4PSczNjUuNDg4MTMxJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMjAnLz4KPHVzZSB4PSczNzEuNzk3ODI4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PSczODAuMzA3NDgyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDMnLz4KPHVzZSB4PSczOTIuMDY4Nzk3JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMjQnLz4KPHVzZSB4PSczOTcuNzU5MjM0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc0MDIuMzExNTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PSc0MDYuNTM4NzInIHk9Jy0xMy4yMzkxNDEnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0MDkuOTE5OTkxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSc0MTYuNDY0ODE1JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMTgnLz4KPHVzZSB4PSc0MjYuNDYwNzAxJyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzYtMTIyJy8+Cjx1c2UgeD0nNDMxLjg5ODU5MicgeT0nLTIxLjMyNjknIHhsaW5rOmhyZWY9JyNnNS0xMTYnLz4KPHVzZSB4PSc0MzQuOTU2NjEzJyB5PSctMjAuMTExODIxJyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nNDQxLjI3MzE2NicgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PSc0NTMuMjI4MzI3JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzYtMjInLz4KPHVzZSB4PSc0NjAuMjcxMjk3JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc0NjQuODIzNjIzJyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nNDY5LjA1MDc4MicgeT0nLTIxLjMyNjknIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0NzIuNDMyMDU0JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHJlY3QgeD0nNDI2LjQ2MDcwMScgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1MC41MjM2NzEnLz4KPHVzZSB4PSc0MzkuODI0ODAxJyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNi0yNycvPgo8dXNlIHg9JzQ0Ni45MDcyMDUnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nNDUxLjQ1OTUzMScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nNDU1LjY4NjY5JyB5PSctNS4wMzg0NzknIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0NTkuMDY3OTYyJyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzQ3OC4xNzk4ODYnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0xOScvPgo8dXNlIHg9JzQ4Ni45ODAyNTknIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0yMScvPgo8dXNlIHg9JzQ5My4yODk5NTYnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nNDk5Ljg3NjQ2MycgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNTA0LjExMDY0NicgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nNTA4LjM0NDgyOCcgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c1LTI0Jy8+Cjx1c2UgeD0nNTEyLjM3ODM2MycgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c3LTQwJy8+Cjx1c2UgeD0nNTE1LjY3MTYxNicgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c1LTExNicvPgo8dXNlIHg9JzUxOC43Mjk2MzcnIHk9Jy0yNy45OTc2MDknIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PSc1MjEuODkxMzk1JyB5PSctMjkuMjEyNjg4JyB4bGluazpocmVmPScjZzctNDEnLz4KPHVzZSB4PSc1MjUuNjgyNzgnIHk9Jy0zNS40NzU5MjgnIHhsaW5rOmhyZWY9JyNnMS00MScvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
defined on
such that  for all .
for all .And if any of the
 is equal to 0, the log-likelihood is defined as:
is equal to 0, the log-likelihood is defined as:
The initialization of the optimization problem is crucial. Two initial points
are proposed:the Generic initial point: in that case, we assume that the GPD is stationary and
is the estimate resulting from the method
buildAsGeneralizedPareto()which follows the strategy described in the methodbuild(). This is the default initial point;the Static initial point: in that case, we still assume that the GPD is stationary and
is the maximum likelihood estimate.
The result class produced by the method provides:
the estimator
,the asymptotic distribution of
,the parameter functions
 ,
,the normalizing function
 ,
,the optimal log-likelihood value
,the GPD distribution at time
,the quantile functions of order
:  .
.
- drawMeanResidualLife(sample)¶
Draw the mean residual life plot.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample drawn from
.
- Returns:
- graph
Graph The graph of
 and its
and its  confidence interval.
confidence interval.
- graph
Notes
This method is complementary to
drawParameterThresholdStability()as a method of threshold selection.Let
