GeneralizedExtremeValueFactory¶
(Source code, png)
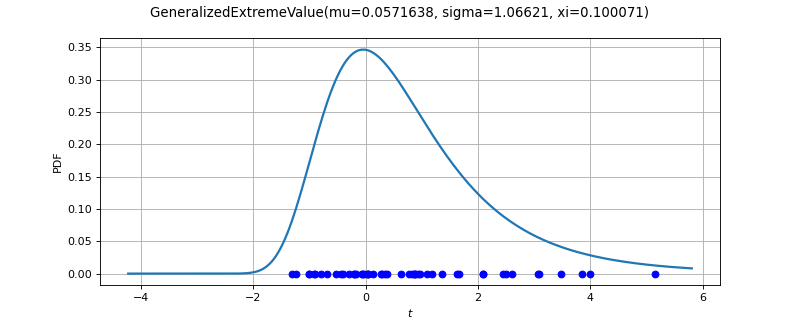
- class GeneralizedExtremeValueFactory(*args)¶
GeneralizedExtremeValue factory.
Methods
build(*args)Estimate the distribution via maximum likelihood.
Estimate the distribution as native distribution.
buildCovariates(*args)Estimate a GEV from covariates.
buildEstimator(*args)Build the distribution and the parameter distribution.
Estimate the distribution from the
 largest order statistics.
largest order statistics.Estimate the distribution and the parameter distribution with the R-maxima method.
buildMethodOfXiProfileLikelihood(sample[, r])Estimate the distribution with the profile likelihood.
Estimate the distribution and the parameter distribution with the profile likelihood.
buildReturnLevelEstimator(result, m)Estimate a return level and its distribution from the GEV parameters.
buildReturnLevelProfileLikelihood(sample, m)Estimate a return level and its distribution with the profile likelihood.
Estimate
 and its distribution with the profile likelihood.
and its distribution with the profile likelihood.buildTimeVarying(*args)Estimate a non stationary GEV from a time-dependent parametric model.
Accessor to the bootstrap size.
Accessor to the object's name.
Accessor to the known parameters indices.
Accessor to the known parameters values.
getName()Accessor to the object's name.
Accessor to the solver.
hasName()Test if the object is named.
setBootstrapSize(bootstrapSize)Accessor to the bootstrap size.
setKnownParameter(values, positions)Accessor to the known parameters.
setName(name)Accessor to the object's name.
setOptimizationAlgorithm(solver)Accessor to the solver.
See also
Notes
Several estimators to build a GeneralizedExtremeValueFactory distribution from a scalar sample are proposed. The details are given in the methods documentation.
The following
ResourceMapentries can be used to tweak the parameters of the optimization solver involved in the different estimators:GeneralizedExtremeValueFactory-DefaultOptimizationAlgorithm
GeneralizedExtremeValueFactory-MaximumCallsNumber
GeneralizedExtremeValueFactory-MaximumAbsoluteError
GeneralizedExtremeValueFactory-MaximumRelativeError
GeneralizedExtremeValueFactory-MaximumObjectiveError
GeneralizedExtremeValueFactory-MaximumConstraintError
GeneralizedExtremeValueFactory-InitializationMethod
GeneralizedExtremeValueFactory-NormalizationMethod
- __init__(*args)¶
- build(*args)¶
Estimate the distribution via maximum likelihood.
Available usages:
build(sample)
build(param)
- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1 from which
 are estimated.
are estimated.- paramsequence of float
The parameters of the
GeneralizedExtremeValue.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution.
- distribution
Notes
The estimation strategy described in
buildAsGeneralizedExtremeValue()is followed.
- buildAsGeneralizedExtremeValue(*args)¶
Estimate the distribution as native distribution.
Available usages:
buildAsGeneralizedExtremeValue()
buildAsGeneralizedExtremeValue(sample)
buildAsGeneralizedExtremeValue(param)
- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1 from which
are estimated.- paramsequence of float
The parameters of the
GeneralizedExtremeValue.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution as a GeneralizedExtremeValue.
In the first usage, the default GeneralizedExtremeValue distribution is built.
- distribution
Notes
The estimate maximizes the log-likelihood of the model.
- buildCovariates(*args)¶
Estimate a GEV from covariates.
- Parameters:
- sample2-d sequence of float
The block maxima grouped in a sample of size
 and one dimension.
and one dimension.- covariates2-d sequence of float
Covariates sample. A constant column is automatically added if it is not provided.
- muIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- sigmaIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- xiIndicessequence of int, optional
Indices of covariates considered for parameter
 .
.By default, an empty sequence.
The index of the constant covariate is added if empty or if the covariates do not initially contain a constant column.
- muLink
Function, optional The
 function.
function.By default, the identity function.
- sigmaLink
Function, optional The
 function.
function.By default, the identity function.
- xiLink
Function, optional The
 function.
function.By default, the identity function.
- initializationMethodstr, optional
The initialization method for the optimization problem: Gumbel or Static.
By default, the method Gumbel (see
ResourceMap, key GeneralizedExtremeValueFactory-InitializationMethod).- normalizationMethodstr, optional
The data normalization method: CenterReduce, MinMax or None.
By default, the method MinMax (see
ResourceMap, key GeneralizedExtremeValueFactory-NormalizationMethod).
- Returns:
- result
CovariatesResult The result class.
- result
Notes
Let
 be a GEV model whose parameters depend on
be a GEV model whose parameters depend on  covariates
denoted by
covariates
denoted by  :
:
We denote by
 the values of associated to the values of the
covariates
the values of associated to the values of the
covariates  .
.For numerical reasons, it is recommended to normalize the covariates. Each covariate
 has its own normalization:
has its own normalization:
and with three ways of defining
 of the covariate :
of the covariate :the CenterReduce method where
 is the
covariate mean and
is the
covariate mean and  is the standard deviation of the covariates;
is the standard deviation of the covariates;the MinMax method where
 is the min value of the covariate
and
is the min value of the covariate
and  its range. This is the default method;
its range. This is the default method;the None method where
 and
and  : in that case, data are not
normalized.
: in that case, data are not
normalized.
Let
be the vector of parameters. Then,  depends on all the covariates
even if each component of only depends on a subset of the covariates. We
denote by
depends on all the covariates
even if each component of only depends on a subset of the covariates. We
denote by  the
the  covariates involved in the
modelling of the component
covariates involved in the
modelling of the component  .
.Each component
can be written as a function of the normalized covariates:
This relation can be written as a function of the real covariates:

where:
 is usually referred to as the inverse-link function of
the component ,
is usually referred to as the inverse-link function of
the component ,each
 .
.
To allow some parameters to remain constant, i.e. independent of the covariates (this will generally be the case for the parameter
), the library systematically
adds the constant covariate to the specified covariates.The complete vector of parameters is defined by:

where
 .
.The estimator of
 maximizes the likelihood of the model which is defined
by:
maximizes the likelihood of the model which is defined
by:
where
 denotes the GEV density function
with parameters
denotes the GEV density function
with parameters
 and evaluated at
and evaluated at  .
.Then, if none of the
 is zero, the log-likelihood is defined by:
is zero, the log-likelihood is defined by:![\ell (\vect{\beta}) = -\sum_{i=1}^{n} \left\{ \log(\sigma(\vect{y}_i)) + (1 + 1 /
\xi(\vect{y}
_i) ) \log\left[ 1+\xi(\vect{y}_i) \left( \frac{z_{\vect{y}_i} - \mu(\vect{y}_i)}
{\sigma(\vect{y}_i)}\right) \right] + \left[ 1 + \xi(\vect{y}_i) \left( \frac{
z_{\vect{y}_i}-
\mu(\vect{y}_i)}{\sigma(\vect{y}_i)} \right) \right]^{-1 / \xi(\vect{y}_i)} \right\}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzU2MS43NjE1MjRwdCcgaGVpZ2h0PSczNS44NjU4NjlwdCcgdmlld0JveD0nMCAtMzUuOTU0MTIzIDU2MS43NjE1MjQgMzUuODY1ODY5Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMy0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzUtMTA1JyBkPSdNMi4wODAxOTktMy43MzAwMTJDMi4wODAxOTktMy44NzM0NzQgMS45NzI2MDMtMy45NjkxMTYgMS44MzUxMTgtMy45NjkxMTZDMS42NzM3MjQtMy45NjkxMTYgMS41MDAzNzQtMy44MTM2OTkgMS41MDAzNzQtMy42NDAzNDlDMS41MDAzNzQtMy40OTA5MDkgMS42MDc5Ny0zLjQwMTI0NSAxLjczOTQ3Ny0zLjQwMTI0NUMxLjkzMDc2LTMuNDAxMjQ1IDIuMDgwMTk5LTMuNTgwNTczIDIuMDgwMTk5LTMuNzMwMDEyWk0xLjcyMTU0NC0xLjY0MzgzNkMxLjc0NTQ1NS0xLjcwMzYxMSAxLjc5OTI1My0xLjg0NzA3MyAxLjgyMzE2My0xLjkwMDg3MkMxLjg0MTA5Ni0xLjk1NDY3IDEuODY1MDA2LTIuMDE0NDQ2IDEuODY1MDA2LTIuMTE2MDY1QzEuODY1MDA2LTIuNDUwODA5IDEuNTY2MTI3LTIuNjM2MTE1IDEuMjY3MjQ4LTIuNjM2MTE1Qy42NTc1MzQtMi42MzYxMTUgLjM2NDYzMy0xLjg0NzA3MyAuMzY0NjMzLTEuNzE1NTY3Qy4zNjQ2MzMtMS42ODU2NzkgLjM4ODU0My0xLjYzMTg4IC40NzIyMjktMS42MzE4OFMuNTczODQ4LTEuNjY3NzQ2IC41OTE3ODEtMS43MjE1NDRDLjc1OTE1My0yLjMwMTM3IDEuMDc1OTY1LTIuNDM4ODU0IDEuMjQzMzM3LTIuNDM4ODU0QzEuMzYyODg5LTIuNDM4ODU0IDEuNDA0NzMyLTIuMzYxMTQ2IDEuNDA0NzMyLTIuMjIzNjYxQzEuNDA0NzMyLTIuMTA0MTEgMS4zNjg4NjctMi4wMTQ0NDYgMS4zNTY5MTItMS45NzI2MDNMMS4wNDYwNzctMS4yMDc0NzJDLjk3NDM0Ni0xLjAzNDEyMiAuOTc0MzQ2LTEuMDIyMTY3IC44OTY2MzgtLjgxODkyOUMuODE4OTI5LS42Mzk2MDEgLjc4OTA0MS0uNTYxODkzIC43ODkwNDEtLjQ2MDI3NEMuNzg5MDQxLS4xNTU0MTcgMS4wNjQwMSAuMDU5Nzc2IDEuMzkyNzc3IC4wNTk3NzZDMS45OTY1MTMgLjA1OTc3NiAyLjI5NTM5Mi0uNzI5MjY1IDIuMjk1MzkyLS44NjA3NzJDMi4yOTUzOTItLjg3MjcyNyAyLjI4OTQxNS0uOTQ0NDU4IDIuMTgxODE4LS45NDQ0NThDMi4wOTgxMzItLjk0NDQ1OCAyLjA5MjE1NC0uOTE0NTcgMi4wNTYyODktLjgwMDk5NkMxLjk2MDY0OC0uNDk2MTM5IDEuNzE1NTY3LS4xMzc0ODQgMS40MTA3MS0uMTM3NDg0QzEuMzAzMTEzLS4xMzc0ODQgMS4yNDkzMTUtLjIwOTIxNSAxLjI0OTMxNS0uMzUyNjc3QzEuMjQ5MzE1LS40NzIyMjkgMS4yODUxODEtLjU2MTg5MyAxLjM2Mjg4OS0uNzQ3MTk4TDEuNzIxNTQ0LTEuNjQzODM2WicvPgo8cGF0aCBpZD0nZzAtMTIxJyBkPSdNNC45MDk1ODktMi45NjQ4ODJDNC45NDE0NjktMy4wNzY0NjMgNC45NDE0NjktMy4wOTI0MDMgNC45NDE0NjktMy4xNTYxNjRDNC45NDE0NjktMy4zNzkzMjggNC43NzQwOTctMy41Mzg3MyA0LjUzNDk5NC0zLjUzODczQzQuMzgzNTYyLTMuNTM4NzMgNC4xMjA1NDgtMy40NDMwODggNC4wMjQ5MDctMy4xODgwNDVDNC4wMDA5OTYtMy4xNDAyMjQgMy45MjkyNjUtMi44NTMzIDMuODg5NDE1LTIuNjg1OTI4TDMuNDE5MTc4LS44MTI5NTFDMy40MTEyMDgtLjgwNDk4MSAzLjA2MDUyMy0uMjYzMDE0IDIuNTEwNTg1LS4yNjMwMTRDMi4wMDA0OTgtLjI2MzAxNCAyLjAwMDQ5OC0uNjc3NDYgMi4wMDA0OTgtLjg0NDgzMkMyLjAwMDQ5OC0xLjI5OTEyOCAyLjIyMzY2MS0xLjg3Mjk3NiAyLjQ4NjY3NS0yLjUzNDQ5NkMyLjUzNDQ5Ni0yLjY0NjA3NyAyLjU3NDM0Ni0yLjc0MTcxOSAyLjU3NDM0Ni0yLjg3NzIxQzIuNTc0MzQ2LTMuMzYzMzg3IDIuMDcyMjI5LTMuNjEwNDYxIDEuNjAxOTkzLTMuNjEwNDYxQy43MTczMS0zLjYxMDQ2MSAuMjcwOTg0LTIuNTY2Mzc2IC4yNzA5ODQtMi4zNTkxNTNDLjI3MDk4NC0yLjIyMzY2MSAuMzkwNTM1LTIuMjIzNjYxIC40OTQxNDctMi4yMjM2NjFDLjY0NTU3OS0yLjIyMzY2MSAuNjc3NDYtMi4yMjM2NjEgLjcyNTI4LTIuMzY3MTIzQy45NDg0NDMtMy4xMDAzNzQgMS4zNjI4ODktMy4yNzU3MTYgMS41NTQxNzItMy4yNzU3MTZDMS42MDE5OTMtMy4yNzU3MTYgMS42ODk2NjQtMy4yNzU3MTYgMS42ODk2NjQtMy4wOTI0MDNDMS42ODk2NjQtMi45MjUwMzEgMS42MTc5MzMtMi43NDE3MTkgMS41NjIxNDItMi42MTQxOTdDMS4wOTE5MDUtMS40NzQ0NzEgMS4wOTE5MDUtMS4yMDM0ODcgMS4wOTE5MDUtMS4wMDQyMzRDMS4wOTE5MDUtLjA4NzY3MSAxLjg4MDk0NiAuMDcxNzMxIDIuNDU0Nzk1IC4wNzE3MzFDMi44MjkzOSAuMDcxNzMxIDMuMTA4MzQ0LS4wNjM3NjEgMy4yNTE4MDYtLjE1OTQwMkMzLjA3NjQ2MyAuNjkzNCAyLjQ0NjgyNCAxLjI4MzE4OCAxLjgzMzEyNiAxLjI4MzE4OEMxLjc3NzMzNSAxLjI4MzE4OCAxLjYwMTk5MyAxLjI4MzE4OCAxLjQwMjc0IDEuMjExNDU3QzEuNjQxODQzIDEuMDY3OTk1IDEuNzIxNTQ0IC44Mjg4OTIgMS43MjE1NDQgLjY2OTQ4OUMxLjcyMTU0NCAuNDE0NDQ2IDEuNTMwMjYyIC4yNjMwMTQgMS4yOTExNTggLjI2MzAxNEMuOTI0NTMzIC4yNjMwMTQgLjY2MTUxOSAuNTczODQ4IC42NjE1MTkgLjkwODU5M0MuNjYxNTE5IDEuMzcwODU5IDEuMTU1NjY2IDEuNjE3OTMzIDEuODMzMTI2IDEuNjE3OTMzQzIuNzczNTk5IDEuNjE3OTMzIDMuOTA1MzU1IDEuMDQ0MDg1IDQuMTYwMzk5IC4wMTU5NEw0LjkwOTU4OS0yLjk2NDg4MlonLz4KPHBhdGggaWQ9J2c2LTI0JyBkPSdNMS42MTc5MzMtMi4zNTExODNDMS45MTI4MjctMi4yMzk2MDEgMi4yMDc3MjEtMi4yMzk2MDEgMi4zODMwNjQtMi4yMzk2MDFDMi42NTQwNDctMi4yMzk2MDEgMy4xNzIxMDUtMi4yMzk2MDEgMy4xNzIxMDUtMi41MjY1MjZDMy4xNzIxMDUtMi43NjU2MjkgMi43NDE3MTktMi43NjU2MjkgMi40NzA3MzUtMi43NjU2MjlDMi4zMTEzMzMtMi43NjU2MjkgMi4wNjQyNTktMi43NjU2MjkgMS43NTM0MjUtMi42NjIwMTdDMS41NzgwODItMi44MjkzOSAxLjUwNjM1MS0zLjA1MjU1MyAxLjUwNjM1MS0zLjI3NTcxNkMxLjUwNjM1MS0zLjcyMjA0MiAxLjgxNzE4Ni00LjI4NzkyIDIuMzk5MDA0LTQuNTY2ODc0QzIuNTc0MzQ2LTQuMzgzNTYyIDIuNzgxNTY5LTQuMzgzNTYyIDIuOTQ4OTQxLTQuMzgzNTYyQzMuMjUxODA2LTQuMzgzNTYyIDMuNzA2MTAyLTQuMzk5NTAyIDMuNzA2MTAyLTQuNjcwNDg2QzMuNzA2MTAyLTQuOTA5NTg5IDMuMjc1NzE2LTQuOTA5NTg5IDIuOTk2NzYyLTQuOTA5NTg5QzIuODYxMjctNC45MDk1ODkgMi43MjU3NzgtNC45MDk1ODkgMi41MDI2MTUtNC44Nzc3MDlDMi40ODY2NzUtNC45MzM0OTkgMi40NjI3NjUtNS4wMTMyIDIuNDYyNzY1LTUuMTE2ODEyQzIuNDYyNzY1LTUuMjI4Mzk0IDIuNDk0NjQ1LTUuMzYzODg1IDIuNDk0NjQ1LTUuMzg3Nzk2QzIuNTAyNjE1LTUuMzk1NzY2IDIuNTAyNjE1LTUuNDI3NjQ2IDIuNTAyNjE1LTUuNDM1NjE2QzIuNTAyNjE1LTUuNTA3MzQ3IDIuNDQ2ODI0LTUuNTU1MTY4IDIuMzkxMDM0LTUuNTU1MTY4QzIuMjE1NjkxLTUuNTU1MTY4IDIuMjE1NjkxLTUuMTk2NTEzIDIuMjE1NjkxLTUuMTI0NzgyQzIuMjE1NjkxLTQuOTczMzUgMi4yNTU1NDItNC44Mzc4NTggMi4yNjM1MTItNC44MjE5MThDMS4zNzA4NTktNC41OTA3ODUgLjgyMDkyMi0zLjk1MzE3NiAuODIwOTIyLTMuMzIzNTM3Qy44MjA5MjItMi45MjUwMzEgMS4wMzYxMTUtMi42NTQwNDcgMS4zMzg5NzktMi40Nzg3MDVDLjQ4NjE3Ny0xLjk5MjUyOCAuMTkxMjgzLTEuMTg3NTQ3IC4xOTEyODMtLjgyMDkyMkMuMTkxMjgzLS4wOTU2NDEgLjkyNDUzMyAuMTY3MzcyIDEuMTc5NTc3IC4yNjMwMTRDMS42MjU5MDMgLjQzMDM4NiAxLjY0MTg0MyAuNDMwMzg2IDIuMDMyMzc5IC41NjU4NzhDMi4yMjM2NjEgLjYzNzYwOSAyLjU0MjQ2NiAuNzU3MTYxIDIuNTk4MjU3IC43ODkwNDFDMi43MjU3NzggLjg2ODc0MiAyLjcyNTc3OCAuOTgwMzI0IDIuNzI1Nzc4IDEuMDI4MTQ0QzIuNzI1Nzc4IDEuMTcxNjA2IDIuNjIyMTY3IDEuNDAyNzQgMi4zNjcxMjMgMS40MDI3NEMyLjMwMzM2MiAxLjQwMjc0IDEuOTc2NTg4IDEuMzg2OCAxLjY1Nzc4MyAxLjE5NTUxN0MxLjU3ODA4MiAxLjEzOTcyNiAxLjU3MDExMiAxLjEzMTc1NiAxLjUzMDI2MiAxLjEzMTc1NkMxLjQ0MjU5IDEuMTMxNzU2IDEuNDE4NjggMS4yMTE0NTcgMS40MTg2OCAxLjI0MzMzN0MxLjQxODY4IDEuMzcwODU5IDEuOTI4NzY3IDEuNjI1OTAzIDIuMzc1MDkzIDEuNjI1OTAzQzIuOTAxMTIxIDEuNjI1OTAzIDMuMjI3ODk1IDEuMTIzNzg2IDMuMjI3ODk1IC43NTcxNjFDMy4yMjc4OTUgLjYxMzY5OSAzLjE3MjEwNSAuNDYyMjY3IDMuMDc2NDYzIC4zNTA2ODVDMi45NzI4NTIgLjIzOTEwMyAyLjg2OTI0IC4xOTkyNTMgMi40MjI5MTQgLjAzOTg1MUMxLjcyOTUxNC0uMjA3MjIzIDEuMjExNDU3LS4zOTA1MzUgMS4wODM5MzUtLjQ2MjI2N0MuODI4ODkyLS41OTc3NTggLjY2MTUxOS0uNzg5MDQxIC42NjE1MTktMS4wNTIwNTVDLjY2MTUxOS0xLjM3ODgyOSAuOTU2NDEzLTEuOTkyNTI4IDEuNjE3OTMzLTIuMzUxMTgzWk0zLjQwMzIzOC00LjY0NjU3NUMzLjMyMzUzNy00LjYzMDYzNSAzLjI0MzgzNi00LjYwNjcyNSAyLjk1NjkxMi00LjYwNjcyNUMyLjc4OTUzOS00LjYwNjcyNSAyLjc1NzY1OS00LjYwNjcyNSAyLjY2MjAxNy00LjY1NDU0NUMyLjc4OTUzOS00LjY4NjQyNiAyLjg2OTI0LTQuNjg2NDI2IDMuMDEyNzAyLTQuNjg2NDI2QzMuMjI3ODk1LTQuNjg2NDI2IDMuMjgzNjg2LTQuNjc4NDU2IDMuNDAzMjM4LTQuNjU0NTQ1Vi00LjY0NjU3NVpNMi44NjkyNC0yLjUwMjYxNUMyLjc5NzUwOS0yLjQ4NjY3NSAyLjcxNzgwOC0yLjQ2Mjc2NSAyLjQwNjk3NC0yLjQ2Mjc2NUMyLjI1NTU0Mi0yLjQ2Mjc2NSAyLjE3NTg0MS0yLjQ2Mjc2NSAyLjA0ODMxOS0yLjUwMjYxNUMyLjIyMzY2MS0yLjU0MjQ2NiAyLjMxOTMwMy0yLjU0MjQ2NiAyLjQ2Mjc2NS0yLjU0MjQ2NkMyLjY5Mzg5OC0yLjU0MjQ2NiAyLjc1NzY1OS0yLjUzNDQ5NiAyLjg2OTI0LTIuNTEwNTg1Vi0yLjUwMjYxNVonLz4KPHBhdGggaWQ9J2c2LTYxJyBkPSdNMy43MDYxMDItNS42NDI4MzlDMy43NTM5MjMtNS43NTQ0MjEgMy43NTM5MjMtNS43NzAzNjEgMy43NTM5MjMtNS43OTQyNzFDMy43NTM5MjMtNS44OTc4ODMgMy42NzQyMjItNS45Nzc1ODQgMy41NzA2MS01Ljk3NzU4NEMzLjQ0MzA4OC01Ljk3NzU4NCAzLjQxMTIwOC01Ljg4MTk0MyAzLjM3OTMyOC01LjgwMjI0MkwuNTE4MDU3IDEuNjU3NzgzQy40NzAyMzcgMS43NjkzNjUgLjQ3MDIzNyAxLjc4NTMwNSAuNDcwMjM3IDEuODA5MjE1Qy40NzAyMzcgMS45MTI4MjcgLjU0OTkzOCAxLjk5MjUyOCAuNjUzNTQ5IDEuOTkyNTI4Qy43ODEwNzEgMS45OTI1MjggLjgxMjk1MSAxLjg5Njg4NyAuODQ0ODMyIDEuODE3MTg2TDMuNzA2MTAyLTUuNjQyODM5WicvPgo8cGF0aCBpZD0nZzYtMTA1JyBkPSdNMi4zNzUwOTMtNC45NzMzNUMyLjM3NTA5My01LjE0ODY5MiAyLjI0NzU3Mi01LjI3NjIxNCAyLjA2NDI1OS01LjI3NjIxNEMxLjg1NzAzNi01LjI3NjIxNCAxLjYyNTkwMy01LjA4NDkzMiAxLjYyNTkwMy00Ljg0NTgyOEMxLjYyNTkwMy00LjY3MDQ4NiAxLjc1MzQyNS00LjU0Mjk2NCAxLjkzNjczNy00LjU0Mjk2NEMyLjE0Mzk2LTQuNTQyOTY0IDIuMzc1MDkzLTQuNzM0MjQ3IDIuMzc1MDkzLTQuOTczMzVaTTEuMjExNDU3LTIuMDQ4MzE5TC43ODEwNzEtLjk0ODQ0M0MuNzQxMjItLjgyODg5MiAuNzAxMzctLjczMzI1IC43MDEzNy0uNTk3NzU4Qy43MDEzNy0uMjA3MjIzIDEuMDA0MjM0IC4wNzk3MDEgMS40MjY2NSAuMDc5NzAxQzIuMTk5NzUxIC4wNzk3MDEgMi41MjY1MjYtMS4wMzYxMTUgMi41MjY1MjYtMS4xMzk3MjZDMi41MjY1MjYtMS4yMTk0MjcgMi40NjI3NjUtMS4yNDMzMzcgMi40MDY5NzQtMS4yNDMzMzdDMi4zMTEzMzMtMS4yNDMzMzcgMi4yOTUzOTItMS4xODc1NDcgMi4yNzE0ODItMS4xMDc4NDZDMi4wODgxNjktLjQ3MDIzNyAxLjc2MTM5NS0uMTQzNDYyIDEuNDQyNTktLjE0MzQ2MkMxLjM0Njk0OS0uMTQzNDYyIDEuMjUxMzA4LS4xODMzMTMgMS4yNTEzMDgtLjM5ODUwNkMxLjI1MTMwOC0uNTg5Nzg4IDEuMzA3MDk4LS43MzMyNSAxLjQxMDcxLS45ODAzMjRDMS40OTA0MTEtMS4xOTU1MTcgMS41NzAxMTItMS40MTA3MSAxLjY1Nzc4My0xLjYyNTkwM0wxLjkwNDg1Ny0yLjI3MTQ4MkMxLjk3NjU4OC0yLjQ1NDc5NSAyLjA3MjIyOS0yLjcwMTg2OCAyLjA3MjIyOS0yLjgzNzM2QzIuMDcyMjI5LTMuMjM1ODY2IDEuNzUzNDI1LTMuNTE0ODE5IDEuMzQ2OTQ5LTMuNTE0ODE5Qy41NzM4NDgtMy41MTQ4MTkgLjIzOTEwMy0yLjM5OTAwNCAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIzOTYwMSAuNDk0MTQ3LTIuMzE5MzAzQy43MTczMS0zLjA3NjQ2MyAxLjA4MzkzNS0zLjI5MTY1NiAxLjMyMzAzOS0zLjI5MTY1NkMxLjQzNDYyLTMuMjkxNjU2IDEuNTE0MzIxLTMuMjUxODA2IDEuNTE0MzIxLTMuMDI4NjQzQzEuNTE0MzIxLTIuOTQ4OTQxIDEuNTA2MzUxLTIuODM3MzYgMS40MjY2NS0yLjU5ODI1N0wxLjIxMTQ1Ny0yLjA0ODMxOVonLz4KPHBhdGggaWQ9J2c2LTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnOC00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c4LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnOC00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c4LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnNC0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2cxLTEyJyBkPSdNLjIzOTEwMyAxLjk2MDY0OEMuMjI3MTQ4IDEuOTg0NTU4IC4xOTEyODMgMi4xMzk5NzUgLjE5MTI4MyAyLjE1MTkzQy4xOTEyODMgMi4zMTkzMDMgLjM3MDYxIDIuMzE5MzAzIC40NzgyMDcgMi4zMTkzMDNDLjcxNzMxIDIuMzE5MzAzIC43MTczMSAyLjI5NTM5MiAuNzg5MDQxIDIuMDQ0MzM0Qy44MjQ5MDcgMS44NTMwNTEgMS41NDIyMTctMS4wMTYxODkgMS41NTQxNzItMS4wNDAxQzIuMDU2Mjg5LS4yMDMyMzggMi45NzY4MzcgLjE0MzQ2MiAzLjkzMzI1IC4xNDM0NjJDNi4zMzYyMzkgLjE0MzQ2MiA3LjY3NTIxOC0xLjY4NTY3OSA3LjY3NTIxOC0zLjI1MTgwNkM3LjY3NTIxOC00LjA4ODY2NyA3LjMwNDYwOC00LjU0Mjk2NCA2LjkxMDA4Ny00Ljg0MTg0M0M3LjM0MDQ3My01LjIwMDQ5OCA3LjgzMDYzNS01Ljk3NzU4NCA3LjgzMDYzNS02LjgwMjQ5MUM3LjgzMDYzNS03LjgxODY4IDcuMDg5NDE1LTguMzkyNTI4IDUuOTY1NjI5LTguMzkyNTI4QzQuMjU2MDQtOC4zOTI1MjggMi40ODY2NzUtNy4wNjU1MDQgMi4wNTYyODktNS4zMzIwMDVMLjIzOTEwMyAxLjk2MDY0OFpNNS42NTQ3OTUtNC43OTQwMjJDNS4zNjc4Ny00LjU5MDc4NSA1LjA2ODk5MS00LjU5MDc4NSA0LjkwMTYxOS00LjU5MDc4NUM0Ljg1Mzc5OC00LjU5MDc4NSA0LjMyNzc3MS00LjU5MDc4NSA0LjMyNzc3MS00LjY4NjQyNkM0LjMyNzc3MS00Ljg3NzcwOSA0LjkxMzU3NC00Ljg3NzcwOSA1LjA2ODk5MS00Ljg3NzcwOUM1LjI4NDE4NC00Ljg3NzcwOSA1LjQyNzY0Ni00Ljg3NzcwOSA1LjY1NDc5NS00Ljc5NDAyMlpNNi4wNjEyNy01LjIxMjQ1M0M1LjY2Njc1LTUuMzA4MDk1IDUuMzMyMDA1LTUuMzA4MDk1IDUuMTA0ODU3LTUuMzA4MDk1QzQuNzIyMjkxLTUuMzA4MDk1IDMuNzUzOTIzLTUuMzA4MDk1IDMuNzUzOTIzLTQuNjYyNTE2QzMuNzUzOTIzLTQuMTYwMzk5IDQuNDcxMjMzLTQuMTYwMzk5IDQuODg5NjY0LTQuMTYwMzk5QzUuMDkyOTAyLTQuMTYwMzk5IDUuNjMwODg0LTQuMTYwMzk5IDYuMTY4ODY3LTQuMzg3NTQ3QzYuMjY0NTA4LTQuMjA4MjE5IDYuMzAwMzc0LTMuOTY5MTE2IDYuMzAwMzc0LTMuNzY1ODc4QzYuMzAwMzc0LTMuMzM1NDkyIDUuOTg5NTM5LTEuODg4OTE3IDUuNjE4OTI5LTEuMjY3MjQ4QzUuMjQ4MzE5LS42ODE0NDUgNC42NjI1MTYtLjI4NjkyNCAzLjkwOTM0LS4yODY5MjRDMi43OTc1MDktLjI4NjkyNCAxLjg2NTAwNi0uOTU2NDEzIDEuODY1MDA2LTIuMDMyMzc5QzEuODY1MDA2LTIuMjcxNDgyIDEuOTI0NzgyLTIuNTIyNTQgMS45NDg2OTItMi42NDIwOTJDMi4xMjgwMi0zLjM0NzQ0NyAyLjUxMDU4NS00LjkxMzU3NCAyLjY1NDA0Ny01LjQzOTYwMUMzLjAzNjYxMy02Ljc0MjcxNSA0LjQ4MzE4OC03Ljk2MjE0MiA1LjkwNTg1My03Ljk2MjE0MkM2LjM0ODE5NC03Ljk2MjE0MiA2LjYxMTIwOC03Ljc0Njk0OSA2LjYxMTIwOC03LjI4MDY5N0M2LjYxMTIwOC02LjkxMDA4NyA2LjMyNDI4NC01LjY3ODcwNSA2LjA2MTI3LTUuMjEyNDUzWicvPgo8cGF0aCBpZD0nZzEtMTIxJyBkPSdNNi44OTgxMzItNC41MDcwOThDNi45NTc5MDgtNC43MjIyOTEgNi45NTc5MDgtNC43NDYyMDIgNi45NTc5MDgtNC43ODIwNjdDNi45NTc5MDgtNS4wNDUwODEgNi43NjY2MjUtNS4zMDgwOTUgNi4zOTYwMTUtNS4zMDgwOTVDNS43NzQzNDYtNS4zMDgwOTUgNS42MzA4ODQtNC43NDYyMDIgNS41NDcxOTgtNC40MjM0MTJMNS4yMzYzNjQtMy4xODAwNzVDNS4wOTI5MDItMi42MDYyMjcgNC44NjU3NTMtMS42ODU2NzkgNC43MzQyNDctMS4xOTU1MTdDNC42NzQ0NzEtLjkzMjUwMyA0LjMwMzg2MS0uNjQ1NTc5IDQuMjY3OTk1LS42MjE2NjlDNC4xMzY0ODgtLjUzNzk4MyAzLjg0OTU2NC0uMzM0NzQ1IDMuNDU1MDQ0LS4zMzQ3NDVDMi43NDk2ODktLjMzNDc0NSAyLjczNzczMy0uOTMyNTAzIDIuNzM3NzMzLTEuMjA3NDcyQzIuNzM3NzMzLTEuOTM2NzM3IDMuMTA4MzQ0LTIuODY5MjQgMy40NDMwODgtMy43MzAwMTJDMy41NjI2NC00LjA0MDg0NyAzLjU5ODUwNi00LjEyNDUzMyAzLjU5ODUwNi00LjMyNzc3MUMzLjU5ODUwNi01LjAyMTE3MSAyLjkwNTEwNi01LjQwMzczNiAyLjI0NzU3Mi01LjQwMzczNkMuOTgwMzI0LTUuNDAzNzM2IC4zODI1NjUtMy43Nzc4MzMgLjM4MjU2NS0zLjUzODczQy4zODI1NjUtMy4zNzEzNTcgLjU2MTg5My0zLjM3MTM1NyAuNjY5NDg5LTMuMzcxMzU3Qy44MTI5NTEtMy4zNzEzNTcgLjg5NjYzOC0zLjM3MTM1NyAuOTQ0NDU4LTMuNTI2Nzc1QzEuMzM4OTc5LTQuODUzNzk4IDEuOTk2NTEzLTQuOTczMzUgMi4xNzU4NDEtNC45NzMzNUMyLjI1OTUyNy00Ljk3MzM1IDIuMzc5MDc4LTQuOTczMzUgMi4zNzkwNzgtNC43MjIyOTFDMi4zNzkwNzgtNC40NDczMjMgMi4yNDc1NzItNC4xMzY0ODggMi4xNzU4NDEtMy45NDUyMDVDMS43MDk1ODktMi43NDk2ODkgMS40NTg1MzEtMi4wNjgyNDQgMS40NTg1MzEtMS40NTg1MzFDMS40NTg1MzEtLjA5NTY0MSAyLjY1NDA0NyAuMDk1NjQxIDMuMzU5NDAyIC4wOTU2NDFDMy42NTgyODEgLjA5NTY0MSA0LjA2NDc1NyAuMDQ3ODIxIDQuNTA3MDk4LS4yNjMwMTRDNC4xNzIzNTQgMS4yMDc0NzIgMy4yNzU3MTYgMS45ODQ1NTggMi40NTA4MDkgMS45ODQ1NThDMi4yOTUzOTIgMS45ODQ1NTggMS45NjA2NDggMS45NjA2NDggMS43MjE1NDQgMS44MTcxODZDMi4xMDQxMSAxLjY2MTc2OCAyLjI5NTM5MiAxLjMzODk3OSAyLjI5NTM5MiAxLjAxNjE4OUMyLjI5NTM5MiAuNTg1ODAzIDEuOTQ4NjkyIC40NjYyNTIgMS43MDk1ODkgLjQ2NjI1MkMxLjI2NzI0OCAuNDY2MjUyIC44NDg4MTcgLjg0ODgxNyAuODQ4ODE3IDEuMzc0ODQ0Qy44NDg4MTcgMS45ODQ1NTggMS40ODI0NDEgMi40MTQ5NDQgMi40NTA4MDkgMi40MTQ5NDRDMy44MjU2NTQgMi40MTQ5NDQgNS40MDM3MzYgMS40OTQzOTYgNS43NzQzNDYgLjAxMTk1NUw2Ljg5ODEzMi00LjUwNzA5OFonLz4KPHBhdGggaWQ9J2cyLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cyLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzItMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzItMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cyLTQwJyBkPSdNNS4zOTE3ODEgMjEuODQyMDkyQzUuMzkxNzgxIDIwLjUyNzAyNCA0LjQ4MzE4OCAxOC41MDY2IDIuNDAyOTg5IDE3LjQ1NDU0NUMzLjY5NDE0NyAxNi43NjExNDYgNS4yMzYzNjQgMTUuMzYyMzkxIDUuMzc5ODI2IDEzLjEyNjc3NUw1LjM5MTc4MSAxMy4wNTUwNDRWNC43NzAxMTJDNS4zOTE3ODEgMy43ODk3ODggNS4zOTE3ODEgMy41NzQ1OTUgNS40ODc0MjIgMy4xMjAyOTlDNS43MDI2MTUgMi4xNjM4ODUgNi4yNzY0NjMgLjk4MDMyNCA3Ljc5NDc3IC4wODM2ODZDNy44OTA0MTEgLjAyMzkxIDcuOTAyMzY2IC4wMTE5NTUgNy45MDIzNjYtLjIwMzIzOEM3LjkwMjM2Ni0uNDY2MjUyIDcuODkwNDExLS40NzgyMDcgNy42MjczOTctLjQ3ODIwN0M3LjQxMjIwNC0uNDc4MjA3IDcuMzg4Mjk0LS40NzgyMDcgNy4wNjU1MDQtLjI4NjkyNEM0LjM4NzU0NyAxLjIzMTM4MiA0LjIzMjEzIDMuNDU1MDQ0IDQuMjMyMTMgMy44NzM0NzRWMTIuMzczNTk5QzQuMjMyMTMgMTMuMjM0MzcxIDQuMjMyMTMgMTQuMjAyNzQgMy42MTA0NjEgMTUuMzAyNjE1QzMuMDYwNTIzIDE2LjI4MjkzOSAyLjQxNDk0NCAxNi43NzMxMDEgMS45MDA4NzIgMTcuMTE5ODAxQzEuNzMzNDk5IDE3LjIyNzM5NyAxLjcyMTU0NCAxNy4yMzkzNTIgMS43MjE1NDQgMTcuNDQyNTlDMS43MjE1NDQgMTcuNjU3NzgzIDEuNzMzNDk5IDE3LjY2OTczOCAxLjgyOTE0MSAxNy43Mjk1MTRDMi44NDUzMyAxOC4zOTkwMDQgMy45MzMyNSAxOS40NjMwMTQgNC4xOTYyNjQgMjEuNDExNzA2QzQuMjMyMTMgMjEuNjc0NzIgNC4yMzIxMyAyMS42OTg2MyA0LjIzMjEzIDIxLjg0MjA5MlYzMS4wMjM2NjFDNC4yMzIxMyAzMS45OTIwMyA0LjgyOTg4OCAzNC4wMDA0OTggNy4xMzcyMzUgMzUuMjE5OTI1QzcuNDEyMjA0IDM1LjM3NTM0MiA3LjQzNjExNSAzNS4zNzUzNDIgNy42MjczOTcgMzUuMzc1MzQyQzcuODkwNDExIDM1LjM3NTM0MiA3LjkwMjM2NiAzNS4zNjMzODcgNy45MDIzNjYgMzUuMTAwMzc0QzcuOTAyMzY2IDM0Ljg4NTE4MSA3Ljg5MDQxMSAzNC44NzMyMjUgNy44NDI1OSAzNC44NDkzMTVDNy4zMjg1MTggMzQuNTI2NTI2IDUuNzYyMzkxIDMzLjU4MjA2NyA1LjQzOTYwMSAzMS41MDE4NjhDNS4zOTE3ODEgMzEuMTkxMDM0IDUuMzkxNzgxIDMxLjE2NzEyMyA1LjM5MTc4MSAzMS4wMTE3MDZWMjEuODQyMDkyWicvPgo8cGF0aCBpZD0nZzItNDEnIGQ9J000LjIzMjEzIDMwLjEyNzAyNEM0LjIzMjEzIDMxLjEwNzM0NyA0LjIzMjEzIDMxLjMyMjU0IDQuMTM2NDg4IDMxLjc3NjgzN0MzLjkyMTI5NSAzMi43MzMyNSAzLjM0NzQ0NyAzMy45MDQ4NTcgMS44MjkxNDEgMzQuODEzNDVDMS43MzM0OTkgMzQuODczMjI1IDEuNzIxNTQ0IDM0Ljg4NTE4MSAxLjcyMTU0NCAzNS4xMDAzNzRDMS43MjE1NDQgMzUuMzc1MzQyIDEuNzMzNDk5IDM1LjM3NTM0MiAyLjAwODQ2OCAzNS4zNzUzNDJDMi4yMTE3MDYgMzUuMzc1MzQyIDIuMjM1NjE2IDM1LjM3NTM0MiAyLjU1ODQwNiAzNS4xODQwNkM1LjIzNjM2NCAzMy42NjU3NTMgNS4zOTE3ODEgMzEuNDQyMDkyIDUuMzkxNzgxIDMxLjAyMzY2MVYyMi41MjM1MzdDNS4zOTE3ODEgMjEuNjYyNzY1IDUuMzkxNzgxIDIwLjY5NDM5NiA2LjAxMzQ1IDE5LjU5NDUyMUM2LjUzOTQ3NyAxOC42NjIwMTcgNy4xNDkxOTEgMTguMTU5OSA3LjcyMzAzOSAxNy43NzczMzVDNy44OTA0MTEgMTcuNjY5NzM4IDcuOTAyMzY2IDE3LjY1Nzc4MyA3LjkwMjM2NiAxNy40NDI1OUM3LjkwMjM2NiAxNy4yODcxNzMgNy45MDIzNjYgMTcuMjI3Mzk3IDcuODU0NTQ1IDE3LjE5MTUzMkM3LjI5MjY1MyAxNi44MzI4NzcgNS43Mzg0ODEgMTUuODQwNTk4IDUuNDI3NjQ2IDEzLjQ4NTQzQzUuMzkxNzgxIDEzLjIyMjQxNiA1LjM5MTc4MSAxMy4xOTg1MDYgNS4zOTE3ODEgMTMuMDU1MDQ0VjMuODczNDc0QzUuMzkxNzgxIDIuOTA1MTA2IDQuNzk0MDIyIC44OTY2MzggMi40ODY2NzUtLjMyMjc5QzIuMjExNzA2LS40NzgyMDcgMi4xODc3OTYtLjQ3ODIwNyAyLjAwODQ2OC0uNDc4MjA3QzEuNzMzNDk5LS40NzgyMDcgMS43MjE1NDQtLjQ3ODIwNyAxLjcyMTU0NC0uMjAzMjM4QzEuNzIxNTQ0LS4wMTE5NTUgMS43MjE1NDQgLjAyMzkxIDEuODA1MjMgLjA3MTczMUM0LjA3NjcxMiAxLjQyMjY2NSA0LjIzMjEzIDMuNDE5MTc4IDQuMjMyMTMgMy44ODU0M1YxMy4wNTUwNDRDNC4yMzIxMyAxNC4zNzAxMTIgNS4xNDA3MjIgMTYuMzkwNTM1IDcuMjIwOTIyIDE3LjQ0MjU5QzUuOTI5NzYzIDE4LjEzNTk5IDQuMzg3NTQ3IDE5LjUzNDc0NSA0LjI0NDA4NSAyMS43NzAzNjFMNC4yMzIxMyAyMS44NDIwOTJWMzAuMTI3MDI0WicvPgo8cGF0aCBpZD0nZzItODgnIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgLjU3Mzg0OCAxMi4wMjY4OTkgLjc0MTIyIDEyLjEzNDQ5NiAuNzY1MTMxQzEyLjc4MDA3NSAuODYwNzcyIDEzLjgyMDE3NCAxLjA2NDAxIDE0Ljc2NDYzMyAxLjY2MTc2OEMxNS4wNjM1MTIgMS44NTMwNTEgMTUuODc2NDYzIDIuMzkxMDM0IDE2LjI4MjkzOSAzLjM1OTQwMkgxNi41ODE4MThMMTUuMTM1MjQzIDBIMS4wMDQyMzRDLjcyOTI2NSAwIC43MTczMSAuMDExOTU1IC42ODE0NDUgLjA4MzY4NkMuNjY5NDg5IC4xMTk1NTIgLjY2OTQ4OSAuMzQ2NyAuNjY5NDg5IC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMLjgwMDk5NiAxNi4zOTA1MzVDLjY4MTQ0NSAxNi41MzM5OTggLjY4MTQ0NSAxNi41OTM3NzMgLjY4MTQ0NSAxNi42MDU3MjlDLjY4MTQ0NSAxNi43MzcyMzUgLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onLz4KPHBhdGggaWQ9J2c5LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOS00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzktNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzktNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnOS02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzktMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzktMTA4JyBkPSdNMi4wNTYyODktOC4yOTY4ODdMLjM5NDUyMS04LjE2NTM4Vi03LjgxODY4QzEuMjA3NDcyLTcuODE4NjggMS4zMDMxMTMtNy43MzQ5OTQgMS4zMDMxMTMtNy4xNDkxOTFWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzE1MDY4LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFTMi42MzAxMzctLjAyMzkxIDIuOTY0ODgyIDBWLS4zNDY3QzIuMTk5NzUxLS4zNDY3IDIuMDU2Mjg5LS4zNDY3IDIuMDU2Mjg5LS44ODQ2ODJWLTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzktMTExJyBkPSdNNS40ODc0MjItMi41NTg0MDZDNS40ODc0MjItNC4xMDA2MjMgNC4zMTU4MTYtNS4zMzIwMDUgMi45MjkwMTYtNS4zMzIwMDVDMS40OTQzOTYtNS4zMzIwMDUgLjM1ODY1NS00LjA2NDc1NyAuMzU4NjU1LTIuNTU4NDA2Qy4zNTg2NTUtMS4wMjgxNDQgMS41NTQxNzIgLjExOTU1MiAyLjkxNzA2MSAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNS40ODc0MjItMS4wNTIwNTUgNS40ODc0MjItMi41NTg0MDZaTTIuOTI5MDE2LS4xNDM0NjJDMi40ODY2NzUtLjE0MzQ2MiAxLjk0ODY5Mi0uMzM0NzQ1IDEuNjAxOTkzLS45MjA1NDhDMS4yNzkyMDMtMS40NTg1MzEgMS4yNjcyNDgtMi4xNjM4ODUgMS4yNjcyNDgtMi42NjYwMDJDMS4yNjcyNDgtMy4xMjAyOTkgMS4yNjcyNDgtMy44NDk1NjQgMS42Mzc4NTgtNC4zODc1NDdDMS45NzI2MDMtNC45MDE2MTkgMi40OTg2My01LjA5MjkwMiAyLjkxNzA2MS01LjA5MjkwMkMzLjM4MzMxMy01LjA5MjkwMiAzLjg4NTQzLTQuODc3NzA5IDQuMjA4MjE5LTQuNDExNDU3QzQuNTc4ODI5LTMuODYxNTE5IDQuNTc4ODI5LTMuMTA4MzQ0IDQuNTc4ODI5LTIuNjY2MDAyQzQuNTc4ODI5LTIuMjQ3NTcyIDQuNTc4ODI5LTEuNTA2MzUxIDQuMjY3OTk1LS45NDQ0NThDMy45MzMyNS0uMzcwNjEgMy4zODMzMTMtLjE0MzQ2MiAyLjkyOTAxNi0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzctMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2c3LTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2c3LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNy02MScgZD0nTTUuMTI4NzY3LTguNTI0MDM1QzUuMTI4NzY3LTguNTM1OTkgNS4yMDA0OTgtOC43MTUzMTggNS4yMDA0OTgtOC43MzkyMjhDNS4yMDA0OTgtOC44ODI2OSA1LjA4MDk0Ni04Ljk2NjM3NiA0Ljk4NTMwNS04Ljk2NjM3NkM0LjkyNTUyOS04Ljk2NjM3NiA0LjgxNzkzMy04Ljk2NjM3NiA0LjcyMjI5MS04LjcwMzM2MkwuNzE3MzEgMi41NDY0NTFDLjcxNzMxIDIuNTU4NDA2IC42NDU1NzkgMi43Mzc3MzMgLjY0NTU3OSAyLjc2MTY0NEMuNjQ1NTc5IDIuOTA1MTA2IC43NjUxMzEgMi45ODg3OTIgLjg2MDc3MiAyLjk4ODc5MkMuOTMyNTAzIDIuOTg4NzkyIDEuMDQwMSAyLjk3NjgzNyAxLjEyMzc4NiAyLjcyNTc3OEw1LjEyODc2Ny04LjUyNDAzNVonLz4KPHBhdGggaWQ9J2c3LTk2JyBkPSdNMS4wOTk4NzUtMi4wMzIzNzlDLjM0NjctMS4yOTExNTggLjE1NTQxNy0xLjExMTgzMSAuMTU1NDE3LTEuMDY0MDFTLjIwMzIzOC0uOTMyNTAzIC4yODY5MjQtLjkzMjUwM0MuMzQ2Ny0uOTMyNTAzIDEuMDI4MTQ0LTEuNTkwMDM3IDEuMTIzNzg2LTEuNjk3NjM0QzEuMTk1NTE3LS44OTY2MzggMS40OTQzOTYgLjE0MzQ2MiAyLjQyNjg5OSAuMTQzNDYyQzIuOTA1MTA2IC4xNDM0NjIgMy4zMzU0OTItLjE1NTQxNyAzLjUyNjc3NS0uMjk4ODc5QzMuNjgyMTkyLS40MTg0MzEgNC4yNTYwNC0uOTA4NTkzIDQuMjU2MDQtMS4wMTYxODlDNC4yNTYwNC0xLjA3NTk2NSA0LjE5NjI2NC0xLjE0NzY5NiA0LjEzNjQ4OC0xLjE0NzY5NkM0LjA4ODY2Ny0xLjE0NzY5NiAzLjkwOTM0LS45NjgzNjkgMy44NjE1MTktLjkyMDU0OEMzLjQ0MzA4OC0uNTE0MDcyIDIuOTE3MDYxLS4wOTU2NDEgMi40Mzg4NTQtLjA5NTY0MUMxLjc5MzI3NS0uMDk1NjQxIDEuNzA5NTg5LTEuMDI4MTQ0IDEuNzA5NTg5LTEuNjczNzI0QzEuNzA5NTg5LTEuNzkzMjc1IDEuNzA5NTg5LTIuMjk1MzkyIDEuNzkzMjc1LTIuMzkxMDM0QzIuNDk4NjMtMy4xMjAyOTkgNC43MTAzMzYtNS40MDM3MzYgNC43MTAzMzYtNy41MTk4MDFDNC43MTAzMzYtNy45OTgwMDcgNC41MzEwMDktOC40MTY0MzggNC4wMTY5MzYtOC40MTY0MzhDMi45MDUxMDYtOC40MTY0MzggMS45MzY3MzctNS45NTM2NzQgMS43NjkzNjUtNS40OTkzNzdDMS43MjE1NDQtNS4zNzk4MjYgMS4wMjgxNDQtMy41Mzg3MyAxLjA5OTg3NS0yLjAzMjM3OVpNMS44MTcxODYtMi43NzM1OTlDMS44MjkxNDEtMi44NDUzMyAyLjM2NzEyMy01Ljk3NzU4NCAzLjM3MTM1Ny03LjY1MTMwOEMzLjU3NDU5NS03Ljk3NDA5NyAzLjc3NzgzMy04LjE3NzMzNSA0LjAxNjkzNi04LjE3NzMzNUM0LjQyMzQxMi04LjE3NzMzNSA0LjQ0NzMyMy03Ljc5NDc3IDQuNDQ3MzIzLTcuNTMxNzU2QzQuNDQ3MzIzLTcuMTEzMzI1IDQuMzI3NzcxLTYuMDM3MzYgMy4yODc2NzEtNC41MzEwMDlDMi45NzY4MzctNC4wODg2NjcgMi40OTg2My0zLjQ5MDkwOSAxLjgxNzE4Ni0yLjc3MzU5OVonLz4KPHBhdGggaWQ9J2c3LTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTk2Jy8+Cjx1c2UgeD0nNC45MTIxMDYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzkuNDY0NDMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzEtMTInLz4KPHVzZSB4PScxNy43NTgyOTcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzI1LjYzMTQ1MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTYxJy8+Cjx1c2UgeD0nMzguMDU2OTMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzQtMCcvPgo8dXNlIHg9JzU1LjQxMzEzNCcgeT0nLTI5Ljk3NjQyNScgeGxpbms6aHJlZj0nI2c2LTExMCcvPgo8dXNlIHg9JzQ5LjM0NzkyNycgeT0nLTI2LjM4OTg2OScgeGxpbms6aHJlZj0nI2cyLTg4Jy8+Cjx1c2UgeD0nNTEuMTMwMzIxJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSc1NC4wMTM0NjEnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2c4LTYxJy8+Cjx1c2UgeD0nNjAuNTk5OTY3JyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzY4LjYwOTA0MScgeT0nLTM1LjQ3NTkyOCcgeGxpbms6aHJlZj0nI2cyLTQwJy8+Cjx1c2UgeD0nNzguMjM5NjQ0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTA4Jy8+Cjx1c2UgeD0nODEuNDkxMzA1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTExJy8+Cjx1c2UgeD0nODcuMzQ0Mjk2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTAzJy8+Cjx1c2UgeD0nOTMuMzU5ODY5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc5Ny45MTIxOTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy0yNycvPgo8dXNlIHg9JzEwNC45OTQ1OTknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzEwOS41NDY5MjUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PScxMTcuMDQ2NTQxJyB5PSctMTIuMjA5NjYxJyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nMTIwLjQyNzgxMycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMTI0Ljk4MDEzOScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQxJy8+Cjx1c2UgeD0nMTMyLjE4OTEyOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nMTQzLjk1MDQ0MycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMTQ4LjUwMjc2OScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQ5Jy8+Cjx1c2UgeD0nMTU3LjAxMjQyMycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nMTY4Ljc3MzczOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQ5Jy8+Cjx1c2UgeD0nMTc0LjYyNjcyOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nMTgwLjQ3OTcxOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTI0Jy8+Cjx1c2UgeD0nMTg2LjE3MDE1NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMTkwLjcyMjQ4MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzE5OC4yMjIwOTgnIHk9Jy0xMi4yMDk2NjEnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PScyMDEuNjAzMzcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzIwNi4xNTU2OTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzIxMi43MDA1MTknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS0xMDgnLz4KPHVzZSB4PScyMTUuOTUyMTgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS0xMTEnLz4KPHVzZSB4PScyMjEuODA1MTcxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktMTAzJy8+Cjx1c2UgeD0nMjI5LjgxMzI0MicgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cyLTIwJy8+Cjx1c2UgeD0nMjM2LjEyMjkzOScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQ5Jy8+Cjx1c2UgeD0nMjQ0LjYzMjU5MycgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQzJy8+Cjx1c2UgeD0nMjU2LjM5MzkwOCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c3LTI0Jy8+Cjx1c2UgeD0nMjYyLjA4NDM0NScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c5LTQwJy8+Cjx1c2UgeD0nMjY2LjYzNjY3MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzI3NC4xMzYyODgnIHk9Jy0xMi4yMDk2NjEnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PScyNzcuNTE3NTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzI4NC4wNjIzODMnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0xOCcvPgo8dXNlIHg9JzI5NC4wNTgyNjknIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnNy0xMjInLz4KPHVzZSB4PScyOTkuNDk2MTYnIHk9Jy0yMS43NDI3MTQnIHhsaW5rOmhyZWY9JyNnMC0xMjEnLz4KPHVzZSB4PSczMDQuODI1MzEyJyB5PSctMTkuNjk0ODUyJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzExLjE0MTg2NScgeT0nLTIzLjUzNTk3NycgeGxpbms6aHJlZj0nI2c0LTAnLz4KPHVzZSB4PSczMjMuMDk3MDI2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzctMjInLz4KPHVzZSB4PSczMzAuMTM5OTk2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSczMzQuNjkyMzIyJyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzEtMTIxJy8+Cjx1c2UgeD0nMzQyLjE5MTkzOScgeT0nLTIwLjcxMzIzNCcgeGxpbms6aHJlZj0nI2c2LTEwNScvPgo8dXNlIHg9JzM0NS41NzMyMTEnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8cmVjdCB4PScyOTQuMDU4MjY5JyB5PSctMTguMjYwMjknIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzU2LjA2NzI1OScvPgo8dXNlIHg9JzMwOC41NTc5MjcnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c3LTI3Jy8+Cjx1c2UgeD0nMzE1LjY0MDMzMScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSczMjAuMTkyNjU3JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSczMjcuNjkyMjc0JyB5PSctNC4wMDg5OTknIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSczMzEuMDczNTQ1JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzM1MS4zMjEwNDInIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0xOScvPgo8dXNlIHg9JzM2MC4xMjE0MTUnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMScvPgo8dXNlIHg9JzM2OS4wODc3NzYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzM4MC44NDkwOTEnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMCcvPgo8dXNlIHg9JzM4Ny4xNTg3ODgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00OScvPgo8dXNlIHg9JzM5NS42Njg0NDInIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MycvPgo8dXNlIHg9JzQwNy40Mjk3NTcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNy0yNCcvPgo8dXNlIHg9JzQxMy4xMjAxOTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzQxNy42NzI1MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2cxLTEyMScvPgo8dXNlIHg9JzQyNS4xNzIxMzcnIHk9Jy0xMi4yMDk2NjEnIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSc0MjguNTUzNDA5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzktNDEnLz4KPHVzZSB4PSc0MzUuMDk4MjMyJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzItMTgnLz4KPHVzZSB4PSc0NDUuMDk0MTE5JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzctMTIyJy8+Cjx1c2UgeD0nNDUwLjUzMjAwOScgeT0nLTIxLjc0MjcxNCcgeGxpbms6aHJlZj0nI2cwLTEyMScvPgo8dXNlIHg9JzQ1NS44NjExNjEnIHk9Jy0xOS42OTQ4NTInIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0NjIuMTc3NzE1JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzQtMCcvPgo8dXNlIHg9JzQ3NC4xMzI4NzUnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnNy0yMicvPgo8dXNlIHg9JzQ4MS4xNzU4NDYnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnOS00MCcvPgo8dXNlIHg9JzQ4NS43MjgxNzEnIHk9Jy0yMy41MzU5NzcnIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSc0OTMuMjI3Nzg4JyB5PSctMjAuNzEzMjM0JyB4bGluazpocmVmPScjZzYtMTA1Jy8+Cjx1c2UgeD0nNDk2LjYwOTA2JyB5PSctMjMuNTM1OTc3JyB4bGluazpocmVmPScjZzktNDEnLz4KPHJlY3QgeD0nNDQ1LjA5NDExOScgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1Ni4wNjcyNTknLz4KPHVzZSB4PSc0NTkuNTkzNzc2JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNy0yNycvPgo8dXNlIHg9JzQ2Ni42NzYxOCcgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzktNDAnLz4KPHVzZSB4PSc0NzEuMjI4NTA2JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnMS0xMjEnLz4KPHVzZSB4PSc0NzguNzI4MTIzJyB5PSctNC4wMDg5OTknIHhsaW5rOmhyZWY9JyNnNi0xMDUnLz4KPHVzZSB4PSc0ODIuMTA5Mzk1JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOS00MScvPgo8dXNlIHg9JzUwMi4zNTY4OTInIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0xOScvPgo8dXNlIHg9JzUxMS4xNTcyNjUnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMi0yMScvPgo8dXNlIHg9JzUxNy40NjY5NjInIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nNTI0LjA1MzQ2OScgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nNTI4LjI4NzY1MScgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c2LTYxJy8+Cjx1c2UgeD0nNTMyLjUyMTgzNCcgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c2LTI0Jy8+Cjx1c2UgeD0nNTM2LjU1NTM2OScgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nNTM5Ljg0ODYyMicgeT0nLTI5LjM0NzUxMicgeGxpbms6aHJlZj0nI2cwLTEyMScvPgo8dXNlIHg9JzU0NS4xNzc3NzQnIHk9Jy0yNy4yOTk2NScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzU0OC4zMzk1MzInIHk9Jy0yOS4zNDc1MTInIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzU1Mi4xMzA5MTcnIHk9Jy0zNS40NzU5MjgnIHhsaW5rOmhyZWY9JyNnMi00MScvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
defined on
 such that
such that  for all
for all  .
.And if any of the
is equal to 0, the log-likelihood is defined as:
The initialization of the optimization problem is crucial. Two initial points
 are proposed:
are proposed:the Gumbel initial point: in that case, we assume that the GEV is a stationary Gumbel distribution and we deduce
 from the mean
from the mean  and standard variation
and standard variation  of the data:
of the data:
 and
and  where
where
 is Euler’s constant; then we take the initial point
is Euler’s constant; then we take the initial point  . This is the default initial point;
. This is the default initial point;the Static initial point: in that case, we assume that the GEV is stationary and
is the maximum likelihood estimate resulting from that assumption.
The result class provides:
the estimator
 ,
,the asymptotic distribution of
,the parameter function
 ,
,the graphs of the parameter functions
 , where all the components of
, where all the components of
 are fixed to a reference value excepted for , for each
are fixed to a reference value excepted for , for each  ,
,the graphs of the parameter functions
 , where all the
components of are fixed to a reference value excepted for
, where all the
components of are fixed to a reference value excepted for
 , for each
, for each  ,
,the normalizing function
 ,
,the optimal log-likelihood value
,the GEV distribution at covariate
,the graphs of the quantile functions of order
 :
:  where all the components
of are fixed to a reference value excepted for , for each ,
where all the components
of are fixed to a reference value excepted for , for each ,the graphs of the quantile functions of order
:  where all the components of are fixed to a
reference value excepted for , for each .
where all the components of are fixed to a
reference value excepted for , for each .
- buildEstimator(*args)¶
Build the distribution and the parameter distribution.
- Parameters:
- sample2-d sequence of float
Data.
- parameters
DistributionParameters Optional, the parametrization.
- Returns:
- resDist
DistributionFactoryResult The results.
- resDist
Notes
According to the way the native parameters of the distribution are estimated, the parameters distribution differs:
Moments method: the asymptotic parameters distribution is normal and estimated by Bootstrap on the initial data;
Maximum likelihood method with a regular model: the asymptotic parameters distribution is normal and its covariance matrix is the inverse Fisher information matrix;
Other methods: the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting (see
KernelSmoothing).
If another set of parameters is specified, the native parameters distribution is first estimated and the new distribution is determined from it:
if the native parameters distribution is normal and the transformation regular at the estimated parameters values: the asymptotic parameters distribution is normal and its covariance matrix determined from the inverse Fisher information matrix of the native parameters and the transformation;
in the other cases, the asymptotic parameters distribution is estimated by Bootstrap on the initial data and kernel fitting.
- buildMethodOfLikelihoodMaximization(sample, r=0)¶
Estimate the distribution from the
largest order statistics.- Parameters:
- sample2-d sequence of float
Block maxima grouped in a sample of size
 and dimension
and dimension  .
.- rint,
 ,
, Number of largest order statistics taken into account among the
stored ones.By default,
 which means that all the maxima are used.
which means that all the maxima are used.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution.
- distribution
Notes
The method estimates a GEV distribution parameterized by
from a given sample.Let us suppose we have a series of independent and identically distributed variables and that data are grouped into
blocks. In each block, the largest observations are recorded.We define the series
 for
for  where the values are sorted
in decreasing order.
where the values are sorted
in decreasing order.The estimator of
maximizes the log-likelihood built from the largest order statistics,
with defined as:If
 , then:
, then:(1)¶
![\ell(\mu, \sigma, \xi) = -nr \log \sigma - \sum_{i=1}^n \biggl[ 1 + \xi \Bigl( \frac{z_i^{(r)} - \mu }{\sigma} \Bigr) \biggr]^{-1/\xi} -\left(\dfrac{1}{\xi} +1 \right) \sum_{i=1}^n \sum_{k=1}^r \log \biggl[ 1 + \xi \Bigl( \frac{z_i^{(k)} - \mu }{\sigma} \Bigr) \biggr]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzQ2My45MjIxNDJwdCcgaGVpZ2h0PSczNC4yNzg0OTlwdCcgdmlld0JveD0nMCAtMzUuNDc0MDEzIDQ2My45MjIxNDIgMzQuMjc4NDk5Jz4KPGRlZnM+CjxwYXRoIGlkPSdnMC0xNicgZD0nTTYuMTU2OTEyIDIwLjg5NzYzNEM2LjE4MDgyMiAyMC45MDk1ODkgNi4yODg0MTggMjEuMDI5MTQxIDYuMzAwMzc0IDIxLjAyOTE0MUg2LjU2MzM4N0M2LjU5OTI1MyAyMS4wMjkxNDEgNi42OTQ4OTQgMjEuMDE3MTg2IDYuNjk0ODk0IDIwLjkwOTU4OUM2LjY5NDg5NCAyMC44NjE3NjggNi42NzA5ODQgMjAuODM3ODU4IDYuNjQ3MDczIDIwLjgwMTk5M0M2LjIxNjY4NyAyMC4zNzE2MDYgNS41NzExMDggMTkuNzE0MDcyIDQuODI5ODg4IDE4LjM5OTAwNEMzLjUzODczIDE2LjEwMzYxMSAzLjA2MDUyMyAxMy4xNTA2ODUgMy4wNjA1MjMgMTAuMjgxNDQ1QzMuMDYwNTIzIDQuOTczMzUgNC41NjY4NzQgMS44NTMwNTEgNi42NTkwMjktLjI2MzAxNEM2LjY5NDg5NC0uMjk4ODc5IDYuNjk0ODk0LS4zMzQ3NDUgNi42OTQ4OTQtLjM1ODY1NUM2LjY5NDg5NC0uNDc4MjA3IDYuNjExMjA4LS40NzgyMDcgNi40Njc3NDYtLjQ3ODIwN0M2LjMxMjMyOS0uNDc4MjA3IDYuMjg4NDE4LS40NzgyMDcgNi4xODA4MjItLjM4MjU2NUM1LjA0NTA4MSAuNTk3NzU4IDMuNzY1ODc4IDIuMjU5NTI3IDIuOTQwOTcxIDQuNzgyMDY3QzIuNDI2ODk5IDYuMzYwMTQ5IDIuMTUxOTMgOC4yODQ5MzIgMi4xNTE5MyAxMC4yNjk0ODlDMi4xNTE5MyAxMy4xMDI4NjQgMi42NjYwMDIgMTYuMzA2ODQ5IDQuNTQyOTY0IDE5LjA4MDQ0OEM0Ljg2NTc1MyAxOS41NDY3IDUuMzA4MDk1IDIwLjAzNjg2MiA1LjMwODA5NSAyMC4wNDg4MTdDNS40Mjc2NDYgMjAuMTkyMjc5IDUuNTk1MDE5IDIwLjM4MzU2MiA1LjY5MDY2IDIwLjQ2NzI0OEw2LjE1NjkxMiAyMC44OTc2MzRaJy8+CjxwYXRoIGlkPSdnMC0xNycgZD0nTTQuOTczMzUgMTAuMjY5NDg5QzQuOTczMzUgNi44MzgzNTYgNC4xNzIzNTQgMy4xOTIwMyAxLjgxNzE4NiAuNTAyMTE3QzEuNjQ5ODEzIC4zMTA4MzQgMS4yMDc0NzItLjE1NTQxNyAuOTIwNTQ4LS40MDY0NzZDLjgzNjg2Mi0uNDc4MjA3IC44MTI5NTEtLjQ3ODIwNyAuNjU3NTM0LS40NzgyMDdDLjUzNzk4My0uNDc4MjA3IC40MzAzODYtLjQ3ODIwNyAuNDMwMzg2LS4zNTg2NTVDLjQzMDM4Ni0uMzEwODM0IC40NzgyMDctLjI2MzAxNCAuNTAyMTE3LS4yMzkxMDNDLjkwODU5MyAuMTc5MzI4IDEuNTU0MTcyIC44MzY4NjIgMi4yOTUzOTIgMi4xNTE5M0MzLjU4NjU1IDQuNDQ3MzIzIDQuMDY0NzU3IDcuNDAwMjQ5IDQuMDY0NzU3IDEwLjI2OTQ4OUM0LjA2NDc1NyAxNS40NTgwMzIgMi42MzAxMzcgMTguNjI2MTUyIC40NzgyMDcgMjAuODEzOTQ4Qy40NTQyOTYgMjAuODM3ODU4IC40MzAzODYgMjAuODczNzI0IC40MzAzODYgMjAuOTA5NTg5Qy40MzAzODYgMjEuMDI5MTQxIC41Mzc5ODMgMjEuMDI5MTQxIC42NTc1MzQgMjEuMDI5MTQxQy44MTI5NTEgMjEuMDI5MTQxIC44MzY4NjIgMjEuMDI5MTQxIC45NDQ0NTggMjAuOTMzNDk5QzIuMDgwMTk5IDE5Ljk1MzE3NiAzLjM1OTQwMiAxOC4yOTE0MDcgNC4xODQzMDkgMTUuNzY4ODY3QzQuNzEwMzM2IDE0LjEzMTAwOSA0Ljk3MzM1IDEyLjE5NDI3MSA0Ljk3MzM1IDEwLjI2OTQ4OVonLz4KPHBhdGggaWQ9J2cwLTE4JyBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAuMjYzMDE0IDguMzMyNzUyLS4yNjMwMTRDOC4zNjg2MTgtLjI5ODg3OSA4LjM2ODYxOC0uMzIyNzkgOC4zNjg2MTgtLjM1ODY1NUM4LjM2ODYxOC0uNDc4MjA3IDguMjg0OTMyLS40NzgyMDcgOC4xMTc1NTktLjQ3ODIwN1M3LjkyNjI3Ni0uNDc4MjA3IDcuNzQ2OTQ5LS4yOTg4NzlDMy43NDE5NjggMy4zNDc0NDcgMi40ODY2NzUgOC44MjI5MTQgMi40ODY2NzUgMTMuODU2MDRDMi40ODY2NzUgMTguNTU0NDIxIDMuNTYyNjQgMjMuMjg4NjY3IDYuNTk5MjUzIDI2Ljg2MzI2M0M2LjgzODM1NiAyNy4xMzgyMzIgNy4yOTI2NTMgMjcuNjI4Mzk0IDcuNzgyODE0IDI4LjA1ODc4QzcuOTI2Mjc2IDI4LjIwMjI0MiA3Ljk1MDE4NyAyOC4yMDIyNDIgOC4xMTc1NTkgMjguMjAyMjQyUzguMzY4NjE4IDI4LjIwMjI0MiA4LjM2ODYxOCAyOC4wODI2OVonLz4KPHBhdGggaWQ9J2cwLTE5JyBkPSdNNi4zMDAzNzQgMTMuODY3OTk1QzYuMzAwMzc0IDkuMTY5NjE0IDUuMjI0NDA4IDQuNDM1MzY3IDIuMTg3Nzk2IC44NjA3NzJDMS45NDg2OTIgLjU4NTgwMyAxLjQ5NDM5NiAuMDk1NjQxIDEuMDA0MjM0LS4zMzQ3NDVDLjg2MDc3Mi0uNDc4MjA3IC44MzY4NjItLjQ3ODIwNyAuNjY5NDg5LS40NzgyMDdDLjUyNjAyNy0uNDc4MjA3IC40MTg0MzEtLjQ3ODIwNyAuNDE4NDMxLS4zNTg2NTVDLjQxODQzMS0uMzEwODM0IC40NjYyNTItLjI2MzAxNCAuNDkwMTYyLS4yMzkxMDNDLjkwODU5MyAuMTkxMjgzIDEuNzA5NTg5IC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgLjk2ODM2OSAyNy40NzI5NzYgLjQ2NjI1MiAyNy45NzUwOTNDLjQ0MjM0MSAyOC4wMTA5NTkgLjQxODQzMSAyOC4wNDY4MjQgLjQxODQzMSAyOC4wODI2OUMuNDE4NDMxIDI4LjIwMjI0MiAuNTI2MDI3IDI4LjIwMjI0MiAuNjY5NDg5IDI4LjIwMjI0MkMuODM2ODYyIDI4LjIwMjI0MiAuODYwNzcyIDI4LjIwMjI0MiAxLjA0MDEgMjguMDIyOTE0QzUuMDQ1MDgxIDI0LjM3NjU4OCA2LjMwMDM3NCAxOC45MDExMjEgNi4zMDAzNzQgMTMuODY3OTk1WicvPgo8cGF0aCBpZD0nZzAtMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzAtMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cwLTg4JyBkPSdNMTUuMTM1MjQzIDE2LjczNzIzNUwxNi41ODE4MTggMTIuOTExNTgySDE2LjI4MjkzOUMxNS44MTY2ODcgMTQuMTU0OTE5IDE0LjU0OTQ0IDE0Ljk2Nzg3IDEzLjE3NDU5NSAxNS4zMjY1MjZDMTIuOTIzNTM3IDE1LjM4NjMwMSAxMS43NTE5MyAxNS42OTcxMzYgOS40NTY1MzggMTUuNjk3MTM2SDIuMjQ3NTcyTDguMzMyNzUyIDguNTU5OUM4LjQxNjQzOCA4LjQ2NDI1OSA4LjQ0MDM0OSA4LjQyODM5NCA4LjQ0MDM0OSA4LjM2ODYxOEM4LjQ0MDM0OSA4LjM0NDcwNyA4LjQ0MDM0OSA4LjMwODg0MiA4LjM1NjY2MyA4LjE4OTI5TDIuNzg1NTU0IC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IC41NzM4NDggMTIuMDI2ODk5IC43NDEyMiAxMi4xMzQ0OTYgLjc2NTEzMUMxMi43ODAwNzUgLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0Qy43MjkyNjUgMCAuNzE3MzEgLjAxMTk1NSAuNjgxNDQ1IC4wODM2ODZDLjY2OTQ4OSAuMTE5NTUyIC42Njk0ODkgLjM0NjcgLjY2OTQ4OSAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TC44MDA5OTYgMTYuMzkwNTM1Qy42ODE0NDUgMTYuNTMzOTk4IC42ODE0NDUgMTYuNTkzNzczIC42ODE0NDUgMTYuNjA1NzI5Qy42ODE0NDUgMTYuNzM3MjM1IC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJy8+CjxwYXRoIGlkPSdnNS00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c1LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnNS00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c1LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnMy0yNCcgZD0nTTEuNjE3OTMzLTIuMzUxMTgzQzEuOTEyODI3LTIuMjM5NjAxIDIuMjA3NzIxLTIuMjM5NjAxIDIuMzgzMDY0LTIuMjM5NjAxQzIuNjU0MDQ3LTIuMjM5NjAxIDMuMTcyMTA1LTIuMjM5NjAxIDMuMTcyMTA1LTIuNTI2NTI2QzMuMTcyMTA1LTIuNzY1NjI5IDIuNzQxNzE5LTIuNzY1NjI5IDIuNDcwNzM1LTIuNzY1NjI5QzIuMzExMzMzLTIuNzY1NjI5IDIuMDY0MjU5LTIuNzY1NjI5IDEuNzUzNDI1LTIuNjYyMDE3QzEuNTc4MDgyLTIuODI5MzkgMS41MDYzNTEtMy4wNTI1NTMgMS41MDYzNTEtMy4yNzU3MTZDMS41MDYzNTEtMy43MjIwNDIgMS44MTcxODYtNC4yODc5MiAyLjM5OTAwNC00LjU2Njg3NEMyLjU3NDM0Ni00LjM4MzU2MiAyLjc4MTU2OS00LjM4MzU2MiAyLjk0ODk0MS00LjM4MzU2MkMzLjI1MTgwNi00LjM4MzU2MiAzLjcwNjEwMi00LjM5OTUwMiAzLjcwNjEwMi00LjY3MDQ4NkMzLjcwNjEwMi00LjkwOTU4OSAzLjI3NTcxNi00LjkwOTU4OSAyLjk5Njc2Mi00LjkwOTU4OUMyLjg2MTI3LTQuOTA5NTg5IDIuNzI1Nzc4LTQuOTA5NTg5IDIuNTAyNjE1LTQuODc3NzA5QzIuNDg2Njc1LTQuOTMzNDk5IDIuNDYyNzY1LTUuMDEzMiAyLjQ2Mjc2NS01LjExNjgxMkMyLjQ2Mjc2NS01LjIyODM5NCAyLjQ5NDY0NS01LjM2Mzg4NSAyLjQ5NDY0NS01LjM4Nzc5NkMyLjUwMjYxNS01LjM5NTc2NiAyLjUwMjYxNS01LjQyNzY0NiAyLjUwMjYxNS01LjQzNTYxNkMyLjUwMjYxNS01LjUwNzM0NyAyLjQ0NjgyNC01LjU1NTE2OCAyLjM5MTAzNC01LjU1NTE2OEMyLjIxNTY5MS01LjU1NTE2OCAyLjIxNTY5MS01LjE5NjUxMyAyLjIxNTY5MS01LjEyNDc4MkMyLjIxNTY5MS00Ljk3MzM1IDIuMjU1NTQyLTQuODM3ODU4IDIuMjYzNTEyLTQuODIxOTE4QzEuMzcwODU5LTQuNTkwNzg1IC44MjA5MjItMy45NTMxNzYgLjgyMDkyMi0zLjMyMzUzN0MuODIwOTIyLTIuOTI1MDMxIDEuMDM2MTE1LTIuNjU0MDQ3IDEuMzM4OTc5LTIuNDc4NzA1Qy40ODYxNzctMS45OTI1MjggLjE5MTI4My0xLjE4NzU0NyAuMTkxMjgzLS44MjA5MjJDLjE5MTI4My0uMDk1NjQxIC45MjQ1MzMgLjE2NzM3MiAxLjE3OTU3NyAuMjYzMDE0QzEuNjI1OTAzIC40MzAzODYgMS42NDE4NDMgLjQzMDM4NiAyLjAzMjM3OSAuNTY1ODc4QzIuMjIzNjYxIC42Mzc2MDkgMi41NDI0NjYgLjc1NzE2MSAyLjU5ODI1NyAuNzg5MDQxQzIuNzI1Nzc4IC44Njg3NDIgMi43MjU3NzggLjk4MDMyNCAyLjcyNTc3OCAxLjAyODE0NEMyLjcyNTc3OCAxLjE3MTYwNiAyLjYyMjE2NyAxLjQwMjc0IDIuMzY3MTIzIDEuNDAyNzRDMi4zMDMzNjIgMS40MDI3NCAxLjk3NjU4OCAxLjM4NjggMS42NTc3ODMgMS4xOTU1MTdDMS41NzgwODIgMS4xMzk3MjYgMS41NzAxMTIgMS4xMzE3NTYgMS41MzAyNjIgMS4xMzE3NTZDMS40NDI1OSAxLjEzMTc1NiAxLjQxODY4IDEuMjExNDU3IDEuNDE4NjggMS4yNDMzMzdDMS40MTg2OCAxLjM3MDg1OSAxLjkyODc2NyAxLjYyNTkwMyAyLjM3NTA5MyAxLjYyNTkwM0MyLjkwMTEyMSAxLjYyNTkwMyAzLjIyNzg5NSAxLjEyMzc4NiAzLjIyNzg5NSAuNzU3MTYxQzMuMjI3ODk1IC42MTM2OTkgMy4xNzIxMDUgLjQ2MjI2NyAzLjA3NjQ2MyAuMzUwNjg1QzIuOTcyODUyIC4yMzkxMDMgMi44NjkyNCAuMTk5MjUzIDIuNDIyOTE0IC4wMzk4NTFDMS43Mjk1MTQtLjIwNzIyMyAxLjIxMTQ1Ny0uMzkwNTM1IDEuMDgzOTM1LS40NjIyNjdDLjgyODg5Mi0uNTk3NzU4IC42NjE1MTktLjc4OTA0MSAuNjYxNTE5LTEuMDUyMDU1Qy42NjE1MTktMS4zNzg4MjkgLjk1NjQxMy0xLjk5MjUyOCAxLjYxNzkzMy0yLjM1MTE4M1pNMy40MDMyMzgtNC42NDY1NzVDMy4zMjM1MzctNC42MzA2MzUgMy4yNDM4MzYtNC42MDY3MjUgMi45NTY5MTItNC42MDY3MjVDMi43ODk1MzktNC42MDY3MjUgMi43NTc2NTktNC42MDY3MjUgMi42NjIwMTctNC42NTQ1NDVDMi43ODk1MzktNC42ODY0MjYgMi44NjkyNC00LjY4NjQyNiAzLjAxMjcwMi00LjY4NjQyNkMzLjIyNzg5NS00LjY4NjQyNiAzLjI4MzY4Ni00LjY3ODQ1NiAzLjQwMzIzOC00LjY1NDU0NVYtNC42NDY1NzVaTTIuODY5MjQtMi41MDI2MTVDMi43OTc1MDktMi40ODY2NzUgMi43MTc4MDgtMi40NjI3NjUgMi40MDY5NzQtMi40NjI3NjVDMi4yNTU1NDItMi40NjI3NjUgMi4xNzU4NDEtMi40NjI3NjUgMi4wNDgzMTktMi41MDI2MTVDMi4yMjM2NjEtMi41NDI0NjYgMi4zMTkzMDMtMi41NDI0NjYgMi40NjI3NjUtMi41NDI0NjZDMi42OTM4OTgtMi41NDI0NjYgMi43NTc2NTktMi41MzQ0OTYgMi44NjkyNC0yLjUxMDU4NVYtMi41MDI2MTVaJy8+CjxwYXRoIGlkPSdnMy02MScgZD0nTTMuNzA2MTAyLTUuNjQyODM5QzMuNzUzOTIzLTUuNzU0NDIxIDMuNzUzOTIzLTUuNzcwMzYxIDMuNzUzOTIzLTUuNzk0MjcxQzMuNzUzOTIzLTUuODk3ODgzIDMuNjc0MjIyLTUuOTc3NTg0IDMuNTcwNjEtNS45Nzc1ODRDMy40NDMwODgtNS45Nzc1ODQgMy40MTEyMDgtNS44ODE5NDMgMy4zNzkzMjgtNS44MDIyNDJMLjUxODA1NyAxLjY1Nzc4M0MuNDcwMjM3IDEuNzY5MzY1IC40NzAyMzcgMS43ODUzMDUgLjQ3MDIzNyAxLjgwOTIxNUMuNDcwMjM3IDEuOTEyODI3IC41NDk5MzggMS45OTI1MjggLjY1MzU0OSAxLjk5MjUyOEMuNzgxMDcxIDEuOTkyNTI4IC44MTI5NTEgMS44OTY4ODcgLjg0NDgzMiAxLjgxNzE4NkwzLjcwNjEwMi01LjY0MjgzOVonLz4KPHBhdGggaWQ9J2czLTEwNScgZD0nTTIuMzc1MDkzLTQuOTczMzVDMi4zNzUwOTMtNS4xNDg2OTIgMi4yNDc1NzItNS4yNzYyMTQgMi4wNjQyNTktNS4yNzYyMTRDMS44NTcwMzYtNS4yNzYyMTQgMS42MjU5MDMtNS4wODQ5MzIgMS42MjU5MDMtNC44NDU4MjhDMS42MjU5MDMtNC42NzA0ODYgMS43NTM0MjUtNC41NDI5NjQgMS45MzY3MzctNC41NDI5NjRDMi4xNDM5Ni00LjU0Mjk2NCAyLjM3NTA5My00LjczNDI0NyAyLjM3NTA5My00Ljk3MzM1Wk0xLjIxMTQ1Ny0yLjA0ODMxOUwuNzgxMDcxLS45NDg0NDNDLjc0MTIyLS44Mjg4OTIgLjcwMTM3LS43MzMyNSAuNzAxMzctLjU5Nzc1OEMuNzAxMzctLjIwNzIyMyAxLjAwNDIzNCAuMDc5NzAxIDEuNDI2NjUgLjA3OTcwMUMyLjE5OTc1MSAuMDc5NzAxIDIuNTI2NTI2LTEuMDM2MTE1IDIuNTI2NTI2LTEuMTM5NzI2QzIuNTI2NTI2LTEuMjE5NDI3IDIuNDYyNzY1LTEuMjQzMzM3IDIuNDA2OTc0LTEuMjQzMzM3QzIuMzExMzMzLTEuMjQzMzM3IDIuMjk1MzkyLTEuMTg3NTQ3IDIuMjcxNDgyLTEuMTA3ODQ2QzIuMDg4MTY5LS40NzAyMzcgMS43NjEzOTUtLjE0MzQ2MiAxLjQ0MjU5LS4xNDM0NjJDMS4zNDY5NDktLjE0MzQ2MiAxLjI1MTMwOC0uMTgzMzEzIDEuMjUxMzA4LS4zOTg