a random variable defined whose excesses above the threshold  follow the Generalized Pareto distribution
follow the Generalized Pareto distribution  .
The mean of excesses of for
.
The mean of excesses of for  is
is
Hence, for all
 is a linear function of .
The threshold is the smallest value of from which the curve is linear.
is a linear function of .
The threshold is the smallest value of from which the curve is linear.The quantity
is estimated by the empirical estimator of the mean:
The estimator
 is asymptotically normal with mean
is asymptotically normal with mean
 and variance
and variance  .
.We denote by
 its realization on the sample drawn from .
The mean and the variance of are respectively estimated by and
its realization on the sample drawn from .
The mean and the variance of are respectively estimated by and  .
.The graph
is termed the mean residual life plot.The confidence level can be set using the
ResourceMapkey GeneralizedParetoFactory-MeanResidualLifeConfidenceLevel The number of threshold points in the graph can be set with the key GeneralizedParetoFactory-MeanResidualLifePointNumber.
- drawParameterThresholdStability(sample, thresholdRange)¶
Draw the parameter threshold stability plot.
- Parameters:
- sample2-d sequence of float, of dimension 1
The sample drawn from
.- uRange
Interval The range of the threshold
![u: [u_{min}, u_{max}]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9Jzc0Ljg5MTY4N3B0JyBoZWlnaHQ9JzExLjk1NTE2OHB0JyB2aWV3Qm94PScwIC04Ljk2NjM3NiA3NC44OTE2ODcgMTEuOTU1MTY4Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMC05NycgZD0nTTMuMTI0Mjg0LTMuMDM2NjEzQzMuMDUyNTUzLTMuMTcyMTA1IDIuODIxNDItMy41MTQ4MTkgMi4zMzUyNDMtMy41MTQ4MTlDMS4zODY4LTMuNTE0ODE5IC4zNDI3MTUtMi40MDY5NzQgLjM0MjcxNS0xLjIyNzM5N0MuMzQyNzE1LS4zOTg1MDYgLjg3NjcxMiAuMDc5NzAxIDEuNDkwNDExIC4wNzk3MDFDMi4wMDA0OTggLjA3OTcwMSAyLjQzODg1NC0uMzI2Nzc1IDIuNTgyMzE2LS40ODYxNzdDMi43MjU3NzggLjA2Mzc2MSAzLjI2Nzc0NiAuMDc5NzAxIDMuMzYzMzg3IC4wNzk3MDFDMy43MzAwMTIgLjA3OTcwMSAzLjkxMzMyNS0uMjIzMTYzIDMuOTc3MDg2LS4zNTg2NTVDNC4xMzY0ODgtLjY0NTU3OSA0LjI0ODA3LTEuMTA3ODQ2IDQuMjQ4MDctMS4xMzk3MjZDNC4yNDgwNy0xLjE4NzU0NyA0LjIxNjE4OS0xLjI0MzMzNyA0LjEyMDU0OC0xLjI0MzMzN1M0LjAwODk2Ni0xLjE5NTUxNyAzLjk2MTE0Ni0uOTk2MjY0QzMuODQ5NTY0LS41NTc5MDggMy42OTgxMzItLjE0MzQ2MiAzLjM4NzI5OC0uMTQzNDYyQzMuMjAzOTg1LS4xNDM0NjIgMy4xMzIyNTQtLjI5NDg5NCAzLjEzMjI1NC0uNTE4MDU3QzMuMTMyMjU0LS42NTM1NDkgMy4yMDM5ODUtLjkyNDUzMyAzLjI1MTgwNi0xLjEyMzc4NlMzLjQxOTE3OC0xLjgwMTI0NSAzLjQ1MTA1OS0xLjk0NDcwN0wzLjYxMDQ2MS0yLjU1MDQzNkMzLjY1MDMxMS0yLjc0MTcxOSAzLjczNzk4My0zLjA3NjQ2MyAzLjczNzk4My0zLjExNjMxNEMzLjczNzk4My0zLjI5OTYyNiAzLjU4NjU1LTMuMzYzMzg3IDMuNDgyOTM5LTMuMzYzMzg3QzMuMzYzMzg3LTMuMzYzMzg3IDMuMTY0MTM0LTMuMjgzNjg2IDMuMTI0Mjg0LTMuMDM2NjEzWk0yLjU4MjMxNi0uODYwNzcyQzIuMTgzODExLS4zMTA4MzQgMS43NjkzNjUtLjE0MzQ2MiAxLjUxNDMyMS0uMTQzNDYyQzEuMTQ3Njk2LS4xNDM0NjIgLjk2NDM4NC0uNDc4MjA3IC45NjQzODQtLjg5MjY1M0MuOTY0Mzg0LTEuMjY3MjQ4IDEuMTc5NTc3LTIuMTIwMDUgMS4zNTQ5MTktMi40NzA3MzVDMS41ODYwNTItMi45NTY5MTIgMS45NzY1ODgtMy4yOTE2NTYgMi4zNDMyMTMtMy4yOTE2NTZDMi44NjEyNy0zLjI5MTY1NiAzLjAxMjcwMi0yLjcwOTgzOCAzLjAxMjcwMi0yLjYxNDE5N0MzLjAxMjcwMi0yLjU4MjMxNiAyLjgxMzQ1LTEuODAxMjQ1IDIuNzY1NjI5LTEuNTk0MDIyQzIuNjYyMDE3LTEuMjE5NDI3IDIuNjYyMDE3LTEuMjAzNDg3IDIuNTgyMzE2LS44NjA3NzJaJy8+CjxwYXRoIGlkPSdnMC0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzAtMTA5JyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjc0NTQ1NS0xLjkyODc2NyAxLjc5MzI3NS0yLjEyMDA1IDEuODA5MjE1LTIuMTk5NzUxQzEuODI1MTU2LTIuMjM5NjAxIDIuMDg4MTY5LTIuNzU3NjU5IDIuNDM4ODU0LTMuMDIwNjcyQzIuNzA5ODM4LTMuMjI3ODk1IDIuOTcyODUyLTMuMjkxNjU2IDMuMTk2MDE1LTMuMjkxNjU2QzMuNDkwOTA5LTMuMjkxNjU2IDMuNjUwMzExLTMuMTE2MzE0IDMuNjUwMzExLTIuNzQ5Njg5QzMuNjUwMzExLTIuNTU4NDA2IDMuNjAyNDkxLTIuMzc1MDkzIDMuNTE0ODE5LTIuMDE2NDM4QzMuNDU5MDI5LTEuODA5MjE1IDMuMzIzNTM3LTEuMjc1MjE4IDMuMjc1NzE2LTEuMDYwMDI1TDMuMTU2MTY0LS41ODE4MThDMy4xMTYzMTQtLjQ0NjMyNiAzLjA2MDUyMy0uMjA3MjIzIDMuMDYwNTIzLS4xNjczNzJDMy4wNjA1MjMgLjAxNTk0IDMuMjExOTU1IC4wNzk3MDEgMy4zMTU1NjcgLjA3OTcwMUMzLjQ1OTAyOSAuMDc5NzAxIDMuNTc4NTgtLjAxNTk0IDMuNjM0MzcxLS4