1MDZDMS4yNTEzMDgtLjU4OTc4OCAxLjMwNzA5OC0uNzMzMjUgMS40MTA3MS0uOTgwMzI0QzEuNDkwNDExLTEuMTk1NTE3IDEuNTcwMTEyLTEuNDEwNzEgMS42NTc3ODMtMS42MjU5MDNMMS45MDQ4NTctMi4yNzE0ODJDMS45NzY1ODgtMi40NTQ3OTUgMi4wNzIyMjktMi43MDE4NjggMi4wNzIyMjktMi44MzczNkMyLjA3MjIyOS0zLjIzNTg2NiAxLjc1MzQyNS0zLjUxNDgxOSAxLjM0Njk0OS0zLjUxNDgxOUMuNTczODQ4LTMuNTE0ODE5IC4yMzkxMDMtMi4zOTkwMDQgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMzk2MDEgLjQ5NDE0Ny0yLjMxOTMwM0MuNzE3MzEtMy4wNzY0NjMgMS4wODM5MzUtMy4yOTE2NTYgMS4zMjMwMzktMy4yOTE2NTZDMS40MzQ2Mi0zLjI5MTY1NiAxLjUxNDMyMS0zLjI1MTgwNiAxLjUxNDMyMS0zLjAyODY0M0MxLjUxNDMyMS0yLjk0ODk0MSAxLjUwNjM1MS0yLjgzNzM2IDEuNDI2NjUtMi41OTgyNTdMMS4yMTE0NTctMi4wNDgzMTlaJy8+CjxwYXRoIGlkPSdnMy0xMDcnIGQ9J00yLjMyNzI3My01LjI5MjE1NEMyLjMzNTI0My01LjMwODA5NSAyLjM1OTE1My01LjQxMTcwNiAyLjM1OTE1My01LjQxOTY3NkMyLjM1OTE1My01LjQ1OTUyNyAyLjMyNzI3My01LjUzMTI1OCAyLjIzMTYzMS01LjUzMTI1OEMyLjE5OTc1MS01LjUzMTI1OCAxLjk1MjY3Ny01LjUwNzM0NyAxLjc2OTM2NS01LjQ5MTQwN0wxLjMyMzAzOS01LjQ1OTUyN0MxLjE0NzY5Ni01LjQ0MzU4NyAxLjA2Nzk5NS01LjQzNTYxNiAxLjA2Nzk5NS01LjI5MjE1NEMxLjA2Nzk5NS01LjE4MDU3MyAxLjE3OTU3Ny01LjE4MDU3MyAxLjI3NTIxOC01LjE4MDU3M0MxLjY1Nzc4My01LjE4MDU3MyAxLjY1Nzc4My01LjEzMjc1MiAxLjY1Nzc4My01LjA2MTAyMUMxLjY1Nzc4My01LjAzNzExMSAxLjY1Nzc4My01LjAyMTE3MSAxLjYxNzkzMy00Ljg3NzcwOUwuNDg2MTc3LS4zNDI3MTVDLjQ1NDI5Ni0uMjIzMTYzIC40NTQyOTYtLjE3NTM0MiAuNDU0Mjk2LS4xNjczNzJDLjQ1NDI5Ni0uMDMxODggLjU2NTg3OCAuMDc5NzAxIC43MTczMSAuMDc5NzAxQy45ODgyOTQgLjA3OTcwMSAxLjA1MjA1NS0uMTc1MzQyIDEuMDgzOTM1LS4yODY5MjRDMS4xNjM2MzYtLjYyMTY2OSAxLjM3MDg1OS0xLjQ2NjUwMSAxLjQ1ODUzMS0xLjgwMTI0NUMxLjg5Njg4Ny0xLjc1MzQyNSAyLjQzMDg4NC0xLjYwMTk5MyAyLjQzMDg4NC0xLjE0NzY5NkMyLjQzMDg4NC0xLjEwNzg0NiAyLjQzMDg4NC0xLjA2Nzk5NSAyLjQxNDk0NC0uOTg4Mjk0QzIuMzkxMDM0LS44ODQ2ODIgMi4zNzUwOTMtLjc3MzEwMSAyLjM3NTA5My0uNzMzMjVDMi4zNzUwOTMtLjI2MzAxNCAyLjcyNTc3OCAuMDc5NzAxIDMuMTg4MDQ1IC4wNzk3MDFDMy41MjI3OSAuMDc5NzAxIDMuNzMwMDEyLS4xNjczNzIgMy44MzM2MjQtLjMxODgwNEM0LjAyNDkwNy0uNjEzNjk5IDQuMTUyNDI4LTEuMDkxOTA1IDQuMTUyNDI4LTEuMTM5NzI2QzQuMTUyNDI4LTEuMjE5NDI3IDQuMDg4NjY3LTEuMjQzMzM3IDQuMDMyODc3LTEuMjQzMzM3QzMuOTM3MjM1LTEuMjQzMzM3IDMuOTIxMjk1LTEuMTk1NTE3IDMuODg5NDE1LTEuMDUyMDU1QzMuNzg1ODAzLS42Nzc0NiAzLjU3ODU4LS4xNDM0NjIgMy4yMDM5ODUtLjE0MzQ2MkMyLjk5Njc2Mi0uMTQzNDYyIDIuOTQ4OTQxLS4zMTg4MDQgMi45NDg5NDEtLjUzMzk5OEMyLjk0ODk0MS0uNjM3NjA5IDIuOTU2OTEyLS43MzMyNSAyLjk5Njc2Mi0uOTE2NTYzQzMuMDA0NzMyLS45NDg0NDMgMy4wMzY2MTMtMS4wNzU5NjUgMy4wMzY2MTMtMS4xNjM2MzZDMy4wMzY2MTMtMS44MTcxODYgMi4yMTU2OTEtMS45NjA2NDggMS44MDkyMTUtMi4wMTY0MzhDMi4xMDQxMS0yLjE5MTc4MSAyLjM3NTA5My0yLjQ2Mjc2NSAyLjQ3MDczNS0yLjU2NjM3NkMyLjkwOTA5MS0yLjk5Njc2MiAzLjI2Nzc0Ni0zLjI5MTY1NiAzLjY1MDMxMS0zLjI5MTY1NkMzLjc1MzkyMy0zLjI5MTY1NiAzLjg0OTU2NC0zLjI2Nzc0NiAzLjkxMzMyNS0zLjE4ODA0NUMzLjQ4MjkzOS0zLjEzMjI1NCAzLjQ4MjkzOS0yLjc1NzY1OSAzLjQ4MjkzOS0yLjc0OTY4OUMzLjQ4MjkzOS0yLjU3NDM0NiAzLjYxODQzMS0yLjQ1NDc5NSAzLjc5Mzc3My0yLjQ1NDc5NUM0LjAwODk2Ni0yLjQ1NDc5NSA0LjI0ODA3LTIuNjMwMTM3IDQuMjQ4MDctMi45NTY5MTJDNC4yNDgwNy0zLjIyNzg5NSA0LjA1Njc4Ny0zLjUxNDgxOSAzLjY1ODI4MS0zLjUxNDgxOUMzLjE5NjAxNS0zLjUxNDgxOSAyLjc4MTU2OS0zLjE2NDEzNCAyLjMyNzI3My0yLjcwOTgzOEMxLjg2NTAwNi0yLjI1NTU0MiAxLjY2NTc1My0yLjE2Nzg3IDEuNTM4MjMyLTIuMTEyMDhMMi4zMjcyNzMtNS4yOTIxNTRaJy8+CjxwYXRoIGlkPSdnMy0xMTAnIGQ9J00xLjU5NDAyMi0xLjMwNzA5OEMxLjYxNzkzMy0xLjQyNjY1IDEuNjk3NjM0LTEuNzI5NTE0IDEuNzIxNTQ0LTEuODQ5MDY2QzEuODMzMTI2LTIuMjc5NDUyIDEuODMzMTI2LTIuMjg3NDIyIDIuMDE2NDM4LTIuNTUwNDM2QzIuMjc5NDUyLTIuOTQwOTcxIDIuNjU0MDQ3LTMuMjkxNjU2IDMuMTg4MDQ1LTMuMjkxNjU2QzMuNDc0OTY5LTMuMjkxNjU2IDMuNjQyMzQxLTMuMTI0Mjg0IDMuNjQyMzQxLTIuNzQ5Njg5QzMuNjQyMzQxLTIuMzExMzMzIDMuMzA3NTk3LTEuNDAyNzQgMy4xNTYxNjQtMS4wMTIyMDRDMy4wNTI1NTMtLjc0OTE5MSAzLjA1MjU1My0uNzAxMzcgMy4wNTI1NTMtLjU5Nzc1OEMzLjA1MjU1My0uMTQzNDYyIDMuNDI3MTQ4IC4wNzk3MDEgMy43Njk4NjMgLjA3OTcwMUM0LjU1MDkzNCAuMDc5NzAxIDQuODc3NzA5LTEuMDM2MTE1IDQuODc3NzA5LTEuMTM5NzI2QzQuODc3NzA5LTEuMjE5NDI3IDQuODEzOTQ4LTEuMjQzMzM3IDQuNzU4MTU3LTEuMjQzMzM3QzQuNjYyNTE2LTEuMjQzMzM3IDQuNjQ2NTc1LTEuMTg3NTQ3IDQuNjIyNjY1LTEuMTA3ODQ2QzQuNDMxMzgyLS40NTQyOTYgNC4wOTY2MzgtLjE0MzQ2MiAzLjc5Mzc3My0uMTQzNDYyQzMuNjY2MjUyLS4xNDM0NjIgMy42MDI0OTEtLjIyMzE2MyAzLjYwMjQ5MS0uNDA2NDc2UzMuNjY2MjUyLS43NjUxMzEgMy43NDU5NTMtLjk2NDM4NEMzLjg2NTUwNC0xLjI2NzI0OCA0LjIxNjE4OS0yLjE4MzgxMSA0LjIxNjE4OS0yLjYzMDEzN0M0LjIxNjE4OS0zLjIyNzg5NSAzLjgwMTc0My0zLjUxNDgxOSAzLjIyNzg5NS0zLjUxNDgxOUMyLjU4MjMxNi0zLjUxNDgxOSAyLjE2Nzg3LTMuMTI0Mjg0IDEuOTM2NzM3LTIuODIxNDJDMS44ODA5NDYtMy4yNTk3NzYgMS41MzAyNjItMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMxODgwNC0yLjcwOTgzOCAuMjM5MTAzLTIuMzExMzMzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4xMDc4NDYgLjA3OTcwMSAxLjIyNzM5Ny0uMDE1OTQgMS4yODMxODgtLjExMTU4MkMxLjMwNzA5OC0uMTU5NDAyIDEuMzcwODU5LS40MzAzODYgMS40MTA3MS0uNTk3NzU4TDEuNTk0MDIyLTEuMzA3MDk4WicvPgo8cGF0aCBpZD0nZzMtMTE0JyBkPSdNMS41MzgyMzItMS4wOTk4NzVDMS42MjU5MDMtMS40NDI1OSAxLjcxMzU3NC0xLjc4NTMwNSAxLjc5MzI3NS0yLjEzNTk5QzEuODAxMjQ1LTIuMTUxOTMgMS44NTcwMzYtMi4zODMwNjQgMS44NjUwMDYtMi40MjI5MTRDMS44ODg5MTctMi40OTQ2NDUgMi4wODgxNjktMi44MjE0MiAyLjI5NTM5Mi0zLjAyMDY3MkMyLjU1MDQzNi0zLjI1MTgwNiAyLjgyMTQyLTMuMjkxNjU2IDIuOTY0ODgyLTMuMjkxNjU2QzMuMDUyNTUzLTMuMjkxNjU2IDMuMTk2MDE1LTMuMjgzNjg2IDMuMzA3NTk3LTMuMTg4MDQ1QzIuOTY0ODgyLTMuMTE2MzE0IDIuOTE3MDYxLTIuODIxNDIgMi45MTcwNjEtMi43NDk2ODlDMi45MTcwNjEtMi41NzQzNDYgMy4wNTI1NTMtMi40NTQ3OTUgMy4yMjc4OTUtMi40NTQ3OTVDMy40NDMwODgtMi40NTQ3OTUgMy42ODIxOTItMi42MzAxMzcgMy42ODIxOTItMi45NDg5NDFDMy42ODIxOTItMy4yMzU4NjYgMy40MzUxMTgtMy41MTQ4MTkgMi45ODA4MjItMy41MTQ4MTlDMi40Mzg4NTQtMy41MTQ4MTkgMi4wNzIyMjktMy4xNTYxNjQgMS45MDQ4NTctMi45NDA5NzFDMS43NDU0NTUtMy41MTQ4MTkgMS4yMDM0ODctMy41MTQ4MTkgMS4xMjM3ODYtMy41MTQ4MTlDLjgzNjg2Mi0zLjUxNDgxOSAuNjM3NjA5LTMuMzMxNTA3IC41MTAwODctMy4wODQ0MzNDLjMyNjc3NS0yLjcyNTc3OCAuMjM5MTAzLTIuMzE5MzAzIC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjIzNjYxIC41MjYwMjctMi40MzA4ODRDLjYyMTY2OS0yLjgyMTQyIC43NjUxMzEtMy4yOTE2NTYgMS4wOTk4NzUtMy4yOTE2NTZDMS4zMDcwOTgtMy4yOTE2NTYgMS4zNTQ5MTktMy4wOTI0MDMgMS4zNTQ5MTktMi45MTcwNjFDMS4zNTQ5MTktMi43NzM1OTkgMS4zMTUwNjgtMi42MjIxNjcgMS4yNTEzMDgtMi4zNTkxNTNDMS4yMzUzNjctMi4yOTUzOTIgMS4xMTU4MTYtMS44MjUxNTYgMS4wODM5MzUtMS43MTM1NzRMLjc4OTA0MS0uNTE4MDU3Qy43NTcxNjEtLjM5ODUwNiAuNzA5MzQtLjE5OTI1MyAuNzA5MzQtLjE2NzM3MkMuNzA5MzQgLjAxNTk0IC44NjA3NzIgLjA3OTcwMSAuOTY0Mzg0IC4wNzk3MDFDMS4yNDMzMzcgLjA3OTcwMSAxLjI5OTEyOC0uMTQzNDYyIDEuMzYyODg5LS40MTQ0NDZMMS41MzgyMzItMS4wOTk4NzVaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2c2LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnNi00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzYtNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzYtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnNi02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzYtMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzYtMTA4JyBkPSdNMi4wNTYyODktOC4yOTY4ODdMLjM5NDUyMS04LjE2NTM4Vi03LjgxODY4QzEuMjA3NDcyLTcuODE4NjggMS4zMDMxMTMtNy43MzQ5OTQgMS4zMDMxMTMtNy4xNDkxOTFWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzE1MDY4LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFTMi42MzAxMzctLjAyMzkxIDIuOTY0ODgyIDBWLS4zNDY3QzIuMTk5NzUxLS4zNDY3IDIuMDU2Mjg5LS4zNDY3IDIuMDU2Mjg5LS44ODQ2ODJWLTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzYtMTExJyBkPSdNNS40ODc0MjItMi41NTg0MDZDNS40ODc0MjItNC4xMDA2MjMgNC4zMTU4MTYtNS4zMzIwMDUgMi45MjkwMTYtNS4zMzIwMDVDMS40OTQzOTYtNS4zMzIwMDUgLjM1ODY1NS00LjA2NDc1NyAuMzU4NjU1LTIuNTU4NDA2Qy4zNTg2NTUtMS4wMjgxNDQgMS41NTQxNzIgLjExOTU1MiAyLjkxNzA2MSAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNS40ODc0MjItMS4wNTIwNTUgNS40ODc0MjItMi41NTg0MDZaTTIuOTI5MDE2LS4xNDM0NjJDMi40ODY2NzUtLjE0MzQ2MiAxLjk0ODY5Mi0uMzM0NzQ1IDEuNjAxOTkzLS45MjA1NDhDMS4yNzkyMDMtMS40NTg1MzEgMS4yNjcyNDgtMi4xNjM4ODUgMS4yNjcyNDgtMi42NjYwMDJDMS4yNjcyNDgtMy4xMjAyOTkgMS4yNjcyNDgtMy44NDk1NjQgMS42Mzc4NTgtNC4zODc1NDdDMS45NzI2MDMtNC45MDE2MTkgMi40OTg2My01LjA5MjkwMiAyLjkxNzA2MS01LjA5MjkwMkMzLjM4MzMxMy01LjA5MjkwMiAzLjg4NTQzLTQuODc3NzA5IDQuMjA4MjE5LTQuNDExNDU3QzQuNTc4ODI5LTMuODYxNTE5IDQuNTc4ODI5LTMuMTA4MzQ0IDQuNTc4ODI5LTIuNjY2MDAyQzQuNTc4ODI5LTIuMjQ3NTcyIDQuNTc4ODI5LTEuNTA2MzUxIDQuMjY3OTk1LS45NDQ0NThDMy45MzMyNS0uMzcwNjEgMy4zODMzMTMtLjE0MzQ2MiAyLjkyOTAxNi0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzEtMCcgZD0nTTUuNTcxMTA4LTEuODA5MjE1QzUuNjk4NjMtMS44MDkyMTUgNS44NzM5NzMtMS44MDkyMTUgNS44NzM5NzMtMS45OTI1MjhTNS42OTg2My0yLjE3NTg0MSA1LjU3MTEwOC0yLjE3NTg0MUgxLjAwNDIzNEMuODc2NzEyLTIuMTc1ODQxIC43MDEzNy0yLjE3NTg0MSAuNzAxMzctMS45OTI1MjhTLjg3NjcxMi0xLjgwOTIxNSAxLjAwNDIzNC0xLjgwOTIxNUg1LjU3MTEwOFonLz4KPHBhdGggaWQ9J2c0LTIyJyBkPSdNMS43MjE1NDQtLjI2MzAxNEMyLjAyMDQyMyAuMDExOTU1IDIuNDYyNzY1IC4xMTk1NTIgMi44NjkyNCAuMTE5NTUyQzMuNjM0MzcxIC4xMTk1NTIgNC4xNjAzOTktLjM5NDUyMSA0LjQzNTM2Ny0uNzY1MTMxQzQuNTU0OTE5LS4xMzE1MDcgNS4wNTcwMzYgLjExOTU1MiA1LjQ3NTQ2NyAuMTE5NTUyQzUuODM0MTIyIC4xMTk1NTIgNi4xMjEwNDYtLjA5NTY0MSA2LjMzNjIzOS0uNTI2MDI3QzYuNTI3NTIyLS45MzI1MDMgNi42OTQ4OTQtMS42NjE3NjggNi42OTQ4OTQtMS43MDk1ODlDNi42OTQ4OTQtMS43NjkzNjUgNi42NDcwNzMtMS44MTcxODYgNi41NzUzNDItMS44MTcxODZDNi40Njc3NDYtMS44MTcxODYgNi40NTU3OTEtMS43NTc0MSA2LjQwNzk3LTEuNTc4MDgyQzYuMjI4NjQzLS44NzI3MjcgNi4wMDE0OTQtLjExOTU1MiA1LjUxMTMzMy0uMTE5NTUyQzUuMTY0NjMzLS4xMTk1NTIgNS4xNDA3MjItLjQzMDM4NiA1LjE0MDcyMi0uNjY5NDg5QzUuMTQwNzIyLS45NDQ0NTggNS4yNDgzMTktMS4zNzQ4NDQgNS4zMzIwMDUtMS43MzM0OTlMNS42NjY3NS0zLjAyNDY1OEM1LjcxNDU3LTMuMjUxODA2IDUuODQ2MDc3LTMuNzg5Nzg4IDUuOTA1ODUzLTQuMDA0OTgxQzUuOTc3NTg0LTQuMjkxOTA1IDYuMTA5MDkxLTQuODA1OTc4IDYuMTA5MDkxLTQuODUzNzk4QzYuMTA5MDkxLTUuMDMzMTI2IDUuOTY1NjI5LTUuMTUyNjc3IDUuNzg2MzAxLTUuMTUyNjc3QzUuNjc4NzA1LTUuMTUyNjc3IDUuNDI3NjQ2LTUuMTA0ODU3IDUuMzMyMDA1LTQuNzQ2MjAyTDQuNDk1MTQzLTEuNDIyNjY1QzQuNDM1MzY3LTEuMTgzNTYyIDQuNDM1MzY3LTEuMTU5NjUxIDQuMjc5OTUtLjk2ODM2OUM0LjEzNjQ4OC0uNzY1MTMxIDMuNjcwMjM3LS4xMTk1NTIgMi45MTcwNjEtLjExOTU1MkMyLjI0NzU3Mi0uMTE5NTUyIDIuMDMyMzc5LS42MDk3MTQgMi4wMzIzNzktMS4xNzE2MDZDMi4wMzIzNzktMS41MTgzMDYgMi4xMzk5NzUtMS45MzY3MzcgMi4xODc3OTYtMi4xMzk5NzVMMi43MjU3NzgtNC4yOTE5MDVDMi43ODU1NTQtNC41MTkwNTQgMi44ODExOTYtNC45MDE2MTkgMi44ODExOTYtNC45NzMzNUMyLjg4MTE5Ni01LjE2NDYzMyAyLjcyNTc3OC01LjI3MjIyOSAyLjU3MDM2MS01LjI3MjIyOUMyLjQ2Mjc2NS01LjI3MjIyOSAyLjE5OTc1MS01LjIzNjM2NCAyLjEwNDExLTQuODUzNzk4TC4zNzA2MSAyLjA2ODI0NEMuMzU4NjU1IDIuMTI4MDIgLjMzNDc0NSAyLjE5OTc1MSAuMzM0NzQ1IDIuMjcxNDgyQy4zMzQ3NDUgMi40NTA4MDkgLjQ3ODIwNyAyLjU3MDM2MSAuNjU3NTM0IDIuNTcwMzYxQzEuMDA0MjM0IDIuNTcwMzYxIDEuMDc1OTY1IDIuMjk1MzkyIDEuMTU5NjUxIDEuOTYwNjQ4TDEuNzIxNTQ0LS4yNjMwMTRaJy8+CjxwYXRoIGlkPSdnNC0yNCcgZD0nTTMuMTIwMjk5IC4wNTk3NzZMMS44NjUwMDYtLjQ0MjM0MUMxLjU1NDE3Mi0uNTYxODkzIC44MzY4NjItLjg0ODgxNyAuODM2ODYyLTEuNTY2MTI3Qy44MzY4NjItMi41OTQyNzEgMi4wOTIxNTQtMy42MzQzNzEgMi4zNDMyMTMtMy42MzQzNzFDMi4zNjcxMjMtMy42MzQzNzEgMi40NzQ3Mi0zLjYxMDQ2MSAyLjUxMDU4NS0zLjU5ODUwNkMyLjgzMzM3NS0zLjUwMjg2NCAzLjE0NDIwOS0zLjUwMjg2NCAzLjM1OTQwMi0zLjUwMjg2NEMzLjczMDAxMi0zLjUwMjg2NCA0LjQzNTM2Ny0zLjUwMjg2NCA0LjQzNTM2Ny0zLjg0OTU2NEM0LjQzNTM2Ny00LjExMjU3OCA0LjAwNDk4MS00LjE0ODQ0MyAzLjQ5MDkwOS00LjE0ODQ0M0MzLjI1MTgwNi00LjE0ODQ0MyAyLjkyOTAxNi00LjE0ODQ0MyAyLjQ5ODYzLTQuMDA0OTgxQzIuMjExNzA2LTQuMjQ0MDg1IDIuMDkyMTU0LTQuNjI2NjUgMi4wOTIxNTQtNC45ODUzMDVDMi4wOTIxNTQtNS42NDI4MzkgMi41MjI1NC02LjU3NTM0MiAzLjQ2Njk5OS03LjAxNzY4NEMzLjY4MjE5Mi02Ljc2NjYyNSAzLjk2OTExNi02Ljc2NjYyNSA0LjIyMDE3NC02Ljc2NjYyNUM0LjUxOTA1NC02Ljc2NjYyNSA1LjI0ODMxOS02Ljc2NjYyNSA1LjI0ODMxOS03LjExMzMyNUM1LjI0ODMxOS03LjQxMjIwNCA0LjY3NDQ3MS03LjQxMjIwNCA0LjI5MTkwNS03LjQxMjIwNEM0LjA1MjgwMi03LjQxMjIwNCAzLjg3MzQ3NC03LjQxMjIwNCAzLjUzODczLTcuMzUyNDI4QzMuNDc4OTU0LTcuNDk1ODkgMy40NjY5OTktNy41MTk4MDEgMy40NjY5OTktNy43ODI4MTRDMy40NjY5OTktNy45OTgwMDcgMy41MTQ4MTktOC4xNjUzOCAzLjUxNDgxOS04LjIwMTI0NUMzLjUxNDgxOS04LjI3Mjk3NiAzLjQ1NTA0NC04LjMyMDc5NyAzLjM5NTI2OC04LjMyMDc5N0MzLjIwMzk4NS04LjMyMDc5NyAzLjIwMzk4NS03Ljg3ODQ1NiAzLjIwMzk4NS03Ljc4MjgxNEMzLjIwMzk4NS03LjYxNTQ0MiAzLjIxNTk0LTcuNDQ4MDcgMy4yODc2NzEtNy4yOTI2NTNDMS44NTMwNTEtNi44NzQyMjIgMS4yMTk0MjctNS44NTgwMzIgMS4yMTk0MjctNS4wODA5NDZDMS4yMTk0MjctNC4zNjM2MzYgMS42OTc2MzQtMy45NjkxMTYgMi4wMjA0MjMtMy43ODk3ODhDLjc4OTA0MS0zLjEyMDI5OSAuMjYzMDE0LTEuOTAwODcyIC4yNjMwMTQtMS4yNTUyOTNDLjI2MzAxNC0uMjE1MTkzIDEuMjA3NDcyIC4xNTU0MTcgMS42Mzc4NTggLjMzNDc0NUwyLjcxMzgyMyAuNzY1MTMxQzMuMDEyNzAyIC44NzI3MjcgMy41MDI4NjQgMS4wNzU5NjUgMy41ODY1NSAxLjEyMzc4NkMzLjcwNjEwMiAxLjIwNzQ3MiAzLjgwMTc0MyAxLjM1MDkzNCAzLjgwMTc0MyAxLjU0MjIxN0MzLjgwMTc0MyAxLjc5MzI3NSAzLjYxMDQ2MSAyLjE5OTc1MSAzLjE5MjAzIDIuMTk5NzUxQzMuMDEyNzAyIDIuMTk5NzUxIDIuNjE4MTgyIDIuMTUxOTMgMi4xODc3OTYgMS44MjkxNDFDMi4xMDQxMSAxLjc1NzQxIDIuMDkyMTU0IDEuNzQ1NDU1IDIuMDQ0MzM0IDEuNzQ1NDU1QzEuOTg0NTU4IDEuNzQ1NDU1IDEuOTI0NzgyIDEuNzkzMjc1IDEuOTI0NzgyIDEuODY1MDA2QzEuOTI0NzgyIDEuOTk2NTEzIDIuNTQ2NDUxIDIuNDM4ODU0IDMuMTkyMDMgMi40Mzg4NTRDMy45NTcxNjEgMi40Mzg4NTQgNC40MjM0MTIgMS42OTc2MzQgNC40MjM0MTIgMS4xODM1NjJDNC40MjM0MTIgLjgxMjk1MSA0LjIyMDE3NCAuNTE0MDcyIDMuODM3NjA5IC4zNDY3TDMuMTIwMjk5IC4wNTk3NzZaTTMuNzMwMDEyLTcuMTEzMzI1QzMuOTMzMjUtNy4xNzMxMDEgNC4xNDg0NDMtNy4xNzMxMDEgNC4zMDM4NjEtNy4xNzMxMDFDNC42OTgzODEtNy4xNzMxMDEgNC43MzQyNDctNy4xNjExNDYgNC45NzMzNS03LjEwMTM3QzQuODI5ODg4LTcuMDQxNTk0IDQuNzM0MjQ3LTcuMDA1NzI5IDQuMjMyMTMtNy4wMDU3MjlDNC4wMDQ5ODEtNy4wMDU3MjkgMy44NjE1MTktNy4wMDU3MjkgMy43MzAwMTItNy4xMTMzMjVaTTIuNzg1NTU0LTMuODM3NjA5QzMuMDcyNDc4LTMuOTA5MzQgMy4zMzU0OTItMy45MDkzNCAzLjQ3ODk1NC0zLjkwOTM0QzMuODczNDc0LTMuOTA5MzQgMy44OTczODUtMy44OTczODUgNC4xNjAzOTktMy44Mzc2MDlDNC4wMjg4OTItMy43Nzc4MzMgMy45MjEyOTUtMy43NDE5NjggMy40MDcyMjMtMy43NDE5NjhDMy4xMjAyOTktMy43NDE5NjggMy4wMDA3NDctMy43NDE5NjggMi43ODU1NTQtMy44Mzc2MDlaJy8+CjxwYXRoIGlkPSdnNC0yNycgZD0nTTYuMDczMjI1LTQuNTA3MDk4QzYuMjI4NjQzLTQuNTA3MDk4IDYuNjIzMTYzLTQuNTA3MDk4IDYuNjIzMTYzLTQuODg5NjY0QzYuNjIzMTYzLTUuMTUyNjc3IDYuMzk2MDE1LTUuMTUyNjc3IDYuMTgwODIyLTUuMTUyNjc3SDMuNTM4NzNDMS43NDU0NTUtNS4xNTI2NzcgLjQ1NDI5Ni0zLjE1NjE2NCAuNDU0Mjk2LTEuNzQ1NDU1Qy40NTQyOTYtLjcyOTI2NSAxLjExMTgzMSAuMTE5NTUyIDIuMTg3Nzk2IC4xMTk1NTJDMy41OTg1MDYgLjExOTU1MiA1LjE0MDcyMi0xLjM5ODc1NSA1LjE0MDcyMi0zLjE5MjAzQzUuMTQwNzIyLTMuNjU4MjgxIDUuMDMzMTI2LTQuMTEyNTc4IDQuNzQ2MjAyLTQuNTA3MDk4SDYuMDczMjI1Wk0yLjE5OTc1MS0uMTE5NTUyQzEuNTkwMDM3LS4xMTk1NTIgMS4xNDc2OTYtLjU4NTgwMyAxLjE0NzY5Ni0xLjQxMDcxQzEuMTQ3Njk2LTIuMTI4MDIgMS41NzgwODItNC41MDcwOTggMy4zMzU0OTItNC41MDcwOThDMy44NDk1NjQtNC41MDcwOTggNC40MjM0MTItNC4yNTYwNCA0LjQyMzQxMi0zLjMzNTQ5MkM0LjQyMzQxMi0yLjkxNzA2MSA0LjIzMjEzLTEuOTEyODI3IDMuODEzNjk5LTEuMjE5NDI3QzMuMzgzMzEzLS41MTQwNzIgMi43Mzc3MzMtLjExOTU1MiAyLjE5OTc1MS0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzQtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2c0LTk2JyBkPSdNMS4wOTk4NzUtMi4wMzIzNzlDLjM0NjctMS4yOTExNTggLjE1NTQxNy0xLjExMTgzMSAuMTU1NDE3LTEuMDY0MDFTLjIwMzIzOC0uOTMyNTAzIC4yODY5MjQtLjkzMjUwM0MuMzQ2Ny0uOTMyNTAzIDEuMDI4MTQ0LTEuNTkwMDM3IDEuMTIzNzg2LTEuNjk3NjM0QzEuMTk1NTE3LS44OTY2MzggMS40OTQzOTYgLjE0MzQ2MiAyLjQyNjg5OSAuMTQzNDYyQzIuOTA1MTA2IC4xNDM0NjIgMy4zMzU0OTItLjE1NTQxNyAzLjUyNjc3NS0uMjk4ODc5QzMuNjgyMTkyLS40MTg0MzEgNC4yNTYwNC0uOTA4NTkzIDQuMjU2MDQtMS4wMTYxODlDNC4yNTYwNC0xLjA3NTk2NSA0LjE5NjI2NC0xLjE0NzY5NiA0LjEzNjQ4OC0xLjE0NzY5NkM0LjA4ODY2Ny0xLjE0NzY5NiAzLjkwOTM0LS45NjgzNjkgMy44NjE1MTktLjkyMDU0OEMzLjQ0MzA4OC0uNTE0MDcyIDIuOTE3MDYxLS4wOTU2NDEgMi40Mzg4NTQtLjA5NTY0MUMxLjc5MzI3NS0uMDk1NjQxIDEuNzA5NTg5LTEuMDI4MTQ0IDEuNzA5NTg5LTEuNjczNzI0QzEuNzA5NTg5LTEuNzkzMjc1IDEuNzA5NTg5LTIuMjk1MzkyIDEuNzkzMjc1LTIuMzkxMDM0QzIuNDk4NjMtMy4xMjAyOTkgNC43MTAzMzYtNS40MDM3MzYgNC43MTAzMzYtNy41MTk4MDFDNC43MTAzMzYtNy45OTgwMDcgNC41MzEwMDktOC40MTY0MzggNC4wMTY5MzYtOC40MTY0MzhDMi45MDUxMDYtOC40MTY0MzggMS45MzY3MzctNS45NTM2NzQgMS43NjkzNjUtNS40OTkzNzdDMS43MjE1NDQtNS4zNzk4MjYgMS4wMjgxNDQtMy41Mzg3MyAxLjA5OTg3NS0yLjAzMjM3OVpNMS44MTcxODYtMi43NzM1OTlDMS44MjkxNDEtMi44NDUzMyAyLjM2NzEyMy01Ljk3NzU4NCAzLjM3MTM1Ny03LjY1MTMwOEMzLjU3NDU5NS03Ljk3NDA5NyAzLjc3NzgzMy04LjE3NzMzNSA0LjAxNjkzNi04LjE3NzMzNUM0LjQyMzQxMi04LjE3NzMzNSA0LjQ0NzMyMy03Ljc5NDc3IDQuNDQ3MzIzLTcuNTMxNzU2QzQuNDQ3MzIzLTcuMTEzMzI1IDQuMzI3NzcxLTYuMDM3MzYgMy4yODc2NzEtNC41MzEwMDlDMi45NzY4MzctNC4wODg2NjcgMi40OTg2My0zLjQ5MDkwOSAxLjgxNzE4Ni0yLjc3MzU5OVonLz4KPHBhdGggaWQ9J2c0LTExMCcgZD0nTTIuNDYyNzY1LTMuNTAyODY0QzIuNDg2Njc1LTMuNTc0NTk1IDIuNzg1NTU0LTQuMTcyMzU0IDMuMjI3ODk1LTQuNTU0OTE5QzMuNTM4NzMtNC44NDE4NDMgMy45NDUyMDUtNS4wMzMxMjYgNC40MTE0NTctNS4wMzMxMjZDNC44ODk2NjQtNS4wMzMxMjYgNS4wNTcwMzYtNC42NzQ0NzEgNS4wNTcwMzYtNC4xOTYyNjRDNS4wNTcwMzYtMy41MTQ4MTkgNC41NjY4NzQtMi4xNTE5MyA0LjMyNzc3MS0xLjUwNjM1MUM0LjIyMDE3NC0xLjIxOTQyNyA0LjE2MDM5OS0xLjA2NDAxIDQuMTYwMzk5LS44NDg4MTdDNC4xNjAzOTktLjMxMDgzNCA0LjUzMTAwOSAuMTE5NTUyIDUuMTA0ODU3IC4xMTk1NTJDNi4yMTY2ODcgLjExOTU1MiA2LjYzNTExOC0xLjYzNzg1OCA2LjYzNTExOC0xLjcwOTU4OUM2LjYzNTExOC0xLjc2OTM2NSA2LjU4NzI5OC0xLjgxNzE4NiA2LjUxNTU2Ny0xLjgxNzE4NkM2LjQwNzk3LTEuODE3MTg2IDYuMzk2MDE1LTEuNzgxMzIgNi4zMzYyMzktMS41NzgwODJDNi4wNjEyNy0uNTk3NzU4IDUuNjA2OTc0LS4xMTk1NTIgNS4xNDA3MjItLjExOTU1MkM1LjAyMTE3MS0uMTE5NTUyIDQuODI5ODg4LS4xMzE1MDcgNC44Mjk4ODgtLjUxNDA3MkM0LjgyOTg4OC0uODEyOTUxIDQuOTYxMzk1LTEuMTcxNjA2IDUuMDMzMTI2LTEuMzM4OTc5QzUuMjcyMjI5LTEuOTk2NTEzIDUuNzc0MzQ2LTMuMzM1NDkyIDUuNzc0MzQ2LTQuMDE2OTM2QzUuNzc0MzQ2LTQuNzM0MjQ3IDUuMzU1OTE1LTUuMjcyMjI5IDQuNDQ3MzIzLTUuMjcyMjI5QzMuMzgzMzEzLTUuMjcyMjI5IDIuODIxNDItNC41MTkwNTQgMi42MDYyMjctNC4yMjAxNzRDMi41NzAzNjEtNC45MDE2MTkgMi4wODAxOTktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4xNzE2MDYtNS4yNzIyMjkgLjkwODU5My01LjA0NTA4MSAuNzA1MzU1LTQuNjM4NjA1Qy40OTAxNjItNC4yMDgyMTkgLjMyMjc5LTMuNDkwOTA5IC4zMjI3OS0zLjQ0MzA4OFMuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODI0OTA3LTQuMzUxNjgxIDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjc5MzI3NS01LjAzMzEyNiAxLjg4ODkxNy00Ljg0MTg0MyAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjM1MDkzNCAuMTE5NTUyIDEuNTE4MzA2IC4wNDc4MjEgMS42MTM5NDgtLjEzMTUwN0MxLjYzNzg1OC0uMTkxMjgzIDEuNzQ1NDU1LS42MDk3MTQgMS44MDUyMy0uODQ4ODE3TDIuMDY4MjQ0LTEuOTI0NzgyTDIuNDYyNzY1LTMuNTAyODY0WicvPgo8cGF0aCBpZD0nZzQtMTE0JyBkPSdNNC42NTA1Ni00Ljg4OTY2NEM0LjI3OTk1LTQuODE3OTMzIDQuMDg4NjY3LTQuNTU0OTE5IDQuMDg4NjY3LTQuMjkxOTA1QzQuMDg4NjY3LTQuMDA0OTgxIDQuMzE1ODE2LTMuOTA5MzQgNC40ODMxODgtMy45MDkzNEM0LjgxNzkzMy0zLjkwOTM0IDUuMDkyOTAyLTQuMTk2MjY0IDUuMDkyOTAyLTQuNTU0OTE5QzUuMDkyOTAyLTQuOTM3NDg0IDQuNzIyMjkxLTUuMjcyMjI5IDQuMTI0NTMzLTUuMjcyMjI5QzMuNjQ2MzI2LTUuMjcyMjI5IDMuMDk2Mzg5LTUuMDU3MDM2IDIuNTk0MjcxLTQuMzI3NzcxQzIuNTEwNTg1LTQuOTYxMzk1IDIuMDMyMzc5LTUuMjcyMjI5IDEuNTU0MTcyLTUuMjcyMjI5QzEuMDg3OTItNS4yNzIyMjkgLjg0ODgxNy00LjkxMzU3NCAuNzA1MzU1LTQuNjUwNTZDLjUwMjExNy00LjIyMDE3NCAuMzIyNzktMy41MDI4NjQgLjMyMjc5LTMuNDQzMDg4Qy4zMjI3OS0zLjM5NTI2OCAuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTQ5OTM4LTMuMzM1NDkyIC41NjE4OTMtMy4zNDc0NDcgLjYzMzYyNC0zLjYyMjQxNkMuODEyOTUxLTQuMzM5NzI2IDEuMDQwMS01LjAzMzEyNiAxLjUxODMwNi01LjAzMzEyNkMxLjgwNTIzLTUuMDMzMTI2IDEuODg4OTE3LTQuODI5ODg4IDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzM4OTc5IC4xMTk1NTIgMS41NjYxMjcgLjAzNTg2NiAxLjYzNzg1OC0uMjAzMjM4QzEuNjczNzI0LS4yOTg4NzkgMi4xMTYwNjUtMi4xMDQxMSAyLjE4Nzc5Ni0yLjM3OTA3OEMyLjI0NzU3Mi0yLjY0MjA5MiAyLjMxOTMwMy0yLjg5MzE1MSAyLjM3OTA3OC0zLjE1NjE2NEMyLjQyNjg5OS0zLjMyMzUzNyAyLjQ3NDcyLTMuNTE0ODE5IDIuNTEwNTg1LTMuNjcwMjM3QzIuNTQ2NDUxLTMuNzc3ODMzIDIuODY5MjQtNC4zNjM2MzYgMy4xNjgxMi00LjYyNjY1QzMuMzExNTgyLTQuNzU4MTU3IDMuNjIyNDE2LTUuMDMzMTI2IDQuMTEyNTc4LTUuMDMzMTI2QzQuMzAzODYxLTUuMDMzMTI2IDQuNDk1MTQzLTQuOTk3MjYgNC42NTA1Ni00Ljg4OTY2NFonLz4KPHBhdGggaWQ9J2c0LTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c0LTk2Jy8+Cjx1c2UgeD0nNC45MTIxMDYnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi00MCcvPgo8dXNlIHg9JzkuNDY0NDMyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtMjInLz4KPHVzZSB4PScxNi41MDc0MDMnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC01OScvPgo8dXNlIHg9JzIxLjc1MTU2MicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c0LTI3Jy8+Cjx1c2UgeD0nMjguMTgzNjMzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtNTknLz4KPHVzZSB4PSczMy40Mjc3OTInIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC0yNCcvPgo8dXNlIHg9JzM5LjExODIzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDEnLz4KPHVzZSB4PSc0Ni45OTEzODUnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi02MScvPgo8dXNlIHg9JzU5LjQxNjg2NicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PSc2OC43MTUzNjMnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC0xMTAnLz4KPHVzZSB4PSc3NS43MDI5NjgnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC0xMTQnLz4KPHVzZSB4PSc4My4yOTU5MzknIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi0xMDgnLz4KPHVzZSB4PSc4Ni41NDc2MDEnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi0xMTEnLz4KPHVzZSB4PSc5Mi40MDA1OTEnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi0xMDMnLz4KPHVzZSB4PScxMDAuNDA4NjYyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PScxMTAuMTQ3NzI5JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzEyOC4xNjgwOTcnIHk9Jy0zMC4yNDIyODknIHhsaW5rOmhyZWY9JyNnMy0xMTAnLz4KPHVzZSB4PScxMjIuMTAyODknIHk9Jy0yNi42NTU3MzMnIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzEyMy44ODUyODQnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2czLTEwNScvPgo8dXNlIHg9JzEyNi43Njg0MjMnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nMTMzLjM1NDkzJyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzEzOS4zNzE1MDcnIHk9Jy0zMi4xNTUyMDUnIHhsaW5rOmhyZWY9JyNnMC0yMCcvPgo8dXNlIHg9JzE0NS42ODEyMDQnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi00OScvPgo8dXNlIHg9JzE1NC4xOTA4NTgnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi00MycvPgo8dXNlIHg9JzE2NS45NTIxNzMnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNC0yNCcvPgo8dXNlIHg9JzE3MS42NDI2MScgeT0nLTI4LjU2ODYxOCcgeGxpbms6aHJlZj0nI2cwLTE2Jy8+Cjx1c2UgeD0nMTc5Ljk3ODAzNicgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2c0LTEyMicvPgo8dXNlIHg9JzE4NS45NDg2NDMnIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnNS00MCcvPgo8dXNlIHg9JzE4OS4yNDE4OTYnIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnMy0xMTQnLz4KPHVzZSB4PScxOTMuMjk4NDkyJyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzUtNDEnLz4KPHVzZSB4PScxODUuNDE1OTI3JyB5PSctMjAuMzIyMjE0JyB4bGluazpocmVmPScjZzMtMTA1Jy8+Cjx1c2UgeD0nMTk5Ljc0NjU0MScgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScyMTEuNzAxNzAxJyB5PSctMjMuMzg2MDI3JyB4bGluazpocmVmPScjZzQtMjInLz4KPHJlY3QgeD0nMTc5Ljk3ODAzNicgeT0nLTE4LjUyNjE1NCcgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMzguNzY2NjI4Jy8+Cjx1c2UgeD0nMTk1LjgyMDE0OCcgeT0nLTcuMDk3NjA2JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHVzZSB4PScyMTkuOTQwMTc4JyB5PSctMjguNTY4NjE4JyB4bGluazpocmVmPScjZzAtMTcnLz4KPHVzZSB4PScyMjcuMDgwMDknIHk9Jy0zMi4xNTUyMDUnIHhsaW5rOmhyZWY9JyNnMC0yMScvPgo8dXNlIHg9JzIzMy4zODk3ODgnIHk9Jy0yOS40Nzg1NTInIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nMjM5Ljk3NjI5NCcgeT0nLTI5LjQ3ODU1MicgeGxpbms6aHJlZj0nI2c1LTQ5Jy8+Cjx1c2UgeD0nMjQ0LjIxMDQ3NycgeT0nLTI5LjQ3ODU1MicgeGxpbms6aHJlZj0nI2czLTYxJy8+Cjx1c2UgeD0nMjQ4LjQ0NDY2JyB5PSctMjkuNDc4NTUyJyB4bGluazpocmVmPScjZzMtMjQnLz4KPHVzZSB4PScyNTUuNjMyOTknIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjY3LjU4ODE1MScgeT0nLTMyLjE1NTIwNScgeGxpbms6aHJlZj0nI2cwLTE4Jy8+Cjx1c2UgeD0nMjc3LjU4NDAzNycgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2c2LTQ5Jy8+CjxyZWN0IHg9JzI3Ny41ODQwMzcnIHk9Jy0xOC41MjYxNTQnIGhlaWdodD0nLjQ3ODE4Nycgd2lkdGg9JzUuODUyOTknLz4KPHVzZSB4PScyNzcuNjY1MzIxJyB5PSctNy4wOTc2MDYnIHhsaW5rOmhyZWY9JyNnNC0yNCcvPgo8dXNlIHg9JzI4Ny4yODkyMDQnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi00MycvPgo8dXNlIHg9JzI5OS4wNTA1MTknIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi00OScvPgo8dXNlIHg9JzMwNC45MDM1MScgeT0nLTMyLjE1NTIwNScgeGxpbms6aHJlZj0nI2cwLTE5Jy8+Cjx1c2UgeD0nMzIxLjc2MTU4NycgeT0nLTMwLjI0MjI4OScgeGxpbms6aHJlZj0nI2czLTExMCcvPgo8dXNlIHg9JzMxNS42OTYzOCcgeT0nLTI2LjY1NTczMycgeGxpbms6aHJlZj0nI2cwLTg4Jy8+Cjx1c2UgeD0nMzE3LjQ3ODc3NCcgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzMtMTA1Jy8+Cjx1c2UgeD0nMzIwLjM2MTkxMycgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzUtNjEnLz4KPHVzZSB4PSczMjYuOTQ4NDInIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2c1LTQ5Jy8+Cjx1c2UgeD0nMzQxLjU2MzUwNScgeT0nLTMwLjI0MjI4OScgeGxpbms6aHJlZj0nI2czLTExNCcvPgo8dXNlIHg9JzMzNC45NTc0OTQnIHk9Jy0yNi42NTU3MzMnIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzMzNS44NzA2NScgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzMtMTA3Jy8+Cjx1c2UgeD0nMzQwLjQ5MjI2NicgeT0nLTEuMTk1NTE0JyB4bGluazpocmVmPScjZzUtNjEnLz4KPHVzZSB4PSczNDcuMDc4NzcyJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzM1NC4yMTg2MDknIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi0xMDgnLz4KPHVzZSB4PSczNTcuNDcwMjcnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi0xMTEnLz4KPHVzZSB4PSczNjMuMzIzMjYnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNi0xMDMnLz4KPHVzZSB4PSczNjkuMzM4ODMzJyB5PSctMzIuMTU1MjA1JyB4bGluazpocmVmPScjZzAtMjAnLz4KPHVzZSB4PSczNzUuNjQ4NTMxJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDknLz4KPHVzZSB4PSczODQuMTU4MTg1JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzYtNDMnLz4KPHVzZSB4PSczOTUuOTE5NScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c0LTI0Jy8+Cjx1c2UgeD0nNDAxLjYwOTkzNycgeT0nLTI4LjU2ODYxOCcgeGxpbms6aHJlZj0nI2cwLTE2Jy8+Cjx1c2UgeD0nNDA5Ljk0NTM2MycgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2c0LTEyMicvPgo8dXNlIHg9JzQxNS45MTU5NycgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2c1LTQwJy8+Cjx1c2UgeD0nNDE5LjIwOTIyMycgeT0nLTI5LjQ5NjQyOScgeGxpbms6aHJlZj0nI2czLTEwNycvPgo8dXNlIHg9JzQyMy44MzA4MzknIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnNS00MScvPgo8dXNlIHg9JzQxNS4zODMyNTQnIHk9Jy0yMC4zMjIyMTQnIHhsaW5rOmhyZWY9JyNnMy0xMDUnLz4KPHVzZSB4PSc0MzAuMjc4ODg3JyB5PSctMjMuMzg2MDI3JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzQ0Mi4yMzQwNDgnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnNC0yMicvPgo8cmVjdCB4PSc0MDkuOTQ1MzYzJyB5PSctMTguNTI2MTU0JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSczOS4zMzE2NDgnLz4KPHVzZSB4PSc0MjYuMDY5OTg1JyB5PSctNy4wOTc2MDYnIHhsaW5rOmhyZWY9JyNnNC0yNycvPgo8dXNlIHg9JzQ1MC40NzI1MjUnIHk9Jy0yOC41Njg2MTgnIHhsaW5rOmhyZWY9JyNnMC0xNycvPgo8dXNlIHg9JzQ1Ny42MTI0MzcnIHk9Jy0zMi4xNTUyMDUnIHhsaW5rOmhyZWY9JyNnMC0yMScvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
defined on
such that  for all
for all  and
and  .