xMTE1ODJDMy42NTgyODEtLjE1OTQwMiAzLjcyMjA0Mi0uNDMwMzg2IDMuNzYxODkzLS41OTc3NThMMy45NDUyMDUtMS4zMDcwOThDMy45NjkxMTYtMS40MjY2NSA0LjA0ODgxNy0xLjcyOTUxNCA0LjA3MjcyNy0xLjg0OTA2NkM0LjE4NDMwOS0yLjI3OTQ1MiA0LjE4NDMwOS0yLjI4NzQyMiA0LjM2NzYyMS0yLjU1MDQzNkM0LjYzMDYzNS0yLjk0MDk3MSA1LjAwNTIzLTMuMjkxNjU2IDUuNTM5MjI4LTMuMjkxNjU2QzUuODI2MTUyLTMuMjkxNjU2IDUuOTkzNTI0LTMuMTI0Mjg0IDUuOTkzNTI0LTIuNzQ5Njg5QzUuOTkzNTI0LTIuMzExMzMzIDUuNjU4NzgtMS4zOTQ3NyA1LjUwNzM0Ny0xLjAxMjIwNEM1LjQyNzY0Ni0uODA0OTgxIDUuNDAzNzM2LS43NDkxOTEgNS40MDM3MzYtLjU5Nzc1OEM1LjQwMzczNi0uMTQzNDYyIDUuNzc4MzMxIC4wNzk3MDEgNi4xMjEwNDYgLjA3OTcwMUM2LjkwMjExNyAuMDc5NzAxIDcuMjI4ODkyLTEuMDM2MTE1IDcuMjI4ODkyLTEuMTM5NzI2QzcuMjI4ODkyLTEuMjE5NDI3IDcuMTY1MTMxLTEuMjQzMzM3IDcuMTA5MzQtMS4yNDMzMzdDNy4wMTM2OTktMS4yNDMzMzcgNi45OTc3NTgtMS4xODc1NDcgNi45NzM4NDgtMS4xMDc4NDZDNi43ODI1NjUtLjQ0NjMyNiA2LjQ0NzgyMS0uMTQzNDYyIDYuMTQ0OTU2LS4xNDM0NjJDNi4wMTc0MzUtLjE0MzQ2MiA1Ljk1MzY3NC0uMjIzMTYzIDUuOTUzNjc0LS40MDY0NzZTNi4wMTc0MzUtLjc2NTEzMSA2LjA5NzEzNi0uOTY0Mzg0QzYuMjE2Njg3LTEuMjY3MjQ4IDYuNTY3MzcyLTIuMTgzODExIDYuNTY3MzcyLTIuNjMwMTM3QzYuNTY3MzcyLTMuMjI3ODk1IDYuMTUyOTI3LTMuNTE0ODE5IDUuNTc5MDc4LTMuNTE0ODE5QzUuMDI5MTQxLTMuNTE0ODE5IDQuNTc0ODQ0LTMuMjI3ODk1IDQuMjE2MTg5LTIuNzMzNzQ4QzQuMTUyNDI4LTMuMzcxMzU3IDMuNjQyMzQxLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuODYxMjctMy41MTQ4MTkgMi4zNzUwOTMtMy4zODcyOTggMS45MzY3MzctMi44MTM0NUMxLjg4MDk0Ni0zLjI5MTY1NiAxLjQ5ODM4MS0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODQ0ODMyLTMuNTE0ODE5IC42NDU1NzktMy4zNDc0NDcgLjUxMDA4Ny0zLjA3NjQ2M0MuMzE4ODA0LTIuNzAxODY4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnMC0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzAtMTIwJyBkPSdNMy45OTMwMjYtMy4xODAwNzVDMy42NDIzNDEtMy4wOTI0MDMgMy42MjY0MDEtMi43ODE1NjkgMy42MjY0MDEtMi43NDk2ODlDMy42MjY0MDEtMi41NzQzNDYgMy43NjE4OTMtMi40NTQ3OTUgMy45MzcyMzUtMi40NTQ3OTVTNC4zODM1NjItMi41OTAyODYgNC4zODM1NjItMi45MzMwMDFDNC4zODM1NjItMy4zODcyOTggMy44ODE0NDUtMy41MTQ4MTkgMy41ODY1NS0zLjUxNDgxOUMzLjIxMTk1NS0zLjUxNDgxOSAyLjkwOTA5MS0zLjI1MTgwNiAyLjcyNTc3OC0yLjk0MDk3MUMyLjU1MDQzNi0zLjM2MzM4NyAyLjEzNTk5LTMuNTE0ODE5IDEuODA5MjE1LTMuNTE0ODE5Qy45NDA0NzMtMy41MTQ4MTkgLjQ1NDI5Ni0yLjUxODU1NSAuNDU0Mjk2LTIuMjk1MzkyQy40NTQyOTYtMi4yMjM2NjEgLjUxMDA4Ny0yLjE5MTc4MSAuNTczODQ4LTIuMTkxNzgxQy42Njk0ODktMi4xOTE3ODEgLjY4NTQzLTIuMjMxNjMxIC43MDkzNC0yLjMyNzI3M0MuODkyNjUzLTIuOTA5MDkxIDEuMzcwODU5LTMuMjkxNjU2IDEuNzg1MzA1LTMuMjkxNjU2QzIuMDk2MTM5LTMuMjkxNjU2IDIuMjQ3NTcyLTMuMDY4NDkzIDIuMjQ3NTcyLTIuNzgxNTY5QzIuMjQ3NTcyLTIuNjIyMTY3IDIuMTUxOTMtMi4yNTU1NDIgMi4wODgxNjktMi4wMDA0OThDMi4wMzIzNzktMS43NjkzNjUgMS44NTcwMzYtMS4wNjAwMjUgMS44MTcxODYtLjkwODU5M0MxLjcwNTYwNC0uNDc4MjA3IDEuNDE4NjgtLjE0MzQ2MiAxLjA2MDAyNS0uMTQzNDYyQzEuMDI4MTQ0LS4xNDM0NjIgLjgyMDkyMi0uMTQzNDYyIC42NTM1NDktLjI1NTA0NEMxLjAyMDE3NC0uMzQyNzE1IDEuMDIwMTc0LS42Nzc0NiAxLjAyMDE3NC0uNjg1NDNDMS4wMjAxNzQtLjg2ODc0MiAuODc2NzEyLS45ODAzMjQgLjcwMTM3LS45ODAzMjRDLjQ4NjE3Ny0uOTgwMzI0IC4yNTUwNDQtLjc5NzAxMSAuMjU1MDQ0LS40OTQxNDdDLjI1NTA0NC0uMTI3NTIyIC42NDU1NzkgLjA3OTcwMSAxLjA1MjA1NSAuMDc5NzAxQzEuNDc0NDcxIC4wNzk3MDEgMS43NjkzNjUtLjIzOTEwMyAxLjkxMjgyNy0uNDk0MTQ3QzIuMDg4MTY5LS4xMDM2MTEgMi40NTQ3OTUgLjA3OTcwMSAyLjgzNzM2IC4wNzk3MDFDMy43MDYxMDIgLjA3OTcwMSA0LjE4NDMwOS0uOTE2NTYzIDQuMTg0MzA5LTEuMTM5NzI2QzQuMTg0MzA5LTEuMjE5NDI3IDQuMTIwNTQ4LTEuMjQzMzM3IDQuMDY0NzU3LTEuMjQzMzM3QzMuOTY5MTE2LTEuMjQzMzM3IDMuOTUzMTc2LTEuMTg3NTQ3IDMuOTI5MjY1LTEuMTA3ODQ2QzMuNzY5ODYzLS41NzM4NDggMy4zMTU1NjctLjE0MzQ2MiAyLjg1MzMtLjE0MzQ2MkMyLjU5MDI4Ni0uMTQzNDYyIDIuMzk5MDA0LS4zMTg4MDQgMi4zOTkwMDQtLjY1MzU0OUMyLjM5OTAwNC0uODEyOTUxIDIuNDQ2ODI0LS45OTYyNjQgMi41NTg0MDYtMS40NDI1OUMyLjYxNDE5Ny0xLjY4MTY5NCAyLjc4OTUzOS0yLjM4MzA2NCAyLjgyOTM5LTIuNTM0NDk2QzIuOTQwOTcxLTIuOTQ4OTQxIDMuMjE5OTI1LTMuMjkxNjU2IDMuNTc4NTgtMy4yOTE2NTZDMy42MTg0MzEtMy4yOTE2NTYgMy44MjU2NTQtMy4yOTE2NTYgMy45OTMwMjYtMy4xODAwNzVaJy8+CjxwYXRoIGlkPSdnMi01OCcgZD0nTTIuMTk5NzUxLTQuNTc4ODI5QzIuMTk5NzUxLTQuOTAxNjE5IDEuOTI0NzgyLTUuMTUyNjc3IDEuNjI1OTAzLTUuMTUyNjc3QzEuMjc5MjAzLTUuMTUyNjc3IDEuMDQwMS00Ljg3NzcwOSAxLjA0MDEtNC41Nzg4MjlDMS4wNDAxLTQuMjIwMTc0IDEuMzM4OTc5LTMuOTkzMDI2IDEuNjEzOTQ4LTMuOTkzMDI2QzEuOTM2NzM3LTMuOTkzMDI2IDIuMTk5NzUxLTQuMjQ0MDg1IDIuMTk5NzUxLTQuNTc4ODI5Wk0yLjE5OTc1MS0uNTg1ODAzQzIuMTk5NzUxLS45MDg1OTMgMS45MjQ3ODItMS4xNTk2NTEgMS42MjU5MDMtMS4xNTk2NTFDMS4yNzkyMDMtMS4xNTk2NTEgMS4wNDAxLS44ODQ2ODIgMS4wNDAxLS41ODU4MDNDMS4wNDAxLS4yMjcxNDggMS4zMzg5NzkgMCAxLjYxMzk0OCAwQzEuOTM2NzM3IDAgMi4xOTk3NTEtLjI1MTA1OSAyLjE5OTc1MS0uNTg1ODAzWicvPgo8cGF0aCBpZD0nZzItOTEnIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonLz4KPHBhdGggaWQ9J2cyLTkzJyBkPSdNMS44NTMwNTEtOC45NjYzNzZILjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUguMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonLz4KPHBhdGggaWQ9J2cxLTU5JyBkPSdNMi4zMzEyNTggLjA0NzgyMUMyLjMzMTI1OC0uNjQ1NTc5IDIuMTA0MTEtMS4xNTk2NTEgMS42MTM5NDgtMS4xNTk2NTFDMS4yMzEzODItMS4xNTk2NTEgMS4wNDAxLS44NDg4MTcgMS4wNDAxLS41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNy0uMDQ3ODIxIDIuMDIwNDIzLS4xNTU0MTdDMi4wNDQzMzQtLjE3OTMyOCAyLjA1NjI4OS0uMTc5MzI4IDIuMDY4MjQ0LS4xNzkzMjhDMi4wOTIxNTQtLjE3OTMyOCAyLjA5MjE1NC0uMDExOTU1IDIuMDkyMTU0IC4wNDc4MjFDMi4wOTIxNTQgLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IC4wNDc4MjFaJy8+CjxwYXRoIGlkPSdnMS0xMTcnIGQ9J000LjA3NjcxMi0uNjkzNEM0LjIzMjEzLS4wMjM5MSA0LjgwNTk3OCAuMTE5NTUyIDUuMDkyOTAyIC4xMTk1NTJDNS40NzU0NjcgLjExOTU1MiA1Ljc2MjM5MS0uMTMxNTA3IDUuOTUzNjc0LS41Mzc5ODNDNi4xNTY5MTItLjk2ODM2OSA2LjMxMjMyOS0xLjY3MzcyNCA2LjMxMjMyOS0xLjcwOTU4OUM2LjMxMjMyOS0xLjc2OTM2NSA2LjI2NDUwOC0xLjgxNzE4NiA2LjE5Mjc3Ny0xLjgxNzE4NkM2LjA4NTE4MS0xLjgxNzE4NiA2LjA3MzIyNS0xLjc1NzQxIDYuMDI1NDA1LTEuNTc4MDgyQzUuODEwMjEyLS43NTMxNzYgNS41OTUwMTktLjExOTU1MiA1LjExNjgxMi0uMTE5NTUyQzQuNzU4MTU3LS4xMTk1NTIgNC43NTgxNTctLjUxNDA3MiA0Ljc1ODE1Ny0uNjY5NDg5QzQuNzU4MTU3LS45NDQ0NTggNC43OTQwMjItMS4wNjQwMSA0LjkxMzU3NC0xLjU2NjEyN0M0Ljk5NzI2LTEuODg4OTE3IDUuMDgwOTQ2LTIuMjExNzA2IDUuMTUyNjc3LTIuNTQ2NDUxTDUuNjQyODM5LTQuNDk1MTQzQzUuNzI2NTI2LTQuNzk0MDIyIDUuNzI2NTI2LTQuODE3OTMzIDUuNzI2NTI2LTQuODUzNzk4QzUuNzI2NTI2LTUuMDMzMTI2IDUuNTgzMDY0LTUuMTUyNjc3IDUuNDAzNzM2LTUuMTUyNjc3QzUuMDU3MDM2LTUuMTUyNjc3IDQuOTczMzUtNC44NTM3OTggNC45MDE2MTktNC41NTQ5MTlDNC43ODIwNjctNC4wODg2NjcgNC4xMzY0ODgtMS41MTgzMDYgNC4wNTI4MDItMS4wOTk4NzVDNC4wNDA4NDctMS4wOTk4NzUgMy41NzQ1OTUtLjExOTU1MiAyLjcwMTg2OC0uMTE5NTUyQzIuMDgwMTk5LS4xMTk1NTIgMS45NjA2NDgtLjY1NzUzNCAxLjk2MDY0OC0xLjA5OTg3NUMxLjk2MDY0OC0xLjc4MTMyIDIuMjk1MzkyLTIuNzM3NzMzIDIuNjA2MjI3LTMuNTM4NzNDMi43NDk2ODktMy45MjEyOTUgMi44MDk0NjUtNC4wNzY3MTIgMi44MDk0NjUtNC4zMTU4MTZDMi44MDk0NjUtNC44Mjk4ODggMi40Mzg4NTQtNS4yNzIyMjkgMS44NjUwMDYtNS4yNzIyMjlDLjc2NTEzMS01LjI3MjIyOSAuMzIyNzktMy41Mzg3MyAuMzIyNzktMy40NDMwODhDLjMyMjc5LTMuMzk1MjY4IC4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NjE4OTMtMy4zMzU0OTIgLjU3Mzg0OC0zLjM4MzMxMyAuNjIxNjY5LTMuNTUwNjg1Qy45MDg1OTMtNC41Nzg4MjkgMS4zNzQ4NDQtNS4wMzMxMjYgMS44MjkxNDEtNS4wMzMxMjZDMS45NDg2OTItNS4wMzMxMjYgMi4xMzk5NzUtNS4wMjExNzEgMi4xMzk5NzUtNC42Mzg2MDVDMi4xMzk5NzUtNC4zMjc3NzEgMi4wMDg0NjgtMy45ODEwNzEgMS44MjkxNDEtMy41MjY3NzVDMS4zMDMxMTMtMi4xMDQxMSAxLjI0MzMzNy0xLjY0OTgxMyAxLjI0MzMzNy0xLjI5MTE1OEMxLjI0MzMzNy0uMDcxNzMxIDIuMTYzODg1IC4xMTk1NTIgMi42NTQwNDcgLjExOTU1MkMzLjQxOTE3OCAuMTE5NTUyIDMuODM3NjA5LS40MDY0NzYgNC4wNzY3MTItLjY5MzRaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScwJyB5PScwJyB4bGluazpocmVmPScjZzEtMTE3Jy8+Cjx1c2UgeD0nOS45ODMyNjknIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi01OCcvPgo8dXNlIHg9JzE2LjU1NTc2JyB5PScwJyB4bGluazpocmVmPScjZzItOTEnLz4KPHVzZSB4PScxOS44MDc0MjEnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS0xMTcnLz4KPHVzZSB4PScyNi40Njk4NicgeT0nMS43OTMyNjMnIHhsaW5rOmhyZWY9JyNnMC0xMDknLz4KPHVzZSB4PSczMy45NjAzODcnIHk9JzEuNzkzMjYzJyB4bGluazpocmVmPScjZzAtMTA1Jy8+Cjx1c2UgeD0nMzYuODQzNTI2JyB5PScxLjc5MzI2MycgeGxpbms6aHJlZj0nI2cwLTExMCcvPgo8dXNlIHg9JzQyLjQ3OTg2MScgeT0nMCcgeGxpbms6aHJlZj0nI2cxLTU5Jy8+Cjx1c2UgeD0nNDcuNzI0MDInIHk9JzAnIHhsaW5rOmhyZWY9JyNnMS0xMTcnLz4KPHVzZSB4PSc1NC4zODY0NTknIHk9JzEuNzkzMjYzJyB4bGluazpocmVmPScjZzAtMTA5Jy8+Cjx1c2UgeD0nNjEuODc2OTg1JyB5PScxLjc5MzI2MycgeGxpbms6aHJlZj0nI2cwLTk3Jy8+Cjx1c2UgeD0nNjYuMzc0OTk1JyB5PScxLjc5MzI2MycgeGxpbms6aHJlZj0nI2cwLTEyMCcvPgo8dXNlIHg9JzcxLjY0MDAyNicgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTkzJy8+CjwvZz4KPC9zdmc+CjwhLS0gREVQVEg9NCAtLT4=) .