.If
 , then:
, then:(2)¶
![\ell(\mu, \sigma, \xi) = -nr \log \sigma - \sum_{i=1}^n \exp \biggl[ - \Bigl( \frac{z_i^{(r)} - \mu }{\sigma} \Bigr) \biggr] - \sum_{i=1}^n \sum_{k=1}^r \Bigl( \frac{z_i^{(k)} - \mu }{\sigma} \Bigr)](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzM0My43NDc1NzJwdCcgaGVpZ2h0PSczNC4yNzg0OTlwdCcgdmlld0JveD0nMjIuMzk3NzEzIC0zNS40NzQwMTMgMzQzLjc0NzU3MiAzNC4yNzg0OTknPgo8ZGVmcz4KPHBhdGggaWQ9J2c0LTQwJyBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgLjcyNTI4IDEuMzM4OTc5LS43NTcxNjEgMS4zMzg5NzktMS45OTI1MjhDMS4zMzg5NzktNC4yODc5MiAyLjI4NzQyMi01LjM2Mzg4NSAyLjY5Mzg5OC01LjczMDUxMUMyLjgwNTQ3OS01LjgzNDEyMiAyLjgxMzQ1LTUuODQyMDkyIDIuODEzNDUtNS44ODE5NDNTMi43ODE1NjktNS45Nzc1ODQgMi43MDE4NjgtNS45Nzc1ODRDMi41NzQzNDYtNS45Nzc1ODQgMi4xNzU4NDEtNS41NzExMDggMi4xMTIwOC01LjQ5OTM3N0MxLjA0NDA4NS00LjM4MzU2MiAuODIwOTIyLTIuOTQ4OTQxIC44MjA5MjItMS45OTI1MjhDLjgyMDkyMi0uMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicvPgo8cGF0aCBpZD0nZzQtNDEnIGQ9J00yLjQ2Mjc2NS0xLjk5MjUyOEMyLjQ2Mjc2NS0yLjc0OTY4OSAyLjMzNTI0My0zLjY1ODI4MSAxLjg0MTA5Ni00LjU5ODc1NUMxLjQ1MDU2LTUuMzMyMDA1IC43MjUyOC01Ljk3NzU4NCAuNTgxODE4LTUuOTc3NTg0Qy41MDIxMTctNS45Nzc1ODQgLjQ3ODIwNy01LjkyMTc5MyAuNDc4MjA3LTUuODgxOTQzQy40NzgyMDctNS44NTAwNjIgLjQ3ODIwNy01LjgzNDEyMiAuNTczODQ4LTUuNzM4NDgxQzEuNjg5NjY0LTQuNjc4NDU2IDEuOTQ0NzA3LTMuMjE5OTI1IDEuOTQ0NzA3LTEuOTkyNTI4QzEuOTQ0NzA3IC4yOTQ4OTQgLjk5NjI2NCAxLjM3ODgyOSAuNTg5Nzg4IDEuNzQ1NDU1Qy40ODYxNzcgMS44NDkwNjYgLjQ3ODIwNyAxLjg1NzAzNiAuNDc4MjA3IDEuODk2ODg3Uy41MDIxMTcgMS45OTI1MjggLjU4MTgxOCAxLjk5MjUyOEMuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgLjM5ODUwNiAyLjQ2Mjc2NS0xLjAzNjExNSAyLjQ2Mjc2NS0xLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c0LTQ5JyBkPSdNMi41MDI2MTUtNS4wNzY5NjFDMi41MDI2MTUtNS4yOTIxNTQgMi40ODY2NzUtNS4zMDAxMjUgMi4yNzE0ODItNS4zMDAxMjVDMS45NDQ3MDctNC45ODEzMiAxLjUyMjI5MS00Ljc5MDAzNyAuNzY1MTMxLTQuNzkwMDM3Vi00LjUyNzAyNEMuOTgwMzI0LTQuNTI3MDI0IDEuNDEwNzEtNC41MjcwMjQgMS44NzI5NzYtNC43NDIyMTdWLS42NTM1NDlDMS44NzI5NzYtLjM1ODY1NSAxLjg0OTA2Ni0uMjYzMDE0IDEuMDkxOTA1LS4yNjMwMTRILjgxMjk1MVYwQzEuMTM5NzI2LS4wMjM5MSAxLjgyNTE1Ni0uMDIzOTEgMi4xODM4MTEtLjAyMzkxUzMuMjM1ODY2LS4wMjM5MSAzLjU2MjY0IDBWLS4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYtLjI2MzAxNCAyLjUwMjYxNS0uMzU4NjU1IDIuNTAyNjE1LS42NTM1NDlWLTUuMDc2OTYxWicvPgo8cGF0aCBpZD0nZzQtNjEnIGQ9J001LjgyNjE1Mi0yLjY1NDA0N0M1Ljk0NTcwNC0yLjY1NDA0NyA2LjEwNTEwNi0yLjY1NDA0NyA2LjEwNTEwNi0yLjgzNzM2UzUuOTEzODIzLTMuMDIwNjcyIDUuNzk0MjcxLTMuMDIwNjcySC43ODEwNzFDLjY2MTUxOS0zLjAyMDY3MiAuNDcwMjM3LTMuMDIwNjcyIC40NzAyMzctMi44MzczNlMuNjI5NjM5LTIuNjU0MDQ3IC43NDkxOTEtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxLS45NjQzODRDNS45MTM4MjMtLjk2NDM4NCA2LjEwNTEwNi0uOTY0Mzg0IDYuMTA1MTA2LTEuMTQ3Njk2UzUuOTQ1NzA0LTEuMzMxMDA5IDUuODI2MTUyLTEuMzMxMDA5SC43NDkxOTFDLjYyOTYzOS0xLjMzMTAwOSAuNDcwMjM3LTEuMzMxMDA5IC40NzAyMzctMS4xNDc2OTZTLjY2MTUxOS0uOTY0Mzg0IC43ODEwNzEtLjk2NDM4NEg1Ljc5NDI3MVonLz4KPHBhdGggaWQ9J2cwLTE2JyBkPSdNNi4xNTY5MTIgMjAuODk3NjM0QzYuMTgwODIyIDIwLjkwOTU4OSA2LjI4ODQxOCAyMS4wMjkxNDEgNi4zMDAzNzQgMjEuMDI5MTQxSDYuNTYzMzg3QzYuNTk5MjUzIDIxLjAyOTE0MSA2LjY5NDg5NCAyMS4wMTcxODYgNi42OTQ4OTQgMjAuOTA5NTg5QzYuNjk0ODk0IDIwLjg2MTc2OCA2LjY3MDk4NCAyMC44Mzc4NTggNi42NDcwNzMgMjAuODAxOTkzQzYuMjE2Njg3IDIwLjM3MTYwNiA1LjU3MTEwOCAxOS43MTQwNzIgNC44Mjk4ODggMTguMzk5MDA0QzMuNTM4NzMgMTYuMTAzNjExIDMuMDYwNTIzIDEzLjE1MDY4NSAzLjA2MDUyMyAxMC4yODE0NDVDMy4wNjA1MjMgNC45NzMzNSA0LjU2Njg3NCAxLjg1MzA1MSA2LjY1OTAyOS0uMjYzMDE0QzYuNjk0ODk0LS4yOTg4NzkgNi42OTQ4OTQtLjMzNDc0NSA2LjY5NDg5NC0uMzU4NjU1QzYuNjk0ODk0LS40NzgyMDcgNi42MTEyMDgtLjQ3ODIwNyA2LjQ2Nzc0Ni0uNDc4MjA3QzYuMzEyMzI5LS40NzgyMDcgNi4yODg0MTgtLjQ3ODIwNyA2LjE4MDgyMi0uMzgyNTY1QzUuMDQ1MDgxIC41OTc3NTggMy43NjU4NzggMi4yNTk1MjcgMi45NDA5NzEgNC43ODIwNjdDMi40MjY4OTkgNi4zNjAxNDkgMi4xNTE5MyA4LjI4NDkzMiAyLjE1MTkzIDEwLjI2OTQ4OUMyLjE1MTkzIDEzLjEwMjg2NCAyLjY2NjAwMiAxNi4zMDY4NDkgNC41NDI5NjQgMTkuMDgwNDQ4QzQuODY1NzUzIDE5LjU0NjcgNS4zMDgwOTUgMjAuMDM2ODYyIDUuMzA4MDk1IDIwLjA0ODgxN0M1LjQyNzY0NiAyMC4xOTIyNzkgNS41OTUwMTkgMjAuMzgzNTYyIDUuNjkwNjYgMjAuNDY3MjQ4TDYuMTU2OTEyIDIwLjg5NzYzNFonLz4KPHBhdGggaWQ9J2cwLTE3JyBkPSdNNC45NzMzNSAxMC4yNjk0ODlDNC45NzMzNSA2LjgzODM1NiA0LjE3MjM1NCAzLjE5MjAzIDEuODE3MTg2IC41MDIxMTdDMS42NDk4MTMgLjMxMDgzNCAxLjIwNzQ3Mi0uMTU1NDE3IC45MjA1NDgtLjQwNjQ3NkMuODM2ODYyLS40NzgyMDcgLjgxMjk1MS0uNDc4MjA3IC42NTc1MzQtLjQ3ODIwN0MuNTM3OTgzLS40NzgyMDcgLjQzMDM4Ni0uNDc4MjA3IC40MzAzODYtLjM1ODY1NUMuNDMwMzg2LS4zMTA4MzQgLjQ3ODIwNy0uMjYzMDE0IC41MDIxMTctLjIzOTEwM0MuOTA4NTkzIC4xNzkzMjggMS41NTQxNzIgLjgzNjg2MiAyLjI5NTM5MiAyLjE1MTkzQzMuNTg2NTUgNC40NDczMjMgNC4wNjQ3NTcgNy40MDAyNDkgNC4wNjQ3NTcgMTAuMjY5NDg5QzQuMDY0NzU3IDE1LjQ1ODAzMiAyLjYzMDEzNyAxOC42MjYxNTIgLjQ3ODIwNyAyMC44MTM5NDhDLjQ1NDI5NiAyMC44Mzc4NTggLjQzMDM4NiAyMC44NzM3MjQgLjQzMDM4NiAyMC45MDk1ODlDLjQzMDM4NiAyMS4wMjkxNDEgLjUzNzk4MyAyMS4wMjkxNDEgLjY1NzUzNCAyMS4wMjkxNDFDLjgxMjk1MSAyMS4wMjkxNDEgLjgzNjg2MiAyMS4wMjkxNDEgLjk0NDQ1OCAyMC45MzM0OTlDMi4wODAxOTkgMTkuOTUzMTc2IDMuMzU5NDAyIDE4LjI5MTQwNyA0LjE4NDMwOSAxNS43Njg4NjdDNC43MTAzMzYgMTQuMTMxMDA5IDQuOTczMzUgMTIuMTk0MjcxIDQuOTczMzUgMTAuMjY5NDg5WicvPgo8cGF0aCBpZD0nZzAtMjAnIGQ9J00yLjk4ODc5MiAyOC4yMDIyNDJINi4xMzMwMDFWMjcuNTQ0NzA3SDMuNjQ2MzI2Vi4xNzkzMjhINi4xMzMwMDFWLS40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicvPgo8cGF0aCBpZD0nZzAtMjEnIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdILjE2NzM3MlYyOC4yMDIyNDJIMy4zMTE1ODJWLS40NzgyMDdILjE2NzM3MlYuMTc5MzI4SDIuNjU0MDQ3VjI3LjU0NDcwN1onLz4KPHBhdGggaWQ9J2cwLTg4JyBkPSdNMTUuMTM1MjQzIDE2LjczNzIzNUwxNi41ODE4MTggMTIuOTExNTgySDE2LjI4MjkzOUMxNS44MTY2ODcgMTQuMTU0OTE5IDE0LjU0OTQ0IDE0Ljk2Nzg3IDEzLjE3NDU5NSAxNS4zMjY1MjZDMTIuOTIzNTM3IDE1LjM4NjMwMSAxMS43NTE5MyAxNS42OTcxMzYgOS40NTY1MzggMTUuNjk3MTM2SDIuMjQ3NTcyTDguMzMyNzUyIDguNTU5OUM4LjQxNjQzOCA4LjQ2NDI1OSA4LjQ0MDM0OSA4LjQyODM5NCA4LjQ0MDM0OSA4LjM2ODYxOEM4LjQ0MDM0OSA4LjM0NDcwNyA4LjQ0MDM0OSA4LjMwODg0MiA4LjM1NjY2MyA4LjE4OTI5TDIuNzg1NTU0IC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IC41NzM4NDggMTIuMDI2ODk5IC43NDEyMiAxMi4xMzQ0OTYgLjc2NTEzMUMxMi43ODAwNzUgLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0Qy43MjkyNjUgMCAuNzE3MzEgLjAxMTk1NSAuNjgxNDQ1IC4wODM2ODZDLjY2OTQ4OSAuMTE5NTUyIC42Njk0ODkgLjM0NjcgLjY2OTQ4OSAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TC44MDA5OTYgMTYuMzkwNTM1Qy42ODE0NDUgMTYuNTMzOTk4IC42ODE0NDUgMTYuNTkzNzczIC42ODE0NDUgMTYuNjA1NzI5Qy42ODE0NDUgMTYuNzM3MjM1IC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJy8+CjxwYXRoIGlkPSdnMi0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzItMTA3JyBkPSdNMi4zMjcyNzMtNS4yOTIxNTRDMi4zMzUyNDMtNS4zMDgwOTUgMi4zNTkxNTMtNS40MTE3MDYgMi4zNTkxNTMtNS40MTk2NzZDMi4zNTkxNTMtNS40NTk1MjcgMi4zMjcyNzMtNS41MzEyNTggMi4yMzE2MzEtNS41MzEyNThDMi4xOTk3NTEtNS41MzEyNTggMS45NTI2NzctNS41MDczNDcgMS43NjkzNjUtNS40OTE0MDdMMS4zMjMwMzktNS40NTk1MjdDMS4xNDc2OTYtNS40NDM1ODcgMS4wNjc5OTUtNS40MzU2MTYgMS4wNjc5OTUtNS4yOTIxNTRDMS4wNjc5OTUtNS4xODA1NzMgMS4xNzk1NzctNS4xODA1NzMgMS4yNzUyMTgtNS4xODA1NzNDMS42NTc3ODMtNS4xODA1NzMgMS42NTc3ODMtNS4xMzI3NTIgMS42NTc3ODMtNS4wNjEwMjFDMS42NTc3ODMtNS4wMzcxMTEgMS42NTc3ODMtNS4wMjExNzEgMS42MTc5MzMtNC44Nzc3MDlMLjQ4NjE3Ny0uMzQyNzE1Qy40NTQyOTYtLjIyMzE2MyAuNDU0Mjk2LS4xNzUzNDIgLjQ1NDI5Ni0uMTY3MzcyQy40NTQyOTYtLjAzMTg4IC41NjU4NzggLjA3OTcwMSAuNzE3MzEgLjA3OTcwMUMuOTg4Mjk0IC4wNzk3MDEgMS4wNTIwNTUtLjE3NTM0MiAxLjA4MzkzNS0uMjg2OTI0QzEuMTYzNjM2LS42MjE2NjkgMS4zNzA4NTktMS40NjY1MDEgMS40NTg1MzEtMS44MDEyNDVDMS44OTY4ODctMS43NTM0MjUgMi40MzA4ODQtMS42MDE5OTMgMi40MzA4ODQtMS4xNDc2OTZDMi40MzA4ODQtMS4xMDc4NDYgMi40MzA4ODQtMS4wNjc5OTUgMi40MTQ5NDQtLjk4ODI5NEMyLjM5MTAzNC0uODg0NjgyIDIuMzc1MDkzLS43NzMxMDEgMi4zNzUwOTMtLjczMzI1QzIuMzc1MDkzLS4yNjMwMTQgMi43MjU3NzggLjA3OTcwMSAzLjE4ODA0NSAuMDc5NzAxQzMuNTIyNzkgLjA3OTcwMSAzLjczMDAxMi0uMTY3MzcyIDMuODMzNjI0LS4zMTg4MDRDNC4wMjQ5MDctLjYxMzY5OSA0LjE1MjQyOC0xLjA5MTkwNSA0LjE1MjQyOC0xLjEzOTcyNkM0LjE1MjQyOC0xLjIxOTQyNyA0LjA4ODY2Ny0xLjI0MzMzNyA0LjAzMjg3Ny0xLjI0MzMzN0MzLjkzNzIzNS0xLjI0MzMzNyAzLjkyMTI5NS0xLjE5NTUxNyAzLjg4OTQxNS0xLjA1MjA1NUMzLjc4NTgwMy0uNjc3NDYgMy41Nzg1OC0uMTQzNDYyIDMuMjAzOTg1LS4xNDM0NjJDMi45OTY3NjItLjE0MzQ2MiAyLjk0ODk0MS0uMzE4ODA0IDIuOTQ4OTQxLS41MzM5OThDMi45NDg5NDEtLjYzNzYwOSAyLjk1NjkxMi0uNzMzMjUgMi45OTY3NjItLjkxNjU2M0MzLjAwNDczMi0uOTQ4NDQzIDMuMDM2NjEzLTEuMDc1OTY1IDMuMDM2NjEzLTEuMTYzNjM2QzMuMDM2NjEzLTEuODE3MTg2IDIuMjE1NjkxLTEuOTYwNjQ4IDEuODA5MjE1LTIuMDE2NDM4QzIuMTA0MTEtMi4xOTE3ODEgMi4zNzUwOTMtMi40NjI3NjUgMi40NzA3MzUtMi41NjYzNzZDMi45MDkwOTEtMi45OTY3NjIgMy4yNjc3NDYtMy4yOTE2NTYgMy42NTAzMTEtMy4yOTE2NTZDMy43NTM5MjMtMy4yOTE2NTYgMy44NDk1NjQtMy4yNjc3NDYgMy45MTMzMjUtMy4xODgwNDVDMy40ODI5MzktMy4xMzIyNTQgMy40ODI5MzktMi43NTc2NTkgMy40ODI5MzktMi43NDk2ODlDMy40ODI5MzktMi41NzQzNDYgMy42MTg0MzEtMi40NTQ3OTUgMy43OTM3NzMtMi40NTQ3OTVDNC4wMDg5NjYtMi40NTQ3OTUgNC4yNDgwNy0yLjYzMDEzNyA0LjI0ODA3LTIuOTU2OTEyQzQuMjQ4MDctMy4yMjc4OTUgNC4wNTY3ODctMy41MTQ4MTkgMy42NTgyODEtMy41MTQ4MTlDMy4xOTYwMTUtMy41MTQ4MTkgMi43ODE1NjktMy4xNjQxMzQgMi4zMjcyNzMtMi43MDk4MzhDMS44NjUwMDYtMi4yNTU1NDIgMS42NjU3NTMtMi4xNjc4NyAxLjUzODIzMi0yLjExMjA4TDIuMzI3MjczLTUuMjkyMTU0WicvPgo8cGF0aCBpZD0nZzItMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2cyLTExNCcgZD0nTTEuNTM4MjMyLTEuMDk5ODc1QzEuNjI1OTAzLTEuNDQyNTkgMS43MTM1NzQtMS43ODUzMDUgMS43OTMyNzUtMi4xMzU5OUMxLjgwMTI0NS0yLjE1MTkzIDEuODU3MDM2LTIuMzgzMDY0IDEuODY1MDA2LTIuNDIyOTE0QzEuODg4OTE3LTIuNDk0NjQ1IDIuMDg4MTY5LTIuODIxNDIgMi4yOTUzOTItMy4wMjA2NzJDMi41NTA0MzYtMy4yNTE4MDYgMi44MjE0Mi0zLjI5MTY1NiAyLjk2NDg4Mi0zLjI5MTY1NkMzLjA1MjU1My0zLjI5MTY1NiAzLjE5NjAxNS0zLjI4MzY4NiAzLjMwNzU5Ny0zLjE4ODA0NUMyLjk2NDg4Mi0zLjExNjMxNCAyLjkxNzA2MS0yLjgyMTQyIDIuOTE3MDYxLTIuNzQ5Njg5QzIuOTE3MDYxLTIuNTc0MzQ2IDMuMDUyNTUzLTIuNDU0Nzk1IDMuMjI3ODk1LTIuNDU0Nzk1QzMuNDQzMDg4LTIuNDU0Nzk1IDMuNjgyMTkyLTIuNjMwMTM3IDMuNjgyMTkyLTIuOTQ4OTQxQzMuNjgyMTkyLTMuMjM1ODY2IDMuNDM1MTE4LTMuNTE0ODE5IDIuOTgwODIyLTMuNTE0ODE5QzIuNDM4ODU0LTMuNTE0ODE5IDIuMDcyMjI5LTMuMTU2MTY0IDEuOTA0ODU3LTIuOTQwOTcxQzEuNzQ1NDU1LTMuNTE0ODE5IDEuMjAzNDg3LTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMjY3NzUtMi43MjU3NzggLjIzOTEwMy0yLjMxOTMwMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMjQzMzM3IC4wNzk3MDEgMS4yOTkxMjgtLjE0MzQ2MiAxLjM2Mjg4OS0uNDE0NDQ2TDEuNTM4MjMyLTEuMDk5ODc1WicvPgo8cGF0aCBpZD0nZzUtNDAnIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4Ni0uNTM3OTgzIDEuODE3MTg2LTIuOTc2ODM3QzEuODE3MTg2LTUuMjk2MTM5IDIuMzc5MDc4LTcuMjkyNjUzIDMuNzY1ODc4LTguNzAzMzYyQzMuODg1NDMtOC44MTA5NTkgMy44ODU0My04LjgzNDg2OSAzLjg4NTQzLTguODcwNzM1QzMuODg1NDMtOC45NDI0NjYgMy44MjU2NTQtOC45NjYzNzYgMy43Nzc4MzMtOC45NjYzNzZDMy42MjI0MTYtOC45NjYzNzYgMi42NDIwOTItOC4xMDU2MDQgMi4wNTYyODktNi45MzM5OThDMS40NDY1NzUtNS43MjY1MjYgMS4xNzE2MDYtNC40NDczMjMgMS4xNzE2MDYtMi45NzY4MzdDMS4xNzE2MDYtMS45MTI4MjcgMS4zMzg5NzktLjQ5MDE2MiAxLjk2MDY0OCAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonLz4KPHBhdGggaWQ9J2c1LTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnNS02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzUtMTAxJyBkPSdNNC41Nzg4MjktMi43NzM1OTlDNC44NDE4NDMtMi43NzM1OTkgNC44NjU3NTMtMi43NzM1OTkgNC44NjU3NTMtMy4wMDA3NDdDNC44NjU3NTMtNC4yMDgyMTkgNC4yMjAxNzQtNS4zMzIwMDUgMi43NzM1OTktNS4zMzIwMDVDMS40MTA3MS01LjMzMjAwNSAuMzU4NjU1LTQuMTAwNjIzIC4zNTg2NTUtMi42MTgxODJDLjM1ODY1NS0xLjA0MDEgMS41NzgwODIgLjExOTU1MiAyLjkwNTEwNiAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNC44NjU3NTMtMS4xNzE2MDYgNC44NjU3NTMtMS40MjI2NjVDNC44NjU3NTMtMS40OTQzOTYgNC44MDU5NzgtMS41NDIyMTcgNC43MzQyNDctMS41NDIyMTdDNC42Mzg2MDUtMS41NDIyMTcgNC42MTQ2OTUtMS40ODI0NDEgNC41OTA3ODUtMS40MjI2NjVDNC4yNzk5NS0uNDE4NDMxIDMuNDc4OTU0LS4xNDM0NjIgMi45NzY4MzctLjE0MzQ2MlMxLjI2NzI0OC0uNDc4MjA3IDEuMjY3MjQ4LTIuNTQ2NDUxVi0yLjc3MzU5OUg0LjU3ODgyOVpNMS4yNzkyMDMtMy4wMDA3NDdDMS4zNzQ4NDQtNC44Nzc3MDkgMi40MjY4OTktNS4wOTI5MDIgMi43NjE2NDQtNS4wOTI5MDJDNC4wNDA4NDctNS4wOTI5MDIgNC4xMTI1NzgtMy40MDcyMjMgNC4xMjQ1MzMtMy4wMDA3NDdIMS4yNzkyMDNaJy8+CjxwYXRoIGlkPSdnNS0xMDMnIGQ9J00xLjQyMjY2NS0yLjE2Mzg4NUMxLjk4NDU1OC0xLjc5MzI3NSAyLjQ2Mjc2NS0xLjc5MzI3NSAyLjU5NDI3MS0xLjc5MzI3NUMzLjY3MDIzNy0xLjc5MzI3NSA0LjQ3MTIzMy0yLjYwNjIyNyA0LjQ3MTIzMy0zLjUyNjc3NUM0LjQ3MTIzMy0zLjg0OTU2NCA0LjM3NTU5Mi00LjMwMzg2MSAzLjk5MzAyNi00LjY4NjQyNkM0LjQ1OTI3OC01LjE2NDYzMyA1LjAyMTE3MS01LjE2NDYzMyA1LjA4MDk0Ni01LjE2NDYzM0M1LjEyODc2Ny01LjE2NDYzMyA1LjE4ODU0My01LjE2NDYzMyA1LjIzNjM2NC01LjE0MDcyMkM1LjExNjgxMi01LjA5MjkwMiA1LjA1NzAzNi00Ljk3MzM1IDUuMDU3MDM2LTQuODQxODQzQzUuMDU3MDM2LTQuNjc0NDcxIDUuMTc2NTg4LTQuNTMxMDA5IDUuMzY3ODctNC41MzEwMDlDNS40NjM1MTItNC41MzEwMDkgNS42Nzg3MDUtNC41OTA3ODUgNS42Nzg3MDUtNC44NTM3OThDNS42Nzg3MDUtNS4wNjg5OTEgNS41MTEzMzMtNS40MDM3MzYgNS4wOTI5MDItNS40MDM3MzZDNC40NzEyMzMtNS40MDM3MzYgNC4wMDQ5ODEtNS4wMjExNzEgMy44Mzc2MDktNC44NDE4NDNDMy40Nzg5NTQtNS4xMTY4MTIgMy4wNjA1MjMtNS4yNzIyMjkgMi42MDYyMjctNS4yNzIyMjlDMS41MzAyNjItNS4yNzIyMjkgLjcyOTI2NS00LjQ1OTI3OCAuNzI5MjY1LTMuNTM4NzNDLjcyOTI2NS0yLjg1NzI4NSAxLjE0NzY5Ni0yLjQxNDk0NCAxLjI2NzI0OC0yLjMwNzM0N0MxLjEyMzc4Ni0yLjEyODAyIC45MDg1OTMtMS43ODEzMiAuOTA4NTkzLTEuMzE1MDY4Qy45MDg1OTMtLjYyMTY2OSAxLjMyNzAyNC0uMzIyNzkgMS40MjI2NjUtLjI2MzAxNEMuODcyNzI3LS4xMDc1OTcgLjMyMjc5IC4zMjI3OSAuMzIyNzkgLjk0NDQ1OEMuMzIyNzkgMS43NjkzNjUgMS40NDY1NzUgMi40NTA4MDkgMi45MTcwNjEgMi40NTA4MDlDNC4zMzk3MjYgMi40NTA4MDkgNS41MjMyODggMS44MTcxODYgNS41MjMyODggLjkyMDU0OEM1LjUyMzI4OCAuNjIxNjY5IDUuNDM5NjAxLS4wODM2ODYgNC43MjIyOTEtLjQ1NDI5NkM0LjExMjU3OC0uNzY1MTMxIDMuNTE0ODE5LS43NjUxMzEgMi40ODY2NzUtLjc2NTEzMUMxLjc1NzQxLS43NjUxMzEgMS42NzM3MjQtLjc2NTEzMSAxLjQ1ODUzMS0uOTkyMjc5QzEuMzM4OTc5LTEuMTExODMxIDEuMjMxMzgyLTEuMzM4OTc5IDEuMjMxMzgyLTEuNTkwMDM3QzEuMjMxMzgyLTEuNzkzMjc1IDEuMzAzMTEzLTEuOTk2NTEzIDEuNDIyNjY1LTIuMTYzODg1Wk0yLjYwNjIyNy0yLjA0NDMzNEMxLjU1NDE3Mi0yLjA0NDMzNCAxLjU1NDE3Mi0zLjI1MTgwNiAxLjU1NDE3Mi0zLjUyNjc3NUMxLjU1NDE3Mi0zLjc0MTk2OCAxLjU1NDE3Mi00LjIzMjEzIDEuNzU3NDEtNC41NTQ5MTlDMS45ODQ1NTgtNC45MDE2MTkgMi4zNDMyMTMtNS4wMjExNzEgMi41OTQyNzEtNS4wMjExNzFDMy42NDYzMjYtNS4wMjExNzEgMy42NDYzMjYtMy44MTM2OTkgMy42NDYzMjYtMy41Mzg3M0MzLjY0NjMyNi0zLjMyMzUzNyAzLjY0NjMyNi0yLjgzMzM3NSAzLjQ0MzA4OC0yLjUxMDU4NUMzLjIxNTk0LTIuMTYzODg1IDIuODU3Mjg1LTIuMDQ0MzM0IDIuNjA2MjI3LTIuMDQ0MzM0Wk0yLjkyOTAxNiAyLjE5OTc1MUMxLjc4MTMyIDIuMTk5NzUxIC45MDg1OTMgMS42MTM5NDggLjkwODU5MyAuOTMyNTAzQy45MDg1OTMgLjgzNjg2MiAuOTMyNTAzIC4zNzA2MSAxLjM4NjggLjA1OTc3NkMxLjY0OTgxMy0uMTA3NTk3IDEuNzU3NDEtLjEwNzU5NyAyLjU5NDI3MS0uMTA3NTk3QzMuNTg2NTUtLjEwNzU5NyA0LjkzNzQ4NC0uMTA3NTk3IDQuOTM3NDg0IC45MzI1MDNDNC45Mzc0ODQgMS42Mzc4NTggNC4wMjg4OTIgMi4xOTk3NTEgMi45MjkwMTYgMi4xOTk3NTFaJy8+CjxwYXRoIGlkPSdnNS0xMDgnIGQ9J00yLjA1NjI4OS04LjI5Njg4N0wuMzk0NTIxLTguMTY1MzhWLTcuODE4NjhDMS4yMDc0NzItNy44MTg2OCAxLjMwMzExMy03LjczNDk5NCAxLjMwMzExMy03LjE0OTE5MVYtLjg4NDY4MkMxLjMwMzExMy0uMzQ2NyAxLjE3MTYwNi0uMzQ2NyAuMzk0NTIxLS4zNDY3VjBDLjcyOTI2NS0uMDIzOTEgMS4zMTUwNjgtLjAyMzkxIDEuNjczNzI0LS4wMjM5MVMyLjYzMDEzNy0uMDIzOTEgMi45NjQ4ODIgMFYtLjM0NjdDMi4xOTk3NTEtLjM0NjcgMi4wNTYyODktLjM0NjcgMi4wNTYyODktLjg4NDY4MlYtOC4yOTY4ODdaJy8+CjxwYXRoIGlkPSdnNS0xMTEnIGQ9J001LjQ4NzQyMi0yLjU1ODQwNkM1LjQ4NzQyMi00LjEwMDYyMyA0LjMxNTgxNi01LjMzMjAwNSAyLjkyOTAxNi01LjMzMjAwNUMxLjQ5NDM5Ni01LjMzMjAwNSAuMzU4NjU1LTQuMDY0NzU3IC4zNTg2NTUtMi41NTg0MDZDLjM1ODY1NS0xLjAyODE0NCAxLjU1NDE3MiAuMTE5NTUyIDIuOTE3MDYxIC4xMTk1NTJDNC4zMjc3NzEgLjExOTU1MiA1LjQ4NzQyMi0xLjA1MjA1NSA1LjQ4NzQyMi0yLjU1ODQwNlpNMi45MjkwMTYtLjE0MzQ2MkMyLjQ4NjY3NS0uMTQzNDYyIDEuOTQ4NjkyLS4zMzQ3NDUgMS42MDE5OTMtLjkyMDU0OEMxLjI3OTIwMy0xLjQ1ODUzMSAxLjI2NzI0OC0yLjE2Mzg4NSAxLjI2NzI0OC0yLjY2NjAwMkMxLjI2NzI0OC0zLjEyMDI5OSAxLjI2NzI0OC0zLjg0OTU2NCAxLjYzNzg1OC00LjM4NzU0N0MxLjk3MjYwMy00LjkwMTYxOSAyLjQ5ODYzLTUuMDkyOTAyIDIuOTE3MDYxLTUuMDkyOTAyQzMuMzgzMzEzLTUuMDkyOTAyIDMuODg1NDMtNC44Nzc3MDkgNC4yMDgyMTktNC40MTE0NTdDNC41Nzg4MjktMy44NjE1MTkgNC41Nzg4MjktMy4xMDgzNDQgNC41Nzg4MjktMi42NjYwMDJDNC41Nzg4MjktMi4yNDc1NzIgNC41Nzg4MjktMS41MDYzNTEgNC4yNjc5OTUtLjk0NDQ1OEMzLjkzMzI1LS4zNzA2MSAzLjM4MzMxMy0uMTQzNDYyIDIuOTI5MDE2LS4xNDM0NjJaJy8+CjxwYXRoIGlkPSdnNS0xMTInIGQ9J00yLjkyOTAxNiAxLjk3MjYwM0MyLjE2Mzg4NSAxLjk3MjYwMyAyLjAyMDQyMyAxLjk3MjYwMyAyLjAyMDQyMyAxLjQzNDYyVi0uNjQ1NTc5QzIuMjM1NjE2LS4zNDY3IDIuNzI1Nzc4IC4xMTk1NTIgMy40OTA5MDkgLjExOTU1MkM0Ljg2NTc1MyAuMTE5NTUyIDYuMDczMjI1LTEuMDQwMSA2LjA3MzIyNS0yLjU4MjMxNkM2LjA3MzIyNS00LjEwMDYyMyA0Ljk0OTQ0LTUuMjcyMjI5IDMuNjQ2MzI2LTUuMjcyMjI5QzIuNTk0MjcxLTUuMjcyMjI5IDIuMDMyMzc5LTQuNTE5MDU0IDEuOTk2NTEzLTQuNDcxMjMzVi01LjI3MjIyOUwuMzM0NzQ1LTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE3MTYwNi00Ljc5NDAyMiAxLjI0MzMzNy00LjcxMDMzNiAxLjI0MzMzNy00LjE4NDMwOVYxLjQzNDYyQzEuMjQzMzM3IDEuOTcyNjAzIDEuMTExODMxIDEuOTcyNjAzIC4zMzQ3NDUgMS45NzI2MDNWMi4zMTkzMDNDLjY0NTU3OSAyLjI5NTM5MiAxLjI5MTE1OCAyLjI5NTM5MiAxLjYyNTkwMyAyLjI5NTM5MkMxLjk3MjYwMyAyLjI5NTM5MiAyLjYxODE4MiAyLjI5NTM5MiAyLjkyOTAxNiAyLjMxOTMwM1YxLjk3MjYwM1pNMi4wMjA0MjMtMy44MTM2OTlDMi4wMjA0MjMtNC4wNDA4NDcgMi4wMjA0MjMtNC4wNTI4MDIgMi4xNTE5My00LjI0NDA4NUMyLjUxMDU4NS00Ljc4MjA2NyAzLjA5NjM4OS01LjAwOTIxNSAzLjU1MDY4NS01LjAwOTIxNUM0LjQ0NzMyMy01LjAwOTIxNSA1LjE2NDYzMy0zLjkyMTI5NSA1LjE2NDYzMy0yLjU4MjMxNkM1LjE2NDYzMy0xLjE1OTY1MSA0LjM1MTY4MS0uMTE5NTUyIDMuNDMxMTMzLS4xMTk1NTJDMy4wNjA1MjMtLjExOTU1MiAyLjcxMzgyMy0uMjc0OTY5IDIuNDc0NzItLjUwMjExN0MyLjE5OTc1MS0uNzc3MDg2IDIuMDIwNDIzLTEuMDE2MTg5IDIuMDIwNDIzLTEuMzUwOTM0Vi0zLjgxMzY5OVonLz4KPHBhdGggaWQ9J2c1LTEyMCcgZD0nTTMuMzQ3NDQ3LTIuODIxNDJDMy42OTQxNDctMy4yNzU3MTYgNC4xOTYyNjQtMy45MjEyOTUgNC40MjM0MTItNC4xNzIzNTRDNC45MTM1NzQtNC43MjIyOTEgNS40NzU0NjctNC44MDU5NzggNS44NTgwMzItNC44MDU5NzhWLTUuMTUyNjc3QzUuMzQzOTYtNS4xMjg3NjcgNS4zMjAwNS01LjEyODc2NyA0Ljg1Mzc5OC01LjEyODc2N0M0LjM5OTUwMi01LjEyODc2NyA0LjM3NTU5Mi01LjEyODc2NyAzLjc3NzgzMy01LjE1MjY3N1YtNC44MDU5NzhDMy45MzMyNS00Ljc4MjA2NyA0LjEyNDUzMy00LjcxMDMzNiA0LjEyNDUzMy00LjQzNTM2N0M0LjEyNDUzMy00LjIzMjEzIDQuMDE2OTM2LTQuMTAwNjIzIDMuOTQ1MjA1LTQuMDA0OTgxTDMuMTgwMDc1LTMuMDM2NjEzTDIuMjQ3NTcyLTQuMjY3OTk1QzIuMjExNzA2LTQuMzE1ODE2IDIuMTM5OTc1LTQuNDIzNDEyIDIuMTM5OTc1LTQuNTA3MDk4QzIuMTM5OTc1LTQuNTc4ODI5IDIuMTk5NzUxLTQuNzk0MDIyIDIuNTU4NDA2LTQuODA1OTc4Vi01LjE1MjY3N0MyLjI1OTUyNy01LjEyODc2NyAxLjY0OTgxMy01LjEyODc2NyAxLjMyNzAyNC01LjEyODc2N0MuOTMyNTAzLTUuMTI4NzY3IC45MDg1OTMtNS4xMjg3NjcgLjE3OTMyOC01LjE1MjY3N1YtNC44MDU5NzhDLjc4OTA0MS00LjgwNTk3OCAxLjAxNjE4OS00Ljc4MjA2NyAxLjI2NzI0OC00LjQ1OTI3OEwyLjY2NjAwMi0yLjYzMDEzN0MyLjY4OTkxMy0yLjYwNjIyNyAyLjczNzczMy0yLjUzNDQ5NiAyLjczNzczMy0yLjQ5ODYzUzEuODA1MjMtMS4yOTExNTggMS42ODU2NzktMS4xMzU3NDFDMS4xNTk2NTEtLjQ5MDE2MiAuNjMzNjI0LS4zNTg2NTUgLjExOTU1Mi0uMzQ2N1YwQy41NzM4NDgtLjAyMzkxIC41OTc3NTgtLjAyMzkxIDEuMTExODMxLS4wMjM5MUMxLjU2NjEyNy0uMDIzOTEgMS41OTAwMzctLjAyMzkxIDIuMTg3Nzk2IDBWLS4zNDY3QzEuOTAwODcyLS4zODI1NjUgMS44NTMwNTEtLjU2MTg5MyAxLjg1MzA1MS0uNzI5MjY1QzEuODUzMDUxLS45MjA1NDggMS45MzY3MzctMS4wMTYxODkgMi4wNTYyODktMS4xNzE2MDZDMi4yMzU2MTYtMS40MjI2NjUgMi42MzAxMzctMS45MTI4MjcgMi45MTcwNjEtMi4yODM0MzdMMy44OTczODUtMS4wMDQyMzRDNC4xMDA2MjMtLjc0MTIyIDQuMTAwNjIzLS43MTczMSA0LjEwMDYyMy0uNjQ1NTc5QzQuMTAwNjIzLS41NDk5MzggNC4wMDQ5ODEtLjM1ODY1NSAzLjY4MjE5Mi0uMzQ2N1YwQzMuOTkzMDI2LS4wMjM5MSA0LjU3ODgyOS0uMDIzOTEgNC45MTM1NzQtLjAyMzkxQzUuMzA4MDk1LS4wMjM5MSA1LjMzMjAwNS0uMDIzOTEgNi4wNDkzMTUgMFYtLjM0NjdDNS40MTU2OTEtLjM0NjcgNS4yMDA0OTgtLjM3MDYxIDQuOTEzNTc0LS43NTMxNzZMMy4zNDc0NDctMi44MjE0MlonLz4KPHBhdGggaWQ9J2cxLTAnIGQ9J003Ljg3ODQ1Ni0yLjc0OTY4OUM4LjA4MTY5NC0yLjc0OTY4OSA4LjI5Njg4Ny0yLjc0OTY4OSA4LjI5Njg4Ny0yLjk4ODc5MlM4LjA4MTY5NC0zLjIyNzg5NSA3Ljg3ODQ1Ni0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyLTMuMjI3ODk1IC45OTIyNzktMy4yMjc4OTUgLjk5MjI3OS0yLjk4ODc5MlMxLjIwNzQ3Mi0yLjc0OTY4OSAxLjQxMDcxLTIuNzQ5Njg5SDcuODc4NDU2WicvPgo8cGF0aCBpZD0nZzMtMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2czLTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2czLTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnMy01OScgZD0nTTIuMzMxMjU4IC4wNDc4MjFDMi4zMzEyNTgtLjY0NTU3OSAyLjEwNDExLTEuMTU5NjUxIDEuNjEzOTQ4LTEuMTU5NjUxQzEuMjMxMzgyLTEuMTU5NjUxIDEuMDQwMS0uODQ4ODE3IDEuMDQwMS0uNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjctLjA0NzgyMSAyLjAyMDQyMy0uMTU1NDE3QzIuMDQ0MzM0LS4xNzkzMjggMi4wNTYyODktLjE3OTMyOCAyLjA2ODI0NC0uMTc5MzI4QzIuMDkyMTU0LS4xNzkzMjggMi4wOTIxNTQtLjAxMTk1NSAyLjA5MjE1NCAuMDQ3ODIxQzIuMDkyMTU0IC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAuMDQ3ODIxWicvPgo8cGF0aCBpZD0nZzMtOTYnIGQ9J00xLjA5OTg3NS0yLjAzMjM3OUMuMzQ2Ny0xLjI5MTE1OCAuMTU1NDE3LTEuMTExODMxIC4xNTU0MTctMS4wNjQwMVMuMjAzMjM4LS45MzI1MDMgLjI4NjkyNC0uOTMyNTAzQy4zNDY3LS45MzI1MDMgMS4wMjgxNDQtMS41OTAwMzcgMS4xMjM3ODYtMS42OTc2MzRDMS4xOTU1MTctLjg5NjYzOCAxLjQ5NDM5NiAuMTQzNDYyIDIuNDI2ODk5IC4xNDM0NjJDMi45MDUxMDYgLjE0MzQ2MiAzLjMzNTQ5Mi0uMTU1NDE3IDMuNTI2Nzc1LS4yOTg4NzlDMy42ODIxOTItLjQxODQzMSA0LjI1NjA0LS45MDg1OTMgNC4yNTYwNC0xLjAxNjE4OUM0LjI1NjA0LTEuMDc1OTY1IDQuMTk2MjY0LTEuMTQ3Njk2IDQuMTM2NDg4LTEuMTQ3Njk2QzQuMDg4NjY3LTEuMTQ3Njk2IDMuOTA5MzQtLjk2ODM2OSAzLjg2MTUxOS0uOTIwNTQ4QzMuNDQzMDg4LS41MTQwNzIgMi45MTcwNjEtLjA5NTY0MSAyLjQzODg1NC0uMDk1NjQxQzEuNzkzMjc1LS4wOTU2NDEgMS43MDk1ODktMS4wMjgxNDQgMS43MDk1ODktMS42NzM3MjRDMS43MDk1ODktMS43OTMyNzUgMS43MDk1ODktMi4yOTUzOTIgMS43OTMyNzUtMi4zOTEwMzRDMi40OTg2My0zLjEyMDI5OSA0LjcxMDMzNi01LjQwMzczNiA0LjcxMDMzNi03LjUxOTgwMUM0LjcxMDMzNi03Ljk5ODAwNyA0LjUzMTAwOS04LjQxNjQzOCA0LjAxNjkzNi04LjQxNjQzOEMyLjkwNTEwNi04LjQxNjQzOCAxLjkzNjczNy01Ljk1MzY3NCAxLjc2OTM2NS01LjQ5OTM3N0MxLjcyMTU0NC01LjM3OTgyNiAxLjAyODE0NC0zLjUzODczIDEuMDk5ODc1LTIuMDMyMzc5Wk0xLjgxNzE4Ni0yLjc3MzU5OUMxLjgyOTE0MS0yLjg0NTMzIDIuMzY3MTIzLTUuOTc3NTg0IDMuMzcxMzU3LTcuNjUxMzA4QzMuNTc0NTk1LTcuOTc0MDk3IDMuNzc3ODMzLTguMTc3MzM1IDQuMDE2OTM2LTguMTc3MzM1QzQuNDIzNDEyLTguMTc3MzM1IDQuNDQ3MzIzLTcuNzk0NzcgNC40NDczMjMtNy41MzE3NTZDNC40NDczMjMtNy4xMTMzMjUgNC4zMjc3NzEtNi4wMzczNiAzLjI4NzY3MS00LjUzMTAwOUMyLjk3NjgzNy00LjA4ODY2NyAyLjQ5ODYzLTMuNDkwOTA5IDEuODE3MTg2LTIuNzczNTk5WicvPgo8cGF0aCBpZD0nZzMtMTEwJyBkPSdNMi40NjI3NjUtMy41MDI4NjRDMi40ODY2NzUtMy41NzQ1OTUgMi43ODU1NTQtNC4xNzIzNTQgMy4yMjc4OTUtNC41NTQ5MTlDMy41Mzg3My00Ljg0MTg0MyAzLjk0NTIwNS01LjAzMzEyNiA0LjQxMTQ1Ny01LjAzMzEyNkM0Ljg4OTY2NC01LjAzMzEyNiA1LjA1NzAzNi00LjY3NDQ3MSA1LjA1NzAzNi00LjE5NjI2NEM1LjA1NzAzNi0zLjUxNDgxOSA0LjU2Njg3NC0yLjE1MTkzIDQuMzI3NzcxLTEuNTA2MzUxQzQuMjIwMTc0LTEuMjE5NDI3IDQuMTYwMzk5LTEuMDY0MDEgNC4xNjAzOTktLjg0ODgxN0M0LjE2MDM5OS0uMzEwODM0IDQuNTMxMDA5IC4xMTk1NTIgNS4xMDQ4NTcgLjExOTU1MkM2LjIxNjY4NyAuMTE5NTUyIDYuNjM1MTE4LTEuNjM3ODU4IDYuNjM1MTE4LTEuNzA5NTg5QzYuNjM1MTE4LTEuNzY5MzY1IDYuNTg3Mjk4LTEuODE3MTg2IDYuNTE1NTY3LTEuODE3MTg2QzYuNDA3OTctMS44MTcxODYgNi4zOTYwMTUtMS43ODEzMiA2LjMzNjIzOS0xLjU3ODA4MkM2LjA2MTI3LS41OTc3NTggNS42MDY5NzQtLjExOTU1MiA1LjE0MDcyMi0uMTE5NTUyQzUuMDIxMTcxLS4xMTk1NTIgNC44Mjk4ODgtLjEzMTUwNyA0LjgyOTg4OC0uNTE0MDcyQzQuODI5ODg4LS44MTI5NTEgNC45NjEzOTUtMS4xNzE2MDYgNS4wMzMxMjYtMS4zMzg5NzlDNS4yNzIyMjktMS45OTY1MTMgNS43NzQzNDYtMy4zMzU0OTIgNS43NzQzNDYtNC4wMTY5MzZDNS43NzQzNDYtNC43MzQyNDcgNS4zNTU5MTUtNS4yNzIyMjkgNC40NDczMjMtNS4yNzIyMjlDMy4zODMzMTMtNS4yNzIyMjkgMi44MjE0Mi00LjUxOTA1NCAyLjYwNjIyNy00LjIyMDE3NEMyLjU3MDM2MS00LjkwMTYxOSAyLjA4MDE5OS01LjI3MjIyOSAxLjU1NDE3Mi01LjI3MjIyOUMxLjE3MTYwNi01LjI3MjIyOSAuOTA4NTkzLTUuMDQ1MDgxIC43MDUzNTUtNC42Mzg2MDVDLjQ5MDE2Mi00LjIwODIxOSAuMzIyNzktMy40OTA5MDkgLjMyMjc5LTMuNDQzMDg4Uy4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NDk5MzgtMy4zMzU0OTIgLjU2MTg5My0zLjM0NzQ0NyAuNjMzNjI0LTMuNjIyNDE2Qy44MjQ5MDctNC4zNTE2ODEgMS4wNDAxLTUuMDMzMTI2IDEuNTE4MzA2LTUuMDMzMTI2QzEuNzkzMjc1LTUuMDMzMTI2IDEuODg4OTE3LTQuODQxODQzIDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzUwOTM0IC4xMTk1NTIgMS41MTgzMDYgLjA0NzgyMSAxLjYxMzk0OC0uMTMxNTA3QzEuNjM3ODU4LS4xOTEyODMgMS43NDU0NTUtLjYwOTcxNCAxLjgwNTIzLS44NDg4MTdMMi4wNjgyNDQtMS45MjQ3ODJMMi40NjI3NjUtMy41MDI4NjRaJy8+CjxwYXRoIGlkPSdnMy0xMTQnIGQ9J000LjY1MDU2LTQuODg5NjY0QzQuMjc5OTUtNC44MTc5MzMgNC4wODg2NjctNC41NTQ5MTkgNC4wODg2NjctNC4yOTE5MDVDNC4wODg2NjctNC4wMDQ5ODEgNC4zMTU4MTYtMy45MDkzNCA0LjQ4MzE4OC0zLjkwOTM0QzQuODE3OTMzLTMuOTA5MzQgNS4wOTI5MDItNC4xOTYyNjQgNS4wOTI5MDItNC41NTQ5MTlDNS4wOTI5MDItNC45Mzc0ODQgNC43MjIyOTEtNS4yNzIyMjkgNC4xMjQ1MzMtNS4yNzIyMjlDMy42NDYzMjYtNS4yNzIyMjkgMy4wOTYzODktNS4wNTcwMzYgMi41OTQyNzEtNC4zMjc3NzFDMi41MTA1ODUtNC45NjEzOTUgMi4wMzIzNzktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4wODc5Mi01LjI3MjIyOSAuODQ4ODE3LTQuOTEzNTc0IC43MDUzNTUtNC42NTA1NkMuNTAyMTE3LTQuMjIwMTc0IC4zMjI3OS0zLjUwMjg2NCAuMzIyNzktMy40NDMwODhDLjMyMjc5LTMuMzk1MjY4IC4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NDk5MzgtMy4zMzU0OTIgLjU2MTg5My0zLjM0NzQ0NyAuNjMzNjI0LTMuNjIyNDE2Qy44MTI5NTEtNC4zMzk3MjYgMS4wNDAxLTUuMDMzMTI2IDEuNTE4MzA2LTUuMDMzMTI2QzEuODA1MjMtNS4wMzMxMjYgMS44ODg5MTctNC44Mjk4ODggMS44ODg5MTctNC40ODMxODhDMS44ODg5MTctNC4yMjAxNzQgMS43NjkzNjUtMy43NTM5MjMgMS42ODU2NzktMy4zODMzMTNMMS4zNTA5MzQtMi4wOTIxNTRDMS4zMDMxMTMtMS44NjUwMDYgMS4xNzE2MDYtMS4zMjcwMjQgMS4xMTE4MzEtMS4xMTE4MzFDMS4wMjgxNDQtLjgwMDk5NiAuODk2NjM4LS4yMzkxMDMgLjg5NjYzOC0uMTc5MzI4Qy44OTY2MzgtLjAxMTk1NSAxLjAyODE0NCAuMTE5NTUyIDEuMjA3NDcyIC4xMTk1NTJDMS4zMzg5NzkgLjExOTU1MiAxLjU2NjEyNyAuMDM1ODY2IDEuNjM3ODU4LS4yMDMyMzhDMS42NzM3MjQtLjI5ODg3OSAyLjExNjA2NS0yLjEwNDExIDIuMTg3Nzk2LTIuMzc5MDc4QzIuMjQ3NTcyLTIuNjQyMDkyIDIuMzE5MzAzLTIuODkzMTUxIDIuMzc5MDc4LTMuMTU2MTY0QzIuNDI2ODk5LTMuMzIzNTM3IDIuNDc0NzItMy41MTQ4MTkgMi41MTA1ODUtMy42NzAyMzdDMi41NDY0NTEtMy43Nzc4MzMgMi44NjkyNC00LjM2MzYzNiAzLjE2ODEyLTQuNjI2NjVDMy4zMTE1ODItNC43NTgxNTcgMy42MjI0MTYtNS4wMzMxMjYgNC4xMTI1NzgtNS4wMzMxMjZDNC4zMDM4NjEtNS4wMzMxMjYgNC40OTUxNDMtNC45OTcyNiA0LjY1MDU2LTQuODg5NjY0WicvPgo8cGF0aCBpZD0nZzMtMTIyJyBkPSdNMS41MTgzMDYtLjk2ODM2OUMyLjAzMjM3OS0xLjU1NDE3MiAyLjQ1MDgwOS0xLjkyNDc4MiAzLjA0ODU2OC0yLjQ2Mjc2NUMzLjc2NTg3OC0zLjA4NDQzMyA0LjA3NjcxMi0zLjM4MzMxMyA0LjI0NDA4NS0zLjU2MjY0QzUuMDgwOTQ2LTQuMzg3NTQ3IDUuNDk5Mzc3LTUuMDgwOTQ2IDUuNDk5Mzc3LTUuMTc2NTg4UzUuNDAzNzM2LTUuMjcyMjI5IDUuMzc5ODI2LTUuMjcyMjI5QzUuMjk2MTM5LTUuMjcyMjI5IDUuMjcyMjI5LTUuMjI0NDA4IDUuMjEyNDUzLTUuMTQwNzIyQzQuOTEzNTc0LTQuNjI2NjUgNC42MjY2NS00LjM3NTU5MiA0LjMxNTgxNi00LjM3NTU5MkM0LjA2NDc1Ny00LjM3NTU5MiAzLjkzMzI1LTQuNDgzMTg4IDMuNzA2MTAyLTQuNzcwMTEyQzMuNDU1MDQ0LTUuMDY4OTkxIDMuMjUxODA2LTUuMjcyMjI5IDIuOTA1MTA2LTUuMjcyMjI5QzIuMDMyMzc5LTUuMjcyMjI5IDEuNTA2MzUxLTQuMTg0MzA5IDEuNTA2MzUxLTMuOTMzMjVDMS41MDYzNTEtMy44OTczODUgMS41MTgzMDYtMy44MjU2NTQgMS42MjU5MDMtMy44MjU2NTRDMS43MjE1NDQtMy44MjU2NTQgMS43MzM0OTktMy44NzM0NzQgMS43NjkzNjUtMy45NTcxNjFDMS45NzI2MDMtNC40MzUzNjcgMi41NDY0NTEtNC41MTkwNTQgMi43NzM1OTktNC41MTkwNTRDMy4wMjQ2NTgtNC41MTkwNTQgMy4yNjM3NjEtNC40MzUzNjcgMy41MTQ4MTktNC4zMjc3NzFDMy45NjkxMTYtNC4xMzY0ODggNC4xNjAzOTktNC4xMzY0ODggNC4yNzk5NS00LjEzNjQ4OEM0LjM2MzYzNi00LjEzNjQ4OCA0LjQxMTQ1Ny00LjEzNjQ4OCA0LjQ3MTIzMy00LjE0ODQ0M0M0LjA3NjcxMi0zLjY4MjE5MiAzLjQzMTEzMy0zLjEwODM0NCAyLjg5MzE1MS0yLjYxODE4MkwxLjY4NTY3OS0xLjUwNjM1MUMuOTU2NDEzLS43NjUxMzEgLjUxNDA3Mi0uMDU5Nzc2IC41MTQwNzIgLjAyMzkxQy41MTQwNzIgLjA5NTY0MSAuNTczODQ4IC4xMTk1NTIgLjY0NTU3OSAuMTE5NTUyUy43MjkyNjUgLjEwNzU5NyAuODEyOTUxLS4wMzU4NjZDMS4wMDQyMzQtLjMzNDc0NSAxLjM4NjgtLjc3NzA4NiAxLjgyOTE0MS0uNzc3MDg2QzIuMDgwMTk5LS43NzcwODYgMi4xOTk3NTEtLjY5MzQgMi40Mzg4NTQtLjM5NDUyMUMyLjY2NjAwMi0uMTMxNTA3IDIuODY5MjQgLjExOTU1MiAzLjI1MTgwNiAuMTE5NTUyQzQuNDIzNDEyIC4xMTk1NTIgNS4wOTI5MDItMS4zOTg3NTUgNS4wOTI5MDItMS42NzM3MjRDNS4wOTI5MDItMS43MjE1NDQgNS4wODA5NDYtMS43OTMyNzUgNC45NjEzOTUtMS43OTMyNzVDNC44NjU3NTMtMS43OTMyNzUgNC44NTM3OTgtMS43NDU0NTUgNC44MTc5MzMtMS42MjU5MDNDNC41NTQ5MTktLjkyMDU0OCAzLjg0OTU2NC0uNjMzNjI0IDMuMzgzMzEzLS42MzM2MjRDMy4xMzIyNTQtLjYzMzYyNCAyLjg5MzE1MS0uNzE3MzEgMi42NDIwOTItLjgyNDkwN0MyLjE2Mzg4NS0xLjAxNjE4OSAyLjAzMjM3OS0xLjAxNjE4OSAxLjg3Njk2MS0xLjAxNjE4OUMxLjc1NzQxLTEuMDE2MTg5IDEuNjI1OTAzLTEuMDE2MTg5IDEuNTE4MzA2LS45NjgzNjlaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScyMi4zOTc3MTMnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy05NicvPgo8dXNlIHg9JzI3LjMwOTgyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtNDAnLz4KPHVzZSB4PSczMS44NjIxNDUnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy0yMicvPgo8dXNlIHg9JzM4LjkwNTExNicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2czLTU5Jy8+Cjx1c2UgeD0nNDQuMTQ5Mjc1JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtMjcnLz4KPHVzZSB4PSc1MC41ODEzNDcnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy01OScvPgo8dXNlIHg9JzU1LjgyNTUwNScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2czLTI0Jy8+Cjx1c2UgeD0nNjEuNTE1OTQzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtNDEnLz4KPHVzZSB4PSc2OS4zODkwOTgnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNS02MScvPgo8dXNlIHg9JzgxLjgxNDU3OScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2cxLTAnLz4KPHVzZSB4PSc5MS4xMTMwNzYnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy0xMTAnLz4KPHVzZSB4PSc5OC4xMDA2ODInIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnMy0xMTQnLz4KPHVzZSB4PScxMDUuNjkzNjUzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtMTA4Jy8+Cjx1c2UgeD0nMTA4Ljk0NTMxNCcgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c1LTExMScvPgo8dXNlIHg9JzExNC43OTgzMDQnIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNS0xMDMnLz4KPHVzZSB4PScxMjIuODA2Mzc1JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzMtMjcnLz4KPHVzZSB4PScxMzIuNTQ1NDQzJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzE1MC41NjU4MScgeT0nLTMwLjI0MjI4OScgeGxpbms6aHJlZj0nI2cyLTExMCcvPgo8dXNlIHg9JzE0NC41MDA2MDMnIHk9Jy0yNi42NTU3MzMnIHhsaW5rOmhyZWY9JyNnMC04OCcvPgo8dXNlIHg9JzE0Ni4yODI5OTcnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2cyLTEwNScvPgo8dXNlIHg9JzE0OS4xNjYxMzcnIHk9Jy0xLjQ2MTM3OCcgeGxpbms6aHJlZj0nI2c0LTYxJy8+Cjx1c2UgeD0nMTU1Ljc1MjY0MycgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzQtNDknLz4KPHVzZSB4PScxNjMuNzYxNzE4JyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzUtMTAxJy8+Cjx1c2UgeD0nMTY4Ljk2NDM3NicgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2c1LTEyMCcvPgo8dXNlIHg9JzE3NS4xNDI1MzInIHk9Jy0xNS4yOTgyNjgnIHhsaW5rOmhyZWY9JyNnNS0xMTInLz4KPHVzZSB4PScxODEuNjQ1ODU0JyB5PSctMzIuMTU1MjA1JyB4bGluazpocmVmPScjZzAtMjAnLz4KPHVzZSB4PScxODcuOTU1NTUyJyB5PSctMTUuMjk4MjY4JyB4bGluazpocmVmPScjZzEtMCcvPgo8dXNlIHg9JzE5Ny4yNTQwNDknIHk9Jy0yOC41Njg2MTgnIHhsaW5rOmhyZWY9JyNnMC0xNicvPgo8dXNlIHg9JzIwNS41ODk0NzUnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnMy0xMjInLz4KPHVzZSB4PScyMTEuNTYwMDgxJyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzQtNDAnLz4KPHVzZSB4PScyMTQuODUzMzM1JyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzItMTE0Jy8+Cjx1c2UgeD0nMjE4LjkwOTkzJyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzQtNDEnLz4KPHVzZSB4PScyMTEuMDI3MzY1JyB5PSctMjAuMzIyMjE0JyB4bGluazpocmVmPScjZzItMTA1Jy8+Cjx1c2UgeD0nMjI1LjM1Nzk3OScgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2cxLTAnLz4KPHVzZSB4PScyMzcuMzEzMTQnIHk9Jy0yMy4zODYwMjcnIHhsaW5rOmhyZWY9JyNnMy0yMicvPgo8cmVjdCB4PScyMDUuNTg5NDc1JyB5PSctMTguNTI2MTU0JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSczOC43NjY2MjgnLz4KPHVzZSB4PScyMjEuNDMxNTg3JyB5PSctNy4wOTc2MDYnIHhsaW5rOmhyZWY9JyNnMy0yNycvPgo8dXNlIHg9JzI0NS41NTE2MTYnIHk9Jy0yOC41Njg2MTgnIHhsaW5rOmhyZWY9JyNnMC0xNycvPgo8dXNlIHg9JzI1Mi42OTE1MjknIHk9Jy0zMi4xNTUyMDUnIHhsaW5rOmhyZWY9JyNnMC0yMScvPgo8dXNlIHg9JzI2MS42NTc4OScgeT0nLTE1LjI5ODI2OCcgeGxpbms6aHJlZj0nI2cxLTAnLz4KPHVzZSB4PScyNzkuNjc4MjU3JyB5PSctMzAuMjQyMjg5JyB4bGluazpocmVmPScjZzItMTEwJy8+Cjx1c2UgeD0nMjczLjYxMzA1JyB5PSctMjYuNjU1NzMzJyB4bGluazpocmVmPScjZzAtODgnLz4KPHVzZSB4PScyNzUuMzk1NDQ0JyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnMi0xMDUnLz4KPHVzZSB4PScyNzguMjc4NTg0JyB5PSctMS40NjEzNzgnIHhsaW5rOmhyZWY9JyNnNC02MScvPgo8dXNlIHg9JzI4NC44NjUwOScgeT0nLTEuNDYxMzc4JyB4bGluazpocmVmPScjZzQtNDknLz4KPHVzZSB4PScyOTkuNDgwMTc1JyB5PSctMzAuMjQyMjg5JyB4bGluazpocmVmPScjZzItMTE0Jy8+Cjx1c2UgeD0nMjkyLjg3NDE2NScgeT0nLTI2LjY1NTczMycgeGxpbms6aHJlZj0nI2cwLTg4Jy8+Cjx1c2UgeD0nMjkzLjc4NzMyJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnMi0xMDcnLz4KPHVzZSB4PScyOTguNDA4OTM2JyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNC02MScvPgo8dXNlIHg9JzMwNC45OTU0NDMnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2c0LTQ5Jy8+Cjx1c2UgeD0nMzEwLjE0Mjc4MScgeT0nLTI4LjU2ODYxOCcgeGxpbms6aHJlZj0nI2cwLTE2Jy8+Cjx1c2UgeD0nMzE4LjQ3ODIwNycgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2czLTEyMicvPgo8dXNlIHg9JzMyNC40NDg4MTQnIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnNC00MCcvPgo8dXNlIHg9JzMyNy43NDIwNjcnIHk9Jy0yOS40OTY0MjknIHhsaW5rOmhyZWY9JyNnMi0xMDcnLz4KPHVzZSB4PSczMzIuMzYzNjgzJyB5PSctMjkuNDk2NDI5JyB4bGluazpocmVmPScjZzQtNDEnLz4KPHVzZSB4PSczMjMuOTE2MDk4JyB5PSctMjAuMzIyMjE0JyB4bGluazpocmVmPScjZzItMTA1Jy8+Cjx1c2UgeD0nMzM4LjgxMTczMScgeT0nLTIzLjM4NjAyNycgeGxpbms6aHJlZj0nI2cxLTAnLz4KPHVzZSB4PSczNTAuNzY2ODkyJyB5PSctMjMuMzg2MDI3JyB4bGluazpocmVmPScjZzMtMjInLz4KPHJlY3QgeD0nMzE4LjQ3ODIwNycgeT0nLTE4LjUyNjE1NCcgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nMzkuMzMxNjQ4Jy8+Cjx1c2UgeD0nMzM0LjYwMjgyOScgeT0nLTcuMDk3NjA2JyB4bGluazpocmVmPScjZzMtMjcnLz4KPHVzZSB4PSczNTkuMDA1MzY5JyB5PSctMjguNTY4NjE4JyB4bGluazpocmVmPScjZzAtMTcnLz4KPC9nPgo8L3N2Zz4KPCEtLSBERVBUSD0wIC0tPg==)
- buildMethodOfLikelihoodMaximizationEstimator(sample, r=0)¶
Estimate the distribution and the parameter distribution with the R-maxima method.
- Parameters:
- sampleM2-d sequence of float
Block maxima grouped in a sample of size
and dimension .- rint, , optional
Number of order statistics taken into account among the
stored ones.By default,
which means that all the maxima are used.
- Returns:
- result
DistributionFactoryLikelihoodResult The result class.
- result
Notes
The method estimates a GEV distribution parameterized by
from a given sample.The estimator
 is defined using the profile log-likelihood as detailed in
is defined using the profile log-likelihood as detailed in
buildMethodOfLikelihoodMaximization().The result class produced by the method provides:
the GEV distribution associated to
 ,
,the asymptotic distribution of
.
- buildMethodOfXiProfileLikelihood(sample, r=0)¶
Estimate the distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
Block maxima grouped in a sample of size
and dimension .- rint, ,
Number of largest order statistics taken into account among the
stored ones.By default,
which means that all the maxima are used.
- Returns:
- distribution
GeneralizedExtremeValue The estimated distribution.
- distribution
Notes
The method estimates a GEV distribution parameterized by
from a given sample.The estimator
is defined using a nested numerical optimization of the log-likelihood:
where
 is detailed in equations (1) and (2) with
is detailed in equations (1) and (2) with  .
.If
then:
The starting point of the optimization is initialized from the probability weighted moments method, see [diebolt2008].
- buildMethodOfXiProfileLikelihoodEstimator(sample, r=0)¶
Estimate the distribution and the parameter distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
Block maxima grouped in a sample of size
and dimension .- rint, ,
Number of largest order statistics taken into account among the
stored ones.
The block maxima sample of dimension 1 from which
are estimated.By default,
which means that all the maxima are used.
- Returns:
- result
ProfileLikelihoodResult The result class.
- result
Notes
The method estimates a GEV distribution parameterized by
from a given sample.The estimator
is defined in buildMethodOfXiProfileLikelihood().The result class produced by the method provides:
the GEV distribution associated to
,the asymptotic distribution of
,the profile log-likelihood function
 ,
,the optimal profile log-likelihood value
 ,
,confidence intervals of level
 of .
of .
- buildReturnLevelEstimator(result, m)¶
Estimate a return level and its distribution from the GEV parameters.
- Parameters:
- result
DistributionFactoryResult Likelihood estimation result of a
GeneralizedExtremeValue- mfloat
The return period expressed in terms of number of blocks.
- result
- Returns:
- distribution
Distribution The asymptotic distribution of
 .
.
- distribution
Notes
Let
 be a random variable which follows a GEV distribution parameterized by
.
be a random variable which follows a GEV distribution parameterized by
.The
-block return level  is the level exceeded on average once every
blocks.
The -block return level can be translated into the annual-scale: if there
are
is the level exceeded on average once every
blocks.
The -block return level can be translated into the annual-scale: if there
are  blocks per year, then the
blocks per year, then the  -year return level
corresponds to the -bock return level where
-year return level
corresponds to the -bock return level where  .