.
- Returns:
- graph
Graph The graphs of
 and
and  .
.
- graph
Notes
This method is complementary to
drawMeanResidualLife()as a method of threshold selection.Let
a random variable whose excesses above the threshold
follow a Generalized Pareto distribution  . Then the excesses of
above also follow a Generalized Pareto distribution
. Then the excesses of
above also follow a Generalized Pareto distribution
 where:
where:(10)¶

Hence, if we define the modified scale parameter
 by:
by:
then , by virtue of (10),
is constant with respect to .Consequently, estimates of
and should be constant (or stable
accounting for sampling variability) above
if is a valid threshold for excesses to follow a Generalized Pareto
distribution.The method draws the graphs of
and
with the respective confidence intervals,
for ![u \in [u_{min}, u_{max}]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9Jzc5LjYxMDE2NXB0JyBoZWlnaHQ9JzExLjk1NTE2OHB0JyB2aWV3Qm94PScwIC04Ljk2NjM3NiA3OS42MTAxNjUgMTEuOTU1MTY4Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMS05NycgZD0nTTMuMTI0Mjg0LTMuMDM2NjEzQzMuMDUyNTUzLTMuMTcyMTA1IDIuODIxNDItMy41MTQ4MTkgMi4zMzUyNDMtMy41MTQ4MTlDMS4zODY4LTMuNTE0ODE5IC4zNDI3MTUtMi40MDY5NzQgLjM0MjcxNS0xLjIyNzM5N0MuMzQyNzE1LS4zOTg1MDYgLjg3NjcxMiAuMDc5NzAxIDEuNDkwNDExIC4wNzk3MDFDMi4wMDA0OTggLjA3OTcwMSAyLjQzODg1NC0uMzI2Nzc1IDIuNTgyMzE2LS40ODYxNzdDMi43MjU3NzggLjA2Mzc2MSAzLjI2Nzc0NiAuMDc5NzAxIDMuMzYzMzg3IC4wNzk3MDFDMy43MzAwMTIgLjA3OTcwMSAzLjkxMzMyNS0uMjIzMTYzIDMuOTc3MDg2LS4zNTg2NTVDNC4xMzY0ODgtLjY0NTU3OSA0LjI0ODA3LTEuMTA3ODQ2IDQuMjQ4MDctMS4xMzk3MjZDNC4yNDgwNy0xLjE4NzU0NyA0LjIxNjE4OS0xLjI0MzMzNyA0LjEyMDU0OC0xLjI0MzMzN1M0LjAwODk2Ni0xLjE5NTUxNyAzLjk2MTE0Ni0uOTk2MjY0QzMuODQ5NTY0LS41NTc5MDggMy42OTgxMzItLjE0MzQ2MiAzLjM4NzI5OC0uMTQzNDYyQzMuMjAzOTg1LS4xNDM0NjIgMy4xMzIyNTQtLjI5NDg5NCAzLjEzMjI1NC0uNTE4MDU3QzMuMTMyMjU0LS42NTM1NDkgMy4yMDM5ODUtLjkyNDUzMyAzLjI1MTgwNi0xLjEyMzc4NlMzLjQxOTE3OC0xLjgwMTI0NSAzLjQ1MTA1OS0xLjk0NDcwN0wzLjYxMDQ2MS0yLjU1MDQzNkMzLjY1MDMxMS0yLjc0MTcxOSAzLjczNzk4My0zLjA3NjQ2MyAzLjczNzk4My0zLjExNjMxNEMzLjczNzk4My0zLjI5OTYyNiAzLjU4NjU1LTMuMzYzMzg3IDMuNDgyOTM5LTMuMzYzMzg3QzMuMzYzMzg3LTMuMzYzMzg3IDMuMTY0MTM0LTMuMjgzNjg2IDMuMTI0Mjg0LTMuMDM2NjEzWk0yLjU4MjMxNi0uODYwNzcyQzIuMTgzODExLS4zMTA4MzQgMS43NjkzNjUtLjE0MzQ2MiAxLjUxNDMyMS0uMTQzNDYyQzEuMTQ3Njk2LS4xNDM0NjIgLjk2NDM4NC0uNDc4MjA3IC45NjQzODQtLjg5MjY1M0MuOTY0Mzg0LTEuMjY3MjQ4IDEuMTc5NTc3LTIuMTIwMDUgMS4zNTQ5MTktMi40NzA3MzVDMS41ODYwNTItMi45NTY5MTIgMS45NzY1ODgtMy4yOTE2NTYgMi4zNDMyMTMtMy4yOTE2NTZDMi44NjEyNy0zLjI5MTY1NiAzLjAxMjcwMi0yLjcwOTgzOCAzLjAxMjcwMi0yLjYxNDE5N0MzLjAxMjcwMi0yLjU4MjMxNiAyLjgxMzQ1LTEuODAxMjQ1IDIuNzY1NjI5LTEuNTk0MDIyQzIuNjYyMDE3LTEuMjE5NDI3IDIuNjYyMDE3LTEuMjAzNDg3IDIuNTgyMzE2LS44NjA3NzJaJy8+CjxwYXRoIGlkPSdnMS0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzEtMTA5JyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjc0NTQ1NS0xLjkyODc2NyAxLjc5MzI3NS0yLjEyMDA1IDEuODA5MjE1LTIuMTk5NzUxQzEuODI1MTU2LTIuMjM5NjAxIDIuMDg4MTY5LTIuNzU3NjU5IDIuNDM4ODU0LTMuMDIwNjcyQzIuNzA5ODM4LTMuMjI3ODk1IDIuOTcyODUyLTMuMjkxNjU2IDMuMTk2MDE1LTMuMjkxNjU2QzMuNDkwOTA5LTMuMjkxNjU2IDMuNjUwMzExLTMuMTE2MzE0IDMuNjUwMzExLTIuNzQ5Njg5QzMuNjUwMzExLTIuNTU4NDA2IDMuNjAyNDkxLTIuMzc1MDkzIDMuNTE0ODE5LTIuMDE2NDM4QzMuNDU5MDI5LTEuODA5MjE1IDMuMzIzNTM3LTEuMjc1MjE4IDMuMjc1NzE2LTEuMDYwMDI1TDMuMTU2MTY0LS41ODE4MThDMy4xMTYzMTQtLjQ0NjMyNiAzLjA2MDUyMy0uMjA3MjIzIDMuMDYwNTIzLS4xNjczNzJDMy4wNjA1MjMgLjAxNTk0IDMuMjExOTU1IC4wNzk3MDEgMy4zMTU1NjcgLjA3OTcwMUMzLjQ1OTAyOSAuMDc5NzAxIDMuNTc4NTgtLjAxNTk0IDMuNjM0MzcxLS4xMTE1ODJDMy42NTgyODEtLjE1OTQwMiAzLjcyMjA0Mi0uNDMwMzg2IDMuNzYxODkzLS41OTc3NThMMy45NDUyMDUtMS4zMDcwOThDMy45NjkxMTYtMS40MjY2NSA0LjA0ODgxNy0xLjcyOTUxNCA0LjA3MjcyNy0xLjg0OTA2NkM0LjE4NDMwOS0yLjI3OTQ1MiA0LjE4NDMwOS0yLjI4NzQyMiA0LjM2NzYyMS0yLjU1MDQzNkM0LjYzMDYzNS0yLjk0MDk3MSA1LjAwNTIzLTMuMjkxNjU2IDUuNTM5MjI4LTMuMjkxNjU2QzUuODI2MTUyLTMuMjkxNjU2IDUuOTkzNTI0LTMuMTI0Mjg0IDUuOTkzNTI0LTIuNzQ5Njg5QzUuOTkzNTI0LTIuMzExMzMzIDUuNjU4NzgtMS4zOTQ3NyA1LjUwNzM0Ny0xLjAxMjIwNEM1LjQyNzY0Ni0uODA0OTgxIDUuNDAzNzM2LS43NDkxOTEgNS40MDM3MzYtLjU5Nzc1OEM1LjQwMzczNi0uMTQzNDYyIDUuNzc4MzMxIC4wNzk3MDEgNi4xMjEwNDYgLjA3OTcwMUM2LjkwMjExNyAuMDc5NzAxIDcuMjI4ODkyLTEuMDM2MTE1IDcuMjI4ODkyLTEuMTM5NzI2QzcuMjI4ODkyLTEuMjE5NDI3IDcuMTY1MTMxLTEuMjQzMzM3IDcuMTA5MzQtMS4yNDMzMzdDNy4wMTM2OTktMS4yNDMzMzcgNi45OTc3NTgtMS4xODc1NDcgNi45NzM4NDgtMS4xMDc4NDZDNi43ODI1NjUtLjQ0NjMyNiA2LjQ0NzgyMS0uMTQzNDYyIDYuMTQ0OTU2LS4xNDM0NjJDNi4wMTc0MzUtLjE0MzQ2MiA1Ljk1MzY3NC0uMjIzMTYzIDUuOTUzNjc0LS40MDY0NzZTNi4wMTc0MzUtLjc2NTEzMSA2LjA5NzEzNi0uOTY0Mzg0QzYuMjE2Njg3LTEuMjY3MjQ4IDYuNTY3MzcyLTIuMTgzODExIDYuNTY3MzcyLTIuNjMwMTM3QzYuNTY3MzcyLTMuMjI3ODk1IDYuMTUyOTI3LTMuNTE0ODE5IDUuNTc5MDc4LTMuNTE0ODE5QzUuMDI5MTQxLTMuNTE0ODE5IDQuNTc0ODQ0LTMuMjI3ODk1IDQuMjE2MTg5LTIuNzMzNzQ4QzQuMTUyNDI4LTMuMzcxMzU3IDMuNjQyMzQxLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuODYxMjctMy41MTQ4MTkgMi4zNzUwOTMtMy4zODcyOTggMS45MzY3MzctMi44MTM0NUMxLjg4MDk0Ni0zLjI5MTY1NiAxLjQ5ODM4MS0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODQ0ODMyLTMuNTE0ODE5IC42NDU1NzktMy4zNDc0NDcgLjUxMDA4Ny0zLjA3NjQ2M0MuMzE4ODA0LTIuNzAxODY4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnMS0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzEtMTIwJyBkPSdNMy45OTMwMjYtMy4xODAwNzVDMy42NDIzNDEtMy4wOTI0MDMgMy42MjY0MDEtMi43ODE1NjkgMy42MjY0MDEtMi43NDk2ODlDMy42MjY0MDEtMi41NzQzNDYgMy43NjE4OTMtMi40NTQ3OTUgMy45MzcyMzUtMi40NTQ3OTVTNC4zODM1NjItMi41OTAyODYgNC4zODM1NjItMi45MzMwMDFDNC4zODM1NjItMy4zODcyOTggMy44ODE0NDUtMy41MTQ4MTkgMy41ODY1NS0zLjUxNDgxOUMzLjIxMTk1NS0zLjUxNDgxOSAyLjkwOTA5MS0zLjI1MTgwNiAyLjcyNTc3OC0yLjk0MDk3MUMyLjU1MDQzNi0zLjM2MzM4NyAyLjEzNTk5LTMuNTE0ODE5IDEuODA5MjE1LTMuNTE0ODE5Qy45NDA0NzMtMy41MTQ4MTkgLjQ1NDI5Ni0yLjUxODU1NSAuNDU0Mjk2LTIuMjk1MzkyQy40NTQyOTYtMi4yMjM2NjEgLjUxMDA4Ny0yLjE5MTc4MSAuNTczODQ4LTIuMTkxNzgxQy42Njk0ODktMi4xOTE3ODEgLjY4NTQzLTIuMjMxNjMxIC43MDkzNC0yLjMyNzI3M0MuODkyNjUzLTIuOTA5MDkxIDEuMzcwODU5LTMuMjkxNjU2IDEuNzg1MzA1LTMuMjkxNjU2QzIuMDk2MTM5LTMuMjkxNjU2IDIuMjQ3NTcyLTMuMDY4NDkzIDIuMjQ3NTcyLTIuNzgxNTY5QzIuMjQ3NTcyLTIuNjIyMTY3IDIuMTUxOTMtMi4yNTU1NDIgMi4wODgxNjktMi4wMDA0OThDMi4wMzIzNzktMS43NjkzNjUgMS44NTcwMzYtMS4wNjAwMjUgMS44MTcxODYtLjkwODU5M0MxLjcwNTYwNC0uNDc4MjA3IDEuNDE4NjgtLjE0MzQ2MiAxLjA2MDAyNS0uMTQzNDYyQzEuMDI4MTQ0LS4xNDM0NjIgLjgyMDkyMi0uMTQzNDYyIC42NTM1NDktLjI1NTA0NEMxLjAyMDE3NC0uMzQyNzE1IDEuMDIwMTc0LS42Nzc0NiAxLjAyMDE3NC0uNjg1NDNDMS4wMjAxNzQtLjg2ODc0MiAuODc2NzEyLS45ODAzMjQgLjcwMTM3LS45ODAzMjRDLjQ4NjE3Ny0uOTgwMzI0IC4yNTUwNDQtLjc5NzAxMSAuMjU1MDQ0LS40OTQxNDdDLjI1NTA0NC0uMTI3NTIyIC42NDU1NzkgLjA3OTcwMSAxLjA1MjA1NSAuMDc5NzAxQzEuNDc0NDcxIC4wNzk3MDEgMS43NjkzNjUtLjIzOTEwMyAxLjkxMjgyNy0uNDk0MTQ3QzIuMDg4MTY5LS4xMDM2MTEgMi40NTQ3OTUgLjA3OTcwMSAyLjgzNzM2IC4wNzk3MDFDMy43MDYxMDIgLjA3OTcwMSA0LjE4NDMwOS0uOTE2NTYzIDQuMTg0MzA5LTEuMTM5NzI2QzQuMTg0MzA5LTEuMjE5NDI3IDQuMTIwNTQ4LTEuMjQzMzM3IDQuMDY0NzU3LTEuMjQzMzM3QzMuOTY5MTE2LTEuMjQzMzM3IDMuOTUzMTc2LTEuMTg3NTQ3IDMuOTI5MjY1LTEuMTA3ODQ2QzMuNzY5ODYzLS41NzM4NDggMy4zMTU1NjctLjE0MzQ2MiAyLjg1MzMtLjE0MzQ2MkMyLjU5MDI4Ni0uMTQzNDYyIDIuMzk5MDA0LS4zMTg4MDQgMi4zOTkwMDQtLjY1MzU0OUMyLjM5OTAwNC0uODEyOTUxIDIuNDQ2ODI0LS45OTYyNjQgMi41NTg0MDYtMS40NDI1OUMyLjYxNDE5Ny0xLjY4MTY5NCAyLjc4OTUzOS0yLjM4MzA2NCAyLjgyOTM5LTIuNTM0NDk2QzIuOTQwOTcxLTIuOTQ4OTQxIDMuMjE5OTI1LTMuMjkxNjU2IDMuNTc4NTgtMy4yOTE2NTZDMy42MTg0MzEtMy4yOTE2NTYgMy44MjU2NTQtMy4yOTE2NTYgMy45OTMwMjYtMy4xODAwNzVaJy8+CjxwYXRoIGlkPSdnMy05MScgZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicvPgo8cGF0aCBpZD0nZzMtOTMnIGQ9J00xLjg1MzA1MS04Ljk2NjM3NkguMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicvPgo8cGF0aCBpZD0nZzAtNTAnIGQ9J002LjU1MTQzMi0yLjc0OTY4OUM2Ljc1NDY3LTIuNzQ5Njg5IDYuOTY5ODYzLTIuNzQ5Njg5IDYuOTY5ODYzLTIuOTg4NzkyUzYuNzU0NjctMy4yMjc4OTUgNi41NTE0MzItMy4yMjc4OTVIMS40ODI0NDFDMS42MjU5MDMtNC44Mjk4ODggMy4wMDA3NDctNS45Nzc1ODQgNC42ODY0MjYtNS45Nzc1ODRINi41NTE0MzJDNi43NTQ2Ny01Ljk3NzU4NCA2Ljk2OTg2My01Ljk3NzU4NCA2Ljk2OTg2My02LjIxNjY4N1M2Ljc1NDY3LTYuNDU1NzkxIDYuNTUxNDMyLTYuNDU1NzkxSDQuNjYyNTE2QzIuNjE4MTgyLTYuNDU1NzkxIC45OTIyNzktNC45MDE2MTkgLjk5MjI3OS0yLjk4ODc5MlMyLjYxODE4MiAuNDc4MjA3IDQuNjYyNTE2IC40NzgyMDdINi41NTE0MzJDNi43NTQ2NyAuNDc4MjA3IDYuOTY5ODYzIC40NzgyMDcgNi45Njk4NjMgLjIzOTEwM1M2Ljc1NDY3IDAgNi41NTE0MzIgMEg0LjY4NjQyNkMzLjAwMDc0NyAwIDEuNjI1OTAzLTEuMTQ3Njk2IDEuNDgyNDQxLTIuNzQ5Njg5SDYuNTUxNDMyWicvPgo8cGF0aCBpZD0nZzItNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2cyLTExNycgZD0nTTQuMDc2NzEyLS42OTM0QzQuMjMyMTMtLjAyMzkxIDQuODA1OTc4IC4xMTk1NTIgNS4wOTI5MDIgLjExOTU1MkM1LjQ3NTQ2NyAuMTE5NTUyIDUuNzYyMzkxLS4xMzE1MDcgNS45NTM2NzQtLjUzNzk4M0M2LjE1NjkxMi0uOTY4MzY5IDYuMzEyMzI5LTEuNjczNzI0IDYuMzEyMzI5LTEuNzA5NTg5QzYuMzEyMzI5LTEuNzY5MzY1IDYuMjY0NTA4LTEuODE3MTg2IDYuMTkyNzc3LTEuODE3MTg2QzYuMDg1MTgxLTEuODE3MTg2IDYuMDczMjI1LTEuNzU3NDEgNi4wMjU0MDUtMS41NzgwODJDNS44MTAyMTItLjc1MzE3NiA1LjU5NTAxOS0uMTE5NTUyIDUuMTE2ODEyLS4xMTk1NTJDNC43NTgxNTctLjExOTU1MiA0Ljc1ODE1Ny0uNTE0MDcyIDQuNzU4MTU3LS42Njk0ODlDNC43NTgxNTctLjk0NDQ1OCA0Ljc5NDAyMi0xLjA2NDAxIDQuOTEzNTc0LTEuNTY2MTI3QzQuOTk3MjYtMS44ODg5MTcgNS4wODA5NDYtMi4yMTE3MDYgNS4xNTI2NzctMi41NDY0NTFMNS42NDI4MzktNC40OTUxNDNDNS43MjY1MjYtNC43OTQwMjIgNS43MjY1MjYtNC44MTc5MzMgNS43MjY1MjYtNC44NTM3OThDNS43MjY1MjYtNS4wMzMxMjYgNS41ODMwNjQtNS4xNTI2NzcgNS40MDM3MzYtNS4xNTI2NzdDNS4wNTcwMzYtNS4xNTI2NzcgNC45NzMzNS00Ljg1Mzc5OCA0LjkwMTYxOS00LjU1NDkxOUM0Ljc4MjA2Ny00LjA4ODY2NyA0LjEzNjQ4OC0xLjUxODMwNiA0LjA1MjgwMi0xLjA5OTg3NUM0LjA0MDg0Ny0xLjA5OTg3NSAzLjU3NDU5NS0uMTE5NTUyIDIuNzAxODY4LS4xMTk1NTJDMi4wODAxOTktLjExOTU1MiAxLjk2MDY0OC0uNjU3NTM0IDEuOTYwNjQ4LTEuMDk5ODc1QzEuOTYwNjQ4LTEuNzgxMzIgMi4yOTUzOTItMi43Mzc3MzMgMi42MDYyMjctMy41Mzg3M0MyLjc0OTY4OS0zLjkyMTI5NSAyLjgwOTQ2NS00LjA3NjcxMiAyLjgwOTQ2NS00LjMxNTgxNkMyLjgwOTQ2NS00LjgyOTg4OCAyLjQzODg1NC01LjI3MjIyOSAxLjg2NTAwNi01LjI3MjIyOUMuNzY1MTMxLTUuMjcyMjI5IC4zMjI3OS0zLjUzODczIC4zMjI3OS0zLjQ0MzA4OEMuMzIyNzktMy4zOTUyNjggLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU2MTg5My0zLjMzNTQ5MiAuNTczODQ4LTMuMzgzMzEzIC42MjE2NjktMy41NTA2ODVDLjkwODU5My00LjU3ODgyOSAxLjM3NDg0NC01LjAzMzEyNiAxLjgyOTE0MS01LjAzMzEyNkMxLjk0ODY5Mi01LjAzMzEyNiAyLjEzOTk3NS01LjAyMTE3MSAyLjEzOTk3NS00LjYzODYwNUMyLjEzOTk3NS00LjMyNzc3MSAyLjAwODQ2OC0zLjk4MTA3MSAxLjgyOTE0MS0zLjUyNjc3NUMxLjMwMzExMy0yLjEwNDExIDEuMjQzMzM3LTEuNjQ5ODEzIDEuMjQzMzM3LTEuMjkxMTU4QzEuMjQzMzM3LS4wNzE3MzEgMi4xNjM4ODUgLjExOTU1MiAyLjY1NDA0NyAuMTE5NTUyQzMuNDE5MTc4IC4xMTk1NTIgMy44Mzc2MDktLjQwNjQ3NiA0LjA3NjcxMi0uNjkzNFonLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzAnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi0xMTcnLz4KPHVzZSB4PSc5Ljk4MzI2OScgeT0nMCcgeGxpbms6aHJlZj0nI2cwLTUwJy8+Cjx1c2UgeD0nMjEuMjc0MjM3JyB5PScwJyB4bGluazpocmVmPScjZzMtOTEnLz4KPHVzZSB4PScyNC41MjU4OTgnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi0xMTcnLz4KPHVzZSB4PSczMS4xODgzMzgnIHk9JzEuNzkzMjYzJyB4bGluazpocmVmPScjZzEtMTA5Jy8+Cjx1c2UgeD0nMzguNjc4ODY0JyB5PScxLjc5MzI2MycgeGxpbms6aHJlZj0nI2cxLTEwNScvPgo8dXNlIHg9JzQxLjU2MjAwNCcgeT0nMS43OTMyNjMnIHhsaW5rOmhyZWY9JyNnMS0xMTAnLz4KPHVzZSB4PSc0Ny4xOTgzMzgnIHk9JzAnIHhsaW5rOmhyZWY9JyNnMi01OScvPgo8dXNlIHg9JzUyLjQ0MjQ5NycgeT0nMCcgeGxpbms6aHJlZj0nI2cyLTExNycvPgo8dXNlIHg9JzU5LjEwNDkzNycgeT0nMS43OTMyNjMnIHhsaW5rOmhyZWY9JyNnMS0xMDknLz4KPHVzZSB4PSc2Ni41OTU0NjMnIHk9JzEuNzkzMjYzJyB4bGluazpocmVmPScjZzEtOTcnLz4KPHVzZSB4PSc3MS4wOTM0NzMnIHk9JzEuNzkzMjYzJyB4bGluazpocmVmPScjZzEtMTIwJy8+Cjx1c2UgeD0nNzYuMzU4NTAzJyB5PScwJyB4bGluazpocmVmPScjZzMtOTMnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD00IC0tPg==) .
The selected threshold is the lowest value of from which the estimates remain
near-constant.
.
The selected threshold is the lowest value of from which the estimates remain
near-constant.The confidence level can be set using the
ResourceMapkey GeneralizedParetoFactory-ThresholdStabilityConfidenceLevel The number of threshold points in the graph can be set with the key GeneralizedParetoFactory-ThresholdStabilityPointNumber.
- getBootstrapSize()¶
Accessor to the bootstrap size.
- Returns:
- sizeint
Size of the bootstrap.
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getKnownParameterIndices()¶
Accessor to the known parameters indices.
- Returns:
- indices
Indices Indices of the known parameters.
- indices
- getKnownParameterValues()¶
Accessor to the known parameters values.
- Returns:
- values
Point Values of known parameters.
- values
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- getOptimizationAlgorithm()¶
Accessor to the solver.
- Returns:
- solver
OptimizationAlgorithm The solver used for numerical optimization of the likelihood.
- solver
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- setBootstrapSize(bootstrapSize)¶
Accessor to the bootstrap size.
- Parameters:
- sizeint
The size of the bootstrap.
- setKnownParameter(values, positions)¶
Accessor to the known parameters.
- Parameters:
- valuessequence of float
Values of known parameters.
- positionssequence of int
Indices of known parameters.
Examples
When a subset of the parameter vector is known, the other parameters only have to be estimated from data.
In the following example, we consider a sample and want to fit a
Betadistribution. We assume that the and
and  parameters are known beforehand.
In this case, we set the third parameter (at index 2) to -1
and the fourth parameter (at index 3) to 1.
parameters are known beforehand.
In this case, we set the third parameter (at index 2) to -1
and the fourth parameter (at index 3) to 1.>>> import openturns as ot >>> ot.RandomGenerator.SetSeed(0) >>> distribution = ot.Beta(2.3, 2.2, -1.0, 1.0) >>> sample = distribution.getSample(10) >>> factory = ot.BetaFactory() >>> # set (a,b) out of (r, t, a, b) >>> factory.setKnownParameter([-1.0, 1.0], [2, 3]) >>> inf_distribution = factory.build(sample)
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
- setOptimizationAlgorithm(solver)¶
Accessor to the solver.
- Parameters:
- solver
OptimizationAlgorithm The solver used for numerical optimization of the likelihood.
- solver
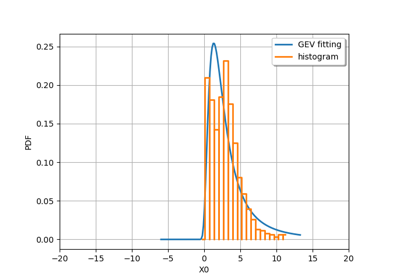
{kind=link}