.The
-block return level is defined as the quantile of order  of the GEV
distribution:
of the GEV
distribution:If
:(3)¶
![z_m = \mu - \frac{\sigma}{\xi} \left[ 1- (-\log(1-p))^{-\xi}\right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzE3NC43OTk3MzJwdCcgaGVpZ2h0PScyMy43NjA0MDFwdCcgdmlld0JveD0nMTA2Ljg3MTYzMSAtMjMuNzYwMzkgMTc0Ljc5OTczMiAyMy43NjA0MDEnPgo8ZGVmcz4KPHBhdGggaWQ9J2cwLTInIGQ9J00yLjQxNDk0NCAxMy44NTYwNEg0LjcxMDMzNlYxMy4zNzc4MzNIMi44OTMxNTFWMEg0LjcxMDMzNlYtLjQ3ODIwN0gyLjQxNDk0NFYxMy44NTYwNFonLz4KPHBhdGggaWQ9J2cwLTMnIGQ9J00yLjU1ODQwNiAxMy44NTYwNFYtLjQ3ODIwN0guMjYzMDE0VjBIMi4wODAxOTlWMTMuMzc3ODMzSC4yNjMwMTRWMTMuODU2MDRIMi41NTg0MDZaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2c1LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnNS00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzUtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnNS02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzUtMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzUtMTA4JyBkPSdNMi4wNTYyODktOC4yOTY4ODdMLjM5NDUyMS04LjE2NTM4Vi03LjgxODY4QzEuMjA3NDcyLTcuODE4NjggMS4zMDMxMTMtNy43MzQ5OTQgMS4zMDMxMTMtNy4xNDkxOTFWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzE1MDY4LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFTMi42MzAxMzctLjAyMzkxIDIuOTY0ODgyIDBWLS4zNDY3QzIuMTk5NzUxLS4zNDY3IDIuMDU2Mjg5LS4zNDY3IDIuMDU2Mjg5LS44ODQ2ODJWLTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzUtMTExJyBkPSdNNS40ODc0MjItMi41NTg0MDZDNS40ODc0MjItNC4xMDA2MjMgNC4zMTU4MTYtNS4zMzIwMDUgMi45MjkwMTYtNS4zMzIwMDVDMS40OTQzOTYtNS4zMzIwMDUgLjM1ODY1NS00LjA2NDc1NyAuMzU4NjU1LTIuNTU4NDA2Qy4zNTg2NTUtMS4wMjgxNDQgMS41NTQxNzIgLjExOTU1MiAyLjkxNzA2MSAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNS40ODc0MjItMS4wNTIwNTUgNS40ODc0MjItMi41NTg0MDZaTTIuOTI5MDE2LS4xNDM0NjJDMi40ODY2NzUtLjE0MzQ2MiAxLjk0ODY5Mi0uMzM0NzQ1IDEuNjAxOTkzLS45MjA1NDhDMS4yNzkyMDMtMS40NTg1MzEgMS4yNjcyNDgtMi4xNjM4ODUgMS4yNjcyNDgtMi42NjYwMDJDMS4yNjcyNDgtMy4xMjAyOTkgMS4yNjcyNDgtMy44NDk1NjQgMS42Mzc4NTgtNC4zODc1NDdDMS45NzI2MDMtNC45MDE2MTkgMi40OTg2My01LjA5MjkwMiAyLjkxNzA2MS01LjA5MjkwMkMzLjM4MzMxMy01LjA5MjkwMiAzLjg4NTQzLTQuODc3NzA5IDQuMjA4MjE5LTQuNDExNDU3QzQuNTc4ODI5LTMuODYxNTE5IDQuNTc4ODI5LTMuMTA4MzQ0IDQuNTc4ODI5LTIuNjY2MDAyQzQuNTc4ODI5LTIuMjQ3NTcyIDQuNTc4ODI5LTEuNTA2MzUxIDQuMjY3OTk1LS45NDQ0NThDMy45MzMyNS0uMzcwNjEgMy4zODMzMTMtLjE0MzQ2MiAyLjkyOTAxNi0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzMtMjQnIGQ9J00xLjYxNzkzMy0yLjM1MTE4M0MxLjkxMjgyNy0yLjIzOTYwMSAyLjIwNzcyMS0yLjIzOTYwMSAyLjM4MzA2NC0yLjIzOTYwMUMyLjY1NDA0Ny0yLjIzOTYwMSAzLjE3MjEwNS0yLjIzOTYwMSAzLjE3MjEwNS0yLjUyNjUyNkMzLjE3MjEwNS0yLjc2NTYyOSAyLjc0MTcxOS0yLjc2NTYyOSAyLjQ3MDczNS0yLjc2NTYyOUMyLjMxMTMzMy0yLjc2NTYyOSAyLjA2NDI1OS0yLjc2NTYyOSAxLjc1MzQyNS0yLjY2MjAxN0MxLjU3ODA4Mi0yLjgyOTM5IDEuNTA2MzUxLTMuMDUyNTUzIDEuNTA2MzUxLTMuMjc1NzE2QzEuNTA2MzUxLTMuNzIyMDQyIDEuODE3MTg2LTQuMjg3OTIgMi4zOTkwMDQtNC41NjY4NzRDMi41NzQzNDYtNC4zODM1NjIgMi43ODE1NjktNC4zODM1NjIgMi45NDg5NDEtNC4zODM1NjJDMy4yNTE4MDYtNC4zODM1NjIgMy43MDYxMDItNC4zOTk1MDIgMy43MDYxMDItNC42NzA0ODZDMy43MDYxMDItNC45MDk1ODkgMy4yNzU3MTYtNC45MDk1ODkgMi45OTY3NjItNC45MDk1ODlDMi44NjEyNy00LjkwOTU4OSAyLjcyNTc3OC00LjkwOTU4OSAyLjUwMjYxNS00Ljg3NzcwOUMyLjQ4NjY3NS00LjkzMzQ5OSAyLjQ2Mjc2NS01LjAxMzIgMi40NjI3NjUtNS4xMTY4MTJDMi40NjI3NjUtNS4yMjgzOTQgMi40OTQ2NDUtNS4zNjM4ODUgMi40OTQ2NDUtNS4zODc3OTZDMi41MDI2MTUtNS4zOTU3NjYgMi41MDI2MTUtNS40Mjc2NDYgMi41MDI2MTUtNS40MzU2MTZDMi41MDI2MTUtNS41MDczNDcgMi40NDY4MjQtNS41NTUxNjggMi4zOTEwMzQtNS41NTUxNjhDMi4yMTU2OTEtNS41NTUxNjggMi4yMTU2OTEtNS4xOTY1MTMgMi4yMTU2OTEtNS4xMjQ3ODJDMi4yMTU2OTEtNC45NzMzNSAyLjI1NTU0Mi00LjgzNzg1OCAyLjI2MzUxMi00LjgyMTkxOEMxLjM3MDg1OS00LjU5MDc4NSAuODIwOTIyLTMuOTUzMTc2IC44MjA5MjItMy4zMjM1MzdDLjgyMDkyMi0yLjkyNTAzMSAxLjAzNjExNS0yLjY1NDA0NyAxLjMzODk3OS0yLjQ3ODcwNUMuNDg2MTc3LTEuOTkyNTI4IC4xOTEyODMtMS4xODc1NDcgLjE5MTI4My0uODIwOTIyQy4xOTEyODMtLjA5NTY0MSAuOTI0NTMzIC4xNjczNzIgMS4xNzk1NzcgLjI2MzAxNEMxLjYyNTkwMyAuNDMwMzg2IDEuNjQxODQzIC40MzAzODYgMi4wMzIzNzkgLjU2NTg3OEMyLjIyMzY2MSAuNjM3NjA5IDIuNTQyNDY2IC43NTcxNjEgMi41OTgyNTcgLjc4OTA0MUMyLjcyNTc3OCAuODY4NzQyIDIuNzI1Nzc4IC45ODAzMjQgMi43MjU3NzggMS4wMjgxNDRDMi43MjU3NzggMS4xNzE2MDYgMi42MjIxNjcgMS40MDI3NCAyLjM2NzEyMyAxLjQwMjc0QzIuMzAzMzYyIDEuNDAyNzQgMS45NzY1ODggMS4zODY4IDEuNjU3NzgzIDEuMTk1NTE3QzEuNTc4MDgyIDEuMTM5NzI2IDEuNTcwMTEyIDEuMTMxNzU2IDEuNTMwMjYyIDEuMTMxNzU2QzEuNDQyNTkgMS4xMzE3NTYgMS40MTg2OCAxLjIxMTQ1NyAxLjQxODY4IDEuMjQzMzM3QzEuNDE4NjggMS4zNzA4NTkgMS45Mjg3NjcgMS42MjU5MDMgMi4zNzUwOTMgMS42MjU5MDNDMi45MDExMjEgMS42MjU5MDMgMy4yMjc4OTUgMS4xMjM3ODYgMy4yMjc4OTUgLjc1NzE2MUMzLjIyNzg5NSAuNjEzNjk5IDMuMTcyMTA1IC40NjIyNjcgMy4wNzY0NjMgLjM1MDY4NUMyLjk3Mjg1MiAuMjM5MTAzIDIuODY5MjQgLjE5OTI1MyAyLjQyMjkxNCAuMDM5ODUxQzEuNzI5NTE0LS4yMDcyMjMgMS4yMTE0NTctLjM5MDUzNSAxLjA4MzkzNS0uNDYyMjY3Qy44Mjg4OTItLjU5Nzc1OCAuNjYxNTE5LS43ODkwNDEgLjY2MTUxOS0xLjA1MjA1NUMuNjYxNTE5LTEuMzc4ODI5IC45NTY0MTMtMS45OTI1MjggMS42MTc5MzMtMi4zNTExODNaTTMuNDAzMjM4LTQuNjQ2NTc1QzMuMzIzNTM3LTQuNjMwNjM1IDMuMjQzODM2LTQuNjA2NzI1IDIuOTU2OTEyLTQuNjA2NzI1QzIuNzg5NTM5LTQuNjA2NzI1IDIuNzU3NjU5LTQuNjA2NzI1IDIuNjYyMDE3LTQuNjU0NTQ1QzIuNzg5NTM5LTQuNjg2NDI2IDIuODY5MjQtNC42ODY0MjYgMy4wMTI3MDItNC42ODY0MjZDMy4yMjc4OTUtNC42ODY0MjYgMy4yODM2ODYtNC42Nzg0NTYgMy40MDMyMzgtNC42NTQ1NDVWLTQuNjQ2NTc1Wk0yLjg2OTI0LTIuNTAyNjE1QzIuNzk3NTA5LTIuNDg2Njc1IDIuNzE3ODA4LTIuNDYyNzY1IDIuNDA2OTc0LTIuNDYyNzY1QzIuMjU1NTQyLTIuNDYyNzY1IDIuMTc1ODQxLTIuNDYyNzY1IDIuMDQ4MzE5LTIuNTAyNjE1QzIuMjIzNjYxLTIuNTQyNDY2IDIuMzE5MzAzLTIuNTQyNDY2IDIuNDYyNzY1LTIuNTQyNDY2QzIuNjkzODk4LTIuNTQyNDY2IDIuNzU3NjU5LTIuNTM0NDk2IDIuODY5MjQtMi41MTA1ODVWLTIuNTAyNjE1WicvPgo8cGF0aCBpZD0nZzMtMTA5JyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjc0NTQ1NS0xLjkyODc2NyAxLjc5MzI3NS0yLjEyMDA1IDEuODA5MjE1LTIuMTk5NzUxQzEuODI1MTU2LTIuMjM5NjAxIDIuMDg4MTY5LTIuNzU3NjU5IDIuNDM4ODU0LTMuMDIwNjcyQzIuNzA5ODM4LTMuMjI3ODk1IDIuOTcyODUyLTMuMjkxNjU2IDMuMTk2MDE1LTMuMjkxNjU2QzMuNDkwOTA5LTMuMjkxNjU2IDMuNjUwMzExLTMuMTE2MzE0IDMuNjUwMzExLTIuNzQ5Njg5QzMuNjUwMzExLTIuNTU4NDA2IDMuNjAyNDkxLTIuMzc1MDkzIDMuNTE0ODE5LTIuMDE2NDM4QzMuNDU5MDI5LTEuODA5MjE1IDMuMzIzNTM3LTEuMjc1MjE4IDMuMjc1NzE2LTEuMDYwMDI1TDMuMTU2MTY0LS41ODE4MThDMy4xMTYzMTQtLjQ0NjMyNiAzLjA2MDUyMy0uMjA3MjIzIDMuMDYwNTIzLS4xNjczNzJDMy4wNjA1MjMgLjAxNTk0IDMuMjExOTU1IC4wNzk3MDEgMy4zMTU1NjcgLjA3OTcwMUMzLjQ1OTAyOSAuMDc5NzAxIDMuNTc4NTgtLjAxNTk0IDMuNjM0MzcxLS4xMTE1ODJDMy42NTgyODEtLjE1OTQwMiAzLjcyMjA0Mi0uNDMwMzg2IDMuNzYxODkzLS41OTc3NThMMy45NDUyMDUtMS4zMDcwOThDMy45NjkxMTYtMS40MjY2NSA0LjA0ODgxNy0xLjcyOTUxNCA0LjA3MjcyNy0xLjg0OTA2NkM0LjE4NDMwOS0yLjI3OTQ1MiA0LjE4NDMwOS0yLjI4NzQyMiA0LjM2NzYyMS0yLjU1MDQzNkM0LjYzMDYzNS0yLjk0MDk3MSA1LjAwNTIzLTMuMjkxNjU2IDUuNTM5MjI4LTMuMjkxNjU2QzUuODI2MTUyLTMuMjkxNjU2IDUuOTkzNTI0LTMuMTI0Mjg0IDUuOTkzNTI0LTIuNzQ5Njg5QzUuOTkzNTI0LTIuMzExMzMzIDUuNjU4NzgtMS4zOTQ3NyA1LjUwNzM0Ny0xLjAxMjIwNEM1LjQyNzY0Ni0uODA0OTgxIDUuNDAzNzM2LS43NDkxOTEgNS40MDM3MzYtLjU5Nzc1OEM1LjQwMzczNi0uMTQzNDYyIDUuNzc4MzMxIC4wNzk3MDEgNi4xMjEwNDYgLjA3OTcwMUM2LjkwMjExNyAuMDc5NzAxIDcuMjI4ODkyLTEuMDM2MTE1IDcuMjI4ODkyLTEuMTM5NzI2QzcuMjI4ODkyLTEuMjE5NDI3IDcuMTY1MTMxLTEuMjQzMzM3IDcuMTA5MzQtMS4yNDMzMzdDNy4wMTM2OTktMS4yNDMzMzcgNi45OTc3NTgtMS4xODc1NDcgNi45NzM4NDgtMS4xMDc4NDZDNi43ODI1NjUtLjQ0NjMyNiA2LjQ0NzgyMS0uMTQzNDYyIDYuMTQ0OTU2LS4xNDM0NjJDNi4wMTc0MzUtLjE0MzQ2MiA1Ljk1MzY3NC0uMjIzMTYzIDUuOTUzNjc0LS40MDY0NzZTNi4wMTc0MzUtLjc2NTEzMSA2LjA5NzEzNi0uOTY0Mzg0QzYuMjE2Njg3LTEuMjY3MjQ4IDYuNTY3MzcyLTIuMTgzODExIDYuNTY3MzcyLTIuNjMwMTM3QzYuNTY3MzcyLTMuMjI3ODk1IDYuMTUyOTI3LTMuNTE0ODE5IDUuNTc5MDc4LTMuNTE0ODE5QzUuMDI5MTQxLTMuNTE0ODE5IDQuNTc0ODQ0LTMuMjI3ODk1IDQuMjE2MTg5LTIuNzMzNzQ4QzQuMTUyNDI4LTMuMzcxMzU3IDMuNjQyMzQxLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuODYxMjctMy41MTQ4MTkgMi4zNzUwOTMtMy4zODcyOTggMS45MzY3MzctMi44MTM0NUMxLjg4MDk0Ni0zLjI5MTY1NiAxLjQ5ODM4MS0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODQ0ODMyLTMuNTE0ODE5IC42NDU1NzktMy4zNDc0NDcgLjUxMDA4Ny0zLjA3NjQ2M0MuMzE4ODA0LTIuNzAxODY4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnMS0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzQtMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2c0LTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2c0LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNC0xMTInIGQ9J00uNTE0MDcyIDEuNTE4MzA2Qy40MzAzODYgMS44NzY5NjEgLjM4MjU2NSAxLjk3MjYwMy0uMTA3NTk3IDEuOTcyNjAzQy0uMjUxMDU5IDEuOTcyNjAzLS4zNzA2MSAxLjk3MjYwMy0uMzcwNjEgMi4xOTk3NTFDLS4zNzA2MSAyLjIyMzY2MS0uMzU4NjU1IDIuMzE5MzAzLS4yMjcxNDggMi4zMTkzMDNDLS4wNzE3MzEgMi4zMTkzMDMgLjA5NTY0MSAyLjI5NTM5MiAuMjUxMDU5IDIuMjk1MzkySC43NjUxMzFDMS4wMTYxODkgMi4yOTUzOTIgMS42MjU5MDMgMi4zMTkzMDMgMS44NzY5NjEgMi4zMTkzMDNDMS45NDg2OTIgMi4zMTkzMDMgMi4wOTIxNTQgMi4zMTkzMDMgMi4wOTIxNTQgMi4xMDQxMUMyLjA5MjE1NCAxLjk3MjYwMyAyLjAwODQ2OCAxLjk3MjYwMyAxLjgwNTIzIDEuOTcyNjAzQzEuMjU1MjkzIDEuOTcyNjAzIDEuMjE5NDI3IDEuODg4OTE3IDEuMjE5NDI3IDEuNzkzMjc1QzEuMjE5NDI3IDEuNjQ5ODEzIDEuNzU3NDEtLjQwNjQ3NiAxLjgyOTE0MS0uNjgxNDQ1QzEuOTYwNjQ4LS4zNDY3IDIuMjgzNDM3IC4xMTk1NTIgMi45MDUxMDYgLjExOTU1MkM0LjI1NjA0IC4xMTk1NTIgNS43MTQ1Ny0xLjYzNzg1OCA1LjcxNDU3LTMuMzk1MjY4QzUuNzE0NTctNC40OTUxNDMgNS4wOTI5MDItNS4yNzIyMjkgNC4xOTYyNjQtNS4yNzIyMjlDMy40MzExMzMtNS4yNzIyMjkgMi43ODU1NTQtNC41MzEwMDkgMi42NTQwNDctNC4zNjM2MzZDMi41NTg0MDYtNC45NjEzOTUgMi4wOTIxNTQtNS4yNzIyMjkgMS42MTM5NDgtNS4yNzIyMjlDMS4yNjcyNDgtNS4yNzIyMjkgLjk5MjI3OS01LjEwNDg1NyAuNzY1MTMxLTQuNjUwNTZDLjU0OTkzOC00LjIyMDE3NCAuMzgyNTY1LTMuNDkwOTA5IC4zODI1NjUtMy40NDMwODhTLjQzMDM4Ni0zLjMzNTQ5MiAuNTE0MDcyLTMuMzM1NDkyQy42MDk3MTQtMy4zMzU0OTIgLjYyMTY2OS0zLjM0NzQ0NyAuNjkzNC0zLjYyMjQxNkMuODcyNzI3LTQuMzI3NzcxIDEuMDk5ODc1LTUuMDMzMTI2IDEuNTc4MDgyLTUuMDMzMTI2QzEuODUzMDUxLTUuMDMzMTI2IDEuOTQ4NjkyLTQuODQxODQzIDEuOTQ4NjkyLTQuNDgzMTg4QzEuOTQ4NjkyLTQuMTk2MjY0IDEuOTEyODI3LTQuMDc2NzEyIDEuODY1MDA2LTMuODYxNTE5TC41MTQwNzIgMS41MTgzMDZaTTIuNTgyMzE2LTMuNzMwMDEyQzIuNjY2MDAyLTQuMDY0NzU3IDMuMDAwNzQ3LTQuNDExNDU3IDMuMTkyMDMtNC41Nzg4MjlDMy4zMjM1MzctNC42OTgzODEgMy43MTgwNTctNS4wMzMxMjYgNC4xNzIzNTQtNS4wMzMxMjZDNC42OTgzODEtNS4wMzMxMjYgNC45Mzc0ODQtNC41MDcwOTggNC45Mzc0ODQtMy44ODU0M0M0LjkzNzQ4NC0zLjMxMTU4MiA0LjYwMjc0LTEuOTYwNjQ4IDQuMzAzODYxLTEuMzM4OTc5QzQuMDA0OTgxLS42OTM0IDMuNDU1MDQ0LS4xMTk1NTIgMi45MDUxMDYtLjExOTU1MkMyLjA5MjE1NC0uMTE5NTUyIDEuOTYwNjQ4LTEuMTQ3Njk2IDEuOTYwNjQ4LTEuMTk1NTE3QzEuOTYwNjQ4LTEuMjMxMzgyIDEuOTg0NTU4LTEuMzI3MDI0IDEuOTk2NTEzLTEuMzg2OEwyLjU4MjMxNi0zLjczMDAxMlonLz4KPHBhdGggaWQ9J2c0LTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMTA2Ljg3MTYzMScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c0LTEyMicvPgo8dXNlIHg9JzExMi4zMDk1MjInIHk9Jy04LjczMTk5NScgeGxpbms6aHJlZj0nI2czLTEwOScvPgo8dXNlIHg9JzEyMy42MTkwMDknIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS02MScvPgo8dXNlIHg9JzEzNi4wNDQ0OScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c0LTIyJy8+Cjx1c2UgeD0nMTQ1Ljc0NDEyNCcgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScxNTguODk0Nzk4JyB5PSctMTguNjEzMDE3JyB4bGluazpocmVmPScjZzQtMjcnLz4KPHJlY3QgeD0nMTU4Ljg5NDc5OCcgeT0nLTEzLjc1MzE0NCcgaGVpZ2h0PScuNDc4MTg3JyB3aWR0aD0nNy4wODI0MDQnLz4KPHVzZSB4PScxNTkuNTkwNzgyJyB5PSctMi4zMjQ1OTYnIHhsaW5rOmhyZWY9JyNnNC0yNCcvPgo8dXNlIHg9JzE2OS4xNjUyMTQnIHk9Jy0yMC4yMDkwMjEnIHhsaW5rOmhyZWY9JyNnMC0yJy8+Cjx1c2UgeD0nMTc0LjE0NjU0OScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c1LTQ5Jy8+Cjx1c2UgeD0nMTgyLjY1NjIwMycgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2cyLTAnLz4KPHVzZSB4PScxOTQuNjExMzYzJyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtNDAnLz4KPHVzZSB4PScxOTkuMTYzNjg5JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzItMCcvPgo8dXNlIHg9JzIxMC40NTQ2ODQnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS0xMDgnLz4KPHVzZSB4PScyMTMuNzA2MzQ1JyB5PSctMTAuNTI1MjU4JyB4bGluazpocmVmPScjZzUtMTExJy8+Cjx1c2UgeD0nMjE5LjU1OTMzNScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c1LTEwMycvPgo8dXNlIHg9JzIyNS41NzQ5MDknIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS00MCcvPgo8dXNlIHg9JzIzMC4xMjcyMzQnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS00OScvPgo8dXNlIHg9JzIzOC42MzY4ODgnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nMjUwLjU5MjA0OScgeT0nLTEwLjUyNTI1OCcgeGxpbms6aHJlZj0nI2c0LTExMicvPgo8dXNlIHg9JzI1Ni40NjcxOTInIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS00MScvPgo8dXNlIHg9JzI2MS4wMTk1MTcnIHk9Jy0xMC41MjUyNTgnIHhsaW5rOmhyZWY9JyNnNS00MScvPgo8dXNlIHg9JzI2NS41NzE4NDMnIHk9Jy0xNS40NjE0NDQnIHhsaW5rOmhyZWY9JyNnMS0wJy8+Cjx1c2UgeD0nMjcyLjE1ODM1JyB5PSctMTUuNDYxNDQ0JyB4bGluazpocmVmPScjZzMtMjQnLz4KPHVzZSB4PScyNzYuNjkwMDE2JyB5PSctMjAuMjA5MDIxJyB4bGluazpocmVmPScjZzAtMycvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
If
:(4)¶

The estimator
of is deduced from the estimator
of .The asymptotic distribution of
 is obtained by the Delta method from the asymptotic distribution of
. It is a normal distribution with mean and variance:
is obtained by the Delta method from the asymptotic distribution of
. It is a normal distribution with mean and variance:
where
 and
and  is the asymptotic covariance of .
is the asymptotic covariance of .
- buildReturnLevelProfileLikelihood(sample, m)¶
Estimate a return level and its distribution with the profile likelihood.
- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1.
- Returns:
- distribution
Normal The asymptotic distribution of
.
- distribution
Notes
Let
be a random variable which follows a GEV distribution parameterized by
.The
-return level is defined in buildReturnLevelEstimator().The estimator is defined using a nested numerical optimization of the log-likelihood:

where
 is the log-likelihood detailed in (1) and (2) with and where we substitued
for using equations (3) or (4).
is the log-likelihood detailed in (1) and (2) with and where we substitued
for using equations (3) or (4).The estimator
of is defined by:
The asymptotic distribution of
is normal.The starting point of the optimization is initialized from the regular maximum likelihood method.
- buildReturnLevelProfileLikelihoodEstimator(sample, m)¶
Estimate
and its distribution with the profile likelihood.- Parameters:
- sample2-d sequence of float
The block maxima sample of dimension 1.
- mfloat
The return period expressed in terms of number of blocks.
- Returns:
- result
ProfileLikelihoodResult The result class.
- result
Notes
Let
be a random variable which follows a GEV distribution parameterized by
.The
-block return level is defined in buildReturnLevelEstimator(). The profile log-likelihood is defined in
is defined in buildReturnLevelProfileLikelihood().The estimator of
 is defined by:
is defined by:
The result class produced by the method provides:
the GEV distribution associated to
,the asymptotic distribution of
,the profile log-likelihood function
 ,
,the optimal profile log-likelihood value
 ,
,confidence intervals of level
of .
- buildTimeVarying(*args)¶
Estimate a non stationary GEV from a time-dependent parametric model.
- Parameters:
- sample2-d sequence of float
The block maxima grouped in a sample of size
and one dimension.- timeStamps2-d sequence of float
Values of
 .
.- basis
Basis Functional basis respectively for
 ,
,  and
and  .
.- muIndicessequence of int, optional
Indices of basis terms considered for parameter
- sigmaIndicessequence of int, optional
Indices of basis terms considered for parameter
- xiIndicessequence of int, optional
Indices of basis terms considered for parameter
- muLink
Function, optional The
function.By default, the identity function.
- sigmaLink
Function, optional The
function.By default, the identity function.
- xiLink
Function, optional The
function.By default, the identity function.
- initializationMethodstr, optional
The initialization method for the optimization problem: Gumbel or Static.
By default, the method Gumbel (see
ResourceMap, key GeneralizedExtremeValueFactory-InitializationMethod).- normalizationMethodstr, optional
The data normalization method: CenterReduce, MinMax or None.
By default, the method MinMax (see
ResourceMap, key GeneralizedExtremeValueFactory-NormalizationMethod).
- Returns:
- result
TimeVaryingResult The result class.
- result
Notes
Let
 be a non stationary GEV distribution:
be a non stationary GEV distribution:
We denote by
 the values of
on the time stamps
the values of
on the time stamps  .
.For numerical reasons, it is recommended to normalize the time stamps. The following mapping is applied:

and with three ways of defining
 :
:the CenterReduce method where
 is the mean time
stamps
and
is the mean time
stamps
and  is the standard deviation of the time stamps;
is the standard deviation of the time stamps;the MinMax method where
 is the first time and
is the first time and  the
range of the time stamps. This is the default method;
the
range of the time stamps. This is the default method;the None method where
 and
and  : in that case, data are not
normalized.
: in that case, data are not
normalized.
If we denote by
is a component of ,
then can be written as a function of :
where:
 is the size of the functional basis involved in the modelling of
,
is the size of the functional basis involved in the modelling of
,- is usually referred to as the inverse-link function of
the parameter ,
each
 is a scalar function
is a scalar function  ,
,each
 .
.
We denote by
 ,
,  and
and  the size of the functional basis of
, and respectively. We denote by
the size of the functional basis of
, and respectively. We denote by
 the complete vector of parameters.
the complete vector of parameters.The estimator of
maximizes the likelihood of the non stationary model which is defined by:
where
 denotes the GEV density function with parameters
denotes the GEV density function with parameters
 evaluated at
evaluated at  .
.Then, if none of the
 is zero, the log-likelihood is defined by:
is zero, the log-likelihood is defined by:![\ell (\vect{\beta}) = -\sum_{i=1}^{n} \left\{ \log(\sigma(t_i)) + (1 + 1 / \xi(t_i) ) \log\left[ 1+\xi(t_i) \left( \frac{z_{t_i} - \mu(t_i)}{\sigma(t_i)}\right) \right] + \left[ 1 + \xi(t_i) \left( \frac{z_{t_i}- \mu(t_i)}{\sigma(t_i)} \right) \right]^{-1 / \xi(t_i)} \right\}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuNC4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzUzNS4zMTMzODdwdCcgaGVpZ2h0PSczNS44NjU4NjlwdCcgdmlld0JveD0nMCAtMzUuOTU0MTIzIDUzNS4zMTMzODcgMzUuODY1ODY5Jz4KPGRlZnM+CjxwYXRoIGlkPSdnNC0xMDUnIGQ9J00yLjA4MDE5OS0zLjczMDAxMkMyLjA4MDE5OS0zLjg3MzQ3NCAxLjk3MjYwMy0zLjk2OTExNiAxLjgzNTExOC0zLjk2OTExNkMxLjY3MzcyNC0zLjk2OTExNiAxLjUwMDM3NC0zLjgxMzY5OSAxLjUwMDM3NC0zLjY0MDM0OUMxLjUwMDM3NC0zLjQ5MDkwOSAxLjYwNzk3LTMuNDAxMjQ1IDEuNzM5NDc3LTMuNDAxMjQ1QzEuOTMwNzYtMy40MDEyNDUgMi4wODAxOTktMy41ODA1NzMgMi4wODAxOTktMy43MzAwMTJaTTEuNzIxNTQ0LTEuNjQzODM2QzEuNzQ1NDU1LTEuNzAzNjExIDEuNzk5MjUzLTEuODQ3MDczIDEuODIzMTYzLTEuOTAwODcyQzEuODQxMDk2LTEuOTU0NjcgMS44NjUwMDYtMi4wMTQ0NDYgMS44NjUwMDYtMi4xMTYwNjVDMS44NjUwMDYtMi40NTA4MDkgMS41NjYxMjctMi42MzYxMTUgMS4yNjcyNDgtMi42MzYxMTVDLjY1NzUzNC0yLjYzNjExNSAuMzY0NjMzLTEuODQ3MDczIC4zNjQ2MzMtMS43MTU1NjdDLjM2NDYzMy0xLjY4NTY3OSAuMzg4NTQzLTEuNjMxODggLjQ3MjIyOS0xLjYzMTg4Uy41NzM4NDgtMS42Njc3NDYgLjU5MTc4MS0xLjcyMTU0NEMuNzU5MTUzLTIuMzAxMzcgMS4wNzU5NjUtMi40Mzg4NTQgMS4yNDMzMzctMi40Mzg4NTRDMS4zNjI4ODktMi40Mzg4NTQgMS40MDQ3MzItMi4zNjExNDYgMS40MDQ3MzItMi4yMjM2NjFDMS40MDQ3MzItMi4xMDQxMSAxLjM2ODg2Ny0yLjAxNDQ0NiAxLjM1NjkxMi0xLjk3MjYwM0wxLjA0NjA3Ny0xLjIwNzQ3MkMuOTc0MzQ2LTEuMDM0MTIyIC45NzQzNDYtMS4wMjIxNjcgLjg5NjYzOC0uODE4OTI5Qy44MTg5MjktLjYzOTYwMSAuNzg5MDQxLS41NjE4OTMgLjc4OTA0MS0uNDYwMjc0Qy43ODkwNDEtLjE1NTQxNyAxLjA2NDAxIC4wNTk3NzYgMS4zOTI3NzcgLjA1OTc3NkMxLjk5NjUxMyAuMDU5Nzc2IDIuMjk1MzkyLS43MjkyNjUgMi4yOTUzOTItLjg2MDc3MkMyLjI5NTM5Mi0uODcyNzI3IDIuMjg5NDE1LS45NDQ0NTggMi4xODE4MTgtLjk0NDQ1OEMyLjA5ODEzMi0uOTQ0NDU4IDIuMDkyMTU0LS45MTQ1NyAyLjA1NjI4OS0uODAwOTk2QzEuOTYwNjQ4LS40OTYxMzkgMS43MTU1NjctLjEzNzQ4NCAxLjQxMDcxLS4xMzc0ODRDMS4zMDMxMTMtLjEzNzQ4NCAxLjI0OTMxNS0uMjA5MjE1IDEuMjQ5MzE1LS4zNTI2NzdDMS4yNDkzMTUtLjQ3MjIyOSAxLjI4NTE4MS0uNTYxODkzIDEuMzYyODg5LS43NDcxOThMMS43MjE1NDQtMS42NDM4MzZaJy8+CjxwYXRoIGlkPSdnNy00MCcgZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIC43MjUyOCAxLjMzODk3OS0uNzU3MTYxIDEuMzM4OTc5LTEuOTkyNTI4QzEuMzM4OTc5LTQuMjg3OTIgMi4yODc0MjItNS4zNjM4ODUgMi42OTM4OTgtNS43MzA1MTFDMi44MDU0NzktNS44MzQxMjIgMi44MTM0NS01Ljg0MjA5MiAyLjgxMzQ1LTUuODgxOTQzUzIuNzgxNTY5LTUuOTc3NTg0IDIuNzAxODY4LTUuOTc3NTg0QzIuNTc0MzQ2LTUuOTc3NTg0IDIuMTc1ODQxLTUuNTcxMTA4IDIuMTEyMDgtNS40OTkzNzdDMS4wNDQwODUtNC4zODM1NjIgLjgyMDkyMi0yLjk0ODk0MSAuODIwOTIyLTEuOTkyNTI4Qy44MjA5MjItLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonLz4KPHBhdGggaWQ9J2c3LTQxJyBkPSdNMi40NjI3NjUtMS45OTI1MjhDMi40NjI3NjUtMi43NDk2ODkgMi4zMzUyNDMtMy42NTgyODEgMS44NDEwOTYtNC41OTg3NTVDMS40NTA1Ni01LjMzMjAwNSAuNzI1MjgtNS45Nzc1ODQgLjU4MTgxOC01Ljk3NzU4NEMuNTAyMTE3LTUuOTc3NTg0IC40NzgyMDctNS45MjE3OTMgLjQ3ODIwNy01Ljg4MTk0M0MuNDc4MjA3LTUuODUwMDYyIC40NzgyMDctNS44MzQxMjIgLjU3Mzg0OC01LjczODQ4MUMxLjY4OTY2NC00LjY3ODQ1NiAxLjk0NDcwNy0zLjIxOTkyNSAxLjk0NDcwNy0xLjk5MjUyOEMxLjk0NDcwNyAuMjk0ODk0IC45OTYyNjQgMS4zNzg4MjkgLjU4OTc4OCAxLjc0NTQ1NUMuNDg2MTc3IDEuODQ5MDY2IC40NzgyMDcgMS44NTcwMzYgLjQ3ODIwNyAxLjg5Njg4N1MuNTAyMTE3IDEuOTkyNTI4IC41ODE4MTggMS45OTI1MjhDLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIC4zOTg1MDYgMi40NjI3NjUtMS4wMzYxMTUgMi40NjI3NjUtMS45OTI1MjhaJy8+CjxwYXRoIGlkPSdnNy00OScgZD0nTTIuNTAyNjE1LTUuMDc2OTYxQzIuNTAyNjE1LTUuMjkyMTU0IDIuNDg2Njc1LTUuMzAwMTI1IDIuMjcxNDgyLTUuMzAwMTI1QzEuOTQ0NzA3LTQuOTgxMzIgMS41MjIyOTEtNC43OTAwMzcgLjc2NTEzMS00Ljc5MDAzN1YtNC41MjcwMjRDLjk4MDMyNC00LjUyNzAyNCAxLjQxMDcxLTQuNTI3MDI0IDEuODcyOTc2LTQuNzQyMjE3Vi0uNjUzNTQ5QzEuODcyOTc2LS4zNTg2NTUgMS44NDkwNjYtLjI2MzAxNCAxLjA5MTkwNS0uMjYzMDE0SC44MTI5NTFWMEMxLjEzOTcyNi0uMDIzOTEgMS44MjUxNTYtLjAyMzkxIDIuMTgzODExLS4wMjM5MVMzLjIzNTg2Ni0uMDIzOTEgMy41NjI2NCAwVi0uMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2LS4yNjMwMTQgMi41MDI2MTUtLjM1ODY1NSAyLjUwMjYxNS0uNjUzNTQ5Vi01LjA3Njk2MVonLz4KPHBhdGggaWQ9J2c3LTYxJyBkPSdNNS44MjYxNTItMi42NTQwNDdDNS45NDU3MDQtMi42NTQwNDcgNi4xMDUxMDYtMi42NTQwNDcgNi4xMDUxMDYtMi44MzczNlM1LjkxMzgyMy0zLjAyMDY3MiA1Ljc5NDI3MS0zLjAyMDY3MkguNzgxMDcxQy42NjE1MTktMy4wMjA2NzIgLjQ3MDIzNy0zLjAyMDY3MiAuNDcwMjM3LTIuODM3MzZTLjYyOTYzOS0yLjY1NDA0NyAuNzQ5MTkxLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MS0uOTY0Mzg0QzUuOTEzODIzLS45NjQzODQgNi4xMDUxMDYtLjk2NDM4NCA2LjEwNTEwNi0xLjE0NzY5NlM1Ljk0NTcwNC0xLjMzMTAwOSA1LjgyNjE1Mi0xLjMzMTAwOUguNzQ5MTkxQy42Mjk2MzktMS4zMzEwMDkgLjQ3MDIzNy0xLjMzMTAwOSAuNDcwMjM3LTEuMTQ3Njk2Uy42NjE1MTktLjk2NDM4NCAuNzgxMDcxLS45NjQzODRINS43OTQyNzFaJy8+CjxwYXRoIGlkPSdnMS0xOCcgZD0nTTguMzY4NjE4IDI4LjA4MjY5QzguMzY4NjE4IDI4LjAzNDg2OSA4LjM0NDcwNyAyOC4wMTA5NTkgOC4zMjA3OTcgMjcuOTc1MDkzQzcuODc4NDU2IDI3LjUzMjc1MiA3LjA3NzQ2IDI2LjczMTc1NiA2LjI3NjQ2MyAyNS40NDA1OThDNC4zNTE2ODEgMjIuMzU2MTY0IDMuNDc4OTU0IDE4LjQ3MDczNSAzLjQ3ODk1NCAxMy44Njc5OTVDMy40Nzg5NTQgMTAuNjUyMDU1IDMuOTA5MzQgNi41MDM2MTEgNS44ODE5NDMgMi45NDA5NzFDNi44MjY0MDEgMS4yNDMzMzcgNy44MDY3MjUgLjI2MzAxNCA4LjMzMjc1Mi0uMjYzMDE0QzguMzY4NjE4LS4yOTg4NzkgOC4zNjg2MTgtLjMyMjc5IDguMzY4NjE4LS4zNTg2NTVDOC4zNjg2MTgtLjQ3ODIwNyA4LjI4NDkzMi0uNDc4MjA3IDguMTE3NTU5LS40NzgyMDdTNy45MjYyNzYtLjQ3ODIwNyA3Ljc0Njk0OS0uMjk4ODc5QzMuNzQxOTY4IDMuMzQ3NDQ3IDIuNDg2Njc1IDguODIyOTE0IDIuNDg2Njc1IDEzLjg1NjA0QzIuNDg2Njc1IDE4LjU1NDQyMSAzLjU2MjY0IDIzLjI4ODY2NyA2LjU5OTI1MyAyNi44NjMyNjNDNi44MzgzNTYgMjcuMTM4MjMyIDcuMjkyNjUzIDI3LjYyODM5NCA3Ljc4MjgxNCAyOC4wNTg3OEM3LjkyNjI3NiAyOC4yMDIyNDIgNy45NTAxODcgMjguMjAyMjQyIDguMTE3NTU5IDI4LjIwMjI0MlM4LjM2ODYxOCAyOC4yMDIyNDIgOC4zNjg2MTggMjguMDgyNjlaJy8+CjxwYXRoIGlkPSdnMS0xOScgZD0nTTYuMzAwMzc0IDEzLjg2Nzk5NUM2LjMwMDM3NCA5LjE2OTYxNCA1LjIyNDQwOCA0LjQzNTM2NyAyLjE4Nzc5NiAuODYwNzcyQzEuOTQ4NjkyIC41ODU4MDMgMS40OTQzOTYgLjA5NTY0MSAxLjAwNDIzNC0uMzM0NzQ1Qy44NjA3NzItLjQ3ODIwNyAuODM2ODYyLS40NzgyMDcgLjY2OTQ4OS0uNDc4MjA3Qy41MjYwMjctLjQ3ODIwNyAuNDE4NDMxLS40NzgyMDcgLjQxODQzMS0uMzU4NjU1Qy40MTg0MzEtLjMxMDgzNCAuNDY2MjUyLS4yNjMwMTQgLjQ5MDE2Mi0uMjM5MTAzQy45MDg1OTMgLjE5MTI4MyAxLjcwOTU4OSAuOTkyMjc5IDIuNTEwNTg1IDIuMjgzNDM3QzQuNDM1MzY3IDUuMzY3ODcgNS4zMDgwOTUgOS4yNTMzIDUuMzA4MDk1IDEzLjg1NjA0QzUuMzA4MDk1IDE3LjA3MTk4IDQuODc3NzA5IDIxLjIyMDQyMyAyLjkwNTEwNiAyNC43ODMwNjRDMS45NjA2NDggMjYuNDgwNjk3IC45NjgzNjkgMjcuNDcyOTc2IC40NjYyNTIgMjcuOTc1MDkzQy40NDIzNDEgMjguMDEwOTU5IC40MTg0MzEgMjguMDQ2ODI0IC40MTg0MzEgMjguMDgyNjlDLjQxODQzMSAyOC4yMDIyNDIgLjUyNjAyNyAyOC4yMDIyNDIgLjY2OTQ4OSAyOC4yMDIyNDJDLjgzNjg2MiAyOC4yMDIyNDIgLjg2MDc3MiAyOC4yMDIyNDIgMS4wNDAxIDI4LjAyMjkxNEM1LjA0NTA4MSAyNC4zNzY1ODggNi4zMDAzNzQgMTguOTAxMTIxIDYuMzAwMzc0IDEzLjg2Nzk5NVonLz4KPHBhdGggaWQ9J2cxLTIwJyBkPSdNMi45ODg3OTIgMjguMjAyMjQySDYuMTMzMDAxVjI3LjU0NDcwN0gzLjY0NjMyNlYuMTc5MzI4SDYuMTMzMDAxVi0uNDc4MjA3SDIuOTg4NzkyVjI4LjIwMjI0MlonLz4KPHBhdGggaWQ9J2cxLTIxJyBkPSdNMi42NTQwNDcgMjcuNTQ0NzA3SC4xNjczNzJWMjguMjAyMjQySDMuMzExNTgyVi0uNDc4MjA3SC4xNjczNzJWLjE3OTMyOEgyLjY1NDA0N1YyNy41NDQ3MDdaJy8+CjxwYXRoIGlkPSdnMS00MCcgZD0nTTUuMzkxNzgxIDIxLjg0MjA5MkM1LjM5MTc4MSAyMC41MjcwMjQgNC40ODMxODggMTguNTA2NiAyLjQwMjk4OSAxNy40NTQ1NDVDMy42OTQxNDcgMTYuNzYxMTQ2IDUuMjM2MzY0IDE1LjM2MjM5MSA1LjM3OTgyNiAxMy4xMjY3NzVMNS4zOTE3ODEgMTMuMDU1MDQ0VjQuNzcwMTEyQzUuMzkxNzgxIDMuNzg5Nzg4IDUuMzkxNzgxIDMuNTc0NTk1IDUuNDg3NDIyIDMuMTIwMjk5QzUuNzAyNjE1IDIuMTYzODg1IDYuMjc2NDYzIC45ODAzMjQgNy43OTQ3NyAuMDgzNjg2QzcuODkwNDExIC4wMjM5MSA3LjkwMjM2NiAuMDExOTU1IDcuOTAyMzY2LS4yMDMyMzhDNy45MDIzNjYtLjQ2NjI1MiA3Ljg5MDQxMS0uNDc4MjA3IDcuNjI3Mzk3LS40NzgyMDdDNy40MTIyMDQtLjQ3ODIwNyA3LjM4ODI5NC0uNDc4MjA3IDcuMDY1NTA0LS4yODY5MjRDNC4zODc1NDcgMS4yMzEzODIgNC4yMzIxMyAzLjQ1NTA0NCA0LjIzMjEzIDMuODczNDc0VjEyLjM3MzU5OUM0LjIzMjEzIDEzLjIzNDM3MSA0LjIzMjEzIDE0LjIwMjc0IDMuNjEwNDYxIDE1LjMwMjYxNUMzLjA2MDUyMyAxNi4yODI5MzkgMi40MTQ5NDQgMTYuNzczMTAxIDEuOTAwODcyIDE3LjExOTgwMUMxLjczMzQ5OSAxNy4yMjczOTcgMS43MjE1NDQgMTcuMjM5MzUyIDEuNzIxNTQ0IDE3LjQ0MjU5QzEuNzIxNTQ0IDE3LjY1Nzc4MyAxLjczMzQ5OSAxNy42Njk3MzggMS44MjkxNDEgMTcuNzI5NTE0QzIuODQ1MzMgMTguMzk5MDA0IDMuOTMzMjUgMTkuNDYzMDE0IDQuMTk2MjY0IDIxLjQxMTcwNkM0LjIzMjEzIDIxLjY3NDcyIDQuMjMyMTMgMjEuNjk4NjMgNC4yMzIxMyAyMS44NDIwOTJWMzEuMDIzNjYxQzQuMjMyMTMgMzEuOTkyMDMgNC44Mjk4ODggMzQuMDAwNDk4IDcuMTM3MjM1IDM1LjIxOTkyNUM3LjQxMjIwNCAzNS4zNzUzNDIgNy40MzYxMTUgMzUuMzc1MzQyIDcuNjI3Mzk3IDM1LjM3NTM0MkM3Ljg5MDQxMSAzNS4zNzUzNDIgNy45MDIzNjYgMzUuMzYzMzg3IDcuOTAyMzY2IDM1LjEwMDM3NEM3LjkwMjM2NiAzNC44ODUxODEgNy44OTA0MTEgMzQuODczMjI1IDcuODQyNTkgMzQuODQ5MzE1QzcuMzI4NTE4IDM0LjUyNjUyNiA1Ljc2MjM5MSAzMy41ODIwNjcgNS40Mzk2MDEgMzEuNTAxODY4QzUuMzkxNzgxIDMxLjE5MTAzNCA1LjM5MTc4MSAzMS4xNjcxMjMgNS4zOTE3ODEgMzEuMDExNzA2VjIxLjg0MjA5MlonLz4KPHBhdGggaWQ9J2cxLTQxJyBkPSdNNC4yMzIxMyAzMC4xMjcwMjRDNC4yMzIxMyAzMS4xMDczNDcgNC4yMzIxMyAzMS4zMjI1NCA0LjEzNjQ4OCAzMS43NzY4MzdDMy45MjEyOTUgMzIuNzMzMjUgMy4zNDc0NDcgMzMuOTA0ODU3IDEuODI5MTQxIDM0LjgxMzQ1QzEuNzMzNDk5IDM0Ljg3MzIyNSAxLjcyMTU0NCAzNC44ODUxODEgMS43MjE1NDQgMzUuMTAwMzc0QzEuNzIxNTQ0IDM1LjM3NTM0MiAxLjczMzQ5OSAzNS4zNzUzNDIgMi4wMDg0NjggMzUuMzc1MzQyQzIuMjExNzA2IDM1LjM3NTM0MiAyLjIzNTYxNiAzNS4zNzUzNDIgMi41NTg0MDYgMzUuMTg0MDZDNS4yMzYzNjQgMzMuNjY1NzUzIDUuMzkxNzgxIDMxLjQ0MjA5MiA1LjM5MTc4MSAzMS4wMjM2NjFWMjIuNTIzNTM3QzUuMzkxNzgxIDIxLjY2Mjc2NSA1LjM5MTc4MSAyMC42OTQzOTYgNi4wMTM0NSAxOS41OTQ1MjFDNi41Mzk0NzcgMTguNjYyMDE3IDcuMTQ5MTkxIDE4LjE1OTkgNy43MjMwMzkgMTcuNzc3MzM1QzcuODkwNDExIDE3LjY2OTczOCA3LjkwMjM2NiAxNy42NTc3ODMgNy45MDIzNjYgMTcuNDQyNTlDNy45MDIzNjYgMTcuMjg3MTczIDcuOTAyMzY2IDE3LjIyNzM5NyA3Ljg1NDU0NSAxNy4xOTE1MzJDNy4yOTI2NTMgMTYuODMyODc3IDUuNzM4NDgxIDE1Ljg0MDU5OCA1LjQyNzY0NiAxMy40ODU0M0M1LjM5MTc4MSAxMy4yMjI0MTYgNS4zOTE3ODEgMTMuMTk4NTA2IDUuMzkxNzgxIDEzLjA1NTA0NFYzLjg3MzQ3NEM1LjM5MTc4MSAyLjkwNTEwNiA0Ljc5NDAyMiAuODk2NjM4IDIuNDg2Njc1LS4zMjI3OUMyLjIxMTcwNi0uNDc4MjA3IDIuMTg3Nzk2LS40NzgyMDcgMi4wMDg0NjgtLjQ3ODIwN0MxLjczMzQ5OS0uNDc4MjA3IDEuNzIxNTQ0LS40NzgyMDcgMS43MjE1NDQtLjIwMzIzOEMxLjcyMTU0NC0uMDExOTU1IDEuNzIxNTQ0IC4wMjM5MSAxLjgwNTIzIC4wNzE3MzFDNC4wNzY3MTIgMS40MjI2NjUgNC4yMzIxMyAzLjQxOTE3OCA0LjIzMjEzIDMuODg1NDNWMTMuMDU1MDQ0QzQuMjMyMTMgMTQuMzcwMTEyIDUuMTQwNzIyIDE2LjM5MDUzNSA3LjIyMDkyMiAxNy40NDI1OUM1LjkyOTc2MyAxOC4xMzU5OSA0LjM4NzU0NyAxOS41MzQ3NDUgNC4yNDQwODUgMjEuNzcwMzYxTDQuMjMyMTMgMjEuODQyMDkyVjMwLjEyNzAyNFonLz4KPHBhdGggaWQ9J2cxLTg4JyBkPSdNMTUuMTM1MjQzIDE2LjczNzIzNUwxNi41ODE4MTggMTIuOTExNTgySDE2LjI4MjkzOUMxNS44MTY2ODcgMTQuMTU0OTE5IDE0LjU0OTQ0IDE0Ljk2Nzg3IDEzLjE3NDU5NSAxNS4zMjY1MjZDMTIuOTIzNTM3IDE1LjM4NjMwMSAxMS43NTE5MyAxNS42OTcxMzYgOS40NTY1MzggMTUuNjk3MTM2SDIuMjQ3NTcyTDguMzMyNzUyIDguNTU5OUM4LjQxNjQzOCA4LjQ2NDI1OSA4LjQ0MDM0OSA4LjQyODM5NCA4LjQ0MDM0OSA4LjM2ODYxOEM4LjQ0MDM0OSA4LjM0NDcwNyA4LjQ0MDM0OSA4LjMwODg0MiA4LjM1NjY2MyA4LjE4OTI5TDIuNzg1NTU0IC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IC41NzM4NDggMTIuMDI2ODk5IC43NDEyMiAxMi4xMzQ0OTYgLjc2NTEzMUMxMi43ODAwNzUgLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0Qy43MjkyNjUgMCAuNzE3MzEgLjAxMTk1NSAuNjgxNDQ1IC4wODM2ODZDLjY2OTQ4OSAuMTE5NTUyIC42Njk0ODkgLjM0NjcgLjY2OTQ4OSAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TC44MDA5OTYgMTYuMzkwNTM1Qy42ODE0NDUgMTYuNTMzOTk4IC42ODE0NDUgMTYuNTkzNzczIC42ODE0NDUgMTYuNjA1NzI5Qy42ODE0NDUgMTYuNzM3MjM1IC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJy8+CjxwYXRoIGlkPSdnMi0wJyBkPSdNNS41NzExMDgtMS44MDkyMTVDNS42OTg2My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjgwOTIxNSA1Ljg3Mzk3My0xLjk5MjUyOFM1LjY5ODYzLTIuMTc1ODQxIDUuNTcxMTA4LTIuMTc1ODQxSDEuMDA0MjM0Qy44NzY3MTItMi4xNzU4NDEgLjcwMTM3LTIuMTc1ODQxIC43MDEzNy0xLjk5MjUyOFMuODc2NzEyLTEuODA5MjE1IDEuMDA0MjM0LTEuODA5MjE1SDUuNTcxMTA4WicvPgo8cGF0aCBpZD0nZzUtMjQnIGQ9J00xLjYxNzkzMy0yLjM1MTE4M0MxLjkxMjgyNy0yLjIzOTYwMSAyLjIwNzcyMS0yLjIzOTYwMSAyLjM4MzA2NC0yLjIzOTYwMUMyLjY1NDA0Ny0yLjIzOTYwMSAzLjE3MjEwNS0yLjIzOTYwMSAzLjE3MjEwNS0yLjUyNjUyNkMzLjE3MjEwNS0yLjc2NTYyOSAyLjc0MTcxOS0yLjc2NTYyOSAyLjQ3MDczNS0yLjc2NTYyOUMyLjMxMTMzMy0yLjc2NTYyOSAyLjA2NDI1OS0yLjc2NTYyOSAxLjc1MzQyNS0yLjY2MjAxN0MxLjU3ODA4Mi0yLjgyOTM5IDEuNTA2MzUxLTMuMDUyNTUzIDEuNTA2MzUxLTMuMjc1NzE2QzEuNTA2MzUxLTMuNzIyMDQyIDEuODE3MTg2LTQuMjg3OTIgMi4zOTkwMDQtNC41NjY4NzRDMi41NzQzNDYtNC4zODM1NjIgMi43ODE1NjktNC4zODM1NjIgMi45NDg5NDEtNC4zODM1NjJDMy4yNTE4MDYtNC4zODM1NjIgMy43MDYxMDItNC4zOTk1MDIgMy43MDYxMDItNC42NzA0ODZDMy43MDYxMDItNC45MDk1ODkgMy4yNzU3MTYtNC45MDk1ODkgMi45OTY3NjItNC45MDk1ODlDMi44NjEyNy00LjkwOTU4OSAyLjcyNTc3OC00LjkwOTU4OSAyLjUwMjYxNS00Ljg3NzcwOUMyLjQ4NjY3NS00LjkzMzQ5OSAyLjQ2Mjc2NS01LjAxMzIgMi40NjI3NjUtNS4xMTY4MTJDMi40NjI3NjUtNS4yMjgzOTQgMi40OTQ2NDUtNS4zNjM4ODUgMi40OTQ2NDUtNS4zODc3OTZDMi41MDI2MTUtNS4zOTU3NjYgMi41MDI2MTUtNS40Mjc2NDYgMi41MDI2MTUtNS40MzU2MTZDMi41MDI2MTUtNS41MDczNDcgMi40NDY4MjQtNS41NTUxNjggMi4zOTEwMzQtNS41NTUxNjhDMi4yMTU2OTEtNS41NTUxNjggMi4yMTU2OTEtNS4xOTY1MTMgMi4yMTU2OTEtNS4xMjQ3ODJDMi4yMTU2OTEtNC45NzMzNSAyLjI1NTU0Mi00LjgzNzg1OCAyLjI2MzUxMi00LjgyMTkxOEMxLjM3MDg1OS00LjU5MDc4NSAuODIwOTIyLTMuOTUzMTc2IC44MjA5MjItMy4zMjM1MzdDLjgyMDkyMi0yLjkyNTAzMSAxLjAzNjExNS0yLjY1NDA0NyAxLjMzODk3OS0yLjQ3ODcwNUMuNDg2MTc3LTEuOTkyNTI4IC4xOTEyODMtMS4xODc1NDcgLjE5MTI4My0uODIwOTIyQy4xOTEyODMtLjA5NTY0MSAuOTI0NTMzIC4xNjczNzIgMS4xNzk1NzcgLjI2MzAxNEMxLjYyNTkwMyAuNDMwMzg2IDEuNjQxODQzIC40MzAzODYgMi4wMzIzNzkgLjU2NTg3OEMyLjIyMzY2MSAuNjM3NjA5IDIuNTQyNDY2IC43NTcxNjEgMi41OTgyNTcgLjc4OTA0MUMyLjcyNTc3OCAuODY4NzQyIDIuNzI1Nzc4IC45ODAzMjQgMi43MjU3NzggMS4wMjgxNDRDMi43MjU3NzggMS4xNzE2MDYgMi42MjIxNjcgMS40MDI3NCAyLjM2NzEyMyAxLjQwMjc0QzIuMzAzMzYyIDEuNDAyNzQgMS45NzY1ODggMS4zODY4IDEuNjU3NzgzIDEuMTk1NTE3QzEuNTc4MDgyIDEuMTM5NzI2IDEuNTcwMTEyIDEuMTMxNzU2IDEuNTMwMjYyIDEuMTMxNzU2QzEuNDQyNTkgMS4xMzE3NTYgMS40MTg2OCAxLjIxMTQ1NyAxLjQxODY4IDEuMjQzMzM3QzEuNDE4NjggMS4zNzA4NTkgMS45Mjg3NjcgMS42MjU5MDMgMi4zNzUwOTMgMS42MjU5MDNDMi45MDExMjEgMS42MjU5MDMgMy4yMjc4OTUgMS4xMjM3ODYgMy4yMjc4OTUgLjc1NzE2MUMzLjIyNzg5NSAuNjEzNjk5IDMuMTcyMTA1IC40NjIyNjcgMy4wNzY0NjMgLjM1MDY4NUMyLjk3Mjg1MiAuMjM5MTAzIDIuODY5MjQgLjE5OTI1MyAyLjQyMjkxNCAuMDM5ODUxQzEuNzI5NTE0LS4yMDcyMjMgMS4yMTE0NTctLjM5MDUzNSAxLjA4MzkzNS0uNDYyMjY3Qy44Mjg4OTItLjU5Nzc1OCAuNjYxNTE5LS43ODkwNDEgLjY2MTUxOS0xLjA1MjA1NUMuNjYxNTE5LTEuMzc4ODI5IC45NTY0MTMtMS45OTI1MjggMS42MTc5MzMtMi4zNTExODNaTTMuNDAzMjM4LTQuNjQ2NTc1QzMuMzIzNTM3LTQuNjMwNjM1IDMuMjQzODM2LTQuNjA2NzI1IDIuOTU2OTEyLTQuNjA2NzI1QzIuNzg5NTM5LTQuNjA2NzI1IDIuNzU3NjU5LTQuNjA2NzI1IDIuNjYyMDE3LTQuNjU0NTQ1QzIuNzg5NTM5LTQuNjg2NDI2IDIuODY5MjQtNC42ODY0MjYgMy4wMTI3MDItNC42ODY0MjZDMy4yMjc4OTUtNC42ODY0MjYgMy4yODM2ODYtNC42Nzg0NTYgMy40MDMyMzgtNC42NTQ1NDVWLTQuNjQ2NTc1Wk0yLjg2OTI0LTIuNTAyNjE1QzIuNzk3NTA5LTIuNDg2Njc1IDIuNzE3ODA4LTIuNDYyNzY1IDIuNDA2OTc0LTIuNDYyNzY1QzIuMjU1NTQyLTIuNDYyNzY1IDIuMTc1ODQxLTIuNDYyNzY1IDIuMDQ4MzE5LTIuNTAyNjE1QzIuMjIzNjYxLTIuNTQyNDY2IDIuMzE5MzAzLTIuNTQyNDY2IDIuNDYyNzY1LTIuNTQyNDY2QzIuNjkzODk4LTIuNTQyNDY2IDIuNzU3NjU5LTIuNTM0NDk2IDIuODY5MjQtMi41MTA1ODVWLTIuNTAyNjE1WicvPgo8cGF0aCBpZD0nZzUtNjEnIGQ9J00zLjcwNjEwMi01LjY0MjgzOUMzLjc1MzkyMy01Ljc1NDQyMSAzLjc1MzkyMy01Ljc3MDM2MSAzLjc1MzkyMy01Ljc5NDI3MUMzLjc1MzkyMy01Ljg5Nzg4MyAzLjY3NDIyMi01Ljk3NzU4NCAzLjU3MDYxLTUuOTc3NTg0QzMuNDQzMDg4LTUuOTc3NTg0IDMuNDExMjA4LTUuODgxOTQzIDMuMzc5MzI4LTUuODAyMjQyTC41MTgwNTcgMS42NTc3ODNDLjQ3MDIzNyAxLjc2OTM2NSAuNDcwMjM3IDEuNzg1MzA1IC40NzAyMzcgMS44MDkyMTVDLjQ3MDIzNyAxLjkxMjgyNyAuNTQ5OTM4IDEuOTkyNTI4IC42NTM1NDkgMS45OTI1MjhDLjc4MTA3MSAxLjk5MjUyOCAuODEyOTUxIDEuODk2ODg3IC44NDQ4MzIgMS44MTcxODZMMy43MDYxMDItNS42NDI4MzlaJy8+CjxwYXRoIGlkPSdnNS0xMDUnIGQ9J00yLjM3NTA5My00Ljk3MzM1QzIuMzc1MDkzLTUuMTQ4NjkyIDIuMjQ3NTcyLTUuMjc2MjE0IDIuMDY0MjU5LTUuMjc2MjE0QzEuODU3MDM2LTUuMjc2MjE0IDEuNjI1OTAzLTUuMDg0OTMyIDEuNjI1OTAzLTQuODQ1ODI4QzEuNjI1OTAzLTQuNjcwNDg2IDEuNzUzNDI1LTQuNTQyOTY0IDEuOTM2NzM3LTQuNTQyOTY0QzIuMTQzOTYtNC41NDI5NjQgMi4zNzUwOTMtNC43MzQyNDcgMi4zNzUwOTMtNC45NzMzNVpNMS4yMTE0NTctMi4wNDgzMTlMLjc4MTA3MS0uOTQ4NDQzQy43NDEyMi0uODI4ODkyIC43MDEzNy0uNzMzMjUgLjcwMTM3LS41OTc3NThDLjcwMTM3LS4yMDcyMjMgMS4wMDQyMzQgLjA3OTcwMSAxLjQyNjY1IC4wNzk3MDFDMi4xOTk3NTEgLjA3OTcwMSAyLjUyNjUyNi0xLjAzNjExNSAyLjUyNjUyNi0xLjEzOTcyNkMyLjUyNjUyNi0xLjIxOTQyNyAyLjQ2Mjc2NS0xLjI0MzMzNyAyLjQwNjk3NC0xLjI0MzMzN0MyLjMxMTMzMy0xLjI0MzMzNyAyLjI5NTM5Mi0xLjE4NzU0NyAyLjI3MTQ4Mi0xLjEwNzg0NkMyLjA4ODE2OS0uNDcwMjM3IDEuNzYxMzk1LS4xNDM0NjIgMS40NDI1OS0uMTQzNDYyQzEuMzQ2OTQ5LS4xNDM0NjIgMS4yNTEzMDgtLjE4MzMxMyAxLjI1MTMwOC0uMzk4NTA2QzEuMjUxMzA4LS41ODk3ODggMS4zMDcwOTgtLjczMzI1IDEuNDEwNzEtLjk4MDMyNEMxLjQ5MDQxMS0xLjE5NTUxNyAxLjU3MDExMi0xLjQxMDcxIDEuNjU3NzgzLTEuNjI1OTAzTDEuOTA0ODU3LTIuMjcxNDgyQzEuOTc2NTg4LTIuNDU0Nzk1IDIuMDcyMjI5LTIuNzAxODY4IDIuMDcyMjI5LTIuODM3MzZDMi4wNzIyMjktMy4yMzU4NjYgMS43NTM0MjUtMy41MTQ4MTkgMS4zNDY5NDktMy41MTQ4MTlDLjU3Mzg0OC0zLjUxNDgxOSAuMjM5MTAzLTIuMzk5MDA0IC4yMzkxMDMtMi4yOTUzOTJDLjIzOTEwMy0yLjIyMzY2MSAuMjk0ODk0LTIuMTkxNzgxIC4zNTg2NTUtMi4xOTE3ODFDLjQ2MjI2Ny0yLjE5MTc4MSAuNDcwMjM3LTIuMjM5NjAxIC40OTQxNDctMi4zMTkzMDNDLjcxNzMxLTMuMDc2NDYzIDEuMDgzOTM1LTMuMjkxNjU2IDEuMzIzMDM5LTMuMjkxNjU2QzEuNDM0NjItMy4yOTE2NTYgMS41MTQzMjEtMy4yNTE4MDYgMS41MTQzMjEtMy4wMjg2NDNDMS41MTQzMjEtMi45NDg5NDEgMS41MDYzNTEtMi44MzczNiAxLjQyNjY1LTIuNTk4MjU3TDEuMjExNDU3LTIuMDQ4MzE5WicvPgo8cGF0aCBpZD0nZzUtMTEwJyBkPSdNMS41OTQwMjItMS4zMDcwOThDMS42MTc5MzMtMS40MjY2NSAxLjY5NzYzNC0xLjcyOTUxNCAxLjcyMTU0NC0xLjg0OTA2NkMxLjgzMzEyNi0yLjI3OTQ1MiAxLjgzMzEyNi0yLjI4NzQyMiAyLjAxNjQzOC0yLjU1MDQzNkMyLjI3OTQ1Mi0yLjk0MDk3MSAyLjY1NDA0Ny0zLjI5MTY1NiAzLjE4ODA0NS0zLjI5MTY1NkMzLjQ3NDk2OS0zLjI5MTY1NiAzLjY0MjM0MS0zLjEyNDI4NCAzLjY0MjM0MS0yLjc0OTY4OUMzLjY0MjM0MS0yLjMxMTMzMyAzLjMwNzU5Ny0xLjQwMjc0IDMuMTU2MTY0LTEuMDEyMjA0QzMuMDUyNTUzLS43NDkxOTEgMy4wNTI1NTMtLjcwMTM3IDMuMDUyNTUzLS41OTc3NThDMy4wNTI1NTMtLjE0MzQ2MiAzLjQyNzE0OCAuMDc5NzAxIDMuNzY5ODYzIC4wNzk3MDFDNC41NTA5MzQgLjA3OTcwMSA0Ljg3NzcwOS0xLjAzNjExNSA0Ljg3NzcwOS0xLjEzOTcyNkM0Ljg3NzcwOS0xLjIxOTQyNyA0LjgxMzk0OC0xLjI0MzMzNyA0Ljc1ODE1Ny0xLjI0MzMzN0M0LjY2MjUxNi0xLjI0MzMzNyA0LjY0NjU3NS0xLjE4NzU0NyA0LjYyMjY2NS0xLjEwNzg0NkM0LjQzMTM4Mi0uNDU0Mjk2IDQuMDk2NjM4LS4xNDM0NjIgMy43OTM3NzMtLjE0MzQ2MkMzLjY2NjI1Mi0uMTQzNDYyIDMuNjAyNDkxLS4yMjMxNjMgMy42MDI0OTEtLjQwNjQ3NlMzLjY2NjI1Mi0uNzY1MTMxIDMuNzQ1OTUzLS45NjQzODRDMy44NjU1MDQtMS4yNjcyNDggNC4yMTYxODktMi4xODM4MTEgNC4yMTYxODktMi42MzAxMzdDNC4yMTYxODktMy4yMjc4OTUgMy44MDE3NDMtMy41MTQ4MTkgMy4yMjc4OTUtMy41MTQ4MTlDMi41ODIzMTYtMy41MTQ4MTkgMi4xNjc4Ny0zLjEyNDI4NCAxLjkzNjczNy0yLjgyMTQyQzEuODgwOTQ2LTMuMjU5Nzc2IDEuNTMwMjYyLTMuNTE0ODE5IDEuMTIzNzg2LTMuNTE0ODE5Qy44MzY4NjItMy41MTQ4MTkgLjYzNzYwOS0zLjMzMTUwNyAuNTEwMDg3LTMuMDg0NDMzQy4zMTg4MDQtMi43MDk4MzggLjIzOTEwMy0yLjMxMTMzMyAuMjM5MTAzLTIuMjk1MzkyQy4yMzkxMDMtMi4yMjM2NjEgLjI5NDg5NC0yLjE5MTc4MSAuMzU4NjU1LTIuMTkxNzgxQy40NjIyNjctMi4xOTE3ODEgLjQ3MDIzNy0yLjIyMzY2MSAuNTI2MDI3LTIuNDMwODg0Qy42MjE2NjktMi44MjE0MiAuNzY1MTMxLTMuMjkxNjU2IDEuMDk5ODc1LTMuMjkxNjU2QzEuMzA3MDk4LTMuMjkxNjU2IDEuMzU0OTE5LTMuMDkyNDAzIDEuMzU0OTE5LTIuOTE3MDYxQzEuMzU0OTE5LTIuNzczNTk5IDEuMzE1MDY4LTIuNjIyMTY3IDEuMjUxMzA4LTIuMzU5MTUzQzEuMjM1MzY3LTIuMjk1MzkyIDEuMTE1ODE2LTEuODI1MTU2IDEuMDgzOTM1LTEuNzEzNTc0TC43ODkwNDEtLjUxODA1N0MuNzU3MTYxLS4zOTg1MDYgLjcwOTM0LS4xOTkyNTMgLjcwOTM0LS4xNjczNzJDLjcwOTM0IC4wMTU5NCAuODYwNzcyIC4wNzk3MDEgLjk2NDM4NCAuMDc5NzAxQzEuMTA3ODQ2IC4wNzk3MDEgMS4yMjczOTctLjAxNTk0IDEuMjgzMTg4LS4xMTE1ODJDMS4zMDcwOTgtLjE1OTQwMiAxLjM3MDg1OS0uNDMwMzg2IDEuNDEwNzEtLjU5Nzc1OEwxLjU5NDAyMi0xLjMwNzA5OFonLz4KPHBhdGggaWQ9J2c1LTExNicgZD0nTTEuNzYxMzk1LTMuMTcyMTA1SDIuNTQyNDY2QzIuNjkzODk4LTMuMTcyMTA1IDIuNzg5NTM5LTMuMTcyMTA1IDIuNzg5NTM5LTMuMzIzNTM3QzIuNzg5NTM5LTMuNDM1MTE4IDIuNjg1OTI4LTMuNDM1MTE4IDIuNTUwNDM2LTMuNDM1MTE4SDEuODI1MTU2TDIuMTEyMDgtNC41NjY4NzRDMi4xNDM5Ni00LjY4NjQyNiAyLjE0Mzk2LTQuNzI2Mjc2IDIuMTQzOTYtNC43MzQyNDdDMi4xNDM5Ni00LjkwMTYxOSAyLjAxNjQzOC00Ljk4MTMyIDEuODgwOTQ2LTQuOTgxMzJDMS42MDk5NjMtNC45ODEzMiAxLjU1NDE3Mi00Ljc2NjEyNyAxLjQ2NjUwMS00LjQwNzQ3MkwxLjIxOTQyNy0zLjQzNTExOEguNDU0Mjk2Qy4zMDI4NjQtMy40MzUxMTggLjE5OTI1My0zLjQzNTExOCAuMTk5MjUzLTMuMjgzNjg2Qy4xOTkyNTMtMy4xNzIxMDUgLjMwMjg2NC0zLjE3MjEwNSAuNDM4MzU2LTMuMTcyMTA1SDEuMTU1NjY2TC42Nzc0Ni0xLjI1OTI3OEMuNjI5NjM5LTEuMDYwMDI1IC41NTc5MDgtLjc4MTA3MSAuNTU3OTA4LS42Njk0ODlDLjU1NzkwOC0uMTkxMjgzIC45NDg0NDMgLjA3OTcwMSAxLjM3MDg1OSAuMDc5NzAxQzIuMjIzNjYxIC4wNzk3MDEgMi43MDk4MzgtMS4wNDQwODUgMi43MDk4MzgtMS4xMzk3MjZDMi43MDk4MzgtMS4yMjczOTcgMi42MzgxMDctMS4yNDMzMzcgMi41OTAyODYtMS4yNDMzMzdDMi41MDI2MTUtMS4yNDMzMzcgMi40OTQ2NDUtMS4yMTE0NTcgMi40Mzg4NTQtMS4wOTE5MDVDMi4yNzk0NTItLjcwOTM0IDEuODgwOTQ2LS4xNDM0NjIgMS4zOTQ3Ny0uMTQzNDYyQzEuMjI3Mzk3LS4xNDM0NjIgMS4xMzE3NTYtLjI1NTA0NCAxLjEzMTc1Ni0uNTE4MDU3QzEuMTMxNzU2LS42Njk0ODkgMS4xNTU2NjYtLjc1NzE2MSAxLjE3OTU3Ny0uODYwNzcyTDEuNzYxMzk1LTMuMTcyMTA1WicvPgo8cGF0aCBpZD0nZzMtMCcgZD0nTTcuODc4NDU2LTIuNzQ5Njg5QzguMDgxNjk0LTIuNzQ5Njg5IDguMjk2ODg3LTIuNzQ5Njg5IDguMjk2ODg3LTIuOTg4NzkyUzguMDgxNjk0LTMuMjI3ODk1IDcuODc4NDU2LTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzItMy4yMjc4OTUgLjk5MjI3OS0zLjIyNzg5NSAuOTkyMjc5LTIuOTg4NzkyUzEuMjA3NDcyLTIuNzQ5Njg5IDEuNDEwNzEtMi43NDk2ODlINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnMC0xMicgZD0nTS4yMzkxMDMgMS45NjA2NDhDLjIyNzE0OCAxLjk4NDU1OCAuMTkxMjgzIDIuMTM5OTc1IC4xOTEyODMgMi4xNTE5M0MuMTkxMjgzIDIuMzE5MzAzIC4zNzA2MSAyLjMxOTMwMyAuNDc4MjA3IDIuMzE5MzAzQy43MTczMSAyLjMxOTMwMyAuNzE3MzEgMi4yOTUzOTIgLjc4OTA0MSAyLjA0NDMzNEMuODI0OTA3IDEuODUzMDUxIDEuNTQyMjE3LTEuMDE2MTg5IDEuNTU0MTcyLTEuMDQwMUMyLjA1NjI4OS0uMjAzMjM4IDIuOTc2ODM3IC4xNDM0NjIgMy45MzMyNSAuMTQzNDYyQzYuMzM2MjM5IC4xNDM0NjIgNy42NzUyMTgtMS42ODU2NzkgNy42NzUyMTgtMy4yNTE4MDZDNy42NzUyMTgtNC4wODg2NjcgNy4zMDQ2MDgtNC41NDI5NjQgNi45MTAwODctNC44NDE4NDNDNy4zNDA0NzMtNS4yMDA0OTggNy44MzA2MzUtNS45Nzc1ODQgNy44MzA2MzUtNi44MDI0OTFDNy44MzA2MzUtNy44MTg2OCA3LjA4OTQxNS04LjM5MjUyOCA1Ljk2NTYyOS04LjM5MjUyOEM0LjI1NjA0LTguMzkyNTI4IDIuNDg2Njc1LTcuMDY1NTA0IDIuMDU2Mjg5LTUuMzMyMDA1TC4yMzkxMDMgMS45NjA2NDhaTTUuNjU0Nzk1LTQuNzk0MDIyQzUuMzY3ODctNC41OTA3ODUgNS4wNjg5OTEtNC41OTA3ODUgNC45MDE2MTktNC41OTA3ODVDNC44NTM3OTgtNC41OTA3ODUgNC4zMjc3NzEtNC41OTA3ODUgNC4zMjc3NzEtNC42ODY0MjZDNC4zMjc3NzEtNC44Nzc3MDkgNC45MTM1NzQtNC44Nzc3MDkgNS4wNjg5OTEtNC44Nzc3MDlDNS4yODQxODQtNC44Nzc3MDkgNS40Mjc2NDYtNC44Nzc3MDkgNS42NTQ3OTUtNC43OTQwMjJaTTYuMDYxMjctNS4yMTI0NTNDNS42NjY3NS01LjMwODA5NSA1LjMzMjAwNS01LjMwODA5NSA1LjEwNDg1Ny01LjMwODA5NUM0LjcyMjI5MS01LjMwODA5NSAzLjc1MzkyMy01LjMwODA5NSAzLjc1MzkyMy00LjY2MjUxNkMzLjc1MzkyMy00LjE2MDM5OSA0LjQ3MTIzMy00LjE2MDM5OSA0Ljg4OTY2NC00LjE2MDM5OUM1LjA5MjkwMi00LjE2MDM5OSA1LjYzMDg4NC00LjE2MDM5OSA2LjE2ODg2Ny00LjM4NzU0N0M2LjI2NDUwOC00LjIwODIxOSA2LjMwMDM3NC0zLjk2OTExNiA2LjMwMDM3NC0zLjc2NTg3OEM2LjMwMDM3NC0zLjMzNTQ5MiA1Ljk4OTUzOS0xLjg4ODkxNyA1LjYxODkyOS0xLjI2NzI0OEM1LjI0ODMxOS0uNjgxNDQ1IDQuNjYyNTE2LS4yODY5MjQgMy45MDkzNC0uMjg2OTI0QzIuNzk3NTA5LS4yODY5MjQgMS44NjUwMDYtLjk1NjQxMyAxLjg2NTAwNi0yLjAzMjM3OUMxLjg2NTAwNi0yLjI3MTQ4MiAxLjkyNDc4Mi0yLjUyMjU0IDEuOTQ4NjkyLTIuNjQyMDkyQzIuMTI4MDItMy4zNDc0NDcgMi41MTA1ODUtNC45MTM1NzQgMi42NTQwNDctNS40Mzk2MDFDMy4wMzY2MTMtNi43NDI3MTUgNC40ODMxODgtNy45NjIxNDIgNS45MDU4NTMtNy45NjIxNDJDNi4zNDgxOTQtNy45NjIxNDIgNi42MTEyMDgtNy43NDY5NDkgNi42MTEyMDgtNy4yODA2OTdDNi42MTEyMDgtNi45MTAwODcgNi4zMjQyODQtNS42Nzg3MDUgNi4wNjEyNy01LjIxMjQ1M1onLz4KPHBhdGggaWQ9J2c4LTQwJyBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYtLjUzNzk4MyAxLjgxNzE4Ni0yLjk3NjgzN0MxLjgxNzE4Ni01LjI5NjEzOSAyLjM3OTA3OC03LjI5MjY1MyAzLjc2NTg3OC04LjcwMzM2MkMzLjg4NTQzLTguODEwOTU5IDMuODg1NDMtOC44MzQ4NjkgMy44ODU0My04Ljg3MDczNUMzLjg4NTQzLTguOTQyNDY2IDMuODI1NjU0LTguOTY2Mzc2IDMuNzc3ODMzLTguOTY2Mzc2QzMuNjIyNDE2LTguOTY2Mzc2IDIuNjQyMDkyLTguMTA1NjA0IDIuMDU2Mjg5LTYuOTMzOTk4QzEuNDQ2NTc1LTUuNzI2NTI2IDEuMTcxNjA2LTQuNDQ3MzIzIDEuMTcxNjA2LTIuOTc2ODM3QzEuMTcxNjA2LTEuOTEyODI3IDEuMzM4OTc5LS40OTAxNjIgMS45NjA2NDggLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJy8+CjxwYXRoIGlkPSdnOC00MScgZD0nTTMuMzcxMzU3LTIuOTc2ODM3QzMuMzcxMzU3LTMuODg1NDMgMy4yNTE4MDYtNS4zNjc4NyAyLjU4MjMxNi02Ljc1NDY3QzEuODc2OTYxLTguMTg5MjkgLjg5NjYzOC04Ljk2NjM3NiAuNzY1MTMxLTguOTY2Mzc2Qy43MTczMS04Ljk2NjM3NiAuNjU3NTM0LTguOTQyNDY2IC42NTc1MzQtOC44NzA3MzVDLjY1NzUzNC04LjgzNDg2OSAuNjU3NTM0LTguODEwOTU5IC44NjA3NzItOC42MDc3MjFDMi4wNTYyODktNy40MDAyNDkgMi43MjU3NzgtNS40Mjc2NDYgMi43MjU3NzgtMi45ODg3OTJDMi43MjU3NzgtLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAuNzc3MDg2IDIuNzM3NzMzQy42NTc1MzQgMi44NDUzMyAuNjU3NTM0IDIuODY5MjQgLjY1NzUzNCAyLjkwNTEwNkMuNjU3NTM0IDIuOTc2ODM3IC43MTczMSAzLjAwMDc0NyAuNzY1MTMxIDMuMDAwNzQ3Qy45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgLjk2ODM2OUMzLjA5NjM4OS0uMjUxMDU5IDMuMzcxMzU3LTEuNTQyMjE3IDMuMzcxMzU3LTIuOTc2ODM3WicvPgo8cGF0aCBpZD0nZzgtNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzgtNDknIGQ9J00zLjQ0MzA4OC03LjY2MzI2M0MzLjQ0MzA4OC03LjkzODIzMiAzLjQ0MzA4OC03Ljk1MDE4NyAzLjIwMzk4NS03Ljk1MDE4N0MyLjkxNzA2MS03LjYyNzM5NyAyLjMxOTMwMy03LjE4NTA1NiAxLjA4NzkyLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OS02LjgzODM1NiAxLjk2MDY0OC02LjgzODM1NiAyLjYxODE4Mi03LjE0OTE5MVYtLjkyMDU0OEMyLjYxODE4Mi0uNDkwMTYyIDIuNTgyMzE2LS4zNDY3IDEuNTMwMjYyLS4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEtLjAyMzkxIDIuNjQyMDkyLS4wMjM5MSAzLjAzNjYxMy0uMDIzOTFTNC41Nzg4MjktLjAyMzkxIDQuOTAxNjE5IDBWLS4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0LS4zNDY3IDMuNDQzMDg4LS40OTAxNjIgMy40NDMwODgtLjkyMDU0OFYtNy42NjMyNjNaJy8+CjxwYXRoIGlkPSdnOC02MScgZD0nTTguMDY5NzM4LTMuODczNDc0QzguMjM3MTExLTMuODczNDc0IDguNDUyMzA0LTMuODczNDc0IDguNDUyMzA0LTQuMDg4NjY3QzguNDUyMzA0LTQuMzE1ODE2IDguMjQ5MDY2LTQuMzE1ODE2IDguMDY5NzM4LTQuMzE1ODE2SDEuMDI4MTQ0Qy44NjA3NzItNC4zMTU4MTYgLjY0NTU3OS00LjMxNTgxNiAuNjQ1NTc5LTQuMTAwNjIzQy42NDU1NzktMy44NzM0NzQgLjg0ODgxNy0zLjg3MzQ3NCAxLjAyODE0NC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzgtMS42NDk4MTNDOC4yMzcxMTEtMS42NDk4MTMgOC40NTIzMDQtMS42NDk4MTMgOC40NTIzMDQtMS44NjUwMDZDOC40NTIzMDQtMi4wOTIxNTQgOC4yNDkwNjYtMi4wOTIxNTQgOC4wNjk3MzgtMi4wOTIxNTRIMS4wMjgxNDRDLjg2MDc3Mi0yLjA5MjE1NCAuNjQ1NTc5LTIuMDkyMTU0IC42NDU1NzktMS44NzY5NjFDLjY0NTU3OS0xLjY0OTgxMyAuODQ4ODE3LTEuNjQ5ODEzIDEuMDI4MTQ0LTEuNjQ5ODEzSDguMDY5NzM4WicvPgo8cGF0aCBpZD0nZzgtMTAzJyBkPSdNMS40MjI2NjUtMi4xNjM4ODVDMS45ODQ1NTgtMS43OTMyNzUgMi40NjI3NjUtMS43OTMyNzUgMi41OTQyNzEtMS43OTMyNzVDMy42NzAyMzctMS43OTMyNzUgNC40NzEyMzMtMi42MDYyMjcgNC40NzEyMzMtMy41MjY3NzVDNC40NzEyMzMtMy44NDk1NjQgNC4zNzU1OTItNC4zMDM4NjEgMy45OTMwMjYtNC42ODY0MjZDNC40NTkyNzgtNS4xNjQ2MzMgNS4wMjExNzEtNS4xNjQ2MzMgNS4wODA5NDYtNS4xNjQ2MzNDNS4xMjg3NjctNS4xNjQ2MzMgNS4xODg1NDMtNS4xNjQ2MzMgNS4yMzYzNjQtNS4xNDA3MjJDNS4xMTY4MTItNS4wOTI5MDIgNS4wNTcwMzYtNC45NzMzNSA1LjA1NzAzNi00Ljg0MTg0M0M1LjA1NzAzNi00LjY3NDQ3MSA1LjE3NjU4OC00LjUzMTAwOSA1LjM2Nzg3LTQuNTMxMDA5QzUuNDYzNTEyLTQuNTMxMDA5IDUuNjc4NzA1LTQuNTkwNzg1IDUuNjc4NzA1LTQuODUzNzk4QzUuNjc4NzA1LTUuMDY4OTkxIDUuNTExMzMzLTUuNDAzNzM2IDUuMDkyOTAyLTUuNDAzNzM2QzQuNDcxMjMzLTUuNDAzNzM2IDQuMDA0OTgxLTUuMDIxMTcxIDMuODM3NjA5LTQuODQxODQzQzMuNDc4OTU0LTUuMTE2ODEyIDMuMDYwNTIzLTUuMjcyMjI5IDIuNjA2MjI3LTUuMjcyMjI5QzEuNTMwMjYyLTUuMjcyMjI5IC43MjkyNjUtNC40NTkyNzggLjcyOTI2NS0zLjUzODczQy43MjkyNjUtMi44NTcyODUgMS4xNDc2OTYtMi40MTQ5NDQgMS4yNjcyNDgtMi4zMDczNDdDMS4xMjM3ODYtMi4xMjgwMiAuOTA4NTkzLTEuNzgxMzIgLjkwODU5My0xLjMxNTA2OEMuOTA4NTkzLS42MjE2NjkgMS4zMjcwMjQtLjMyMjc5IDEuNDIyNjY1LS4yNjMwMTRDLjg3MjcyNy0uMTA3NTk3IC4zMjI3OSAuMzIyNzkgLjMyMjc5IC45NDQ0NThDLjMyMjc5IDEuNzY5MzY1IDEuNDQ2NTc1IDIuNDUwODA5IDIuOTE3MDYxIDIuNDUwODA5QzQuMzM5NzI2IDIuNDUwODA5IDUuNTIzMjg4IDEuODE3MTg2IDUuNTIzMjg4IC45MjA1NDhDNS41MjMyODggLjYyMTY2OSA1LjQzOTYwMS0uMDgzNjg2IDQuNzIyMjkxLS40NTQyOTZDNC4xMTI1NzgtLjc2NTEzMSAzLjUxNDgxOS0uNzY1MTMxIDIuNDg2Njc1LS43NjUxMzFDMS43NTc0MS0uNzY1MTMxIDEuNjczNzI0LS43NjUxMzEgMS40NTg1MzEtLjk5MjI3OUMxLjMzODk3OS0xLjExMTgzMSAxLjIzMTM4Mi0xLjMzODk3OSAxLjIzMTM4Mi0xLjU5MDAzN0MxLjIzMTM4Mi0xLjc5MzI3NSAxLjMwMzExMy0xLjk5NjUxMyAxLjQyMjY2NS0yLjE2Mzg4NVpNMi42MDYyMjctMi4wNDQzMzRDMS41NTQxNzItMi4wNDQzMzQgMS41NTQxNzItMy4yNTE4MDYgMS41NTQxNzItMy41MjY3NzVDMS41NTQxNzItMy43NDE5NjggMS41NTQxNzItNC4yMzIxMyAxLjc1NzQxLTQuNTU0OTE5QzEuOTg0NTU4LTQuOTAxNjE5IDIuMzQzMjEzLTUuMDIxMTcxIDIuNTk0MjcxLTUuMDIxMTcxQzMuNjQ2MzI2LTUuMDIxMTcxIDMuNjQ2MzI2LTMuODEzNjk5IDMuNjQ2MzI2LTMuNTM4NzNDMy42NDYzMjYtMy4zMjM1MzcgMy42NDYzMjYtMi44MzMzNzUgMy40NDMwODgtMi41MTA1ODVDMy4yMTU5NC0yLjE2Mzg4NSAyLjg1NzI4NS0yLjA0NDMzNCAyLjYwNjIyNy0yLjA0NDMzNFpNMi45MjkwMTYgMi4xOTk3NTFDMS43ODEzMiAyLjE5OTc1MSAuOTA4NTkzIDEuNjEzOTQ4IC45MDg1OTMgLjkzMjUwM0MuOTA4NTkzIC44MzY4NjIgLjkzMjUwMyAuMzcwNjEgMS4zODY4IC4wNTk3NzZDMS42NDk4MTMtLjEwNzU5NyAxLjc1NzQxLS4xMDc1OTcgMi41OTQyNzEtLjEwNzU5N0MzLjU4NjU1LS4xMDc1OTcgNC45Mzc0ODQtLjEwNzU5NyA0LjkzNzQ4NCAuOTMyNTAzQzQuOTM3NDg0IDEuNjM3ODU4IDQuMDI4ODkyIDIuMTk5NzUxIDIuOTI5MDE2IDIuMTk5NzUxWicvPgo8cGF0aCBpZD0nZzgtMTA4JyBkPSdNMi4wNTYyODktOC4yOTY4ODdMLjM5NDUyMS04LjE2NTM4Vi03LjgxODY4QzEuMjA3NDcyLTcuODE4NjggMS4zMDMxMTMtNy43MzQ5OTQgMS4zMDMxMTMtNy4xNDkxOTFWLS44ODQ2ODJDMS4zMDMxMTMtLjM0NjcgMS4xNzE2MDYtLjM0NjcgLjM5NDUyMS0uMzQ2N1YwQy43MjkyNjUtLjAyMzkxIDEuMzE1MDY4LS4wMjM5MSAxLjY3MzcyNC0uMDIzOTFTMi42MzAxMzctLjAyMzkxIDIuOTY0ODgyIDBWLS4zNDY3QzIuMTk5NzUxLS4zNDY3IDIuMDU2Mjg5LS4zNDY3IDIuMDU2Mjg5LS44ODQ2ODJWLTguMjk2ODg3WicvPgo8cGF0aCBpZD0nZzgtMTExJyBkPSdNNS40ODc0MjItMi41NTg0MDZDNS40ODc0MjItNC4xMDA2MjMgNC4zMTU4MTYtNS4zMzIwMDUgMi45MjkwMTYtNS4zMzIwMDVDMS40OTQzOTYtNS4zMzIwMDUgLjM1ODY1NS00LjA2NDc1NyAuMzU4NjU1LTIuNTU4NDA2Qy4zNTg2NTUtMS4wMjgxNDQgMS41NTQxNzIgLjExOTU1MiAyLjkxNzA2MSAuMTE5NTUyQzQuMzI3NzcxIC4xMTk1NTIgNS40ODc0MjItMS4wNTIwNTUgNS40ODc0MjItMi41NTg0MDZaTTIuOTI5MDE2LS4xNDM0NjJDMi40ODY2NzUtLjE0MzQ2MiAxLjk0ODY5Mi0uMzM0NzQ1IDEuNjAxOTkzLS45MjA1NDhDMS4yNzkyMDMtMS40NTg1MzEgMS4yNjcyNDgtMi4xNjM4ODUgMS4yNjcyNDgtMi42NjYwMDJDMS4yNjcyNDgtMy4xMjAyOTkgMS4yNjcyNDgtMy44NDk1NjQgMS42Mzc4NTgtNC4zODc1NDdDMS45NzI2MDMtNC45MDE2MTkgMi40OTg2My01LjA5MjkwMiAyLjkxNzA2MS01LjA5MjkwMkMzLjM4MzMxMy01LjA5MjkwMiAzLjg4NTQzLTQuODc3NzA5IDQuMjA4MjE5LTQuNDExNDU3QzQuNTc4ODI5LTMuODYxNTE5IDQuNTc4ODI5LTMuMTA4MzQ0IDQuNTc4ODI5LTIuNjY2MDAyQzQuNTc4ODI5LTIuMjQ3NTcyIDQuNTc4ODI5LTEuNTA2MzUxIDQuMjY3OTk1LS45NDQ0NThDMy45MzMyNS0uMzcwNjEgMy4zODMzMTMtLjE0MzQ2MiAyLjkyOTAxNi0uMTQzNDYyWicvPgo8cGF0aCBpZD0nZzYtMjInIGQ9J00xLjcyMTU0NC0uMjYzMDE0QzIuMDIwNDIzIC4wMTE5NTUgMi40NjI3NjUgLjExOTU1MiAyLjg2OTI0IC4xMTk1NTJDMy42MzQzNzEgLjExOTU1MiA0LjE2MDM5OS0uMzk0NTIxIDQuNDM1MzY3LS43NjUxMzFDNC41NTQ5MTktLjEzMTUwNyA1LjA1NzAzNiAuMTE5NTUyIDUuNDc1NDY3IC4xMTk1NTJDNS44MzQxMjIgLjExOTU1MiA2LjEyMTA0Ni0uMDk1NjQxIDYuMzM2MjM5LS41MjYwMjdDNi41Mjc1MjItLjkzMjUwMyA2LjY5NDg5NC0xLjY2MTc2OCA2LjY5NDg5NC0xLjcwOTU4OUM2LjY5NDg5NC0xLjc2OTM2NSA2LjY0NzA3My0xLjgxNzE4NiA2LjU3NTM0Mi0xLjgxNzE4NkM2LjQ2Nzc0Ni0xLjgxNzE4NiA2LjQ1NTc5MS0xLjc1NzQxIDYuNDA3OTctMS41NzgwODJDNi4yMjg2NDMtLjg3MjcyNyA2LjAwMTQ5NC0uMTE5NTUyIDUuNTExMzMzLS4xMTk1NTJDNS4xNjQ2MzMtLjExOTU1MiA1LjE0MDcyMi0uNDMwMzg2IDUuMTQwNzIyLS42Njk0ODlDNS4xNDA3MjItLjk0NDQ1OCA1LjI0ODMxOS0xLjM3NDg0NCA1LjMzMjAwNS0xLjczMzQ5OUw1LjY2Njc1LTMuMDI0NjU4QzUuNzE0NTctMy4yNTE4MDYgNS44NDYwNzctMy43ODk3ODggNS45MDU4NTMtNC4wMDQ5ODFDNS45Nzc1ODQtNC4yOTE5MDUgNi4xMDkwOTEtNC44MDU5NzggNi4xMDkwOTEtNC44NTM3OThDNi4xMDkwOTEtNS4wMzMxMjYgNS45NjU2MjktNS4xNTI2NzcgNS43ODYzMDEtNS4xNTI2NzdDNS42Nzg3MDUtNS4xNTI2NzcgNS40Mjc2NDYtNS4xMDQ4NTcgNS4zMzIwMDUtNC43NDYyMDJMNC40OTUxNDMtMS40MjI2NjVDNC40MzUzNjctMS4xODM1NjIgNC40MzUzNjctMS4xNTk2NTEgNC4yNzk5NS0uOTY4MzY5QzQuMTM2NDg4LS43NjUxMzEgMy42NzAyMzctLjExOTU1MiAyLjkxNzA2MS0uMTE5NTUyQzIuMjQ3NTcyLS4xMTk1NTIgMi4wMzIzNzktLjYwOTcxNCAyLjAzMjM3OS0xLjE3MTYwNkMyLjAzMjM3OS0xLjUxODMwNiAyLjEzOTk3NS0xLjkzNjczNyAyLjE4Nzc5Ni0yLjEzOTk3NUwyLjcyNTc3OC00LjI5MTkwNUMyLjc4NTU1NC00LjUxOTA1NCAyLjg4MTE5Ni00LjkwMTYxOSAyLjg4MTE5Ni00Ljk3MzM1QzIuODgxMTk2LTUuMTY0NjMzIDIuNzI1Nzc4LTUuMjcyMjI5IDIuNTcwMzYxLTUuMjcyMjI5QzIuNDYyNzY1LTUuMjcyMjI5IDIuMTk5NzUxLTUuMjM2MzY0IDIuMTA0MTEtNC44NTM3OThMLjM3MDYxIDIuMDY4MjQ0Qy4zNTg2NTUgMi4xMjgwMiAuMzM0NzQ1IDIuMTk5NzUxIC4zMzQ3NDUgMi4yNzE0ODJDLjMzNDc0NSAyLjQ1MDgwOSAuNDc4MjA3IDIuNTcwMzYxIC42NTc1MzQgMi41NzAzNjFDMS4wMDQyMzQgMi41NzAzNjEgMS4wNzU5NjUgMi4yOTUzOTIgMS4xNTk2NTEgMS45NjA2NDhMMS43MjE1NDQtLjI2MzAxNFonLz4KPHBhdGggaWQ9J2c2LTI0JyBkPSdNMy4xMjAyOTkgLjA1OTc3NkwxLjg2NTAwNi0uNDQyMzQxQzEuNTU0MTcyLS41NjE4OTMgLjgzNjg2Mi0uODQ4ODE3IC44MzY4NjItMS41NjYxMjdDLjgzNjg2Mi0yLjU5NDI3MSAyLjA5MjE1NC0zLjYzNDM3MSAyLjM0MzIxMy0zLjYzNDM3MUMyLjM2NzEyMy0zLjYzNDM3MSAyLjQ3NDcyLTMuNjEwNDYxIDIuNTEwNTg1LTMuNTk4NTA2QzIuODMzMzc1LTMuNTAyODY0IDMuMTQ0MjA5LTMuNTAyODY0IDMuMzU5NDAyLTMuNTAyODY0QzMuNzMwMDEyLTMuNTAyODY0IDQuNDM1MzY3LTMuNTAyODY0IDQuNDM1MzY3LTMuODQ5NTY0QzQuNDM1MzY3LTQuMTEyNTc4IDQuMDA0OTgxLTQuMTQ4NDQzIDMuNDkwOTA5LTQuMTQ4NDQzQzMuMjUxODA2LTQuMTQ4NDQzIDIuOTI5MDE2LTQuMTQ4NDQzIDIuNDk4NjMtNC4wMDQ5ODFDMi4yMTE3MDYtNC4yNDQwODUgMi4wOTIxNTQtNC42MjY2NSAyLjA5MjE1NC00Ljk4NTMwNUMyLjA5MjE1NC01LjY0MjgzOSAyLjUyMjU0LTYuNTc1MzQyIDMuNDY2OTk5LTcuMDE3Njg0QzMuNjgyMTkyLTYuNzY2NjI1IDMuOTY5MTE2LTYuNzY2NjI1IDQuMjIwMTc0LTYuNzY2NjI1QzQuNTE5MDU0LTYuNzY2NjI1IDUuMjQ4MzE5LTYuNzY2NjI1IDUuMjQ4MzE5LTcuMTEzMzI1QzUuMjQ4MzE5LTcuNDEyMjA0IDQuNjc0NDcxLTcuNDEyMjA0IDQuMjkxOTA1LTcuNDEyMjA0QzQuMDUyODAyLTcuNDEyMjA0IDMuODczNDc0LTcuNDEyMjA0IDMuNTM4NzMtNy4zNTI0MjhDMy40Nzg5NTQtNy40OTU4OSAzLjQ2Njk5OS03LjUxOTgwMSAzLjQ2Njk5OS03Ljc4MjgxNEMzLjQ2Njk5OS03Ljk5ODAwNyAzLjUxNDgxOS04LjE2NTM4IDMuNTE0ODE5LTguMjAxMjQ1QzMuNTE0ODE5LTguMjcyOTc2IDMuNDU1MDQ0LTguMzIwNzk3IDMuMzk1MjY4LTguMzIwNzk3QzMuMjAzOTg1LTguMzIwNzk3IDMuMjAzOTg1LTcuODc4NDU2IDMuMjAzOTg1LTcuNzgyODE0QzMuMjAzOTg1LTcuNjE1NDQyIDMuMjE1OTQtNy40NDgwNyAzLjI4NzY3MS03LjI5MjY1M0MxLjg1MzA1MS02Ljg3NDIyMiAxLjIxOTQyNy01Ljg1ODAzMiAxLjIxOTQyNy01LjA4MDk0NkMxLjIxOTQyNy00LjM2MzYzNiAxLjY5NzYzNC0zLjk2OTExNiAyLjAyMDQyMy0zLjc4OTc4OEMuNzg5MDQxLTMuMTIwMjk5IC4yNjMwMTQtMS45MDA4NzIgLjI2MzAxNC0xLjI1NTI5M0MuMjYzMDE0LS4yMTUxOTMgMS4yMDc0NzIgLjE1NTQxNyAxLjYzNzg1OCAuMzM0NzQ1TDIuNzEzODIzIC43NjUxMzFDMy4wMTI3MDIgLjg3MjcyNyAzLjUwMjg2NCAxLjA3NTk2NSAzLjU4NjU1IDEuMTIzNzg2QzMuNzA2MTAyIDEuMjA3NDcyIDMuODAxNzQzIDEuMzUwOTM0IDMuODAxNzQzIDEuNTQyMjE3QzMuODAxNzQzIDEuNzkzMjc1IDMuNjEwNDYxIDIuMTk5NzUxIDMuMTkyMDMgMi4xOTk3NTFDMy4wMTI3MDIgMi4xOTk3NTEgMi42MTgxODIgMi4xNTE5MyAyLjE4Nzc5NiAxLjgyOTE0MUMyLjEwNDExIDEuNzU3NDEgMi4wOTIxNTQgMS43NDU0NTUgMi4wNDQzMzQgMS43NDU0NTVDMS45ODQ1NTggMS43NDU0NTUgMS45MjQ3ODIgMS43OTMyNzUgMS45MjQ3ODIgMS44NjUwMDZDMS45MjQ3ODIgMS45OTY1MTMgMi41NDY0NTEgMi40Mzg4NTQgMy4xOTIwMyAyLjQzODg1NEMzLjk1NzE2MSAyLjQzODg1NCA0LjQyMzQxMiAxLjY5NzYzNCA0LjQyMzQxMiAxLjE4MzU2MkM0LjQyMzQxMiAuODEyOTUxIDQuMjIwMTc0IC41MTQwNzIgMy44Mzc2MDkgLjM0NjdMMy4xMjAyOTkgLjA1OTc3NlpNMy43MzAwMTItNy4xMTMzMjVDMy45MzMyNS03LjE3MzEwMSA0LjE0ODQ0My03LjE3MzEwMSA0LjMwMzg2MS03LjE3MzEwMUM0LjY5ODM4MS03LjE3MzEwMSA0LjczNDI0Ny03LjE2MTE0NiA0Ljk3MzM1LTcuMTAxMzdDNC44Mjk4ODgtNy4wNDE1OTQgNC43MzQyNDctNy4wMDU3MjkgNC4yMzIxMy03LjAwNTcyOUM0LjAwNDk4MS03LjAwNTcyOSAzLjg2MTUxOS03LjAwNTcyOSAzLjczMDAxMi03LjExMzMyNVpNMi43ODU1NTQtMy44Mzc2MDlDMy4wNzI0NzgtMy45MDkzNCAzLjMzNTQ5Mi0zLjkwOTM0IDMuNDc4OTU0LTMuOTA5MzRDMy44NzM0NzQtMy45MDkzNCAzLjg5NzM4NS0zLjg5NzM4NSA0LjE2MDM5OS0zLjgzNzYwOUM0LjAyODg5Mi0zLjc3NzgzMyAzLjkyMTI5NS0zLjc0MTk2OCAzLjQwNzIyMy0zLjc0MTk2OEMzLjEyMDI5OS0zLjc0MTk2OCAzLjAwMDc0Ny0zLjc0MTk2OCAyLjc4NTU1NC0zLjgzNzYwOVonLz4KPHBhdGggaWQ9J2c2LTI3JyBkPSdNNi4wNzMyMjUtNC41MDcwOThDNi4yMjg2NDMtNC41MDcwOTggNi42MjMxNjMtNC41MDcwOTggNi42MjMxNjMtNC44ODk2NjRDNi42MjMxNjMtNS4xNTI2NzcgNi4zOTYwMTUtNS4xNTI2NzcgNi4xODA4MjItNS4xNTI2NzdIMy41Mzg3M0MxLjc0NTQ1NS01LjE1MjY3NyAuNDU0Mjk2LTMuMTU2MTY0IC40NTQyOTYtMS43NDU0NTVDLjQ1NDI5Ni0uNzI5MjY1IDEuMTExODMxIC4xMTk1NTIgMi4xODc3OTYgLjExOTU1MkMzLjU5ODUwNiAuMTE5NTUyIDUuMTQwNzIyLTEuMzk4NzU1IDUuMTQwNzIyLTMuMTkyMDNDNS4xNDA3MjItMy42NTgyODEgNS4wMzMxMjYtNC4xMTI1NzggNC43NDYyMDItNC41MDcwOThINi4wNzMyMjVaTTIuMTk5NzUxLS4xMTk1NTJDMS41OTAwMzctLjExOTU1MiAxLjE0NzY5Ni0uNTg1ODAzIDEuMTQ3Njk2LTEuNDEwNzFDMS4xNDc2OTYtMi4xMjgwMiAxLjU3ODA4Mi00LjUwNzA5OCAzLjMzNTQ5Mi00LjUwNzA5OEMzLjg0OTU2NC00LjUwNzA5OCA0LjQyMzQxMi00LjI1NjA0IDQuNDIzNDEyLTMuMzM1NDkyQzQuNDIzNDEyLTIuOTE3MDYxIDQuMjMyMTMtMS45MTI4MjcgMy44MTM2OTktMS4yMTk0MjdDMy4zODMzMTMtLjUxNDA3MiAyLjczNzczMy0uMTE5NTUyIDIuMTk5NzUxLS4xMTk1NTJaJy8+CjxwYXRoIGlkPSdnNi02MScgZD0nTTUuMTI4NzY3LTguNTI0MDM1QzUuMTI4NzY3LTguNTM1OTkgNS4yMDA0OTgtOC43MTUzMTggNS4yMDA0OTgtOC43MzkyMjhDNS4yMDA0OTgtOC44ODI2OSA1LjA4MDk0Ni04Ljk2NjM3NiA0Ljk4NTMwNS04Ljk2NjM3NkM0LjkyNTUyOS04Ljk2NjM3NiA0LjgxNzkzMy04Ljk2NjM3NiA0LjcyMjI5MS04LjcwMzM2MkwuNzE3MzEgMi41NDY0NTFDLjcxNzMxIDIuNTU4NDA2IC42NDU1NzkgMi43Mzc3MzMgLjY0NTU3OSAyLjc2MTY0NEMuNjQ1NTc5IDIuOTA1MTA2IC43NjUxMzEgMi45ODg3OTIgLjg2MDc3MiAyLjk4ODc5MkMuOTMyNTAzIDIuOTg4NzkyIDEuMDQwMSAyLjk3NjgzNyAxLjEyMzc4NiAyLjcyNTc3OEw1LjEyODc2Ny04LjUyNDAzNVonLz4KPHBhdGggaWQ9J2c2LTk2JyBkPSdNMS4wOTk4NzUtMi4wMzIzNzlDLjM0NjctMS4yOTExNTggLjE1NTQxNy0xLjExMTgzMSAuMTU1NDE3LTEuMDY0MDFTLjIwMzIzOC0uOTMyNTAzIC4yODY5MjQtLjkzMjUwM0MuMzQ2Ny0uOTMyNTAzIDEuMDI4MTQ0LTEuNTkwMDM3IDEuMTIzNzg2LTEuNjk3NjM0QzEuMTk1NTE3LS44OTY2MzggMS40OTQzOTYgLjE0MzQ2MiAyLjQyNjg5OSAuMTQzNDYyQzIuOTA1MTA2IC4xNDM0NjIgMy4zMzU0OTItLjE1NTQxNyAzLjUyNjc3NS0uMjk4ODc5QzMuNjgyMTkyLS40MTg0MzEgNC4yNTYwNC0uOTA4NTkzIDQuMjU2MDQtMS4wMTYxODlDNC4yNTYwNC0xLjA3NTk2NSA0LjE5NjI2NC0xLjE0NzY5NiA0LjEzNjQ4OC0xLjE0NzY5NkM0LjA4ODY2Ny0xLjE0NzY5NiAzLjkwOTM0LS45NjgzNjkgMy44NjE1MTktLjkyMDU0OEMzLjQ0MzA4OC0uNTE0MDcyIDIuOTE3MDYxLS4wOTU2NDEgMi40Mzg4NTQtLjA5NTY0MUMxLjc5MzI3NS0uMDk1NjQxIDEuNzA5NTg5LTEuMDI4MTQ0IDEuNzA5NTg5LTEuNjczNzI0QzEuNzA5NTg5LTEuNzkzMjc1IDEuNzA5NTg5LTIuMjk1MzkyIDEuNzkzMjc1LTIuMzkxMDM0QzIuNDk4NjMtMy4xMjAyOTkgNC43MTAzMzYtNS40MDM3MzYgNC43MTAzMzYtNy41MTk4MDFDNC43MTAzMzYtNy45OTgwMDcgNC41MzEwMDktOC40MTY0MzggNC4wMTY5MzYtOC40MTY0MzhDMi45MDUxMDYtOC40MTY0MzggMS45MzY3MzctNS45NTM2NzQgMS43NjkzNjUtNS40OTkzNzdDMS43MjE1NDQtNS4zNzk4MjYgMS4wMjgxNDQtMy41Mzg3MyAxLjA5OTg3NS0yLjAzMjM3OVpNMS44MTcxODYtMi43NzM1OTlDMS44MjkxNDEtMi44NDUzMyAyLjM2NzEyMy01Ljk3NzU4NCAzLjM3MTM1Ny03LjY1MTMwOEMzLjU3NDU5NS03Ljk3NDA5NyAzLjc3NzgzMy04LjE3NzMzNSA0LjAxNjkzNi04LjE3NzMzNUM0LjQyMzQxMi04LjE3NzMzNSA0LjQ0NzMyMy03Ljc5NDc3IDQuNDQ3MzIzLTcuNTMxNzU2QzQuNDQ3MzIzLTcuMTEzMzI1IDQuMzI3NzcxLTYuMDM3MzYgMy4yODc2NzEtNC41MzEwMDlDMi45NzY4MzctNC4wODg2NjcgMi40OTg2My0zLjQ5MDkwOSAxLjgxNzE4Ni0yLjc3MzU5OVonLz4KPHBhdGggaWQ9J2c2LTExNicgZD0nTTIuNDAyOTg5LTQuODA1OTc4SDMuNTAyODY0QzMuNzMwMDEyLTQuODA1OTc4IDMuODQ5NTY0LTQuODA1OTc4IDMuODQ5NTY0LTUuMDIxMTcxQzMuODQ5NTY0LTUuMTUyNjc3IDMuNzc3ODMzLTUuMTUyNjc3IDMuNTM4NzMtNS4xNTI2NzdIMi40ODY2NzVMMi45MjkwMTYtNi44OTgxMzJDMi45NzY4MzctNy4wNjU1MDQgMi45NzY4MzctNy4wODk0MTUgMi45NzY4MzctNy4xNzMxMDFDMi45NzY4MzctNy4zNjQzODQgMi44MjE0Mi03LjQ3MTk4IDIuNjY2MDAyLTcuNDcxOThDMi41NzAzNjEtNy40NzE5OCAyLjI5NTM5Mi03LjQzNjExNSAyLjE5OTc1MS03LjA1MzU0OUwxLjczMzQ5OS01LjE1MjY3N0guNjA5NzE0Qy4zNzA2MS01LjE1MjY3NyAuMjYzMDE0LTUuMTUyNjc3IC4yNjMwMTQtNC45MjU1MjlDLjI2MzAxNC00LjgwNTk3OCAuMzQ2Ny00LjgwNTk3OCAuNTczODQ4LTQuODA1OTc4SDEuNjM3ODU4TC44NDg4MTctMS42NDk4MTNDLjc1MzE3Ni0xLjIzMTM4MiAuNzE3MzEtMS4xMTE4MzEgLjcxNzMxLS45NTY0MTNDLjcxNzMxLS4zOTQ1MjEgMS4xMTE4MzEgLjExOTU1MiAxLjc4MTMyIC4xMTk1NTJDMi45ODg3OTIgLjExOTU1MiAzLjYzNDM3MS0xLjYyNTkwMyAzLjYzNDM3MS0xLjcwOTU4OUMzLjYzNDM3MS0xLjc4MTMyIDMuNTg2NTUtMS44MTcxODYgMy41MTQ4MTktMS44MTcxODZDMy40OTA5MDktMS44MTcxODYgMy40NDMwODgtMS44MTcxODYgMy40MTkxNzgtMS43NjkzNjVDMy40MDcyMjMtMS43NTc0MSAzLjM5NTI2OC0xLjc0NTQ1NSAzLjMxMTU4Mi0xLjU1NDE3MkMzLjA2MDUyMy0uOTU2NDEzIDIuNTEwNTg1LS4xMTk1NTIgMS44MTcxODYtLjExOTU1MkMxLjQ1ODUzMS0uMTE5NTUyIDEuNDM0NjItLjQxODQzMSAxLjQzNDYyLS42ODE0NDVDMS40MzQ2Mi0uNjkzNCAxLjQzNDYyLS45MjA1NDggMS40NzA0ODYtMS4wNjQwMUwyLjQwMjk4OS00LjgwNTk3OFonLz4KPHBhdGggaWQ9J2c2LTEyMicgZD0nTTEuNTE4MzA2LS45NjgzNjlDMi4wMzIzNzktMS41NTQxNzIgMi40NTA4MDktMS45MjQ3ODIgMy4wNDg1NjgtMi40NjI3NjVDMy43NjU4NzgtMy4wODQ0MzMgNC4wNzY3MTItMy4zODMzMTMgNC4yNDQwODUtMy41NjI2NEM1LjA4MDk0Ni00LjM4NzU0NyA1LjQ5OTM3Ny01LjA4MDk0NiA1LjQ5OTM3Ny01LjE3NjU4OFM1LjQwMzczNi01LjI3MjIyOSA1LjM3OTgyNi01LjI3MjIyOUM1LjI5NjEzOS01LjI3MjIyOSA1LjI3MjIyOS01LjIyNDQwOCA1LjIxMjQ1My01LjE0MDcyMkM0LjkxMzU3NC00LjYyNjY1IDQuNjI2NjUtNC4zNzU1OTIgNC4zMTU4MTYtNC4zNzU1OTJDNC4wNjQ3NTctNC4zNzU1OTIgMy45MzMyNS00LjQ4MzE4OCAzLjcwNjEwMi00Ljc3MDExMkMzLjQ1NTA0NC01LjA2ODk5MSAzLjI1MTgwNi01LjI3MjIyOSAyLjkwNTEwNi01LjI3MjIyOUMyLjAzMjM3OS01LjI3MjIyOSAxLjUwNjM1MS00LjE4NDMwOSAxLjUwNjM1MS0zLjkzMzI1QzEuNTA2MzUxLTMuODk3Mzg1IDEuNTE4MzA2LTMuODI1NjU0IDEuNjI1OTAzLTMuODI1NjU0QzEuNzIxNTQ0LTMuODI1NjU0IDEuNzMzNDk5LTMuODczNDc0IDEuNzY5MzY1LTMuOTU3MTYxQzEuOTcyNjAzLTQuNDM1MzY3IDIuNTQ2NDUxLTQuNTE5MDU0IDIuNzczNTk5LTQuNTE5MDU0QzMuMDI0NjU4LTQuNTE5MDU0IDMuMjYzNzYxLTQuNDM1MzY3IDMuNTE0ODE5LTQuMzI3NzcxQzMuOTY5MTE2LTQuMTM2NDg4IDQuMTYwMzk5LTQuMTM2NDg4IDQuMjc5OTUtNC4xMzY0ODhDNC4zNjM2MzYtNC4xMzY0ODggNC40MTE0NTctNC4xMzY0ODggNC40NzEyMzMtNC4xNDg0NDNDNC4wNzY3MTItMy42ODIxOTIgMy40MzExMzMtMy4xMDgzNDQgMi44OTMxNTEtMi42MTgxODJMMS42ODU2NzktMS41MDYzNTFDLjk1NjQxMy0uNzY1MTMxIC41MTQwNzItLjA1OTc3NiAuNTE0MDcyIC4wMjM5MUMuNTE0MDcyIC4wOTU2NDEgLjU3Mzg0OCAuMTE5NTUyIC42NDU1NzkgLjExOTU1MlMuNzI5MjY1IC4xMDc1OTcgLjgxMjk1MS0uMDM1ODY2QzEuMDA0MjM0LS4zMzQ3NDUgMS4zODY4LS43NzcwODYgMS44MjkxNDEtLjc3NzA4NkMyLjA4MDE5OS0uNzc3MDg2IDIuMTk5NzUxLS42OTM0IDIuNDM4ODU0LS4zOTQ1MjFDMi42NjYwMDItLjEzMTUwNyAyLjg2OTI0IC4xMTk1NTIgMy4yNTE4MDYgLjExOTU1MkM0LjQyMzQxMiAuMTE5NTUyIDUuMDkyOTAyLTEuMzk4NzU1IDUuMDkyOTAyLTEuNjczNzI0QzUuMDkyOTAyLTEuNzIxNTQ0IDUuMDgwOTQ2LTEuNzkzMjc1IDQuOTYxMzk1LTEuNzkzMjc1QzQuODY1NzUzLTEuNzkzMjc1IDQuODUzNzk4LTEuNzQ1NDU1IDQuODE3OTMzLTEuNjI1OTAzQzQuNTU0OTE5LS45MjA1NDggMy44NDk1NjQtLjYzMzYyNCAzLjM4MzMxMy0uNjMzNjI0QzMuMTMyMjU0LS42MzM2MjQgMi44OTMxNTEtLjcxNzMxIDIuNjQyMDkyLS44MjQ5MDdDMi4xNjM4ODUtMS4wMTYxODkgMi4wMzIzNzktMS4wMTYxODkgMS44NzY5NjEtMS4wMTYxODlDMS43NTc0MS0xLjAxNjE4OSAxLjYyNTkwMy0xLjAxNjE4OSAxLjUxODMwNi0uOTY4MzY5WicvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c2LTk2Jy8+Cjx1c2UgeD0nNC45MTIxMDYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzkuNDY0NDMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzAtMTInLz4KPHVzZSB4PScxNy43NTgyOTcnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzI1LjYzMTQ1MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTYxJy8+Cjx1c2UgeD0nMzguMDU2OTMyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzMtMCcvPgo8dXNlIHg9JzU1LjQxMzEzNCcgeT0nLTI5Ljk3NjQyNScgeGxpbms6aHJlZj0nI2c1LTExMCcvPgo8dXNlIHg9JzQ5LjM0NzkyNycgeT0nLTI2LjM4OTg2OScgeGxpbms6aHJlZj0nI2cxLTg4Jy8+Cjx1c2UgeD0nNTEuMTMwMzIxJyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc1NC4wMTM0NjEnIHk9Jy0xLjE5NTUxNCcgeGxpbms6aHJlZj0nI2c3LTYxJy8+Cjx1c2UgeD0nNjAuNTk5OTY3JyB5PSctMS4xOTU1MTQnIHhsaW5rOmhyZWY9JyNnNy00OScvPgo8dXNlIHg9JzY4LjYwOTA0MScgeT0nLTM1LjQ3NTkyOCcgeGxpbms6aHJlZj0nI2cxLTQwJy8+Cjx1c2UgeD0nNzguMjM5NjQ0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTA4Jy8+Cjx1c2UgeD0nODEuNDkxMzA1JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTExJy8+Cjx1c2UgeD0nODcuMzQ0Mjk2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTAzJy8+Cjx1c2UgeD0nOTMuMzU5ODY5JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc5Ny45MTIxOTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0yNycvPgo8dXNlIHg9JzEwNC45OTQ1OTknIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzEwOS41NDY5MjUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScxMTMuNzc0MDg0JyB5PSctMTMuMjM5MTQxJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMTE3LjE1NTM1NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMTIxLjcwNzY4MicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMTI4LjkxNjY3MScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMTQwLjY3Nzk4NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMTQ1LjIzMDMxMicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQ5Jy8+Cjx1c2UgeD0nMTUzLjczOTk2NScgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQzJy8+Cjx1c2UgeD0nMTY1LjUwMTI4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PScxNzEuMzU0MjcxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtNjEnLz4KPHVzZSB4PScxNzcuMjA3MjYxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMjQnLz4KPHVzZSB4PScxODIuODk3Njk4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PScxODcuNDUwMDI0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMTkxLjY3NzE4NCcgeT0nLTEzLjIzOTE0MScgeGxpbms6aHJlZj0nI2c1LTEwNScvPgo8dXNlIHg9JzE5NS4wNTg0NTUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzE5OS42MTA3ODEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzIwNi4xNTU2MDUnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC0xMDgnLz4KPHVzZSB4PScyMDkuNDA3MjY2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtMTExJy8+Cjx1c2UgeD0nMjE1LjI2MDI1NicgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTEwMycvPgo8dXNlIHg9JzIyMy4yNjgzMjcnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0yMCcvPgo8dXNlIHg9JzIyOS41NzgwMjQnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzIzOC4wODc2NzgnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MycvPgo8dXNlIHg9JzI0OS44NDg5OTMnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0yNCcvPgo8dXNlIHg9JzI1NS41Mzk0MzEnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnOC00MCcvPgo8dXNlIHg9JzI2MC4wOTE3NTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PScyNjQuMzE4OTE2JyB5PSctMTMuMjM5MTQxJyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMjY3LjcwMDE4OCcgeT0nLTE1LjAzMjQwNCcgeGxpbms6aHJlZj0nI2c4LTQxJy8+Cjx1c2UgeD0nMjc0LjI0NTAxMScgeT0nLTMxLjg4OTM0MScgeGxpbms6aHJlZj0nI2cxLTE4Jy8+Cjx1c2UgeD0nMjg0LjI0MDg5NycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTEyMicvPgo8dXNlIHg9JzI4OS42Nzg3ODgnIHk9Jy0yMS4zMjY5JyB4bGluazpocmVmPScjZzUtMTE2Jy8+Cjx1c2UgeD0nMjkyLjczNjgwOScgeT0nLTIwLjExMTgyMScgeGxpbms6aHJlZj0nI2c0LTEwNScvPgo8dXNlIHg9JzI5OS4wNTMzNjInIHk9Jy0yMy4xMjAxNjMnIHhsaW5rOmhyZWY9JyNnMy0wJy8+Cjx1c2UgeD0nMzExLjAwODUyMycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTIyJy8+Cjx1c2UgeD0nMzE4LjA1MTQ5MycgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMzIyLjYwMzgxOScgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2c2LTExNicvPgo8dXNlIHg9JzMyNi44MzA5NzknIHk9Jy0yMS4zMjY5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzMwLjIxMjI1JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHJlY3QgeD0nMjg0LjI0MDg5NycgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1MC41MjM2NzEnLz4KPHVzZSB4PScyOTcuNjA0OTk3JyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNi0yNycvPgo8dXNlIHg9JzMwNC42ODc0MDEnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nMzA5LjIzOTcyNycgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nMzEzLjQ2Njg4NycgeT0nLTUuMDM4NDc5JyB4bGluazpocmVmPScjZzUtMTA1Jy8+Cjx1c2UgeD0nMzE2Ljg0ODE1OCcgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSczMzUuOTYwMDgyJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMTknLz4KPHVzZSB4PSczNDQuNzYwNDU1JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMjEnLz4KPHVzZSB4PSczNTMuNzI2ODE2JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDMnLz4KPHVzZSB4PSczNjUuNDg4MTMxJyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMjAnLz4KPHVzZSB4PSczNzEuNzk3ODI4JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDknLz4KPHVzZSB4PSczODAuMzA3NDgyJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDMnLz4KPHVzZSB4PSczOTIuMDY4Nzk3JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzYtMjQnLz4KPHVzZSB4PSczOTcuNzU5MjM0JyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc0MDIuMzExNTYnIHk9Jy0xNS4wMzI0MDQnIHhsaW5rOmhyZWY9JyNnNi0xMTYnLz4KPHVzZSB4PSc0MDYuNTM4NzInIHk9Jy0xMy4yMzkxNDEnIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0MDkuOTE5OTkxJyB5PSctMTUuMDMyNDA0JyB4bGluazpocmVmPScjZzgtNDEnLz4KPHVzZSB4PSc0MTYuNDY0ODE1JyB5PSctMzEuODg5MzQxJyB4bGluazpocmVmPScjZzEtMTgnLz4KPHVzZSB4PSc0MjYuNDYwNzAxJyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzYtMTIyJy8+Cjx1c2UgeD0nNDMxLjg5ODU5MicgeT0nLTIxLjMyNjknIHhsaW5rOmhyZWY9JyNnNS0xMTYnLz4KPHVzZSB4PSc0MzQuOTU2NjEzJyB5PSctMjAuMTExODIxJyB4bGluazpocmVmPScjZzQtMTA1Jy8+Cjx1c2UgeD0nNDQxLjI3MzE2NicgeT0nLTIzLjEyMDE2MycgeGxpbms6aHJlZj0nI2czLTAnLz4KPHVzZSB4PSc0NTMuMjI4MzI3JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzYtMjInLz4KPHVzZSB4PSc0NjAuMjcxMjk3JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzgtNDAnLz4KPHVzZSB4PSc0NjQuODIzNjIzJyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nNDY5LjA1MDc4MicgeT0nLTIxLjMyNjknIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0NzIuNDMyMDU0JyB5PSctMjMuMTIwMTYzJyB4bGluazpocmVmPScjZzgtNDEnLz4KPHJlY3QgeD0nNDI2LjQ2MDcwMScgeT0nLTE4LjI2MDI5JyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSc1MC41MjM2NzEnLz4KPHVzZSB4PSc0MzkuODI0ODAxJyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnNi0yNycvPgo8dXNlIHg9JzQ0Ni45MDcyMDUnIHk9Jy02LjgzMTc0MicgeGxpbms6aHJlZj0nI2c4LTQwJy8+Cjx1c2UgeD0nNDUxLjQ1OTUzMScgeT0nLTYuODMxNzQyJyB4bGluazpocmVmPScjZzYtMTE2Jy8+Cjx1c2UgeD0nNDU1LjY4NjY5JyB5PSctNS4wMzg0NzknIHhsaW5rOmhyZWY9JyNnNS0xMDUnLz4KPHVzZSB4PSc0NTkuMDY3OTYyJyB5PSctNi44MzE3NDInIHhsaW5rOmhyZWY9JyNnOC00MScvPgo8dXNlIHg9JzQ3OC4xNzk4ODYnIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0xOScvPgo8dXNlIHg9JzQ4Ni45ODAyNTknIHk9Jy0zMS44ODkzNDEnIHhsaW5rOmhyZWY9JyNnMS0yMScvPgo8dXNlIHg9JzQ5My4yODk5NTYnIHk9Jy0yOS4yMTI2ODgnIHhsaW5rOmhyZWY9JyNnMi0wJy8+Cjx1c2UgeD0nNDk5Ljg3NjQ2MycgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c3LTQ5Jy8+Cjx1c2UgeD0nNTA0LjExMDY0NicgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c1LTYxJy8+Cjx1c2UgeD0nNTA4LjM0NDgyOCcgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c1LTI0Jy8+Cjx1c2UgeD0nNTEyLjM3ODM2MycgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c3LTQwJy8+Cjx1c2UgeD0nNTE1LjY3MTYxNicgeT0nLTI5LjIxMjY4OCcgeGxpbms6aHJlZj0nI2c1LTExNicvPgo8dXNlIHg9JzUxOC43Mjk2MzcnIHk9Jy0yNy45OTc2MDknIHhsaW5rOmhyZWY9JyNnNC0xMDUnLz4KPHVzZSB4PSc1MjEuODkxMzk1JyB5PSctMjkuMjEyNjg4JyB4bGluazpocmVmPScjZzctNDEnLz4KPHVzZSB4PSc1MjUuNjgyNzgnIHk9Jy0zNS40NzU5MjgnIHhsaW5rOmhyZWY9JyNnMS00MScvPgo8L2c+Cjwvc3ZnPgo8IS0tIERFUFRIPTAgLS0+)
defined on
such that  for all .
for all .And if any of the
is equal to 0, the log-likelihood is defined as:
The initialization of the optimization problem is crucial. Two initial points
are proposed:the Gumbel initial point: in that case, we assume that the GEV is a stationary Gumbel distribution and we deduce
from the empirical mean and the empirical standard variation
of the data:
and where
is Euler’s constant; then we take the initial point . This is the default initial point;the Static initial point: in that case, we assume that the GEV is stationary and
is the maximum likelihood estimate resulting from that assumption.
The result class produced by the method provides:
the estimator
,the asymptotic distribution of
,the parameter functions
 ,
,the normalizing function
 ,
,the optimal log-likelihood value
,the GEV distribution at time
,the quantile functions of order
:  .
.
- getBootstrapSize()¶
Accessor to the bootstrap size.
- Returns:
- sizeint
Size of the bootstrap.
- getClassName()¶
Accessor to the object’s name.
- Returns:
- class_namestr
The object class name (object.__class__.__name__).
- getKnownParameterIndices()¶
Accessor to the known parameters indices.
- Returns:
- indices
Indices Indices of the known parameters.
- indices
- getKnownParameterValues()¶
Accessor to the known parameters values.
- Returns:
- values
Point Values of known parameters.
- values
- getName()¶
Accessor to the object’s name.
- Returns:
- namestr
The name of the object.
- getOptimizationAlgorithm()¶
Accessor to the solver.
- Returns:
- solver
OptimizationAlgorithm The solver used for numerical optimization of the moments.
- solver
- hasName()¶
Test if the object is named.
- Returns:
- hasNamebool
True if the name is not empty.
- setBootstrapSize(bootstrapSize)¶
Accessor to the bootstrap size.
- Parameters:
- sizeint
The size of the bootstrap.
- setKnownParameter(values, positions)¶
Accessor to the known parameters.
- Parameters:
- valuessequence of float
Values of known parameters.
- positionssequence of int
Indices of known parameters.
Examples
When a subset of the parameter vector is known, the other parameters only have to be estimated from data.
In the following example, we consider a sample and want to fit a
Betadistribution. We assume that the and
and  parameters are known beforehand.
In this case, we set the third parameter (at index 2) to -1
and the fourth parameter (at index 3) to 1.
parameters are known beforehand.
In this case, we set the third parameter (at index 2) to -1
and the fourth parameter (at index 3) to 1.>>> import openturns as ot >>> ot.RandomGenerator.SetSeed(0) >>> distribution = ot.Beta(2.3, 2.2, -1.0, 1.0) >>> sample = distribution.getSample(10) >>> factory = ot.BetaFactory() >>> # set (a,b) out of (r, t, a, b) >>> factory.setKnownParameter([-1.0, 1.0], [2, 3]) >>> inf_distribution = factory.build(sample)
- setName(name)¶
Accessor to the object’s name.
- Parameters:
- namestr
The name of the object.
- setOptimizationAlgorithm(solver)¶
Accessor to the solver.
- Parameters:
- solver
OptimizationAlgorithm The solver used for numerical optimization of the moments.
- solver
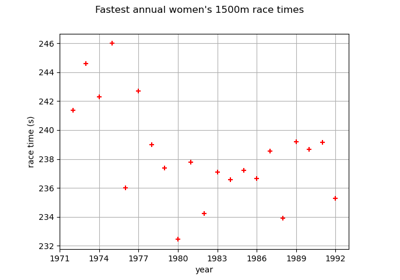
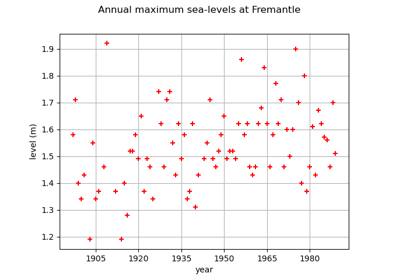
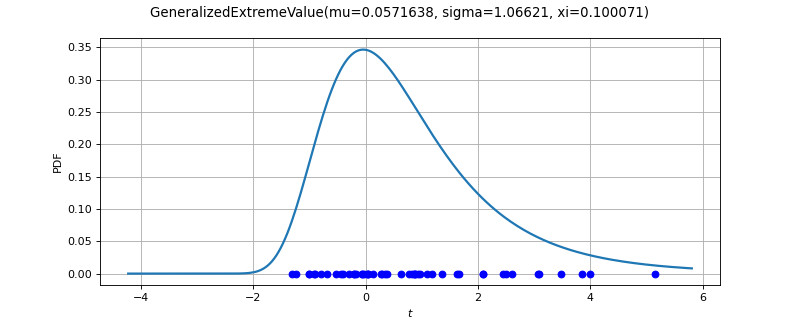{kind=link}